#it works only with parser engines
Explore tagged Tumblr posts
Visit Tumblr Blog
Explore Tumblr blogs with no restrictions, modern design and the best experience.
Last Seen Tumblr Blogs





Fun Fact
Mobile Tumblr US users spend an average of 4.04 minutes per session on the app.
Text

THE FUCKING DOORS (Open issue on Github)
They haunt me. Every fucking time I fix it, something goes wrong again. DO NOT CREATE MAZE WITH INTERACTIVE DOORS> IT IS NOT WORTH IT!!!!
Harcourt bug fix coming probably this weekend. Lots things fixed (mostly minor, but annoying). Spam me with reports (DISCORD) if you found something.
(will try to have a walkthrough for the endings within the month too)
#the trials and tribulations of edward harcourt#bug fixes#just don't#it works only with parser engines#because it's coded in there
10 notes
·
View notes
Text
For everyone who asked: a dialogue parser for BG3 alongside with the parsed dialogue for the newest patch. The parser is not mine, but its creator a) is amazing, b) wished to stay anonymous, and c) uploaded the parser to github - any future versions will be uploaded there first!
UPD: The parser was updated!! Now all the lines are parsed, AND there are new features like audio and dialogue tree visualisation. See below!
Patch 7 dialogue is uploaded!
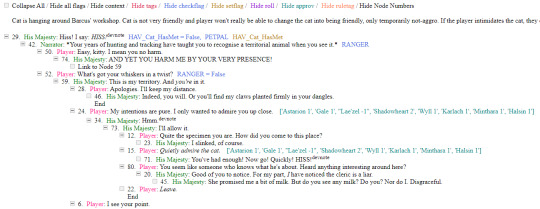
If you don't want to touch the parser and just want the dialogues, make sure to download the whole "BG3 ... (1.6)" folder and keep the "styles" folder within: it is needed for the html files functionality (hide/show certain types of information as per the menu at the top, jumps when you click on [jump], color for better readability, etc). See the image below for what it should look like. The formatting was borrowed from TORcommunity with their blessing.
If you want to run the parser yourself instead of downloading my parsed files, it's easy:
run bg3dialogreader.exe, OPEN any .pak file inside of your game's '\steamapps\common\Baldurs Gate 3\Data' folder,
select your language
press ‘LOAD’, it'll create a database file with all the tags, flags, etc.
Once that is done, press ‘EXPORT all dialogs to html’, and give it a minute or two to finish.
Find the parser dialogue in ‘Dialogs’ folder. If you move the folder elsewhere, move the ‘styles’ folder as well! It contains the styles you need for the color coding and functionality to keep working!
New features:
Once you've created the database (after step three above), you can also preview the dialogue trees inside of the parser and extract only what you need:

You can also listen to the correspinding audio files by clicking the line in the right window. But to do that, as the parser tells you, you need to download and put the filed from vgmstream-win64.zip inside of the parser's main folder (restart the parser after).
You can CONVERT the bg3 dialogue to the format that the Divinity Original Sin 2's Editor understands. That way, you can view the dialogues as trees! Unlike the html files, the trees don't show ALL the relevant information, but it's much easier to orient yourself in.


To get that, you DO need to have bought and installed Larian's previous game, Divinity Original Sin 2. It comes with a tool called 'The Divinity Engine 2'. Here you can read about how to unstall and lauch it. Once you have it, you need to load/create a project. We're trying to get to the point where the tool allows you to open the Dialog Editor. Then you can Open any bg3 dialogue file you want. And in case you want it, here's an in-depth Dialog Editor tutorial. But if you simply want to know how to open the Editor, here's the gist:
Update: In order to see the names of the speakers (up to ten), you can put the _merged.lsf file inside of the "\Divinity Original Sin 2\DefEd\Data\Public\[your project's name here]\RootTemplates\_merged.lsf" file path.
Feel free to ask if you have any questions! Please let me know if you modify the parser, I'd be curious to know what you added, and will possibly add it to the google drive.
2K notes
·
View notes
Text
Friday Fun-day Five-star day!
I kinda missed... 5/5-day organised by Jess Levine, where you rate 5 games on itch.io (because the algo sucks ass, and you should tell people that you liked their stuff). So I'm doing my part but a bit later. And maybe a bit more than once? like a Throwback-Thursday-When-I-Remember-It's-Thursday type of thing

friday fun-day 5-[star] day Sharing some of my favourite indie games
For this first FFF edition, here are 5 of my favourite IF games. Of varying sizes (5min-2h?), of varying themes, of varying mechanics, but all freaking great! 100% 5-star games in my book (and on itch)! It's hard to choose just five dams...
Computerfriend by Kit Riemer (@adz)
Vanitas by Sweetfish/Ayu (@sweetfishes)
SPILL YOUR GUT by Coral Nulla (@nullamirrors)
InGirum by BenyDanette
The Dying of the Light, by Amanda Walker
If you want some words about them, check below (+ links to reviews):
Computerfriend by Kit Riemer
I wrote a whole review about this game two years ago, but I still think about it often. It's so weird and nihilistic that it becomes strangely comforting. I've been coming back to it a couple of times this past year, especially when things gotten tough - I don't know if the bleakness that become so familiar I needed more of it? I keep finding new neat stuff every time somehow (that or I keep forgetting what I'd already seen).
It even has a mini-sequel! And I highly recommend Verses too (I didn't get it, but it's really good.
Vanitas by Sweetfish
It feels like since I reviewed it, this tiny game became even more relevant. Cohost is gone, Twitter is... something I guess, Reddit is even more a cesspool, and people keep moving around. What will the new flavour of the month be, before it gets enshittified too. I've also returned to it recently, when reading more about the Web Revival and working on my website. It's that comforting feeling that wherever we end up on the internet, we'll find each other.
SPILL YOUR GUT by Coral Nulla
This was part of the reviews that never made it to Tumblr (but you can read it here!), which is a shame, because more people should know about this game. Actually, they should know about the GUT trilogy (since, this is the third opus): GUT THE MOVIE (EctoComp/BareBones 2023), and the Sequel (Really Bad IF). And play it in order. They all hold a dear place in my hear, but I think the third one takes the cake. It's both the WTF-ness of it all, layered and layered and layered. You get lost so easily, within the mazes, and the prose, and the story. But it's worth it. Play each section of this game order though (or the final one won't hit as hard).
InGirum by BenyDanette
It's honestly a crime this game has like 3 ratings on itch (and I contributed to the 3rd this week, because I'd forgotten to do the English version when I reviewed it - and it's the only review on IFDB), or isn't streamed by people. It's so so SO good! You've got a pseudo-documentary style look over an anthology, with a calm but kind of creepy voice-over, bits of puzzle-like anxiety-riddling mini-games, and an interface that really blew me away. It truly brought the best of the bisty/binksi engine. Everything was so well planned, so well executed - it all makes sense in the context of the game.
And for the last one, I'll go with a parser.
The Dying of the Light by Amanda Walker
This was one of my truly favourite game published in 2023. It's difficult to play through it, but that makes the game even more compelling. I talked about it in my review of the game, that even its obvious mechanical flaws push the message further. Having passed some death anniversaries (relevant here) recently, I was reminded how true this game was, how raw it was, how devastating it was. And how understanding it was.
I hope yall check them out, maybe leave a rating or comment.
#interactive fiction#internet culture#complete#friday fun-day 5-star-day#5 for 5#itch.io#twine game#indie games
17 notes
·
View notes
Text
Version 598
youtube
windows
zip
exe
macOS
app
linux
tar.zst
I had a great week fixing bugs and cleaning code.
full changelog
fixing some mistakes
First off, I apologise to those who were hit by the 'serialisation' problems where certain importers were not saving correctly. I screwed up my import folder deduplication code last week; I had a test to make sure the deduplication transformation worked, but the test missed that some importers were not saving correctly afterwards. If you were hit by an import folder, subscription, or downloader page that would not save, this is now completely fixed. Nothing was damaged (it just could not save new work), and you do not have to do anything, so please just unpause anything that was paused and you should return to normal.
I hate having these errors, which are basically just a typo, so I have rejigged my testing regime to explicitly check for this with all my weekly changes. I hope it will not happen again, or at least not so stupidly. Let me know if you have any more trouble!
Relatedly, I went on a code-cleaning binge this week and hammered out a couple hundred 'linting' (code-checking) warnings, and found a handful of small true-positive problems in the mess. I've cleared out a whole haystack here, and I am determined to keep it clean, so future needles should stick out.
other stuff
I moved around a bunch of the checkboxes in the options dialog. Stuff that was in the options->tags and options->search pages is separated into file search, tag editing, and tag autocomplete tabs. The drag and drop options are also overhauled and moved to a new options->exporting page.
I rewrote the main 'ListBook' widget that the options dialog uses (where you have a list on the left that chooses panels on the right). If you have many tag services and they do not fit with the normal tabbed notebook, then under the new options->tag editing, you can now set to convert all tag service dialogs to use a ListBook instead. Everything works the same, it is just a different shape of widget.
A page that has no files selected now only uses the first n files (default 4096) to compute its 'selection tags' list when there are no files selected. This saves a bunch of update CPU time on big pages, particularly if you are looking at a big importer page that is continuously adding new files. You can change the n, including removing it entirely, under options->tag presentation.
If you are an advanced downloader maker, 'subsidiary page parsers' are now import/export/duplicate-able under the parsing UI.
job listing
I was recently contacted by a recruiter at Spellbrush, which is a research firm training AI models to produce anime characters, and now looking to get into games. I cannot apply for IRL reasons, and I am happy working on hydrus, but I talked with the guy and he was sensible and professional and understood the culture. There are several anime-fluent programmers in the hydrus community, so I offered to put the listings up on my weekly post today. If you have some experience and are interested in getting paid to do this, please check it out:
Spellbrush design and train the diffusion models powering both nijijourney and midjourney -- some of the largest-parameter count diffusion models in the world, with a unique focus on anime-style aesthetics. Our team is one of the strongest in the world, many of whom graduated from top universities like MIT and Harvard, worked on AI research at companies like Tencent, Google Deepmind, and Meta, and we have two international math olympiad medalists on our team.
We're looking for a generalist engineer to help us with various projects from architecting and building out our GPU orchestrator, to managing our data pipelines. We have one of the largest GPU inference clusters in the world outside of FAANG, spanning multiple physical datacenters. There's no shortage of interesting distributed systems and data challenges to solve when generating anime images at our scale.
Please note that this is not a remote role. We will sponsor work visas to Tokyo or San Francisco if necessary!
Software Engineer
AI Infra Engineer
next week
I did not find time for much duplicates auto-resolution work this week, so back to that.
0 notes
Text
Time to offer an actual breakdown of what's going on here for those who are are anti or disinterested in AI, and aren't familiar with how they work, because the replies are filled with discussions on how this is somehow a down-step in the engine or that this is a sign of model collapse.
And the situation is, as always, not so simple.
Different versions of the same generator always prompt differently. This has nothing to do with their specific capabilities, and everything to do with the way the technology works. New dataset means new weights, and as the text parser AI improves (and with it prompt understanding) you will get wildly different results from the same prompt.
The screencap was in .webp (ew) so I had to download it for my old man eyes to zoom in close enough to see the prompt, which is:
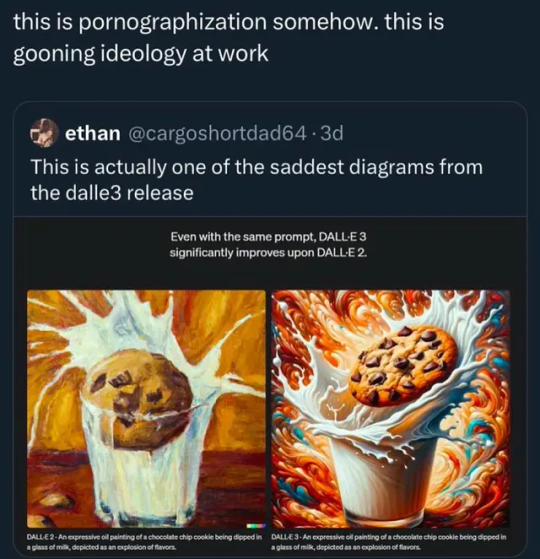
An expressive oil painting of a chocolate chip cookie being dipped in a glass of milk, represented as an explosion of flavors.
Now, the first thing we do when people make a claim about prompting, is we try it ourselves, so here's what I got with the most basic version of dall-e 3, the one I can access free thru bing:

Huh, that's weird. Minus a problem with the rim of the glass melting a bit, this certainly seems to be much more painterly than the example for #3 shown, and seems to be a wildly different style.



The other three generated with that prompt are closer to what the initial post shows, only with much more stability about the glass. See, most AI generators generate results in sets, usually four, and, as always:
Everything you see AI-wise online is curated, both positive and negative.*
You have no idea how many times the OP ran each prompt before getting the samples they used.
Earlier I had mentioned that the text parser improvements are an influence here, and here's why-
The original prompt reads:
An expressive oil painting of a chocolate chip cookie being dipped in a glass of milk, represented as an explosion of flavors.
V2 (at least in the sample) seems to have emphasized the bolded section, and seems to have interpreted "expressive" as "expressionist"


On the left, Dall-E2's cookie, on the right, Emil Nolde, Autumn Sea XII (Blue Water, Orange Clouds), 1910. Oil on canvas.
Expressionism being a specific school of art most people know from artists like Evard Munch. But "expressive" does not mean "expressionist" in art, there's lots of art that's very expressive but is not expressionist.
V3 still makes this error, but less so, because it's understanding of English is better.
V3 seems to have focused more on the section of the prompt I underlined, attempting to represent an explosion of flavors, and that language is going to point it toward advertising aesthetics because that's where the term 'explosion of flavor' is going to come up the most.
And because sex and food use the same advertising techniques, and are used as visual metaphors for one another, there's bound to be crossover.
But when we update the prompt to ask specifically for something more like the v2 image, things change fast:
An oil painting in the expressionist style of a chocolate chip cookie being dipped in a glass of milk, represented as an explosion of flavors, impasto, impressionism, detail from a larger work, amateur
We've moved the most important part (oil painting) to the front, put that it is in an expressionist style, added 'impasto' to tell it we want visible brush strokes, I added impressionism because the original gen had some picassoish touches and there's a lot of blurring between impressionism and expressionism, and then added "detail from a larger work" so it would be of a similar zoom-in quality, and 'amateur' because the original had a sort of rough learners' vibe.




Shown here with all four gens for full disclosure.
Boy howdy, that's a lot closer to the original image. Still higher detail, stronger light/dark balance, better textbook composition, and a much stronger attempt to look like an oil painting.
TL:DR The robot got smarter and stopped mistaking adjectives for art styles.
Also, this is just Dall-E 3, and Dall-E is not a measure for what AI image generators are capable of.
I've made this point before in this thread about actual AI workflows, and in many, many other places, but OpenAI makes tech demos, not products. They have powerful datasets because they have a lot of investor money and can train by raw brute force, but they don't really make any efforts to turn those demos into useful programs.
Midjourney and other services staying afloat on actual user subscriptions, on the other hand, may not have as powerful of a core dataset, but you can do a lot more with it because they have tools and workflows for those applications.
The "AI look" is really just the "basic settings" look.
It exists because of user image rating feedback that's used to refine the model. It tends to emphasize a strong light/dark contrast, shininess, and gloss, because those are appealing to a wide swath of users who just want to play with the fancy etch-a-sketch and make some pretty pictures.
Thing is, it's a numerical setting, one you can adjust on any generator worth its salt. And you can get out of it with prompting and with a half dozen style reference and personalization options the other generators have come up with.
As a demonstration, I set midjourney's --s (style) setting to 25 (which is my favored "what I ask for but not too unstable" preferred level when I'm not using moodboards or my personalization profile) and ran the original prompt:

3/4 are believably paintings at first glance, albeit a highly detailed one on #4, and any one could be iterated or inpainted to get even more painterly, something MJ's upscaler can also add in its 'creative' setting.
And with the revised prompt:

Couple of double cookies, but nothing remotely similar to what the original screencap showed for DE3.
*Unless you're looking at both the prompt and raw output.
original character designs vs sakimichan fanart
#ai tutorial#ai discourse#model collapse#dall-e 3#midjourney#chocolate chip cookie#impressionism#expressionism#art history#art#ai art#ai assisted art#ai myths
1K notes
·
View notes
Text
Capturing the ambience of skate. (2007)

We'll mainly be exploring the Xbox 360 version, as it offers the highest quality BIG sound archives. However, the PS3 release is seemingly more popular with modders.
Extract BIG archives
There are lots of tools out there, but look no further than big4f.
Converting Xbox 360 SNS audio
ea_multi_xma can unpack two stereo streams from each of the SNS quads.
Its companion, xma_parse AKA xma_test, can then be used to reveal the format of these. It also has other capabilities, but we won't be using them here:
xma_test.exe 00_Quad_Tunnels.sns_stream1
XMA/XMA2 stream parser 0.11 by hcs version: XMA2 offset: 0 block size: 8000 data size: 171800
We can use this information about our sns_stream1/sns_stream2 to author an appropriate vgmstream TXTH file:
codec = XMA2 channels = 2 sample_rate = 48000 num_samples = data_size

Converting PS3 SNS audio
Run EALayer3 on each SNS file to losslessly convert each to an MP3. However, this seemingly gets us only the forward two channels for each quad.
ealayer3.exe --parser-5 13_ArtGallery.sns
On both consoles, Skate's ambient tracks sound like they are subject to a high-pass filter when played back in-game.
Extracting MUS audio
Like other Electronic Arts games of its era, Skate's soundtrack is stored in chunks, within MUS archives. I ran into two snags here: one, there is apparently a distinct MUS format used by earlier EA games. And two, while MUS is apparently used by contemporaneous Need for Speed and The Sims games, I couldn't use this information to find a MUS extractor which suited my needs.

Fortunately I was able to find an archived QuickBMS script by AlphaTwentyThree which extracts MUS archives. He has a apparently also written some tools perfect for our task ("Electronic Arts mus extractor") but sadly, I couldn't find working downloads for them.
After dumping each MUS, run ea_multi_xma and then vgmstream as before. We will however, use a 48000 sample rate.
codec = XMA2 channels = 2 sample_rate = 48000 num_samples = data_size
His own guide recommends using xma_test to rebuild streams, but I found this unnecessary, at least in Skate's case. With your TXTH and executables in place, run this Windows batch script:
for %%i in (*.ea) DO ea_multi_xma.exe %%i for %%i in (*.ea_stream1) DO vgmstream-cli.exe %%i
Extracting ABK audio
These files, like B_Ball_Game.abk found inside the emitters BIG archive, can be played with vgmstream without any modifications.
Identifying sounds
Sadly I couldn't figure out where/how the game configures which emitters play in a given region.
Capturing footage
Free Skate mode allows you to disable Skate's HUD from the settings menu. You should also turn off visual effects to avoid the sepia overlay whenever our player-character is idle.

We can achieve free camera mode using tuukkas's free camera Cheat Engine table. You'll need an older (<0.0.28-15342) version of RPCS3 and the international edition of Skate, i.e. BLES00124. I recommend enabling the table's mouse-and-keyboard controls.
Skate can run at 60fps on emulators provided you have a capable machine. If you'd rather capture on Xenia (I couldn't find a free camera solution, sadly) be sure to disable vsync.
Appendix 0: Extracting other sounds
Some of Skate's VO and SFX files are mono, so adjust your TXTH accordingly.
Appendix 1: Extracting textures
See this and this.
Appendix 2: Extracting the secret garage band practice session
This the sub-streams of this ambient easter egg can be found inside the World_Stream MUS archive, spanning World_Stream_333 through World_Stream_357. Use the following TXTX. Note the empirically-determined sample count - it's 553 fewer than what vgmstream will erroneously you when you specify data_size.
codec = XMA2 channels = 1 sample_rate = 44100 num_samples = 1418711
1 note
·
View note
Text
Some code I've been meaning to perfect, but don't have the energy to.
I know this is a very sharp departure from what I used to post. I haven't had the energy to take them for a while; plus I'm fat now. Sorry about that. There was a good time when my boobs were big and the belly not as round -- more like triple-stacked -- but come on. We don't post nipples on this site.
I also didn't have enough energy to follow through on many of my things. A lot of them are still VERY USEFUL things to me at least, but everything's just too much of a drain. There's a possibility of someone also finding these things useful, so I figured a blog post will help make them somewhat findable with a search engine.
Well, I suppose GitHub pages would be a better place. But I've already got kind of a blog here...
Windows argument passing in node and cygwin
Python plistlib for openstep formats
Windows argument passing
The thing about command-line on Windows is that it's the wild west. Programs do not actually receive an argv[] array like you have been conditioned by C to believe; instead they get a "cmdline" string to do whatever the hell they want with it.
Still, in that sea of insanity, there is one constant. Regular programmers are lazy. They just use whatever the runtime library does with the command line. In these cases you get a somewhat predictable behavior -- "somewhat", because even amount Microsoft runtimes the behavior differs -- and you can write some sort of an escaping function.
Beyond the runtime, cmd.exe also has its own understanding of how quoting works. Most disgustingly, it understands where double-quoted parts start and end differently from msvcrt. I've got a trick for that.
Node
The node PR, at https://github.com/nodejs/node/pull/29576, is focused on quoting. It's got proper quoting for bash, pwsh, and cmd + msvcrt. It's got very strong test cases (throw them at other people's things: they might break!) and good documentation. What it didn't have is communication and rizz. You're advised to skip to the "files changed" tab.
The cmd "trick" is explained at https://github.com/Artoria2e5/node/blob/c0a6aff35cd3ff6d3bd0e3687776158e97466c93/lib/child_process.js#L850. The gist is that msvcrt and .NET treats two double-quotes as if it's an escaped double-quote. It's undocumented, sure, but Microsoft's own code relies on it.
doc/api/child_process.md has a good chunk of text explaining how Windows cmdline works and who deviates from the norm. And that leads to our next suspect: Cygwin.
Cygwin
Cygwin is the way to run POSIX things on Windows these days. Sure there's MSYS2, but guess what? It's a Cygwin fork. If you are using the official Windows build of git, you're using MSYS2, which in turn means you're using Cygwin code.
Cygwin is not msvcrt, obviously. But what's less obvious is that it doesn't process cmdline the same way. That bites you HARD when you want to run a Cygwin program on a file with weird characters.
The patchset at https://github.com/mirror/newlib-cygwin/pull/5, formerly a botched e-mail exchange ending with me being too tired to split the patchset (come on, it's almost impossible to have intermediate stages that build, let alone work!), was my answer to the problem. It rewrites the cmdline parser to be msvcrt-compatible, while still keeping the Unix-style globbing and @-expansion features.
It's fucking awesome is what it was. It's written in C++ with in-place processing. What else can you ask for.
Oh, in case you want to know what my current answer to the problem is: roll into a ball and cry.
Openstep plistlib
So if you use an Apple product and do things that Apple don't really like you to do, you have probably came across a "plist". Nowadays plists are either an opaque binary file or a very wordy XML. Back in the good old days plists were not like that at all: they read more like JSON, except they only supported strings and dicts.
Python's plistlib does not care about the old style. It should, because it's fucking beautiful. It's also as functional as the new stuff is, as long as you use the GNUStep extensions.
I wrote a Python package to do just that (or did I? does it work yet?). https://github.com/Artoria2e5/text-plistlib As far as I can recall it works on a round-trip smoke test, but some extension decisions needed to be hammered out. It uses tatsu though, so there's no chance of getting into the plistlib part of the standard library.
I think I've also got some other things related to this plist format open somewhere. I wanted to write a parser for opencore to cut down on this XML misery, but COME ON IT'S C. I can't even keep track of a plain recursive descent parser in Python (why else am I using a parser generator?), to do it in C? No way. I'm also too lazy to learn yacc, thank you very much.
Other things
something about https://marc.info/?l=openssh-unix-dev&m=168509072920594&w=2
Dream the DRM receiver/broadcaster has bad Opus options. Dev said I should open a branch. I think I can't, because I can't even get the official binary to run. I also lost my slightly illegal SDR kit.
I've definitely forgotten older things.
0 notes
Text
Top 5 AI projects in 2023

Introduction AI isn't just for the biggest tech companies in the world. Fortunately, many small-scale firms may benefit from AI technology by implementing creative AI concepts. Even a shopkeeper may utilize AI technology to keep track of his goods since the software tools needed to construct and deploy the AI are so inexpensive.
The field of research and development, which foresees AI's unavoidable continued expansion and existence in the future, empowers AI to have stronger learning and assessment skills. This is the perfect time to start working on AI projects if you're interested in technology.
In this article, we'll discuss various AI project ideas to aid in your understanding of how AI operates.
Firstly, What is AI? Artificial intelligence, or AI, is the ability that robots have to evaluate and carry out activities on their own, without assistance from a human. AI uses machine learning techniques to automate and make devices self-sufficient.
There are four types of AI: Reactive Machine Limited Memory AI Machines Theory of Mind Self Aware AI
Engineering and programming are necessary for the creation of AI. To integrate these two fields of expertise, you'll need a strong education and dedication, but the numerous job alternatives and lucrative payoffs are well worth the effort.
The typical annual income for an AI expert is $125,000, and a variety of positions are available, including machine learning engineer, data scientist, and business intelligence developer. We heartily recommend taking courses like Skillslash's Advanced Data Science & AI course, Business analytics course, etc. if you're interested in studying the principles of AI.
The computer and space industries are not the only ones using AI. Your smart Televisions, smartphones, and even speakers all include artificial intelligence. As AI touches practically every business, you have a wide range of project ideas and career opportunities at your disposal. It has the potential to take the place of people in various occupations. Yet along with such replacements will come a demand for AI specialists in the industry. As a result, AI is the ability of the century, and we as a species are continuously discovering new applications for it.
AI Projects to Practice Below are some great AI Projects to start working on in 2023:
Prediction of Stock Prices - A stock price predictor is among the simplest AI project ideas for beginners. For AI experts, the stock market has long been of interest. Why? because the stock market contains so much densely packed information. Several datasets are available for you to work with.
Also, this project is a fantastic chance for students who want to learn how the finance sector functions and are interested in pursuing careers in finance. Remember that the feedback loop on the stock market is rather small. As a consequence, your forecast algorithm, which you employed for the AI, is verified.
You may start by predicting the 3-month price variation of equities utilizing data from open data sources and the shown historical inflation of the stocks. These two will serve as your algorithm's main building blocks. To develop your stock predictor, you may also utilize the LSTM model and Plotly dash Python framework.
Resume Parser - HR managers sift through the stack of applications for hours looking for the ideal applicant for a vacancy. Finding the perfect résumé is simple thanks to AI, though. Build an AI-based resume parser that analyzes resumes using keyword recognition. You may use keywords to tell the AI system to look for certain qualifications and experiences.
However, keep in mind that this screening procedure may also have disadvantages. As many candidates are aware of keyword matching algorithms, they attempt to game the system by stuffing their resumes with as many keywords as they can.
It's an excellent practice to develop an AI system that scans resumes for anything suspect by looking at both the keywords and how frequently they are used. To do this, you may utilize the Kaggle dataset to build the model for the project. The title and the candidate's resume's information are the only two columns in the dataset.
Using the NLTK Python package, you may pre-process the data. Following that, you may create the clustering method, which enables you to group the terms and talents that an applicant must possess in order to be hired.
Detection of Instagram Spam - Many spam messages from persons attempting to sell them an MLL or other item have been reported by several Instagram users. You can identify these spam comments and messages using an Instagram spam detector, however there isn't a reliable dataset online that can teach your app about spam comments.
To begin, use Python to query the Instagram API and retrieve all unlabeled comments that have been posted on Instagram. Utilize keywords to identify which comments should be flagged as spam after training the AI using data from Kaggle's YouTube spam collection.
You can also employ the N-Gram method, which gives greater weight to phrases that appear more frequently in spam comments. After that, you may contrast these terms with online escape remarks. Instead, you may use a distance-based method like cosine similarity. Depending on the kind of preprocessing you do at the beginning, these may produce findings that are more accurate.
Chatbot - When clients visit a company's website, chatbots provide them with rapid support. Using proven frameworks that are currently utilized by several MNCs for their websites, you may construct an AI chatbot. Identify the most frequent user inquiries and sketch out the various conversational processes to create a successful chatbot. Before integrating the modules into the chatbot dialogue, add the logic. If you decide to make a chatbot, make sure to properly test it before making it available to the general public. To check for any possible problems, get individuals to test it out. Choose the appropriate platform to display the capabilities of your AI chatbot after training it.
E-commerce Product Recommendation System - You can see advertisements for e-commerce items on your social networking profiles. Why? It is a result of AI. To provide e-commerce suggestions, the AI algorithm uses information from your prior purchases and website visits. But, a lot of companies are increasingly making spur-of-the-moment ideas. As they employ AI to study how each user interacts with and selects things on their website.
You'll need an existing framework that makes use of machine learning algorithms before you can construct an AI project for recommending products for use in online commerce. Machine learning methods for recommendation systems fall into two types. The collaboration comes first, followed by content-based filtering. Yet, if you want to create your own version, you should unquestionably combine the two.
Conclusion AI is a fascinating field of technology that will continue to have a major impact on how we live our lives. Try out the aforementioned AI projects to familiarize yourself with the resource and increase your understanding. And if you want a sturdier grasp on this subject, Skillslash's courses (as mentioned above) are always there for support and guidance. The real-work experience provided by Skillslash is undoubtedly one of the best in the market today and truly worth the trial.
0 notes
Text
To answer your question, yes, they can and do search the internet (if asked, and if the specific bot supports it).
The llm itself, in most reasonable setups, is basically a parser for user intent. That's why it's not really that big of a deal that they guess the next token - that's the best thing they *could* do. They don't need to "know" things. They just need to be able to guess what the user means without expecting exact string literals, and be able to guess tokens to put together useable language, and synthesize data fed to them from other functions.
User asks a question, optionally telling the llm to search online. The llm outputs a function call requesting internet search of the inference code. Inference code catches this, runs a number of searches (anywhere from one to several tens, depending on the bot, the user, and the content), related data is sniffed from the search, usually by a smaller model, and passed back to the llm, who's job is then to summarize for the user. This isn't the only way they can reference data, but is in a sense a sort of web-mediated Retrieval Augmented Generation, which works the same way - documents are converted into a vector database for fast indexing of "what" and "where". User asks a question. Smaller model queries vector DB for relation to user input. If matches are found, relevant text is passed to the llm to summarise back to the user. This is one way that LLMs can be adapted to certain domains - by making domain specific data available to them. (and finetuning but thats in the weeds from here)
and on the topic of internet search and RAG, small local models can do this, as well, with plugins to search the internet, as can the models of most inference providers.
Though, depending on what the model has been trained on, it can sometimes have a useable knowledge for certain domains without access to the internet, but, in general, yes, the llm itself is a 3 dimensional array of floating point values that spits a response. a text engine. But it's only the language core. Which is adapted for different use cases by inference code. This is one reason LLMs and AI based on them are difficult to discourse about meaningfully, because we could be talking about the model (a set of frozen floating point values in memory) or its interface, or the functions made available to it, or the output of all of that, together, and most people only have the barest grasp of what the model even is, let alone to throw in the complexity of functions that may or may not be there depending on the software surrounding the model in the implementation.
tldr; yes they can google and how much they can google is alterable at inference time in code. The default for openrouter is five max searches per query but this can be changed by passing a parameter to the models api at inference time.
one of the things that really pisses me off about how companies are framing the narrative on text generators is that they've gone out of their way to establish that the primary thing they are For is to be asked questions, like factual questions, when this is in no sense what they're inherently good at and given how they work it's miraculous that it ever works at all.
They've even got people calling it a "ChatGPT search". Now, correct me if I'm wrong software mutuals, but as i understand it, no searching is actually happening, right? Not in the moment when you ask the question. Maybe this varies across interfaces; maybe the one they've got plugged into Google is in some sense responding to content fed to it in the moment out of a conventional web search, but your like chatbot interface LLM isn't searching shit is it, it's working off data it's already been trained on and it can only work off something that isn't in there if you feed it the new text
i would be far less annoyed if they were still pitching them as like virtual buddies you can talk to or short story generators or programs that can rephrase and edit text that you feed to them
76 notes
·
View notes
Text
Here’s some resources to help you make text-based interactive fiction games!
Totally unprompted! There’s certainly nothing going on in a certain forum right now (or rather an on-going issue). Nope, I just thought it would be nice to share some resources. ;)
-----
Twine
Twine is such an easy tool to use. It uses its own scripting language Sugarcube (there’s also Harlowe and Snowman, but they don’t have the same functionality and creator support as Sugarcube does to my knowledge), Javascript, and CSS.
Twine is FREE!!!
Sugarcube literally gives you a save function (which does browser and save to desktop)!!! Be the save-hoarding goblin you were born to be!
It’s criminally easy to make games with Twine. They make it easy to make stats, relationships, and other info pages. When setting up the paths you can literally see arrows pointing where they lead, you can move passages around visually so you can group them up by chapter/scene/etc......to be fair once your game gets BIG it can get messy and confusing.
I have coding experience prior to finding Twine, but I’m absolutely certain anyone can make great games with Twine. If all your doing is making text-based ‘more story than game’ games, then you’ll be doing minimal coding (setting variables, if/else statements, using text boxes, etc) so you shouldn’t have any issues.
If you do have issues I’m 99% certain someone has had your issue before, and the answer is one google search away.
You can use Twine in your browser, just be careful to not mess with the data/cookies or you can lose your games (totally not speaking from experience)....archive your games often if you use Twine in browser. You can also download Twine, so you can use it offline!
Links:
Twine
SugarCube v2 Documentation - Your new best friend.
With the Settings API you can add a mature filter, different style themes (great for light/dark themes and color blind themes...or just different themes to look cool), difficulty settings, volume control, etc.
HiEv’s SugarCube 2 Sample Code - An ever-expanding collection of code, tips, macros, widgets. A good mix of fun and useful stuff.
^ Includes a great pronoun widget!!! To be fair it’s not the most user-friendly widget at first, especially if you aren’t a coder, but in the long run a widget like this is a great tool for customizing pronouns. It allows you to write a character in the code with one set of pronouns throughout the game ($They $are a great $person), the widget selects the correct word through an switch (aka a fancy if/else) statement when the character is assigned a pronoun......so when playing a female it would display as “She is a great girl”, a male would be “He is a great guy”, and nonbinary would be “They are a great person”. You can add neopronouns this way too!
Chapel’s custom macros - Chapel has a lot of cool macros, but a lot of them are more advanced. Very few have been useful for the kinds of games I want to make, but they may be useful for you.
r/twinegames - Twine has some older forums, which are still up (though not active) and have helpful answers on them, but the current forum is found on reddit.
w3schools - When it’s time to style your game, this will be your lifeline. Even today, like...seven years after first learning CSS I still come back to w3schools all the time. !!!Twine has funky class/id selectors for it’s built in stuff so refer back to the SugarCube Documentation!!!
-----
Itch.io
Itch doesn’t take ownership of your content!
It doesn’t have DRM!
You can host your games for free, paid, or free with donation.
It does take a cut of your sales “The Company shall be entitled to a share of the revenue Publishers receive from Transactions which shall be calculated on the gross revenue from the Transactions“ (I’ve seen 30% but I’ve also seen “Lets you choose what to give them” so I’m not exactly sure how much their cut is).
THERE IS NO RESTRICTION ON CONTENT ASSUMING IT’S LEGAL (though if collecting payment you may be under different restrictions per the payment provider’s policy), so please make all the twisted, dark, disturbing, and/or sexual games you want!!!
Links:
Itch.io
-----
r/interactivefictions
r/interactivefictions is a good place for game recs, coding/writing resources, etc.
Links:
r/interactivefictions
-----
Tumblr
Tumblr is...well we’re all on here so we know how tumblr is like.
Great tags to look at: #interactive fiction, #interactive novel, #interactive game, #twine game, #dev log, #IF, #if game, #upcoming game, #promo post
Tumblr is a great platform, but as every creator knows...Reblog!!! Reblog!!! Reblog!!! The lifeblood of tumblr is reblogging.
I’ve found SOOOO many games I would never have known existed through if-creator’s blogs just because they reblogged a post from another if-creator.
@interact-if and @iorifd are doing great work! They collect games, share helpful coding/writing tips, etc. Go show them some love! Interact-if runs the subreddit mentioned above, and iorifd is working on a database for visual novels and text-based games.
-----
IFDB (Interactive Fiction Database)
IFDB is a database for interactive fiction games. You can add new game listings, write reviews, make game polls, make game recommendation lists, etc.
IFDB seems to like their parser games (parsers being where you type in commands like “go west”, “open door”, etc).
It actually has a pretty good filter and ignore system.
Links:
IFDB
-----
Obviously this isn’t the end all be all of dev tools or hosting platforms for interactive fiction. Ink is a scripting tool similar to Twine I’ve only heard of recently that might be interesting to you. Ren’Py, although primarily a visual novel engine, can be used to make text-based games. The only other hosting alternative I know is DashingDon, I THINK they only host ChoiceScript games and I don’t think you can sell through them, but it’s a good place regardless.
Cheers! :D
#Game development#Interactive Fiction#IF#IF game#Twine#I want to start making games...I know the coding part...it's just the story and writing part :////#lmaoooo maybe some day#for now I will continue to enjoy IFs from the sidelines
458 notes
·
View notes
Text
ParserComp 2022 Review: Desrosier's Discovery
Play here: https://benergize.itch.io/desrosiers-discovery
To be brief: Desrosier's Discovery was a mixed bag for me.
I think it should be noted outright that this was apparently a homebrew parser engine, and I think that despite anything else I might say that's an incredible achievement. It worked well, has a clean look, and I would honestly love to try coding in it in the future. Well done to the team on that one.
Perhaps the only technical note there: I'd love to be able to hit Enter to advance the prompt even when I'm not clicked into the dialog box. Now onto the game itself.
In Desrosier's Discovery, you are tasked with responding to a professor's mysterious summons. You do so by exploring Drescott Island to try and figure out what exactly has happened to the professor's dig site.
The story and execution are simple and engaging, offering a clear hook from the beginning.
However, I got tripped up a bit in the actual content of the game. I breezed through as many endings as I could find (a rarity for me, so it says quite a bit that I really did want to stick with this game), somehow never scoring above "Apprentice" - I clearly must be missing something, but found it difficult to ascertain *what*. There are apparently more tidbits to be found, but they're not obvious enough to push through the noise of everything that's going on. The simplicity of the engine makes it harder to highlight items or objects, so I think I'd like to see more obvious clues in the text.
Similarly, I found the humor hit or miss. There were a few genuinely funny moments, and a few that just felt distasteful. But that's a personal preference, not a technical criticism.
In many ways, this game feels a bit like a wacky fever dream. It's quick, easily repeated, entertaining, and liable to go in any direction it wants. It has some perfectly charming moments, but I don't think this one worked for me in the way I was hoping.
Still, I absolutely applaud the authors' ingenuity and clarity of vision.
4 notes
·
View notes
Text
Weekly devlog, 2022-07-18
Enemy scripting is almost done! This is one of the last major systems that needs to be implemented in the engine, and once it is fully working it will make it much easier to design levels that are interesting and challenging.
There's four major parts to the system: data structures to represent the AI, a parser to load the scripts from files, the actual execution of the scripts, and a preliminary compiler that will let me translate human-readable scripts into a terse, easy-to-parse format. While the parser is working great, I have yet to actually write the compiler, so for the time being I've had to manipulate the terse files by hand, which is... suboptimal. But last time I had to write this kind of compiler (for the dialogue system) it only took a day or two, so I'm optimistic.
A lot of the work of debugging this system was done live on my twitch channel today! I plan to do this with some regularity (once every week or two), although sometimes the things I'm working on won't lend themselves well to streaming. Follow EpiglottalAxolotl on Twitch if you're interested in seeing this in the future.
5 notes
·
View notes
Text
Oh I def meant code reuse, but also there would need to be a fair amount of encapsulation even for one-shot sections of a program so the user could refer to them easily. The language would have to be pretty hierarchical in order to facilitate navigation among its parts with an audio interface. There's probably a best practice around verbose naming so that, at its best, the higher-level overview sounds like a story.
As for the linguistics angle, you would probably use only five or six vowel-ranges for all commands to avoid ambiguity. The most common of those (editing, navigation, variable assignment, looping, conditional, mathematical, &c.) would be the shortest. I think it'd be 2-3 syllable combinations for most of that stuff to avoid ambiguity. Single-syllable words should be reserved for ultra-frequent things like "start line" and "open group", while a simple prefix could change the meaning to "end line" or "close group". The parser would do a lot of work detecting instances when endings like that should be implied so the user can safely forget...
There's a LOT of details, but in broad strokes I see no reason it wouldn't work just fine. If we wanted to I'll bet we could hack together a prototype in a few months time. VTT engines are pretty advanced now so the hard work's already been done, really. Still, it probably IS too much yack.
And I liked the comedy sketch about vocal punctuation. Making the system take so long to execute that the meaning of the text is just buried is hilarious!
This seems like it is relevant to @kithpendragon ‘s interests
5 notes
·
View notes
Text
Magor Investigates… by Larry Horsfield
============= Links
Play the game See other reviews of the game See other games by Larry
============= Synopsis
You are Magor, court sorcerer to King Kelson Haldane, the young king of the kingdom of Hecate. You are in your chambers, having just had a herald bring the news that the king and Duke Alaric Blackmoon have arrived back from their journey to the Great Sand Sea to investigate reports of Xixon lizardmen being seen down there. The herald also told you, most unusually, that Kelson & Alaric will be coming to see YOU instead of you having to go to the king's audience chamber and that the visit will be informal, so no bowing will be required. You wonder what tales they will have to tell you? "Fancy that," you think to yourself. "The king coming to see me!"….
============= Other Info
Magor Investigates… is an ADRIFT parser, submitted to the 2023 Edition of the IFComp. It was ranked 64th overall. This is the 4th instalment of the Adventures in the World of Alaric Blackmoon series. (this is the first one I've played)
Status: Completed Genre: Fantasy
CW: /
============= Playthrough
Played: 13-Dec-2023 Playtime: around 30min Rating: 3 /5 Thoughts: But we investigate little...
============= Review
Magor Investigates... is a relatively short linear parser, where you play Magor, the court's sorcerer. Though the game is part of a series and a larger universe, it is not required to have played other instalments to complete this game (relevant information is provided in-game). In this entry, you are tasked by the king to work some genealogy magic and find whether the monarch has some relations to another crowned head. While there is no walkthrough, a comprehensive hint system is implemented.
Spoilers ahead. It is recommended to play the game first. The review is based on my understanding/reading of the story.
This was a quaint and low-stake little game. With the return of the King after a difficult quest, you are given the simple (though maybe tedious task) to trace back your monarch's lineage and hopefully find a connection to another royal family. But oh, no! the Archivist is down with a bad stomach ache and can't let you browse to your heart's content. Good news! Being a sorcerer, you have an extensive library, which includes a tome on remedies. Fix up the concoction, nurse the archivist, go back to your main task, and report back to the King. End Credits!
From the premise, and the length advertised on the IFComp website at an hour and a half, I... expected more. Even though I loved the cozy and low stake vibes of the game (with a non-existent difficulty, and super well hinted actions), I was done within a third of the expected time, having completed the 9 out of 10 tasks. The discussions with other NPC are triggered after an action, which you (the player) do not control/cannot change (you can't ask people questions). This is a bit of a shame, because those discussions are at times lengthy (had to scroll back up at multiple occasions), and could have been broken into multiple actions. As for the investigation, only one action is require before the task is complete. And even if the game includes many room, the engine does not let you explore much of it, as it tries to railroad you into one specific path.
Another gripe I had with this game was the visual aspect. I am all for funky and bright interfaces, but the use of this particular palette with the Comic Sans font was quite painful to the eye. And when you have long block of texts on the screen, it is not really comfortable to read. For this aspect, I was kinda glad the game was fairly short.
It was a cute short game, otherwise.
#Magor Investigates...#Larry Horsfield#interactive fiction#complete#2023#review#ifcomp#adrift game#parser
3 notes
·
View notes
Text
How NodeJS works behind the scene?

let's start by learning a little bit about Node working. So let's represent that structure in terms of Node dependence, which is a few libraries on which Node depends for efficiency. Node operating time, therefore, has several dependencies, and most important:
V8 engine
libuv
Node is a JavaScript run time based on Google's V8 engine, right? And then, that’s why it seems as a dependency. If it were not for the V8, Node would have no way of understanding the JavaScript code.
What is V8 engine?
And of course, the V8 is an important part of the Node architecture. Also, the V8 engine is the one that converts JavaScript code into machine code that a computer can actually understand. And the V8 itself is written in C ++ code. But that alone isn't enough to create a whole server-side like Node. And that’s why we also have libuv in Node.
What is Libuv?
And libuv is an open-source library with a strong focus on asynchronous IO. This layer is what gives Node access to a working computer program, file system, communications, and more. The important thing to note is that libuv is actually written entirely in C ++ and not in JavaScript. Apart from that, libuv also uses two of the most important features of Node.JS:
The event loop
The thread pool
And in simple terms, the event loop is responsible for handling simple tasks such as using telephones and network cables while the thread pool is for heavy work such as file access or compression or something like that. Node itself is a program written in C ++ and JavaScript and not just JavaScript. Now the beauty of this is that Node.JS binds all these libraries together, whether written in C ++ or JavaScript, and gives developers access to their works with pure JavaScript. So it really gives us a really good layer of extraction to make our lives a lot easier instead of liking dirt with the C ++ code. That would be a terrible thing, wouldn't it? So again, this build allows us to write 100 percent pure JavaScript code, working with Node.JS and still accessing functions such as file readings, background scenes actually used in libuv or other libraries in the C ++ language. And when it comes to other libraries, Node actually relies not only on V8 and Libuv, but also on the HTTP-parser to split HTTP, ic-ares, or something similar for certain DNS application objects, OpenSSL for Keepography, and compression.
So at the end, when all these pieces fit together properly, we end up with Node.JS ready to be used in server-side applications. And next, you'll learn more about the Node threads and the event loop.
So stay tuned for that.
2 notes
·
View notes
Text
50 Most Important Artificial Intelligence Interview Questions and Answers

Artificial Intelligence is one of the most happening fields today and the demand for AI jobs and professionals with the right skills is huge. Businesses are projected to invest heavily in artificial intelligence and machine learning in the coming years. This will lead to an increased demand for such professionals with AI skills who can help them revolutionize business operations for better productivity and profits. If you are preparing for an AI-related job interview, you can check out these AI interview questions and answers that will give you a good grip on the subject matter.
1. What is Artificial Intelligence?
Artificial intelligence, also known as machine intelligence, focuses on creating machines that can behave like humans. It is one of the wide-ranging branches of computer science which deals with the creation of smart machines that can perform tasks that usually need human intelligence. Google’s search engine is one of the most common examples of artificial intelligence.
2. What are the different domains of Artificial Intelligence?
Artificial intelligence mainly has six different domains. These are neural networks, machine learning, expert systems, robotics, fuzzy logic systems, natural language processing are the different domains of artificial intelligence. Together they help in creating an environment where machines mimic human behavior and do tasks that are usually done by them.
3. What are the different types of Artificial Intelligence?
There are seven different types of artificial intelligence. They are limited memory AI, Reactive Machines AI, Self Aware AI, Theory of Mind AI, Artificial General Intelligence (AGI), Artificial Narrow Intelligence (ANI) and Artificial Superhuman Intelligence (ASI). These different types of artificial intelligence differ in the form of complexities, ranging from basic to the most advanced ones.
4. What are the areas of application of Artificial Intelligence?
Artificial intelligence finds its application across various sectors. Speech recognition, computing, humanoid robots, computer software, bioinformatics, aeronautics and space are some of the areas where artificial intelligence can be used.
5. What is the agent in Artificial Intelligence ?
Agents can involve programs, humans and robots, and are something that perceives the environment through sensors and acts upon it with the help of effectors. Some of the different types of agents are goal-based agents, simple reflex agent, model-based reflex agent, learning agent and utility-based agent.
6. What is Generality in Artificial Intelligence?
It is the simplicity with which the method can be made suitable for different domains of application. It also means how the agent responds to unknown or new data. If it manages to predict a better outcome depending on the environment, it can be termed as a good agent. Likewise, if it does not respond to the unknown or new data, it can be called a bad agent. The more generalized the algorithm is, the better it is.
7. What is the use of semantic analyses in Artificial Intelligence?
Semantic analysis is used for extracting the meaning from the group of sentences in artificial intelligence. The semantic technology classifies the rational arrangement of sentences to recognize the relevant elements and recognize the topic.
8. What is an Artificial Intelligence Neural Network?
An artificial neural network is basically an interconnected group of nodes which takes inspiration from the simplification of neurons in a human brain. They can create models that exactly imitate the working of a biological brain. These models can recognize speech and objects as humans do.
9. What is a Dropout?
It is a tool that prevents a neural network from overfitting. It can further be classified as a regularization technique that is patented by Google to reduce overfitting in neural networks. This is achieved by preventing composite co-adaptations on training data. The word dropout refers to dropping out units in a neural network.
10. How can Tensor Flow run on Hadoop?
The path of the file needs to be changed for reading and writing data for an HDFS path.
11. Where can the Bayes rule be used in Artificial Intelligence?
It can be used to answer probabilistic queries that are conditioned on one piece of evidence. It can easily calculate the subsequent step of the robot when the current executed step is given. Bayes' rule finds its wide application in weather forecasting.
12. How many terms are required for building a Bayes model?
Only three terms are required for building a Bayes model. These three terms include two unconditional probabilities and one conditional probability.
13. What is the result between a node and its predecessors when creating a Bayesian network?
The result is that a node can provisionally remain independent of its precursor. For constructing Bayesian networks, the semantics were led to the consequence to derive this method.
14. How can a Bayesian network be used to solve a query?
The network must be a part of the joint distribution after which it can resolve a query once all the relevant joint entries are added. The Bayesian network presents a holistic model for its variables and their relationships. Due to this, it can easily respond to probabilistic questions about them.
15. What is prolog in Artificial Intelligence?
Prolog is a logic-based programming language in artificial intelligence. It is also a short for programming logic and is widely used in the applications of artificial intelligence, especially expert systems.
17. How are artificial learning and machine learning related to each other?
Machine learning is a subset of artificial learning and involves training machines in a manner by which they behave like humans without being clearly programmed. Artificial intelligence can be considered as a wider concept of machines where they can execute tasks that humans can consider smart. It also considers giving machines the access to information and making them learn on their own.
18. What is the difference between best-first search and breadth-first search?
They are similar strategies in which best-first search involves the expansion of nodes in acceptance with the evaluation function. For the latter, the expansion is in acceptance with the cost function of the parent node. Breadth-first search is always complete and will find solutions if they exist. It will find the best solution based on the available resources.
19. What is a Top-Down Parser?
It is something that hypothesizes a sentence and predicts lower-level constituents until the time when individual pre-terminal symbols are generated. It can be considered as a parsing strategy through which the highest level of the parse tree is looked upon first and it will be worked down with the help of rewriting grammar rules. An example of this could be the LL parsers that use the top-down parsing strategy.
20. On which search method is A* algorithm based?
It is based on the best first search method because it highlights optimization, path and different characteristics. When search algorithms have optimality, they will always find the best possible solution. In this case, it would be about finding the shortest route to the finish state.
21. Which is not a popular property of a logical rule-based system?
Attachment is a property that is not considered desirable in a logical rule-based system in artificial intelligence.
22. When can an algorithm be considered to be complete?
When an algorithm terminates with an answer when one exists, it can be said to be complete. Further, if an algorithm can guarantee a correct answer for any random input, it can be considered complete. If answers do not exist, it should guarantee to return failure.
23. How can different logical expressions look identical?
They can look identical with the help of the unification process. In unification, the lifted inference rules need substitutions through which different logical expressions can look identical. The unify algorithm combines two sentences to return a unifier.
24. How Does Partial order involve?
It involves searching for possible plans rather than possible situations. The primary idea involves generating a plan piece by piece. A partial order can be considered a binary relation that is antisymmetric, reflexive and transitive.
25. What are the two steps involved in constructing a plan ?
The first step is to add an operator, followed by adding an ordering constraint between operators. The planning process in Artificial Intelligence is primarily about decision-making of robots or computer programs to achieve the desired objectives. It will involve choosing actions in a sequence that will work systematically towards solving the given problems.
26. What is the difference between classical AI and statistical AI?
Classical AI is related to deductive thought that is given as constraints, while statistical AI is related to inductive thought that involves a pattern, trend induction, etc. Another major difference is that C++ is the favorite language of statistical AI, while LISP is the favorite language of classical AI. However, for a system to be truly intelligent, it will require the properties of deductive and inductive thought.
27. What does a production rule involve?
It involves a sequence of steps and a set of rules. A production system, also known as a production rule system, is used to provide artificial intelligence. The rules are about behavior and also the mechanism required to follow those rules.
28 .What are FOPL and its role in Artificial Intelligence?
First Order Predicate Logic (FOPL) provides a language that can be used to express assertions. It also provides an inference system to deductive apparatus. It involves quantification over simple variables and they can be seen only inside a predicate. It gives reasoning about functions, relations and world entities.
29 What does FOPL language include?
It includes a set of variables, predicate symbols, constant symbols, function symbols, logical connective, existential quantifier and a universal quantifier. The wffs that are obtained will be according to the FOPL and will represent the factual information of AI studies.
30. What is the role of the third component in the planning system?
Its role is to detect the solutions to problems when they are found. search method is the one that consumes less memory. It is basically a traversal technique due to which less space is occupied in memory. The algorithm is recursive in nature and makes use of backtracking.
31. What are the components of a hybrid Bayesian network?
The hybrid Bayesian network components include continuous and discrete variables. The conditional probability distributions are used as numerical inputs. One of the common examples of the hybrid Bayesian network is the conditional linear Gaussian (CLG) model.
32. How can inductive methods be combined with the power of first-order representations?
Inductive methods can be combined with first-order representations with the help of inductive logic programming.
33. What needs to be satisfied in inductive logic programming?
Inductive logic programming is one of the areas of symbolic artificial intelligence. It makes use of logic programming that is used to represent background knowledge, hypotheses and examples. To satisfy the entailment constraint, the inductive logic programming must prepare a set of sentences for the hypothesis.
34. What is a heuristic function?
Also simply known as heuristic, a heuristic function is a function that helps rank alternatives in search algorithms. This is done at each branching step which is based on the existing information that decides the branch that must be followed. It involves the ranking of alternatives at each step which is based on the information that helps decide which branch must be followed.
35. What are scripts and frames in artificial intelligence?
Scripts are used in natural language systems that help organize a knowledge repository of the situations. It can also be considered a structure through which a set of circumstances can be expected to follow one after the other. It is very similar to a chain of situations or a thought sequence. Frames are a type of semantic networks and are one of the recognized ways of showcasing non-procedural information.
36. How can a logical inference algorithm be solved in Propositional Logic?
Logical inference algorithms can be solved in propositional logic with the help of validity, logical equivalence and satisfying ability.
37. What are the signals used in Speech Recognition?
Speech is regarded as the leading method for communication between human beings and dependable speech recognition between machines. An acoustic signal is used in speech recognition to identify a sequence of words that is uttered by the speaker. Speech recognition develops technologies and methodologies that help the recognition and translation of the human language into text with the help of computers.
38. Which model gives the probability of words in speech recognition?
In speech recognition, the Diagram model gives the probability of each word that will be followed by other words.
39. Which search agent in artificial intelligence operates by interleaving computation and action?
The online search would involve taking the action first and then observing the environment.
40. What are some good programming languages in artificial intelligence?
Prolog, Lisp, C/C++, Java and Python are some of the most common programming languages in artificial intelligence. These languages are highly capable of meeting the various requirements that arise in the designing and development of different software.
41. How can temporal probabilistic reasoning be solved with the help of algorithms?
The Hidden Markov Model can be used for solving temporal probabilistic reasoning. This model observes the sequence of emission and after a careful analysis, it recovers the state of sequence from the data that was observed.
42. What is the Hidden Markov Model used for?
It is a tool that is used for modelling sequence behavior or time-series data in speech recognition systems. A statistical model, the hidden Markov model (HMM) describes the development of events that are dependent on internal factors. Most of the time, these internal factors cannot be directly observed. The hidden states lead to the creation of a Markov chain. The underlying state determines the probability allocation of the observed symbol.
43. What are the possible values of the variables in HMM?
The possible values of the variable in HMM are the “Possible States of the World”.
44. Where is the additional variable added in HMM?
The additional state variables are usually added to a temporal model in HMM.
45 . How many literals are available in top-down inductive learning methods?
Equality and inequality, predicates and arithmetic literals are the three literals available in top-down inductive learning methods.
46. What does compositional semantics mean?
Compositional semantics is a process that determines the meaning of P*Q from P,Q and*. Also simply known as CS, the compositional semantics is also known as the functional dependence of the connotation of an expression or the parts of that expression. Many people might have the question if a set of NL expressions can have any compositional semantics.
47. How can an algorithm be planned through a straightforward approach?
The most straightforward approach is using state-space search as it considers everything that is required to find a solution. The state-space search can be solved in two ways. These include backward from the goal and forward from the initial state.
48. What is Tree Topology?
Tree topology has many connected elements that are arranged in the form of branches of a tree. There is a minimum of three specific levels in the hierarchy. Since any two given nodes can have only one mutual connection, the tree topologies can create a natural hierarchy between parent and child.
If you wish to learn an Artificial Intelligence Course, Great Learning is offering several advanced courses in the subject. An artificial intelligence Certification will provide candidates the AI skills that are required to grab a well-paying job as an AI engineer in the business world. There are several AI Courses that are designed to give candidates extensive hands-on learning experience. Great Learning is offering Machine Learning and Artificial Intelligence courses at great prices. Contact us today for more details. The future of AI is very bright, so get enrolled today to make a dream AI career.
#artificial intelligence#Interview Questions#interview q&a#machine learning#career#ai#learn ai#interview question
4 notes
·
View notes