#mongodb install centos
Explore tagged Tumblr posts
Visit Tumblr Blog
Explore Tumblr blogs with no restrictions, modern design and the best experience.
Last Seen Tumblr Blogs





Fun Fact
The KCSC sent more than 20K requests to delete posts related to prostitution and porn to Tumblr from January to June 2017.
Text
标题即关键词+TG@yuantou2048
蜘蛛池系统搭建教程+TG@yuantou2048
在互联网时代,网站的优化和推广变得尤为重要。而“蜘蛛池”作为一种高效的网站优化手段,被越来越多的人所熟知。本文将详细介绍如何搭建一个属于自己的蜘蛛池系统。
什么是蜘蛛池?
蜘蛛池是一种模拟搜索引擎爬虫行为的技术,通过模拟大量爬虫对目标网站进行访问,从而提高网站的收录速度和排名。它的工作原理是利用大量的虚拟用户代理(User-Agent)来模拟真实用户的访问行为,让搜索引擎认为该网站非常受欢迎,进而提升其在搜索结果中的排名。
搭建蜘蛛池系统的步骤
第一步:选择合适的服务器
首先,你需要一台性能稳定的服务器。建议选择配置较高的云服务器,以确保能够承载大量的并发请求。
第二步:安装基础环境
1. 操作系统:推荐使用Linux系统,如Ubuntu或CentOS。
2. 编程语言:Python是目前最常用的编程语言之一,可以方便地编写爬虫程序。
3. 数据库:MySQL或MongoDB等数据库用于存储爬取的数据。
第三步:编写爬虫程序
- 使用Python的Scrapy框架来编写爬虫程序。Scrapy是一个开源的爬虫框架,支持快速开发和部署爬虫项目。
- 安装Python环境,并安装Scrapy框架。
```bash
sudo apt-get update
sudo apt-get install python3-pip
pip3 install scrapy
```
第四步:编写爬虫脚本
创建一个新的Scrapy项目:
```bash
scrapy startproject mySpiderPool
cd mySpiderPool
```
编写爬虫代码,定义需要爬取的URL列表以及解析规则。
```python
import scrapy
class MySpider(scrapy.Spider):
name = 'myspider'
start_urls = ['http://example.com']
def parse(self, response):
编写具体的爬虫逻辑
pass
```
第五步:运行爬虫
```bash
scrapy crawl your_spider_name
```
第六步:配置爬虫
在`settings.py`中配置爬虫的基本设置,例如下载延迟、并发请求数量等参数。
```python
mySpider/spiders/myspider.py
import scrapy
class MySpider(scrapy.Spider):
name = 'myspider'
start_urls = ['http://example.com']
def parse(self, response):
解析网页内容
pass
```
第七步:部署与监控
- 将爬虫部署到服务器上,并定期检查日志文件,监控爬虫的运行状态。
第八步:维护与优化
- 根据需求调整爬虫的行为,比如设置爬虫的速度、重试次数等。
第九步:自动化执行
- 使用定时任务(如CronJob)实现自动化的爬虫任务。
注意事项
- 确保遵守robots.txt协议,避免对目标网站造成过大的负担。
- 遵守相关法律法规,合理合法地使用蜘蛛池系统,确保不违反任何法律或道德规范。
结语
通过以上步骤,你已经成功搭建了一个基本的蜘蛛池系统。但请务必注意,使用蜘蛛池时要遵循各网站的robots.txt文件规定,尊重网站的爬取策略,避免对目标网站造成不必要的压力。
总结
蜘蛛池系统可以帮助提高网站的SEO效果,但请确保你的行为符合网络爬虫的相关规定,避免过度抓取导致封禁IP地址等问题。
希望这篇教程能帮助你更好地理解和使用蜘蛛池系统。如果你有任何问题或疑问,欢迎加入我们的社区交流群组获取更多技术支持。
希望这篇文章对你有所帮助!
加飞机@yuantou2048

谷歌快排
Google外链代发
0 notes
Text
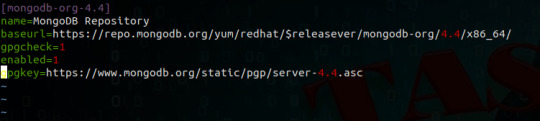
Install MongoDB on CentOS 7 Linux Step by Step.
Install MongoDB on CentOS 7 Linux Step by Step.
We will see How to Install MongoDB on CentOS 7 Linux Step by Step, MongoDB is a No-SQL database that is written in C++, It uses a JSON-like structure. MongoDB is a cross-platform and document-oriented database. The initial release of the MongoDB was on 11 February 2009, you can find the main website of the MongoDB as well the git repository So let’s install MongoDB on CentOS 7 Linux Step by…
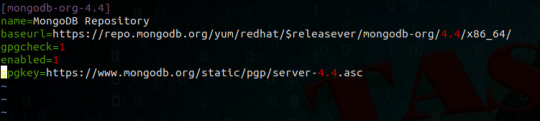
View On WordPress
#install mongodb#install mongodb centos 7#install mongodb centos 7.5#install mongodb on centos 7#install mongodb on linux#install mongodb on ubuntu#mongodb centos install yum#mongodb install centos#mongodb install linux
0 notes
Link
MongoDB is a NoSQL database that is designed to store large data amounts in document-oriented storage with a dynamic schema. Install MongoDB centos 7 is the leading NoSQL database used in modern web applications.
0 notes
Link
0 notes
Text
Linux - Cara Instal MongoDB 4 pada Debian 10
Linux – Cara Instal MongoDB 4 pada Debian 10

MongoDB adalah server basis data NoSQL, cross-platform dan opensource yang dikembangkan oleh MongoDB Inc. MongoDB menggunakan JSON untuk menyimpan datanya dan populer untuk menangani sejumlah data besar dengan skalabilitas, ketersediaan tinggi, dan kinerja tinggi.
Table of Contents Mengimpor Key GPG MongoDB di Debian Menginstal Repositori APT MongoDB 4 pada Debian Menginstal libcurl3 di Debian Mengin…
View On WordPress
#Cara Install MongoDB di CentOS#Cara Install MongoDB di Ubuntu#Cara Install MongoDB di Ubuntu 18.04#How to Install MongoDB 4.0 on Debian 9/8/7#Install MongoDB di Linux
0 notes
Text
All applications generate information when running, this information is stored as logs. As a system administrator, you need to monitor these logs to ensure the proper functioning of the system and therefore prevent risks and errors. These logs are normally scattered over servers and management becomes harder as the data volume increases. Graylog is a free and open-source log management tool that can be used to capture, centralize and view real-time logs from several devices across a network. It can be used to analyze both structured and unstructured logs. The Graylog setup consists of MongoDB, Elasticsearch, and the Graylog server. The server receives data from the clients installed on several servers and displays it on the web interface. Below is a diagram illustrating the Graylog architecture Graylog offers the following features: Log Collection – Graylog’s modern log-focused architecture can accept nearly any type of structured data, including log messages and network traffic from; syslog (TCP, UDP, AMQP, Kafka), AWS (AWS Logs, FlowLogs, CloudTrail), JSON Path from HTTP API, Beats/Logstash, Plain/Raw Text (TCP, UDP, AMQP, Kafka) e.t.c Log analysis – Graylog really shines when exploring data to understand what is happening in your environment. It uses; enhanced search, search workflow and dashboards. Extracting data – whenever log management system is in operations, there will be summary data that needs to be passed to somewhere else in your Operations Center. Graylog offers several options that include; scheduled reports, correlation engine, REST API and data fowarder. Enhanced security and performance – Graylog often contains sensitive, regulated data so it is critical that the system itself is secure, accessible, and speedy. This is achieved using role-based access control, archiving, fault tolerance e.t.c Extendable – with the phenomenal Open Source Community, extensions are built and made available in the market to improve the funmctionality of Graylog This guide will walk you through how to run the Graylog Server in Docker Containers. This method is preferred since you can run and configure Graylog with all the dependencies, Elasticsearch and MongoDB already bundled. Setup Prerequisites. Before we begin, you need to update the system and install the required packages. ## On Debian/Ubuntu sudo apt update && sudo apt upgrade sudo apt install curl vim git ## On RHEL/CentOS/RockyLinux 8 sudo yum -y update sudo yum -y install curl vim git ## On Fedora sudo dnf update sudo dnf -y install curl vim git 1. Install Docker and Docker-Compose on Linux Of course, you need the docker engine to run the docker containers. To install the docker engine, use the dedicated guide below: How To Install Docker CE on Linux Systems Once installed, check the installed version. $ docker -v Docker version 20.10.13, build a224086 You also need to add your system user to the docker group. This will allow you to run docker commands without using sudo sudo usermod -aG docker $USER newgrp docker With docker installed, proceed and install docker-compose using the guide below: How To Install Docker Compose on Linux Verify the installation. $ docker-compose version Docker Compose version v2.3.3 Now start and enable docker to run automatically on system boot. sudo systemctl start docker && sudo systemctl enable docker 2. Provision the Graylog Container The Graylog container will consist of the Graylog server, Elasticsearch, and MongoDB. To be able to achieve this, we will capture the information and settings in a YAML file. Create the YAML file as below: vim docker-compose.yml In the file, add the below lines: version: '2' services: # MongoDB: https://hub.docker.com/_/mongo/ mongodb: image: mongo:4.2 networks: - graylog #DB in share for persistence volumes: - /mongo_data:/data/db # Elasticsearch: https://www.elastic.co/guide/en/elasticsearch/reference/7.10/docker.html
elasticsearch: image: docker.elastic.co/elasticsearch/elasticsearch-oss:7.10.2 #data folder in share for persistence volumes: - /es_data:/usr/share/elasticsearch/data environment: - http.host=0.0.0.0 - transport.host=localhost - network.host=0.0.0.0 - "ES_JAVA_OPTS=-Xms512m -Xmx512m" ulimits: memlock: soft: -1 hard: -1 mem_limit: 1g networks: - graylog # Graylog: https://hub.docker.com/r/graylog/graylog/ graylog: image: graylog/graylog:4.2 #journal and config directories in local NFS share for persistence volumes: - /graylog_journal:/usr/share/graylog/data/journal environment: # CHANGE ME (must be at least 16 characters)! - GRAYLOG_PASSWORD_SECRET=somepasswordpepper # Password: admin - GRAYLOG_ROOT_PASSWORD_SHA2=e1b24204830484d635d744e849441b793a6f7e1032ea1eef40747d95d30da592 - GRAYLOG_HTTP_EXTERNAL_URI=http://192.168.205.4:9000/ entrypoint: /usr/bin/tini -- wait-for-it elasticsearch:9200 -- /docker-entrypoint.sh networks: - graylog links: - mongodb:mongo - elasticsearch restart: always depends_on: - mongodb - elasticsearch ports: # Graylog web interface and REST API - 9000:9000 # Syslog TCP - 1514:1514 # Syslog UDP - 1514:1514/udp # GELF TCP - 12201:12201 # GELF UDP - 12201:12201/udp # Volumes for persisting data, see https://docs.docker.com/engine/admin/volumes/volumes/ volumes: mongo_data: driver: local es_data: driver: local graylog_journal: driver: local networks: graylog: driver: bridge In the file, replace: GRAYLOG_PASSWORD_SECRET with your own password which must be at least 16 characters GRAYLOG_ROOT_PASSWORD_SHA2 with a SHA2 password obtained using the command: echo -n "Enter Password: " && head -1 1514/tcp, :::1514->1514/tcp, 0.0.0.0:9000->9000/tcp, 0.0.0.0:1514->1514/udp, :::9000->9000/tcp, :::1514->1514/udp, 0.0.0.0:12201->12201/tcp, 0.0.0.0:12201->12201/udp, :::12201->12201/tcp, :::12201->12201/udp thor-graylog-1 1a21d2de4439 docker.elastic.co/elasticsearch/elasticsearch-oss:7.10.2 "/tini -- /usr/local…" 31 seconds ago Up 28 seconds 9200/tcp, 9300/tcp thor-elasticsearch-1 1b187f47d77e mongo:4.2 "docker-entrypoint.s…" 31 seconds ago Up 28 seconds 27017/tcp thor-mongodb-1 If you have a firewall enabled, allow the Graylog service port through it. ##For Firewalld sudo firewall-cmd --zone=public --add-port=9000/tcp --permanent sudo firewall-cmd --reload ##For UFW sudo ufw allow 9000/tcp 5. Access the Graylog Web UI Now open the Graylog web interface using the URL http://IP_address:9000. Log in using the username admin and SHA2 password(StrongPassw0rd) set in the YAML. On the dashboard, let’s create the first input to get logs by navigating to the systems tab and selecting input. Now search for Raw/Plaintext TCP and click launch new input Once launched, a pop-up window will appear as below. You only need to change the name for the input, port(1514), and select the node, or “Global” for the location for the input. Leave the other details as they are. Save the file and try sending a plain text message to the Graylog Raw/Plaintext TCP input on port 1514. echo 'First log message' | nc localhost 1514 ##OR from another server##
echo 'First log message' | nc 192.168.205.4 1514 On the running Raw/Plaintext Input, show received messages The received message should be displayed as below. You can as well export this to a dashboard as below. Create the dashboard by providing the required information. You will have the dashboard appear under the dashboards tab. Conclusion That is it! We have triumphantly walked through how to run the Graylog Server in Docker Containers. Now you can monitor and access logs on several servers with ease. I hope this was significant to you.
0 notes
Text
How to install gdb on centos

#HOW TO INSTALL GDB ON CENTOS HOW TO#
#HOW TO INSTALL GDB ON CENTOS INSTALL#
#HOW TO INSTALL GDB ON CENTOS SOFTWARE#
#HOW TO INSTALL GDB ON CENTOS FREE#
> Processing Dependency: devtoolset-7-runtime for package: devtoolset-7-gcc-7.3.1-5.4.el7.x86_64
#HOW TO INSTALL GDB ON CENTOS INSTALL#
Here is the output in our ~]# yum install devtoolset-7-gcc* STEP 2) Install the development tools and GNU GCC 7, which is part of the “devtools” package > Package centos-release-scl-rh.noarch 0: will be installedĬentos-release-scl noarch extras 12 kĬentos-release-scl-rh noarch extras 12 k > Processing Dependency: centos-release-scl-rh for package: > Package centos-release-scl.noarch 0: will be installed Loading mirror speeds from cached hostfile Here is the output in our ~]# yum -y install centos-release-scl
#HOW TO INSTALL GDB ON CENTOS HOW TO#
So here is how to install GNU GCC 7: STEP 1) Install the repository in your system This article is to install GNU GCC 7 on CentOS 7 and we have a new one to install GNU GCC 8 – How to install GNU GCC 8 on CentOS 7. To have a newer version of the same components, you can have multiple version of GNU GCC – you can install with no worries of breaking your system GNU GCC 6 and 7.Not only GNU GCC, but you can also have PHP, Ruby, Python, famous databases like Mysql, MongoDB, PostgreSQL and many more Multiple version installed of the same components, you can have multiple GNU GCC installed without breaking your system or compiling manually.We can say these packages are officially maintained by CentOS 7 team and as a whole Red Hat/CentOS officials and community developers! The collection aims at
#HOW TO INSTALL GDB ON CENTOS SOFTWARE#
There are repositories, which would surely break your system at one point even they do not break it at first installing a newer version of GNU GCC! There is a really easy and “official” way to have newer development software in CentOS 7 by using the Software Collection –
#HOW TO INSTALL GDB ON CENTOS FREE#
It offers us free enterprise-class operating system, which is compatible with Red Hat, but in many situations, we need a newer (not even a bleeding edge) tools from a trusted source not from an unknown third repository! Let’s say you are a developer and you need newer than GCC 4.8 (which is more than 5 years old and at present, we have stable GCC 8.x stable branch). In order to close this display screen, you need to use the following combination: CTRL + A + D.CentOS 7 is a very stable and conservative operating system. In order for it to be available for the entire system, we will need to run the following command: make install Configuring CPULimit Using the Applicationīy entering the special top command it is possible to view the list of processes. When this process completes, a binary file will appear in the cpulimit-2.5 directory. The next step is to run make to start compiling CPULimit: make The next step is to run make to start compiling CPULimit: cd cpulimit-2.5 Then you need to install and, therefore, unpack the archive: cd ~ To quickly and successfully install this utility, you need make, screen, and wget. Some applications that may be limited include Nginx, PHP, Java. It is worth noting here that most applications will run normally. Essentially, applications will turn on or off quickly enough to limit the program to the desired number of cycles. It works as follows: CPULimit is not designed to work with applications that use job control, for example as they can be destroyed when CPULimit sends the SIGSTOP stop signal. One of the important differences is that cpulimit does not manage system boot, unlike cputool. Cpulimit is used to limit the CPU usage of a process in the same way as CPUTool, however it offers more use cases than its counterpart. CPULimit is a utility designed to work with Linux servers to limit the use of resources by an application.
0 notes
Text
Best drupal hosting 2021

#Best drupal hosting 2021 full
#Best drupal hosting 2021 software
#Best drupal hosting 2021 plus
#Best drupal hosting 2021 free
Read our comprehensive Hostwinds review (opens in new tab). Hostwinds also offers rolling contracts, so you can try the service for a month and change it if you're not satisfied. In contrast, HostWinds' unmanaged packages start at $4.99 and go as high as $328.99 a month. Regular managed Linux VPS plans start at $8.24 a month for 1GB RAM, one CPU core, 30GB disk space, and 1TB traffic, and go all the way up to $395.24 for 96GB RAM, 16 cores, 750GB disk space, and 9TB traffic. You’ll also find one-click Nextcloud (opens in new tab) install, and more.Īnd because there are no management fees, you’ll receive 50% off your package. For example, site management is conducted through cPanel, while WordPress and other installs are automated via Softaculous. Still, experienced Linux users shouldn’t find this too intimidating.īut even with these advanced features, many components of Hostwinds' plans are still fairly straightforward and simple to use.
#Best drupal hosting 2021 software
For example, if you stumble across a hard-to-solve software issue it’s you who will have to find a way to fix it. It’s important to remember that deciding on an unmanaged package will require you to be more responsible for it-it won’t be the responsibility of your hosting provider. What’s more, it’s possible for you to set up and configure your chosen OS in any way you choose and tweak your backup system. You can take your pick from a wide range of OSs, including openSUSE, CentOS, Ubuntu, Fedora, and Debian. With Hostwinds' unmanaged VPS plans, you are given total control over your hosting.
#Best drupal hosting 2021 full
Read our full SiteGround review (opens in new tab). So for a Linux-based site that you hope to scale up, this provider definitely has the right tools for the task. If you decide a dedicated server would best serve your needs, you’ll get some serious extras, including Nginx-based cache options for WordPress, Memcached and HHVM to boost performance, along with Git integration.Įven though many of these features may be surplus to requirements, they do give users a good indication of the level of technical expertise SiteGround can offer.
#Best drupal hosting 2021 plus
These packages begin at $100 a month plus tax. Everything is pre-installed and managed for your convenience. SiteGround’s VPS-style cloud hosting includes a well-defined CentOS system, PostgreSQL, MySQL 5, 5 PHP versions, Apache, Nginx, HHVM, an Exim mail server, a private DNS setup, and Iptables firewall. All this comes at a cost of just $4.99 a month plus tax for year one, then $14.99 afterward.
#Best drupal hosting 2021 free
Of course, home users can’t expect this degree of support, but SiteGround's shared hosting plan has a lot going for it too, with cPanel (opens in new tab) and SSH access, free Let's Encrypt SSLs, unlimited emails and databases, Cloudflare integration, HTTP/2-enabled servers, daily backups, and open-all-hours support via phone, live chat, and a ticket system. Its website lists a range of the technologies it can support on its platform, including smart Linux containers, bespoke private clouds, database replication, and advanced technical knowledge of MySQL, PHP, WordPress, Drupal, Apache, Nginx, MongoDB, ElasticSearch, Redis, Memcached, Solr, and others. If you don’t find what you’re looking for in its standard products, the company can build you a custom solution. SiteGround takes advanced technical support up a notch. Read our detailed InMotion Hosting review (opens in new tab). You have a choice of OSs, including CentOS, Debian, or Ubuntu, and if you come across any problems during the setup phase, InMotion’s Launch Assist gives you a two-hour time slot with qualified tech support to help you iron out any issues. We were pleased to find that even its managed VPS hosting provided users with root access, enabling a good degree of low-level control. This plan enables you to choose your OS and firewall and then install, configure, and optimize the server in any way you like. The more powerful upgrades are just as reasonably priced-you can get optional self-managed cloud VPS (opens in new tab) hosting from $5 a month for year one. But this is just the tip of the iceberg.įor example, as well as having PrestaShop, WordPress (opens in new tab), and Joomla pre-installation options, you also get WP-CLI, enabling you to manage numerous WordPress installations via the command line. And all of this comes at a very reasonable price: InMotion’s plans start at just $2.49 a month on a three-year plan. Technical users are very well-catered for too, with plans that include support for PostreSQL and MySQL databases, Ruby, Perl, PHP 7, Python, and SSH (secure shell protocol) access.
0 notes
Text
如何在服务器上搭建蜘蛛池?
在互联网时代,数据的抓取和分析变得越来越重要。而“蜘蛛池”(也称为爬虫池)是进行大规模网页抓取的一种有效方式。本文将详细介绍如何在服务器上搭建一个高效的蜘蛛池,帮助你更好地理解和操作这一技术。
1. 了解蜘蛛池
蜘蛛池是一种用于自动化网络爬虫任务的系统。它通过管理多个爬虫进程,实现对大量网站的高效、稳定抓取。通常,蜘蛛池会包含以下几个关键组件:
爬虫程序:负责具体的网页抓取工作。
任务调度器:管理和调度爬虫任务,确保资源的有效利用。
数据库:存储抓取到的数据以及爬虫的状态信息。
代理池:提供IP地址,以避免被目标网站封禁。
2. 准备工作
在开始搭建之前,你需要准备以下几项:
服务器环境:选择一台性能稳定的服务器,操作系统建议使用Linux,如Ubuntu或CentOS。
编程语言与框架:Python 是目前最常用的爬虫开发语言,可以使用 Scrapy 或 Beautiful Soup 等框架。
数据库:MySQL 或 MongoDB 都是不错的选择,用于存储抓取的数据。
代理服务:购买或自建代理池,以应对反爬机制。
3. 搭建步骤
3.1 安装基础软件
首先,确保你的服务器已经安装了必要的基础软件:
```bash
sudo apt-get update
sudo apt-get install python3-pip
pip3 install scrapy beautifulsoup4 pymongo
```
3.2 编写爬虫代码
使用 Scrapy 创建一个新的爬虫项目:
```bash
scrapy startproject spiderpool
cd spiderpool
```
然后,在 `spiders` 目录下创建一个新的爬虫文件,编写具体的爬虫逻辑。
3.3 配置数据库
根据你选择的数据库类型,配置相应的连接信息。例如,对于 MongoDB:
```python
ITEM_PIPELINES = {
'spiderpool.pipelines.MongoDBPipeline': 300,
}
MONGODB_URI = "mongodb://localhost:27017/"
MONGODB_DATABASE = "spiderpool"
```
3.4 设置代理池
为了防止 IP 被封,需要设置代理池。可以使用免费的代理列表,或者购买付费的代理服务。
```python
DOWNLOADER_MIDDLEWARES = {
'scrapy.downloadermiddlewares.httpproxy.HttpProxyMiddleware': None,
'spiderpool.middlewares.ProxyMiddleware': 543,
}
```
3.5 运行爬虫
最后,���动爬虫并监控其运行状态:
```bash
scrapy crawl your_spider_name
```
4. 结语
搭建蜘蛛池是一个复杂但有趣的过程,它不仅能够提高数据抓取的效率,还能帮助你更好地理解网络爬虫的工作原理。希望本文能为你提供一些有用的指导。如果你有任何问题或建议,欢迎在评论区留言讨论!
请根据实际需求调整上述代码和配置。
加飞机@yuantou2048

谷歌留痕
负面删除
0 notes
Text
Install MongoDB on AWS EC2 Instances.
Install MongoDB on AWS EC2 Instances.
We will see how to install MongoDB on AWS ec2 Instances, amazon Linux 2 or we can install MongoDB of any version on the AWS Linux 2 server in this article. The Amazon Linux 2 server is the RPM-based server with the 5 years Long Term Support by AWS. (Amazon Web Services). MongoDB is a No-SQL database which is written in C++, It uses a JSON like structure. MongoDB is a cross-platform and…
View On WordPress
#aws mongodb service#install mongo shell on amazon linux#install mongodb#install mongodb centos 7#install mongodb centos 8#install MongoDB in AWS ec2 instance#install MongoDB in AWS linux.#install MongoDB on amazon ec2#install MongoDB on amazon linux#install MongoDB on amazon linux AMI#install mongodb on aws#install MongoDB on AWS server#install MongoDB shell amazon linux#mongodb install linux
0 notes
Link
Run this script in the MongoDB directory to install MongoDB amazon Linux and create and configure the admin username and password to login to MongoDB. Once MongoDB is installed, run the reboot command to reboot the machine.
0 notes
Text
How to Install MongoDB Community Edition on Linux
How to Install MongoDB Community Edition on Linux
Install MongoDB Community Edition on Linux MongoDB provides packages for common Linux systems for the best installation experience. The recommended approach to run MongoDB is using these packages. The following guidelines will walk you through the installation of these systems: Install MongoDB Community Edition on Red Hat or CentOS Using the yum package manager, install MongoDB 5.0 Community…

View On WordPress
0 notes
Text
This is a complete guide on How to Install and Configure Graylog Server on Ubuntu 18.04 for Centralized Log management. Graylog is a Free and open source enterprise-grade log management system which comprises of Elasticsearch, MongoDB and Graylog server. For CentOS 7 server, we have how to Install Graylog with Elasticsearch 6.x on CentOS 7. Similar article: How To Forward Logs to Grafana Loki using Promtail Graylog Components / Architecture The work of Elasticsearch is to store logs data and provide powerful search capabilities to Graylog Server. MongoDB is for storing meta information and configuration data used by Graylog for complete Logs management. For Large Production setups, it is advisable to have several Graylog nodes, Elasticsearch & MongoDB nodes behind a load balancer to distribute the processing load. Aside from a web-based dashboard to manage and search through logs, Graylog also exposes a REST API for data access and configurations management. Below is a basic architectural overview of Graylog architecture. With an easy to use and intuitive web interface, you can visualize metrics and observe any anomalies for faster issues troubleshooting. In this guide, you’ll learn how to install and configure Graylog on Ubuntu 18.04 Server. Step 1: Update system It is a rule of thumb to update your system before installing any packages. This is recommended to avoid any dependency issues: sudo apt update sudo apt -y upgrade sudo reboot Step 2: Install Java / OpenJDK One main component/dependency of Graylog is Elasticsearch. Elasticsearch requires Java 8 installed for it to run. You can install Oracle Java or its open source alternative – OpenJDK. Here we will install OpenJDK. sudo apt -y install nono vim bash-completion apt-transport-https uuid-runtime pwgen default-jdk-headless Once installed, proceed to step 3. Step 3: Install ElasticSearch 7.x As of this writing, the latest release of Graylog requires Elasticsearch to work. Install ElasticSearch with the commands below. Add ElasticSearch repository: wget -qO - https://artifacts.elastic.co/GPG-KEY-elasticsearch | sudo apt-key add - echo "deb https://artifacts.elastic.co/packages/oss-7.x/apt stable main" | sudo tee -a /etc/apt/sources.list.d/elastic-7.x.list Install ElasticSearch OSS on Ubuntu 18.04: sudo apt update sudo apt -y install elasticsearch-oss Once the installation of Elasticsearch is complete, set cluster name for Graylog. sudo vim /etc/elasticsearch/elasticsearch.yml Set on line 17 cluster.name: graylog action.auto_create_index: false Restart the elasticsearch service: sudo systemctl daemon-reload sudo systemctl enable elasticsearch.service sudo systemctl restart elasticsearch.service Confirm status is running: $ systemctl status elasticsearch.service ● elasticsearch.service - Elasticsearch Loaded: loaded (/usr/lib/systemd/system/elasticsearch.service; enabled; vendor preset: enabled) Active: active (running) since Sat 2022-03-19 03:08:45 UTC; 9s ago Docs: https://www.elastic.co Main PID: 4269 (java) Tasks: 51 (limit: 4915) CGroup: /system.slice/elasticsearch.service └─4269 /usr/share/elasticsearch/jdk/bin/java -Xshare:auto -Des.networkaddress.cache.ttl=60 -Des.networkaddress.cache.negative.ttl=10 -XX:+AlwaysPreTouch -Xss1m -Djava.awt.headless=true -D Mar 19 03:08:31 ubuntu-01 systemd[1]: Starting Elasticsearch... Mar 19 03:08:45 ubuntu-01 systemd[1]: Started Elasticsearch. Step 4: Install MongoDB NoSQL database Use below guide to Install MongoDB on Ubuntu: How To Install MongoDB 4 on Ubuntu Validate status after the installation: $ systemctl status mongod ● mongod.service - MongoDB Database Server Loaded: loaded (/lib/systemd/system/mongod.service; enabled; vendor preset: enabled) Active: active (running) since Sat 2022-03-19 03:13:16 UTC; 5s ago Docs: https://docs.mongodb.org/manual Main PID: 5599 (mongod) CGroup: /system.slice/mongod.service
└─5599 /usr/bin/mongod --config /etc/mongod.conf Mar 19 03:13:16 ubuntu-01 systemd[1]: Started MongoDB Database Server. Step 5: Install Graylog on Ubuntu 18.04 Now that we have installed MongoDB and Elasticsearch, the last piece is the installation of Graylog server. Add Graylog repository and install graylog-server package using apt. Download graylog repository debian file: wget https://packages.graylog2.org/repo/packages/graylog-4.2-repository_latest.deb Enable the repository on your Ubuntu system. $ sudo dpkg -i graylog-4.2-repository_latest.deb Selecting previously unselected package graylog-4.2-repository. (Reading database ... 92818 files and directories currently installed.) Preparing to unpack graylog-4.2-repository_latest.deb ... Unpacking graylog-4.2-repository (1-4) ... Setting up graylog-4.2-repository (1-4) ... Install Graylog on Ubuntu 18.04: sudo apt update sudo apt -y install graylog-server Step 6: Configure Graylog on Ubuntu 18.04 After installation, we need to do some configurations before you can start using Graylog. Generate root password: You need to generate a 256-bit hash for the for admin user password: $ echo -n "Enter Password: " && head -1
0 notes
Link
0 notes
Link
こんにちは。GMOリサーチでインフラを担当しているオカモトです。 コロナの影響で引きこもり生活が続く中、皆様いかがお過ごしでしょうか。 今回、Googleが先日公開した「Tsunami」というオープンソースのセキュリティスキャナーを試してみたのでその内容をご紹介します。 1.Tsunamiって何? Tsunamiは、2020年6月18日木曜日(現地時間)にGoogleがオープンソースのプロジェクトとして公開したセキュリティスキャナーです。 GoogleではGKE(Google Kubernetes Engine)を使ってインターネットからアクセスを受けているシステムの脆弱性診断にTsunamiを使っているそうです。 ・Tsunamiのリリースに関する記事は以下のURLから確認できます。 Google Open Source Blog https://opensource.googleblog.com/2020/06/tsunami-extensible-network-scanning.html Tsunamiは以下の目標・理念を掲げて開発を進めているそうで、超大規模なシステムを高速にスキャンするような用途でも使いやすいソフトウェアを目指しているようです。 Tsunami supports small manually curated set of vulnerabilities(手動でリストアップされた少数の脆弱性に対してのスキャンをサポート)Tsunami detects high severity, RCE-like vulnerabilities, which often actively exploited in the wild(遠隔からのコード実行のような緊急度の高い脆弱性を検知する)Tsunami generates scan results with high confidence and minimal false-positive rate(誤検出率を最小限に抑えた信頼性の高いスキャン結果を生成する)Tsunami detectors are easy to implement.(脆弱性の検知器は簡単に実装できる)Tsunami is easy to scale, executes fast and scans non-intrusively.(簡単にスケールできる。高速に実行され、対象システムに侵入せずにスキャンする)2.Tsunamiの仕組み 公式の資料によるとTsunamiの脆弱性診断の流れは以下のような感じで進むそうです。 出典: Tsunami Scan Orchestration https://github.com/google/tsunami-security-scanner/blob/master/docs/orchestration.md 大きく分けて、Reconnaisance(調査/偵察)とVulnerability Verification(脆弱性の検証)の2つのステップで実行されるそうで、各ステップの役割は以下の通りになります。 Reconnaisance(調査/偵察) Reconnaisance(調査/偵察)のステップでは、ポートスキャンとフィンガープリントの2つのフェーズで対象システムに関する情報を可能な限り収集します。 <ポートスキャン> 対象システムの開いているポート、使われているプロトコル、ネットワークサービスなどを検出するフェーズ。 車輪の再発明をしないために、nmapやmasscanなどの既存のソフトウェアを内部で利用したプラグインを使うことを想定しているようです。 デフォルトではnmapのプラグインが使えます。 <フィンガープリント> 検知したポートで動いているサービスやウェブアプリケーションを検出するフェーズ。 1つのポートで複数のウェブアプリケーションが動いているような場合でも、それぞれのウェブアプリケーションを識別することを目指しているようです。 (例、TCPポートの443でリバースプロキシとしてnginxが動いている状態で、/blogではWordPress、/forumではphpBBが動いているというような構成)。 残念ながら今はまだ実装されてないみたいです。 Vulnerability Verification(脆弱性の検証) Vulnerability Verification(脆弱性の検証)のステップでは、前のステップで収集した情報に基づいて、脆弱性検知のプラグインを並列に実行して対象に脆弱性がないか検証します。 脆弱性検知のプラグインは、基本的には1つの脆弱性に対して1つのプラグインとして実装されることを想定しているようです。 また将来的な構想として、脆弱性検知のプラグインをJavaで実装するほかにPythonやGoなど別の言語でも実装できるようにしたいそうです。 ※現��公開されているTsunamiは開発者に試してもらうことを目的としたPre-Alpha版なので、将来的に仕様に大きな変更が入る可能性があります。 3.Tsunamiを実際にインストールしてみた 今回は以下の環境のサーバーを使って試してみました。 CentOS Linux release 7.7.1908 (Core) 3.10.0-1062.4.1.el7.x86_64 ① 必要なパッケージのインストール 以下のバージョン以降のnmapとncrackが必要となるので、それぞれ公式サイトよりバイナリ及びソースコードをダウンロードしてインストールします。 nmap = 7.80 ncrack = 0.7 nmapとncrackの最新安定版はこちらからダウンロードできます。 ● nmap(binary/source) https://nmap.org/download.html ● ncrack(source) https://nmap.org/ncrack/ また、今回のテスト環境ではncrackのコンパイルのためopensslのバージョンを上げる必要があったので以下のバージョンのopensslもインストールしています。 お使いの環境によってはその他にも必要なものがあるかもしれません。 # 必要なバイナリ及びソースコードのダウンロード $ sudo su - # cd /usr/local/src/ # wget https://nmap.org/dist/nmap-7.80-1.x86_64.rpm # wget https://nmap.org/ncrack/dist/ncrack-0.7.tar.gz # wget https://www.openssl.org/source/openssl-1.1.1g.tar.gz # nmapのインストール # rpm -vhU nmap-7.80-1.x86_64.rpm # nmap --version Nmap version 7.80 ( https://nmap.org ) Platform: x86_64-redhat-linux-gnu Compiled with: nmap-liblua-5.3.5 openssl-1.0.2s nmap-libssh2-1.8.2 nmap-libz-1.2.11 nmap-libpcre-7.6 nmap-libpcap-1.9.0 nmap-libdnet-1.12 ipv6 Compiled without: Available nsock engines: epoll poll select # # openssl-1.1.1gのインストール # tar xvzf openssl-1.1.1g.tar.gz # cd openssl-1.1.1g/ # ./config --prefix=/usr/local/openssl-1.1.1g shared zlib # make depend # make # make test # make install # cd /etc/ld.so.conf.d/ # vi openssl-1.1.1g.conf # cat openssl-1.1.1g.conf /usr/local/openssl-1.1.1g/lib # # ncrackのインストール # cd /usr/local/src # mv ncrack-0.7 /usr/local/ # cd /usr/local/ncrack-0.7/ # ./configure --with-openssl=/usr/local/openssl-1.1.1g/ # make # make install # ncrack --version Ncrack version 0.7 ( http://ncrack.org ) Modules: SSH, RDP, FTP, Telnet, HTTP(S), Wordpress, POP3(S), IMAP, CVS, SMB, VNC, SIP, Redis, PostgreSQL, MQTT, MySQL, MSSQL, MongoDB, Cassandra, WinRM, OWA, DICOM # ② Tsunamiのインストール 公式に用意されているquick_start.shというスクリプトを使ってTsunamiをインストールします。 このquick_start.shを実行すると、以下の処理を実行してくれます。 ※gitでcloneするのでgitがインストールされている必要があります。 google/tsunami-security-scanner と google/tsunami-security-scanner-plugins の2つのリポジトリを $HOME/tsunami/repos ディレクトリ以下にgit cloneする全ての Google Tsunami plugins をコンパイル、できたjarファイルをすべて $HOME/tsunami/plugins ディレクトリへ移動するTsunami scannerをコンパイル、できたJarファイルを $HOME/tsunami ディレクトリへ移動するサンプルの設定ファイルのtsunami.yaml を $HOME/tsunami ディレクトリへ移動するサンプルとして127.0.0.1に対してスキャンを実行するコマンドを表示する ● Tsunamiの���ンストール $ bash -c "$(curl -sfL https://raw.githubusercontent.com/google/tsunami-security-scanner/master/quick_start.sh)" 実行すると必要なファイルやプログラムのダウンロードやインストール、jarファイルのビルドをしてくれます。すべてのjarファイルのビルドが正常に完了すると最後に以下のようなメッセージが表示されます。 BUILD SUCCESSFUL in 1m 40s 14 actionable tasks: 14 executed Build successful, execute the following command to scan 127.0.0.1: cd /home/okamoto/tsunami && \ java -cp "tsunami-main-0.0.2-SNAPSHOT-cli.jar:/home/okamoto/tsunami/plugins/*" \ -Dtsunami-config.location=/home/okamoto/tsunami/tsunami.yaml \ com.google.tsunami.main.cli.TsunamiCli \ --ip-v4-target=127.0.0.1 \ --scan-results-local-output-format=JSON \ --scan-results-local-output-filename=/tmp/tsunami-output.json Tsunamiのファイル群は$HOME/tsunami/以下にインストールされています。 $ ls -l tsunami/ total 16112 drwxr-xr-x 2 okamoto r_admin 316 Jun 25 17:23 plugins drwxr-xr-x 4 okamoto r_admin 78 Jun 25 17:22 repos -rw-r--r-- 1 okamoto r_admin 16492741 Jun 25 17:25 tsunami-main-0.0.2-SNAPSHOT-cli.jar -rw-r--r-- 1 okamoto r_admin 130 Jun 25 17:25 tsunami.yaml $ プラグインは$HOME/tsunami/pluginsのディレクトリに格納されています。 デフォルトだとポートスキャナーのプラグインが1つ、脆弱性検知のためのプラグインが5つ用意されています。 $ ls -l plugins/ total 148 -rw-r--r-- 1 okamoto r_admin 7156 Jun 25 19:03 exposed_hadoop_yarn_api-0.0.1-SNAPSHOT.jar -rw-r--r-- 1 okamoto r_admin 6194 Jun 25 19:03 exposed_jenkins_ui-0.0.1-SNAPSHOT.jar -rw-r--r-- 1 okamoto r_admin 5899 Jun 25 19:03 exposed_jupyter_notebook-0.0.1-SNAPSHOT.jar -rw-r--r-- 1 okamoto r_admin 39515 Jun 25 19:03 ncrack_weak_credential_detector-0.0.1-SNAPSHOT.jar -rw-r--r-- 1 okamoto r_admin 76185 Jun 25 19:03 nmap_port_scanner-0.0.1-SNAPSHOT.jar -rw-r--r-- 1 okamoto r_admin 6249 Jun 25 19:03 wordpress_exposed_installation_page-0.0.1-SNAPSHOT.jar $ 4.Tsunamiの設定を書いてみる Tsunamiはyaml形式のファイルで設定を読み込むことができます。 初めから用意されているyamlファイルが$HOME/tsunami/tsunami.yamlにあるので、これを編集して設定を記述します。 今回はデフォルトで用意されているnmapを使ったポートスキャナーのプラグインの設定を1-1024番のウェルノウンポートのみスキャンするよう設定してみます。 $ cd tsunami/ $ vi tsunami.yaml $ cat tsunami.yaml plugins: google: port_scanner: nmap: port_targets: "1-1024" $ 5.セキュリティスキャンをやってみよう Tsunamiのビルドが成功した際のメッセージの最後の部分で、以下のようなローカルホスト(127.0.0.1)をスキャンするためのコマンドが表示されます。 cd /home/okamoto/tsunami && \ java -cp "tsunami-main-0.0.2-SNAPSHOT-cli.jar:/home/okamoto/tsunami/plugins/*" \ -Dtsunami-config.location=/home/okamoto/tsunami/tsunami.yaml \ com.google.tsunami.main.cli.TsunamiCli \ --ip-v4-target=127.0.0.1 \ --scan-results-local-output-format=JSON \ --scan-results-local-output-filename=/tmp/tsunami-output.json 今回はこのコマンドを使って試しにローカルホストに対してセキュリティスキャンをしてみます。 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 $ cd /home/okamoto/tsunami && java -cp "tsunami-main-0.0.2-SNAPSHOT-cli.jar:/home/okamoto/tsunami/plugins/*" -Dtsunami-config.location=/home/okamoto/tsunami/tsunami.yaml com.google.tsunami.main.cli.TsunamiCli --ip-v4-target=127.0.0.1 --scan-results-local-output-format=JSON --scan-results-local-output-filename=/tmp/tsunami-output.json (省略) INFO: Tsunami scanning workflow traces: Port scanning phase (16.74 s) with 1 plugin(s): /Tsunami Dev ([email protected])/PORT_SCAN/NmapPortScanner/0.1 Service fingerprinting phase (296.7 ms) with 0 plugin(s): Vuln detection phase (22.06 ms) with 5 plugin(s): /Tsunami Team ([email protected])/VULN_DETECTION/NcrackWeakCredentialDetectorPlugin/0.1 was selected for the following services: ssh (TCP, port 22), smtp (TCP, port 25), rpcbind (TCP, port 111) /Tsunami Team ([email protected])/VULN_DETECTION/YarnExposedManagerApiDetector/0.1 was selected for the following services: ssh (TCP, port 22), smtp (TCP, port 25), rpcbind (TCP, port 111) /Tsunami Team ([email protected])/VULN_DETECTION/JenkinsExposedUiDetector/0.1 was selected for the following services: ssh (TCP, port 22), smtp (TCP, port 25), rpcbind (TCP, port 111) /Tsunami Team ([email protected])/VULN_DETECTION/JupyterExposedUiDetector/0.1 was selected for the following services: ssh (TCP, port 22), smtp (TCP, port 25), rpcbind (TCP, port 111) /Tsunami Team ([email protected])/VULN_DETECTION/WordPressInstallPageDetector/0.1 was selected for the following services: ssh (TCP, port 22), smtp (TCP, port 25), rpcbind (TCP, port 111) # of detected vulnerability: 0. Jun 25, 2020 7:53:15 PM com.google.tsunami.main.cli.TsunamiCli run INFO: Tsunami scan finished, saving results. Jun 25, 2020 7:53:15 PM com.google.tsunami.common.io.archiving.RawFileArchiver archive INFO: Archiving data to file system with filename '/tmp/tsunami-output.json'. Jun 25, 2020 7:53:15 PM com.google.tsunami.main.cli.TsunamiCli run INFO: TsunamiCli finished... Jun 25, 2020 7:53:15 PM com.google.tsunami.main.cli.TsunamiCli main INFO: Full Tsunami scan took 19.54 s. $ ずらずらと実行時のログが表示された後、最後に上記のようなスキャン結果が表示されます。 ポートスキャンに約17秒、脆弱性の検証に約22マイクロ秒の時間がかかったというような各ステップの実行時間や、ポートスキャンで見つかったサービスに対して各Detectorを実行した結果などを確認できます。 6.まとめ Pre-Alpha版ということでドキュメントもほとんどなく機能的にもまだまだ足りない状態で、全体的にまだまだこれからという印象を受けました。 ですが、Reconnaisanceの結果として見つかったサービスに対して脆弱性検知のプラグインを適用していくというTsunamiの基本的な動作の流れは確認することができました。 新たな脆弱性が見つかったらサクッと脆弱性検知のプラグインを書いて流す、そんな使い方になりそうです。 超大規模環境を迅速に脆弱性診断することを目指しているTsunami、ご興味ある方はGithubなど覗いてみてはいかがでしょうか。 自分も時間があればまた自作のプラグインを組み込んでの脆弱性診断などにチャレンジしてみたいと思います。 最後まで読んでいただきありがとうございました!
0 notes
Link
Install on Red Hat part of MongoDB’s documentation and check in case there is another version accessible. Follow the means underneath to install MongoDB Linux from the most recent stable form of MongoDB on your CentOS server.
0 notes