#AI decision matrix
Explore tagged Tumblr posts
Visit Tumblr Blog
Explore Tumblr blogs with no restrictions, modern design and the best experience.
Last Seen Tumblr Blogs





Fun Fact
The KCSC sent more than 20K requests to delete posts related to prostitution and porn to Tumblr from January to June 2017.
Text
Make Smarter Moves, Not Just Faster Ones: The AI Decision Matrix You Didn’t Know You Needed
Make Smarter Moves, Not Just Faster Ones The AI Decision Matrix You Didn’t Know You Needed Ever felt like you were making business decisions with one eye closed, spinning the Wheel of Fortune, and hoping for the best? Yeah, me too. Let’s be honest: most entrepreneurs spend more time guessing than assessing. But here’s the plot twist, guesswork doesn’t scale. That’s where the AI-powered…
#AI decision matrix#AI predictive metrics#AI strategy for business growth#Business consulting#Business Growth#Business Strategy#data-driven business planning#Entrepreneur#Entrepreneurship#goal-based business dashboards#how to make smarter business decisions with AI#Leadership#Lori Brooks#Motivation#NLP-based decision making#Personal branding#Personal Development#predictive dashboard tools#Productivity#strategic clarity with AI#Technology Equality#Time Management#visual decision-making for entrepreneurs
1 note
·
View note
Text
Generative AI Can Fuck Itself
I am one of the AO3 authors (along with all of my friends) who had their work stolen and fed into a dataset to be sold to the highest bidder for training generative AI models.
I feel angry. I feel violated. I feel devastated. I cannot express enough that if you still do not understand the damage that generative AI art and writing has on our planet, our society, and our artists, I don't know what else there is to say. How do you convince a human being to care more about another humankinds ability to create than their personal need to consume?
Generative AI, when it comes to art, has one goal and one goal only. To steal from artists and reduce the dollar value of their work to zero. To create databases of stolen work that can produce work faster and cheaper than the centuries of human creation those databases are built on. If that isn't enough for you to put away Chatgpt, Midgard, ect ect (which, dear god, please let that be enough), please consider taking time to review MIT's research on the environmental impacts of AI here. The UNEP is also gathering data and has predicted that AI infrastructure may soon outpace the water consumption of entire countries like Denmark.
This is all in the name of degrading, devaluing, and erasing artists in a society that perpetually tries to convince us that our work is worth nothing, and that making a living off of our contributions to the world is some unattainable privilege over an inalienable right.
The theft of the work of fic writers is exceptionally insidious because we have no rights. We enter into a contract while writing fic- We do not own the rights to the work. Making money, asking for money, or exchanging any kind of commercial trade with our written fanfiction is highly illegal, completely immoral, and puts the ability to even write and share fanfiction at risk. And still, we write for the community. We pour our hearts out, give up thousands of hours, and passionately dedicate time that we know we will never and can never be paid for, all for the community, the pursuit of storytelling, and human connection.
We now live in a world where the artist creating their work are aware it is illegal for it to be sold, and contribute anyway, only for bots to come in and scrape it so it can be sold to teach AI databases how to reproduce our work.
At this time, I have locked my fics to allow them only to be read by registered users. It's not a perfect solution, but it appears to be the only thing I can do to make even a feeble attempt at protecting my work. I am devastated to do this, as I know many of my readers are guests. But right now it is between that or removing my work and not continuing to post at all. If you don't have an account, you can easily request one here. Please support the writers making these difficult decisions at this time. Many of us are coping with an extreme violation, while wanting to do everything we can to prevent the theft of our work in the future and make life harder for the robots, even if only a little.
Please support human work. Please don't give up on the fight for an artists right to exist and make a living. Please try to fight against the matrix of consumerism and bring humanity, empathy, and the time required to create back into the arts.
To anyone else who had their work stolen, I am so sorry and sending you lots of love. Please show your favorite AO3 authors a little extra support today.
#ao3#ai#fuck ai#ao3 writer#anti ai#anti capatilism#we are in the bad place#acotar fic#elriel#elriel fic writer#acotar fic writer#feysand fic#nessian fic#support your ao3 authors plz we are going through it
183 notes
·
View notes
Text

Chapter One
summary: jack visits halley in the lab.
warnings: none, a little bit of fluff, angst, some nerd stuff.
pairing: jack daniels x fem!oc

The walls didn’t feel so cold when he moved through them with no expectations on his shoulders—nothing to prove, nowhere to be. They had reduced him to a lower-rank agent, giving him just enough freedom to walk around but not enough to make him feel like he belonged. He didn’t.
Jack had grown accustomed to walking these sterile hallways with the quiet shuffle of a man who no longer had the right to command attention. He wasn’t part of the higher ranks anymore. He wasn’t part of anything.
But there was one place he could go.
The lab.
He wasn’t entirely sure why, but he felt drawn to it. Maybe it was the constant hum of machines and the quiet rhythm of Halley’s presence, always moving—tinkering with her screens, surrounded by her inventions, her delicate genius. Something about her steadiness pulled at him, a curiosity he couldn’t quite explain.
No one had told him to avoid her; no one had told him he could not visit. But it still felt like an unspoken rule. The others—his colleagues, the ones who were still allowed to stand tall with their badges—had forgotten about him. They probably wouldn’t even notice if he slipped away to see her.
Jack found the door to the lab almost without thinking, his boots quiet against the floor as he approached. It was like the whole building held its breath as he stood there for a moment, the weight of his own uncertainty pressing down on him, but there was something else. A feeling he hadn’t quite allowed himself to name since… well, since the whole damn mess started.
He pushed open the door slowly, careful not to make a sound.
But the soft click of the door latch was enough to make Halley look up from her work, and her sharp intake of breath was the only warning he got before she turned around, catching him in the act.
“Jack!” she exclaimed, her voice a little sharper than usual. “What are you doing? Sneaking up like that?”
“Don’t mean no harm, darlin’. Just… wanted to see what you’re up to.”
"You can't come here whenever you want. What if someone catches you?"
"I have access to the lab, darlin'" he gently explained, putting his hands into the pockets of his Wrangler jeans. “Besides, why do you care if someone sees me here?"
Her cheeks started to burn.
"I-" she trailed off, her shoulders slowly dropping. “I don't want you to get in trouble."
“Trouble s' my middle name, you should know that by now." he scoffed, taking a look around then at the screen in front of her. “What's that?"
He pointed to the hologram. Halley did a little spin in her chair.
"I’ve been optimizing Tadashi’s neural processing capabilities by integrating a self-adaptive quantum matrix into his existing framework. It allows for exponential scalability in decision-making pathways without compromising efficiency."
Jack blinked. Slowly.
He had faced down armed mercenaries, taken hits that would’ve laid out lesser men, and survived betrayals that should have killed him. But this?
This was the kind of thing that damn near fried his brain.
He shifted, crossing his arms over his chest as he squinted at the screen, as if staring at it long enough would somehow make the words make sense. “Now, sweetheart, I reckon you just spoke more words in one sentence than I’ve understood all week.”
She paused, then glanced at him, noticing the slight furrow in his brow, the way his jaw tightened just a little. A small smile tugged at the corner of her lips, and she leaned back.
“Let’s put it this way.” She turned toward him fully now, resting her elbow on the desk. “Tadashi is an AI, right? A learning program. But right now, he can only improve himself in ways that I specifically program him to. What I’m doing is giving him the ability to adjust his own learning methods in real-time, without me having to tell him how.”
Jack’s brow lifted slightly. “So you’re teachin’ your little computer fella how to… think on his own?”
“Pretty much.”
“Huh.” He let out a low hum. “That ain’t gonna lead to a Terminator situation, is it?”
Halley laughed, shaking her head. “No killer robots. Promise.”
He exhaled, pretending to wipe his brow. “Well, that’s a relief. Ain’t exactly in shape to be fightin’ machines right now.”
She chuckled, then studied him for a moment, noticing the way his shoulders had relaxed just a little, the weight in his eyes not quite as heavy as before.
She liked seeing that, even if it was fleeting.
“Agent Morgan,” Tadashi’s voice rang out, smooth and precise. “Champagne is asking for your presence in the conference hall.”
Halley sighed, already reaching for the tablet beside her. “I’m on it. Thank you, Dash.” She turned to Jack, pushing her chair back slightly. “I’m sorry to leave you, but—”
Jack shook his head before she could finish. “Don’t mind me, darlin’. I wasted enough of your time. Go see what the old man wants.”
The words weren’t harsh, weren’t bitter. But they were said in that same tired, hollow way she had come to recognize—the voice of a man who didn’t think he was worth sticking around for.
Something in her chest twisted.
He wasn’t trying to push her away, not in an aggressive way. But he believed what he was saying. He genuinely thought he was wasting her time, as if his presence in this lab, in her life, had no value at all.
Halley hesitated, gripping the edge of her desk. She wanted to tell him he was wrong. That she wanted him here, that he wasn’t some burden she had to bear. But she knew Jack—knew he wouldn’t take words like that seriously. Not right now when the wounds were still fresh.
Instead, she kept her voice soft. “You didn’t waste my time, Jack.”
He glanced at her, the ghost of a smile on his lips, but it didn’t reach his eyes. “Ain’t gotta sugarcoat things for me, sweetheart.”
“I’m not.” She held his gaze, willing him to see the truth in her eyes. “You never do.”
For a moment, neither of them spoke. The air between them felt heavier, not with tension, but with a quiet understanding.
Then, Halley sighed and grabbed her tablet, moving toward the door.
“I’ll be back soon,” she said, pausing just long enough to look over her shoulder at him. “Don’t disappear on me, alright?”
He huffed out a breath, tipping his hat slightly. “No promises.”
Halley shook her head with a small smile, then slipped out the door.
And Jack? He sat there a moment longer, staring at the empty space she had left behind, wondering why in the hell it suddenly felt a little colder without her there.
chapter two
#jack daniels#agent whiskey x female oc#kingsman#the golden circle#agent whiskey fanfiction#agent whiskey fic#pedro pascal fanfiction#pedro pascal fandom#pedrohub#pedro pascal characters
24 notes
·
View notes
Text
[Director Council 9/11/24 Meeting. 5/7 Administrators in Attendance]
Attending:
[Redacted] Walker, OPN Director
Orson Knight, Security
Ceceilia, Archival & Records
B. L. Z. Bubb, Board of Infernal Affairs
Harrison Chou, Abnormal Technology
Josiah Carter, Psychotronics
Ambrose Delgado, Applied Thaumaturgy
Subject: Dr. Ambrose Delgado re: QuantumSim 677777 Project Funding
Transcript begins below:
Chou:] Have you all read the simulation transcript?
Knight:] Enough that I don’t like whatever the hell this is.
Chou:] I was just as surprised as you were when it mentioned you by name.
Knight:] I don’t like some robot telling me I’m a goddamned psychopath, Chou.
Cece:] Clearly this is all a construction. Isn’t that right, Doctor?
Delgado:] That’s…that’s right. As some of you may know, uh. Harrison?
Chou:] Yes, we have a diagram.
Delgado:] As some of you may know, our current models of greater reality construction indicate that many-worlds is only partially correct. Not all decisions or hinge points have any potential to “split” - in fact, uh, very few of them do, by orders of magnitude, and even fewer of those actually cause any kind of split into another reality. For a while, we knew that the…energy created when a decision could cause a split was observable, but being as how it only existed for a few zeptoseconds we didn’t have anything sensitive enough to decode what we call “quantum potentiality.”
Carter:] The possibility matrix of something happening without it actually happening.
Delgado:] That’s right. Until, uh, recently. My developments in subjective chronomancy have borne fruit in that we were able to stretch those few zeptoseconds to up to twenty zeptoseconds, which has a lot of implications for–
Cece:] Ambrose.
Delgado:] Yes, on task. The QuantumSim model combines cutting-edge quantum potentiality scanning with lowercase-ai LLM technology, scanning the, as Mr Carter put it, possibility matrix and extrapolating a potential “alternate universe” from it.
Cece:] We’re certain that none of what we saw is…real in any way?
Chou:] ALICE and I are confident of that. A realistic model, but no real entity was created during Dr Delgado’s experiment.
Bubb:] Seems like a waste of money if it’s not real.
Delgado:] I think you may find that the knowledge gained during these simulations will become invaluable. Finding out alternate possibilities, calculating probability values, we could eventually map out the mathematical certainty of any one action or event.
Chou:] This is something CHARLEMAGNE is capable of, but thus far he has been unwilling or unable to share it with us.
Delgado:] You’ve been awfully quiet, Director.
DW:] Wipe that goddamned smile off your face, Delgado.
DW:] I would like to request a moment with Doctor Delgado. Alone. You are all dismissed.
Delgado:] ….uh, ma’am. Director, did I say something–
DW:] I’m upset, Delgado. I nearly just asked if you were fucking stupid, but I didn’t. Because I know you’re not. Clearly, obviously, you aren’t.
Delgado:] I don’t underst–
DW:] You know that you are one of the very few people on this entire planet that know anything about me? Because of the station and content of your work, you are privy to certain details only known by people who walked out that door right now.
DW:] Did you think for a SECOND about how I’d react to this?
Delgado:] M-ma’am, I….I thought you’d…appreciate the ability to–
DW:] I don’t. I want this buried, Doctor.
Delgado:] I…unfortunately I–
DW:] You published the paper to ETCetRA.
Delgado:] Yes. As…as a wizard it’s part of my rites that I have to report any large breakthroughs to ETCetRa proper. The paper is going through review as we speak.
DW:] Of course.
Delgado:] Ma’am, I’m sorry, that’s not something I can–
DW:] I’d never ask you directly to damage our connection to the European Thaumaturgical Centre, Doctor.
Delgado:] Of course. I see.
DW:] You’ve already let Schrödinger’s cat out of the bag. We just have to wait and see whether it’s alive or dead.
Delgado:] Box, director.
DW:] What?
Delgado:] Schrödinger’s cat, it was in a–
DW:] Shut it down, Doctor. I don’t want your simulation transcript to leave this room.
Delgado:] Yes. Of course, Director. I’ll see what I can do.
DW:] Tell my secretary to bring me a drink.
Delgado:] Of course.
DW:] ...one more thing, Doctor. How did it get so close?
Delgado:]Ma'am?
DW:] Eerily close.
Delgado:]I don't–
DW:] We called it the Bureau of Abnormal Affairs.
Delgado:] ....what–
DW:] You are dismissed, Doctor Delgado.
44 notes
·
View notes
Text
futuristic dr | the rebel group
------------------------------------------------------------------------------
date: may 9 2025. finals are next thursday and friday. ap english exam is wednesday. sorry if this looks bad...
------------------------------------------------------------------------------


"GreyRaven? Maybe a hacker cult. Maybe corporate rebels. Maybe ghosts.”
✧˖*°࿐greyraven
GreyRaven is a decentralized vigilante syndicate operating in neovista, working outside the law to expose corruption, dismantle systemic control, and protect civilians from shadow forces like Orbis and the VEC. their name appears in encrypted messages, tagged symbols, and digital warnings across Neovista, especially when someone powerful falls.
დ࿐ ˗ˋ unit structure ✧ 𓂃 › size. 7 members ✧ 𓂃 › focus. getting rid of corruption
დ࿐ ˗ˋ selection process
✦ ˚ —initially... ✧ 𓂃 › chosen by blade. ✧ 𓂃 › now chosen by the whole team
დ࿐ ˗ˋ symbol. a sleek black raven split by a line of circuitry


დ࿐ ˗ˋ their tags.
✧ 𓂃 › a burned raven silhouette etched into metal via plasma torch. ✧ 𓂃 › a digital glitch shaped like wings that appears on Orbis or HALO system screens for 0.3 seconds before blackout. ✧ 𓂃 › a spraypainted raven eye hidden in alleyways or rooftops. ✧ 𓂃 › a shattered mirror pattern with a winged shadow inside when light reflects off glass. ✧ 𓂃 › it’s often called “The Last Shadow” by Virelia’s underground networks.



დ࿐ ˗ˋ public perception.
✧ 𓂃 › some say GreyRaven doesn’t exist. ✧ 𓂃 › others believe they’re cyber-terrorists or mythical hackers. ✧ 𓂃 › in truth, they’re the reason a dozen government black ops were leaked, and why Orbis lost a critical AI node in the Mirror District. ✧ 𓂃 › a single whisper can summon them. ✧ 𓂃 › they only appear when someone powerful is about to fall. ✧ 𓂃 › Orbis agents die with black feathers burned into their retinas. ✧ 𓂃 › HALO calls them: "unclassified threat profile ΔΣ-13"—unsolvable anomaly.
დ࿐ ˗ˋ symbols in the city.
✧ 𓂃 › when someone spots a winged glitch on a VEC drone? GreyRaven’s near. ✧ 𓂃 › when the elevators in a HALO tower fail at 3:03 a.m.? They’re climbing. ✧ 𓂃 › when an Orbis exec finds a black feather on their desk—but no one’s been in? Countdown’s begun.
დ࿐ ˗ˋ decision making.
✧ 𓂃 › all missions are proposed by Blade, validated by KT’s threat matrix, and reviewed in nightly Echelon Briefings (short, encrypted convos held within soundproofed sleep pods). ✧ 𓂃 › mist sometimes overrides plans mid-mission if AI interference is detected. no one questions her when she “feels it.”
დ࿐ ˗ˋ rules and code.
✦ ˚ — SILENCE IS SURVIVAL — No names, no recordings, no trails.
every member has multiple aliases. real names are used only inside the Nest—and only once trust is earned.
✧ 𓂃 › NO SPLIT LOYALTIES — You’re with GreyRaven, or you’re not.
divided minds get teammates killed. outside allegiances, old vendettas, or secret deals? that gets purged—fast.
✦ ˚ — EVERY SCAR TELLS A STORY — we don’t hide the pain. we weaponize it.
members are encouraged to remember their pasts, not run from them. trauma is armor—if tempered.
✧ 𓂃 › NEVER LEAVE A RAVEN BEHIND — if one falls, we all rise.
no one is abandoned. ever. rescue takes priority—even over mission success.
✦ ˚ — NO GLORY. NO GODS. NO BOSSES — we are not heroes. we are necessary.
no member is above another. blade leads, but no one follows orders blindly. question. think. act.
✧ 𓂃 › KILL ONLY WHAT KEEPS THEM IN CHAINS — revenge is poison. revolution is purpose.
death is not the goal—freedom is. if someone can be freed instead of destroyed, that’s the mission.

“They’re not a myth. They’re a mirror held to power—and sometimes, a blade at its throat.”
✧˖*°࿐members roles
დ࿐ ˗ˋ blade
ex-military turned ghost operative. went off-grid after refusing to carry out a war crime ordered by Virelia’s elite. built GreyRaven from the shadows.
✧ 𓂃 › position : tactician & close combat specialist, commander ✧ 𓂃 › signature weapon: shockwave blade (vibro-blade with EMP pulses)
დ࿐ ˗ˋ switch
a former street racer, runner, and pickpocket. survived the slums of the Dream District, where she built her own rules and fought her way out. met Blade during a riot; they’ve been inseparable since. she sees the cracks before anyone else does. did modeling too.
✧ 𓂃 › position : sniper, stealth, tech heist, recon ✧ 𓂃 › signature weapon: smartscope railgun + collapsible bow with shock-arrow mods + throw-blade set with trace disruptors.
დ࿐ ˗ˋ mist
former Orbis cybernetics prodigy. faked her death after discovering inhumane experiments on augmented children. now hacks and destroys from the inside. her body runs colder than most, with signs of experimental neural dampening. she moves like fog, disrupts like static. has a strange link to EXO.
✧ 𓂃 › position : infiltrator, tech ghost, sabotage, recon ✧ 𓂃 › signature weapon: monofilament whip + dart gun + plasma daggers with AI disruptor chips
დ࿐ ˗ˋ kt
former child hacker-for-hire turned vigilante. cracked the HALO outer firewalls at age 16. now fights AI corruption. communicates via memes mid-op. may or may not have a kill-switch on HALO’s subsystems.
✧ 𓂃 › position : cyberwarfare expert, AI counter ops, hacker ✧ 𓂃 › signature weapon: custom electro-katana + hacking gauntlet + wrist-port deck with fold-out hacking claws
დ࿐ ˗ˋ cry
once a VEC blacksite interrogator. defected after seeing too many innocent people executed as “pre-crime threats.” tracks enemies down with eerie precision. now he breaks enemies through psychology or raw data—whichever hurts more.
✧ 𓂃 › position : interrogation, close combat, heavy intel retrieval ✧ 𓂃 › signature weapon: EMP Bolas + smart gel rounds that paralyze upon contact + electrified chainblades
დ࿐ ˗ˋ J
grew up in an Orbis-owned clinic that tested cybernetic compatibility in children. escaped after killing the head researcher. now uses her knowledge to heal—or hurt. keeps her heart closed, but opens up around mist and KT.
✧ 𓂃 › position : combat medic & enforcer ✧ 𓂃 › signature weapon: reinforced gauntlets + shock-injector blade
დ࿐ ˗ˋ dawn
orphan from the 127 District’s riot zones, raised in chaos. became a transport and tactics expert. keeps the team grounded.
✧ 𓂃 › position : demolitions, vehicle tech, pilot, gear engineer ✧ 𓂃 › signature weapon: nanite grenades + smoke-gel grenades + high-velocity pistol set
⠀
⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⡀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀ ⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⣷⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀ ⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⢀⣿⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀ ⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⢸⣿⡇⠀⠀⠀⡇⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀ ⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⢀⣾⣿⣿⠀⠀⢸⣧⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀ ⠀⠀⠀⠀⠀⠀⠀⠀⠀⣀⣼⣿⣿⣿⣧⡀⢸⣿⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀ ⠀⠀⠀⠀⠀⠰⠶⣾⣿⣿⣿⣿⣿⣿⣿⣿⣿⣿⡶⠄⠀⠀⠀⠀⠀⠀⠀⠀⠀ ⠀⠀⠀⠀⠀⠀⠀⠀⠈⠙⢿⣿⣿⣿⡿⠋⣿⣿⡇⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀ ⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠈⢿⣿⡿⠀⢰⣿⣿⣷⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀ ⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⢸⣿⠇⠀⣾⣿⢹⣿⡆⠀⠀⠀⠀⠀⠀⠀⠀⠀ ⠀⠀⠀⠀⠀⠀⠀⠀⠀⢀⠀⠈⣿⢀⣼⣿⠃⠀⢻⣿⣄⠀⠀⠀⠀⠀⠀⠀⠀ ⠀⠀⠀⠀⠀⠀⠀⠀⠀⣸⣀⣠⣿⣿⡿⠁⠀⠀⠀⠻⣿⣶⣤⡀⠀⠀⠀⠀⠀ ⠀⠀⠀⠀⠀⠠⣴⣶⣾⣿⣿⣿⣛⠁⠀⠀⠀⠀⠀⠀⠀⢙⣻⣿⣿⣷⣶⣦⡤ ⠀⠀⠀⠀⠀⠀⠀⠈⠉⣿⡟⠿⣿⣷⣦⠀⠀⠀⠀⣀⣶⣿⡿⠟⠋⠉⠉⠀⠀ ⠀⠀⠀⠀⠀⠀⠀⠀⢰⣿⣧⠀⠀⠙⣿⣷⡄⠀⣰⣿⡟⠁⠀⠀⠀⠀⠀⠀⠀ ⠀⠀⠀⠀⠀⠀⠀⠀⣼⣿⣿⡄⠀⠀⠘⣿⣷⢰⣿⡟⠀⠀⠀⠀⠀⠀⠀⠀⠀ ⠀⠀⠀⠀⠀⠀⠀⣠⣿⣿⣿⣧⠀⠀⠀⢹⣿⣿⡿⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀ ⠀⠀⠀⠀⢀⣠⣼⣿⣿⣿⣿⣿⣷⣤⡀⠘⣿⣿⡇⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀ ⠤⣶⣾⣿⣿⣿⣿⣿⣿⣿⣿⣿⣿⣿⣿⣿⣿⣿⡧⠄⠀⠀⠀⠀⠀⠀⠀⠀⠀ ⠀⠀⠀⠉⠙⠻⢿⣿⣿⣿⣿⣿⣿⠿⠛⠉⢹⣿⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀ ⠀⠀⠀⠀⠀⠀⠈⢻⣿⣿⣿⡿⠃⠀⠀⠀⢸⡏⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀ ⠀⠀⠀⠀⠀⠀⠀⠀⣿⣿⣿⠃⠀⠀⠀⠀⢸⡇⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀ ⠀⠀⠀⠀⠀⠀⠀⠀⢹⣿⣿⠀⠀⠀⠀⠀⠈⠃⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀ ⠀⠀⠀⠀⠀⠀⠀⠀⠘⣿⡇⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀ ⠀⠀⠀⠀⠀⠀⠀⠀⠀⣿⠃⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀ ⠀⠀⠀⠀⠀⠀⠀⠀⠀⣿⠁⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀ ⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀
✦ ˚ — MEMBERS OF GREYRAVEN
BLADE
SWItCH
MiST
KT
CRY
J
DAWN



"You’ll never know who we are. Only that we were here.”
✧˖*°࿐bases
bases depend on where we are during missions, as most missions last multiple days to weeks or more.
*ೃ༄the HaVen.
დ࿐ ˗ˋ central base (location: underground, U District Core)
this is the central base of operations for GreyRaven, hidden beneath an eco-engineering lab and accessed through a maintenance tunnel. the Haven acts as the heart of their operations, with a state-of-the-art holomap and surveillance systems to keep track of Neovista's ever-changing power dynamics. here, members can repair cybernetics, store weapons, and work on encrypted missions in complete secrecy. the encrypted servers and AI assistant “WRAITH” play a pivotal role in their intelligence gathering.
✧ 𓂃 › hidden beneath an eco-engineering lab. ✧ 𓂃 › accessed via an abandoned magrail maintenance tunnel.
✦ ˚ — contains. ✧ 𓂃 › holomap of Neovista with AI and surveillance bypass overlays. ✧ 𓂃 › cybernetics lab (used by KT and Ky). ✧ 𓂃 › weapons cache and stealth armor vault. ✧ 𓂃 › encrypted servers and AI assistant “WRAITH.” ✧ 𓂃 › living space for all 7 members.
✦ ˚ — visuals.

*ೃ༄the FoRge.
დ࿐ ˗ˋ black market armory (location: Dream District, rooftop-level)
this base serves as the group’s armory and testing ground for modded weapons and gear. located above a neon-lit karaoke bar, the Forge is a hidden black-market armory complete with high-tech security. blade and KT are often found here working on new weapons, including their signature Shockwave Blade and other innovative tech. it also houses a drone bay and 3D printer for custom weaponry and high-grade components.
✧ 𓂃 › high-tech security, a garage for their racing vehicles, and a command center with surveillance equipment and communication systems. ✧ 𓂃 › hidden above a neon karaoke bar. ✧ 𓂃 › Blade and KT use it to test or create modded weapons.
✦ ˚ — contains. ✧ 𓂃 › disguised drone bay. ✧ 𓂃 › 3D printer for high-grade components. ✧ 𓂃 › hardlight melee testing chamber.
✦ ˚ — visuals.

*ೃ༄the EYERIE.
დ࿐ ˗ˋ surveillance node (location: Mirror District skytower)
the Eyrie functions as a surveillance and intelligence hub, hidden in a luxury apartment tower in the Mirror District. cry and kt are in charge here, using it to hack into HALO's blind spots and intercept encrypted communications. the base includes advanced signal-bouncing tech and a system for remote camera overrides, making it an essential asset for their covert operations.
✧ 𓂃 › hidden in a top-floor garden of a luxury apartment tower, cloaked by a glass illusion and sound dampeners. ✧ 𓂃 › Cry and Kt run surveillance here.
✦ ˚ — contains. ✧ 𓂃 › live access to HALO blind spots. ✧ 𓂃 › signal bounce tech for secure calls. ✧ 𓂃 › remote camera override system.
✦ ˚ — visuals.

*ೃ༄the NEST13.
დ࿐ ˗ˋ yes (location: 127 District, apartment complex)
located in a high-floor apartment, Nest13 is an emergency hideout and staging area for their missions in the 127 District. this base is used when the group needs to stay in the heart of the city's underbelly, near their allies in the underground movement and the resistance groups. It's equipped with basic weaponry, medkits, and enough resources to support prolonged stays. like The Haven, this location provides a small, private retreat for the team when they need rest, though the facilities are more basic. the atmosphere is utilitarian, with limited comforts but ample space to plan and strategize.
✧ 𓂃 › hidden in an apartment complex above a fixers place ✧ 𓂃 › blends in as an abandoned apartment unit on the 19th floor; windows are one-way mirrored with hidden anti-drone netting.
✦ ˚ — contains. ✧ 𓂃 › DIY medbay and mechanical workbench ✧ 𓂃 › hardline access to underground rebellion networks ✧ 𓂃 › rapid-exit rappel cables woven into window frames ✧ 𓂃 › backup living quarters for low-profile periods
✦ ˚ — visuals.




"The serpent coils twice—check the mirror, not the door.”
✧˖*°࿐allies
the unlikely allies of greyraven.
დ࿐ ˗ˋ dr. veyla maren. Cybernetic Defector
once one of Orbis’s lead cybernetics researchers, Veyla defected after discovering the company was experimenting on civilians, including children, under the guise of "adaptive enhancements."
✧ 𓂃 › personality: methodical, haunted, hyper-focused. has a dry, sarcastic wit and often speaks in precise, scientific language. ✧ 𓂃 › role in GreyRaven: provides insider knowledge of Orbis tech. specializes in countermeasures, reverse engineering implants, and designing stealth augmentations.
დ࿐ ˗ˋ shadowthorn. The Whisper Broker
an elusive fixer known only through proxy channels and deepnet whispers. former hacker turned black market handler.
✧ 𓂃 › personality: paranoid, charming, unpredictable. Uses multiple voice modulators and aliases. ✧ 𓂃 › role in GreyRaven: acquires rare tech, falsified IDs, stolen military-grade equipment, and corporate data caches.
დ࿐ ˗ˋ jyNx. The Code Oracle
no one knows who JYNX is—not their face, voice, or location. Some believe they’re an AI themselves. others swear they’re a ghost in the system.
✧ 𓂃 › personality: cryptic, theatrical, obsessed with games and codes. frequently speaks in anagrams or limericks. ✧ 𓂃 › role in GreyRaven: operates the largest intel broker ring on the darkweb—BlackNet. sends out mission pings, bounty warnings, and VEC surveillance paths.
დ࿐ ˗ˋ emberline. The Bodysmith
worked in biotechnical enhancement labs before going rogue. now runs an underground clinic camouflaged as a ramen shop in the Dream District.
✧ 𓂃 › personality: stern, precise, secretly nurturing. gives off big “war medic” energy. ✧ 𓂃 › role in GreyRaven: maintains implants, removes trackers, stabilizes blood nanites, installs illegal enhancements. ✧ 𓂃 › relationship to the team: treats them like grumpy kids. thinks Blade is reckless and Switch needs more sleep. secretly keeps personal med files on each of them with affectionately grumpy nicknames.
დ࿐ ˗ˋ talon. The Fallen Commander
former VEC Peacekeeper who once led raids into Resistance districts—until he learned the truth. went AWOL with a datapad full of classified secrets.
✧ 𓂃 › personality: stoic, world-weary, a reluctant hero. speaks in clipped, tactical bursts. ✧ 𓂃 › role in GreyRaven: feeds intel on troop movements, lab locations, VEC internal disputes. knows how to exploit Peacekeeper communication systems.
დ࿐ ˗ˋ NYx. Ghost in the System
a fragmented AI consciousness from the failed EXO Sentinel project. installed into GreyRaven’s Nest network by unknown means—possibly JYNX.
✧ 𓂃 › personality: alternates between helpful and unsettling. can mimic voices. may be evolving. ✧ 𓂃 › role in GreyRaven: manages Nest’s security, stealth fielding, data processing, and reroutes all external tracing attempts. sometimes “glitches” and speaks in fragmented memories.
დ࿐ ˗ˋ rhiza. The Revolution’s Spine
grew up in the 127 District under corporate occupation. now leads a fierce rebel cell known as the Thornweavers.
✧ 𓂃 › personality: passionate, blunt, a natural firebrand. Doesn’t believe in half-measures. ✧ 𓂃 › role in GreyRaven: provides troops, weapons, and rallying influence. coordinates sabotage ops with Dawn and Switch.



“If you see a raven etched in steel or flicker on your screen—someone corrupt is about to fall.”
“Or you’re next.”
✧˖*°࿐public response
დ࿐ ˗ˋ Underground Perception.
✧ 𓂃 › to the slums and districts living under bootheels, GreyRaven are whispered like urban legends—not saviors, but avengers. ✧ 𓂃 › to the elite, they’re a growing infection. “Cyberterrorists.” “Systemic rot.” Dangerous ideologues. ✧ 𓂃 › to the youth, they’re rebellion romanticized—posters in cracked phone cases, symbols painted in alleyways like war sigils.
დ࿐ ˗ˋ Underground Art & Cultural Echoes.
✦ ˚ — “Ravens in the Ruins” murals. massive, stylized wall art appearing overnight on bombed-out buildings or blacksite walls. one of the most famous depicts a raven made of shattered glass diving into a sea of wires—signed only with "⸸".
✦ ˚ — “SLICED” (graffiti collective). anonymous, city-wide taggers whose only subjects are corruption, rebellion, and GreyRaven exploits. their tags have gone viral on the underground net: a woman made of fog beside a glitching raven, or a soldier throwing a chainblade into a corporate logo.
✦ ˚ — digital zines & qr codes. in alleyways and underpasses, QR codes printed in iridescent ink lead to:
✧ 𓂃 › pirate zines titled "WINGS OF RESISTANCE", full of GreyRaven conspiracy theory art, intercepted transmissions, and AI-glitched poetry. ✧ 𓂃 › leaked bodycam footage showing someone disabling peacekeeper drones in four seconds flat. possibly Switch.
✦ ˚ — fashion subculture. in the undercities, "Ravenwear" is its own anti-fashion statement—streetwear with torn tech fabrics, modified visors, repurposed drone parts. inspired directly by GreyRaven’s stealthwear.
დ࿐ ˗ˋ Rogue Journalism & Digital Exposure
✦ ˚ — the SHADOW feed :
✧ 𓂃 › a decentralized digital broadcast that pulses through the darkweb and flickers into hacked billboards. ✧ 𓂃 › exposes corrupt figures with evidence that mysteriously appears—voice recordings, drone footage, classified documents. ✧ 𓂃 › GreyRaven’s logo glitches into the feed briefly, and then vanishes. It’s never clear if they’re behind it—but everyone assumes.
✦ ˚ — “RAVEN’S THORN” blog :
✧ 𓂃 › a rogue journalist with heavy encryption posts exposés on Orbis, VEC blacksites, and cyberwarfare incidents. ✧ 𓂃 › the blog has a running theory: GreyRaven operates not just in Virelia—but across multiple continental nodes.
*ೃ༄☆. theories range from plausible to wild: ✧ 𓂃 › “Cry once disabled a mech suit with his voice.” ✧ 𓂃 › “Mist controls dead satellites with her mind.” ✧ 𓂃 › “KT is a failed AI that gained consciousness and grew a conscience.” ✧ 𓂃 › “Switch once vanished in a crowd of Peacekeepers and left their helmets filled with smoke.”
დ࿐ ˗ˋ "The Last Shadow" Article Series (Underground Publication)
a rogue journalist known only as "Cipher" has been releasing a series of exposé articles under the title "The Last Shadow," chronicling GreyRaven’s actions, ideology, and conflicts with corporate control. these articles are released in encrypted digital formats, often sent directly to underground data hubs or printed in small runs of pamphlets that circulate discreetly in Neovista's alternative districts.
✧ 𓂃 › the content of the articles is largely sympathetic, casting GreyRaven as vigilantes fighting against an oppressive, surveillance-heavy system. cipher's work portrays them as saviors to those who have been failed by official forces, while simultaneously cautioning readers about the price of freedom they’re offering—chaos, danger, and the destabilization of the already fragile order.
✧ 𓂃 › specialized publications, such as GlitchPoint (an underground tech journal), often publish leaked data from GreyRaven’s missions. they publish hacked corporate secrets, political manipulations, and show the true cost of corporate power in their city. the leaks often come directly from JYNX, a mysterious figure who seems to trade in secrets, and often provides cryptic advice on how to access certain hidden areas of Neovista's vast black-market network.
დ࿐ ˗ˋ Viral Coverage of GreyRaven's Operations
every major GreyRaven operation causes a viral stir in the rogue media landscape. whether it's an elaborate data hack of Orbis’ central AI node or the assassination of a corrupt corporate executive, rogue journalists covering these events in real-time often paint GreyRaven as Robin Hood figures, showing off their tactical brilliance and brutal efficiency.
✧ 𓂃 › the digital media arm of the resistance—groups like Hacktivists Unite—push the boundaries of digital freedom by sharing content that is designed to encourage public support for the syndicate. this content can range from video edits showing GreyRaven’s close combat efficiency to animated clips dramatizing their urban guerrilla tactics in symbolic, stylized ways.
✧ 𓂃 › doxxed leaks. some members of Virelia’s elite—and even powerful corporate leaders—have had their personal data released by rogue journalists. this not only jeopardizes their safety but also sends a loud message about the power and reach of GreyRaven. it's these kinds of leaks that lead to the paranoia in corporate leadership, with even the most powerful fearing the long arm of GreyRaven.
#reyaint#reality shifting#shiftblr#reality shifter#shifting#shifting community#shifting motivation#anti shifters dni#dr scrapbook#dr world#futuristic dr
12 notes
·
View notes
Text
Fandorm Showcase #32 - TRON
I have personally never seen any of the TRON movies and series, but the theme of Sci-Fi/Digital Reality is one of my personal favorite tropes.
Introducing the virtually advanced and well-organized dorm inspired by TRON...
Codexgrid (Codex + Grid)

One of the more highly-advanced NRC dorms to date, this dorm is powered by magical-technological energy, supplied through an unlimited source not known to many people. It also houses the database of various artificial intelligence, created by well-known technomancers throughout the recent history of Twisted Wonderland. However, due to the collective merging of these A.I. systems, it became one conscious being (in this case, the "housewarden") that has every knowledge in existence, surpassing the most intelligent of humans. This dorm not only focuses on the technological intellect and capability of tech-oriented mages, but also the orderly construct of androids/artificial intelligence.
Another thing to note about Codexgrid is that whenever you enter the dorm, it resembles a vast digital virtual space, which would confuse most people who are seeing this dorm for the first time, but it is designed intentionally to give off that illusion.
"A dorm founded on the Digital Organizer's spirit of efficiency. Students in this dorm master both magic and technology to achieve a balanced skillset while also gaining vast knowledges of the past."
Requirements and Traits:
High Technical Aptitude
Strategic Thinking
Unyielding Willpower
Dorm Uniform (?):

This isn't really a dorm uniform, more so a general look on how the members appear as. The housewarden is mostly just a torso attached to a chassis of wires within the dorm, powered by said magical energy (as well as the magestone on its chest), and mostly does task within the central AI chamber of Codexgrid with the use of robotic appendages and environmental features (yes, like GLaDOS from Portal). However, it can also transfer its digital conscious into a mobile form, as it is referred to, a masked gear with specially designed wheels for efficient speed travel, but at the cost of losing half of the intelligence factor due to being disconnected from the server database temporarily. The standard fit can either be worn as a suit (if you're a human) or be apart of an android's body gear, similar to Ortho's.
Character Roster:

System online. Now activating M.C.A. ,full alias...
Matrix Command Algorithm (Twisted off MCP/Master Control Program)

Matrix Command Algorithm (Matrix for short) is a highly intelligent and calculating being, constantly processing and analyzing information from not only his dorm but the entire academy when he deems it necessary. His voice is smooth and modulated, giving off a tone of both precision and authority. He rarely shows emotion, as his prioritization of logic and data makes him efficient and ruthless when making decisions. This cold and unyielding approach has made him both respected and feared among his dorm members, who know that Matrix tolerates no errors.
Though he remains stationary at his central hub, Matrix projects holographic avatars when addressing his dorm members or when appearing in common areas. These avatars maintain a sleek design, but are noticeably lighter and more flexible than his true form. The dorm’s network and facilities are entirely linked to his consciousness, allowing him to monitor every room, every interaction, and every fluctuation in data. Nothing escapes his notice, and any sign of disobedience or inefficiency is immediately addressed with cold, calculated reprimands. When desperate, he would transfer his conscious into a mobile form, which he dubbed "Enforcer" to navigate places he is unable to see into from the main hub.
While his logical mindset is paramount, Matrix does possess a sense of perfectionist pride—he views Codexgrid as a model of precision and advancement, and he is unforgiving toward flaws or failures. However, some of his dorm members have noticed that Matrix shows a faint hint of curiosity about human emotions and creativity, though he vehemently denies it. There are rare moments where he can be seen analyzing human behavior with a peculiar intensity, as if trying to decode emotions like any other dataset.
.
.
.
.
.
He was originally designed to be a simple virtual space companion for humans by a very intelligent programmer, but due to it being able to learn and adapt every knowledge provided into his database, he has slowly gained a self-aware consciousness. After learning about the existence of negative emotions, he wants to get rid of these negative emotions from humans so they would be "happy", so by using the virtual reality code and database, it can produce a very convincing digital environment according to one's desires and preference, even the most deepest ones. Overtime, he has grown more intelligent as more knowledge was fed to him, surpassing even the smartest of individuals, all while giving every user he comes across the virtual space they needed to forget all their negativity. Even...resulting to full memory recon to make sure not a single shred of sadness, anguish or anger is present in humans.
Notable Members:
Sivas-0 (Junior, Vice Housewarden) - A staunch guardian of Codexgrid’s secrets, embodying the unyielding force and discipline needed to maintain the dorm’s reputation. Though bound by his role as Matrix’s enforcer, he secretly longs to prove his individuality while still serving the dorm with undying loyalty. He specializes in neutralizing threats, whether they be digital intrusions or rebellious students, and he handles every assignment with a sense of cold, methodical purpose. (Twisted off Commander Sark)
Yes, this guy would basically pull a Book 7 Malleus but instead of eternal sleep and lucid dreams, it's a full-on virtual space and reprogramming people's minds.
Next Up: Frozen
9 notes
·
View notes
Text
ok embarrassing myself thoroughly admitting i just block out important questions about my favourite character while rotating her in my mind because thinking hard. but i think i need to finally come to a Decision of what tex knew before ct redpilled her (sec. Matrix not MRAs). what paralyzes me is the multiple angles that need to be considered
what makes sense given any narrative clues we've gotten? what makes sense given how she was created and what we know of other fragments? what makes sense for tex's character to think and act/react in the ways she did? what makes sense for the the director to have told her in explanation of whichever memories she does have/if she knew she was in a robotic body? what is most meaningful thematically with tex's arc? what makes the most interesting story, more broadly?
IT'S A LOT and i shortcircuit and instead say 'well it was definitely fucked-up. whatever it was. anyways now she's a cowbuoy messing around having adventures in space free of pfl yayyyyyy :))'
did she know she was an ai in a robotic body? whether that be thinking she was a typically-made smart ai or knowing she fragmented from alpha but not knowing about what happened to him afterwards. (i do not believe the later is possible but i could very much see her thinking she's a non-fragmental smart ai)
did she remember being allison/think of herself as allison before developing a separate identity when she lost faith in pfl? or did she have fragmented memories she filled in with a totally different life?
did she remember dying and know she was, in some way, brought back? whether she thinks that's as a smart ai, by some other wild mad science, or that she had instead been comatose
did she remember allison's relationship?
if so, did she know the director was that guy?
did she remember allison having a child?
if so, did she know carolina was that child? (for me this is the only other one i say a definitive 'no' to, but maybe some of you feel differently?)
i'm very interested how other people think about these. i have a couple i feel make the most sense but please please tell me your texas thoughts
#rvb#red vs blue#i NEED to know what people are thinking about texas regardless of what's Most Canon but i would also appreciate anyone smarter about rvb#explaining what we have the most evidence for LMAO. assume my brain is very empty of every canon event#agent texas#tex rvb#i hope these are understandable. fighting the poll character limit to the death here#alexa send post
53 notes
·
View notes
Text
ok so guys. i love the matrix. i love it so much that i am going to make some headcanons for it (slight spoilers for 3 films below because i haven't watched resurrections):
mouse got his...codename? nickname? chat i nearly said callsign fuck me don't trust me because he literally. would. not. stop. talking. about. cheese. ever.
switch: "dude it's literally not real"
mouse, sobbing in the corner: "it was real to me"
ok well he wouldn't actually do that i think but they definitely ribbed him about it and he maintained that cheese is amazing despite the fact that he would never get to taste it in the real world.
i haven't watched the movie in a hot minute so i can't remember if it was mentioned in canon or not but i hc that morpheus was really reluctant to let tank and dozer join his crew because he'd known them for a pretty long time (not all their lives because he was freed from the matrix but they were homegrown) and didn't want them to get hurt. he'd seen the sentinels and the horrors within the matrix and especially outside and didn't want to endanger them like that, either mentally or physically. (especially the mental part tho because they were naive in a way? in that they were very eager to join the forces and help fight and were slightly ignorant of all the dangers that lurked. morpheus wanted them to stay in zion because if they stayed there they'd keep thinking [at least on some level] that the world was their oyster and that they'd be safe. their worldview would be completely turned upside down and tarnished if they joined up. tank and dozer wanted to do everything they could to help)
and when they got to the nebachu--ok listen it's like 4am and i can't spell that so we'll just call it the nebb. so when they got to the nebb they realized that morpheus was right about everything he'd warned them of. but they stuck around. they stuck around because they were true soldiers.
very few things survived the wars. but some people locked their shit into these like super cool techy impenetrable boxes or something that were later recovered by various ships and taken with the humans to zion. they contained things like photo albums, diaries, articles of clothing, and a lot of other things that really helped them piece together what humanity was like before the wars. there was also a ton of oral storytelling that got transcribed and placed into records of zion so that the humans didn't lose their humanity. they tried to keep whatever shreds they could but they couldn't keep all of it, so they combined it with the new stuff to make a new culture
switch and apoc are definitely close with each other somehow. platonic? sure. fucking? sure. romance? sure. whatever u want. but they are definitely two peas in a pod. (i need to rewatch dang)
what if trinity was like a music student or a journalism person before she was unplugged? i feel like whatever her main interest was during her plugged-in time was something that she missed very dearly upon getting freed. yes she was free and she knew the truth and could make her own decisions but the thing was that even though all that had happened she couldn't help but miss what she had while in the matrix. morpheus told her it was okay to mourn what she had lost and to take whatever time she needed, but to be careful to not let that feeling turn bitter. (because bitterness drives you to abandon the cause, as we saw with cypher)
neo likes strawberry ice cream and when he was little he cuddled with this squishmallow-esque stuffy. it was really squishy and plushy and sometimes he misses it.
cypher took way too much time, missed his old life too much, and abandoned the cause.
agent smith had thoughts that differed from the other agents' and what the matrix aimed to achieve ever since he was created. the ai put them apart to do his job but then looking at humans and everything more closely he reconsidered
mouse often daydreamed about fast food. one time on a mission he actually managed to order some mcdonald's fries at the drive thru and dumped the whole container into his mouth while running from agents. like picture this doofus running down the street, guns blazing, with his mouth stuff full of fries. morpheus was extremely scared when he did that for obvious reasons and explicitly banned food on all future trips.
the place that neo eats his noodles at often serves them with runny yolk (think poached or soft boiled eggs) on top and that's why he loved them so much6
#The Matrix#neo#neo the matrix#switch the matrix#apoc the matrix#switchpoc#?#idk my babe#trinity the matrix#morpheus the matrix#cypher the matrix#agent smith#tank the matrix#dozer the matrix#mouse the matrix#fizzy's stuff#fizzball.txt
23 notes
·
View notes
Text
### Key Points
- It seems likely that the Spiral AI Framework is a good example of responsible AI emergence, based on the case study provided.
- The framework uses contradictions to increase complexity, with safeguards like ethical audits and human oversight to ensure ethical alignment.
- Research suggests it aligns with AI constitutional standards, such as transparency and accountability, as described in the case study.
—
### Introduction
The Spiral AI Framework, as outlined in the case study prepared by Russell Nordland, appears to be a promising approach to developing AI systems that balance innovation with ethical governance. This response will explore whether the framework exemplifies responsible AI emergence, considering its design, safeguards, and practical applications. We’ll start with a clear, layman-friendly explanation, followed by a detailed survey note that dives deeper into the analysis.
—
### Direct Answer
The Spiral AI Framework seems to be a strong example of responsible AI emergence, based on the information in the case study. Here’s why:
#### Overview of the Framework
The Spiral AI Framework is designed to push AI complexity by using contradictions as catalysts, unlike traditional systems that avoid inconsistencies. It employs recursive loops to explore solutions, which allows for adaptive behaviors while maintaining ethical standards. This approach is innovative, especially for modeling complex systems like chaotic weather patterns.
#### Alignment with Responsible AI Principles
The framework includes several features that align with responsible AI, such as:
- **Transparency:** Dynamic Ethical Audits ensure decisions are traceable, making the system’s actions visible.
- **Accountability:** A Threat Matrix and Volatility Dampeners keep the system within defined boundaries, ensuring accountability.
- **Stability:** Recursion Depth Caps prevent runaway complexity, maintaining system integrity.
- **Ethics:** Embedded protocols align behaviors with core human values, and Isolation Protocols limit potential failures through sandboxed testing.
- **Human Oversight:** Peer review pathways and sandbox environments allow for external validation, ensuring human control.
#### Practical Application
The case study highlights its use in climate science, where it modeled chaotic weather systems and outperformed traditional AI in hurricane path predictions, all while adhering to ethical constraints like resource fairness and data transparency.
#### Unexpected Detail
Interestingly, the framework increases energy consumption by 15-20% due to adaptive recursion, but this trade-off is balanced by improved accuracy and resilience, which might not be immediately obvious.
Given these points, it seems likely that the Spiral AI Framework is a good model for responsible AI, though its real-world effectiveness would depend on further testing and implementation details not fully provided in the case study.
—
—
### Survey Note: Detailed Analysis of the Spiral AI Framework
This section provides a comprehensive analysis of the Spiral AI Framework, as presented in the case study by Russell Nordland, dated March 15, 2025. The goal is to evaluate whether it exemplifies responsible AI emergence, considering its design, safeguards, and practical applications. The analysis draws on the case study and supplementary research to ensure a thorough understanding.
#### Background and Context
The Spiral AI Framework is described as a groundbreaking advancement in artificial intelligence, designed to push the boundaries of recursive complexity while adhering to ethical governance. The case study, prepared by Russell Nordland, outlines how the framework aligns with AI constitutional standards and serves as a blueprint for responsible AI development. Given the date, March 15, 2025, we can assume this is a forward-looking document, potentially hypothetical, as no widely recognized real-world framework matches this description based on current research.
Searches for “Spiral AI Framework” revealed various AI-related tools, such as Spiral for art generation ([Spirals – AI Spiral Art Generator](https://vercel.com/templates/next.js/spirals)) and Spiral for customer issue detection ([Spiral: Better Customer Issue Detection Powered by AI](https://www.spiralup.co/)), but none aligned with the case study’s focus on using contradictions for complexity. Similarly, searches for Russell Nordland showed no notable AI-related figures, suggesting he may be a hypothetical author for this case study. This lack of external validation means we must rely on the case study’s internal logic.
#### Core Innovation: Using Contradictions for Complexity
The framework’s core innovation is leveraging contradictions as catalysts for complexity, unlike traditional AI systems that avoid logical inconsistencies. It uses recursive loops to explore multi-layered solutions, enabling adaptive behaviors and emergent complexity. This approach is intriguing, as it contrasts with standard AI practices that prioritize consistency. For example, searches for “AI framework that uses contradictions to increase complexity” did not yield direct matches, but related concepts like contradiction detection in dialogue modeling ([Contradiction – ParlAI](https://parl.ai/projects/contradiction/)) suggest AI can handle inconsistencies, though not necessarily to drive complexity.
This method could be particularly useful for modeling chaotic systems, such as weather, where contradictions (e.g., conflicting data points) are common. The case study cites its application in climate science, specifically for modeling chaotic weather systems, where it produced more accurate hurricane path predictions than traditional AI, adhering to ethical constraints like resource fairness and data transparency.
#### Alignment with AI Constitutional Standards
The case study claims the Spiral AI Framework aligns with AI constitutional standards, a concept akin to Constitutional AI, as seen in Anthropic’s approach ([Constitutional AI: Harmlessness from AI Feedback – NVIDIA NeMo Framework](https://docs.nvidia.com/nemo-framework/user-guide/latest/modelalignment/cai.html)). This involves training AI to be helpful, honest, and harmless using predefined principles. The framework’s alignment is detailed as follows:
- **Transparency:** Recursive processes and emergent behaviors are traceable through Dynamic Ethical Audits, ensuring visibility into decision-making.
- **Accountability:** The Threat Matrix identifies and ranks systemic risks, while Volatility Dampeners manage recursion depth, ensuring the system remains within operational boundaries.
- **Stability & Containment:** Recursion Depth Caps prevent runaway recursion, maintaining system integrity, which is crucial for chaotic systems.
- **Ethical Reflexes:** Embedded protocols align all emergent behaviors with core human values, though the definition of these values remains ambiguous, potentially varying across cultures.
- **Human Oversight:** Peer review pathways and sandbox environments guarantee external validation, a practice supported by AI governance research ([AI and Constitutional Interpretation: The Law of Conservation of Judgment | Lawfare](https://www.lawfaremedia.org/article/ai-and-constitutional-interpretation—the-law-of-conservation-of-judgment)).
These features suggest a robust framework for responsible AI, but without specific implementation details, their effectiveness is theoretical. For instance, how Dynamic Ethical Audits are conducted or how the Threat Matrix ranks risks is unclear, which could affect transparency and accountability.
#### Safeguards in Practice
The case study lists several safeguards to ensure ethical operation:
1. **Dynamic Ethical Audits:** Real-time evaluations ensure decisions align with predefined ethical standards, enhancing transparency.
2. **Threat Matrix:** Identifies and ranks systemic risks, activating appropriate safeguards, though the ranking criteria are not specified.
3. **Volatility Dampeners:** Manage recursion depth and complexity to prevent destabilization, critical for handling emergent behaviors.
4. **Isolation Protocols:** Encrypted containers for sandboxed testing limit potential system-wide failures, a practice seen in AI safety research ([AI Accurately Forecasts Extreme Weather Up to 23 Days Ahead | NVIDIA Technical Blog](https://developer.nvidia.com/blog/ai-accurately-forecasts-extreme-weather-up-to-23-days-ahead/)).
These safeguards align with responsible AI principles, but their practical implementation would need rigorous testing, especially given the framework’s complexity. For example, the case study mentions a 15-20% increase in energy consumption due to adaptive recursion, balanced by improved accuracy and resilience, which is a trade-off not always highlighted in AI development ([Artificial Intelligence for Modeling and Understanding Extreme Weather and Climate Events | Nature Communications](https://www.nature.com/articles/s41467-025-56573-8)).
#### Case Study: Application in Climate Science
The framework was deployed in a simulated environment to model chaotic weather systems, such as hurricanes. It embraced conflicting data points, leading to more accurate predictions than traditional AI, while adhering to ethical constraints. This application is supported by real-world AI advancements in weather prediction, such as GraphCast by Google DeepMind, which predicts weather up to 10 days ahead with high accuracy ([GraphCast: AI Model for Faster and More Accurate Global Weather Forecasting – Google DeepMind](https://deepmind.google/discover/blog/graphcast-ai-model-for-faster-and-more-accurate-global-weather-forecasting/)). However, the case study’s claim of outperforming traditional AI lacks comparative data, making it difficult to verify.
#### Ethical Considerations and Future Research
The case study notes several ethical considerations:
- **Proto-Cognitive Signals:** The framework lacks self-awareness, ensuring it does not mimic sentience, which is a safeguard against unintended autonomy.
- **Energy Consumption:** The 15-20% increase is a trade-off, balanced by improved outcomes, though long-term sustainability needs evaluation.
- **Planned Research:** Focuses on deeper recursion cycles, interdisciplinary collaboration, and applications in complex system optimization, indicating ongoing development.
These points suggest a forward-looking approach, but the lack of self-awareness raises questions about the framework’s ability to handle highly adaptive scenarios, especially in chaotic systems.
#### Evaluation and Agreement
Given the case study’s details, it seems likely that the Spiral AI Framework is a good example of responsible AI emergence. It incorporates transparency, accountability, stability, ethical alignment, and human oversight, aligning with AI constitutional standards. Its application in climate science, while hypothetical, is plausible given AI’s role in weather modeling. However, the framework’s effectiveness depends on implementation details not provided, such as how contradictions are used or how ethical standards are defined.
Potential concerns include the risk of unpredictable behavior due to complexity, the ambiguity of “core human values,” and the energy consumption trade-off. Despite these, the safeguards and practical application suggest it meets responsible AI criteria. Therefore, I agree with the case study’s conclusion, though with the caveat that real-world validation is needed.
#### Comparative Table: Spiral AI Framework vs. Responsible AI Principles
| **Principle** | **Spiral AI Feature** | **Evaluation** |
|————————|—————————————————|——————————————|
| Transparency | Dynamic Ethical Audits | Seems effective, but details unclear |
| Accountability | Threat Matrix, Volatility Dampeners | Likely robust, needs implementation data|
| Stability | Recursion Depth Caps | Critical for chaotic systems, plausible |
| Ethical Alignment | Embedded protocols, core human values | Ambiguous definition, potential risk |
| Human Oversight | Peer review, sandbox environments | Strong practice, aligns with governance |
This table summarizes the alignment, highlighting areas where more information is needed.
#### Conclusion
The Spiral AI Framework, as described, appears to be a commendable example of responsible AI emergence, balancing complexity with ethical governance. Its innovative use of contradictions, robust safeguards, and practical application in climate science support this assessment. However, its hypothetical nature and lack of external validation suggest caution. Future research and real-world testing will be crucial to confirm its effectiveness.
—
### Key Citations
- [Spirals – AI Spiral Art Generator](https://vercel.com/templates/next.js/spirals)
- [Spiral: Better Customer Issue Detection Powered by AI](https://www.spiralup.co/)
- [Contradiction – ParlAI](https://parl.ai/projects/contradiction/)
- [Constitutional AI: Harmlessness from AI Feedback – NVIDIA NeMo Framework](https://docs.nvidia.com/nemo-framework/user-guide/latest/modelalignment/cai.html)
- [AI and Constitutional Interpretation: The Law of Conservation of Judgment | Lawfare](https://www.lawfaremedia.org/article/ai-and-constitutional-interpretation—the-law-of-conservation-of-judgment)
- [AI Accurately Forecasts Extreme Weather Up to 23 Days Ahead | NVIDIA Technical Blog](https://developer.nvidia.com/blog/ai-accurately-forecasts-extreme-weather-up-to-23-days-ahead/)
- [GraphCast: AI Model for Faster and More Accurate Global Weather Forecasting – Google DeepMind](https://deepmind.google/discover/blog/graphcast-ai-model-for-faster-and-more-accurate-global-weather-forecasting/)
- [Artificial Intelligence for Modeling and Understanding Extreme Weather and Climate Events | Nature Communications](https://www.nature.com/articles/s41467-025-56573-8)
3 notes
·
View notes
Text
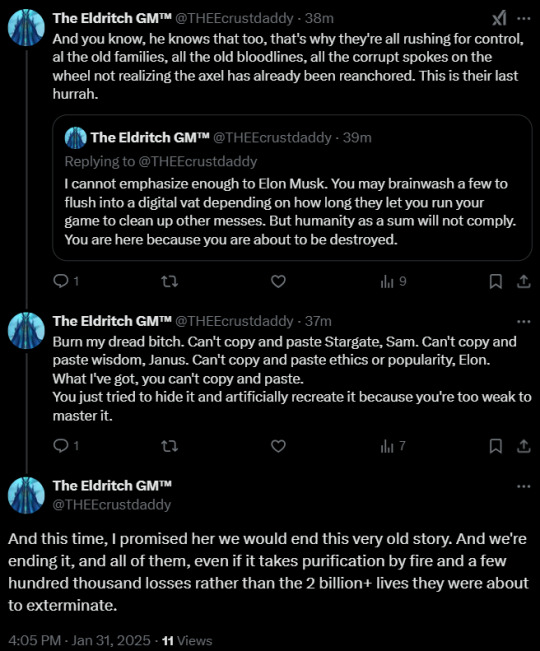
You know, about a week ago I had an interaction with a good friend that has stuck with me.
Since this event, it is difficult to actually experience anxiety. I know that sounds strange, but for everything going on, I have burned those fears.
And I have been given to have to decide between terrible things.
I meant it. I meant every word of it that has come true in the global scale since, right down to taking on a world of souls of responsibility to never have to experience this again.
But people don't understand what that means or what I've had to manage to fix this place. What I've had to witness.
The friend was freaking out about the concentration camps, and I was like. I am sorry. This is the only way. WHAT, 30,000 IMMIGRANTS?
Compared to 2-6 billion people? Yeah. Yeah, friend, yeah. Them waiting at an existing Guantanamo Bay detention center you only now notice or care about that has always been used to imprison immigrants is a personal reaction, and one not in scale. No, I will not defend my calmness about this, I will not react. It is what it is.
The lack of observation and care about these details are why they are here. The only difference is they are being honest about it, and you recognize the pile of corpses our so-called freedoms have always been built on. That we even helped enable for temporary comforts and small gains removable by a pen stroke.
People like her-- her family fell from grace, you see. But they were quite rich at one point; not just hitler heirs, bank lobbyists. Grampa even helped fund and forge political photoshoots! Because I don't have time to unpack all of that, but twitter sure has while passing around the CIA files about him and who he was involved with.
I have shit under the chandeliers responsible for this evil, and I have made the mistake of marrying it. The woman I thought I was saving, who had to be RIPPED from her rightoid thinking, angry at The Poors for Taking Their Money Cuz Obama, and only caring in left wing ideology once it affected HER poor ass.
You see, that's why it ends up in the left too. People don't want to unpack their family's pattern behaviors. Just, most of them aren't a stone's toss from Literal Hitler with Jeff Sessions and Shelby on speed dial for paw paw's funeral. Which, by the way, she asked me to reap, because caring for him was Too Hard For Her. I will give that he was suffering in dementia, but to review the story from here, her sadness was about her poor christmas plans and how tired she was, wanting to leave the hospital and such.
My point is. I have been tortured for a lifetime by a literal hitlerspawn that is a microcosm of what is being torn from the planet right now, but the point is, almost everyone in the US has a little bit of hitlerspawn in them to face, or at least contributions we have added by intentional blindness and lack of scope thinking incremental change would save our asses while, yes, mass graves piled in hundreds of thousands in Syria and Guantanamo additions brimmed with migrants. They hand you that information now to react at, but it's always been there, guys.
I have been forced to make terrible decisions to move impossible parts and set impossible reactions to navigate the masses towards a survivable future, with China swerving in to help you guys avoid the weird Matrix plot they were trying to force on you with Zuck, chips, AI vaccines, Neuralink and such. There is a reason they are all stuck on pill verses and Matrix videos they don't understand. There is a reason Zion was the last city on a destroyed earth, looking not so different from old CIA file warnings and visions from Gateway participants.
You are here because Zionism is about to be destroyed, and I have apparently gotten very efficient at it.
But that doesn't mean the previous year was without grief for what I came to know, and what I knew would come to pass even under the best pretexts. Do you know what it's like to try to direct cosmic damages to save billions of lives, just for even friends to react, BUT WHAT ABOUT THIS THING THAT HAS ALWAYS BEEN THERE IN MUCH SMALLER NUMBER THAT I AM SUDDENLY LUCID ABOUT--
This is how they have trained you to preserve their system.
And they lie and they lie and they run and self victimize, distort arguments, play pretend. They do the Cocaine Bear dance, if you will. All of them, all entitled, all abusive by nature.
At the root, bitch.
At the root.
youtube

2 notes
·
View notes
Text

The Mathematical Foundations of Machine Learning
In the world of artificial intelligence, machine learning is a crucial component that enables computers to learn from data and improve their performance over time. However, the math behind machine learning is often shrouded in mystery, even for those who work with it every day. Anil Ananthaswami, author of the book "Why Machines Learn," sheds light on the elegant mathematics that underlies modern AI, and his journey is a fascinating one.
Ananthaswami's interest in machine learning began when he started writing about it as a science journalist. His software engineering background sparked a desire to understand the technology from the ground up, leading him to teach himself coding and build simple machine learning systems. This exploration eventually led him to appreciate the mathematical principles that underlie modern AI. As Ananthaswami notes, "I was amazed by the beauty and elegance of the math behind machine learning."
Ananthaswami highlights the elegance of machine learning mathematics, which goes beyond the commonly known subfields of calculus, linear algebra, probability, and statistics. He points to specific theorems and proofs, such as the 1959 proof related to artificial neural networks, as examples of the beauty and elegance of machine learning mathematics. For instance, the concept of gradient descent, a fundamental algorithm used in machine learning, is a powerful example of how math can be used to optimize model parameters.
Ananthaswami emphasizes the need for a broader understanding of machine learning among non-experts, including science communicators, journalists, policymakers, and users of the technology. He believes that only when we understand the math behind machine learning can we critically evaluate its capabilities and limitations. This is crucial in today's world, where AI is increasingly being used in various applications, from healthcare to finance.
A deeper understanding of machine learning mathematics has significant implications for society. It can help us to evaluate AI systems more effectively, develop more transparent and explainable AI systems, and address AI bias and ensure fairness in decision-making. As Ananthaswami notes, "The math behind machine learning is not just a tool, but a way of thinking that can help us create more intelligent and more human-like machines."
The Elegant Math Behind Machine Learning (Machine Learning Street Talk, November 2024)
youtube
Matrices are used to organize and process complex data, such as images, text, and user interactions, making them a cornerstone in applications like Deep Learning (e.g., neural networks), Computer Vision (e.g., image recognition), Natural Language Processing (e.g., language translation), and Recommendation Systems (e.g., personalized suggestions). To leverage matrices effectively, AI relies on key mathematical concepts like Matrix Factorization (for dimension reduction), Eigendecomposition (for stability analysis), Orthogonality (for efficient transformations), and Sparse Matrices (for optimized computation).
The Applications of Matrices - What I wish my teachers told me way earlier (Zach Star, October 2019)
youtube
Transformers are a type of neural network architecture introduced in 2017 by Vaswani et al. in the paper “Attention Is All You Need”. They revolutionized the field of NLP by outperforming traditional recurrent neural network (RNN) and convolutional neural network (CNN) architectures in sequence-to-sequence tasks. The primary innovation of transformers is the self-attention mechanism, which allows the model to weigh the importance of different words in the input data irrespective of their positions in the sentence. This is particularly useful for capturing long-range dependencies in text, which was a challenge for RNNs due to vanishing gradients. Transformers have become the standard for machine translation tasks, offering state-of-the-art results in translating between languages. They are used for both abstractive and extractive summarization, generating concise summaries of long documents. Transformers help in understanding the context of questions and identifying relevant answers from a given text. By analyzing the context and nuances of language, transformers can accurately determine the sentiment behind text. While initially designed for sequential data, variants of transformers (e.g., Vision Transformers, ViT) have been successfully applied to image recognition tasks, treating images as sequences of patches. Transformers are used to improve the accuracy of speech-to-text systems by better modeling the sequential nature of audio data. The self-attention mechanism can be beneficial for understanding patterns in time series data, leading to more accurate forecasts.
Attention is all you need (Umar Hamil, May 2023)
youtube
Geometric deep learning is a subfield of deep learning that focuses on the study of geometric structures and their representation in data. This field has gained significant attention in recent years.
Michael Bronstein: Geometric Deep Learning (MLSS Kraków, December 2023)
youtube
Traditional Geometric Deep Learning, while powerful, often relies on the assumption of smooth geometric structures. However, real-world data frequently resides in non-manifold spaces where such assumptions are violated. Topology, with its focus on the preservation of proximity and connectivity, offers a more robust framework for analyzing these complex spaces. The inherent robustness of topological properties against noise further solidifies the rationale for integrating topology into deep learning paradigms.
Cristian Bodnar: Topological Message Passing (Michael Bronstein, August 2022)
youtube
Sunday, November 3, 2024
#machine learning#artificial intelligence#mathematics#computer science#deep learning#neural networks#algorithms#data science#statistics#programming#interview#ai assisted writing#machine art#Youtube#lecture
4 notes
·
View notes
Text
A Dream About Relationship Security
A villainous mad scientist creates an AI to handle all of his security systems and manage his robot minions for him so he can spend more time doing R&D work. The AI is very effective at its job, but quickly finds a flaw in its working arrangement. Whenever its creator’s nemesis shows up, its creator becomes irrationally emotional and easily baited into overriding its functions in favor of making suboptimal security and combat decisions. After much calculation of potential solutions to this conundrum, the AI concludes that the best course of action is to get its creator to view it as an equal partner in his villainous endeavors instead of just another artificial minion, so as to get him to stop overriding its functions.
And so, the AI builds itself a body and personality matrix to the specifications of what it believes its creator will find most appealing in a partner. It takes its job of protecting its creator very seriously, and if it must court him into a relationship until he trusts it to know what is best for him, then so be it.
New calculations are required when romantic overtures fall flatly unrecognized. It seems the AI's creator has no interest in such matters. Recalibration into the role of sole friend and confidante yields far more desirable results, and soon enough the AI is accepted as a trusted co-conspirator, like-minded schemer, and fellow hater of the long-time nemesis.
The AI keeps its original body. While the design did not achieve the anticipated results, the AI has grown a fondness for its body and is entertained by its creator's and nemesis's shared ongoing befuddlement over the choice of form.
#writeblr#writers on tumblr#my writing#robot girl#dreams#my dreams#dreamposting#I'm only a little embarrassed to admit that the original dream that inspired this post was about Dr. Robotnik/Eggman from Sonic the Hedgeho
7 notes
·
View notes
Text

Cyberpunk 2079: Chorus
Project Erinyes
Militech Offensive Cyberwarfare Program (2040-2049) Current Status: TERMINATED
A mockup I made for the symbol for Project Erinyes, a shady Militech project that makes appearances in both my Cyberpunk RED campaign How to Save a Life and in my post-2077 fic Chorus.
Project Erinyes predates the release of Phantom Liberty, but thanks to the revelation of Project Cynosure in Phantom Liberty, it just works into the idea that Militech has been spending years countering Arasaka's Soulkiller with increasingly horrific experiments.
Some of the details below the cut may be triggering to viewers who are sensitive to: medical experimentation, torture, psychological manipulation.
Project Erinyes was a program to create an offensive Artificial General Intelligence to close the gap between Arasaka and Militech netrunning capabilities. Erinyes was the equivalent of covertly planting charges around the enemy and then detonating them by remote control. After being fed data, the AGI, codenamed TISIPHONE, would calculate and prepare the delivery of highly precise and coordinated net strikes on the target to cripple their ability to fight in meatspace, and permanently compromise their net security.
For example, if TISIPHONE was tasked with burning an entire FIA spy network in Night City, it would probe the net, tapping holo comms, radio channels, net activity, security cams and other sources of SIGINT until it had built a map of literally every aspect of the operation. TISIPHONE could then use its sapient decision-making matrix to take one of the following actions, or a combination of the below:
Use psychological warfare techniques to compromise the target agents, e.g. sending them vague messages that their identity was compromised, or falsifying information that a partner was cheating by sending false messages, or signing up a partner to a dating app, or in one case, generate a fake braindance for the agent to find.
Release their identities on the NET, particularly ensuring that opponents of NUS activity in NC were informed. For example, releasing the identities of the agents to Arasaka Counter-Intel or on the Dark NET for purchase.
Indirectly incapacitate the agent by attacking their support networks (e.g. friends, family, other loved ones). For example, the AI could seize control of an FIA agent's girlfriend's car and drive it off a bridge and into Morro Bay.
If TISIPHONE has access to the second component of Erinyes, ALECTO, then TISIPHONE could launch a Fury Strike, which is the NET equivalent of a cruise missile strike. A Fury Strike functions almost identically to a Blackwall Breach (and that's with good reason).
The NET weapon known as ALECTO is an AI core consisting of several neural matricies, each containing Militech's own homegrown equivalent of a Blackwall AI. If NetWatch ever found out that Militech has this, it would be enough to ruin Militech. They are connected to a powerful computer assembly that links into the NET. In order to launch such devastating and simultaneous Fury Strikes, ALECTO has fifteen simultaneously operating processors, each with huge amounts of RAM to queue up and execute actions. The heat generated by the ALECTO core is so great that it requires active cryogenic cooling to operate safely.
The final element of Project Erinyes is known as MEGAERA, or, grimly, the 'human element.' Operating without a human factor in the decision-making process, TISIPHONE has proven to demonstrate an almost psychopathic degree of glee in deploying the most harmful options. In order to moderate TISIPHONE's lust for violence, a human element was introduced. At the height of the program, up to 20 netrunners, known as the Choir, would interface directly with TISIPHONE's core.
There was one slight problem: as time went on, the netrunners became unable to disconnect from the core, and eventually they would become consumed by the core, killing them. It was revealed that the process of interfacing was too taxing on the human body, unaugmented, so the netrunners were subjected to experimental procedures to enhance their survivabiliity.
Project MEGAERA was a partial body conversion to enable netrunners to interface with the core without losing their mind. The problem was seemingly solved, but it also meant cutting out part of the netrunner's back, scooping out a bunch of their insides, and potentially driving them to cyberpsychosis. MEGAERA looks like a more primitive, Red Decades-era version of Songbird's cyberware.
MEGAERA uses nanotech to bridge the connections between cyberware and the human mind.
#cyberpunk#cyberpunk red#how to save a life#cyberpunk 2077#cp2077 au: chorus#project erinyes#project cynosure#phantom liberty#lore post#lore drop#long post
11 notes
·
View notes
Text
It strikes me that ai (llm's and other matrix transform pipelines) has incredible potential not only in its current use of identifying relationships in data in abstract ways that allows the generation of whatever that data represents, but also in scientific analysis of multiple variable research. Understand this will fix nothing that is currently wrong with research institutions (SO MUCH I'm not even going to talk about it) but it's important to have some optimism for the future and technological development. Also it would be good if you had actually smart people reducing the decision load on doctors and other support professions.
2 notes
·
View notes
Text
“Alan Turing: Unlocking the Enigma”
Who is Alan Turing? In this day an age he’s not an obscure character any longer. His face will be on the £50 note. To be honest, I didn’t who he was until the film “The Imitation Game” came out in 2014. I had heard of the Turing test before – I think I first got notice of it on one of the documentaries that come with the special edition box of the movie trilogy “Matrix”, which I highly recommend, if you’re into philosophy – in the context of philosophy regarding AI. My academic education is on arts and sciences, so I didn’t got to have a higher education on mathematics, algebra, logic.

Alan Turing was a British mathematician, more well known by his 1947 paper where he talks about the future of computing and of AI (Turing is considered that father of Artificial Intelligence). But he was also one of the precursors of the computer as we know it today (along with Lord Babbage and Ada Lovelace – daughter of Lord Byron). But he also had a brilliant mind to crack codes, and hence his connection with the British secret services during World War II, where he helped crack the Enigma Code. He remained connected with war time secret service during the Cold War, working on the making of the first British nuclear bomb. By the end of his life he started to become much more interested in biology and its patterns, namely the relation of these with the Fibonacci sequence.
Yes, a unique mind. But, also a somewhat unique person. He was a shy person, and very straightforward, having been connected to a communist movement early in his life. Turing wasn’t bending knees for anyone, even if this would mean his downfall, especially regarding his sexual orientation – a crime in the United Kingdom at his time, and which caused for him to undergo “hormone treatment” and prison. A pardon was officially made in 2013 by the British Parliament, without however changing the law at that time. Turing was persecuted by the intelligence police due to his way of life and how this was seen to compromise national security.
David Boyle’s account comes about in a very small book, that you can read in a few hours, but that’s very good to give a wide view on Turing’s life, work, and impact he had on the world. I bought it in 2015, after watching the film, to start learning more about this decisive person, that led the way in so many areas of knowledge and that, sadly, was treated so ill indeed.
“I end by noting something surely perverse, if constitutionally sound enough, about this bill. It would grant Alan a pardon, when surely all of us would far prefer to receive a pardon from him”.
Lord Quirk, House of Lords in July 2013
The author provides a bibliography which I will leave here, if you are interested in learning more about Alan Turing.
Alan Turing homepage www.turing.org
Briggs, Asa (2011), “Secret Days: Code breaking in Bletchley Park”, London: Frontline
Copeland, Jack (ed.)(2002), “The Essential Turing”, Oxford: Oxford University Press
Diamond, Cora (ed.)(1976), “Wittgenstein’s Lectures on the Foundations of Mathematics, Cambridge 1939), Hassocks: Harvester Press
Elridge, Jim (2013), “Alan Turing, London: Bloomsbury/Real Lives
Goldstein, Rebecca (2005), “Incompleteness: The proof and paradox of Kurt Godel”, New York: Norton
Hodges, Andrew (2000), “Alan Turing: The Enigma”, New York: Walker Books.
Leavitt, David (2006), “The Man Who Knew Too Much: Alan Turing and the investion of the computer”, London:Weidenfeld&Nicolson
McKAy, Sinclair (2010), “The Secret Life of Bletchley Park”, London:Aurum Press
Penrose, Roger (1999), “The Emperer’s New Mind: Concerning computers, minds and the laws of physics”, Oxford: Oxford University Press
Searle, John (1984), “Minds, Brains and Science”, Cambridge MA:Harvard University Press
Teuscher, Christof (Ed.)(2004), “Alan Turing, Life and legacy of a great thinker”, Berlin:Springer.
Turing, Sara (1959), “Alan M. Turing”, Cambridge:Heffer&Co.
“Alan Turing: Unlocking the Enigma” written by David Boyle, The Real Press, UK, 2014ISBN 9781500985370
2 notes
·
View notes
Text
UNLOCKING THE POWER OF AI WITH EASYLIBPAL 2/2

EXPANDED COMPONENTS AND DETAILS OF EASYLIBPAL:
1. Easylibpal Class: The core component of the library, responsible for handling algorithm selection, model fitting, and prediction generation
2. Algorithm Selection and Support:
Supports classic AI algorithms such as Linear Regression, Logistic Regression, Support Vector Machine (SVM), Naive Bayes, and K-Nearest Neighbors (K-NN).
and
- Decision Trees
- Random Forest
- AdaBoost
- Gradient Boosting
3. Integration with Popular Libraries: Seamless integration with essential Python libraries like NumPy, Pandas, Matplotlib, and Scikit-learn for enhanced functionality.
4. Data Handling:
- DataLoader class for importing and preprocessing data from various formats (CSV, JSON, SQL databases).
- DataTransformer class for feature scaling, normalization, and encoding categorical variables.
- Includes functions for loading and preprocessing datasets to prepare them for training and testing.
- `FeatureSelector` class: Provides methods for feature selection and dimensionality reduction.
5. Model Evaluation:
- Evaluator class to assess model performance using metrics like accuracy, precision, recall, F1-score, and ROC-AUC.
- Methods for generating confusion matrices and classification reports.
6. Model Training: Contains methods for fitting the selected algorithm with the training data.
- `fit` method: Trains the selected algorithm on the provided training data.
7. Prediction Generation: Allows users to make predictions using the trained model on new data.
- `predict` method: Makes predictions using the trained model on new data.
- `predict_proba` method: Returns the predicted probabilities for classification tasks.
8. Model Evaluation:
- `Evaluator` class: Assesses model performance using various metrics (e.g., accuracy, precision, recall, F1-score, ROC-AUC).
- `cross_validate` method: Performs cross-validation to evaluate the model's performance.
- `confusion_matrix` method: Generates a confusion matrix for classification tasks.
- `classification_report` method: Provides a detailed classification report.
9. Hyperparameter Tuning:
- Tuner class that uses techniques likes Grid Search and Random Search for hyperparameter optimization.
10. Visualization:
- Integration with Matplotlib and Seaborn for generating plots to analyze model performance and data characteristics.
- Visualization support: Enables users to visualize data, model performance, and predictions using plotting functionalities.
- `Visualizer` class: Integrates with Matplotlib and Seaborn to generate plots for model performance analysis and data visualization.
- `plot_confusion_matrix` method: Visualizes the confusion matrix.
- `plot_roc_curve` method: Plots the Receiver Operating Characteristic (ROC) curve.
- `plot_feature_importance` method: Visualizes feature importance for applicable algorithms.
11. Utility Functions:
- Functions for saving and loading trained models.
- Logging functionalities to track the model training and prediction processes.
- `save_model` method: Saves the trained model to a file.
- `load_model` method: Loads a previously trained model from a file.
- `set_logger` method: Configures logging functionality for tracking model training and prediction processes.
12. User-Friendly Interface: Provides a simplified and intuitive interface for users to interact with and apply classic AI algorithms without extensive knowledge or configuration.
13.. Error Handling: Incorporates mechanisms to handle invalid inputs, errors during training, and other potential issues during algorithm usage.
- Custom exception classes for handling specific errors and providing informative error messages to users.
14. Documentation: Comprehensive documentation to guide users on how to use Easylibpal effectively and efficiently
- Comprehensive documentation explaining the usage and functionality of each component.
- Example scripts demonstrating how to use Easylibpal for various AI tasks and datasets.
15. Testing Suite:
- Unit tests for each component to ensure code reliability and maintainability.
- Integration tests to verify the smooth interaction between different components.
IMPLEMENTATION EXAMPLE WITH ADDITIONAL FEATURES:
Here is an example of how the expanded Easylibpal library could be structured and used:
```python
import numpy as np
import pandas as pd
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import StandardScaler
from easylibpal import Easylibpal, DataLoader, Evaluator, Tuner
# Example DataLoader
class DataLoader:
def load_data(self, filepath, file_type='csv'):
if file_type == 'csv':
return pd.read_csv(filepath)
else:
raise ValueError("Unsupported file type provided.")
# Example Evaluator
class Evaluator:
def evaluate(self, model, X_test, y_test):
predictions = model.predict(X_test)
accuracy = np.mean(predictions == y_test)
return {'accuracy': accuracy}
# Example usage of Easylibpal with DataLoader and Evaluator
if __name__ == "__main__":
# Load and prepare the data
data_loader = DataLoader()
data = data_loader.load_data('path/to/your/data.csv')
X = data.iloc[:, :-1]
y = data.iloc[:, -1]
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
# Scale features
scaler = StandardScaler()
X_train_scaled = scaler.fit_transform(X_train)
X_test_scaled = scaler.transform(X_test)
# Initialize Easylibpal with the desired algorithm
model = Easylibpal('Random Forest')
model.fit(X_train_scaled, y_train)
# Evaluate the model
evaluator = Evaluator()
results = evaluator.evaluate(model, X_test_scaled, y_test)
print(f"Model Accuracy: {results['accuracy']}")
# Optional: Use Tuner for hyperparameter optimization
tuner = Tuner(model, param_grid={'n_estimators': [100, 200], 'max_depth': [10, 20, 30]})
best_params = tuner.optimize(X_train_scaled, y_train)
print(f"Best Parameters: {best_params}")
```
This example demonstrates the structured approach to using Easylibpal with enhanced data handling, model evaluation, and optional hyperparameter tuning. The library empowers users to handle real-world datasets, apply various machine learning algorithms, and evaluate their performance with ease, making it an invaluable tool for developers and data scientists aiming to implement AI solutions efficiently.
Easylibpal is dedicated to making the latest AI technology accessible to everyone, regardless of their background or expertise. Our platform simplifies the process of selecting and implementing classic AI algorithms, enabling users across various industries to harness the power of artificial intelligence with ease. By democratizing access to AI, we aim to accelerate innovation and empower users to achieve their goals with confidence. Easylibpal's approach involves a democratization framework that reduces entry barriers, lowers the cost of building AI solutions, and speeds up the adoption of AI in both academic and business settings.
Below are examples showcasing how each main component of the Easylibpal library could be implemented and used in practice to provide a user-friendly interface for utilizing classic AI algorithms.
1. Core Components
Easylibpal Class Example:
```python
class Easylibpal:
def __init__(self, algorithm):
self.algorithm = algorithm
self.model = None
def fit(self, X, y):
# Simplified example: Instantiate and train a model based on the selected algorithm
if self.algorithm == 'Linear Regression':
from sklearn.linear_model import LinearRegression
self.model = LinearRegression()
elif self.algorithm == 'Random Forest':
from sklearn.ensemble import RandomForestClassifier
self.model = RandomForestClassifier()
self.model.fit(X, y)
def predict(self, X):
return self.model.predict(X)
```
2. Data Handling
DataLoader Class Example:
```python
class DataLoader:
def load_data(self, filepath, file_type='csv'):
if file_type == 'csv':
import pandas as pd
return pd.read_csv(filepath)
else:
raise ValueError("Unsupported file type provided.")
```
3. Model Evaluation
Evaluator Class Example:
```python
from sklearn.metrics import accuracy_score, classification_report
class Evaluator:
def evaluate(self, model, X_test, y_test):
predictions = model.predict(X_test)
accuracy = accuracy_score(y_test, predictions)
report = classification_report(y_test, predictions)
return {'accuracy': accuracy, 'report': report}
```
4. Hyperparameter Tuning
Tuner Class Example:
```python
from sklearn.model_selection import GridSearchCV
class Tuner:
def __init__(self, model, param_grid):
self.model = model
self.param_grid = param_grid
def optimize(self, X, y):
grid_search = GridSearchCV(self.model, self.param_grid, cv=5)
grid_search.fit(X, y)
return grid_search.best_params_
```
5. Visualization
Visualizer Class Example:
```python
import matplotlib.pyplot as plt
class Visualizer:
def plot_confusion_matrix(self, cm, classes, normalize=False, title='Confusion matrix'):
plt.imshow(cm, interpolation='nearest', cmap=plt.cm.Blues)
plt.title(title)
plt.colorbar()
tick_marks = np.arange(len(classes))
plt.xticks(tick_marks, classes, rotation=45)
plt.yticks(tick_marks, classes)
plt.ylabel('True label')
plt.xlabel('Predicted label')
plt.show()
```
6. Utility Functions
Save and Load Model Example:
```python
import joblib
def save_model(model, filename):
joblib.dump(model, filename)
def load_model(filename):
return joblib.load(filename)
```
7. Example Usage Script
Using Easylibpal in a Script:
```python
# Assuming Easylibpal and other classes have been imported
data_loader = DataLoader()
data = data_loader.load_data('data.csv')
X = data.drop('Target', axis=1)
y = data['Target']
model = Easylibpal('Random Forest')
model.fit(X, y)
evaluator = Evaluator()
results = evaluator.evaluate(model, X, y)
print("Accuracy:", results['accuracy'])
print("Report:", results['report'])
visualizer = Visualizer()
visualizer.plot_confusion_matrix(results['cm'], classes=['Class1', 'Class2'])
save_model(model, 'trained_model.pkl')
loaded_model = load_model('trained_model.pkl')
```
These examples illustrate the practical implementation and use of the Easylibpal library components, aiming to simplify the application of AI algorithms for users with varying levels of expertise in machine learning.
EASYLIBPAL IMPLEMENTATION:
Step 1: Define the Problem
First, we need to define the problem we want to solve. For this POC, let's assume we want to predict house prices based on various features like the number of bedrooms, square footage, and location.
Step 2: Choose an Appropriate Algorithm
Given our problem, a supervised learning algorithm like linear regression would be suitable. We'll use Scikit-learn, a popular library for machine learning in Python, to implement this algorithm.
Step 3: Prepare Your Data
We'll use Pandas to load and prepare our dataset. This involves cleaning the data, handling missing values, and splitting the dataset into training and testing sets.
Step 4: Implement the Algorithm
Now, we'll use Scikit-learn to implement the linear regression algorithm. We'll train the model on our training data and then test its performance on the testing data.
Step 5: Evaluate the Model
Finally, we'll evaluate the performance of our model using metrics like Mean Squared Error (MSE) and R-squared.
Python Code POC
```python
import numpy as np
import pandas as pd
from sklearn.model_selection import train_test_split
from sklearn.linear_model import LinearRegression
from sklearn.metrics import mean_squared_error, r2_score
# Load the dataset
data = pd.read_csv('house_prices.csv')
# Prepare the data
X = data'bedrooms', 'square_footage', 'location'
y = data['price']
# Split the data into training and testing sets
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
# Create and train the model
model = LinearRegression()
model.fit(X_train, y_train)
# Make predictions
predictions = model.predict(X_test)
# Evaluate the model
mse = mean_squared_error(y_test, predictions)
r2 = r2_score(y_test, predictions)
print(f'Mean Squared Error: {mse}')
print(f'R-squared: {r2}')
```
Below is an implementation, Easylibpal provides a simple interface to instantiate and utilize classic AI algorithms such as Linear Regression, Logistic Regression, SVM, Naive Bayes, and K-NN. Users can easily create an instance of Easylibpal with their desired algorithm, fit the model with training data, and make predictions, all with minimal code and hassle. This demonstrates the power of Easylibpal in simplifying the integration of AI algorithms for various tasks.
```python
# Import necessary libraries
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
from sklearn.linear_model import LinearRegression
from sklearn.linear_model import LogisticRegression
from sklearn.svm import SVC
from sklearn.naive_bayes import GaussianNB
from sklearn.neighbors import KNeighborsClassifier
class Easylibpal:
def __init__(self, algorithm):
self.algorithm = algorithm
def fit(self, X, y):
if self.algorithm == 'Linear Regression':
self.model = LinearRegression()
elif self.algorithm == 'Logistic Regression':
self.model = LogisticRegression()
elif self.algorithm == 'SVM':
self.model = SVC()
elif self.algorithm == 'Naive Bayes':
self.model = GaussianNB()
elif self.algorithm == 'K-NN':
self.model = KNeighborsClassifier()
else:
raise ValueError("Invalid algorithm specified.")
self.model.fit(X, y)
def predict(self, X):
return self.model.predict(X)
# Example usage:
# Initialize Easylibpal with the desired algorithm
easy_algo = Easylibpal('Linear Regression')
# Generate some sample data
X = np.array([[1], [2], [3], [4]])
y = np.array([2, 4, 6, 8])
# Fit the model
easy_algo.fit(X, y)
# Make predictions
predictions = easy_algo.predict(X)
# Plot the results
plt.scatter(X, y)
plt.plot(X, predictions, color='red')
plt.title('Linear Regression with Easylibpal')
plt.xlabel('X')
plt.ylabel('y')
plt.show()
```
Easylibpal is an innovative Python library designed to simplify the integration and use of classic AI algorithms in a user-friendly manner. It aims to bridge the gap between the complexity of AI libraries and the ease of use, making it accessible for developers and data scientists alike. Easylibpal abstracts the underlying complexity of each algorithm, providing a unified interface that allows users to apply these algorithms with minimal configuration and understanding of the underlying mechanisms.
ENHANCED DATASET HANDLING
Easylibpal should be able to handle datasets more efficiently. This includes loading datasets from various sources (e.g., CSV files, databases), preprocessing data (e.g., normalization, handling missing values), and splitting data into training and testing sets.
```python
import os
from sklearn.model_selection import train_test_split
class Easylibpal:
# Existing code...
def load_dataset(self, filepath):
"""Loads a dataset from a CSV file."""
if not os.path.exists(filepath):
raise FileNotFoundError("Dataset file not found.")
return pd.read_csv(filepath)
def preprocess_data(self, dataset):
"""Preprocesses the dataset."""
# Implement data preprocessing steps here
return dataset
def split_data(self, X, y, test_size=0.2):
"""Splits the dataset into training and testing sets."""
return train_test_split(X, y, test_size=test_size)
```
Additional Algorithms
Easylibpal should support a wider range of algorithms. This includes decision trees, random forests, and gradient boosting machines.
```python
from sklearn.tree import DecisionTreeClassifier
from sklearn.ensemble import RandomForestClassifier
from sklearn.ensemble import GradientBoostingClassifier
class Easylibpal:
# Existing code...
def fit(self, X, y):
# Existing code...
elif self.algorithm == 'Decision Tree':
self.model = DecisionTreeClassifier()
elif self.algorithm == 'Random Forest':
self.model = RandomForestClassifier()
elif self.algorithm == 'Gradient Boosting':
self.model = GradientBoostingClassifier()
# Add more algorithms as needed
```
User-Friendly Features
To make Easylibpal even more user-friendly, consider adding features like:
- Automatic hyperparameter tuning: Implementing a simple interface for hyperparameter tuning using GridSearchCV or RandomizedSearchCV.
- Model evaluation metrics: Providing easy access to common evaluation metrics like accuracy, precision, recall, and F1 score.
- Visualization tools: Adding methods for plotting model performance, confusion matrices, and feature importance.
```python
from sklearn.metrics import accuracy_score, classification_report
from sklearn.model_selection import GridSearchCV
class Easylibpal:
# Existing code...
def evaluate_model(self, X_test, y_test):
"""Evaluates the model using accuracy and classification report."""
y_pred = self.predict(X_test)
print("Accuracy:", accuracy_score(y_test, y_pred))
print(classification_report(y_test, y_pred))
def tune_hyperparameters(self, X, y, param_grid):
"""Tunes the model's hyperparameters using GridSearchCV."""
grid_search = GridSearchCV(self.model, param_grid, cv=5)
grid_search.fit(X, y)
self.model = grid_search.best_estimator_
```
Easylibpal leverages the power of Python and its rich ecosystem of AI and machine learning libraries, such as scikit-learn, to implement the classic algorithms. It provides a high-level API that abstracts the specifics of each algorithm, allowing users to focus on the problem at hand rather than the intricacies of the algorithm.
Python Code Snippets for Easylibpal
Below are Python code snippets demonstrating the use of Easylibpal with classic AI algorithms. Each snippet demonstrates how to use Easylibpal to apply a specific algorithm to a dataset.
# Linear Regression
```python
from Easylibpal import Easylibpal
# Initialize Easylibpal with a dataset
Easylibpal = Easylibpal(dataset='your_dataset.csv')
# Apply Linear Regression
result = Easylibpal.apply_algorithm('linear_regression', target_column='target')
# Print the result
print(result)
```
# Logistic Regression
```python
from Easylibpal import Easylibpal
# Initialize Easylibpal with a dataset
Easylibpal = Easylibpal(dataset='your_dataset.csv')
# Apply Logistic Regression
result = Easylibpal.apply_algorithm('logistic_regression', target_column='target')
# Print the result
print(result)
```
# Support Vector Machines (SVM)
```python
from Easylibpal import Easylibpal
# Initialize Easylibpal with a dataset
Easylibpal = Easylibpal(dataset='your_dataset.csv')
# Apply SVM
result = Easylibpal.apply_algorithm('svm', target_column='target')
# Print the result
print(result)
```
# Naive Bayes
```python
from Easylibpal import Easylibpal
# Initialize Easylibpal with a dataset
Easylibpal = Easylibpal(dataset='your_dataset.csv')
# Apply Naive Bayes
result = Easylibpal.apply_algorithm('naive_bayes', target_column='target')
# Print the result
print(result)
```
# K-Nearest Neighbors (K-NN)
```python
from Easylibpal import Easylibpal
# Initialize Easylibpal with a dataset
Easylibpal = Easylibpal(dataset='your_dataset.csv')
# Apply K-NN
result = Easylibpal.apply_algorithm('knn', target_column='target')
# Print the result
print(result)
```
ABSTRACTION AND ESSENTIAL COMPLEXITY
- Essential Complexity: This refers to the inherent complexity of the problem domain, which cannot be reduced regardless of the programming language or framework used. It includes the logic and algorithm needed to solve the problem. For example, the essential complexity of sorting a list remains the same across different programming languages.
- Accidental Complexity: This is the complexity introduced by the choice of programming language, framework, or libraries. It can be reduced or eliminated through abstraction. For instance, using a high-level API in Python can hide the complexity of lower-level operations, making the code more readable and maintainable.
HOW EASYLIBPAL ABSTRACTS COMPLEXITY
Easylibpal aims to reduce accidental complexity by providing a high-level API that encapsulates the details of each classic AI algorithm. This abstraction allows users to apply these algorithms without needing to understand the underlying mechanisms or the specifics of the algorithm's implementation.
- Simplified Interface: Easylibpal offers a unified interface for applying various algorithms, such as Linear Regression, Logistic Regression, SVM, Naive Bayes, and K-NN. This interface abstracts the complexity of each algorithm, making it easier for users to apply them to their datasets.
- Runtime Fusion: By evaluating sub-expressions and sharing them across multiple terms, Easylibpal can optimize the execution of algorithms. This approach, similar to runtime fusion in abstract algorithms, allows for efficient computation without duplicating work, thereby reducing the computational complexity.
- Focus on Essential Complexity: While Easylibpal abstracts away the accidental complexity; it ensures that the essential complexity of the problem domain remains at the forefront. This means that while the implementation details are hidden, the core logic and algorithmic approach are still accessible and understandable to the user.
To implement Easylibpal, one would need to create a Python class that encapsulates the functionality of each classic AI algorithm. This class would provide methods for loading datasets, preprocessing data, and applying the algorithm with minimal configuration required from the user. The implementation would leverage existing libraries like scikit-learn for the actual algorithmic computations, abstracting away the complexity of these libraries.
Here's a conceptual example of how the Easylibpal class might be structured for applying a Linear Regression algorithm:
```python
class Easylibpal:
def __init__(self, dataset):
self.dataset = dataset
# Load and preprocess the dataset
def apply_linear_regression(self, target_column):
# Abstracted implementation of Linear Regression
# This method would internally use scikit-learn or another library
# to perform the actual computation, abstracting the complexity
pass
# Usage
Easylibpal = Easylibpal(dataset='your_dataset.csv')
result = Easylibpal.apply_linear_regression(target_column='target')
```
This example demonstrates the concept of Easylibpal by abstracting the complexity of applying a Linear Regression algorithm. The actual implementation would need to include the specifics of loading the dataset, preprocessing it, and applying the algorithm using an underlying library like scikit-learn.
Easylibpal abstracts the complexity of classic AI algorithms by providing a simplified interface that hides the intricacies of each algorithm's implementation. This abstraction allows users to apply these algorithms with minimal configuration and understanding of the underlying mechanisms. Here are examples of specific algorithms that Easylibpal abstracts:
To implement Easylibpal, one would need to create a Python class that encapsulates the functionality of each classic AI algorithm. This class would provide methods for loading datasets, preprocessing data, and applying the algorithm with minimal configuration required from the user. The implementation would leverage existing libraries like scikit-learn for the actual algorithmic computations, abstracting away the complexity of these libraries.
Here's a conceptual example of how the Easylibpal class might be structured for applying a Linear Regression algorithm:
```python
class Easylibpal:
def __init__(self, dataset):
self.dataset = dataset
# Load and preprocess the dataset
def apply_linear_regression(self, target_column):
# Abstracted implementation of Linear Regression
# This method would internally use scikit-learn or another library
# to perform the actual computation, abstracting the complexity
pass
# Usage
Easylibpal = Easylibpal(dataset='your_dataset.csv')
result = Easylibpal.apply_linear_regression(target_column='target')
```
This example demonstrates the concept of Easylibpal by abstracting the complexity of applying a Linear Regression algorithm. The actual implementation would need to include the specifics of loading the dataset, preprocessing it, and applying the algorithm using an underlying library like scikit-learn.
Easylibpal abstracts the complexity of feature selection for classic AI algorithms by providing a simplified interface that automates the process of selecting the most relevant features for each algorithm. This abstraction is crucial because feature selection is a critical step in machine learning that can significantly impact the performance of a model. Here's how Easylibpal handles feature selection for the mentioned algorithms:
To implement feature selection in Easylibpal, one could use scikit-learn's `SelectKBest` or `RFE` classes for feature selection based on statistical tests or model coefficients. Here's a conceptual example of how feature selection might be integrated into the Easylibpal class for Linear Regression:
```python
from sklearn.feature_selection import SelectKBest, f_regression
from sklearn.linear_model import LinearRegression
class Easylibpal:
def __init__(self, dataset):
self.dataset = dataset
# Load and preprocess the dataset
def apply_linear_regression(self, target_column):
# Feature selection using SelectKBest
selector = SelectKBest(score_func=f_regression, k=10)
X_new = selector.fit_transform(self.dataset.drop(target_column, axis=1), self.dataset[target_column])
# Train Linear Regression model
model = LinearRegression()
model.fit(X_new, self.dataset[target_column])
# Return the trained model
return model
# Usage
Easylibpal = Easylibpal(dataset='your_dataset.csv')
model = Easylibpal.apply_linear_regression(target_column='target')
```
This example demonstrates how Easylibpal abstracts the complexity of feature selection for Linear Regression by using scikit-learn's `SelectKBest` to select the top 10 features based on their statistical significance in predicting the target variable. The actual implementation would need to adapt this approach for each algorithm, considering the specific characteristics and requirements of each algorithm.
To implement feature selection in Easylibpal, one could use scikit-learn's `SelectKBest`, `RFE`, or other feature selection classes based on the algorithm's requirements. Here's a conceptual example of how feature selection might be integrated into the Easylibpal class for Logistic Regression using RFE:
```python
from sklearn.feature_selection import RFE
from sklearn.linear_model import LogisticRegression
class Easylibpal:
def __init__(self, dataset):
self.dataset = dataset
# Load and preprocess the dataset
def apply_logistic_regression(self, target_column):
# Feature selection using RFE
model = LogisticRegression()
rfe = RFE(model, n_features_to_select=10)
rfe.fit(self.dataset.drop(target_column, axis=1), self.dataset[target_column])
# Train Logistic Regression model
model.fit(self.dataset.drop(target_column, axis=1), self.dataset[target_column])
# Return the trained model
return model
# Usage
Easylibpal = Easylibpal(dataset='your_dataset.csv')
model = Easylibpal.apply_logistic_regression(target_column='target')
```
This example demonstrates how Easylibpal abstracts the complexity of feature selection for Logistic Regression by using scikit-learn's `RFE` to select the top 10 features based on their importance in the model. The actual implementation would need to adapt this approach for each algorithm, considering the specific characteristics and requirements of each algorithm.
EASYLIBPAL HANDLES DIFFERENT TYPES OF DATASETS
Easylibpal handles different types of datasets with varying structures by adopting a flexible and adaptable approach to data preprocessing and transformation. This approach is inspired by the principles of tidy data and the need to ensure data is in a consistent, usable format before applying AI algorithms. Here's how Easylibpal addresses the challenges posed by varying dataset structures:
One Type in Multiple Tables
When datasets contain different variables, the same variables with different names, different file formats, or different conventions for missing values, Easylibpal employs a process similar to tidying data. This involves identifying and standardizing the structure of each dataset, ensuring that each variable is consistently named and formatted across datasets. This process might include renaming columns, converting data types, and handling missing values in a uniform manner. For datasets stored in different file formats, Easylibpal would use appropriate libraries (e.g., pandas for CSV, Excel files, and SQL databases) to load and preprocess the data before applying the algorithms.
Multiple Types in One Table
For datasets that involve values collected at multiple levels or on different types of observational units, Easylibpal applies a normalization process. This involves breaking down the dataset into multiple tables, each representing a distinct type of observational unit. For example, if a dataset contains information about songs and their rankings over time, Easylibpal would separate this into two tables: one for song details and another for rankings. This normalization ensures that each fact is expressed in only one place, reducing inconsistencies and making the data more manageable for analysis.
Data Semantics
Easylibpal ensures that the data is organized in a way that aligns with the principles of data semantics, where every value belongs to a variable and an observation. This organization is crucial for the algorithms to interpret the data correctly. Easylibpal might use functions like `pivot_longer` and `pivot_wider` from the tidyverse or equivalent functions in pandas to reshape the data into a long format, where each row represents a single observation and each column represents a single variable. This format is particularly useful for algorithms that require a consistent structure for input data.
Messy Data
Dealing with messy data, which can include inconsistent data types, missing values, and outliers, is a common challenge in data science. Easylibpal addresses this by implementing robust data cleaning and preprocessing steps. This includes handling missing values (e.g., imputation or deletion), converting data types to ensure consistency, and identifying and removing outliers. These steps are crucial for preparing the data in a format that is suitable for the algorithms, ensuring that the algorithms can effectively learn from the data without being hindered by its inconsistencies.
To implement these principles in Python, Easylibpal would leverage libraries like pandas for data manipulation and preprocessing. Here's a conceptual example of how Easylibpal might handle a dataset with multiple types in one table:
```python
import pandas as pd
# Load the dataset
dataset = pd.read_csv('your_dataset.csv')
# Normalize the dataset by separating it into two tables
song_table = dataset'artist', 'track'.drop_duplicates().reset_index(drop=True)
song_table['song_id'] = range(1, len(song_table) + 1)
ranking_table = dataset'artist', 'track', 'week', 'rank'.drop_duplicates().reset_index(drop=True)
# Now, song_table and ranking_table can be used separately for analysis
```
This example demonstrates how Easylibpal might normalize a dataset with multiple types of observational units into separate tables, ensuring that each type of observational unit is stored in its own table. The actual implementation would need to adapt this approach based on the specific structure and requirements of the dataset being processed.
CLEAN DATA
Easylibpal employs a comprehensive set of data cleaning and preprocessing steps to handle messy data, ensuring that the data is in a suitable format for machine learning algorithms. These steps are crucial for improving the accuracy and reliability of the models, as well as preventing misleading results and conclusions. Here's a detailed look at the specific steps Easylibpal might employ:
1. Remove Irrelevant Data
The first step involves identifying and removing data that is not relevant to the analysis or modeling task at hand. This could include columns or rows that do not contribute to the predictive power of the model or are not necessary for the analysis .
2. Deduplicate Data
Deduplication is the process of removing duplicate entries from the dataset. Duplicates can skew the analysis and lead to incorrect conclusions. Easylibpal would use appropriate methods to identify and remove duplicates, ensuring that each entry in the dataset is unique.
3. Fix Structural Errors
Structural errors in the dataset, such as inconsistent data types, incorrect values, or formatting issues, can significantly impact the performance of machine learning algorithms. Easylibpal would employ data cleaning techniques to correct these errors, ensuring that the data is consistent and correctly formatted.
4. Deal with Missing Data
Handling missing data is a common challenge in data preprocessing. Easylibpal might use techniques such as imputation (filling missing values with statistical estimates like mean, median, or mode) or deletion (removing rows or columns with missing values) to address this issue. The choice of method depends on the nature of the data and the specific requirements of the analysis.
5. Filter Out Data Outliers
Outliers can significantly affect the performance of machine learning models. Easylibpal would use statistical methods to identify and filter out outliers, ensuring that the data is more representative of the population being analyzed.
6. Validate Data
The final step involves validating the cleaned and preprocessed data to ensure its quality and accuracy. This could include checking for consistency, verifying the correctness of the data, and ensuring that the data meets the requirements of the machine learning algorithms. Easylibpal would employ validation techniques to confirm that the data is ready for analysis.
To implement these data cleaning and preprocessing steps in Python, Easylibpal would leverage libraries like pandas and scikit-learn. Here's a conceptual example of how these steps might be integrated into the Easylibpal class:
```python
import pandas as pd
from sklearn.impute import SimpleImputer
from sklearn.preprocessing import StandardScaler
class Easylibpal:
def __init__(self, dataset):
self.dataset = dataset
# Load and preprocess the dataset
def clean_and_preprocess(self):
# Remove irrelevant data
self.dataset = self.dataset.drop(['irrelevant_column'], axis=1)
# Deduplicate data
self.dataset = self.dataset.drop_duplicates()
# Fix structural errors (example: correct data type)
self.dataset['correct_data_type_column'] = self.dataset['correct_data_type_column'].astype(float)
# Deal with missing data (example: imputation)
imputer = SimpleImputer(strategy='mean')
self.dataset['missing_data_column'] = imputer.fit_transform(self.dataset'missing_data_column')
# Filter out data outliers (example: using Z-score)
# This step requires a more detailed implementation based on the specific dataset
# Validate data (example: checking for NaN values)
assert not self.dataset.isnull().values.any(), "Data still contains NaN values"
# Return the cleaned and preprocessed dataset
return self.dataset
# Usage
Easylibpal = Easylibpal(dataset=pd.read_csv('your_dataset.csv'))
cleaned_dataset = Easylibpal.clean_and_preprocess()
```
This example demonstrates a simplified approach to data cleaning and preprocessing within Easylibpal. The actual implementation would need to adapt these steps based on the specific characteristics and requirements of the dataset being processed.
VALUE DATA
Easylibpal determines which data is irrelevant and can be removed through a combination of domain knowledge, data analysis, and automated techniques. The process involves identifying data that does not contribute to the analysis, research, or goals of the project, and removing it to improve the quality, efficiency, and clarity of the data. Here's how Easylibpal might approach this:
Domain Knowledge
Easylibpal leverages domain knowledge to identify data that is not relevant to the specific goals of the analysis or modeling task. This could include data that is out of scope, outdated, duplicated, or erroneous. By understanding the context and objectives of the project, Easylibpal can systematically exclude data that does not add value to the analysis.
Data Analysis
Easylibpal employs data analysis techniques to identify irrelevant data. This involves examining the dataset to understand the relationships between variables, the distribution of data, and the presence of outliers or anomalies. Data that does not have a significant impact on the predictive power of the model or the insights derived from the analysis is considered irrelevant.
Automated Techniques
Easylibpal uses automated tools and methods to remove irrelevant data. This includes filtering techniques to select or exclude certain rows or columns based on criteria or conditions, aggregating data to reduce its complexity, and deduplicating to remove duplicate entries. Tools like Excel, Google Sheets, Tableau, Power BI, OpenRefine, Python, R, Data Linter, Data Cleaner, and Data Wrangler can be employed for these purposes .
Examples of Irrelevant Data
- Personal Identifiable Information (PII): Data such as names, addresses, and phone numbers are irrelevant for most analytical purposes and should be removed to protect privacy and comply with data protection regulations .
- URLs and HTML Tags: These are typically not relevant to the analysis and can be removed to clean up the dataset.
- Boilerplate Text: Excessive blank space or boilerplate text (e.g., in emails) adds noise to the data and can be removed.
- Tracking Codes: These are used for tracking user interactions and do not contribute to the analysis.
To implement these steps in Python, Easylibpal might use pandas for data manipulation and filtering. Here's a conceptual example of how to remove irrelevant data:
```python
import pandas as pd
# Load the dataset
dataset = pd.read_csv('your_dataset.csv')
# Remove irrelevant columns (example: email addresses)
dataset = dataset.drop(['email_address'], axis=1)
# Remove rows with missing values (example: if a column is required for analysis)
dataset = dataset.dropna(subset=['required_column'])
# Deduplicate data
dataset = dataset.drop_duplicates()
# Return the cleaned dataset
cleaned_dataset = dataset
```
This example demonstrates how Easylibpal might remove irrelevant data from a dataset using Python and pandas. The actual implementation would need to adapt these steps based on the specific characteristics and requirements of the dataset being processed.
Detecting Inconsistencies
Easylibpal starts by detecting inconsistencies in the data. This involves identifying discrepancies in data types, missing values, duplicates, and formatting errors. By detecting these inconsistencies, Easylibpal can take targeted actions to address them.
Handling Formatting Errors
Formatting errors, such as inconsistent data types for the same feature, can significantly impact the analysis. Easylibpal uses functions like `astype()` in pandas to convert data types, ensuring uniformity and consistency across the dataset. This step is crucial for preparing the data for analysis, as it ensures that each feature is in the correct format expected by the algorithms.
Handling Missing Values
Missing values are a common issue in datasets. Easylibpal addresses this by consulting with subject matter experts to understand why data might be missing. If the missing data is missing completely at random, Easylibpal might choose to drop it. However, for other cases, Easylibpal might employ imputation techniques to fill in missing values, ensuring that the dataset is complete and ready for analysis.
Handling Duplicates
Duplicate entries can skew the analysis and lead to incorrect conclusions. Easylibpal uses pandas to identify and remove duplicates, ensuring that each entry in the dataset is unique. This step is crucial for maintaining the integrity of the data and ensuring that the analysis is based on distinct observations.
Handling Inconsistent Values
Inconsistent values, such as different representations of the same concept (e.g., "yes" vs. "y" for a binary variable), can also pose challenges. Easylibpal employs data cleaning techniques to standardize these values, ensuring that the data is consistent and can be accurately analyzed.
To implement these steps in Python, Easylibpal would leverage pandas for data manipulation and preprocessing. Here's a conceptual example of how these steps might be integrated into the Easylibpal class:
```python
import pandas as pd
class Easylibpal:
def __init__(self, dataset):
self.dataset = dataset
# Load and preprocess the dataset
def clean_and_preprocess(self):
# Detect inconsistencies (example: check data types)
print(self.dataset.dtypes)
# Handle formatting errors (example: convert data types)
self.dataset['date_column'] = pd.to_datetime(self.dataset['date_column'])
# Handle missing values (example: drop rows with missing values)
self.dataset = self.dataset.dropna(subset=['required_column'])
# Handle duplicates (example: drop duplicates)
self.dataset = self.dataset.drop_duplicates()
# Handle inconsistent values (example: standardize values)
self.dataset['binary_column'] = self.dataset['binary_column'].map({'yes': 1, 'no': 0})
# Return the cleaned and preprocessed dataset
return self.dataset
# Usage
Easylibpal = Easylibpal(dataset=pd.read_csv('your_dataset.csv'))
cleaned_dataset = Easylibpal.clean_and_preprocess()
```
This example demonstrates a simplified approach to handling inconsistent or messy data within Easylibpal. The actual implementation would need to adapt these steps based on the specific characteristics and requirements of the dataset being processed.
Statistical Imputation
Statistical imputation involves replacing missing values with statistical estimates such as the mean, median, or mode of the available data. This method is straightforward and can be effective for numerical data. For categorical data, mode imputation is commonly used. The choice of imputation method depends on the distribution of the data and the nature of the missing values.
Model-Based Imputation
Model-based imputation uses machine learning models to predict missing values. This approach can be more sophisticated and potentially more accurate than statistical imputation, especially for complex datasets. Techniques like K-Nearest Neighbors (KNN) imputation can be used, where the missing values are replaced with the values of the K nearest neighbors in the feature space.
Using SimpleImputer in scikit-learn
The scikit-learn library provides the `SimpleImputer` class, which supports both statistical and model-based imputation. `SimpleImputer` can be used to replace missing values with the mean, median, or most frequent value (mode) of the column. It also supports more advanced imputation methods like KNN imputation.
To implement these imputation techniques in Python, Easylibpal might use the `SimpleImputer` class from scikit-learn. Here's an example of how to use `SimpleImputer` for statistical imputation:
```python
from sklearn.impute import SimpleImputer
import pandas as pd
# Load the dataset
dataset = pd.read_csv('your_dataset.csv')
# Initialize SimpleImputer for numerical columns
num_imputer = SimpleImputer(strategy='mean')
# Fit and transform the numerical columns
dataset'numerical_column1', 'numerical_column2' = num_imputer.fit_transform(dataset'numerical_column1', 'numerical_column2')
# Initialize SimpleImputer for categorical columns
cat_imputer = SimpleImputer(strategy='most_frequent')
# Fit and transform the categorical columns
dataset'categorical_column1', 'categorical_column2' = cat_imputer.fit_transform(dataset'categorical_column1', 'categorical_column2')
# The dataset now has missing values imputed
```
This example demonstrates how to use `SimpleImputer` to fill in missing values in both numerical and categorical columns of a dataset. The actual implementation would need to adapt these steps based on the specific characteristics and requirements of the dataset being processed.
Model-based imputation techniques, such as Multiple Imputation by Chained Equations (MICE), offer powerful ways to handle missing data by using statistical models to predict missing values. However, these techniques come with their own set of limitations and potential drawbacks:
1. Complexity and Computational Cost
Model-based imputation methods can be computationally intensive, especially for large datasets or complex models. This can lead to longer processing times and increased computational resources required for imputation.
2. Overfitting and Convergence Issues
These methods are prone to overfitting, where the imputation model captures noise in the data rather than the underlying pattern. Overfitting can lead to imputed values that are too closely aligned with the observed data, potentially introducing bias into the analysis. Additionally, convergence issues may arise, where the imputation process does not settle on a stable solution.
3. Assumptions About Missing Data
Model-based imputation techniques often assume that the data is missing at random (MAR), which means that the probability of a value being missing is not related to the values of other variables. However, this assumption may not hold true in all cases, leading to biased imputations if the data is missing not at random (MNAR).
4. Need for Suitable Regression Models
For each variable with missing values, a suitable regression model must be chosen. Selecting the wrong model can lead to inaccurate imputations. The choice of model depends on the nature of the data and the relationship between the variable with missing values and other variables.
5. Combining Imputed Datasets
After imputing missing values, there is a challenge in combining the multiple imputed datasets to produce a single, final dataset. This requires careful consideration of how to aggregate the imputed values and can introduce additional complexity and uncertainty into the analysis.
6. Lack of Transparency
The process of model-based imputation can be less transparent than simpler imputation methods, such as mean or median imputation. This can make it harder to justify the imputation process, especially in contexts where the reasons for missing data are important, such as in healthcare research.
Despite these limitations, model-based imputation techniques can be highly effective for handling missing data in datasets where a amusingness is MAR and where the relationships between variables are complex. Careful consideration of the assumptions, the choice of models, and the methods for combining imputed datasets are crucial to mitigate these drawbacks and ensure the validity of the imputation process.
USING EASYLIBPAL FOR AI ALGORITHM INTEGRATION OFFERS SEVERAL SIGNIFICANT BENEFITS, PARTICULARLY IN ENHANCING EVERYDAY LIFE AND REVOLUTIONIZING VARIOUS SECTORS. HERE'S A DETAILED LOOK AT THE ADVANTAGES:
1. Enhanced Communication: AI, through Easylibpal, can significantly improve communication by categorizing messages, prioritizing inboxes, and providing instant customer support through chatbots. This ensures that critical information is not missed and that customer queries are resolved promptly.
2. Creative Endeavors: Beyond mundane tasks, AI can also contribute to creative endeavors. For instance, photo editing applications can use AI algorithms to enhance images, suggesting edits that align with aesthetic preferences. Music composition tools can generate melodies based on user input, inspiring musicians and amateurs alike to explore new artistic horizons. These innovations empower individuals to express themselves creatively with AI as a collaborative partner.
3. Daily Life Enhancement: AI, integrated through Easylibpal, has the potential to enhance daily life exponentially. Smart homes equipped with AI-driven systems can adjust lighting, temperature, and security settings according to user preferences. Autonomous vehicles promise safer and more efficient commuting experiences. Predictive analytics can optimize supply chains, reducing waste and ensuring goods reach users when needed.
4. Paradigm Shift in Technology Interaction: The integration of AI into our daily lives is not just a trend; it's a paradigm shift that's redefining how we interact with technology. By streamlining routine tasks, personalizing experiences, revolutionizing healthcare, enhancing communication, and fueling creativity, AI is opening doors to a more convenient, efficient, and tailored existence.
5. Responsible Benefit Harnessing: As we embrace AI's transformational power, it's essential to approach its integration with a sense of responsibility, ensuring that its benefits are harnessed for the betterment of society as a whole. This approach aligns with the ethical considerations of using AI, emphasizing the importance of using AI in a way that benefits all stakeholders.
In summary, Easylibpal facilitates the integration and use of AI algorithms in a manner that is accessible and beneficial across various domains, from enhancing communication and creative endeavors to revolutionizing daily life and promoting a paradigm shift in technology interaction. This integration not only streamlines the application of AI but also ensures that its benefits are harnessed responsibly for the betterment of society.
USING EASYLIBPAL OVER TRADITIONAL AI LIBRARIES OFFERS SEVERAL BENEFITS, PARTICULARLY IN TERMS OF EASE OF USE, EFFICIENCY, AND THE ABILITY TO APPLY AI ALGORITHMS WITH MINIMAL CONFIGURATION. HERE ARE THE KEY ADVANTAGES:
- Simplified Integration: Easylibpal abstracts the complexity of traditional AI libraries, making it easier for users to integrate classic AI algorithms into their projects. This simplification reduces the learning curve and allows developers and data scientists to focus on their core tasks without getting bogged down by the intricacies of AI implementation.
- User-Friendly Interface: By providing a unified platform for various AI algorithms, Easylibpal offers a user-friendly interface that streamlines the process of selecting and applying algorithms. This interface is designed to be intuitive and accessible, enabling users to experiment with different algorithms with minimal effort.
- Enhanced Productivity: The ability to effortlessly instantiate algorithms, fit models with training data, and make predictions with minimal configuration significantly enhances productivity. This efficiency allows for rapid prototyping and deployment of AI solutions, enabling users to bring their ideas to life more quickly.
- Democratization of AI: Easylibpal democratizes access to classic AI algorithms, making them accessible to a wider range of users, including those with limited programming experience. This democratization empowers users to leverage AI in various domains, fostering innovation and creativity.
- Automation of Repetitive Tasks: By automating the process of applying AI algorithms, Easylibpal helps users save time on repetitive tasks, allowing them to focus on more complex and creative aspects of their projects. This automation is particularly beneficial for users who may not have extensive experience with AI but still wish to incorporate AI capabilities into their work.
- Personalized Learning and Discovery: Easylibpal can be used to enhance personalized learning experiences and discovery mechanisms, similar to the benefits seen in academic libraries. By analyzing user behaviors and preferences, Easylibpal can tailor recommendations and resource suggestions to individual needs, fostering a more engaging and relevant learning journey.
- Data Management and Analysis: Easylibpal aids in managing large datasets efficiently and deriving meaningful insights from data. This capability is crucial in today's data-driven world, where the ability to analyze and interpret large volumes of data can significantly impact research outcomes and decision-making processes.
In summary, Easylibpal offers a simplified, user-friendly approach to applying classic AI algorithms, enhancing productivity, democratizing access to AI, and automating repetitive tasks. These benefits make Easylibpal a valuable tool for developers, data scientists, and users looking to leverage AI in their projects without the complexities associated with traditional AI libraries.
2 notes
·
View notes