#data api
Explore tagged Tumblr posts
Visit Tumblr Blog
Explore Tumblr blogs with no restrictions, modern design and the best experience.
Last Seen Tumblr Blogs





Fun Fact
In 2020, 44% of users from Denmark used Tumblr daily.
Text
API Payments
Optimize your payment processes effortlessly with the API Payments solution. This Application Programming Interface serves as a gateway, enabling secure and efficient integration of payment functionalities into your applications. Streamline transactions, enhance user experience, and ensure a seamless payment flow by harnessing the power of API related Payments for a reliable and user-friendly financial experience.
1 note
·
View note
Text
API Food
Relish the taste of API food by glancing at our food section. Delve deep into the world of cooking details, entailing recipes and nutritional facts. This API furnishes a plethora of options, empowering developers to easily add food-related features to their apps. No more waiting! Explore its varied choices for a broad range of yummy experiences in your coding adventure.
1 note
·
View note
Text
KYC Data API India
Experience seamless KYC compliance in India through our robust Data API. Ensure swift, secure verifications with confidence. Elevate your standards today.
0 notes
Text
All this talk about Tumblr disappearing and how we should export our blogs.
Writing R code to download all the notes from ONE Tumblr post has been an irritating adventure.
The main problems:
The API only gives you ~50 notes per call - no pagination, no offset, no “get everything” option. Tumblr: Fuck you, API user.
You’re limited to 300 API calls per minute.
Even if you respect that limit, Tumblr will still get cranky and start throwing 429 “Too Many Requests” errors.
When you reach the end of a post’s notes, the API just… repeats the last note forever instead of stopping.
There’s no reliable way to know when you’ve hit the end unless you build that check yourself.
Tags and added text from reblogs are a completely separate part of the API - not included with the likes, reblogs, and replies you get from the /notes endpoint. Why? Tumblr: Fuck you, API user.
Did I mention that the API is a rickety piece of shit? It forced me to get a bit creative. I built a loop that steps backward in time using timestamps to get around the lack of pagination. Since the API only gives you the most recent ~50 notes, I had to manually request older and older notes, one batch at a time - with built-in retries, cooldowns, and rate-aware pacing to avoid getting blocked.
My script works now. It politely crawls back through thousands of notes, exits cleanly when it hits the end, and saves everything to a CSV file.
Was it worth it? Eh.
#a rare data science post#tumblr's rickety API#what a motherfucker#those posts telling people to use the API to download their entire blog#good luck with that#wheezes with laugher
57 notes
·
View notes
Text






"Saturdays by Twin Shadow (feat. HAIM)" is how I've mentally started every post I've made here on a Saturday for the past however many years that song's been out.
I decided I needed bath bombs so I set out to do that and only realized my error when I saw the traffic control person as soon as I turned into the mall. On the Saturday before Christmas. lol
My upstairs neighbor moved out a month ago so I no longer hear about their sex life through my ceiling. My next door neighbor moved out last week so I no longer have to wear my active noise cancelling earplugs to muffle their snoring. It’s quieter around here, but the hot water takes longer to find my tap in the morning.
I deleted a whole chapter about that computer case. You’re welcome.
Never did end up doing Christmas cards this year. I’ve got mixed feelings about that.
I want to do a bunch of dumb end of year data analysis things, but I have to pull a bunch of data to do it, and that’ll take me like a dozen minutes, and that's like a dozen minutes that I could spend not doing that thing. You see my dilemma. Stay tuned, I guess?
I’m the only one on my team not scheduled off on Monday and I think Tuesday next week (and, actually, most of the next 2 weeks). It’s easy enough to keep Teams active and my work email open while I tinker on side quests.
The checkout person at LUSH is always like “oh, are these a gift?” as I unload 9 bath bombs from my basket, as if they don't get many solo middle aged dudes stocking up on bath bombs on Saturday afternoons.
Turns out I miscounted and have 1 too many bath bombs so I’m taking a bath about it.
#that first line was going to be the whole post 🤷♂️#I intentionally don’t schedule these 2 weeks off so that I can provide coverage while folks spend time doing family stuff#the property management company lowered the asking rent by $150/mo on the longest-vacant units and they're still not finding any takers#that dude next door S N O R E D so freaking loud#like me wearing regular ear plugs NEXT DOOR weren't enough!!#this week i learned about sleeper computers and that generic family computers from like 25 years ago are going for $200+ on ebay#i do enjoy pulling data from web apis so maybe i'll do that next week instead of whatever i should be doing for work#unrelated: i hate when the definition of a word is a different form of the word#like indulgence is the act of indulging and indulging is the past participle of indulge and i have to look up 3 words to confirm what i kno#you're a computer just figure out what i want and tell me the answer!
29 notes
·
View notes
Text
An interoperability rule for your money

This is the final weekend to back the Kickstarter campaign for the audiobook of my next novel, The Lost Cause. These kickstarters are how I pay my bills, which lets me publish my free essays nearly every day. If you enjoy my work, please consider backing!

"If you don't like it, why don't you take your business elsewhere?" It's the motto of the corporate apologist, someone so Hayek-pilled that they see every purchase as a ballot cast in the only election that matters – the one where you vote with your wallet.
Voting with your wallet is a pretty undignified way to go through life. For one thing, the people with the thickest wallets get the most votes, and for another, no matter who you vote for in that election, the Monopoly Party always wins, because that's the part of the thick-wallet set.
Contrary to the just-so fantasies of Milton-Friedman-poisoned bootlickers, there are plenty of reasons that one might stick with a business that one dislikes – even one that actively harms you.
The biggest reason for staying with a bad company is if they've figured out a way to punish you for leaving. Businesses are keenly attuned to ways to impose switching costs on disloyal customers. "Switching costs" are all the things you have to give up when you take your business elsewhere.
Businesses love high switching costs – think of your gym forcing you to pay to cancel your subscription or Apple turning off your groupchat checkmark when you switch to Android. The more it costs you to move to a rival vendor, the worse your existing vendor can treat you without worrying about losing your business.
Capitalists genuinely hate capitalism. As the FBI informant Peter Thiel says, "competition is for losers." The ideal 21st century "market" is something like Amazon, a platform that gets 45-51 cents out of every dollar earned by its sellers. Sure, those sellers all compete with one another, but no matter who wins, Amazon gets a cut:
https://pluralistic.net/2023/09/28/cloudalists/#cloud-capital
Think of how Facebook keeps users glued to its platform by making the price of leaving cutting of contact with your friends, family, communities and customers. Facebook tells its customers – advertisers – that people who hate the platform stick around because Facebook is so good at manipulating its users (this is a good sales pitch for a company that sells ads!). But there's a far simpler explanation for peoples' continued willingness to let Mark Zuckerberg spy on them: they hate Zuck, but they love their friends, so they stay:
https://www.eff.org/deeplinks/2021/08/facebooks-secret-war-switching-costs
One of the most important ways that regulators can help the public is by reducing switching costs. The easier it is for you to leave a company, the more likely it is they'll treat you well, and if they don't, you can walk away from them. That's just what the Consumer Finance Protection Bureau wants to do with its new Personal Financial Data Rights rule:
https://www.consumerfinance.gov/about-us/newsroom/cfpb-proposes-rule-to-jumpstart-competition-and-accelerate-shift-to-open-banking/
The new rule is aimed at banks, some of the rottenest businesses around. Remember when Wells Fargo ripped off millions of its customers by ordering its tellers to open fake accounts in their name, firing and blacklisting tellers who refused to break the law?
https://www.npr.org/sections/money/2016/10/07/497084491/episode-728-the-wells-fargo-hustle
While there are alternatives to banks – local credit unions are great – a lot of us end up with a bank by default and then struggle to switch, even though the banks give us progressively worse service, collectively rip us off for billions in junk fees, and even defraud us. But because the banks keep our data locked up, it can be hard to shop for better alternatives. And if we do go elsewhere, we're stuck with hours of tedious clerical work to replicate all our account data, payees, digital wallets, etc.
That's where the new CFPB order comes in: the Bureau will force banks to "share data at the person’s direction with other companies offering better products." So if you tell your bank to give your data to a competitor – or a comparison shopping site – it will have to do so…or else.
Banks often claim that they block account migration and comparison shopping sites because they want to protect their customers from ripoff artists. There are certainly plenty of ripoff artists (notwithstanding that some of them run banks). But banks have an irreconcilable conflict of interest here: they might want to stop (other) con-artists from robbing you, but they also want to make leaving as painful as possible.
Instead of letting shareholder-accountable bank execs in back rooms decide what the people you share your financial data are allowed to do with it, the CFPB is shouldering that responsibility, shifting those deliberations to the public activities of a democratically accountable agency. Under the new rule, the businesses you connect to your account data will be "prohibited from misusing or wrongfully monetizing the sensitive personal financial data."
This is an approach that my EFF colleague Bennett Cyphers and I first laid our in our 2021 paper, "Privacy Without Monopoly," where we describe how and why we should shift determinations about who is and isn't allowed to get your data from giant, monopolistic tech companies to democratic institutions, based on privacy law, not corporate whim:
https://www.eff.org/wp/interoperability-and-privacy
The new CFPB rule is aimed squarely at reducing switching costs. As CFPB Director Rohit Chopra says, "Today, we are proposing a rule to give consumers the power to walk away from bad service and choose the financial institutions that offer the best products and prices."
The rule bans banks from charging their customers junk fees to access their data, and bans businesses you give that data to from "collecting, using, or retaining data to advance their own commercial interests through actions like targeted or behavioral advertising." It also guarantees you the unrestricted right to revoke access to your data.
The rule is intended to replace the current state-of-the-art for data sharing, which is giving your banking password to third parties who go and scrape that data on your behalf. This is a tactic that comparison sites and financial dashboards have used since 2006, when Mint pioneered it:
https://www.eff.org/deeplinks/2019/12/mint-late-stage-adversarial-interoperability-demonstrates-what-we-had-and-what-we
A lot's happened since 2006. It's past time for American bank customers to have the right to access and share their data, so they can leave rotten banks and go to better ones.
The new rule is made possible by Section 1033 of the Consumer Financial Protection Act, which was passed in 2010. Chopra is one of the many Biden administrative appointees who have acquainted themselves with all the powers they already have, and then used those powers to help the American people:
https://pluralistic.net/2022/10/18/administrative-competence/#i-know-stuff
It's pretty wild that the first digital interoperability mandate is going to come from the CFPB, but it's also really cool. As Tim Wu demonstrated in 2021 when he wrote Biden's Executive Order on Promoting Competition in the American Economy, the administrative agencies have sweeping, grossly underutilized powers that can make a huge difference to everyday Americans' lives:
https://www.eff.org/de/deeplinks/2021/08/party-its-1979-og-antitrust-back-baby
If you'd like an essay-formatted version of this post to read or share, here's a link to it on pluralistic.net, my surveillance-free, ad-free, tracker-free blog:
https://pluralistic.net/2023/10/21/let-my-dollars-go/#personal-financial-data-rights

My next novel is The Lost Cause, a hopeful novel of the climate emergency. Amazon won't sell the audiobook, so I made my own and I'm pre-selling it on Kickstarter!
Image: Steve Morgan (modified) https://commons.wikimedia.org/wiki/File:U.S._National_Bank_Building_-_Portland,_Oregon.jpg
Stefan Kühn (modified) https://commons.wikimedia.org/wiki/File:Abrissbirne.jpg
CC BY-SA 3.0 https://creativecommons.org/licenses/by-sa/3.0/deed.en
-
Rhys A. (modified) https://www.flickr.com/photos/rhysasplundh/5201859761/in/photostream/
CC BY 2.0 https://creativecommons.org/licenses/by/2.0/
#pluralistic#cfpb#interoperability mandates#mint#scraping#apis#privacy#privacy without monopoly#consumer finance protection bureau#Personal Financial Data Rights#interop#data hoarding#junk fees#switching costs#section 1033#interoperability
159 notes
·
View notes
Text
The problem with doing a project (my book database project) is that I keep having Ideas that I have neither the time nor the wherewithal to accomplish.
#book tagging database project#anyway it would be cool to be able to have some sort of link to goodreads/storygraph#so that you could see data on all of the books you've read#and/or also have a way to flag books that you're thinking about for querying or tbr or whatever#i truly do not want to replicate a book tracking system#that seems like a pain#but being able to connect to one to supplement it seems cool#but again#this is just like#a vague idea i had#that will never actually happen#because i can't even successfully manage the simple improvements#much less complicated api shit
12 notes
·
View notes
Text
not me finding out that fandom wikis do not have an api (which is like a specialised ui for programmers that a lot of websites have where you can more directly access resources off the website with programming tools, f.e. if one piece wiki had one, you could tell your coding languages like "hey get all the strawhat pirates' names and heights off their character pages and put them in my database here please" and it would be able to get that info off the wiki for you) so I will have to learn web scraping to get data off there for visualising ship stats project I have planned for my data analysis portfolio instead now smh
#coding#ship stats#the things I do for my shenanigans#but turns out bootcamp don't cover the *getting the data* part of data stuff#only the how you organise and move around and what you can do with the data once you have it#and I'm over here like but I wanna be able to assemble whatever public data sets I want to play with :c#shoutout to reddit for other people asking about this already cause I'm not the only geek tryna get wiki data for shenanigans#at least I'll get good use out of knowing how to scrape shit off non-api websites I guess u.u
15 notes
·
View notes
Text
Abathur

At Abathur, we believe technology should empower, not complicate.
Our mission is to provide seamless, scalable, and secure solutions for businesses of all sizes. With a team of experts specializing in various tech domains, we ensure our clients stay ahead in an ever-evolving digital landscape.
Why Choose Us? Expert-Led Innovation – Our team is built on experience and expertise. Security First Approach – Cybersecurity is embedded in all our solutions. Scalable & Future-Proof – We design solutions that grow with you. Client-Centric Focus – Your success is our priority.
#Software Development#Web Development#Mobile App Development#API Integration#Artificial Intelligence#Machine Learning#Predictive Analytics#AI Automation#NLP#Data Analytics#Business Intelligence#Big Data#Cybersecurity#Risk Management#Penetration Testing#Cloud Security#Network Security#Compliance#Networking#IT Support#Cloud Management#AWS#Azure#DevOps#Server Management#Digital Marketing#SEO#Social Media Marketing#Paid Ads#Content Marketing
2 notes
·
View notes
Text
Moments Lab Secures $24 Million to Redefine Video Discovery With Agentic AI
New Post has been published on https://thedigitalinsider.com/moments-lab-secures-24-million-to-redefine-video-discovery-with-agentic-ai/
Moments Lab Secures $24 Million to Redefine Video Discovery With Agentic AI

Moments Lab, the AI company redefining how organizations work with video, has raised $24 million in new funding, led by Oxx with participation from Orange Ventures, Kadmos, Supernova Invest, and Elaia Partners. The investment will supercharge the company’s U.S. expansion and support continued development of its agentic AI platform — a system designed to turn massive video archives into instantly searchable and monetizable assets.
The heart of Moments Lab is MXT-2, a multimodal video-understanding AI that watches, hears, and interprets video with context-aware precision. It doesn’t just label content — it narrates it, identifying people, places, logos, and even cinematographic elements like shot types and pacing. This natural-language metadata turns hours of footage into structured, searchable intelligence, usable across creative, editorial, marketing, and monetization workflows.
But the true leap forward is the introduction of agentic AI — an autonomous system that can plan, reason, and adapt to a user’s intent. Instead of simply executing instructions, it understands prompts like “generate a highlight reel for social” and takes action: pulling scenes, suggesting titles, selecting formats, and aligning outputs with a brand’s voice or platform requirements.
“With MXT, we already index video faster than any human ever could,” said Philippe Petitpont, CEO and co-founder of Moments Lab. “But with agentic AI, we’re building the next layer — AI that acts as a teammate, doing everything from crafting rough cuts to uncovering storylines hidden deep in the archive.”
From Search to Storytelling: A Platform Built for Speed and Scale
Moments Lab is more than an indexing engine. It’s a full-stack platform that empowers media professionals to move at the speed of story. That starts with search — arguably the most painful part of working with video today.
Most production teams still rely on filenames, folders, and tribal knowledge to locate content. Moments Lab changes that with plain text search that behaves like Google for your video library. Users can simply type what they’re looking for — “CEO talking about sustainability” or “crowd cheering at sunset” — and retrieve exact clips within seconds.
Key features include:
AI video intelligence: MXT-2 doesn’t just tag content — it describes it using time-coded natural language, capturing what’s seen, heard, and implied.
Search anyone can use: Designed for accessibility, the platform allows non-technical users to search across thousands of hours of footage using everyday language.
Instant clipping and export: Once a moment is found, it can be clipped, trimmed, and exported or shared in seconds — no need for timecode handoffs or third-party tools.
Metadata-rich discovery: Filter by people, events, dates, locations, rights status, or any custom facet your workflow requires.
Quote and soundbite detection: Automatically transcribes audio and highlights the most impactful segments — perfect for interview footage and press conferences.
Content classification: Train the system to sort footage by theme, tone, or use case — from trailers to corporate reels to social clips.
Translation and multilingual support: Transcribes and translates speech, even in multilingual settings, making content globally usable.
This end-to-end functionality has made Moments Lab an indispensable partner for TV networks, sports rights holders, ad agencies, and global brands. Recent clients include Thomson Reuters, Amazon Ads, Sinclair, Hearst, and Banijay — all grappling with increasingly complex content libraries and growing demands for speed, personalization, and monetization.
Built for Integration, Trained for Precision
MXT-2 is trained on 1.5 billion+ data points, reducing hallucinations and delivering high confidence outputs that teams can rely on. Unlike proprietary AI stacks that lock metadata in unreadable formats, Moments Lab keeps everything in open text, ensuring full compatibility with downstream tools like Adobe Premiere, Final Cut Pro, Brightcove, YouTube, and enterprise MAM/CMS platforms via API or no-code integrations.
“The real power of our system is not just speed, but adaptability,” said Fred Petitpont, co-founder and CTO. “Whether you’re a broadcaster clipping sports highlights or a brand licensing footage to partners, our AI works the way your team already does — just 100x faster.”
The platform is already being used to power everything from archive migration to live event clipping, editorial research, and content licensing. Users can share secure links with collaborators, sell footage to external buyers, and even train the system to align with niche editorial styles or compliance guidelines.
From Startup to Standard-Setter
Founded in 2016 by twin brothers Frederic Petitpont and Phil Petitpont, Moments Lab began with a simple question: What if you could Google your video library? Today, it’s answering that — and more — with a platform that redefines how creative and editorial teams work with media. It has become the most awarded indexing AI in the video industry since 2023 and shows no signs of slowing down.
“When we first saw MXT in action, it felt like magic,” said Gökçe Ceylan, Principal at Oxx. “This is exactly the kind of product and team we look for — technically brilliant, customer-obsessed, and solving a real, growing need.”
With this new round of funding, Moments Lab is poised to lead a category that didn’t exist five years ago — agentic AI for video — and define the future of content discovery.
#2023#Accessibility#adobe#Agentic AI#ai#ai platform#AI video#Amazon#API#assets#audio#autonomous#billion#brands#Building#CEO#CMS#code#compliance#content#CTO#data#dates#detection#development#discovery#editorial#engine#enterprise#event
2 notes
·
View notes
Text
today's great work conversation:
"hey, I posted to that API you wrote, and the data that came out on the other side contains stuff from the database instead of my request body. is that a bug?"
"why did you submit a request body? there's no mention of one in the story. that API doesn't expect, or look at, a request body. how did you even decide what to put in the body?"
"well it was left over from a different test and I didn't remove it"
#programming stuff#fascinated by this idea that if you submit some arbitrary data to an API#it should do its best to make something out of it#i hijack Amazon by making an AWS call where I add a body of {“amazonsNewCeo”: “Ashley”} and the system automatically puts me in charge
34 notes
·
View notes
Text
hey uh
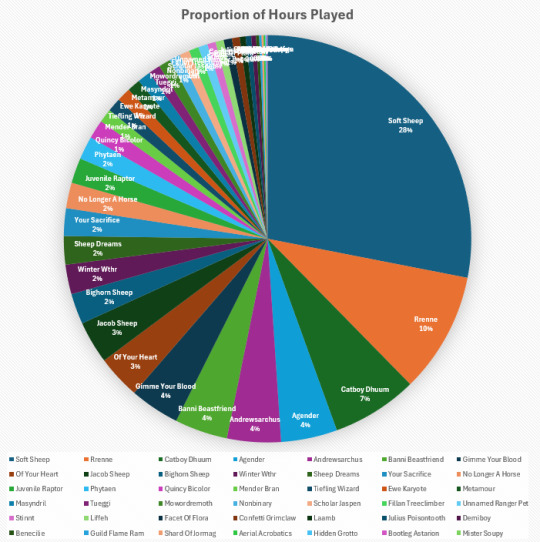
#this is just ripped from my main acct so it excludes EU and alt NA bc i do NOT have it in me to manually add in that data#beloved friend holly set up a spreadsheet function that rips data from an API key and I had to visualize this when I noticed it#jsyk rrenne was made only a few months after launch#sheep was made in...2016? I think?
8 notes
·
View notes
Text
Here’s the third exciting installment in my series about backing up one Tumblr post that absolutely no one asked for. The previous updates are linked here.
Previously on Tumblr API Hell
Some blogs returned 404 errors. After investigating with Allie's help, it turns out it’s not a sideblog issue — it’s a privacy setting. It pleases me that Tumblr's rickety API respects the word no.
Also, shoutout to the one line of code in my loop that always broke when someone reblogged without tags. Fixed it.
What I got working:
Tags added during reblogs of the post
Any added commentary (what the blog actually wrote)
Full post metadata so I can extract other information later (ie. outside the loop)
New questions I’m trying to answer:
While flailing around in the JSON trying to figure out which blog added which text (because obviously Tumblr’s rickety API doesn’t just tell you), I found that all the good stuff lives in a deeply nested structure called trail. It splits content into HTML chunks — but there’s no guarantee about order, and you have to reconstruct it yourself.
Here’s a stylized diagram of what trail looks like in the JSON list (which gets parsed as a data frame in R):

I started wondering:
Can I use the trail to reconstruct a version tree to see which path through the reblog chain was the most influential for the post?
This would let me ask:
Which version of the post are people reblogging?
Does added commentary increase the chance it gets reblogged again?
Are some blogs “amplifiers” — their version spreads more than others?
It’s worth thinking about these questions now — so I can make sure I’m collecting the right information from Tumblr’s rickety API before I run my R code on a 272K-note post.
Summary
Still backing up one post. Just me, 600+ lines of R code, and Tumblr’s API fighting it out at a Waffle House parking lot. The code’s nearly ready — I’m almost finished testing it on an 800-note post before trying it on my 272K-note Blaze post. Stay tuned… Zero fucks given?
If you give zero fucks about my rickety API series, you can block my data science tag, #a rare data science post, or #tumblr's rickety API. But if we're mutuals then you know how it works here - you get what you get. It's up to you to curate your online experience. XD
#a rare data science post#tumblr's rickety API#fuck you API user#i'll probably make my R code available in github#there's a lot of profanity in the comments#just saying
24 notes
·
View notes
Text
he literally just said on a rally (why is he even doing them still wtf) that he wants to bring the economy back to 1929 we're all so fucking screwed.... we're so fucking screwed
the social stuff can be mitigated... this can't, we're so screwed globally :|
#personal#i guess im not even thinking about job hopping for higher pay this year anymore lol#i'll eat other people's jobs with my automation scripts so that i'm not the layoff#i'm already getting added to the job eater team once im back from vacation.... cause i know some python and the job eating#software uses python for api data requests#like i'm the artist they chose to put on the /automation job eating/ team lol#like im literally the ONLY artist not in a true managerial role put on this team cause i can code a little...and translate to cs nerd#(and all the scripts that i've made at work are just adaptations of my gif automation process... so if#weird boyband special interest mixed with hypernumeracy type autism saves me and my husband from this stupidity#i'll be annoyed but grateful)
4 notes
·
View notes
Text
Protect Your Laravel APIs: Common Vulnerabilities and Fixes
API Vulnerabilities in Laravel: What You Need to Know
As web applications evolve, securing APIs becomes a critical aspect of overall cybersecurity. Laravel, being one of the most popular PHP frameworks, provides many features to help developers create robust APIs. However, like any software, APIs in Laravel are susceptible to certain vulnerabilities that can leave your system open to attack.

In this blog post, we’ll explore common API vulnerabilities in Laravel and how you can address them, using practical coding examples. Additionally, we’ll introduce our free Website Security Scanner tool, which can help you assess and protect your web applications.
Common API Vulnerabilities in Laravel
Laravel APIs, like any other API, can suffer from common security vulnerabilities if not properly secured. Some of these vulnerabilities include:
>> SQL Injection SQL injection attacks occur when an attacker is able to manipulate an SQL query to execute arbitrary code. If a Laravel API fails to properly sanitize user inputs, this type of vulnerability can be exploited.
Example Vulnerability:
$user = DB::select("SELECT * FROM users WHERE username = '" . $request->input('username') . "'");
Solution: Laravel’s query builder automatically escapes parameters, preventing SQL injection. Use the query builder or Eloquent ORM like this:
$user = DB::table('users')->where('username', $request->input('username'))->first();
>> Cross-Site Scripting (XSS) XSS attacks happen when an attacker injects malicious scripts into web pages, which can then be executed in the browser of a user who views the page.
Example Vulnerability:
return response()->json(['message' => $request->input('message')]);
Solution: Always sanitize user input and escape any dynamic content. Laravel provides built-in XSS protection by escaping data before rendering it in views:
return response()->json(['message' => e($request->input('message'))]);
>> Improper Authentication and Authorization Without proper authentication, unauthorized users may gain access to sensitive data. Similarly, improper authorization can allow unauthorized users to perform actions they shouldn't be able to.
Example Vulnerability:
Route::post('update-profile', 'UserController@updateProfile');
Solution: Always use Laravel’s built-in authentication middleware to protect sensitive routes:
Route::middleware('auth:api')->post('update-profile', 'UserController@updateProfile');
>> Insecure API Endpoints Exposing too many endpoints or sensitive data can create a security risk. It’s important to limit access to API routes and use proper HTTP methods for each action.
Example Vulnerability:
Route::get('user-details', 'UserController@getUserDetails');
Solution: Restrict sensitive routes to authenticated users and use proper HTTP methods like GET, POST, PUT, and DELETE:
Route::middleware('auth:api')->get('user-details', 'UserController@getUserDetails');
How to Use Our Free Website Security Checker Tool
If you're unsure about the security posture of your Laravel API or any other web application, we offer a free Website Security Checker tool. This tool allows you to perform an automatic security scan on your website to detect vulnerabilities, including API security flaws.
Step 1: Visit our free Website Security Checker at https://free.pentesttesting.com. Step 2: Enter your website URL and click "Start Test". Step 3: Review the comprehensive vulnerability assessment report to identify areas that need attention.
Screenshot of the free tools webpage where you can access security assessment tools.
Example Report: Vulnerability Assessment
Once the scan is completed, you'll receive a detailed report that highlights any vulnerabilities, such as SQL injection risks, XSS vulnerabilities, and issues with authentication. This will help you take immediate action to secure your API endpoints.
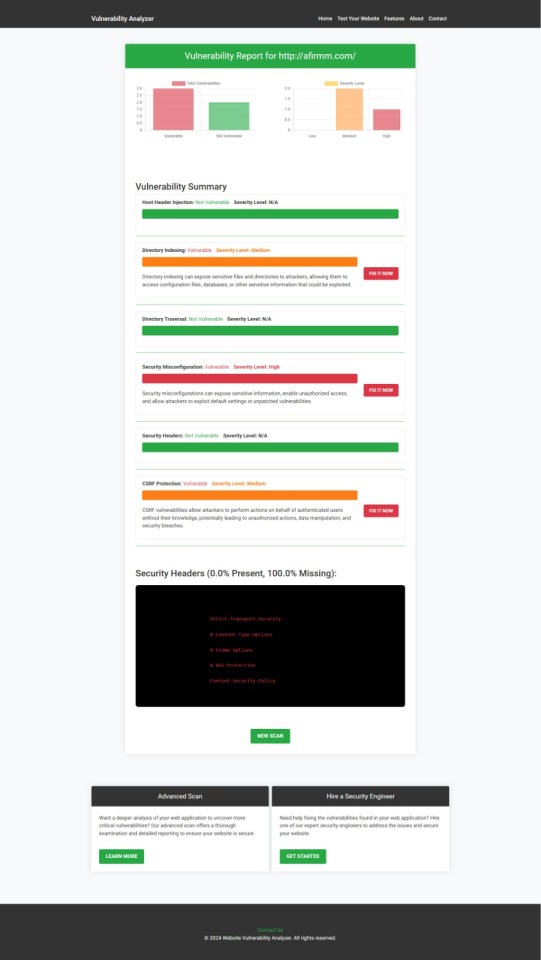
An example of a vulnerability assessment report generated with our free tool provides insights into possible vulnerabilities.
Conclusion: Strengthen Your API Security Today
API vulnerabilities in Laravel are common, but with the right precautions and coding practices, you can protect your web application. Make sure to always sanitize user input, implement strong authentication mechanisms, and use proper route protection. Additionally, take advantage of our tool to check Website vulnerability to ensure your Laravel APIs remain secure.
For more information on securing your Laravel applications try our Website Security Checker.
#cyber security#cybersecurity#data security#pentesting#security#the security breach show#laravel#php#api
2 notes
·
View notes