#open source code
Explore tagged Tumblr posts
Visit Tumblr Blog
Explore Tumblr blogs with no restrictions, modern design and the best experience.
Last Seen Tumblr Blogs





Fun Fact
Tumblr has 16.74 million mobile monthly users in the US.
Text


Unexpected Guests Chapter 10, Act Two: Page 6
First / Previous / Next
Out of sight doesn't mean out of mind.... Gaster won't let anything interfere with his goal.
Look for the next update on Nov. 16th!
#undertale#undertale comic#unexpected guests comic#frisk (undertale)#alphys (undertale)#it was nice to draw alphys nerding out -u-#that's a real theory she's discussing but it's basically one guy who advocates for it--typically not a good sign for validity in science >>#but it's great for worlds based on meta video games :>#i couldn't find an easy way to use undertale's source code so that's... just the opening narration in binary =u=;;;#so. no secrets there >>;
2K notes
·
View notes
Text
feel like i've finally gotten to the point where the answer to "will i be able to figure out how to do the thing" is almost always yes, and then the operative question becomes "will i be able to figure out how to do the thing quickly". and unfortunately the answer there is usually no
225 notes
·
View notes
Text
So i was talking to my friends about how sad it is that art and media is seen as content these days, and not as art. mostly just to consume adn then scroll past, and i was thinking hey wouldn't it be cool if people had their own little websites? people used to do this but now everything is done on big platforms. and i had this cool idea of a website that hosts little websites that you can customize and instead of having a feed, you'd share websites YOU like on your own website so people look around!!!!
and then my friend told me THIS ACTUALLY EXCISTS
ITS CALLED NEOCITIES
ITS A FREE WEBSITE, ITS OPEN SOURCE, NO ADS BECAUSE ITS 100% DONATION FUNDED AND ITS BEAUTIFULL

ITS ALL I EVER WANTED, its a perfect space to set up all you're creative endevours and art! to make galleries or to just have your own website!!!
but some people do INSANELY cool things on here!! like
They made a beautifull and unique website thats fun to explore! just messing around clicking on stuff brings you to unique and interesting places!!!!

it is perfection, look at how interesting it is!!!!! there is even more that i couldnt fit into 1 screenshot.
compare this to the boring websites you scroll on daily, wouldnt you much rather find and explore websites like these? i feel it would be much more rewarding to "explore" artists, then to scroll past them. you genuinely have to DO something to enjoy it and thats amazing.
the only thing that is holding Neocities back is the fact you have to know a bit of html and css to make a website BUT THATS SUPER EASY TO LEARN!!!!
SO GO NOW, MAKE YOUR OWN CUTE AND COOL AND INTERESTING WEBSITE PLEASE, LETS GO BACK TO A TIME WHERE WEBSITES LOOKED COOL AND INTERESTING
ALSO FOLLOW MY WEBSITE I ONLY JUST STARTED SO ITS SHIT BUT THATS THE BEAUTY OF IT
TO REPEAT ONE LAST TIME, A FREE, ADLESS, OPEN SOURCE, WEBSITE HOSTING PLATFORM, THAT LETS YOU MAKE AND HOST YOUR OWN WEBSITE FOR FREE, WITH A COOL AND UNIQUE COMMUNITY
#art#artwork#pixel art#pixel artist#digital art#artists on tumblr#neocities#old internet#old web#website#html css#code#coding#html#htmlcoding#open source#social media#social networks#digital artist#small artist
137 notes
·
View notes
Text
Hey you! Arknights player who is totally representative of the playerbase at large? Do you have opinions? Do you want to form opinions on things you never thought about before? Inspired by (stealing directly from) this Tom Scott video:
youtube
Who is the best arknights operator? (best is left ambiguous intentionally, IDC how you vote, although I'd prefer there to be a reason.) The poll is hosted at:
https://arkpoll.nyansequitur.gay/
(Leaderboard will not populate until an op has at least 5 votes one way or another.)
#or just. use this to generate crackships or something#cn spoilers because i did not feel like filtering cn ops out#not sure having a visible leaderboard is a good idea#but also I want it to not just be voting into the void#I spent a lot of time trying to make it more user-friendly#this is my first time doing web dev that other people will see but the code is open source and the github project is linked#arknights#arknights cn#arknights spoilers#Youtube
55 notes
·
View notes
Text
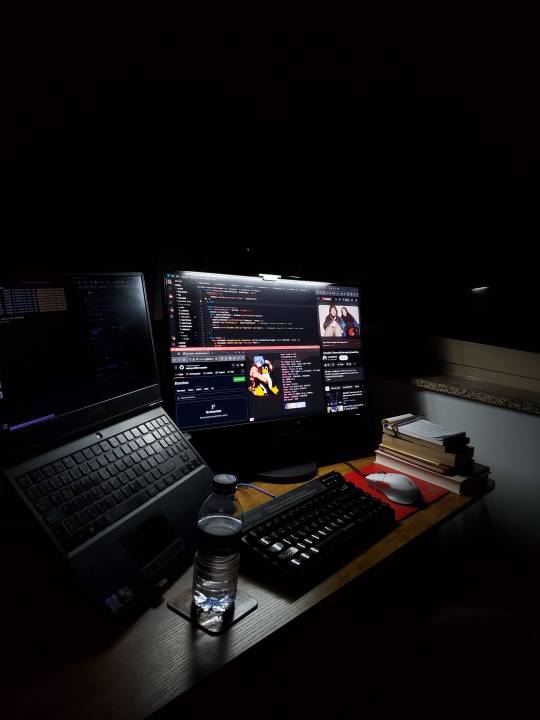

"He is back and he is seeking revenge!!" That’s what one of my teammates said after we wrapped up a big performance upgrade on a server that was… let’s say, not performing its best. Highs and lows, right? Complex, data-heavy, fast, reliable, and done for the best 'top dogs' in the game (me included).
And then another kind of thing... I was talking with a friend who’s been struggling to find a job in his field (he's studying management, which is a solid and common path). So, why not help a little bit? (That is what is in the image, do not call me a click baiter*)
I strongly believe that if you're struggling to get into any area, a nice way to present yourself is by having a page—it can be pure HTML/CSS or a cloned repo with some kind of "personal website template" using all the NodeJS you want.
Then, turn it into a DNS like "yourname-myprofession.com" so you can show a clean, well-designed QR Code with your avatar during interviews. It’s a cleanest way possible to present your résumé and experience. Tech skills are like magic, especially for those who haven't seen it before.
#study aesthetic#study blog#coding#programmer#programming#software development#developer#software#student#study space#study art#study motivation#study#studyblr#studyblr europe#studyblr community#study inspiration#studying#studyspo#linux#linuxposting#arch linux#open source#computers#github#softwareengineering#software engineer#software engineering#information technology#study life
21 notes
·
View notes
Text
i need more mutuals who are into coding and engineering!! more info under the cut!!
I planned to become an electrical engineer like my stepdad but then I decided to change my path to programming. I'm currently studying at technikum (<- wikipedia link so I don't have to explain the whole polish learning system), programmer major.
this year I have exams from web development (10th Jan - theory, 16th Jan - practical exams) and next year I have exams from App development (both mobile and desktop).
I know C family languages, Java, Python and those ones I am currently using. I also know a bit of Kotlin and I think I will continue learning it.
For web dev I know HTML and CSS ofc but also PHP and JS.
Planning on learning more languages I can use for App and operating system development as well as just to know them cause I want to after this year's exams!
my learning list:
Lua (I heard it's easy but I can't really get myself to read anything about this atm idk why)
Ruby
Assembly
Rust
As for electrical engineering I don't know much tbh but I would like to learn! I just used CAD programs for technical drawings (dad taught me some basic things when I was still thinking about going his path) helped my dad fix things on his Solar farm, houses of our neighbors and I made a few very simple circuits for fun a few years ago. Now I'm mostly focused on programming but since I learned most of the things I need for exams I have more time to do whatever I want now!
I'd like to get to know more people so I can share and mostly learn new things since even though I'm coding for years I consider myself a beginner and I am a total beginner when it comes to electrical engineering.
I'm willing to be friends or at least mutuals with anyone who codes or makes websites or is in STEM! no matter what your specialty/interest is exactly and no matter if you are a total beginner or a professional ^__^
I'd also like to have some mutuals who are into old web development and retro computing!!!!!!!!
edit: I forgot but I'm also interested in physics and quantum physics
#dear.diary୨୧#stemblr#women in stem#stem#programming#coding#web development#web design#old web#retrocomputing#computing#engineering#technology#techindustry#computers#computer#templeos#terry a davis#terry davis#linux#open source#github#calculus#physics#quantum physics#mathblr#mathematics
38 notes
·
View notes
Text
Maybe I don't understand something, and I definitely don't understand something, but why did everyone believe the information from the article, the sources of which are some mysterious insiders?
#The Sims 2 rerelease#сan we just get the open source code?#or at least just a 64-bit version for Windows
24 notes
·
View notes
Text
"Open" "AI" isn’t

Tomorrow (19 Aug), I'm appearing at the San Diego Union-Tribune Festival of Books. I'm on a 2:30PM panel called "Return From Retirement," followed by a signing:
https://www.sandiegouniontribune.com/festivalofbooks

The crybabies who freak out about The Communist Manifesto appearing on university curriculum clearly never read it – chapter one is basically a long hymn to capitalism's flexibility and inventiveness, its ability to change form and adapt itself to everything the world throws at it and come out on top:
https://www.marxists.org/archive/marx/works/1848/communist-manifesto/ch01.htm#007
Today, leftists signal this protean capacity of capital with the -washing suffix: greenwashing, genderwashing, queerwashing, wokewashing – all the ways capital cloaks itself in liberatory, progressive values, while still serving as a force for extraction, exploitation, and political corruption.
A smart capitalist is someone who, sensing the outrage at a world run by 150 old white guys in boardrooms, proposes replacing half of them with women, queers, and people of color. This is a superficial maneuver, sure, but it's an incredibly effective one.
In "Open (For Business): Big Tech, Concentrated Power, and the Political Economy of Open AI," a new working paper, Meredith Whittaker, David Gray Widder and Sarah B Myers document a new kind of -washing: openwashing:
https://papers.ssrn.com/sol3/papers.cfm?abstract_id=4543807
Openwashing is the trick that large "AI" companies use to evade regulation and neutralizing critics, by casting themselves as forces of ethical capitalism, committed to the virtue of openness. No one should be surprised to learn that the products of the "open" wing of an industry whose products are neither "artificial," nor "intelligent," are also not "open." Every word AI huxters say is a lie; including "and," and "the."
So what work does the "open" in "open AI" do? "Open" here is supposed to invoke the "open" in "open source," a movement that emphasizes a software development methodology that promotes code transparency, reusability and extensibility, which are three important virtues.
But "open source" itself is an offshoot of a more foundational movement, the Free Software movement, whose goal is to promote freedom, and whose method is openness. The point of software freedom was technological self-determination, the right of technology users to decide not just what their technology does, but who it does it to and who it does it for:
https://locusmag.com/2022/01/cory-doctorow-science-fiction-is-a-luddite-literature/
The open source split from free software was ostensibly driven by the need to reassure investors and businesspeople so they would join the movement. The "free" in free software is (deliberately) ambiguous, a bit of wordplay that sometimes misleads people into thinking it means "Free as in Beer" when really it means "Free as in Speech" (in Romance languages, these distinctions are captured by translating "free" as "libre" rather than "gratis").
The idea behind open source was to rebrand free software in a less ambiguous – and more instrumental – package that stressed cost-savings and software quality, as well as "ecosystem benefits" from a co-operative form of development that recruited tinkerers, independents, and rivals to contribute to a robust infrastructural commons.
But "open" doesn't merely resolve the linguistic ambiguity of libre vs gratis – it does so by removing the "liberty" from "libre," the "freedom" from "free." "Open" changes the pole-star that movement participants follow as they set their course. Rather than asking "Which course of action makes us more free?" they ask, "Which course of action makes our software better?"
Thus, by dribs and drabs, the freedom leeches out of openness. Today's tech giants have mobilized "open" to create a two-tier system: the largest tech firms enjoy broad freedom themselves – they alone get to decide how their software stack is configured. But for all of us who rely on that (increasingly unavoidable) software stack, all we have is "open": the ability to peer inside that software and see how it works, and perhaps suggest improvements to it:
https://www.youtube.com/watch?v=vBknF2yUZZ8
In the Big Tech internet, it's freedom for them, openness for us. "Openness" – transparency, reusability and extensibility – is valuable, but it shouldn't be mistaken for technological self-determination. As the tech sector becomes ever-more concentrated, the limits of openness become more apparent.
But even by those standards, the openness of "open AI" is thin gruel indeed (that goes triple for the company that calls itself "OpenAI," which is a particularly egregious openwasher).
The paper's authors start by suggesting that the "open" in "open AI" is meant to imply that an "open AI" can be scratch-built by competitors (or even hobbyists), but that this isn't true. Not only is the material that "open AI" companies publish insufficient for reproducing their products, even if those gaps were plugged, the resource burden required to do so is so intense that only the largest companies could do so.
Beyond this, the "open" parts of "open AI" are insufficient for achieving the other claimed benefits of "open AI": they don't promote auditing, or safety, or competition. Indeed, they often cut against these goals.
"Open AI" is a wordgame that exploits the malleability of "open," but also the ambiguity of the term "AI": "a grab bag of approaches, not… a technical term of art, but more … marketing and a signifier of aspirations." Hitching this vague term to "open" creates all kinds of bait-and-switch opportunities.
That's how you get Meta claiming that LLaMa2 is "open source," despite being licensed in a way that is absolutely incompatible with any widely accepted definition of the term:
https://blog.opensource.org/metas-llama-2-license-is-not-open-source/
LLaMa-2 is a particularly egregious openwashing example, but there are plenty of other ways that "open" is misleadingly applied to AI: sometimes it means you can see the source code, sometimes that you can see the training data, and sometimes that you can tune a model, all to different degrees, alone and in combination.
But even the most "open" systems can't be independently replicated, due to raw computing requirements. This isn't the fault of the AI industry – the computational intensity is a fact, not a choice – but when the AI industry claims that "open" will "democratize" AI, they are hiding the ball. People who hear these "democratization" claims (especially policymakers) are thinking about entrepreneurial kids in garages, but unless these kids have access to multi-billion-dollar data centers, they can't be "disruptors" who topple tech giants with cool new ideas. At best, they can hope to pay rent to those giants for access to their compute grids, in order to create products and services at the margin that rely on existing products, rather than displacing them.
The "open" story, with its claims of democratization, is an especially important one in the context of regulation. In Europe, where a variety of AI regulations have been proposed, the AI industry has co-opted the open source movement's hard-won narrative battles about the harms of ill-considered regulation.
For open source (and free software) advocates, many tech regulations aimed at taming large, abusive companies – such as requirements to surveil and control users to extinguish toxic behavior – wreak collateral damage on the free, open, user-centric systems that we see as superior alternatives to Big Tech. This leads to the paradoxical effect of passing regulation to "punish" Big Tech that end up simply shaving an infinitesimal percentage off the giants' profits, while destroying the small co-ops, nonprofits and startups before they can grow to be a viable alternative.
The years-long fight to get regulators to understand this risk has been waged by principled actors working for subsistence nonprofit wages or for free, and now the AI industry is capitalizing on lawmakers' hard-won consideration for collateral damage by claiming to be "open AI" and thus vulnerable to overbroad regulation.
But the "open" projects that lawmakers have been coached to value are precious because they deliver a level playing field, competition, innovation and democratization – all things that "open AI" fails to deliver. The regulations the AI industry is fighting also don't necessarily implicate the speech implications that are core to protecting free software:
https://www.eff.org/deeplinks/2015/04/remembering-case-established-code-speech
Just think about LLaMa-2. You can download it for free, along with the model weights it relies on – but not detailed specs for the data that was used in its training. And the source-code is licensed under a homebrewed license cooked up by Meta's lawyers, a license that only glancingly resembles anything from the Open Source Definition:
https://opensource.org/osd/
Core to Big Tech companies' "open AI" offerings are tools, like Meta's PyTorch and Google's TensorFlow. These tools are indeed "open source," licensed under real OSS terms. But they are designed and maintained by the companies that sponsor them, and optimize for the proprietary back-ends each company offers in its own cloud. When programmers train themselves to develop in these environments, they are gaining expertise in adding value to a monopolist's ecosystem, locking themselves in with their own expertise. This a classic example of software freedom for tech giants and open source for the rest of us.
One way to understand how "open" can produce a lock-in that "free" might prevent is to think of Android: Android is an open platform in the sense that its sourcecode is freely licensed, but the existence of Android doesn't make it any easier to challenge the mobile OS duopoly with a new mobile OS; nor does it make it easier to switch from Android to iOS and vice versa.
Another example: MongoDB, a free/open database tool that was adopted by Amazon, which subsequently forked the codebase and tuning it to work on their proprietary cloud infrastructure.
The value of open tooling as a stickytrap for creating a pool of developers who end up as sharecroppers who are glued to a specific company's closed infrastructure is well-understood and openly acknowledged by "open AI" companies. Zuckerberg boasts about how PyTorch ropes developers into Meta's stack, "when there are opportunities to make integrations with products, [so] it’s much easier to make sure that developers and other folks are compatible with the things that we need in the way that our systems work."
Tooling is a relatively obscure issue, primarily debated by developers. A much broader debate has raged over training data – how it is acquired, labeled, sorted and used. Many of the biggest "open AI" companies are totally opaque when it comes to training data. Google and OpenAI won't even say how many pieces of data went into their models' training – let alone which data they used.
Other "open AI" companies use publicly available datasets like the Pile and CommonCrawl. But you can't replicate their models by shoveling these datasets into an algorithm. Each one has to be groomed – labeled, sorted, de-duplicated, and otherwise filtered. Many "open" models merge these datasets with other, proprietary sets, in varying (and secret) proportions.
Quality filtering and labeling for training data is incredibly expensive and labor-intensive, and involves some of the most exploitative and traumatizing clickwork in the world, as poorly paid workers in the Global South make pennies for reviewing data that includes graphic violence, rape, and gore.
Not only is the product of this "data pipeline" kept a secret by "open" companies, the very nature of the pipeline is likewise cloaked in mystery, in order to obscure the exploitative labor relations it embodies (the joke that "AI" stands for "absent Indians" comes out of the South Asian clickwork industry).
The most common "open" in "open AI" is a model that arrives built and trained, which is "open" in the sense that end-users can "fine-tune" it – usually while running it on the manufacturer's own proprietary cloud hardware, under that company's supervision and surveillance. These tunable models are undocumented blobs, not the rigorously peer-reviewed transparent tools celebrated by the open source movement.
If "open" was a way to transform "free software" from an ethical proposition to an efficient methodology for developing high-quality software; then "open AI" is a way to transform "open source" into a rent-extracting black box.
Some "open AI" has slipped out of the corporate silo. Meta's LLaMa was leaked by early testers, republished on 4chan, and is now in the wild. Some exciting stuff has emerged from this, but despite this work happening outside of Meta's control, it is not without benefits to Meta. As an infamous leaked Google memo explains:
Paradoxically, the one clear winner in all of this is Meta. Because the leaked model was theirs, they have effectively garnered an entire planet's worth of free labor. Since most open source innovation is happening on top of their architecture, there is nothing stopping them from directly incorporating it into their products.
https://www.searchenginejournal.com/leaked-google-memo-admits-defeat-by-open-source-ai/486290/
Thus, "open AI" is best understood as "as free product development" for large, well-capitalized AI companies, conducted by tinkerers who will not be able to escape these giants' proprietary compute silos and opaque training corpuses, and whose work product is guaranteed to be compatible with the giants' own systems.
The instrumental story about the virtues of "open" often invoke auditability: the fact that anyone can look at the source code makes it easier for bugs to be identified. But as open source projects have learned the hard way, the fact that anyone can audit your widely used, high-stakes code doesn't mean that anyone will.
The Heartbleed vulnerability in OpenSSL was a wake-up call for the open source movement – a bug that endangered every secure webserver connection in the world, which had hidden in plain sight for years. The result was an admirable and successful effort to build institutions whose job it is to actually make use of open source transparency to conduct regular, deep, systemic audits.
In other words, "open" is a necessary, but insufficient, precondition for auditing. But when the "open AI" movement touts its "safety" thanks to its "auditability," it fails to describe any steps it is taking to replicate these auditing institutions – how they'll be constituted, funded and directed. The story starts and ends with "transparency" and then makes the unjustifiable leap to "safety," without any intermediate steps about how the one will turn into the other.
It's a Magic Underpants Gnome story, in other words:
Step One: Transparency
Step Two: ??
Step Three: Safety
https://www.youtube.com/watch?v=a5ih_TQWqCA
Meanwhile, OpenAI itself has gone on record as objecting to "burdensome mechanisms like licenses or audits" as an impediment to "innovation" – all the while arguing that these "burdensome mechanisms" should be mandatory for rival offerings that are more advanced than its own. To call this a "transparent ruse" is to do violence to good, hardworking transparent ruses all the world over:
https://openai.com/blog/governance-of-superintelligence
Some "open AI" is much more open than the industry dominating offerings. There's EleutherAI, a donor-supported nonprofit whose model comes with documentation and code, licensed Apache 2.0. There are also some smaller academic offerings: Vicuna (UCSD/CMU/Berkeley); Koala (Berkeley) and Alpaca (Stanford).
These are indeed more open (though Alpaca – which ran on a laptop – had to be withdrawn because it "hallucinated" so profusely). But to the extent that the "open AI" movement invokes (or cares about) these projects, it is in order to brandish them before hostile policymakers and say, "Won't someone please think of the academics?" These are the poster children for proposals like exempting AI from antitrust enforcement, but they're not significant players in the "open AI" industry, nor are they likely to be for so long as the largest companies are running the show:
https://papers.ssrn.com/sol3/papers.cfm?abstract_id=4493900

I'm kickstarting the audiobook for "The Internet Con: How To Seize the Means of Computation," a Big Tech disassembly manual to disenshittify the web and make a new, good internet to succeed the old, good internet. It's a DRM-free book, which means Audible won't carry it, so this crowdfunder is essential. Back now to get the audio, Verso hardcover and ebook:
http://seizethemeansofcomputation.org
If you'd like an essay-formatted version of this post to read or share, here's a link to it on pluralistic.net, my surveillance-free, ad-free, tracker-free blog:
https://pluralistic.net/2023/08/18/openwashing/#you-keep-using-that-word-i-do-not-think-it-means-what-you-think-it-means
Image: Cryteria (modified) https://commons.wikimedia.org/wiki/File:HAL9000.svg
CC BY 3.0 https://creativecommons.org/licenses/by/3.0/deed.en
#pluralistic#llama-2#meta#openwashing#floss#free software#open ai#open source#osi#open source initiative#osd#open source definition#code is speech
253 notes
·
View notes
Text
The “no one would ever work for free” crowd never really considered the eternal bond between humans and increasingly complex tools
#anarchism#anarchist#anarchocommunism#praxis#communism#communist#revolution#leftism#leftist#politics#work#free work#open source#coding#code
143 notes
·
View notes
Text
Is there an actually complete guide to AO3's limited HTML somewhere? I know for a fact that some features work but only under slightly weird rules.
For example, if you're using the <a> tag to form an anchor to refer to later, you HTML will end up looking like <a name="Anchor" rel="nofollow" id="Anchor"> when it's done auto-correcting in the Preview. If you type in <a name="Anchor"> or <a name="Anchor" id="NotAnchor">, it will autocorrect to that, but if you type <a id="Anchor"> it will correct to an <a> tag whose only attribute is rel, or <a rel="nofollow">. (The rel="nofollow" attribute has no practical effect for most users' purposes.)
I know that AO3 will autocorrect any incompatible HTML to compatible HTML, but I don't know what the compatible HTML is, and the above <a name="Anchor"> example demonstrates that some things are compatible but don't look compatible unless you do them right!
This is especially confusing because the editor will autocorrect some HTML as soon as you switch from the HTML editor to the Rich Text editor - but it won't correct everything. I've attempted to do slightly funky things with styling that seemingly worked just fine in the editor, but vanish when I preview the chapter.
For example, here I am trying to use using the Greek character Ψ as a list bullet. When I originally typed it into the html field, I used the actual character Ψ. As soon as I switched to rich text and then back to html, it had autocorrected to Ψ, which is the escape character for Ψ. (For those who don't know, escape characters are a special code to tell the browser that this is NOT supposed to be code. <p> is an html tag; < p > will literally render "< p >".) So, it accepted the style attribute and the list-style-type, but it forced it into an escape character. So far so good.
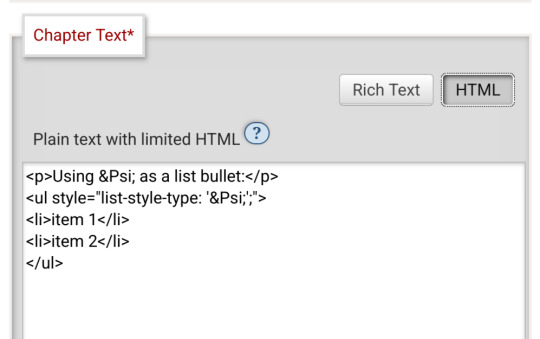
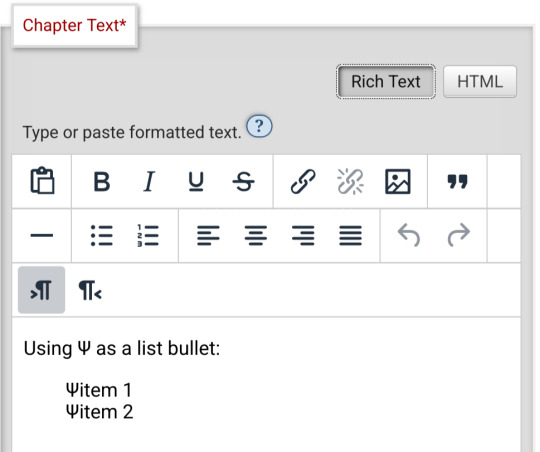
Until I click preview. Now the custom bullet is gone, replaced with the standard circle. If I click edit again, the code has removed the CSS attribute that changed the bullet... and also replaced the escape character Ψ with the character Ψ.
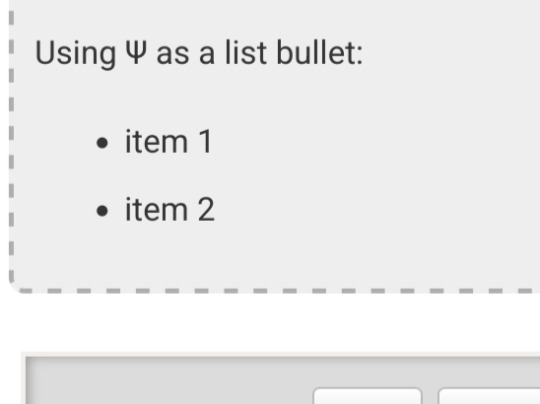
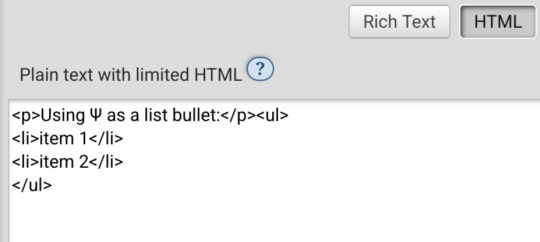
Weird.
#ao3#otw#html#ao3 formatting#ao3 html#I do not mind the lack of a clear standard at all#OTW is a nonprofit full of overworked staff and volunteers#and complete documentation is very hard#I just wanna be able to nerd more effectively#Can anyone direct me to the part of the open-source code that dictates HTML autocorrection? Is that a thing I can examine?
19 notes
·
View notes
Text

I haven't seen this in years (it was around in 2005 in one form or another and I'm sure it is older than that), and it still makes me smile.
19 notes
·
View notes
Note
can we get the source code for your infinite gender gauntlet? i wanna do the same thing but for sexuality/attraction
Fun fact, MOST of the things I've done for Zampanio are raw javascript, so they are as easy to remix as possible! For the Infinite Gender Gauntlet how you go about doing this is, so long as you can view the Document Object Model like so:

You can see the list of files it pulls in: utils, data and index.
Of course, reading someone's code is its own Adventure (its mazes all the way down) but that's 100% of what controls that page. data and utils is filled with things I use for other sims as well, so you'll find a lot of dead ends in there: I'd recommend starting with index and seeing what it actually uses. And of course, its interacting with the page itself, you can see the raw html file here: view-source:http://eyedolgames.com/Gender/
Looking forward to what you (and anyone else!) makes with it, def ping me!
#zampanio#gender gauntlet#source code#seriously everything i do is open source#remix it#expand it#i want to click a random link some night at 2 in the morning and be shook to my core when i see my own work but wearing a new face#because someones remix of something i did went viral and got bigger than the source
16 notes
·
View notes
Text
Can we upgrade open-source decentralized services, tools, and networks so decentralization can be the default options for startups and developers..?? can we achieve big tech's security and stability with decentralized networks ??
Share any thoughts or ideas you have... what you think ?
NOTICE: I'm not talking about web3 or crypto.
98 notes
·
View notes
Text


Some screen sharing of challenging backend Java code that I was testing, although it was quite basic, to be honest.
Additionally, my notebook contained a pretty basic code base for a producer class that I wrote by hand. I want to become very skilled in creating Java classes based on the producer-consumer pattern using Kafka.
#coding#linux#programming#programmer#developer#software development#software#student#study aesthetic#study blog#university student#studyblr#study motivation#studying#university#learning#study#studynotes#studyblr community#java#vim#neovim#vimterminal#clivim#iusevimbtw#linuxposting#open source#computers#debian#notebook
33 notes
·
View notes
Text
update: local lesbian forced to learn at least very basic coding. 7 dead 32 injured
#.txt#this is not for new perspectives unfortunately#this is bc i realized that actually i am much more prone to remember things in my routine when i am verbally reminded#and i cannot expect other people to manage my schedule so it would be v beneficial for me to have some kind of virtual assistant device#but i refuse to have alexa or any type of apple + google device listening in my home for Many reasons#long story short i'm going to be trying to work with an open source software i found online to put something together that suits My needs#but i'm defo going to need to sit my ass down and do some Actual learning re programming#and not the fake coding i've been slapping together for new perspectives#sighhhhh#oh well
4 notes
·
View notes
Text
Growing my (code)base
The open-source coding challenge I started back in June is approaching its first API freeze, in other words, version 1.0 ! On Monday night I released v0.9.8 with the following line counts:
+ 66K lines of code (excluding blanks and comments)
+ of which 40K are Java and 22K are C++
Compare with v0.9.0 (from October), which contained 42K lines of code, of which 23K were Java and 15K were C++.
4 notes
·
View notes