#database snapshots SQL
Explore tagged Tumblr posts
Visit Tumblr Blog
Explore Tumblr blogs with no restrictions, modern design and the best experience.
Last Seen Tumblr Blogs





Fun Fact
BuzzFeed published a report claiming that Tumblr was utilized as a distribution channel for Russian agents to influence American voting habits during the 2016 presidential election in Feb 2018.
Text
Ad-hoc Copying of Large SQL Tables from Production to Development in SQL Server 2022: Best Methodologies
Picture this: You’re a database whiz, knee-deep in the nitty-gritty of moving colossal tables from the bustling world of production to the calmer waters of development or testing. It’s no small feat, especially when you’re juggling tables that are bursting at the seams with data, running into the hundreds of millions of rows. The challenge? Doing this dance without stepping on the toes of data…
View On WordPress
#bulk copy program BCP#database snapshots SQL#SELECT INTO SQL technique#SQL Server 2022 data migration#SSIS data transformation
0 notes
Text
Database snapshots are potent concepts in SQL Server that allow us to create a read-only and static copy of a database. Let's Explore Deeply:
https://madesimplemssql.com/database-snapshot-in-sql-server/

1 note
·
View note
Text
Cost Optimization Strategies in Public Cloud

Businesses around the globe have embraced public cloud computing to gain flexibility, scalability, and faster innovation. While the cloud offers tremendous advantages, many organizations face an unexpected challenge: spiraling costs. Without careful planning, cloud expenses can quickly outpace expectations. That’s why cost optimization has become a critical component of cloud strategy.
Cost optimization doesn’t mean cutting essential services or sacrificing performance. It means using the right tools, best practices, and strategic planning to make the most of every dollar spent on the cloud. In this article, we explore proven strategies to reduce unnecessary spending while maintaining high availability and performance in a public cloud environment.
1. Right-Sizing Resources
Many businesses overprovision their cloud resources, thinking it's safer to allocate more computing power than needed. However, this leads to wasted spending. Right-sizing involves analyzing usage patterns and scaling down resources to match actual needs.
You can:
Use monitoring tools to analyze CPU and memory utilization
Adjust virtual machine sizes to suit workloads
Switch to serverless computing when possible, paying only for what you use
This strategy ensures optimal performance at the lowest cost.
2. Take Advantage of Reserved Instances
Most public cloud providers, including AWS, Azure, and Google Cloud, offer Reserved Instances (RIs) at discounted prices for long-term commitments. If your workload is predictable and long-term, reserving instances for one or three years can save up to 70% compared to on-demand pricing.
This is ideal for production environments, baseline services, and other non-variable workloads.
3. Auto-Scaling Based on Demand
Auto-scaling helps match computing resources with current demand. During off-peak hours, cloud services automatically scale down to reduce costs. When traffic spikes, resources scale up to maintain performance.
Implementing auto-scaling not only improves cost efficiency but also ensures reliability and customer satisfaction.
4. Delete Unused or Orphaned Resources
Cloud environments often accumulate unused resources—volumes, snapshots, IP addresses, or idle virtual machines. These resources continue to incur charges even when not in use.
Make it a regular practice to:
Audit and remove orphaned resources
Clean up unattached storage volumes
Delete old snapshots and unused databases
Cloud management tools can automate these audits, helping keep your environment lean and cost-effective.
5. Use Cost Monitoring and Alerting Tools
Every major public cloud provider offers native cost management tools:
AWS Cost Explorer
Azure Cost Management + Billing
Google Cloud Billing Reports
These tools help track spending in real time, break down costs by service, and identify usage trends. You can also set budgets and receive alerts when spending approaches limits, helping prevent surprise bills.
6. Implement Tagging for Cost Allocation
Properly tagging resources makes it easier to identify who is spending what within your organization. With tagging, you can allocate costs by:
Project
Department
Client
Environment (e.g., dev, test, prod)
This visibility empowers teams to take ownership of their cloud spending and look for optimization opportunities.
7. Move to Serverless and Managed Services
In many cases, serverless and managed services provide a more cost-efficient alternative to traditional infrastructure.
Consider using:
Azure Functions or AWS Lambda for event-driven applications
Cloud SQL or Azure SQL Database for managed relational databases
Firebase or App Engine for mobile and web backends
These services eliminate the need for server provisioning and maintenance while offering a pay-as-you-go pricing model.
8. Choose the Right Storage Class
Public cloud providers offer different storage classes based on access frequency:
Hot storage for frequently accessed data
Cool or infrequent access storage for less-used files
Archive storage for long-term, rarely accessed data
Storing data in the appropriate class ensures you don’t pay premium prices for data you seldom access.
9. Leverage Spot and Preemptible Instances
Spot instances (AWS) or preemptible VMs (Google Cloud) offer up to 90% savings compared to on-demand pricing. These instances are ideal for:
Batch processing
Testing environments
Fault-tolerant applications
Since these instances can be interrupted, they’re not suitable for every workload, but when used correctly, they can slash costs significantly.
10. Train Your Teams
Cost optimization isn’t just a technical task—it’s a cultural one. When developers, DevOps, and IT teams understand how cloud billing works, they make smarter decisions.
Regular training and workshops can:
Increase awareness of cost-effective architectures
Encourage the use of automation tools
Promote shared responsibility for cloud cost management
Final Thoughts
Public cloud computing offers unmatched agility and scalability, but without deliberate cost control, organizations can face financial inefficiencies. By right-sizing, leveraging automation, utilizing reserved instances, and fostering a cost-aware culture, companies can enjoy the full benefits of the cloud without overspending.
Cloud optimization is a continuous journey—not a one-time fix. Regular reviews and proactive planning will keep your cloud costs aligned with your business goals.
#PublicCloudComputing#CloudCostOptimization#Azure#AWS#GoogleCloud#CloudStrategy#Serverless#CloudSavings#ITBudget#CloudArchitecture#digitalmarketing
0 notes
Text
Mastering Power BI Dashboards
In today’s data-driven world, businesses rely heavily on insightful analysis to make informed decisions. Power BI, developed by Microsoft, has emerged as one of the leading business intelligence tools that help organizations convert raw data into interactive and visually compelling dashboards. Whether you are a business analyst, data professional, or a beginner exploring data visualization, mastering Power BI dashboards can significantly enhance your analytical capabilities.
Understanding Power BI Dashboards
A Power BI dashboard is a collection of visual elements, including charts, graphs, maps, and tables, designed to present a consolidated view of data. Unlike reports, which can be multiple pages long, dashboards are single-page, interactive snapshots that provide key insights at a glance. They pull data from multiple sources, ensuring that businesses can track key performance indicators (KPIs) and trends effectively.
Dashboards in Power BI are often used for:
Business Performance Monitoring: Tracking sales, revenue, and operational efficiency.
Customer Insights: Understanding purchasing behaviors and customer engagement.
Financial Analysis: Evaluating profit margins, expenses, and budget allocations.
Marketing Performance: Analyzing campaign success and return on investment.
Why Power BI Dashboards Are Essential
Power BI dashboards are widely used across industries due to their flexibility, scalability, and integration capabilities. Here are some key reasons why they have become indispensable:
1. Real-Time Data Analysis
Power BI dashboards can connect to live data sources, ensuring that users receive up-to-date insights in real-time. This capability is crucial for businesses that rely on dynamic data, such as e-commerce platforms or financial institutions.
2. User-Friendly Interface
With a drag-and-drop functionality, Power BI makes it easy to create stunning dashboards without requiring advanced coding skills. This democratizes data analysis, allowing even non-technical users to build meaningful visualizations.
3. Seamless Integration
Power BI integrates seamlessly with various Microsoft tools like Excel, Azure, and SQL Server, as well as third-party applications such as Google Analytics, Salesforce, and SAP. This ensures smooth data flow and analysis from multiple sources.
4. Customization and Interactive Features
Users can customize dashboards based on their specific requirements, apply filters, and use drill-down features to explore detailed insights. This level of interactivity makes dashboards more engaging and useful for decision-making.
5. Enhanced Collaboration
Power BI’s cloud-based service allows teams to share dashboards securely, enabling collaborative decision-making. Users can also access dashboards on mobile devices, ensuring data accessibility from anywhere.
How to Build an Effective Power BI Dashboard
Creating a well-structured Power BI dashboard requires a clear understanding of business objectives, data sources, and visualization techniques. Follow these steps to build an impactful dashboard:
Step 1: Define Your Objectives
Before designing a dashboard, determine what insights you need to extract. Are you tracking sales growth? Analyzing website traffic? Understanding customer demographics? Defining clear objectives ensures that your dashboard serves its intended purpose.
Step 2: Collect and Prepare Data
Gather data from relevant sources, such as databases, APIs, spreadsheets, or cloud services. Clean and transform the data to ensure accuracy, consistency, and usability. Power BI’s Power Query Editor helps in cleaning and shaping data efficiently.
Step 3: Choose the Right Visualizations
Select charts, graphs, and tables that best represent your data. Some commonly used visualizations in Power BI dashboards include:
Bar Charts: Best for comparing categorical data.
Line Charts: Ideal for tracking trends over time.
Pie Charts: Suitable for showing proportions.
Maps: Useful for geographical analysis.
KPI Indicators: Highlight performance metrics at a glance.
Step 4: Design an Intuitive Layout
A well-organized layout enhances readability and engagement. Place the most important insights at the top, use contrasting colors to highlight key metrics, and avoid cluttering the dashboard with unnecessary elements.
Step 5: Implement Filters and Slicers
Filters and slicers allow users to interact with the dashboard and customize the data displayed. This adds flexibility and makes the dashboard more user-centric.
Step 6: Test and Optimize
Before sharing the dashboard, test its functionality by exploring different scenarios. Optimize loading speed by minimizing unnecessary calculations and large datasets. Ensure that the dashboard is responsive across different devices.
Best Practices for Power BI Dashboards
To create high-impact Power BI dashboards, follow these best practices:
Keep It Simple: Avoid overcrowding the dashboard with too many visuals. Focus on key insights.
Use Consistent Colors and Themes: Maintain a uniform color scheme to enhance visual appeal.
Leverage Data Storytelling: Present data in a way that tells a compelling story, making it easier for users to interpret.
Ensure Data Accuracy: Regularly update data sources to maintain credibility.
Enable Performance Optimization: Optimize DAX calculations and data models to enhance dashboard efficiency.
Conclusion
Mastering Power BI dashboards is a valuable skill that can boost career opportunities in data analytics, business intelligence, and decision-making roles. With its user-friendly interface, real-time data capabilities, and seamless integration, Power BI has become the go-to tool for professionals across various industries. Whether you are a beginner or an experienced analyst, learning Power BI through the best course can enhance your ability to create powerful dashboards that drive business success. Start exploring Power BI today and unlock the potential of data visualization for informed decision-making.
0 notes
Text
Deep dive into restoring data and disaster recovery capabilities in Snowflake.

1. Introduction
Data loss can occur due to accidental deletions, corruption, system failures, or cyberattacks. In cloud-based data warehouses like Snowflake, having a well-structured disaster recovery (DR) plan is critical for business continuity.
Snowflake provides built-in data restoration features that help organizations recover from failures efficiently, including:
Time Travel for short-term historical data recovery.
Fail-Safe for emergency last-resort data retrieval.
Replication and Failover to ensure availability across regions/clouds.
In this deep dive, we will explore these capabilities and best practices for implementing a robust DR strategy in Snowflake.
2. Snowflake’s Data Restoration and Disaster Recovery Features
a. Time Travel: Recovering Historical Data
Time Travel allows users to access past versions of data or even restore deleted objects. This is useful for:
Undoing accidental deletions or updates
Comparing historical data versions
Restoring dropped tables or schemas
How Time Travel Works
Snowflake retains historical data based on the table type and account edition:
Standard Edition: Retention up to 1 day
Enterprise & Higher Editions: Retention up to 90 days
Using Time Travel
Querying Historical Data
sql
SELECT * FROM my_table AT (TIMESTAMP => '2025-02-21 12:00:00');
sql
SELECT * FROM my_table BEFORE (STATEMENT => 'xyz');
Restoring a Dropped Table
sql
UNDROP TABLE my_table;
Cloning Data for Quick Recovery
sql
CREATE TABLE my_table_clone CLONE my_table AT (OFFSET => -60*5);
(Creates a table clone from 5 minutes ago.)
⏳ Limitations: Time Travel does not protect data indefinitely; once the retention period expires, Snowflake permanently removes older versions.
b. Fail-Safe: Last-Resort Recovery
Fail-Safe provides an additional 7-day retention beyond Time Travel for Enterprise and Business Critical accounts. It is meant for disaster recovery and not for user-driven restores.
Key Features of Fail-Safe:
✅ Automatically enabled (no user action needed). ✅ Retains deleted data for 7 days after the Time Travel period ends. ✅ Used only in emergency scenarios where Snowflake must intervene.
Example Scenario:
If a table’s Time Travel retention is 7 days and you drop it on Day 1, you can restore it using UNDROP within that period. If you realize the loss on Day 9, Time Travel won’t help, but Fail-Safe can be used by Snowflake support.
❗ Limitations:
Users cannot query Fail-Safe data.
Recovery is only possible by contacting Snowflake support.
c. Replication & Failover: Ensuring High Availability
Replication is a critical disaster recovery mechanism that allows Snowflake accounts to maintain readable or writable copies of databases across multiple regions/clouds.
How Replication Works:
Data is copied from a primary region (e.g., AWS us-east-1) to one or more secondary regions (e.g., Azure Europe).
Failover ensures seamless redirection of queries to the replica in case of an outage.
Setting Up Database Replication
Enable Replication for a Database:
sql
ALTER DATABASE my_db ENABLE REPLICATION TO ACCOUNTS 'us_east_replica';
Manually Sync Changes to the Replica:
sql
ALTER DATABASE my_db REFRESH;
Performing a Failover (Switch to Replica):
sql
ALTER REPLICATION GROUP my_rep_group FAILOVER TO ACCOUNT 'us_east_replica';
✅ Benefits:
Disaster recovery in case of a regional outage.
Minimized downtime during planned maintenance.
Business continuity even in multi-cloud environments.
d. Continuous Data Protection Best Practices
To prevent data loss and corruption, follow these best practices: ✔ Use Cloning: Instant backups for testing and sandboxing. ✔ Automate Backups: Create periodic snapshots of tables. ✔ Set Proper Permissions: Prevent unauthorized DROP or TRUNCATE actions. ✔ Monitor Data Changes: Track changes using INFORMATION_SCHEMA.
Example:sqlSELECT * FROM INFORMATION_SCHEMA.TABLE_STORAGE_METRICS WHERE TABLE_NAME = 'my_table';
3. Implementing a Disaster Recovery Plan in Snowflake
A strong disaster recovery strategy involves:
a. Setting Recovery Objectives (RTO & RPO)
Recovery Time Objective (RTO): The maximum acceptable downtime.
Recovery Point Objective (RPO): The maximum tolerable data loss.
Example:
If your business requires 0 data loss, cross-region replication is necessary.
If your RPO is 1 hour, you can use automated snapshots and Time Travel.
b. Automating Backups & Data Snapshots
Automate periodic snapshots using Task Scheduling in Snowflake:sqlCREATE TASK daily_backup WAREHOUSE = my_wh SCHEDULE = 'USING CRON 0 0 * * * UTC' AS CREATE TABLE backup_table CLONE my_table;
c. Testing the Disaster Recovery Plan
Simulate data loss scenarios quarterly.
Validate Time Travel, Failover, and Replication.
Train teams to execute recovery procedures.
4. Best Practices for Data Restoration & Disaster Recovery in Snowflake
🔹 1. Optimize Time Travel Retention
Critical tables → Set retention up to 90 days.
Less important tables → Lower retention to reduce costs.
🔹 2. Enable Replication for Critical Workloads
Use cross-region and multi-cloud replication for high availability.
Validate that failover works correctly.
🔹 3. Combine Snowflake with External Backup Solutions
Use Amazon S3, Azure Blob, or Google Cloud Storage for long-term backups.
Schedule incremental extracts for extra security.
🔹 4. Monitor & Audit DR Processes
Regularly review:
sql
SHOW REPLICATION ACCOUNTS; SHOW FAILOVER GROUPS;Set up alerts for unauthorized data modifications.
5. Conclusion
Snowflake offers powerful data restoration and disaster recovery features to protect businesses from data loss. A well-structured Time Travel, Fail-Safe, and Replication strategy ensures that organizations can recover quickly from disasters.
By following best practices such as automating backups, monitoring data changes, and testing DR plans, businesses can minimize downtime and enhance resilience.
WEBSITE: https://www.ficusoft.in/snowflake-training-in-chennai/
0 notes
Text
Cloud Cost Optimization Strategies: Reducing Expenses Without Sacrificing Performance
As organizations increasingly rely on cloud infrastructure, cloud cost optimization has become a top priority. While cloud services offer flexibility and scalability, they can also lead to unexpected expenses if not managed properly. The challenge is to reduce cloud costs without compromising performance, security, or availability.
This blog explores proven strategies for cloud cost optimization, helping businesses maximize ROI while maintaining efficiency.
1. Understanding Cloud Cost Challenges
Before optimizing costs, it’s essential to understand where cloud spending can spiral out of control:
🔴 Common Cost Pitfalls in Cloud Computing
Underutilized Resources – Idle virtual machines (VMs), storage, and databases consuming costs unnecessarily.
Over-Provisioning – Paying for computing power that exceeds actual demand.
Lack of Monitoring – Poor visibility into usage patterns and billing leads to inefficiencies.
Data Transfer Costs – High egress charges from excessive data movement between cloud services.
Inefficient Scaling – Failure to implement auto-scaling results in overpaying during low-demand periods.
💡 Solution? Implement cloud cost optimization strategies that ensure you're only paying for what you need.
2. Cloud Cost Optimization Strategies
✅ 1. Rightsize Your Cloud Resources
Analyze CPU, memory, and storage usage to determine the appropriate instance size.
Use cloud-native tools like:
AWS Cost Explorer
Azure Advisor
Google Cloud Recommender
Scale down or terminate underutilized instances to cut costs.
✅ 2. Implement Auto-Scaling and Load Balancing
Use auto-scaling to dynamically adjust resource allocation based on traffic demands.
Implement load balancing to distribute workloads efficiently, reducing unnecessary resource consumption.
🔹 Example: AWS Auto Scaling Groups ensure instances are added or removed automatically based on demand.
✅ 3. Optimize Storage Costs
Move infrequently accessed data to low-cost storage tiers like:
Amazon S3 Glacier (AWS)
Azure Cool Storage
Google Cloud Coldline Storage
Delete obsolete snapshots and redundant backups to avoid unnecessary costs.
✅ 4. Use Reserved Instances & Savings Plans
Reserved Instances (RIs) – Prepay for cloud resources to get discounts (e.g., up to 72% savings on AWS RIs).
Savings Plans – Commit to a specific usage level for long-term discounts on cloud services.
💡 Best for: Organizations with predictable workloads that don’t require frequent scaling.
✅ 5. Leverage Spot Instances for Cost Savings
Spot Instances (AWS), Preemptible VMs (GCP), and Low-Priority VMs (Azure) offer discounts up to 90% compared to on-demand pricing.
Ideal for batch processing, big data analytics, and machine learning workloads.
🚀 Example: Netflix uses AWS Spot Instances to reduce rendering costs for video processing.
✅ 6. Monitor and Optimize Cloud Spending with Cost Management Tools
Track real-time usage and spending with:
AWS Cost Explorer & Trusted Advisor
Azure Cost Management + Billing
Google Cloud Billing Reports
Set up budget alerts and anomaly detection to prevent unexpected cost spikes.
✅ 7. Reduce Data Transfer and Egress Costs
Minimize inter-region and cross-cloud data transfers to avoid high bandwidth charges.
Use Content Delivery Networks (CDNs) like Cloudflare, AWS CloudFront, or Azure CDN to reduce data movement costs.
💡 Pro Tip: Keeping data in the same region where applications run reduces network charges significantly.
✅ 8. Optimize Software Licensing Costs
Use open-source alternatives instead of expensive third-party software.
Leverage Bring-Your-Own-License (BYOL) models for Microsoft SQL Server, Oracle, and SAP workloads to save costs.
✅ 9. Implement FinOps (Cloud Financial Management)
FinOps (Financial Operations) integrates finance, engineering, and IT teams to manage cloud spending effectively.
Establish spending accountability and ensure that each team optimizes its cloud usage.
✅ 10. Automate Cost Optimization with AI and Machine Learning
AI-powered cost optimization tools automatically analyze and recommend cost-saving actions.
Examples:
CloudHealth by VMware (multi-cloud cost management)
Harness Cloud Cost Management (AI-driven insights for Kubernetes and cloud spending)
💡 AI-driven automation ensures cost efficiency without manual intervention.
3. Best Practices for Sustainable Cloud Cost Management
🔹 Set up real-time budget alerts to track unexpected spending. 🔹 Regularly review and adjust reserved instance plans to avoid waste. 🔹 Continuously monitor cloud resource usage and eliminate redundant workloads. 🔹 Adopt a multi-cloud or hybrid cloud strategy to optimize pricing across different providers. 🔹 Educate teams on cloud cost optimization to promote a cost-conscious culture.
Conclusion
Effective cloud cost optimization isn’t just about cutting expenses—it’s about achieving the right balance between cost savings and performance. By implementing AI-driven automation, rightsizing resources, leveraging cost-effective storage options, and adopting FinOps practices, businesses can reduce cloud expenses without sacrificing security, compliance, or performance.
Looking for expert cloud cost optimization solutions? Salzen Cloud helps businesses maximize their cloud investment while ensuring performance and scalability.
0 notes
Text
What Is Amazon EBS? Features Of Amazon EBS And Pricing

Amazon Elastic Block Store: High-performance, user-friendly block storage at any size
What is Amazon EBS?
Amazon Elastic Block Store provides high-performance, scalable block storage with Amazon EC2 instances. AWS Elastic Block Store can create and manage several block storage resources:
Amazon EBS volumes: Amazon EC2 instances can use Amazon EBS volumes. A volume associated to an instance can be used to install software and store files like a local hard disk.
Amazon EBS snapshots: Amazon EBS snapshots are long-lasting backups of Amazon EBS volumes. You can snapshot Amazon EBS volumes to backup data. Afterwards, you can always restore new volumes from those snapshots.
Advantages of the Amazon Elastic Block Store
Quickly scale
For your most demanding, high-performance workloads, including mission-critical programs like Microsoft, SAP, and Oracle, scale quickly.
Outstanding performance
With high availability features like replication within Availability Zones (AZs) and io2 Block Express volumes’ 99.999% durability, you can guard against failures.
Optimize cost and storage
Decide which storage option best suits your workload. From economical dollar-per-GB to high performance with the best IOPS and throughput, volumes vary widely.
Safeguard
You may encrypt your block storage resources without having to create, manage, and safeguard your own key management system. Set locks on data backups and limit public access to prevent unwanted access to your data.
Easy data security
Amazon EBS Snapshots, a point-in-time copy that can be used to allow disaster recovery, move data across regions and accounts, and enhance backup compliance, can be used to protect block data storage both on-site and in the cloud. With its integration with Amazon Data Lifecycle Manager, AWS further streamlines snapshot lifecycle management by enabling you to establish policies that automate various processes, such as snapshot creation, deletion, retention, and sharing.
How it functions
A high-performance, scalable, and user-friendly block storage solution, Amazon Elastic Block Store was created for Amazon Elastic Compute Cloud (Amazon EC2).Image credit to AWS
Use cases
Create your cloud-based, I/O-intensive, mission-critical apps
Switch to the cloud for mid-range, on-premises storage area network (SAN) applications. Attach block storage that is both high-performance and high-availability for applications that are essential to the mission.
Utilize relational or NoSQL databases
Install and expand the databases of your choosing, such as Oracle, Microsoft SQL Server, PostgreSQL, MySQL, Cassandra, MongoDB, and SAP HANA.
Appropriately scale your big data analytics engines
Detach and reattach volumes effortlessly, and scale clusters for big data analytics engines like Hadoop and Spark with ease.
Features of Amazon EBS
It offers the following features:
Several volume kinds: Amazon EBS offers a variety of volume types that let you maximize storage efficiency and affordability for a wide range of uses. There are two main sorts of volume types: HDD-backed storage for workloads requiring high throughput and SSD-backed storage for transactional workloads.
Scalability: You can build Amazon EBS volumes with the performance and capacity requirements you want. You may adjust performance or dynamically expand capacity using Elastic Volumes operations as your needs change, all without any downtime.
Recovery and backup: Back up the data on your disks using Amazon EBS snapshots. Those snapshots can subsequently be used to transfer data between AWS accounts, AWS Regions, or Availability Zones or to restore volumes instantaneously.
Data protection: Encrypt your Amazon EBS volumes and snapshots using Amazon EBS encryption. To secure data-at-rest and data-in-transit between an instance and its connected volume and subsequent snapshots, encryption procedures are carried out on the servers that house Amazon EC2 instances.
Data availability and durability: io2 Block Express volumes have an annual failure rate of 0.001% and a durability of 99.999%. With a 0.1% to 0.2% yearly failure rate, other volume types offer endurance of 99.8% to 99.9%. To further guard against data loss due to a single component failure, volume data is automatically replicated across several servers in an Availability Zone.
Data archiving: EBS Snapshots Archive provides an affordable storage tier for storing full, point-in-time copies of EBS Snapshots, which you must maintain for a minimum of ninety days in order to comply with regulations. and regulatory purposes, or for upcoming project releases.
Related services
These services are compatible with Amazon EBS:
In the AWS Cloud, Amazon Elastic Compute Cloud lets you start and control virtual machines, or EC2 instances. Like hard drives, EBS volumes may store data and install software.
You can produce and maintain cryptographic keys with AWS Key Management Service, a managed service. Data saved on your Amazon EBS volumes and in your Amazon EBS snapshots can be encrypted using AWS KMS cryptographic keys.
EBS snapshots and AMIs supported by EBS are automatically created, stored, and deleted with Amazon Data Lifecycle Manager, a managed service. Backups of your Amazon EC2 instances and Amazon EBS volumes can be automated with Amazon Data Lifecycle Manager.
EBS direct APIs: These services let you take EBS snapshots, write data to them directly, read data from them, and determine how two snapshots differ or change from one another.
Recycle Bin is a data recovery solution that lets you recover EBS-backed AMIs and mistakenly erased EBS snapshots.
Accessing Amazon EBS
The following interfaces are used to build and manage your Amazon EBS resources:
Amazon EC2 console
A web interface for managing and creating snapshots and volumes.
AWS Command Line Interface
A command-line utility that enables you to use commands in your command-line shell to control Amazon EBS resources. Linux, Mac, and Windows are all compatible.
AWS Tools for PowerShell
A set of PowerShell modules for scripting Amazon EBS resource activities from the command line.
Amazon CloudFormation
It’s a fully managed AWS service that allows you describe your AWS resources using reusable JSON or YAML templates, and then it will provision and setup those resources for you.
Amazon EC2 Query API
The HTTP verbs GET or POST and a query parameter called Action are used in HTTP or HTTPS requests made through the Amazon EC2 Query API.
Amazon SDKs
APIs tailored to particular languages that let you create apps that interface with AWS services. Numerous well-known programming languages have AWS SDKs available.
Amazon EBS Pricing
You just pay for what you provision using Amazon EBS. See Amazon EBS pricing for further details.
Read more on Govindhtech.com
#AmazonEBS#ElasticBlockStore#AmazonEC2#EBSvolumes#EC2instances#EBSSnapshots#News#Technews#Technology#Technologynews#Technologytrends#Govindhtech
0 notes
Text
Mastering SQL Injection (SQLi) Protection for Symfony with Examples
Understanding and Preventing SQL Injection (SQLi) in Symfony Applications
SQL Injection (SQLi) remains one of the most common and damaging vulnerabilities affecting web applications. This guide will dive into what SQLi is, why Symfony developers should be aware of it, and practical, example-based strategies to prevent it in Symfony applications.

What is SQL Injection (SQLi)?
SQL Injection occurs when attackers can insert malicious SQL code into a query, allowing them to access, alter, or delete database data. For Symfony apps, this can happen if inputs are not properly handled. Consider the following unsafe SQL query:
php
$query = "SELECT * FROM users WHERE username = '" . $_POST['username'] . "' AND password = '" . $_POST['password'] . "'";
Here, attackers could input SQL code as the username or password, potentially gaining unauthorized access.
How to Prevent SQL Injection in Symfony
Symfony provides tools that, when used correctly, can prevent SQL Injection vulnerabilities. Here are the best practices, with examples, to secure your Symfony app.
1. Use Prepared Statements (Example Included)
Prepared statements ensure SQL queries are safely constructed by separating SQL code from user inputs. Here’s an example using Symfony's Doctrine ORM:
php
// Safe SQL query using Doctrine $repository = $this->getDoctrine()->getRepository(User::class); $user = $repository->findOneBy([ 'username' => $_POST['username'], 'password' => $_POST['password'] ]);
Doctrine’s findOneBy() automatically prepares statements, preventing SQL Injection.
2. Validate and Sanitize Input Data
Input validation restricts the type and length of data users can input. Symfony’s Validator component makes this easy:
php
use Symfony\Component\Validator\Validation; use Symfony\Component\Validator\Constraints as Assert; $validator = Validation::createValidator(); $input = $_POST['username']; $violations = $validator->validate($input, [ new Assert\Length(['max' => 20]), new Assert\Regex(['pattern' => '/^[a-zA-Z0-9_]+$/']) ]); if (count($violations) > 0) { // Handle invalid input }
In this example, only alphanumeric characters are allowed, and the input length is limited to 20 characters, reducing SQL Injection risks.
3. Use Doctrine’s Query Builder for Safe Queries
The Symfony Query Builder simplifies creating dynamic queries while automatically escaping input data. Here’s an example:
php
$qb = $this->createQueryBuilder('u'); $qb->select('u') ->from('users', 'u') ->where('u.username = :username') ->setParameter('username', $_POST['username']); $query = $qb->getQuery(); $result = $query->getResult();
By using setParameter(), Symfony binds the input parameter safely, blocking potential injection attacks.
Using Free Tools for Vulnerability Assessment
To check your application’s security, visit our Free Tools page. Here’s a snapshot of the free tools page where you can scan your website for SQL Injection vulnerabilities:

These tools help you identify security issues and provide guidance on securing your Symfony application.
Example: Vulnerability Assessment Report
Once you’ve completed a vulnerability scan, you’ll receive a detailed report outlining detected issues and recommended fixes. Here’s an example screenshot of a vulnerability assessment report generated by our free tool:

This report gives insights into potential SQL Injection vulnerabilities and steps to improve your app’s security.
Additional Resources
For more guidance on web security and SQL Injection prevention, check out our other resources:
Pentest Testing – Get expert penetration testing services.
Cyber Rely – Access comprehensive cybersecurity resources.
Conclusion
SQL Injection vulnerabilities can be effectively mitigated with the right coding practices. Symfony’s built-in tools like Doctrine, the Query Builder, and the Validator are valuable resources for safeguarding your application. Explore our free tools and vulnerability assessments to strengthen your Symfony app’s security today!
#cybersecurity#sql#sqlserver#penetration testing#pentesting#cyber security#the security breach show#data security#security
1 note
·
View note
Text
How to Create an Outstanding Data Analyst Resume: A Detailed Guide
Crafting a compelling resume is crucial for any professional, but for data analysts, it's particularly important. With the increasing demand for data-driven decision-making in organizations, data analysts are in high demand. However, this also means the competition is fierce. To stand out, you need a well-crafted data analyst resume that showcases your technical skills, experience, and ability to derive actionable insights from complex data sets.
Why Your Data Analyst Resume Matters
Before diving into the structure of an effective resume, it's essential to understand why your data analyst resume is so important. Your resume is often the first point of contact between you and a potential employer. It needs to capture attention quickly and convey your qualifications in a clear and concise manner. A well-structured data analyst resume sample can serve as an excellent guide, helping you highlight the right skills, experience, and accomplishments that align with the job you're applying for.
Key Sections to Include in Your Data Analyst Resume Sample
Contact Information Start with your full name, phone number, email address, and LinkedIn profile. If you have a professional portfolio or GitHub repository that showcases your work, include links to these as well.
Professional Summary The professional summary is a brief section that sits at the top of your resume, providing a snapshot of your experience and skills. This is your chance to make a strong first impression. For example: "Detail-oriented data analyst with 4+ years of experience in interpreting and analyzing data in various industries. Proficient in Python, SQL, and Excel with a strong background in statistical analysis and data visualization."
Technical Skills As a data analyst, your technical skills are one of the most critical aspects of your resume. Create a separate section where you list your proficiency in various tools and technologies. This might include:
Programming Languages: Python, R, SQL
Data Visualization Tools: Tableau, Power BI, Matplotlib
Statistical Software: SAS, SPSS
Database Management Systems: MySQL, PostgreSQL, MongoDB
Excel Skills: Advanced Excel, including pivot tables, VLOOKUP, and macros
Professional Experience Your work experience should be listed in reverse chronological order, starting with your most recent position. Each entry should include the job title, company name, location, and dates of employment. Use bullet points to detail your responsibilities and achievements. Quantify your accomplishments when possible, as this provides a clearer picture of your impact. For example:
"Analyzed and interpreted data sets to improve marketing strategies, resulting in a 20% increase in customer acquisition."
"Developed automated dashboards in Tableau, reducing reporting time by 50%."
Projects If you're a data analyst, the projects you've worked on are a vital part of your resume. Include a section specifically dedicated to showcasing your most significant projects. For each project, provide a brief description, the tools and technologies used, and the outcomes. This could be a great place to demonstrate your proficiency with large data sets, machine learning models, or advanced statistical methods.
Education Include your educational background, starting with the highest degree obtained. List the degree name, institution, location, and graduation year. If you've taken any courses or earned certifications relevant to data analysis, include them here as well. Certifications like Google Data Analytics or IBM Data Analyst Professional Certificate can add significant value to your resume.
Certifications Certifications are a great way to showcase your dedication to the field and your commitment to professional growth. Include any relevant certifications you’ve earned in data analysis, programming, or related areas.
Additional Skills While not always necessary, an additional skills section can be useful if you have relevant expertise that doesn't fit neatly into the other categories. This could include soft skills like communication, teamwork, or project management, which are also important for data analysts.
Tips for Creating an Effective Data Analyst Resume
Use Industry-Specific Keywords: To ensure your data analyst resume sample is optimized for applicant tracking systems (ATS), incorporate relevant keywords from the job description. Keywords might include "data visualization," "statistical analysis," or "machine learning."
Be Concise: While it's important to provide enough detail, avoid being overly verbose. Keep your resume to one or two pages, focusing on the most relevant information.
Highlight Achievements: Rather than just listing responsibilities, focus on your achievements. Use metrics and results to demonstrate your impact.
Tailor Your Resume for Each Application: Customize your resume for each job application by highlighting the skills and experience most relevant to the specific position.
Conclusion
Crafting a data analyst resume that stands out requires careful attention to detail, clear communication of your skills and experience, and a focus on measurable achievements. By following the guidelines outlined in this blog and studying a well-structured data analyst resume sample, you can create a resume that captures the attention of hiring managers and helps you secure your desired role.
At Resume Format, we understand the importance of a polished resume in today's competitive job market. Whether you're building a data analyst resume or any other professional resume, our tools and resources can help you create a compelling resume that highlights your strengths. With Resume Format, you can easily make your resume online for free and increase your chances of landing that dream job.
#resume format#resume templates#cv format#biodata format#simple resume format#resume format for job#cv template#resume model#biodata format for job#resume format for experienced#best resume format#professional resume format#cv format for job#ats friendly resume format#biodata template for job#resume download#one page resume#resume web site#biodata format for job application#creative resume#professional biodata format#cv biodata format#resume ppt#free resume templates download#free resume format template#cv format free#free curriculum vitae template#resume for teacher job#teacher resume format#teacher resume template
0 notes
Text
Embracing Snapshot Backups for Multi-Terabyte SQL Server 2022 Environments
In the bustling world of data management, where databases swell beyond the terabyte threshold, traditional backup methodologies stagger under the weight of time-consuming processes. Enter the knight in shining armor: snapshot backups. These backups are not just about speed; they’re a paradigm shift, offering a beacon of hope for quick restoration without the drag. Yet, this shift isn’t just a…
View On WordPress
#fast database restore techniques#multi-terabyte database management#SQL Server backup strategies#SQL Server snapshot backups#storage-level snapshot technology
0 notes
Text
Database snapshots are potent concepts in SQL Server that allow us to create a read-only and static copy of a database. Let's Explore Deeply:
https://madesimplemssql.com/database-snapshot-in-sql-server/
Follow us on FB: https://www.facebook.com/profile.php?id=100091338502392
&
Join our Group: https://www.facebook.com/groups/652527240081844

1 note
·
View note
Text
Explore the Best Full Stack Developer Course in Pune with SyntaxLevelUp

Introduction
In today’s rapidly evolving tech landscape, full stack developers are in high demand. These versatile professionals possess a comprehensive understanding of both front-end and back-end development, making them valuable assets to any development team. If you're in Pune and looking to become a full stack developer course in pune, SyntaxLevelUp offers a comprehensive course designed to equip you with the necessary skills and knowledge. In this blog, we’ll delve into what this course offers and explore the associated fees.
Why Choose Full Stack Development?
Full stack development covers both the client-side (front-end) and server-side (back-end) of applications. This dual expertise allows developers to create fully functional and interactive web applications. Here are some reasons why learning full stack developer training in pune is a smart career move:
High Demand: Companies seek professionals who can handle multiple facets of development.
Versatility: With knowledge of both front and back ends, you have the flexibility to work on various projects.
Better Salary: Full stack developers course in pune often command higher salaries compared to their specialized counterparts.
Comprehensive Understanding: Knowing the entire stack allows for better problem-solving and efficient project management.
SyntaxLevelUp: Your Gateway to Full Stack Mastery
Course Overview
SyntaxLevelUp's Full Stack Developer Course in Pune is meticulously designed to transform beginners into proficient full stack developers classes in pune. Here’s a snapshot of what the course includes:
Duration: 6 months (part-time)
Mode: Online and in-person classes
Curriculum: HTML, CSS, JavaScript, React, Node.js, Express.js, MongoDB, SQL, and more
Projects: Hands-on projects to build a robust portfolio
Mentorship: Guidance from industry experts
Certification: Upon completion, receive a certification to bolster your resume
Detailed Curriculum
Introduction to Web Development:
Basics of HTML, CSS, and JavaScript
Version control with Git and GitHub
Front-End Development:
Advanced JavaScript and ES6
Frameworks and Libraries: React.js, Redux
Responsive design with Bootstrap and CSS3
Back-End Development:
Server-side scripting with Node.js
Building APIs with Express.js
Database management with MongoDB and SQL
Full Stack Integration:
RESTful APIs
Authentication and Authorization
Deployment with Heroku and AWS
Capstone Projects:
E-commerce application
Social media platform
Personal portfolio website
Fees Structure
Investing in your education is a significant decision. SyntaxLevelUp offers a competitive fee structure to ensure you get the best value for your money. Here’s the breakdown:
Registration Fee: ₹5,000
Course Fee: ₹70,000 (can be paid in installments)
Installment Plan:
Initial Payment: ₹20,000
Monthly Installments: ₹10,000 over 5 months
Discounts: Early bird discounts and scholarships for meritorious students
Why SyntaxLevelUp?
Experienced Faculty: Learn from industry veterans with years of experience in full stack developer course in pune.
Hands-On Learning: Practical projects ensure you gain real-world experience.
Flexible Learning: Choose between online and in-person classes to suit your schedule.
Career Support: Job placement assistance to help you land your dream job.
Conclusion
Embarking on a journey to become a full stack developer training in pune is a rewarding decision, and SyntaxLevelUp in Pune is your perfect partner in this endeavor. With a comprehensive curriculum, expert guidance, and practical projects, you'll be well-equipped to thrive in the tech industry. Don't miss out on the opportunity to transform your career. Enroll today and take the first step towards becoming a full stack developer!
For more information, visit SyntaxLevelUp and kickstart your coding career now.
FAQs
1. What prerequisites are required for the course?
Basic understanding of programming is beneficial but not mandatory. The course starts with fundamentals.
2. Can I switch between online and in-person classes?
Yes, SyntaxLevelUp offers flexibility to switch between learning modes.
3. What kind of projects will I work on?
You will work on real-world projects like an e-commerce site, social media platform, and more to build a strong portfolio.
4. Is there job placement support after course completion?
Yes, SyntaxLevelUp provides career support including job placement assistance and resume building.
Looking for top-tier full stack developer training in Pune? SyntaxLevelUp offers the best full stack developer course in Pune, tailored for both beginners and experienced professionals. Our comprehensive curriculum covers front-end technologies like Angular and React, back-end frameworks like Spring Boot, and essential DevOps skills. With hands-on projects, expert instructors, and robust placement support, we ensure you're job-ready. Join us at SyntaxLevelUp and transform your career in full stack web development.
#fullstack training in pune#full stack developer course in pune#full stack developer course in pune with placement#full stack java developer course in pune#full stack developer classes in pune#full stack course in pune#best full stack developer course in pune#full stack classes in pune#full stack web development course in pune
0 notes
Text
ORACLE APM

Oracle APM: The Key to Unlocking Optimal Application Performance
In today’s fast-paced digital world, the performance of your applications plays a crucial role in user experience, business success, and overall brand reputation. Even minor performance hiccups can lead to user frustration, lost revenue, and damaged brand image. That’s where Oracle Application Performance Monitoring (APM) steps in as your indispensable ally.
What is Oracle APM?
Oracle APM is a powerful cloud-based suite of tools designed to provide deep visibility into the performance of your applications. It enables you to monitor everything from end-user experience to the intricate details of your backend code. Oracle APM gives you the insights to quickly detect, isolate, and resolve performance bottlenecks, ensuring your applications deliver the speed and responsiveness your users demand.
Why Oracle APM Matters
Proactive Problem Solving: Oracle APM shifts your approach from reactive troubleshooting to proactive problem prevention. It alerts you to potential issues before they escalate into major outages, minimizing disruptions and safeguarding customer satisfaction.
End-to-End Visibility: Break down silos and gain a holistic view of performance across your entire application stack. Oracle APM traces transactions from the user’s browser to databases and third-party services, revealing dependencies and potential bottlenecks.
Faster Root Cause Analysis: Isolate the root cause of performance problems with lightning speed. Oracle APM allows you to drill down into code-level details, correlate performance data with logs, and eliminate guesswork for efficient troubleshooting.
Optimizing User Experience: Quantify and improve the real user experience. Oracle APM measures page load times, response rates, and error occurrences, helping you prioritize actions that will deliver tangible improvements for your users.
Data-Driven Decisions: Base your development and operational strategies on hard data. Oracle APM’s rich analytics and reporting features provide insights into performance trends, the impact of code changes, and resource utilization.
Key Features of Oracle APM
Real User Monitoring (RUM): Understand how your applications are performing for real users across different browsers, devices, and locations.
Synthetic Monitoring: Simulate user actions, proactively test critical paths, and get alerted to issues before your users encounter them.
Distributed Tracing: Trace complex transactions through distributed systems, pinpointing where bottlenecks occur.
Code-Level Diagnostics: Get deep visibility into Java and database performance with the ability to capture thread snapshots and SQL query details.
Log Analytics: Correlate performance data with logs for faster troubleshooting.
Customizable Dashboards and Alerts: Create tailored visualizations and set threshold-based alerts to stay on top of critical metrics.
Getting Started with Oracle APM
Oracle APM offers flexible deployment options and can be integrated with a wide array of applications and technologies. Start by visiting the Oracle Cloud website to explore the service, create a free trial account, and delve into its powerful capabilities.
In Conclusion
Oracle APM is an invaluable tool for any organization serious about delivering exceptional application performance. By providing the visibility, analytics, and insights you need, it empowers you to keep your applications running smoothly and ensure a delightful user experience.
youtube
You can find more information about Oracle Apex in this Oracle Apex Link
Conclusion:
Unogeeks is the No.1 IT Training Institute for Oracle Apex Training. Anyone Disagree? Please drop in a comment
You can check out our other latest blogs on Oracle Apex here – Oarcle Apex Blogs
You can check out our Best In Class Oracle Apex Details here – Oracle Apex Training
Follow & Connect with us:
———————————-
For Training inquiries:
Call/Whatsapp: +91 73960 33555
Mail us at: [email protected]
Our Website ➜ https://unogeeks.com
Follow us:
Instagram: https://www.instagram.com/unogeeks
Facebook: https://www.facebook.com/UnogeeksSoftwareTrainingInstitute
Twitter: https://twitter.com/unogeeks
0 notes
Text
Mastering SQL Joins: Unleashing the Power of Data Relationships
In the realm of relational databases, the ability to harness the power of data relationships is crucial for effective data retrieval and analysis. SQL (Structured Query Language) plays a pivotal role in this regard, offering a variety of join operations to combine data from multiple tables. In this article, we will delve into the art of mastering SQL joins and explore how they unlock the potential of data relationships.
Understanding the Basics of SQL Joins
Before delving into the intricacies of structured query language joins, it's essential to grasp the fundamentals. A join is essentially a way to combine rows from two or more tables based on a related column between them. The most common types of joins are INNER JOIN, LEFT JOIN, RIGHT JOIN, and FULL JOIN.
INNER JOIN: Merging Data with Commonalities
The INNER JOIN is the fundamental join type, extracting only the rows with matching values in both tables. Consider two tables: 'employees' and 'departments.' An INNER JOIN on the 'department_id' column would yield rows containing information where the 'department_id' is common between the two tables.
LEFT JOIN: Embracing Unmatched Rows
When you want to retrieve all rows from the left table and the matching rows from the right table, even if there are no matches, the LEFT JOIN comes into play. This join is particularly useful when dealing with scenarios where some data might be missing in one of the tables.
RIGHT JOIN: The Mirror Image of LEFT JOIN
Conversely, the RIGHT JOIN retrieves all rows from the right table and the matching rows from the left table. While it achieves a similar result to the LEFT JOIN, the distinction lies in which table data is prioritized.
FULL JOIN: A Comprehensive Data Snapshot
The FULL JOIN combines the results of both LEFT JOIN and RIGHT JOIN, providing a comprehensive snapshot of the data from both tables. This join type is beneficial when you want to capture all the information from both tables, matched and unmatched.
Cross Join: Cartesian Product Unleashed
A Cross Join, also known as a Cartesian Join, returns the Cartesian product of the two tables involved. It pairs each row from the first table with every row from the second table, resulting in a potentially vast dataset. While less commonly used than other joins, it has its applications, such as generating combinations.
Self-Join: Connecting Rows within the Same Table
In some scenarios, you may need to join a table with itself to establish relationships between rows within the same table. This is known as a self-join, and it involves creating aliases for the table to differentiate between the two instances. Self-joins are particularly useful when dealing with hierarchical data or organizational structures.
Utilizing Joins in Real-world Scenarios
To truly master SQL joins, it's crucial to apply them in real-world scenarios. Consider a business scenario where you need to analyze sales data stored in one table and customer information in another. A well-crafted INNER JOIN on the common 'customer_id' column can seamlessly merge the two datasets, enabling you to derive insights such as which customers generate the most revenue.
Optimizing Joins for Performance
While SQL joins are powerful, inefficient usage can lead to performance bottlenecks, especially with large datasets. To optimize performance, consider indexing the columns used in join conditions. Indexing allows the database engine to quickly locate and retrieve the relevant rows, significantly enhancing query speed. Additionally, carefully choose the appropriate join type based on the specific requirements of your query to avoid unnecessary computations
In conclusion, mastering SQL joins is a crucial skill for any data professional or developer working with relational databases. The ability to navigate and utilize different join types empowers individuals to extract meaningful insights from complex datasets, enabling informed decision-making. Whether you're merging employee and department data or analyzing sales and customer information, SQL joins are the key to unlocking the full potential of data relationships. As you delve deeper into the world of SQL, continue honing your join skills, and watch as the intricate web of data relationships unfolds before you
#onlinetraining#career#elearning#learning#programming#technology#automation#online courses#security#startups
0 notes
Text
The World of DATA

Data is an essential element to an organization as it represents important information for the organization and the business. Database stores all data in a structured form of relational tables. Therefore Database Management System (DBMS) helps to manage present data in the database as a set of applications. It aids to organize data for better performance and faster retrieval by maintaining catalogs. However as databases are lined with some applications, by hampering the applications it is possible to attack a database in more than one way. The matter of attacking a database becomes serious when users of databases are leaking the information to unknown sources around the world.
Types of Attacks on Database Inference: To get sensitive information Count can be used with the Sum function. Another method is Tracker attack. It locates specific data and using additional queries that produce small results can be recorded. Basically the attacker adds additional records to be retried for different queries. Then the two sets of records begin to cancel out each other and only the wanted data is left. A general form of tracker attack requires some algebra and logic to find the data distributions in a data base, thus the attacker would use it to find chosen components. Passive Attacks on Databases: Static leakage: This type of attack uses a snapshot of the database. Information can be gained from a database by closely observing a snapshot of it. Linkage leakage: This type of attack uses plain text values. Plain text values information can be gained by linking table values to the position of those values in index.
Dynamic leakage: This type of attack requires changes to be made in a database. Any changes made in a database over a period of sometime can be monitored and information about the plain text values can be gained.
Active Attacks on Databases: Spoofing: This type of attack makes code text value is replaced by a generated value Splicing: Code text value is replaced by different code text value Replay: Code text value is replaced with an old version that was previously updated or deleted
SQLIA (SQL Injection Attack) Bypassing web authentication: Attackers use the input field, this is used in the query’s that will be conditioned.
Database Fingerprinting: Attackers make logically wrong and or illegal queries. This causes the DBMS to produces error messages. The error message will contain the names of database objects used. Thus, from the error message, the attackers can guess the database used by application as different databases have different styles of reporting an error. Injection with the union query: Attackers get data from a table that is completely different from the one that was planned by the developer. Damaging with additional injected query: An attacker would enter input such as additional query along with the original query that is generated. Remote execution of stored procedures: Attackers execute stored procedures which may have harmful effect after an execution.
Ordinary Attacks: Legitimate users can take the advantage of the access rights given and can expose the hidden and sensitive data to an attacker or to anyone outside the organization.

Countermeasures Against Database Attacks Access Control Mechanisms This is a technique to maintain data. When an attacker tries to access any data, Access Control Mechanism will check the rights of that person against set authorizations. They are specified by security administrators or security officers. Besides Access Control Mechanism, a strong authentication is also required to authenticate the valid user of a database system and then access control will help defining different permissions on different data of database. Techniques to fight with SQLIA SQLIA is a dangerous attack thus methods to prevent vary. Positive tainting and Syntax aware evaluation: The valid input strings are initially provided to system for detection of SQLIA. It classifies input strings and spreads non trusted strings away. Syntax aware evaluation is done on the broadcast strings in order to decide the strings that are not trusted. Syntax assessment is performed at the database meeting point.
Data Encryption File System Encryption: The physical disk where database exist in is encrypted. Entire database is encrypted using single encryption key. DBMS Level Encryption: In this scheme static leakage attacks and splicing attacks are prevented.
Data Scrambling Data scrambling is used when users have proper access to data in the database but still it is required to secure sensitive information from them.
Auditing This technique is used to prevent Inference attack on databases. Examinations of such queries can help in finding inference attack and can be avoided in later stage.
All in all databases are the primary form of storage for organizations. This is why the attacks on databases are increasing, because they reveal important data to the attacker.
#technology news#technology trend#database#data#industry data#datascience#dataanalytics#the next generation#A.I
1 note
·
View note
Text
PostgreSQL 的 SERIALIZABLE 的 bug
PostgreSQL 的 SERIALIZABLE 的 bug
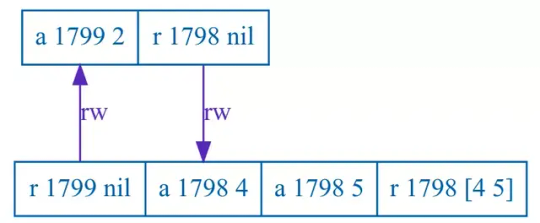
這是 Jespen 第一次測試 PostgreSQL,就順利找出可重製的 bug 了:「PostgreSQL 12.3」。
第一個 bug 是 REPEATABLE READ 下的問題,不過因為 SQL-92 定義不夠嚴謹的關係,其實算不算是 bug 有討論的空間,這點作者 Kyle Kingsbury 在文章裡也有提出來:
Whether PostgreSQL’s repeatable-read behavior is correct therefore depends on one’s interpretation of the standard. It is surprising that a database based on snapshot isolation would reject the strict interpretation chosen by the…
View On WordPress
#bug#database#db#isolation#jespen#level#pgsql#postgresql#rdbms#read#repeatable#serializable#snapshot#sql#transaction
0 notes