#data lake vs data warehouse aws
Explore tagged Tumblr posts
Visit Tumblr Blog
Explore Tumblr blogs with no restrictions, modern design and the best experience.
Last Seen Tumblr Blogs





Fun Fact
Tumblr has a 66 index score for customer satisfaction in the US.
Text

ETL vS. ELT - TERMINOLOGIA DE ENGENHARIA DE DADOS
Uma forma simples de compará-los é usando o exemplo do suco de laranja:
ETL (Extrair -> Transformar -> Carregar)
1. Extrair: Colher laranjas da árvore
(Coletar dados
brutos de bancos de dados, APls ou arquivos);
2. Transformar: Espremer as laranjas em suco antes de armazenar O (Limpar, filtrar e formatar os dados);
3. Carregar: Armazenar o suco pronto na geladeira (Salvar dados estruturados em um data warehouse);
Usado em: Finanças e Saúde (Os dados devem estar
limpos antes do armazenamento)
ELT (Extrair -> Carregar -> Transformar)
1. Extrair: Colher laranjas da árvore
(Coletar dados
brutos de bancos de dados, APIs ou arquivos)
2. Carregar: Armazenar as laranjas inteiras na geladeira primeiro (Salvar dados brutos em um data lake ou armazém na nuvem)
3. Transformar: Fazer suco quando necessário O (Processar e analisar dados posteriormente)
• Usado em: Big Data e Cloud (Transformações mais rápidas e escaláveis)
Stack tecnológica: Snowflake, BigQuery, Databricks,
AWS Redshift
0 notes
Text
Data Engineer vs Data Analyst vs Data Scientist vs ML Engineer: Choose Your Perfect Data Career!

In today’s rapidly evolving tech world, career opportunities in data-related fields are expanding like never before. However, with multiple roles like Data Engineer vs Data Analyst vs Data Scientist vs ML Engineer, newcomers — and even seasoned professionals — often find it confusing to understand how these roles differ.
At Yasir Insights, we think that having clarity makes professional selections more intelligent. We’ll go over the particular duties, necessary abilities, and important differences between these well-liked Data Engineer vs Data Analyst vs Data Scientist vs ML Engineer data positions in this blog.
Also Read: Data Engineer vs Data Analyst vs Data Scientist vs ML Engineer
Introduction to Data Engineer vs Data Analyst vs Data Scientist vs ML Engineer
The Data Science and Machine Learning Development Lifecycle (MLDLC) includes stages like planning, data gathering, preprocessing, exploratory analysis, modelling, deployment, and optimisation. In order to effectively manage these intricate phases, the burden is distributed among specialised positions, each of which plays a vital part in the project’s success.
Data Engineer
Who is a Data Engineer?
The basis of the data ecosystem is built by data engineers. They concentrate on collecting, sanitising, and getting data ready for modelling or further analysis. Think of them as mining precious raw materials — in this case, data — from complex and diverse sources.
Key Responsibilities:
Collect and extract data from different sources (APIS, databases, web scraping).
Design and maintain scalable data pipelines.
Clean, transform, and store data in warehouses or lakes.
Optimise database performance and security.
Required Skills:
Strong knowledge of Data Structures and Algorithms.
Expertise in Database Management Systems (DBMS).
Familiarity with Big Data tools (like Hadoop, Spark).
Hands-on experience with cloud platforms (AWS, Azure, GCP).
Proficiency in building and managing ETL (Extract, Transform, Load) pipelines.
Data Analyst
Who is a Data Analyst?
Data analysts take over once the data has been cleansed and arranged. Their primary responsibility is to evaluate data in order to get valuable business insights. They provide answers to important concerns regarding the past and its causes.
Key Responsibilities:
Perform Exploratory Data Analysis (EDA).
Create visualisations and dashboards to represent insights.
Identify patterns, trends, and correlations in datasets.
Provide reports to support data-driven decision-making.
Required Skills:
Strong Statistical knowledge.
Proficiency in programming languages like Python or R.
Expertise in Data Visualisation tools (Tableau, Power BI, matplotlib).
Excellent communication skills to present findings clearly.
Experience working with SQL databases.
Data Scientist
Who is a Data Scientist?
Data Scientists build upon the work of Data Analysts by developing predictive models and machine learning algorithms. While analysts focus on the “what” and “why,” Data Scientists focus on the “what’s next.”
Key Responsibilities:
Design and implement Machine Learning models.
Perform hypothesis testing, A/B testing, and predictive analytics.
Derive strategic insights for product improvements and new innovations.
Communicate technical findings to stakeholders.
Required Skills:
Mastery of Statistics and Probability.
Strong programming skills (Python, R, SQL).
Deep understanding of Machine Learning algorithms.
Ability to handle large datasets using Big Data technologies.
Critical thinking and problem-solving abilities.
Machine Learning Engineer
Who is a Machine Learning Engineer?
Machine Learning Engineers (MLES) take the models developed by Data Scientists and make them production-ready. They ensure models are deployed, scalable, monitored, and maintained effectively in real-world systems.
Key Responsibilities:
Deploy machine learning models into production environments.
Optimise and scale ML models for performance and efficiency.
Continuously monitor and retrain models based on real-time data.
Collaborate with software engineers and data scientists for integration.
Required Skills:
Strong foundations in Linear Algebra, Calculus, and Probability.
Mastery of Machine Learning frameworks (TensorFlow, PyTorch, Scikit-learn).
Proficiency in programming languages (Python, Java, Scala).
Knowledge of Distributed Systems and Software Engineering principles.
Familiarity with MLOps tools for automation and monitoring.
Summary: Data Engineer vs Data Analyst vs Data Scientist vs ML Engineer
Data Engineer
Focus Area: Data Collection & Processing
Key Skills: DBMS, Big Data, Cloud Computing
Objective: Build and maintain data infrastructure
Data Analyst
Focus Area: Data Interpretation & Reporting
Key Skills: Statistics, Python/R, Visualisation Tools
Objective: Analyse data and extract insights
Data Scientist
Focus Area: Predictive Modelling
Key Skills: Machine Learning, Statistics, Data Analysis
Objective: Build predictive models and strategies
Machine Learning Engineer
Focus Area: Model Deployment & Optimisation
Key Skills: ML Frameworks, Software Engineering
Objective: Deploy and optimise ML models in production
Frequently Asked Questions (FAQS)
Q1: Can a Data Engineer become a Data Scientist?
Yes! With additional skills in machine learning, statistics, and model building, a Data Engineer can transition into a Data Scientist role.
Q2: Is coding necessary for Data Analysts?
While deep coding isn’t mandatory, familiarity with SQL, Python, or R greatly enhances a Data Analyst’s effectiveness.
Q3: What is the difference between a Data Scientist and an ML Engineer?
Data Scientists focus more on model development and experimentation, while ML Engineers focus on deploying and scaling those models.
Q4: Which role is the best for beginners?
If you love problem-solving and analysis, start as a Data Analyst. If you enjoy coding and systems, a Data Engineer might be your path.
Published By:
Mirza Yasir Abdullah Baig
Repost This Article and built Your Connection With Others
0 notes
Text
ETL Pipelines: How Data Moves from Raw to Insights

Introduction
Businesses collect raw data from various sources.
ETL (Extract, Transform, Load) pipelines help convert this raw data into meaningful insights.
This blog explains ETL processes, tools, and best practices.
1. What is an ETL Pipeline?
An ETL pipeline is a process that Extracts, Transforms, and Loads data into a data warehouse or analytics system.
Helps in cleaning, structuring, and preparing data for decision-making.
1.1 Key Components of ETL
Extract: Collect data from multiple sources (databases, APIs, logs, files).
Transform: Clean, enrich, and format the data (filtering, aggregating, converting).
Load: Store data into a data warehouse, data lake, or analytics platform.
2. Extract: Gathering Raw Data
Data sources: Databases (MySQL, PostgreSQL), APIs, Logs, CSV files, Cloud storage.
Extraction methods:
Full Extraction: Pulls all data at once.
Incremental Extraction: Extracts only new or updated data.
Streaming Extraction: Real-time data processing (Kafka, Kinesis).
3. Transform: Cleaning and Enriching Data
Data Cleaning: Remove duplicates, handle missing values, normalize formats.
Data Transformation: Apply business logic, merge datasets, convert data types.
Data Enrichment: Add contextual data (e.g., join customer records with location data).
Common Tools: Apache Spark, dbt, Pandas, SQL transformations.
4. Load: Storing Processed Data
Load data into a Data Warehouse (Snowflake, Redshift, BigQuery, Synapse) or a Data Lake (S3, Azure Data Lake, GCS).
Loading strategies:
Full Load: Overwrites existing data.
Incremental Load: Appends new data.
Batch vs. Streaming Load: Scheduled vs. real-time data ingestion.
5. ETL vs. ELT: What’s the Difference?

ETL is best for structured data and compliance-focused workflows.
ELT is ideal for cloud-native analytics, handling massive datasets efficiently.
6. Best Practices for ETL Pipelines
✅ Optimize Performance: Use indexing, partitioning, and parallel processing. ✅ Ensure Data Quality: Implement validation checks and logging. ✅ Automate & Monitor Pipelines: Use orchestration tools (Apache Airflow, AWS Glue, Azure Data Factory). ✅ Secure Data Transfers: Encrypt data in transit and at rest. ✅ Scalability: Choose cloud-based ETL solutions for flexibility.
7. Popular ETL Tools
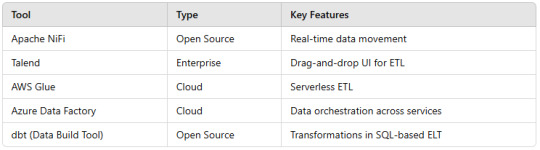
Conclusion
ETL pipelines streamline data movement from raw sources to analytics-ready formats.
Choosing the right ETL/ELT strategy depends on data size, speed, and business needs.
Automated ETL tools improve efficiency and scalability.
WEBSITE: https://www.ficusoft.in/data-science-course-in-chennai/
0 notes
Text
How Does CAI Differ from CDI in Informatica Cloud?
Informatica Cloud is a powerful platform that offers various integration services to help businesses manage and process data efficiently. Two of its core components—Cloud Application Integration (CAI) and Cloud Data Integration (CDI)—serve distinct but complementary purposes. While both are essential for a seamless data ecosystem, they address different integration needs. This article explores the key differences between CAI and CDI, their use cases, and how they contribute to a robust data management strategy. Informatica Training Online

What is Cloud Application Integration (CAI)?
Cloud Application Integration (CAI) is designed to enable real-time, event-driven integration between applications. It facilitates communication between different enterprise applications, APIs, and services, ensuring seamless workflow automation and business process orchestration. CAI primarily focuses on low-latency and API-driven integration to connect diverse applications across cloud and on-premises environments.
Key Features of CAI: Informatica IICS Training
Real-Time Data Processing: Enables instant data exchange between systems without batch processing delays.
API Management: Supports REST and SOAP-based web services to facilitate API-based interactions.
Event-Driven Architecture: Triggers workflows based on system events, such as new data entries or user actions.
Process Automation: Helps in automating business processes through orchestration of multiple applications.
Low-Code Development: Provides a drag-and-drop interface to design and deploy integrations without extensive coding.
Common Use Cases of CAI:
Synchronizing customer data between CRM (Salesforce) and ERP (SAP).
Automating order processing between e-commerce platforms and inventory management systems.
Enabling chatbots and digital assistants to interact with backend databases in real time.
Creating API gateways for seamless communication between cloud and on-premises applications.
What is Cloud Data Integration (CDI)?
Cloud Data Integration (CDI), on the other hand, is focused on batch-oriented and ETL-based data integration. It enables organizations to extract, transform, and load (ETL) large volumes of data from various sources into a centralized system such as a data warehouse, data lake, or business intelligence platform.
Key Features of CDI: Informatica Cloud Training
Batch Data Processing: Handles large datasets and processes them in scheduled batches.
ETL & ELT Capabilities: Transforms and loads data efficiently using Extract-Transform-Load (ETL) or Extract-Load-Transform (ELT) approaches.
Data Quality and Governance: Ensures data integrity, cleansing, and validation before loading into the target system.
Connectivity with Multiple Data Sources: Integrates with relational databases, cloud storage, big data platforms, and enterprise applications.
Scalability and Performance Optimization: Designed to handle large-scale data operations efficiently.
Common Use Cases of CDI:
Migrating legacy data from on-premises databases to cloud-based data warehouses (e.g., Snowflake, AWS Redshift, Google BigQuery).
Consolidating customer records from multiple sources for analytics and reporting.
Performing scheduled data synchronization between transactional databases and data lakes.
Extracting insights by integrating data from IoT devices into a centralized repository.
CAI vs. CDI: Key Differences
CAI is primarily designed for real-time application connectivity and event-driven workflows, making it suitable for businesses that require instant data exchange. It focuses on API-driven interactions and process automation, ensuring seamless communication between enterprise applications. On the other hand, CDI is focused on batch-oriented data movement and transformation, enabling organizations to manage large-scale data processing efficiently.
While CAI is ideal for integrating cloud applications, automating workflows, and enabling real-time decision-making, CDI is better suited for ETL/ELT operations, data warehousing, and analytics. The choice between CAI and CDI depends on whether a business needs instant data transactions or structured data transformations for reporting and analysis. IICS Online Training
Which One Should You Use?
Use CAI when your primary need is real-time application connectivity, process automation, and API-based data exchange.
Use CDI when you require batch processing, large-scale data movement, and structured data transformation for analytics.
Use both if your organization needs a hybrid approach, where real-time data interactions (CAI) are combined with large-scale data transformations (CDI).
Conclusion
Both CAI and CDI play crucial roles in modern cloud-based integration strategies. While CAI enables seamless real-time application interactions, CDI ensures efficient data transformation and movement for analytics and reporting. Understanding their differences and choosing the right tool based on business needs can significantly improve data agility, process automation, and decision-making capabilities within an organization.
For More Information about Informatica Cloud Online Training
Contact Call/WhatsApp: +91-9989971070
Visit: https://www.visualpath.in/informatica-cloud-training-in-hyderabad.html
Visit Blog: https://visualpathblogs.com/category/informatica-cloud/
WhatsApp: https://www.whatsapp.com/catalog/919989971070/
#Informatica Training in Hyderabad#IICS Training in Hyderabad#IICS Online Training#Informatica Cloud Training#Informatica Cloud Online Training#Informatica IICS Training#Informatica Training Online#Informatica Cloud Training in Chennai#Informatica Cloud Training In Bangalore#Best Informatica Cloud Training in India#Informatica Cloud Training Institute#Informatica Cloud Training in Ameerpet
0 notes
Text
Data Engineering Interview Questions and Answers
Summary: Master Data Engineering interview questions & answers. Explore key responsibilities, common topics (Big Data's 4 Vs!), and in-depth explanations. Get interview ready with bonus tips to land your dream Data Engineering job!

Introduction
The ever-growing volume of data presents exciting opportunities for data engineers. As the architects of data pipelines and custodians of information flow, data engineers are in high demand.
Landing your dream Data Engineering role requires not only technical proficiency but also a clear understanding of the specific challenges and responsibilities involved. This blog equips you with the essential Data Engineering interview questions and answers, helping you showcase your expertise and secure that coveted position.
Understanding the Role of a Data Engineer
Data engineers bridge the gap between raw data and actionable insights. They design, build, and maintain data pipelines that ingest, transform, store, and analyse data. Here are some key responsibilities of a data engineer:
Data Acquisition: Extracting data from various sources like databases, APIs, and log files.
Data Transformation: Cleaning, organizing, and transforming raw data into a usable format for analysis.
Data Warehousing and Storage: Designing and managing data storage solutions like data warehouses and data lakes.
Data Pipelines: Building and maintaining automated processes that move data between systems.
Data Security and Governance: Ensuring data security, access control, and compliance with regulations.
Collaboration: Working closely with data analysts, data scientists, and other stakeholders.
Common Data Engineering Interview Questions
Now that you understand the core responsibilities, let's delve into the most frequently asked Data Engineering interview questions:
What Is the Difference Between A Data Engineer And A Data Scientist?
While both work with data, their roles differ. Data engineers focus on building and maintaining data infrastructure, while data scientists use the prepared data for analysis and building models.
Explain The Concept of Data Warehousing And Data Lakes.
Data warehouses store structured data optimized for querying and reporting. Data lakes store both structured and unstructured data in a raw format, allowing for future exploration.
Can You Describe the ELT (Extract, Load, Transform) And ETL (Extract, Transform, Load) Processes?
Both ELT and ETL are data processing techniques used to move data from various sources to a target system for analysis. While they achieve the same goal, the key difference lies in the order of operations:
ELT (Extract, Load, Transform):
Extract: Data is extracted from its original source (databases, log files, etc.).
Load: The raw data is loaded directly into a data lake, a large storage repository for raw data in various formats.
Transform: Data is transformed and cleaned within the data lake as needed for specific analysis or queries.
ETL (Extract, Transform, Load):
Extract: Similar to ELT, data is extracted from its source.
Transform: The extracted data is cleansed, transformed, and organized into a specific format suitable for analysis before loading.
Load: The transformed data is then loaded into the target system, typically a data warehouse optimized for querying and reporting.
What Are Some Common Data Engineering Tools and Technologies?
Data Engineers wield a powerful toolkit to build and manage data pipelines. Here are some essentials:
Programming Languages: Python (scripting, data manipulation), SQL (database querying).
Big Data Frameworks: Apache Hadoop (distributed storage & processing), Apache Spark (in-memory processing for speed).
Data Streaming: Apache Kafka (real-time data pipelines).
Cloud Platforms: AWS, GCP, Azure (offer data storage, processing, and analytics services).
Data Warehousing: Tools for designing and managing data warehouses (e.g., Redshift, Snowflake).
Explain How You Would Handle a Situation Where A Data Pipeline Fails?
Data pipeline failures are inevitable, but a calm and structured approach can minimize downtime. Here's the key:
Detect & Investigate: Utilize monitoring tools and logs to pinpoint the failure stage and root cause (data issue, code bug, etc.).
Fix & Recover: Implement a solution (data cleaning, code fix, etc.), potentially recover lost data if needed, and thoroughly test the fix.
Communicate & Learn: Keep stakeholders informed and document the incident, including the cause, solution, and lessons learned to prevent future occurrences.
Bonus Tips: Automate retries for specific failures, use version control for code, and integrate data quality checks to prevent issues before they arise.
By following these steps, you can efficiently troubleshoot data pipeline failures and ensure the smooth flow of data for your critical analysis needs.
Detailed Answers and Explanations
Here are some in-depth responses to common Data Engineering interview questions:
Explain The Four Vs of Big Data (Volume, Velocity, Variety, And Veracity).
Volume: The massive amount of data generated today.
Velocity: The speed at which data is created and needs to be processed.
Variety: The diverse types of data, including structured, semi-structured, and unstructured.
Veracity: The accuracy and trustworthiness of the data.
Describe Your Experience with Designing and Developing Data Pipelines.
Explain the specific tools and technologies you've used, the stages involved in your data pipelines (e.g., data ingestion, transformation, storage), and the challenges you faced while designing and implementing them.
How Do You Handle Data Security and Privacy Concerns Within a Data Engineering Project?
Discuss security measures like access control, data encryption, and anonymization techniques you've implemented. Highlight your understanding of relevant data privacy regulations like GDPR (General Data Protection Regulation).
What Are Some Strategies for Optimising Data Pipelines for Performance?
Explain techniques like data partitioning, caching, and using efficient data structures to improve the speed and efficiency of your data pipelines.
Can You Walk us Through a Specific Data Engineering Project You've Worked On?
This is your opportunity to showcase your problem-solving skills and technical expertise. Describe the project goals, the challenges you encountered, the technologies used, and the impact of your work.
Tips for Acing Your Data Engineering Interview
Acing the Data Engineering interview goes beyond technical skills. Here, we unveil powerful tips to boost your confidence, showcase your passion, and leave a lasting impression on recruiters, ensuring you land your dream Data Engineering role!
Practice your answers: Prepare for common questions and rehearse your responses to ensure clarity and conciseness.
Highlight your projects: Showcase your technical skills by discussing real-world Data Engineering projects you've undertaken.
Demonstrate your problem-solving skills: Be prepared to walk through a Data Engineering problem and discuss potential solutions.
Ask insightful questions: Show your genuine interest in the role and the company by asking thoughtful questions about the team, projects, and Data Engineering challenges they face.
Be confident and enthusiastic: Project your passion for Data Engineering and your eagerness to learn and contribute.
Dress professionally: Make a positive first impression with appropriate attire that reflects the company culture.
Follow up: Send a thank-you email to the interviewer(s) reiterating your interest in the position.
Conclusion
Data Engineering is a dynamic and rewarding field. By understanding the role, preparing for common interview questions, and showcasing your skills and passion, you'll be well on your way to landing your dream Data Engineering job.
Remember, the journey to becoming a successful data engineer is a continuous learning process. Embrace challenges, stay updated with the latest technologies, and keep pushing the boundaries of what's possible with data.
#Data Engineering Interview Questions and Answers#data engineering interview#data engineering#engineering#data science#data modeling#data engineer#data engineering career#data engineer interview questions#how to become a data engineer#data engineer jobs
0 notes
Text
AMAZON SNOWFLAKE

Unlocking the Power of Amazon Snowflake: Your Guide to a Scalable Data Warehouse
In today’s data-driven world, finding the right tools to manage massive amounts of information is critical to business success. Enter Amazon Snowflake, a powerhouse cloud data warehouse built to revolutionize how you store, process, and unlock insights from your data. Let’s explore why Snowflake on AWS is a game-changer.
What is Amazon Snowflake?
At its core, Snowflake is a fully managed, cloud-based data warehouse solution offered as a Software-as-a-Service (SaaS). That means no installation headaches and no hardware to maintain – just scalable, lightning-fast data power on demand! Here’s what sets it apart:
Cloud-Native Architecture: Snowflake leverages Amazon Web Services (AWS) ‘s power and flexibility to enable virtually unlimited scalability and seamless integration with other AWS services.
Separation of Storage and Compute: You pay separately for the data you store and the compute resources (virtual warehouses) you use to process it. This offers incredible cost control and the ability to scale up or down based on workload.
Multi-Cluster Shared Data: Snowflake allows access to the same data from multiple compute clusters. This is perfect for separating workloads (e.g., development vs. production) without duplicating data.
Near-Zero Maintenance: Forget manual tuning and optimization; let Snowflake handle the heavy lifting.
Key Benefits of Snowflake
Effortless Scalability: Handle fluctuating data volumes with ease. Need more power during peak seasons? Spin additional virtual warehouses and scale them back down quickly when the rush ends.
Concurrency without Compromise: Snowflake can support numerous simultaneous users and queries without performance suffering, which is essential for data-intensive businesses.
Pay-As-You-Go Pricing: Only pay for the resources you use. This model appeals to businesses with unpredictable workloads or those looking to control costs tightly.
Seamless Data Sharing: Securely share governed data sets within your organization or with external partners and customers without any complex data movement.
Broad Support: Snowflake works with various business intelligence (BI) and data analysis tools as well as SQL and semi-structured data formats (like JSON and XML).
Typical Use Cases
Modern Data Warehousing: Snowflake is tailor-made to centralize data from multiple sources, creating a single source of truth for your organization.
Data Lakes: Combine structured and semi-structured data in a Snowflake environment, streamlining big data analytics.
Data-Driven Applications: Thanks to Snowflake’s speed and scalability, build applications powered by real-time data insights.
Business Intelligence and Reporting: Snowflake powers your BI dashboards and reports, enabling faster and more informed business decisions.
Getting Started with Snowflake on AWS
Ready to try it out? Snowflake offers a generous free trial so that you can test the waters. If you’re already using AWS, integration is a breeze.
Let’s Summarize
Amazon Snowflake is a cloud data warehousing force to be reckoned with. If you need a solution that combines limitless scale, ease of use, flexibility, cost-effectiveness, and lightning-fast performance, Snowflake warrants a serious look. Embrace the power of the cloud and let Snowflake become the backbone of your data strategy.
youtube
You can find more information about Snowflake in this Snowflake
Conclusion:
Unogeeks is the No.1 IT Training Institute for SAP Training. Anyone Disagree? Please drop in a comment
You can check out our other latest blogs on Snowflake here – Snowflake Blogs
You can check out our Best In Class Snowflake Details here – Snowflake Training
Follow & Connect with us:
———————————-
For Training inquiries:
Call/Whatsapp: +91 73960 33555
Mail us at: [email protected]
Our Website ➜ https://unogeeks.com
Follow us:
Instagram: https://www.instagram.com/unogeeks
Facebook: https://www.facebook.com/UnogeeksSoftwareTrainingInstitute
Twitter: https://twitter.com/unogeeks
0 notes
Text
A Beginner’s Guide to Data Warehousing
New Post has been published on https://thedigitalinsider.com/a-beginners-guide-to-data-warehousing/
A Beginner’s Guide to Data Warehousing
In this digital economy, data is paramount. Today, all sectors, from private enterprises to public entities, use big data to make critical business decisions.
However, the data ecosystem faces numerous challenges regarding large data volume, variety, and velocity. Businesses must employ certain techniques to organize, manage, and analyze this data.
Enter data warehousing!
Data warehousing is a critical component in the data ecosystem of a modern enterprise. It can streamline an organization’s data flow and enhance its decision-making capabilities. This is also evident in the global data warehousing market growth, which is expected to reach $51.18 billion by 2028, compared to $21.18 billion in 2019.
This article will explore data warehousing, its architecture types, key components, benefits, and challenges.
What is Data Warehousing?
Data warehousing is a data management system to support Business Intelligence (BI) operations. It is a process of collecting, cleaning, and transforming data from diverse sources and storing it in a centralized repository. It can handle vast amounts of data and facilitate complex queries.
In BI systems, data warehousing first converts disparate raw data into clean, organized, and integrated data, which is then used to extract actionable insights to facilitate analysis, reporting, and data-informed decision-making.
Moreover, modern data warehousing pipelines are suitable for growth forecasting and predictive analysis using artificial intelligence (AI) and machine learning (ML) techniques. Cloud data warehousing further amplifies these capabilities offering greater scalability and accessibility, making the entire data management process even more flexible.
Before we discuss different data warehouse architectures, let’s look at the major components that constitute a data warehouse.
Key Components of Data Warehousing
Data warehousing comprises several components working together to manage data efficiently. The following elements serve as a backbone for a functional data warehouse.
Data Sources: Data sources provide information and context to a data warehouse. They can contain structured, unstructured, or semi-structured data. These can include structured databases, log files, CSV files, transaction tables, third-party business tools, sensor data, etc.
ETL (Extract, Transform, Load) Pipeline: It is a data integration mechanism responsible for extracting data from data sources, transforming it into a suitable format, and loading it into the data destination like a data warehouse. The pipeline ensures correct, complete, and consistent data.
Metadata: Metadata is data about the data. It provides structural information and a comprehensive view of the warehouse data. Metadata is essential for governance and effective data management.
Data Access: It refers to the methods data teams use to access the data in the data warehouse, e.g., SQL queries, reporting tools, analytics tools, etc.
Data Destination: These are physical storage spaces for data, such as a data warehouse, data lake, or data mart.
Typically, these components are standard across data warehouse types. Let’s briefly discuss how the architecture of a traditional data warehouse differs from a cloud-based data warehouse.
Architecture: Traditional Data Warehouse vs Active-Cloud Data Warehouse
A Typical Data Warehouse Architecture
Traditional data warehouses focus on storing, processing, and presenting data in structured tiers. They are typically deployed in an on-premise setting where the relevant organization manages the hardware infrastructure like servers, drives, and memory.
On the other hand, active-cloud warehouses emphasize continuous data updates and real-time processing by leveraging cloud platforms like Snowflake, AWS, and Azure. Their architectures also differ based on their applications.
Some key differences are discussed below.
Traditional Data Warehouse Architecture
Bottom Tier (Database Server): This tier is responsible for storing (a process known as data ingestion) and retrieving data. The data ecosystem is connected to company-defined data sources that can ingest historical data after a specified period.
Middle Tier (Application Server): This tier processes user queries and transforms data (a process known as data integration) using Online Analytical Processing (OLAP) tools. Data is typically stored in a data warehouse.
Top Tier (Interface Layer): The top tier serves as the front-end layer for user interaction. It supports actions like querying, reporting, and visualization. Typical tasks include market research, customer analysis, financial reporting, etc.
Active-Cloud Data Warehouse Architecture
Bottom Tier (Database Server): Besides storing data, this tier provides continuous data updates for real-time data processing, meaning that data latency is very low from source to destination. The data ecosystem uses pre-built connectors or integrations to fetch real-time data from numerous sources.
Middle Tier (Application Server): Immediate data transformation occurs in this tier. It is done using OLAP tools. Data is typically stored in an online data mart or data lakehouse.
Top Tier (Interface Layer): This tier enables user interactions, predictive analytics, and real-time reporting. Typical tasks include fraud detection, risk management, supply chain optimization, etc.
Best Practices in Data Warehousing
While designing data warehouses, the data teams must follow these best practices to increase the success of their data pipelines.
Self-Service Analytics: Properly label and structure data elements to keep track of traceability – the ability to track the entire data warehouse lifecycle. It enables self-service analytics that empowers business analysts to generate reports with nominal support from the data team.
Data Governance: Set robust internal policies to govern the use of organizational data across different teams and departments.
Data Security: Monitor the data warehouse security regularly. Apply industry-grade encryption to protect your data pipelines and comply with privacy standards like GDPR, CCPA, and HIPAA.
Scalability and Performance: Streamline processes to improve operational efficiency while saving time and cost. Optimize the warehouse infrastructure and make it robust enough to manage any load.
Agile Development: Follow an agile development methodology to incorporate changes to the data warehouse ecosystem. Start small and expand your warehouse in iterations.
Benefits of Data Warehousing
Some key data warehouse benefits for organizations include:
Improved Data Quality: A data warehouse provides better quality by gathering data from various sources into a centralized storage after cleansing and standardizing.
Cost Reduction: A data warehouse reduces operational costs by integrating data sources into a single repository, thus saving data storage space and separate infrastructure costs.
Improved Decision Making: A data warehouse supports BI functions like data mining, visualization, and reporting. It also supports advanced functions like AI-based predictive analytics for data-driven decisions about marketing campaigns, supply chains, etc.
Challenges of Data Warehousing
Some of the most notable challenges that occur while constructing a data warehouse are as follows:
Data Security: A data warehouse contains sensitive information, making it vulnerable to cyber-attacks.
Large Data Volumes: Managing and processing big data is complex. Achieving low latency throughout the data pipeline is a significant challenge.
Alignment with Business Requirements: Every organization has different data needs. Hence, there is no one-size-fits-all data warehouse solution. Organizations must align their warehouse design with their business needs to reduce the chances of failure.
To read more content related to data, artificial intelligence, and machine learning, visit Unite AI.
#Accessibility#agile#Agile Development#ai#AI 101#Analysis#Analytics#applications#architecture#Article#artificial#Artificial Intelligence#AWS#azure#bi#Big Data#billion#Business#Business Intelligence#ccpa#challenge#Cloud#cloud data#cloud data warehouse#comprehensive#continuous#cyber#data#data analysis#data analytics
0 notes
Link
A data lake is a consolidated repository for accumulating all the structured and unstructured data at a large scale or small scale. Talking about buzzwords today regarding data management, and listing here is Data Lakes, and Data Warehouse, what are they, why and where to deploy them. So, in this blog, we will unpack their definition, key differences, and what we see in the near future.
#data lakes vs data warehouse vs data mart#data lake vs data warehouse architecture#data lake vs data warehouse vs databases#data lake architecture#data warehouse vs data mart#data lake vs data warehouse aws
0 notes
Text
https://ridgeant.com/blogs/snowflake-vs-redshift-vs-databricks/
Amazon Redshift is a data warehouse product that forms part of the larger cloud-computing platform Amazon Web Services. It makes use of SQL to analyze structured and semi-structured data across data warehouses, operational databases, and data lakes, with the use of AWS-designed hardware and machine learning.
0 notes
Text
Azure Full Course - Learn Microsoft Azure in 8 Hours | Azure Tutorial For Beginners | Edureka

** Azure Training - https://www.edureka.co/microsoft-certified-azure-solution-architect-certification-training ** This Edureka Azure Full Course video will help you understand and learn Azure & its services in detail. This Azure Tutorial is ideal for both beginners as well as professionals who want to master Azure services. Below are the topics covered in this Azure Tutorial for Beginners video: 00:00 Introduction 3:02 Why Cloud? 3:07 Before Cloud Computing 6:17 What is Cloud? 8:07 What is Cloud Computing? 8:42 Service Models 9:32 SaaS 10:17 PaaS 10:37 IaaS 11:17 Deployment Models 11:27 Public Cloud 11:57 Private Cloud 12:07 Hybrid Cloud 12:42 Cloud Providers 25:12 Azure Fundamentals 25:17 Getting Started with Azure 27:42 What is Microsoft Azure? 28:17 Use-case 30:02 How will we implement this? 34:02 Azure Components 34:12 App Service 34:22 Compute Domain 40:57 Blob Storage 41:22 Storage Domain 46:16 MySQL for Azure 46:49 Auto Scaling & Load Balancing 49:43 How to launch services in Azure? 1:04:53 Demo 1:23:08 Azure Pricing 1:28:33 Storage Domain 1:29:33 Why Storage? 1:33:48 Storage vs Database 1:34:58 What is Azure Storage? 1:41:38 Components of Azure Storage 2:12:35 Network Domain 2:12:40 Virtual Networks 2:13:35 What is Virtual Machine? 2:14:35 Why Virtual Networks? 2:15:35 What is Virtual Network? 2:16:50 What are Azure Subnet? 2:18:35 Network Security Groups 2:19:05 Virtual Network Architecture 2:20:00 Demo 3:08:24 Access Management 3:08:34 Azure Active Directory 3:09:14 What is Azure Active Directory? 3:12:26 Windows AD vs Azure AD 3:14:11 Service Audience 3:15:56 Azure Active Directory Editions 3:16:31 Azure Active Directory Tenants 3:36:06 Azure DevOps 3:36:26 What is DevOps? 3:42:21 Components of Azure DevOps 3:48:11 Azure Boards 4:20:16 Azure Data Factory 4:21:21 Why Data Factory? 4:23:06 What is Data Factory? 4:25:51 Data Factory Concepts 4:27:26 What is Data Lake? 4:29:01 Data Lake Concepts 4:33:31 Data Lake vs Data Warehouse 4:36:46 Demo: Move Data From SQL DB to Blog Storage 4:59:16 Important Services & Pointers 4:59:26 Azure Machine Learning 5:01:26 Machine Learning 5:06:01 Machine Learning Algorithms 5:08:36 Various Processes in ML Lifecycle 5:11:41 Microsoft Azure ML Studio 5:34:56 Azure IoT 5:35:46 What is IoT? 5:41:11 IoT on Azure 5:44:56 Azure IoT Components 5:57:31 Azure BoT Service 6:00:31 What are ChatBots? 6:04:36 Need for Chatbots 6:07:51 Demo: Creating a ChatBot for Facebook Messenger 6:41:06 AWS vs Azure vs GCP 6:51:36 Security 6:52:16 Integration 6:53:06 Analytics & ML 6:53:51 DevOps 6:54:26 Hybrid Capabilities 6:55:01 PaaS Offerings 6:55:26 Learning Curve 6:55:46 Scalability 6:56:26 Cost Efficient 6:57:11 The Final View 6:59:01 Cloud Careers 6:59:11 Azure Interview Questions 7:36:06 Cloud Engineer Jobs, Salary, Skills & Responsibilities 7:36:41 Cloud Engineer Job & Salary Trends 7:46:51 Cloud Engineer Job Skills & Description 7:51:51 Cloud Engineer Responsibilities -------------------------------------------------------------------------------------------------------- Instagram: https://www.instagram.com/edureka_learning Facebook: https://www.facebook.com/edurekaIN/ Twitter: https://twitter.com/edurekain LinkedIn: https://www.linkedin.com/company/edureka ---------------------------------------------------------------------------------------------------------- Got a question on the topic? Please share it in the comment section below and our experts will answer it for you. For more information, please write back to us at [email protected] or call us at IND: 9606058406 / US: 18338555775 (toll-free).
0 notes
Text
Не только Apache NiFi: еще 6 ETL-фреймворков загрузки и маршрутизации данных в Big Data и IoT
Несмотря на очевидные достоинства Apache NiFi, этой Big Data платформе быстрой загрузке и маршрутизации данных, активно применяемой в интернете вещей (Internet of Things, IoT), в т.ч. индустриальном (Industrial Iot, IIoT), также свойственны и некоторые недостатки. Сегодня мы поговорим об альтернативах Apache NiFi: Flume, Sqoop, Chuckwa, Gobblin, Falcon, а также Fluentd и StreamSets Data Collector. Читайте в нашей статье про сходства и отличия этих средств передачи больших данных.
Что такое маршрутизация Big Data и зачем она нужна
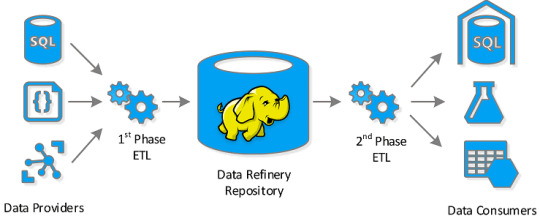
Под маршрутизацией данных мы будем понимать процесс сбора информации из различных источников (локальных и облачных файловых хранилищ, баз данных, IoT/IIoT-устройств), их агрегацию по определенным параметрам и дальнейшую передачу в другие системы-приемники (файловые хранилища, базы данных, брокеры сообщений и пр.). Как правило, функция хранения данных не входит в задачи маршрутизатора. Таким образом, маршрутизаторы данных выполняют типичный набор ETL-операций (Extract, Transform, Load). Вообще в Big Data выделяют 2 режима работы с данными, в т.ч. в отношении их загрузки и маршрутизации [1]: · пакетный, который используется для очень больших файлов или в сит��ациях, не критичных к временной задержке отклика (latency). Файлы, которые нужно передать, собираются в течение определенного периода времени, а затем отправляются вместе в виде пакетов. · потоковый, когда данные поступают в реальном времени и должны быть загружены во внешнюю систему незамедлительно. На практике ETL-операции с большими данными, как в пакетном, так и в потоковом режимах, необходимы для загрузки информации в корпоративные хранилища (Data Warehouse, DWH) и озера данных (Data Lake), а также визуального представления информации по разным измерениям OLAP-кубов в витринах данных (дэшбордах) систем бизнес-аналитики (Business Intelligence).
Элементы ETL-процессов в Big Data
Apache NiFi vs Gobblin и StreamSets Data Collector: краткий обзор средств потокового и пакетного ETL
Некоторые ETL-инструменты Big Data, в частности, Apache NiFi и Gobblin, хорошо работают с обоими режимами передачи данных. Gobblin, как и NiFi, является универсальной системой сбора информации для извлечения, преобразования и загрузки большого объема данных из различных источников данных (баз данных, REST API, серверов FTP/SFTP и т.д.). Обе этих платформы часто используются в задачах интеграции и построения конвейера данных, обеспечивая работу со популярными файловыми форматами Big Data (AVRO, Parquet, JSON), и могут быть развернуты на локальном кластере под управлением YARN/Mesos или в облаке Amazon Web Services (AWS). Однако, Apache Goblin, в отличие от NiFi, поддерживает MapReduce, что обеспечивает отказоустойчивость при работе с HDFS [2]. Тем не менее, несмотря на схожесть в прикладном назначении, Apache NiFi, в отличие от Gobblin, имеет графический интерфейс и оформлен в виде отдельного приложения. Это отличие позволяет работать с Apache NiFi широкому кругу пользователей – от аналитика до администратора Big Data, а не только разработчику или инженеру данных [3]. С точки зрения пользовательского интерфейса Apache NiFi можно сравнить с другим ETL-средством, StreamSets Data Collector – инфраструктурой непрерывного приема больших данных с открытым исходным кодом корпоративного уровня. В рамках наглядного пользовательского интерфейса она позволяет разработчикам, инженерам и ученым по данным легко создавать конвейеры маршрутизации потоковых данных со сложными сценариями загрузки. В качестве приемников и источников информации StreamSets Data Collector интегрирована с Apache Hadoop (HDFS, HBase, Hive), NoSQL-СУБД (Cassandra, MongoDB), поисковыми системами (Apache Solr, Elasticsearch), реляционными СУБД (Oracle, MS SQL Server, MySQL, PostgreSQL, Netezza, Teradata и пр., которые поддерживают JDBC-подключение), системами управления очередями сообщений (Apache Kafka, JMS, Kinesis), локальными и облачными файловыми хранилищами (Amazon S3 и т.д.) [4]. Однако, нельзя сказать, что Apache NiFi полностью заменяет StreamSets Data Collector или наоборот – у этих ETL-инструментов разные варианты использования (use cases) [5], подробнее о которых мы расскажем в новой статье. Также конкурентным преимуществом Apache NiFi можно назвать его легковесный вариант MiNiFi, который часто используется в IoT/IIoT-проектах благодаря своей быстроте и малой ресурсоемкости. Пример прототипа системы Industrial Internet of Things на базе Apache NiFi и MiNiFi мы рассматривали здесь. Еще стоит отметить возможности передачи данных в комплексных Big Data фреймворках, которые обеспечивают обработку информации и могут работать как в поточном, так и в пакетном режимах. В частности, к таким платформам относятся Apache Flink, Apex и Storm (с помощью высокоуровневого API-интерфейса Trident). Однако, в связи с их многофункциональностью, эти инструменты редко используются только в качестве средства сбора и передачи данных в Big Data и IoT/IIoT-проектах. Поэтому сравнивать их с Apache NiFi и другими подобными решениями несколько некорректно, а, значит, их рассмотрение останется за рамками настоящей статьи. Среди фреймворков пакетной загрузки больших данных из разных источников наиболее популярными считаются следующие проекты фонда Apache Software Foundation (ASF): Chukwa, Sqoop и Falcon. А для потоковой передачи часто используются Apache Flume и Fluentd. Подробнее про все эти Big Data маршрутизаторы мы поговорим в следующий раз.

ETL-конвейер в Big Data Освойте все тонкости установки, администрирования и эксплуатации платформ маршрутизации больших данных на нашем практическом курсе Кластер Apache NiFi в лицензированном учебном центре обучения и повышения квалификации ИТ-специалистов (менеджеров, архитекторов, инженеров, администраторов, Data Scientist’ов и аналитиков Big Data) в Москве.

Смотреть расписание занятий

Зарегистрироваться на курс Источники 1. https://moluch.ru/archive/202/49512/ 2. https://gobblin.readthedocs.io/ 3. https://stackoverflow.com/questions/49010622/apache-nifi-vs-gobblin 4. https://github.com/streamsets/datacollector 5. https://statsbot.co/blog/open-source-etl/ Read the full article
0 notes
Text
What is ETL?

In our articles related to AI and Big Data in healthcare, we always talk about ETL as the core of the core process. We do not write a lot about ETL itself, though. In this post, we’ll give a short overview of this procedure and its applications in businesses.
ETL is the abbreviation for Extract, Transform, Load that are three database functions:
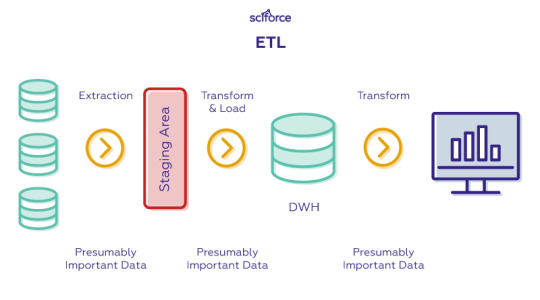
Extract is the process of reading data that is assumed to be important. The data can be either raw collected from multiple and different types of sources or taken from a source database.
Transform is the process of converting the extracted data from its previous format into the format required by another database. The transformation occurs by using rules or lookup tables or by combining the data with other data.
Load is the process of writing the data into the target database, data warehouse or another system
ETL in its essence is a type of data integration used to blend data from multiple sources.
ETL vs. ELT
The ETL paradigm is inherent to Data Warehousing, and Big Data has significantly changed the order of the processes. In Big Data, data is “lifted and shifted” wholesale to a repository, such as a Data Lake, and is held there in the original format. It is transformed “on the fly” when needed by Data Scientists, creating the procedure of ELT, or Extract, Load, Transform.
One of the main benefits of ELT is a shorter load time. As we can take advantage of the built-in processing capability of data warehouses, we can reduce the time that data spends in transit. This capability is most useful when processing large data sets required for business intelligence and big data analytics.
In practice, however, things are not so black and white. Many Data Lakes, for example, contain intermediate merged and transformed data structures to ensure that each Data Scientist doesn’t repeat the same work, or carry it out in a different way.

Where are ETL/ELT used?
ETL is not a new technology: businesses have relied on it for many years to get a consolidated view of the data. The most common uses of ETL include:
ETL and traditional uses
Traditionally, ETL is used to consolidate, collect and join data from external suppliers or to migrate data from legacy systems to new systems with different data formats. ETL tools surface data from a data store in a comprehensible for business people format, making it easier to analyze and report on. The key beneficiaries of these applications are retailers and healthcare providers.
ETL and metadata
ETL provides a deep historical context and a consolidated view for the business by surfacing the metadata. As data architectures become more complex, it’s important to track how the different data elements are used and related within one organization. Metadata helps understand the lineage of data and its impact on other data assets in the organization.
ETL and Data Quality
ETL and ELT are extensively used for data cleansing, profiling and auditing ensuring that data is trustworthy. ETL tools can be integrated with data quality tools, such as those used for data profiling, deduplication or validation.
ETL and Self-Service Data Access
Self-service data preparation is a fast-growing field that puts the power of accessing, blending and transforming data into the hands of business users and other nontechnical data professionals. ETL codifies and reuses processes that move data without requiring technical skills to write code or scripts. With this approach integrated into the ETL process, less time is spent on data preparation, improving professionals’ productivity.
ETL/ELT for Big Data
As today the demand for big data grows, ETL vendors add new transformations to support the emerging requirements to handle large amounts of data and new data sources. Adapters give access to a huge variety of data sources, including data from videos, social media, the Internet of Things, server logs, spatial data, streams, etc., Data integration tools interact with these adapters to extract and load data efficiently.
ETL for Hadoop
Taking a step further, advanced ETL tools load and convert structured and unstructured data into Hadoop. These tools can read and write multiple files in parallel, simplifying the way the data is merged into a common transformation process. ETL also supports integration across transactional systems, operational data stores, BI platforms, master data management (MDM) hubs and the cloud.
How is it built?
When building an ETL infrastructure, you need to integrate data sources, and carefully plan and test to ensure you transform source data correctly. There exist three basic ways to build an ETL process, loosely reflecting three stages in the evolution of ETL:
Traditional ETL batch processing
This approach requires meticulously preparing and validating data and transforming it in a rigid process. Data is transferred and processed in batches from source databases to the data warehouse. Traditional ETL works. but it is complex to build; it is rigid and unsuitable for many modern requirements. It is challenging to build an enterprise ETL pipeline from scratch, so such ETL tools as Stitch or Blendo are used to automate the process.
ETL with stream processing
Modern data processes often include real time data. In this case, you cannot extract and transform data in large batches, so you have to perform ETL on data streams. This approach implies that you use a modern stream processing framework like Kafka or Spark, so that you can pull data in real time from a source, manipulate it on the fly, and load it to a target system such as Amazon Redshift.
Serverless ETL
The recent rise of serverless architecture has opened new possibilities for simplification of the ETL process. Without a dedicated infrastructure to provision or manage. New ETL systems can handle provisioning, configuration, and scaling of the resources required to run your ETL jobs on a fully managed, scale-out Apache Spark environment. The most prominent of such services is the new AWS Glue that crawls data sources, identifies data formats, and suggests schemas and transformations, automating most of the work for users.
Automated data pipeline without ETL
With the new cloud-based data warehouse technology, it is possible to do ETL without actually having an ETL system. Cloud-based automated data warehouses can have built-in end-to-end data management. They rely on a self-optimizing architecture with machine learning and natural language processing (NLP) in their core to automatically extract and transform data to match analytics requirements.
Organizations need ETL and ELT to bring data together, maintain accuracy and provide the auditing required for data warehousing, reporting and analytics. As a rule, ETL and ELT tools work in conjunction with other data integration tools and are closely related to other aspects of data management — such as data quality, data governance, virtualization and metadata. In the present-day settings, it is important, however, to expand one’s view and to adopt stream processing, or even fully automated data warehousing, thus building a more effective data pipeline.
0 notes
Video
youtube
Amazon (AWS) QuickSight, Glue, Athena & S3 Fundamentals
0 notes
Text
Data Warehouses vs Databases
During the spring semester of my freshman year, I was enrolled in CS 3200: Database design, where I became well acquainted with relational databases, ER diagrams, and SQL. I knew that having a comprehensive understanding of databases would be vital as a data science major, both in my future classes and my future co-ops.
This spring, while exploring NUCareers, I noticed that a lot of co-ops in the areas of business intelligence, data analytics and occasionally data science, had a common term located somewhere in their descriptions: “data warehousing”. Despite having taken Database Design, I didn’t have a strong understanding of what data warehouses are and how they differ from databases. That inspired me to write this blog post.
As explained in the lecture, databases are an organized collection of data. Relational databases are the most widely used type of database, with information organized into connected two-dimensional tables that are periodically indexed.
Data warehouses are systems used for data collection and analysis, in which data is pulled from multiple sources. As AWS explains on their website, “data flows into a data warehouse from transactional systems, relational databases, and other sources, typically on a regular cadence. Business analysts, data scientists, and decision makers access the data through business intelligence (BI) tools, SQL clients, and other analytics applications.” (https://aws.amazon.com/data-warehouse/)
The primary difference between databases and data warehouses is that databases are used for Online Transaction Processing (OLTP), while data warehouses are used for Online Analytical Processing (OLAP). OLTP encompasses day-to-day transactions and involves smaller queries such as INSERT, UPDATE, and DELETE statements. OLAP queries are more complex. Managers and analysts use them to select, extract, and aggregate data to identify tends and gain insights about their businesses.
Another difference between databases and data warehouses is that databases are typically normalized, while data warehouses are not. Relational databases are often structured in the 3rd normal form to remove redundancies and group related data together in tables. Data warehouses are willing to accept some redundancies in exchange for having fewer tables, because this allows for faster processing.
A third difference between data warehouses and databases are that data warehouses contain historical data while normalized databases usually only contain current data. As the data warehousing platform Panoply elaborates, “data warehouses typically store historical data by integrating copies of transaction data from disparate sources. Data warehouses can also use real-time data feeds for reports that use the most current, integrated information.” (https://panoply.io/data-warehouse-guide/the-difference-between-a-database-and-a-data-warehouse/)
A data lake is third type of data store, which differs greatly from both databases and data warehouses. According to the software and data solutions company Talend, there are four primary differences between a data warehouse and data lake. Data lakes can store structured, semi-structured, and most commonly, raw, unstructured data. Typically the data stored in a data lake does not yet have a defined purpose, while data warehouses store data used for analytics purposes. Data lakes are used more commonly by data scientists because of the raw nature of the data, while data warehouses can be used by any business professional. Data stored in lakes are also easier to access and change because they haven’t been processed, but the trade-off is that some processing will be required to make the data usable. (https://www.talend.com/resources/data-lake-vs-data-warehouse/)
0 notes