#data warehouse etl testing
Explore tagged Tumblr posts
Visit Tumblr Blog
Explore Tumblr blogs with no restrictions, modern design and the best experience.
Last Seen Tumblr Blogs





Fun Fact
Mobile US users spent an average of 115.8 minutes on Tumblr app monthly.
Text
What is iceDQ?
iceDQ is a purpose-built platform with integrated data testing, data monitoring and AI based data observability capabilities.
iceDQ is the only platform that works across the entire data development lifecycle – development, QA, and production – ensuring robust data processes and reliable data.
#icedq#etl testing#data warehouse testing#data migration testing#bi testing#etl testing tool#production data monitoring#data migration testing tools#etl testing tools#data reliability engineering
0 notes
Text
In today's data-driven world, seamless data integration and processing are crucial for informed decision-making. Matillion, a robust ETL (Extract, Transform, Load) tool, has gained popularity for its ability to streamline these processes.
In this blog, you will learn how it efficiently moves and transforms data from various sources to cloud data warehouses, making data management easier. Apart from this, you'll also get a brief understanding of its constraints and best practices for transforming large datasets.
By understanding these aspects, you can maximize your business capabilities and drive forward excellently.
#etl testing#ETL#etl#etl tool#data engineering#data management#big data#biggest data#data warehouses#data management software#blog#nitorinfotech#software development#software services#software engineering#artificial intelligence#ascendion
0 notes
Text
Essential Predictive Analytics Techniques
With the growing usage of big data analytics, predictive analytics uses a broad and highly diverse array of approaches to assist enterprises in forecasting outcomes. Examples of predictive analytics include deep learning, neural networks, machine learning, text analysis, and artificial intelligence.
Predictive analytics trends of today reflect existing Big Data trends. There needs to be more distinction between the software tools utilized in predictive analytics and big data analytics solutions. In summary, big data and predictive analytics technologies are closely linked, if not identical.
Predictive analytics approaches are used to evaluate a person's creditworthiness, rework marketing strategies, predict the contents of text documents, forecast weather, and create safe self-driving cars with varying degrees of success.
Predictive Analytics- Meaning
By evaluating collected data, predictive analytics is the discipline of forecasting future trends. Organizations can modify their marketing and operational strategies to serve better by gaining knowledge of historical trends. In addition to the functional enhancements, businesses benefit in crucial areas like inventory control and fraud detection.
Machine learning and predictive analytics are closely related. Regardless of the precise method, a company may use, the overall procedure starts with an algorithm that learns through access to a known result (such as a customer purchase).
The training algorithms use the data to learn how to forecast outcomes, eventually creating a model that is ready for use and can take additional input variables, like the day and the weather.
Employing predictive analytics significantly increases an organization's productivity, profitability, and flexibility. Let us look at the techniques used in predictive analytics.
Techniques of Predictive Analytics
Making predictions based on existing and past data patterns requires using several statistical approaches, data mining, modeling, machine learning, and artificial intelligence. Machine learning techniques, including classification models, regression models, and neural networks, are used to make these predictions.
Data Mining
To find anomalies, trends, and correlations in massive datasets, data mining is a technique that combines statistics with machine learning. Businesses can use this method to transform raw data into business intelligence, including current data insights and forecasts that help decision-making.
Data mining is sifting through redundant, noisy, unstructured data to find patterns that reveal insightful information. A form of data mining methodology called exploratory data analysis (EDA) includes examining datasets to identify and summarize their fundamental properties, frequently using visual techniques.
EDA focuses on objectively probing the facts without any expectations; it does not entail hypothesis testing or the deliberate search for a solution. On the other hand, traditional data mining focuses on extracting insights from the data or addressing a specific business problem.
Data Warehousing
Most extensive data mining projects start with data warehousing. An example of a data management system is a data warehouse created to facilitate and assist business intelligence initiatives. This is accomplished by centralizing and combining several data sources, including transactional data from POS (point of sale) systems and application log files.
A data warehouse typically includes a relational database for storing and retrieving data, an ETL (Extract, Transfer, Load) pipeline for preparing the data for analysis, statistical analysis tools, and client analysis tools for presenting the data to clients.
Clustering
One of the most often used data mining techniques is clustering, which divides a massive dataset into smaller subsets by categorizing objects based on their similarity into groups.
When consumers are grouped together based on shared purchasing patterns or lifetime value, customer segments are created, allowing the company to scale up targeted marketing campaigns.
Hard clustering entails the categorization of data points directly. Instead of assigning a data point to a cluster, soft clustering gives it a likelihood that it belongs in one or more clusters.
Classification
A prediction approach called classification involves estimating the likelihood that a given item falls into a particular category. A multiclass classification problem has more than two classes, unlike a binary classification problem, which only has two types.
Classification models produce a serial number, usually called confidence, that reflects the likelihood that an observation belongs to a specific class. The class with the highest probability can represent a predicted probability as a class label.
Spam filters, which categorize incoming emails as "spam" or "not spam" based on predetermined criteria, and fraud detection algorithms, which highlight suspicious transactions, are the most prevalent examples of categorization in a business use case.
Regression Model
When a company needs to forecast a numerical number, such as how long a potential customer will wait to cancel an airline reservation or how much money they will spend on auto payments over time, they can use a regression method.
For instance, linear regression is a popular regression technique that searches for a correlation between two variables. Regression algorithms of this type look for patterns that foretell correlations between variables, such as the association between consumer spending and the amount of time spent browsing an online store.
Neural Networks
Neural networks are data processing methods with biological influences that use historical and present data to forecast future values. They can uncover intricate relationships buried in the data because of their design, which mimics the brain's mechanisms for pattern recognition.
They have several layers that take input (input layer), calculate predictions (hidden layer), and provide output (output layer) in the form of a single prediction. They are frequently used for applications like image recognition and patient diagnostics.
Decision Trees
A decision tree is a graphic diagram that looks like an upside-down tree. Starting at the "roots," one walks through a continuously narrowing range of alternatives, each illustrating a possible decision conclusion. Decision trees may handle various categorization issues, but they can resolve many more complicated issues when used with predictive analytics.
An airline, for instance, would be interested in learning the optimal time to travel to a new location it intends to serve weekly. Along with knowing what pricing to charge for such a flight, it might also want to know which client groups to cater to. The airline can utilize a decision tree to acquire insight into the effects of selling tickets to destination x at price point y while focusing on audience z, given these criteria.
Logistics Regression
It is used when determining the likelihood of success in terms of Yes or No, Success or Failure. We can utilize this model when the dependent variable has a binary (Yes/No) nature.
Since it uses a non-linear log to predict the odds ratio, it may handle multiple relationships without requiring a linear link between the variables, unlike a linear model. Large sample sizes are also necessary to predict future results.
Ordinal logistic regression is used when the dependent variable's value is ordinal, and multinomial logistic regression is used when the dependent variable's value is multiclass.
Time Series Model
Based on past data, time series are used to forecast the future behavior of variables. Typically, a stochastic process called Y(t), which denotes a series of random variables, are used to model these models.
A time series might have the frequency of annual (annual budgets), quarterly (sales), monthly (expenses), or daily (daily expenses) (Stock Prices). It is referred to as univariate time series forecasting if you utilize the time series' past values to predict future discounts. It is also referred to as multivariate time series forecasting if you include exogenous variables.
The most popular time series model that can be created in Python is called ARIMA, or Auto Regressive Integrated Moving Average, to anticipate future results. It's a forecasting technique based on the straightforward notion that data from time series' initial values provides valuable information.
In Conclusion-
Although predictive analytics techniques have had their fair share of critiques, including the claim that computers or algorithms cannot foretell the future, predictive analytics is now extensively employed in virtually every industry. As we gather more and more data, we can anticipate future outcomes with a certain level of accuracy. This makes it possible for institutions and enterprises to make wise judgments.
Implementing Predictive Analytics is essential for anybody searching for company growth with data analytics services since it has several use cases in every conceivable industry. Contact us at SG Analytics if you want to take full advantage of predictive analytics for your business growth.
2 notes
·
View notes
Text
#IoT Testing#Internet of Things#Device Testing#Functional Testing#Performance Testing#Security Testing#Interoperability Testing#Usability Testing#Regression Testing#IoT Security#Smart Devices#Connected Systems#IoT Protocols#GQATTech#IoT Solutions#Data Privacy#System Integration#User Experience#IoT Performance#Compliance Testing#POS Testing#Point of Sale#Retail Technology#Transaction Processing#System Reliability#Customer Experience#Compatibility Testing#Retail Operations#Payment Systems#PCI DSS Compliance
0 notes
Text
Data Engineering vs Data Science: Which Course Should You Take Abroad?
The rapid growth of data-driven industries has brought about two prominent and in-demand career paths: Data Engineering and Data Science. For international students dreaming of a global tech career, these two fields offer promising opportunities, high salaries, and exciting work environments. But which course should you take abroad? What are the key differences, career paths, skills needed, and best study destinations?
In this blog, we’ll break down the key distinctions between Data Engineering and Data Science, explore which path suits you best, and highlight the best countries and universities abroad to pursue these courses.
What is Data Engineering?
Data Engineering focuses on designing, building, and maintaining data pipelines, systems, and architecture. Data Engineers prepare data so that Data Scientists can analyze it. They work with large-scale data processing systems and ensure that data flows smoothly between servers, applications, and databases.
Key Responsibilities of a Data Engineer:
Developing, testing, and maintaining data pipelines
Building data architectures (e.g., databases, warehouses)
Managing ETL (Extract, Transform, Load) processes
Working with tools like Apache Spark, Hadoop, SQL, Python, and AWS
Ensuring data quality and integrity
What is Data Science?
analysis, machine learning, and data visualization. Data Scientists use data to drive business decisions, create predictive models, and uncover trends.
Key Responsibilities of a Data Scientist:
Cleaning and analyzing large datasets
Building machine learning and AI models
Creating visualizations to communicate findings
Using tools like Python, R, SQL, TensorFlow, and Tableau
Applying statistical and mathematical techniques to solve problems
Which Course Should You Take Abroad?
Choosing between Data Engineering and Data Science depends on your interests, academic background, and long-term career goals. Here’s a quick guide to help you decide:
Take Data Engineering if:
You love building systems and solving technical challenges.
You have a background in software engineering, computer science, or IT.
You prefer backend development, architecture design, and working with infrastructure.
You enjoy automating data workflows and handling massive datasets.
Take Data Science if:
You’re passionate about data analysis, problem-solving, and storytelling with data.
You have a background in statistics, mathematics, computer science, or economics.
You’re interested in machine learning, predictive modeling, and data visualization.
You want to work on solving real-world problems using data.
Top Countries to Study Data Engineering and Data Science
Studying abroad can enhance your exposure, improve career prospects, and provide access to global job markets. Here are some of the best countries to study both courses:
1. Germany
Why? Affordable education, strong focus on engineering and analytics.
Top Universities:
Technical University of Munich
RWTH Aachen University
University of Mannheim
2. United Kingdom
Why? Globally recognized degrees, data-focused programs.
Top Universities:
University of Oxford
Imperial College London
4. Sweden
Why? Innovation-driven, excellent data education programs.
Top Universities:
KTH Royal Institute of Technology
Lund University
Chalmers University of Technology
Course Structure Abroad
Whether you choose Data Engineering or Data Science, most universities abroad offer:
Bachelor’s Degrees (3-4 years):
Focus on foundational subjects like programming, databases, statistics, algorithms, and software engineering.
Recommended for students starting out or looking to build from scratch.
Master’s Degrees (1-2 years):
Ideal for those with a bachelor’s in CS, IT, math, or engineering.
Specializations in Data Engineering or Data Science.
Often include hands-on projects, capstone assignments, and internship opportunities.
Certifications & Short-Term Diplomas:
Offered by top institutions and platforms (e.g., MITx, Coursera, edX).
Helpful for career-switchers or those seeking to upgrade their skills.
Career Prospects and Salaries
Both fields are highly rewarding and offer excellent career growth.
Career Paths in Data Engineering:
Data Engineer
Data Architect
Big Data Engineer
ETL Developer
Cloud Data Engineer
Average Salary (Globally):
Entry-Level: $70,000 - $90,000
Mid-Level: $90,000 - $120,000
Senior-Level: $120,000 - $150,000+
Career Paths in Data Science:
Data Scientist
Machine Learning Engineer
Business Intelligence Analyst
Research Scientist
AI Engineer
Average Salary (Globally):
Entry-Level: $75,000 - $100,000
Mid-Level: $100,000 - $130,000
Senior-Level: $130,000 - $160,000+
Industry Demand
The demand for both data engineers and data scientists is growing rapidly across sectors like:
E-commerce
Healthcare
Finance and Banking
Transportation and Logistics
Media and Entertainment
Government and Public Policy
Artificial Intelligence and Machine Learning Startups
According to LinkedIn and Glassdoor reports, Data Engineer roles have surged by over 50% in recent years, while Data Scientist roles remain in the top 10 most in-demand jobs globally.
Skills You’ll Learn Abroad
Whether you choose Data Engineering or Data Science, here are some skills typically covered in top university programs:
For Data Engineering:
Advanced SQL
Data Warehouse Design
Apache Spark, Kafka
Data Lake Architecture
Python/Scala Programming
Cloud Platforms: AWS, Azure, GCP
For Data Science:
Machine Learning Algorithms
Data Mining and Visualization
Statistics and Probability
Python, R, MATLAB
Tools: Jupyter, Tableau, Power BI
Deep Learning, AI Basics
Internship & Job Opportunities Abroad
Studying abroad often opens doors to internships, which can convert into full-time job roles.
Countries like Germany, Canada, Australia, and the UK allow international students to work part-time during studies and offer post-study work visas. This means you can gain industry experience after graduation.
Additionally, global tech giants like Google, Amazon, IBM, Microsoft, and Facebook frequently hire data professionals across both disciplines.
Final Thoughts: Data Engineering vs Data Science – Which One Should You Choose?
There’s no one-size-fits-all answer, but here’s a quick recap:
Choose Data Engineering if you’re technically inclined, love working on infrastructure, and enjoy building systems from scratch.
Choose Data Science if you enjoy exploring data, making predictions, and translating data into business insights.
Both fields are highly lucrative, future-proof, and in high demand globally. What matters most is your interest, learning style, and career aspirations.
If you're still unsure, consider starting with a general data science or computer science program abroad that allows you to specialize in your second year. This way, you get the best of both worlds before narrowing down your focus.
Need Help Deciding Your Path?
At Cliftons Study Abroad, we guide students in selecting the right course and country tailored to their goals. Whether it’s Data Engineering in Germany or Data Science in Canada, we help you navigate admissions, visa applications, scholarships, and more.
Contact us today to take your first step towards a successful international data career!
0 notes
Text
Your Data Science Career Roadmap: Navigating the Jobs and Levels

The field of data science is booming, offering a myriad of exciting career opportunities. However, for many, the landscape of job titles and progression paths can seem like a dense forest. Are you a Data Analyst, a Data Scientist, or an ML Engineer? What's the difference, and how do you climb the ladder?
Fear not! This guide will provide a clear roadmap of common data science jobs and their typical progression levels, helping you chart your course in this dynamic domain.
The Core Pillars of a Data Science Career
Before diving into specific roles, it's helpful to understand the three main pillars that define much of the data science ecosystem:
Analytics: Focusing on understanding past and present data to extract insights and inform business decisions.
Science: Focusing on building predictive models, often using machine learning, to forecast future outcomes or automate decisions.
Engineering: Focusing on building and maintaining the infrastructure and pipelines that enable data collection, storage, and processing for analytics and science.
While there's often overlap, many roles lean heavily into one of these areas.
Common Data Science Job Roles and Their Progression
Let's explore the typical roles and their advancement levels:
I. Data Analyst
What they do: The entry point for many into the data world. Data Analysts collect, clean, analyze, and visualize data to answer specific business questions. They often create dashboards and reports to present insights to stakeholders.
Key Skills: SQL, Excel, data visualization tools (Tableau, Power BI), basic statistics, Python/R for data manipulation (Pandas, dplyr).
Levels:
Junior Data Analyst: Focus on data cleaning, basic reporting, and assisting senior analysts.
Data Analyst: Independent analysis, creating comprehensive reports and dashboards, communicating findings.
Senior Data Analyst: Leading analytical projects, mentoring junior analysts, working on more complex business problems.
Progression: Can move into Data Scientist roles (by gaining more ML/statistical modeling skills), Business Intelligence Developer, or Analytics Manager.
II. Data Engineer
What they do: The architects and builders of the data infrastructure. Data Engineers design, construct, and maintain scalable data pipelines, data warehouses, and data lakes. They ensure data is accessible, reliable, and efficient for analysts and scientists.
Key Skills: Strong programming (Python, Java, Scala), SQL, NoSQL databases, ETL tools, cloud platforms (AWS, Azure, GCP), big data technologies (Hadoop, Spark, Kafka).
Levels:
Junior Data Engineer: Assisting in pipeline development, debugging, data ingestion tasks.
Data Engineer: Designing and implementing data pipelines, optimizing data flows, managing data warehousing.
Senior Data Engineer: Leading complex data infrastructure projects, setting best practices, mentoring, architectural design.
Principal Data Engineer / Data Architect: High-level strategic design of data systems, ensuring scalability, security, and performance across the organization.
Progression: Can specialize in Big Data Engineering, Cloud Data Engineering, or move into Data Architect roles.
III. Data Scientist
What they do: The problem-solvers who use advanced statistical methods, machine learning, and programming to build predictive models and derive actionable insights from complex, often unstructured data. They design experiments, evaluate models, and communicate technical findings to non-technical audiences.
Key Skills: Python/R (with advanced libraries like Scikit-learn, TensorFlow, PyTorch), advanced statistics, machine learning algorithms, deep learning (for specialized roles), A/B testing, data modeling, strong communication.
Levels:
Junior Data Scientist: Works on specific model components, assists with data preparation, learns from senior scientists.
Data Scientist: Owns end-to-end model development for defined problems, performs complex analysis, interprets results.
Senior Data Scientist: Leads significant data science initiatives, mentors juniors, contributes to strategic direction, handles ambiguous problems.
Principal Data Scientist / Lead Data Scientist: Drives innovation, sets technical standards, leads cross-functional projects, influences product/business strategy with data insights.
Progression: Can move into Machine Learning Engineer, Research Scientist, Data Science Manager, or even Product Manager (for data products).
IV. Machine Learning Engineer (MLE)
What they do: Bridge the gap between data science models and production systems. MLEs focus on deploying, optimizing, and maintaining machine learning models in real-world applications. They ensure models are scalable, reliable, and perform efficiently in production environments (MLOps).
Key Skills: Strong software engineering principles, MLOps tools (Kubeflow, MLflow), cloud computing, deployment frameworks, understanding of ML algorithms, continuous integration/delivery (CI/CD).
Levels:
Junior ML Engineer: Assists in model deployment, monitoring, and basic optimization.
ML Engineer: Responsible for deploying and maintaining ML models, building robust ML pipelines.
Senior ML Engineer: Leads the productionization of complex ML systems, optimizes for performance and scalability, designs ML infrastructure.
Principal ML Engineer / ML Architect: Defines the ML architecture across the organization, researches cutting-edge deployment strategies, sets MLOps best practices.
Progression: Can specialize in areas like Deep Learning Engineering, NLP Engineering, or move into AI/ML leadership roles.
V. Other Specialized & Leadership Roles
As you gain experience and specialize, other roles emerge:
Research Scientist (AI/ML): Often found in R&D departments or academia, these roles focus on developing novel algorithms and pushing the boundaries of AI/ML. Requires strong theoretical understanding and research skills.
Business Intelligence Developer/Analyst: More focused on reporting, dashboards, and operational insights, often using specific BI tools.
Quantitative Analyst (Quant): Primarily in finance, applying complex mathematical and statistical models for trading, risk management, and financial forecasting.
Data Product Manager: Defines, develops, and launches data-driven products, working at the intersection of business, technology, and data science.
Data Science Manager / Director / VP of Data Science / Chief Data Officer (CDO): Leadership roles that involve managing teams, setting strategy, overseeing data initiatives, and driving the overall data culture of an organization. These roles require strong technical acumen combined with excellent leadership and business communication skills.
Charting Your Own Path
Your data science career roadmap isn't linear, and transitions between roles are common. To advance, consistently focus on:
Continuous Learning: The field evolves rapidly. Stay updated with new tools, techniques, and research.
Building a Portfolio: Showcase your skills through personal projects, Kaggle competitions, and open-source contributions.
Domain Expertise: Understanding the business context where you apply data science makes your work more impactful.
Communication Skills: Being able to clearly explain complex technical concepts to non-technical stakeholders is paramount for leadership.
Networking: Connect with other professionals in the field, learn from their experiences, and explore new opportunities.
Whether you aspire to be a deep-dive researcher, a production-focused engineer, or a strategic leader, the data science landscape offers a fulfilling journey for those willing to learn and adapt. Where do you see yourself on this exciting map?
#data scientist#online course#ai#artificial intelligence#technology#data science#data science course#data science career
0 notes
Text
Machine Learning Infrastructure: The Foundation of Scalable AI Solutions

Introduction: Why Machine Learning Infrastructure Matters
In today's digital-first world, the adoption of artificial intelligence (AI) and machine learning (ML) is revolutionizing every industry—from healthcare and finance to e-commerce and entertainment. However, while many organizations aim to leverage ML for automation and insights, few realize that success depends not just on algorithms, but also on a well-structured machine learning infrastructure.
Machine learning infrastructure provides the backbone needed to deploy, monitor, scale, and maintain ML models effectively. Without it, even the most promising ML solutions fail to meet their potential.
In this comprehensive guide from diglip7.com, we’ll explore what machine learning infrastructure is, why it’s crucial, and how businesses can build and manage it effectively.
What is Machine Learning Infrastructure?
Machine learning infrastructure refers to the full stack of tools, platforms, and systems that support the development, training, deployment, and monitoring of ML models. This includes:
Data storage systems
Compute resources (CPU, GPU, TPU)
Model training and validation environments
Monitoring and orchestration tools
Version control for code and models
Together, these components form the ecosystem where machine learning workflows operate efficiently and reliably.
Key Components of Machine Learning Infrastructure
To build robust ML pipelines, several foundational elements must be in place:
1. Data Infrastructure
Data is the fuel of machine learning. Key tools and technologies include:
Data Lakes & Warehouses: Store structured and unstructured data (e.g., AWS S3, Google BigQuery).
ETL Pipelines: Extract, transform, and load raw data for modeling (e.g., Apache Airflow, dbt).
Data Labeling Tools: For supervised learning (e.g., Labelbox, Amazon SageMaker Ground Truth).
2. Compute Resources
Training ML models requires high-performance computing. Options include:
On-Premise Clusters: Cost-effective for large enterprises.
Cloud Compute: Scalable resources like AWS EC2, Google Cloud AI Platform, or Azure ML.
GPUs/TPUs: Essential for deep learning and neural networks.
3. Model Training Platforms
These platforms simplify experimentation and hyperparameter tuning:
TensorFlow, PyTorch, Scikit-learn: Popular ML libraries.
MLflow: Experiment tracking and model lifecycle management.
KubeFlow: ML workflow orchestration on Kubernetes.
4. Deployment Infrastructure
Once trained, models must be deployed in real-world environments:
Containers & Microservices: Docker, Kubernetes, and serverless functions.
Model Serving Platforms: TensorFlow Serving, TorchServe, or custom REST APIs.
CI/CD Pipelines: Automate testing, integration, and deployment of ML models.
5. Monitoring & Observability
Key to ensure ongoing model performance:
Drift Detection: Spot when model predictions diverge from expected outputs.
Performance Monitoring: Track latency, accuracy, and throughput.
Logging & Alerts: Tools like Prometheus, Grafana, or Seldon Core.
Benefits of Investing in Machine Learning Infrastructure
Here’s why having a strong machine learning infrastructure matters:
Scalability: Run models on large datasets and serve thousands of requests per second.
Reproducibility: Re-run experiments with the same configuration.
Speed: Accelerate development cycles with automation and reusable pipelines.
Collaboration: Enable data scientists, ML engineers, and DevOps to work in sync.
Compliance: Keep data and models auditable and secure for regulations like GDPR or HIPAA.
Real-World Applications of Machine Learning Infrastructure
Let’s look at how industry leaders use ML infrastructure to power their services:
Netflix: Uses a robust ML pipeline to personalize content and optimize streaming.
Amazon: Trains recommendation models using massive data pipelines and custom ML platforms.
Tesla: Collects real-time driving data from vehicles and retrains autonomous driving models.
Spotify: Relies on cloud-based infrastructure for playlist generation and music discovery.
Challenges in Building ML Infrastructure
Despite its importance, developing ML infrastructure has its hurdles:
High Costs: GPU servers and cloud compute aren't cheap.
Complex Tooling: Choosing the right combination of tools can be overwhelming.
Maintenance Overhead: Regular updates, monitoring, and security patching are required.
Talent Shortage: Skilled ML engineers and MLOps professionals are in short supply.
How to Build Machine Learning Infrastructure: A Step-by-Step Guide
Here’s a simplified roadmap for setting up scalable ML infrastructure:
Step 1: Define Use Cases
Know what problem you're solving. Fraud detection? Product recommendations? Forecasting?
Step 2: Collect & Store Data
Use data lakes, warehouses, or relational databases. Ensure it’s clean, labeled, and secure.
Step 3: Choose ML Tools
Select frameworks (e.g., TensorFlow, PyTorch), orchestration tools, and compute environments.
Step 4: Set Up Compute Environment
Use cloud-based Jupyter notebooks, Colab, or on-premise GPUs for training.
Step 5: Build CI/CD Pipelines
Automate model testing and deployment with Git, Jenkins, or MLflow.
Step 6: Monitor Performance
Track accuracy, latency, and data drift. Set alerts for anomalies.
Step 7: Iterate & Improve
Collect feedback, retrain models, and scale solutions based on business needs.
Machine Learning Infrastructure Providers & Tools
Below are some popular platforms that help streamline ML infrastructure: Tool/PlatformPurposeExampleAmazon SageMakerFull ML development environmentEnd-to-end ML pipelineGoogle Vertex AICloud ML serviceTraining, deploying, managing ML modelsDatabricksBig data + MLCollaborative notebooksKubeFlowKubernetes-based ML workflowsModel orchestrationMLflowModel lifecycle trackingExperiments, models, metricsWeights & BiasesExperiment trackingVisualization and monitoring
Expert Review
Reviewed by: Rajeev Kapoor, Senior ML Engineer at DataStack AI
"Machine learning infrastructure is no longer a luxury; it's a necessity for scalable AI deployments. Companies that invest early in robust, cloud-native ML infrastructure are far more likely to deliver consistent, accurate, and responsible AI solutions."
Frequently Asked Questions (FAQs)
Q1: What is the difference between ML infrastructure and traditional IT infrastructure?
Answer: Traditional IT supports business applications, while ML infrastructure is designed for data processing, model training, and deployment at scale. It often includes specialized hardware (e.g., GPUs) and tools for data science workflows.
Q2: Can small businesses benefit from ML infrastructure?
Answer: Yes, with the rise of cloud platforms like AWS SageMaker and Google Vertex AI, even startups can leverage scalable machine learning infrastructure without heavy upfront investment.
Q3: Is Kubernetes necessary for ML infrastructure?
Answer: While not mandatory, Kubernetes helps orchestrate containerized workloads and is widely adopted for scalable ML infrastructure, especially in production environments.
Q4: What skills are needed to manage ML infrastructure?
Answer: Familiarity with Python, cloud computing, Docker/Kubernetes, CI/CD, and ML frameworks like TensorFlow or PyTorch is essential.
Q5: How often should ML models be retrained?
Answer: It depends on data volatility. In dynamic environments (e.g., fraud detection), retraining may occur weekly or daily. In stable domains, monthly or quarterly retraining suffices.
Final Thoughts
Machine learning infrastructure isn’t just about stacking technologies—it's about creating an agile, scalable, and collaborative environment that empowers data scientists and engineers to build models with real-world impact. Whether you're a startup or an enterprise, investing in the right infrastructure will directly influence the success of your AI initiatives.
By building and maintaining a robust ML infrastructure, you ensure that your models perform optimally, adapt to new data, and generate consistent business value.
For more insights and updates on AI, ML, and digital innovation, visit diglip7.com.
0 notes
Text
Data Engineer vs Data Analyst vs Data Scientist vs ML Engineer: Choose Your Perfect Data Career!

In today’s rapidly evolving tech world, career opportunities in data-related fields are expanding like never before. However, with multiple roles like Data Engineer vs Data Analyst vs Data Scientist vs ML Engineer, newcomers — and even seasoned professionals — often find it confusing to understand how these roles differ.
At Yasir Insights, we think that having clarity makes professional selections more intelligent. We’ll go over the particular duties, necessary abilities, and important differences between these well-liked Data Engineer vs Data Analyst vs Data Scientist vs ML Engineer data positions in this blog.
Also Read: Data Engineer vs Data Analyst vs Data Scientist vs ML Engineer
Introduction to Data Engineer vs Data Analyst vs Data Scientist vs ML Engineer
The Data Science and Machine Learning Development Lifecycle (MLDLC) includes stages like planning, data gathering, preprocessing, exploratory analysis, modelling, deployment, and optimisation. In order to effectively manage these intricate phases, the burden is distributed among specialised positions, each of which plays a vital part in the project’s success.
Data Engineer
Who is a Data Engineer?
The basis of the data ecosystem is built by data engineers. They concentrate on collecting, sanitising, and getting data ready for modelling or further analysis. Think of them as mining precious raw materials — in this case, data — from complex and diverse sources.
Key Responsibilities:
Collect and extract data from different sources (APIS, databases, web scraping).
Design and maintain scalable data pipelines.
Clean, transform, and store data in warehouses or lakes.
Optimise database performance and security.
Required Skills:
Strong knowledge of Data Structures and Algorithms.
Expertise in Database Management Systems (DBMS).
Familiarity with Big Data tools (like Hadoop, Spark).
Hands-on experience with cloud platforms (AWS, Azure, GCP).
Proficiency in building and managing ETL (Extract, Transform, Load) pipelines.
Data Analyst
Who is a Data Analyst?
Data analysts take over once the data has been cleansed and arranged. Their primary responsibility is to evaluate data in order to get valuable business insights. They provide answers to important concerns regarding the past and its causes.
Key Responsibilities:
Perform Exploratory Data Analysis (EDA).
Create visualisations and dashboards to represent insights.
Identify patterns, trends, and correlations in datasets.
Provide reports to support data-driven decision-making.
Required Skills:
Strong Statistical knowledge.
Proficiency in programming languages like Python or R.
Expertise in Data Visualisation tools (Tableau, Power BI, matplotlib).
Excellent communication skills to present findings clearly.
Experience working with SQL databases.
Data Scientist
Who is a Data Scientist?
Data Scientists build upon the work of Data Analysts by developing predictive models and machine learning algorithms. While analysts focus on the “what” and “why,” Data Scientists focus on the “what’s next.”
Key Responsibilities:
Design and implement Machine Learning models.
Perform hypothesis testing, A/B testing, and predictive analytics.
Derive strategic insights for product improvements and new innovations.
Communicate technical findings to stakeholders.
Required Skills:
Mastery of Statistics and Probability.
Strong programming skills (Python, R, SQL).
Deep understanding of Machine Learning algorithms.
Ability to handle large datasets using Big Data technologies.
Critical thinking and problem-solving abilities.
Machine Learning Engineer
Who is a Machine Learning Engineer?
Machine Learning Engineers (MLES) take the models developed by Data Scientists and make them production-ready. They ensure models are deployed, scalable, monitored, and maintained effectively in real-world systems.
Key Responsibilities:
Deploy machine learning models into production environments.
Optimise and scale ML models for performance and efficiency.
Continuously monitor and retrain models based on real-time data.
Collaborate with software engineers and data scientists for integration.
Required Skills:
Strong foundations in Linear Algebra, Calculus, and Probability.
Mastery of Machine Learning frameworks (TensorFlow, PyTorch, Scikit-learn).
Proficiency in programming languages (Python, Java, Scala).
Knowledge of Distributed Systems and Software Engineering principles.
Familiarity with MLOps tools for automation and monitoring.
Summary: Data Engineer vs Data Analyst vs Data Scientist vs ML Engineer
Data Engineer
Focus Area: Data Collection & Processing
Key Skills: DBMS, Big Data, Cloud Computing
Objective: Build and maintain data infrastructure
Data Analyst
Focus Area: Data Interpretation & Reporting
Key Skills: Statistics, Python/R, Visualisation Tools
Objective: Analyse data and extract insights
Data Scientist
Focus Area: Predictive Modelling
Key Skills: Machine Learning, Statistics, Data Analysis
Objective: Build predictive models and strategies
Machine Learning Engineer
Focus Area: Model Deployment & Optimisation
Key Skills: ML Frameworks, Software Engineering
Objective: Deploy and optimise ML models in production
Frequently Asked Questions (FAQS)
Q1: Can a Data Engineer become a Data Scientist?
Yes! With additional skills in machine learning, statistics, and model building, a Data Engineer can transition into a Data Scientist role.
Q2: Is coding necessary for Data Analysts?
While deep coding isn’t mandatory, familiarity with SQL, Python, or R greatly enhances a Data Analyst’s effectiveness.
Q3: What is the difference between a Data Scientist and an ML Engineer?
Data Scientists focus more on model development and experimentation, while ML Engineers focus on deploying and scaling those models.
Q4: Which role is the best for beginners?
If you love problem-solving and analysis, start as a Data Analyst. If you enjoy coding and systems, a Data Engineer might be your path.
Published By:
Mirza Yasir Abdullah Baig
Repost This Article and built Your Connection With Others
0 notes
Text
Strengthen Your Data Quality Framework with iceDQ v2.0
Building a strong foundation for data quality is vital to making strategic decisions. With the iceDQ v2.0 User Training, you'll gain the technical knowledge and strategic mindset to design, monitor, and optimize a reliable data quality framework.
What You Will Gain:
7 progressive chapters guiding you from basics to advanced features.
Over 30 interactive videos to reinforce concepts visually.
Real-world business examples to bridge the theory-practice gap.
Final certification to demonstrate your expertise.
Practical tools and workflows you can deploy immediately.
This course empowers professionals to handle data complexities, whether in healthcare, finance, retail, or any other domain. You’ll learn to automate validations, set up monitoring dashboards, and ensure compliance with data standards.
Make your organization data-ready. Start the iceDQ v2.0 training now and establish a strong data quality culture.
#data migration testing#data migration testing tools#etl testing tools#bi testing#etl testing tool#data warehouse testing#etl testing#production data monitoring#data reliability engineering#icedq
0 notes
Text
How to Ace a Data Engineering Interview: Tips & Common Questions
The demand for data engineers is growing rapidly, and landing a job in this field requires thorough preparation. If you're aspiring to become a data engineer, knowing what to expect in an interview can help you stand out. Whether you're preparing for your first data engineering role or aiming for a more advanced position, this guide will provide essential tips and common interview questions to help you succeed. If you're in Bangalore, enrolling in a Data Engineering Course in Hebbal, Data Engineering Course in Indira Nagar, or Data Engineering Course in Jayanagar can significantly boost your chances of success by providing structured learning and hands-on experience.
Understanding the Data Engineering Interview Process
Data engineering interviews typically consist of multiple rounds, including:
Screening Round – A recruiter assesses your background and experience.
Technical Round – Tests your knowledge of SQL, databases, data pipelines, and cloud computing.
Coding Challenge – A take-home or live coding test to evaluate your problem-solving abilities.
System Design Interview – Focuses on designing scalable data architectures.
Behavioral Round – Assesses your teamwork, problem-solving approach, and communication skills.
Essential Tips to Ace Your Data Engineering Interview
1. Master SQL and Database Concepts
SQL is the backbone of data engineering. Be prepared to write complex queries and optimize database performance. Some important topics include:
Joins, CTEs, and Window Functions
Indexing and Query Optimization
Data Partitioning and Sharding
Normalization and Denormalization
Practice using platforms like LeetCode, HackerRank, and Mode Analytics to refine your SQL skills. If you need structured training, consider a Data Engineering Course in Indira Nagar for in-depth SQL and database learning.
2. Strengthen Your Python and Coding Skills
Most data engineering roles require Python expertise. Be comfortable with:
Pandas and NumPy for data manipulation
Writing efficient ETL scripts
Automating workflows with Python
Additionally, learning Scala and Java can be beneficial, especially for working with Apache Spark.
3. Gain Proficiency in Big Data Technologies
Many companies deal with large-scale data processing. Be prepared to discuss and work with:
Hadoop and Spark for distributed computing
Apache Airflow for workflow orchestration
Kafka for real-time data streaming
Enrolling in a Data Engineering Course in Jayanagar can provide hands-on experience with these technologies.
4. Understand Data Pipeline Architecture and ETL Processes
Expect questions on designing scalable and efficient ETL pipelines. Key topics include:
Extracting data from multiple sources
Transforming and cleaning data efficiently
Loading data into warehouses like Redshift, Snowflake, or BigQuery
5. Familiarize Yourself with Cloud Platforms
Most data engineering roles require cloud computing expertise. Gain hands-on experience with:
AWS (S3, Glue, Redshift, Lambda)
Google Cloud Platform (BigQuery, Dataflow)
Azure (Data Factory, Synapse Analytics)
A Data Engineering Course in Hebbal can help you get hands-on experience with cloud-based tools.
6. Practice System Design and Scalability
Data engineering interviews often include system design questions. Be prepared to:
Design a scalable data warehouse architecture
Optimize data processing pipelines
Choose between batch and real-time data processing
7. Prepare for Behavioral Questions
Companies assess your ability to work in a team, handle challenges, and solve problems. Practice answering:
Describe a challenging data engineering project you worked on.
How do you handle conflicts in a team?
How do you ensure data quality in a large dataset?
Common Data Engineering Interview Questions
Here are some frequently asked questions:
SQL Questions:
Write a SQL query to find duplicate records in a table.
How would you optimize a slow-running query?
Explain the difference between partitioning and indexing.
Coding Questions: 4. Write a Python script to process a large CSV file efficiently. 5. How would you implement a data deduplication algorithm? 6. Explain how you would design an ETL pipeline for a streaming dataset.
Big Data & Cloud Questions: 7. How does Apache Kafka handle message durability? 8. Compare Hadoop and Spark for large-scale data processing. 9. How would you choose between AWS Redshift and Google BigQuery?
System Design Questions: 10. Design a data pipeline for an e-commerce company that processes user activity logs. 11. How would you architect a real-time recommendation system? 12. What are the best practices for data governance in a data lake?
Final Thoughts
Acing a data engineering interview requires a mix of technical expertise, problem-solving skills, and practical experience. By focusing on SQL, coding, big data tools, and cloud computing, you can confidently approach your interview. If you’re looking for structured learning and practical exposure, enrolling in a Data Engineering Course in Hebbal, Data Engineering Course in Indira Nagar, or Data Engineering Course in Jayanagar can provide the necessary training to excel in your interviews and secure a high-paying data engineering job.
0 notes
Text
Understanding Data Testing and Its Importance

In today’s data-driven world, businesses rely heavily on accurate and high-quality data to make critical decisions. Data testing is a crucial process that ensures the accuracy, consistency, and reliability of data within databases, data warehouses, and software applications. By implementing robust data testing services, organizations can avoid costly errors, improve decision-making, and enhance operational efficiency.
What is Data Testing?
Data testing is the process of validating data for accuracy, integrity, consistency, and completeness. It involves checking whether the data being used in an application or system meets predefined quality standards. Organizations use data testing to detect discrepancies, missing values, duplicate records, or incorrect formats that can compromise data integrity.
Key Aspects of Data Testing
Data Validation – Ensures that data conforms to predefined rules and constraints.
Data Integrity Testing – Checks for consistency and correctness of data across different databases and systems.
Data Migration Testing – Validates data movement from one system to another without loss or corruption.
ETL Testing – Tests the Extract, Transform, Load (ETL) process to ensure accurate data extraction, transformation, and loading into the target system.
Regression Testing – Ensures that changes in data do not negatively impact the system’s functionality.
Performance Testing – Assesses the speed and reliability of data processes under varying conditions.
Why Are Data Testing Services Essential?
With the exponential growth of data, organizations cannot afford to overlook data quality. Investing in professional data testing services provides several benefits:
Prevention of Data Errors: Identifying and fixing data issues before they impact business processes.
Regulatory Compliance: Ensuring data adheres to industry regulations such as GDPR, HIPAA, and SOX.
Optimized Performance: Ensuring that databases and applications run efficiently with high-quality data.
Enhanced Decision-Making: Reliable data enables better business insights and informed decision-making.
Seamless Data Integration: Ensuring smooth data migration and integration between different platforms.
How to Implement Effective Data Testing?
Define Clear Data Quality Standards: Establish rules and benchmarks for data accuracy, consistency, and completeness.
Automate Testing Where Possible: Leverage automation tools for efficient and accurate data validation.
Conduct Regular Data Audits: Periodic testing helps identify and rectify data anomalies.
Use Robust Data Testing Tools: Tools like Informatica, Talend, and Apache Nifi help streamline the process.
Engage Professional Data Testing Services: Partnering with expert service providers ensures thorough testing and high-quality data.
Conclusion
In an era where data fuels business success, ensuring its accuracy and reliability is paramount. Data testing services play a crucial role in maintaining data integrity and enhancing operational efficiency. Organizations that invest in proper data testing can mitigate risks, improve compliance, and make data-driven decisions with confidence. Prioritizing data testing today means securing a smarter and more efficient business future.
0 notes
Text
ETL and Data Testing Services: Why Data Quality Is the Backbone of Business Success | GQAT Tech
Data drives decision-making in the digital age. Businesses use data to build strategies, attain insights, and measure performance to plan for growth opportunities. However, data-driven decision-making only exists when the data is clean, complete, accurate, and trustworthy. This is where ETL and Data Testing Services are useful.
GQAT Tech provides ETL (Extract, Transform, Load) and Data Testing Services so your data pipelines can run smoothly. Whether you are migrating legacy data, developing on a data warehouse, or merging with other data, GQAT Tech services help ensure your data is an asset and not a liability.
What is ETL and Why Is It Important?
ETL (extract, transform, load) is a process for data warehousing and data integration, which consists of:
Extracting data from different sources
Transforming the data to the right format or structure
Loading the transformed data into a central system, such as a data warehouse.
Although ETL can simplify data processing, it can also create risks in that data can be lost, misformatted, corrupted, or misapplied transformation rules. This is why ETL testing is very important.
The purpose of ETL testing is to ensure that the data is:
Correctly extracted from the source systems
Accurately transformed according to business logic
Correctly loaded into the destination systems.
Why Choose GQAT Tech for ETL and Data Testing?
At GQAT Tech combine our exceptional technical expertise and premier technology and custom-built frameworks to ensure your data is accurate and certified with correctness.
1. End-to-End Data Validation
We will validate your data across the entire ETL process – extract, transform, and load- to confirm the source and target systems are 100% consistent.
2. Custom-Built Testing Frameworks
Every company has a custom data workflow. We build testing frameworks fit for your proprietary data environments, business rules, and compliance requirements.
3. Automation + Accuracy
We automate to the highest extent using tools like QuerySurge, Talend, Informatica, SQL scripts, etc. This helps a) reduce the amount of testing effort, b) avoid human error.
4. Compliance Testing
Data Privacy and compliance are obligatory today. We help you comply with regulations like GDPR, HIPAA, SOX, etc.
5. Industry Knowledge
GQAT has years of experience with clients in Finance, Healthcare, Telecom, eCommerce, and Retail, which we apply to every data testing assignment.
Types of ETL and Data Testing Services We Offer
Data Transformation Testing
We ensure your business rules are implemented accurately as part of the transformation process. Don't risk incorrect aggregations, mislabels, or logical errors in your final reports.
Data Migration Testing
We ensure that, regardless of moving to the cloud or the legacy to modern migration, all the data is transitioned completely, accurately, and securely.
BI Report Testing
We validate that both dashboards and business reports reflect the correct numbers by comparing visual data to actual backend data.
Metadata Testing
We validate schema, column names, formats, data types, and other metadata to ensure compatibility of source and target systems.
Key Benefits of GQAT Tech’s ETL Testing Services
1. Increase Data Security and Accuracy
We guarantee that valid and necessary data will only be transmitted to your system; we can reduce data leakage and security exposures.
2. Better Business Intelligence
Good data means quality outputs; dashboards and business intelligence you can trust, allowing you to make real-time choices with certainty.
3. Reduction of Time and Cost
We also lessen the impact of manual mistakes, compress timelines, and assist in lower rework costs by automating data testing.
4. Better Customer Satisfaction
Good data to make decisions off of leads to good customer experiences, better insights, and improved services.
5. Regulatory Compliance
By implementing structured testing, you can ensure compliance with data privacy laws and standards in order to avoid fines, penalties, and audits.
Why GQAT Tech?
With more than a decade of experience, we are passionate about delivering world-class ETL & Data Testing Services. Our purpose is to help you operate from clean, reliable data to exercise and action with confidence to allow you to scale, innovate, and compete more effectively.
Visit Us: https://gqattech.com Contact Us: [email protected]
#ETL Testing#Data Testing Services#Data Validation#ETL Automation#Data Quality Assurance#Data Migration Testing#Business Intelligence Testing#ETL Process#SQL Testing#GQAT Tech
0 notes
Text
Best Informatica Cloud | Informatica Training in Ameerpet
How Does Dynamic Mapping Work in CDI?
Informatica Cloud Data Integration (CDI) provides robust ETL and ELT capabilities, enabling enterprises to manage and transform their data efficiently. One of its most powerful features is Dynamic Mapping, which allows organizations to create reusable and flexible data integration solutions without modifying mappings manually for each change in source or target structures.

What is Dynamic Mapping?
Dynamic Mapping in CDI is a feature that allows mappings to automatically adjust to changes in source and target schemas. Instead of hardcoding column names and data types, users can define mappings that dynamically adapt, making data pipelines more scalable and resilient to structural changes. Informatica IDMC Training
Key Benefits of Dynamic Mapping
Flexibility – Easily accommodate changes in source or target structures without redesigning mappings.
Reusability – Use the same mapping logic across multiple datasets without creating separate mappings.
Reduced Maintenance Effort – Eliminates the need for frequent manual updates when schemas evolve.
Improved Efficiency – Reduces development time and enhances agility in managing data integration workflows.
How Dynamic Mapping Works in CDI
Dynamic Mapping operates using several key components that allow it to function efficiently: Informatica Cloud Training
1. Dynamic Schema Handling
In CDI, you can configure mappings to fetch metadata dynamically from the source system. This means that when a new column is added, modified, or removed, the mapping can recognize the changes and adjust accordingly.
2. Dynamic Ports
Dynamic ports allow you to handle varying schemas without specifying each field manually. You can use parameterized field rules to determine which fields should be included, excluded, or renamed dynamically.
3. Parameterized Transformations
Transformations like Aggregator, Filter, and Expression can be parameterized, meaning they can adapt dynamically based on incoming metadata. This ensures that business rules applied to the data remain relevant, even when structures change.
4. Use of Parameter Files
Dynamic mappings often leverage parameter files, which store variable values such as connection details, field rules, and transformation logic. These files can be updated externally without modifying the core mapping, ensuring greater adaptability.
5. Dynamic Target Mapping
When working with dynamic targets, CDI allows mappings to adjust based on target metadata. This is particularly useful for handling data lakes, data warehouses, and cloud storage, where new tables or columns might be added frequently.
Steps to Implement Dynamic Mapping in CDI
To configure a Dynamic Mapping in CDI, follow these steps: Informatica IDMC Training
Create a Mapping – Define a new mapping in Informatica CDI.
Enable Dynamic Schema Handling – Select the option to read metadata dynamically from the source.
Use Dynamic Ports – Configure the mapping to recognize new or changing columns automatically.
Parameterize Transformations – Define business rules that adapt dynamically to the dataset.
Leverage Parameter Files – Store mapping configurations externally to avoid hardcoding values.
Deploy and Test – Execute the mapping to verify that it dynamically adjusts to changes.
Use Cases for Dynamic Mapping in CDI: Informatica Cloud IDMC Training
Multi-Source Data Integration – Load data from different databases, cloud storage, or APIs with varying schemas.
Data Warehousing and ETL Automation – Streamline ETL pipelines by accommodating schema evolution.
Schema Drift Management – Handle changes in incoming data structures without breaking existing workflows.
Metadata-Driven Data Pipelines – Automate data processing in environments with frequently changing datasets.
Conclusion
Dynamic Mapping in Informatica CDI is a game-changer for organizations dealing with evolving data structures. By enabling mappings to adapt automatically, it enhances flexibility, reduces maintenance effort, and streamlines data integration processes. Businesses leveraging this capability can significantly improve efficiency, ensuring that their data pipelines remain robust and scalable in dynamic environments.
For More Information about Informatica Cloud Online Training
Contact Call/WhatsApp: +91 7032290546
Visit: https://www.visualpath.in/informatica-cloud-training-in-hyderabad.html
#Informatica Training in Hyderabad#IICS Training in Hyderabad#IICS Online Training#Informatica Cloud Training#Informatica Cloud Online Training#Informatica IICS Training#Informatica IDMC Training#Informatica Training in Ameerpet#Informatica Online Training in Hyderabad#Informatica Training in Bangalore#Informatica Training in Chennai#Informatica Training in India#Informatica Cloud IDMC Training
0 notes
Text
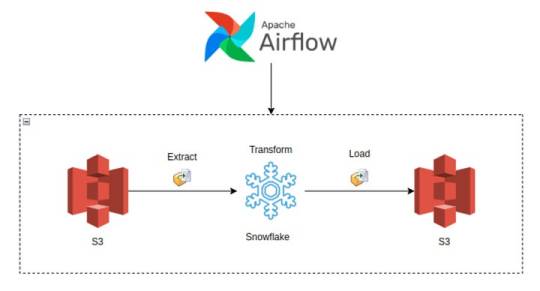
Building Data Pipelines with Snowflake and Apache Airflow

1. Introduction to Snowflake
Snowflake is a cloud-native data platform designed for scalability and ease of use, providing data warehousing, data lakes, and data sharing capabilities. Unlike traditional databases, Snowflake’s architecture separates compute, storage, and services, making it highly scalable and cost-effective. Some key features to highlight:
Zero-Copy Cloning: Allows you to clone data without duplicating it, making testing and experimentation more cost-effective.
Multi-Cloud Support: Snowflake works across major cloud providers like AWS, Azure, and Google Cloud, offering flexibility in deployment.
Semi-Structured Data Handling: Snowflake can handle JSON, Parquet, XML, and other formats natively, making it versatile for various data types.
Automatic Scaling: Automatically scales compute resources based on workload demands without manual intervention, optimizing cost.
2. Introduction to Apache Airflow
Apache Airflow is an open-source platform used for orchestrating complex workflows and data pipelines. It’s widely used for batch processing and ETL (Extract, Transform, Load) tasks. You can define workflows as Directed Acyclic Graphs (DAGs), making it easy to manage dependencies and scheduling. Some of its features include:
Dynamic Pipeline Generation: You can write Python code to dynamically generate and execute tasks, making workflows highly customizable.
Scheduler and Executor: Airflow includes a scheduler to trigger tasks at specified intervals, and different types of executors (e.g., Celery, Kubernetes) help manage task execution in distributed environments.
Airflow UI: The intuitive web-based interface lets you monitor pipeline execution, visualize DAGs, and track task progress.
3. Snowflake and Airflow Integration
The integration of Snowflake with Apache Airflow is typically achieved using the SnowflakeOperator, a task operator that enables interaction between Airflow and Snowflake. Airflow can trigger SQL queries, execute stored procedures, and manage Snowflake tasks as part of your DAGs.
SnowflakeOperator: This operator allows you to run SQL queries in Snowflake, which is useful for performing actions like data loading, transformation, or even calling Snowflake procedures.
Connecting Airflow to Snowflake: To set this up, you need to configure a Snowflake connection within Airflow. Typically, this includes adding credentials (username, password, account, warehouse, and database) in Airflow’s connection settings.
Example code for setting up the Snowflake connection and executing a query:pythonfrom airflow.providers.snowflake.operators.snowflake import SnowflakeOperator from airflow import DAG from datetime import datetimedefault_args = { 'owner': 'airflow', 'start_date': datetime(2025, 2, 17), }with DAG('snowflake_pipeline', default_args=default_args, schedule_interval=None) as dag: run_query = SnowflakeOperator( task_id='run_snowflake_query', sql="SELECT * FROM my_table;", snowflake_conn_id='snowflake_default', # The connection ID in Airflow warehouse='MY_WAREHOUSE', database='MY_DATABASE', schema='MY_SCHEMA' )
4. Building a Simple Data Pipeline
Here, you could provide a practical example of an ETL pipeline. For instance, let’s create a pipeline that:
Extracts data from a source (e.g., a CSV file in an S3 bucket),
Loads the data into a Snowflake staging table,
Performs transformations (e.g., cleaning or aggregating data),
Loads the transformed data into a production table.
Example DAG structure:pythonfrom airflow.providers.snowflake.operators.snowflake import SnowflakeOperator from airflow.providers.amazon.aws.transfers.s3_to_snowflake import S3ToSnowflakeOperator from airflow import DAG from datetime import datetimewith DAG('etl_pipeline', start_date=datetime(2025, 2, 17), schedule_interval='@daily') as dag: # Extract data from S3 to Snowflake staging table extract_task = S3ToSnowflakeOperator( task_id='extract_from_s3', schema='MY_SCHEMA', table='staging_table', s3_keys=['s3://my-bucket/my-file.csv'], snowflake_conn_id='snowflake_default' ) # Load data into Snowflake and run transformation transform_task = SnowflakeOperator( task_id='transform_data', sql='''INSERT INTO production_table SELECT * FROM staging_table WHERE conditions;''', snowflake_conn_id='snowflake_default' ) extract_task >> transform_task # Define task dependencies
5. Error Handling and Monitoring
Airflow provides several mechanisms for error handling:
Retries: You can set the retries argument in tasks to automatically retry failed tasks a specified number of times.
Notifications: You can use the email_on_failure or custom callback functions to notify the team when something goes wrong.
Airflow UI: Monitoring is easy with the UI, where you can view logs, task statuses, and task retries.
Example of setting retries and notifications:pythonwith DAG('data_pipeline_with_error_handling', start_date=datetime(2025, 2, 17)) as dag: task = SnowflakeOperator( task_id='load_data_to_snowflake', sql="SELECT * FROM my_table;", snowflake_conn_id='snowflake_default', retries=3, email_on_failure=True, on_failure_callback=my_failure_callback # Custom failure function )
6. Scaling and Optimization
Snowflake’s Automatic Scaling: Snowflake can automatically scale compute resources based on the workload. This ensures that data pipelines can handle varying loads efficiently.
Parallel Execution in Airflow: You can split your tasks into multiple parallel branches to improve throughput. The task_concurrency argument in Airflow helps manage this.
Task Dependencies: By optimizing task dependencies and using Airflow’s ability to run tasks in parallel, you can reduce the overall runtime of your pipelines.
Resource Management: Snowflake supports automatic suspension and resumption of compute resources, which helps keep costs low when there is no processing required.1. Introduction to Snowflake
0 notes
Text
Implementing the Tableau to Power BI Migration: A Strategic Approach for Transition
migrating from Tableau to Power BI offers organizations an opportunity to unlock new levels of analytics performance, cost-efficiency, and integration within the Microsoft ecosystem. However, transitioning from one BI tool to another is a complex process that requires careful planning and execution. In this guide, we explore the essential steps and strategies for a successful Tableau to Power BI migration, ensuring smooth data model conversion, optimized performance, robust security implementation, and seamless user adoption. Whether you're looking to modernize your analytics environment or improve cost management, understanding the key components of this migration is crucial to achieving long-term success.
Understanding the Tableau to Power BI migration Landscape
When planning a Tableau to Power BI migration , organizations must first understand the fundamental differences between these platforms. The process requires careful consideration of various factors, including data architecture redesign and cross-platform analytics transition. A successful Tableau to Power BI migration starts with a thorough assessment of your current environment.
Strategic Planning and Assessment
The foundation of any successful Tableau to Power BI migration lies in comprehensive planning. Organizations must conduct a thorough migration assessment framework to understand their current Tableau implementation. This involves analyzing existing reports, dashboards, and data sources while documenting specific requirements for the transition.
Technical Implementation Framework
Data Architecture and Integration
The core of Tableau to Power BI migration involves data model conversion and proper database connection transfer. Organizations must implement effective data warehouse integration strategies while ensuring proper data gateway configuration. A successful Tableau to Power BI migration requires careful attention to ETL process migration and schema migration planning.
Development and Conversion Process
During the Tableau to Power BI migration, special attention must be paid to DAX formula conversion and LOD expression transformation. The process includes careful handling of calculated field migration and implementation of proper parameter configuration transfer. Organizations should establish a robust development environment setup to ensure smooth transitions.
Performance Optimization Strategy
A critical aspect of Tableau to Power BI migration involves implementing effective performance tuning methods. This includes establishing proper query performance optimization techniques and memory usage optimization strategies. Organizations must focus on resource allocation planning and workload distribution to maintain optimal performance.
Security Implementation
Security remains paramount during Tableau to Power BI migration. Organizations must ensure proper security model transfer and implement robust access control implementation. The process includes setting up row-level security migration and establishing comprehensive data protection protocols.
User Management and Training
Successful Tableau to Power BI migration requires careful attention to user access migration and license transfer process. Organizations must implement effective group policy implementation strategies while ensuring proper user mapping strategy execution. This includes developing comprehensive user training materials and establishing clear knowledge transfer plans.
Testing and Quality Assurance
Implementing thorough migration testing protocols ensures successful outcomes. Organizations must establish comprehensive validation framework setup procedures and implement proper quality assurance methods. This includes conducting thorough user acceptance testing and implementing effective dashboard testing strategy procedures.
Maintenance and Support Planning
Post-migration success requires implementing effective post-migration monitoring systems and establishing proper system health checks. Organizations must focus on performance analytics and implement comprehensive usage monitoring setup procedures to ensure continued success.
Ensuring Long-term Success and ROI
A successful Tableau to Power BI migration requires ongoing attention to maintenance and optimization. Organizations must establish proper maintenance scheduling procedures and implement effective backup procedures while ensuring comprehensive recovery planning.
Partner with DataTerrain for Migration Excellence
At DataTerrain, we understand the complexities of Tableau to Power BI migration. Our team of certified professionals brings extensive experience in managing complex migrations, ensuring seamless transitions while maintaining business continuity. We offer:
Comprehensive Migration Services: Our expert team handles every aspect of your migration journey, from initial assessment to post-migration support.
Technical Excellence: With deep expertise in both Tableau and Power BI, we ensure optimal implementation of all technical components.
Proven Methodology: Our structured approach, refined through numerous successful migrations, ensures predictable outcomes and minimal disruption.
Transform your business intelligence capabilities with DataTerrain's expert Tableau to Power BI migration services. Contact us today for a free consultation and discover how we can guide your organization through a successful migration journey.
1 note
·
View note
Text
Best DBT Course in Hyderabad | Data Build Tool Training
What is DBT, and Why is it Used in Data Engineering?
DBT, short for Data Build Tool, is an open-source command-line tool that allows data analysts and engineers to transform data in their warehouses using SQL. Unlike traditional ETL (Extract, Transform, Load) processes, which manage data transformations separately, DBT focuses solely on the Transform step and operates directly within the data warehouse.
DBT enables users to define models (SQL queries) that describe how raw data should be cleaned, joined, or transformed into analytics-ready datasets. It executes these models efficiently, tracks dependencies between them, and manages the transformation process within the data warehouse. DBT Training

Key Features of DBT
SQL-Centric: DBT is built around SQL, making it accessible to data professionals who already have SQL expertise. No need for learning complex programming languages.
Version Control: DBT integrates seamlessly with version control systems like Git, allowing teams to collaborate effectively while maintaining an organized history of changes.
Testing and Validation: DBT provides built-in testing capabilities, enabling users to validate their data models with ease. Custom tests can also be defined to ensure data accuracy.
Documentation: With dbt, users can automatically generate documentation for their data models, providing transparency and fostering collaboration across teams.
Modularity: DBT encourages the use of modular SQL code, allowing users to break down complex transformations into manageable components that can be reused. DBT Classes Online
Why is DBT Used in Data Engineering?
DBT has become a critical tool in data engineering for several reasons:
1. Simplifies Data Transformation
Traditionally, the Transform step in ETL processes required specialized tools or complex scripts. DBT simplifies this by empowering data teams to write SQL-based transformations that run directly within their data warehouses. This eliminates the need for external tools and reduces complexity.
2. Works with Modern Data Warehouses
DBT is designed to integrate seamlessly with modern cloud-based data warehouses such as Snowflake, BigQuery, Redshift, and Databricks. By operating directly in the warehouse, it leverages the power and scalability of these platforms, ensuring fast and efficient transformations. DBT Certification Training Online
3. Encourages Collaboration and Transparency
With its integration with Git, dbt promotes collaboration among teams. Multiple team members can work on the same project, track changes, and ensure version control. The autogenerated documentation further enhances transparency by providing a clear view of the data pipeline.
4. Supports CI/CD Pipelines
DBT enables teams to adopt Continuous Integration/Continuous Deployment (CI/CD) workflows for data transformations. This ensures that changes to models are tested and validated before being deployed, reducing the risk of errors in production.
5. Focus on Analytics Engineering
DBT shifts the focus from traditional ETL to ELT (Extract, Load, Transform). With raw data already loaded into the warehouse, dbt allows teams to spend more time analyzing data rather than managing complex pipelines.
Real-World Use Cases
Data Cleaning and Enrichment: DBT is used to clean raw data, apply business logic, and create enriched datasets for analysis.
Building Data Models: Companies rely on dbt to create reusable, analytics-ready models that power dashboards and reports. DBT Online Training
Tracking Data Lineage: With its ability to visualize dependencies, dbt helps track the flow of data, ensuring transparency and accountability.
Conclusion
DBT has revolutionized the way data teams approach data transformations. By empowering analysts and engineers to use SQL for transformations, promoting collaboration, and leveraging the scalability of modern data warehouses, dbt has become a cornerstone of modern data engineering. Whether you are cleaning data, building data models, or ensuring data quality, dbt offers a robust and efficient solution that aligns with the needs of today’s data-driven organizations.
Visualpath is the Best Software Online Training Institute in Hyderabad. Avail complete Data Build Tool worldwide. You will get the best course at an affordable cost.
Attend Free Demo
Call on - +91-9989971070.
Visit: https://www.visualpath.in/online-data-build-tool-training.html
WhatsApp: https://www.whatsapp.com/catalog/919989971070/
Visit Blog: https://databuildtool1.blogspot.com/
#DBT Training#DBT Online Training#DBT Classes Online#DBT Training Courses#Best Online DBT Courses#DBT Certification Training Online#Data Build Tool Training in Hyderabad#Best DBT Course in Hyderabad#Data Build Tool Training in Ameerpet
0 notes