
In this space I will share the very best tutorials for: Stable Diffusion, Stable Diffusion XL (SDXL), Stable Diffusion 3, PixArt, Stable Cascade, Large Language Models (LLMs), Text to Speech, Speech to Text, ChatGPT, GPT-4, Image to Video Animation, Video to Video Animation, Deep Fakes, SwarmUI, ComfyUI, Fooocus, SUPIR, V-Express, InstantId, ControlNet, IP Adapters, RunPod, Massed Compute, Cloud, Kaggle, Google Colab, Automatic1111 SD Web UI, TensorRT, DreamBooth, LoRA, Training, Fine Tuning, Kohya, OneTrainer, Text to 3D, Image to 3D, Upscale, Inpainting, Outpainting, Superscale, AI-assisted Digital Art Generation, Super-Resolution, Image Enhancement, Image Restoration, Video Restoration, Synthetic Voice, Voice Training, Speech Synthesis, Zero-shot Generation, Virtual Characters, Image Generation, Text Generation, Music Generation, Video Generation, Deepfakes and Face Swapping, Style Transfer, 3D Model Generation, Text-to-Speech (TTS), Generative Adversarial Networks (GANs), Variational Autoencoders (VAEs), Text Summarization, Machine Translation, Synthetic Data Generation, DALL-E, Midjourney, Whisper, Image Captioning, Dataset Generation, Dataset Preparation, Dataset Preprocessing, Image Processing, RunwayML and many more.
Don't wanna be here? Send us removal request.
Statistics
We looked inside some of the posts by secourses and here's what we found interesting.
Average Info
Notes Per Post
5
Likes Per Post
5
Reblog Per Post
0
Reply Per Post
0
Time Between Posts
7 days
Number of Posts By Type
Text
5
Last Seen Tumblr Blogs





Fun Fact
Kazakhstan’s Minister of Communications and Informatics has blocked the Tumblr site because it contained 60 sites of terrorism, extremism, and pornography in 2015.
Text
youtube
FLUX Local & Cloud Tutorial With SwarmUI - FLUX: The Pioneering Open Source txt2img Model Surpasses Midjourney & Others - FLUX: The Anticipated SD3
🔗 Comprehensive Tutorial Video Link ▶️ https://youtu.be/bupRePUOA18
FLUX marks the first instance where an open source txt2img model genuinely outperforms and generates superior quality images with better prompt adherence compared to #Midjourney, Adobe Firefly, Leonardo Ai, Playground Ai, Stable Diffusion, SDXL, SD3, and Dall E3. #FLUX is a creation of Black Forest Labs, with its team primarily consisting of the original #StableDiffusion developers, and its quality is truly awe-inspiring. These statements are not exaggerations; you'll understand after watching the tutorial. This guide will demonstrate how to effortlessly download and utilize FLUX models on your personal computer and cloud services like Massed Compute, RunPod, and a complimentary Kaggle account.
🔗 FLUX Instructions Post (publicly accessible, no login required) ⤵️ ▶️ https://www.patreon.com/posts/106135985
🔗 FLUX Models 1-Click Robust Auto Downloader Scripts ⤵️ ▶️ https://www.patreon.com/posts/109289967
🔗 Primary Windows SwarmUI Tutorial (Watch For Usage Instructions) ⤵️ ▶️ https://youtu.be/HKX8_F1Er_w
🔗 Cloud SwarmUI Tutorial (Massed Compute - RunPod - Kaggle) ⤵️ ▶️ https://youtu.be/XFUZof6Skkw
🔗 SECourses Discord Channel for Comprehensive Support ⤵️ ▶️ https://discord.com/servers/software-engineering-courses-secourses-772774097734074388
🔗 SECourses Reddit ⤵️ ▶️ https://www.reddit.com/r/SECourses/
🔗 SECourses GitHub ⤵️ ▶️ https://github.com/FurkanGozukara/Stable-Diffusion
🔗 FLUX 1 Official Blog Post Announcement ⤵️ ▶️ https://blackforestlabs.ai/announcing-black-forest-labs/
Video Segments
0:00 Introduction to the groundbreaking open source txt2img model FLUX 5:01 Our approach to installing FLUX model into SwarmUI and its usage 5:33 Guide to accurately downloading FLUX models manually 5:54 Automatic 1-click download process for FP16 and optimized FP8 FLUX models 6:45 Distinguishing between FLUX model precisions and types for your specific needs 7:56 Correct folder placement for FLUX models 8:07 Updating SwarmUI to the latest version for FLUX compatibility 8:58 Utilizing FLUX models after SwarmUI initialization 9:44 Applying CFG scale to FLUX model 10:23 Monitoring server debug logs in real-time 10:49 Turbo model image generation speed on RTX 3090 Ti GPU 10:59 Potential blurriness in some turbo model outputs 11:30 Image generation with the development model 11:53 Switching to FP16 precision for FLUX model in SwarmUI 12:31 Differences between FLUX development and turbo models 13:05 Testing high-resolution capabilities of FLUX at 1536x1536 and its VRAM usage 13:41 1536x1536 resolution FLUX image generation speed on RTX 3090 Ti GPU with SwarmUI 13:56 Checking for shared VRAM usage and its impact on generation speed 14:35 Cloud-based SwarmUI and FLUX usage - no local PC or GPU required 14:48 Using pre-installed SwarmUI on Massed Compute's 48 GB GPU at $0.31/hour with FLUX dev FP16 model 16:05 FLUX model download process on Massed Compute instance 17:15 FLUX model download speeds on Massed Compute 18:19 Time required to download all premium FP16 FLUX and T5 models on Massed Compute 18:52 One-click SwarmUI update and launch on Massed Compute 19:33 Accessing Massed Compute's SwarmUI from your PC's browser via ngrok - mobile compatibility included 21:08 Comparison between Midjourney and open source FLUX images using identical prompts 22:02 Configuring DType to FP16 for enhanced image quality on Massed Compute with FLUX 22:12 Analyzing FLUX-generated image against Midjourney's output for the same prompt 23:00 SwarmUI installation and FLUX model download guide for RunPod 25:01 Comparing step speed and VRAM usage of FLUX Turbo vs Dev models 26:04 FLUX model download process on RunPod post-SwarmUI installation 26:55 Restarting SwarmUI after pod reboot or power cycle 27:42 Troubleshooting invisible CFG scale panel in SwarmUI 27:54 Quality comparison between FLUX and top-tier Stable Diffusion XL (SDXL) models via popular CivitAI image 29:20 FLUX image generation speed on L40S GPU with FP16 precision 29:43 Comparative analysis of FLUX image vs popular CivitAI SDXL image 30:05 Impact of increased step count on image quality 30:33 Generating larger 1536x1536 pixel images 30:45 Installing nvitop and assessing VRAM usage for 1536px resolution and FP16 DType 31:25 Speed reduction when increasing image resolution from 1024px to 1536px 31:42 Utilizing SwarmUI and FLUX models on a free Kaggle account, mirroring local PC usage 32:29 Instructions for joining SECourses discord channel and contacting for assistance and AI discussions
FLUX.1 [dev] is a 12 billion parameter rectified flow transformer designed for text-to-image generation.
Key Attributes State-of-the-art output quality, second only to our flagship model FLUX.1 [pro]. Competitive prompt adherence, matching closed source alternatives. Enhanced efficiency through guidance distillation training. Open weights to foster new scientific research and enable artists to develop innovative workflows.
The FLUX.1 suite comprises text-to-image models that establish new benchmarks in image detail, prompt adherence, style diversity, and scene complexity for text-to-image synthesis.
To balance accessibility and model capabilities, FLUX.1 is available in three variants: FLUX.1 [pro], FLUX.1 [dev], and FLUX.1 [schnell]:
FLUX.1 [pro]: The pinnacle of FLUX.1, offering unparalleled image generation with superior prompt following, visual quality, image detail, and output diversity.
FLUX.1 [dev]: An open-weight, guidance-distilled model for non-commercial applications. Directly derived from FLUX.1 [pro], it achieves similar quality and prompt adherence while being more efficient than standard models of comparable size. FLUX.1 [dev] weights are accessible on HuggingFace.
FLUX.1 [schnell]: Our most rapid model, optimized for local development and personal use. FLUX.1 [schnell] is openly available under an Apache2.0 license. Like FLUX.1 [dev], weights are available on Hugging Face, and inference code can be found on GitHub and in HuggingFace's Diffusers.
Transformer-powered Flow Models at Scale
All public FLUX.1 models are built on a hybrid architecture of multimodal and parallel diffusion transformer blocks, scaled to 12B parameters. FLUX 1 improves upon previous state-of-the-art diffusion models by incorporating flow matching, a versatile and conceptually straightforward method for training generative models, which includes diffusion as a special case.
Furthermore, FLUX 1 enhances model performance and hardware efficiency by integrating rotary positional embeddings and parallel attention layers.
A New Benchmark for Image Synthesis
FLUX.1 sets a new standard in image synthesis. FLUX.1 [pro] and [dev] surpass popular models like Midjourney v6.0, DALL·E 3 (HD), and SD3-Ultra in various aspects: Visual Quality, Prompt Following, Size/Aspect Variability, Typography, and Output Diversity.
FLUX.1 [schnell] stands as the most advanced few-step model to date, outperforming not only its in-class competitors but also robust non-distilled models like Midjourney v6.0 and DALL·E 3 (HD).
FLUX models are specifically fine-tuned to maintain the entire output diversity from pretraining. Compared to current state-of-the-art models, they offer significantly enhanced possibilities.
#art#photography#memes#funny#fashion#aesthetic#love#music#anime#quotes#flux#food#travel#nature#cute#selfie#poetry#books#writing#movies#cats#dogs#gaming#LGBT#feminism#politics#mental health#fitness#architecture#beauty
3 notes
·
View notes
Text
youtube
Kling AI Video Has Finally Been Released Globally (Available in All Countries), Free to Use and Astonishing - Comprehensive Guide
Complete Tutorial Link ▶️ https://youtu.be/zcpqAxYV1_w
You've likely encountered those astounding AI-generated videos. The moment has arrived. The renowned Kling AI is now accessible worldwide at no cost. In this instructional video, I'll demonstrate how to register for Kling AI for free using only an email address and utilize its impressive text-to-video animation, image-to-video animation, text-to-image, and image-to-image capabilities. This video will present non-cherry-picked results, giving you an accurate understanding of the model's actual quality and capabilities, unlike those highly selective example demonstrations. Nevertheless, #KlingAI remains the sole #AI model that rivals OpenAI's #SORA and is available for real-world use.
🔗 Kling AI Official Website ⤵️ ▶️ https://www.klingai.com/
🔗 SECourses Discord Channel for Comprehensive Support ⤵️ ▶️ https://discord.com/servers/software-engineering-courses-secourses-772774097734074388
🔗 Our GitHub Repository ⤵️ ▶️ https://github.com/FurkanGozukara/Stable-Diffusion
🔗 Our Reddit ⤵️ ▶️ https://www.reddit.com/r/SECourses/
0:00 Introduction to Kling AI - premier video generator AI model 0:28 Kling AI free registration process 1:17 Generating a prompt idea using Claude 3.5 for free to use with Kling AI for video creation 1:54 Testing a challenging prompt on Kling AI with various parameters 2:56 Optimizing LLM-generated prompts for text-to-video (AI) platforms 3:20 Daily free video generation limit and Kling AI's credit system 3:48 Generating multiple videos simultaneously 4:21 Maximum video duration possible with Kling AI's free version 4:54 Comparing different configurations for text-to-video generation on Kling AI 5:38 Crafting a prompt for image-to-image video/animation generation 5:55 Creating an AI video from an input image 7:11 Comparing various configurations for image-to-video generation on Kling AI 8:50 Optimal image-to-video animation configuration for Kling AI 9:45 Utilizing Kling AI's text-to-image feature
Kuaishou Initiates Comprehensive Public Testing of 'Kling AI' for Global Users, Enhances Model Capabilities
Kuaishou Technology (HKD Counter Stock Code: 01024 / RMB Counter Stock Code: 81024) (along with its subsidiaries and consolidated affiliated entities, hereafter referred to as "Kuaishou" or the "Company"), a prominent content community and social platform, recently announced significant upgrades to the foundation model of its "Kling AI" (可灵AI) video generation model, with the beta version now accessible to users worldwide via web portal (Chinese version: https://klingai.kuaishou.com/ ; English version: https://klingai.com/).
In response to growing demand from its extensive roster of content creators, Kuaishou has not only initiated beta testing of Kling AI for a broad audience but also launched a subscription program for users in mainland China, offering Kling AI users more tailored features across different subscription tiers. The Company anticipates launching international subscriptions in the near future.
Improved Foundation Model Enhances User Experience
In the month since its unveiling, Kling AI has undergone multiple enhancements. With the introduction of the subscription program, the foundation model now offers even more upgraded features. The latest round of improvements significantly enhances overall video quality. Videos produced by the upgraded model exhibit improved composition and color tone, boasting superior overall aesthetics. Motion performance has also been considerably enhanced, with greater range and accuracy of movement.
Earlier versions of Kling AI offered capabilities such as image-to-video generation and video extension. At the recent World Artificial Intelligence Conference, Kling AI was officially launched on the web along with several new features, including extending the text-to-video generation duration to 10 seconds. With the latest upgrade, users can expect an even more refined AI video-generating experience.
Full Beta Testing Launch and Limited-Time Subscription Discount
As the world's first accessible, real-image-level video generation large model for ordinary users, Kling AI has been immensely popular since it began accepting applications on June 6. After receiving over one million applications, more than 300,000 users were granted early access. With today's announcement, Kuaishou has fully launched the beta version to everyone, bringing the exciting Kling AI experience to a wider audience. Users will receive 66 daily "Inspiration Credits" that can be used to redeem specific functions or value-added services on the Kling AI platform, equivalent to producing about six free videos.
Alongside the upgrade, Kling AI has also officially introduced an all-new subscription program for users in mainland China. Users can select from three subscription tiers on Kling AI's official website: Gold, Platinum and Diamond, with monthly prices of RMB66, RMB266 and RMB666, respectively.
#aesthetic#anime#art#books#comics#fashion#landscape#gaming#food#fanart#sdr2#sdv#sdv fanart#sd#dmmd#slam dunk#sdcc#sw#Youtube
1 note
·
View note
Text
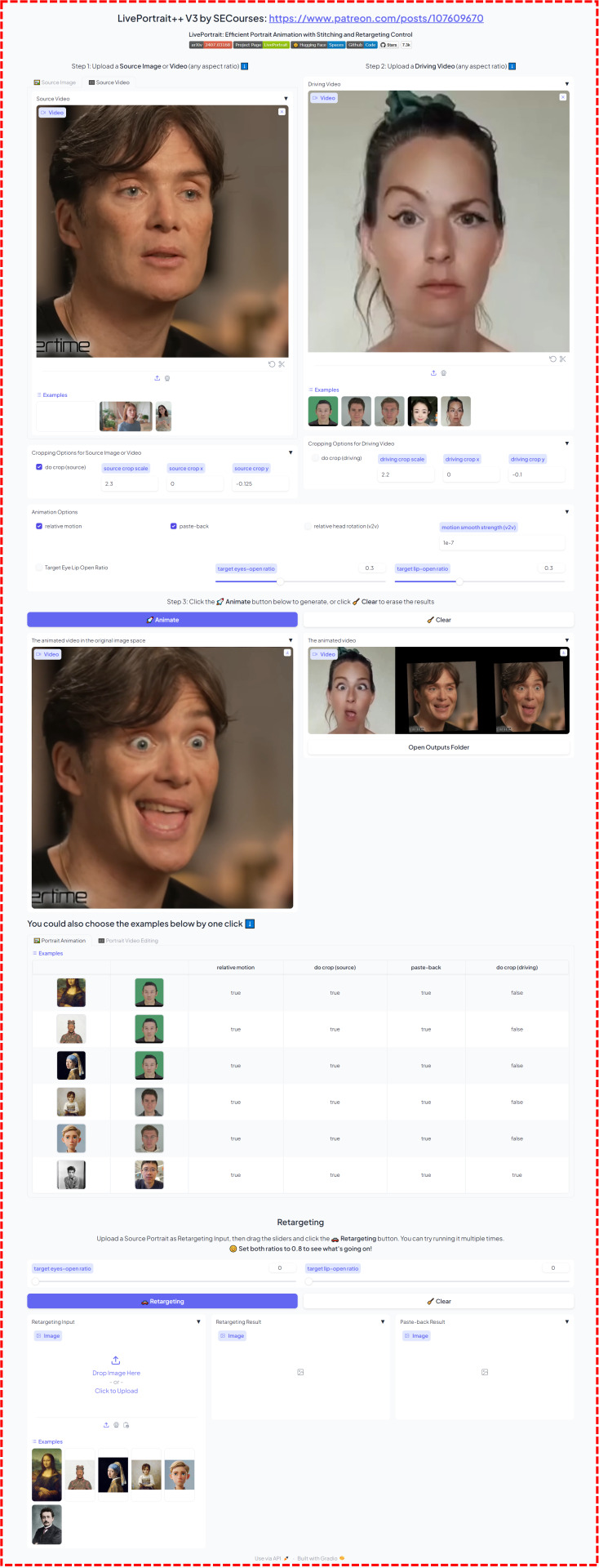
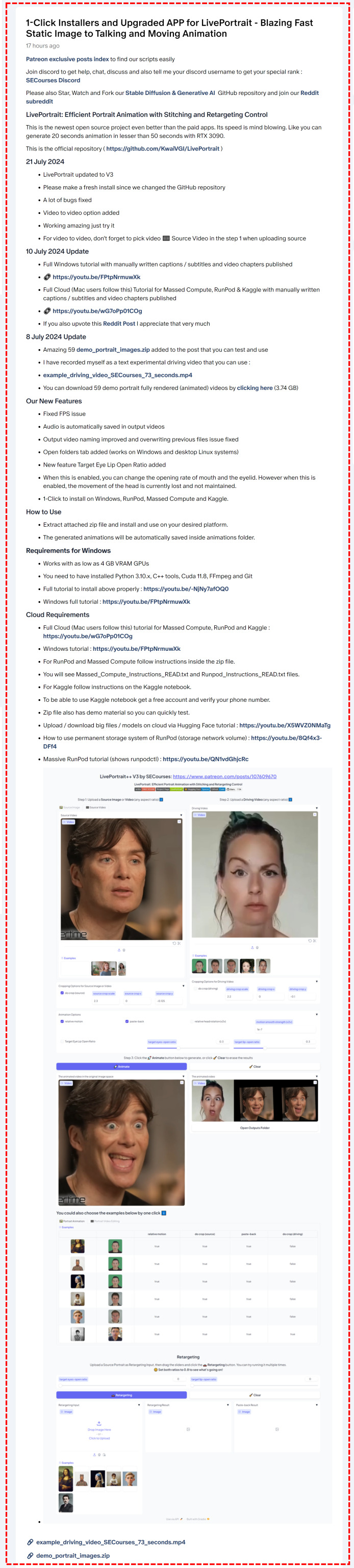
LivePortrait AI: Transform Static Photos into Talking Videos. It now supports Video-to-Video conversion and Superior Expression Transfer at Incredible Speed
LivePortrait AI: Transform Static Photos into Talking Videos. It now supports Video-to-Video conversion and Superior Expression Transfer at Incredible Speed
A new tutorial is anticipated to showcase the latest changes and features in V3, which introduces Video-to-Video functionality and other enhancements.
This post provides information for both Windows (local) and Cloud installations (Massed Compute, RunPod, and free Kaggle Account).
youtube
The V3 update has introduced video-to-video capability. If you're seeking a one-click installation method for LivePortrait, an open-source zero-shot image-to-animation application on Windows, for local use, this tutorial is essential. It introduces the cutting-edge image-to-animation open-source generator, Live Portrait. Simply provide a static image and a driving video, and within seconds, you'll have an impressively functional animation. LivePortrait is remarkably fast and adept at preserving facial expressions from the input video. The results will astound you.
🔗 Windows Local Installation Tutorial ️⤵️ ▶️ https://youtu.be/FPtpNrmuwXk
🔗 LivePortrait Installers Scripts ⤵️ ▶️ https://www.patreon.com/posts/107609670
🔗 Requirements Step by Step Tutorial ⤵️ ▶️ https://youtu.be/-NjNy7afOQ0
🔗 Cloud Massed Compute, RunPod & Kaggle Tutorial (Mac users can follow this tutorial) ⤵️ ▶️ https://youtu.be/wG7oPp01COg
🔗 Official LivePortrait GitHub Repository ⤵️ ▶️ https://github.com/KwaiVGI/LivePortrait
🔗 SECourses Discord Channel to Get Full Support ⤵️ ▶️ https://discord.com/servers/software-engineering-courses-secourses-772774097734074388
🔗 Paper of LivePortrait: Efficient Portrait Animation with Stitching and Retargeting Control ⤵️ ▶️ https://arxiv.org/pdf/2407.03168
The video tutorial covers the following topics: 0:00 Introduction to LivePortrait, the state-of-the-art image-to-animation open-source application 2:20 Downloading and installing the LivePortrait Gradio application on your computer 3:27 Requirements for the LivePortrait application and their installation 4:07 Verifying correct installation of requirements 5:02 Confirming successful installation and saving installation logs 5:37 Launching the LivePortrait application post-installation 5:57 Additional materials provided, including portrait images, driving video, and rendered videos 7:28 Using the LivePortrait application 8:06 VRAM usage when generating a 73-second animation video 8:33 Animating the first image 8:50 Monitoring the animation process status 10:10 Completion of the first animation video 10:24 Resolution of the rendered animation videos 10:45 Original output resolution of LivePortrait 11:27 Improvements and new features coded on top of the official demo app 11:51 Default save location for generated animated videos 12:35 The effect of the Relative Motion option 13:41 The effect of the Do Crop option 14:17 The effect of the Paste Back option 15:01 The effect of the Target Eyelid Open Ratio option 17:02 How to join the SECourses Discord channel
With the V3 update adding video-to-video functionality, this tutorial is ideal for those interested in using LivePortrait but lacking a powerful GPU, Mac users, or those preferring cloud-based solutions. It guides you through the one-click installation and use of LivePortrait on #MassedCompute, #RunPod, and even a free #Kaggle account. After this tutorial, you'll find running LivePortrait on cloud services as straightforward as running it locally. LivePortrait is the latest state-of-the-art static image to talking animation generator, surpassing even paid services in both speed and quality.
youtube
🔗 Cloud (no-GPU) Installations Tutorial for Massed Compute, RunPod and free Kaggle Account ️⤵️ ▶️ https://youtu.be/wG7oPp01COg
🔗 LivePortrait Installers Scripts ⤵️ ▶️ https://www.patreon.com/posts/107609670
🔗 Windows Tutorial - Watch To Learn How To Use ⤵️ ▶️ https://youtu.be/FPtpNrmuwXk
🔗 Official LivePortrait GitHub Repository ⤵️ ▶️ https://github.com/KwaiVGI/LivePortrait
🔗 SECourses Discord Channel to Get Full Support ⤵️ ▶️ https://discord.com/servers/software-engineering-courses-secourses-772774097734074388
🔗 Paper of LivePortrait: Efficient Portrait Animation with Stitching and Retargeting Control ⤵️ ▶️ https://arxiv.org/pdf/2407.03168
🔗 Upload / download big files / models on cloud via Hugging Face tutorial ⤵️ ▶️ https://youtu.be/X5WVZ0NMaTg
🔗 How to use permanent storage system of RunPod (storage network volume) ⤵️ ▶️ https://youtu.be/8Qf4x3-DFf4
🔗 Massive RunPod tutorial (shows runpodctl) ⤵️ ▶️ https://youtu.be/QN1vdGhjcRc
The cloud tutorial video covers: 0:00 Introduction to the LivePortrait cloud tutorial 2:26 Installing and using LivePortrait on MassedCompute with a discount coupon code 4:28 Applying the special Massed Compute coupon for a 50% discount 4:50 Setting up ThinLinc client for Massed Compute virtual machine connection 5:33 Configuring ThinLinc client's synchronization folder for file transfer 6:20 Transferring installer files to Massed Compute sync folder 6:39 Connecting to initialized Massed Compute virtual machine and installing LivePortrait 9:22 Starting and using LivePortrait on MassedCompute post-installation 10:20 Launching a second LivePortrait instance on the second GPU in Massed Compute 12:20 Locating and downloading generated animation videos 13:23 Installing LivePortrait on RunPod cloud service 14:54 Selecting the appropriate RunPod template 15:20 Setting up RunPod proxy access ports 16:21 Uploading installer files to RunPod's JupyterLab interface and initiating installation 17:07 Starting LivePortrait on RunPod post-installation 17:17 Launching LivePortrait on the second GPU as a second instance 17:31 Connecting to LivePortrait via RunPod's proxy connection 17:55 Animating the first image on RunPod with a 73-second driving video 18:27 Animation generation time (highlighting the app's impressive speed) 18:41 Understanding and resolving input upload errors 19:17 One-click download of all generated animations on RunPod 20:28 Monitoring animation generation progress 21:07 Installing and using LivePortrait for free on a Kaggle account 24:10 Generating the first animation on Kaggle 24:22 Ensuring full upload of input images and videos to avoid errors 24:35 Monitoring animation status and progress on Kaggle 24:45 Resource usage (GPU, CPU, RAM, VRAM) and animation speed on Kaggle 25:05 Downloading all generated animations on Kaggle with one click 26:12 Restarting LivePortrait on Kaggle without reinstallation 26:36 Joining the SECourses Discord channel for support and discussion
#ai#art#tutorial#guide#anime#animation#lecture#tech#technology#fashion#fanart#comics#books#aesthetic#food#landscape#gaming#tbb tech#technoblade#technically#technews#computing#phones#computers#electronics#Youtube
1 note
·
View note
Text
How to Use SwarmUI & Stable Diffusion 3 on Cloud Services Kaggle (free), Massed Compute & RunPod
Tutorial Video : https://youtu.be/XFUZof6Skkw
youtube
In this video, I demonstrate how to install and use #SwarmUI on cloud services. If you lack a powerful GPU or wish to harness more GPU power, this video is essential. You'll learn how to install and utilize SwarmUI, one of the most powerful Generative AI interfaces, on Massed Compute, RunPod, and Kaggle (which offers free dual T4 GPU access for 30 hours weekly). This tutorial will enable you to use SwarmUI on cloud GPU providers as easily and efficiently as on your local PC. Moreover, I will show how to use Stable Diffusion 3 (#SD3) on cloud. SwarmUI uses #ComfyUI backend.
🔗 The Public Post (no login or account required) Shown In The Video With The Links ➡️ https://www.patreon.com/posts/stableswarmui-3-106135985
🔗 Windows Tutorial for Learn How to Use SwarmUI ➡️ https://youtu.be/HKX8_F1Er_w
youtube
🔗 How to download models very fast to Massed Compute, RunPod and Kaggle and how to upload models or files to Hugging Face very fast tutorial ➡️ https://youtu.be/X5WVZ0NMaTg
youtube
🔗 SECourses Discord ➡️ https://discord.com/servers/software-engineering-courses-secourses-772774097734074388
🔗 Stable Diffusion GitHub Repo (Please Star, Fork and Watch) ➡️ https://github.com/FurkanGozukara/Stable-Diffusion
Coupon Code for Massed Compute : SECourses Coupon works on Alt Config RTX A6000 and also RTX A6000 GPUs
0:00 Introduction to SwarmUI on cloud services tutorial (Massed Compute, RunPod & Kaggle) 3:18 How to install (pre-installed we just 1-click update) and use SwarmUI on Massed Compute virtual Ubuntu machines like in your local PC 4:52 How to install and setup synchronization folder of ThinLinc client to access and use Massed Compute virtual machine 6:34 How to connect and start using Massed Compute virtual machine after it is initialized and status is running 7:05 How to 1-click update SwarmUI on Massed Compute before start using it 7:46 How to setup multiple GPUs on SwarmUI backend to generate images on each GPU at the same time with amazing queue system 7:57 How to see status of all GPUs with nvitop command 8:43 Which pre installed Stable Diffusion models we have on Massed Compute 9:53 New model downloading speed of Massed Compute 10:44 How do I notice GPU backend setup error of 4 GPU setup 11:42 How to monitor status of all running 4 GPUs 12:22 Image generation speed, step speed on RTX A6000 on Massed Compute for SD3 12:50 How to setup and use CivitAI API key to be able to download gated (behind a login) models from CivitAI 13:55 How to quickly download all of the generated images from Massed Compute 15:22 How to install latest SwarmUI on RunPod with accurate template selection 16:50 Port setup to be able to connect SwarmUI after installation 17:50 How to download and run installer sh file for RunPod to install SwarmUI 19:47 How to restart Pod 1 time to fix backends loading forever error 20:22 How to start SwarmUI again on RunPod 21:14 How to download and use Stable Diffusion 3 (SD3) on RunPod 22:01 How to setup multiple GPU backends system on RunPod 23:22 Generation speed on RTX 4090 (step speed for SD3) 24:04 How to quickly download all generated images on RunPod to your computer / device 24:50 How to install and use SwarmUI and Stable Diffusion 3 on a free Kaggle account 28:39 How to change model root folder path on SwarmUI on Kaggle to use temporary disk space 29:21 Add another backend to utilize second T4 GPU on Kaggle 29:32 How to cancel run and start SwarmUI again (restarting) 31:39 How to use Stable Diffusion 3 model on Kaggle and generate images 33:06 Why we did get out of RAM error and how we fixed it on Kaggle 33:45 How to disable one of the back ends to prevent RAM error when using T5 XXL text encoder twice 34:04 Stable Diffusion 3 image generation speed on T4 GPU on Kaggle 34:35 How to download all of the generated images on Kaggle at once to your computer / device
#art#artists on tumblr#anime#aesthetic#design#fashion#illustration#inspiration#landscape#photography#nature#architecture#drawing#digital art#music#writing#poetry#love#travel#vintage#comics#movies#books#quotes#fanart#fandom#gaming#food#crafts#diy
0 notes
Text
Zero to Hero Stable Diffusion 3 Tutorial with Amazing SwarmUI SD Web UI that Utilizes ComfyUI
Zero to Hero Stable Diffusion 3 Tutorial with Amazing SwarmUI SD Web UI that Utilizes ComfyUI : https://youtu.be/HKX8_F1Er_w
youtube
Do not skip any part of this tutorial to master how to use Stable Diffusion 3 (SD3) with the most advanced generative AI open source APP SwarmUI. Automatic1111 SD Web UI or Fooocus are not supporting the #SD3 yet. Therefore, I am starting to make tutorials for SwarmUI as well. #StableSwarmUI is officially developed by the StabilityAI and your mind will be blown after you watch this tutorial and learn its amazing features. StableSwarmUI uses #ComfyUI as the back end thus it has all the good features of ComfyUI and it brings you easy to use features of Automatic1111 #StableDiffusion Web UI with them. I really liked SwarmUI and planning to do more tutorials for it.
🔗 The Public Post (no login or account required) Shown In The Video With The Links ➡️ https://www.patreon.com/posts/stableswarmui-3-106135985
0:00 Introduction to the Stable Diffusion 3 (SD3) and SwarmUI and what is in the tutorial 4:12 Architecture and features of SD3 5:05 What each different model files of Stable Diffusion 3 means 6:26 How to download and install SwarmUI on Windows for SD3 and all other Stable Diffusion models 8:42 What kind of folder path you should use when installing SwarmUI 10:28 If you get installation error how to notice and fix it 11:49 Installation has been completed and now how to start using SwarmUI 12:29 Which settings I change before start using SwarmUI and how to change your theme like dark, white, gray 12:56 How to make SwarmUI save generated images as PNG 13:08 How to find description of each settings and configuration 13:28 How to download SD3 model and start using on Windows 13:38 How to use model downloader utility of SwarmUI 14:17 How to set models folder paths and link your existing models folders in SwarmUI 14:35 Explanation of Root folder path in SwarmUI 14:52 VAE of SD3 do we need to download? 15:25 Generate and model section of the SwarmUI to generate images and how to select your base model 16:02 Setting up parameters and what they do to generate images 17:06 Which sampling method is best for SD3 17:22 Information about SD3 text encoders and their comparison 18:14 First time generating an image with SD3 19:36 How to regenerate same image 20:17 How to see image generation speed and step speed and more information 20:29 Stable Diffusion 3 it per second speed on RTX 3090 TI 20:39 How to see VRAM usage on Windows 10 22:08 And testing and comparing different text encoders for SD3 22:36 How to use FP16 version of T5 XXL text encoder instead of default FP8 version 25:27 The image generation speed when using best config for SD3 26:37 Why VAE of the SD3 is many times better than previous Stable Diffusion models, 4 vs 8 vs 16 vs 32 channels VAE 27:40 How to and where to download best AI upscaler models 29:10 How to use refiner and upscaler models to improve and upscale generated images 29:21 How to restart and start SwarmUI 32:01 The folders where the generated images are saved 32:13 Image history feature of SwarmUI 33:10 Upscaled image comparison 34:01 How to download all upscaler models at once 34:34 Presets feature in depth 36:55 How to generate forever / infinite times
37:13 Non-tiled upscale caused issues 38:36 How to compare tiled vs non-tiled upscale and decide best 39:05 275 SwarmUI presets (cloned from Fooocus) I prepared and the scripts I coded to prepare them and how to import those presets 42:10 Model browser feature 43:25 How to generate TensorRT engine for huge speed up 43:47 How to update SwarmUI 44:27 Prompt syntax and advanced features 45:35 How to use Wildcards (random prompts) feature 46:47 How to see full details / metadata of generated images 47:13 Full guide for extremely powerful grid image generation (like X/Y/Z plot) 47:35 How to put all downloaded upscalers from zip file 51:37 How to see what is happening at the server logs 53:04 How to continue grid generation process after interruption 54:32 How to open grid generation after it has been completed and how to use it 56:13 Example of tiled upscaling seaming problem
1:00:30 Full guide for image history 1:02:22 How to directly delete images and star them 1:03:20 How to use SD 1.5 and SDXL models and LoRAs 1:06:24 Which sampler method is best 1:06:43 How to use image to image 1:08:43 How to use edit image / inpainting 1:10:38 How to use amazing segmentation feature to automatically inpaint any part of images 1:15:55 How to use segmentation on existing images for inpainting and get perfect results with different seeds 1:18:19 More detailed information regarding upscaling and tiling and SD3 1:20:08 Seams perfect explanation and example and how to fix it 1:21:09 How to use queue system 1:21:23 How to use multiple GPUs with adding more backends 1:24:38 Loading model in low VRAM mode 1:25:10 How to fix colors over saturation 1:27:00 Best image generation configuration for SD3 1:27:44 How to apply upscale to your older generated images quickly via preset 1:28:39 Other amazing features of SwarmUI 1:28:49 Clip tokenization and rare token OHWX







#ai art#art#anime#ai artwork#ai#ai generated#sdxl#stable diffusion#aiartcommunity#digital art#digital illustration#digital drawing#digital painting#comfyui#swarmui#sd3#artists on tumblr#digital artist#art on tumblr#artwork#illustration#drawings#ai art generator#ai art generation#tutorial#art tutorial#guide#art resources#tools#tech
0 notes