#text_file
Explore tagged Tumblr posts
Visit Tumblr Blog
Explore Tumblr blogs with no restrictions, modern design and the best experience.
Last Seen Tumblr Blogs





Fun Fact
In 2020, 44% of users from Denmark used Tumblr daily.
Text
Hoy veremos como enviar nuestra depuracion a un archivo para su postterior analisis. Espero les sea de utilidad!
0 notes
Text
CS575 Project 1: Phone Directory (Sorting and Searching)
1) Develop a telephone directory that consists of name and phone number pairs similar to the one in your smartphone with following functionalities. [90%] ● Your program should be able to create a new phone directory by reading from a text file. To do this, implement “void create(text_file)” function. In the text file, the name and phone number of a person should be separated by a comma, and there…
0 notes
Text
Today's tech dev advice
Trying various variations of eol=lf in Gitattributes on GitHub, does jack squat for Python-generated uploaded files.
Instead, append newline='\n' to all lines in your Python scripts that have "w", in them, so that it becomes something like with open(OUTPUT, "w", encoding="utf-8", newline='\n') as text_file:
#github#git#python#script#this took me several years too long to find any relevant google search results for whatsoever#the hard-to-find search results didn't exactly help on my insanity#tech#life tips
1 note
·
View note
Text
python extract tables from html file and convert to python array and send a delimited version to file
import re filename_input = "src.html" filename_output = "out.data.txt" def get_tables_from_html(html): # inclusive tables = re.findall(r'<table.*?>.*?</table>',html, re.DOTALL) return tables def get_tr_from_html_ex(html): # exclusive tables = re.findall(r'<tr.*?>(.*?)</tr>',html, re.DOTALL) return tables def get_td_from_html_ex(html): # exclusive tables = re.findall(r'<td.*?>(.*?)</td>',html, re.DOTALL) return tables def get_ahref_from_html_ex(html): # exclusive tables = re.findall(r'<a.*?>(.*?)</a>',html, re.DOTALL) return tables def strip_tags(html): # exclusive html = re.sub(r'<.*?>', " ", html).strip() return html def html_table_to_array(table_html): rows = get_tr_from_html_ex(table_html) data = [] for tr in rows: data.append(get_td_from_html_ex(tr)) return data def file_put_contents(the_file, the_str): with open(the_file, "w") as text_file: text_file.write(the_str) file_data = None with open(filename_input, 'r') as f: file_data = f.read() if file_data != None: tables = get_tables_from_html(file_data) the_str = "" for table in tables: the_str += "-= -----------------------=-------\r\n" # print(table) table_data = html_table_to_array(table) for tr in table_data: col_count = len(tr) for td in tr: td = strip_tags(td) if(col_count > 2): the_str += td + "|" if(col_count > 2): the_str += "\r\n" print(the_str) file_put_contents(filename_output, the_str)
#python#html#extract#tables#table#delim#file#parse#columns#rows#snippets#data processing#data#data handling#file read#file write#re#regex#regular expressions#coding#coder#programmer#programming#htm#web
0 notes
Text
CSV to Parquet

Today is day-off, so I prepared the data in order to run a benchmark test of my query engine.
I was trying to convert CSV to Parquet using Pandas.
import os import pandas from zipfile import ZipFile files = os.listdir("/var/data/csv") for file in files: if file[-4:] == '.zip': yyyy_mm = file[-10:-4] print(yyyy_mm) zip_file = ZipFile("/var/data/csv/" + file) dfs = {text_file.filename: pandas.read_csv(zip_file.open(text_file.filename)) for text_file in zip_file.infolist() if text_file.filename.endswith('.csv')} for k, df in dfs.items(): df.to_parquet("/var/data/parquet/" + yyyy_mm + ".parquet")
Each zip file contains several files, but only one CSV. So I thought that I could convert with this code (as above). However after it converted some files, it was crushed.
005_10 sys:1: DtypeWarning: Columns (37) have mixed types.Specify dtype option on import or set low_memory=False. Traceback (most recent call last): File "<stdin>", line 8, in <module> File "/usr/local/anaconda3/envs/to-arrow/lib/python3.7/site-packages/pandas/util/_decorators.py", line 199, in wrapper return func(*args, **kwargs) File "/usr/local/anaconda3/envs/to-arrow/lib/python3.7/site-packages/pandas/core/frame.py", line 2463, in to_parquet **kwargs, File "/usr/local/anaconda3/envs/to-arrow/lib/python3.7/site-packages/pandas/io/parquet.py", line 397, in to_parquet **kwargs, File "/usr/local/anaconda3/envs/to-arrow/lib/python3.7/site-packages/pandas/io/parquet.py", line 152, in write table = self.api.Table.from_pandas(df, **from_pandas_kwargs) File "pyarrow/table.pxi", line 1479, in pyarrow.lib.Table.from_pandas File "/usr/local/anaconda3/envs/to-arrow/lib/python3.7/site-packages/pyarrow/pandas_compat.py", line 591, in dataframe_to_arrays for c, f in zip(columns_to_convert, convert_fields)] File "/usr/local/anaconda3/envs/to-arrow/lib/python3.7/site-packages/pyarrow/pandas_compat.py", line 591, in <listcomp> for c, f in zip(columns_to_convert, convert_fields)] File "/usr/local/anaconda3/envs/to-arrow/lib/python3.7/site-packages/pyarrow/pandas_compat.py", line 577, in convert_column raise e File "/usr/local/anaconda3/envs/to-arrow/lib/python3.7/site-packages/pyarrow/pandas_compat.py", line 571, in convert_column result = pa.array(col, type=type_, from_pandas=True, safe=safe) File "pyarrow/array.pxi", line 301, in pyarrow.lib.array File "pyarrow/array.pxi", line 83, in pyarrow.lib._ndarray_to_array File "pyarrow/error.pxi", line 84, in pyarrow.lib.check_status pyarrow.lib.ArrowInvalid: ('Could not convert 1338 with type str: tried to convert to double', 'Conversion failed for column WheelsOff with type object')
It looks like the file contains an unexpected type of value... I will fix this tomorrow.
0 notes
Text
Executing SQL Statements from a Text File
Executing SQL Statements from a Text File
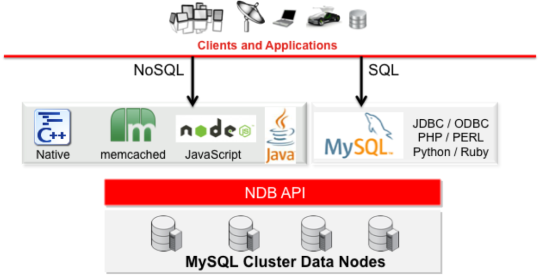
Executing SQL Statements from a Text File
The mysql client typically is used interactively, like this:
shell> mysql db_name
However, it is also possible to put your SQL statements in a file and then tell mysql to read its input from that file.
To do so, create a text file text_file that contains the statements you wish to execute. Then invoke mysql as shown here:
shell> mysql db_name < text_file
View On WordPress
#command line - How can I run an SQL script in MySQL? - Stack Overflow#database name like this#Executing SQL Statements from a Text File#Executing SQL Statements from a Text File - MySQL :: Developer Zone#How can I run an SQL script in MySQL?#MySQL#mysql query from file#PASSWORD#run a mysql query#Run SQL script files#run SQL Statements from a Text File#simply login to mysql shell and the sql file as follows:#SQL query from a Text File#with user name
0 notes
Text
Externer Einwurf:
Transdisziplinarität ist nun nicht primärer Inhalt der community, sondern mehr eine von mehreren Säulen der ganzen Unternehmung. Aber wir wollen ja nicht verschweigen, dass auch andere Menschen sich über begrifflichen Brückenbau und entsprechende Kataloge Gedanken machen. Die hier verlinkte Sammlung ist damit vielleicht eine optionale Unterfütterung der bisherigen Katalogisierungsunternehmung und eher eine Art weiterführender Lektüre. Core Terms in Transdisciplinary Researchby Pohl and Hirsch Hadorn: http://www.transdisciplinarity.ch/td-net/Literatur/Publikationen-td-net/mainColumnParagraphs/07/text_files/file1/document/HB_Core_terms.pdf
0 notes
Text
Hall’s Theorem and an Application to Cards
Today, we’ll work a little bit in graph theory and discuss Hall’s Theorem.
Hall’s Theorem, or what’s sometimes referred to as Hall’s Marriage Theorem, is a theorem which states the following: there is a complete matching on a connected bipartite graph if and only if for every subset A of V_1 we have
$$ |A| \leq |N(A)| $$
where we define N(A) to be the set of all nodes such that there is a node in V_1 that shares an edge with it.
There’s a lot of terminology here, and I recommend in order to better understand it you look at the wikipedia post for Hall’s Marriage Theorem, found here. There is a pretty cool application of this theorem which we’ll explore today. The application is as follows: Given any deck of cards, create 13 piles of four cards taken randomly from the deck. Then one is able to select one card from each pile such that we have all of the cards ranging Ace to King.
In order to play around with this concept, we’re going to need two packages --- the random module, and the networkx module for graph theory. Using these, we are able to construct examples of the application using only four functions. The idea of this is that we generate a deck, randomly place these cards into piles, or in this case into various indices of a dictionary, and then, using the networkx package, we are able to find a complete matching with a little bit of math trickery. The functions are as follows:
check_card(x): This one is just a formatting function. It takes an input of a number, ranging from 0 to 12, and if it’s 0 it returns “A”, if it’s 10 it returns “J”, if it’s 11 it returns “Q”, and if it’s 12 it returns “K”, which correspond to Ace, Jack, Queen, and King respectively.
#return the card value def check_card(x): if x == 0: return "A" if x == 10: return "J" if x == 11: return "Q" if x==12: return "K" return x
generator(): This function takes no input. It generates a list from 0 to 52 which contains four copies of each number from 0 to 12. We then create a dictionary called pile, and for each index from 1 to 13 we randomly select objects from the deck and place them in the index, removing them from the deck list in the process. We then return the pile dictionary when we’re done.
def generator(): #holds the list of cards list_of_cards = [] #generates the list for i in range(13): for j in range(4): list_of_cards.append(i) #holds the piles pile = {} #adds cards to each pile for i in range(13): pile[i+1] = [] for j in range(4): x = random.choice(list_of_cards) pile[i+1].append(x) list_of_cards.remove(x) return pile
find_complete_collection(pile): This is where the trick comes in. We create a bipartite graph, with the nodes in our first set, V_1, denoting the 13 piles, and the nodes in the second set, V_2, denoting our 13 cards. We draw an edge between a node from V_1 to V_2 if the card denote by the node in V_2 is in the pile corresponding to the node in V_1. Note that this pairing creates the condition necessary for Hall’s theorem; i.e.,
$$ |A| \leq |N(A)|$$
for all
$$A \subset V_1.$$
Then, using the networkx package, we are able to find the maximum_matching and, after formatting it to be a little nicer to deal with, we return it.
#Finds a complete matching def find_complete_collection(pile): G = nx.Graph() for i in pile: G.add_node(i) for k in range(13, 27): G.add_node(k) V1 = [] V2 = [] for i in range(13): V1.append(i) V2.append(i+13) for i in V1: for j in pile[i+1]: G.add_edge(i, j+13) z= nx.bipartite.maximum_matching(G) listing = {} for i in range(13): listing[i] = z[i] return listing
check_halls(coll): Here, we simply check the condition that there is a complete matching. In other words, we check that every pile appears once, and every card appears once.
def check_halls(coll): #first, check if all of the piles are used check = [] for i in range(13): check.append(i) for i in coll: if i in check: check.remove(i) if len(check) != 0: return False #now, check if all of the cards are used for i in range(13): check.append(i) for i in coll: if coll[i]-13 in check: check.remove(coll[i]-13) if len(check) != 0: return False return True
pile_writer(number_of_times): Here, there isn’t much going on. We simply iterate over the number_of_times, and each time we do this we append it to a text file dubbed Card_Piles.txt. We display what each pile has, and also what the complete matching produced by our prior function is.
#outputs it to a text file in a nice format def pile_writer(number_of_times): text_file = open("Card_Piles.txt", "w") for k in range(number_of_times): pile = generator() text_file.write("Time " + str(k+1) + ":\n") text_file.write("\n") for i in range(13): text_file.write("Pile " + str(i+1) +":\n") strng = "" for j in pile[i+1]: strng += str(check_card(j)) strng += ", " strng2 = "" for i in range(10): strng2 += strng[i] text_file.write(strng2 + "\n") text_file.write("\n") text_file.write("Complete collection: " ) gh = find_complete_collection(pile) strngg = "" for z in gh: strngg += str(check_card(gh[z] - 13)) strngg += str(" from ") strngg += "Pile " strngg += str(z+1) if z == 12: strngg += " " else: strngg += ", " text_file.write(strngg) text_file.write("\n \n") text_file.write("Is there a complete matching?") if check_halls(gh) == True: text_file.write(" Yes") else: text_file.write(" No") text_file.write("\n \n")
I ran it for around 10 times, and in the Github is the text file of what was produced. Notice that every time we have a complete matching, regardless of how we randomly chose the piles. This matches the theorem that is established by Hall.
To see the code for yourself, you can find it here. To see the corresponding text file, you can find it here.
0 notes
Text
Tweet Scraping
Today, we’ll be scraping tweets.
First, I’d like to thank the user Yanofsky on Github for the inspiration for the project. Much of the work here was thanks to him, and he really should take the credit. What I created was really a slight modification of his code.
We’ll just be doing a basic scrape of a users Tweets and saving them into a text file. First, we’ll need to acquire a few keys. If you don’t have a Twitter account, it is a requirement to have one in order to use the Twitter API, which is called Tweepy. See the link for more on the documentation of Tweepy.
Once you’ve made your Twitter account, you’ll go to https://apps.twitter.com and create an app. Select a name for your app (it doesn’t really matter what for our purposes) and then create the app. You’ll want to find four different keys --- the consumer key, the consumer secret key, the access token, and the access secret token. Save those somewhere safe, or keep the tab open for quick reference.
Now, we start actually coding. You’ll want to first import two things:
import tweepy from tweepy import OAuthHandler
After importing those two things, save your keys in the following variables where the empty quotations are:
consumer_key = '' consumer_secret = '' access_token = '' access_secret = ''
Then, with all of that saved, we load up the following code:
auth = OAuthHandler(consumer_key, consumer_secret) auth.set_access_token(access_token, access_secret) api = tweepy.API(auth)
and now we have access to the API using the api prefix on our code! See the documentation link for more information on what you can do with tweepy.
There’s only one function in the script, called the save_tweet function.
save_tweet(screen): The save tweet function takes only one parameter, which is the screen name. Note that this is the username of the person you wish to pull the tweets of, and it must be in a string (so wrap it in quotations). We start by initializing an empty list called tweets. We then initialize a new list called new_tweets which will hold the temporary tweets that we call each time. We then use the function api.user_timeline, with the parameters screen_name = screen and count = 200. Hypothetically, we would like to set count to be arbitrarily high so that it pulls all of the tweets, however the function caps out at 200 tweets per call. So, we start by calling the initial 200, and then we extend our tweets list by this new_tweets. Under a variable called maxdate, we save the last date called (which is found by using tweets[-1].id-1). Then, we start a while loop. Within the while loop, we add a new parameter to api.user_timeline --- we set max_id = maxdate. We essentially do everything we just did before, except we update the maxdate variable to the most recent date. The while loop terminates when new_tweets has length 0.
We then create another list, called savetweets. Here, we’ll have the actual text of the tweets that we’re saving. We run a for loop for each item in tweets, appending to savetweets the text of the tweet in tweets (say that three times fast). We then finish up the script by opening a text file, and for each tweet in savedtweets we write the tweet on a new line. We terminate the script by closing the text file.
def save_text(screen): #an empty list to hold a list of objects tweets = [] #pulls the initial 200 tweets (max) new_tweets = api.user_timeline(screen_name = screen, count = 200) #gets the last date that was retrieved maxdate = new_tweets[-1].id - 1 print('init') #extends the list adding the newtweet objects tweets.extend(new_tweets) while len(new_tweets) != 0: #pulls the next 200 tweets new_tweets = api.user_timeline(screen_name = screen, count = 200, max_id = maxdate) #extends the list again tweets.extend(new_tweets) #gets the next maxdate maxdate = tweets[-1].id - 1 #lets the user know how far along we are print('loaded ' + str(len(tweets)) + ' tweets so far') print('finished loading!') #this is the actual text savetweets = [] #for i in the tweets list, pull the text and save it in a new list for i in tweets: savetweets.append(i.text) print('now saving it to a text file...') #open a file text_file = open(str(screen) + "_tweets.txt", "w") #write the tweet on a new line for i in savetweets: text_file.write(i + "\n") #close the file text_file.close() print('finished!')
The script can be found here, and the test text file can be found here.
0 notes