#AI training datasets
Explore tagged Tumblr posts
Visit Tumblr Blog
Explore Tumblr blogs with no restrictions, modern design and the best experience.
Last Seen Tumblr Blogs





Fun Fact
Celebrities use Tumblr as well.
Text
Training AI using copyrighted datasets leading to lawsuits
0 notes
Text
De-Identified Medical Imaging Data for AI & Clinical Research | Segmed
Access millions of de-identified medical imaging studies with Segmed, empowering life sciences and technology industries to accelerate AI development and clinical research.
#De-identified medical imaging data#AI training datasets#Clinical research data#RWID#Medical Imaging Data#real world imaging#life science#real world data#radiology#real world evidence
0 notes
Text
Evolution of AI Training Data: From Data Origins to Intelligent Horizons

With the rise of AI in people’s lives, the need to acknowledge good training data has not been more significant in the past. AI, ML, and Big data play an important role in various industries including government, corporate, science, and more.
The AI market has been expanding like wildfire. AI Market size was 1.3 billion USD in 2021. It is expected to grow to a whopping 2.8 trillion by 2023, according to McKinsey Global Survey. According to IBM, 35% of companies are already using AI and 45% of companies are exploring AI to adopt them in the future.
Even though AI and ML are quite a buzzing topic nowadays, the “thing” that fuels AI and ML remains under the shadow. AI Training data is something that trains the AI to function in the manner it should. And the quality of data matters a lot in this respect.
In this blog, we’ll explore the evolution of AI training dataset, understand what qualifies as a quality dataset, and dive into its past, present, and future.
What is AI Training Data? — In Simple Terms
Training data is a set of carefully curated information that is fed to a system for training. The quality of training data fed to any system determines the AI’s success. Better quality data means better intelligence of the computer or system.
While training any data, loads of information are fed to the system. For example, for teaching the system about cats, a whole lot of cat images, videos, characteristic info, etc will be provided to the system. So, when the system encounters any such information or visuals about a cat, it understands that it’s a cat, and provides more information about the cat from its database if needed.
This also means that the data must be so accurate and diversified, that the system must not confuse every four-legged animal as a cat.
So, AI training data is like training a child. Kids are taught language by labeling A, B, C, D, etc. Similarly, the Machine is also trained about the information by feeding data to it.
What is the Definition of AI Training Data?
A collection of labeled data fed into the machine-learning algorithm to enable it to make accurate predictions is called AI training data. On the basis of the data, the ML system tries to identify, recognize, and understand the relations between different components and make necessary decisions by evaluating them.
So, for enhancing the overall quality of machine learning, the data fed to it must be both in large quantity and good quality. The data must be unbiased, diversified, and valuable. Also, it needs to be well-structured, annotated, and labeled training data.
The Three Phases of AI Training Data
Let’s dive into the timeline of AI Training data evolution.
The beginning phase of AI Training Data
The beginning phase of AI Training data was sans Machine learning. That is, humans (programmers) manually created new rules to create accurate module outputs by evaluating the existing module outputs. This was the 1990s.
During 2000–2005, Machine learning began to rise. The first major database was created, which was not very efficient. It was slow and expensive and relied on the resources.
From 2005 to 2010, Amazon’s MTurk entered the playground and provided a widely-available platform for developing datasets at scale.
2010–2015 encountered human labeling and annotation. Human non-programmers evaluated the medium output and annotated data. It was this time when deep learning models came into play, known as data-hungry neural models.
Since 2015, Adoptive models began to rise. That means a system needs small datasets for making predictions. They do that by linking this small information with the pre-existing information. These state-of-the-art pre-trained adaptive models became available to others for free.
AI and ML are becoming more accessible to people other than programmers such as analysts, business owners, decision, and policymakers, or simply people who are interested in AI and ML. The non-programmers can evaluate the data models too, without the need for complex AI models.
Quality over Quantity: Previously, the quantity of data was given value. It was thought that more quantity means accuracy in module output. With time scientists realized that for accurate results, quality matters more, such as data completeness, reliability, validity, availability, and timeliness.
What was lacking in early AI Training data? A combination of poor training data and a lack of advanced computer systems resulted in the early AI system fiasco.
The lack of quality training data resulted in faulty recognition of visuals. Due to the lack of speech datasets, spoken language recognition did not come to fruition too. Additionally, computers at that time did not have good storage capacities, which was one of the major setbacks in recording large datasets essential for machine learning.
Quality AI Training Data: The Transition
In order to upgrade to a better Machine learning process, It was crucial that systems learn to mimic human intelligence and make decisions like them. This needed to thrive on high-quality and high-quantity data.
For better recognition of patterns and accurate decisions, a data sample that contains all the possible variables is needed.
Need for Quality Training Data For the advancement in AI Technology, quality AI Training data is needed. In order for ML models to be reliable, there is a need for efficient data collection, annotation, and labeling methodologies.
Quality Data Collection, Filtering, and Accuracy Data needs to go through iterative data refining steps to draw accurate outcomes. An ML model needs, thousands of accurately labeled and annotated information and visuals to link its trained information with the information existing in the real world. That’s when it provides accurate results.
The ML algorithm ML will render useless if the data is not reliable.
Need for Data Diversity and Representative Training Data In today’s world, even humans are scorned for being biased. Then it is crucial that the machines are unbiased, just, and competent. This goal could be achieved by gathering diverse information globally. A homogenous dataset will serve only a particular group of people when it is structured to serve “humans”. A biased model would be considered an inaccurate model.
The curated data needs to be annotated and labeled with diverse information that is balanced and represents the diverse population.
AI Training Data: The Future
Although both the quantity and quality of data are relevant, the relationship between quantity and quality of data differs with each prompt.
Data Collection and Annotation Techniques Breakthrough There need to be effective policies for data collection and annotation, in order to derive accurate results. These policies are needed to minimize faulty output or errors such as inaccurate content, misrepresentation, incomplete measurements, data duplication, errors in data collection, erroneous measurements, and curation errors.
There are various methods of accurate data collection including data mining, web scraping, data extraction, and crowdsourcing.
Ethical Values in Training Data Training data collection is prone to various ethical issues such as bias, non-consent, lack of transparency, and vulnerable data privacy.
Data now contains vulnerable data including facial images, voice recordings, fingerprints, and other sensitive biometric data that puts people’s crucial data at risk. Thus, it is important to adhere to ethical and legal processes to maintain a healthy environment and avoid lawsuits.
Potential for Improved Quality and Diverse Training Data With time, the relevance and adoption of AI are only going to become more pronounced. The credit goes to awareness and interest in promoting high-quality AI growth and a vast number of AI data providers.
The present times encounter data providers that use advanced technologies to derive high-quality, diversified, ethical, and legal data. These are also adept at accurately labeling, annotating, and customizing data for different ML projects.
The Bottom Line
In order to create top-notch AI models, businesses or institutes needs to collaborate with organizations that have an accurate and reliable understanding of data and how to integrate it.
Globose Technology Solutions Pvt Ltd is a leading vendor of high-quality data to train and validate your systems to execute your AI projects effectively and efficiently. Partner with us and experience reliability and competency at their best. Previous
0 notes
Text

AI training datasets is a comprehensive and curated collection of structured and/or unstructured data specifically designed for machine learning (ML) purposes. It serves as a vital resource for training, validating, and testing ML algorithms and models
0 notes
Text
i want to be in your dataset. put me in your dataset. let me innnnnn
#i love filling out surveys and being part of studies and getting my work included in ai training data#like haha yesss i get to be part of the people who statisticly represent all of my demographic#currently like right this second i'm in a study where i'm representing several thousand people#i'm so powerful and fucking up this dataset spectacularly with my powerfully abnormal behavior lol#anyway hope you all enjoy being represented by me 💪#natalie does textposts
12 notes
·
View notes
Text
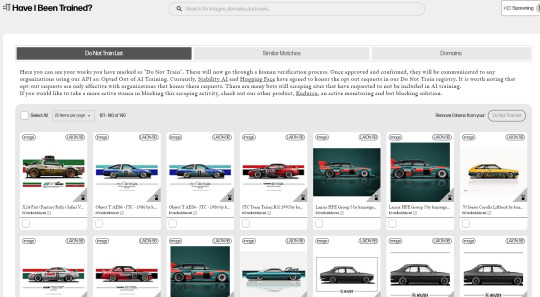
Just a heads up to any non AI artists that use red bubble (among many more). They are allowing your work to be used by the LAION-5B data set for use in AI training. haveibeentrained.com is free to use
9 notes
·
View notes
Text
I loooooove trying to find a picture of a certain fish's fins because they're so hard to see and multiple images are both AI generated and completely fucking wrong!
#i fucking hate gen. ai and i do think youre a bad person if youve heard that the companies behind them steal data from#actual writers and artists to train from not to mention the environmental impact. its unethical as hell and unless youre using your own#device to generate things based on your own dataset created by you its not going to be anywhere near ethical. if you used to use it and#dont anymore thats one thing because people grow and change or whatever but if youre still using it what the hell.#anyway fuck generative ai all my homies hate generative ai#i cant wait for generative ai to cannibalize itself and crash and burn#anyway shrimp ai rant over back to sunshine and rainbows and blood and gore and gay robots and angels
4 notes
·
View notes
Text
in my job i sometimes use ai to create deep learning models to automatically detect objects in aerial photographs. essentially this is training a computer to do a satellite captcha where it wants so find sidewalks. this kind of ai is what is actually helpful bc there are terabytes upon terabytes of aerial photography and all kinds of 3d elevation data that would be near impossible for us to analyze on our own. ai in this case is doing a job that you couldnt feasibly hire staff to do
#noaa has a dataset showing landuse/landcover for every coastal state and ALL of alaska that they plan on updating every 5 years#this data at a 1 meter scale wouldnt be possible without ai algorithms trained to detect pavement#and houses and foliage and then break down what TYPE of foliage it is based on laser reflectivity#like this is amazing stuff that actually has good use cases in adapting to climate change#chat gpt tho? no way
2 notes
·
View notes
Text
dipping my toe into fandom discourse here, which is never a great idea, but—i really am baffled by the contingent of fans who apparently want AO3 to not only denounce but ban AI-generated works, as if there were any reliable way to distinguish between mediocre writing produced by a human and mediocre writing produced by an AI…?
#i saw someone say elsewhere‚ and agree‚ that all a ban would accomplish wld be to discourage fans who make use of AI from indicating as much#i do personally think the best writing won't be by AIs#or at least‚ it'll have been edited with a fine-toothed comb by a human who's got a really good sense of style and story themself#such that they could've produced the writing unaided‚ and the AI armature is just a crutch#but imo the big issues with AI are like. (1) the dataset it gets trained on—#though like. human artists *also* view other people's art and incorporate it into their body of influences‚ tbh?#we just get mad when they copy someone else's work TOO directly. but it's in their heads informing the art they produce!—#and (2) its potential to put humans out of work—which i have *huge* sympathy for‚ but also… that's been true of every machine ever invented#(also like. fandom is a gift economy‚ not paid work‚ so that aspect of things literally doesn't apply in an AO3 context.)#but like people have brought up the luddites in connection with this and. yeah.#ultimately there's always still a place for human operators and human oversight and human curation of the machines' raw output#and so ultimately i think we'll just have to work out what that place will be in this context#and in the meantime—i'd hope people would disclose when work has been created using AI#which they absolutely *won't* do if sites are out there banning it! people who want to use it will still use it‚ and just lie!#like you can say 'but then you don't get the satisfaction of knowing you're being praised for work *you* did‚ bc the AI did it!'#'surely that sense of being an impostor will discourage people!'#but like. hello. i've seen (and reported) multiple *very clear* instances of fic plagiarism.#the fact that those 'authors' were getting praised for‚ not only work they didn't do‚ but *someone else's* work‚ did not deter them!#saw someone going 'AO3 has its particular set of organizing principles & that's valid! we should just make our own sites where we ban AI!'#and like. hello: if your mini-archive gets popular enough that ppl want to be part of it‚ posters who use AI *will* just lie to you???#(i'm curious abt the overlap between that camp and users who think DNIs are effective‚ lol.)#anyway.#Fannish Ethical Concerns
9 notes
·
View notes
Text
Well in the end it comes down to recognizing when you can’t have a good faith conversation. I can understand the arguments being made and where it comes from but I fundamentally disagree with some of the foundations of these beliefs and will not budge. Nuance necessitates some alignment, I think.
#my ramblings#at this moment I don’t think you can separate the conversation of ai as a tool from the CURRENT ONGOING ethical issues#this isn’t theoretical it is right now for real being used in a specific way#if you’re curating your own datasets (??) for training (???) obviously there are ways to address it#but the major tools being used#are largely unethical full stop#and go beyond ‘unethical but you kind of can accept it and it’s necessary for day-to-day life’#in my opinion at least#there are ai tools that can be used without exploiting artists#like yknow filters or some of those color tools or van gogh generator#van gogh’s dead so it’s not really exploitation of his art unless it’s like. I dunno. sold as if it were a commission#instead of an ai generated product#plus I feel like some of the arguments I’ve read frame things in kinda weird way#like artists are gatekeeping art rather than developing their skills#and there are unproductive ways to frame arguments that raise concerns about ai#but making it about the argument rather than the tool is missing the forest for the trees#well yknow how it is#I simply won’t see those takes anymore
9 notes
·
View notes
Text
i think there's definitely potential for artists to use ai art in their own work. ai is a tool, and artists will definitely find ways to use it in their creative process. the problem for me is when tech dudebros (and inevitably larger corporations) completely ignore what makes art art, use ai to completely replace any human artists, and claim that they are artists for typing a sentence into a text field
#there are also issues with where ai gets its datasets#it should be getting it from stock images public domain works and people who volunteer stuff#but instead it's taking its training images from stuff that includes the work of still-living often poor artists#idk man i'm just thinking out loud here#fiona talks
2 notes
·
View notes
Text
I see non scientific staff at my workplace thinking they can use generative LLM ai to generate boilerplate documents and operating procedures, and then I, as science and laboratory staff, point out how the documents it generates are direct life safety hazards if followed, and fix them, and remind them that I do not have time for this, and that if I did this as a scientist to write science, it would directly cost me my job.
(However, my right wing government, in a pacific rim nation that regularly experiences earthquakes, volcanoes, tropical and subtropical storms, and tsunamis, has just forced 1/5 of staff at my workplace, the national geoscience agency that does the critical national research and science infrastructure to respond to these events, to be disestablished/redundant, while giving hundreds of millions in tax kickbacks to their tobacco company and other corporate mates, so I'm pretty cynical about their motives and wish them all the success in using AI to replace us that they deserve...)
I don't talk about it much but I do work at Google and I just want to contribute, as a small addendum to the wider conversation about AI, and how much it sucks, and how stupid it is, and how if you make garlic oil like it tells you to you will give botulism to your entire family -
we don't use it.
like internally. we don't use it.
I mean that we don't use it for anything. because we know it's years away from being better than human judgment in basically any way. sometimes they try to encourage us to use it, for low stakes things, like drafting an e-mail or something. and mostly we don't.
we are the ones MAKING AI and SELLING AI and we don't actually use AI because we know it sucks.
stocks are up through so that's something
#ai isnt.#ai is a grift#ai when imposed for staff/budget/corporate reasons is useless#It has good uses when done for tightly constrained reasons on carefully defined training datasets by people with ethics. Emphasis on ethic
15K notes
·
View notes
Text
AI training datasets is a comprehensive and curated collection of structured and/or unstructured data specifically designed for machine learning (ML) purposes. It serves as a vital resource for training, validating, and testing ML algorithms and models
0 notes
Text
"AI Engorgement" refers to the phenomenon where an AI model absorbs too much misinformation in its training data. This corrupts the model's base truth, leading to strange glitches. An engorged image model, when prompted to create images for "cat" and "historical", generated the following:


AI Engorgement may trigger a complete dissolution of truth within a model, leading it to back conspiracy theories, clearly debunked facts, and mistake fiction for reality. It is believed that the systematic siphoning of unreality by AI datasets is already revealing signs of engorgement in every major model.
21K notes
·
View notes
Text
making this poll on behalf of a non-tumblr friend of mine who works with content moderation for a server & other back-end developer jobs who wants an artist(s) perspective on the issue re: AI & non-generative, non LLM usage. from his understanding, the issue with AI & artists is that (generative) AI that scrapes artists' work & generates content is that it's art theft/exploitative & otherwise undermines and discredits creative's hard work, input, etc.
*for example, an ethical reason might be for preventing NSFW images (porn, gore, etc) that violate TOS on a 13+ website, but an unethical use might be aiding in facial recognition software. how you define "ethical" versus "unethical" is up to you. his original example: scraping a site that hosts NSFW images/comics to train a model to detect NSFW image uploads on a kid-friendly website that violate TOS or flag NSFW uploads into a kid-friendly Discord server where human moderators may not be able to keep up in a high-activity channel or in a "raid."
#text#ai ethics#polls#anti generative ai#to be clear: i as an artist am against generative AI but i see the value in creating training datasets#long post
0 notes
Text
So...every single one of my fics except for my crack one were scraped. Fuck, that's so disappointing.
Anyway, if you've posted any work on ao3, I highly recommend using the tools linked here if you want to know if your fic(s) got scraped this March.
Alright! Sorry for being so absent today! I was building a tool so you can all check your own names on demand.
I am asking that you not talk about it on Hugging Face. I'm sure word will get there eventually, but I'd like to avoid them accessing this as much as possible. Feel absolutely free to spread around Tumblr.
AO3 search tool is here! Use page 1 to search scraped fics by username. Use page 2 to search by work ID (which you'll need to do if you're looking for an anonymous work).
Or you can use this version, which is strongly recommended if you've published more than about 20 fics on the username you're searching.
If you're unsure which to use:
The first link is better if your entire username is a common word. For example, if you're username is just "bread" then you probably can't search yourself in the second link. The first version is way slower, so I recommend trying the second link first and using the first link as a backup option if the second fails.
The first link contains a page to search by work ID. This is good if you have an anonymous or orphaned fic, since that's not going to appear by searching your username.
The second link is better if you have a LOT of fics. It will give you a count of fics so you don't have to add them up. It will show the top 2,000 work results found.
If you have more than 2,000 published works, first off, I am jealous of your motivation. But second, that won't display right on the public version of the tools. You can send an ask or DM to have me do a custom search for you if you have more than 2,000 total works under 1 username.
You can also ask or DM if your entire username is a common word, because you're likely to get drowned out of the search results in that case. Try the tool first, but if it returns a lot of author results for your search, and YOUR name isn't in the results, ask me! There's a decent chance you're in there, but one of the tool's weak points is searching extremely common words.
In case this post breaches containment: this is a tool that only has access to the work IDs, titles, author names, chapter counts, and hit counts of the scraped fics for this most recent scrape discovered in April 2025. There is no other work data in this tool. This never had the content of your works loaded to it, only info to help you check if your works were scraped. If you need additional metadata, I can search my offline copy for you if you share a work ID number and tell me what data you're looking for. I will never search the full work text for anyone, but I can check things like word counts and tags.
Please come yell if the tool stops working, and I'll fix as fast as I can. Version 1 is slow as hell, but it does load eventually. Give it up to 10 minutes, and if it seems down after that, please alert me via ask! Anons are on if you're shy. Version 2 typically loads results within 1 minute and handles most users well.
On mobile, enable screen rotation and turn your phone sideways. It's a litttttle easier to use like that. It works better if you can use desktop.
Some FAQs below the cut:
"What do I need to do now?": At this time, the main place where this dataset was shared is disabled. As far as I'm aware, you don't need to do anything, but I'll update if I hear otherwise. If you're worried about getting scraped again, locking your fics to users only is NOT a guarantee, but it's a little extra protection. There are methods that can protect you more, but those will come at a cost of hiding your works from more potential readers as well.
"I don't want to know!": This tool is 100% optional. If you don't want to know, simply don't click the link. You are totally welcome to block me if it makes you feel more comfortable.
"Can I see the exact content they scraped?": Nope, not through me. I don't have the time to vet every single person to make sure they are who they say they are, and I don't want to risk giving a scraped copy of your fic to anyone else. If you really want to see this, you can find the info out there still and look it up yourself, but I can't be the one to do it for you.
"Are locked fics safe?": Not safe, but so far, it appears that locked fics were scraped less often than public fics. The only fics I haven't seen scraped as of right now are fics in unrevealed collections, which even logged-in users can't view without permission from the owner.
"My work wasn't a fic. It was an image/video/podfic.": You're safe! All the scrape got was stuff like the tags you used and your title and author name. The work content itself is a blank gap.
"It's slow.": Unfortunately, a 13 million row data dashboard is always going to be on the slow side. I think I've done everything I can to speed it up, but it may still take up to 10 minutes to load. It's faster if you can use desktop, but it should work on your phone too.
"My fic isn't there.": If it was published after March 15th, 2025, that was likely after all of the scraping took place. Otherwise, from what I can tell so far, the scraper's code just... wasn't very good, so most likely, your fic was missed by random chance. I am continuing to look for methods to reduce the chances of a work getting scraped anyway, and I will share on this blog if/when I find something that works.
Thanks to everyone who helped with the cost to host the tool! I appreciate you so so so much. As of this edit, I've received more donations than what I paid to make this tool so you do NOT need to keep sending money. (But I super appreciate everyone who did help fund this! I just wanna make sure we all know it's all paid for now.)
(Made some quick edits to the post on 04-May-2025 to update information a bit!)
#300k words...and now it could potentially be used to train AI#sigh. anyway#I know the ao3 legal team is already working hard on making the dataset permanently inaccessible#but DAMN if this isn’t kind of soul crushing#I HATE AIIIII#fanfiction writer#fanfiction#ao3 author#ao3#ao3 fanfic#writing community#writeblr
4K notes
·
View notes