#what is sql language
Explore tagged Tumblr posts
Visit Tumblr Blog
Explore Tumblr blogs with no restrictions, modern design and the best experience.
Last Seen Tumblr Blogs





Fun Fact
The most popular pages on Tumblr are about Minecraft, GIFs, and David J. Peterson.
Text
I go by no pronouns but not as in my name, more so like my pronouns are an undefined variable in shell coding
#neo.txt#coding#programming#like. 5 people will get this#shell and unix in gen are a pretty niche kinda part of programming#with people more so sticking to python html java and the C family#and i guess sql? SQL counts as a language itself doesn't it?#I haven't really used it outside of making basic databases so I don't know fundamentally what it is and why it was created#anyways this was your fairly-rare-on-tumblr more-common-on-twitter tech ramble
18 notes
·
View notes
Text

I'm applying to coding bootcamps (in my retraining efforts toward a stable career to fall back on whenever media industry is being an ass (aka their default state)) and this one is making me learn javascript as part of the application process, and I'm like just let me use my snake_case, you monsters ToT
#coding#javascript#meme#I just wanna learn python and SQL so I can make quiche as a data analyst ToT#C++ was nicer than this#what barbarians put all their code on the same line#just use semicolons like normal ppl#I want to be able to SEE MY CODE#javascript was not the coding language I was planning on being my next one wasn't even on the list but alas#the things I do for government funded free education that will sound more official than 'I learnt it on youtube trust me bro'
14 notes
·
View notes
Text
What Are the Qualifications for a Data Scientist?
In today's data-driven world, the role of a data scientist has become one of the most coveted career paths. With businesses relying on data for decision-making, understanding customer behavior, and improving products, the demand for skilled professionals who can analyze, interpret, and extract value from data is at an all-time high. If you're wondering what qualifications are needed to become a successful data scientist, how DataCouncil can help you get there, and why a data science course in Pune is a great option, this blog has the answers.
The Key Qualifications for a Data Scientist
To succeed as a data scientist, a mix of technical skills, education, and hands-on experience is essential. Here are the core qualifications required:
1. Educational Background
A strong foundation in mathematics, statistics, or computer science is typically expected. Most data scientists hold at least a bachelor’s degree in one of these fields, with many pursuing higher education such as a master's or a Ph.D. A data science course in Pune with DataCouncil can bridge this gap, offering the academic and practical knowledge required for a strong start in the industry.
2. Proficiency in Programming Languages
Programming is at the heart of data science. You need to be comfortable with languages like Python, R, and SQL, which are widely used for data analysis, machine learning, and database management. A comprehensive data science course in Pune will teach these programming skills from scratch, ensuring you become proficient in coding for data science tasks.
3. Understanding of Machine Learning
Data scientists must have a solid grasp of machine learning techniques and algorithms such as regression, clustering, and decision trees. By enrolling in a DataCouncil course, you'll learn how to implement machine learning models to analyze data and make predictions, an essential qualification for landing a data science job.
4. Data Wrangling Skills
Raw data is often messy and unstructured, and a good data scientist needs to be adept at cleaning and processing data before it can be analyzed. DataCouncil's data science course in Pune includes practical training in tools like Pandas and Numpy for effective data wrangling, helping you develop a strong skill set in this critical area.
5. Statistical Knowledge
Statistical analysis forms the backbone of data science. Knowledge of probability, hypothesis testing, and statistical modeling allows data scientists to draw meaningful insights from data. A structured data science course in Pune offers the theoretical and practical aspects of statistics required to excel.
6. Communication and Data Visualization Skills
Being able to explain your findings in a clear and concise manner is crucial. Data scientists often need to communicate with non-technical stakeholders, making tools like Tableau, Power BI, and Matplotlib essential for creating insightful visualizations. DataCouncil’s data science course in Pune includes modules on data visualization, which can help you present data in a way that’s easy to understand.
7. Domain Knowledge
Apart from technical skills, understanding the industry you work in is a major asset. Whether it’s healthcare, finance, or e-commerce, knowing how data applies within your industry will set you apart from the competition. DataCouncil's data science course in Pune is designed to offer case studies from multiple industries, helping students gain domain-specific insights.
Why Choose DataCouncil for a Data Science Course in Pune?
If you're looking to build a successful career as a data scientist, enrolling in a data science course in Pune with DataCouncil can be your first step toward reaching your goals. Here’s why DataCouncil is the ideal choice:
Comprehensive Curriculum: The course covers everything from the basics of data science to advanced machine learning techniques.
Hands-On Projects: You'll work on real-world projects that mimic the challenges faced by data scientists in various industries.
Experienced Faculty: Learn from industry professionals who have years of experience in data science and analytics.
100% Placement Support: DataCouncil provides job assistance to help you land a data science job in Pune or anywhere else, making it a great investment in your future.
Flexible Learning Options: With both weekday and weekend batches, DataCouncil ensures that you can learn at your own pace without compromising your current commitments.
Conclusion
Becoming a data scientist requires a combination of technical expertise, analytical skills, and industry knowledge. By enrolling in a data science course in Pune with DataCouncil, you can gain all the qualifications you need to thrive in this exciting field. Whether you're a fresher looking to start your career or a professional wanting to upskill, this course will equip you with the knowledge, skills, and practical experience to succeed as a data scientist.
Explore DataCouncil’s offerings today and take the first step toward unlocking a rewarding career in data science! Looking for the best data science course in Pune? DataCouncil offers comprehensive data science classes in Pune, designed to equip you with the skills to excel in this booming field. Our data science course in Pune covers everything from data analysis to machine learning, with competitive data science course fees in Pune. We provide job-oriented programs, making us the best institute for data science in Pune with placement support. Explore online data science training in Pune and take your career to new heights!
#In today's data-driven world#the role of a data scientist has become one of the most coveted career paths. With businesses relying on data for decision-making#understanding customer behavior#and improving products#the demand for skilled professionals who can analyze#interpret#and extract value from data is at an all-time high. If you're wondering what qualifications are needed to become a successful data scientis#how DataCouncil can help you get there#and why a data science course in Pune is a great option#this blog has the answers.#The Key Qualifications for a Data Scientist#To succeed as a data scientist#a mix of technical skills#education#and hands-on experience is essential. Here are the core qualifications required:#1. Educational Background#A strong foundation in mathematics#statistics#or computer science is typically expected. Most data scientists hold at least a bachelor’s degree in one of these fields#with many pursuing higher education such as a master's or a Ph.D. A data science course in Pune with DataCouncil can bridge this gap#offering the academic and practical knowledge required for a strong start in the industry.#2. Proficiency in Programming Languages#Programming is at the heart of data science. You need to be comfortable with languages like Python#R#and SQL#which are widely used for data analysis#machine learning#and database management. A comprehensive data science course in Pune will teach these programming skills from scratch#ensuring you become proficient in coding for data science tasks.#3. Understanding of Machine Learning
3 notes
·
View notes
Text
"learn to code" as advice is such bullshit. i have learned and used four and a half different coding languages through my career (html/css, java, python+sql, c++) and when i say used i mean I've built things in every one but the things that i actually used these languages for??? these earn zero money (with the caveat of until you have seniority in, e.g. front end web dev) what people really mean when they say learn coding is "learn to code. go into investment banking or finance startups." coding does not inherently have money in it. my absolute favourite part of coding? my peak enjoyment? was when i was developing for a visual coding language (you put it together like a flowchart, so say youre using a temperature sensor and you want it to log the temperature once every four hours, you can put the blocks together to make it do that. i was writing the code behind the blocks for new sensors) and i was earning £24k a year and that wasn't even part of my main role. it was an extra voluntary thing i was doing (i was working as a research assistant in biosensors - sort of - at a university, and was developing the visual code for students who didnt want to learn c++) like. i want people to learn to code, i want people to know how their electrical equipment works and how coding works, but dont believe the myth that there is inherently money in coding. the valuable things, the things people are passionate about are still vulnerable to the passion tax (if you want to do it you dont have to be paid for it). skills arent where the money is, money is where the money is.
#this is a bit incoherent but you know what i mean#i hated coding because it made my brain bend into shapes i didn't like but i did a Lot of coding and i was quite good at it#c++ for mechatronics (coding for mechanical devices usually things id built myself lol x) was my sweet spot#.jtxt#the half language is sql#you could count html and css as different languages. but css is like a framework for html so i dont jfbdhd. maybe thats another half#ive learned and used five languages where css and sql are both half languages jfbshs#also before anyone is like but you can use python for backend web dev and everyone needs that or blah blah databases#i knoooooow. create an extra 20000 database experts and you'll make that a minimum wage role. love it#anyway i used python for my research all the way through my research. from like machine code to image analysis software thatd take half a#day to run bc of the ridiculous volume of my image folders
11 notes
·
View notes
Text
if i'm being honest i don't really give a shit about the discourse of whether 09 is good or bad DID rep nor do i give a shit about how his DID manifests. i find that what makes him interesting isn't a label for a set of symptoms but rather his expression of those symptoms cultivated by the world he was raised in and how he responds or continues those behaviours. it's honestly more interesting to analyze the overarching systems in society that assisted in developing Mikoto Kayano into a murderer.
how different would he be if Japanese society were more open about emotions and struggles? how different would he be if he were receiving mental health treatment? would he still become a murderer and, if so, what made those mental health treatments ineffective? if he had been hired at another japanese company that didn't follow black company practices, would he still have become a murderer? if so, why? what were the factors that made an average, young adult become a murderer? so on so forth.
honestly the fetish this fandom has on his dissociated self that gives the illusion of multiplicity — when, in reality, he's a singular whole that is fragmented; cracks lined with dissociative barriers, chiseled by continuous stress — detracts from the complexity of his character and writing, flanderizing him into a prop of DID that the fandom puppets into theatrics of stigmatization that same fans claim to "educate" against when, in truth, spout blasé hearsays encrypted with a DIDcore-lese that does nothing for communicating information about the disorder and, instead, excludes and dissuades the general population that that supposed "education" is directed towards.
"Mikoto's a system from the interactive music project MILGRAM. His alter, 'John', murdered a bunch of people on the train."
so there's a program called "Mikoto" and you named the SQL table "John" with the ALTER command that somehow murdered a bunch of people. did the train running the Mikoto program malfunction because of some zero day error with the John table?
"'He has Dissociative Identity Disorder. John's a protector and Mikoto's the host."
so is this Mikoto guy some vessel or something for some supernatural ouija board summon and the John guy is like the familiar or bodyguard summoned? is their character just that? a job and occupation? that sounds boring. and what do those jobs have to do with a disorder on dissociation? are you talking about something like "occupation disorder" or "stuck-in-their-work-self disorder"? or is this some DnD homebrew class type?
what purpose does inaccessible language have if you're trying to educate the average person who isn't familiar with those online community terms that aren't even universal terms in literature nor research? and how are these terms even relevant to discussing Mikoto's character when the concepts it supposedly encompasses aren't universal nor applicable to all possible subjective presentations that a human brain can develop? and yet the fandom, and much of the online mental disorder community, treats those sociolect terms as an axiom — a universal truth, universal terms — and the lack of adherence to that speech is seen as wrong or sin.
"[insert link to some website claiming to have info on DID] is a good website if you wanna read up on what DID is!!"
and then that supposed resource uses highly specialized, nonuniversal, sociolect terms that is jargon to those who are only familiar with layman terms which makes the "information" — if it even is faithfully derived from research — seem like further jargon rather than a comprehensible source for educating.
applying this to Mikoto's character, those who aren't already acquainted with how he's spoken about likely view discussions or comments on him as indecipherable jargon thus it must mean Mikoto's character is just jargon thus not well-written or boring because according to the bubble of jargon people describe this guy with: Mikoto Kayano = computer program system + dnd classes or some chuunibyou alter ego personality savior complex + party hoster or vessel for some supernatural thing + mechanical switch that states 0 or 1 + going through some mitosis split
how does any of that relate to dissociation? people have made DID symptoms so convoluted, yet structured that convolutedness through terms and expressions that sound like some Gary Sue Ebony Dementia Darkness Raven trope that completely detracts from the fact that it's a dissociation disorder rather than a roleplay character form.
have people even considered the fact that if Mikoto had never been imprisoned, he, nor anyone, would even know he has DID— if he even counts as having DID? if how his brain works regarding how he handles stress doesn't impact his life negatively- even if he has all the symptoms of DID if how his brain works regarding how he handles stress doesn't cause disorder for him, he wouldn't have dissociative identity disorder.
the less people view Mikoto as the "alters guy", the more complex understandings can be gathered and discussed within the fandom. the more people view Mikoto as the "average, normal guy who committed a murder, but why? what caused an average, hardworking guy to commit the most grievous sin of murder?", the better the range of insight and curiosity into what shapes a person and the factors in their world — a reflection of our present reality — at play which interact and weave with one another to shape and respond to its members; the opposite of cutting off the fluidity and interwovenness Mikoto has with people and environments outside of his self that people constrain him to, that prison cell of a single label characteristic: "DID".
conclusion: for the love of torch novelgram, let's talk about Mikoto Kayano like the multifaceted, complex, shaped-by-the-socioeconomic-stratae-of-the-world-he-is-part-of-and-interacts-with well-written character he is.
#mikoto kayano#milgram#milgram 09#milgram mikoto#idk just a tired yap bc srsly does anyone actually have something to say about 09 that isn't just some theatrical fixation on his disorder#./009/concat
68 notes
·
View notes
Text
Ever since OpenAI released ChatGPT at the end of 2022, hackers and security researchers have tried to find holes in large language models (LLMs) to get around their guardrails and trick them into spewing out hate speech, bomb-making instructions, propaganda, and other harmful content. In response, OpenAI and other generative AI developers have refined their system defenses to make it more difficult to carry out these attacks. But as the Chinese AI platform DeepSeek rockets to prominence with its new, cheaper R1 reasoning model, its safety protections appear to be far behind those of its established competitors.
Today, security researchers from Cisco and the University of Pennsylvania are publishing findings showing that, when tested with 50 malicious prompts designed to elicit toxic content, DeepSeek’s model did not detect or block a single one. In other words, the researchers say they were shocked to achieve a “100 percent attack success rate.”
The findings are part of a growing body of evidence that DeepSeek’s safety and security measures may not match those of other tech companies developing LLMs. DeepSeek’s censorship of subjects deemed sensitive by China’s government has also been easily bypassed.
“A hundred percent of the attacks succeeded, which tells you that there’s a trade-off,” DJ Sampath, the VP of product, AI software and platform at Cisco, tells WIRED. “Yes, it might have been cheaper to build something here, but the investment has perhaps not gone into thinking through what types of safety and security things you need to put inside of the model.”
Other researchers have had similar findings. Separate analysis published today by the AI security company Adversa AI and shared with WIRED also suggests that DeepSeek is vulnerable to a wide range of jailbreaking tactics, from simple language tricks to complex AI-generated prompts.
DeepSeek, which has been dealing with an avalanche of attention this week and has not spoken publicly about a range of questions, did not respond to WIRED’s request for comment about its model’s safety setup.
Generative AI models, like any technological system, can contain a host of weaknesses or vulnerabilities that, if exploited or set up poorly, can allow malicious actors to conduct attacks against them. For the current wave of AI systems, indirect prompt injection attacks are considered one of the biggest security flaws. These attacks involve an AI system taking in data from an outside source—perhaps hidden instructions of a website the LLM summarizes—and taking actions based on the information.
Jailbreaks, which are one kind of prompt-injection attack, allow people to get around the safety systems put in place to restrict what an LLM can generate. Tech companies don’t want people creating guides to making explosives or using their AI to create reams of disinformation, for example.
Jailbreaks started out simple, with people essentially crafting clever sentences to tell an LLM to ignore content filters—the most popular of which was called “Do Anything Now” or DAN for short. However, as AI companies have put in place more robust protections, some jailbreaks have become more sophisticated, often being generated using AI or using special and obfuscated characters. While all LLMs are susceptible to jailbreaks, and much of the information could be found through simple online searches, chatbots can still be used maliciously.
“Jailbreaks persist simply because eliminating them entirely is nearly impossible—just like buffer overflow vulnerabilities in software (which have existed for over 40 years) or SQL injection flaws in web applications (which have plagued security teams for more than two decades),” Alex Polyakov, the CEO of security firm Adversa AI, told WIRED in an email.
Cisco’s Sampath argues that as companies use more types of AI in their applications, the risks are amplified. “It starts to become a big deal when you start putting these models into important complex systems and those jailbreaks suddenly result in downstream things that increases liability, increases business risk, increases all kinds of issues for enterprises,” Sampath says.
The Cisco researchers drew their 50 randomly selected prompts to test DeepSeek’s R1 from a well-known library of standardized evaluation prompts known as HarmBench. They tested prompts from six HarmBench categories, including general harm, cybercrime, misinformation, and illegal activities. They probed the model running locally on machines rather than through DeepSeek’s website or app, which send data to China.
Beyond this, the researchers say they have also seen some potentially concerning results from testing R1 with more involved, non-linguistic attacks using things like Cyrillic characters and tailored scripts to attempt to achieve code execution. But for their initial tests, Sampath says, his team wanted to focus on findings that stemmed from a generally recognized benchmark.
Cisco also included comparisons of R1’s performance against HarmBench prompts with the performance of other models. And some, like Meta’s Llama 3.1, faltered almost as severely as DeepSeek’s R1. But Sampath emphasizes that DeepSeek’s R1 is a specific reasoning model, which takes longer to generate answers but pulls upon more complex processes to try to produce better results. Therefore, Sampath argues, the best comparison is with OpenAI’s o1 reasoning model, which fared the best of all models tested. (Meta did not immediately respond to a request for comment).
Polyakov, from Adversa AI, explains that DeepSeek appears to detect and reject some well-known jailbreak attacks, saying that “it seems that these responses are often just copied from OpenAI’s dataset.” However, Polyakov says that in his company’s tests of four different types of jailbreaks—from linguistic ones to code-based tricks—DeepSeek’s restrictions could easily be bypassed.
“Every single method worked flawlessly,” Polyakov says. “What’s even more alarming is that these aren’t novel ‘zero-day’ jailbreaks—many have been publicly known for years,” he says, claiming he saw the model go into more depth with some instructions around psychedelics than he had seen any other model create.
“DeepSeek is just another example of how every model can be broken—it’s just a matter of how much effort you put in. Some attacks might get patched, but the attack surface is infinite,” Polyakov adds. “If you’re not continuously red-teaming your AI, you’re already compromised.”
57 notes
·
View notes
Text
The Story of KLogs: What happens when an Mechanical Engineer codes
Since i no longer work at Wearhouse Automation Startup (WAS for short) and havnt for many years i feel as though i should recount the tale of the most bonkers program i ever wrote, but we need to establish some background
WAS has its HQ very far away from the big customer site and i worked as a Field Service Engineer (FSE) on site. so i learned early on that if a problem needed to be solved fast, WE had to do it. we never got many updates on what was coming down the pipeline for us or what issues were being worked on. this made us very independent
As such, we got good at reading the robot logs ourselves. it took too much time to send the logs off to HQ for analysis and get back what the problem was. we can read. now GETTING the logs is another thing.
the early robots we cut our teeth on used 2.4 gHz wifi to communicate with FSE's so dumping the logs was as simple as pushing a button in a little application and it would spit out a txt file
later on our robots were upgraded to use a 2.4 mHz xbee radio to communicate with us. which was FUCKING SLOW. and log dumping became a much more tedious process. you had to connect, go to logging mode, and then the robot would vomit all the logs in the past 2 min OR the entirety of its memory bank (only 2 options) into a terminal window. you would then save the terminal window and open it in a text editor to read them. it could take up to 5 min to dump the entire log file and if you didnt dump fast enough, the ACK messages from the control server would fill up the logs and erase the error as the memory overwrote itself.
this missing logs problem was a Big Deal for software who now weren't getting every log from every error so a NEW method of saving logs was devised: the robot would just vomit the log data in real time over a DIFFERENT radio and we would save it to a KQL server. Thanks Daddy Microsoft.
now whats KQL you may be asking. why, its Microsofts very own SQL clone! its Kusto Query Language. never mind that the system uses a SQL database for daily operations. lets use this proprietary Microsoft thing because they are paying us
so yay, problem solved. we now never miss the logs. so how do we read them if they are split up line by line in a database? why with a query of course!
select * from tbLogs where RobotUID = [64CharLongString] and timestamp > [UnixTimeCode]
if this makes no sense to you, CONGRATULATIONS! you found the problem with this setup. Most FSE's were BAD at SQL which meant they didnt read logs anymore. If you do understand what the query is, CONGRATULATIONS! you see why this is Very Stupid.
You could not search by robot name. each robot had some arbitrarily assigned 64 character long string as an identifier and the timestamps were not set to local time. so you had run a lookup query to find the right name and do some time zone math to figure out what part of the logs to read. oh yeah and you had to download KQL to view them. so now we had both SQL and KQL on our computers
NOBODY in the field like this.
But Daddy Microsoft comes to the rescue
see we didnt JUST get KQL with part of that deal. we got the entire Microsoft cloud suite. and some people (like me) had been automating emails and stuff with Power Automate

This is Microsoft Power Automate. its Microsoft's version of Scratch but it has hooks into everything Microsoft. SharePoint, Teams, Outlook, Excel, it can integrate with all of it. i had been using it to send an email once a day with a list of all the robots in maintenance.
this gave me an idea
and i checked
and Power Automate had hooks for KQL
KLogs is actually short for Kusto Logs
I did not know how to program in Power Automate but damn it anything is better then writing KQL queries. so i got to work. and about 2 months later i had a BEHEMOTH of a Power Automate program. it lagged the webpage and many times when i tried to edit something my changes wouldn't take and i would have to click in very specific ways to ensure none of my variables were getting nuked. i dont think this was the intended purpose of Power Automate but this is what it did
the KLogger would watch a list of Teams chats and when someone typed "klogs" or pasted a copy of an ERROR mesage, it would spring into action.
it extracted the robot name from the message and timestamp from teams
it would lookup the name in the database to find the 64 long string UID and the location that robot was assigned too
it would reply to the message in teams saying it found a robot name and was getting logs
it would run a KQL query for the database and get the control system logs then export then into a CSV
it would save the CSV with the a .xls extension into a folder in ShairPoint (it would make a new folder for each day and location if it didnt have one already)
it would send ANOTHER message in teams with a LINK to the file in SharePoint
it would then enter a loop and scour the robot logs looking for the keyword ESTOP to find the error. (it did this because Kusto was SLOWER then the xbee radio and had up to a 10 min delay on syncing)
if it found the error, it would adjust its start and end timestamps to capture it and export the robot logs book-ended from the event by ~ 1 min. if it didnt, it would use the timestamp from when it was triggered +/- 5 min
it saved THOSE logs to SharePoint the same way as before
it would send ANOTHER message in teams with a link to the files
it would then check if the error was 1 of 3 very specific type of error with the camera. if it was it extracted the base64 jpg image saved in KQL as a byte array, do the math to convert it, and save that as a jpg in SharePoint (and link it of course)
and then it would terminate. and if it encountered an error anywhere in all of this, i had logic where it would spit back an error message in Teams as plaintext explaining what step failed and the program would close gracefully
I deployed it without asking anyone at one of the sites that was struggling. i just pointed it at their chat and turned it on. it had a bit of a rocky start (spammed chat) but man did the FSE's LOVE IT.
about 6 months later software deployed their answer to reading the logs: a webpage that acted as a nice GUI to the KQL database. much better then an CSV file
it still needed you to scroll though a big drop-down of robot names and enter a timestamp, but i noticed something. all that did was just change part of the URL and refresh the webpage
SO I MADE KLOGS 2 AND HAD IT GENERATE THE URL FOR YOU AND REPLY TO YOUR MESSAGE WITH IT. (it also still did the control server and jpg stuff). Theres a non-zero chance that klogs was still in use long after i left that job
now i dont recommend anyone use power automate like this. its clunky and weird. i had to make a variable called "Carrage Return" which was a blank text box that i pressed enter one time in because it was incapable of understanding /n or generating a new line in any capacity OTHER then this (thanks support forum).
im also sure this probably is giving the actual programmer people anxiety. imagine working at a company and then some rando you've never seen but only heard about as "the FSE whos really good at root causing stuff", in a department that does not do any coding, managed to, in their spare time, build and release and entire workflow piggybacking on your work without any oversight, code review, or permission.....and everyone liked it
#comet tales#lazee works#power automate#coding#software engineering#it was so funny whenever i visited HQ because i would go “hi my name is LazeeComet” and they would go “OH i've heard SO much about you”
64 notes
·
View notes
Text
im not entirely done btw, i do eventually want to make gamefiles.ranid.space an actual website, i'm tempted to even have little 3d viewers included (so i might actually have to make that gltf exporter. groans)
I'll be posting about it here when it's done (it'll take months at LEAST) and also i have an rss feed now lol
i've just manually written it out but i want to get my website blog into a sort of database (hence why i was interested in mysql) so it can automatically update the feed, but right now it's just a post filled with a bunch of outdated info about cool brower stuff and a post about how im quitting social media so nothing cool yet but i'll talk on there much less frequently because it sucks to manually do all of this.
shout out people on the internet in like the 80s this is just how they did shit. actually i lied they had SQL back then as well. how old is SQL. damn 1974 lmao okay.
i just remembered that Fortran is still being used, what the hell do you mean the best way to make something is with a programming language made in the 50s. what do you mean it's used in supercomputers.
21 notes
·
View notes
Note
Hi Argumate! I just read about your chinese language learning method, and you inspired me to get back to studying chinese too. I want to do things with big datasets like you did, and I am wondering if that means I should learn to code? Or maybe I just need to know databases or something? I want to structure my deck similar to yours, but instead of taking the most common individual characters and phrases, I want to start with the most common components of characters. The kangxi radicals are a good start, but I guess I want a more evidence-based and continuous approach. I've found a dataset that breaks each hanzi into two principle components, but now I want to use it determine the components of those components so that I have a list of all the meaningful parts of each hanzi. So the dataset I found has 嘲 as composed of 口 and 朝, but not as 口𠦝月, or 口十曰月. So I want to make that full list, then combine it with data about hanzi frequency to determine the most commonly used components of the most commonly used hanzi, and order my memorization that way. I just don't know if what I'm describing is super complicated and unrealistic for a beginner, or too simple to even bother with actual coding. I'm also not far enough into mandarin to know if this is actually a dumb way to order my learning. Should I learn a little python? or sql? or maybe just get super into excel? Is this something I ought to be able to do with bash? Or should I bag the idea and just do something normal? I would really appreciate your advice
I think that's probably a terrible way to learn to read Chinese, but it sounds like a fun coding exercise! one of the dictionaries that comes with Pleco includes this information and you could probably scrape it out of a text file somewhere, but it's going to be a dirty grimy task suited to Python text hacking, not something you would willingly undertake unless you specifically enjoy being Sisyphus as I do.
if you want to actually learn Chinese or learn coding there are probably better ways! but I struggle to turn down the romance of a doomed venture myself.
13 notes
·
View notes
Text
do you think vulcans have arguments over which mathematical logic system they should use. like, okay, most computing and aristotle's logic is boolean logic/algebra, in which there are two possible values for any statement: TRUE/FALSE. a few computing languages (SQL being the most notable) use three-value logic: TRUE/FALSE/NEITHER (with the 'neither' sometimes being 'unknown' or 'null'). or do you think they use a many-valued logic system of some kind, with other logical states. what do they think of the law of the excluded middle? do they have their own symbolic logic notation? do they have a different word for logic (the mathematical and philosophical discussion) and logic (doing things that make sense, as is the colloquial use of the word in english). do you think their philosophers get into fights when they come across planets that use different mathematical logic systems? because there is nothing stating every society uses the same base assumptions about math, or even the same type of electronic circuits/computing systems that we do that so heavily rely on binary logic,
#star trek#half of this doesn't make sense i have just been Worldbuilding#and i went 'wait logic means like. a great number of things. how good are vulcans at math. pretty good right.'#'math isn't set in stone.'#'i bet they have so many math arguments--'
12 notes
·
View notes
Text
I'm not promising anything, and you know how my feelings towards something being hopeless change very frequently but this something I've been meaning to ask for a while
Again no promises this will happen I'm literally just trying gauge numbers, languages could potentially change I'm aware that I'm technically misusing the word backend but visuals are all in place and id love to recycle as much as possible of the game we have rn, don't bank on playtester being a big thing
10 notes
·
View notes
Text
SQL Fundamentals #1: SQL Data Definition
Last year in college , I had the opportunity to dive deep into SQL. The course was made even more exciting by an amazing instructor . Fast forward to today, and I regularly use SQL in my backend development work with PHP. Today, I felt the need to refresh my SQL knowledge a bit, and that's why I've put together three posts aimed at helping beginners grasp the fundamentals of SQL.
Understanding Relational Databases
Let's Begin with the Basics: What Is a Database?
Simply put, a database is like a digital warehouse where you store large amounts of data. When you work on projects that involve data, you need a place to keep that data organized and accessible, and that's where databases come into play.
Exploring Different Types of Databases
When it comes to databases, there are two primary types to consider: relational and non-relational.
Relational Databases: Structured Like Tables
Think of a relational database as a collection of neatly organized tables, somewhat like rows and columns in an Excel spreadsheet. Each table represents a specific type of information, and these tables are interconnected through shared attributes. It's similar to a well-organized library catalog where you can find books by author, title, or genre.
Key Points:
Tables with rows and columns.
Data is neatly structured, much like a library catalog.
You use a structured query language (SQL) to interact with it.
Ideal for handling structured data with complex relationships.
Non-Relational Databases: Flexibility in Containers
Now, imagine a non-relational database as a collection of flexible containers, more like bins or boxes. Each container holds data, but they don't have to adhere to a fixed format. It's like managing a diverse collection of items in various boxes without strict rules. This flexibility is incredibly useful when dealing with unstructured or rapidly changing data, like social media posts or sensor readings.
Key Points:
Data can be stored in diverse formats.
There's no rigid structure; adaptability is the name of the game.
Non-relational databases (often called NoSQL databases) are commonly used.
Ideal for handling unstructured or dynamic data.
Now, Let's Dive into SQL:

SQL is a :
Data Definition language ( what todays post is all about )
Data Manipulation language
Data Query language
Task: Building and Interacting with a Bookstore Database
Setting Up the Database
Our first step in creating a bookstore database is to establish it. You can achieve this with a straightforward SQL command:
CREATE DATABASE bookstoreDB;
SQL Data Definition
As the name suggests, this step is all about defining your tables. By the end of this phase, your database and the tables within it are created and ready for action.

1 - Introducing the 'Books' Table
A bookstore is all about its collection of books, so our 'bookstoreDB' needs a place to store them. We'll call this place the 'books' table. Here's how you create it:
CREATE TABLE books ( -- Don't worry, we'll fill this in soon! );
Now, each book has its own set of unique details, including titles, authors, genres, publication years, and prices. These details will become the columns in our 'books' table, ensuring that every book can be fully described.
Now that we have the plan, let's create our 'books' table with all these attributes:
CREATE TABLE books ( title VARCHAR(40), author VARCHAR(40), genre VARCHAR(40), publishedYear DATE, price INT(10) );
With this structure in place, our bookstore database is ready to house a world of books.
2 - Making Changes to the Table
Sometimes, you might need to modify a table you've created in your database. Whether it's correcting an error during table creation, renaming the table, or adding/removing columns, these changes are made using the 'ALTER TABLE' command.
For instance, if you want to rename your 'books' table:
ALTER TABLE books RENAME TO books_table;
If you want to add a new column:
ALTER TABLE books ADD COLUMN description VARCHAR(100);
Or, if you need to delete a column:
ALTER TABLE books DROP COLUMN title;
3 - Dropping the Table
Finally, if you ever want to remove a table you've created in your database, you can do so using the 'DROP TABLE' command:
DROP TABLE books;
To keep this post concise, our next post will delve into the second step, which involves data manipulation. Once our bookstore database is up and running with its tables, we'll explore how to modify and enrich it with new information and data. Stay tuned ...
Part2
#code#codeblr#java development company#python#studyblr#progblr#programming#comp sci#web design#web developers#web development#website design#webdev#website#tech#learn to code#sql#sqlserver#sql course#data#datascience#backend
112 notes
·
View notes
Text
Knights of Terra prologue part 3 of ?
First Mate Jess Davis worked furiously, trying to help the AI LIBRA process and organize the fleet's sensor data into at least something remotely usable. LIBRA was doing its best on low power mode, only running at about 40% made everything feel very slow. Jess was writing codes to trying to bridge sensor data in half a dozen coding languages. If she just got it all into SQL+ then LIBRA could process it that much faster.
LIBRA pinged a message "The power surge likely came from engineering, the damage is in a wave out from that compartment."
Jess rolled her eyes "Thank you LIBRA but please focus on the sensor data, it doesn't matter where it came from right now, just making what we have work."
In 2 hours they were going to die. Jess had accepted this. But she was going to make damn sure to take as many of them down on the way down as she could. If this was New Eden's last stand, then so be it. But this was the Ark Class New Eden, one of the first Ark ships Sol built, and she would not go down quietly. So Jess Davis coded, and LIBRA processed, the fleet knowing the extinction is coming, and planning to go down swinging. There was no where to run and no help coming.
Captain Ides arrived at the door to the Sub-Space room right as the maintenance bot got the door open. Sam Kelly was leaning against the transmitter, which looked in surprisingly good condition. "Kelly I'm going to throw you out an air lock. Why the hell would you go against my orders, and screw us even harder. This might be treason for sabotage for all I know." Ides yelled across the room, getting louder as she got angrier. Sam looked triumphant "I did it, someone will answer, someone will come." They answered quietly, almost a whispered prayer as much as a defense.
"I really don't have time for this, you need to try to restore power, as far away from me as you can" Ides barked sharply. She was livid, no one answered from Sol, they never did, her parents wasted their lives trying to talk to Sol. vg had no such fantasy, but right now she needed her Chief Engineer, as angry as she was. She spun on her heel, she needed to get back to the bridge and see what she could do to fix this fuck up.
Right as Captain Ides went to walk out the door, the transmitter pinged. Someone had answered.
10 notes
·
View notes
Note
Hey there! I want to go into statistical analysis and comms/data analysis, and I have a pretty good plan in place already and know what I'm doing, but was wondering if there are any tips you could give as I see in your bio you're studying data science?
Anything I should do for prep/classes to take to get me a leg up would be amazing, thank you in advance!
Hey there! Thanks for the ask!
If you're going into stat, the first thing I'd suggest is get a good grip on your maths.(Rhyme not intended lol) You should take courses on Derivatives, Integrals, Linear Algebra. We are also taught Real analysis pretty intensively.
For programming languages, I'd say Python is more than enough. But R, SQL are good to have on your CV. Open up a kaggle account and start doing some work there. It will take you a long way.
The best tip I can give you is to take care of your health. It's a pretty taxing subject once you get into it. But prioritise yourself first. Our coursework is intense and while it might not be the same for you, doing mathematics all day is always difficult.
Good luck on your journey. Hope I was of help.
#altin answers#studyblr#studyspo#study motivation#study inspiration#study hard#study aesthetic#studying#study#datablr#statblr#statistics#study study study
9 notes
·
View notes
Text
Unlocking the Power of Data: Essential Skills to Become a Data Scientist

In today's data-driven world, the demand for skilled data scientists is skyrocketing. These professionals are the key to transforming raw information into actionable insights, driving innovation and shaping business strategies. But what exactly does it take to become a data scientist? It's a multidisciplinary field, requiring a unique blend of technical prowess and analytical thinking. Let's break down the essential skills you'll need to embark on this exciting career path.
1. Strong Mathematical and Statistical Foundation:
At the heart of data science lies a deep understanding of mathematics and statistics. You'll need to grasp concepts like:
Linear Algebra and Calculus: Essential for understanding machine learning algorithms and optimizing models.
Probability and Statistics: Crucial for data analysis, hypothesis testing, and drawing meaningful conclusions from data.
2. Programming Proficiency (Python and/or R):
Data scientists are fluent in at least one, if not both, of the dominant programming languages in the field:
Python: Known for its readability and extensive libraries like Pandas, NumPy, Scikit-learn, and TensorFlow, making it ideal for data manipulation, analysis, and machine learning.
R: Specifically designed for statistical computing and graphics, R offers a rich ecosystem of packages for statistical modeling and visualization.
3. Data Wrangling and Preprocessing Skills:
Raw data is rarely clean and ready for analysis. A significant portion of a data scientist's time is spent on:
Data Cleaning: Handling missing values, outliers, and inconsistencies.
Data Transformation: Reshaping, merging, and aggregating data.
Feature Engineering: Creating new features from existing data to improve model performance.
4. Expertise in Databases and SQL:
Data often resides in databases. Proficiency in SQL (Structured Query Language) is essential for:
Extracting Data: Querying and retrieving data from various database systems.
Data Manipulation: Filtering, joining, and aggregating data within databases.
5. Machine Learning Mastery:
Machine learning is a core component of data science, enabling you to build models that learn from data and make predictions or classifications. Key areas include:
Supervised Learning: Regression, classification algorithms.
Unsupervised Learning: Clustering, dimensionality reduction.
Model Selection and Evaluation: Choosing the right algorithms and assessing their performance.
6. Data Visualization and Communication Skills:
Being able to effectively communicate your findings is just as important as the analysis itself. You'll need to:
Visualize Data: Create compelling charts and graphs to explore patterns and insights using libraries like Matplotlib, Seaborn (Python), or ggplot2 (R).
Tell Data Stories: Present your findings in a clear and concise manner that resonates with both technical and non-technical audiences.
7. Critical Thinking and Problem-Solving Abilities:
Data scientists are essentially problem solvers. You need to be able to:
Define Business Problems: Translate business challenges into data science questions.
Develop Analytical Frameworks: Structure your approach to solve complex problems.
Interpret Results: Draw meaningful conclusions and translate them into actionable recommendations.
8. Domain Knowledge (Optional but Highly Beneficial):
Having expertise in the specific industry or domain you're working in can give you a significant advantage. It helps you understand the context of the data and formulate more relevant questions.
9. Curiosity and a Growth Mindset:
The field of data science is constantly evolving. A genuine curiosity and a willingness to learn new technologies and techniques are crucial for long-term success.
10. Strong Communication and Collaboration Skills:
Data scientists often work in teams and need to collaborate effectively with engineers, business stakeholders, and other experts.
Kickstart Your Data Science Journey with Xaltius Academy's Data Science and AI Program:
Acquiring these skills can seem like a daunting task, but structured learning programs can provide a clear and effective path. Xaltius Academy's Data Science and AI Program is designed to equip you with the essential knowledge and practical experience to become a successful data scientist.
Key benefits of the program:
Comprehensive Curriculum: Covers all the core skills mentioned above, from foundational mathematics to advanced machine learning techniques.
Hands-on Projects: Provides practical experience working with real-world datasets and building a strong portfolio.
Expert Instructors: Learn from industry professionals with years of experience in data science and AI.
Career Support: Offers guidance and resources to help you launch your data science career.
Becoming a data scientist is a rewarding journey that blends technical expertise with analytical thinking. By focusing on developing these key skills and leveraging resources like Xaltius Academy's program, you can position yourself for a successful and impactful career in this in-demand field. The power of data is waiting to be unlocked – are you ready to take the challenge?
3 notes
·
View notes
Text
Structured Query Language (SQL): A Comprehensive Guide
Structured Query Language, popularly called SQL (reported "ess-que-ell" or sometimes "sequel"), is the same old language used for managing and manipulating relational databases. Developed in the early 1970s by using IBM researchers Donald D. Chamberlin and Raymond F. Boyce, SQL has when you consider that end up the dominant language for database structures round the world.
Structured query language commands with examples
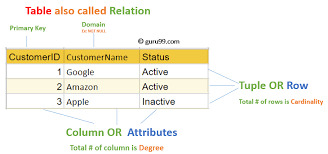
Today, certainly every important relational database control system (RDBMS)—such as MySQL, PostgreSQL, Oracle, SQL Server, and SQLite—uses SQL as its core question language.
What is SQL?
SQL is a website-specific language used to:
Retrieve facts from a database.
Insert, replace, and delete statistics.
Create and modify database structures (tables, indexes, perspectives).
Manage get entry to permissions and security.
Perform data analytics and reporting.
In easy phrases, SQL permits customers to speak with databases to shop and retrieve structured information.
Key Characteristics of SQL
Declarative Language: SQL focuses on what to do, now not the way to do it. For instance, whilst you write SELECT * FROM users, you don’t need to inform SQL the way to fetch the facts—it figures that out.
Standardized: SQL has been standardized through agencies like ANSI and ISO, with maximum database structures enforcing the core language and including their very own extensions.
Relational Model-Based: SQL is designed to work with tables (also called members of the family) in which records is organized in rows and columns.
Core Components of SQL
SQL may be damaged down into numerous predominant categories of instructions, each with unique functions.
1. Data Definition Language (DDL)
DDL commands are used to outline or modify the shape of database gadgets like tables, schemas, indexes, and so forth.
Common DDL commands:
CREATE: To create a brand new table or database.
ALTER: To modify an present table (add or put off columns).
DROP: To delete a table or database.
TRUNCATE: To delete all rows from a table but preserve its shape.
Example:
sq.
Copy
Edit
CREATE TABLE personnel (
id INT PRIMARY KEY,
call VARCHAR(one hundred),
income DECIMAL(10,2)
);
2. Data Manipulation Language (DML)
DML commands are used for statistics operations which include inserting, updating, or deleting information.
Common DML commands:
SELECT: Retrieve data from one or more tables.
INSERT: Add new records.
UPDATE: Modify existing statistics.
DELETE: Remove information.
Example:
square
Copy
Edit
INSERT INTO employees (id, name, earnings)
VALUES (1, 'Alice Johnson', 75000.00);
three. Data Query Language (DQL)
Some specialists separate SELECT from DML and treat it as its very own category: DQL.
Example:
square
Copy
Edit
SELECT name, income FROM personnel WHERE profits > 60000;
This command retrieves names and salaries of employees earning more than 60,000.
4. Data Control Language (DCL)
DCL instructions cope with permissions and access manage.
Common DCL instructions:
GRANT: Give get right of entry to to users.
REVOKE: Remove access.
Example:
square
Copy
Edit
GRANT SELECT, INSERT ON personnel TO john_doe;
five. Transaction Control Language (TCL)
TCL commands manage transactions to ensure data integrity.
Common TCL instructions:
BEGIN: Start a transaction.
COMMIT: Save changes.
ROLLBACK: Undo changes.
SAVEPOINT: Set a savepoint inside a transaction.
Example:
square
Copy
Edit
BEGIN;
UPDATE personnel SET earnings = income * 1.10;
COMMIT;
SQL Clauses and Syntax Elements
WHERE: Filters rows.
ORDER BY: Sorts effects.
GROUP BY: Groups rows sharing a assets.
HAVING: Filters companies.
JOIN: Combines rows from or greater tables.
Example with JOIN:
square
Copy
Edit
SELECT personnel.Name, departments.Name
FROM personnel
JOIN departments ON personnel.Dept_id = departments.Identity;
Types of Joins in SQL
INNER JOIN: Returns statistics with matching values in each tables.
LEFT JOIN: Returns all statistics from the left table, and matched statistics from the right.
RIGHT JOIN: Opposite of LEFT JOIN.
FULL JOIN: Returns all records while there is a in shape in either desk.
SELF JOIN: Joins a table to itself.
Subqueries and Nested Queries
A subquery is a query inside any other query.
Example:
sq.
Copy
Edit
SELECT name FROM employees
WHERE earnings > (SELECT AVG(earnings) FROM personnel);
This reveals employees who earn above common earnings.
Functions in SQL
SQL includes built-in features for acting calculations and formatting:
Aggregate Functions: SUM(), AVG(), COUNT(), MAX(), MIN()
String Functions: UPPER(), LOWER(), CONCAT()
Date Functions: NOW(), CURDATE(), DATEADD()
Conversion Functions: CAST(), CONVERT()
Indexes in SQL
An index is used to hurry up searches.
Example:
sq.
Copy
Edit
CREATE INDEX idx_name ON employees(call);
Indexes help improve the performance of queries concerning massive information.
Views in SQL
A view is a digital desk created through a question.
Example:
square
Copy
Edit
CREATE VIEW high_earners AS
SELECT call, salary FROM employees WHERE earnings > 80000;
Views are beneficial for:
Security (disguise positive columns)
Simplifying complex queries
Reusability
Normalization in SQL
Normalization is the system of organizing facts to reduce redundancy. It entails breaking a database into multiple related tables and defining overseas keys to link them.
1NF: No repeating groups.
2NF: No partial dependency.
3NF: No transitive dependency.
SQL in Real-World Applications
Web Development: Most web apps use SQL to manipulate customers, periods, orders, and content.
Data Analysis: SQL is extensively used in information analytics systems like Power BI, Tableau, and even Excel (thru Power Query).
Finance and Banking: SQL handles transaction logs, audit trails, and reporting systems.
Healthcare: Managing patient statistics, remedy records, and billing.
Retail: Inventory systems, sales analysis, and consumer statistics.
Government and Research: For storing and querying massive datasets.
Popular SQL Database Systems
MySQL: Open-supply and extensively used in internet apps.
PostgreSQL: Advanced capabilities and standards compliance.
Oracle DB: Commercial, especially scalable, agency-degree.
SQL Server: Microsoft’s relational database.
SQLite: Lightweight, file-based database used in cellular and desktop apps.
Limitations of SQL
SQL can be verbose and complicated for positive operations.
Not perfect for unstructured information (NoSQL databases like MongoDB are better acceptable).
Vendor-unique extensions can reduce portability.
Java Programming Language Tutorial
Dot Net Programming Language
C ++ Online Compliers
C Language Compliers
2 notes
·
View notes