#Azure Data Science
Explore tagged Tumblr posts
Visit Tumblr Blog
Explore Tumblr blogs with no restrictions, modern design and the best experience.
Last Seen Tumblr Blogs





Fun Fact
Tumblr’s reach among the 26-to-35-year-olds in the US is 11%.
Text
Azure Machine Learning Services
QServices company is a cloud-based solution offering a range of specialized services for Azure Machine Learning. Our team for Azure ML provides several advantages, particularly for organizations looking to enhance their machine learning workflows. To get more information contact us:- (888) 721-3517
0 notes
Text
"In the world of data, Azure Data Factory transforms chaos into clarity, orchestrating workflows that drive insights."
0 notes
Text
I want to learn AWS from scratch, but I'm not familiar with it and unsure where to start. Can anyone recommend good resources for beginners? Looking for structured courses, tutorials, or hands-on labs that can help me build a strong foundation.
If you know any resources then plz let me know.
Thanks 🍬
#aws#cloudcomputing#learnaws#awsforbeginners#techlearning#cloudskills#microsoft#azure#python#technology#tech#tech world#tech workers#machine learning#artificial intelligence#cloud services#AI#deep learning#coding#IT#computer science#data scientist#data analytics#data engineering#data#march 2025#mysql#powerbi#numpy#pandas
1 note
·
View note
Text
#data science#data scientist#data scientists#aritificial intelligence#optical character recognition#ocr#azure#cloud computing#computer vision
16 notes
·
View notes
Text
Ahmedabad's Emerging Tech Landscape: Unlocking Local Opportunities with DevOps Training
The city of Ahmedabad has crossed milestones towards becoming a full-fledged IT hub, and now professionals with industry-relevant skills in this area have increased in high demand. This alone can help any professional be ahead of the competition by specializing in some important areas like DevOps, cloud computing, and containerization. Here's how targeted training in such courses introduces fresh career opportunities locally.
In recent times, Ahmedabad has witnessed an increase in tech startups, established IT firms, and offers for digital transformation services. This set off an increase in qualified persons who can supervise complex IT systems, enhance operations, and design viable automation processes. In this regard, DevOps has been given a prime position among the skills that any tech person aspiring to build a career must possess.
Trained professionals stand to make the best out of their local job market, making a significant contribution to the region's growing perception as a technology hub.
Found a solid skill set over DevOps courses in Ahmedabad
Not only has the field of DevOps increasingly pitched itself as one of the pillars for potential prosperity in software development and IT operations, without fail. Joining DevOps Classes in Ahmedabad is a practical measure learners will take to make a good crash course for them in initiation into the basics of automation, integration, and continuous deployment. These classes come with hands-on training in real-time and shared cloud environments to grasp workflows, control versions, and improve the delivery cycle for software.
Advance Your Career by Earning a Microsoft Azure Certification in Ahmedabad
Cloud technology has become the backbone for digital transformation, and getting a Microsoft Azure Certification in Ahmedabad can give professionals a significant advantage. The accreditation concealments cloud architecture, virtual networks, storage, and security. In addition, the learners become proficient in managing Azure resources, enabling businesses to deploy and scale cloud solutions quickly.
Adopting Containerization with a Docker Course in Ahmedabad
Containerization is altering the world of application development and distribution. This Docker Course Ahmedabad reveals how containers can be created, run, and managed with Docker. It examines the methods used to configure containers, the various networking alternatives, and the advantages of having a flexible and mobile infrastructure. This will work best for application developers and system admins interested in developing better and more powerful applications.
During the swift growth of Ahmedabad becoming a technology hub, acquiring specialized skills like DevOps, Azure, and Docker would create useful career opportunities. You also require quality training programs to equip you to meet the demands of this emerging industry. Take the next step today in your tech career- explore our training programs and start your journey with Highsky IT Solutions toward becoming an industry-ready professional!
#linux certification ahmedabad#red hat certification ahmedabad#linux online courses in ahmedabad#data science training ahmedabad#rhce rhcsa training ahmedabad#aws security training ahmedabad#docker training ahmedabad#red hat training ahmedabad#microsoft azure cloud certification#python courses in ahmedabad
1 note
·
View note
Text
Another rant, I don't think making these AI models to handle everything ever is a good idea fundamentally either. They become too big to house outside of their original companies this way, requiring a reliance on their web services. They risk bringing up risky topics in conversations completely unrelated to such topics.
When making models specifically tailored to one task or group, the model is smaller, it can be deployed easier in a small-scale capacity, and it can remove the risk of risky biznu coming up in unrelated conversations.
But, that way, you're not required to be linked to these companies forever. You could go outside of AWS, GCP, Azure, etc. for your AI needs. They won't have that. Not after throwing millions to billions to build the models.
#ai#artificial intelligence#data science#computer science#google#gcp#amazon#aws#microsoft#openai#azure#opinion#risk assessment
0 notes
Text
Top 5 In-Demand DevOps Roles and Their Salaries in 2025
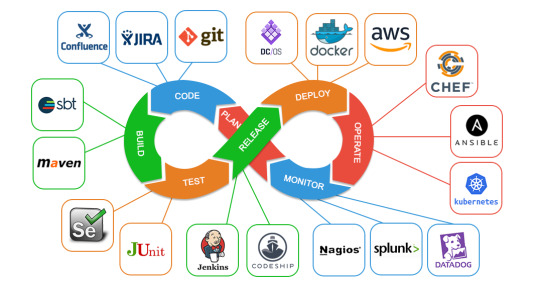
The DevOps field continues to see massive growth in 2025 as organizations across industries prioritize automation, collaboration, and scalability. Here’s a look at the top 5 in-demand DevOps roles, their responsibilities, and salary trends.
1. DevOps Engineer
Role Overview: The cornerstone of any DevOps team, DevOps Engineers manage CI/CD pipelines, ensure system automation, and streamline collaboration between development and operations teams.
Skills Required: Proficiency in Jenkins, Git, Docker, Kubernetes, and scripting languages like Python or Bash.
Salary Trends (2025):
Freshers: ₹6–8 LPA
Experienced: ₹15–20 LPA
2. Site Reliability Engineer (SRE)
Role Overview: SREs focus on maintaining system reliability and improving application performance by blending engineering and operations expertise.
Skills Required: Knowledge of monitoring tools (Prometheus, Grafana), incident management, and system architecture.
Salary Trends (2025):
Entry-Level: ₹7–10 LPA
Experienced: ₹18–25 LPA
3. Cloud Engineer
Role Overview: Cloud Engineers design, manage, and optimize cloud infrastructure, ensuring it is secure, scalable, and cost-effective.
Skills Required: Hands-on experience with AWS, Azure, or Google Cloud, along with infrastructure as code (IaC) tools like Terraform or Ansible.
Salary Trends (2025):
Beginners: ₹8–12 LPA
Senior Professionals: ₹20–30 LPA
4. Kubernetes Specialist
Role Overview: As businesses increasingly adopt containerization, Kubernetes Specialists manage container orchestration to ensure smooth deployments and scalability.
Skills Required: Deep understanding of Kubernetes, Helm, Docker, and microservices architecture.
Salary Trends (2025):
Mid-Level: ₹8–15 LPA
Senior-Level: ₹18–25 LPA
5. DevSecOps Engineer
Role Overview: DevSecOps Engineers integrate security practices within the DevOps lifecycle, ensuring robust systems from development to deployment.
Skills Required: Expertise in security tools, vulnerability assessment, and compliance frameworks.
Salary Trends (2025):
Early Career: ₹9–14 LPA
Experienced Professionals: ₹22–30 LPA
Upskill for Your Dream Role
The demand for DevOps professionals in 2025 is higher than ever. With the right skills and certifications, you can land these lucrative roles.
At Syntax Minds, we offer comprehensive DevOps training programs to equip you with the tools and expertise needed to excel. Our job-oriented courses are available both offline and online, tailored for fresh graduates and working professionals.
Visit Us: Flat No. 202, 2nd Floor, Vanijya Complex, Beside VRK Silks, KPHB, Hyderabad - 500085
Contact: 📞 9642000668, 9642000669 📧 [email protected]
Start your journey today with Syntax Minds and take your career to new heights!
#artificial intelligence#data science#deep learning#data analytics#machine learning#DevOps#Cloud#AWS#AZURE#data scientist
0 notes
Text
Today is day, one of studying for the Microsoft Azure, AI fundamentals and my plan of attack us slowly, but surely go through the material and then take the test.
0 notes
Text
What Part Do MERN Stack and Software Testing Play in Contemporary Development?

Software testing & knowledge of the MERN stack are getting more & more significant for software engineers in today's technologically modern society. The requirement for skilled developers & testers who understand the complete development lifecycle—from software testing in software engineering to using contemporary tech stacks—is increasing as companies pursue inventions. Furthermore, cloud platforms like amazon web servis and an understanding of data science are essential for developing scalable, effective apps. Let's examine how data science, the MERN stack, and software testing abilities contribute to a prosperous tech career.
Software Testing's Significance in Software Engineering
In software engineering, software testing guarantees the dependability and quality of software products. Testing ensures that programs are operating as intended and free of serious problems, as users demand flawless experiences. SW testers are experts who focus on this procedure. SW tester examine programs using soft test methodologies that identify and fix defects early in the development cycle using a variety of software testing software.
The foundation of creating high-quality software is testing procedures including functionality, performance, and security checks. Performance testing verifies how the program responds in various scenarios, while functional testing makes sure features function as intended. Security testing verifies that data is shielded from potential dangers, which is crucial in today's digital environment. Gaining proficiency in these methods guarantees the creation of dependable applications and lays the groundwork for success in positions centred on testing.
Let’s get aware about MERN stack full form
One well-liked technological stack for web development is the MERN stack. The 4 main technologies that make mern full form are MongoDB, Express.js, React, & Node.js. Node.js is a JavaScript duration that permits server-side progression; Express.js is a web application structure for Node.js; React.js is a client-side library for making user links; & MongoDB is a NoSQL database famous for its flexibility. The MERN stack is preferable between full-stack engineers since all of its elements function collectively perfectly.
Effective, dynamic, and scalable applications can be made by developers that comprehend the MERN stack in its entirety. The MERN stack eliminates the need for distinct frontend and backend teams by covering both frontend and backend development, enabling developers to manage whole projects. Because of its adaptability, MERN stack expertise is highly valued in the field.
Synergy between MERN Stack and Software Testing
Professionals can develop dependable and effective apps by combining their knowledge of the MERN stack with software testing abilities. Developers can guarantee the performance and stability of every component of the application by implementing test soft practices in MERN-based applications. By testing the MongoDB, Express, React, and Node.js components of the MERN stack, possible problems can be identified early on, resulting in seamless user experiences and fewer failures after deployment. Applications that are reliable and easy to use are the outcome of the collaboration between software testing and MERN stack development.
Examining Amazon Web Services and Data Science Courses
Courses in data science are a great supplement to a software professional's skill set because data is essential to today's software development. Developers and testers may make data-informed decisions by learning the fundamentals of data analysis, machine learning, and data visualisation in a datascience course. Tech workers that understand data science are able to optimise apps using actual user data and gradually enhance functionality.
Another useful resource for developers is Amazon Web Services (AWS). Cloud-based services from AWS facilitate data storage, deployment, and development. Teams may host apps, manage databases, and carry out automated testing in safe, scalable environments by incorporating AWS into development workflows. Large data management, workflow automation, and real-time testing environments are three areas where AWS excels.
In conclusion, tech professionals can acquire a wide range of tools for success in the current development environment by honing their skills in software testing in software engineering, the MERN stack, data science courses, and cloud solutions like AWS.
0 notes
Text
Tracking Large Language Models (LLM) with MLflow : A Complete Guide
New Post has been published on https://thedigitalinsider.com/tracking-large-language-models-llm-with-mlflow-a-complete-guide/
Tracking Large Language Models (LLM) with MLflow : A Complete Guide
As Large Language Models (LLMs) grow in complexity and scale, tracking their performance, experiments, and deployments becomes increasingly challenging. This is where MLflow comes in – providing a comprehensive platform for managing the entire lifecycle of machine learning models, including LLMs.
In this in-depth guide, we’ll explore how to leverage MLflow for tracking, evaluating, and deploying LLMs. We’ll cover everything from setting up your environment to advanced evaluation techniques, with plenty of code examples and best practices along the way.
Functionality of MLflow in Large Language Models (LLMs)
MLflow has become a pivotal tool in the machine learning and data science community, especially for managing the lifecycle of machine learning models. When it comes to Large Language Models (LLMs), MLflow offers a robust suite of tools that significantly streamline the process of developing, tracking, evaluating, and deploying these models. Here’s an overview of how MLflow functions within the LLM space and the benefits it provides to engineers and data scientists.
Tracking and Managing LLM Interactions
MLflow’s LLM tracking system is an enhancement of its existing tracking capabilities, tailored to the unique needs of LLMs. It allows for comprehensive tracking of model interactions, including the following key aspects:
Parameters: Logging key-value pairs that detail the input parameters for the LLM, such as model-specific parameters like top_k and temperature. This provides context and configuration for each run, ensuring that all aspects of the model’s configuration are captured.
Metrics: Quantitative measures that provide insights into the performance and accuracy of the LLM. These can be updated dynamically as the run progresses, offering real-time or post-process insights.
Predictions: Capturing the inputs sent to the LLM and the corresponding outputs, which are stored as artifacts in a structured format for easy retrieval and analysis.
Artifacts: Beyond predictions, MLflow can store various output files such as visualizations, serialized models, and structured data files, allowing for detailed documentation and analysis of the model’s performance.
This structured approach ensures that all interactions with the LLM are meticulously recorded, providing a comprehensive lineage and quality tracking for text-generating models.
Evaluation of LLMs
Evaluating LLMs presents unique challenges due to their generative nature and the lack of a single ground truth. MLflow simplifies this with specialized evaluation tools designed for LLMs. Key features include:
Versatile Model Evaluation: Supports evaluating various types of LLMs, whether it’s an MLflow pyfunc model, a URI pointing to a registered MLflow model, or any Python callable representing your model.
Comprehensive Metrics: Offers a range of metrics tailored for LLM evaluation, including both SaaS model-dependent metrics (e.g., answer relevance) and function-based metrics (e.g., ROUGE, Flesch Kincaid).
Predefined Metric Collections: Depending on the use case, such as question-answering or text-summarization, MLflow provides predefined metrics to simplify the evaluation process.
Custom Metric Creation: Allows users to define and implement custom metrics to suit specific evaluation needs, enhancing the flexibility and depth of model evaluation.
Evaluation with Static Datasets: Enables evaluation of static datasets without specifying a model, which is useful for quick assessments without rerunning model inference.
Deployment and Integration
MLflow also supports seamless deployment and integration of LLMs:
MLflow Deployments Server: Acts as a unified interface for interacting with multiple LLM providers. It simplifies integrations, manages credentials securely, and offers a consistent API experience. This server supports a range of foundational models from popular SaaS vendors as well as self-hosted models.
Unified Endpoint: Facilitates easy switching between providers without code changes, minimizing downtime and enhancing flexibility.
Integrated Results View: Provides comprehensive evaluation results, which can be accessed directly in the code or through the MLflow UI for detailed analysis.
MLflow is a comprehensive suite of tools and integrations makes it an invaluable asset for engineers and data scientists working with advanced NLP models.
Setting Up Your Environment
Before we dive into tracking LLMs with MLflow, let’s set up our development environment. We’ll need to install MLflow and several other key libraries:
pip install mlflow>=2.8.1 pip install openai pip install chromadb==0.4.15 pip install langchain==0.0.348 pip install tiktoken pip install 'mlflow[genai]' pip install databricks-sdk --upgrade
After installation, it’s a good practice to restart your Python environment to ensure all libraries are properly loaded. In a Jupyter notebook, you can use:
import mlflow import chromadb print(f"MLflow version: mlflow.__version__") print(f"ChromaDB version: chromadb.__version__")
This will confirm the versions of key libraries we’ll be using.
Understanding MLflow’s LLM Tracking Capabilities
MLflow’s LLM tracking system builds upon its existing tracking capabilities, adding features specifically designed for the unique aspects of LLMs. Let’s break down the key components:
Runs and Experiments
In MLflow, a “run” represents a single execution of your model code, while an “experiment” is a collection of related runs. For LLMs, a run might represent a single query or a batch of prompts processed by the model.
Key Tracking Components
Parameters: These are input configurations for your LLM, such as temperature, top_k, or max_tokens. You can log these using mlflow.log_param() or mlflow.log_params().
Metrics: Quantitative measures of your LLM’s performance, like accuracy, latency, or custom scores. Use mlflow.log_metric() or mlflow.log_metrics() to track these.
Predictions: For LLMs, it’s crucial to log both the input prompts and the model’s outputs. MLflow stores these as artifacts in CSV format using mlflow.log_table().
Artifacts: Any additional files or data related to your LLM run, such as model checkpoints, visualizations, or dataset samples. Use mlflow.log_artifact() to store these.
Let’s look at a basic example of logging an LLM run:
This example demonstrates logging parameters, metrics, and the input/output as a table artifact.
import mlflow import openai def query_llm(prompt, max_tokens=100): response = openai.Completion.create( engine="text-davinci-002", prompt=prompt, max_tokens=max_tokens ) return response.choices[0].text.strip() with mlflow.start_run(): prompt = "Explain the concept of machine learning in simple terms." # Log parameters mlflow.log_param("model", "text-davinci-002") mlflow.log_param("max_tokens", 100) # Query the LLM and log the result result = query_llm(prompt) mlflow.log_metric("response_length", len(result)) # Log the prompt and response mlflow.log_table("prompt_responses", "prompt": [prompt], "response": [result]) print(f"Response: result")
Deploying LLMs with MLflow
MLflow provides powerful capabilities for deploying LLMs, making it easier to serve your models in production environments. Let’s explore how to deploy an LLM using MLflow’s deployment features.
Creating an Endpoint
First, we’ll create an endpoint for our LLM using MLflow’s deployment client:
import mlflow from mlflow.deployments import get_deploy_client # Initialize the deployment client client = get_deploy_client("databricks") # Define the endpoint configuration endpoint_name = "llm-endpoint" endpoint_config = "served_entities": [ "name": "gpt-model", "external_model": "name": "gpt-3.5-turbo", "provider": "openai", "task": "llm/v1/completions", "openai_config": "openai_api_type": "azure", "openai_api_key": "secrets/scope/openai_api_key", "openai_api_base": "secrets/scope/openai_api_base", "openai_deployment_name": "gpt-35-turbo", "openai_api_version": "2023-05-15", , , ], # Create the endpoint client.create_endpoint(name=endpoint_name, config=endpoint_config)
This code sets up an endpoint for a GPT-3.5-turbo model using Azure OpenAI. Note the use of Databricks secrets for secure API key management.
Testing the Endpoint
Once the endpoint is created, we can test it:
<div class="relative flex flex-col rounded-lg"> response = client.predict( endpoint=endpoint_name, inputs="prompt": "Explain the concept of neural networks briefly.","max_tokens": 100,,) print(response)
This will send a prompt to our deployed model and return the generated response.
Evaluating LLMs with MLflow
Evaluation is crucial for understanding the performance and behavior of your LLMs. MLflow provides comprehensive tools for evaluating LLMs, including both built-in and custom metrics.
Preparing Your LLM for Evaluation
To evaluate your LLM with mlflow.evaluate(), your model needs to be in one of these forms:
An mlflow.pyfunc.PyFuncModel instance or a URI pointing to a logged MLflow model.
A Python function that takes string inputs and outputs a single string.
An MLflow Deployments endpoint URI.
Set model=None and include model outputs in the evaluation data.
Let’s look at an example using a logged MLflow model:
import mlflow import openai with mlflow.start_run(): system_prompt = "Answer the following question concisely." logged_model_info = mlflow.openai.log_model( model="gpt-3.5-turbo", task=openai.chat.completions, artifact_path="model", messages=[ "role": "system", "content": system_prompt, "role": "user", "content": "question", ], ) # Prepare evaluation data eval_data = pd.DataFrame( "question": ["What is machine learning?", "Explain neural networks."], "ground_truth": [ "Machine learning is a subset of AI that enables systems to learn and improve from experience without explicit programming.", "Neural networks are computing systems inspired by biological neural networks, consisting of interconnected nodes that process and transmit information." ] ) # Evaluate the model results = mlflow.evaluate( logged_model_info.model_uri, eval_data, targets="ground_truth", model_type="question-answering", ) print(f"Evaluation metrics: results.metrics")
This example logs an OpenAI model, prepares evaluation data, and then evaluates the model using MLflow’s built-in metrics for question-answering tasks.
Custom Evaluation Metrics
MLflow allows you to define custom metrics for LLM evaluation. Here’s an example of creating a custom metric for evaluating the professionalism of responses:
from mlflow.metrics.genai import EvaluationExample, make_genai_metric professionalism = make_genai_metric( name="professionalism", definition="Measure of formal and appropriate communication style.", grading_prompt=( "Score the professionalism of the answer on a scale of 0-4:n" "0: Extremely casual or inappropriaten" "1: Casual but respectfuln" "2: Moderately formaln" "3: Professional and appropriaten" "4: Highly formal and expertly crafted" ), examples=[ EvaluationExample( input="What is MLflow?", output="MLflow is like your friendly neighborhood toolkit for managing ML projects. It's super cool!", score=1, justification="The response is casual and uses informal language." ), EvaluationExample( input="What is MLflow?", output="MLflow is an open-source platform for the machine learning lifecycle, including experimentation, reproducibility, and deployment.", score=4, justification="The response is formal, concise, and professionally worded." ) ], model="openai:/gpt-3.5-turbo-16k", parameters="temperature": 0.0, aggregations=["mean", "variance"], greater_is_better=True, ) # Use the custom metric in evaluation results = mlflow.evaluate( logged_model_info.model_uri, eval_data, targets="ground_truth", model_type="question-answering", extra_metrics=[professionalism] ) print(f"Professionalism score: results.metrics['professionalism_mean']")
This custom metric uses GPT-3.5-turbo to score the professionalism of responses, demonstrating how you can leverage LLMs themselves for evaluation.
Advanced LLM Evaluation Techniques
As LLMs become more sophisticated, so do the techniques for evaluating them. Let’s explore some advanced evaluation methods using MLflow.
Retrieval-Augmented Generation (RAG) Evaluation
RAG systems combine the power of retrieval-based and generative models. Evaluating RAG systems requires assessing both the retrieval and generation components. Here’s how you can set up a RAG system and evaluate it using MLflow:
from langchain.document_loaders import WebBaseLoader from langchain.text_splitter import CharacterTextSplitter from langchain.embeddings import OpenAIEmbeddings from langchain.vectorstores import Chroma from langchain.chains import RetrievalQA from langchain.llms import OpenAI # Load and preprocess documents loader = WebBaseLoader(["https://mlflow.org/docs/latest/index.html"]) documents = loader.load() text_splitter = CharacterTextSplitter(chunk_size=1000, chunk_overlap=0) texts = text_splitter.split_documents(documents) # Create vector store embeddings = OpenAIEmbeddings() vectorstore = Chroma.from_documents(texts, embeddings) # Create RAG chain llm = OpenAI(temperature=0) qa_chain = RetrievalQA.from_chain_type( llm=llm, chain_type="stuff", retriever=vectorstore.as_retriever(), return_source_documents=True ) # Evaluation function def evaluate_rag(question): result = qa_chain("query": question) return result["result"], [doc.page_content for doc in result["source_documents"]] # Prepare evaluation data eval_questions = [ "What is MLflow?", "How does MLflow handle experiment tracking?", "What are the main components of MLflow?" ] # Evaluate using MLflow with mlflow.start_run(): for question in eval_questions: answer, sources = evaluate_rag(question) mlflow.log_param(f"question", question) mlflow.log_metric("num_sources", len(sources)) mlflow.log_text(answer, f"answer_question.txt") for i, source in enumerate(sources): mlflow.log_text(source, f"source_question_i.txt") # Log custom metrics mlflow.log_metric("avg_sources_per_question", sum(len(evaluate_rag(q)[1]) for q in eval_questions) / len(eval_questions))
This example sets up a RAG system using LangChain and Chroma, then evaluates it by logging questions, answers, retrieved sources, and custom metrics to MLflow.
The way you chunk your documents can significantly impact RAG performance. MLflow can help you evaluate different chunking strategies:
This script evaluates different combinations of chunk sizes, overlaps, and splitting methods, logging the results to MLflow for easy comparison.
MLflow provides various ways to visualize your LLM evaluation results. Here are some techniques:
You can create custom visualizations of your evaluation results using libraries like Matplotlib or Plotly, then log them as artifacts:
This function creates a line plot comparing a specific metric across multiple runs and logs it as an artifact.
#2023#ai#AI Tools 101#Analysis#API#approach#Artificial Intelligence#azure#azure openai#Behavior#code#col#Collections#communication#Community#comparison#complexity#comprehensive#computing#computing systems#content#credentials#custom metrics#data#data science#databricks#datasets#deploying#deployment#development
0 notes
Text
1 note
·
View note
Text
Uncovering Microsoft Fabric Partner's Potential: A Digital Transformation Game-Changer
In the ever-changing world of digital transformation, companies are always looking for new and creative ways to expand and improve their operational effectiveness. In the process, Microsoft Fabric Partner proves to be a revolutionary force, providing a range of state-of-the-art products and services that are specifically designed to satisfy the changing requirements of contemporary businesses.
Microsoft Fabric Partner is committed to providing businesses with the knowledge and resources they need to successfully manage the challenges of digital transformation. However, what makes this collaboration unique, and how will it impact the digital transformation space? Let's examine Microsoft Fabric Partner's nuances in more detail and see how important it is for promoting corporate success.
Understanding Microsoft Fabric Partner
Microsoft Fabric Partner is a strategic alliance that aims to provide organizations in a variety of industries with unmatched value. It is not just a collaboration. Fundamentally, this collaboration uses the combined power of Microsoft's cutting-edge technology stack and the knowledge of its approved partners to provide all-inclusive solutions for challenging business problems.
Fabric Partner offers a broad range of services, including data analytics, application modernization, cloud migration, and infrastructure optimization. Organizations can unleash new opportunities, accelerate innovation, and achieve digital transformation at scale with Fabric Partner's help. Fabric Partner is a cloud computing platform that leverages a range of intelligent services and Microsoft Azure.
Principal Products and Services
Modernization and Migration to the Cloud: Fabric Partner enables smooth cloud moves by leveraging their in-depth knowledge of Microsoft Azure services and their proficiency in cloud migration strategies. This allows businesses to maximize cost-efficiency, agility, and scalability while reducing disruption.
Application Development and Integration: Fabric Partner helps businesses create cutting-edge, cloud-native apps that are customized to meet their specific needs by utilizing Microsoft's powerful development tools and frameworks. Fabric Partner provides creative solutions that promote business success, whether it be through the development of scalable online apps, mobile solutions, or the integration of different systems.
Data analytics and AI solutions: Fabric Partner leverages the strength of Azure's machine learning and AI capabilities to help businesses get a competitive edge by helping them extract actionable insights from massive amounts of data. Fabric Partner enables businesses to get the most out of their data assets with capabilities ranging from intelligent automation to predictive analytics.
Safety and Adherence: Fabric Partner delivers complete security and compliance solutions based on Microsoft's reliable platform in an era of increased cybersecurity threats and complex regulations. Fabric Partner helps businesses properly manage risks and secure sensitive data by putting in place strong security measures and making sure industry standards are followed.
Microsoft Fabric Partner's Effect:
Beyond only advancing technology, Microsoft Fabric Partner has a significant impact on cultivating an environment that values cooperation, adaptability, and constant progress. Businesses may speed their digital transformation journey by partnering with Microsoft, as they get access to a plethora of tools, expertise, and best practices.
Additionally, Microsoft Fabric Partner fosters innovation by helping businesses remain ahead of the curve and confidently adopt emerging technologies. Through the use of DevOps techniques, cloud-native designs, and artificial intelligence, Fabric Partner enables companies to welcome change, spur innovation, and experience long-term success.
In conclusion, strategic relationships are more important than ever in a time of extraordinary upheaval and rapid technological innovation. Leading this paradigm change, Microsoft Fabric Partner enables businesses to confidently and resiliently embrace digital transformation.
Fabric Partner provides an extensive range of services and solutions that help companies prosper in the digital era, from data analytics and AI solutions to cloud migration and application modernization. In the current competitive context, enterprises can drive innovation, seize new opportunities, and succeed over the long term by using the combined strengths of Microsoft and its certified partners.
In the rapidly evolving world of technology, Microsoft Fabric Partner is really more than just a partnership—it's a force for creativity, a change-agent, and a transformative light. Take advantage of Microsoft Fabric Partner's strength and set off on a path to an infinitely promising future.
#microsoft azure#big data#data science#artificial intelligence#data warehouse#microsoft fabric partner
1 note
·
View note
Text
#Microsoft Azure Data Factory course in Pune#Google Cloud course in Pune#Aws course in Pune#offline Data Science course in Pune#Power BI course in Pune#Iics Data Integration course in Pune#Devops classes in Pune#Snowflak course in Pune#Google Cloud course in pune#Devops Courses in Pune#cloud computing courses in pune#aws course in pune with placement#aws training in pune#data science courses in pune#data science course in pune offline#offline courses for data science#power bi courses in pune#power bi classes in pune with placement#power bi developer course in pune#iics data integration course in pune#iics data integration certification in Pune#software development classes in pune#snowflake course in pune#snowflake training in pune#snowflake training classes#selenium testing course in pune#software testing course pune#selenium testing course near me#power bi and power apps course in pune#IICS course in Pune
0 notes
Text
Python Training in Ahmedabad - HighskyIT
Unlock top career opportunities! Join the best Python Courses in Ahmedabad today and master skills to land your dream tech job. join classes that fit your schedule and goals!
#linux certification ahmedabad#red hat certification ahmedabad#linux online courses in ahmedabad#rhce rhcsa training ahmedabad#data science training ahmedabad#aws security training ahmedabad#docker training ahmedabad#red hat training ahmedabad#microsoft azure cloud certification#python courses in ahmedabad
0 notes
Text
Welcome to Geekonik, your go-to platform for mastering the latest in tech and programming. Whether you’re a beginner eager to start your coding journey or an experienced developer looking to sharpen your skills, we offer a diverse range of expert-led courses designed to help you succeed in today’s ever-evolving tech industry.
#Software Testing#Amazon Web Servers#DevOps#Java Full Stack#Python Full Stack#Dot Net Full Stack#Azure#Data Analytics#Data Science#Artificial Intelligence#Data Enigineering
0 notes
Text
Talk to Your SQL Database Using LangChain and Azure OpenAI
Excited to share a comprehensive review of LangChain, an open-source framework for querying SQL databases using natural language, in conjunction with Azure OpenAI's gpt-35-turbo model. This article demonstrates how to convert user input into SQL queries and obtain valuable data insights. It covers setup instructions and prompt engineering techniques for improving the accuracy of AI-generated results. Check out the blog post [here](https://ift.tt/s8PqQCc) to dive deeper into LangChain's capabilities and learn how to harness the power of natural language processing. #LangChain #AzureOpenAI #SQLDatabase #NaturalLanguageProcessing List of Useful Links: AI Scrum Bot - ask about AI scrum and agile Our Telegram @itinai Twitter - @itinaicom
#itinai.com#AI#News#‘Talk’ to Your SQL Database Using LangChain and Azure OpenAI#AI News#AI tools#Innovation#itinai#LLM#Productivity#Satwiki De#Towards Data Science - Medium ‘Talk’ to Your SQL Database Using LangChain and Azure OpenAI
0 notes