#web scraping and data intelligence
Explore tagged Tumblr posts
Visit Tumblr Blog
Explore Tumblr blogs with no restrictions, modern design and the best experience.
Last Seen Tumblr Blogs





Fun Fact
Kazakhstan’s Minister of Communications and Informatics has blocked the Tumblr site because it contained 60 sites of terrorism, extremism, and pornography in 2015.
Text
How to Start a Dry Fruit Bites Business | Online Demand & Orders

Introduction
The demand for healthy snacks is rising, and dry fruit bites have become a popular choice among health-conscious consumers. If you're considering starting a dry fruit bites business, understanding market demand and tracking online orders is essential. Actowiz Solutions provides data-driven insights to help entrepreneurs analyze trends, customer preferences, and order frequency. In this guide, we’ll explore how to establish a successful dry fruit bites business and leverage online platforms to maximize sales.
Understanding the Market Demand for Dry Fruit Bites

a) Why Dry Fruit Bites Are in Demand
Health-conscious consumers prefer nutrient-rich snacks.
Growing awareness about organic and sugar-free options.
Suitable for fitness enthusiasts, working professionals, and children.
Increasing popularity in India, USA, UAE, UK, and Australia.
b) Market Trends and Growth Analysis
The global healthy snacks market is projected to grow at a CAGR of 6.6%.
E-commerce platforms like Amazon, Flipkart, and health stores report high demand for dry fruit bites.
Seasonal demand spikes during festivals, corporate gifting, and weddings.
Subscription-based snack services are gaining popularity.
How to Start a Dry Fruit Bites Business

a) Sourcing Quality Ingredients
Partner with reliable suppliers of dry fruits (almonds, cashews, dates, walnuts, etc.).
Ensure organic certification and quality testing.
Experiment with flavors like honey-glazed, cocoa-coated, and spice-infused bites.
b) Production & Packaging
Invest in machinery for hygienic and automated production.
Use eco-friendly packaging to attract environmentally conscious buyers.
Display nutritional information and certifications clearly on labels.
c) Setting Up an Online Store
Register on marketplaces like Amazon, Flipkart, BigBasket, and specialty food platforms.
Create your own e-commerce website with SEO-optimized content.
Use high-quality images and detailed product descriptions.
How to Get Daily Online Orders for Dry Fruit Bites

a) Leveraging E-commerce Platforms
Optimize product listings with SEO keywords like “healthy dry fruit snacks” and “organic nut bites.”
Use competitive pricing strategies and offer discounts on bulk purchases.
Ensure prompt delivery with third-party logistics services.
b) Digital Marketing Strategies
i) SEO & Content Marketing
Publish blogs on topics like “Best Healthy Snacks for Weight Loss” and “Nutritional Benefits of Dry Fruit Bites.”
Use SEO keywords like “buy dry fruit bites online,” “best dry fruit snacks,” and “organic fruit bites.”
ii) Social Media & Influencer Marketing
Promote on Instagram, Facebook, and LinkedIn with engaging visuals.
Collaborate with fitness influencers and nutritionists for brand endorsements.
iii) Paid Advertising & Email Campaigns
Run targeted ads on Google Ads and Facebook.
Send promotional emails and newsletters with discounts and new product launches.
How Actowiz Solutions Helps in Market Analysis & Order Tracking

Actowiz Solutions provides real-time data insights for entrepreneurs to track:
Online sales trends and demand forecasting.
Competitor analysis and pricing strategies.
Customer behavior patterns and purchase frequency.
Market penetration strategies using AI-driven data analytics.
With advanced web scraping and data intelligence solutions, Actowiz Solutions helps businesses stay ahead in the competitive snack industry
#data-driven insights#competitive pricing strategies#web scraping and data intelligence#data-backed strategies
0 notes
Text
Block This AI-Tool Account On Fanfiction Dot Net ASAP
If you are still using FFnet like I am, block this AI Tool Account That Pretends to be a Fic Writer who randomly leaves reviews in a very ominous way that bothers me. I got a barrage of emails informing of sudden reviews and follows. Each review is a copypasta, and I felt like my fics were being branded. SO BLOCK IT IS!
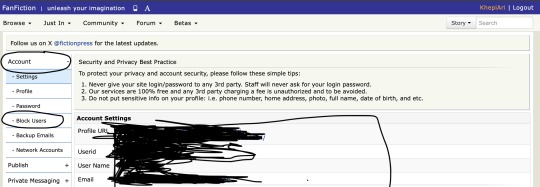
Log in, choose the account option, find the block users option like in the screengrab below, then add this FFId: 16123984 into the slot and select save.
I honestly don't know if this app can data scrape or not, since we don't have an option to lock or private our FFnet accounts, keep blocking anything that you think is suspicious.
Here is the Link to the account. They have one AI-Generated so-called Naruto Fic, which literally has nothing to do with Naruto.
Account ID: 16123984
Account Link:
Share, reblog, amplify!
#ffnet#fanfiction dot net#fanfiction dot hell#AI data scraping#ai tools#ai is theft#data scraping#ai is a plague#fic writing#fic writers#writing for the web#writers on tumblr#writing community#writers#fic writer problems#ao3 writer#ao3 author#fanfiction#fanfic writing#fanfic woes#artificial intelligence
10 notes
·
View notes
Text
Online food delivery apps scraping
3i Data Scraping provides Food ordering data extractor to scrape online food delivery apps like DoorDash, Postmates, goPuff, Seamless, Zomato, Ubereats, Grubhub, Swiggy, etc.

#food delivery app scraping#Extract Food Ordering Apps Data#web scrape food delivery#food delivery app data extraction#Extract food menu details#competitive price intelligence#food ordering data extractor
3 notes
·
View notes
Text
Think Google Maps is just for directions? Think again. Businesses are turning pins into powerful insights from competitor tracking to lead generation. 👉 Read the article to know more: https://shorturl.at/20KM8
#GoogleMapsData #WebScraping #LocationIntelligence #DataDriven #PromptCloud
#google maps#location intelligence#machine learning#big data#artificial intelligence#data driven#web scraping
0 notes
Text
Data or web scraping is the process of automatically extracting information from websites. This typically involves using software tools or scripts to navigate web pages, retrieve data, and store it in a structured format, such as a spreadsheet or database.
#data extraction#pricing intelligence#web scrapping#web scraping tool#web data extraction#data mining#data scraping#web data scraping services#price monitoring
0 notes
Text
Google Search Results Data Scraping

Google Search Results Data Scraping
Harness the Power of Information with Google Search Results Data Scraping Services by DataScrapingServices.com. In the digital age, information is king. For businesses, researchers, and marketing professionals, the ability to access and analyze data from Google search results can be a game-changer. However, manually sifting through search results to gather relevant data is not only time-consuming but also inefficient. DataScrapingServices.com offers cutting-edge Google Search Results Data Scraping services, enabling you to efficiently extract valuable information and transform it into actionable insights.
The vast amount of information available through Google search results can provide invaluable insights into market trends, competitor activities, customer behavior, and more. Whether you need data for SEO analysis, market research, or competitive intelligence, DataScrapingServices.com offers comprehensive data scraping services tailored to meet your specific needs. Our advanced scraping technology ensures you get accurate and up-to-date data, helping you stay ahead in your industry.
List of Data Fields
Our Google Search Results Data Scraping services can extract a wide range of data fields, ensuring you have all the information you need:
-Business Name: The name of the business or entity featured in the search result.
- URL: The web address of the search result.
- Website: The primary website of the business or entity.
- Phone Number: Contact phone number of the business.
- Email Address: Contact email address of the business.
- Physical Address: The street address, city, state, and ZIP code of the business.
- Business Hours: Business operating hours
- Ratings and Reviews: Customer ratings and reviews for the business.
- Google Maps Link: Link to the business’s location on Google Maps.
- Social Media Profiles: LinkedIn, Twitter, Facebook
These data fields provide a comprehensive overview of the information available from Google search results, enabling businesses to gain valuable insights and make informed decisions.
Benefits of Google Search Results Data Scraping
1. Enhanced SEO Strategy
Understanding how your website ranks for specific keywords and phrases is crucial for effective SEO. Our data scraping services provide detailed insights into your current rankings, allowing you to identify opportunities for optimization and stay ahead of your competitors.
2. Competitive Analysis
Track your competitors’ online presence and strategies by analyzing their rankings, backlinks, and domain authority. This information helps you understand their strengths and weaknesses, enabling you to adjust your strategies accordingly.
3. Market Research
Access to comprehensive search result data allows you to identify trends, preferences, and behavior patterns in your target market. This information is invaluable for product development, marketing campaigns, and business strategy planning.
4. Content Development
By analyzing top-performing content in search results, you can gain insights into what types of content resonate with your audience. This helps you create more effective and engaging content that drives traffic and conversions.
5. Efficiency and Accuracy
Our automated scraping services ensure you get accurate and up-to-date data quickly, saving you time and resources.
Best Google Data Scraping Services
Scraping Google Business Reviews
Extract Restaurant Data From Google Maps
Google My Business Data Scraping
Google Shopping Products Scraping
Google News Extraction Services
Scrape Data From Google Maps
Google News Headline Extraction
Google Maps Data Scraping Services
Google Map Businesses Data Scraping
Google Business Reviews Extraction
Best Google Search Results Data Scraping Services in USA
Dallas, Portland, Los Angeles, Virginia Beach, Fort Wichita, Nashville, Long Beach, Raleigh, Boston, Austin, San Antonio, Philadelphia, Indianapolis, Orlando, San Diego, Houston, Worth, Jacksonville, New Orleans, Columbus, Kansas City, Sacramento, San Francisco, Omaha, Honolulu, Washington, Colorado, Chicago, Arlington, Denver, El Paso, Miami, Louisville, Albuquerque, Tulsa, Springs, Bakersfield, Milwaukee, Memphis, Oklahoma City, Atlanta, Seattle, Las Vegas, San Jose, Tucson and New York.
Conclusion
In today’s data-driven world, having access to detailed and accurate information from Google search results can give your business a significant edge. DataScrapingServices.com offers professional Google Search Results Data Scraping services designed to meet your unique needs. Whether you’re looking to enhance your SEO strategy, conduct market research, or gain competitive intelligence, our services provide the comprehensive data you need to succeed. Contact us at [email protected] today to learn how our data scraping solutions can transform your business strategy and drive growth.
Website: Datascrapingservices.com
Email: [email protected]
#Google Search Results Data Scraping#Harness the Power of Information with Google Search Results Data Scraping Services by DataScrapingServices.com. In the digital age#information is king. For businesses#researchers#and marketing professionals#the ability to access and analyze data from Google search results can be a game-changer. However#manually sifting through search results to gather relevant data is not only time-consuming but also inefficient. DataScrapingServices.com o#enabling you to efficiently extract valuable information and transform it into actionable insights.#The vast amount of information available through Google search results can provide invaluable insights into market trends#competitor activities#customer behavior#and more. Whether you need data for SEO analysis#market research#or competitive intelligence#DataScrapingServices.com offers comprehensive data scraping services tailored to meet your specific needs. Our advanced scraping technology#helping you stay ahead in your industry.#List of Data Fields#Our Google Search Results Data Scraping services can extract a wide range of data fields#ensuring you have all the information you need:#-Business Name: The name of the business or entity featured in the search result.#- URL: The web address of the search result.#- Website: The primary website of the business or entity.#- Phone Number: Contact phone number of the business.#- Email Address: Contact email address of the business.#- Physical Address: The street address#city#state#and ZIP code of the business.#- Business Hours: Business operating hours#- Ratings and Reviews: Customer ratings and reviews for the business.
0 notes
Text
Nowadays, Artificial intelligence is the most popular technology. It delivers quality data in many areas, like remote sensing, medical diagnostics, and web data scraping. Deep learning and applications are both parts of the AI concept.
For More Information:-
0 notes
Text
Mastering Data Collection in Machine Learning: A Comprehensive Guide -
Artificial intelligence, mastering the art of data collection is paramount to unlocking the full potential of machine learning algorithms. By adopting systematic methods, overcoming challenges, and adopting best practices, organizations can harness the power of data to drive innovation, gain competitive advantage, and provide transformative solutions across various domains. Through careful data collection, Globose Technology Solutions remains at the forefront of AI innovation, enabling clients to harness the power of data-driven insights for sustainable growth and success.
#Data Collection#Machine Learning#Artificial Intelligence#Data Quality#Data Privacy#Web Scraping#Sensor Data Acquisition#Data Labeling#Bias in Data#Data Analysis#Public Datasets#Data-driven Decision Making#Data Mining#Data Visualization#data collection company#dataset
1 note
·
View note
Text
7 Competitive Intelligence Benefits for e-Commerce Business

E-commerce businesses are used to gathering and analyzing data. This is one of the reasons why they are willing to pay more for analytics software than others.
But what about competitors? How do you know if you are doing better than your rivals? Gathering competitive intelligence is the key to boosting sellers' ROI. It helps you understand your customers, competitors, and the marketplace as a whole. It is a meaningful way to stay one step ahead of the competition.
What Is Competitive Intelligence In E-Commerce?
Competitive intelligence is collecting and using information about your competition to your advantage. It might sound like spying, but it is a prevalent practice used by all companies — even yours!
You can learn from your competitors' successes and mistakes. If you know what they are doing right, you can replicate their success in your own business. And if they're making mistakes, you can avoid them. If you are not already using competitive intelligence, it's time to start. Here are a few reasons why.
#Competitive intelligence#eCommerce Data Scraping#Competitive Pricing Intelligence#web data scraping#mobile app scraping#ecommerce web scraping tool#Data Scraping Services
0 notes
Text
Humans now share the web equally with bots, according to a major new report – as some fear that the internet is dying. In recent months, the so-called “dead internet theory” has gained new popularity. It suggests that much of the content online is in fact automatically generated, and that the number of humans on the web is dwindling in comparison with bot accounts. Now a new report from cyber security company Imperva suggests that it is increasingly becoming true. Nearly half, 49.6 per cent, of all internet traffic came from bots last year, its “Bad Bot Report” indicates. That is up 2 per cent in comparison with last year, and is the highest number ever seen since the report began in 2013. In some countries, the picture is worse. In Ireland, 71 per cent of internet traffic is automated, it said. Some of that rise is the result of the adoption of generative artificial intelligence and large language models. Companies that build those systems use bots scrape the internet and gather data that can then be used to train them. Some of those bots are becoming increasingly sophisticated, Imperva warned. More and more of them come from residential internet connections, which makes them look more legitimate. “Automated bots will soon surpass the proportion of internet traffic coming from humans, changing the way that organizations approach building and protecting their websites and applications,” said Nanhi Singh, general manager for application security at Imperva. “As more AI-enabled tools are introduced, bots will become omnipresent.”
235 notes
·
View notes
Text
Has anyone used SquidgeWorld Archive ( https://squidgeworld.org/ ) to read/post fanfictions ? Apparently it's exactly like Ao3 but with a clear position against AI :

Their Terms of Service state :
7. Added May 13th, 2023: Artificial Intelligence (A.I.) generated works are not supported in the archive. The only exception to this rule would be partial only in posts that are clearly marked meta as part of discussion of said works. Otherwise, no. AI generated works are not welcomed in the archive 8. Added September 24th, 2023: Web scraping by artificial intelligence (AI), or any process of extracting data from the contents of this website for the purpose of use with artificial intelligence (AI) is strictly prohibited. Any data collection, content aggregation, or use of contents on this website in any way for training datasets or machine learning models is expressly prohibited. For more information, contact us via the “Contact Us” section of this website, or via any of the links on other Squidge.org property websites.
It sounds nice ! I love Ao3 but indeed it doesn't mention AI, simply stating that "AI generated works are allowed". So it's good that at least some fanwork websites are addressing the issue ! Hopefully Ao3 will release a clear rule against web scraping / machine learning for all posted works.
Now if you're wondering what is available right now on SqWA, I haven't checked all my favorite tags yet. If you're planning on writing something, maybe give it a go ?? So we'll have more to look forward to !
37 notes
·
View notes
Text
#data-driven insights#competitive pricing strategies#web scraping and data intelligence#data-backed strategies
0 notes
Text
Brazil: Children’s Personal Photos Misused to Power AI Tools
Data Privacy Safeguards Needed to Protect against Exploitation

The personal photos of Brazilian children are being used to create powerful artificial intelligence (AI) tools without the children’s knowledge or consent, Human Rights Watch said today. These photos are being scraped off the web into a large data set that companies then use to train their AI tools. In turn, others are using these tools to create malicious deepfakes that put even more children at risk of exploitation and harm.
“Children should not have to live in fear that their photos might be stolen and weaponized against them,” said Hye Jung Han, children’s rights and technology researcher and advocate at Human Rights Watch. “The government should urgently adopt policies to protect children’s data from AI-fueled misuse.”
Analysis by Human Rights Watch found that LAION-5B, a data set used to train popular AI tools and built by scraping most of the internet, contains links to identifiable photos of Brazilian children. Some children’s names are listed in the accompanying caption or the URL where the image is stored. In many cases, their identities are easily traceable, including information on when and where the child was at the time their photo was taken.
Continue reading.
#brazil#brazilian politics#politics#data rights#artificial intelligence#mod nise da silveira#image description in alt
24 notes
·
View notes
Text
Online food delivery apps scraping
3i Data Scraping provides Food ordering data extractor to scrape online food delivery apps like DoorDash, Postmates, goPuff, Seamless, Zomato, Ubereats, Grubhub, Swiggy, etc.

#food delivery app scraping#Extract Food Ordering Apps Data#web scrape food delivery#food delivery app data extraction#Extract food menu details#competitive price intelligence
1 note
·
View note
Text
Kashmir Hill’s “Your Face Belongs to Us”

This Friday (September 22), I'm (virtually) presenting at the DIG Festival in Modena, Italy. That night, I'll be in person at LA's Book Soup for the launch of Justin C Key's "The World Wasn’t Ready for You." On September 27, I'll be at Chevalier's Books in Los Angeles with Brian Merchant for a joint launch for my new book The Internet Con and his new book, Blood in the Machine.

Your Face Belongs To Us is Kashmir Hill's new tell-all history of Clearview AI, the creepy facial recognition company whose origins are mired in far-right politics, off-the-books police misconduct, sales to authoritarian states and sleazy one-percenter one-upmanship:
https://www.penguinrandomhouse.com/books/691288/your-face-belongs-to-us-by-kashmir-hill/
Hill is a fitting chronicler here. Clearview first rose to prominence – or, rather, notoriety – with the publication of her 2020 expose on the company, which had scraped more than a billion facial images from the web, and then started secretly marketing a search engine for faces to cops, spooks, private security firms, and, eventually, repressive governments:
https://www.nytimes.com/2020/01/18/technology/clearview-privacy-facial-recognition.html
Hill's original blockbuster expose was followed by an in-depth magazine feature and then a string more articles, which revealed the company's origins in white nationalist movements, and the mercurial jourey of its founder, Hoan Ton-That:
https://www.nytimes.com/interactive/2021/03/18/magazine/facial-recognition-clearview-ai.html
The story of Clearview's technology is an interesting one, a story about the machine learning gold-rush where modestly talented technologists who could lay hands on sufficient data could throw it together with off-the-shelf algorithms and do things that had previously been considered impossible. While Clearview has plenty of competitors today, as recently as a couple of years ago, it played like a magic trick.
That's where the more interesting story of Clearview's founding comes in. Hill is a meticulous researcher and had the benefit of a disaffected – and excommunicated – Clearview co-founder, who provided her with masses of internal communications. She also benefited from the court documents from the flurry of lawsuits that Clearview prompted.
What emerges from these primary sources – including multiple interviews with Ton-That – is a story about a move-fast-and-break-things company at the tail end of the forgiveness-not-permission era of technological development. Clearview's founders are violating laws and norms, they're short on cash, and they're racing across the river on the backs of alligators, hoping to reach the riches on the opposite bank without losing a leg.
A decade ago, they might have played as heroes. Today, they're just grifters – bullshitters faking it until they make it, lying to Hill (and getting caught out), and the rest of us. The founders themselves are erratic weirdos, and not the fun kind of weirdos, either. Ton-That – who emigrated to Silicon Valley from Australia as a teenager, seeking a techie's fortune – comes across as a bro-addled dimbulb who threw his lot in with white nationalists, MAGA Republicans, Rudy Guiliani bagmen, Peter Theil, and assorted other tech-adjascent goblins.
Meanwhile, biometrics generally – and facial recognition specifically – is a discipline with a long and sordid history, inextricably entwined with phrenology and eugenics, as Hill describes in a series of interstitial chapters that recount historical attempts to indentify the facial features that correspond with criminality and low intelligence.
These interstitials are woven into a-ha moments from Clearview's history, in which various investors, employees, hangers-on, competitors and customers speculate about how a facial-recognition system could eventually not just recognize criminals, but predict criminality. It's a potent reminder of the AI industry's many overlaps with "race-science" and other quack beliefs.
Hill also describes how Clearview and its competitors' recklessness and arrogance created the openings for shrewd civil libertarians to secure bipartisan support for biometric privacy laws, most notably Illinois' best-of-breed Biometric Information Privacy Act:
https://www.ilga.gov/legislation/ilcs/ilcs3.asp?ActID=3004&ChapterID=57
But by the end of the book, Hill makes the case that Ton-That and his competitors have gotten away with it. Facial recognition is now so easy to build that – she says – we're unlikely to abolish it, despite all the many horrifying ways that FR could fuck up our societies. It's a sobering conclusion, and while Hill holds out some hope for curbing the official use of FR, she seems resigned to a future in which – for example – creepy guys covertly snap photos of women on the street, use those pictures to figure out their names and addresses, and then stalk and harass them.
If she's right, this is Ton-That's true legacy, and the legacy of the funders who handed him millions to spend building this. Perhaps someone else would have stepped into that sweaty, reckless-grifter-shaped hole if Ton-That hadn't been there to fill it, but in our timeline, we can say that Ton-That was the bumbler who helped destroy something precious.

If you'd like an essay-formatted version of this post to read or share, here's a link to it on pluralistic.net, my surveillance-free, ad-free, tracker-free blog:
https://pluralistic.net/2023/09/20/steal-your-face/#hoan-ton-that
#pluralistic#books#reviews#gift guide#clearview ai#facial recognition#biometrics#eugenics#crime#privacy#cop shit#hoan ton-that
84 notes
·
View notes
Text
Connecting the dots of recent research suggests a new future for traditional websites:
Artificial Intelligence (AI)-powered search can provide a full answer to a user’s query 75% of the time without the need for the user to go to a website, according to research by The Atlantic.
A worldwide survey from the University of Toronto revealed that 22% of ChatGPT users “use it as an alternative to Google.”
Research firm Gartner forecasts that traffic to the web from search engines will fall 25% by 2026.
Pew Research found that a quarter of all web pages developed between 2013 and 2023 no longer exist.
The large language models (LLMs) of generative AI that scraped their training data from websites are now using that data to eliminate the need to go to many of those same websites. Respected digital commentator Casey Newton concluded, “the web is entering a state of managed decline.” The Washington Post headline was more dire: “Web publishers brace for carnage as Google adds AI answers.”
From decentralized information to centralized conclusions
Created by Sir Tim Berners-Lee in 1989, the World Wide Web redefined the nature of the internet into a user-friendly linkage of diverse information repositories. “The first decade of the web…was decentralized with a long-tail of content and options,” Berners-Lee wrote this year on the occasion of its 35th anniversary. Over the intervening decades, that vision of distributed sources of information has faced multiple challenges. The dilution of decentralization began with powerful centralized hubs such as Facebook and Google that directed user traffic. Now comes the ultimate disintegration of Berners-Lee’s vision as generative AI reduces traffic to websites by recasting their information.
The web’s open access to the world’s information trained the large language models (LLMs) of generative AI. Now, those generative AI models are coming for their progenitor.
The web allowed users to discover diverse sources of information from which to draw conclusions. AI cuts out the intellectual middleman to go directly to conclusions from a centralized source.
The AI paradigm of cutting out the middleman appears to have been further advanced in Apple’s recent announcement that it will incorporate OpenAI to enable its Siri app to provide ChatGPT-like answers. With this new deal, Apple becomes an AI-based disintermediator, not only eliminating the need to go to websites, but also potentially disintermediating the need for the Google search engine for which Apple has been paying $20 billion annually.
The Atlantic, University of Toronto, and Gartner studies suggest the Pew research on website mortality could be just the beginning. Generative AI’s ability to deliver conclusions cannibalizes traffic to individual websites threatening the raison d’être of all websites, especially those that are commercially supported.
Echoes of traditional media and the web
The impact of AI on the web is an echo of the web’s earlier impact on traditional information providers. “The rise of digital media and technology has transformed the way we access our news and entertainment,” the U.S. Census Bureau reported in 2022, “It’s also had a devastating impact on print publishing industries.” Thanks to the web, total estimated weekday circulation of U.S. daily newspapers fell from 55.8 million in 2000 to 24.2 million by 2020, according to the Pew Research Center.
The World Wide Web also pulled the rug out from under the economic foundation of traditional media, forcing an exodus to proprietary websites. At the same time, it spawned a new generation of upstart media and business sites that took advantage of its low-cost distribution and high-impact reach. Both large and small websites now feel the impact of generative AI.
Barry Diller, CEO of media owner IAC, harkened back to that history when he warned a year ago, “We are not going to let what happened out of free internet happen to post-AI internet if we can help it.” Ominously, Diller observed, “If all the world’s information is able to be sucked up in this maw, and then essentially repackaged in declarative sentence in what’s called chat but isn’t chat…there will be no publishing; it is not possible.”
The New York Times filed a lawsuit against OpenAI and Microsoft alleging copyright infringement from the use of Times data to train LLMs. “Defendants seek to free-ride on The Times’s massive investment in its journalism,” the suit asserts, “to create products that substitute for The Times and steal audiences away from it.”1
Subsequently, eight daily newspapers owned by Alden Global Capital, the nation’s second largest newspaper publisher, filed a similar suit. “We’ve spent billions of dollars gathering information and reporting news at our publications, and we can’t allow OpenAI and Microsoft to expand the Big Tech playbook of stealing our work to build their own businesses at our expense,” a spokesman explained.
The legal challenges are pending. In a colorful description of the suits’ allegations, journalist Hamilton Nolan described AI’s threat as an “Automated Death Star.”
“Providential opportunity”?
Not all content companies agree. There has been a groundswell of leading content companies entering into agreements with OpenAI.
In July 2023, the Associated Press became the first major content provider to license its archive to OpenAI. Recently, however, the deal-making floodgates have opened. Rupert Murdoch’s News Corp, home of The Wall Street Journal, New York Post, and multiple other publications in Australia and the United Kingdom, German publishing giant Axel Springer, owner of Politico in the U.S. and Bild and Welt in Germany, venerable media company The Atlantic, along with new media company Vox Media, the Financial Times, Paris’ Le Monde, and Spain’s Prisa Media have all contracted with OpenAI for use of their product.
Even Barry Diller’s publishing unit, Dotdash Meredith, agreed to license to OpenAI, approximately a year after his apocalyptic warning.
News Corp CEO Robert Thomson described his company’s rationale this way in an employee memo: “The digital age has been characterized by the dominance of distributors, often at the expense of creators, and many media companies have been swept away by a remorseless technological tide. The onus is now on us to make the most of this providential opportunity.”
“There is a premium for premium journalism,” Thomson observed. That premium, for News Corp, is reportedly $250 million over five years from OpenAI. Axel Springer’s three-year deal is reportedly worth $25 to $30 million. The Financial Times terms were reportedly in the annual range of $5 to $10 million.
AI companies’ different approaches
While publishers debate whether AI is “providential opportunity” or “stealing our work,” a similar debate is ongoing among AI companies. Different generative AI companies have different opinions whether to pay for content, and if so, which kind of content.
When it comes to scraping information from websites, most of the major generative AI companies have chosen to interpret copyright law’s “fair use doctrine” allowing the unlicensed use of copyrighted content in certain circumstances. Some of the companies have even promised to indemnify their users if they are sued for copyright infringement.
Google, whose core business is revenue generated by recommending websites, has not sought licenses to use the content on those websites. “The internet giant has long resisted calls to compensate media companies for their content, arguing that such payments would undermine the nature of the open web,” the New York Times explained. Google has, however, licensed the user-generated content on social media platform Reddit, and together with Meta has pursued Hollywood rights.
OpenAI has followed a different path. Reportedly, the company has been pitching a “Preferred Publisher Program” to select content companies. Industry publication AdWeek reported on a leaked presentation deck describing the program. The publication said OpenAI “disputed the accuracy of the information” but claimed to have confirmed it with four industry executives. Significantly, the OpenAI pitch reportedly offered not only cash remuneration, but also other benefits to cooperating publishers.
As of early June 2024, other large generative AI companies have not entered into website licensing agreements with publishers.
Content companies surfing an AI tsunami
On the content creation side of the equation, major publishers are attempting to avoid a repeat of their disastrous experience in the early days of the web while smaller websites are fearful the impact on them could be even greater.
As the web began to take business from traditional publishers, their leadership scrambled to find a new economic model. Ultimately, that model came to rely on websites, even though website advertising offered them pennies on their traditional ad dollars. Now, even those assets are under attack by the AI juggernaut. The content companies are in a new race to develop an alternative economic model before their reliance on web search is cannibalized.
The OpenAI Preferred Publisher Program seems to be an attempt to meet the needs of both parties.
The first step in the program is direct compensation. To Barry Diller, for instance, the fact his publications will get “direct compensation for our content” means there is “no connection” between his apocalyptic warning 14 months ago and his new deal with OpenAI.
Reportedly, the cash compensation OpenAI is offering has two components: “guaranteed value” and “variable value.” Guaranteed value is compensation for access to the publisher’s information archive. Variable value is payment based on usage of the site’s information.
Presumably, those signing with OpenAI see it as only the first such agreement. “It is in my interest to find agreements with everyone,” Le Monde CEO Louis Dreyfus explained.
But the issue of AI search is greater than simply cash. Atlantic CEO Nicolas Thompson described the challenge: “We believe that people searching with AI models will be one of the fundamental ways that people navigate to the web in the future.” Thus, the second component in OpenAI’s proposal to publishers appears to be promotion of publisher websites within the AI-generated content. Reportedly, when certain publisher content is utilized, there will be hyperlinks and hover links to the websites themselves, in addition to clickable buttons to the publisher.
Finally, the proposal reportedly offers publishers the opportunity to reshape their business using generative AI technology. Such tools include access to OpenAI content for the publishers’ use, as well as the use of OpenAI for writing stories and creating new publishing content.
Back to the future?
Whether other generative AI and traditional content companies embrace this kind of cooperation model remains to be seen. Without a doubt, however, the initiative by both parties will have its effects.
One such effect was identified in a Le Monde editorial explaining their licensing agreement with OpenAI. Such an agreement, they argued, “will make it more difficult for other AI platforms to evade or refuse to participate.” This, in turn, could have an impact on the copyright litigation, if not copyright law.
We have seen new technology-generated copyright issues resolved in this way before.2 Finding a credible solution that works for both sides is imperative. The promise of AI is an almost boundless expansion of information and the knowledge it creates. At the same time, AI cannot be a continued degradation of the free flow of ideas and journalism that is essential for democracy to function.
Newton’s Law in the AI age
In 1686 Sir Isaac Newton posited his three laws of motion. The third of these holds that for every action there is an equal and opposite reaction. Newton described the consequence of physical activity; generative AI is raising the same consequential response for informational activity.
The threat of generative AI has pushed into the provision of information and the economics of information companies. We know the precipitating force, the consequential effects on the creation of content and free flow of information remain a work in progress.
13 notes
·
View notes