#amazon lambda java example
Explore tagged Tumblr posts
Visit Tumblr Blog
Explore Tumblr blogs with no restrictions, modern design and the best experience.
Last Seen Tumblr Blogs





Fun Fact
Tumblr.com rank in the US is 25.
Text
AWS Lambda Compute Service Tutorial for Amazon Cloud Developers
Full Video Link - https://youtube.com/shorts/QmQOWR_aiNI Hi, a new #video #tutorial on #aws #lambda #awslambda is published on #codeonedigest #youtube channel. @java @awscloud @AWSCloudIndia @YouTube #youtube @codeonedigest #codeonedigest #aws #amaz
AWS Lambda is a serverless compute service that runs your code in response to events and automatically manages the underlying compute resources for you. These events may include changes in state such as a user placing an item in a shopping cart on an ecommerce website. AWS Lambda automatically runs code in response to multiple events, such as HTTP requests via Amazon API Gateway, modifications…

View On WordPress
#amazon lambda java example#aws#aws cloud#aws lambda#aws lambda api gateway#aws lambda api gateway trigger#aws lambda basic#aws lambda code#aws lambda configuration#aws lambda developer#aws lambda event trigger#aws lambda eventbridge#aws lambda example#aws lambda function#aws lambda function example#aws lambda function s3 trigger#aws lambda java#aws lambda server#aws lambda service#aws lambda tutorial#aws training#aws tutorial#lambda service
0 notes
Text
The Role of the AWS Software Development Kit (SDK) in Modern Application Development
The Amazon Web Services (AWS) Software Development Kit (SDK) serves as a fundamental tool for developers aiming to create robust, scalable, and secure applications using AWS services. By streamlining the complexities of interacting with AWS's extensive ecosystem, the SDK enables developers to prioritize innovation over infrastructure challenges.
Understanding AWS SDK
The AWS SDK provides a comprehensive suite of software tools, libraries, and documentation designed to facilitate programmatic interaction with AWS services. By abstracting the intricacies of direct HTTP requests, it offers a more intuitive and efficient interface for tasks such as instance creation, storage management, and database querying.
The AWS SDK is compatible with multiple programming languages, including Python (Boto3), Java, JavaScript (Node.js and browser), .NET, Ruby, Go, PHP, and C++. This broad compatibility ensures that developers across diverse technical environments can seamlessly integrate AWS features into their applications.
Key Features of AWS SDK
Seamless Integration: The AWS SDK offers pre-built libraries and APIs designed to integrate effortlessly with AWS services. Whether provisioning EC2 instances, managing S3 storage, or querying DynamoDB, the SDK simplifies these processes with clear, efficient code.
Multi-Language Support: Supporting a range of programming languages, the SDK enables developers to work within their preferred coding environments. This flexibility facilitates AWS adoption across diverse teams and projects.
Robust Security Features: Security is a fundamental aspect of the AWS SDK, with features such as automatic API request signing, IAM integration, and encryption options ensuring secure interactions with AWS services.
High-Level Abstractions: To reduce repetitive coding, the SDK provides high-level abstractions for various AWS services. For instance, using Boto3, developers can interact with S3 objects directly without dealing with low-level request structures.
Support for Asynchronous Operations: The SDK enables asynchronous programming, allowing non-blocking operations that enhance the performance and responsiveness of high-demand applications.
Benefits of Using AWS SDK
Streamlined Development: By offering pre-built libraries and abstractions, the AWS SDK significantly reduces development overhead. Developers can integrate AWS services efficiently without navigating complex API documentation.
Improved Reliability: Built-in features such as error handling, request retries, and API request signing ensure reliable and robust interactions with AWS services.
Cost Optimization: The SDK abstracts infrastructure management tasks, allowing developers to focus on optimizing applications for performance and cost efficiency.
Comprehensive Documentation and Support: AWS provides detailed documentation, tutorials, and code examples, catering to developers of all experience levels. Additionally, an active developer community offers extensive resources and guidance for troubleshooting and best practices.
Common Use Cases
Cloud-Native Development: Streamline the creation of serverless applications with AWS Lambda and API Gateway using the SDK.
Data-Driven Applications: Build data pipelines and analytics platforms by integrating services like Amazon S3, RDS, or Redshift.
DevOps Automation: Automate infrastructure management tasks such as resource provisioning and deployment updates with the SDK.
Machine Learning Integration: Incorporate machine learning capabilities into applications by leveraging AWS services such as SageMaker and Rekognition.
Conclusion
The AWS Software Development Kit is an indispensable tool for developers aiming to fully leverage the capabilities of AWS services. With its versatility, user-friendly interface, and comprehensive features, it serves as a critical resource for building scalable and efficient applications. Whether you are a startup creating your first cloud-native solution or an enterprise seeking to optimize existing infrastructure, the AWS SDK can significantly streamline the development process and enhance application functionality.
Explore the AWS SDK today to unlock new possibilities in cloud-native development.
0 notes
Text
What Are Examples of AWS Managed Services?
In today's fast-paced digital world, businesses are increasingly relying on cloud services to optimize their operations and deliver exceptional user experiences. Amazon Web Services (AWS) has emerged as a dominant player in the cloud computing space, providing a wide array of services to cater to diverse business needs. AWS-managed services offer a remarkable advantage by offloading the burden of managing infrastructure and allowing organizations to focus on their core competencies. In this blog, we will explore some prominent examples of AWS-managed services and delve into their benefits, highlighting how Flentas, an AWS consulting partner, also offers managed services to help businesses thrive in the cloud era.
Amazon RDS (Relational Database Service)
One of the most widely used managed services offered by AWS is Amazon RDS. It simplifies the management of relational databases such as MySQL, PostgreSQL, Oracle, and SQL Server. Amazon RDS handles essential database tasks like provisioning, patching, backup, recovery, and scaling, allowing developers to focus on their applications rather than database administration. With features like automated backups, automated software patching, and easy replication, Amazon RDS streamlines database management and improves availability, durability, and performance.
Amazon DynamoDB
For those in need of a NoSQL database, Amazon DynamoDB is an excellent choice. It is a fully managed, highly scalable, and secure database service that supports both document and key-value data models. DynamoDB takes care of infrastructure provisioning, software patching, and database scaling, ensuring high availability and performance. With its seamless integration with other AWS services, such as Lambda and API Gateway, DynamoDB becomes an ideal choice for building serverless applications and microservices that require low-latency data access.
Amazon Elastic Beanstalk
Amazon Elastic Beanstalk provides a platform as a service (PaaS) for deploying and managing applications without worrying about infrastructure details. It supports popular programming languages like Java, .NET, Python, PHP, Ruby, and more. Elastic Beanstalk handles the deployment, capacity provisioning, load balancing, and auto-scaling of your applications, allowing developers to focus on writing code. It integrates with other AWS services, enabling easy access to services like RDS, DynamoDB, and S3. With Elastic Beanstalk, developers can quickly deploy and manage their applications, reducing time-to-market and enhancing productivity.
Amazon Redshift
When it comes to data warehousing, Amazon Redshift is a powerful managed service offered by AWS. It is specifically designed for big data analytics and provides high-performance querying and scalable storage. Redshift takes care of infrastructure management, including provisioning, patching, and backups, while also delivering automatic data compression and encryption. With its columnar storage technology, parallel query execution, and integration with popular business intelligence tools like Tableau, Redshift enables businesses to analyze vast amounts of data efficiently and derive valuable insights.
AWS Lambda
AWS Lambda is a serverless computing service that allows you to run your code without provisioning or managing servers. It executes your code in response to events, such as changes to data in an S3 bucket or updates to a DynamoDB table. AWS Lambda scales automatically, ensuring that your code runs smoothly even under high loads. By utilizing Lambda, businesses can reduce costs by paying only for the actual compute time consumed by their applications. It seamlessly integrates with other AWS services, enabling developers to build highly scalable and event-driven architectures easily.
In the realm of cloud computing, AWS-managed services provide businesses with a competitive edge by alleviating the complexities of infrastructure management. This blog has explored a few notable examples of AWS-managed services, including Amazon RDS, Amazon S3, Amazon EC2, Amazon Athena, and AWS Lambda. These services enable organizations to organizations to optimize their operations, reduce costs, and rapidly innovate in the cloud. It's worth noting that Flentas, as an AWS consulting partner, also offers AWS cloud managed services to assist businesses in harnessing the full potential of AWS. By partnering with Flentas, organizations can leverage our expertise in cloud technology.
For more details about our services please visit our website – Flentas Services
0 notes
Text
AWS Lambda: Harnessing Serverless Computing

AWS Lambda graviton is a serverless compute service that runs your code in response to events and automatically manages the underlying compute resources for you. This article will explore the capabilities, use cases, and best practices for AWS Lambda, incorporating relevant examples and code snippets.
Understanding AWS Lambda graviton AWS Lambda allows you to run code without provisioning or managing servers. You can run code for virtually any type of application or backend service with zero administration. Lambda automatically scales your application by running code in response to each trigger.
Key Features of AWS Lambda Automatic Scaling: Lambda functions automatically scale with the number of triggers. Cost-Effective: You only pay for the compute time you consume. Event-Driven: Integrates with AWS services seamlessly to respond to events. Setting Up a Lambda Function 1. Create a Function: In the AWS Management Console, select Lambda and create a new function.
2. Configure Triggers: Choose triggers like HTTP requests via Amazon API Gateway or file uploads to S3.
3. Upload Your Code: Write your function code in languages like Python, Node.js, Java, or Go.
Example of a simple Lambda function in Python: import json
def lambda_handler(event, context):
print(“Received event: “ + json.dumps(event, indent=2))
return {
‘statusCode’: 200,
‘body’: json.dumps(‘Hello from Lambda!’)
} Deployment and Execution Deploy your code by uploading it directly in the AWS Console or through AWS CLI.
Lambda functions are stateless; they can quickly scale and process individual triggers independently.
Integrating AWS Lambda with Other Services Lambda can be integrated with services like Amazon S3, DynamoDB, Kinesis, and API Gateway. This integration allows for a wide range of applications like data processing, real-time file processing, and serverless web applications.
Monitoring and Debugging AWS Lambda integrates with CloudWatch for logging and monitoring. Use CloudWatch metrics to monitor the invocation, duration, and performance of your functions.
Best Practices for Using AWS Lambda Optimize Execution Time: Keep your Lambda functions lean to reduce execution time. Error Handling: Implement robust error handling within your Lambda functions. Security: Use IAM roles and VPC to secure your Lambda functions. Version Control: Manage different versions and aliases of your Lambda functions for better control. Use Cases for AWS Lambda Web Applications: Build serverless web applications by integrating with Amazon API Gateway. Data Processing: Real-time processing of data streams or batch files. Automation: Automate AWS services and resources management. Performance Tuning and Limitations Be aware of the execution limits like execution timeout and memory allocation. Optimize your code for cold start performance. Cost Management Monitor and manage the number of invocations and execution duration to control costs. Utilize AWS Lambda’s pricing calculator to estimate costs. Conclusion AWS Lambda graviton represents a paradigm shift in cloud computing, offering a highly scalable, event-driven platform that is both powerful and cost-effective. By understanding and implementing best practices for Lambda and incorporating ECS agents, developers can build highly responsive, efficient, and scalable applications without the overhead of managing servers. ECS agent enhance this infrastructure by enabling the seamless deployment and management of Docker containers, offering a flexible and efficient approach to application development and deployment. With Lambda and ECS agents working together, developers can leverage the benefits of serverless computing while ensuring optimal performance and resource utilization in containerized environments.
1 note
·
View note
Text
"6 Ways to Trigger AWS Step Functions Workflows: A Comprehensive Guide"
To trigger an AWS Step Functions workflow, you have several options depending on your use case and requirements:
AWS Management Console: You can trigger a Step Functions workflow manually from the AWS Management Console by navigating to the Step Functions service, selecting your state machine, and then clicking on the "Start execution" button.
AWS SDKs: You can use AWS SDKs (Software Development Kits) available for various programming languages such as Python, JavaScript, Java, etc., to trigger Step Functions programmatically. These SDKs provide APIs to start executions of your state machine.
AWS CLI (Command Line Interface): AWS CLI provides a command-line interface to AWS services. You can use the start-execution command to trigger a Step Functions workflow from the command line.
AWS CloudWatch Events: You can use CloudWatch Events to schedule and trigger Step Functions workflows based on a schedule or specific events within your AWS environment. For example, you can trigger a workflow based on a time-based schedule or in response to changes in other AWS services.
AWS Lambda: You can integrate Step Functions with AWS Lambda functions. You can trigger a Step Functions workflow from a Lambda function, allowing you to orchestrate complex workflows in response to events or triggers handled by Lambda functions.
Amazon API Gateway: If you want to trigger a Step Functions workflow via HTTP requests, you can use Amazon API Gateway to create RESTful APIs. You can then configure API Gateway to trigger your Step Functions workflow when it receives an HTTP request.
These are some of the common methods for triggering AWS Step Functions workflows. The choice of method depends on your specific requirements, such as whether you need manual triggering, event-based triggering, or integration with other AWS services.
#AWS#StepFunctions#WorkflowAutomation#CloudComputing#AWSManagement#Serverless#DevOps#AWSLambda#AWSCLI#AWSConsole#magistersign#onlinetraining#cannada#support#usa
0 notes
Text
Is AWS Lambda serverless computing?

Yes, AWS Lambda is a serverless computing service provided by Amazon Web Services (AWS). Serverless computing is a cloud computing model that allows you to run code without provisioning or managing servers. AWS Lambda is a prime example of a serverless platform, and it offers the following key features:
No Server Management
With AWS Lambda, you don't need to worry about server provisioning, scaling, patching, or maintenance. AWS takes care of all the underlying infrastructure, allowing you to focus solely on your code.
Event-Driven
AWS Lambda functions are triggered by specific events, such as changes to data in an Amazon S3 bucket, updates to a database table, or HTTP requests via Amazon API Gateway. When an event occurs, Lambda automatically runs the associated function.
Auto-Scaling
AWS Lambda scales your functions automatically based on the incoming workload. It can handle a single request or millions of requests simultaneously, ensuring that you only pay for the compute resources you use.
Stateless
Lambda functions are stateless, meaning they don't maintain persistent server-side state between invocations. They operate independently for each event, making them highly scalable and fault-tolerant.
Pay-Per-Use
With Lambda, you are billed based on the number of requests and the execution time of your functions. There is no charge for idle resources, which makes it cost-effective for workloads with variable or sporadic traffic.
Integration with Other AWS Service
Lambda integrates seamlessly with various AWS services, making it a powerful tool for building event-driven applications and workflows. It can be used for data processing, real-time file processing, backend API logic, and more.
Support for Multiple Programming Languages
AWS Lambda supports a variety of programming languages, including Python, Node.js, Java, Ruby, C#, PowerShell, and custom runtimes. This flexibility allows you to choose the language that best suits your application.
0 notes
Text
Go Serverless with Java and Azure Functions
Digital transformation has made waves in many industries, with revolutionary models such as Infrastructure as a Service (IaaS) and Software as a Service (SaaS) making digital tools much more accessible and flexible, allowing you to rent the services you require rather than make large investments in owning them. Functions as a Service (FaaS) follows the same logic; if we think of digital infrastructure as storage boxes, this is a framework that allows us to rent storage as needed. Organizations can go serverless with one of many cloud service providers, such as Microsoft Azure, Amazon Web Services (AWS), and Google Cloud, rather than owning and managing everything through a private cloud. This enables us to develop and launch applications without the need to build and maintain our infrastructure, which can be expensive and time-consuming.
Amazon Web Services (AWS) pioneered serverless computing in 2014, with competitors such as Google and Microsoft quickly catching up (Thomas Koenig from Netcentric hosted a talk on AWS serverless functions). Since then, technology has advanced rapidly, with industry leaders constantly pushing for innovation in functionality. Many of our enterprise clients use Azure today, and Azure Functions has developed functionality to compete with top competitors like AWS Lambda. So, as an example of how serverless computing can benefit your business with efficient and cost-effective solutions, consider Azure Functions.
An introduction to Azure Functions
Azure Functions is a serverless computing platform that uses events to accelerate app development by providing a more streamlined way to deploy code and logic in the cloud. The following are the primary components of an Azure function:
1. Events (Triggers)
An event must occur for a function to be executed; Azure refers to these as triggers. There are numerous types, with HTTP and webhooks being the most common, where functions are invoked with HTTP requests and respond to webhooks. There is also blob storage triggers that fire when a file is added to a storage container and timer triggers that can be set to fire at specific times.
2. Data (Bindings)
Then there's data, which is pulled in before and pushed out after a function is executed. These are known as bindings in Azure, and each function can have multiple bindings. By avoiding data connectors, bindings help to reduce boilerplate code and improve development efficiency.
3. Coding and Configuration
Finally, the functions have code and configuration. C#, Node.js, Python, F#, Java, and PowerShell are all supported by Azure. For more complex, nuanced cases, you can also use your custom runtime.
Configuring Azure Functions for your team
Keep in mind that functions running in the cloud are inactive until they are initialized. This is referred to as a "cold start." Microsoft provides several hosting plans to help mitigate this potential issue:
Consumption Plan: This is the default serverless plan and is essentially a pay-as-you-go plan. When your functions are running, you are only charged for the resources used.
Premium Plan: The Premium Plan includes the same demand-based auto-scaling as the Consumption Plan, but with the added benefit of using pre-warmed or standby instances. This means that functions are already initialized and ready to be triggered, reducing the cold start issue for organizations that require real-time responses.
App Service Plan: With this plan, virtual machines are always running, eliminating the need for cold starts. This is ideal for long-running operations or when more accurate scaling and costing are required.
How to Effectively Use Functions
To begin with, there are a few general guidelines to follow when writing functions:
Functions should only perform one task.
Idempotent functions are those that can be scaled in parallel.
Functions should be completed as soon as possible (Note: Azure's Consumption Plan restricts function runtime to 10 minutes).
Durable Functions are available in Azure when your setups become more complex than small functions performing single tasks. You can also chain functions, fan-in, and fan-out to spread the execution of your functions, and set up other patterns with these.
Example: Using Azure Functions to import product data in bulk
In a recent search project, we needed to import product data from the Product Information Management (PIM) system to the Elasticsearch search engine. We used Azure Functions with the Consumption plan to pay only for the execution time during the import because the batch import would run daily. The cold start issue would not be a problem because we did not require quick initial responses during the batch import.
The PIM begins the process every day by exporting, compressing, and uploading product data to Azure Blob Storage.
When the product data zips are uploaded, the Unzip Function is bound to the product-import container in Azure Blob Storage and is triggered. The Unzip function extracts each zip into a 1GB JSON file and uploads it to a new Blob Storage container.
When product data in JSON format is uploaded, the Import Function is bound to the product-process container and is triggered. It parses product JSONs, runs the business logic flow, and then sends product data to Elasticsearch for indexing.
This is one example of how we can use Azure Functions to create a powerful, streamlined solution. It is simple to set up, saves time and effort, and costs only a few euros per month to run on the consumption plan.
Azure Functions is open source and constantly evolving, making it simple to stay up to date on the latest features and exchange best practices and examples with the developer community. Many of our enterprise clients already use Microsoft Azure as a Cloud Service Provider, making Azure's serverless capabilities, fast business logic implementation, and pay-as-you-go pricing a no-brainer to integrate into their tech stack. We can collaborate with these teams to implement new solutions in the cloud faster with FaaS, and the transparent and pay-as-you-go pricing models are the icing on the cake. The Azure Function is a powerful tool with many configuration options for organizations with varying needs; it is best to work with an experienced team to tailor the right solution for you.
How can Cambay Consulting help you?
We strive to be our customers' most valuable partner by expertly guiding them to the cloud and providing ongoing support. Cambay Consulting, a Microsoft Gold Partner, offers "Work from Home" offerings to customers for them to quickly and efficiently deploy work from home tools, solutions, and best practices to mitigate downtime, ensure business continuity, and improve employee experience and productivity.
What does Cambay Consulting provide?
Through our talented people, innovative culture, and technical and business expertise, we achieve powerful results and outcomes that improve our clients' businesses and help them compete and succeed in today's digital world. We assist customers in achieving their digital transformation goals and objectives by providing services based on Microsoft technology, such as Managed Delivery, Project, and Change Management.
0 notes
Text

Amazon is one of the app development leaders in supplying various cloud services, boasting numerous dozens and counting. Amazon EC2 is one of the maximum famous Amazon services and is the main part of the Amazon Cloud computing software development platform that changed into offered in 2006. Amazon EC2 is broadly used nowadays, however, the recognition of every other Amazon web development provider referred to as Lambda is likewise growing.
AWS lambda vs AWS EC2
AWS Lambda vs AWS EC2
AWS EC2
AWS EC2 is a provider that lets in the use of digital machines referred to as EC2 times within the app developers cloud and supplying scalability. You can extrude the quantity of disk space, CPU overall flutter development performance, reminiscence, etc. You can choose the bottom photo with the essential pre-hooked-up working machine which includes Linux or Windows after which configure maximum OS settings in addition to putting in custom app development. You have the foundation to get entry to on your Amazon EC2 times and may create extra users. Manage the whole thing you want to manipulate your EC2 along with rebooting and closing down the example. The class of AWS EC2 providers is referred to as Infrastructure as a Service.
AWS Lambda
AWS Lambda is a computing platform that lets you run a bit of code written on one of the supported app development programming languages – Java, JavaScript, or Python web development while a cause related to an occasion is fired. You don’t want to configure the digital server and surroundings to run the software development that you’ve got written. Just insert your app development code within the AWS Lambda interface, accomplice the Lambda feature with the occasion, and run the software development within the cloud while needed, without looking after server control and surroundings configuration.
AWS Lambda vs AWS EC2 process
Security
Amazon EC2: For EC2, you’ve got complete manipulate over machine-stage safety. However, due to the fact you want to configure the app developers agencies, Network ACLs, and VPC subnet course tables to manipulate visitors within and out of the example, it may take time to make certain the machine is completely steady.
Winner: Lambda is greater regular out of the box, at the same time as flutter development EC2 offers greater manage over protection.
Monitoring
Amazon EC2: When walking EC2 times, you want to intently tune numerous metrics:
Availability – To keep away from an outage in production, you want to recognize if every one of the EC2 times walking a software development is healthful or now no longer.
System mistakes – Machine mistakes may be observed within the machine log report like /var/log/Syslog. You can mixture those logs to Amazon CloudWatch with the aid of using putting in the agent or use Syslog to ahead the logs to every other device like Splunk or ELK.
Activity auditing – EC2 wishes lots of guide configuration and every now and then it is able to pass wrong.
Performance metrics – You could display CPU utilization and disk utilization thru CloudWatch logs.
Cost monitoring – EC2 times count, EBS quantity utilization, and app development community utilization are very critical to display as auto-scaling can drastically have an web development effect on AWS billing. CloudWatch affords an app developers few facts approximately the community utilization for example however doesn’t deliver basic facts of what number of times are being used, or how a whole lot garage and community bandwidth is used on the account stage.
How to Choose?
AWS Lambda and AWS EC2 have clean differences. Neither one is higher than the opposite, however, there are conditions in which one is extra flutter development ideal than the opposite. AWS Lambda is most usually used while facts manipulation wishes to arise on a constant app development basis. Let’s say which you want to add purchaser facts into the cloud, however, you want to obfuscate fabric while it lands within the S3 bucket. A lambda feature could be an excellent solution.
As quickly because the document is positioned within the S3 bucket, a lambda feature will understand that occasion as something referred to as a cause. Once that cause is pulled, the lambda will loop via the bucket and mask the facts. If this system fails for a few reasons, the report could be eliminated from the S3 bucket.
EC2 is right for growing web development. You could spin up an EC2 example, and on that example, there will be a NoSQL database that includes DynamoDB to save consumer app development facts. Load balancers and gateways may also be positioned onto the example to provide get entry to the internet.
Conclusion
Today’s weblog submit has in comparison AWS EC2 and AWS Lambda due to the fact of AWS Lambda vs AWS EC2 is a famous subject matter nowadays. AWS EC2 is a provider that represents the conventional cloud infrastructure (IaaS) and lets you run EC2 times as VMs, configure environments, and run custom app development. AWS Lambda is the implementation of Function as a service by means of using amazon that lets you run your software development while not having to fear approximately underlying infrastructure. AWS Lambda affords you a serverless structure and lets you run a app developers bit of code within the cloud after an occasion cause is activated.
0 notes
Text
Saturday (17-7-2021)
54 + of Best Selection with a 100 % discount
Udemy Paid Courses (FREE AND CERTIFIED)
Udemy (https://www.udemy.com/course/functional-skills-math-level-1/?couponCode=03814548E5DE82DAE997)
Functional Skills Math Level 1 (Mental Math Course)
Udemy (https://www.udemy.com/course/fitvucut-ve-kariyerrehberi/?couponCode=3AF21493750B69EAD65C)
Fit Vücut ve Kariyer Rehberi - Visualization Method
Udemy (https://www.udemy.com/course/full-stack-programming-for-complete-beginners-in-python/?couponCode=JULYFREE)
Full Stack Programming for Complete Beginners in Python
Udemy (https://www.udemy.com/course/storytelling-with-imagery-for-persuasion/?couponCode=395053B43814DE564E6F)
Storytelling With Imagery For Persuasion & Personal Brand
Udemy (https://www.udemy.com/course/managerial-accounting-cost-accounting/?couponCode=6C9F0714081F917F47D5)
Managerial Accounting / Cost Accounting
Udemy (https://www.udemy.com/course/html-css-certification-course-for-beginners-e/?couponCode=A9N6U1RFF12IE93CBK)
HTML & CSS - Certification Course for Beginners
Udemy (https://www.udemy.com/course/corporate-finance/?couponCode=B0EB1C11DC7BCBED32D0)
Corporate Finance
Udemy (https://www.udemy.com/course/python-for-beginners-learn/?couponCode=4B686399428F233495)
Python for beginners - Learn all the basics of python
Udemy (https://www.udemy.com/course/complete-course-in-autocad-electrical-2021/?couponCode=LOADCALC)
Complete Course in AutoCAD Electrical 2021
Udemy (https://www.udemy.com/course/200-questions-answers-pmp-exam-2021-new-6th-edition-v/?couponCode=3E0D629246187E351BE9)
+1000 Questions & Answers PMP EXAM 2021 (New 6th Edition V)
Udemy (https://www.udemy.com/course/learning-solidworks-for-students-engineers-and-designers/?couponCode=WORK3D)
Learning SOLIDWORKS : For Students, Engineers, and Designers
Udemy (https://www.udemy.com/course/filosofia-de-la-persuasion/?couponCode=JULIO-FREE)
Filosofía de la Persuasión: El poder de las palabras
Udemy (https://www.udemy.com/course/taller-literario-como-escribir-poesia-cuento-y-novela/?couponCode=JULIO-FREE)
Taller literario: Cómo escribir poesía, cuento y novela
Udemy (https://www.udemy.com/course/la-mejor-version-de-vos-sobre-durmientes-y-jugadores/?couponCode=JULIO-FREE)
La Mejor Versión de Vos: "Cómo No Ser un Durmiente".
Udemy (https://www.udemy.com/course/best-keto-recipes-thai-food-ketogenic-diet-thai-cooking/?couponCode=KETOTH012021)
Best Keto Recipes Thai Food Ketogenic Diet Thai Cooking
Udemy (https://www.udemy.com/course/video-editing-with-adobe-premiere-pro-cc-for-beginners/?couponCode=76CE6356FADC12548358)
Video Editing with Adobe Premiere Pro CC 2021 for Beginners
Udemy (https://www.udemy.com/course/new-aws-certified-cloud-practitioner-2021/?couponCode=100FREECOUPON3DAYS)
[NEW] Amazon AWS Certified Cloud Practitioner 225 questions
Udemy (https://www.udemy.com/course/programming-fundamentals-with-pythonincluded-opp/?couponCode=PROGRAMMING-PYTHON)
Programming Fundamentals with Python(Included OPP)
Udemy (https://www.udemy.com/course/adobe-illustrator-cc-2020-master-course/?couponCode=TRY10FREE72106)
Adobe Illustrator 2021 Ultimate Course
Udemy (https://www.udemy.com/course/adobe-animate-cc-2020-master-course/?couponCode=TRY10FREE72106)
Adobe Animate 2021 Ultimate Course
Udemy (https://www.udemy.com/course/adobe-after-effects-cc-2020/?couponCode=TRY10FREE72106)
Adobe After Effects 2021 Ultimate Course
Udemy (https://www.udemy.com/course/angular-net-core-aplicacion-de-preguntas-y-respuestas/?couponCode=FREE-JULIO)
Angular - NET Core - Aplicacion de Preguntas y Respuestas
Udemy (https://www.udemy.com/course/learn-asana-master-course/?couponCode=TRY10FREE72106)
Asana Ultimate Course 2021
Udemy (https://www.udemy.com/course/scrum-genman/?couponCode=SCRFRJU)
Scrum Fundamentals for Scrum Master and Agile Projects- 2021
Udemy (https://www.udemy.com/course/como-escribir-letras-de-canciones-pop-rock-blues/?couponCode=JULIO-FREE)
Cómo Escribir Letras de Canciones Pop, Rock & Blues
Udemy (https://www.udemy.com/course/philosophy-of-astrobiology/?couponCode=UDEMY2021)
Philosophy of Astrobiology
Udemy (https://www.udemy.com/course/java-basico-para-recruiters-y-no-programadores/?couponCode=JULIO-FREE)
Java Básico para Recruiters y no Programadores
Udemy (https://www.udemy.com/course/local-digital-marketing/?couponCode=JULYGOODNESS7)
Complete Digital Marketing Course for Local Businesses 2021
Udemy (https://www.udemy.com/course/make-money-online-for-beginners/?couponCode=3C6C627F6CC7C8E7CAC8)
How to Make Money Online for Beginners: Follow PROVEN STEPS!
Udemy (https://www.udemy.com/course/stockmarket/?couponCode=18584B5F7A2564C5879C)
Stock Market Investopedia: Investing, Trading & Shorting
Udemy (https://www.udemy.com/course/the-python-programming-for-anyone-immersive-training/?couponCode=3D1F07E970D5F29FF96E)
The Python Programming For Everyone Immersive Training
Udemy (https://www.udemy.com/course/maya-for-absolute-beginners-in-bangla/?couponCode=ARIFSIRMAYA22)
Maya for Absolute Beginners in Bangla
Udemy (https://www.udemy.com/course/local-seo-2022/?couponCode=JULYGOODNESS77)
Local SEO 2021 Made Simple & Fun + Google Maps & TripAdvisor
Udemy (https://www.udemy.com/course/new-python-programming-the-complete-guide-2021-edition/?couponCode=CBA7C53E9F5882329C2E)
The Python Developer Essentials 2021 Immersive Bootcamp
Udemy (https://www.udemy.com/course/teachonskillshare/?couponCode=A6C148CA215CA25CF608)
Skillshare: Teaching, Marketing & Promotions Complete Course
Udemy (https://www.udemy.com/course/excel-quick-start-guide-from-beginner-to-expert/?couponCode=ZXLFRLY)
Zero to Hero in Microsoft Excel: Complete Excel guide 2021
Udemy (https://www.udemy.com/course/the-ultimate-python-programming-a-z-masterclass/?couponCode=D3D95243006AF21258B2)
The Python Programming A-Z Definitive Diploma in 2021
Udemy (https://www.udemy.com/course/the-intermediate-python-training-boost-your-python-skills/?couponCode=EB40F8EC115E639CD39D)
Intermediate Python Immersive Training | Boost your career
Udemy (https://www.udemy.com/course/time-management-mastery-boost-productivity-and-save-time/?couponCode=A1A34838F2CB7CE3C5E4)
Time Management Mastery - Boost Productivity and Save Time
Udemy (https://www.udemy.com/course/az-204-mock-test/?couponCode=DD8800604AF5840F351C)
AZ-204 Mock Tests
Udemy (https://www.udemy.com/course/labview-nxg-sql-server/?couponCode=DFB1CA92924E568B47EE)
LabVIEW NXG and SQL
Udemy (https://www.udemy.com/course/learn-microsoft-publisher-2016-complete-course-for-beginners/?couponCode=EA741A18929FF23F1A29)
Learn Microsoft Publisher 2016 Complete Course for Beginners
Udemy (https://www.udemy.com/course/python-programming-beyond-the-basics-intermediate-training/?couponCode=9BD46ABF6ABE7366B312)
Python Programming Beyond The Basics & Intermediate Training
Udemy (https://www.udemy.com/course/nanotechnology/?couponCode=NANO-LEARN-FREE)
Nanotechnology : Introduction, Essentials, and Opportunities
Udemy (https://www.udemy.com/course/alteryx-masterclass-for-data-analytics-etl-and-reporting/?couponCode=ALTFRETLY)
Alteryx Masterclass for Data Analytics, ETL and Reporting
Udemy (https://www.udemy.com/course/aprende-las-bases-de-programacion-con-c/?couponCode=F7A972D9367E80D9746B)
Aprende las bases de programación con C
Udemy (https://www.udemy.com/course/control-systems-lab-kic-652-using-matlab/?couponCode=248A95E363A3ACD57BD0)
Control Systems Lab
Udemy (https://www.udemy.com/course/software-architecture-learnit/?couponCode=ARCH_JUL_FREE_2)
Software Architecture and Clean Code Design in OOP
Udemy (https://www.udemy.com/course/first-steps-into-public-speaking-u/?couponCode=JULY2021)
First Steps Into Public Speaking
Udemy (https://www.udemy.com/course/learn-javascript-from-beginner-to-advanced/?couponCode=JS_JUL_FREE_2)
Complete Javascript & jQuery Course with Bonus Vue JS Intro
Udemy (https://www.udemy.com/course/learn-aspnet-mvc-and-entity-framework/?couponCode=ASPNET_JUL_FREE_2)
Learn ASP.Net MVC and Entity Framework (Database First)
Udemy (https://www.udemy.com/course/advanced-php-web-development-w-mysql-github-bootstrap-4/?couponCode=PHP_JUL_FREE_2)
Modern PHP Web Development w/ MySQL, GitHub & Heroku
Udemy (https://www.udemy.com/course/functional-programming-learnit/?couponCode=FP_JUL_FREE_2)
Functional Programming + Lambdas, Method References, Streams
Udemy (https://www.udemy.com/course/java-development-for-beginners-learnit/?couponCode=JAVA_JUL_FREE_2)
Java from Zero to First Job - Practical Guide, 600+ examples
Get Real-Time Updates about new courses offers
(Here): https://t.me/udemyz
Join Us

0 notes
Text
Use AWS Lambda functions with Amazon Neptune
Many Amazon Neptune connected data applications for knowledge graphs, identity graphs, and fraud graphs use AWS Lambda functions to query Neptune. This post provides general connection management, error handling, and workload balancing guidance for using any of the popular Gremlin drivers and language variants to connect to Neptune from a Lambda function. The connection management guidance here applies primarily to applications that use Gremlin drivers with long-lived WebSocket connections to connect to Neptune. The recommended way of querying Neptune from a Lambda function that uses a Gremlin driver has changed with recent engine releases, from opening and closing a WebSocket connection per Lambda invocation, to using a single connection for the duration of the function’s execution context. This post explains the reason for the change, illustrated with specific examples of Lambda functions written in Java, JavaScript, and Python. The error handling and workload balancing guidance in this post applies not only to Lambda functions that use Gremlin drivers, but also to functions that connect to a Neptune Gremlin or SPARQL endpoint over HTTP. Background In this section, we discuss the Lambda function lifecycle, Gremlin WebSocket connections, and Neptune connections. Lambda function lifecycle and Gremlin WebSocket connections If you use a Gremlin driver and a Gremlin language variant to query Neptune, the driver connects to the database using a WebSocket connection. WebSockets are designed to support long-lived client-server connection scenarios. Lambda, on the other hand, is designed to support short-lived and stateless runs. A Lambda function runs in an execution context. This execution context isolates the function from other functions, and is created the first time the function is invoked. After an execution context has been created for a function, Lambda can reuse it for subsequent invocations of the same function. Although a single execution context can handle multiple invocations of a function, it can’t handle concurrent invocations of the function. If your function is invoked simultaneously by multiple clients, Lambda spins up additional execution contexts to host new instances of the function. Each of these new contexts may in turn be reused for subsequent invocations of the function. At some point, Lambda recycles a context—particularly if it has been inactive for some time. A common best practice when using Lambda to query a database is to open the database connection outside the Lambda handler function so it can be reused with each handler call. If the database connection drops at some point, you can reconnect from inside the handler. But there is a danger of connection leaks with this approach. If an idle connection stays open much longer after an execution context is destroyed, intermittent Lambda invocation scenarios can gradually leak connections, thereby exhausting database resources. Neptune connections Neptune’s connection limits and connection timeouts have changed with engine releases. With early engine releases, every instance supported up to 60,000 WebSocket connections. This has changed so that now the maximum number of concurrent WebSocket connections per Neptune instance is different for each instance type. Furthermore, with engine version 1.0.3.0, Neptune reduced the idle timeout for connections, from 1 hour down to approximately 20 minutes. If a client doesn’t close a connection, the connection is closed automatically after an idle timeout of 20–25 minutes. Lambda doesn’t document execution context lifetimes, but experiments have shown that the new Neptune connection timeout aligns well with inactive Lambda execution context timeouts: by the time an inactive context is recycled, there’s a good chance its connection has already been closed by Neptune, or will be closed soon after. Recommendations In this section, we provide recommendations on connections, read and write requests, cold starts, and Lambda extensions. Using a single connection for the lifetime of an execution context Use a single connection and graph traversal source for the entire lifetime of the Lambda execution context rather than per function invocation. Each function invocation handles a single client request. Concurrent client requests are handled by different function instances running in separate execution contexts. Because an execution context only ever services a single request at a time, there’s no need to maintain a pool of connections to handle concurrent requests inside a function instance. If the Gremlin driver you’re using has a connection pool, configure it to use a single connection. Handling connection issues and retrying connections if necessary Use retry logic around the query to handle connection failures. Although the goal is to maintain a single connection for the lifetime of an execution context, unexpected network events can cause this connection to be stopped abruptly. Connection failures manifest as different errors depending on the driver you’re using. You should code your function to handle these connection issues and attempt a reconnection if necessary. Some Gremlin drivers automatically handle reconnections; others require you to build your own reconnection logic. The Java driver, for example, automatically attempts to re-establish connectivity to Neptune on behalf of your client code. With this driver, your function code needs only to back off and retry the query. The JavaScript and Python drivers, in contrast, don’t implement any automatic reconnection logic. With these drivers, your function code has to back off and attempt to reconnect before retrying the query. The code examples in this document include appropriate reconnection logic. Considerations for write requests If your Lambda function modifies data in Neptune, you should consider adopting a backoff-and-retry strategy to handle the following exceptions: ConcurrentModificationException – The Neptune transaction semantics mean that write requests can sometimes fail with a ConcurrentModificationException. To handle these situations, consider implementing an exponential backoff-based retry mechanism. ReadOnlyViolationException – Because the cluster topology can change at any moment as a result of both planned and unplanned cluster events, write responsibilities may migrate from one instance in the cluster to another. If your function code attempts to send a write request to an instance that is no longer the primary, the request fails with a ReadOnlyViolationException. When this happens, your code should close the existing connection, reconnect to the cluster endpoint, and retry the request. If you use a backoff-and-retry strategy to handle write request issues, consider implementing idempotent queries for create and update requests (using, for example, fold().coalesce().unfold()). Considerations for read requests If you have multiple read replicas in your cluster, you likely want to balance read requests across these replicas. One option is to use the reader endpoint. The reader endpoint distributes connections across replicas even if the cluster topology changes as a result of you adding or removing replicas, or promoting a replica to become the new primary. However, in some circumstances, using the reader endpoint can result in an uneven use of cluster resources. The reader endpoint works by periodically changing the host to which the DNS entry points. If a client opens a lot of connections before the DNS entry changes, all the connection requests are sent to a single Neptune instance. This can be the case with a high throughput Lambda scenario: a large number of concurrent requests to your Lambda function causes multiple execution contexts to be created, each with its own connection. If those connections are all created almost simultaneously, the majority will likely point to the same replica in the cluster, and will stay pointing to that replica until Lambda recycles the execution contexts. One way you can distribute requests across instances is to configure your Lambda function to connect to an instance endpoint, chosen at random from a list of replica instance endpoints, rather than the reader endpoint. The downside of this approach is that it requires the Lambda code to handle changes in the cluster topology by monitoring the cluster and updating the endpoint list whenever the membership of the cluster changes. If you’re writing a Java Lambda function that needs to balance read requests across instances in your cluster, you can use the Gremlin client for Amazon Neptune, a Java Gremlin client that is aware of your cluster topology, and which fairly distributes connections and requests across a set of instances in a Neptune cluster. For a sample Java Lambda function that uses the Gremlin client for Amazon Neptune, see Load balance graph queries using the Amazon Neptune Gremlin Client. Cold starts Java code compilation can be slower in a Lambda function than on an Amazon Elastic Compute Cloud (Amazon EC2) instance. CPU cycles in a Lambda function scale with the amount of memory assigned to the function. Lambda allocates CPU power linearly in proportion to the amount of memory configured. At 1,792 MB, a function has the equivalent of one full vCPU (one vCPU-second of credits per second). The impact of the relative lack of CPU cycles in low-memory Lambda functions is particularly pronounced with large Java functions. Consider assigning more memory to your function to increase the CPU power available for compiling and running your code. AWS Identity and Access Management (IAM) database authentication can affect cold starts, particularly if the function has to generate a new signing key. This is less of an issue after the first request because after the IAM database authentication is used to establish a WebSocket connection, it’s only periodically used to check that the connections’ credentials are still valid. (If the server closes the connection for any reason, including because the IAM credentials are now stale, you should ensure the Lambda opens a new connection with refreshed credentials.) Lambda extensions Lambda exposes the execution context lifecycle as Init, Invoke, and Shutdown phases. You can use Lambda extensions to write code that cleans up external resources, such as database connections, when an execution context is recycled. The example functions later in this post don’t use the execution lifecycle extensions—testing has shown that the function implementations conserve database resources without using the extensions—but the lifecycle phases do provide for additional control over connection lifetimes should you wish to take advantage of them. Examples The following example Lambda functions, written in Java, JavaScript, and Python, illustrate upserting a single vertex with a randomly generated ID into Neptune using the fold().coalesce().unfold() idiom. Much of the code in each function is boilerplate code, responsible for managing the connection to Neptune and retrying the connection and query if an error occurs. The real application logic is implemented in doQuery(), and the query itself in the query() method. If you use these examples as the basis of your own Lambda functions, concentrate on modifying the doQuery() and query() methods. The functions are configured to retry failed queries five times, waiting 1 second between retries. The functions expect values for a number of Lambda environment variables: NEPTUNE_ENDPOINT – The Neptune cluster endpoint. NEPTUNE_PORT – The Neptune port. USE_IAM – Can be true or false. If your database has IAM database authentication enabled, supply a value of true. The Lambda then Sigv4 signs connection requests to Neptune. (If the server closes the connection because the IAM credentials are stale, the function opens a new connection with refreshed credentials.) For IAM database authentication requests, ensure the Lambda function’s execution role has an appropriate IAM policy that allows the function to connect to your Neptune DB cluster using IAM database authentication. Ensure also that the function is running in a subnet with access to Neptune, and that the Neptune VPC security group allows ingress (on 8182) from the Lambda function’s security group. Java The Java driver by default maintains a pool of connections. Configure Cluster with minConnectionPoolSize(1) and maxConnectionPoolSize(1) so that the driver opens only a single connection. The Cluster object can be slow to build because it creates one or more serializers (Gyro by default, plus another if you’ve configured it for serialization other than Gyro), which take a while to instantiate. (The unnecessary creation of a Gyro serializer is removed in 3.4.9.) The connection pool is initialized with the first request. At this point, the driver sets up the Netty stack, allocates byte buffers, and creates a signing key (if using IAM DB authentication), all of which can add to latency. The Java driver’s connection pool monitors the availability of server hosts. If a connection fails, the driver automatically attempts to reconnect to the database using a background task. You can use reconnectInterval() to configure the interval between reconnection attempts. While the driver is attempting to reconnect, your Lambda function can simply retry the query. (If the interval between retries is smaller than the interval between reconnect attempts, retries on a failed connection fail again because the host is still considered unavailable.) Use Java 8 rather than Java 11; Netty optimizations are not enabled by default in Java 11. This example uses Retry4j for retries. To use the Sigv4 signing driver in your Java Lambda function, see the dependency requirements in Connecting to Neptune Using Java and Gremlin with Signature Version 4 Signing. The following is the Lambda function code in Java: package com.amazonaws.examples.social; import com.amazonaws.services.lambda.runtime.Context; import com.amazonaws.services.lambda.runtime.RequestStreamHandler; import com.evanlennick.retry4j.CallExecutor; import com.evanlennick.retry4j.CallExecutorBuilder; import com.evanlennick.retry4j.Status; import com.evanlennick.retry4j.config.RetryConfig; import com.evanlennick.retry4j.config.RetryConfigBuilder; import org.apache.tinkerpop.gremlin.driver.Cluster; import org.apache.tinkerpop.gremlin.driver.SigV4WebSocketChannelizer; import org.apache.tinkerpop.gremlin.driver.remote.DriverRemoteConnection; import org.apache.tinkerpop.gremlin.driver.ser.Serializers; import org.apache.tinkerpop.gremlin.process.traversal.AnonymousTraversalSource; import org.apache.tinkerpop.gremlin.process.traversal.dsl.graph.GraphTraversalSource; import org.apache.tinkerpop.gremlin.structure.T; import java.io.*; import java.time.temporal.ChronoUnit; import java.util.HashMap; import java.util.Map; import java.util.Random; import java.util.concurrent.Callable; import java.util.function.Function; import static java.nio.charset.StandardCharsets.UTF_8; import static org.apache.tinkerpop.gremlin.process.traversal.dsl.graph.__.addV; import static org.apache.tinkerpop.gremlin.process.traversal.dsl.graph.__.unfold; public class MyHandler implements RequestStreamHandler { private final GraphTraversalSource g; private final CallExecutor executor; private final Random idGenerator = new Random(); public MyHandler() { this.g = AnonymousTraversalSource .traversal() .withRemote(DriverRemoteConnection.using(createCluster())); this.executor = new CallExecutorBuilder() .config(createRetryConfig()) .build(); } @Override public void handleRequest(InputStream input, OutputStream output, Context context) throws IOException { doQuery(input, output); } private void doQuery(InputStream input, OutputStream output) throws IOException { try { Map args = new HashMap<>(); args.put("id", idGenerator.nextInt()); String result = query(args); try (Writer writer = new BufferedWriter(new OutputStreamWriter(output, UTF_8))) { writer.write(result); } } finally { input.close(); output.close(); } } private String query(Map args) { int id = (int) args.get("id"); @SuppressWarnings("unchecked") Callable query = () -> g.V(id) .fold() .coalesce( unfold(), addV("Person").property(T.id, id)) .id().next(); Status status = executor.execute(query); return status.getResult().toString(); } private Cluster createCluster() { Cluster.Builder builder = Cluster.build() .addContactPoint(System.getenv("NEPTUNE_ENDPOINT")) .port(Integer.parseInt(System.getenv("NEPTUNE_PORT"))) .enableSsl(true) .minConnectionPoolSize(1) .maxConnectionPoolSize(1) .serializer(Serializers.GRAPHBINARY_V1D0) .reconnectInterval(2000); if (Boolean.parseBoolean(getOptionalEnv("USE_IAM", "true"))) { builder = builder.channelizer(SigV4WebSocketChannelizer.class); } return builder.create(); } private RetryConfig createRetryConfig() { return new RetryConfigBuilder() .retryOnCustomExceptionLogic(retryLogic()) .withDelayBetweenTries(1000, ChronoUnit.MILLIS) .withMaxNumberOfTries(5) .withFixedBackoff() .build(); } private Function retryLogic() { return e -> { StringWriter stringWriter = new StringWriter(); e.printStackTrace(new PrintWriter(stringWriter)); String message = stringWriter.toString(); // Check for connection issues if (message.contains("Timed out while waiting for an available host") || message.contains("Timed-out waiting for connection on Host") || message.contains("Connection to server is no longer active") || message.contains("Connection reset by peer") || message.contains("SSLEngine closed already") || message.contains("Pool is shutdown") || message.contains("ExtendedClosedChannelException") || message.contains("Broken pipe")) { return true; } // Concurrent writes can sometimes trigger a ConcurrentModificationException. // In these circumstances you may want to backoff and retry. if (message.contains("ConcurrentModificationException")) { return true; } // If the primary fails over to a new instance, existing connections to the old primary will // throw a ReadOnlyViolationException. You may want to back and retry. if (message.contains("ReadOnlyViolationException")) { return true; } return false; }; } private String getOptionalEnv(String name, String defaultValue) { String value = System.getenv(name); if (value != null && value.length() > 0) { return value; } else { return defaultValue; } } } JavaScript The JavaScript driver doesn’t maintain a connection pool: it always opens a single connection. The Lambda function uses the Sigv4 signing utilities from gremlin-aws-sigv4 for signing requests to an IAM database authentication enabled database, and the retry function from the async module to handle backoff-and-retry attempts. Terminal steps return a promise. For next(), this is a {value, done} tuple. Connection errors are raised inside the handler, and dealt with using some backoff-and-retry logic in line with the recommendations outlined in this article, with one exception. There is one kind of connection issue that the driver does not treat as an exception, and which cannot therefore be accommodated by this backoff-and-retry logic. The problem is that if a connection is closed after a driver sends a request, but before the driver receives a response, the query appears to complete, but with a null return value. As far as the Lambda function’s client is concerned, the function appears to complete successfully, but with an empty response. The impact of this issue depends on how your application treats an empty response. Some applications may treat an empty response from a read request as an error, but others may mistakenly treat this as an empty result. Write requests too that encounter this connection issue will return an empty response. Does a successful invocation with an empty response signal success or failure? If the client invoking a write function simply treats the successful invocation of the function to mean the write to the database has been committed, rather than inspecting the body of the response, the system may appear to lose data. The cause of this issue is in how the driver treats events emitted by the underlying socket. When the underlying network socket is closed with an ECONNRESET error, the Websocket used by the driver is closed and emits a ‘ws close’ event. There’s nothing in the driver, however, to handle this event in a way that could be used to provoke an exception. As a result, the query ‘disappears’. To work around this issue, the Lambda function shown here adds a ‘ws close’ event handler that throws an exception to the driver when creating a remote connection. This exception won’t, however, be raised along the Gremlin query’s request-response path, and can’t therefore be used to trigger any backoff-and-retry logic within the Lambda function itself. Instead, the exception thrown by the ‘ws close’ event handler results in an unhandled exception that causes the Lambda invocation to fail. This allows the client that invokes the function to handle the error and retry the Lambda invocation if appropriate. This article recommends that you implement backoff-and-retry logic in your Lambda function to protect your clients from intermittent connection issues. The workaround for this issue stands outside these recommendations in that it requires the client to also implement some retry logic to handle functions that fail because of this particular connection issue. See the following code: const gremlin = require('gremlin'); const async = require('async'); const {getUrlAndHeaders} = require('gremlin-aws-sigv4/lib/utils'); const traversal = gremlin.process.AnonymousTraversalSource.traversal; const DriverRemoteConnection = gremlin.driver.DriverRemoteConnection; const t = gremlin.process.t; const __ = gremlin.process.statics; let conn = null; let g = null; async function query(context) { const id = context.id; return g.V(id) .fold() .coalesce( __.unfold(), __.addV('User').property(t.id, id) ) .id().next(); } async function doQuery() { const id = Math.floor(Math.random() * 10000).toString(); let result = await query({id: id}); return result['value']; } exports.handler = async (event, context) => { const getConnectionDetails = () => { if (process.env['USE_IAM'] == 'true'){ return getUrlAndHeaders( process.env['NEPTUNE_ENDPOINT'], process.env['NEPTUNE_PORT'], {}, '/gremlin', 'wss'); } else { const database_url = 'wss://' + process.env['NEPTUNE_ENDPOINT'] + ':' + process.env['NEPTUNE_PORT'] + '/gremlin'; return { url: database_url, headers: {}}; } }; const createRemoteConnection = () => { const { url, headers } = getConnectionDetails(); const c = new DriverRemoteConnection( url, { mimeType: 'application/vnd.gremlin-v2.0+json', headers: headers }); c._client._connection.on('close', (code, message) => { console.info(`close - ${code} ${message}`); if (code == 1006){ console.error('Connection closed prematurely'); throw new Error('Connection closed prematurely'); } }); return c; }; const createGraphTraversalSource = (conn) => { return traversal().withRemote(conn); }; if (conn == null){ console.info("Initializing connection") conn = createRemoteConnection(); g = createGraphTraversalSource(conn); } return async.retry( { times: 5, interval: 1000, errorFilter: function (err) { // Add filters here to determine whether error can be retried console.warn('Determining whether retriable error: ' + err.message); // Check for connection issues if (err.message.startsWith('WebSocket is not open')){ console.warn('Reopening connection'); conn.close(); conn = createRemoteConnection(); g = createGraphTraversalSource(conn); return true; } // Check for ConcurrentModificationException if (err.message.includes('ConcurrentModificationException')){ console.warn('Retrying query because of ConcurrentModificationException'); return true; } // Check for ReadOnlyViolationException if (err.message.includes('ReadOnlyViolationException')){ console.warn('Retrying query because of ReadOnlyViolationException'); return true; } return false; } }, doQuery); }; Python The Python code uses the backoff module. Set pool_size=1 and message_serializer=serializer.GraphSONSerializersV2d0(). See the following code: import os, sys, backoff, math from random import randint from gremlin_python import statics from gremlin_python.driver.driver_remote_connection import DriverRemoteConnection from gremlin_python.driver.protocol import GremlinServerError from gremlin_python.driver import serializer from gremlin_python.process.anonymous_traversal import traversal from gremlin_python.process.graph_traversal import __ from gremlin_python.process.strategies import * from gremlin_python.process.traversal import T from tornado.websocket import WebSocketClosedError from tornado import httpclient from botocore.auth import SigV4Auth from botocore.awsrequest import AWSRequest from botocore.credentials import ReadOnlyCredentials from types import SimpleNamespace reconnectable_err_msgs = [ 'ReadOnlyViolationException', 'Server disconnected', 'Connection refused' ] retriable_err_msgs = ['ConcurrentModificationException'] + reconnectable_err_msgs network_errors = [WebSocketClosedError, OSError] retriable_errors = [GremlinServerError] + network_errors def prepare_iamdb_request(database_url): service = 'neptune-db' method = 'GET' access_key = os.environ['AWS_ACCESS_KEY_ID'] secret_key = os.environ['AWS_SECRET_ACCESS_KEY'] region = os.environ['AWS_REGION'] session_token = os.environ['AWS_SESSION_TOKEN'] creds = SimpleNamespace( access_key=access_key, secret_key=secret_key, token=session_token, region=region, ) request = AWSRequest(method=method, url=database_url, data=None) SigV4Auth(creds, service, region).add_auth(request) return httpclient.HTTPRequest(database_url, headers=request.headers.items()) def is_retriable_error(e): is_retriable = False err_msg = str(e) if isinstance(e, tuple(network_errors)): is_retriable = True else: is_retriable = any(retriable_err_msg in err_msg for retriable_err_msg in retriable_err_msgs) print('error: [{}] {}'.format(type(e), err_msg)) print('is_retriable: {}'.format(is_retriable)) return is_retriable def is_non_retriable_error(e): return not is_retriable_error(e) def reset_connection_if_connection_issue(params): is_reconnectable = False e = sys.exc_info()[1] err_msg = str(e) if isinstance(e, tuple(network_errors)): is_reconnectable = True else: is_reconnectable = any(reconnectable_err_msg in err_msg for reconnectable_err_msg in reconnectable_err_msgs) print('is_reconnectable: {}'.format(is_reconnectable)) if is_reconnectable: global conn global g conn.close() conn = create_remote_connection() g = create_graph_traversal_source(conn) @backoff.on_exception(backoff.constant, tuple(retriable_errors), max_tries=5, jitter=None, giveup=is_non_retriable_error, on_backoff=reset_connection_if_connection_issue, interval=1) def query(**kwargs): id = kwargs['id'] return (g.V(id) .fold() .coalesce( __.unfold(), __.addV('User').property(T.id, id) ) .id().next()) def doQuery(event): return query(id=str(randint(0, 10000))) def lambda_handler(event, context): return doQuery(event) def create_graph_traversal_source(conn): return traversal().withRemote(conn) def create_remote_connection(): print('Creating remote connection') return DriverRemoteConnection( connection_string(), 'g', pool_size=1, message_serializer=serializer.GraphSONSerializersV2d0()) def connection_string(): database_url = 'wss://{}:{}/gremlin'.format(os.environ['NEPTUNE_ENDPOINT'], os.environ['NEPTUNE_PORT']) if 'USE_IAM' in os.environ and os.environ['USE_IAM'] == 'true': return prepare_iamdb_request(database_url) else: return database_url conn = create_remote_connection() g = create_graph_traversal_source(conn) Conclusion This post updates the recommendations around querying Neptune using a Gremlin client from a Lambda function. It’s now good practice to use a single WebSocket connection for the lifetime of a Lambda execution context, with the function handling connection issues and retrying connections as necessary. The post includes sample Lambda functions written in Java, JavaScript, and Python, which you can use as templates for your own functions. For links to documentation, blog posts, videos, and code repositories containing other samples and tools, see Amazon Neptune resources. Before you begin designing your database, we also recommend that you consult the AWS Reference Architectures for Using Graph Databases GitHub repo, where you can inform your choices about graph data models and query languages, and browse examples of reference deployment architectures. About the author Ian Robinson is a Principal Graph Architect with Amazon Neptune. He is a co-author of ‘Graph Databases’ and ‘REST in Practice’ (both from O’Reilly) and a contributor to ‘REST: From Research to Practice’ (Springer) and ‘Service Design Patterns’ (Addison-Wesley). https://aws.amazon.com/blogs/database/use-aws-lambda-functions-with-amazon-neptune/
0 notes
Text
interview nike
amazon simple notification service sns vs sqs elkstash testing bugs in java debugging in java building rest api in nod.js with aws lambda,api gateway build api gateway rest api with lambda integration create an index - amazon dynamoDB managing indexes amazon dynamoDB store files in dynamodb dynamodb datatypes ...what did u use aws dynamodb dynamodb create table aws node js aws lambda performance running api's written java in aws lambda aws lambda return aws lambda performance optimization aws lambda and java spring boot terraform script aws lambda spring bean scopes spring boot and oauth2 arraylist vs linked list access modifiers in java securing rest api with spring security time complexit o(n) o(1) best big o value practical examples of big o notation break a monolith into microservices increase team productivity using spring boot ////////////////////////////////////////
0 notes
Text
Creating voice skills for Amazon Alexa and Google Assistant

The arrival of good internet and easy availability, inexpensive devices had led everyone onto the internet. The average screen time for every user had shot up. Clinical studies for the effect on eyes have been alarming, to say the least.
In this context, the latest innovation from the technical world has been voice-activated gadgets and AI Helpers. Voice-based AI helpers like Siri, Alexa, and Google Assistant have become almost ubiquitous in our lives now and often offer two-way conversations.
Virtual assistants usually aim to make your everyday tasks faster and easier. This is primarily done by Alexa Skill Development or “Actions” for Google. Voice skills are apps that allow the assistant to interface between the hardware and software components.
In smart homes, this could involve picking up your voice command and using it to control your home temperature. It could also be something as simple as turning your speakers on for you. Or it could involve using the voice recognition software to interface with other software like Spotify or even the internet to look for answers.
Also Read: Amazon launches battery-powered Echo Input in India

The Alexa Skill Kit (ASK) allows you to build and develop these functionalities for your own custom experience. Amazon’s vast collection of self-service APIs, tools, documentation, and code samples also makes this task very easy. There are Alexa Skill Development Companies that create such skills but individual skill developers can do so too. One may want to create a skill to answer queries from the internet. One may want to ask Alexa to place a food order for you. Or the custom skill could be as complex as an interactive multiplayer game.
How does one build a voice skill?
To begin with, we must understand the basic pipeline of a simple query to Alexa or Assistant. When a user speaks a command, the software breaks up the audio into blocks. Then the software uses Speech to Text to convert the audio blocks into a series of requests.
These requests are processed in the cloud, interfaced with the required software/hardwares and an appropriate response is generated. The response generated is returned to the user by using Text to Speech which allows Alexa/Assistant to speak to you. You can break down the process of making a skill into 4 steps.
1. Designing your Skill
When designing your skill, it is recommended you try to plan what your skill is going to do. What is the goal of your skill? Can the same information/task be done from a website and may not need voice support?
What information needs to be collected from the user to process the task?
You will also want to decide what features will enhance user experience. Will the skill support in-skill purchases? Will it be interfacing with some hardware? What other features can be added?
You will have to design a voice-user interface. Write a script to map out how users interact with a skill and convert it into a “Storyboard”. How does Alexa respond when the skill is invoked for the first time? How will Alexa respond when it has enough information to perform a task? If it has not collected enough information, how can it ask for more? You will have to add variations to your script for better user experience and build a storyboard for each. As an example, there could be multiple welcome or good bye messages. You will also have to choose an invocation name for the skill that the user will speak to use the skill.
Lastly, you might want to decide whether to publish your skill to different local or international markets. If so, will the skill need to be customised for them? How will you account for all the different languages, dialects and cultural connotations of phrases?
2. Set up the Skill in the developer console
You will have to enter a name for your skill. This will be publicly displayed. You will also have to choose which language you will be using to code. On Amazon Web Services (AWS), node.js, java, python, C#, or go are supported and additional languages can be added.
You will have to choose the ‘interaction model’ for your skill. The developer console offers four options. Custom interaction models will give you complete control over the skill. There are also the pre-built models for flash briefing, smart homes, and consuming and video content.
Once configured on the console, you can actually build your skill.
3. Build the Skill
The main building task is to create a way to accept requests from the assistant and send responses back. You can do it on the Amazon Web Services (AWS), using lambda functions to run your code on a cloud without managing servers. You can also host your skill on any cloud provider by building a web service for it.
If you are using pre-built models, you may need to perform account linking for some models. You may need to enable permissions to user information and consent. Other features like location services, reminders and messaging may also have to be enabled. You will also need an Amazon Resource Name (ARN) endpoint to know where to send the responses and end the skill. All these options can be found on the developer console.
For custom skills, you will have to create an interaction model for your skill. You will have to build a collection of utterances, or phrases that you expect the user to speak to the assistant. Including subtle variations on phrases and words makes for a better user experience as not all users will invoke the skill in the same way. Each utterance can be broken down into intents and slots. Intents represent what action the user wants to do and what request Alexa can handle. Slots which represent information that Alexa needs for that action to be performed. If the user says “Alexa, plan a trip to city X on Date Y”, the intent is to plan a trip using a particular app. This may also involve booking tickets and accommodation. The slots are the application that Alexa must use to plan the trip, the city to be visited and the dates for the visit. If all information is not collected, Alexa must be prompted to ask for the missing slots.
All these things can be built on the developer console or on the ASK command-line interface. For custom skills, the endpoint must be identified, any interfacing with external softwares or hardwares must be done and utterance ambiguity must be removed.
4. Test your skill
You can use the utterance profiler to test how these are broken into intents and slots. Any ambiguity in utterances can be removed and a larger sample utterances data bank can be identified.
The test page on the console will allow you to test your Alexa SKill Kit features without having a device, either though voice or text. There are different benchmarks for each model before a test can be successfully conducted.
You also can test your skill on any device that has Alexa enabled.
There also command line commands (invoke skill or simulate skill) that can be used for testing.
You can also beta test your skill by making it available to a select group of users. This is optional
This is a brief overview of the skill building process. Detailed steps, breakdowns of the interaction models, and how to maximize user experience can be found on the development page of amazon. You can get a skill published and certified if it meets the guidelines on the certification page of the development console.
This will allow the general users to use it. Meanwhile, you can continue to modify it and make upgrades to your skill. The process of building custom skills for Alexa or Google Assistant is a multi-step process that can be learned with a little bit of effort. Excellent resources exist for the same. Go get started and build your custom experience today.
More to read:
How to increase battery life on Android phones
Best Android Tablets to Buy in 2020
How to stream PUBG Mobile on YouTube
The post Creating voice skills for Amazon Alexa and Google Assistant appeared first on Androidical.
from https://ift.tt/301EboG
0 notes
Text
Can Salesforce Keep Growing? Five Possibilities for Marc Benioff

Editor’s note: This article was contributed to Cloud Wars by Jiri Kram, a solution architect who studied Fintech at MIT and specializes in cloud computing and blockchain. He is a highly respected commentator on LinkedIn, where he originally published this piece on May 6. This article marks Jiri’s third appearance on Cloud Wars; you can see his first two Cloud Wars articles here and here. While Jiri is a good friend of Cloud Wars, the views expressed are his, and do not necessarily reflect the views of Cloud Wars. In particular, I think there is almost no chance that Jiri’s idea of Keith Block returning to Oracle or going to Microsoft will come to pass, and I think there’s an equally tiny likelihood for Jiri’s idea that Thomas Kurian will have Google Cloud develop a database designed to compete with Oracle’s. But multiple views make for interesting debates, so with those qualifiers made, we invite you to enjoy this latest set of provocative ideas from Jiri Kram. Can Salesforce keep growing despite the crisis? That’s a billion-dollar question. And it doesn’t have a straightforward answer. Salesforce has enjoyed so far 35% growth, and the future looks rosy. Can this trend sustain in an environment when IaaS is outgrowing any other cloud category? And how do the Cloud Wars between AWS / Microsoft / Google / Oracle affect Salesforce? Let’s dive in and see what challenges and strategic options Marc Benioff is facing. Will Salesforce say sayonara to Oracle? In 3 years, it will be exactly ten years after Salesforce signed a deal with Oracle. Ever since then, there were various attempts to test if Salesforce can run without Oracle database foundation. These attempts led in creation and acquisition of many new services Einstein, MuleSoft, Commerce Cloud, Marketing Cloud, Pardot, Quip, Heroku that wasn’t built on top of Oracle. Thus, creating a situation when 50% of Salesforce (Sales Cloud, Service Cloud, Force Platform) runs still use Oracle database and java, while the rest use mix of AWS and Azure. The only question is if Salesforce will manage to migrate schema to other databases. Let’s explore Salesforce’s options Stay on Oracle and migrate to Oracle Autonomous Database Migrate Oracle databases to AWS RDS for Oracle Migrate Oracle databases to AWS Aurora or AWS Postgres Create a hybrid deployment use AWS RDS for Oracle for some workloads and move to AWS Aurora, DynamoDB or Postgres Deal with Thomas Kurian 1. Staying on Oracle and migrate to Oracle Autonomous Database This option is possible, due to Keith Block’s departure from Salesforce. If Oracle hires Mr. Block, he would be able to close the deal with Marc Benioff for extending or expanding the Oracle contract. Although it may sound to many unrealistic, technically, this option is the lowest risk for Salesforce. Problem with Oracle database foundation of Salesforce is a simple fact. Beyond core products like Sales Cloud, Service Cloud and Force Platform, there is also AppExchange that contains around 3,500 applications from many vendors. Given all these applications uses in some way shape or form Oracle technologies (schema = objects, fields; security model = profiles, roles, permission sets, OWD; logic = apex / oracle application express; UI = visualforce / oracle JSP). Migrating all of those to some other platform might be very risky, so if Keith Block ends up at Oracle, then it is likely he would attempt this deal.

2. Migrate Oracle databases to AWS RDS for Oracle This option is also very tempting because Salesforce already has experience with this setting. For example, the Canadian data centre is running on AWS and therefore, it’s likely that Salesforce would be able to deliver Oracle-based schema they are using AWS RDS (Relational Databases Service) for Oracle. Given that AWS now supports all versions of Oracle database including 19c, which was the last version before starts delivering Autonomous Database, RDS should be sufficient for Salesforce purpose. Why? Salesforce licensing deal with Oracle signed in 2012 contained ten years deal but without Oracle Autonomous Database, which didn’t exist by then. AWS RDS now supports all major version 11g, 12c, 18c and 19c so it’s possible this could be sufficient for Salesforce. It’s also relatively safe move, as there is no major change, the primary impact is data centre is operated by AWS and not by Salesforce team, so all maintenance like patching, upgrading, scaling and so of the database wouldn’t need to be done by Salesforce team. This could both reduce Salesforce’s operating cost and help them innovate faster because they would benefit from any development on the AWS side.
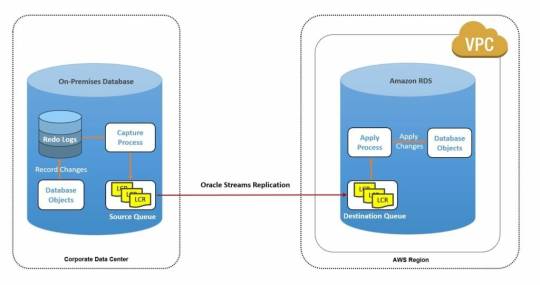
3. Migrate Oracle databases to AWS Aurora or AWS Postgres Similar to the previous scenario, here Salesforce would be using AWS RDS but instead running licensed Oracle databases. They would start using either AWS own relational database Aurora or Postgres, which Salesforce already uses in Heroku. My guess is that Salesforce is more likely to use Aurora, because Amazon uses this relational database themselves for the most challenging workloads, which previously ran on Oracle. Aurora, unlike using RDS with Oracle, would also come with the benefit of single cost per database. In case Salesforce would be using RDS for Oracle, here cost of such infrastructure would also be influenced by license cost from Oracle. If Oracle would increase maintenance or any other fees for running Oracle outside of Oracle approved infrastructure (see “Oracle license audit”), you can quickly see that running Oracle on AWS might come with some challenges to consider. So if Salesforce’s Oracle workloads would be migrated to AWS Aurora, then Salesforce would gain an advantage in controlling the cost of the database. If this is done successfully, Salesforce would be able to reduce own cost while price same and thus increasing margin and attractiveness for investors. The only problem is the migration of AppExchange. It’s possible to imagine the migration of core Oracle-based services like Sales Cloud and Service Cloud. But the migration of Force Platform, which has many millions of apps build on top of it and is bundled to commercial offers via AppExchange, might not be so smooth.

4. Create a hybrid deployment use AWS RDS for Oracle for some workloads and move to AWS Aurora, DynamoDB or Postgres I believe that the Salesforce engineering team will opt for this. The reason is straightforward. Unlike the big bang approach (e.g. let’s take everything and migrate to Aurora), in this scenario, moving off Oracle is phased. Salesforce would likely split migration as follows: 1) workloads that require a relational database, 2) workloads that can use NoSQL database, 3) workloads that are currently in a relational database but doesn’t need to database. Then they would differentiate further: 1) workloads that require a relational database but are using capabilities that can be recreated in Aurora, 2) workloads that are bind to other Oracle technologies and that are not easy to replicate in Aurora. After that hybrid deployment would be stood up; 1) Oracle workloads are first migrated to AWS RDS for Oracle, 2) After that some Oracle workloads are migrated to Aurora some stay on Oracle, 3) Workloads migrated to Aurora are tested and if there is no technical issue, it will start to run in parallel, means APIs will be slowly transition from Oracle RDS to Aurora, 4) If transition to Aurora is successful, RDS Oracle instances will be stopped and kept as backup, 5) Meanwhile workloads that could be converted to NoSQL will be switched to DynamoDB and run in parallel with those in RDS, 6) When conversation is successful DynamoDB will be replacing in selected API connectivity to previous RDS, 7) When transition from RDS to Dynamo is completed then RDS is stopped and kept as backup, 8) Some feature programmed in Java and PL SQL as workarounds on older versions of Oracle database could be developed externally for example using AWS Lambda functions, 9) Same as with RDS new Lambda functions replacing previous code for Oracle will be tested and run in parallel with Oracle, 10) After its clear Lambda functions can replace custom development done in Java for Oracle, then Lambda will start to replace Oracle in APIs, ultimately replacing it. Yes, this will be a long and complicated journey, but many other AWS customers did it, and so it’s technically possible. Once again, however, the main problem is the logistics around AppExchange as the transition from Oracle to AWS can’t impact a running application. Imagine the scenario when Vlocity, Veeva, Apttus, FinancialForce, nCino, ServiceMax and other ISV applications would have any piece of code pointing to Oracle and thus leading to stop instances.
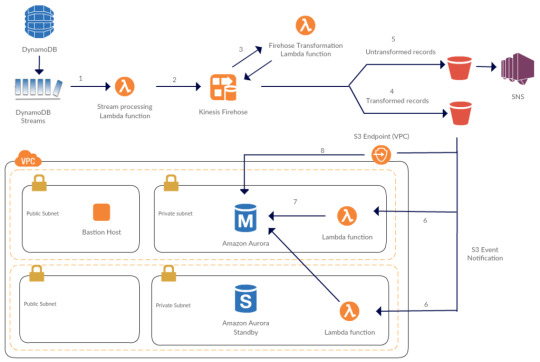
5. Deal with Thomas Kurian This option is improbable, but it’s not impossible. Thomas Kurian came from Oracle, and his primary goal is to replace Oracle. To do this, he will have to beat Oracle at its own game – database. Google currently doesn’t have a database that could be equal to Oracle or AWS Aurora. So it’s likely Kurian will develop a brand new database with his strategic hires from Oracle and will challenge Larry Ellison in the market. Having Salesforce as a reference would be not just a big boost for Google capabilities, but also a highly strategic message. Kurian would steal the most critical SaaS application in the world running on Oracle. And of course, Google sales are full of ex-Oracle people that would use this to visit every single strategic Oracle client and offer them alternative to both AWS Aurora and Oracle. Thomas Kurian is brilliant, and he loves winning. Challenging Larry in his own game could be too tempting for Thomas not to think about. For Google, there might also be another thing in play: many top Salesforce dealmakers were hired by Google, and so there is a direct link between both companies. Besides, Google can buy Salesforce in case they would feel Amazon would consider it. And, let’s not forget Keith Block can join any of players mention above Oracle (to make a deal with Salesforce), AWS (to make a deal with Salesforce to fight Oracle) or Google (to help Thomas Kurian making a deal with Salesforce to challenge AWS and Oracle). One more thing… Some say Keith Block could join Microsoft and, thus, would be the one controlling Salesforce on infrastructure level could be Azure. Impossible? Do you remember Marketing Cloud already runs on Azure? Back to you, Marc and Keith. RECOMMENDED READING Jiri’s first Cloud Wars article: To Combat COVID-19, a Retail App Becomes a ‘Smart Quarantine’ Solution Jiri’s second Cloud wars article: The 10 Most-Valuable Industries in the Wake of COVID-19 Can Larry Ellison Turn Zoom & Autonomous DB into Big-Time Oracle Cloud Revenue? Q1 Cloud Revenue Roundup: Microsoft, AWS and Google Total $26.3 Billion How Bill McDermott’s Magic Touch Has Made ServiceNow a Cloud Superstar Microsoft CEO Satya Nadella: 10 Thoughts on the Post-COVID-19 World Microsoft & Amazon Lead Top 5 Beyond $150 Billion in Cloud Revenue in 2020 Google Outpaces Microsoft, Amazon in Cloud-Revenue Growth at 52% Zoom Picks Oracle for Cloud Infrastructure; Larry Ellison’s First YouTube Video Subscribe to the Cloud Wars Newsletter for in-depth analysis of the major cloud vendors from the perspective of business customers. It’s free, it’s exclusive and it’s great! The post Can Salesforce Keep Growing? Five Possibilities for Marc Benioff appeared first on . https://cloudwars.co/salesforce/can-salesforce-keep-growing-five-possibilities-marc-benioff/ -- Link of source Read the full article
0 notes
Link
Last week was Salesforce’s annual #Dreamforce conference in San Francisco, when over 100,000 Salesforce fans descend upon the city to listen to the latest innovations from Salesforce. I was unable to attend this year, but followed along closely at home to the announcements, and the one that stood out to me in particular was not Salesforce Blockchain, Einstein Voice or Customer 360 – it was the Salesforce Evergreen announcement that for me could be the real game changer. The Impact of Serverless To understand why you have to perhaps take a step back and look at how the rise of AWS and in particular, the AWS Lambda and the serverless paradigm has impacted development. Take the following example – you want to upload an image in Salesforce against a case both before and after work is completed. These images should be stored off platform in Amazon S3 and you want to have both the original and a thumbnail, with the thumbnail being displayed on the case. Whilst uploading the images to S3 could be done via Apex in Salesforce, the resizing must be done off platform currently. So how do we do this and where? We can either have an endpoint available on a platform like Heroku with a dyno running, or have a Lambda function that will run whenever called. Thats the key difference here, we have to have the Heroku dyno (at least 1) running to handle requests whereas with Lambda we are only paying per executed function. (Note this example is based upon a Lambda example from AWS you can read about here.) Whilst I am a big fan of Heroku, use cases like this lend themselves more to Lambda for running small jobs and repetitive functions where there is no need for a full web server framework to be setup, just receiving and processing some data from an event. Such scenarios are becoming more common as organisations want to connect more pieces of their process seamlessly. This has driven a number of people towards using serverless based solutions to handle these simple problems – they just need the code to run and perform the action. Many organisations are also working to modularise their systems into more discrete functional blocks, often referred to as microservices. I’ve written before on Salesforce and Microservices and spoken on the topic previously at Dreamforce 2015 and Dreamforce 2017. Previously, the conversation has always been how to make Salesforce interact nicely with serverless systems, or how to rearchitect parts of your existing Salesforce setup to operate in a more modular way. As soon as some more complicated processing was required (such as image resizing) you were forced off platform and had to decide which platform to use. How would you manage security and authentication? How could you invoke the new service – API via code or a Platform Event? You couldn’t think of doing all this on Salesforce – until now. Enter Evergreen Salesforce Evergreen is a new toolkit that will allow developers to write small functions and microservices using Apex, Java and Node.js which can be invoked natively from within Salesforce using both declarative and code based tools, as well as having native visibility to the platform – so no need to manage authentication. Taking our previous example, instead of a service running off platform, whether Heroku or AWS, we could now have a small set of functions that are called directly from the declarative tools in Salesforce. Whenever a case is closed. upload the images from Salesforce to S3, process these images and update the case. No additional infrastructure needed, no authentication required, all on a single platform. This is truly game changing, by allowing developers to build these functions using existing languages in Java and Node.js, you are enabling the developer to utilise all of the existing ecosystem of functionality out there. For example, npm, the package ecosystem for Node.js, has somewhere in the region of a million packages, covering all types of functionality – csv parsing to providing random jokes. Almost all of these libraries become available for use alongside your existing Salesforce applications with all the plumbing and authentication done for you! You simply add in what you need, leveraging the existing tools and off you go. Similarly, if you have an existing complex function in Java from an existing application, you can migrate that to become an Evergreen function and deploy it for use from within Salesforce! As wonderful a language as Apex is there are some things that it cannot do or that Java or Node.js will be a better tool for, now you can leverage these languages to do more with your Salesforce data. Summary The new Evergreen toolkit is going to make a huge difference to what is possible for Salesforce developers and opens up exciting new possibilities which should lead to some incredible new solutions. I am already signed up for updates from Salesforce on the Developer Preview and will be looking ahead for different applications for this toolkit for our customers. If you want to read more, Salesforce have posted a blog here. The post Salesforce Evergreen – A Game Changer For Salesforce Developers appeared first on Cloud Galacticos.
0 notes
Text
300+ TOP AWS Interview Questions and Answers
AWS Interview Questions for freshers experienced :-
1. What is Amazon Web Services? AWS stands for Amazon Web Services, which is a cloud computing platform. It is designed in such a way that it provides cloud services in the form of small building blocks, and these blocks help create and deploy various types of applications in the cloud. These sequences of small blocks are integrated to deliver the services in a highly scalable manner. 2. What are the Main Components of AWS? The Key Components of AWS are: Simple Email Service: It allows you to send emails with the help of regular SMTP or by using a restful API call Route 53: It’s a DNS web service. Simple Storage Device S3: It is a widely used storage device service in AWS Identity and Access Management Elastic compute cloud( EC2): It acts as an on-demand computing resource for hosting applications. EC2 is very helpful in time of uncertain workloads. Elastic Block Store: It allows you to store constant volumes of data which is integrated with EC2 and enable you to data persist. Cloud watch: It allows you to watch the critical areas of the AWS with which you can even set a reminder for troubleshooting. 3. What S3 is all about? S3 is the abbreviation for a simple storage service. It is used for storing and retrieving data at any time and anywhere on the web. S3 makes web-scale computing easier for developers. The payment mode of S3 is available on a pay as you go basis. 4. What is AMI? It stands for Amazon Machine Image. The AMI contains essential information required to launch an instance, and it is a copy of AMI running in the cloud. You can download as many examples as possible from multiple AIMs. 5. What is the relationship between an instance and AMI? Using a single AMI, you can download as many instances as you can. An instance type is used to define the hardware of the host computer for your situation. Each instance is unique and provides the facilities in computational and storage capabilities. Once you install an instance, it looks similar to a traditional host with which we can interact in the same way we do with a computer. 6. What are the things that are included in the AIM? An AIM consists of the things which are mentioned below: A template for the instance Launch permissions A block mapping which decides the volume to be attached when it gets launched. 7. What is an EIP? The Elastic IP address (EIP) is a static Ipv4 address offered by AWS to manage dynamic cloud computing services. Connect your AWS account with EIP so that if you want static IPv4 address for your instance, you can be associated with the EIP which enables communication with the internet. 8. What is CloudFront? CloudFront is a content delivery network offered by AWS, and it speeds up the distribution of dynamic and static web content such as .css, .js, .html and image files to the users. It delivers the content with low latency and high transfer speed to the users. AWS provides CDN for less price and it suits best for startups. 9. What is VPC? Virtual Private Cloud (VPC) allows you to launch AWS resources into the virtual network. It allows users to create and customize network configurations according to users’ business requirements. 10. What is the VPC peering connection? VPC peering connection VPC peering connection is a networking connection that allows connecting one VPC with the other. It enables the route traffic between two VPCs using IPv6 and Ipv4 addresses. Instances within the VPCs behave like as they are in the same network.

AWS Interview Questions 11. What is the procedure to send a request to Amazon S3? S3 in Amazon is a RESt service, and you can send requests by using the AWS SDK or REST API wrapper libraries. 12. What are NAT gateways? Network Address Translation (NAT. allows instances to connect in a private subnet with the internet and other AWS services. NAT prevents the internet to have an initial connection with the instances. 13. What is SNS? Amazon Simple Notification Service (SNS)is a web service provided by the AWS. It manages and delivers the messages or notifications to the users and clients from any cloud platform. In SNS, there are two types of clients: subscribers and publishers. Publishers produce and send a message to the subscriber instance through the communication channels. Subscribers receive the notification from the publisher over one of the supported protocols such as Amazon SQS, HTTP, and Lambda, etc. Amazon SNS automatically triggers the service and sends an email with a message that “ your EC2 instance is growing” when you are using Auto Scaling. 14. What is SQS? Amazon SQS stands for Simple Queue Service, and it manages the message queue service. Using this service, you can move the data or message from one application to another even though it is not in the running or active state. SQS sends messages between multiple services, including S3, DynamoDB, EC2 Instance, and also it uses the Java message queue service to delivery the information. The maximum visibility timeout of a message is 12 hours in the SQS queue. 15. What are the types of queues in SQS? There are two types of queues in SQS. They are as follows: Standard Queues: It is a default queue type. It provides an unlimited number of transactions per second and at least once message delivery option. FIFO Queues: FIFO queues are designed to ensure that the order of messages is received and sent is strictly preserved as in the exact order that they sent. 16. Explain the types of instances available? Below stated are the available instances: General-purpose Storage optimized Accelerated computing Computer-optimized Memory-optimized 17. Explain about DynamoDB? If you want to have a faster and flexible NoSQL database, then the right thing available is DynamoDB, which is a flexible and efficient database model available in Amazon web services. 18. What is Glacier? Amazon Glacier is one of the most important services provided by AWS. The Glacier is an online web storage service that provides you with low cost and effective storage with security features for archival and data backup. With Glacier, you can store the information effectively for months, years, or even decades. 19. What is Redshift? Redshift is a big data product used as a data warehouse in the cloud. It is the fast, reliable and powerful product of big data warehouse. 20. What are the Types of AMI Provided by AWS? Below listed are the two kinds of AMIs provided by AWS: EBS backed Instance store backed Till now, you have seen basic interview questions. Now, we will move to the Intermediate Questions. 21. What is an ELB? Elastic Load Balancer is a load balancing service offered by AWS. It distributes incoming resources and controls the application traffic to meet traffic demands. 22. What are the types of load balancers in EC2? There are three types of load balancers in EC2. They are as follows: Subscribe to our youtube channel to get new updates..! Application Load Balancer: Application load balancer designed to make routing decisions at the application layer. ALC supports dynamic host port mapping and path-based routings. Network Load Balancer: Network load balancer is designed to make routing decisions at the transport layer. It handles millions of requests per second. Using the flow hash routing algorithm, NCL selects the target from the target groups after receiving a connection from the load balancer. Classic Load Balancer: Classic load balancer is designed to make routing decisions either at the application layer or transport layer. It requires a fixed relationship between container instance port and load balancer port. 23. Explain what is a T2 instance? T2 instance T2 instance is one of the low-cost Amazon instances that provides a baseline level of CPU performance. 24. Mention the security best practices for Amazon EC2. Security best practices for Amazon EC2 are as below: Security and network Storage Resource Management Recovery and Backup 25. While connecting to your instance, what are the possible connection issues one might face? The following are the connection issues faced by the user: User key not recognized by the server Permission denied Connection timeout Cannot connect using user’s browser Server unexpectedly closed network connection Unprotected private key Cannot ping the instance Server refused host key The private key must begin with “BEGIN RSA PRIVATE KEY” and end with “ END RSA PRIVATE KEY.” 26. What are key-pairs in AWS? Amazon EC2 uses both public and private keys to encrypt and decrypt the login information. The sender uses a public key to encrypt the data and the receiver uses a private key to decrypt the data. Private and public keys are known as key pairs. The public key enables you to access the instance securely and a private key is used instead of a password. 27. What is SimpleDB? SimpleDB is one of Amazon services offered by AWS. It is a distributed database and highly available NoSQL data store that offloads the work of database administrators. 28. What is Elastic Beanstalk? Elastic Beanstalk is the best service offered by AWS for deploying and managing applications. It assists applications developed in Java, .Net, Node.js, PHP, Ruby, and Python. When you deploy the application, Elastic beanstalk builts the selected supported platform versions and AWS services like S3, SNS, EC2, cloud watch and autoscaling to run your application. 29. Mention a few benefits of the Elastic beanstalk. Benefits of the Elastic beanstalk Following are the few benefits of the Elastic Beanstalk: Easy and simple: Elastic Beanstalk enables you to manage and deploy the application easily and quickly. Autoscaling: Beanstalk scales up or down automatically when your application traffic increases or decreases. Developer productivity: Developers can easily deploy the application without any knowledge, but they need to maintain the application securely and user-friendly. Cost-effective: No charge for Beanstalk. Charges are applied for the AWS service resources which you are using for your application. Customization: Elastic Beanstalk allows users to select the configurations of AWS services that user want to use them for application development. Management and updates: It updates the application automatically when it changes the platform. Platform updates and infrastructure management are taken care of by AWS professionals. 30. Define regions and availability zones in Amazon EC2. regions and availability zones in amazon ec2 Amazon web service has a global infrastructure that is divided into availability zones and regions. Each region is divided into a geographic area and it has multiple isolated locations called availability zones. 31. What is Amazon EC2 Root Device Volume? When the developer launches the instance, the root device volume is used to boot the instance that contains the image. When the developer introduces the Amazon EC2, all AMIs are propped up by an Amazon EC2 instance store. 32. What is Server Load Balancing? A Server load balancer (SLB. provides content delivery and networking services using load balancing algorithms. SLB distributes the network traffic equally across a group of servers to ensure high-performance application delivery. 33. How does a server load balancer work? aws server load balancer The server load balancer works based on two approaches. They are: Transport level load balancing Application level load balancing 34. What are the advantages of the Server load balancer? The advantages of server load balancer are as follows: Increases scalability Redundancy Maintenance and performance 35. Explain the process to secure the data for carrying in the cloud. One thing that must be taken into consideration is that no one should resize the data while it is moving from one point to another. The other thing to consider is there should not be any kind of leakage with the security key from the multiple storerooms in the cloud. Dividing the information into different types and by encrypting it into the valid methods could help you in securing the data in the cloud. 36. What are the layers available in cloud computing? AWS Certification Training! Explore Curriculum Below listed are the various layers of cloud computing SaaS: Software as a Service PaaS: Platform as a Service IaaS: Infrastructure as a Service 37. Explain the layers of Cloud architecture? We have five different types of layers available, which are: SC- Storage controller CC- cluster controller NC- Node controller Walrus CLC- cloud controller 38. What are the reserved instances? It is nothing but a reservation of resources for one or three years and utilized whenever you need it. The reservation comes on a subscription basis available for a term of 1 year and three years. The hourly rate goes down as the usage increases. Purchasing reservations isn’t just associated with the reservation of resources, but also, it comes with the capacity that is required for a particular zone. 39. What is meant by a cloud watch? Cloud watching is a monitoring tool in Amazon Web Services with which you can monitor different resources of your organization. You can have a look at various things like health, applications, network, etc. 40. How many types of cloud watches do we have? We have two types of cloud watches: essential monitoring and detailed monitoring. The necessary tracking will come to you at free of cost, but when it comes to detailed control, you need to pay for it. 41. Explain the cloud watch metrics that are meant for EC2 instances? The available metrics for EC2 instances are Disk reads, CPU utilization, network packetsOut, CPUCreditUsage, Disk writes, network packetsIn, networkOut, and CPUCreditBalance. 42. What would be the minimum and maximum size of the individual objects that you can store in S3? The minimum size of the object that you can store in S3 is 0 bytes, and the maximum size of an individual object that you can save is 5TB. 43. Explain the various storage classes available in S3? Below mentioned are the storage classes available in S3. Standard frequency accessed One-zone infrequency accessed RRS - reduced redundancy storage Standard infrequency accessed Glacier 44. What are the methods to encrypt the data in S3? We have three different methods available for encrypting the data in S3. They are as follows. Server-Side Encryption - C Server-Side Encryption - S3 Server-Side Encryption - KMS 45. On what basis the pricing of the S3 is decided? The pricing for S3 is decided by taking into consideration the below topics. Data transfer Storage used Number of requests Transfer acceleration Storage management 46. Is the property of broadcast or multicast supported by Amazon VPC? No, at present, Amazon VPC is not supporting any multicast or broadcast. 47. How many IP addresses are allowed for each account in AWS? For each AWS account, 5 VPC elastic addresses are allowed. 48. What is meant by Edge location? The actual content is cached at the places called edge locations. So whenever a user searches for the content, he will find the same at the edge locations. 49. What is Snowball? Snowball is an option available in AWS to transport. Using snowball, one can transfer the data into the AWS and out of it. It helps us in transporting massive amounts of data from one destination to another. It helps in lowering the networking expenditure. 50. Explain the advantages of auto-scaling? Below listed are the advantages of autoscaling. Better availability Better cost management High fault-tolerant 51. What is subnet? When a large amount of IP addresses are divided into small chunks, then these tiny chunks are called Subnets. 52. What is the number of subnets that we can have per VPC? Under one VPC, we can have 200 subnets. 53. What is AWS CloudTrail? AWS Cloudtrail is an AWS service that helps you to enable governance, risk auditing and compliance of your AWS account. Cloud trail records event when actions are taken by the role, user or an AWS service. Events include when actions are taken by AWS command-line interface, AWS management console, APIs and AWS SDKs. 54. What is meant by Elasticache? Upcoming Batches - AWS Training! 14 NOVThursday 6:30 AM IST 17 NOVSunday 7:00 AM IST 21 NOVThursday 6:30 AM IST 24 NOVSunday 6:30 AM IST More Batches Elasticache is a web service that makes the path easier to deploy and store the data in the cloud easily. 55. Explain about AWS Lambda. AWS Lambda is a computational service that enables you to run code without maintaining any servers. It automatically executes the code whenever needed. You are required to pay for the time that you have used it for. Lambda enables you to run the code virtually for any kind of application without managing any servers. 56. What is Geo Restriction in CloudFront? It is an important feature available in AWS which helps you in preventing the users from accessing the content from specific regions. CloudFront is useful for distributing the content only to desired locations. 57. What is Amazon EMR? Amazon EMR is a survived cluster stage and it helps you to create data structures before the intimation. Big data technologies such as Apache Hadoop and Spark are the tools that enable you to investigate a large amount of data. You can use the data for making analytical goals by using the apache hive and other relevant open source technologies. 58. What is the actual boot time taken to instance stored-backend AMI? It takes less than 5 minutes to store the instance-backed AMI. 59. Explain the essential features of the Amazon cloud search. Below listed are the essential features of Amazon cloud search. Prefixes Searches Enter text search Boolean searches Range searches Autocomplete Advice 60. Give a few examples of DB engines that are used in AWS RDS. Following are few examples of DB engines which are used in AWS RDS: MariaDB OracleDB MS-SQL DB MYSQL DB Postgre DB 61. What is the security group? In AWS the in and out traffic to instances is controlled with virtual firewalls which are known as Security groups. Security groups allow you to control traffic based on various aspects such as protocol, port and source destination. 62. What is the difference between block storage and file storage? Block Storage: it functions at a lower level and manages the data asset of blocks. File Storage: The file storage operates at a higher level or operational level and manages data in the form of files and folders. 63. Explain the types of Routing policies available in Amazon route S3. Latency-based Weighted Failover Simple Geolocation 64. List the default tables that we get when we create AWS VPC. Network ACL Security group Route table 65. List the different ways to access AWS. We have three different ways to access AWS, such as: Console SDK CLI 66. What are the EBS volumes? The EBS is the abbreviation for Elastic Block Stores. These blocks act as a persistent volume which can be attached to the instances. The EBS volumes will store the data even if you stop the instances. 67. How can you control the security to your VPC? You can use security groups, network access controls (ACLs) and flow logs to control your VPC security. AWS Questions and Answers Pdf Download Read the full article
0 notes
Text
Amazon DocumentDB (with MongoDB compatibility) read autoscaling
Amazon Document DB (with MongoDB compatibility) is a fast, scalable, highly available, and fully managed document database service that supports MongoDB workloads. Its architecture supports up to 15 read replicas, so applications that connect as a replica set can use driver read preference settings to direct reads to replicas for horizontal read scaling. Moreover, as read replicas are added or removed, the drivers adjust to automatically spread the load over the current read replicas, allowing for seamless scaling. Amazon DocumentDB separates storage and compute, so adding and removing read replicas is fast and easy regardless of how much data is stored in the cluster. Unlike other distributed databases, you don’t need to copy data to new read replicas. Although you can use the Amazon DocumentDB console, API, or AWS Command Line Interface (AWS CLI) to add and remove read replicas manually, it’s possible to automatically change the number of read replicas to adapt to changing workloads. In this post, I describe how to use Application Auto Scaling to automatically add or remove read replicas based on cluster load. I also demonstrate how this system works by modifying the load on a cluster and observing how the number of read replicas change. The process includes three steps: Deploy an Amazon DocumentDB cluster and required autoscaling resources. Generate load on the Amazon DocumentDB cluster to trigger a scaling event. Monitor cluster performance as read scaling occurs. Solution overview Application Auto Scaling allows you to automatically scale AWS resources based on the value of an Amazon CloudWatch metric, using an approach called target tracking scaling. Target tracking scaling uses a scaling policy to define which CloudWatch metric to track, and the AWS resource to scale, called the scalable target. When you register a target tracking scaling policy, Application Auto Scaling automatically creates the required CloudWatch metric alarms and manages the scalable target according to the policy definition. The following diagram illustrates this architecture. Application Auto Scaling manages many different AWS services natively, but as of this writing, Amazon DocumentDB is not included among these. However, you can still define an Amazon DocumentDB cluster as a scalable target by creating an Auto Scaling custom resource, which allows our target tracking policy to manage an Amazon DocumentDB cluster’s configuration through a custom HTTP API. This API enables the Application Auto Scaling service to query and modify a resource. The following diagram illustrates this architecture. We create the custom HTTP API with two AWS services: Amazon API Gateway and AWS Lambda. API Gateway provides the HTTP endpoint, and two Lambda functions enable Application Auto Scaling to discover the current number of read replicas, and increase or decrease the number of read replicas. One Lambda function handles the status query (a GET operation), and the other handles adjusting the number of replicas (a PATCH operation). Our complete architecture looks like the following diagram. Required infrastructure Before we try out Amazon DocumentDB read autoscaling, we create an AWS CloudFormation stack that deploys the following infrastructure: An Amazon Virtual Private Cloud (VPC) with two public and two private subnets to host our Amazon DocumentDB cluster and other resources. An Amazon DocumentDB cluster consisting of one write and two read replicas, all of size db.r5.large. A jump host (Amazon Elastic Compute Cloud (Amazon EC2)) that we use to run the load test. It lives in a private subnet and we access it via AWS Systems Manager Session Manager, so we don’t need to manage SSH keys or security groups to connect. The autoscaler, which consists of a REST API backed by two Lambda functions. A preconfigured CloudWatch dashboard with a set of useful charts for monitoring the Amazon DocumentDB write and read replicas. Start by cloning the autoscaler code from its Git repository. Navigate to that directory. Although you can create the stack on the AWS CloudFormation console, I’ve provided a script in the repository to make the creation process easier. Create an Amazon Simple Storage Service (Amazon S3) bucket to hold the CloudFormation templates: aws s3 mb s3:// On the Amazon S3 console, enable versioning for the bucket. We use versions to help distinguish new versions of the Lambda deployment packages. Run a script to create deployment packages for our Lambda functions: ./scripts/zip-lambda.sh Invoke the create.sh script, passing in several parameters. The template prefix is the folder in the S3 bucket where we store the Cloud Formation templates. ./scripts/create.sh For example, see the following code: ./scripts/create.sh cfn PrimaryPassword docdbautoscale us-east-1 The Region should be the same Region in which the S3 bucket was created. If you need to update the stack, pass in –update as the last argument. Now you wait for the stack to create. When the stack is complete, on the AWS CloudFormation console, note the following values on the stack Outputs tab: DBClusterIdentifier DashboardName DbEndpoint DbUser JumpHost VpcId ApiEndpoint When we refer to these later on, they appear in brackets, like Also note your AWS Region and account number. Register the autoscaler: cd scripts python register.py Autoscaler design The autoscaler implements the custom resource scaling pattern from the Application Auto Scaling service. In this pattern, we have a REST API that offers a GET method to obtain the status of the resource we want to scale, and a PATCH method that updates the resource. The GET method The Lambda function that implements the GET method takes an Amazon DocumentDB cluster identifier as input and returns information about the desired and actual number of read replicas. The function first retrieves the current value of the desired replica count, which we store in the Systems Manager Parameter Store: param_name = "DesiredSize-" + cluster_id r = ssm.get_parameter( Name= param_name) desired_count = int(r['Parameter']['Value']) Next, the function queries Amazon DocumentDB for information about the read replicas in the cluster: r = docdb.describe_db_clusters( DBClusterIdentifier=cluster_id) cluster_info = r['DBClusters'][0] readers = [] for member in cluster_info['DBClusterMembers']: member_id = member['DBInstanceIdentifier'] member_type = member['IsClusterWriter'] if member_type == False: readers.append(member_id) It interrogates Amazon DocumentDB for information about the status of each of the replicas. That lets us know if a scaling action is ongoing (a new read replica is creating). See the following code: r = docdb.describe_db_instances(Filters=[{'Name':'db-cluster-id','Values': [cluster_id]}]) instances = r['DBInstances'] desired_count = len(instances) - 1 num_available = 0 num_pending = 0 num_failed = 0 for i in instances: instance_id = i['DBInstanceIdentifier'] if instance_id in readers: instance_status = i['DBInstanceStatus'] if instance_status == 'available': num_available = num_available + 1 if instance_status in ['creating', 'deleting', 'starting', 'stopping']: num_pending = num_pending + 1 if instance_status == 'failed': num_failed = num_failed + 1 Finally, it returns information about the current and desired number of replicas: responseBody = { "actualCapacity": float(num_available), "desiredCapacity": float(desired_count), "dimensionName": cluster_id, "resourceName": cluster_id, "scalableTargetDimensionId": cluster_id, "scalingStatus": scalingStatus, "version": "1.0" } response = { 'statusCode': 200, 'body': json.dumps(responseBody) } return response The PATCH method The Lambda function that handles a PATCH request takes the desired number of read replicas as input: {"desiredCapacity":2.0} The function uses the Amazon DocumentDB Python API to gather information about the current state of the cluster, and if a scaling action is required, it adds or removes a replica. When adding a replica, it uses the same settings as the other replicas in the cluster and lets Amazon DocumentDB choose an Availability Zone automatically. When removing replicas, it chooses the Availability Zone that has the most replicas available. See the following code: # readers variable was initialized earlier to a list of the read # replicas. reader_type and reader_engine were copied from # another replica. desired_count is essentially the same as # desiredCapacity. if scalingStatus == 'Pending': print("Initiating scaling actions on cluster {0} since actual count {1} does not equal desired count {2}".format(cluster_id, str(num_available), str(desired_count))) if num_available < desired_count: num_to_create = desired_count - num_available for idx in range(num_to_create): docdb.create_db_instance( DBInstanceIdentifier=readers[0] + '-' + str(idx) + '-' + str(int(time.time())), DBInstanceClass=reader_type, Engine=reader_engine, DBClusterIdentifier=cluster_id ) else: num_to_remove = num_available - desired_count for idx in range(num_to_remove): # get the AZ with the most replicas az_with_max = max(reader_az_cnt.items(), key=operator.itemgetter(1))[0] LOGGER.info(f"Removing read replica from AZ {az_with_max}, which has {reader_az_cnt[az_with_max]} replicas") # get one of the replicas from that AZ reader_list = reader_az_map[az_with_max] reader_to_delete = reader_list[0] LOGGER.info(f"Removing read replica {reader_to_delete}") docdb.delete_db_instance( DBInstanceIdentifier=reader_to_delete) reader_az_map[az_with_max].remove(reader_to_delete) reader_az_cnt[az_with_max] -= 1 We also store the latest desired replica count in the Parameter Store: r = ssm.put_parameter( Name=param_name, Value=str(desired_count), Type='String', Overwrite=True, AllowedPattern='^d+$' ) Defining the scaling target and scaling policy We use the boto3 API to register the scaling target. The MinCapacity and MaxCapacity are set to 2 and 15 in the scaling target, because we always want at least two read replicas, and 15 is the maximum number of read replicas. The following is the relevant snippet from the registration script: # client is the docdb boto3 client response = client.register_scalable_target( ServiceNamespace='custom-resource', ResourceId='https://' + ApiEndpoint + '.execute-api.' + Region + '.amazonaws.com/prod/scalableTargetDimensions/' + DBClusterIdentifier, ScalableDimension='custom-resource:ResourceType:Property', MinCapacity=2, MaxCapacity=15, RoleARN='arn:aws:iam::' + Account + ':role/aws-service-role/custom-resource.application-autoscaling.amazonaws.com/AWSServiceRoleForApplicationAutoScaling_CustomResource' ) The script also creates the autoscaling policy. There are several important configuration parameters in this policy. I selected CPU utilization on the read replicas as the target metric (CPU utilization is not necessarily the best metric for your workload’s scaling trigger; other options such as BufferCacheHitRatio may provide better behavior). I set the target value at an artificially low value of 5% to more easily trigger a scaling event (a more realistic value for a production workload is 70–80%). I also set a long cooldown period of 10 minutes for both scale-in and scale-out to avoid having replicas added or removed too frequently. You need to determine the cooldown periods that are most appropriate for your production workload. The following is the relevant snippet from the script: response = client.put_scaling_policy( PolicyName='docdbscalingpolicy', ServiceNamespace='custom-resource', ResourceId='https://' + ApiEndpoint + '.execute-api.' + Region + '.amazonaws.com/prod/scalableTargetDimensions/' + DBClusterIdentifier, ScalableDimension='custom-resource:ResourceType:Property', PolicyType='TargetTrackingScaling', TargetTrackingScalingPolicyConfiguration={ 'TargetValue': 5.0, 'CustomizedMetricSpecification': { 'MetricName': 'CPUUtilization', 'Namespace': 'AWS/DocDB', 'Dimensions': [ { 'Name': 'Role', 'Value': 'READER' }, { 'Name': 'DBClusterIdentifier', 'Value': DBClusterIdentifier } ], 'Statistic': 'Average', 'Unit': 'Percent' }, 'ScaleOutCooldown': 600, 'ScaleInCooldown': 600, 'DisableScaleIn': False } ) Generating load I use the YCSB framework to generate load. Complete the following steps: Connect to the jump host using Session Manager: aws ssm start-session --target Install YCSB: sudo su - ec2-user sudo yum -y install java curl -O --location https://github.com/brianfrankcooper/YCSB/releases/download/0.17.0/ycsb-0.17.0.tar.gz tar xfvz ycsb-0.17.0.tar.gz cd ycsb-0.17.0 Run the load tester. We use workloadb, which is a read-heavy workload: ./bin/ycsb load mongodb -s -P workloads/workloadb -p recordcount=10000000 -p mongodb.url=”mongodb://:@:27017/?replicaSet=rs0&readPreference=secondaryPreferred&retryWrites=false” > load.dat ./bin/ycsb run mongodb -threads 10 -target 100 -s -P workloads/workloadb -p recordcount=10000000 -p mongodb.url=”mongodb://< PrimaryUser>:@:27017/?replicaSet=rs0&readPreference=secondaryPreferred&retryWrites=false” > run.dat These two commands load data in the Amazon DocumentDB database and run a read-heavy workload using that data. Monitoring scaling activity and cluster performance The CloudFormation stack created a CloudWatch dashboard that shows several metrics. The following screenshot shows the dashboard for the writer node. The following screenshot shows the dashboard for the read replicas. As YCSB runs, watch the dashboard to see the load increase. When the CPU load on the readers exceeds our 5% target, the autoscaler should add a read replica. We can verify that by checking the Amazon DocumentDB console and observing the number of instances in the cluster. Cleaning up If you deployed the CloudFormation templates used in this post, consider deleting the stack if you don’t want to keep the resources. Conclusion In this post, I showed you how to use a custom Application Auto Scaling resource to automatically add or remove read replicas to an Amazon DocumentDB cluster, based on a specific performance metric and scaling policy. Before using this approach in a production setting, you should decide which Amazon DocumentDB performance metric best reflects when your workload needs to scale in or scale out, determine the target value for that metric, and settle on a cooldown period that lets you respond to cluster load without adding or removing replicas too frequently. As a baseline, you could try a scaling policy that triggers a scale-up when CPUUtilization is over 70% or FreeableMemory is under 10%. About the Author Randy DeFauw is a principal solutions architect at Amazon Web Services. He works with the AWS customers to provide guidance and technical assistance on database projects, helping them improve the value of their solutions when using AWS. https://aws.amazon.com/blogs/database/amazon-documentdb-with-mongodb-compatibility-read-autoscaling/
0 notes