#aws lambda api gateway trigger
Explore tagged Tumblr posts
Visit Tumblr Blog
Explore Tumblr blogs with no restrictions, modern design and the best experience.
Last Seen Tumblr Blogs





Fun Fact
After the announcement of the deal with Yahoo!, there were 170K signatures of unhappy Tumblr users petitioning to prevent the sale in 2013.
Text
AWS Lambda Compute Service Tutorial for Amazon Cloud Developers
Full Video Link - https://youtube.com/shorts/QmQOWR_aiNI Hi, a new #video #tutorial on #aws #lambda #awslambda is published on #codeonedigest #youtube channel. @java @awscloud @AWSCloudIndia @YouTube #youtube @codeonedigest #codeonedigest #aws #amaz
AWS Lambda is a serverless compute service that runs your code in response to events and automatically manages the underlying compute resources for you. These events may include changes in state such as a user placing an item in a shopping cart on an ecommerce website. AWS Lambda automatically runs code in response to multiple events, such as HTTP requests via Amazon API Gateway, modifications…

View On WordPress
#amazon lambda java example#aws#aws cloud#aws lambda#aws lambda api gateway#aws lambda api gateway trigger#aws lambda basic#aws lambda code#aws lambda configuration#aws lambda developer#aws lambda event trigger#aws lambda eventbridge#aws lambda example#aws lambda function#aws lambda function example#aws lambda function s3 trigger#aws lambda java#aws lambda server#aws lambda service#aws lambda tutorial#aws training#aws tutorial#lambda service
0 notes
Text
Mastering AWS DevOps in 2025: Best Practices, Tools, and Real-World Use Cases
In 2025, the cloud ecosystem continues to grow very rapidly. Organizations of every size are embracing AWS DevOps to automate software delivery, improve security, and scale business efficiently. Mastering AWS DevOps means knowing the optimal combination of tools, best practices, and real-world use cases that deliver success in production.
This guide will assist you in discovering the most important elements of AWS DevOps, the best practices of 2025, and real-world examples of how top companies are leveraging AWS DevOps to compete.
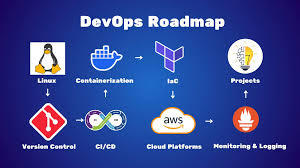
What is AWS DevOps
AWS DevOps is the union of cultural principles, practices, and tools on Amazon Web Services that enhances an organization's capacity to deliver applications and services at a higher speed. It facilitates continuous integration, continuous delivery, infrastructure as code, monitoring, and cooperation among development and operations teams.
Why AWS DevOps is Important in 2025
As organizations require quicker innovation and zero downtime, DevOps on AWS offers the flexibility and reliability to compete. Trends such as AI integration, serverless architecture, and automated compliance are changing how teams adopt DevOps in 2025.
Advantages of adopting AWS DevOps:
1 Faster deployment cycles
2 Enhanced system reliability
3 Flexible and scalable cloud infrastructure
4 Automation from code to production
5 Integrated security and compliance
Best AWS DevOps Tools to Learn in 2025
These are the most critical tools fueling current AWS DevOps pipelines:
AWS CodePipeline
Your release process can be automated with our fully managed CI/CD service.
AWS CodeBuild
Scalable build service for creating ready-to-deploy packages, testing, and building source code.
AWS CodeDeploy
Automates code deployments to EC2, Lambda, ECS, or on-prem servers with zero-downtime approaches.
AWS CloudFormation and CDK
For infrastructure as code (IaC) management, allowing repeatable and versioned cloud environments.
Amazon CloudWatch
Facilitates logging, metrics, and alerting to track application and infrastructure performance.
AWS Lambda
Serverless compute that runs code in response to triggers, well-suited for event-driven DevOps automation.
AWS DevOps Best Practices in 2025
1. Adopt Infrastructure as Code (IaC)
Utilize AWS CloudFormation or Terraform to declare infrastructure. This makes it repeatable, easier to collaborate on, and version-able.
2. Use Full CI/CD Pipelines
Implement tools such as CodePipeline, GitHub Actions, or Jenkins on AWS to automate deployment, testing, and building.
3. Shift Left on Security
Bake security in early with Amazon Inspector, CodeGuru, and Secrets Manager. As part of CI/CD, automate vulnerability scans.
4. Monitor Everything
Utilize CloudWatch, X-Ray, and CloudTrail to achieve complete observability into your system. Implement alerts to detect and respond to problems promptly.
5. Use Containers and Serverless for Scalability
Utilize Amazon ECS, EKS, or Lambda for autoscaling. These services lower infrastructure management overhead and enhance efficiency.
Real-World AWS DevOps Use Cases
Use Case 1: Scalable CI/CD for a Fintech Startup
AWS CodePipeline and CodeDeploy were used by a financial firm to automate deployments in both production and staging environments. By containerizing using ECS and taking advantage of CloudWatch monitoring, they lowered deployment mistakes by 80 percent and attained near-zero downtime.
Use Case 2: Legacy Modernization for an Enterprise
A legacy enterprise moved its on-premise applications to AWS with CloudFormation and EC2 Auto Scaling. Through the adoption of full-stack DevOps pipelines and the transformation to microservices with EKS, they enhanced time-to-market by 60 percent.
Use Case 3: Serverless DevOps for a SaaS Product
A SaaS organization utilized AWS Lambda and API Gateway for their backend functions. They implemented quick feature releases and automatically scaled during high usage without having to provision infrastructure using CodeBuild and CloudWatch.
Top Trends in AWS DevOps in 2025
AI-driven DevOps: Integration with CodeWhisperer, CodeGuru, and machine learning algorithms for intelligence-driven automation
Compliance-as-Code: Governance policies automated using services such as AWS Config and Service Control Policies
Multi-account strategies: Employing AWS Organizations for scalable, secure account management
Zero Trust Architecture: Implementing strict identity-based access with IAM, SSO, and MFA
Hybrid Cloud DevOps: Connecting on-premises systems to AWS for effortless deployments
Conclusion
In 2025, becoming a master of AWS DevOps means syncing your development workflows with cloud-native architecture, innovative tools, and current best practices. With AWS, teams are able to create secure, scalable, and automated systems that release value at an unprecedented rate.
Begin with automating your pipelines, securing your deployments, and scaling with confidence. DevOps is the way of the future, and AWS is leading the way.
Frequently Asked Questions
What distinguishes AWS DevOps from DevOps? While AWS DevOps uses AWS services and tools to execute DevOps, DevOps itself is a practice.
Can small teams benefit from AWS DevOps
Yes. AWS provides fully managed services that enable small teams to scale and automate without having to handle complicated infrastructure.
Which programming languages does AWS DevOps support
AWS supports the big ones - Python, Node.js, Java, Go, .NET, Ruby, and many more.
Is AWS DevOps for enterprise-scale applications
Yes. Large enterprises run large-scale, multi-region applications with millions of users using AWS DevOps.
1 note
·
View note
Text
Integrating ROSA Applications with AWS Services (CS221)
As cloud-native architectures become the backbone of modern application deployments, combining the power of Red Hat OpenShift Service on AWS (ROSA) with native AWS services unlocks immense value for developers and DevOps teams alike. In this blog post, we explore how to integrate ROSA-hosted applications with AWS services to build scalable, secure, and cloud-optimized solutions — a key skill set emphasized in the CS221 course.
🚀 What is ROSA?
Red Hat OpenShift Service on AWS (ROSA) is a managed OpenShift platform that runs natively on AWS. It allows organizations to deploy Kubernetes-based applications while leveraging the scalability and global reach of AWS, without managing the underlying infrastructure.
With ROSA, you get:
Fully managed OpenShift clusters
Integrated with AWS IAM and billing
Access to AWS services like RDS, S3, DynamoDB, Lambda, etc.
Native CI/CD, container orchestration, and operator support
🧩 Why Integrate ROSA with AWS Services?
ROSA applications often need to interact with services like:
Amazon S3 for object storage
Amazon RDS or DynamoDB for database integration
Amazon SNS/SQS for messaging and queuing
AWS Secrets Manager or SSM Parameter Store for secrets management
Amazon CloudWatch for monitoring and logging
Integration enhances your application’s:
Scalability — Offload data, caching, messaging to AWS-native services
Security — Use IAM roles and policies for fine-grained access control
Resilience — Rely on AWS SLAs for critical components
Observability — Monitor and trace hybrid workloads via CloudWatch and X-Ray
🔐 IAM and Permissions: Secure Integration First
A crucial part of ROSA-AWS integration is managing IAM roles and policies securely.
Steps:
Create IAM Roles for Service Accounts (IRSA):
ROSA supports IAM Roles for Service Accounts, allowing pods to securely access AWS services without hardcoding credentials.
Attach IAM Policy to the Role:
Example: An application that uploads files to S3 will need the following permissions:{ "Effect": "Allow", "Action": ["s3:PutObject", "s3:GetObject"], "Resource": "arn:aws:s3:::my-bucket-name/*" }
Annotate OpenShift Service Account:
Use oc annotate to associate your OpenShift service account with the IAM role.
📦 Common Integration Use Cases
1. Storing App Logs in S3
Use a Fluentd or Loki pipeline to export logs from OpenShift to Amazon S3.
2. Connecting ROSA Apps to RDS
Applications can use standard drivers (PostgreSQL, MySQL) to connect to RDS endpoints — make sure to configure VPC and security groups appropriately.
3. Triggering AWS Lambda from ROSA
Set up an API Gateway or SNS topic to allow OpenShift applications to invoke serverless functions in AWS for batch processing or asynchronous tasks.
4. Using AWS Secrets Manager
Mount secrets securely in pods using CSI drivers or inject them using operators.
🛠 Hands-On Example: Accessing S3 from ROSA Pod
Here’s a quick walkthrough:
Create an IAM Role with S3 permissions.
Associate the role with a Kubernetes service account.
Deploy your pod using that service account.
Use AWS SDK (e.g., boto3 for Python) inside your app to access S3.
oc create sa s3-access oc annotate sa s3-access eks.amazonaws.com/role-arn=arn:aws:iam::<account-id>:role/S3AccessRole
Then reference s3-access in your pod’s YAML.
📚 ROSA CS221 Course Highlights
The CS221 course from Red Hat focuses on:
Configuring service accounts and roles
Setting up secure access to AWS services
Using OpenShift tools and operators to manage external integrations
Best practices for hybrid cloud observability and logging
It’s a great choice for developers, cloud engineers, and architects aiming to harness the full potential of ROSA + AWS.
✅ Final Thoughts
Integrating ROSA with AWS services enables teams to build robust, cloud-native applications using best-in-class tools from both Red Hat and AWS. Whether it's persistent storage, messaging, serverless computing, or monitoring — AWS services complement ROSA perfectly.
Mastering these integrations through real-world use cases or formal training (like CS221) can significantly uplift your DevOps capabilities in hybrid cloud environments.
Looking to Learn or Deploy ROSA with AWS?
HawkStack Technologies offers hands-on training, consulting, and ROSA deployment support. For more details www.hawkstack.com
0 notes
Text
Build A Smarter Security Chatbot With Amazon Bedrock Agents

Use an Amazon Security Lake and Amazon Bedrock chatbot for incident investigation. This post shows how to set up a security chatbot that uses an Amazon Bedrock agent to combine pre-existing playbooks into a serverless backend and GUI to investigate or respond to security incidents. The chatbot presents uniquely created Amazon Bedrock agents to solve security vulnerabilities with natural language input. The solution uses a single graphical user interface (GUI) to directly communicate with the Amazon Bedrock agent to build and run SQL queries or advise internal incident response playbooks for security problems.
User queries are sent via React UI.
Note: This approach does not integrate authentication into React UI. Include authentication capabilities that meet your company's security standards. AWS Amplify UI and Amazon Cognito can add authentication.
Amazon API Gateway REST APIs employ Invoke Agent AWS Lambda to handle user queries.
User queries trigger Lambda function calls to Amazon Bedrock agent.
Amazon Bedrock (using Claude 3 Sonnet from Anthropic) selects between querying Security Lake using Amazon Athena or gathering playbook data after processing the inquiry.
Ask about the playbook knowledge base:
The Amazon Bedrock agent queries the playbooks knowledge base and delivers relevant results.
For Security Lake data enquiries:
The Amazon Bedrock agent takes Security Lake table schemas from the schema knowledge base to produce SQL queries.
When the Amazon Bedrock agent calls the SQL query action from the action group, the SQL query is sent.
Action groups call the Execute SQL on Athena Lambda function to conduct queries on Athena and transmit results to the Amazon Bedrock agent.
After extracting action group or knowledge base findings:
The Amazon Bedrock agent uses the collected data to create and return the final answer to the Invoke Agent Lambda function.
The Lambda function uses an API Gateway WebSocket API to return the response to the client.
API Gateway responds to React UI via WebSocket.
The chat interface displays the agent's reaction.
Requirements
Prior to executing the example solution, complete the following requirements:
Select an administrator account to manage Security Lake configuration for each member account in AWS Organisations. Configure Security Lake with necessary logs: Amazon Route53, Security Hub, CloudTrail, and VPC Flow Logs.
Connect subscriber AWS account to source Security Lake AWS account for subscriber queries.
Approve the subscriber's AWS account resource sharing request in AWS RAM.
Create a database link in AWS Lake Formation in the subscriber AWS account and grant access to the Security Lake Athena tables.
Provide access to Anthropic's Claude v3 model for Amazon Bedrock in the AWS subscriber account where you'll build the solution. Using a model before activating it in your AWS account will result in an error.
When requirements are satisfied, the sample solution design provides these resources:
Amazon S3 powers Amazon CloudFront.
Chatbot UI static website hosted on Amazon S3.
Lambda functions can be invoked using API gateways.
An Amazon Bedrock agent is invoked via a Lambda function.
A knowledge base-equipped Amazon Bedrock agent.
Amazon Bedrock agents' Athena SQL query action group.
Amazon Bedrock has example Athena table schemas for Security Lake. Sample table schemas improve SQL query generation for table fields in Security Lake, even if the Amazon Bedrock agent retrieves data from the Athena database.
A knowledge base on Amazon Bedrock to examine pre-existing incident response playbooks. The Amazon Bedrock agent might propose investigation or reaction based on playbooks allowed by your company.
Cost
Before installing the sample solution and reading this tutorial, understand the AWS service costs. The cost of Amazon Bedrock and Athena to query Security Lake depends on the amount of data.
Security Lake cost depends on AWS log and event data consumption. Security Lake charges separately for other AWS services. Amazon S3, AWS Glue, EventBridge, Lambda, SQS, and SNS include price details.
Amazon Bedrock on-demand pricing depends on input and output tokens and the large language model (LLM). A model learns to understand user input and instructions using tokens, which are a few characters. Amazon Bedrock pricing has additional details.
The SQL queries Amazon Bedrock creates are launched by Athena. Athena's cost depends on how much Security Lake data is scanned for that query. See Athena pricing for details.
Clear up
Clean up if you launched the security chatbot example solution using the Launch Stack button in the console with the CloudFormation template security_genai_chatbot_cfn:
Choose the Security GenAI Chatbot stack in CloudFormation for the account and region where the solution was installed.
Choose “Delete the stack”.
If you deployed the solution using AWS CDK, run cdk destruct –all.
Conclusion
The sample solution illustrates how task-oriented Amazon Bedrock agents and natural language input may increase security and speed up inquiry and analysis. A prototype solution using an Amazon Bedrock agent-driven user interface. This approach may be expanded to incorporate additional task-oriented agents with models, knowledge bases, and instructions. Increased use of AI-powered agents can help your AWS security team perform better across several domains.
The chatbot's backend views data normalised into the Open Cybersecurity Schema Framework (OCSF) by Security Lake.
#securitychatbot#AmazonBedrockagents#graphicaluserinterface#Bedrockagent#chatbot#chatbotsecurity#Technology#TechNews#technologynews#news#govindhtech
0 notes
Link
[ad_1] Welcome devs to the world of development and automation. Today, we are diving into an exciting project in which we will be creating a Serverless Image Processing Pipeline with AWS services. The project starts with creating S3 buckets for storing uploaded images and processed Thumbnails, and eventually using many services like Lambda, API Gateway (To trigger the Lambda Function), DynamoDB (storing image Metadata), and at last we will run this program in ECS cluster by creating a Docker image of the project. This project is packed with cloud services and development tech stacks like Next.js, and practicing this will further enhance your understanding of Cloud services and how they interact with each other. So with further ado, let’s get started! Note: The code and instructions in this post are for demo use and learning only. A production environment will require a tighter grip on configurations and security. Prerequisites Before we get into the project, we need to ensure that we have the following requirements met in our system: An AWS Account: Since we use AWS services for the project, we need an AWS account. A configured IAM User with required services access would be appreciated. Basic Understanding of AWS Services: Since we are dealing with many AWS services, it is better to have a decent understanding of them, such as S3, which is used for storage, API gateway to trigger Lambda function, and many more. Node Installed: Our frontend is built with Next.js, so having Node in your system is necessary. For Code reference, here is the GitHub repo. AWS Services Setup We will start the project by setting up our AWS services. First and foremost, we will create 2 S3 buckets, namely sample-image-uploads-bucket and sample-thumbnails-bucket. The reason for this long name is that the bucket name has to be unique all over the AWS Workspace. So to create the bucket, head over to the S3 dashboard and click ‘Create Bucket’, select ‘General Purpose’, and give it a name (sample-image-uploads-bucket) and leave the rest of the configuration as default. Similarly, create the other bucket named sample-thumbnails-bucket, but in this bucket, make sure you uncheck Block Public Access because we will need it for our ECS Cluster. We need to ensure that the sample-thumbnails-bucket has public read access, so that ECS Frontend can display them. For that, we will attach the following policy to that bucket: "Version": "2012-10-17", "Statement": [ "Sid": "PublicRead", "Effect": "Allow", "Principal": "*", "Action": "s3:GetObject", "Resource": "arn:aws:s3:::sample-thumbnails-bucket/*" ] After creating buckets, let’s move to our Database for storing image metadata. We will create a DynamoDb table for that. Go to your DynamoDb console, click on Create Table, give it a name (image_metadata), and in the primary key select string, name it image_id. AWS services will communicate with each other, so they need a role with proper permissions. To create a role, go to the IAM dashboard, select Role, and click on Create Role. Under trust identity type, select AWS service, and under use case, choose Lambda. Attach the following policies: AmazonS3FullAccess AmazonDynamoDBFullAccess CloudWatchLogsFullAccess Give this role a name (Lambda-Image-Processor-Role) and save it. Creating Lambda Function We have our Lambda role, buckets, and DynamoDb table ready, so now let’s create the Lambda function which will process the image and make the thumbnail out of it, since we are using the Pillow library to process the images, Lambda by default doesn’t provide that. To fix this, we will add a layer in the Lambda function. To do that, follow the following steps: Now go to your Lambda dashboard, click on Create a Function. Select Author from Scratch and choose Python 3.9 as the runtime language, give it a name: image-processor, and in the Code tab, you have the Upload from Option, select that, choose zip file, and upload your Zip file of the image-processor. Go to Configuration, and under the Permissions column, Edit the configuration by changing the existing role to the role we created Lambda-Image-Processor-Role. Now go to your S3 bucket (sample-image-uploads-bucket) and go to its Properties section and scroll down to Event Notification, here click on Create Event Notification, give it a name (trigger-image-processor) and in the event type, select PUT and select the lambda function we created (image-processor). Now, since Pillow doesn’t come built-in with the lambda library, we will do the following steps to fix that: Go to your Lambda function (image-processor) and scroll down to the Layer section, here click on Add Layer. In the Add Layer section, select Specify an ARN and provide this ARN arn:aws:lambda:us-east-1:770693421928:layer:Klayers-p39-pillow:1 . Change the region accordingly; I am using us-east-1. Add the layer. Now in the Code tab of your Lambda-Function you would be having a lambda-function.py, put the following content inside the lambda_function.py: import boto3 import uuid import os from PIL import Image from io import BytesIO import datetime s3 = boto3.client('s3') dynamodb = boto3.client('dynamodb') UPLOAD_BUCKET = '' THUMBNAIL_BUCKET = '' DDB_TABLE = 'image_metadata' def lambda_handler(event, context): record = event['Records'][0] bucket = record['s3']['bucket']['name'] key = record['s3']['object']['key'] response = s3.get_object(Bucket=bucket, Key=key) image = Image.open(BytesIO(response['Body'].read())) image.thumbnail((200, 200)) thumbnail_buffer = BytesIO() image.save(thumbnail_buffer, 'JPEG') thumbnail_buffer.seek(0) thumbnail_key = f"thumb_key" s3.put_object( Bucket=THUMBNAIL_BUCKET, Key=thumbnail_key, Body=thumbnail_buffer, ContentType='image/jpeg' ) image_id = str(uuid.uuid4()) original_url = f"https://UPLOAD_BUCKET.s3.amazonaws.com/key" thumbnail_url = f"https://THUMBNAIL_BUCKET.s3.amazonaws.com/thumbnail_key" uploaded_at = datetime.datetime.now().isoformat() dynamodb.put_item( TableName=DDB_TABLE, Item= 'image_id': 'S': image_id, 'original_url': 'S': original_url, 'thumbnail_url': 'S': thumbnail_url, 'uploaded_at': 'S': uploaded_at ) return 'statusCode': 200, 'body': f"Thumbnail created: thumbnail_url" Now, we will need another Lambda function for API Gateway because that will act as the entry point for our frontend ECS app to fetch image data from DynamoDB. To create the lambda function, go to your Lambda Dashboard, click on create function, select Author from scratch and python 3.9 as runtime, give it a name, get-image-metadata, and in the configuration, select the same role that we assigned to other Lambda functions (Lambda-Image-Processor-Role) Now, in the Code section of the function, put the following content: import boto3 import json dynamodb = boto3.client('dynamodb') TABLE_NAME = 'image_metadata' def lambda_handler(event, context): try: response = dynamodb.scan(TableName=TABLE_NAME) images = [] for item in response['Items']: images.append( 'image_id': item['image_id']['S'], 'original_url': item['original_url']['S'], 'thumbnail_url': item['thumbnail_url']['S'], 'uploaded_at': item['uploaded_at']['S'] ) return 'statusCode': 200, 'headers': "Content-Type": "application/json" , 'body': json.dumps(images) except Exception as e: return 'statusCode': 500, 'body': f"Error: str(e)" Creating the API Gateway The API Gateway will act as the entry point for your ECS Frontend application to fetch image data from DynamoDB. It will connect to the Lambda function that queries DynamoDB and returns the image metadata. The URL of the Gateway is used in our Frontend app to display images. To create the API Gateway, do the following steps: Go to the AWS Management Console → Search for API Gateway → Click Create API. Select HTTP API. Click on Build. API name: image-gallery-api Add integrations: Select Lambda and select the get_image_metadata function Select Method: Get and Path: /images Endpoint type: Regional Click on Next and create the API Gateway URL. Before creating the Frontend, let’s test the application manually. First go to your Upload S3 Bucket (sample-image-uploads-bucket) and upload a jpg/jpeg image; other image will not work as your function only processes these two types:In the Picture above, I have uploaded an image titled “ghibil-art.jpg” file, and once uploaded, it will trigger the Lambda function, that will create the thumbnail out of it named as “thumbnail-ghibil-art.jpg” and store it in sample-thumbnails-bucket and the information about the image will be stored in image-metadata table in DynamoDb. In the image above, you can see the Item inside the Explore Item section of our DynamoDb table “image-metadata.” To test the API-Gateway, we will check the Invoke URL of our image-gallery-API followed by /images. It will show the following output, with the curl command: Now our application is working fine, we can deploy a frontend to visualise the project. Creating the Frontend App For the sake of Simplicity, we will be creating a minimal, simple gallery frontend using Next.js, Dockerize it, and deploy it on ECS. To create the app, do the following steps: Initialization npx create-next-app@latest image-gallery cd image-gallery npm install npm install axios Create the Gallery Component Create a new file components/Gallery.js: 'use client'; import useState, useEffect from 'react'; import axios from 'axios'; import styles from './Gallery.module.css'; const Gallery = () => const [images, setImages] = useState([]); const [loading, setLoading] = useState(true); useEffect(() => const fetchImages = async () => try const response = await axios.get('https:///images'); setImages(response.data); setLoading(false); catch (error) console.error('Error fetching images:', error); setLoading(false); ; fetchImages(); , []); if (loading) return Loading...; return ( images.map((image) => ( new Date(image.uploaded_at).toLocaleDateString() )) ); ; export default Gallery; Make Sure to Change the Gateway-URL to your API_GATEWAY_URL Add CSS Module Create components/Gallery.module.css: .gallery display: grid; grid-template-columns: repeat(auto-fill, minmax(200px, 1fr)); gap: 20px; padding: 20px; max-width: 1200px; margin: 0 auto; .imageCard background: #fff; border-radius: 8px; box-shadow: 0 2px 5px rgba(0,0,0,0.1); overflow: hidden; transition: transform 0.2s; .imageCard:hover transform: scale(1.05); .thumbnail width: 100%; height: 150px; object-fit: cover; .date text-align: center; padding: 10px; margin: 0; font-size: 0.9em; color: #666; .loading text-align: center; padding: 50px; font-size: 1.2em; Update the Home Page Modify app/page.js: import Gallery from '../components/Gallery'; export default function Home() return ( Image Gallery ); Next.js’s built-in Image component To use Next.js’s built-in Image component for better optimization, update next.config.mjs: const nextConfig = images: domains: ['sample-thumbnails-bucket.s3.amazonaws.com'], , ; export default nextConfig; Run the Application Visit in your browser, and you will see the application running with all the thumbnails uploaded. For demonstration purposes, I have put four images (jpeg/jpg) in my sample-images-upload-bucket. Through the function, they are transformed into thumbnails and stored in the sample-thumbnail-bucket. The application looks like this: Containerising and Creating the ECS Cluster Now we are almost done with the project, so we will continue by creating a Dockerfile of the project as follows: # Use the official Node.js image as a base FROM node:18-alpine AS builder # Set working directory WORKDIR /app # Copy package files and install dependencies COPY package.json package-lock.json ./ RUN npm install # Copy the rest of the application code COPY . . # Build the Next.js app RUN npm run build # Use a lightweight Node.js image for production FROM node:18-alpine # Set working directory WORKDIR /app # Copy built files from the builder stage COPY --from=builder /app ./ # Expose port EXPOSE 3000 # Run the application CMD ["npm", "start"] Now we will build the Docker image using: docker build -t sample-nextjs-app . Now that we have our Docker image, we will push it to AWS ECR repo, for that, do the following steps: Step 1: Push the Docker Image to Amazon ECR Go to the AWS Management Console → Search for ECR (Elastic Container Registry) → Open ECR. Create a new repository: Click Create repository. Set Repository name (e.g., sample-nextjs-app). Choose Private (or Public if required). Click Create repository. Push your Docker image to ECR: In the newly created repository, click View push commands. Follow the commands to: Authenticate Docker with ECR. Build, tag, and push your image. You need to have AWS CLI configured for this step. Step 2: Create an ECS Cluster aws ecs create-cluster --cluster-name sample-ecs-cluster Step 3: Create a Task Definition In the ECS Console, go to Task Definitions. Click Create new Task Definition. Choose Fargate → Click Next step. Set task definition details: Name: sample-nextjs-task Task role: ecsTaskExecutionRole (Create one if missing). "Version": "2012-10-17", "Statement": [ "Sid": "Statement1", "Effect": "Allow", "Action": [ "ecr:GetDownloadUrlForLayer", "ecr:BatchGetImage", "ecr:GetAuthorizationToken", "ecr:BatchCheckLayerAvailability" ], "Resource": "arn:aws:ecr:us-east-1:624448302051:repository/sample-nextjs-app" ] Task memory & CPU: Choose appropriate values (e.g., 512MB & 256 CPU). Define the container: Click Add container. Container name: sample-nextjs-container. Image URL: Paste the ECR image URI from Step 1. Port mappings: Set 3000 for both container and host ports. Click Add. Click Create. Step 4: Create an ECS Service Go to “ECS” → Click Clusters → Select your cluster (sample-ecs-cluster). Click Create Service. Choose Fargate → Click Next step. Set up the service: Task definition: Select sample-nextjs-task. Cluster: sample-ecs-cluster. Service name: sample-nextjs-service. Number of tasks: 1 (Can scale later). Networking settings: Select an existing VPC. Choose Public subnets. Enable Auto-assign Public IP. Click Next step → Create service. Step 5: Access the Application Go to ECS > Clusters > sample-ecs-cluster. Click on the Tasks tab. Click on the running task. Find the Public IP under Network. Open a browser and go to:http://:3000 Your Next.js app should be live! 🚀 Conclusion This marks the end of the blog. Today, we divided into many AWS services: s3, IAM, ECR, Lambda function, ECS, Fargate, and API Gateway. We started the project by creating s3 buckets and eventually deployed our application in an ECS cluster. Throughout this guide, we covered containerizing the Next.js app, pushing it to ECR, configuring ECS task definitions, and deploying via the AWS console. This setup allows for automated scaling, easy updates, and secure API access—all key benefits of a cloud-native deployment. Potential production configurations may include changes like below: Implementing more restrictive IAM permissions, improving control over public access to S3 buckets (using CloudFront, pre-signed URLs, or a backend proxy instead of making the sample-thumbnails-bucket public) Adding error handling and pagination (especially for DynamoDB queries) Utilizing secure VPC/network configurations for ECS (like using an Application Load Balancer and private subnets instead of direct public IPs) Addressing scaling concerns by replacing the DynamoDB.scan operation within the metadata-fetching Lambda with the DynamoDB.query Using environment variables instead of a hardcoded API gateway URL in the Next.js code [ad_2] Source link
0 notes
Text
The Future of Cloud: Best Serverless Development Company Trends

Introduction
Cloud computing is evolving, and one of the most innovative advancements is serverless technology. A Serverless development company eliminates the need for businesses to manage servers, allowing them to focus on building scalable and cost-effective applications. As more organizations adopt serverless computing, it's essential to understand the trends and benefits of working with a serverless provider.
From automating infrastructure management to reducing operational costs, serverless development is revolutionizing how businesses operate in the cloud. This blog explores the role of serverless development, key trends, and how companies can benefit from partnering with a serverless provider.
Why Choose a Serverless Development Company?
A Serverless development company provides cloud-based solutions that handle backend infrastructure automatically. Instead of provisioning and maintaining servers, businesses only pay for what they use. This reduces costs, enhances scalability, and improves efficiency.
Companies across industries are leveraging serverless technology to deploy cloud applications quickly. Whether it's handling high-traffic websites, processing large-scale data, or integrating AI-driven solutions, serverless computing offers unmatched flexibility and reliability.
Latest Trends in Serverless Computing
The adoption of serverless technology is on the rise, with various trends shaping the industry. Some key developments include:
Multi-cloud serverless computing for better flexibility and redundancy.
Enhanced security frameworks to protect cloud-based applications.
Integration of AI and machine learning to automate workflows.
Low-code and no-code development enabling faster application deployment.
These trends indicate that a Serverless development company is not just about reducing costs but also about optimizing business operations for the future.
Top 10 SaaS Development Companies Driving Serverless Adoption
The SaaS industry is a significant player in the adoption of serverless computing. Many SaaS providers are integrating serverless architecture to enhance their platforms.
Here are the Top 10 SaaS Development Companies leading the way in serverless innovation:
Amazon Web Services (AWS Lambda)
Microsoft Azure Functions
Google Cloud Functions
IBM Cloud Functions
Netlify
Cloudflare Workers
Vercel
Firebase Cloud Functions
Twilio Functions
StackPath
These companies are paving the way for serverless solutions that enable businesses to scale efficiently without traditional server management.
Best SaaS Examples in 2025 Showcasing Serverless Success
Many successful SaaS applications leverage serverless technology to provide seamless experiences. Some of the Best SaaS Examples in 2025 using serverless include:
Slack for real-time messaging with scalable cloud infrastructure.
Shopify for handling e-commerce transactions efficiently.
Zoom for seamless video conferencing and collaboration.
Dropbox for secure and scalable cloud storage solutions.
Stripe for processing payments with high reliability.
These SaaS companies use serverless technology to optimize performance and enhance customer experiences.
Guide to SaaS Software Development with Serverless Technology
A Guide to SaaS Software Development with serverless technology involves several crucial steps:
Choose the right cloud provider – AWS, Azure, or Google Cloud.
Leverage managed services – Databases, authentication, and API gateways.
Optimize event-driven architecture – Serverless functions triggered by events.
Implement security best practices – Encryption, IAM policies, and monitoring.
Monitor and scale efficiently – Using automated scaling mechanisms.
These steps help businesses build robust SaaS applications with minimal infrastructure management.
Custom Software Development Company and Serverless Integration
A custom software development company can integrate serverless technology into tailored software solutions. Whether it's developing enterprise applications, e-commerce platforms, or AI-driven solutions, serverless computing enables companies to deploy scalable applications without worrying about server management.
By partnering with a custom software provider specializing in serverless, businesses can streamline development cycles, reduce costs, and improve system reliability.
How Cloud-Based Apps Benefit from Serverless Architecture
The shift towards cloud-based apps has accelerated the adoption of serverless computing. Serverless architecture allows cloud applications to:
Scale automatically based on demand.
Reduce operational costs with pay-as-you-go pricing.
Enhance security with managed cloud services.
Improve application performance with faster response times.
As more companies move towards cloud-native applications, serverless technology will continue to be a game-changer in modern app development.
Conclusion
The Serverless development company landscape is growing, enabling businesses to build scalable, cost-efficient applications with minimal infrastructure management. As serverless trends continue to evolve, partnering with the right development company can help businesses stay ahead in the competitive cloud computing industry.
Whether you're developing SaaS applications, enterprise solutions, or AI-driven platforms, serverless technology provides a flexible and efficient approach to modern software development. Embrace the future of cloud computing with serverless solutions and transform the way your business operates.
0 notes
Text
AWS Proto Unveils Stunning AI-Powered Avatar Holograms

In today's rapidly evolving world, technology is transforming our interactions at an unprecedented pace. At the forefront of this innovation are AI-Powered Avatar Holograms. Through an exciting collaboration between Proto Inc. and Amazon Web Services (AWS), a new era of holographic communication is emerging that redefines how we connect, share, and interact across various industries. Let’s dive into the fascinating advancements that this collaboration has to offer!
Advanced Holographic Technology
Proto Inc. has introduced the Proto AI Persona Suite, a collection of advanced AI-driven holographic tools designed for seamless interaction. Key Components of the Proto AI Persona Suite - AI Conversational Persona: Engages in real-time conversations with lifelike holographic representations. - AI Text-to-Persona: Converts written text into vibrant holograms that communicate naturally. - AI Persona Translator: Offers accurate translations of spoken content into multiple languages with a human touch.
Integration with AWS for Enhanced Capabilities
The partnership with AWS plays a crucial role in the development and functionality of these holographic avatars. By migrating to Amazon Bedrock, Proto has harnessed cutting-edge generative AI technologies, leading to significant improvements in their offerings. Live Demonstrations at Major Events At the Mobile World Congress (MWC) 2024, Proto and AWS showcased the powerful capabilities of their collaboration through a live avatar broadcast, demonstrating how these holograms could revolutionize content sharing and audience engagement.
Innovative Text-to-Hologram Pipeline
A standout feature of this collaboration is the groundbreaking text-to-hologram pipeline. This technology allows users to create dynamic holographic content efficiently, using just a few lines of text. The process utilizes Amazon Cognito for secure access, the API Gateway for user queries, and AWS Lambda to trigger holographic content production.
Industry Applications and Future Directions
The applications of AI-Powered Avatar Holograms span various fields, bringing transformative benefits including: - Enhanced educational tools enabling remote learning. - Innovative marketing strategies featuring virtual product demonstrations. - Revolutionized healthcare services with remote specialist consultations. - Personalized client interactions in hospitality and customer service. Exclusive Showcase at Upcoming Events As the momentum grows, both Proto and AWS are prepared to showcase these advancements at AWS re:Invent 2024, granting attendees an exclusive glimpse of the future of holographic technology.
Conclusion: A Bright Future for AI-Powered Avatar Holograms
The innovative collaboration between Proto Inc. and AWS is redefining the landscape of AI-Powered Avatar Holograms. These advancements are paving the way toward realistic, immersive interactions that can benefit numerous industries. As technology continues to evolve, we can anticipate exciting developments, making our digital experiences more engaging and personalized. Have thoughts or questions? Leave a comment below! And don’t forget to share this article with your friends to spread the word about the future of holographic communication. For more tech news and updates, check out FROZENLEAVES NEWS. ``` Read the full article
0 notes
Text
Lambda Live: Building Event-Driven Architectures
In today’s fast-evolving tech landscape, event-driven architectures (EDAs) are rapidly becoming the go-to solution for building scalable, resilient, and efficient applications. At the heart of this shift is AWS Lambda, a serverless computing service that enables developers to run code without provisioning or managing servers. In this article, we’ll explore how AWS Lambda powers event-driven architectures, enabling real-time processing, automation, and seamless integration between various services.
What is an Event-Driven Architecture?
Event-driven architecture is a design pattern where systems react to events rather than following a traditional request-response model. Events, which can be anything from a user action (like clicking a button) to a change in the system (such as an update to a database), trigger specific actions or workflows. This design allows applications to decouple components, making them more flexible, responsive, and easier to scale.
In an EDA, there are three main components:
Producers – These generate events. For example, a sensor generating temperature data or a user updating a file.
Event Routers – These are responsible for routing events to the appropriate consumers.
Consumers – These are services or systems that react to the events and process them.
AWS Lambda fits perfectly into this model by allowing the creation of stateless functions that execute code in response to events, without requiring the overhead of managing infrastructure.
Why AWS Lambda?
Lambda is designed to handle a wide variety of events from different AWS services, including S3, DynamoDB, SNS, SQS, API Gateway, and many others. This ability to integrate with multiple services makes Lambda an essential tool in building a robust event-driven system.
Here are some of the key advantages of using AWS Lambda in an event-driven architecture:
Scalability: Lambda automatically scales the number of instances to match the rate of incoming events, handling thousands of concurrent executions without any intervention.
Cost Efficiency: You only pay for the compute time that your code actually uses, making Lambda highly cost-efficient, especially for systems with unpredictable workloads.
High Availability: AWS Lambda runs your code across multiple availability zones, ensuring that your functions are available even in the event of failure in one region.
Automatic Event Triggering: Lambda can automatically trigger in response to events from dozens of AWS services, making it easy to connect components and build a distributed, event-driven system.
Building an Event-Driven Architecture with AWS Lambda
Let’s walk through the steps of building an event-driven architecture using AWS Lambda, with an example of processing real-time file uploads.
1. Event Source: Amazon S3
In this example, the event that triggers the Lambda function will be the upload of a file to an Amazon S3 bucket. When a file is uploaded, S3 generates an event that can trigger a Lambda function to perform any processing required.
2. Lambda Function: Processing the File
Once the file is uploaded, the Lambda function is invoked. This function could perform tasks such as:
Validating the file format
Processing the contents (e.g., converting a file format or extracting metadata)
Storing results in a database or triggering other workflows
For example, if the uploaded file is an image, the Lambda function could generate thumbnails and store them in another S3 bucket.
3. Event Routing: Amazon SNS/SQS
Once the Lambda function processes the file, it can send a notification or trigger further processing. For instance, it might publish a message to Amazon SNS to notify downstream systems or forward a message to an SQS queue for another service to pick up and process asynchronously.
4. Chaining Lambda Functions: Step Functions
For more complex workflows, AWS Step Functions can be used to orchestrate multiple Lambda functions in a sequence. For instance, you might have one function for validating the file, another for processing it, and a final one for notifying other services.
Common Use Cases for Lambda in Event-Driven Architectures
AWS Lambda's flexibility and scalability make it a popular choice for a wide variety of use cases in event-driven architectures. Some common scenarios include:
Real-Time Data Processing: Whether it's logs, clickstreams, or IoT sensor data, Lambda can process data streams in real-time from services like Amazon Kinesis or DynamoDB Streams.
Automating Workflows: Lambda can automate processes such as responding to changes in an S3 bucket, scaling resources based on usage patterns, or orchestrating complex data pipelines.
Serverless APIs: By combining AWS API Gateway and Lambda, developers can build fully serverless APIs that react to HTTP requests, scale automatically, and are highly cost-effective.
Security and Monitoring: Lambda can respond to security events, such as analyzing CloudTrail logs in real-time for suspicious activity or automatically applying patches to resources in response to vulnerability reports.
Best Practices for Using AWS Lambda in Event-Driven Architectures
To make the most out of AWS Lambda in an event-driven architecture, consider these best practices:
Optimize Cold Starts: Cold starts can impact performance, especially for functions that aren’t frequently triggered. Use provisioned concurrency to keep functions "warm" when latency is critical.
Implement Idempotency: Since events may sometimes be delivered multiple times, ensure that your Lambda functions can handle duplicate invocations without causing errors or inconsistencies.
Monitor and Log: Use AWS CloudWatch Logs and X-Ray to monitor the performance of your Lambda functions, track events, and troubleshoot issues in real-time.
Error Handling and Retries: Set up proper error handling and retries for Lambda functions, especially when integrating with services like SQS or Kinesis that may require reprocessing of failed events.
Security: Apply the principle of least privilege by ensuring that Lambda functions only have access to the resources they need. Use AWS IAM roles carefully to define access permissions.
Conclusion
Event-driven architectures represent the future of cloud-native application development, and AWS Lambda is at the forefront of this paradigm shift. By leveraging Lambda’s ability to respond to events from a variety of sources, you can build scalable, flexible, and resilient systems that are both cost-effective and easy to maintain. Whether you’re processing real-time data streams, automating workflows, or building a serverless API, AWS Lambda is a powerful tool that can streamline and enhance your event-driven architecture.
Follow Us- https://www.instagram.com/lamdaevents/
0 notes
Text
Exploring AWS Lambda: The Future of Server less Computing
As technology continues to evolve, so does the way we build and deploy applications. Among the transformative advancements in cloud computing, AWS Lambda emerges as a leading force in the realm of serverless architecture. This innovative service from Amazon Web Services (AWS) enables developers to run code without the complexities of managing servers, paving the way for greater efficiency and scalability.
If you want to advance your career at the AWS Course in Pune, you need to take a systematic approach and join up for a course that best suits your interests and will greatly expand your learning path.

What is AWS Lambda?
AWS Lambda is a serverless compute service that allows you to execute code in response to specific events, such as changes in data, user requests, or system states. With Lambda, you can trigger functions from various AWS services like S3, DynamoDB, Kinesis, and API Gateway, allowing you to construct dynamic, event-driven applications effortlessly.
Key Features of AWS Lambda
Event-Driven Execution: AWS Lambda automatically responds to events, executing your code when specified triggers occur. This means you can concentrate on developing your application logic rather than managing infrastructure.
Automatic Scalability: As demand fluctuates, AWS Lambda scales your application automatically. Whether handling a single request or thousands, Lambda adjusts seamlessly to meet your needs.
Cost Efficiency: With a pay-as-you-go pricing model, you only pay for the compute time you consume. This means no charges when your code isn’t running, making it a cost-effective choice for many applications.
Multi-Language Support: AWS Lambda supports several programming languages, including Node.js, Python, Java, C#, and Go, giving developers the flexibility to work in their preferred languages.
Integration with AWS Services: Lambda works harmoniously with other AWS services, enabling you to build intricate applications effortlessly and take advantage of the broader AWS ecosystem.

To master the intricacies of AWS and unlock its full potential, individuals can benefit from enrolling in the AWS Online Training.
Exciting Use Cases for AWS Lambda
Real-Time Data Processing: Use Lambda to process data streams in real-time, such as transforming and analyzing data as it flows through services like Kinesis or responding to file uploads in S3.
API Development: Combine AWS Lambda with API Gateway to create robust RESTful APIs, allowing you to manage HTTP requests without the overhead of server management.
Automation of Tasks: Automate routine tasks, such as backups, monitoring, and notifications, facilitating smoother operations and reducing manual effort.
Microservices Architecture: Build applications using microservices, where individual Lambda functions handle specific tasks, enhancing modularity and maintainability.
Getting Started with AWS Lambda
Ready to dive into AWS Lambda? Here’s how you can get started:
Create an AWS Account: Sign up for an AWS account if you don’t already have one.
Access the AWS Management Console: Navigate to the Lambda service within the console.
Create a Lambda Function: Select a runtime, write your code (or upload a zip file), and configure your function settings.
Set Up Event Triggers: Configure triggers from other AWS services to execute your Lambda function based on specific events.
Testing and Monitoring: Utilize AWS CloudWatch to monitor performance, logs, and errors, helping you optimize your function.
Conclusion
AWS Lambda represents a paradigm shift in how applications are built and deployed. By embracing serverless architecture, developers can focus on writing code and delivering features without the burden of managing infrastructure. Whether you’re crafting a small application or a large-scale service, AWS Lambda provides the flexibility and scalability necessary to thrive in the modern cloud landscape.
0 notes
Text
🚀 Integrating ROSA Applications with AWS Services (CS221)
As cloud-native applications evolve, seamless integration between orchestration platforms like Red Hat OpenShift Service on AWS (ROSA) and core AWS services is becoming a vital architectural requirement. Whether you're running microservices, data pipelines, or containerized legacy apps, combining ROSA’s Kubernetes capabilities with AWS’s ecosystem opens the door to powerful synergies.
In this blog, we’ll explore key strategies, patterns, and tools for integrating ROSA applications with essential AWS services — as taught in the CS221 course.
🧩 Why Integrate ROSA with AWS Services?
ROSA provides a fully managed OpenShift experience, but its true potential is unlocked when integrated with AWS-native tools. Benefits include:
Enhanced scalability using Amazon S3, RDS, and DynamoDB
Improved security and identity management through IAM and Secrets Manager
Streamlined monitoring and observability with CloudWatch and X-Ray
Event-driven architectures via EventBridge and SNS/SQS
Cost optimization by offloading non-containerized workloads
🔌 Common Integration Patterns
Here are some popular integration patterns used in ROSA deployments:
1. Storage Integration:
Amazon S3 for storing static content, logs, and artifacts.
Use the AWS SDK or S3 buckets mounted using CSI drivers in ROSA pods.
2. Database Services:
Connect applications to Amazon RDS or Amazon DynamoDB for persistent storage.
Manage DB credentials securely using AWS Secrets Manager injected into pods via Kubernetes secrets.
3. IAM Roles for Service Accounts (IRSA):
Securely grant AWS permissions to OpenShift workloads.
Set up IRSA so pods can assume IAM roles without storing credentials in the container.
4. Messaging and Eventing:
Integrate with Amazon SNS/SQS for asynchronous messaging.
Use EventBridge to trigger workflows from container events (e.g., pod scaling, job completion).
5. Monitoring & Logging:
Forward logs to CloudWatch Logs using Fluent Bit/Fluentd.
Collect metrics with Prometheus Operator and send alerts to Amazon CloudWatch Alarms.
6. API Gateway & Load Balancers:
Expose ROSA services using AWS Application Load Balancer (ALB).
Enhance APIs with Amazon API Gateway for throttling, authentication, and rate limiting.
📚 Real-World Use Case
Scenario: A financial app running on ROSA needs to store transaction logs in Amazon S3 and trigger fraud detection workflows via Lambda.
Solution:
Application pushes logs to S3 using the AWS SDK.
S3 triggers an EventBridge rule that invokes a Lambda function.
The function performs real-time analysis and writes alerts to an SNS topic.
This serverless integration offloads processing from ROSA while maintaining tight security and performance.
✅ Best Practices
Use IRSA for least-privilege access to AWS services.
Automate integration testing with CI/CD pipelines.
Monitor both ROSA and AWS services using unified dashboards.
Encrypt data in transit and at rest using AWS KMS + OpenShift secrets.
🧠 Conclusion
ROSA + AWS is a powerful combination that enables enterprises to run secure, scalable, and cloud-native applications. With the insights from CS221, you’ll be equipped to design robust architectures that capitalize on the strengths of both platforms. Whether it’s storage, compute, messaging, or monitoring — AWS integrations will supercharge your ROSA applications.
For more details visit - https://training.hawkstack.com/integrating-rosa-applications-with-aws-services-cs221/
0 notes
Text
Implementing Serverless Architecture: A Practical Guide to AWS Lambda, Azure Functions, and Google Cloud Functions
In today's cloud-centric world, serverless architecture has emerged as a game-changer for businesses seeking to reduce operational overhead while increasing agility and scalability. This blog post will walk you through implementing serverless architectures using platforms like AWS Lambda, Azure Functions, and Google Cloud Functions.
What is Serverless Architecture?
Serverless architecture is a cloud computing model where the cloud provider manages the infrastructure, allowing you to focus solely on writing and deploying code. Unlike traditional server-based architectures, where you need to manage and maintain servers, serverless computing abstracts away this layer, letting you concentrate on application logic.
Why Serverless?
The serverless approach offers several benefits:
Cost-Efficiency: You only pay for the compute resources when your code runs, with no charge when it's idle.
Automatic Scaling: Serverless platforms scale automatically based on the incoming traffic, ensuring that your application is always ready to handle demand.
Reduced Maintenance: Since there's no server management involved, you can reduce the time spent on infrastructure and focus more on development and innovation.
Serverless Platforms Overview
1. AWS Lambda
AWS Lambda is one of the most popular serverless platforms, offering a highly reliable way to run code in response to events or triggers. It supports various programming languages, including Python, Node.js, Java, and more. AWS Lambda is tightly integrated with other AWS services, making it an ideal choice for existing AWS users.
Key Features:
Event-driven architecture
Granular billing with per-millisecond charging
Seamless integration with AWS services like S3, DynamoDB, and API Gateway
2. Azure Functions
Azure Functions is Microsoft's serverless offering that allows you to run event-driven code in response to various triggers, such as HTTP requests, database changes, or messages from a queue. It's particularly suitable for organizations already using the Azure ecosystem.
Key Features:
Supports multiple programming languages
Built-in DevOps capabilities for continuous deployment
Rich set of triggers and bindings
3. Google Cloud Functions
Google Cloud Functions is Google's serverless platform, designed to build lightweight, event-driven applications that can respond to cloud events. It's tightly integrated with Google Cloud services, making it a great fit for those leveraging Google's ecosystem.
Key Features:
Pay-as-you-go pricing model
Auto-scaling to handle fluctuating workloads
Simple setup and deployment with the Google Cloud Console
Implementation Approach
Implementing serverless architecture requires a strategic approach to ensure seamless integration and optimal performance. Here’s a step-by-step guide to get you started:
Step 1: Choose Your Platform
Decide which serverless platform (AWS Lambda, Azure Functions, or Google Cloud Functions) best fits your requirements. Factors like your existing tech stack, familiarity with cloud providers, and specific use cases will influence this decision.
Step 2: Design Event-Driven Triggers
Design your application to respond to specific triggers or events, such as HTTP requests, file uploads, database updates, or other events. This ensures that your functions execute only when required, saving both time and resources.
Step 3: Code Development
Write your code using supported programming languages like Python, JavaScript, C#, or Java. Ensure that your code is modular, concise, and focuses on the logic needed to handle specific events.
Step 4: Deployment
Deploy your functions using your chosen platform's console or through a CI/CD pipeline. Serverless platforms often have built-in deployment tools that simplify this process, allowing you to release updates quickly and easily.
Step 5: Monitor and Optimize
Monitor the performance of your serverless functions through built-in analytics and logging tools. Analyze metrics like execution time, memory usage, and error rates to optimize performance and reduce costs.
Benefits of Serverless Architecture
Implementing serverless architecture offers several benefits that can transform your business operations:
Reduced Costs: Pay only for the compute power you use, eliminating the need for costly idle server resources.
Scalability: Serverless platforms automatically handle scaling to meet your application’s demands, ensuring high availability and performance.
Faster Time-to-Market: Focus on developing features and functionality without worrying about infrastructure management.
Increased Flexibility: Easily integrate with other cloud services to build robust, scalable applications.
Real-World Use Cases
Many organizations have successfully adopted serverless architectures to streamline operations:
Data Processing: Automate data processing tasks like ETL (Extract, Transform, Load) using serverless functions triggered by data uploads.
API Backends: Build scalable RESTful APIs that can handle millions of requests using serverless architecture.
Chatbots: Create real-time chatbots that respond to user inputs through cloud-based serverless functions.
Conclusion
Serverless architecture is transforming how we build and deploy applications by removing the complexities of infrastructure management. Implementing serverless platforms like AWS Lambda, Azure Functions, and Google Cloud Functions can help you reduce costs, improve scalability, and focus more on delivering business value. By adopting a serverless approach, you'll stay ahead in today's fast-paced digital landscape.
Ready to go serverless? Start exploring the possibilities with AWS Lambda, Azure Functions, and Google Cloud Functions today!
Interested in more insights on serverless architectures and cloud-native services? Stay tuned to our blog for the latest updates and best practices!
For more details click www.hawkstack.com
0 notes
Text
AWS Lambda: Harnessing Serverless Computing

AWS Lambda graviton is a serverless compute service that runs your code in response to events and automatically manages the underlying compute resources for you. This article will explore the capabilities, use cases, and best practices for AWS Lambda, incorporating relevant examples and code snippets.
Understanding AWS Lambda graviton AWS Lambda allows you to run code without provisioning or managing servers. You can run code for virtually any type of application or backend service with zero administration. Lambda automatically scales your application by running code in response to each trigger.
Key Features of AWS Lambda Automatic Scaling: Lambda functions automatically scale with the number of triggers. Cost-Effective: You only pay for the compute time you consume. Event-Driven: Integrates with AWS services seamlessly to respond to events. Setting Up a Lambda Function 1. Create a Function: In the AWS Management Console, select Lambda and create a new function.
2. Configure Triggers: Choose triggers like HTTP requests via Amazon API Gateway or file uploads to S3.
3. Upload Your Code: Write your function code in languages like Python, Node.js, Java, or Go.
Example of a simple Lambda function in Python: import json
def lambda_handler(event, context):
print(“Received event: “ + json.dumps(event, indent=2))
return {
‘statusCode’: 200,
‘body’: json.dumps(‘Hello from Lambda!’)
} Deployment and Execution Deploy your code by uploading it directly in the AWS Console or through AWS CLI.
Lambda functions are stateless; they can quickly scale and process individual triggers independently.
Integrating AWS Lambda with Other Services Lambda can be integrated with services like Amazon S3, DynamoDB, Kinesis, and API Gateway. This integration allows for a wide range of applications like data processing, real-time file processing, and serverless web applications.
Monitoring and Debugging AWS Lambda integrates with CloudWatch for logging and monitoring. Use CloudWatch metrics to monitor the invocation, duration, and performance of your functions.
Best Practices for Using AWS Lambda Optimize Execution Time: Keep your Lambda functions lean to reduce execution time. Error Handling: Implement robust error handling within your Lambda functions. Security: Use IAM roles and VPC to secure your Lambda functions. Version Control: Manage different versions and aliases of your Lambda functions for better control. Use Cases for AWS Lambda Web Applications: Build serverless web applications by integrating with Amazon API Gateway. Data Processing: Real-time processing of data streams or batch files. Automation: Automate AWS services and resources management. Performance Tuning and Limitations Be aware of the execution limits like execution timeout and memory allocation. Optimize your code for cold start performance. Cost Management Monitor and manage the number of invocations and execution duration to control costs. Utilize AWS Lambda’s pricing calculator to estimate costs. Conclusion AWS Lambda graviton represents a paradigm shift in cloud computing, offering a highly scalable, event-driven platform that is both powerful and cost-effective. By understanding and implementing best practices for Lambda and incorporating ECS agents, developers can build highly responsive, efficient, and scalable applications without the overhead of managing servers. ECS agent enhance this infrastructure by enabling the seamless deployment and management of Docker containers, offering a flexible and efficient approach to application development and deployment. With Lambda and ECS agents working together, developers can leverage the benefits of serverless computing while ensuring optimal performance and resource utilization in containerized environments.
1 note
·
View note
Text
Building Scalable Applications with AWS Lambda: A Complete Tutorial

Are you curious about AWS Lambda but not sure where to begin? Look no further! In this AWS Lambda tutorial, we'll walk you through the basics in simple terms.
AWS Lambda is like having a magic wand for your code. Instead of worrying about servers, you can focus on writing functions to perform specific tasks. It's perfect for building applications that need to scale quickly or handle unpredictable workloads.
To start, you'll need an AWS account. Once you're logged in, navigate to the Lambda console. From there, you can create a new function and choose your preferred programming language. Don't worry if you're not a coding expert – Lambda supports many languages, including Python, Node.js, and Java.
Next, define your function's triggers. Triggers are events that invoke your function, such as changes to a database or incoming HTTP requests. You can set up triggers using services like API Gateway or S3.
After defining your function, it's time to test and deploy. Lambda provides tools for testing your function locally before deploying it to the cloud. Once you're satisfied, simply hit deploy, and Lambda will handle the rest.
Congratulations! You've now dipped your toes into the world of AWS Lambda. Keep experimenting and exploring – the possibilities are endless!
For more detailed tutorials and resources, visit Tutorial and Example.
Now, go forth and build amazing things with AWS Lambda!
0 notes
Text
"6 Ways to Trigger AWS Step Functions Workflows: A Comprehensive Guide"
To trigger an AWS Step Functions workflow, you have several options depending on your use case and requirements:
AWS Management Console: You can trigger a Step Functions workflow manually from the AWS Management Console by navigating to the Step Functions service, selecting your state machine, and then clicking on the "Start execution" button.
AWS SDKs: You can use AWS SDKs (Software Development Kits) available for various programming languages such as Python, JavaScript, Java, etc., to trigger Step Functions programmatically. These SDKs provide APIs to start executions of your state machine.
AWS CLI (Command Line Interface): AWS CLI provides a command-line interface to AWS services. You can use the start-execution command to trigger a Step Functions workflow from the command line.
AWS CloudWatch Events: You can use CloudWatch Events to schedule and trigger Step Functions workflows based on a schedule or specific events within your AWS environment. For example, you can trigger a workflow based on a time-based schedule or in response to changes in other AWS services.
AWS Lambda: You can integrate Step Functions with AWS Lambda functions. You can trigger a Step Functions workflow from a Lambda function, allowing you to orchestrate complex workflows in response to events or triggers handled by Lambda functions.
Amazon API Gateway: If you want to trigger a Step Functions workflow via HTTP requests, you can use Amazon API Gateway to create RESTful APIs. You can then configure API Gateway to trigger your Step Functions workflow when it receives an HTTP request.
These are some of the common methods for triggering AWS Step Functions workflows. The choice of method depends on your specific requirements, such as whether you need manual triggering, event-based triggering, or integration with other AWS services.
#AWS#StepFunctions#WorkflowAutomation#CloudComputing#AWSManagement#Serverless#DevOps#AWSLambda#AWSCLI#AWSConsole#magistersign#onlinetraining#cannada#support#usa
0 notes
Text
Understanding Serverless Computing in AWS: A Modern Approach to Scalable Cloud Architecture
In today’s fast-paced digital world, businesses are under constant pressure to deliver reliable, scalable, and cost-effective applications. Traditional server-based models often fall short in terms of agility and efficiency. Enter serverless computing, a revolutionary approach that lets developers build and run applications without worrying about managing infrastructure. At the forefront of this innovation is Amazon Web Services (AWS), which offers a robust serverless ecosystem designed to accelerate development and minimize operational complexity.
What is Serverless Computing in AWS?
Serverless computing in AWS training allows you to execute code without provisioning or managing servers. Instead of handling the heavy lifting—like capacity planning, scaling, patching, and server management—AWS takes care of it all. Developers simply upload their code as individual functions, and AWS automatically handles the rest.
This model is primarily powered by AWS Lambda, the core compute service that enables the execution of event-driven functions. These functions can be triggered by events from a wide range of AWS services, including S3, DynamoDB, API Gateway, and CloudWatch.
Why Serverless is Gaining Popularity
Focus on Code, Not Infrastructure
One of the most appealing aspects of serverless computing is its simplicity. Developers can focus solely on writing the application logic without spending time on backend server management. This results in faster development cycles and reduced time to market.
Built for Events and Automation
Serverless applications in AWS are event-driven. This means they respond automatically to specific triggers—such as file uploads, database changes, API calls, or scheduled tasks. This architecture promotes a highly automated and responsive system design..
Key Benefits of AWS Serverless Computing
Seamless Auto-Scaling
With AWS Lambda, your functions scale automatically based on demand. Whether you have ten users or ten thousand, Lambda ensures that the right number of function instances are running to handle the load. There’s no need for manual intervention or configuration adjustments.
Pay Only for What You Use
Serverless computing follows a pay-per-use billing model. You're only charged for the number of requests your function receives and the time it takes to run. This makes it a highly cost-efficient option, especially for startups and businesses with fluctuating workloads.
Stateless Function Execution
Each serverless function is stateless, which means every invocation is independent. There's no shared state between executions, ensuring higher reliability and making horizontal scaling effortless. For persistent data storage, you can integrate with AWS services like DynamoDB or S3.
Broad Language Support
AWS Lambda supports a variety of programming languages including Python, Node.js, Java, Ruby, C#, and PowerShell. Additionally, AWS allows developers to bring in custom runtimes for even more flexibility in building their functions.
Seamless Integration Across AWS Ecosystem
One of the biggest advantages of going serverless with AWS is the seamless integration across its vast array of services. Whether it’s storing data in Amazon S3, managing authentication with Amazon Cognito, or coordinating workflows with Step Functions, AWS provides all the building blocks needed for modern application development.
Ideal Use Cases for Serverless Architectures
Serverless computing is not just a theoretical concept—it’s being actively used in a wide range of applications:
Web and mobile backends: Handle API calls, user authentication, and data processing without managing servers.
Data processing pipelines: Automate workflows such as log analysis, image processing, and data transformation.
Real-time notifications: Send instant alerts or push notifications based on event triggers.
Scheduled tasks: Run periodic functions for cleanups, data sync, or maintenance.
Challenges to Keep in Mind
While serverless offers numerous advantages, it’s important to be aware of some limitations:
Cold starts: Functions may experience slight delays when invoked after a period of inactivity.
Execution limits: AWS Lambda has limits on execution duration, memory, and package size.
Monitoring complexity: Debugging and monitoring distributed functions may require additional tools like AWS CloudWatch or third-party observability platforms.
The Future of Serverless in Cloud Computing
Serverless computing is evolving rapidly and is now considered a mainstream approach for cloud-native applications. With continued enhancements in tooling, performance, and integration capabilities, serverless is poised to become the backbone of scalable, resilient, and agile application development in the coming years.
Conclusion: Why You Should Consider Serverless with AWS
If you're aiming to build applications that are agile, scalable, and cost-efficient, AWS serverless architecture is a powerful option to explore. By eliminating the overhead of server management, you can redirect your efforts toward innovation and delivering value to your users.
Ready to get started? Whether you're launching a startup or modernizing legacy systems, adopting serverless computing with AWS can simplify your cloud journey and enhance your productivity. Dive in today and experience the future of application development—without the servers.
0 notes
Text
AWS Address Lookup API and Lambda Functions
The files are in CSV format and the metadata is in plain text. The file list is organized by manuscript and contains a row per manuscript with a number of fields. Each manuscript has an ETag, which represents a unique version of the manuscript. The ETag is a 64-bit integer value that is computed from the contents of an object.
AWS provides multiple ways to expose your services publicly, including EC2 instances with public access and the more common use of Elastic IPs for load balancers. Exposing these services can allow attackers to run port scans to identify weaknesses in your infrastructure and target attacks based on identified vulnerabilities.
This blog post shows how to leverage AWS API Gateway and Lambda functions to perform address validation using Amazon Location Service Places. The service offers point-of-interest search functionality, and can convert a text string into geographic coordinates (geocoding) or reverse geocode a coordinate into a street address (reverse geocoding). The service also provides data storage options for your results.
To start, create an HTTP API in the AWS API Gateway console by selecting “API Gateway” in the Function Configuration form’s dropdown and choosing “Create a new API”. Once the API is created, select it in the console’s details page and open the Function Designer to set up connections for the Lambda function. These connections take the form of triggers -- various AWS services that can invoke your Lambda -- and destinations -- other AWS services that can route your lambda’s return values.
youtube
"
SITES WE SUPPORT
Address lookup API– Blogspot
SOCIAL LINKS
Facebook Twitter LinkedIn Instagram Pinterest
"
1 note
·
View note