#web proxy server
Explore tagged Tumblr posts
Visit Tumblr Blog
Explore Tumblr blogs with no restrictions, modern design and the best experience.
Last Seen Tumblr Blogs





Fun Fact
There were a total of 171.5 billion posts on Tumblr in 2019.
Text
Victorian Government data published on dark web
youtube
#ausgov#politas#auspol#tasgov#taspol#australia#invasion of privacy#privacy#internet#cybernews#cybersecurity#cyberattack#vicpol#vicgov#russia#http proxy#proxy service#proxy servers#dark web#darkweb#i.t.#information technology#it#infotech#cyber security#security#tor#onion#onions#ransom
6 notes
·
View notes
Text
If you’re as obsessed with data, tech, and the endless possibilities of the internet as I am, you’re going to want to hear about ProxyJet. This platform is not just changing the game; it’s completely revolutionizing how we approach data collection. Let me break down why ProxyJet is the MVP of proxy services.
Why ProxyJet is a Game-Changer:
Speed is Key: Imagine getting your proxy setup done in less than 20 seconds. With ProxyJet, that’s not a dream—it’s reality. This means more time diving into the data that matters most to you, and less time waiting around.
A Proxy for Every Purpose: Whether you’re into web scraping, protecting your privacy, or just exploring the digital world, ProxyJet has a type of proxy for you. Rotating Residential, Static Residential, Mobile, Datacenter—take your pick. Each one is tailored to specific needs and challenges.
Worldwide Reach: Access over 75M+ IPs across the globe. This isn’t just about being able to scrape or access data—it’s about breaking down geographical barriers and unlocking a world of information.
Pricing that Makes Sense: Starting from $0.25/GB, ProxyJet offers flexible pricing that ensures you’re only paying for what you need. It’s like having your cake and eating it too, but with data.
The Technical Stuff: We’re talking a 99.9% success rate, people. This platform is reliable, efficient, and designed to make your data collection as seamless as possible.
Why I’m All In:
In a world where data is gold, having the right tools to mine that gold is crucial. ProxyJet isn’t just another tool; it’s the Swiss Army knife for anyone looking to harness the power of the internet. Whether you’re a seasoned developer, a marketer, or just someone curious about the digital landscape, ProxyJet is your gateway to exploring the vast, uncharted territories of the web.
So, What’s Next?
If you’re ready to level up your data game, take a leap into ProxyJet. It’s not just about collecting data; it’s about unlocking potential, discovering new horizons, and empowering your online adventures.
Dive in, explore, and let’s revolutionize the way we interact with the digital world together. Check out ProxyJet at https://proxyjet.io/ and start your journey.
#ai scraping#data scraping#proxy#scraping#web scraping api#web scraping services#web scraping tools#proxy server
1 note
·
View note
Text
Proxy Server: Enhancing Performance, Security and Privacy

A proxy server operates as a go-between for clients and servers, enabling data flow and giving numerous advantages in speed optimization, security upgrades, and user privacy. Read More.
0 notes
Photo

看看網頁版全文 ⇨ 如何取得使用者的IP?從反向代理伺服器、網頁伺服器到程式語言來看 / How to Get the User's IP? From Reverse Proxy Server, Web Server to Programming Language https://blog.pulipuli.info/2023/04/blog-post_18.html 看來目前是做不到「真的透明」的反向代理伺服器了。 ---- # 真實IP / The "Real IP"。 網路服務中加入反向代理伺服器的人,通常都會有這個問題:「怎麼取得使用者真實的IP?」。 如果你使用PHP,那我們通常會用$_SERVER["REMOTE_ADDR"]來取得使用者的IP位置。 但如果該伺服器位於反向代理伺服器的後頭,那$_SERVER["REMOTE_ADDR"]抓到的會是反向代理伺服器的IP,並非來自使用者真實的IP。 為此,使用NGINX架設反向代理伺服器的教學中,大多會建議在反向代理伺服器的NGINX中加入以下設定,將使用者的IP包裝在X-Real-IP中。 [Code...] 如此一來,後端伺服器(backend,或說是上游伺服器 upstream)的PHP程式碼便能在 $_SERVER["HTTP_X_READ_IP"]取得使用者真實的IP (192.168.122.1)。 再回來看到這張網路架構圖。 在取得使用者IP的這個問題上,可以把整體架構分成四個角色:。 - 使用者 (Client) :這裡真實IP給的例子是192.168.122.1。 - 反向代理伺服器 (Reverse Proxy):使用NGINX架設。該伺服器的IP是192.168.122.133。 - 網頁伺服器 (Web Server):提供網頁內容的真實網頁,可以用Apache架設,也可以用NGINX架設。IP是192.168.122.77。 - PHP:產生網頁的程式語言。該程式語言用來辨別使用者IP的主要方式是$_SERVER["REMOTE_ADDR"]。但如果反向代理伺服器有設定X-Real-IP的話,也可以用$_SERVER["HTTP_X_REAL_IP"]取得使用者的IP。 當我們在討論「如何取得使用者IP」的問題時,一定要搞清楚我們討論的角色是哪一層。 到底是後端的程式語言PHP或ASP.NET?還是網頁伺服器的Apache或NGINX?還是我們想要在前端的反向代理伺服器實作這個功能?。 理想上,如果能在反向代理伺服器就將使用者的真實IP傳遞給後端的網頁伺服器跟程式語言,而且能夠讓後端伺服器誤以為請求就是來自使用者本人,那應該是最理想的做法。 但目前的結論是:做不到。 以下讓我們從前端到後端一一來看看要怎麼做。 ---- 繼續閱讀 ⇨ 如何取得使用者的IP?從反向代理伺服器、網頁伺服器到程式語言來看 / How to Get the User's IP? From Reverse Proxy Server, Web Server to Programming Language https://blog.pulipuli.info/2023/04/blog-post_18.html
0 notes
Text
so you've probably been warned against clicking strange links and to especially avoid revealing your personal information online, even in "private" accounts. But what about a "cute" spin-the-wheel link above a tumblr poll?? (like the post in the following screenshot)
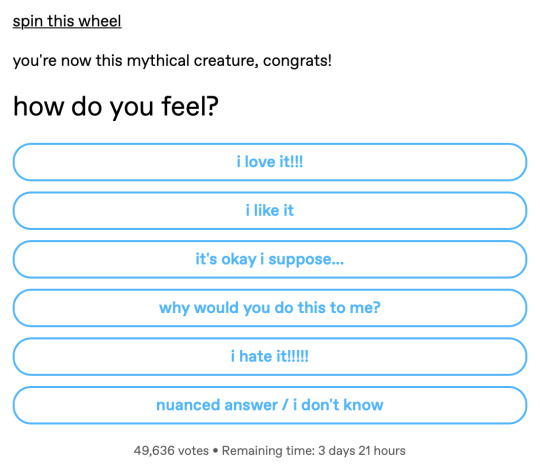
FYI: getting people to click an external link is a great strategy for gathering more details about a mostly anonymous user in a forum or tumblr or wherever. Here's some reasons why: 1. If you shared a unique link in a restricted forum or channel or community or chatroom or public fandom blog or at the end of a fic on ao3, you can be sure only the people of interest could click on it 2. That URL could lead to fucking anything of their choosing. Do they want to do an intensive browser fingerprint or get a log of IP addresses? Do they want to estimate the hardware specs of everyone's machines? Do they want to try loading other things on the page to test for adblockers or other blacklists? (an additional kind of profiling) 3. People LOVE to give away identifying information for the sake of a poll or cute name generator. Here are some questions I've seen recently and what information it can point to: - First anime? (fuzzy proxy for age and country) - First celebrity crush? (fuzzy proxy for age and country) - First album? (fuzzy proxy for age and country) - First name using first letter of last name, Last name using birthday month (do I need to spell this out? last name and birthday month) - What word do you use for [common item]? (region, language, culture, class) - Getting people to talk about astrology (you've all given away your birth month for free, wtf) Another fun fact about "Spin The Wheel" links: they can generate ad revenue for someone! Fun fact about Quizzes: they can help build deeper advertising profiles for linkbait sites like facebook or buzzfeed or the daily mail or tmz Another fun fact: besides the info the Spin The Wheel or Name Generator pages save direct to the server, the page can encode that information back into where the wheel stops or the name it gives you. That makes it easier to gather information because it's recorded 1st on the server (controlled by person fishing to unmask someone) 2nd back in the post notes or in the discord channel or wherever. And we all know how much people want to gab about the Fun poll or survey or quiz and reveal even more information. Another fun fact about Spin the Wheel or Name Generator or Quiz pages: You might be seeing a list of options nobody else saw that only appear for IP addresses from a certain region! And if you post your result (that would be mostly unique) it's an INSTANT indication that the person from [region] is logged in. (same goes for browser fingerprint - which device a certain person has) I remember a line from an article about digital detectives (I think it was feds tracking dark web stuff), it said they wait for YEARS for someone to post or log in just to confirm a person of interest was in a certain place at a certain time. You and I probably don't remember the information we leaked years and years ago in the notes of a post or on a retweet of some idiot, but any people who might want to figure you out probably have a huge spreadsheet with everything recorded. They can and do analyze and annotate it all, and can start to narrow down where you are, how old you are, your interests, hobbies, class background, devices you use etc. You might be thinking: "but I don't worry about federal agents or intelligence agencies, why do I care?" What if tomorrow your post goes viral, truly globally Viral? You can go from tumblr nobody to target for stalkers and/or hate crimes instantly. An even more serious example from this year: What if you've been advocating for years for people that are now scapegoat of the day for the fascists? What if a federal agent is tasked with creating a list of "those people" for surveillance? The less information you have unintentionally posted about yourself the better. A perhaps more personal and private example: what if you had to get away from a city or country or person or persons or family and didn't want them to follow you? People with a grudge will go to great lengths to get back at someone
#privacy online is bigger than direct reveals of the big details like dob or location#gotta be careful#some people make it their life's work to tease out key information without you ever noticing - they're experts#be cautious and wary out there#you don't know who's reading your posts or sharing your dms or charting your ip addresses#my blog#digital privacy
31 notes
·
View notes
Text
so -- in case you end up in the same situation as me, and are trying to set up several small web projects with different domains onto one box in your house, but you're behind NAT and a dynamic ip as most are -- what will NOT work for you is tailscale funnel.
don't get me wrong. tailscale works great. but funnel is quirky, and it turns out it's VERY insistent on doing its own TLS stuff. in practical terms, this means that you can't CNAME to it, so you're stuck with just the auto-generated url. it's functional, but only in the most hacky scenarios.
instead, what i'm doing is:
renting a small ($5/mo) vps and adding it to my tailnet
running caddy, forwarding all requests to my home box via tailnet on http (see this guide)
on home box, also run caddy, accepting & trusting http from upstream proxies
using that caddy, distribute requests to proper servers on the box via docker network
that way each domain gets its TLS done right, but the fancy nat-punching and ddns-like work is handled by tailscale, and traffic to the home box is re-sorted to the right servers. i only got a proof of concept working tonight but im hopeful i can get this really going this week and kill my big vps's.
9 notes
·
View notes
Text
The Marvel Trumps Hate 2024 Auction is Over! Now What?
Everyone, thank you so much for your bids and your help in making this auction a success. We couldn’t have done this without you! Now that we've wrapped up the auction, here’s what will happen:
1) Emails will be going out to winners as soon as possible, with instructions on how to submit your donation. As there were so many enthusiastic last-minute bids, our web server needs a little while to recover and there may be a delay. Please give it some time! If you believe you're a winning bidder and don't see the win notification email in your inbox or spam folder after 48 hours, please email [email protected] so that we can send another copy to you. If you receive an email and you’re someone’s proxy bidder, please forward the email to the bidder you’re representing and CC us so that we know who to contact henceforth about the auction. We encourage you to check your email inbox over the next four days even if you don't think you won. Some creators take on more than one winner, and you might get lucky if you had the second highest bid!
Please do not contact your creator or make your donation before you receive the email confirming your win. We also ask that you refrain from asking creators if they're taking on a second winner for their auction(s); not everyone is eligible to do so and not everyone is able or comfortable even if they are, so we don't want creators to feel awkward or pressured.
2) Once you get that win confirmation, you have until 11:59 PM ET on Saturday, November 2 (what time is that for me?) to respond with your proof of donation. Please follow the directions in the email sent to you. Check out our Donation Guide and Bidders FAQ if you’re still unsure about how to donate. If you don’t respond to our email before the donation deadline, we’ll move on to the next highest bidder and your bid will be made void.
3) Once we receive proof of donation, we MTH mods will put the winning bidder and their respective creator in contact with each other via email. It may take 1–3 days to get the connection email due to the volume of emails we handle. You don’t need to reply to this email when it comes or CC the mods in any correspondence between yourselves after this point. This is the first point at which creators are involved.
Creators, remember that your bidder has until our donation deadline of November 2 at 11:59 PM ET to donate. We’ll only be matching creators and winners after proof of donation has been received, so please be patient and wait for the connection email.
16 notes
·
View notes
Text
this is really only a small point in the end, but like... the first thing that made us solidly go "nope!" about the idea of a school for plurals was the mention of everyone having a badge connected to simplyplural that would show the current fronter.
like, not even going into the personal part, our first point is: who would manage the simplyplural account, first of all? taking us, for example, doing shit on our phone is incredibly difficult and overwhelming. there's a reason why we don't answer 90% of asks we get (on this blog, on the plurillean-confessions blog, etc) on our phone, and as far as we can tell, simplyplural is primarily a mobile app (actually, we're trying to register on the web, and it just straight up is not working--either it tells us that our password isn't valid even though it is, or it gets stuck in a loading loop). and there's probably folks who would struggle to manage a simplyplural themselves in general, regardless of where it was.
okay, so, then who would manage the account if the person it's for can't? we sure as hell wouldn't trust someone else to manage something that's so personal, let alone someone who is meant to be an authority figure, so that puts staff entirely out of the picture if you're trying to make this a safe and comfortable place. and of course, there's every chance that whoever is chosen to manage the simplyplural just... won't listen to the system in question. won't add new members the system says are there for whatever reason, won't change pronouns or apeparances, etc.
alright. alrightalrightalright. put managing it to the side. let's talk about the display of who's fronting, right? two problems i can immediately foresee:
(1a) privacy. this is immediately a huge concern for privacy, say for headmates who want to log themselves fronting, but don't want other people to know they're there. for a while, one of our headmates (Mimic) used a completely different pk proxy while talking in certain servers because it was worried that, if people knew who it was, they would immediately run it out of the place.
(2a) multiple fronters at once. unless this badge is huge or the text or whatever else is on there is tiny, how are you going to manage multiple fronters? multiple badges? okay, how many badges is the maximum? because, for example, when Wolf fronts, all of us are always there. so that's immediately 6 people. and usually, there's more than just Wolf. often, other folks such as Arratay, Parrot, and Lewis are around. that's 9 people all fronting at once. how are you going to deal with that?
and (2b) hey, the whole point of showing who's fronting is to show who is talking, right? what about in cases where someone blips in for a few seconds to add in a random comment before leaving? what if this regularly happens to the point where it could get confusing about who said what unless someone shows up on the badge (like with us, where mentioning a certain headmate or something they're interested in will get their attention, and they'll often send in a quick "hi" or a short (or long) infodump about whatever we're talking about before promptly leaving)?
oh, and not to mention (2c + 1b) what about headmates who front a lot because of something, but don't talk? if they're fronting, they'd supposedly show on the badge, but it wouldn't be them talking. some months ago, we joined a server for a game that was a special interest of Guppy's, and ze would pretty much be in front every time we were playing the game or engaging with the server. note: ze never said a single word, ze always had someone else talking for hir because ze was too anxious to talk to people and let people know ze was there.
and then, of course (2d) what about systems who are almost constantly blurry? who often have multiple headmates fronting at once, but when they're fronting, it's basically just thoughts-and-feelings soup that can't easily be separated into "headmate 1" and "headmate 2"? or systems that struggle to figure out who specifically is fronting for one reason or another? what then?
i don't know. maybe it's just us, but that comment was the very first thing that really put us off. (and then, of course, followed by the whole "ooo it's an experiment!" thing.) that was the thing that immediately put a sour taste in our mouth. it's small potatoes compared to... everything else, but we were really put off by it (and we're honestly surprised nobody else has said anything about it).
#original posts#we're not main tagging this one just because this is mostly just a thought spill (and we don't want to risk getting into any arguments)#but it's perfectly fine to reblog if you want
31 notes
·
View notes
Text
followup - the case of tiktok and zlibrary
i think a potential rejoinder to that piracy post is that the point of obscurity isn't to avoid discovery by the feds (impossible, even with private word of mouth), but to keep the scale small enough that it's not worth the effort to suppress.
an example brought up in a few replies is the case of ZLibrary, which hosts a large collection of pirated ebooks. the story goes, there were widely circulating TikTok posts promoting ZLibrary. ZLibrary became very popular. not long after, the US justice system moved to seize its domain names, meaning that if you typed in the URL to ZLibrary, the DNS (Domain Name System) would not direct you to ZLibrary's servers, but to a page saying the feds had seized this domain.
(this can be compared with the more standard practice of ordering ISPs to block a domain. in this case, the DNS registration is untouched, but your ISP will intercept requests to that domain, usually serving a blank page instead. this is easy to bypass using a VPN. in the ZLibrary case, the US government actually overwrote the DNS records, so nobody could obtain the IP address of ZLibrary from that particular URL anymore.)
imo there is no question that the feds knew about ZLibrary before it got popular on TikTok. however, you could still argue that they would not have been so quick to seize its domains if ZLibrary had been less popular. (not 100% sure if that's true. it takes time for the courts to make their move.)
but that's not the end of the story. subsequently, ZLibrary came back under a variety of domains - and also over the I2P and Tor anonymisation networks, which do not rely on the DNS. It was also backed up by the "Anna's Archive" project. if you want to download a book from ZLibrary today... it's not even hard. you can literally just get the current URLs on Wikipedia.
so if the story of ZLibrary demonstrates anything, it is that to some extent, the domain name system was a vulnerability. but only to some extent. because the site can register new domains faster than the feds can squash them. as long as the servers remain out of reach of the feds, domains can change, and proxies can be established.
this is all by design. the internet was invented to route around obstructions (for example, a computer getting blown up by a nuclear bomb). the web and the DNS, less so - but while it's mildly inconvenient to have to find a new URL for ZLibrary, it's not a show-stopper.
so i reckon if anything the case of ZLibrary demonstrates that with the right system design, even when the feds make their move, it's possible to bounce back. TikTok did not kill ZLibrary, at most they just tripped it up for a bit.
79 notes
·
View notes
Text
ok since i've been sharing some piracy stuff i'll talk a bit about how my personal music streaming server is set up. the basic idea is: i either buy my music on bandcamp or download it on soulseek. all of my music is stored on an external hard drive connected to a donated laptop that's next to my house's internet router. this laptop is always on, and runs software that lets me access and stream my any song in my collection to my phone or to other computers. here's the detailed setup:
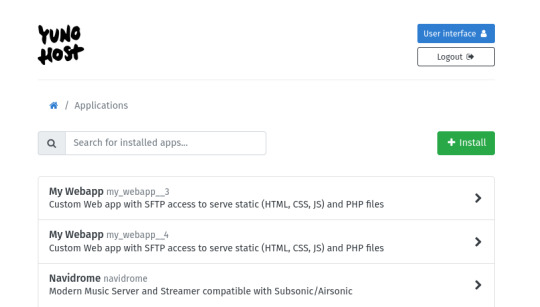
my home server is an old thinkpad laptop with a broken keyboard that was donated to me by a friend. it runs yunohost, a linux distribution that makes it simpler to reuse old computers as servers in this way: it gives you a nice control panel to install and manage all kinds of apps you might want to run on your home server, + it handles the security part by having a user login page & helping you install an https certificate with letsencrypt.
***
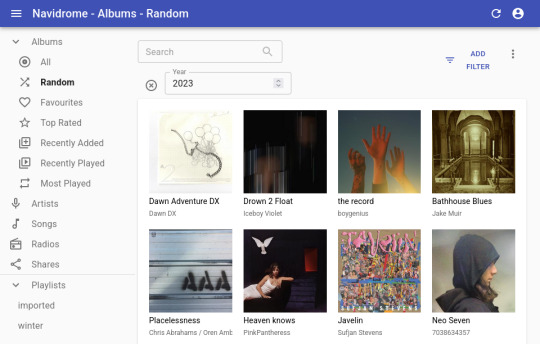
to stream my music collection, i use navidrome. this software is available to install from the yunohost control panel, so it's straightforward to install. what it does is take a folder with all your music and lets you browse and stream it, either via its web interface or through a bunch of apps for android, ios, etc.. it uses the subsonic protocol, so any app that says it works with subsonic should work with navidrome too.
***
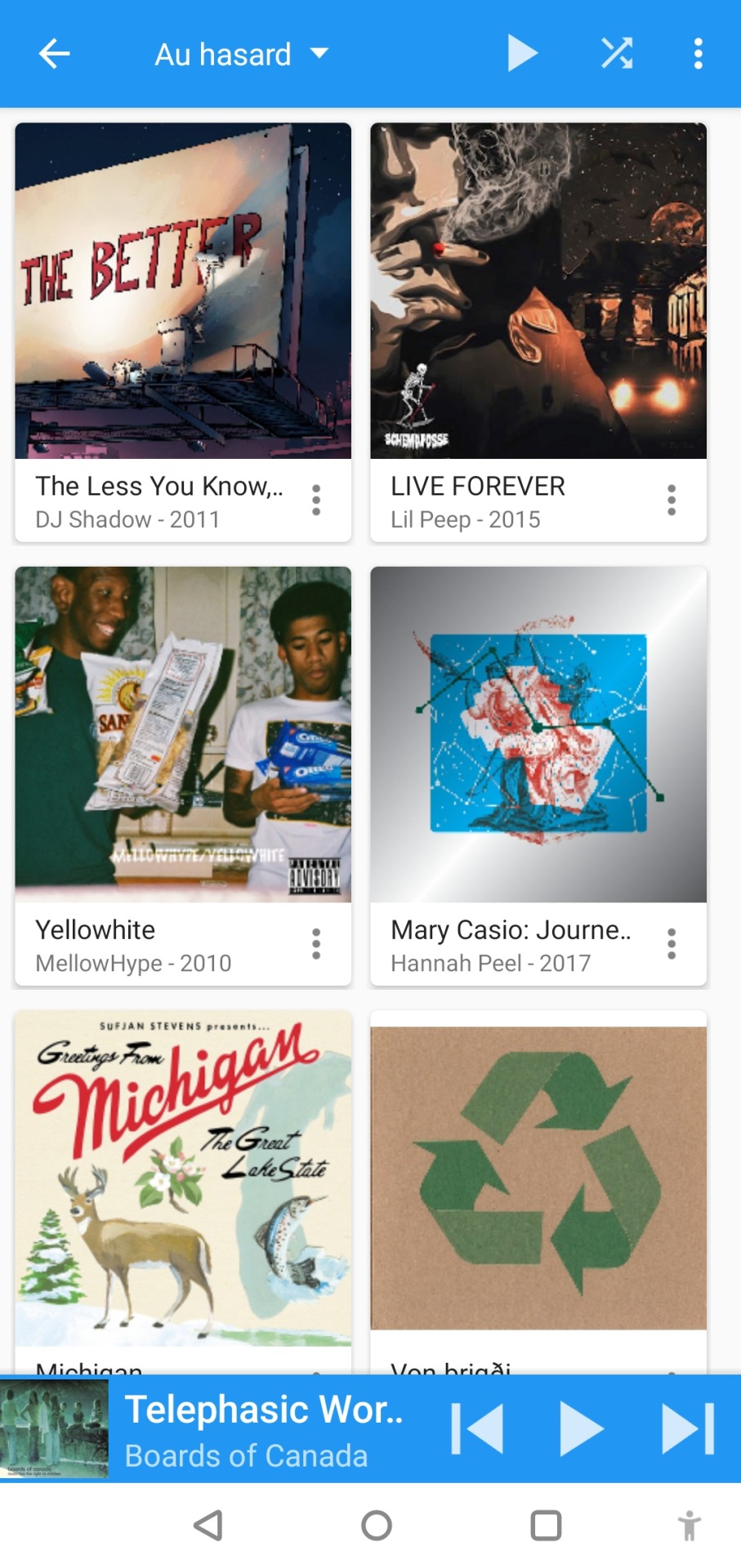
to listen to my music on my phone, i use DSub. It's an app that connects to any server that follows the subsonic API, including navidrome. you just have to give it the address of your home server, and your username and password, and it fetches your music and allows you to stream it. as mentionned previously, there's a bunch of alternative apps for android, ios, etc. so go take a look and make your pick. i've personally also used and enjoyed substreamer in the past. here are screenshots of both:
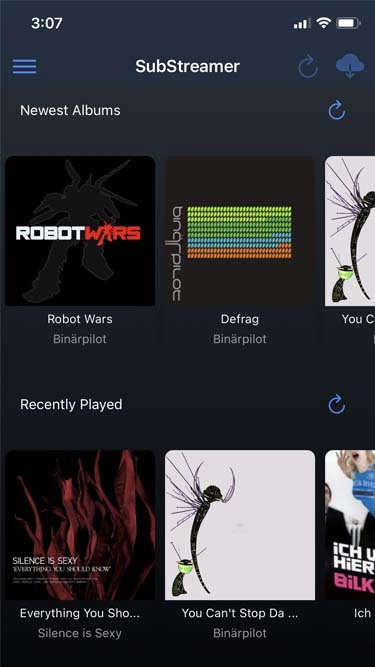
***
to listen to my music on my computer, i use tauon music box. i was a big fan of clementine music player years ago, but it got abandoned, and the replacement (strawberry music player) looks super dated now. tauon is very new to me, so i'm still figuring it out, but it connects to subsonic servers and it looks pretty so it's fitting the bill for me.

***
to download new music onto my server, i use slskd which is a soulseek client made to run on a web server. soulseek is a peer-to-peer software that's found a niche with music lovers, so for anything you'd want to listen there's a good chance that someone on soulseek has the file and will share it with you. the official soulseek client is available from the website, but i'm using a different software that can run on my server and that i can access anywhere via a webpage, slskd. this way, anytime i want to add music to my collection, i can just go to my server's slskd page, download the files, and they directly go into the folder that's served by navidrome.
slskd does not have a yunohost package, so the trick to make it work on the server is to use yunohost's reverse proxy app, and point it to the http port of slskd 127.0.0.1:5030, with the path /slskd and with forced user authentification. then, run slskd on your server with the --url-base slskd, --no-auth (it breaks otherwise, so it's best to just use yunohost's user auth on the reverse proxy) and --no-https (which has no downsides since the https is given by the reverse proxy anyway)

***
to keep my music collection organized, i use beets. this is a command line software that checks that all of the tags on your music are correct and puts the file in the correct folder (e.g. artist/album/01 trackname.mp3). it's a pretty complex program with a ton of features and settings, i like it to make sure i don't have two copies of the same album in different folders, and to automatically download the album art and the lyrics to most tracks, etc. i'm currently re-working my config file for beets, but i'd be happy to share if someone is interested.
that's my little system :) i hope it gives the inspiration to someone to ditch spotify for the new year and start having a personal mp3 collection of their own.
34 notes
·
View notes
Text
[Full Text] Emerging Media Companies, Tracking Cookies, and Data Privacy -- An open letter to Critical Role, Dropout, and fellow audience members
Summary / TL;DR
Both Critical Role (CR) and Dropout have begun exclusively using links provided by third-party digital marketing solution companies in their email newsletters.
Every link in each of the newsletters (even the unsubscribe link) goes through a third-party domain which is flagged as a tracking server by the uBlock Origin browser extension.
Third-party tracking cookies are strictly unnecessary and come with a wide array of risks, including non-consensual targeted advertising, targeted misinformation, doxxing, and the potential for abuse by law enforcement.
You are potentially putting your privacy at risk every time you click on any of the links in either of these newsletters.
IMO these advertising companies (and perhaps CR/Dropout by proxy) are likely breaking the law in the EU and California by violating the GDPR and CCPA respectively.
Even if Critical Role and Dropout are not directly selling or exploiting your personal data, they are still profiting off of it by contracting with, and receiving services from, companies who almost certainly are. The value of your personal data is priced into the cost of these services.
They should stop, and can do so without any loss of web functionality.
1/7. What is happening?
Critical Role and Dropout have begun exclusively using links provided by third-party digital marketing solution companies in their email newsletters.

[ID: A screenshot of the Dropout newsletter alongside the page’s HTML source which shows that the target destination for an anchor element in the email leads to d2xR2K04.na1.hubspotlinks.com. End ID.]

[ID: A screenshot of the CR newsletter alongside the page’s HTML source which shows that the target destination for an anchor element in the email leads to trk.klclick.com. End ID.]
The domains attached to these links are flagged as advertising trackers by the uBlock Origin browser extension.

[ID: Screenshot of a Firefox web browser. The page displays a large warning icon and reads “uBlock Origin has prevented the following page from loading [...] because of the following filter: `||hubspotlinks.com` found in Peter Lowe’s Ad and tracking server list. End ID.]

[ID: Screenshot of a Firefox web browser. The page displays a large warning icon and reads “uBlock Origin has prevented the following page from loading [...] because of the following filter: `||klclick1.com` found in Peter Lowe’s Ad and tracking server list. End ID.]
In both cases, every link in the newsletter goes through the flagged third-party domain, and the intended endpoint (Twitter, their store page, etc.) is completely obscured and inaccessible from within the email itself. Even the unsubscribe links feed through the tracking service.
You can test this yourself in your own email client by hovering your cursor over a link in the email without clicking it and watching to see what URL pops up. You may have noticed this yourself if you use uBlock Origin as an ad-blocker.
I don’t know for certain when this first started. It’s possible that this has been going on for a year or more at this point, or it may have started just a few months ago. Either way: it ought to stop.
2/7. What is a tracking cookie?
A tracking cookie is a unique, universally identifiable value placed on your machine by somebody with the intention of checking for that value later to identify you (or at least to identify your machine).
Tracking cookies are used by companies to create advertising behaviour profiles. These profiles are supposedly anonymous, but even if the marketing companies creating them are not lying about that (a tough sell for me personally, but your mileage may vary when it comes to corporations with 9-figure annual incomes), the data can often be de-anonymized.
If this happens, the data can be used to identify the associated user, potentially including their full name, email address, phone number, and physical address—all of which may then be associated with things like their shopping habits, hobbies, preferences, the identities of their friends and family, gender, political opinions, job history, credit score, sexuality, and even when they ovulate.
Now, it is important to note that not all cookies are tracking cookies. A cookie is just some data from a web page that persists on your machine and gets sent back to the server that put it there. Cookies in general are not necessarily malicious or harmful, and are often essential to certain web features functioning correctly (e.g. keeping the user logged in on their web browser after they close the tab). But the thing to keep in mind is that a domain has absolute control over the information that has been stored on your computer by that domain, so allowing cookies is a matter of trusting the specific domain that wants to put them there. You can look at the outgoing information being sent from your machine, but its purpose cannot be determined without knowing what is being done with it on the other side, and these marketing companies ought not to have the benefit of your doubt when they have already been flagged by privacy watchdogs.
3/7. What’s the harm?
Most urgently, as I touched on above: The main source of harm is from corporations profiting off of your private data without your informed consent. However, targeted advertising is actually the least potentially harmful outcome of tracking cookies.
1/6. Data brokers
A data broker is an individual or company that specializes in collecting personal data (such as personal income, ethnicity, political beliefs, geolocation data, etc.) and selling or licensing such information to third parties for a variety of uses, such as background checks conducted by employers and landlords, two universally benevolent groups of people.
There are varying regulations around the world limiting the collection of information on individuals, and the State of California passed a law attempting to address this problem in 2018, following in the footsteps of the EU’s GDPR, but in the jurisdiction of the United States there is no federal regulation protecting consumers from data brokers. In fact, due to the rising interest in federal regulation, data broker firms lobbied to the tune of $29 million in the year 2020 alone.
2/6. De-anonymization techniques
Data re-identification or de-anonymization is the practice of combining datasets (such as advertising profiles) and publicly available information (such as scraped data from social media profiles) in order to discover patterns that may reveal the identities of some or all members of a dataset otherwise intended to be anonymous.
Using the 1990 census, Professor Latanya Sweeney of the Practice of Government and Technology at the Harvard Kennedy School found that up to 87% of the U.S. population can be identified using a combination of their 5-digit zip code, gender, and date of birth. [Link to the paper.]
Individuals whose datasets are re-identified are at risk of having their private information sold to organizations without their knowledge or consent. Once an individual’s privacy has been breached as a result of re-identification, future breaches become much easier: as soon as a link is made between one piece of data and a person’s real identity, that person is no longer anonymous and is at far greater risk of having their data from other sources similarly compromised.
3/6. Doxxing
Once your data has been de-anonymized, you are significantly more vulnerable to all manner of malicious activity: from scam calls and emails to identity theft to doxxing. This is of particular concern for members of minority groups who may be targeted by hate-motivated attacks.
4/6. Potential for abuse by government and law enforcement
Excerpt from “How period tracking apps and data privacy fit into a post-Roe v. Wade climate” by Rina Torchinsky for NPR:
Millions of people use apps to help track their menstrual cycles. Flo, which bills itself as the most popular period and cycle tracking app, has amassed 43 million active users. Another app, Clue, claims 12 million monthly active users. The personal health data stored in these apps is among the most intimate types of information a person can share. And it can also be telling. The apps can show when their period stops and starts and when a pregnancy stops and starts. That has privacy experts on edge because this data—whether subpoenaed or sold to a third party—could be used to suggest that someone has had or is considering an abortion. ‘We're very concerned in a lot of advocacy spaces about what happens when private corporations or the government can gain access to deeply sensitive data about people’s lives and activities,’ says Lydia X. Z. Brown, a policy counsel with the Privacy and Data Project at the Center for Democracy and Technology. ‘Especially when that data could put people in vulnerable and marginalized communities at risk for actual harm.’
Obviously Critical Role and Dropout are not collecting any sort of data related to their users’ menstrual cycles, but the thing to keep in mind is that any data that is exposed to third parties can be sold and distributed without your knowledge or consent and then be used by disinterested—or outright malicious—actors to de-anonymize your data from other sources, included potentially highly compromising data such as that collected by these period-tracking apps. Data privacy violations have compounding dangers, and should be proactively addressed wherever possible. The more of your personal data exists in the hands of third parties, the more it is to be de-anonymized.
5/6. Targeted misinformation
Data brokers are often incredibly unscrupulous actors, and will sell your data to whomever can afford to buy it, no questions asked. The most high-profile case of the consequences of this is the Facebook—Cambridge Analytica data scandal, wherein the personal data of Facebook users were acquired by Cambridge Analytica Ltd. and compiled alongside information collected from other data brokers. By giving this third-party app permission to acquire their data back in 2015, Meta (then Facebook) also gave the app access to information on their users’ friend networks: this resulted in the data of some 87 million users being collected and exploited.
The data collected by Cambridge Analytica was widely used by political strategists to influence elections and, by and large, undermine democracy around the world: While its parent company SCL had been influencing elections in developing countries for decades, Cambridge Analytica focused more on the United Kingdom and the United States. CEO Alexander Nix said the organization was involved in 44 American political races in 2014. In 2016, they worked for Donald Trump’s presidential campaign as well as for Leave.EU, one of the organisations campaigning for the United Kingdom to leave the European Union.
6/6. The Crux: Right to Privacy Violations
Even if all of the above were not concerns, every internet user should object to being arbitrarily tracked on the basis of their right to privacy. Companies should not be entitled to create and profit from personality profiles about you just because you purchased unrelated products or services from them. This right to user privacy is the central motivation behind laws like the EU’s GDPR and California’s CCPA (see Section 6).
4/7. Refuting Common Responses
1/3. “Why are you so upset? This isn’t a big deal.”
Commenter: Oh, if you’re just talking about third party cookies, that’s not a big deal … Adding a cookie to store that ‘this user clicked on a marketing email from critical role’ is hardly [worth worrying about].
Me: I don’t think you understand what tracking cookies are. They are the digital equivalent of you going to a drive through and someone from the restaurant running out of the store and sticking a GPS monitor onto your car.
Commenter: Kind of. It’s more like slapping a bumper sticker on that says, in restaurant-ese, ‘Hi I’m [name] and I went to [restaurant] once!’
This is actually an accurate correction. My metaphor was admittedly overly simplistic, but the correction specifies only so far as is comfortable for the commenter. If we want to construct a metaphor that is as accurate as possible, it would go something like this:
You drive into the McDonald’s parking lot. As you are pulling in, unbeknownst to you, a Strange Man pops out of a nearby bush (that McDonald’s has allowed him to place here deliberately for this express purpose), and sticks an invisible bumper sticker onto the back of your car. The bumper sticker is a tracker that tells the Strange Man which road you took to drive to McDonald’s, what kind of car you drive, and what (if anything) you ordered from McDonald’s while you were inside. It might also tell him where you parked in the parking lot, what music you were listening to in your car on the way in, which items you looked at on the menu and for how long, if you went to the washroom, which washroom you went into, how long you were in the washroom, and the exact location of every step you took inside the building.
Now, as soon as you leave the McDonald’s, the bumper sticker goes silent and stops being able to report information. But, let’s say next week you decide to go to the Grocery Store, and (again, unbeknownst to you), the Strange Man also has a deal with the Grocery Store. So as you’re driving into the grocery store’s parking lot, he pops out of another bush and goes to put another bumper sticker onto your car. But as he’s doing so, he notices the bumper sticker he’s already placed there a week ago that only he can see (unless you’ve done the car-equivalent of clearing your browser cache), and goes “ah, it’s Consumer #1287499290! I’ll make sure to file all of this new data under my records for Consumer #1287499290!”
You get out of your car and start to walk into the Grocery Store, but before you open the door, the Strange Man whispers to the Grocery Store: “Hey, I know you’re really trying to push your cereal right now, want me to make it more likely that this person buys some cereal from you?” and of course the Grocery Store agrees—this was the whole reason they let him set up that weird parking lot bush in the first place.
So the Strange Man runs around the store rearranging shelves. He doesn’t know your name (all the data he collects is strictly anonymous after all!) but he does know that you chose the cutesy toy for your happy meal at McDonald’s, so he changes all of the cereal packaging labels in the store to be pastel-coloured and covered in fluffy bears and unicorns. And maybe you were already going to the Grocery Store to buy cereal, and maybe you’re actually very happy to buy some cereal in a package that seems to cater specifically to your interests, but wouldn’t you feel at least a little violated if you found out that this whole process occurred without your knowledge? Especially if you felt like you could trust the people who owned the Grocery Store? They’re not really your friend or anything, but maybe you thought that they were compassionate and responsible members of the community, and part of the reason that you shopped at their store was to support that kind of business.
2/3. “Everyone does it, get over it.”
Commenter: [The marketing company working with CR] is an industry standard at this point, particularly for small businesses. Major partner of Shopify, a fairly big player. If you don't have a software development team, using industry standard solutions like these is the easy, safe option.
This sounds reasonable, but it actually makes it worse, not better, that Critical Role and Dropout are doing this. All this excuse tells me is that most businesses using Shopify (or at least the majority of those that use its recommended newsletter service) have a bush for the Strange Man set up in their parking lot.
Contracting with these businesses is certainly the easy option, but it is decidedly not the safe one.
3/3. “They need to do it for marketing reasons.”
Commenter 1: Email marketing tools like [this] use tracking to measure open and click rates. I get why you don’t want to be tracked, but it’s very hard to run a sizeable email newsletter without any user data.
Commenter 2: I work in digital marketing … every single email you get from a company has something similar to this. Guaranteed. This looks totally standard.
I am a web programmer by trade. It is my full time job. Tracking the metrics that Critical Role and Dropout are most likely interested in does not require embedding third-party tracking cookies in their fans’ web browsers. If you feel comfortable taking my word on that, feel free to skip the next section. If you’re skeptical (or if you just want to learn a little bit about how the internet works) please read on.
5/7. Tracking cookies are never necessary
We live in a technocracy. We live in a world in which technology design dictates the rules we live by. We don’t know these people, we didn’t vote for them in office, there was no debate about their design. But yet, the rules that they determine by the design decisions they make—many of them somewhat arbitrary—end up dictating how we will live our lives. —Latanya Sweeney
1/3. Definitions
A website is a combination of 2 computer programs. One of the two programs runs on your computer (laptop/desktop/phone/etc.) and the other runs on another computer somewhere in the world. The program running on your computer is the client program. The program running on the other computer is the server program.
A message sent from the client to the server is a request. A message sent from the server to the client is a response.
Cookies are bits of data that the server sends to the client in a response that the client then sends back to the server as an attachment to its subsequent requests.
A session is a series of sequential interactions between a client and server. When either of the two programs stops running (e.g. when you close a browser tab), the session is ended and any future interactions will take place in a new session.
A URL is a Uniform Resource Locator. You may also sometimes see the initialism URI—in which the ‘I’ stands for Identifier—but they effectively refer to the same thing, which is the place to find a specific thing on the internet. For our purposes, a “link” and a URL mean the same thing.
2/3. What do Critical Role and Dropout want?
These media companies (in my best estimation) are contracting with the digital advertising companies in order to get one or more of the following things:
Customer identity verification (between sessions)
Marketing campaign analytics
Customer preference profiles
Customer behaviour profiles
3/3. How can they get these things without tracking cookies?
Accounts. Dropout has an account system already. As Beacon is a thing now I have to assume Critical Role does as well, therefore this is literally already something they can do without any additional parties getting involved.
URL Query Parameters. So you want to know which of your social media feeds is driving the most traffic to your storefront. You could contract a third-party advertising company to do this for you, but as we have seen this might not be the ideal option. Instead, when posting your links to said feeds, attach a little bit of extra text to the end of the URL link so: becomes or or even These extra bits of information at the end of a URL are query parameters, and act as a way for the client to specify some instructions for the server when sending a request. In effect, a URL with query parameters allows the client to say to the server “I want this thing under these conditions”. The benefit of this approach is, of course, that you actually know precisely what information is being collected (the stuff in the parameters) and precisely what is being done with it, and you’ve avoided exposing any of your user data to third parties.
Internal data collection. Optionally associate a user’s email address with their preferences on the site. Prompt them to do this whenever they purchase anything or do any action that might benefit from having some saved preference, informing them explicitly when you do so and giving them the opportunity to opt-out.
Internal data collection. The same as above, but let the user know you are also tracking their movements while on your site. You can directly track user behaviour down to every single mouse movement if you really want to—again, no need to get an outside party involved to snoop on your fans. But you shouldn’t do that because it’s a little creepy!
At the end of the day, it will of course be more work to set up and maintain these things, and thus it will inevitably be more expensive—but that discrepancy in expense represents profit that these companies are currently making on the basis of violating their fans’ right to privacy.
6/7. Breaking the Law
The data subject shall have the right to object, on grounds relating to his or her particular situation, at any time to processing of personal data concerning him or her [...] The controller shall no longer process the personal data unless the controller demonstrates compelling legitimate grounds for the processing which override the interests, rights and freedoms of the data subject or for the establishment, exercise or defence of legal claims. Where personal data are processed for direct marketing purposes, the data subject shall have the right to object at any time to processing of personal data concerning him or her for such marketing, which includes profiling to the extent that it is related to such direct marketing. Where the data subject objects to processing for direct marketing purposes, the personal data shall no longer be processed for such purposes. At the latest at the time of the first communication with the data subject, the right referred to in paragraphs 1 and 2 shall be explicitly brought to the attention of the data subject and shall be presented clearly and separately from any other information. — General Data Protection Regulation, Art. 21
Nobody wants to break the law and be caught. I am not accusing anyone of anything and this is just my personal speculation on publicly-available information. I am not a lawyer; I merely make computer go beep-boop. If you have any factual corrections for this or any other section in this document please leave a comment and I will update the text with a revision note. Before I try my hand at the legal-adjacent stuff, allow me to wade in with the tech stuff.
Cookies are sometimes good and sometimes bad. Cookies from someone you trust are usually good. Cookies from someone you don’t know are occasionally bad. But you can take proactive measures against bad cookies. You should always default to denying any cookies that go beyond the “essential” or “functional” categorizations on any website of which you are remotely suspicious. Deny as many cookies as possible. Pay attention to what the cookie pop-ups actually say and don’t just click on the highlighted button: it is usually “Accept All”, which means that tracking and advertising cookies are fair game from the moment you click that button onward. It is illegal for companies to arbitrarily provide you a worse service for opting out of being tracked (at least it is in the EU and California).
It is my opinion (and again, I am not a legal professional, just a web developer, so take this with a grain of salt) that the links included in the newsletter emails violate both of these laws. If a user of the email newsletter residing in California or the EU wishes to visit any of the links included in said email without being tracked, they have no way of doing so. None of the actual endpoints are available in the email, effectively forcing the user to go through the third-party domain and submit themselves to being tracked in order to utilize the service they have signed up for. Furthermore, it is impossible to unsubscribe directly from within the email without also submitting to the third-party tracking.

[ID: A screenshot of the unsubscribe button in the CR newsletter alongside the page HTML which shows that the target destination for the anchor element is a trk.klclick.com page. End ID.]
As a brief aside: Opening the links in a private/incognito window is a good idea, but will not completely prevent your actions from being tracked by the advertiser. My recommendation: install uBlock Origin to warn you of tracking domains (it is a completely free and open-source project available on most major web browsers), and do not click on any links in either of these newsletters until they change their practices.
Now, it may be the case that the newsletters are shipped differently to those residing in California or the EU (if you are from either of these regions please feel free to leave a comment on whether or not this is the case), but ask yourself: does that make this any better? Sure, maybe then Critical Role and Dropout (or rather, the advertising companies they contract with) aren’t technically breaking the law, but it shows that the only thing stopping them from exploiting your personal data is potential legal repercussions, rather than any sort of commitment to your right to privacy. But I expect that the emails are not, in fact, shipping any differently in jurisdictions with more advanced privacy legislation—it wouldn’t be the first time a major tech giant blatantly flaunted EU regulations.
Without an additional browser extension such as uBlock Origin, a user clicking on the links in these emails may not even be aware that they have interacted with the advertising agency at all, let alone what sort of information that agency now has pertaining to them, nor do they have any ability to opt out of this data collection.
For more information about your right to privacy—something that only those living in the EU or California currently have—you can read explanations of the legislations at the following links (take note that these links, and all of the links embedded in this paper, are anchored directly to the destinations they purport to be, and do not sneakily pass through an additional domain before redirecting you):
7/7. Conclusion
Never attribute to malice that which can be adequately explained by neglect, ignorance or incompetence. —Hanlon’s Razor
The important thing to make clear here is this: Even if Critical Role and Dropout are not directly selling or exploiting your personal data, they are still profiting off of it by contracting with, and receiving services from, companies whom I believe are. You may not believe me.
I do not believe that the management teams at Critical Role and Dropout are evil or malicious. Ignorance seems to be the most likely cause of this situation. Someone at some marketing company told them that this type of thing was helpful, necessary, and an industry standard, and they had no reason to doubt that person’s word. Maybe that person had no reason to doubt the word of the person who told them. Maybe there are a few people in that chain, maybe quite a few. I do not expect everyone running a company to be an expert in this stuff (hell, I’m nowhere close to being an expert in this stuff myself—I only happened to notice this at all because of a browser extension I just happened to have installed to block ads), but what I do expect is that they change their behaviour when the potential harms of their actions have been pointed out to them, which is why I have taken the time to write this.
PS. To the employees of Critical Role and Dropout
It is my understanding that these corporations were both founded with the intention of being socially responsible alongside turning a profit. By using services like the ones described above, you are, however unintentionally, profiting off of the personal datasets of your fans that are being compiled and exploited without their informed consent. You cannot say, implicitly or explicitly, “We’re not like those other evil companies! We care about more than just extracting as much money from our customers as possible!” while at the same time utilizing these services, and it is my hope that after reading this you will make the responsible choice and stop doing so.
Thank you for reading,
era
Originally Published: 23 May 2024
Last Updated: 28 May 2024
#critical role#dimension 20#dropout#dropout tv#brennan lee mulligan#sam reich#critical role campaign 3#cr3#midst podcast#candela obscura#make some noise#game changer#smarty pants#very important people#web security#data privacy#gdpr#ccpa#open letter
10 notes
·
View notes
Text
Tiện ích Foxyproxy - Cách thêm Proxy vào trình duyệt Firefox & Google Chrome Bằng Foxyproxy
Tiện ích Foxyproxy Standard là gì? Nếu thường xuyên cần thay đổi thông tin IP trên trình duyệt Google Chrome, Firefox, Microsoft Egde, Cốc Cốc.. Chắc hẳn bạn đã không còn xa lạ với các tiện ích đổi IP như: Simple Proxy Switcher, Proxy Helper, Proxy SwitchyOmega,.. trong đó có 1 số tiên ích đã chết đi sống lại nhiều lần vì không tuân thủ các quy định.

Tiện ích Foxyproxy Standard
FoxyProxy là 1 tiện ích giúp đăng nhập và quản lý Proxy có mã nguồn mở và hoàn toàn miễn phí. Tiện ích FoxyProxy hoạt động như một trung gian giữa trình duyệt của người dùng và các trang web bạn truy cập. FoxyProxy thay đổi các trình duyệt gửi yêu cầu đến mạng Internet bằng cách điều hướng lưu lượng qua các máy chủ proxy mà bạn đã cấu hình trước đó.
Nguyên lý hoạt động cơ bản của Tiện ích Foxyproxy
Foxyproxy hoạt động như một trung gian giữa trình duyệt của bạn và các trang web bạn truy cập. Nó thay đổi cách trình duyệt gửi yêu cầu đến mạng Internet bằng phương pháp điều hướng lưu lượng qua các máy chủ Proxy mà bạn đã cấu hình.
Quy trình chuyển hướng thông tin proxy của Foxyproxy
Trình duyệt gửi yêu cầu kết nối: Khi bạn truy cập một trang web, trình duyệt sẽ gửi yêu cầu HTTP/HTTPS/SOCKS tới server của trang đó.
Foxyproxy kiểm tra quy tắc Proxy: Nó sẽ xem yêu cầu đó có khớp với các quy tắc bạn đã cấu hình không (ví dụ: chỉ dùng proxy cho các trang cụ thể hoặc cho tất cả lưu lượng).
Điều hướng lưu lượng qua Proxy:
Nếu yêu cầu khớp với quy tắc, FoxyProxy sẽ gửi yêu cầu đến máy chủ proxy thay vì truy cập trực tiếp trang web.
Máy chủ proxy nhận yêu cầu rồi chuyển tiếp đến trang web đích.
Khi nhận được phản hồi từ trang web, proxy lại gửi dữ liệu trở lại trình duyệt.
Hiển thị kết quả: Bạn sẽ thấy nội dung trang web như bình thường, nhưng thực tế tất cả lưu lượng đã đi qua Proxy.
Tính năng tiện ích Foxyproxy Standard?
Tự động chuyển đổi proxy theo tab trình duyệt, mẫu URL, vùng chứa Firefox, cửa sổ duyệt riêng tư hoặc lựa chọn thủ công từ danh sách thả xuống.
Tùy chỉnh màu sắc và hiển thị cờ quốc gia để dễ dàng nhận biết proxy đang được sử dụng.
Nhập/Xuất toàn bộ cài đặt: hoặc chỉ các mẫu URL để chia sẻ với người khác. Có thể đồng bộ hóa cài đặt proxy với các phiên bản Firefox khác thông qua Firefox Sync.
Hỗ trợ phím tắt giúp chuyển đổi proxy nhanh chóng và thực hiện các thao tác khác một cách tiện lợi.
Cho phép bật/tắt WebRTC để tăng cường bảo mật và ngăn chặn rò rỉ địa chỉ IP.
Tính năng thêm nhanh giúp bổ sung các mẫu URL mới vào cấu hình proxy dễ dàng.
Cho phép loại trừ toàn bộ các trang web khỏi mọi kết nối thông qua proxy.
Trình kiểm tra mẫu URL tích hợp giúp kiểm tra và khắc phục lỗi trong quy tắc định tuyến.
Ghi nhật ký nâng cao hiển thị thông tin về proxy đã sử dụng và thời điểm sử dụng để hỗ trợ gỡ lỗi.
Tải và đăng nhập Proxy vào Foxyproxy trình duyệt Firefox
Chuẩn bị đăng nhập
Thuê Proxy hoặc mua các dịch vụ Proxy từ các nhà cung cấp uy tín.
Tải về ứng dụng tìm kiếm từ khóa "Foxyproxy" trên trình duyệt tải về đúng URL bản chính thức
Đăng nhập Proxy vào ứng dụng Foxyproxy
Bước 1: Truy cập vào tiện ích nhấn chuột trái -> chọn Option
Bước 2: Chọn Import -> chọn Import Proxy List
Bước 3: Nhập/dán định dạng IP:Port:Username:Password vào khung nhập Proxy, sau đó nhấn Import
Bước 4: Chọn giao thức Proxy này chọn HTTP hoặc SOCKS5 tùy vào Proxy của bạn là định dạng nào trong 2 định dạng này. Sau đó nhấn Save
Bước 5: Click chuột trái vào tiện ích -> chọn IP bạn vừa nhập trong danh sách hiểu thị (bên dưới cùng danh sách)
Bước 6: Hoàn thành tạo Task trình duyệt mới nhập truy cập vào trang check IP (có thể sử dụng trang: https://kiemtraip.vn/).
Nếu kết quả trả về đúng IP đã nhập. Chúc mừng bạn đã đăng nhập Proxy thành công, trình duyệt đang sử dụng IP của máy chủ Proxy. 🔥Lưu ý: Khi bạn sử dụng tiện ích này trên trình duyệt Google Chrome cách đăng nhập tương tự với trình duyệt Firefox. Tuy nhiên đối với trình duyệt Firefox tiện ích chưa hỗ trợ giao thức SOCKS5 Proxy. Vì thế khi sử dụng tại Chrome chỉ có thể sử dụng HTTP Proxy.
Bạn có thể theo dõi video hướng dẫn tại kênh youtube chính thức của THUECLOUD.COM dưới đây. https://youtu.be/ffiRUsFlneM
//www.youtube.com/embed/ffiRUsFlneM
Các câu hỏi thường gặp khi sử dụng tiện ích Foxyproxy
👉 Đăng nhập tương tự như hướng dẫn nhưng kiểm tra IP không có kết nối?
Nếu đã đăng nhập đúng không có mạng có thể do kết nối Proxy chưa được tạo. Liên hệ với nhà cung cấp đảm bảo Proxy trong tình trạng kết nối bình thường.
Lấy nhầm cổng (Port Proxy) đảm bảo lấy đúng cổng và chọn đúng cổng HTTP/SOCKS5
👉 Tôi có thể đăng nhập loại Proxy nào trên tiện ích này?
Bạn có thể đăng nhập tất cả các loại Proxy lên tiện ích như: Proxy IPv4 dùng riêng, Proxy dân cư xoay, Proxy dân cư tĩnh. Hoặc các loại Proxy nhà mạng Viettel, Vinaphone, FPT hoặc Mobifone.
👉 Tôi có thể đăng nhập nhiều IP để chuyển đổi IP qua lại tùy lúc không?
Bạn có thể đăng nhập theo List IP có sẵn, sau đó chọn proxy muốn sử dụng trên mục quản lý Proxy tiện ích đã nhập trước đó.
👉 Proxy mất kết nối trình duyệt có tự động sử dụng IP gốc của máy không?
Không, tiện ích giữ nguyên trang thái IP của Proxy không trở về IP gốc của máy tính.
👉 Tắt máy tính bật lại tiện ích có tự động kết nối với Proxy không?
Có, tiện ích kết nối với Proxy liện tục, trừ khi người dùng Disable trên tiện ích.
Kết luận
Trên đây là bài hướng dẫn cách đăng đăng nhập Proxy lên tiện ích FoxyProxy trên trình duyệt Firefox. Với các bước trên bạn hoàn toàn có thể đăng nhập và thay đổi IP cho bất kỳ hồ sơ trình duyệt nào trên máy tính giúp phân luồng điều hướng sử dụng IP 1 cách hợp lý.
Trong quá trình thực hiện nếu gặp lỗi có thể liên hệ với bộ phận CSKH của chúng tôi để được hỗ trợ Free. Ngoài ra đội ngũ tư vấn và giải đáp về các dịch vụ Proxy tại trang web mà THUECLOUD.COM đang cung cấp.
Chúc bạn thành công!
THUECLOUD là dịch vụ cho thuê máy chủ ảo Cloud VPS & PROXY. Chúng tôi cung cấp tất cả các dòng máy chủ ảo VPS, Cloud VPS, GPU Server, Dedicated Server chất lư��ng cao hệ điều hành Windows/Linux.
#Proxy vietnam#Proxy usa#Proxy trình duyệt#proxy tôc do cao#Proxy ipv4 dùng riêng#proxy dancutinh
2 notes
·
View notes
Text
The social network X suffered intermittent outages on Monday, a situation owner Elon Musk attributed to a “massive cyberattack.” Musk said in an initial X post that the attack was perpetrated by “either a large, coordinated group and/or a country.” In a post on Telegram, a pro-Palestinian group known as Dark Storm Team took credit for the attacks within a few hours. Later on Monday, though, Musk claimed in an interview on Fox Business Network that the attacks had come from Ukrainian IP addresses.
Web traffic analysis experts who tracked the incident on Monday were quick to emphasize that the type of attacks X seemed to face—distributed denial-of-service, or DDoS, attacks—are launched by a coordinated army of computers, or a “botnet,” pummeling a target with junk traffic in an attempt to overwhelm and take down its systems. Botnets are typically dispersed around the world, generating traffic with geographically diverse IP addresses, and they can include mechanisms that make it harder to determine where they are controlled from.
“It’s important to recognize that IP attribution alone is not conclusive. Attackers frequently use compromised devices, VPNs, or proxy networks to obfuscate their true origin," says Shawn Edwards, chief security officer of the network connectivity firm Zayo.
X did not return WIRED's requests for comment about the attacks.
Multiple researchers tell WIRED that they observed five distinct attacks of varying length against X's infrastructure, the first beginning early Monday morning with the final burst on Monday afternoon.
The internet intelligence team at Cisco's ThousandEyes tells WIRED in a statement, “During the disruptions, ThousandEyes observed network conditions that are characteristic of a DDoS attack, including significant traffic loss conditions which would have hindered users from reaching the application.”
DDoS attacks are common, and virtually all modern internet services experience them regularly and must proactively defend themselves. As Musk himself put it on Monday, “We get attacked every day.” Why, then, did these DDoS attacks cause outages for X? Musk said it was because “this was done with a lot of resources,” but independent security researcher Kevin Beaumont and other analysts see evidence that some X origin servers, which respond to web requests, weren't properly secured behind the company's Cloudflare DDoS protection and were publicly visible. As a result, attackers could target them directly. X has since secured the servers.
“The botnet was directly attacking the IP and a bunch more on that X subnet yesterday. It's a botnet of cameras and DVRs,” Beaumont says.
A few hours after the final attack concluded, Musk told Fox Business host Larry Kudlow in an interview, “We're not sure exactly what happened, but there was a massive cyberattack to try to bring down the X system with IP addresses originating in the Ukraine area.”
Musk has mocked Ukraine and its president, Volodymyr Zelensky, repeatedly since Russia invaded its neighbor in February 2022. A major campaign donor to President Donald Trump, Musk now heads the so-called Department of Government Efficiency, or DOGE, which has razed the US federal government and its workforce in the weeks since Trump's inauguration. Meanwhile, the Trump administration has recently warmed relations with Russia and moved the US away from its longtime support of Ukraine. Musk has already been involved in these geopolitics in the context of a different company he owns, SpaceX, which operates the satellite internet service Starlink that many Ukrainians rely on.
DDoS traffic analysis can break down the firehose of junk traffic in different ways, including by listing the countries that had the most IP addresses involved in an attack. But one researcher from a prominent firm, who requested anonymity because they are not authorized to speak about X, noted that they did not even see Ukraine in the breakdown of the top 20 IP address origins involved in the X attacks.
If Ukrainian IP addresses did contribute to the attacks, though, numerous researchers say that the fact alone is not noteworthy.
“What we can conclude from the IP data is the geographic distribution of traffic sources, which may provide insights into botnet composition or infrastructure used,” Zayo’s Edwards says. “What we can’t conclude with certainty is the actual perpetrator’s identity or intent.”
6 notes
·
View notes
Text
Web of Light and Shadow Signal Search Details

Dear Proxy, the Exclusive Channel Web of Light and Shadow will soon be available. Signal Search reception rate will be boosted for Evelyn (Attack - Fire)!
[Event Duration]
2025/02/12 12:00:00 (server time) — 2025/03/11 14:59:59 (server time)
[Signal Search Details]
During the event, limited S-Rank Agent Evelyn (Attack - Fire) and A-Rank Agents Anton (Attack - Electric) and Nicole (Support - Ether) have significantly boosted reception rates!
※ The limited S-Rank Agent above will not become available in the Star-Studded Cast Stable Channel.
※ This Channel is an Exclusive Channel. The Search count for guaranteed Signals is cumulative across all Exclusive Channels but is independent of and unaffected by other types of Channels.
※ For more information on Signal Searches, please press Details at the bottom-left of the search page.
The Final Callback - Audition Stage
• Requirements: Reach Inter-Knot Lv. 8, and unlock the Event feature in the Main Story Prologue - Intermission.
• Event Duration: 2025/02/12 12:00:00 (server time) — 2025/03/11 14:59:59 (server time)
• Event Contents: Proxies can try out Agents Evelyn (Attack - Fire), Anton (Attack - Electric), and Nicole (Support - Ether) in audition stages. Upon clearing the stage for the first time, Proxies can claim rewards on the results screen.
>> Official Hoyolab link <<
5 notes
·
View notes
Text
Burp Suite
This week I wanted to cover a powerful tool that assists in web application security. Burp Suite is a well-known tool developed by PortSwigger. Burp Suite is an integrated platform used to test web application security by using a variety of different features it provides. One of these features Burp Suite has is an intercepting proxy that allows you to inspect and modify traffic between the browser and the server at each step. Scanner allows you to automatically detect certain vulnerabilities like SQL injection and cross-site scripting. Intruder automates custom attacks to test certain security parameters, generally passwords. Repeater allows for manual modification and replaying of edited requests for more in-depth testing.
All in all Burp Suite provides a simplified way and process for identifying and discovering vulnerabilities. It has a very user-friendly interface that assists in applying all the different features and makes it easy to learn. It also allows for user consummation that allows users to create custom rules and integrate third-party extensions. It is one of the most renowned tools in cyber security and brings an active and engaging community along with it. Burp Suite I is something I highly recommend to those striving to develop their cyber security skills to get their hands on. Not only will you become more proficient in the tool itself, but it will also teach you about how web applications and servers work.
Source:
2 notes
·
View notes
Text
Progress so far of mobile server (dev log)
So I was successful in turning my old phone into apache web server. The phone had some hardware issue that it always clicked on the screen randomly so I had to maneuverer my way installing Linux and apache into the phone. I had to set up proxies as well to connect to it with the open internet. So far it is working well. Sometimes I have to reroute the connections since it is running over mobile data? I am thinking of getting a dynamic DNS. But I have never tried dynamic DNS before so I am not ready to explore that yet. Plus, I don't know if I would get a static IP from it or a straight away domain name? I mean both are okay, but both have pros and cons of the usage.
Like if I get a static IP , I can run virtual hosts in apache and run multiple websites pointing A record of the domain to the same website.
And lets say if I get a subdomain from the dynamic DNS, I can point CNAME record of the domain to subdomain? But will virtual hosts work with it? I don't know. I suppose it should but it could not work also. Hmm.. lets see, I think I have done this before, apache virtual hosts works with CNAME.
But there is another issue that one of the website runs behind a SOCKS5 proxy, How will I accommodate that? The issue is that, since its Ubuntu running over VM over lineage OS in phone, I can't get low number ports such 80 or 443 so I have to somehow use Dynamic DNS and SOCKS5 proxy to redirect traffic at higher port number.
I mean, I still have oracle VPS running so I may not need virtual hosts in mobile server. So maybe I will venture this when I need it.
I am just wondering whether I should run Docker to run my game server then redirect the traffic with apache virtual hosts, reverse proxy with SOCKS5 proxy? I don't even know if it work. Theoretically it should work.
14 notes
·
View notes