#data analysis in python
Explore tagged Tumblr posts
Visit Tumblr Blog
Explore Tumblr blogs with no restrictions, modern design and the best experience.
Last Seen Tumblr Blogs





Fun Fact
Tumblr is available in 18 languages.
Text
Hey everyone! enjoying my (two) week break of uni, so I've been lazy and playing games. Today, working on Python, I'm just doing repetition of learning the basics; Variables, Data types, Logic statements, etc. Hope everyone has a good week!
#codeblr#coding#python#university#uni life#studying#datascience#data analytics#data analysis#studyblr#student life#study motivation#study blog#student
78 notes
·
View notes
Text
Python Libraries to Learn Before Tackling Data Analysis
To tackle data analysis effectively in Python, it's crucial to become familiar with several libraries that streamline the process of data manipulation, exploration, and visualization. Here's a breakdown of the essential libraries:
1. NumPy
- Purpose: Numerical computing.
- Why Learn It: NumPy provides support for large multi-dimensional arrays and matrices, along with a collection of mathematical functions to operate on these arrays efficiently.
- Key Features:
- Fast array processing.
- Mathematical operations on arrays (e.g., sum, mean, standard deviation).
- Linear algebra operations.
2. Pandas
- Purpose: Data manipulation and analysis.
- Why Learn It: Pandas offers data structures like DataFrames, making it easier to handle and analyze structured data.
- Key Features:
- Reading/writing data from CSV, Excel, SQL databases, and more.
- Handling missing data.
- Powerful group-by operations.
- Data filtering and transformation.
3. Matplotlib
- Purpose: Data visualization.
- Why Learn It: Matplotlib is one of the most widely used plotting libraries in Python, allowing for a wide range of static, animated, and interactive plots.
- Key Features:
- Line plots, bar charts, histograms, scatter plots.
- Customizable charts (labels, colors, legends).
- Integration with Pandas for quick plotting.
4. Seaborn
- Purpose: Statistical data visualization.
- Why Learn It: Built on top of Matplotlib, Seaborn simplifies the creation of attractive and informative statistical graphics.
- Key Features:
- High-level interface for drawing attractive statistical graphics.
- Easier to use for complex visualizations like heatmaps, pair plots, etc.
- Visualizations based on categorical data.
5. SciPy
- Purpose: Scientific and technical computing.
- Why Learn It: SciPy builds on NumPy and provides additional functionality for complex mathematical operations and scientific computing.
- Key Features:
- Optimized algorithms for numerical integration, optimization, and more.
- Statistics, signal processing, and linear algebra modules.
6. Scikit-learn
- Purpose: Machine learning and statistical modeling.
- Why Learn It: Scikit-learn provides simple and efficient tools for data mining, analysis, and machine learning.
- Key Features:
- Classification, regression, and clustering algorithms.
- Dimensionality reduction, model selection, and preprocessing utilities.
7. Statsmodels
- Purpose: Statistical analysis.
- Why Learn It: Statsmodels allows users to explore data, estimate statistical models, and perform tests.
- Key Features:
- Linear regression, logistic regression, time series analysis.
- Statistical tests and models for descriptive statistics.
8. Plotly
- Purpose: Interactive data visualization.
- Why Learn It: Plotly allows for the creation of interactive and web-based visualizations, making it ideal for dashboards and presentations.
- Key Features:
- Interactive plots like scatter, line, bar, and 3D plots.
- Easy integration with web frameworks.
- Dashboards and web applications with Dash.
9. TensorFlow/PyTorch (Optional)
- Purpose: Machine learning and deep learning.
- Why Learn It: If your data analysis involves machine learning, these libraries will help in building, training, and deploying deep learning models.
- Key Features:
- Tensor processing and automatic differentiation.
- Building neural networks.
10. Dask (Optional)
- Purpose: Parallel computing for data analysis.
- Why Learn It: Dask enables scalable data manipulation by parallelizing Pandas operations, making it ideal for big datasets.
- Key Features:
- Works with NumPy, Pandas, and Scikit-learn.
- Handles large data and parallel computations easily.
Focusing on NumPy, Pandas, Matplotlib, and Seaborn will set a strong foundation for basic data analysis.
7 notes
·
View notes
Text
Understanding Outliers in Machine Learning and Data Science

In machine learning and data science, an outlier is like a misfit in a dataset. It's a data point that stands out significantly from the rest of the data. Sometimes, these outliers are errors, while other times, they reveal something truly interesting about the data. Either way, handling outliers is a crucial step in the data preprocessing stage. If left unchecked, they can skew your analysis and even mess up your machine learning models.
In this article, we will dive into:
1. What outliers are and why they matter.
2. How to detect and remove outliers using the Interquartile Range (IQR) method.
3. Using the Z-score method for outlier detection and removal.
4. How the Percentile Method and Winsorization techniques can help handle outliers.
This guide will explain each method in simple terms with Python code examples so that even beginners can follow along.
1. What Are Outliers?
An outlier is a data point that lies far outside the range of most other values in your dataset. For example, in a list of incomes, most people might earn between $30,000 and $70,000, but someone earning $5,000,000 would be an outlier.
Why Are Outliers Important?
Outliers can be problematic or insightful:
Problematic Outliers: Errors in data entry, sensor faults, or sampling issues.
Insightful Outliers: They might indicate fraud, unusual trends, or new patterns.
Types of Outliers
1. Univariate Outliers: These are extreme values in a single variable.
Example: A temperature of 300°F in a dataset about room temperatures.
2. Multivariate Outliers: These involve unusual combinations of values in multiple variables.
Example: A person with an unusually high income but a very low age.
3. Contextual Outliers: These depend on the context.
Example: A high temperature in winter might be an outlier, but not in summer.
2. Outlier Detection and Removal Using the IQR Method
The Interquartile Range (IQR) method is one of the simplest ways to detect outliers. It works by identifying the middle 50% of your data and marking anything that falls far outside this range as an outlier.
Steps:
1. Calculate the 25th percentile (Q1) and 75th percentile (Q3) of your data.
2. Compute the IQR:
{IQR} = Q3 - Q1
Q1 - 1.5 \times \text{IQR}
Q3 + 1.5 \times \text{IQR} ] 4. Anything below the lower bound or above the upper bound is an outlier.
Python Example:
import pandas as pd
# Sample dataset
data = {'Values': [12, 14, 18, 22, 25, 28, 32, 95, 100]}
df = pd.DataFrame(data)
# Calculate Q1, Q3, and IQR
Q1 = df['Values'].quantile(0.25)
Q3 = df['Values'].quantile(0.75)
IQR = Q3 - Q1
# Define the bounds
lower_bound = Q1 - 1.5 * IQR
upper_bound = Q3 + 1.5 * IQR
# Identify and remove outliers
outliers = df[(df['Values'] < lower_bound) | (df['Values'] > upper_bound)]
print("Outliers:\n", outliers)
filtered_data = df[(df['Values'] >= lower_bound) & (df['Values'] <= upper_bound)]
print("Filtered Data:\n", filtered_data)
Key Points:
The IQR method is great for univariate datasets.
It works well when the data isn’t skewed or heavily distributed.
3. Outlier Detection and Removal Using the Z-Score Method
The Z-score method measures how far a data point is from the mean, in terms of standard deviations. If a Z-score is greater than a certain threshold (commonly 3 or -3), it is considered an outlier.
Formula:
Z = \frac{(X - \mu)}{\sigma}
is the data point,
is the mean of the dataset,
is the standard deviation.
Python Example:
import numpy as np
# Sample dataset
data = {'Values': [12, 14, 18, 22, 25, 28, 32, 95, 100]}
df = pd.DataFrame(data)
# Calculate mean and standard deviation
mean = df['Values'].mean()
std_dev = df['Values'].std()
# Compute Z-scores
df['Z-Score'] = (df['Values'] - mean) / std_dev
# Identify and remove outliers
threshold = 3
outliers = df[(df['Z-Score'] > threshold) | (df['Z-Score'] < -threshold)]
print("Outliers:\n", outliers)
filtered_data = df[(df['Z-Score'] <= threshold) & (df['Z-Score'] >= -threshold)]
print("Filtered Data:\n", filtered_data)
Key Points:
The Z-score method assumes the data follows a normal distribution.
It may not work well with skewed datasets.
4. Outlier Detection Using the Percentile Method and Winsorization
Percentile Method:
In the percentile method, we define a lower percentile (e.g., 1st percentile) and an upper percentile (e.g., 99th percentile). Any value outside this range is treated as an outlier.
Winsorization:
Winsorization is a technique where outliers are not removed but replaced with the nearest acceptable value.
Python Example:
from scipy.stats.mstats import winsorize
import numpy as np
Sample data
data = [12, 14, 18, 22, 25, 28, 32, 95, 100]
Calculate percentiles
lower_percentile = np.percentile(data, 1)
upper_percentile = np.percentile(data, 99)
Identify outliers
outliers = [x for x in data if x < lower_percentile or x > upper_percentile]
print("Outliers:", outliers)
# Apply Winsorization
winsorized_data = winsorize(data, limits=[0.01, 0.01])
print("Winsorized Data:", list(winsorized_data))
Key Points:
Percentile and Winsorization methods are useful for skewed data.
Winsorization is preferred when data integrity must be preserved.
Final Thoughts
Outliers can be tricky, but understanding how to detect and handle them is a key skill in machine learning and data science. Whether you use the IQR method, Z-score, or Wins
orization, always tailor your approach to the specific dataset you’re working with.
By mastering these techniques, you’ll be able to clean your data effectively and improve the accuracy of your models.
#science#skills#programming#bigdata#books#machinelearning#artificial intelligence#python#machine learning#data centers#outliers#big data#data analysis#data analytics#data scientist#database#datascience#data
4 notes
·
View notes
Text
Mars Crater Study-1
This article was written as a practice exercise with reference to the information provided in the COURSERA course, specifically the Mars Crater Study.
=========================================
My program,
import pandas as pd
import statsmodels.formula.api as smf
# Set display format
pd.set_option('display.float_format', lambda x: '%.2f' % x)
# Read dataset
data = pd.read_csv('marscrater_pds.csv')
# Convert necessary variables to numeric format
data['DIAM_CIRCLE_IMAGE'] = pd.to_numeric(data['DIAM_CIRCLE_IMAGE'], errors='coerce')
data['DEPTH_RIMFLOOR_TOPOG'] = pd.to_numeric(data['DEPTH_RIMFLOOR_TOPOG'], errors='coerce')
# Perform basic linear regression analysis
print("OLS regression model for the association between crater diameter and depth")
reg1 = smf.ols('DEPTH_RIMFLOOR_TOPOG ~ DIAM_CIRCLE_IMAGE', data=data).fit()
print(reg1.summary())
=========================================
Output results,
Dep. Variable: DEPTH_RIMFLOOR_TOPOG
R-squared:0.344
Model: OLS
Adj. R-squared:0.344
Method:Least Squares
F-statistic:2.018e+05
Date:Thu, 27 Mar 2025
Prob (F-statistic):0.00
Time:14:58:20
Log-Likelihood:1.1503e+05
No. Observations:384343
AIC:-2.301e+05
Df Residuals:384341
BIC:-2.300e+05
Df Model: 1
Covariance Type:nonrobust
coef std err t P>|t| [0.025 0.975]
Intercept 0.0220 0.000 70.370 0.000 0.021 0.023
DIAM_CIRCLE_IMAGE
0.0151 3.37e-05 449.169 0.000 0.015 0.015
Omnibus:390327.615
Durbin-Watson:1.276
Prob(Omnibus):0.000
Jarque-Bera (JB):4086668077.223
Skew: -3.506
Prob(JB):0.00
Kurtosis:508.113
Cond. No.10.1
=========================================
Results Summary:
Regression Model Results:
R-squared: 0.344, indicating that the model explains approximately 34.4% of the variability in crater depth.
Regression Coefficient (DIAMCIRCLEIMAGE): 0.0151, meaning that for each unit increase in crater diameter, the depth increases by an average of 0.0151 units.
p-value: 0.000, indicating that the effect of diameter on depth is statistically significant.
Intercept: 0.0220, which is the predicted crater depth when the diameter is zero.
Conclusion:
The analysis shows a significant positive association between crater diameter and depth. While the model provides some explanatory power, other factors likely influence crater depth, and further exploration is recommended.
2 notes
·
View notes
Text
What Are the Qualifications for a Data Scientist?
In today's data-driven world, the role of a data scientist has become one of the most coveted career paths. With businesses relying on data for decision-making, understanding customer behavior, and improving products, the demand for skilled professionals who can analyze, interpret, and extract value from data is at an all-time high. If you're wondering what qualifications are needed to become a successful data scientist, how DataCouncil can help you get there, and why a data science course in Pune is a great option, this blog has the answers.
The Key Qualifications for a Data Scientist
To succeed as a data scientist, a mix of technical skills, education, and hands-on experience is essential. Here are the core qualifications required:
1. Educational Background
A strong foundation in mathematics, statistics, or computer science is typically expected. Most data scientists hold at least a bachelor’s degree in one of these fields, with many pursuing higher education such as a master's or a Ph.D. A data science course in Pune with DataCouncil can bridge this gap, offering the academic and practical knowledge required for a strong start in the industry.
2. Proficiency in Programming Languages
Programming is at the heart of data science. You need to be comfortable with languages like Python, R, and SQL, which are widely used for data analysis, machine learning, and database management. A comprehensive data science course in Pune will teach these programming skills from scratch, ensuring you become proficient in coding for data science tasks.
3. Understanding of Machine Learning
Data scientists must have a solid grasp of machine learning techniques and algorithms such as regression, clustering, and decision trees. By enrolling in a DataCouncil course, you'll learn how to implement machine learning models to analyze data and make predictions, an essential qualification for landing a data science job.
4. Data Wrangling Skills
Raw data is often messy and unstructured, and a good data scientist needs to be adept at cleaning and processing data before it can be analyzed. DataCouncil's data science course in Pune includes practical training in tools like Pandas and Numpy for effective data wrangling, helping you develop a strong skill set in this critical area.
5. Statistical Knowledge
Statistical analysis forms the backbone of data science. Knowledge of probability, hypothesis testing, and statistical modeling allows data scientists to draw meaningful insights from data. A structured data science course in Pune offers the theoretical and practical aspects of statistics required to excel.
6. Communication and Data Visualization Skills
Being able to explain your findings in a clear and concise manner is crucial. Data scientists often need to communicate with non-technical stakeholders, making tools like Tableau, Power BI, and Matplotlib essential for creating insightful visualizations. DataCouncil’s data science course in Pune includes modules on data visualization, which can help you present data in a way that’s easy to understand.
7. Domain Knowledge
Apart from technical skills, understanding the industry you work in is a major asset. Whether it’s healthcare, finance, or e-commerce, knowing how data applies within your industry will set you apart from the competition. DataCouncil's data science course in Pune is designed to offer case studies from multiple industries, helping students gain domain-specific insights.
Why Choose DataCouncil for a Data Science Course in Pune?
If you're looking to build a successful career as a data scientist, enrolling in a data science course in Pune with DataCouncil can be your first step toward reaching your goals. Here’s why DataCouncil is the ideal choice:
Comprehensive Curriculum: The course covers everything from the basics of data science to advanced machine learning techniques.
Hands-On Projects: You'll work on real-world projects that mimic the challenges faced by data scientists in various industries.
Experienced Faculty: Learn from industry professionals who have years of experience in data science and analytics.
100% Placement Support: DataCouncil provides job assistance to help you land a data science job in Pune or anywhere else, making it a great investment in your future.
Flexible Learning Options: With both weekday and weekend batches, DataCouncil ensures that you can learn at your own pace without compromising your current commitments.
Conclusion
Becoming a data scientist requires a combination of technical expertise, analytical skills, and industry knowledge. By enrolling in a data science course in Pune with DataCouncil, you can gain all the qualifications you need to thrive in this exciting field. Whether you're a fresher looking to start your career or a professional wanting to upskill, this course will equip you with the knowledge, skills, and practical experience to succeed as a data scientist.
Explore DataCouncil’s offerings today and take the first step toward unlocking a rewarding career in data science! Looking for the best data science course in Pune? DataCouncil offers comprehensive data science classes in Pune, designed to equip you with the skills to excel in this booming field. Our data science course in Pune covers everything from data analysis to machine learning, with competitive data science course fees in Pune. We provide job-oriented programs, making us the best institute for data science in Pune with placement support. Explore online data science training in Pune and take your career to new heights!
#In today's data-driven world#the role of a data scientist has become one of the most coveted career paths. With businesses relying on data for decision-making#understanding customer behavior#and improving products#the demand for skilled professionals who can analyze#interpret#and extract value from data is at an all-time high. If you're wondering what qualifications are needed to become a successful data scientis#how DataCouncil can help you get there#and why a data science course in Pune is a great option#this blog has the answers.#The Key Qualifications for a Data Scientist#To succeed as a data scientist#a mix of technical skills#education#and hands-on experience is essential. Here are the core qualifications required:#1. Educational Background#A strong foundation in mathematics#statistics#or computer science is typically expected. Most data scientists hold at least a bachelor’s degree in one of these fields#with many pursuing higher education such as a master's or a Ph.D. A data science course in Pune with DataCouncil can bridge this gap#offering the academic and practical knowledge required for a strong start in the industry.#2. Proficiency in Programming Languages#Programming is at the heart of data science. You need to be comfortable with languages like Python#R#and SQL#which are widely used for data analysis#machine learning#and database management. A comprehensive data science course in Pune will teach these programming skills from scratch#ensuring you become proficient in coding for data science tasks.#3. Understanding of Machine Learning
3 notes
·
View notes
Text

Unlock your potential in programming with the exceptional Python Course in Delhi, offered by Brillica Services. This Python Programming Course in Delhi is designed for both beginners and experienced programmers, ensuring top-notch Python Coaching in Delhi. Whether you aim to launch a career in software development, enhance your skills, or explore specialized areas like data science and web development, our course is the perfect starting point.
Our Python Course in Delhi emphasizes practical, hands-on learning. At Brillica Services, we believe in learning by doing. Our Python Classes in Delhi revolve around real-world projects and case studies, allowing you to apply theoretical knowledge to practical scenarios. Guided by industry experts, our Python Training Institute in Delhi ensures you gain valuable insights and skills that are highly regarded in the job market.
2 notes
·
View notes
Text
2 notes
·
View notes
Text

🚀 Ready to become a Data Science pro? Join our comprehensive Data Science Course and unlock the power of data! 📊💡
🔍 Learn: Excel PowerBi Python & R Machine Learning Data Visualization Real-world Projects
👨🏫 Taught by industry experts 💼 Career support & networking
3 notes
·
View notes
Text
Girl wake up, new project idea just dropped.
Source: etymologynerd on Instagram
#data science#python#sentiment analysis#coding#code project#projects#engineering#stem#dating#relatable
2 notes
·
View notes
Text

Learn Python To Secure Your Future In Data Science
Python is one of the most important coding or programming languages that is used by more than 8 million programmers as their main programming language.Now let's talk about how to learn Python. Python language is the basic and the easiest language compared to any other language.
To more info Visit us :- https://www.sssi.in/blog/engineering/learn-python-to-secure-your-future
#learn python#online training python#python developers#python basics#learn python for data analysis#python programming#coding python for beginners
3 notes
·
View notes
Text
Hyperparameter tuning in machine learning
The performance of a machine learning model in the dynamic world of artificial intelligence is crucial, we have various algorithms for finding a solution to a business problem. Some algorithms like linear regression , logistic regression have parameters whose values are fixed so we have to use those models without any modifications for training a model but there are some algorithms out there where the values of parameters are not fixed.
Here's a complete guide to Hyperparameter tuning in machine learning in Python!
#datascience #dataanalytics #dataanalysis #statistics #machinelearning #python #deeplearning #supervisedlearning #unsupervisedlearning
#machine learning#data analysis#data science#artificial intelligence#data analytics#deep learning#python#statistics#unsupervised learning#feature selection
3 notes
·
View notes
Text
Hey! and welcome back!
As Uni is about to begin in a few days....I upgraded to a third monitor! Also!! I job a Data entry job! Big things moving forward :)
Let me introduce myself;
I'm Mick, (she/her) and I currently study Data Analytics. I'll be 26 in July and I love to read and play video games in my free time. I also like to watch football (LIVERPOOL xx)
Im currently taking the time to learn Excel and Python. However, I know for school I'll be learning Python, SQL and maybe some other things.
FOLLOW me along on this journey and if you have any questions please ask!
#codeblr#python#coding#data analytics#study blog#study motivation#studyblr#student life#excel#student#physics#maths#pc setup#data analysis#data entry work#data entry projects#data scientist#study aesthetic
29 notes
·
View notes
Text
Understanding IHD with Data Science
Ischemic Heart Disease (IHD), more commonly recognized as coronary artery disease, is a profound health concern that stems from a decreased blood supply to the heart. Such a decrease is typically due to fatty deposits or plaques narrowing the coronary arteries. These arteries, as vital conduits delivering oxygen-rich blood to the heart, play a paramount role in ensuring the heart's efficient functioning. An obstruction or reduced flow within these arteries can usher in adverse outcomes, with heart attacks being the most dire. Given the gravity of IHD, the global medical community emphasizes the essence of early detection and prompt intervention to manage its repercussions effectively.
A New Age in Healthcare: Embracing Data Science
As we stand on the cusp of the fourth industrial revolution, technology's intertwining with every domain is evident. The healthcare sector is no exception. The integration of data science in healthcare is not merely an augmentation; it's a paradigm shift. Data science, with its vast array of tools and methodologies, is fostering new avenues to understand, diagnose, and even predict various health conditions long before they manifest pronounced symptoms.
Machine Learning: The Vanguard of Modern Medical Research
Among the myriad of tools under the vast umbrella of data science, Machine Learning (ML) shines exceptionally bright. An essential offshoot of artificial intelligence, ML capitalizes on algorithms and statistical models, granting computers the capability to process vast amounts of data and discern patterns without being explicitly programmed.
In the healthcare realm, the applications of ML are manifold. From predicting potential disease outbreaks based on global health data trends to optimizing patient flow in bustling hospitals, ML is progressively becoming a linchpin in medical operations. One of its most lauded applications, however, is its prowess in early disease prediction, and IHD detection stands as a testament to this.
Drawn to the immense potential ML holds, I ventured into a research project aimed at harnessing the RandomForestClassifier model's capabilities. Within the medical research sphere, this model is celebrated for its robustness and adaptability, making it a prime choice for my endeavor.
Deep Dive into the Findings
The results from the ML model were heartening. With an accuracy rate of 90%, the model’s prowess in discerning the presence of IHD based on an array of parameters was evident. Such a high accuracy rate is pivotal, considering the stakes at hand – the very health of a human heart. 9 times out of 10 the model is correct at its predictions.
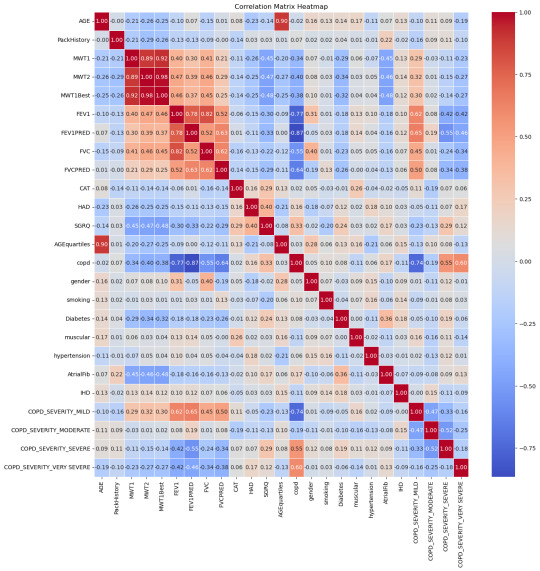
Breaking down the data, some correlations with IHD stood out prominently:
Moderate COPD (Chronic Obstructive Pulmonary Disease) – 15%: COPD's inclusion is noteworthy. While primarily a lung condition, its linkage with heart health has been a topic of numerous studies. A compromised respiratory system can inadvertently strain the heart, underscoring the interconnectedness of our bodily systems.
Diabetes – 18%: The correlation between diabetes and heart health isn't novel. Elevated blood sugar levels over extended periods can damage blood vessels, including the coronary arteries.
Age (segmented in quarterlies) – 15%: Age, as an immutable factor, plays a significant role. With age, several bodily systems gradually wear down, rendering individuals more susceptible to a plethora of conditions, IHD included.
Smoking habits – 14%: The deleterious effects of smoking on lung health are well-documented. However, its impact extends to the cardiovascular system, with nicotine and other chemicals adversely affecting heart functions.
MWT1 and MWT2 (indicators of physical endurance) – 13% and 14% respectively: Physical endurance and heart health share an intimate bond. These metrics, gauging one's physical stamina, can be precursors to potential heart-related anomalies.
Redefining Patient Care in the Machine Learning Era
Armed with these insights, healthcare can transcend its conventional boundaries. A deeper understanding of IHD's contributors empowers medical professionals to devise comprehensive care strategies that are both preventive and curative.
Moreover, the revelations from this study underscore the potential for proactive medical interventions. Instead of being reactive, waiting for symptoms to manifest, healthcare providers can now adopt a preventive stance. Patients exhibiting the highlighted risk factors can be placed under more meticulous observation, ensuring that potential IHD developments are nipped in the bud.
With the infusion of machine learning, healthcare is on the cusp of a personalized revolution. Gone are the days of one-size-fits-all medical approaches. Recognizing the uniqueness of each patient's health profile, machine learning models like the one employed in this study can pave the way for hyper-personalized care regimens.
As machine learning continues to entrench itself in healthcare, a future where disease predictions are accurate, interventions are timely, and patient care is unparalleled isn't merely a vision; it's an impending reality.
#heart disease#ihd#ischemic heart disease#programming#programmer#python#python programming#machine learning#data analysis#data science#data visualization#aicommunity#ai#artificial intelligence#medical research#medical technology
3 notes
·
View notes
Text
Python 3.12.0 is on the horizon, promising groundbreaking features! Expect robust error handling, precise typing, and major performance boosts. This release isn’t just an update; it’s a leap for developer productivity and innovation. What features excite you the most? Join the conversation!
#python#update#web development#data analysis#machine learning#pyhthon development#pythonprogramming#mobiosolutions
2 notes
·
View notes
Text
How to create good quality programming assignments
Not only are our programmers highly skilled, but they also have a thorough understanding of the market. They can assist you with programming projects of a similar nature because they have extensive programming language knowledge.
Mark the answers to all of the questions in your books before starting with the first one. Don't simply write; read, comprehend, and add a few lines of your own. Do this neatly, with enough space between paragraphs, and don't forget to include examples or charts. And make an effort to complete it ahead of schedule and submit it on time.

These are the stages for writing an assignment:
1. Develop a Plan
Making a plan for your programming project can keep you on track and help you concentrate on programming concepts.
Check the value of your assignment and the final grade %. You may use this to determine how much time to allocate.
Start working on the list of chores.
Set a time limit for each assignment and move backwards from the deadline date.
2. Examine your programming issue or query.
You must first understand what a programming question or assignment topic implies in order to respond to it. Carefully read it and attempt to understand what is expected of you.
3. Create a framework or outline.
Your task becomes easier to write down once you've established a structure. Although the sort of assignment you are working on will give you a clear framework, you should also go through the question and notation schedule since they will show you how the instructor intends to organise the subject. What ought to be mentioned and which parts are worth the most points.
4. Locate pertinent information
Before you begin writing, you must study your topic and gather useful and trustworthy facts. When you obtain the material, you must review it to ensure that it is appropriate for your work.
2 notes
·
View notes
Text
Exploratory Data Analysis of Demographic Variables Using Python.

**1) الكود المستخدم (البرنامج الأول):
import pandas as pd
data = { 'Gender': ['Male', 'Female', 'Female', 'Male', 'Male', 'Female', 'Male', None], 'AgeGroup': ['18-24', '25-34', '18-24', '35-44', '18-24', '25-34', None, '25-34'], 'Education': ['Bachelor', 'High School', 'Bachelor', 'Master', None, 'Bachelor', 'High School', 'Bachelor'] }
df = pd.DataFrame(data)
طباعة أول 5 صفوف
print(df.head())
التوزيعات
print("\nDistribution for Gender:") print(df['Gender'].value_counts(dropna=False))
print("\nDistribution for Age Group:") print(df['AgeGroup'].value_counts(dropna=False))
print("\nDistribution for Education:") print(df['Education'].value_counts(dropna=False))
2) مخرجات البرنامج (جداول التكرار):
Distribution for Gender: Male 4 Female 3 None 1 Name: Gender, dtype: int64
Distribution for Age Group: 18-24 3 25-34 3 35-44 1 None 1 Name: AgeGroup, dtype: int64
Distribution for Education: Bachelor 4 High School 2 Master 1 None 1 Name: Education, dtype: int64
3) وصف توزيعات التردد:
Gender (النوع): يوجد 4 مشاركين من الذكور و3 من الإناث، بالإضافة إلى ملاحظة واحدة مفقودة (غير محددة).
Age Group (الفئة العمرية): أكثر الفئات تكرارًا هما "18-24" و"25-34" حيث ظهرت كل منهما 3 مرات، بينما ظهرت "35-44" مرة واحدة فقط، وهناك ملاحظة واحدة مفقودة.
Education (المستوى التعليمي): أكثر القيم تكرارًا كانت شهادة "Bachelor" (4 مرات)، تليها "High School" (مرتين)، ثم "Master" مرة واحدة، ويوجد صف واحد لم تُسجل فيه قيمة.
0 notes