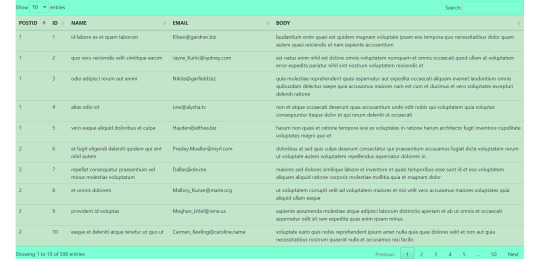
#get data from api and show in table
Explore tagged Tumblr posts
Visit Tumblr Blog
Explore Tumblr blogs with no restrictions, modern design and the best experience.
Last Seen Tumblr Blogs





Fun Fact
Users from the US are the majority of Tumblr visitors.
Text
Fetch data from api and show in table with jquery dataTable plugin.
#react#react js#jquery dataTable plugin#fetch data from api#fetch data from api and show in table#get data from api and show in table#javascript#frontend#webtutorialstack
0 notes
Text
holy grail of last.fm and spotify music data sites. i'd still say check the actual link but i've copy pasted most of the info n the links below
Spotify
Sites, apps and programs that use your Spotify account, Spotify API or both.
Spotify sites:
Obscurify: Tells you how unique you music taste is in compare to other Obscurify users. Also shows some recommendations. Mobile friendly.
Skiley: Web app to better manage your playlists and discover new music. This has so many functions and really the only thing I miss is search field for when you are managing playlists. You can take any playlist you "own" and order it by many different rules (track name, album name, artist name, BPM, etc.), or just randomly shuffle it (say bye to bad Spotify shuffle). You can also normalize it. For the other functions you don't even need the rights to edit the playlist. Those consists of splitting playlist, filtering out song by genre or year to new playlist, creating similar playlists or exporting it to CFG, CSV, JSON, TXT or XML.
You can also use it to discover music based on your taste and it has a stats section - data different from Last.fm.
Also, dark mode and mobile friendly.
Sort your music: Lets you sort your playlist by all kinds of different parameters such as BPM, artist, length and more. Similar to Skiley, but it works as an interactive table with songs from selected playlist.
Run BPM: Filters playlists based on parameters like BPM, Energy, etc. Great visualized with colorful sliders. Only downside - shows not even half of my playlists. Mobile friendly.
Fylter.in: Sort playlist by BMP, loudness, length, etc and export to Spotify
Spotify Charts: Daily worldwide charts from Spotify. Mobile friendly
Kaleidosync: Spotify visualizer. I would personally add epilepsy warning.
Duet: Darthmouth College project. Let's you compare your streaming data to other people. Only downside is, those people need to be using the site too, so you have to get your friends to log in. Mobile friendly.
Discover Quickly: Select any playlist and you will be welcomed with all the songs in a gridview. Hover over song to hear the best part. Click on song to dig deeper or save the song.
Dubolt: Helps you discover new music. Select an artist/song to view similar ones. Adjust result by using filters such as tempo, popularity, energy and others.
SongSliders: Sort your playlists, create new one, find new music. Also can save Discover weekly every monday.
Stats for Spotify: Shows you Top tracks and Top artists, lets you compare them to last visit. Data different from Last.fm. Mobile friendly
Record Player: This site is crazy. It's a Rube Goldberg Machine. You take a picture (any picture) Google Cloud Vision API will guess what it is. The site than takes Google's guess and use it to search Spotify giving you the first result to play. Mobile friendly.
Author of this site has to pay for the Google Cloud if the site gets more than 1000 requests a month! I assume this post is gonna blow up and the limit will be easily reached. Author suggests to remix the app and set it up with your own Google Cloud to avoid this. If your are able to do so, do it please. Or reach out to the author on Twitter and donate a little if you can.
Spotify Playlist Randomizer: Site to randomize order of the songs in playlist. There are 3 shuffling methods you can choose from. Mobile friendly.
Replayify: Another site showing you your Spotify data. Also lets you create a playlist based on preset rules that cannot be changed (Top 5 songs by Top 20 artists from selected time period/Top 50 songs from selected time period). UI is nice and clean. Mobile friendly, data different from Last.fm.
Visualify: Simpler replayify without the option to create playlists. Your result can be shared with others. Mobile friendly, data different from Last.fm.
The Church Of Koen: Collage generator tool to create collages sorted by color and turn any picture to collage. Works with Last.fm as well.
Playedmost: Site showing your Spotify data in nice grid view. Contains Top Artists, New Artists, Top Tracks and New Tracks. Data different from Last.fm, mobile friendly.
musictaste.space: Shows you some stats about your music habits and let's you compare them to others. You can also create Covid-19 playlist :)
Playlist Manager: Select two (or more) playlists to see in a table view which songs are shared between them and which are only in one of them. You can add songs to playlists too.
Boil the Frog: Choose to artists and this site will create playlists that slowly transitions between one artist's style to the other.
SpotifyTV: Great tool for searching up music videos of songs in your library and playlists.
Spotify Dedup and Spotify Organizer: Both do the same - remove duplicates. Spotify Dedup is mobile friendly.
Smarter Playlists: It lets you build a complex program by assembling components to create new playlists. This seems like a very complex and powerful tool.
JBQX: Do you remember plug.dj? Well this is same thing, only using Spotify instead of YouTube as a source for music. You can join room and listen to music with other people, you all decide what will be playing, everyone can add a song to queue.
Spotify Buddy: Let's you listen together with other people. All can control what's playing, all can listen on their own devices or only one device can be playing. You don't need to have Spotify to control the queue! In my opinion it's great for parties as a wireless aux cord. Mobile friendly.
Opslagify: Shows how much space would one need to download all of their Spotify playlists as .mp3s.
Whisperify: Spotify game! Music quiz based on what you are listening to. Do you know your music? Mobile friendly.
Popularity Contest: Another game. Two artists, which one is more popular according to Spotify data? Mobile friendly, doesn't require Spotify login.
Spotify Apps:
uTrack: Android app which generates playlist from your top tracks. Also shows top artists, tracks and genres - data different from Last.fm.
Statistics for Spotify: uTrack for iOS. I don't own iOS device so I couldn't test it. iOS users, share your opinions in comments please :).
Spotify Programs:
Spicetify: Spicetify used to be a skin for Rainmeter. You can still use it as such, but the development is discontinued. You will need to have Rainmeter installed if you want to try. These days it works as a series of PowerShell commands. New and updated version here. Spicetify lets you redesign Spotify desktop client and add new functions to it like Trash Bin, Shuffle+, Christian Mode etc. It doesn't work with MS Store app, .exe Spotify client is required.
Library Bridger: The main purpose of this program is to create Spotify playlists from your locally saved songs. But it has some extra functions, check the link.
Last.fm
Sites, apps and programs using Last.fm account, Last.fm API or both.
Last.fm sites:
Last.fm Mainstream Calculator: How mainstream is music you listen to? Mobile friendly.
My Music Habits: Shows different graphs about how many artists, tracks and albums from selected time period comes from your overall top artists/tracks/albums.
Explr.fm: Where are the artists you listen to from? This site shows you just that on interactive world map.
Descent: The best description I can think of is music dashboard. Shows album art of currently playing song along with time and weather.
Semi-automatic Last.fm scrobbler: One of the many scrobblers out there. You can scrobble along with any other Last.fm user.
The Universal Scrobbler: One of the best manual scrobblers. Mobile friendly.
Open Scrobbler: Another manual scrobbler. Mobile friendly
Vinyl Scrobbler: If you listen to vinyl and use Last.fm, this is what you need.
Last.fm collage generator, Last.fm top albums patchwork generator and yet another different Last.fm collage generator: Sites to make collages based on your Last.fm data. The last one is mobile friendly.
The Church Of Koen: Collage generator tool to create collages sorted by color and turn any picture to collage. Works with Spotify as well.
Musicorum: So far the best tool for generating collages based on Last.fm data that I ever seen. Grid up to 20x20 tiles and other styles, some of which resemble very well official Spotify collages that Spotify generates at the end of the year. Everything customizable and even supports Instagram story format. Mobile friendly.
Nicholast.fm: Simple site for stats and recommendations. Mobile friendly.
Scatter.fm: Creates graph from your scrobbles that includes every single scrobble.
Lastwave: Creates a wave graph from your scrobbles. Mobile friendly.
Artist Cloud: Creates artist cloud image from you scrobbles. Mobile friendly.
Last.fm Tools: Lets you generate Tag Timeline, Tag Cloud, Artist Timeline and Album Charter. Mobile friendly.
Last Chart: This site shows different types of beautiful graphs visualizing your Last.fm data. Graph types are bubble, force, map, pack, sun, list, cloud and stream. Mobile friendly.
Sergei.app: Very nice looking graphs. Mobile friendly.
Last.fm Time Charts: Generates charts from your Last.fm data. Sadly it seems that it only supports artists, not albums or tracks.
ZERO Charts: Generates Billboard like charts from Last.fm data. Requires login, mobile friendly.
Skihaha Stats: Another great site for viewing different Last.fm stats.
Jakeledoux: What are your Last.fm friends listening to right now? Mobile friendly.
Last History: View your cumulative listening history. Mobile friendly.
Paste my taste: Generates short text describing your music taste.
Last.fm to CSV: Exports your scrobbles to CSV format. Mobile friendly.
Pr.fm: Syncs your scrobbles to your Strava activity descriptions as a list based on what you listened to during a run or biking session, etc. (description by u/mturi, I don't use Strava, so I have no idea how does it work :))
Last.fm apps:
Scroball for Last.fm: An Android app I use for scrobbling, when I listen to something else than Spotify.
Web Scrobbler: Google Chrome and Firefox extension scrobbler.
Last.fm programs:
Last.fm Scrubbler WPF: My all time favourite manual scrobbler for Last.fm. You can scrobbler manually, from another user, from database (I use this rather than Vinyl Scrobbler when I listen to vinyls) any other sources. It can also generate collages, generate short text describing your music taste and other extra functions.
Last.fm Bulk Edit: Userscript, Last.fm Pro is required. Allows you to bulk edit your scrobbles. Fix wrong album/track names or any other scrobble parameter easily.
8 notes
·
View notes
Text
The New Alchemy of Business Partnerships

Gone are the days when business partnerships resembled simple transactions — one company providing a service to another in exchange for payment. As we move through 2025, the most successful collaborations feel less like contracts and more like creative marriages, where the combination of two organizations produces something neither could achieve alone.
Eric Hannelius, CEO of Pepper Pay, describes this evolution: “The partnerships that truly move the needle today are those where both parties bring complementary strengths to the table, then work together to create unexpected value. It’s not about what you can get from each other, but what you can build together.”
Shared Vision, Separate Strengths.
The most dynamic partnerships balance alignment with autonomy. While both organizations need enough common ground to move in the same direction, they maintain their unique identities and capabilities. Consider how some of today’s most innovative tech companies partner with traditional manufacturers — the former contributes cutting-edge ideas, the latter provides production expertise, and together they create products that disrupt entire markets.
Eric Hannelius notes an interesting pattern: “The magic happens when partners share an end goal but take different paths to get there. We recently collaborated with a sustainability startup where we handled payment infrastructure while they focused on carbon tracking. The integration created something entirely new that benefited both our customer bases in ways we hadn’t anticipated.”
Technology as the Invisible Bridge.
In 2025, partnerships live or die by their digital integration. The most successful collaborations build technological bridges between systems — not superficial connections, but deep integrations allowing data and insights to flow both ways seamlessly. A retailer partnering with a logistics provider might share real-time inventory data that helps optimize delivery routes while improving stock management for both parties.
“The strongest partnerships today are API-first by design,” observes Eric Hannelius. “They’re built on systems that communicate effortlessly, almost as if they’re part of the same organization. When done well, the technology fades into the background, letting the partnership’s value shine through.”
The Trust Paradox.
Modern partnerships require a new kind of trust — one that embraces transparency while protecting competitive advantages. This delicate balance comes from clear agreements about what can be shared and what must remain proprietary. Progressive companies are finding innovative ways to collaborate openly while safeguarding their core interests.
Static partnership agreements struggle in today’s rapidly changing environment. The collaborations that thrive build flexibility into their DNA, with regular checkpoints to reassess and recalibrate. Some forward-thinking companies now include “evolution clauses” in their agreements — structured opportunities to reinvent the partnership as markets shift.
“The most durable partnerships aren’t rigid structures,” says Eric Hannelius. “They function more like jazz ensembles — there’s a framework, but plenty of room for improvisation as circumstances change. We’ve found quarterly ‘reset’ meetings invaluable for keeping collaborations fresh and responsive.”
Measuring Beyond the Obvious.
Traditional partnership metrics often focus narrowly on immediate financial gains, but the most impactful 2025 collaborations track different indicators. How much knowledge transfers between organizations? What unexpected innovations emerge? How does the partnership affect employee engagement on both sides?
Eric Hannelius points to an enlightening example: “One of our most valuable partnerships showed modest financial results initially, but the cross-pollination of ideas transformed both our product roadmaps. Now we track ‘innovation spillover’ as carefully as we track revenue sharing.”
The Human Connection in Digital Alliances.
Even in our tech-driven world, partnerships ultimately depend on personal connections. The collaborations that last create opportunities for people to connect across organizations — not just at the executive level, but among the teams doing the actual work. Shared training programs, cross-company brainstorming sessions, and even informal social exchanges can cement relationships far beyond what contracts alone achieve.
“Technology enables modern partnerships, but people power them,” reflects Eric Hannelius. “We’ve seen projects stall until the right individuals from each organization connected personally. That human spark often makes all the difference between a good partnership and a great one.”
As we progress through 2025, the most successful businesses will be those that master partnership alchemy — combining vision, technology, and human connection to create collaborative gold. These alliances won’t just support existing business models; they’ll invent new ones.
Eric Hannelius leaves us with this perspective: “The partnerships that will define the coming years won’t just share value — they’ll create new value that didn’t exist before. In an increasingly complex world, the ability to collaborate deeply may become the ultimate competitive advantage.”
For businesses ready to move beyond transactional relationships, the opportunity is clear: build partnerships that are living, evolving creations rather than static agreements. When two organizations truly combine their strengths with trust and flexibility, the results can exceed even their most ambitious expectations.
0 notes
Text
Easiest Way to Insert Records in Salesforce Using Salesforce Inspector

Salesforce is a powerful platform that empowers businesses to manage their customer data, automate workflows, and drive productivity across departments. But whether you're a seasoned Salesforce user or just getting started, data management—especially inserting records—can sometimes be a tedious process. The native Data Import Wizard or Data Loader tools, while powerful, can be cumbersome for quick, small-scale inserts.
Enter Salesforce Inspector, a lightweight Chrome extension that offers a streamlined and efficient way to view, export, and insert records directly into Salesforce with just a few clicks. For businesses in fast-paced markets like Chicago, speed and accuracy are everything. This blog explores the easiest way to insert records using Salesforce Inspector and why working with a trusted Salesforce consultant in Chicago can help you maximize this tool’s potential.
What is Salesforce Inspector?
Salesforce Inspector is a free Chrome browser extension that enhances the Salesforce user interface by allowing power users and admins to access metadata, query data via SOQL, and perform quick data manipulation tasks. One of its standout features is the ability to insert records directly into Salesforce using a user-friendly spreadsheet interface.
Whether you're updating contact lists, loading test data, or adding multiple leads on the fly, Salesforce Inspector can save you time and reduce errors compared to traditional methods.
Benefits of Using Salesforce Inspector
Before diving into the "how," let’s look at why Salesforce Inspector is a game-changer:
No Installation Required Beyond Browser Extension No need to install external software like Data Loader. It works directly in your Chrome browser.
Lightning-Fast Data Entry Insert, update, delete, and export data in real-time without leaving the Salesforce interface.
Excel-Like Experience You can copy-paste from Excel or Google Sheets directly into Salesforce Inspector.
Supports Standard and Custom Objects Whether it's Accounts or a custom object like "Project Milestone," Salesforce Inspector can handle it.
Ideal for Developers, Admins, and Consultants It’s widely used by professionals across roles, including the experienced Salesforce developers in Chicago who often use it to test and validate changes during sandbox deployments.
Step-by-Step: How to Insert Records Using Salesforce Inspector
Let’s walk through how to easily insert records in Salesforce using Salesforce Inspector.
Step 1: Install the Extension
Head over to the Chrome Web Store and search for Salesforce Inspector. Install it and pin the icon next to your browser’s address bar for easy access.
Step 2: Log in to Salesforce
Open your Salesforce org (production or sandbox). Ensure that you’re logged into the correct environment where you want to insert data.
Step 3: Launch Salesforce Inspector
Click the Salesforce Inspector icon in the browser. A small menu will appear on the right side of your screen.
Choose “Data Import” from the menu.
Step 4: Choose Object Type
You’ll now be prompted to select the object you want to insert records into, such as:
Lead
Contact
Account
Custom Object (e.g., Property__c)
Once selected, a blank data entry table appears.
Step 5: Add or Paste Records
You can now:
Manually enter the records by typing in the fields.
Paste multiple rows directly from Excel or Google Sheets.
Make sure your column headers match the Salesforce API field names (e.g., FirstName, LastName, Email).
Step 6: Click "Insert"
Once your records are ready, click the “Insert” button.
Salesforce Inspector will validate your data and show real-time success or error messages for each row. It also returns the new record IDs for reference.
Common Use Cases for Salesforce Inspector in Chicago-Based Businesses
✅ Marketing Campaigns
Need to load a list of new leads gathered at a conference in downtown Chicago? Instead of going through the clunky import wizard, Salesforce Inspector allows marketers to quickly insert new leads in bulk.
✅ Testing and QA
Salesforce developers in Chicago often use Salesforce Inspector to quickly insert test data into a sandbox environment during development sprints.
✅ Small Batch Data Fixes
Let’s say you need to update 10 records across different objects. With Inspector, you can make these adjustments without exporting/importing massive CSV files.
✅ Custom Object Management
Chicago businesses using industry-specific custom Salesforce objects (real estate, finance, healthcare, etc.) benefit from Inspector's flexible schema handling. Working with a Salesforce consulting partner in Chicago can help tailor these processes to specific verticals.
Pro Tips for Using Salesforce Inspector Effectively
Use SOQL Explorer First Before inserting records, use the built-in SOQL query feature to review existing data and avoid duplicates.
Save Your Insert Templates Keep Excel templates for frequently inserted objects. This makes the process even faster the next time.
Validate Fields Ensure required fields and validation rules are considered before inserting, or you’ll encounter errors.
Work in Sandbox First Always test in a sandbox if you’re inserting many records. This helps catch schema mismatches or trigger issues.
Why Work with Salesforce Consultants in Chicago?
Although Salesforce Inspector is straightforward, it’s important to use it responsibly—especially when working with large volumes of data or complex object relationships. A Salesforce consultant in Chicago can help you implement data governance best practices and avoid costly mistakes.
They also help with:
Field Mapping: Understanding the correct API names for fields and objects
Data Model Design: Ensuring your org’s schema supports your business needs
Automation Testing: Making sure flows and triggers behave correctly after inserts
Training Staff: Teaching your internal team how to use Salesforce Inspector effectively
Whether you're inserting a few records or revamping your entire data strategy, Salesforce consulting in Chicago brings expert guidance and local market insights.
Real-World Example: Retail Business in Chicago
A retail chain based in Chicago needed to regularly import loyalty program participants from in-store sign-up sheets. Initially using Data Loader, the process was time-consuming and required IT intervention.
With the support of a Salesforce consulting partner in Chicago, they switched to using Salesforce Inspector for small weekly imports. The result?
85% time reduction in data loading tasks
Zero IT dependency for day-to-day inserts
Increased data quality due to real-time validation
The Role of Salesforce Developers in Chicago
For companies with complex data needs, a Salesforce developer in Chicago plays a crucial role in extending Inspector’s utility. Developers can:
Write Apex triggers to handle post-insert logic
Customize validations or automate follow-up actions
Build automated tools that complement Inspector for larger-scale processes
In short, developers bring structure, logic, and safety nets to the data management process.
Final Thoughts
Salesforce Inspector is one of the simplest and most efficient ways to insert records into Salesforce. Whether you're working with standard or custom objects, it dramatically reduces the time required for data entry, testing, and validation.
For businesses in Chicago—from retail to real estate to healthcare—leveraging Salesforce Inspector with expert support from local Salesforce consultants in Chicago ensures that you get speed without sacrificing accuracy or governance.
Whether you’re just exploring Salesforce or managing an enterprise-level deployment, don’t underestimate the power of smart tools combined with expert support. The easiest way to manage Salesforce data is not just using the right tools—but using them the right way.
If you're looking to optimize your Salesforce workflows, consider partnering with a certified Salesforce consulting partner in Chicago or engaging a Salesforce developer in Chicago to elevate your data strategy to the next level.
#salesforce consultant in chicago#salesforce consulting in chicago#salesforce consulting partner in chicago#salesforce consultants in chicago#salesforce developer in chicago#Easiest Way to Insert Records in Salesforce Using Salesforce Inspector
0 notes
Text
Aaron Kesler, Director of AI Product Management at SnapLogic – Interview Series
New Post has been published on https://thedigitalinsider.com/aaron-kesler-director-of-ai-product-management-at-snaplogic-interview-series/
Aaron Kesler, Director of AI Product Management at SnapLogic – Interview Series

Aaron Kesler, Director of AI Product Management at SnapLogic, is a certified product leader with over a decade of experience building scalable frameworks that blend design thinking, jobs to be done, and product discovery. He focuses on developing new AI-driven products and processes while mentoring aspiring PMs through his blog and coaching on strategy, execution, and customer-centric development.
SnapLogic is an AI-powered integration platform that helps enterprises connect applications, data, and APIs quickly and efficiently. With its low-code interface and intelligent automation, SnapLogic enables faster digital transformation across data engineering, IT, and business teams.
You’ve had quite the entrepreneurial journey, starting STAK in college and going on to be acquired by Carvertise. How did those early experiences shape your product mindset?
This was a really interesting time in my life. My roommate and I started STAK because we were bored with our coursework and wanted real-world experience. We never imagined it would lead to us getting acquired by what became Delaware’s poster startup. That experience really shaped my product mindset because I naturally gravitated toward talking to businesses, asking them about their problems, and building solutions. I didn’t even know what a product manager was back then—I was just doing the job.
At Carvertise, I started doing the same thing: working with their customers to understand pain points and develop solutions—again, well before I had the PM title. As an engineer, your job is to solve problems with technology. As a product manager, your job shifts to finding the right problems—the ones that are worth solving because they also drive business value. As an entrepreneur, especially without funding, your mindset becomes: how do I solve someone’s problem in a way that helps me put food on the table? That early scrappiness and hustle taught me to always look through different lenses. Whether you’re at a self-funded startup, a VC-backed company, or a healthcare giant, Maslow’s “basic need” mentality will always be the foundation.
You talk about your passion for coaching aspiring product managers. What advice do you wish you had when you were breaking into product?
The best advice I ever got—and the advice I give to aspiring PMs—is: “If you always argue from the customer’s perspective, you’ll never lose an argument.” That line is deceptively simple but incredibly powerful. It means you need to truly understand your customer—their needs, pain points, behavior, and context—so you’re not just showing up to meetings with opinions, but with insights. Without that, everything becomes HIPPO (highest paid person’s opinion), a battle of who has more power or louder opinions. With it, you become the person people turn to for clarity.
You’ve previously stated that every employee will soon work alongside a dozen AI agents. What does this AI-augmented future look like in a day-to-day workflow?
What may be interesting is that we are already in a reality where people are working with multiple AI agents – we’ve helped our customers like DCU plan, build, test, safeguard, and put dozens of agents to help their workforce. What’s fascinating is companies are building out organization charts of AI coworkers for each employee, based on their needs. For example, employees will have their own AI agents dedicated to certain use cases—such as an agent for drafting epics/user stories, one that assists with coding or prototyping or issues pull requests, and another that analyzes customer feedback – all sanctioned and orchestrated by IT because there’s a lot on the backend determining who has access to which data, which agents need to adhere to governance guidelines, etc. I don’t believe agents will replace humans, yet. There will be a human in the loop for the foreseeable future but they will remove the repetitive, low-value tasks so people can focus on higher-level thinking. In five years, I expect most teams will rely on agents the same way we rely on Slack or Google Docs today.
How do you recommend companies bridge the AI literacy gap between technical and non-technical teams?
Start small, have a clear plan of how this fits in with your data and application integration strategy, keep it hands-on to catch any surprises, and be open to iterating from the original goals and approach. Find problems by getting curious about the mundane tasks in your business. The highest-value problems to solve are often the boring ones that the unsung heroes are solving every day. We learned a lot of these best practices firsthand as we built agents to assist our SnapLogic finance department. The most important approach is to make sure you have secure guardrails on what types of data and applications certain employees or departments have access to.
Then companies should treat it like a college course: explain key terms simply, give people a chance to try tools themselves in controlled environments, and then follow up with deeper dives. We also make it known that it is okay not to know everything. AI is evolving fast, and no one’s an expert in every area. The key is helping teams understand what’s possible and giving them the confidence to ask the right questions.
What are some effective strategies you’ve seen for AI upskilling that go beyond generic training modules?
The best approach I’ve seen is letting people get their hands on it. Training is a great start—you need to show them how AI actually helps with the work they’re already doing. From there, treat this as a sanctioned approach to shadow IT, or shadow agents, as employees are creative to find solutions that may solve super particular problems only they have. We gave our field team and non-technical teams access to AgentCreator, SnapLogic’s agentic AI technology that eliminates the complexity of enterprise AI adoption, and empowered them to try building something and to report back with questions. This exercise led to real learning experiences because it was tied to their day-to-day work.
Do you see a risk in companies adopting AI tools without proper upskilling—what are some of the most common pitfalls?
The biggest risks I’ve seen are substantial governance and/or data security violations, which can lead to costly regulatory fines and the potential of putting customers’ data at risk. However, some of the most frequent risks I see are companies adopting AI tools without fully understanding what they are and are not capable of. AI isn’t magic. If your data is a mess or your teams don’t know how to use the tools, you’re not going to see value. Another issue is when organizations push adoption from the top down and don’t take into consideration the people actually executing the work. You can’t just roll something out and expect it to stick. You need champions to educate and guide folks, teams need a strong data strategy, time, and context to put up guardrails, and space to learn.
At SnapLogic, you’re working on new product development. How does AI factor into your product strategy today?
AI and customer feedback are at the heart of our product innovation strategy. It’s not just about adding AI features, it’s about rethinking how we can continually deliver more efficient and easy-to-use solutions for our customers that simplify how they interact with integrations and automation. We’re building products with both power users and non-technical users in mind—and AI helps bridge that gap.
How does SnapLogic’s AgentCreator tool help businesses build their own AI agents? Can you share a use case where this had a big impact?
AgentCreator is designed to help teams build real, enterprise-grade AI agents without writing a single line of code. It eliminates the need for experienced Python developers to build LLM-based applications from scratch and empowers teams across finance, HR, marketing, and IT to create AI-powered agents in just hours using natural language prompts. These agents are tightly integrated with enterprise data, so they can do more than just respond. Integrated agents automate complex workflows, reason through decisions, and act in real time, all within the business context.
AgentCreator has been a game-changer for our customers like Independent Bank, which used AgentCreator to launch voice and chat assistants to reduce the IT help desk ticket backlog and free up IT resources to focus on new GenAI initiatives. In addition, benefits administration provider Aptia used AgentCreator to automate one of its most manual and resource-intensive processes: benefits elections. What used to take hours of backend data entry now takes minutes, thanks to AI agents that streamline data translation and validation across systems.
SnapGPT allows integration via natural language. How has this democratized access for non-technical users?
SnapGPT, our integration copilot, is a great example of how GenAI is breaking down barriers in enterprise software. With it, users ranging from non-technical to technical can describe the outcome they want using simple natural language prompts—like asking to connect two systems or triggering a workflow—and the integration is built for them. SnapGPT goes beyond building integration pipelines—users can describe pipelines, create documentation, generate SQL queries and expressions, and transform data from one format to another with a simple prompt. It turns out, what was once a developer-heavy process into something accessible to employees across the business. It’s not just about saving time—it’s about shifting who gets to build. When more people across the business can contribute, you unlock faster iteration and more innovation.
What makes SnapLogic’s AI tools—like AutoSuggest and SnapGPT—different from other integration platforms on the market?
SnapLogic is the first generative integration platform that continuously unlocks the value of data across the modern enterprise at unprecedented speed and scale. With the ability to build cutting-edge GenAI applications in just hours — without writing code — along with SnapGPT, the first and most advanced GenAI-powered integration copilot, organizations can vastly accelerate business value. Other competitors’ GenAI capabilities are lacking or nonexistent. Unlike much of the competition, SnapLogic was born in the cloud and is purpose-built to manage the complexities of cloud, on-premises, and hybrid environments.
SnapLogic offers iterative development features, including automated validation and schema-on-read, which empower teams to finish projects faster. These features enable more integrators of varying skill levels to get up and running quickly, unlike competitors that mostly require highly skilled developers, which can slow down implementation significantly. SnapLogic is a highly performant platform that processes over four trillion documents monthly and can efficiently move data to data lakes and warehouses, while some competitors lack support for real-time integration and cannot support hybrid environments.
What excites you most about the future of product management in an AI-driven world?
What excites me most about the future of product management is the rise of one of the latest buzzwords to grace the AI space “vibe coding”—the ability to build working prototypes using natural language. I envision a world where everyone in the product trio—design, product management, and engineering—is hands-on with tools that translate ideas into real, functional solutions in real time. Instead of relying solely on engineers and designers to bring ideas to life, everyone will be able to create and iterate quickly.
Imagine being on a customer call and, in the moment, prototyping a live solution using their actual data. Instead of just listening to their proposed solutions, we could co-create with them and uncover better ways to solve their problems. This shift will make the product development process dramatically more collaborative, creative, and aligned. And that excites me because my favorite part of the job is building alongside others to solve meaningful problems.
Thank you for the great interview, readers who wish to learn more should visit SnapLogic.
#Administration#adoption#Advice#agent#Agentic AI#agents#ai#AI adoption#AI AGENTS#AI technology#ai tools#AI-powered#APIs#application integration#applications#approach#assistants#automation#backlog#bank#Behavior#Blog#Born#bridge#Building#Business#charts#Cloud#code#coding
0 notes
Text
Structural Stories (2 of 2)

(Originally posted on 11th February 2022)
In the first part of this article I tried to explain why architectural design is still very much needed, and needs to be laid-out coherently.
When people buy that argument, the next debate is usually on precisely what should make it onto paper. There’s no single right answer, because architecture depends on context—and is partly an art form in any case. But a few universal rules do apply.
First, think about the stakeholders and their questions. List the significant questions, and for each one imagine the diagram, table, bullet list, graph … whatever, that best answers it. Often the best way to articulate the answer is with more than one of these in concert, because whilst a diagram can replace a thousand words, it also tends to leave ambiguity, so benefits from an accompanying narrative. I can’t tell you how many times I've seen this go wrong, with authors unclear on the message their diagram conveys, or using a picture to explain something which is essentially tabular, or choosing to nest items which have no such real relationship. If you’re unsure what form to use then Gene Zelazny's books offer some good generic advice. Or try the 5-Second Test (see chapter 21 here) on a colleague to see if your creation readily indicates what’s going on.
What to include? Start by covering elements introduced or modified in your initiative. Then contextualise by showing anything already in place that will interact with those. The difference between the old and the new should scream off the page, so in a system with any real complexity, showing separate “before” and “after” versions can be especially powerful.
A super-important (often-overlooked) feature of an architecture document is the set of architecture decisions made. Readers shouldn’t have to infer; instead each decision should be highlighted, showing the list of options considered, the pros and cons of each, and the considered choice that was eventually made. Before decisions are made, there should always be a set of principles to inform decision-making (many of which might be inherited company standards) and these principles should also be visible to readers.
And what about timing? In Agile settings we accept that not all of the architecture is known before development starts. But write-down what you can, highlight gaps so they’re not forgotten later, and organise documents so they’re easy to iterate on—just like the technology they describe.
Just as important as any of this are the language, notation and format of documents. We are, after all, aiming for readability and ease of understanding. Here are my top 6 tips:
a) Sequence the story so it builds on what the reader already knows – for example, don’t begin with storage plans for data described later, or sketch infrastructure to support an application explained on the next page.
b) Keep notation absolutely consistent throughout the document – if your APIs are blue hexagons, then they’re blue hexagons. Please don’t make one of them a red square later, because we’ll assume that something has changed, and (if we’re awake) we’ll ask what it was.
c) Keep your labels absolutely consistent throughout the document – component “AB” should never be renamed “AlphaBeta” later on. As the author, you can probably relate the two, but anyone else has to double-check that they’re the same. Don’t even change fonts or font sizes unless you need to—these are all ways to indicate a difference to the reader, who will then experience dissonance, slowing everyone down.
d) If you’re using “before” and “after” diagrams to highlight changes, please don’t change diagram elements which stay the same in the real world—it’s 100x easier when we can flip between two similar diagrams, immediately see what changes, and get real meaning from that. Yes, this can be difficult to depict if “before” and “after” look very different. The easiest way is to first draw the “super-diagram” containing all the elements from both diagrams. When you’ve got that ready, just delete the bits that don’t apply, to create the “before” and “after” views.
e) If you’re in PowerPoint, KeyNote, Visio etc. please remember that an architecture document is still a document, not a presentation. It needs to stand alone, without the voiceover. Yes, you could offer instead to present the material, but beware the downsides (see reason #3 from part 1).
f) Finally, use good grammar throughout, and avoid making space-filler assertions that you don’t really mean! (More common than you might think.) Again, we’re simply trying to make the reader’s job easier, because we respect their stake in the solution, and/or value their inputs.
Disclaimer: These opinions are mine alone, so are not necessarily shared by my current employer or other organisation with which I'm connected.
0 notes
Text
Node JS and Databases
Steps to Build a Blog Application
1. Project Setup
First, you create a new Node.js project on your computer.
You also install necessary tools like Express (for creating a web server) and Mongoose or MySQL (for interacting with the database).
Nodemon can be used during development to restart the server automatically when code changes.
2. Folder Structure
Organize your project files so that everything is easy to manage.
Models: This folder will store database schemas (like the blog post structure).
Routes: These handle requests to different parts of your blog (e.g., showing all posts or creating new ones).
Views: These are the templates used to render your pages (like home, post details).
Public: A place for static files (CSS stylesheets, images).
3. Setting Up the Database
You can use either MongoDB (a NoSQL database) or MySQL (a relational database) to store your blog posts.
MongoDB is easier for beginners because you don't need to define strict tables.
You create a "Blog" model, which defines the structure of each blog post (e.g., it should have a title, content, and a timestamp).
The database connection is established at the beginning so the app can interact with it throughout.
4. Handling HTTP Requests with Express
The Express framework helps manage the flow of the app:
When a user visits the home page, the server sends a list of all blog posts.
When they click on a specific post, it shows the details of that post.
There is also a form where users can create new posts by submitting titles and content.
You create routes to manage these requests. Each route corresponds to a specific URL (e.g., / for the home page, /post/:id to view a post).
5. Creating Views (Templates)
To make your pages dynamic, you use EJS (or another templating engine like Handlebars). Templates allow you to display different content based on the data from the database.
For example:
The home page lists all available blog posts with links to view them individually.
The post page shows the title, content, and date of a single post.
There can also be a form on the home page that lets users submit new posts.
6. Routing and User Interaction
When users visit the homepage, the server pulls data from the database and shows a list of posts.
Clicking on a post’s link takes them to a detailed view of that post.
Users can also add a new post by submitting a form. When they do, the app saves the new post in the database and refreshes the list.
7. Starting the App
You need to make sure both the database server and Node.js app are running.
MongoDB needs to be started separately (if using it).
The Node.js server listens for requests and responds based on the routes you’ve created.
The server is accessible via http://localhost:3000. You can open this in a browser to test the blog app.
8. Testing the Blog API (Optional)
To make sure everything works correctly, you can use tools like Postman to test your routes:
Test retrieving all posts by making a GET request.
Test creating a new post by sending a POST request with sample data.
You can also build error handling to manage invalid inputs.
9. Future Improvements
After setting up the basic blog, you can add advanced features:
User Authentication: Allow users to log in and manage their own posts.
Comments: Add a comment section for each post.
Pagination: Break long lists of posts into pages for better readability.
CSS Styling: Make the blog look more attractive with a custom stylesheet.
Summary
This blog app involves setting up a Node.js server, connecting it to a database to store posts, and using templates to render pages. When users visit the blog, they can view, create, or manage posts, all of which are stored in the database. Express routes manage the requests, and the views ensure everything is displayed neatly.
This project gives you hands-on experience with backend development using Node.js, along with frontend templates, and a solid understanding of working with databases.
Fullstack Seekho is launching a new full stack training in Pune 100% job Guarantee Course. Below are the list of Full Stack Developer Course in Pune:
1. Full Stack Web Development Course in Pune and MERN Stack Course in Pune
2. Full Stack Python Developer Course in Pune
3. full stack Java course in Pune And Java full stack developer course with placement
4. Full Stack Developer Course with Placement Guarantee
Visit the website and fill the form and our counsellors will connect you!
0 notes
Text
FLARE Capa, Identifies Malware Capabilities Automatically

Capa is FLARE’s latest open-source malware analysis tool. Google Cloud platform lets the community encode, identify, and exchange malicious behaviors. It uses decades of reverse engineering knowledge to find out what a program performs, regardless of your background. This article explains capa, how to install and use it, and why you should utilize it in your triage routine now.
Problem
In investigations, skilled analysts can swiftly analyze and prioritize unfamiliar files. However, basic malware analysis skills are needed to determine whether a software is harmful, its participation in an assault, and its prospective capabilities. An skilled reverse engineer can typically restore a file’s full functionality and infer the author’s purpose.
Malware analysts can rapidly triage unfamiliar binaries to acquire first insights and guide analysis. However, less experienced analysts sometimes don’t know what to look for and struggle to spot the unexpected. Unfortunately, strings / FLOSS and PE viewers offer the least information, forcing users to mix and interpret data.
Malware Triage 01-01
Practical Malware Analysis Lab 01-01 illustrates this. Google Cloud want to know how the software works. The file’s strings and import table with relevant values are shown in Figure 1.Image credit to Google cloud
This data allows reverse engineers to deduce the program’s functionality from strings and imported API functions, but no more. Sample may generate mutex, start process, or interact via network to IP address 127.26.152.13. Winsock (WS2_32) imports suggest network capabilities, but their names are unavailable since they are imported by ordinal.
Dynamically evaluating this sample may validate or reject hypotheses and uncover new functionality. Sandbox reports and dynamic analysis tools only record code path activity. This excludes features activated following a successful C2 server connection. Google seldom advise malware analysis with an active Internet connection
We can see the following functionality with simple programming and Windows API knowledge. The malware:
Uses a mutex to limit execution to one
Created a TCP socket with variables 2 = AF_INET, 1 = SOCK_STREAM, and 6 = IPPROTO_TCP.
IP 127.26.152.13 on port 80
Transmits and gets data
Checks data against sleep and exec
Develops new method
Malware may do these actions, even if not all code paths execute on each run. Together, the results show that the virus is a backdoor that can execute any program provided by a hard-coded C2 server. This high-level conclusion helps us scope an investigation and determine how to react to the danger.
Automation of Capability Identification
Malware analysis is seldom simple. A binary with hundreds or thousands of functions might propagate intent artifacts. Reverse engineering has a high learning curve and needs knowledge of assembly language and operating system internals.
After enough effort, it is discern program capabilities from repeating API calls, strings, constants, and other aspects. It show using capa that several of its primary analytical results can be automated. The technology codifies expert knowledge and makes it accessible to the community in a flexible fashion. Capa detects characteristics and patterns like a person, producing high-level judgments that may guide further investigation. When capa detects unencrypted HTTP communication, you may need to investigate proxy logs or other network traces.
Introducing capa
The output from capa against its sample program virtually speaks for itself. Each left item in the main table describes a capability in this example. The right-hand namespace groups similar capabilities. capa defined all the program capabilities outlined in the preceding part well.
Capa frequently has unanticipated outcomes. Capa to always present the evidence required to determine a capability. The “create TCP socket” conclusion output from capa . Here, it can see where capa detected the necessary characteristics in the binary. While they wait for rule syntax, it may assume they’re a logic tree with low-level characteristics.
How it Works
Its two major components algorithmically triage unknown programs. First, a code analysis engine collects text, disassembly, and control flow from files. Second, a logic engine identifies rule-based feature pairings. When the logic engine matches, it reports the rule’s capability.
Extraction of Features
The code analysis engine finds program low-level characteristics. It can describe its work since all its characteristics, including strings and integers, are human-recognizable. These characteristics are usually file or disassembly-related.
File characteristics, like the PE file header, are retrieved from raw file data and structure. Skimming the file may reveal this. Other than strings and imported APIs, they include exported function and section names.
Advanced static analysis of a file extracts disassembly characteristics, which reconstructs control flow. Figure displays API calls, instruction mnemonics, integers, and string references in disassembly.Image credit to Google cloud
It applies its logic at the right level since sophisticated analysis can differentiate between functions and other scopes in a program. When unrelated APIs are utilized in distinct functions, capa rules may match them against each function separately, preventing confusion.
It is developed for flexible and extensible feature extraction. Integrating code analysis backends is simple. It standalone uses a vivisect analysis framework. The IDA Python backend lets you run it in IDA Pro. various code analysis engines may provide various feature sets and findings. The good news is that this seldom causes problems.
Capa Rules
A capa rule describes a program capability using an organized set of characteristics. If all needed characteristics are present, capa declares the program capable.
Its rules are YAML documents with metadata and logic assertions. Rule language includes counting and logical operators. The “create TCP socket” rule requires a basic block to include the numbers 6, 1, and 2 and calls to API methods socket or WSASocket. Basic blocks aggregate assembly code low-level, making them perfect for matching closely connected code segments. It enables function and file matching in addition to basic blocks. Function scope connects all features in a disassembled function, whereas file scope includes all file features.
Rule names define capabilities, whereas namespaces assign them to techniques or analytic categories. Its output capability table showed the name and namespace. Author and examples may be added to the metadata. To unit test and validate every rule, Google Cloud utilizes examples to reference files and offsets with known capabilities. Please maintain a copy of capa rules since they detail real-world malware activities. Meta information like capa’s support for the ATT&CK and Malware Behavior Catalog frameworks will be covered in a future article.
Installation
The offer standalone executables for Windows, Linux, and OSX to simplify capa use. It provide the Python tool’s source code on GitHub. The capa repository has updated installation instructions.
Latest FLARE-VM versions on GitHub feature capa.
Usage
Run capa and provide the input file to detect software capabilities:
Suspicious.exe
Capa supports shellcode and Windows PE (EXE, DLL, SYS). For instance, to analyze 32-bit shellcode, capa must be given the file format and architecture:
Capa sc32 shellcode.bin
It has two verbosity levels for detailed capability information. Use highly verbose to see where and why capa matched rules:
Suspicious.exe capa
Use the tag option to filter rule meta data to concentrate on certain rules:
Suspicious.exe capa -t “create TCP socket”
Show capa’s help to show all available options and simplify documentation:
$capa-h
Contributing
Google cloud believe capa benefits the community and welcome any contribution. Google cloud appreciate criticism, suggestions, and pull requests. Starting with the contributing document is ideal.
Rules underpin its identifying algorithm. It aims to make writing them entertaining and simple.
Utilize a second GitHub repository for its embedded rules to segregate work and conversations from its main code. Rule repository is a git submodule in its main repository.
Conclusion
FLARE’s latest malware analysis tool is revealed in this blog article. The open-source capa framework encodes, recognizes, and shares malware behaviors. Believe the community needs this tool to combat the number of malware it encounter during investigations, hunting, and triage. It uses decades of knowledge to explain a program, regardless of your background.
Apply it to your next malware study. The program is straightforward to use and useful for forensic analysts, incident responders, and reverse engineers.
Read more on govindhtech.com
#FLARECapa#IdentifiesMalware#GoogleCloud#CapabilitiesAutomatically#malwareanalysis#Sandbox#Malware#Introducingcapa#Python#Automation#MalwareTriage0101#technology#technews#news#govindhtech
0 notes
Text
The Ultimate Guide Make Money Online With 20 Proven Strategy
When you know what you’re doing, making money online is pretty straightforward. You can do it full-time or part-time right from the comfort of your home. Who wouldn’t want to work in their pajamas and pull in some extra cash?? In this article, we explore some different ways to earn money online. To learn how to make money online, read this article from start to finish.
TABLE OF CONTENT
How To Make Money From YouTube WITHOUT Uploading a Single Video!
Build A Full Online Business With Chat GPT Help!
How To Make Money Online Selling Prompts!
How To Make Money With Simple Excel Files
How to Earn From Google Without Blogging ($3000/Month)
The Best Online Business To Start Now! Drop Hosting ($2000/Month)
How To Using AI Go From Zero to $114,350 (Act Fast)
Make $1000/Month With Affiliate Marketing Automation!
How I Make Money With APIs (Revealing My Secrets!)
How to Make $910 In 30 Days – Step by Step
Affiliate Marketing Case Study For Beginners – Earn 138$ in 1 Week
How To Make $1000 Per Month With Drop Servicing
How to Get Website Visitors for Free from Quora [8 Secret Tips]-319k Views!
How to Earn $0.41 Per Click (The Real Legit Way)
How To Make Money Sending Emails (Practical Guide)
How to Turn $ 10 Into $ 1000 Flipping Domains
How to Earn $500 in 27 Days Online Challenge Start Now!
How To Make $910 In 30 Days – Step by Step
How To Pick a Profitable Niche For Your Blog
Free Affiliate Marketing Course (Beginner To Advanced)
Method #1 : How To Make Money From YouTube WITHOUT Uploading a Single Video!
Many people become YOUTUBERS. They create content according to their respective skills and goals but do you know there is a way to make money from YUOTUBE without having to upload videos. This sounds strange but it can be done with an unusual idea. The Idea is very simple collect data from YOUTUBE and monetize it. Super simple. Here I show you step by step how to do this Idea.
0 notes
Text
API Testing Market Projected to Show Strong Growth

Global API Testing Market Report from AMA Research highlights deep analysis on market characteristics, sizing, estimates and growth by segmentation, regional breakdowns & country along with competitive landscape, player’s market shares, and strategies that are key in the market. The exploration provides a 360° view and insights, highlighting major outcomes of the industry. These insights help the business decision-makers to formulate better business plans and make informed decisions to improved profitability. In addition, the study helps venture or private players in understanding the companies in more detail to make better informed decisions. Major Players in This Report Include, Astegic (United States), Axway (United States), Bleum (China), CA Technologies (United States), Cigniti Technologies (India), Cygnet Infotech (India), IBM (United States), Inflectra Corporation (United States), Infosys (India), Load Impact (Sweden). Free Sample Report + All Related Graphs & Charts @: https://www.advancemarketanalytics.com/sample-report/114161-global-api-testing-market API testing is a type of software testing that involves testing of a set of application programming interfaces (APIs) directly and as part of integration testing to determine if they meet expectations for functionality, performance, reliability, and security. It is a formal specification that acts as a guaranteed contract between two separate pieces of software. The automation for API testing requires less code so it can provide faster and better test coverage. It helps the companies to reduce the risks. Market Drivers
Rise In the Cloud Applications and Interconnect Platforms
Increasing Adoption of API Testing
Market Trend
Data Regulations and Policies
Opportunities
Increasing Requirements of Modern Testing Methods
Advancements in the Testing Technologies
Challenges
Lack of Awareness among the People
Enquire for customization in Report @: https://www.advancemarketanalytics.com/enquiry-before-buy/114161-global-api-testing-market In this research study, the prime factors that are impelling the growth of the Global API Testing market report have been studied thoroughly in a bid to estimate the overall value and the size of this market by the end of the forecast period. The impact of the driving forces, limitations, challenges, and opportunities has been examined extensively. The key trends that manage the interest of the customers have also been interpreted accurately for the benefit of the readers. The API Testing market study is being classified by Type (Automated Testing {Functionality Testing, Reliability Testing, Load Testing, Security Testing, Creativity Testing, Proficiency Testing and Others}, Manual Testing {Exploratory Testing, Usability Testing and Ad-hoc Testing}), Application (IT and Telecommunication, Banking, Financial Services, and Insurance, Retail and Ecommerce, Media and Entertainment, Healthcare, Manufacturing, Government, Others), Deployment (Cloud-Based, On-Premises) The report concludes with in-depth details on the business operations and financial structure of leading vendors in the Global API Testing market report, Overview of Key trends in the past and present are in reports that are reported to be beneficial for companies looking for venture businesses in this market. Information about the various marketing channels and well-known distributors in this market was also provided here. This study serves as a rich guide for established players and new players in this market. Get Reasonable Discount on This Premium Report @ https://www.advancemarketanalytics.com/request-discount/114161-global-api-testing-market Extracts from Table of Contents API Testing Market Research Report Chapter 1 API Testing Market Overview Chapter 2 Global Economic Impact on Industry Chapter 3 Global Market Competition by Manufacturers Chapter 4 Global Revenue (Value, Volume*) by Region Chapter 5 Global Supplies (Production), Consumption, Export, Import by Regions Chapter 6 Global Revenue (Value, Volume*), Price* Trend by Type Chapter 7 Global Market Analysis by Application ………………….continued This report also analyzes the regulatory framework of the Global Markets API Testing Market Report to inform stakeholders about the various norms, regulations, this can have an impact. It also collects in-depth information from the detailed primary and secondary research techniques analyzed using the most efficient analysis tools. Based on the statistics gained from this systematic study, market research provides estimates for market participants and readers. Contact US : Craig Francis (PR & Marketing Manager) AMA Research & Media LLP Unit No. 429, Parsonage Road Edison, NJ New Jersey USA – 08837 Phone: +1 201 565 3262, +44 161 818 8166 [email protected]
#Global API Testing Market#API Testing Market Demand#API Testing Market Trends#API Testing Market Analysis#API Testing Market Growth#API Testing Market Share#API Testing Market Forecast#API Testing Market Challenges
0 notes
Text
25 Best GPTs To Use For Productivity & Efficiency

With ChatGPT introducing the ability to create custom AI models known as GPTs, there has been an explosion of new GPTs optimized for different use cases.
The GPTs can help streamline workflows and make you more productive.
In this article, we’ll highlight 10 of the best GPTs to try if you want to work smarter and faster.
Whether you’re a writer, programmer, analyst, or just want to get more done each day, these GPTs can level up your efficiency.
Let’s dive in and see how you can integrate them into your work.
Best GPTs For Work Productivity & Efficiency
Work Productivity:
AI PDF: This GPT helps you handle PDF documents up to 2GB per file and allows 1000s of PDFs to upload.
Canva: Use this GPT to create designs for presentations, logos, social media posts, and more.
VideoGPT By VEED: Use this to generate videos and grow your audience.
Slide Maker: This GPT helps you to create beautiful PowerPoint presentation slides and can read any link for content.
Diagrams: Show Me:
Doc Maker: This GPT generates beautiful PDFs in seconds. From resumes, reports, and proposals to anything.
Research & Analysis:
Consensus: This is an AI research assistant that helps you search 200M academic papers from consensus and gets science-based answers and draft content with accurate citations.
Scholar AI: This helps you to generate new hypotheses, and analyze text, figures, and tables from 200+M scientific papers and books.
Scispace: This GPT helps you to get help on your research from 282 million articles and get citation-backed answers.
AutoExpert: This GPT will help you to provide a concise analysis covering authors, key findings, methodology, and relevance once you upload a research paper.
Programming:
AskTheCode: This will help you ask about any aspect of the code when you provide a GitHub repository URL.
Code Tutor: This GPT will help you write your codes and help your code to work.
DesignerGPT: This GPT will help you create and host beautiful websites.
Screenshot to Code GPT: Using this GPT, you can upload a screenshot and it will convert to clean HTML/Tailwind/JS code.
Java Assistant: It’s a Java code assistant and debugger
API Docs: This will get access to OpenAI API, GPTs, documents, and cookbooks.
Powered By Dall-E:
Logo Creator: This helps you to generate logo designs and you can easily make professional logos and app icons with various styles and color palettes.
Storybook Vision: It will convert photos into Pixar-style illustrations.
MJ Prompt Generator: This helps you to generate detailed, creative, optimized prompts that are ready to use in Midjourney V6.
By ChatGPT:
Dall-E: This GPT will help you turn your imagination into images.
Data Analyst: You can use this GPT to drop any files and it can help analyze and visualize your data.
Hot Mods: It will help you modify your images into something wild.
Creative Writing Coach: It will help you to get feedback on your writing to improve your skills.
Web Browser: IT can browse the web and help you gather information and conduct research.
ChatGPT Classic: This is the latest version of GPT-4 with no additional capabilities.
Conclusion
The key to increasing productivity is to work smarter, not harder.
With the right GPT by your side, you can accelerate tasks like research, analysis, writing, and content creation.
We’ve just scratched the surface of what’s possible when combining focused AI models with human creativity and critical thinking.
As more GPTs continue to be developed, workers and businesses can increasingly automate rote work and focus their energy on high-value priorities.
So give some of these productivity GPTs a spin, and you may be surprised by how much time and effort they can help you save!
0 notes
Text
Global General Data Protection Regulation Services Market Analysis 2024 – Estimated Market Size And Key Drivers
The General Data Protection Regulation Services by The Business Research Company provides market overview across 60+ geographies in the seven regions - Asia-Pacific, Western Europe, Eastern Europe, North America, South America, the Middle East, and Africa, encompassing 27 major global industries. The report presents a comprehensive analysis over a ten-year historic period (2010-2021) and extends its insights into a ten-year forecast period (2023-2033).
Learn More On The General Data Protection Regulation Services Market: https://www.thebusinessresearchcompany.com/report/general-data-protection-regulation-services-global-market-report
According to The Business Research Company’s General Data Protection Regulation Services, The general data protection regulation services market size has grown exponentially in recent years. It will grow from $1.98 billion in 2023 to $2.44 billion in 2024 at a compound annual growth rate (CAGR) of 23.1%. The growth in the historic period can be attributed to concerns over data privacy and security breaches, globalization and cross-border data transfers, increased digitization of business processes, recognition of the need for standardized data protection regulations, high-profile data breaches and incidents driving regulatory attention.
The general data protection regulation services market size is expected to see exponential growth in the next few years. It will grow to $5.7 billion in 2028 at a compound annual growth rate (CAGR) of 23.7%. The growth in the forecast period can be attributed to evolving regulatory landscape and enforcement measures, continued growth in data-driven technologies, rising awareness and emphasis on individual privacy rights, increased adoption of cloud computing and data analytics, increasing use of mobile phones. Major trends in the forecast period include development of advanced encryption and data protection technologies, integration of privacy by design principles in software development, emergence of data protection impact assessments as a standard practice, expansion of gdpr compliance services to cover emerging technologies, growing demand for third-party gdpr compliance auditing and certification.
The increase in the number of cyberattacks is expected to propel the growth of the general data protection regulation services market going forward. A cyber attack is an attempt to enter a computer, computing system, or computer network without authorization with the goal of causing harm. Cyber attackers would enable hackers to gain access to a person’s or company’s financial accounts using sensitive data, among other potentially damaging actions. General data protection regulation services (GDPR) provide a secure way to protect sensitive data from nauthorized access, theft, or exposure. For instance, in 2021, according to the Federal Bureau of Investigation’s Internet Crime Report, a US-based federal agency for investigating cyber attacks and intrusions in the USA, complaints registered under cybercrimes reached a total of 84.73k cases, showing an increase of 7% from 2020. Therefore, an increasing number of cyberattacks is driving the general data protection services market.
Get A Free Sample Of The Report (Includes Graphs And Tables): https://www.thebusinessresearchcompany.com/sample.aspx?id=7472&type=smp
The general data protection regulation services market covered in this report is segmented –
1) By Type of Deployment: On-Premise, Cloud 2) By Offering: Data Management, Data Discovery and Mapping, Data Governance, API Management 3) By Organization Size: Large Enterprises, Small and Medium-Sized Enterprises 4) By End User: Banking, Financial Services, and Insurance (BFSI), Telecom and IT, Retail and Consumer Goods, Healthcare and Life Sciences, Manufacturing, Other End-user Industries
The increase in the trend of shifting towards new and advanced technology is the key trend gaining popularity in the general data protection regulation services market. Major companies operating in the general data protection regulation services market are focused on developing new technological solutions to strengthen their position. For instance, in July 2022, GhangorCloud, a US-based cybersecurity solutions provider company, launched a novel platform named CAPE, which stands for Compliance and Privacy Enforcement. CAPE is an innovative unified compliance and data privacy solution that offers patented intelligent automation for enforcing consumer data privacy requirements with the most cost-effective implementation. The platform harnesses the power of AI and incorporates an eDiscovery engine, which autonomously identifies and categorizes content, subsequently generating privacy enforcement policies without the need for human intervention. The CAPE platform delivers real-time automation of various tasks encompassing data discovery, compliance, and privacy enforcement, effectively addressing the challenges associated with modern data compliance and privacy systems to ensure swift and accurate operations.
The general data protection regulation services market report table of contents includes:
Executive Summary
Market Characteristics
Market Trends And Strategies
Impact Of COVID-19
Market Size And Growth
Segmentation
Regional And Country Analysis . . .
Competitive Landscape And Company Profiles
Key Mergers And Acquisitions
Future Outlook and Potential Analysis
Contact Us: The Business Research Company Europe: +44 207 1930 708 Asia: +91 88972 63534 Americas: +1 315 623 0293 Email: [email protected]
Follow Us On: LinkedIn: https://in.linkedin.com/company/the-business-research-company Twitter: https://twitter.com/tbrc_info Facebook: https://www.facebook.com/TheBusinessResearchCompany YouTube: https://www.youtube.com/channel/UC24_fI0rV8cR5DxlCpgmyFQ Blog: https://blog.tbrc.info/ Healthcare Blog: https://healthcareresearchreports.com/ Global Market Model: https://www.thebusinessresearchcompany.com/global-market-model
0 notes
Text
Aaron Kesler, Sr. Product Manager, AI/ML at SnapLogic – Interview Series
New Post has been published on https://thedigitalinsider.com/aaron-kesler-sr-product-manager-ai-ml-at-snaplogic-interview-series/
Aaron Kesler, Sr. Product Manager, AI/ML at SnapLogic – Interview Series

Aaron Kesler, Sr. Product Manager, AI/ML at SnapLogic, is a certified product leader with over a decade of experience building scalable frameworks that blend design thinking, jobs to be done, and product discovery. He focuses on developing new AI-driven products and processes while mentoring aspiring PMs through his blog and coaching on strategy, execution, and customer-centric development.
SnapLogic is an AI-powered integration platform that helps enterprises connect applications, data, and APIs quickly and efficiently. With its low-code interface and intelligent automation, SnapLogic enables faster digital transformation across data engineering, IT, and business teams.
You’ve had quite the entrepreneurial journey, starting STAK in college and going on to be acquired by Carvertise. How did those early experiences shape your product mindset?
This was a really interesting time in my life. My roommate and I started STAK because we were bored with our coursework and wanted real-world experience. We never imagined it would lead to us getting acquired by what became Delaware’s poster startup. That experience really shaped my product mindset because I naturally gravitated toward talking to businesses, asking them about their problems, and building solutions. I didn’t even know what a product manager was back then—I was just doing the job.
At Carvertise, I started doing the same thing: working with their customers to understand pain points and develop solutions—again, well before I had the PM title. As an engineer, your job is to solve problems with technology. As a product manager, your job shifts to finding the right problems—the ones that are worth solving because they also drive business value. As an entrepreneur, especially without funding, your mindset becomes: how do I solve someone’s problem in a way that helps me put food on the table? That early scrappiness and hustle taught me to always look through different lenses. Whether you’re at a self-funded startup, a VC-backed company, or a healthcare giant, Maslow’s “basic need” mentality will always be the foundation.
You talk about your passion for coaching aspiring product managers. What advice do you wish you had when you were breaking into product?
The best advice I ever got—and the advice I give to aspiring PMs—is: “If you always argue from the customer’s perspective, you’ll never lose an argument.” That line is deceptively simple but incredibly powerful. It means you need to truly understand your customer—their needs, pain points, behavior, and context—so you’re not just showing up to meetings with opinions, but with insights. Without that, everything becomes HIPPO (highest paid person’s opinion), a battle of who has more power or louder opinions. With it, you become the person people turn to for clarity.
You’ve previously stated that every employee will soon work alongside a dozen AI agents. What does this AI-augmented future look like in a day-to-day workflow?
What may be interesting is that we are already in a reality where people are working with multiple AI agents – we’ve helped our customers like DCU plan, build, test, safeguard, and put dozens of agents to help their workforce. What’s fascinating is companies are building out organization charts of AI coworkers for each employee, based on their needs. For example, employees will have their own AI agents dedicated to certain use cases—such as an agent for drafting epics/user stories, one that assists with coding or prototyping or issues pull requests, and another that analyzes customer feedback – all sanctioned and orchestrated by IT because there’s a lot on the backend determining who has access to which data, which agents need to adhere to governance guidelines, etc. I don’t believe agents will replace humans, yet. There will be a human in the loop for the foreseeable future but they will remove the repetitive, low-value tasks so people can focus on higher-level thinking. In five years, I expect most teams will rely on agents the same way we rely on Slack or Google Docs today.
How do you recommend companies bridge the AI literacy gap between technical and non-technical teams?
Start small, have a clear plan of how this fits in with your data and application integration strategy, keep it hands-on to catch any surprises, and be open to iterating from the original goals and approach. Find problems by getting curious about the mundane tasks in your business. The highest-value problems to solve are often the boring ones that the unsung heroes are solving every day. We learned a lot of these best practices firsthand as we built agents to assist our SnapLogic finance department. The most important approach is to make sure you have secure guardrails on what types of data and applications certain employees or departments have access to.
Then companies should treat it like a college course: explain key terms simply, give people a chance to try tools themselves in controlled environments, and then follow up with deeper dives. We also make it known that it is okay not to know everything. AI is evolving fast, and no one’s an expert in every area. The key is helping teams understand what’s possible and giving them the confidence to ask the right questions.
What are some effective strategies you’ve seen for AI upskilling that go beyond generic training modules?
The best approach I’ve seen is letting people get their hands on it. Training is a great start—you need to show them how AI actually helps with the work they’re already doing. From there, treat this as a sanctioned approach to shadow IT, or shadow agents, as employees are creative to find solutions that may solve super particular problems only they have. We gave our field team and non-technical teams access to AgentCreator, SnapLogic’s agentic AI technology that eliminates the complexity of enterprise AI adoption, and empowered them to try building something and to report back with questions. This exercise led to real learning experiences because it was tied to their day-to-day work.
Do you see a risk in companies adopting AI tools without proper upskilling—what are some of the most common pitfalls?
The biggest risks I’ve seen are substantial governance and/or data security violations, which can lead to costly regulatory fines and the potential of putting customers’ data at risk. However, some of the most frequent risks I see are companies adopting AI tools without fully understanding what they are and are not capable of. AI isn’t magic. If your data is a mess or your teams don’t know how to use the tools, you’re not going to see value. Another issue is when organizations push adoption from the top down and don’t take into consideration the people actually executing the work. You can’t just roll something out and expect it to stick. You need champions to educate and guide folks, teams need a strong data strategy, time, and context to put up guardrails, and space to learn.
At SnapLogic, you’re working on new product development. How does AI factor into your product strategy today?
AI and customer feedback are at the heart of our product innovation strategy. It’s not just about adding AI features, it’s about rethinking how we can continually deliver more efficient and easy-to-use solutions for our customers that simplify how they interact with integrations and automation. We’re building products with both power users and non-technical users in mind—and AI helps bridge that gap.
How does SnapLogic’s AgentCreator tool help businesses build their own AI agents? Can you share a use case where this had a big impact?
AgentCreator is designed to help teams build real, enterprise-grade AI agents without writing a single line of code. It eliminates the need for experienced Python developers to build LLM-based applications from scratch and empowers teams across finance, HR, marketing, and IT to create AI-powered agents in just hours using natural language prompts. These agents are tightly integrated with enterprise data, so they can do more than just respond. Integrated agents automate complex workflows, reason through decisions, and act in real time, all within the business context.
AgentCreator has been a game-changer for our customers like Independent Bank, which used AgentCreator to launch voice and chat assistants to reduce the IT help desk ticket backlog and free up IT resources to focus on new GenAI initiatives. In addition, benefits administration provider Aptia used AgentCreator to automate one of its most manual and resource-intensive processes: benefits elections. What used to take hours of backend data entry now takes minutes, thanks to AI agents that streamline data translation and validation across systems.
SnapGPT allows integration via natural language. How has this democratized access for non-technical users?
SnapGPT, our integration copilot, is a great example of how GenAI is breaking down barriers in enterprise software. With it, users ranging from non-technical to technical can describe the outcome they want using simple natural language prompts—like asking to connect two systems or triggering a workflow—and the integration is built for them. SnapGPT goes beyond building integration pipelines—users can describe pipelines, create documentation, generate SQL queries and expressions, and transform data from one format to another with a simple prompt. It turns out, what was once a developer-heavy process into something accessible to employees across the business. It’s not just about saving time—it’s about shifting who gets to build. When more people across the business can contribute, you unlock faster iteration and more innovation.
What makes SnapLogic’s AI tools—like AutoSuggest and SnapGPT—different from other integration platforms on the market?
SnapLogic is the first generative integration platform that continuously unlocks the value of data across the modern enterprise at unprecedented speed and scale. With the ability to build cutting-edge GenAI applications in just hours — without writing code — along with SnapGPT, the first and most advanced GenAI-powered integration copilot, organizations can vastly accelerate business value. Other competitors’ GenAI capabilities are lacking or nonexistent. Unlike much of the competition, SnapLogic was born in the cloud and is purpose-built to manage the complexities of cloud, on-premises, and hybrid environments.
SnapLogic offers iterative development features, including automated validation and schema-on-read, which empower teams to finish projects faster. These features enable more integrators of varying skill levels to get up and running quickly, unlike competitors that mostly require highly skilled developers, which can slow down implementation significantly. SnapLogic is a highly performant platform that processes over four trillion documents monthly and can efficiently move data to data lakes and warehouses, while some competitors lack support for real-time integration and cannot support hybrid environments.
What excites you most about the future of product management in an AI-driven world?
What excites me most about the future of product management is the rise of one of the latest buzzwords to grace the AI space “vibe coding”—the ability to build working prototypes using natural language. I envision a world where everyone in the product trio—design, product management, and engineering—is hands-on with tools that translate ideas into real, functional solutions in real time. Instead of relying solely on engineers and designers to bring ideas to life, everyone will be able to create and iterate quickly.
Imagine being on a customer call and, in the moment, prototyping a live solution using their actual data. Instead of just listening to their proposed solutions, we could co-create with them and uncover better ways to solve their problems. This shift will make the product development process dramatically more collaborative, creative, and aligned. And that excites me because my favorite part of the job is building alongside others to solve meaningful problems.
Thank you for the great interview, readers who wish to learn more should visit SnapLogic.
#Administration#adoption#Advice#agent#Agentic AI#agents#ai#AI adoption#AI AGENTS#AI technology#ai tools#AI-powered#AI/ML#APIs#application integration#applications#approach#assistants#automation#backlog#bank#Behavior#Blog#Born#bridge#Building#Business#charts#Cloud#code
0 notes
Text
Enabling CSV data uploads via a Salesforce Screen Flow
This is a tutorial for how to build a Salesforce Screen Flow that leverages this CSV to records lightning web component to facilitate importing data from another system via an export-import process.
My colleague Molly Mangan developed the plan for deploying this to handle nonprofit organization CRM import operations, and she delegated a client buildout to me. I’ve built a few iterations since.
I prefer utilizing a custom object as the import target for this Flow. You can choose to upload data to any standard or custom object, but an important caveat with the upload LWC component is that the column headers in the uploaded CSV file have to match the API names of corresponding fields on the object. Using a custom object enables creating field names that exactly match what comes out of the upstream system. My goal is to enable a user process that requires zero edits, just simply download a file from one system and upload it to another.
The logic can be as sophisticated as you need. The following is a relatively simple example built to transfer data from Memberpress to Salesforce. It enables users to upload a list that the Flow then parses to find or create matching contacts.
Flow walkthrough
To build this Flow, you have to first install the UnofficialSF package and build your custom object.
The Welcome screen greets users with a simple interface inviting them to upload a file or view instructions.

Toggling on the instructions exposes a text block with a screenshot that illustrates where to click in Memberpress to download the member file.
Note that the LWC component’s Auto Navigate Next option utilizes a Constant called Var_True, which is set to the Boolean value True. It’s a known issue that just typing in “True” doesn’t work here. With this setting enabled, a user is automatically advanced to the next screen upon uploading their file.
On the screen following the file upload, a Data Table component shows a preview of up to 1,500 records from the uploaded CSV file. After the user confirms that the data looks right, they click Next to continue.
Before entering the first loop, there’s an Assignment step to set the CountRows variable.

Here’s how the Flow looks so far..

With the CSV data now uploaded and confirmed, it’s time to start looping through the rows.
Because I’ve learned that a CSV file can sometimes unintentionally include some problematic blank rows, the first step after starting the loop is to check for a blank value in a required field. If username is null then the row is blank and it skips to the next row.

The next step is another decision which implements a neat trick that Molly devised. Each of our CSV rows will need to query the database and might need to write to the database, but the SOQL 100 governor limit seriously constrains how many can be processed at one time. Adding a pause to the Flow by displaying another screen to the user causes the transaction in progress to get committed and governor limits are reset. There’s a downside that your user will need to click Next to continue every 20 or 50 or so rows. It’s better than needing to instruct them to limit their upload size to no more than that number.

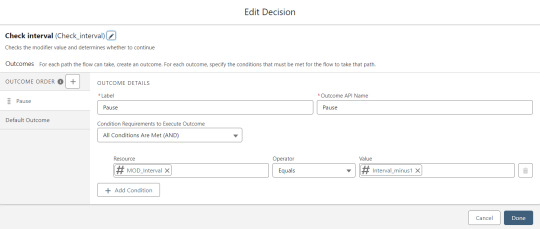
With those first two checks done, the Flow queries the Memberpress object looking for a matching User ID. If a match is found, the record has been uploaded before. The only possible change we’re worried about for existing records is the Memberships field, so that field gets updated on the record in the database. The Count_UsersFound variable is also incremented.

On the other side of the decision, if no Memberpress User record match is found then we go down the path of creating a new record, which starts with determining if there’s an existing Contact. A simple match on email address is queried, and Contact duplicate detection rules have been set to only Report (not Alert). If Alert is enabled and a duplicate matching rule gets triggered, then the Screen Flow will hit an error and stop.

If an existing Contact is found, then that Contact ID is written to the Related Contact field on the Memberpress User record and the Count_ContactsFound variable is incremented. If no Contact is found, then the Contact_Individual record variable is used to stage a new Contact record and the Count_ContactsNotFound variable is incremented.

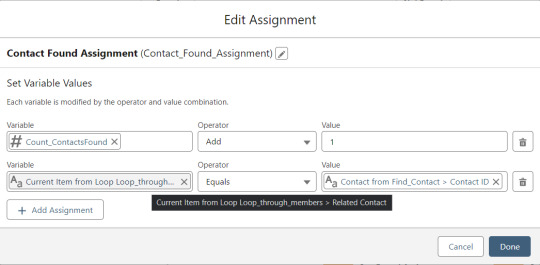

Contact_Individual is then added to the Contact_Collection record collection variable, the current Memberpress User record in the loop is added to the User_Collection record collection variable, and the Count_Processed variable is incremented.


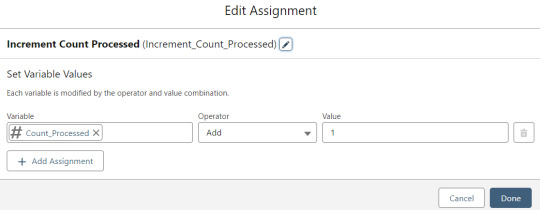
After the last uploaded row in the loop finishes, then the Flow is closed out by writing Contact_Collection and User_Collection to the database. Queueing up individuals into collections in this manner causes Salesforce to bulkify the write operations which helps avoid hitting governor limits. When the Flow is done, a success screen with some statistics is displayed.


The entire Flow looks like this:
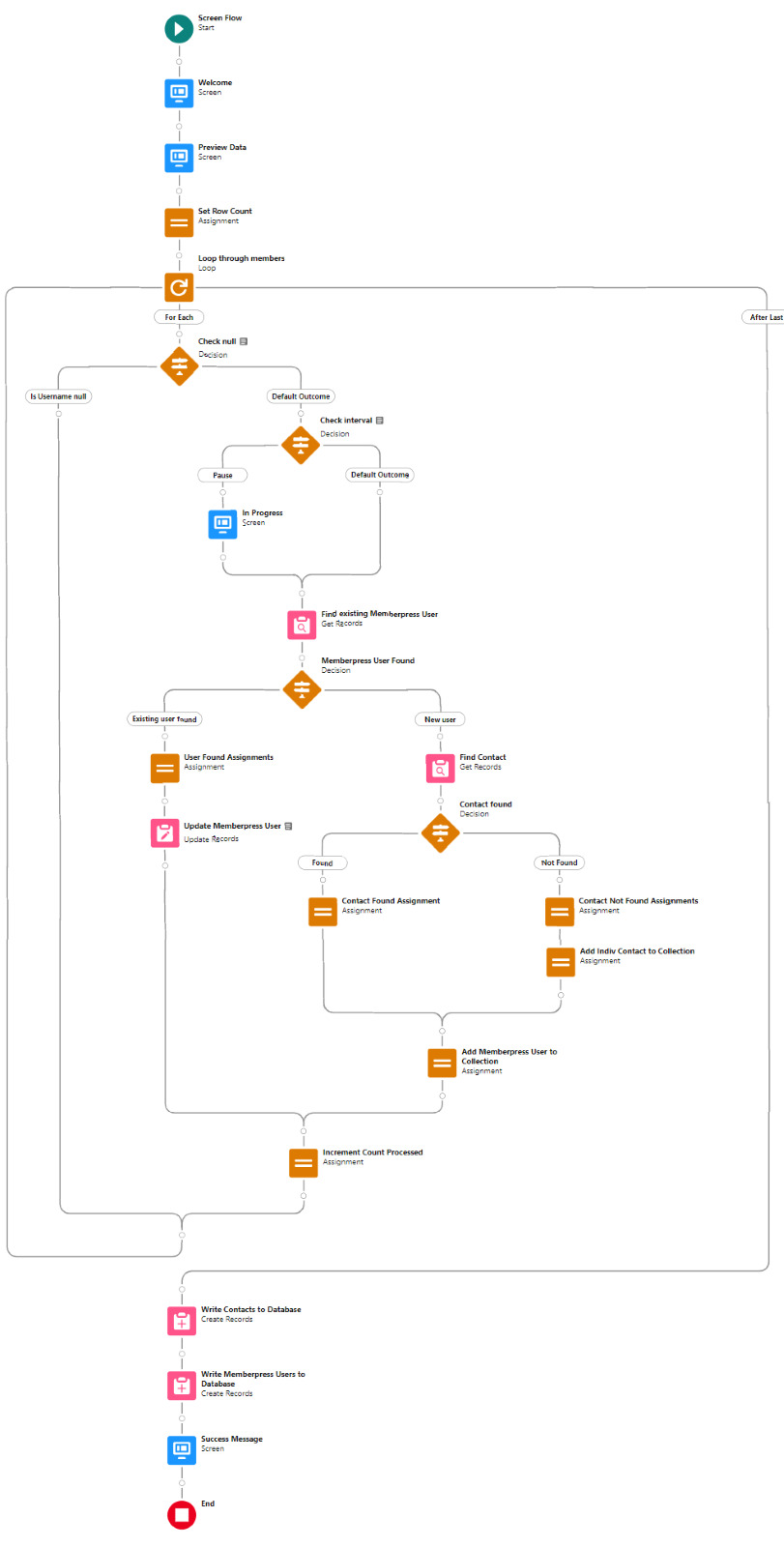
Flow variables
Interval_value determines the number of rows to process before pausing and prompting the user to click next to continue.
Interval_minus1 is Interval_value minus one.
MOD_Interval is the MOD function applied to Count_Processed and Interval_value.

The Count_Processed variable is set to start at -1.

Supporting Flows
Sometimes one Flow just isn’t enough. In this case there are three additional record triggered Flows configured on the Memberpress User object to supplement Screen Flow data import operations.
One triggers on new Memberpress User records only when the Related Contact field is blank. A limitation of the way the Screen Flow batches new records into collections before writing them to the database is that there’s no way to link a new contact to a new Memberpress User. So instead when a new Memberpress User record is created with no Related Contact set, this Flow kicks in to find the Contact by matching email address. This Flow’s trigger order is set to 10 so that it runs first.
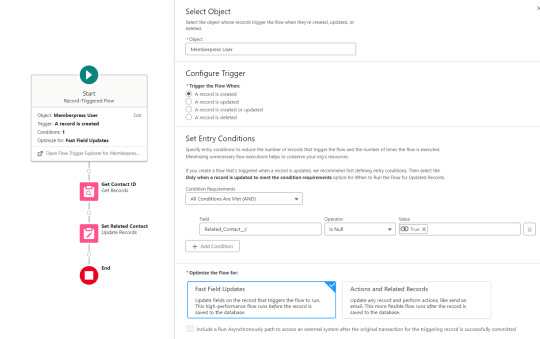
The next one triggers on any new Memberpress User record, reaching out to update the registration date and membership level fields on the Related Contact record

The last one triggers on updated Memberpress User records only when the memberships field has changed, reaching out to update the membership level field on the Related Contact record


0 notes
Text
Why SEOs Need to Embrace AI
It’s no question that the AI conversation has dominated the SEO community during the last year. The implications of this new technology are both extremely exciting and a little scary at the same time. At Go Fish Digital, we’ve been following these trends closely and refining our processes around the possibilities that AI brings.
Within both the SEO and larger technology communities, there is a huge discrepancy of opinions.
Many are weary of the implications and skeptical on the long-term benefits for marketers.
Some believe that this is a passing trend similar to voice search.
Others believe that this is a revolutionary technology that will impact every aspect of search in the future.
Out of curiosity, I performed a poll on my Linkedin page. I asked if SEOs thought that ChatGPT was going to disrupt SEO:
Nearly two-thirds of respondents said that ChatGPT is going to change our industry. I tend to agree with them. As a community, we need to be getting prepared for the imminent changes that AI is going to bring.
SEOs need to embrace AI
I believe that as a community, we need to be paying attention to this generational technology. While the tools certainly have their shortcomings, the outputs they’re producing already are nothing short of impressive. These tools will allow us to become more educated, more efficient and more technical.
It’s important that we not only keep in mind where these technologies are today. We must understand and expect that these tools will get exponentially better over time. The performance of GPT-4 is already significantly improved from GPT-3.5
GPT-3.5 feels unusable compared to GPT-4
— Paul Shapiro (@fighto) May 9, 2023
Thinking about a 5-year time horizon, these tools will advance far beyond what we’re seeing in today’s versions. This is why SEOs need to be adopting these technologies right now. The ones that do, will be well-positioned for the future of marketing.
Improving our SEO efficiencies
Back in March, I was curious as to how many SEOs were utilizing ChatGPT in their day-to-day workflows. Despite the fact that it was relatively new, I wondered how quick SEOs were to adopt using it:
To my surprise, 52% of respondents already claimed to be using ChatGPT to help with regular SEO tasks. This poll was conducted just 3 months after it’s initial release.
This makes sense as there are a lot of really great use cases for SEO tasks that we do on a daily basis. By using AI technology like ChatGPT, you can significantly improve the efficiency at which you’re able to work on some of these tasks.
A simple example is keyword research. With ChatGPT, you can immediately create large seed lists of potential keywords that have semantic relationships to the core topics that your website is trying to compete for.
Tom Demers recently wrote a great guide on Search Engine Land where he walks through his process of using AI for keyword research. In the guide he shows multiple examples of how he was able to use different types of prompts to directly identify keywords or find sources to mine for query opportunities.
He even showcased how he was able to export data from third-party SEO tools and bring it into a table format within the ChatGPT interface:
Content ideation is another great example of a tactical task that ChatGPT can leverage. Here I prompted ChatGPT to give me 30 different topic ideas about “The Metaverse”. It delivered them in about 30 seconds:
If I ran a technology blog, I could vet that against existing content on the site and find gaps where search opportunities might exist. Even if there was no direct SEO value, these topics still help position us as a topical authority in a particular content area.
You could even use ChatGPT to optimize your site’s content at scale. Tools such as GPT For Work allow you to connect to Google Sheets to the ChatGPT API. This allows you to feed in dynamic prompts and get the output back in Google Sheets.
As a result, you could create thousands of title tags and meta descriptions. You could give a site a baseline level of optimization with about 30 minutes of setup:
From a tactical perspective, there are so many use cases for ChatGPT to help with SEO.
Keyword research
Content ideation
Content evaluation
Schema generation
Featured snippet creation
Title tags and meta descriptions
Ideas for new content sections
Readability improvements
While there are many resources available, Alyeda Solis wrote a fantastic guide on the different use cases for SEO.
If you’re performing SEO in any capacity, it’s very likely that you can find a use case where your day-to-day efficiencies can be improved by utilizing some of these processes. This will allow us to produce a more efficient output and spend time working on initiatives that are less prone to automation.
Enhancing our knowledge base
I believe that only looking at strictly tactical implementations would be using AI far within its limits. There are many other great applications for the SEO community beyond that.
One of the best use cases that we see many industries using ChatGPT for is to enhance their knowledge base. AI can be an excellent teacher when prompted correctly. It can summarize information exceptionally quickly and give it to us in an output that’s completely customized to our learning style.
For example, the late-great Bill Slawski used to analyze patents that Google filed for. These patents are more technical and Bill used a long-form writing style.
We started testing running Bill’s patents through ChatGPT and prompted it to summarize core points. A successful prompt was “Summarize the whole article in 5 bullet points. Explain like I’m in high school”:
For my learning style, this allowed me to get enough detail to understand the patent and its implications without having the output oversimplify Bill’s ideas. If I was curious about any given idea, I could simply prompt ChatGPT to elaborate more and it would allow me to go deeper.
You could also get summaries from Google’s documentation. Here I fed it text from Google’s page on canonical tags and asked it to give me best practices.
How many of us struggle with technical SEO, web technology or understanding how search engines work? With ChatGPT the work of great technical minds like Bill and Google’s documentation essentially becomes democratized. Now when you encounter an SEO topic that you don’t understand, you can use AI as a teacher.
Of course, there are drawbacks to this. These types of summaries might not fully represent an author’s work as content must be left out and elements such as tone of voice aren’t taken in to consideration.
However, as a whole, this is a very powerful thing. Now the knowledge base that exists around SEO is more accessible to the entire community.
Empowering a community of creators
Personally, I think the most exciting aspect of the implications of AI for the SEO community are the technical possibilities that it opens up. While many of us are technically minded, not everyone has a background in development.
ChatGPT is going to enable the SEO community to become creators.
With the right prompting, you’ll now be able to create code that you weren’t able to before. That’s going to significantly impact your effectiveness as a search marketer.
For example, Screaming Frog is now opened up so much more for SEOs. I recently needed to scrape the BreadcrumbList structured data of REI’s site. When doing similar tasks before, it’s taken hours of debugging, re-running crawls and even meetings with other members of our team.
I asked ChatGPT to create a Screaming Frog extract and fed it sample HTML. Within 5 minutes, I was able to get a working XPath that allowed me to extract exactly what I needed:
The process could be applied to many other tools. ChatGPT could help you create API calls, SQL queries, Python scripts and many other things. This will empower the community to create new things that might not have been possible for many people.
On top of one-off pieces of code, you’ll now be able to create tools that are fully customized to your exact needs.
I’ve never created a Chrome extension before. However, ChatGPT has the power to take the prompts you give it and turn it into a fully functioning extension.
With about 30 minutes of prompting and debugging, it was able to create a custom SEO extension that pulls data such as title tags, meta descriptions, H1s, URL and more:
While there are great tools like this available, I could customize this extension to the exact specifications that I want.
You can even create tools that help improve your SEO efficiencies. My colleague Dan Hinckley was able to further iterate on this extension.
By connecting it to the ChatGPT API, he was able to create an SEO extension for our team that provides recommendations for title tags, H1, new content sections, and more:

Now this gives the entire team at Go Fish Digital a new tool to use as part of their process. We can quickly find page-level SEO opportunities and can decide which ones are worth actioning on for a given recommendation.
I suspect that ChatGPT will produce other solutions similar to this in the community. By embracing the power of AI, SEO teams will be able to identify the needs that they have and create a solution that perfectly fits their internal processes.
Conclusion
To us, it’s clear that AI is going to have a significant impact on the SEO community. The data already shows that SEOs see these technologies as having the power to significantly disrupt the industry and are already incorporating tools like ChatGPT into their day-to-day processes. I believe the SEOs that adapt to these changes will be the ones that see the most success.
Marketers that are able to leverage AI to improve efficiencies, grow their knowledge base and build customized solutions to improve their processes will be well-positioned for whatever the future of search holds.
Chris will be speaking at MozCon 2023 this August in Seattle! Join us for inspiring sessions with our incredible lineup of speakers.
We hope you're as excited as we are for August 7th and 8th to hurry up and get here. And again, if you haven't grabbed your ticket yet and need help making a case we have a handy template to convince your boss!
Register for MozCon

0 notes
Text
Gudu SQLFlow, One of the Best Data Lineage Tools on the Market of 2022
In large data warehouses and data lakes, complete data lineage can be used for data traceability, impact analysis of table and field changes, proof of data compliance, and data quality checks.

So what exactly is data lineage?
It is the pedigree of the data. In short, it refers to a record of how the data arrived at a particular location, as well as the intermediate steps and transformations which happen as the data moves through the business system. In essence, the data lineage gives us a detailed map of the data journey, including all the steps along the way.
How does Gudu SQLFlow work?
Gudu SQLFlow gives complete data lineage by analyzing SQL scripts. It can handle SQL statements of more than 20 kinds of databases, including complex stored procedures and dynamic SQL statements. With the powerful SQL processing capability of the self-developed general-purpose SQL parser, Gudu SQLFlow is your first choice for analyzing SQL data lineage.
https://www.bilibili.com/video/BV1E64y1q779
This video introduces how to use Gudu SQLFlow to quickly discover the data lineage of each table and field in the create view SQL statement, and display it in a visual way.
Gudu SQLFlow Features:
a. provides a visual representation of the overall flow of data;
b. automated SQL data lineage analysis across Databases, ETL, Business Intelligence, Cloud and Hadoop environments by parsing SQL Script and stored procedure;
c. depicts all the data movement graphically;
d. supports more than 20 major databases and still growing;
e. very affordable price;
f. provides automation in building the lineage no matter where the SQL resides: databases, file system, Github, Bitbucket and etc.
g. shows data flows in a way that is user-friendly, clear, and understandable and gets full visibility into your BI environment;
h. discovers root-cause of reporting errors, and creates invaluable business confidence;
i. simplifies regulatory compliance. The visualization of data lineage provides greater transparency and audit ability;
j. enables impact analysis at a granular level, drill down into table, column, and query-level lineage;
k. even better, Gudu SQLFlow provides a 30 days free premium account.
Composition of Gudu SQLFlow
a. Backend consists of a series of Java programs, responsible for SQL parsing, data lineage analysis, layout of visual elements, identity authentication, etc.
b. Frontend is composed of a series of javascript and html codes, which are responsible for the submission of SQL and the visual display of data lineage.
c. The Grabit tool, a Java program, is responsible for collecting SQL scripts from databases, version control systems, and file systems, and submitting them to the backend for data lineage analysis.
d. Restful API, a complete set of APIs, allows users to interact with the background through programming languages such as Java, C#, Python, and PHP to complete data lineage analysis.
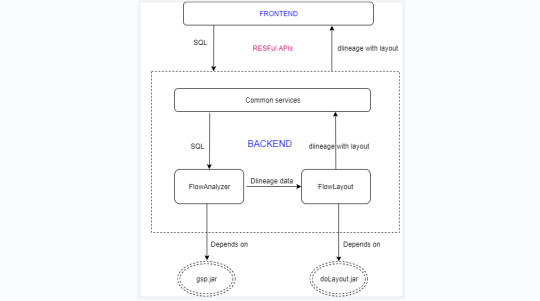
Conclusion
Thank you for reading my article and hope it can let you to have a better understanding of Gudu SQLFlow. If you want to know more about Gudu SQLFlow, I would like to advise you to visit their website for more information.
As a data lineage analysis tool, Gudu SQLFlow can not only analyze SQL script files, obtain data lineage, and perform visual display, but also allow users to provide data lineage in CSV format and perform visual display.
2 notes
·
View notes