#string concatenation should not be n^2..
Explore tagged Tumblr posts
Visit Tumblr Blog
Explore Tumblr blogs with no restrictions, modern design and the best experience.
Last Seen Tumblr Blogs





Fun Fact
The Tumblr office adopted Tommy, an 11-year-old Pomeranian.
Text
Haskell voice: we have strings and growable vectors! you wanted linked lists, right?
like we made fun of PHP for having shit like mysql_escape_string and mysql_real_escape_string because mysql_escape_string had a horrible bug but they didn't want to remove it for compatibility reasons meanwhile C has the footguns and solutions of strcpy and strncpy and and printf and snprintf and vsnprintf.
At least PHP deprecated the mysql library and made a new one since PHP5!
83 notes
·
View notes
Text
7 Essential JavaScript Features Every Developer Should Know Early.
JavaScript is the backbone of modern web development. Whether you're just starting out or already have some coding experience, mastering the core features of JavaScript early on can make a big difference in your growth as a developer. These essential features form the building blocks for writing cleaner, faster, and more efficient code.

Here are 7 JavaScript features every developer should get familiar with early in their journey:
Let & Const Before ES6, var was the only way to declare variables. Now, let and const offer better ways to manage variable scope and immutability.
let allows you to declare block-scoped variables.
const is for variables that should not be reassigned.
javascript Copy Edit let count = 10; const name = "JavaScript"; // name = "Python"; // This will throw an error Knowing when to use let vs. const helps prevent bugs and makes code easier to understand.
Arrow Functions Arrow functions offer a concise syntax and automatically bind this, which is useful in callbacks and object methods.
javascript Copy Edit // Traditional function function add(a, b) { return a + b; }
// Arrow function const add = (a, b) => a + b; They’re not just syntactic sugar—they simplify your code and avoid common scope issues.
Template Literals Template literals (${}) make string interpolation more readable and powerful, especially when dealing with dynamic content.
javascript Copy Edit const user = "Alex"; console.log(Hello, ${user}! Welcome back.); No more awkward string concatenation—just cleaner, more intuitive strings.
Destructuring Assignment Destructuring allows you to extract values from objects or arrays and assign them to variables in a single line.
javascript Copy Edit const user = { name: "Sara", age: 25 }; const { name, age } = user; console.log(name); // "Sara" This feature reduces boilerplate and improves clarity when accessing object properties.
Spread and Rest Operators The spread (…) and rest (…) operators may look the same, but they serve different purposes:
Spread: Expands an array or object.
Rest: Collects arguments into an array.
javascript Copy Edit // Spread const arr1 = [1, 2]; const arr2 = […arr1, 3, 4];
// Rest function sum(…numbers) { return numbers.reduce((a, b) => a + b); } Understanding these makes working with arrays and objects more flexible and expressive.
Promises & Async/Await JavaScript is asynchronous by nature. Promises and async/await are the key to writing asynchronous code that reads like synchronous code.
javascript Copy Edit // Promise fetch('https://api.example.com/data') .then(response => response.json()) .then(data => console.log(data));
// Async/Await async function getData() { const response = await fetch('https://api.example.com/data'); const data = await response.json(); console.log(data); } Mastering these will help you handle APIs, databases, and other async operations smoothly.
Array Methods (map, filter, reduce) High-order array methods are essential for transforming and managing data.
javascript Copy Edit const numbers = [1, 2, 3, 4, 5];
// map const doubled = numbers.map(n => n * 2);
// filter const even = numbers.filter(n => n % 2 === 0);
// reduce const sum = numbers.reduce((total, n) => total + n, 0); These methods are clean, efficient, and favored in modern JavaScript codebases.
Final Thoughts Learning these JavaScript features early gives you a solid foundation to write better, more modern code. They’re widely used in frameworks like React, Vue, and Node.js, and understanding them will help you grow faster as a developer.
Start with these, build projects to apply them, and your JavaScript skills will take off.
0 notes
Text
Essential Algorithms and Data Structures for Competitive Programming
Competitive programming is a thrilling and intellectually stimulating field that challenges participants to solve complex problems efficiently and effectively. At its core, competitive programming revolves around algorithms and data structures—tools that help you tackle problems with precision and speed. If you're preparing for a competitive programming contest or just want to enhance your problem-solving skills, understanding essential algorithms and data structures is crucial. In this blog, we’ll walk through some of the most important ones you should be familiar with.
1. Arrays and Strings
Arrays are fundamental data structures that store elements in a contiguous block of memory. They allow for efficient access to elements via indexing and are often the first data structure you encounter in competitive programming.
Operations: Basic operations include traversal, insertion, deletion, and searching. Understanding how to manipulate arrays efficiently can help solve a wide range of problems.
Strings are arrays of characters and are often used to solve problems involving text processing. Basic string operations like concatenation, substring search, and pattern matching are essential.
2. Linked Lists
A linked list is a data structure where elements (nodes) are stored in separate memory locations and linked together using pointers. There are several types of linked lists:
Singly Linked List: Each node points to the next node.
Doubly Linked List: Each node points to both the next and previous nodes.
Circular Linked List: The last node points back to the first node.
Linked lists are useful when you need to frequently insert or delete elements as they allow for efficient manipulation of the data.
3. Stacks and Queues
Stacks and queues are abstract data types that operate on a last-in-first-out (LIFO) and first-in-first-out (FIFO) principle, respectively.
Stacks: Useful for problems involving backtracking or nested structures (e.g., parsing expressions).
Queues: Useful for problems involving scheduling or buffering (e.g., breadth-first search).
Both can be implemented using arrays or linked lists and are foundational for many algorithms.
4. Hashing
Hashing involves using a hash function to convert keys into indices in a hash table. This allows for efficient data retrieval and insertion.
Hash Tables: Hash tables provide average-case constant time complexity for search, insert, and delete operations.
Collisions: Handling collisions (when two keys hash to the same index) using techniques like chaining or open addressing is crucial for effective hashing.
5. Trees
Trees are hierarchical data structures with a root node and child nodes. They are used to represent hierarchical relationships and are key to many algorithms.
Binary Trees: Each node has at most two children. They are used in various applications such as binary search trees (BSTs), where the left child is less than the parent, and the right child is greater.
Binary Search Trees (BSTs): Useful for dynamic sets where elements need to be ordered. Operations like insertion, deletion, and search have an average-case time complexity of O(log n).
Balanced Trees: Trees like AVL trees and Red-Black trees maintain balance to ensure O(log n) time complexity for operations.
6. Heaps
A heap is a specialized tree-based data structure that satisfies the heap property:
Max-Heap: The value of each node is greater than or equal to the values of its children.
Min-Heap: The value of each node is less than or equal to the values of its children.
Heaps are used in algorithms like heap sort and are also crucial for implementing priority queues.
7. Graphs
Graphs represent relationships between entities using nodes (vertices) and edges. They are essential for solving problems involving networks, paths, and connectivity.
Graph Traversal: Algorithms like Breadth-First Search (BFS) and Depth-First Search (DFS) are used to explore nodes and edges in graphs.
Shortest Path: Algorithms such as Dijkstra’s and Floyd-Warshall help find the shortest path between nodes.
Minimum Spanning Tree: Algorithms like Kruskal’s and Prim’s are used to find the minimum spanning tree in a graph.
8. Dynamic Programming
Dynamic Programming (DP) is a method for solving problems by breaking them down into simpler subproblems and storing the results of these subproblems to avoid redundant computations.
Memoization: Storing results of subproblems to avoid recomputation.
Tabulation: Building a table of results iteratively, bottom-up.
DP is especially useful for optimization problems, such as finding the shortest path, longest common subsequence, or knapsack problem.
9. Greedy Algorithms
Greedy Algorithms make a series of choices, each of which looks best at the moment, with the hope that these local choices will lead to a global optimum.
Applications: Commonly used for problems like activity selection, Huffman coding, and coin change.
10. Graph Algorithms
Understanding graph algorithms is crucial for competitive programming:
Shortest Path Algorithms: Dijkstra’s Algorithm, Bellman-Ford Algorithm.
Minimum Spanning Tree Algorithms: Kruskal’s Algorithm, Prim’s Algorithm.
Network Flow Algorithms: Ford-Fulkerson Algorithm, Edmonds-Karp Algorithm.
Preparing for Competitive Programming: Summer Internship Program
If you're eager to dive deeper into these algorithms and data structures, participating in a summer internship program focused on Data Structures and Algorithms (DSA) can be incredibly beneficial. At our Summer Internship Program, we provide hands-on experience and mentorship to help you master these crucial skills. This program is designed for aspiring programmers who want to enhance their competitive programming abilities and prepare for real-world challenges.
What to Expect:
Hands-On Projects: Work on real-world problems and implement algorithms and data structures.
Mentorship: Receive guidance from experienced professionals in the field.
Workshops and Seminars: Participate in workshops that cover advanced topics and techniques.
Networking Opportunities: Connect with peers and industry experts to expand your professional network.
By participating in our DSA Internship, you’ll gain practical experience and insights that will significantly boost your competitive programming skills and prepare you for success in contests and future career opportunities.
In conclusion, mastering essential algorithms and data structures is key to excelling in competitive programming. By understanding and practicing these concepts, you can tackle complex problems with confidence and efficiency. Whether you’re just starting out or looking to sharpen your skills, focusing on these fundamentals will set you on the path to success.
Ready to take your skills to the next level? Join our Summer Internship Program and dive into the world of algorithms and data structures with expert guidance and hands-on experience. Your journey to becoming a competitive programming expert starts here!
0 notes
Text
C standard library is abysmal and every part of it was misdesigned, I can pick a random part of it and see it all fall apart.
The way locales are done means you can't reliably print out formatted numbers in a locale-indepenent fashion as there's no locale-accepting version of say, printf.
string.h is an embarrassment. strncpy is not a string function as its post-condition does not create a string at its destination in every case. It is also not a "safe version of strcpy" either, wrongly misleading people into thinking it is. The intended use of strcat results in O(n^2) performance when concatenating many strings. While the null-terminated string representation has problems on its own, string.h compounds them significantly.
Null-terminated strings and string.h are a symptom of a larger problem of C that is an utter lack of sensible buffer management, like some form of a slice type, contained within a single variable. But also you can't write one because the type system does not have any form of expressing a "generic type" like the built-in array types, or pointer types. Every such type has to be provided by the base language and this results in a situation where complex numbers, atomics and others are introduced as a language feature (!).
The type system is a joke and will let you assign integers to pointer variables, and this will only result in a compiler warning.
Compiler warnings are something you _have_ to enable in order to have any form of reasonable software development experience, but this is once again a something you have to remember while writing your Makefiles. -Wall does not enable "all warnings" because it broke somebody important's code when compiled together with "-Werror" and so "all warnings" in this context means "enable all warnings the compiler had in like nineteen-ninety-something". Newbies will not know to do enable warnings, as most tutorials are written by people who have no clue themselves. The solution to this problem would be introducing a concept "so okay, compiler, give me a reasonable set of warning flags as you believe is appropriate for 2024" and later on when you're feeling up to grabbing more diagnostics to warn about, you bump the warning wave into a next number, but such thing is yet to be introduced.
The way C99 variable length arrays interact with sizeof operator makes me cringe (if any part of the expression touches a VLA, sizeof becomes a runtime operation instead of compile time one), to the point I am glad that C11 no longer makes VLAs mandatory so I hope most implementations will nope out of them.
The C language syntax is also a joke and has its own thorns.
The most reasonable way to use C language is to avoid touching the C standard library at all, but this results in bespoke solutions incompatible with other people's bespoke solutions. Check a random project you will likely see it reimplement a string type.
In some ways you could dismiss these issues and treat C as a some form of portable assembler ("the language that provides you a mechanism but no policy, you're the one responsible for policy"), but you will be hindered by the gradual change of how undefined behaviour is treated both by the community and by the compilers over the years. It used to mean "several compilers did it differently so we're leaving it up to them" but nowadays is interpreted as "compiler will assume that every code path that leads to the code that would exhibit undefined behaviour is assumed to never happen" which leads to "interesting" situations where null checks are optimized away out of the produced binary code, increasing the severity of security holes many many times, and making the mapping from C code to assembly not obvious, making the supposed advantage of C illusory.
And then when you point all of this out the community will victim blame you and say that you should have been more careful.
Chat gimmick blogs are interacting with me what does this mean
2K notes
·
View notes
Text
The Excel Formulas You Need to Know to Save Time
There are numerous Excel formulas that can be useful in various situations, but here are some essential Excel formulas that most users should know: SUM: Adds up all the numbers in a range of cells. Example: =SUM(A1:A5). AVERAGE: Calculates the average of a range of numbers. Example: =AVERAGE(B1:B10). MAX: Returns the largest number in a range. Example: =MAX(C1:C20). MIN: Returns the smallest number in a range. Example: =MIN(D1:D15). COUNT: Counts the number of cells that contain numbers in a range. Example: =COUNT(E1:E30). IF: Performs a conditional operation. It returns one value if a condition is true and another if it's false. Example: =IF(A1>10, "Yes", "No"). VLOOKUP: Searches for a value in the first column of a table and returns a value in the same row from a specified column. Example: =VLOOKUP(G1, A1:B10, 2, FALSE). HLOOKUP: Similar to VLOOKUP, but searches horizontally in a table. Example: =HLOOKUP(G1, A1:G10, 3, FALSE). INDEX and MATCH: Used together, these functions can perform powerful lookups. INDEX returns a value from a specific row and column in a range, and MATCH searches for a value in a range and returns its relative position. Example: =INDEX(A1:B10, MATCH(G1, A1:A10, 0), 2). CONCATENATE (or CONCAT): Combines text from multiple cells into one cell. Example: =CONCATENATE(A1, " ", B1). LEFT and RIGHT: Extracts a specified number of characters from the left or right of a cell's content. Example: =LEFT(A1, 3). LEN: Returns the length (number of characters) of a text string. Example: =LEN(A1). TRIM: Removes extra spaces from text. Example: =TRIM(A1). DATE: Creates a date value. Example: =DATE(2023, 9, 7). TODAY: Returns the current date. Example: =TODAY(). NOW: Returns the current date and time. Example: =NOW(). SUMIF: Adds up all numbers in a range that meet a specified condition. Example: =SUMIF(B1:B10, ">50"). COUNTIF: Counts the number of cells in a range that meet a specified condition. Example: =COUNTIF(C1:C20, "=75"). IFERROR: Returns a custom value if a formula generates an error. Example: =IFERROR(A1/B1, "N/A"). SUMIFS: Adds up numbers in a range that meet multiple conditions. Example: =SUMIFS(B1:B10, A1:A10, "Apples", C1:C10, ">10"). COUNTIFS: Counts the number of cells that meet multiple criteria. Example: =COUNTIFS(A1:A10, "Bananas", B1:B10, ">5"). AVERAGEIFS: Calculates the average of a range based on multiple criteria. Example: =AVERAGEIFS(D1:D15, E1:E15, "Red", F1:F15, ">50"). IF, AND, OR: Combining these functions can create more complex conditional statements. Example: =IF(AND(A1>10, B1="Yes"), "Pass", "Fail"). SUMPRODUCT: Multiplies corresponding components in arrays and returns the sum of those products. Example: =SUMPRODUCT(A1:A5, B1:B5). TEXT: Converts a number into text with a specified format. Example: =TEXT(NOW(), "dd-mmm-yyyy hh:mm:ss"). PROPER: Capitalizes the first letter of each word in a text string. Example: =PROPER("john doe"). UPPER and LOWER: Converts text to all uppercase or all lowercase. Example: =UPPER("hello") and =LOWER("WORLD"). SUBTOTAL: Performs various aggregate functions (e.g., SUM, AVERAGE) on filtered data sets. Example: =SUBTOTAL(109, B1:B100). RANK: Returns the rank of a number within a list. Example: =RANK(A1, A1:A10, 1). ROUND: Rounds a number to a specified number of decimal places. Example: =ROUND(A1, 2). ROUNDUP and ROUNDDOWN: Round a number up or down to the nearest specified decimal place. Example: =ROUNDUP(A1, 0) and =ROUNDDOWN(B1, 1). PI: Returns the mathematical constant Pi (π). Example: =PI(). RAND and RANDBETWEEN: Generates random numbers. RAND() returns a decimal between 0 and 1, while RANDBETWEEN(min, max) generates a random integer within a specified range. DAYS: Calculates the number of days between two dates. Example: =DAYS(B1, C1). NETWORKDAYS: Calculates the number of working days between two dates, excluding weekends and specified holidays. Example: =NETWORKDAYS(B1, C1, holidays). DGET: Retrieves a single value from a database based on specified criteria. PMT: Calculates the monthly payment for a loan based on interest rate, principal, and term. Example: =PMT(0.05/12, 5*12, 10000). NPV: Calculates the net present value of a series of cash flows based on a discount rate. Example: =NPV(0.1, C1:C5). IRR: Calculates the internal rate of return for a series of cash flows. Example: =IRR(D1:D5). Conclusion: In conclusion, Excel offers a rich arsenal of formulas and functions that cater to a wide range of data manipulation and analysis needs. The formulas and functions listed in the previous responses cover the fundamentals, from basic arithmetic calculations to conditional statements, text manipulation, and advanced financial and statistical analysis. Familiarity with these Excel formulas empowers users to efficiently manage data, perform calculations, and derive valuable insights. Read the full article
0 notes
Text
A real programmer
They say a real programmer is lazy. They hate doing things so much they spend weeks writing tools that will save them minutes. Of course, sometimes they write tools that will save lots of people centuries.
What I’m getting at is I wrote a script today. It tells you the word count of each chapter in your story.
I say “chapter”, but really I mean –
What do you call it, when you, you know:
“Blah, blah, blah”, said Percy.
Little he know, the fool, that that blah was the last blah he would every blah.
On the following Tuesday I packed up my jimjams and set out into the Wild.
You don’t call that a chapter. I’ll die before I call it a scene (I’m not a director, and I don’t secretly wish I was one).
Well, anyway, my script counts up those. I wrote it in C. Would you like to C?
#include <err.h> #include "../wc/wc.h" #include "../cat/cat.h" #include "../split/split.h" int main (int argc, char **argv) { if (argc < 2) errx (1, "usage: %s file", *argv); char *buf; int ret = cat_paths_into_buf (&buf, (const char *[]) {argv[1]}, 1, 0); size_t n_bufs; char **bufs = split (buf, strchr (buf, '\0'), (char *[]) {"##"}, 1, &n_bufs, 1); struct wc wc; each (buf, &bufs[1], n_bufs - 1) { wc = wc_str (*buf); printf ("%zu: %zu\n", buf - bufs + 1 - 1, wc.words); } }
I’ll tell you some interesting things about this program.
1!!!!!!!!!!!!!!!!!!!!!!! (each)
I like to use a macro to loop over arrays. In C, traditionally you do
for (int i = 0; i < /\* eg \*/ 100; i++) { /\* eg \*/ printf ("%d\n", the_thing[i]) }; }
And I think that’s more universally useful. I think if you were going to have just one kind of for loop, that would be it. But I like the other kind, the kind you get in Bash and no doubt Python and all the rest: “for THING in THINGS”.
The each macro lets me do that. Actually I can do that without a macro, and did for a long time.
for (struct thing *thing = things; thing < things + n_things; thing++) { (*thing).whatever = "joy"; }
But that’s pretty painful to write because it makes your eyes bleed.
2!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!
I include the header files “wc.h”, “cat.h” and “split.h”. These are libs I’ve written. split.h is straightforward: split a string. cat and wc, though, might be interesting to talk about.
C’s a bad language to write little scripts like this in, or so, I feel, people believe. But I say screw you.
What makes C bad as scripting language is the standard library. It doesn’t have convenient functions. As an example there no function simply split a string. There’s strtok. It’s not really the same. There’s no join, launch_emacs, no nothin. There’s actually no dynamic array struct-plus-function. Maybe because no one would agree on the best way to do it?
The program I pasted: would it really be that much shorter in Python? I say NO! Not that much shorter. Not when you have libs like wc, cat. But you have to write those yourself.
You can use big general-purpose libraries like glib and maybe one day I will. I’ve never liked the idea of linking to such a big binary just to write programs like the one I. But I think that’s empty prejudice. Most scripts you write yourself in Bash are personal. I mean, they run on your machine, and glib (or whatever) is on your machine.
My wc and cat libs are based, you’ll know if you’re in the know, on Unix commands: wc (wordcount) and cat (concatenate – it reads in files, outputs them to the screen).
I’ve thought for a long time I’d love to see GNU’s Coreutils designed as C libraries. The commands would be frontends for those libraries. Because, like I say, the pain in C isn’t the language, it’s the low-level nature of its standard library.
Even other libraries are obnoxiously low-level. There’s a commonly-used library, PCRE (Perl-Compatible Regular Expressions). It’s very clever, well made, has loads of functions.
But it doesn’t have a “match” function! I swear, I’ve looked. There’s no function you can call to just figure out if a bit of text matches a pattern. Instead you’re expected to compile a regex, then execute it, checking for errors along the way. It about six lines for something that in in other languages is simply “==” or “=~”.
So, of course, the first thing you do when faced with that is wrap it in your own function, regmatch and forget about all the rest.
What else do I have to complain about?
Nothing. What a disgrace.
That was a pretty incoherent blog post, but I’ve overdone it on the coffee / energy drinks and have a headache.
Oh
I suppose I should say something about the story. I’ll tell you I’ve come up with a name: The Long, Thin Tail of God. I’ll also spurt out here the names I considered. Fast content, ker-splat, paste it in.
Home
Lonely
Marrowbone War
Burane Massacre
Big Rock on a Beach
Big House on the Hill
The Whore of Black Lake
To Jump on My Bed
Jumping At Every Sound
An Archaeologist
A Spy
It Wasn’t Sheer Bliss
Ice-cold home
As If I Was A Stranger
Xunotic
Xunophillia
Xunophobia
Because You’re not worthy, Soraen
Right in the Centre of Town
Yes, I Would Have Said
Keep the Fire Burning
Eternal Flame
What a Lot of Work it Must Take
The Burané Massacre.
The Ape-People
The Monkey God
The Strange Tale of the Long, Thin Tail
The Long, Thin tail – that’s a nice pun.
The Long, Thin Tail of God
I went with the Tail one for a very practical reason: the story is, in the end, about this monkey god, Xu. And there’s bugger all about him in story until near the end. I kind of liked that. I like stories that surprise me. I don’t have strong opinions about how stories should be.
But I know if I don’t drop heavy hints about the God before he’s mentioned at the end, people will say, “Huh? Where did he come from?”
He came from your mama! Now shut up and just enjoy the damn story!
0 notes
Text
DEFCON 28 Badge Challenge
If you are still working on the Badge challenge, be warned! Spoilers below!
If you’d like to play along, you can grab all of the required materials for free at:
https://media.defcon.org/DEF%20CON%2028/DEF%20CON%20Safe%20Mode%20Badge.rar

Exposition:
Before getting into the badge challenge write-up, we would first like to take a moment to thank all those who helped make this possible. First and foremost, a big shout out to 1o57 for putting together these amazing puzzles every year, and the sacrifices required to make it happen. Also a big thanks to the DEFCON organizers as a whole, who allow people like us to engage in these puzzle-solving shenanigans, and giving 1o57 a place to create and foster the hacker mindset.
Finally, a big thank you and congratulations goes out to Co9’s newest members, and four complete DEFCON newbies (congrats on your first con!):
Cr0wn_Gh0ul (@Cr0wn_Gh0ul)
JTobCat (@jtobcat)
LeFevre (@Lefevre)
motive (@leemsparks)
With that, let’s get into it.
The DEFCON 28 Badge
The Council of 9, undaunted by the irregular startup routine of DEFCON Safe Mode, prepared to scuffle and rumpus against the bewildering puzzles of 1o57 once again. After purchasing our DC28 badges, the fun began.
As 1o57 puzzles go, you never have an official starting place. You have to find it. So as we found answers or interesting information, we would record it for possible future use, and move on to the next thing we could find. Eventually, the breadcrumbs resolve into a path to follow.
This years badge consisted of three physical items:
A traditional printed cassette tape insert booklet
An old school audio cassette tape
The Lanyard
Booklet
The cassette tape insert booklet had several codes printed across it.
First, looking at the track listing:

Taking the first letter of each song on the side A tracklist spells out “LOSTINTIME”. For the uninitiated, 1o57 is the longtime Defcon badge designer and puzzlemaster. These track names also contain hints for later - Keywords like Lissajous.
Color Block Sub Cipher

Written, the color boxes read
Orange White Pink
Purple White/Green Orange/Green
Blue/Green Green Pink White
Purple/Green White/Green Orange White
and
Orange Blue Yellow/Yellow Green/White Purple
Green/White Green/White Yellow
By substituting the letters directly below for colors the first image, decodes to DEF CON SAFE MODE. It's basically a key.

So the second is

Skull Text

This string of text wasn’t nearly as simple to decipher. This skull artwork was a throwback to DC21, which had us scurrying to find notes and write-ups on the Badge puzzles from that year. Ultimately, however, we found the solution by taking the text string and pasting it into a 6x6 route transposition cipher, yielding:
tIstFCOnRFoofFioumYrgureoohrDOuntlon

Which is read Come on four dot four is right in front of you
We didn’t yet know what to do with this, so we put it aside for later.
Cipher Text Page

Xbaw maek wzme pgty zvxy izwk iwhk lnhy
agrl rrlp fsis xadh uflx dsqh rzrg qegu
itwb wveq aslo moii xmzx mvea rtil yekd
lvks jrbo arvy nmjz wodi gcxe tkrr cyir
xbsu rwyf slwr ixyk lrwz sbzr zbpg rrrw
hjsi alXX 1o57
The solution to this text really came from the fact that we were paying attention to 1o57 dropping random hints in various locations - not from anything in the booklet itself. 1o57 had played a video on his Twitch channel from The Adventures of Buckaroo Banzai Across the Eighth Dimension. Most notably, Buckaroo is famous for using the phrase: “No matter where you go there you are”
Using this as an OTP key...
nomatterwhereyougothereyouarenomatterwhereyougothereyouarenomatterwhereyougothereyouarenomatterwhereyougothereyouarenomatterwhereyougothereyouarenomatterwhereyougothere
...you get another Buckaroo quote (actually written by Greek philosopher Odysseas Elytis) :
Know that as in life there is much that many have looked up on but few have seen because as my father told me and his father told him you will come to learn a great deal if you study the insignificant in depth
Cassette Tape
With the booklet sorted, we turned our attention to the DC28 cassette tape. Upon listening to the tape, there are some immediate … features… that stick out.
Tones

One of the first things anyone listening to the tape will notice is the odd tones that sound at different times, and seem to repeat. These were halves of a DTMF (Dual-tone Multi-Frequency) tone, known better by many as “touchtones”, and appeared in two (2) groups of fourteen (14) tones that repeated three (3) times. By combining these single frequency pairs back together, we restored the dual frequencies and, by examining the peak frequency of the tones, we were able to identify the keypresses that generated the given tones. The flow of tones came out as:

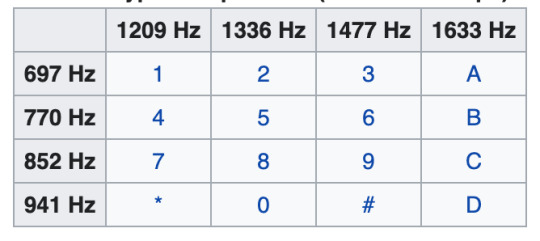
DTMF Numbers: 2 6 3 3 9 6 7 3 7 9 9 9 4 9
We’re not done yet, though! Not yielding any immediate plaintext, we continued checking for a second-stage decipherment. As we’ve learned from other puzzles, any phone-related cipher should be checked for T9 coding, which turned out to be exactly what we have here.
By looking at a phone keypad,
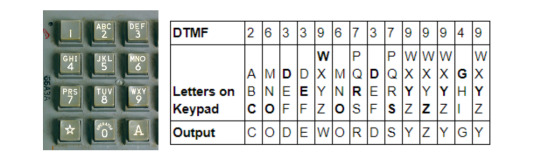
Reading those indices onto the available letters, we get: CODEWORDSYZYGY
Oscilloscope
It’s not just the obvious side of the audio that we need to examine - the audio on the cassettes had much more than meets the … ears. Based on some hints that 1o57 dropped, and our experience with past puzzles, we decided to examine the audio for any hidden waveforms or other hidden data. Using a software oscilloscope, we examined the tape audio and discovered plenty of hidden text, as well as Lissajous patterns (remember that word from the Tracklist? Ya, that was the hint to get us here). The patterns we saw included a spaceship, a heptagon, a butterfly, and some very interesting text. The text we needed was:


The full text that shows up in the oscilloscope reads:
FIND A KEY AT LOSTBOY.NET SLASH PALEBLUEDOT
These two lead us to http://lostboy.net/PaleBlueDot
When we found this, though, the site was not yet active (since DEFCON hadn’t officially started). Oh well, better solve the Lanyard while we wait.
The Lanyard
This year’s lanyard proved to be quite tricky. We went through several iterations of attempts to make sense out of it. Pictured below is the lanyard with our attempts at dividing up and delineating each shape.

1o57 offered quite a few hints about the symbols on the lanyard - and with good reason. Finding the appropriate reading for the text was pretty difficult. Here are some of the most important hints that came out:
...now excuse me while I go read more about French aristocrats fleeing a post 1789 revolution.
More hints will start flowing from the font of knowledge tomorrow after DEFCON officially starts....
These sorts of hints eventually point towards the Crackly font, hosted on emigre.com (https://www.emigre.com/PDF/Crackly.pdf). Using this font, we were able to extract the following values from the lanyard segments:

Note first those mad MSPaint skills. Note second that all of those numbers are below 26, we immediately changed them into letters, giving us:
Q X U N
E K K E
V I O Q
Q G C O
Throwing this through a ROT, because you should always ROT everything, discovered that it was ROT-24’d. (Side note: Why ROT-24? Because ROT-24 is a negative ROT-28. Tricksy)
O V S L
C I I C
T G M O
O E A M
While not immediately obvious, one observant council member noted the presence of the C-O-M series of letters when reading in the vertical 4x4 pattern. Reading it in this way gave us what we were after:
OCTOVIGESIMALCOM → http://octovigesimal.com
Octovigesimal.com
This new page contained quite a bit of new content that we needed to sort through, and any answers were certainly not obvious.



Image filename: besidenequals2.jpg
The summation equation written at the bottom of the Goonies skull key implied that we need something that follows the pattern 1.1 + 2.2 + 3.3 + 4.4. The banner of the website implies that we need to look at the album “The Great 28” by Chuck Berry. This is further hinted at by the text “Record your answer~”, as in a record. We even think the tilde, from the latin for ‘title’ was probably part of the hint.

Upon looking at the Track list of “The Great 28” we saw that there is a track called Come On, which is right before a track called “Nadine (Is it You)”. This seems to link back to the text that we extract from the cipher text on the cassette tape insert “Come On Four Dot Four is right in front of you” Come On happens to be Section 4 track 4 of the album (4.4) and is “right in front of” (before) “Is it You”.
Going with that train of thought, and concatenating the titles of tracks 1.1, 2.2, 3.3, and 4.4:
Chuck Berry - The Great 28:
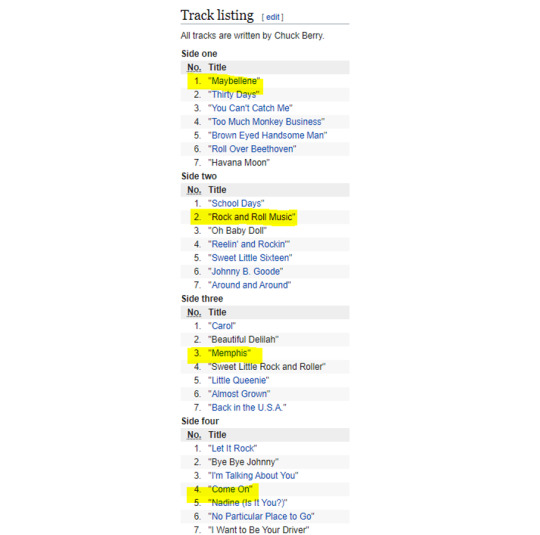
we get: MaybelleneRockandRollMusicMemphisComeOn
However, we don’t know what to do with this yet. Note it and move on.
Last on this site, but certainly not least, is another URL. Hidden right in plain sight underneath the logo is a pointer to the URL “Base-28.com”.

Alright, time to move on.
base-28.com

The first thing to look at here is the ciphertext in the top center of the page. We have a few strings to play with from previous solves. With the earth, moon and sun being in a line on the page, we figured it was a good opportunity to try the key that we found previously (from the audio DTMF codes): SYZYGY. This ciphertext is Vigenere encoded with SYZYGY as the key, and decodes to Who are you going to call? Definitely sounds like Ghostbusters to us.
Also of note here, is that the image on the arcade cabinet was identified as being the Temple of Gozer - a Ghostbusters scene. This scene is actually Chapter 28 on the GhostBusters DVD, and is titled “Crossing Streams”. This reinforces the Ghostbusters clue that the vigenere text gives us, and will prove critical to the next step.
On either side of the website we see pictures of members of the band The Commodores. 64 of them, in fact. These two clues combined tell us that we need to look at the Ghostbusters Commodore 64 game. What specifically about it? We don’t know yet.
Visually, it looks like this...

Pale Blue Dot
The Lissajous from the audio on the cassette tape pointed us to lostboy.net/PaleBlueDot. Upon accessing this page, we were greeted with… a wall of numbers. A giant freaking wall of numbers. Oh, and a joke.
How many Sagans does it take to change a lightbulb?

A quick google search will reveal the hilarious answer: “Billions and billions”
How it’s supposed to be solved
The numbers in the image are divided by the decimal, with a number of seemingly arbitrary length on the left, and eight (8) digits to the right of the decimal.
Left-Hand Numbers
Noticing that the numbers, with appending a few leading 0s, can be paired into values all less than 26.
Separating them out, and converting them via Letter-Numbers
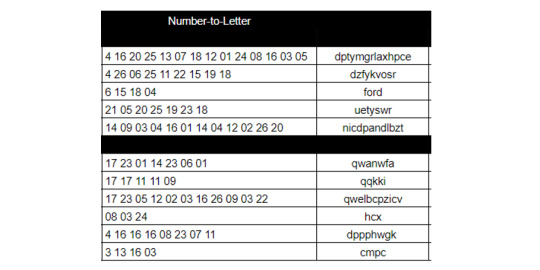
Then, Vigenere decode using the key “billionsandbillions” (from the Sagan riddle) to get the plaintext:
ChineseTakeout
CrunchBar
Eggs
Twinkie
Marshmallows
Popcorn
Pizza
PotatoChips
Gum
Cheezits
Beer
These resulting words are the Game Franchise Username for the Ghostbusters c64 game, save bankroll amount. This consists of the Username (left side decoded) + 8 digit account number (right side number), with the decimal separating the two.
Right-Hand Numbers
The numbers on the right of the decimal, being 8 digits, are the account numbers for the Ghostbusters game. These can be plugged into the game (via an emulator) to discover the corresponding amount of money that is ‘saved’.
Emulator Franchise Username and account number screen:
Account Amount after validation of Username screen:

The Final Step
Realizing that these account balances all have trailing ��00’s, remove the 0’s and convert the remaining numbers into letters to reveal the next destination.
Numbers: 13 25 19 20 5 18 25 19 3 9 5 14 3 5 20 8 5 1 20 5 18
Letters: M Y S T E R Y S C I E N C E T H E A T E R
Also, noting that each segment in the graphic is separated by the text ‘PaleBlueDot’, place a dot between the words, to arrive at a web address.
https://mysteryscience.theater
How we actually solved it (the narrative of pain)
One of our immediate observations was that the numbers always had eight digits on the right of the decimal. From the base-28.com site we knew about the c64 Ghostbusters game, and had the Crossing Streams chapter title as a potential hint that we needed to use clues across websites. In our reading about the c64 game, we learned that it was one of the first that allowed players to ‘save’ their game. Researching how this ‘save’ feature worked, we noted that it always used 8-digit account numbers, which curiously lined up with our 8-digit numbers to the right of the decimal. This felt like a crazy idea at the time, but we were frustrated enough to try it. Given the account numbers, we needed to find a way to reverse out the Names and Balances that would give those account numbers.
This video explains how the ‘save’ feature works: https://www.youtube.com/watch?v=_3cpbCCfK5A
Rather than digging into the algorithm, like we should have done, we discovered a Chrome extension that generated Ghostbusters accounts.

We tempted fate and downloaded the extension, only to rip out the code in order to reverse the algorithm. With that, we wrote the below brute forcer which, after inputting a Name, would try all possible account balances and then check if any of the resulting account numbers matched any of the account numbers from the image.

We immediately set out trying names that came from 1o57’s Twitch streams or other areas of the puzzle so far - and we found a few that worked:
'REAGAN,RONALD',
'POLLY,SKATING'
'SOTER,STEVEN',
'MORANIS, RICK',
'BROLIN,JOSH',
'HOUSE,BRICK'
But note that we said ‘a few’. We couldn’t find hits for every account balance. Fortunately, these were enough to assure us that we weren’t crazy, and we began attempting to interpret our output. While working through this, we realized that we didn’t even need the names. Using the information from the aforementioned YouTube video, we learned how to derive the information we needed. Take the account number for 1o57 which is 27710104. Reverse the number by pairs to get 04017127. Then convert from octal to hex, you get 101E57. The middle byte, 1E, is the hash of the name. The account balance is the first and third byte, so 1057. We filled in the remaining few accounts to come up with a full dataset. As it turns out, the whole page could have been solved like this on a calculator.
Examining the resulting balances, and knowing that the game’s algorithm divided the balance by 100, we dropped the trailing ‘00’ and then converted the remaining numbers into letters, revealing the string mysterysciencetheater. After trying this on a few of the known sites with no luck, we discovered that this was pointing us to mysteryscience.theater The PaleBlueDot in the middle of the numbers was also a hint to look for a domain.
While we had discovered some new information, it was not a complete solution. We still hadn’t used the left-hand side numbers from the PBD image, so we now shifted our focus to those numbers. After realizing that the numbers seemed to be relatively low when split into their component digits, we tried Letter-Number conversion again. We then Vigenere’d that output with the riddle answer ‘billionsandbillions’, and came up with a list of delicious food from the Ghostbusters movie. As it turns out, these were the names we were supposed to use to get the balances via a Ghostbusters c64 emulator. oops.
The complete output was:
Mysteryscience.theater
This page was kind of interesting in that there wasn’t really much to do with it… at least not immediately. From time to time, 1o57 will time-gate an area of his puzzles, and this is exactly what we ran into here. So, fast forwarding something like 24 hours, let’s begin examining the final puzzle-filled state of the page.
The top of the page now contained ciphertext. After a few attempts at deciphering it, we tried one of our old unused pieces of data (the concatenated list of Chuck Berry song titles) as a key and were greeted with a successful decipherment:
An y QewpFyyvRqd,
WehjhwpIclpVtme:
Ioqfig oloage.
Using OTP key: MaybelleneRockandRollMusicMemphisComeOn
On a PaleBlueDot,
WrestleWithThis:
Things change.
The meaning from this was clear! Head on over to http://lostboy.net/PaleBlueDot/WrestleWithThis
WrestleWithThis

Not much to see on this page, just the text “It’s only a tiny problem” and a YouTube video.
In the page source was the following comment:
<!- bFNhZ2FuQExv ->
And the title of the page was:
Wrestle With This y6nk3z9y
The comment Base64 decodes to lSagan@Lo
Additionally, the hint on the page about a ‘tiny’ problem, combined with the page title, resulted in a tinyurl link for our next destination:
tinyurl.com/y6nk3z9y → http://lostboy.net/PaleBlueDot/EverythingWasFineWithOurSystem.jpg
EverythingWasFineWithOurSystem

The image on this page immediately presents us with two sets of ciphertext, and a curious little man yelling at us from the corner.
As seen lightly overlaid into the blue of the car:
U2VuZCBDb3Nt =base64=> Send Cosm
And in the rear light:
TG9zdGJvWSBkb3Qgc2xhc2ggSEhI =base64=> LostboY dot slash HHH
Navigating to http://lostboy.net/HHH, we were greeted with two more youtube videos. The first one was titled “Close but no Cigar”. Immediately realizing that this meant we hadn’t interpreted the clue correctly, we Nope’d right the heck out of there. Luckily, we also knew what HHH was referencing from watching 1o57’s Twitch stream on 8/7. so we wasted no time in discovering the correct endpoint.
lostboy.net/HappyHarryHardOn
Here we go, a YouTube video and some encoded text. This feels right. The video was of RayParker Jr. performing the GhostBusters theme song, and below it was the text “What a singer! LostboY.net/PaleBlueDot/?” Also on the page was the text “F1LZuQ9E4JQ”.

The F1… text was another YouTube video; Chuck Berry and Tina Turner performing Rock n Roll Music. In an interesting twist, we discovered that by sorting the video comments by Newest first, there was a comment from NEW SOUND AGENCY with the text “b3MgdG8gQ2Fy”.
Also, if we look at the NEW SOUND AGENCY channel on YouTube, it has just one video of 1o57 playing around with a MiniMoog. Yep, this is a clue. This text of the comment base64 decodes to “os to Car”....hmmm.. That seems to fit with the other ciphertext we’ve found so far.
As for the URL, the team immediately recalled that Ray Parker Jr. may have, probably, almost certainly, likely, stolen the Ghost Busters theme music from Huey Lewis and the News’ “I Want A New Drug”. The next URL, then, was pretty simple to guess:
http://lostboy.net/PaleBlueDot/HueyLewis/
HueyLewis (and the Solve)
This page was pretty simple. A single ciphertext was present on the image and gave us the following:
c3Rib1kubmV0 =base64=> stboY.net

And finally, putting together all of the fragments that had been discovered:
U2VuZCBDb3Ntb3MgdG8gQ2FybFNhZ2FuQExvc3Rib1kubmV0
Base64 decodes to => Send Cosmos to [email protected]
We shot off an e-mail (several e-mails?) as directed, and got replies letting us know that Defcon 28 Badge Challenge: Complete … phew. The e-mail also linked to another video and requested that we watch it as a team.
We immediately shared a screen as a team and viewed the video together.
With that, DC28 badge challenge was complete.
@TheCouncilOf9
Co9.io
0 notes
Text
7 – Save Data
Finally, we have to store the results. The desired file format and data structure highly depends on your use case. For this tutorial, we will create a plain text file in the .txt format. For each article we are going to create a new file, give it an appropriate file name and fill it with the scraped text paragraphs. We prepend the article with metadata that we scraped and prefix it with a defining key.
To create a new text file in python, we need a filename first. Keep in mind how multiple files are presented and organized in your file browser. We want to sort our output files by date, so my goal is to create the following taxonomy:
YYYY-DD_title-of-the-article.txt
First, we want to get the year and month of the publishing date for our filename. Since we only scraped a literal string such as “May 2020”, we have to tinker a little to transform our string.
We split the string May 2020 into two slices at the space character with .split(' '). The result should be: date[0] = May and date[1] = 2020. Remember that date is a BeautifulSoup object, and we have to call .text to work with the element’s text content.
#split date at space date = date.text.split(' ')
Instead of literal months, a two-digit month representation easily sortable and doesn’t need to be translated. We create the list months which contains all the names of the months. Next, we let python find our literal month, which is stored in date[0] with the .index function. Caution: we have to increase the returned index value by 1, as list indices start with zero, months however start at 1. Finally, we convert this index to a string which allows us to add a leading zero for month digits smaller than 10. For example: The fifth month May will now be named 05 instead of 5.
#create list months months = ['January', 'February', 'March', 'April', 'May', 'June', 'July', 'August', 'September', 'October', 'November', 'December'] #convert the month date[0] into the respectively number of the month month = str(months.index(date[0]) + 1) #if the length of the String is less than 2, add a leading 0 if len(month)
Obtaining the year is relatively straightforward: we take the second slice of the date date[1] and convert it into a string:
#get the year as a string from date year = str(date[1])
The final element of our filename is the title of the article. We already scraped the title. However, file names should not contain special characters or spaces, as some software applications do not recognize such files. Thus, we replace spaces with dashes and trim any slashes from the tile and store our transformed title in the new string filetitle. Now we are ready to manufacture our file name by concatenating year, month and filename, separated by dash or underscore and suffixed by the plain text file type .txt
#replace spaces with dashes and trim slashes filetitle = title.replace(' ', '-').replace('/', '') #manufacture the filename from the scraped and transformed metadata filename = year + '-' + month + '_' + filetitle + '.txt'
With our name we can create a new file variable f with the open command. The second argument refers to the mode in which the file is opened: w is the write mode, as we are going to write lines to our file. With the file opened, we write our data to the file line by line. Notice the \n on each line end. This expression adds a line break after each string. We use it twice on the 'Title_' line in order to separate our metadata from the article text with an empty line.
#create an article file f = open(filename,'w') f.write('Year_' + year + '\n') f.write('Month_' + month + '\n') f.write('Author_' + author + '\n') f.write('Title_ ' + title + '\n\n') f.write(text) f.close()
8 — The final code
from bs4 import BeautifulSoup import requests import urllib.request import time # Set the URL you want to webscrape from # articlelinklist url = 'https://www.thewhitereview.org/fiction/' # Connect to the URL response = requests.get(url) # Parse HTML and save to BeautifulSoup object soup = BeautifulSoup(response.text, "html.parser") links = [] li_items = soup.find_all('li','a-z-item') for link in li_items: link = link.find('a') url = link.get('href') links.append(url) for link in links: response = requests.get(link) time.sleep(3) soup = BeautifulSoup(response.text, "html.parser") #author sidebar = soup.find('aside', "left-sidebar") authorheadline = sidebar.find_all('h3') author = authorheadline[1] author = author.text #date date = sidebar.find('p') date= date.text.split(' ') months = ['January', 'February', 'March', 'April', 'May', 'June', 'July', 'August', 'September', 'October', 'November', 'December'] month = str(months.index(date[0]) + 1) if len(month) < 2: month = "0" + month year = str(date[1]) #title title = soup.find('div', "article-title-name") title = title.text.strip() filetitle = title.replace(" ", "-").replace("/", "") #text content = soup.find('div', 'article-content') paragraphs = content.find_all('p') text = "" for p in paragraphs: if p.text != " " and "This story featured in" not in p.text: text += p.text + "\n" filename = year + '-' + month + '_' + filetitle + '.txt' f = open(filename,'w') f.write('Year_ ' + year + '\n') f.write('Month_ ' + month + '\n') f.write('Author_ ' + author + '\n') f.write('Title_ ' + title + '\n\n') f.write(text) f.close()
0 notes
Text
300+ TOP MATLAB Objective Questions and Answers
MATLAB Multiple Choice Questions :-
1. What does Matlab stand for? a) Math Laboratory b) Matrix Laboratory c) Mathworks d) Nothing e) none of the above Ans: b 2. What symbol precedes all comments in Matlab? a) “ b) % c) // d) 3. Which of the following is not a pre-defined variable in Matlab. a) pi b) inf c) i d) gravity e) j Ans: d 4. This Matlab command clears all data and variables stored in memory: a) clc b) clear c) delete d) deallocate e) none of the above Ans: b 5. Characters in Matlab are represented in their value in memory. a) decimal b) ASCII c) hex d) string e) none of the above Ans: b 6. Which is these is not an aspect of a for/while loop: a) update b) initialization c) runner d) condition e) all are aspects of loops Ans: c 7. To better manage memory and prevent unnecessary memory allocations, Matlab uses: a) vectors b) scalars c) matrix math d) delayed copy e) licenses Ans: d 8. To print a newline in a fprintf statement, you must use the following escape character: a) \t b) \nl c) \nxt d) \n e) none of the above Ans: d 9. In Matlab, this keyword immediately moves to the next iteration of the loop: a) update b) goto c) continue d) break e) none of the above Ans: c 10. Which of the following will correctly define x, y, and z as symbols? a) sym (x, y, z) b) syms x y z c) syms x, y, z d) sym x, y, z e) none of the above Ans: b

MATLAB MCQs 11. Which of these is the way to access the first element in a vector named v (assuming there is at least one element in the vector)? a) v(0) b) v(1) c) v d) v(: , 0) e) none of the above Ans: b 12. Which of the following is used to see if two elements are equal in MATLAB? a) != b) == c) isequal d) = e) none of the above Ans: b 13. If vector = . What will the value of a be equal to if this code is entered into MATLAB >> = size (vector)? a) 1 2 3 4 b) 12 c) 1 d) 4 e) 3 Ans: e 14. What is the value of ans that is printed when the following code is run: isnumeric(32) a) 1 b) 0 c) 32 d) yes e) true Ans: a 15. If I want to save a formatted string to memory, but don’t want to print it out, which command should I use? a) fprintf b)sprintf c) disp d) echo Ans: b MATLAB Objective type Questions with Answers 32. To add a comment to the mfile, the MATLAB command is A ) % B ) ; C ) comment(' ') D ) & Ans: a 33. When used in the fprintf command, the %g is used as the A ) single character display B ) fixed point display C ) string notation display D ) default number display Ans: d 34. When used in the fprintf command, the \n is used to A ) add a space between any two characters B ) add a line space (enter key) C ) place a number into the comment D ) clear the comment Ans: b 35. To display 'Question 2' in the command window, the correct command is A ) disp(Question 2) B ) display('Question 2') C ) disp('Question 2') D ) Question 2 Ans: c 36. The clc command is used to A ) clear the command window B ) erase everything in the mfile C ) clean the desktop D ) save the existing mfile Ans: a 37. The num2str command A ) converts a number to string B ) converts string to a number C ) concatenates numbers and strings D ) concatenates strings Ans: a 38. The output of the last line is aa=2 as=num2str(aa) cat= A ) cat2 B ) cat 2 C ) ??? Undefined function or variable 'as' D ) cat aa Ans: a 39. To join one or more strings into a single string is known as A ) concatenation B ) joining C ) string conversion D ) string theory Ans: a 40. The output of cat= is A ) catdog B ) cat dog C ) cat&dog D ) CatDog Ans: a MATLAB Questions and Answers pdf Download Read the full article
0 notes
Text
Week 4
++ if something is “broken” a property can be violated faster than brute force ++
Bits of Security and brute force
Bits of work represents how much security a particular system has / how much protection it has against a brute force attack / how hard it is to brute force. An attacker would have to perform operations to break it
1 bit = 2 options
2^10 ~ 1,000 2^20 ~ 1 million 2^30 ~ 1 billion
Eg/ if we have a 10 digit password – a-z, A-Z, 0-9 only then
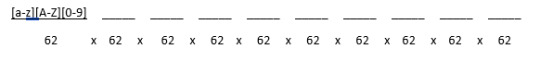
62 options for each digit = 62^10 options
2^6 ~ 64, so we have (2^6)^10 = 2^60 -> 60 bits of work to brute force this password
But the average time it would take to brute force, is half the total time i.e. so 59 bits of work
Brute forcing is really slow, definitely not an efficient way to crack something. With 256 bits of work is probably enough to not be cracked. We can be smarter about how we decrypt things, especially when we know they’re in English. See index of coincidence post for more on English letter frequency distribution.
Since most English-speaking people use English words in their passwords, and communicate in English, we can greatly reduce the amount of work it takes to crack an encrypted message/password thanks to the lack of entropy within the English language.
There are 2^25 possible combinations of English letters in a 5 letter word
There are only 2^13 valid words
Each letter added to a password adds ~ 2.5 bits of work
Patterns and entropy + English language + Claude Shannon
Redundancy in English language -> rules like i before e except after c, q must be followed by u
Grammar, parts of speech, we can’t just make up words and make sense. All these things contribute to English language being redundant. Thanks to redundancy, we can better understand English when everything is not clear. For example
msot poelpe can raed a sneatnce if the frsit and lsat lterets are the smae,
despite other letters being jumbled. Similarly when there is a lot of background noise we can often still discern what is being said, despite not hearing the annunciation of every letter.
An N-gram is used to calculate the entropy of English. We can statistically calculate the randomness of the next letter when we know the previous N-1 letters. As N increases, the entropy approaches H (i.e. we get closer to knowing the true entropy value of English ? )
Calculating the statistics of Fn has a difficulty of O(26^N)
F0 = 4.7 -> this is the maximum entropy value for English letters, where each letter has equal probability.
Fword = 2.62 -> the average word contains 4.5 letters
Since we can read sentences without spaces almost always, spaces become redundant. We exclude this to get a more accurate representation of entropy.
Maximum redundancy is when all letters have the same likelihood
Man in the Middle Attack
2 people think they are communicating privately with each other, when in fact there is an attacker in the middle relaying ( and maybe altering ) messages between the two. The attacker is able to intercept all messages between the two people as well as interject new ones. Attackers may also target information inside devices
These attacks can be done when the two are communicating via unencrypted Wi-Fi and the attacker is within range of the same access point. This is known as Wi-Fi Eavesdropping. The attacker may set up a Wi-Fi connection that appears legitimate (evil twin?) and wait for someone to connect, instantly gaining access to their device. They may also create a fake node to steal the data of anyone who connects
Session hijacking is another form of a MITM attack. Attackers will access the session created between your device and a website when you enter where they can steal your cookies – containing information such as passwords, pre-fill forms (i.e. bank details, addresses, phone numbers, company details – basically all your personal info) and access other accounts with these details.
Email interception -> monitoring communication between parties, gathering important data including transaction details, bank account information, personal details before impersonating an organisation and targeting individuals for example changing the receiving bank details to their own.
Man in the middle attacks highlight the importance of the Integrity and Authentication principles. It is essential that information is tamper-evident so that the receiving party can verify the authenticity of a message / communications.
Replay Attack
Kind of like a MITM attack, an attacker may intercept communications and then delays or resends it fraudulently deceiving the receiver.
Hash Functions
A regular hash function is any function used to convert data of any size down to data of fixed size. The same text will always result in the same hash – i.e. they are deterministic. A hash is quick to compute and very hard to reverse.
A cryptographic hash function is used to secure messages in transmission. It is unlikely that any two messages will have the same hash. In order for a cryptographic hash function to be secure it must fulfil 6 properties:
1. deterministic
2. quick computation
3. pre-image resistant -> infeasible to determine the message before hashing
4. avalanche effect -> small changes to message = big changes to hash
5. collision resistant -> unique inputs should produce unique hashes
6. puzzle friendly -> H(k|x) = Y – it must be infeasible to find x such that concatenating a random point with x produces the hash equal to Y
Collisions
A hash collision is when two distinct sets of data generate the same hash value. They are unavoidable when a very large set of data is mapped to a short string. This is unfortunate as collisions can be exploited by programs that compare hash values, for example password authentication.
Collision Resistance -> Find any 2 messages, m1 and m2 such that H(m1) = H(m2)
Second Pre-Image Attack -> given, H(m1) and m1, find m2 such that H(m1) = H(m2) (m1 != m2)
Pre-Image Attack -> given only H(m1) find m2 such that H(m1) = H(m2)
Message Authentication Codes (MACs)
A MAC is a way of authenticating and providing integrity to a message via a crypto hash – i.e. if you want to ensure the recipient knows that it has come from you, unaltered. It consists of 3 efficient algorithms
- G: key generation algorithm – a key is selected from the key space at random
Both the sender and receiver must share this symmetric key, K
- S: a signing algorithm – returns a tag given the key and the message
- V: verifying algorithm – returns accepted after verifying the authenticity of the message
For an MAC to be secure it should be computationally infeasible to compute a tag of the message without knowledge of the key

Take a message – combine with key – hash the result – send message w MAC – reperform MAC to verify w shared secret.
These are all bad:
MAC = hash ( key | message ) - vulnerable to a length extension attack
MAC = hash ( message | key ) – can still forge messages with collision
MAC = hash ( key | message | key )
We want HMAC:
HMAC = hash ( key | hash ( key | msg ) )
MACs do not provide non-repudiation – i.e. if there is a dispute over the origins of a message it cannot prove the message was sent by the sender.
0 notes
Text
Mid-Semester Revision Thread
Blob of text for my own midterm study that I thought I may as well put on my blog.
Questions taken from Jasper’s midterm stuff.
What are the six most common letters in English text?
ATEION
What are the important properties of a cryptographic hash function?
- hashes are fixed length
- changing one character in plain text, changes the hash significantly
- the plain text is difficult to be reversed from the hash
- two different strings are unlikely to evaluate to the same hash
- the same string will always evaluate to the same hash
What are the CIA properties?
Confidentiality
Integrity
Authentication
(Deniability)
Substitution Cipher 1
Cipher solved! You are awesome! You solved the cipher: NEVER LET THE FUTURE DISTURB YOU. YOU WILL MEET IT, IF YOU HAVE TO, WITH THE SAME WEAPONS OF REASON WHICH TODAY ARM YOU AGAINST THE PRESENT.
Substitution Cipher 2
Cipher solved! You are awesome! You solved the cipher: PASS THEN THROUGH THIS LITTLE SPACE OF TIME CONFORMABLY TO NATURE, AND END THY JOURNEY IN CONTENT, JUST AS AN OLIVE FALLS OFF WHEN IT IS RIPE, BLESSING NATURE WHO PRODUCED IT, AND THANKING THE TREE ON WHICH IT GREW.
Substitution Cipher 3
Cipher solved! You are awesome! You solved the cipher: ALEXANDER THE GREAT FOUND THE PHILOSOPHER LOOKING ATTENTIVELY AT A PILE OF HUMAN BONES. DIOGENES EXPLAINED, "I AM SEARCHING FOR THE BONES OF YOUR FATHER BUT CANNOT DISTINGUISH THEM FROM THOSE OF A SLAVE.
Substitution Cipher 4
Cipher solved! You are awesome! You solved the cipher: PEOPLE ARE FRUGAL IN GUARDING THEIR PERSONAL PROPERTY; BUT AS SOON AS IT COMES TO SQUANDERING TIME THEY ARE MOST WASTEFUL OF THE ONE THING IN WHICH IT IS RIGHT TO BE STINGY.
Lecture Points That I Deem Important
Lecture 1
Vulnerabilities: weakness in a system
Exploit: something that uses a vulnerability to compromise a system
Threat: what you are up against
Kerckhoff’s Principles:
1. The system must be practically, if not mathematically, indecipherable; 2. It should not require secrecy, and it should not be a problem if it falls into enemy hands; 3. It must be possible to communicate and remember the key without using written notes, and correspondents must be able to change or modify it at will; 4. It must be applicable to telegraph communications; 5. It must be portable, and should not require several persons to handle or operate; 6. Lastly, given the circumstances in which it is to be used, the system must be easy to use and should not be stressful to use or require its users to know and comply with a long list of rules.
Security Through Obscurity - relying on secrecy or complexity for security
Confidentiality - Ensuring that only authorised people can access certain information.
Integrity - Maintaining the “trustworthiness” of a message. I.e. ensuring the message is not altered or destroyed by an unauthorised party.
Authentication - an act, process, or method of showing something to be real, true, or genuine.
Bell LaPadua – levels of confidentiality (single point of failure at top)
Ciphers: - Substitution: letters (or a group of letters) are substituted with other letters. - Transposition: letters remain the same, but the order is changed.
Lecture 2
Vignere Cipher - Take a password and shift the encrypted message by the alphabetical order of the password (e.g. ABBA).
Steganography - hide existence of the message (e.g. hiding data in a cd)
One Time Pad - like Vignere but the password is the length of the message and completely random, once used the cypher should be discarded
Type 1 Error - false positive
Type 2 Error - false negative
Security By Design - reduce single point of failures, trust no one, build security from beginning rather than after system built.
Lecture 3
Risk:
- Risk is still there and bad even if nothing goes wrong - Humans are especially bad at preparing for Low Probability-High Impact events as we normally base our risk assessment on things we have experienced or can easily visualise happening.
Dealing with risk:
1. Prevention - remove vulnerabilities that allow the risk to occur.
2. Limitation - put in place things that will reduce the impact of a risk occurring.
3. Passing the risk to a 3rd party - reduces impact by having a “backup” (e.g. insurance)
4. Wearing the risk - If a risk cannot be fully prevented, it is necessary to just “wear the risk “.
Public Key Cryptography - release a public key that everyone can use to send you encrypted messages that only you can decrypt using your private key.
Lecture 4
Substitution Cipher Example:
26! combinations of English letters for substitution cipher.
Would take a very long time to brute force.
But, English language has patterns
Entropy - degree of randomness
Hashing:
Hash functions must return the same results each time
Hash collisions - different items map to the same thing
Hash functions summarise variable information into fixed, deterministic information
Sometimes it’s easier to look at the hash data rather than the original data
Clustering in data causes clustering in the hash
Birthday attack exploits hash collision
Hash is like a signature. Original message and hash can be tampered with
Birthday Attack - exploits the mathematics behind the “birthday problem” to find hash collisions. Work required to find collision is 2^(n/2) where n is size of the hash (e.g. 16 bit hash = 2^8 to solve).
Types of Hash Attacks:
preimage attack: given hash(M) find M
2nd preimage attack: given M find M' where hash(M)=hash(M')
collision attack: find any two messages M, M' where hash(M) = hash(M')
Lecture 5
Separate data and control - Users have access to data, but they shouldn’t have access to control
Wired Equivalent Privacy (WEP):
A stream of bits (A) is sent from one point to another
A random stream of bits (B) is generated using an algorithm, such as RC4 (very insecure)
The XOR function turns A into a stream of bits with the statistical properties of randomness.
A (xor) B -> C (Encrypted Stream of bits)
C (xor) B -> Gives back A again
Hashes
MD5, SHA0, SHA1 - broken
SHA2, SHA3 - not broken
SHA3 only one not vulnerable to length extension attacks
Broken - property can be violated faster than brute force (e.g. birthday attack)
Length Extension Attack
a length extension attack is a type of attack where an attacker can use Hash(message1) and the length of message1 to calculate Hash(message1 ‖ message2) for an attacker-controlled message2, without needing to know the content of message1. Algorithms like MD5, SHA-1, and SHA-2 that are based on the Merkle–Damgård construction are susceptible to this kind of attack.
When a Merkle–Damgård based hash is misused as a message authentication code with construction H(secret ‖ message), and message and the length of secret is known, a length extension attack allows anyone to include extra information at the end of the message and produce a valid hash without knowing the secret. Note that since HMAC doesn't use this construction, HMAC hashes are not prone to length extension attacks.
Merkle Damgard Construction
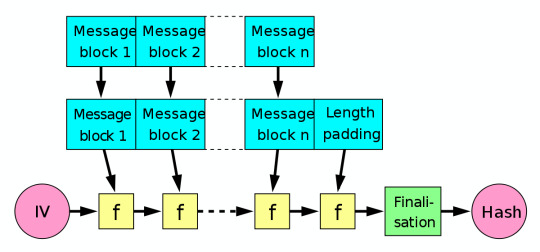
1. break message into a series of blocks
2. start with IV (initialisation vector)
3. Given hash function f, it takes in IV and block 1, output goes into f again with block 2 etc.
4. After doing this with all blocks, final hash is produced
MAC
Insert shared secret at the front of the hash, as the first block
MAC = h(key | data) - h is a hash function, key|data is the password concatenated with the message
Flaw:
If someone has sent a message, and you have the hash and the message length, you can extend the message.
You can take the hash you have, pass it into f again with a new message, thereby extending the original message. This is a Length Extension Attack.
Best MAC to use is HMAC (hash-based message authentication code)
HMAC = h(key | h(key | m))
Salting a hash
Salting a hash is something that gets added to the password before it gets hashed. Salt can be a single string, or a unique string for each user. If your salt is unique for each user, each user's password is almost guaranteed to be unique before hashing. The goal is to make the amount of work to decode a hash as great as possible, to deter hackers.
Key Stretching
Key stretching is designing a hash to be slow, such that it adds even more work for a hacker to decrypt a table of passwords. The added time for an individual user would be negligible by comparison.
Module Stuff That I Deem Important
Coincidence Index
Shift a cipher text any amount and line it up with itself
Count the coincidences (when the same letter lines up)
Divide coincidences by the length of the lined up text
Multiply by 26
Merkle Puzzles
Let's say Bob wants to securely communicate with Alice.
Alice creates 1000 unique pairs of a unique Identifier, and a key : 1000 x (identifier, key)
Alice encrypts each pair separately with relatively weak encryption - encryption((identifier, key), randomWeakKey)
Alice then sends all 1000 encrypted blobs to Bob
Bob chooses one encrypted blob at random and brute forces every password until it is cracked
Bob is left with a unique identifier and a key. Maybe : (sausage, A3D19F)
Bob encrypts the message with the key, and then tells Alice is he using the key corresponding to the ID 'sausage'
Alice looks up 'sausage' on her list, and finds the corresponding key
Alice decodes the message using the key A3D19F
Attacker will need to decrypt (on average) n/2 times (500 in this case), whereas the recipient need only decrypt 1.
RSA
Step 1 : Choose values for p & q (prime numbers)
Step 2 : Calculate n for the keys (n = p * q)
Step 3 : Calculate Euler's totient (ϕ) ((p-1) * (q-1))
Step 4 : Choose a value e for the public key (e must not share any factors with phi)
Step 5 : Choose a value d for the private key (e * d mod ϕ = 1)
Encrypting with Public Key: c = me mod n
Decrypting with Private Key: m = cd mod n
Hashing
A cryptographic hash has the following properties:
Reduces any amount of text or data into a fixed output
The same text will always result in the same hash (deterministic)
Its quick to compute
It should be hard to reverse
It's hard to find two different texts that has the same hash
If you make a small change to the text, it will change lots of things in the hash
0 notes
Text
freeCodeCamp ES6 Course Notes Part 2
As I mentioned before, now that there’s a new freeCodeCamp learning curriculum, I resolved to go through each of the lessons and finish all of them.
I was able to finish all the Responsive Web Design courses including all the projects. Check out this post for more info about these projects.
Check out the following articles for the notes I took while going through the course:
Flexbox Notes
CSS Grid Notes
Now that I’m done with the Responsive Web Design Certification course, the next course is the Javascript Algorithms And Data Structures Certification course.
The first part of that course is Basic JavaScript. Check out the notes I took while going through that course:
Part 1
Part 2
Part 3
The second part of the JavaScript course is the ES6 or ECMAScript 6 course. This is part 2 of the notes I took while going through said course. You can find part 1 here.
You can find the ES6 or ECMAScript 6 course here: https://learn.freecodecamp.org/javascript-algorithms-and-data-structures/es6
Use Destructuring Assignment to Pass an Object as a Function's Parameters
You can destructure the object in a function argument itself.

var harryPotter = { name: "Harry Potter", age: 1, address: "Godric's Hollow", livingWith: ["James", "Lily"], godfather: "Sirius Black", status: "Boy-Who-Lived", country: "England" }; var updateInfo = (function() { "use strict"; return function updateInfo({name, age, address, livingWith}) { harryPotter.age = 11; harryPotter.address = "4 Privet Drive"; harryPotter.livingWith = ["Vernon", "Petunia", "Dudley"]; return `${name} is now ${harryPotter.age}. He lives in ${harryPotter.address} with his relatives: ${harryPotter.livingWith}.` }; })(); console.log(harryPotter); //returns the harryPotter object console.log(updateInfo(harryPotter)); //returns Harry Potter is now 11. He lives in 4 Privet Drive with his relatives: Vernon,Petunia,Dudley.
Use destructuring assignment within the argument to the function half to send only max and min inside the function.
const stats = { max: 56.78, standard_deviation: 4.34, median: 34.54, mode: 23.87, min: -0.75, average: 35.85 }; const half = (function() { "use strict"; return function half({max, min}) { return (stats.max + stats.min) / 2.0; }; })(); console.log(stats); // should be object console.log(half(stats)); // should be 28.015
Create Strings using Template Literals
template literal - “special type of string that makes creating complex strings easier.”
Template literals allow you to create multi-line strings and to use string interpolation features to create strings.
const siriusBlack = { firstName: "Sirius", middleName: "Orion", lastName: "Black", bloodStatus: "Pureblood", brother: "Regulus", cousins: ["Bellatrix", "Andromeda", "Narcissa"], birthday: "3 November, 1959", nickname: "Padfoot", father: "Orion", mother: "Walburga" }; // Template literal with multi-line and string interpolation const siriusInfo = `Harry Potter's godfather is ${siriusBlack.firstName} ${siriusBlack.middleName} ${siriusBlack.lastName}. He is a ${siriusBlack.bloodStatus} from the Noble and Most Ancient House of ${siriusBlack.lastName}. He was born on ${siriusBlack.birthday} to ${siriusBlack.father} and ${siriusBlack.mother} ${siriusBlack.lastName}. He has a younger brother named ${siriusBlack.brother}. He has 3 cousins: ${siriusBlack.cousins}. His friends called him ${siriusBlack.nickname}.`; console.log(siriusInfo); Harry Potter's godfather is Sirius Orion Black. He is a Pureblood from the Noble and Most Ancient House of Black. He was born on 3 November, 1959 to Orion and Walburga Black. He has a younger brother named Regulus. He has 3 cousins: Bellatrix,Andromeda,Narcissa. His friends called him Padfoot.
The example above uses “backticks (`), not quotes ('or "), to wrap the string.”
“The string is multi-line, both in the code and the output” without having to insert \n within strings.
The ${variable}syntax used above is a placeholder. Basically, you won't have to use concatenation with the +operator anymore. To add variables to strings, you just drop the variable in a template string and wrap it with ${and }. Similarly, you can include other expressions in your string literal, for example ${a + b}.
Use template literal syntax with backticks to display each entry of the result object's failure array. Each entry should be wrapped inside an li element with the class attribute text-warning, and listed within the resultDisplayArray.
const result = { success: ["max-length", "no-amd", "prefer-arrow-functions"], failure: ["no-var", "var-on-top", "linebreak"], skipped: ["id-blacklist", "no-dup-keys"] }; function makeList(arr) { "use strict"; const resultDisplayArray = [`<li class="text-warning">${arr[0]}</li>`, `<li class="text-warning">${arr[1]}</li>`, `<li class="text-warning">${arr[2]}</li>`]; return resultDisplayArray; } /** * makeList(result.failure) should return: * [ `<li class="text-warning">no-var</li>`, * `<li class="text-warning">var-on-top</li>`, * `<li class="text-warning">linebreak</li>` ] **/ const resultDisplayArray = makeList(result.failure);
Alternative solution: use map function
const result = { success: ["max-length", "no-amd", "prefer-arrow-functions"], failure: ["no-var", "var-on-top", "linebreak"], skipped: ["id-blacklist", "no-dup-keys"] }; function makeList(arr) { "use strict"; const resultDisplayArray = arr.map(item => `<li class="text-warning">${item}</li>`); return resultDisplayArray; } /** * makeList(result.failure) should return: * [ `<li class="text-warning">no-var</li>`, * `<li class="text-warning">var-on-top</li>`, * `<li class="text-warning">linebreak</li>` ] **/ const resultDisplayArray = makeList(result.failure);
var hpGroups = { marauders: ["Sirius", "James", "Peter", "Remus"], goldenTrio: ["Harry", "Ron", "Hermione"], hogwartsFounders: ["Helga", "Rowena", "Salazar", "Godric"] }; var hpList = (list) => { "use strict"; var results = list.map(hp => `<li class="hp-info">${hp}</li> `); return results; } console.log(hpList(hpGroups.marauders)); //returns <li class="hp-info">Sirius</li> ,<li class="hp-info">James</li> ,<li class="hp-info">Peter</li> ,<li class="hp-info">Remus</li> console.log(hpList(hpGroups.hogwartsFounders)); //returns <li class="hp-info">Helga</li> ,<li class="hp-info">Rowena</li> ,<li class="hp-info">Salazar</li> ,<li class="hp-info">Godric</li>
Write Concise Object Literal Declarations Using Simple Fields

var hpChara = (firstName, lastName, gender, hogwartsHouse) => { "use strict"; return{ firstName, lastName, gender, hogwartsHouse }; }; console.log(hpChara("Hermione", "Granger", "Female", "Gryffindor")); {firstName: "Hermione", lastName: "Granger", gender: "Female", hogwartsHouse: "Gryffindor"} console.log(hpChara("Luna", "Lovegood", "Female", "Ravenclaw")); {firstName: "Luna", lastName: "Lovegood", gender: "Female", hogwartsHouse: "Ravenclaw"} console.log(hpChara("Draco", "Malfoy", "Male", "Slytherin")); {firstName: "Draco", lastName: "Malfoy", gender: "Male", hogwartsHouse: "Slytherin"}
Write Concise Declarative Functions with ES6

Refactor the function setGear inside the object bicycle to use the shorthand syntax described above.
const bicycle = { gear: 2, setGear(newGear) { "use strict"; this.gear = newGear; } }; bicycle.setGear(3); console.log(bicycle.gear); bicycle.setGear(48); //changes gear value to 48
const astoriaInfo = { fullName: "Astoria Greengrass", setInfo(newInfo) { "use strict"; this.fullName = newInfo; } }; astoriaInfo.setInfo("Astoria Malfoy"); console.log(astoriaInfo.fullName); //returns Astoria Malfoy
Use class Syntax to Define a Constructor Function
keyword class - new syntax to help create objects

function makeHorcrux() { "use strict"; class Horcrux { constructor(item) { this.item = item; } } return Horcrux; } const Horcrux = makeHorcrux(); const ravenclawsDiadem = new Horcrux("Ravenclaw's Diadem"); console.log(ravenclawsDiadem.item); //returns Ravenclaw's Diadem const hufflepuffsCup = new Horcrux("Hufflepuff's Cup"); console.log(hufflepuffsCup.item); //returns Hufflepuff's Cup
Use class keyword and write a proper constructor to create the Vegetable class.
The Vegetable lets you create a vegetable object, with a property name, to be passed to constructor.
function makeClass() { "use strict"; class Vegetable { constructor(name) { this.name = name; } } return Vegetable; } const Vegetable = makeClass(); const carrot = new Vegetable('carrot'); console.log(carrot.name); //returns 'carrot'
function makeWands() { "use strict"; class HPWands { constructor(wood, core) { this.wood = wood; this.core = core; } } return HPWands; } const HPWands = makeWands(); const harrysWand = new HPWands("Holly", "Phoenix Feather"); console.log(`Harry Potter has a ${harrysWand.wood} and ${harrysWand.core} wand.`); //returns Harry Potter has a Holly and Phoenix Feather wand. const fleursWand = new HPWands("Rosewood", "Veela Hair"); console.log(`Fleur Delacour has a ${fleursWand.wood} and ${fleursWand.core} wand.`); //returns Fleur Delacour has a Rosewood and Veela Hair wand.
Use getters and setters to Control Access to an Object
You can obtain values from an object, and set a value of a property within an object.
Getter functions are meant to simply return (get) the value of an object's private variable to the user without the user directly accessing the private variable.
Setter functions are meant to modify (set) the value of an object's private variable based on the value passed into the setter function. This change could involve calculations, or even overwriting the previous value completely.

class Book { constructor(title) { this._title = title; } //getter function get bookTitle() { return this._title; //returns or gets the title of the book } //setter function set bookTitle(updatedTitle) { this._title = updatedTitle; //set or update the title of the book } } const hp = new Book("Harry Potter and the Sorcerer's Stone"); console.log(hp.bookTitle); //returns Harry Potter and the Sorcerer's Stone hp.bookTitle = "Harry Potter and the Philosopher's Stone"; //updates or changes the book title console.log(hp._title); //returns Harry Potter and the Philosopher's Stone
class StudentInfo { constructor(name, age) { this.name = name; this.age = age; } //getter function get student() { return `The student's name is ${this.name} and their age is ${this.age}.` ; } //setter function set student(updatedInfo) { this.age = updatedInfo; this.name = updatedInfo; } } const hermioneInfo = new StudentInfo("Hermione Granger", 11); console.log(hermioneInfo.student); //returns The student's name is Hermione Granger and their age is 11. hermioneInfo.age = 17; hermioneInfo.name = "Hermione Weasley"; console.log(hermioneInfo.student); //returns The student's name is Hermione Weasley and their age is 17.
class Wands { constructor(name, wood, core) { this.name = name; this.wood = wood; this.core = core; } //getter function get wand() { return `${this.name} has a ${this.core} and ${this.wood} wand.`; } //setter function set wand(updatedInfo) { this.name = updatedInfo; this.wood = updatedInfo; this.core = updatedInfo; } } const ronsWand = new Wands("Ron Weasley", "Unicorn Hair", "Ash"); console.log(ronsWand.wand); //returns Ron Weasley has a Unicorn Hair and Ash wand. ronsWand.wood = "Willow"; console.log(ronsWand.wand); //returns Ron Weasley has a Unicorn Hair and Willow wand. ronsWand.wood = "Chestnut"; ronsWand.core = "Dragon Hearstring"; console.log(ronsWand.wand); //returns Ron Weasley has a Dragon Heartstring and Chestnut wand.
Use class keyword to create a Thermostat class. The constructor accepts Fahrenheit temperature.
Now create getter and setter in the class, to obtain the temperature in Celsius scale.
Remember that C = 5/9 * (F - 32)and F = C * 9.0 / 5 + 32, where F is the value of temperature in Fahrenheit scale, and C is the value of the same temperature in Celsius scale
When you implement this, you would be tracking the temperature inside the class in one scale - either Fahrenheit or Celsius.
This is the power of getter or setter - you are creating an API for another user, who would get the correct result, no matter which one you track.
In other words, you are abstracting implementation details from the consumer.
function makeClass() { "use strict"; class Thermostat { constructor(temperature) { this.temperature = temperature; } //getter function get celsius() { return this.temperature; } //setter function set celsius(updatedTemp) { this.celsius = updatedTemp; } } return Thermostat; } const Thermostat = makeClass(); const thermos = new Thermostat(76); // setting in Fahrenheit scale let temp = thermos.temperature; // 24.44 in C thermos.temperature = 26; temp = thermos.temperature; // 26 in C
Differences Between import and require
the function require()would be used to import the functions and code in external files and modules. While handy, this presents a problem: some files and modules are rather large, and you may only need certain code from those external resources.
ES6 gives us a very handy tool known as import. With it, we can choose which parts of a module or file to load into a given file, saving time and memory.

For more info, refer to this: https://learn.freecodecamp.org/javascript-algorithms-and-data-structures/es6/understand-the-differences-between-import-and-require
Add the appropriate import statement that will allow the current file to use the capitalizeString function. The file where this function lives is called "string_functions", and it is in the same directory as the current file.
"use strict"; capitalizeString("hello!"); import { capitalizeString } from "string_functions"
Use export to Reuse a Code Block
import - “can be leveraged to import small amounts of code from large files.”
export - “When we want some code - a function, or a variable - to be usable in another file, we must export it in order to import it into another file.”
Like import, export is a non-browser feature.
named export - use this to “import any code we export into another file with the import syntax”. Also, this allows you to “make multiple functions and variables available for use in other files”

//export the two variables export const black = "sirius"; export const potter = "james";
Use * to Import Everything from a File

The code below requires the contents of a file, "capitalize_strings", found in the same directory as it, imported. Add the appropriate import *statement to the top of the file, using the object provided.
"use strict"; import * as capitalizeStrings from "capitalize_strings";
//another example: import * as gobletOfFire from "triwizard_tournament"; import * as voldemortsHorcruxes from "founders_items";
Create an Export Fallback with export default
export default - another export syntax. “Usually you will use this syntax if only one value is being exported from a file. It is also used to create a fallback value for a file or module.”

"use strict"; //The following function should be the fallback value for the module //function subtract(x,y) {return x - y;} export default function subtract(x,y) {return x - y;}
Import a Default Export
To import a default export, you need to use a different import syntax.

"use strict"; //import the default export, subtract, from the file "math_functions", found in the same directory as this file. import subtract from "math_functions"; subtract(7,4);
#es6#freecodecamp#learn javascript#how to code#learn to code#ecmascript#learn programming#learn ecmascript 6#javascript#learn es6#learn js#js#programming#coding#resources#learn how to code#my notes#ecmascript 6#learning resources
0 notes
Link

ES6 is the next generation of JavaScript syntax with some added features that make your code more modern and readable. In this article, I will go over some of the most essential features of ES6 so you too can write less and do more.
const and let
I won’t go into detail here since I’ve already written another blog post on the uses of var, let, and const here. The gist is that your go-to identifier in Javascript should be const. However, if you know or think you’ll need to reassign it (in a for-loop, switch statement, or in algorithm swapping, for example), use let.
Template Literals
Template literals are very useful because they let you create strings without the need to concatenate the values. For example,
const book = { name: 'The Martian' } console.log('You are reading ' + book.name + '., \n and this is a new line…'
We can improve the syntax of the previous console.log with the following code:
console.log(`You are reading ${book.name}., and this is a new line…`)
Note that template literals are enclosed in back-ticks. To interpolate a variable value, simply set the variable name inside a dollar sign and curly braces. As you saw in the example, template literals can also be used for multiline strings. There is no need to use \n anymore. Simply hit Enter on the keyboard to take the string to a new line.
Arrow Functions
Arrow functions are great for simplifying the syntax of functions. For example:
function myFunc(name) { return 'Hello' + name } console.log(myFunc('World'))
With ES6, we can simplify things like so:
const myFunc = name => { return `Hello ${name}` }
Or if the function has a single statement like our example, you can simplify it even further by omitting the keyword return and the curly brackets like so:
const myFunc = name => `Hello ${name}`
In addition, if the function does not receive any argument, we can use empty parentheses:
const hello = () => console.log('Hello!')
Default Parameters
With ES6, it’s possible to define default parameter values for functions.
function sum(x = 1, y = 2) { return x + y } console.log(sum(3)) // 5
In the above example, since we did not pass y as a parameter, it will have a value of 2 by default. So, 3 + 2 === 5.
Destructuring
Destruction allows us to initialize multiple variables at once.
let [x, y] = ['a', 'b']
Array destructuring can also be used to swap values at once without the need to create temp variables which is very useful for sorting algorithms.
[x, y] = [y, x]
Another useful functionality is called property shorthand.
let [x, y] = ['a', 'b'] let obj = {x, y} console.log(obj) // { x: 'a', y: 'b' }
One last functionality we’ll go over is called shorthand method names. This allows us to declare functions inside objects as if they were properties.
const hello = { name: 'World', printHello() { console.log('Hello') } } console.log(hello.printoHello())
Spread and Rest Operators
In ES5, we could turn arrays into parameters using the apply() function. ES6 has the spread operator (...) for this purpose. For example, consider a sum function that sums three values:
let params = [3, 4, 5] console.log(sum(...params))
The spread operator can also be used as a rest parameter like so:
function restParameter(x, y, ...a) { return (x + y) * a.length } console.log(restParameter(1, 2, 'hello', true, 7)) // 9
Classes
ES6 also introduced a cleaner way of declaring classes. Consider the following:
function Book(title, author) { this.title = title this.author = author } Book.prototype.printTitle = function() { console.log(this.title) }
With ES6, we can simplify the syntax like so:
class Book { constructor(title, author) { This.title = title this.author = author } printAuthor() { console.log(this.author) } }
With ES6, we can use a simplified syntax for inheritance between classes using the keyword extends. As you’ll see in the following example, we can also use the keyword super inside the constructor to refer to the constructor superclass.
class ITBook extends Book { constructor(title, author, technology) { super(title, author) this.technology = technology } }
Conclusion
I hope you found this guide helpful for reviewing some of what I consider to be very useful features of ES6.
0 notes
Text
Turning a Fixed-Size Object into a Responsive Element
I was in a situation recently where I wanted to show an iPhone on a website. I wanted users to be able to interact with an application demo on this “mock” phone, so it had to be rendered in CSS, not an image. I found a great library called marvelapp/devices.css. The library implemented the device I needed with pure CSS, and they looked great, but there was a problem: the devices it offered were not responsive (i.e. they couldn’t be scaled). An open issue listed a few options, but each had browser incompatibilities or other issues. I set out to modify the library to make the devices responsive.
Here is the final resizable library. Below, we’ll walk through the code involved in creating it.
The original library was written in Sass and implements the devices using elements with fixed sizing in pixels. The authors also provided a straightforward HTML example for each device, including the iPhone X we’ll be working with throughout this article. Here’s a look at the original. Note that the device it renders, while detailed, is rather large and does not change sizes.
CodePen Embed Fallback
Here’s the approach
There are three CSS tricks that I used to make the devices resizable:
calc(), a CSS function that can perform calculations, even when inputs have different units
--size-divisor, a CSS custom property used with the var() function
@media queries separated by min-width
Let’s take a look at each of them.
calc()
The CSS calc() function allows us to change the size of the various aspects of the device. The function takes an expression as an input and returns the evaluation of the function as the output, with appropriate units. If we wanted to make the devices half of their original size, we would need to divide every pixel measurement by 2.
Before:
width: 375px;
After:
width: calc(375px / 2);
The second snippet yields a length half the size of the first snippet. Every pixel measurement in the original library will need to be wrapped in a calc() function for this to resize the whole device.
var(–size-divisor)
A CSS variable must first be declared at the beginning of the file before it can be used anywhere.
:root { --size-divisor: 3; }
With that, this value is accessible throughout the stylesheet with the var() function. This will be exceedingly useful as we will want all pixel counts to be divided by the same number when resizing devices, while avoiding magic numbers and simplifying the code needed to make the devices responsive.
width: calc(375px / var(--size-divisor));
With the value defined above, this would return the original width divided by three, in pixels.
@media
To make the devices responsive, they must respond to changes in screen size. We achieve this using media queries. These queries watch the width of the screen and fire if the screen size crosses given thresholds. I chose the breakpoints based on Bootstrap’s sizes for xs, sm, and so on.
There is no need to set a breakpoint at a minimum width of zero pixels; instead, the :root declaration at the beginning of the file handles these extra-small screens. These media queries must go at the end of the document and be arranged in ascending order of min-width.
@media (min-width: 576px) { :root { --size-divisor: 2; } } @media (min-width: 768px) { :root { --size-divisor: 1.5; } } @media (min-width: 992px) { :root { --size-divisor: 1; } } @media (min-width: 1200px) { :root { --size-divisor: .67; } }
Changing the values in these queries will adjust the magnitude of resizing that the device undergoes. Note that calc() handles floats just as well as integers.
Preprocessing the preprocessor with Python
With these tools in hand, I needed a way to apply my new approach to the multi-thousand-line library. The resulting file will start with a variable declaration, include the entire library with each pixel measurement wrapped in a calc() function, and end with the above media queries.
Rather than prepare the changes by hand, I created a Python script that automatically converts all of the pixel measurements.
def scale(token): if token[-2:] == ';\n': return 'calc(' + token[:-2] + ' / var(--size-divisor));\n' elif token[-3:] == ');\n': return '(' + token[:-3] + ' / var(--size-divisor));\n' return 'calc(' + token + ' / var(--size-divisor))'
This function, given a string containing NNpx, returns calc(NNpx / var(--size-divisor));. Throughout the file, there are fortunately only three matches for pixels: NNpx, NNpx; and NNpx);. The rest is just string concatenation. However, these tokens have already been generated by separating each line by space characters.
def build_file(scss): out = ':root {\n\t--size-divisor: 3;\n}\n\n' for line in scss: tokens = line.split(' ') for i in range(len(tokens)): if 'px' in tokens[i]: tokens[i] = scale(tokens[i]) out += ' '.join(tokens) out += "@media (min-width: 576px) {\n \ :root {\n\t--size-divisor: 2;\n \ }\n}\n\n@media (min-width: 768px) {\n \ :root {\n\t--size-divisor: 1.5;\n \ }\n}\n\n@media (min-width: 992px) { \ \n :root {\n\t--size-divisor: 1;\n \ }\n}\n\n@media (min-width: 1200px) { \ \n :root {\n\t--size-divisor: .67;\n }\n}" return out
This function, which builds the new library, begins by declaring the CSS variable. Then, it iterates through the entire old library in search of pixel measurements to scale. For each of the hundreds of tokens it finds that contain px, it scales that token. As the iteration progresses, the function preserves the original line structure by rejoining the tokens. Finally, it appends the necessary media queries and returns the entire library as a string. A bit of code to run the functions and read and write from files finishes the job.
if __name__ == '__main__': f = open('devices_old.scss', 'r') scss = f.readlines() f.close() out = build_file(scss) f = open('devices_new.scss', 'w') f.write(out) f.close()
This process creates a new library in Sass. To create the CSS file for final use, run:
sass devices_new.scss devices.css
This new library offers the same devices, but they are responsive! Here it is:
CodePen Embed Fallback
To read the actual output file, which is thousands of lines, check it out on GitHub.
Other approaches
While the results of this process are pretty compelling, it was a bit of work to get them. Why didn’t I take a simpler approach? Here are three more approaches with their advantages and drawbacks.
zoom
One initially promising approach would be to use zoom to scale the devices. This would uniformly scale the device and could be paired with media queries as with my solution, but would function without the troublesome calc() and variable.
This won’t work for a simple reason: zoom is a non-standard property. Among other limitations, it is not supported in Firefox.
Replace px with em
Another find-and-replace approach prescribes replacing all instances of px with em. Then, the devices shrink and grow according to font size. However, getting them small enough to fit on a mobile display may require minuscule font sizes, smaller than the minimum sizes browsers, like Chrome, enforce. This approach could also run into trouble if a visitor to your website is using assistive technology that increases font size.
This could be addressed by scaling all of the values down by a factor of 100 and then applying standard font sizes. However, that requires just as much preprocessing as this article’s approach, and I think it is more elegant to perform these calculations directly rather than manipulate font sizes.
scale()
The scale() function can change the size of entire objects. The function returns a <transform-function>, which can be given to a transform attribute in a style. Overall, this is a strong approach, but does not change the actual measurement of the CSS device. I prefer my approach, especially when working with complex UI elements rendered on the device’s “screen.”
Chris Coyier prepared an example using this approach.
CodePen Embed Fallback
In conclusion
Hundreds of calc() calls might not be the first tool I would reach for if implementing this library from scratch, but overall, this is an effective approach for making existing libraries resizable. Adding variables and media queries makes the objects responsive. Should the underlying library be updated, the Python script would be able to process these changes into a new version of our responsive library.
The post Turning a Fixed-Size Object into a Responsive Element appeared first on CSS-Tricks.
Turning a Fixed-Size Object into a Responsive Element published first on https://deskbysnafu.tumblr.com/
0 notes
Text
Turning a Fixed-Size Object into a Responsive Element
I was in a situation recently where I wanted to show an iPhone on a website. I wanted users to be able to interact with an application demo on this “mock” phone, so it had to be rendered in CSS, not an image. I found a great library called marvelapp/devices.css. The library implemented the device I needed with pure CSS, and they looked great, but there was a problem: the devices it offered were not responsive (i.e. they couldn’t be scaled). An open issue listed a few options, but each had browser incompatibilities or other issues. I set out to modify the library to make the devices responsive.
Here is the final resizable library. Below, we’ll walk through the code involved in creating it.
The original library was written in Sass and implements the devices using elements with fixed sizing in pixels. The authors also provided a straightforward HTML example for each device, including the iPhone X we’ll be working with throughout this article. Here’s a look at the original. Note that the device it renders, while detailed, is rather large and does not change sizes.
CodePen Embed Fallback
Here’s the approach
There are three CSS tricks that I used to make the devices resizable:
calc(), a CSS function that can perform calculations, even when inputs have different units
--size-divisor, a CSS custom property used with the var() function
@media queries separated by min-width
Let’s take a look at each of them.
calc()
The CSS calc() function allows us to change the size of the various aspects of the device. The function takes an expression as an input and returns the evaluation of the function as the output, with appropriate units. If we wanted to make the devices half of their original size, we would need to divide every pixel measurement by 2.
Before:
width: 375px;
After:
width: calc(375px / 2);
The second snippet yields a length half the size of the first snippet. Every pixel measurement in the original library will need to be wrapped in a calc() function for this to resize the whole device.
var(–size-divisor)
A CSS variable must first be declared at the beginning of the file before it can be used anywhere.
:root { --size-divisor: 3; }
With that, this value is accessible throughout the stylesheet with the var() function. This will be exceedingly useful as we will want all pixel counts to be divided by the same number when resizing devices, while avoiding magic numbers and simplifying the code needed to make the devices responsive.
width: calc(375px / var(--size-divisor));
With the value defined above, this would return the original width divided by three, in pixels.
@media
To make the devices responsive, they must respond to changes in screen size. We achieve this using media queries. These queries watch the width of the screen and fire if the screen size crosses given thresholds. I chose the breakpoints based on Bootstrap’s sizes for xs, sm, and so on.
There is no need to set a breakpoint at a minimum width of zero pixels; instead, the :root declaration at the beginning of the file handles these extra-small screens. These media queries must go at the end of the document and be arranged in ascending order of min-width.
@media (min-width: 576px) { :root { --size-divisor: 2; } } @media (min-width: 768px) { :root { --size-divisor: 1.5; } } @media (min-width: 992px) { :root { --size-divisor: 1; } } @media (min-width: 1200px) { :root { --size-divisor: .67; } }
Changing the values in these queries will adjust the magnitude of resizing that the device undergoes. Note that calc() handles floats just as well as integers.
Preprocessing the preprocessor with Python
With these tools in hand, I needed a way to apply my new approach to the multi-thousand-line library. The resulting file will start with a variable declaration, include the entire library with each pixel measurement wrapped in a calc() function, and end with the above media queries.
Rather than prepare the changes by hand, I created a Python script that automatically converts all of the pixel measurements.
def scale(token): if token[-2:] == ';\n': return 'calc(' + token[:-2] + ' / var(--size-divisor));\n' elif token[-3:] == ');\n': return '(' + token[:-3] + ' / var(--size-divisor));\n' return 'calc(' + token + ' / var(--size-divisor))'
This function, given a string containing NNpx, returns calc(NNpx / var(--size-divisor));. Throughout the file, there are fortunately only three matches for pixels: NNpx, NNpx; and NNpx);. The rest is just string concatenation. However, these tokens have already been generated by separating each line by space characters.
def build_file(scss): out = ':root {\n\t--size-divisor: 3;\n}\n\n' for line in scss: tokens = line.split(' ') for i in range(len(tokens)): if 'px' in tokens[i]: tokens[i] = scale(tokens[i]) out += ' '.join(tokens) out += "@media (min-width: 576px) {\n \ :root {\n\t--size-divisor: 2;\n \ }\n}\n\n@media (min-width: 768px) {\n \ :root {\n\t--size-divisor: 1.5;\n \ }\n}\n\n@media (min-width: 992px) { \ \n :root {\n\t--size-divisor: 1;\n \ }\n}\n\n@media (min-width: 1200px) { \ \n :root {\n\t--size-divisor: .67;\n }\n}" return out
This function, which builds the new library, begins by declaring the CSS variable. Then, it iterates through the entire old library in search of pixel measurements to scale. For each of the hundreds of tokens it finds that contain px, it scales that token. As the iteration progresses, the function preserves the original line structure by rejoining the tokens. Finally, it appends the necessary media queries and returns the entire library as a string. A bit of code to run the functions and read and write from files finishes the job.
if __name__ == '__main__': f = open('devices_old.scss', 'r') scss = f.readlines() f.close() out = build_file(scss) f = open('devices_new.scss', 'w') f.write(out) f.close()
This process creates a new library in Sass. To create the CSS file for final use, run:
sass devices_new.scss devices.css
This new library offers the same devices, but they are responsive! Here it is:
CodePen Embed Fallback
To read the actual output file, which is thousands of lines, check it out on GitHub.
Other approaches
While the results of this process are pretty compelling, it was a bit of work to get them. Why didn’t I take a simpler approach? Here are three more approaches with their advantages and drawbacks.
zoom
One initially promising approach would be to use zoom to scale the devices. This would uniformly scale the device and could be paired with media queries as with my solution, but would function without the troublesome calc() and variable.
This won’t work for a simple reason: zoom is a non-standard property. Among other limitations, it is not supported in Firefox.
Replace px with em
Another find-and-replace approach prescribes replacing all instances of px with em. Then, the devices shrink and grow according to font size. However, getting them small enough to fit on a mobile display may require minuscule font sizes, smaller than the minimum sizes browsers, like Chrome, enforce. This approach could also run into trouble if a visitor to your website is using assistive technology that increases font size.
This could be addressed by scaling all of the values down by a factor of 100 and then applying standard font sizes. However, that requires just as much preprocessing as this article’s approach, and I think it is more elegant to perform these calculations directly rather than manipulate font sizes.
scale()
The scale() function can change the size of entire objects. The function returns a <transform-function>, which can be given to a transform attribute in a style. Overall, this is a strong approach, but does not change the actual measurement of the CSS device. I prefer my approach, especially when working with complex UI elements rendered on the device’s “screen.”
Chris Coyier prepared an example using this approach.
CodePen Embed Fallback
In conclusion
Hundreds of calc() calls might not be the first tool I would reach for if implementing this library from scratch, but overall, this is an effective approach for making existing libraries resizable. Adding variables and media queries makes the objects responsive. Should the underlying library be updated, the Python script would be able to process these changes into a new version of our responsive library.
The post Turning a Fixed-Size Object into a Responsive Element appeared first on CSS-Tricks.
source https://css-tricks.com/turning-a-fixed-size-object-into-a-responsive-element/
from WordPress https://ift.tt/2xPui3o via IFTTT
0 notes
Text
Spark Actions
Overview
In our Apache Spark tutorial journey, we have learnt how to create Spark RDD using Java, Spark Transformations. In this article, we are going to explain Spark Actions. Spark Actions are another type of operations which returns final values to Driver program or writes the data to external system.
You can find all the Java files of this article at our Git repository.
1.1 count()
count is an action which returns number of elements in the RDD, usually it is used to get an idea of RDD size before performing any operation on RDD.
JavaRDD<String> likes = javaSparkContext.parallelize(Arrays.asList("Java")); JavaRDD<String> learn = javaSparkContext.parallelize(Arrays.asList("Spark","Scala")); JavaRDD<String> likeToLearn = likes.union(learn); //Learning::2 System.out.println("Learning::"+learn.count());
1.2 collect()
we can use collect action to retrieve the entire RDD. This can be useful if your program filters RDDs down to a very small size and you’d like to deal with it locally.
Note:
Keep in mind that your entire dataset must fit in memory on a single machine to use collect() on it, so collect() shouldn’t be used on large datasets.
reusing the above example, we can print the likeToLearn RDD elements in system console using collect action like,
List<String> result = likeToLearn.collect(); //Prints I like [Java, Spark, Scala] System.out.println("I like "+result.toString());
Now, moving forward we want continue the example by adding few other skills in our skillset.
We can use below snippet to add new learning skills in our learn RDD.
String[] newlyLearningSkills = {"Elastic Search","Spring Boot"}; JavaRDD<String> learningSkills = learn.union(javaSparkContext.parallelize(Arrays.asList(newlyLearningSkills))); //learningSkills::[Spark, Scala, Elastic Search, Spring Boot] System.out.print("learningSkills::"+learningSkills.collect().toString());
Here, we are using union to add new skills in learn RDD, so as a result we can get new RDD i.e learningSkills RDD.
1.3 take(n)
we can use take spark action to retrieve a small number of elements in the RDD at the driver program. We then iterate over them locally to print out information at the driver.
countinuing our example, now we have added new skills and as a result we do have learningSkills Spark RDD.
Now, If we call take action on learningSkills RDD like,
List<String> learning4Skills = learningSkills.take(4); //Learning 4 Skills::[Spark, Scala, Elastic Search, Spring Boot] System.out.println("Learning 4 Skills::"+learning4Skills.toString());
We will get 4 different skills from learningSkills RDD.
1.4 top(n)
Spark top action returns top(n) elements from RDD. In order to get top 2 learning skills from our learningSkills RDD, we can call top(2) action like,
List<String> learningTop2Skills = learningSkills.top(2); //Learning top 2 Skills::[Spring Boot, Spark] System.out.println("Learning top 2 Skills::"+learningTop2Skills.toString());
So, as a result we will get new RDD i.e learningTop2Skills and we can print the top 2 learning skills as shown in code snippet.
Note: Here, we have not defined any ordering, so it uses default ordering. we can use
public static java.util.List<T> top(int num,java.util.Comparator<T> comp) method for specifying custom Comparator while using top action.
1.5 countByValue()
countByValue Spark action returns occurence of each element in the given RDD.
so, in case, if we call countByValue action on learningSkills RDD, It will return a Map<String,Long>where each element is stored as Key in Map and Value represents its count.
Map<String,Long> skillCountMap= learningSkills.countByValue(); for(Map.Entry<String,Long> entry: skillCountMap.entrySet()){ System.out.println("key::"+entry.getKey()+"\t"+"value:"+entry.getValue()); }
Output
key::Scala value:1 key::Spark value:1 key::Elastic Search value:1 key::Spring Boot value:1
1.6 reduce()
The reduce action takes two elments as input and it returns one element as output. The output element must be of same type as input element. The simple example of such function is an addition function. We can add the elements of RDD, count the number of words. reduce action accepts commutative and associative operations as an argument.
So in our case lets take a list of integers and add them using reduce action as shown below.
The result will be sum of all the integers i.e 21.
JavaRDD<Integer> intRdd = javaSparkContext.parallelize(Arrays.asList(1,2,3,4,5,6)); Integer result = intRdd.reduce((v1, v2) -> v1+v2); System.out.println("result::"+result);
1.7 fold()
Spark fold action is similar to reduce action, apart from that it takes “Zero value” as input, so “Zero Value” is used for the initial call on each partition.
Note: Zero value is that it should be the identity element of that operation i.e 0 for Sum, 1 for Multiplication and division, empty list for concatenation etc.
Key Difference: The key difference between fold() and reduce() is that, reduce() throws an exception for empty collection, but fold() is defined for empty collection.
Return type : The return type of fold() is same as that of the element of RDD we are operating on.
ProTip: You can minimize object creation in fold() by modifying and returning the first of the two parameters in place. However, you should not modify the second parameter.
JavaRDD<Integer> intRdd = javaSparkContext.parallelize(Arrays.asList(1,2,3,4,5,6)); Integer foldResult = intRdd.fold(0,((v1, v2) -> (v1+v2))); System.out.println("Fold result::"+foldResult);
1.8 aggregate()
fold() and reduce() spark actions works well for operations where we are returning the same return type as RDD type, but many times we want to return a different type.
For example, when computing a running average, we need to keep track of both the count so far and the number of elements, which requires us to return a pair. We could work around this by first using map() where we transform every element into the element and the number 1, which is the type we want to return, so that the reduce() function can work on pairs.
The aggregate() function frees us from the constraint of having the return be the same type as the RDD we are working on.
Input: With aggregate() spark action like fold(), we have to supply,
An initial zero value of the type we want to return.
A function to combine the elements from our RDD with the accumulator.
We need to supply a second function to merge two accumulators, given that each node accumulates its own results locally.
We can use aggregate() to compute the average of an RDD, avoiding a map() before the fold().
For better explaination of aggregate spark action, lets consider an example where we are interested in calculating moving average of integer numbers,
So following code will calculate the moving average of integers from 1 to 10.
You can find the complete example of the Aggregate spark action at our git repository.
JavaRDD<Integer> intRDD = javaSparkContext.parallelize(Arrays.asList(1,2,3,4,5,6,7,8,9,10)); Function2<AverageCount, Integer, AverageCount> addAndCount = new Function2<AverageCount, Integer, AverageCount>() { public AverageCount call(AverageCount a, Integer x) { a.total += x; a.num += 1; return a; } }; Function2<AverageCount, AverageCount, AverageCount> combine = new Function2<AverageCount, AverageCount, AverageCount>() { public AverageCount call(AverageCount a, AverageCount b) { a.total += b.total; a.num += b.num; return a; } }; AverageCount initial = new AverageCount(0, 0); AverageCount currentMovingAverage = intRDD.aggregate(initial, addAndCount, combine); System.out.println("Moving Average:"+currentMovingAverage.avg());
Now, if you run this code, you will get moving average as 5.5, lets add another 3 values, i.e 11,12,13 using following snippet.
JavaRDD<Integer> anotherIntRDD = javaSparkContext.parallelize(Arrays.asList(11,12,13)); JavaRDD<Integer> resultantRDD = intRDD.union(anotherIntRDD); AverageCount newMovingAverage = resultantRDD.aggregate(initial, addAndCount, combine); System.out.println("Changed Moving Average:"+newMovingAverage.avg());
Now if you run the program, you will get the changed moving average i.e 7.
1.9 foreach()
When we have a situation where we want to apply operation on each element of RDD, but it should not return value to the driver. In this case, foreach() function is useful. A good example of this would be posting JSON to a webserver or inserting records into a database. In either case, the foreach() action lets us perform computations on each element in the RDD without bringing it back locally.
In our case we are simply printing each element of our previously derived RDD i.e learningSkills RDD.
So we can use following line to print all the elements of learningSkills RDD.
learningSkills.foreach(element -> System.out.println(element));
1.10 saveAsTextFile()
Outputting text files is also quite simple. The method saveAsTextFile(), we have already demonstrated in our passing function to spark example, This spark action takes a path and will output the contents of the RDD to that file. The path is treated as a directory and Spark will output multiple files underneath that directory. This allows Spark to write the output from multiple nodes. With this method we don’t get to control which files end up with which segments of our data, but there are other output formats that do allow this.
we have used following code snippet to save the RDDs to textFiles.
adultMinorCountsRDD.saveAsTextFile(args[1]); aggregatedFamilyPairsRDD.saveAsTextFile(args[2]);
2. API & References
We have used Spark API for Java for writing this article, you can find complete John Party problem solution at our Git repository.
3. Conclusion
Apache Spark computes the result when it encounters a Spark Action. Thus, this lazy evaluation decreases the overhead of computation and make the system more efficient. If you have any query about Spark Actions, feel free to share with us. We will be happy to solve them.
0 notes