#Bayesian statistical analysis
Explore tagged Tumblr posts
Visit Tumblr Blog
Explore Tumblr blogs with no restrictions, modern design and the best experience.
Last Seen Tumblr Blogs





Fun Fact
70% of Tumblr users say the Dashboard is their favorite place to spend time online.
Text
The ancient Greek craftsmen achieved a machining precision of 0.001 inches - a truly mind-boggling accomplishment for the era!
0 notes
Photo
*sigh*
one of the most important skills that is utterly drilled into you in academia is critical thinking. In an arts degree, you must learn to dissect an argument – if you cannot analyse effectively, you won't get through. In a science degree, you will be taught not only how to read papers, but how to critique them. Science is defined by the scientific method – and as tedious as it may sound, there is no skill more important than being able to scientific method your way through life.
The most important part of research is knowing how to do research – how do you find high-quality papers? What is high-quality evidence? Is it actually appropriate? What does 'significant' actually mean? The media loooves to deploy these terms without having a clue what the scientific meaning is – and as a result, the public get fooled. If you do not know how to do research, you will not find good information by doing your own research.
For example – members of the public who do their own 'research' into trans healthcare might come across the Cass Review, and see that it doesn't find much 'high-quality evidence' for gender-affirming care. They might think 'okay, guess trans healthcare is bad/experimental'. But if you've done academia, you'll know that 'high-quality' is just a synonym for 'randomised control trial' (RCT). For most research, RCTs are the gold standard. But RCTs require that people be unable to tell which condition they're in – that is, if they're receiving a placebo, they won't be able to tell. But with gender-affirming care, you can't exactly conceal the effects of hormones or surgery from a participant – after all, growing boobs/having a voice break/getting facial hair/altered sexual function is kinda hard to not notice. So, an RCT would actually be a completely inappropriate study design. Ergo ‘high-quality’ evidence is a misnomer, since it’d be really poor evidence for whether the treatment is helpful. As such, we know that so-called low-quality evidence is both more appropriate and perfectly sufficient. Academia is crucial to learning to debunk bad research.
And before y’all claim ‘but the papers being cited are all the ones that are getting funding – it’s just corrupt’ – you do realise being taught to spot bad science means that we get explicitly told how to spot corruption? Often, we can learn to tell when papers’ results are dodgy. Academia is about learning not to accept status or fame as a good enough reason to trust something. While I agree there are massive problems with some fields getting underfunded, or with science deprioritising certain social groups, abolishing science will only make this worse.
So. In conclusion, academia may be flawed, but it’s by far the best thing we have for learning to think critically. Anti-intellectualism is a blight on society, and horribly dangerous - it gets folks killed.


#I’m doing a double arts/psych degree so this matters to me. Dearly#I hate to tell you but learning statistics and scientific methods is really important#And learning to argue effectively and critique bad logic/bad science will save you from so much bs#Also. You have to know how the papers work in order to critique them#(E.g. ‘significance does not necessarily mean much’; ‘a Bayesian analysis woulda been better’)#(I love Bayesian methods)#The ‘common statistical/reporting/logical failures’ part of my psych degree has been invaluable#important#science#academia#cass review#anti-intellectualism#anti intellectualism
163K notes
·
View notes
Text
Advanced Methodologies for Algorithmic Bias Detection and Correction
I continue today the description of Algorithmic Bias detection. Photo by Google DeepMind on Pexels.com The pursuit of fairness in algorithmic systems necessitates a deep dive into the mathematical and statistical intricacies of bias. This post will provide just a small glimpse of some of the techniques everyone can use, drawing on concepts from statistical inference, optimization theory, and…

View On WordPress
#AI#Algorithm#algorithm design#algorithmic bias#Artificial Intelligence#Bayesian Calibration#bias#chatgpt#Claude#Copilot#Explainable AI#Gemini#Machine Learning#math#Matrix Calibration#ML#Monte Carlo Simulation#optimization theory#Probability Calibration#Raffaello Palandri#Reliability Assessment#Sobol sensitivity analysis#Statistical Hypothesis#statistical inference#Statistics#Stochastic Controls#stochastic processes#Threshold Adjustment#Wasserstein Distance#XAI
0 notes
Text
Brb, flirting with a man on tinder by referencing Bayesian style statistical analysis.
8 notes
·
View notes
Text
A colossal study of 85 million people has tied COVID-19 vaccines to a alarming surge in heart attack rates, sounding a dire warning about the jabs’ risks. Published in the International Journal of Preventive Medicine, this peer-reviewed analysis exposes a troubling link between vaccination and life-threatening cardiovascular events.
The research, titled COVID-19 Vaccination and Cardiovascular Events: A Systematic Review and Bayesian Multivariate Meta-Analysis of Preventive, Benefits, and Risk, appeared in the journal’s March edition. Spanning data from 85 million individuals, the study’s findings reveal a significant increase in severe heart-related incidents post-vaccination, fueling concerns about the safety of COVID-19 shots.
Independentsentinel . com reports: It leaves serious questions about the long-term health impacts of mRNA (Pfizer and Moderna) and viral vector vaccines (AstraZeneca and Johnson & Johnson).
Rheleh Karimi, a biostatistician at Isfahan University of Medical Sciences in Iran, led the study. He collaborated with international researchers from Spain and Portugal. They used advanced Bayesian statistical methods.
The study found staggering increases and risk for major cardiovascular events following the COVID-19 vaccination – particularly after the first and second doses.
Coronary Artery Disease (CAD):
Overall, a 70% increased risk
Pfizer (BNT162b2): 64% increased risk
Second dose (any vaccine): A massive 244% increased risk
Heart Attacks (Myocardial Infarction):
Second dose (any vaccine): 286% increased risk
Pfizer (any dose): 87% increased risk
Second dose of Pfizer: 284% increased risk
Stroke:
Pfizer (any dose): 109% increased risk
First dose of Pfizer: 269% increased risk
First dose (any vaccine): 240% increased risk
Arrhythmia:
First dose (any vaccine): 199% increased risk
AstraZeneca (ChAdOx1): 711% increased risk
First dose of AstraZeneca: 389% increased risk
The chart shows the findings with different doses and vaccine types:
6 notes
·
View notes
Text
like it is funny to think about the initial google bayesian spam filter that was so good it seemed magical -- it uses statistical analysis to detect spam that differs, statistically, from non-spam!! -- and how ultimately the thing polluting the web now is oh yeah we invented a generator that creates text that's statistically identical to human-generated text. whoops!
6 notes
·
View notes
Text
Are Ashkenazi Jews white? Short answer, No!
Ashkenazi Jews may appear white, but are not. Some identify as white and some don't. Even many jewish news articles claim their not white.
But what do the facts say?
Ashkenazi Jews are a genetically and culturally Middle Eastern people, who only began to “integrate” into European society after the rise of Liberalism in the 17th or 18th Century. Their history in Europe has been full of conflict. Being continually massacred, and expelled from every single European country that they have ever inhabited. It was clear that white Europeans considered jews to be categorically separate race from them. (plus the Jews also considered themselves separate from white Europeans as well). Plus the overwhelming majority have distinctly non-European phenotypes that are obviously Middle Eastern in origin.

Plus, the claim that they're white, is not supported by scientific, genetic evidence.
Despite their long-term residence in different countries and isolation from one another, most Jewish populations were not significantly different from one another at the genetic level.
Admixture estimates suggested low levels of European Y-chromosome gene flow into Ashkenazi and Roman Jewish communities. Jewish and Middle Eastern non-Jewish populations were not statistically different. The results support the hypothesis that the paternal gene pools of Jewish communities from Europe, North Africa, and the Middle East descended from a common Middle Eastern ancestral population, and suggest that most Jewish communities have remained relatively isolated from neighboring non-Jewish communities during and after the Diaspora.”
The m values based on haplotypes Med and 1L were ~13% ± 10%, suggesting a rather small European contribution to the Ashkenazi paternal gene pool. When all haplotypes were included in the analysis, m increased to 23% ± 7%. This value was similar to the estimated Italian contribution to the Roman Jewish paternal gene pool.
About 80 Sephardim, 80 Ashkenazim and 100 Czechoslovaks were examined for the Yspecific RFLPs revealed by the probes p12f2 and p40a,f on TaqI DNA digests. The aim of the study was to investigate the origin of the Ashkenazi gene pool through the analysis of markers which, having an exclusively holoandric transmission, are useful to estimate paternal gene flow. The comparison of the two groups of Jews with each other and with Czechoslovaks (which have been taken as a representative source of foreign Y-chromosomes for Ashkenazim) shows a great similarity between Sephardim and Ashkenazim who are very different from Czechoslovaks. On the other hand both groups of Jews appear to be closely related to Lebanese. A preliminary evaluation suggests that the contribution of foreign males to the Ashkenazi gene pool has been very low (1 % or less per generation).
Jewish populations show a high level of genetic similarity to each other, clustering together in several types of analysis of population structure. These results support the view that the Jewish populations largely share a common Middle Eastern ancestry and that over their history they have undergone varying degrees of admixture with non-Jewish populations of European descent. We find that the Jewish populations show a high level of genetic similarity to each other, clustering together in several types of analysis of population structure. Further, Bayesian clustering, neighbor-joining trees, and multidimensional scaling place the Jewish populations as intermediate between the non-Jewish Middle Eastern and European populations. These results support the view that the Jewish populations largely share a common Middle Eastern ancestry and that over their history they have undergone varying degrees of admixture with non-Jewish populations of European descent.
A sample of 526 Y chromosomes representing six Middle Eastern populations (Ashkenazi, Sephardic, and Kurdish Jews from Israel; Muslim Kurds; Muslim Arabs from Israel and the Palestinian Authority Area; and Bedouin from the Negev) was analyzed for 13 binary polymorphisms and six microsatellite loci. The investigation of the genetic relationship among three Jewish communities revealed that Kurdish and Sephardic Jews were indistinguishable from one another, whereas both differed slightly, yet significantly, from Ashkenazi Jews. The differences among Ashkenazim may be a result of low-level gene flow from European populations and/or genetic drift during isolation.
Archaeologic and genetic data support that both Jews and Palestinians came from the ancient Canaanites, who extensively mixed with Egyptians, Mesopotamian and Anatolian peoples in ancient times. Thus, Palestinian-Jewish rivalry is based in cultural and religious, but not in genetic, differences.
One study 2010 study stated that Both Ashkenazi Jews and Sephardic jews share only 30% European DNA with the rest being of middle east decent. And by a recent 2020 study on remains from Bronze Age (over 3000 years ago) southern Levantine (Canaanite) populations suggests Ashkenazi Jews derive more than half of their ancestry from Bronze Age Levantine populations with the remaining 41% of their ancestry being European and 50% being Middle Eastern.
24 notes
·
View notes
Text

In the search for life on exoplanets, finding nothing is something too
What if humanity's search for life on other planets returns no hits? A team of researchers led by Dr. Daniel Angerhausen, a Physicist in Professor Sascha Quanz's Exoplanets and Habitability Group at ETH Zurich and a SETI Institute affiliate, tackled this question by considering what could be learned about life in the universe if future surveys detect no signs of life on other planets. The study, which has just been published in The Astronomical Journal and was carried out within the framework of the Swiss National Centre of Competence in Research, PlanetS, relies on a Bayesian statistical analysis to establish the minimum number of exoplanets that should be observed to obtain meaningful answers about the frequency of potentially inhabited worlds.
Accounting for uncertainty
The study concludes that if scientists were to examine 40 to 80 exoplanets and find a "perfect" no-detection outcome, they could confidently conclude that fewer than 10 to 20 percent of similar planets harbour life. In the Milky Way, this 10 percent would correspond to about 10 billion potentially inhabited planets. This type of finding would enable researchers to put a meaningful upper limit on the prevalence of life in the universe, an estimate that has, so far, remained out of reach.
There is, however, a relevant catch in that ‘perfect’ null result: Every observation comes with a certain level of uncertainty, so it's important to understand how this affects the robustness of the conclusions that may be drawn from the data. Uncertainties in individual exoplanet observations take different forms: Interpretation uncertainty is linked to false negatives, which may correspond to missing a biosignature and mislabeling a world as uninhabited, whereas so-called sample uncertainty introduces biases in the observed samples. For example, if unrepresentative planets are included even though they fail to have certain agreed-upon requirements for the presence of life.
Asking the right questions
"It's not just about how many planets we observe – it's about asking the right questions and how confident we can be in seeing or not seeing what we're searching for," says Angerhausen. "If we're not careful and are overconfident in our abilities to identify life, even a large survey could lead to misleading results."
Such considerations are highly relevant to upcoming missions such as the international Large Interferometer for Exoplanets (LIFE) mission led by ETH Zurich. The goal of LIFE is to probe dozens of exoplanets similar in mass, radius, and temperature to Earth by studying their atmospheres for signs of water, oxygen, and even more complex biosignatures. According to Angerhausen and collaborators, the good news is that the planned number of observations will be large enough to draw significant conclusions about the prevalence of life in Earth's galactic neighbourhood.
Still, the study stresses that even advanced instruments require careful accounting and quantification of uncertainties and biases to ensure that outcomes are statistically meaningful. To address sample uncertainty, for instance, the authors point out that specific and measurable questions such as, "Which fraction of rocky planets in a solar system's habitable zone show clear signs of water vapor, oxygen, and methane?" are preferable to the far more ambiguous, "How many planets have life?"
The influence of previous knowledge
Angerhausen and colleagues also studied how assumed previous knowledge – called a prior in Bayesian statistics – about given observation variables will affect the results of future surveys. For this purpose, they compared the outcomes of the Bayesian framework with those given by a different method, known as the Frequentist approach, which does not feature priors. For the kind of sample size targeted by missions like LIFE, the influence of chosen priors on the results of the Bayesian analysis is found to be limited and, in this scenario, the two frameworks yield comparable results.
"In applied science, Bayesian and Frequentist statistics are sometimes interpreted as two competing schools of thought. As a statistician, I like to treat them as alternative and complementary ways to understand the world and interpret probabilities," says co-author Emily Garvin, who's currently a PhD student in Quanz' group. Garvin focussed on the Frequentist analysis that helped to corroborate the team's results and to verify their approach and assumptions. "Slight variations in a survey's scientific goals may require different statistical methods to provide a reliable and precise answer," notes Garvin. "We wanted to show how distinct approaches provide a complementary understanding of the same dataset, and in this way present a roadmap for adopting different frameworks."
Finding signs of life could change everything
This work shows why it's so important to formulate the right research questions, to choose the appropriate methodology and to implement careful sampling designs for a reliable statistical interpretation of a study's outcome. "A single positive detection would change everything," says Angerhausen, "but even if we don't find life, we'll be able to quantify how rare – or common – planets with detectable biosignatures really might be."
IMAGE: The first Earth-size planet orbiting a star in the “habitable zone” — the range of distance from a star where liquid water might pool on the surface of an orbiting planet. Credit NASA Ames/SETI Institute/JPL-Caltech
4 notes
·
View notes
Text
The Philosophy of Statistics
The philosophy of statistics explores the foundational, conceptual, and epistemological questions surrounding the practice of statistical reasoning, inference, and data interpretation. It deals with how we gather, analyze, and draw conclusions from data, and it addresses the assumptions and methods that underlie statistical procedures. Philosophers of statistics examine issues related to probability, uncertainty, and how statistical findings relate to knowledge and reality.
Key Concepts:
Probability and Statistics:
Frequentist Approach: In frequentist statistics, probability is interpreted as the long-run frequency of events. It is concerned with making predictions based on repeated trials and often uses hypothesis testing (e.g., p-values) to make inferences about populations from samples.
Bayesian Approach: Bayesian statistics, on the other hand, interprets probability as a measure of belief or degree of certainty in an event, which can be updated as new evidence is obtained. Bayesian inference incorporates prior knowledge or assumptions into the analysis and updates it with data.
Objectivity vs. Subjectivity:
Objective Statistics: Objectivity in statistics is the idea that statistical methods should produce results that are independent of the individual researcher’s beliefs or biases. Frequentist methods are often considered more objective because they rely on observed data without incorporating subjective priors.
Subjective Probability: In contrast, Bayesian statistics incorporates subjective elements through prior probabilities, meaning that different researchers can arrive at different conclusions depending on their prior beliefs. This raises questions about the role of subjectivity in science and how it affects the interpretation of statistical results.
Inference and Induction:
Statistical Inference: Philosophers of statistics examine how statistical methods allow us to draw inferences from data about broader populations or phenomena. The problem of induction, famously posed by David Hume, applies here: How can we justify making generalizations about the future or the unknown based on limited observations?
Hypothesis Testing: Frequentist methods of hypothesis testing (e.g., null hypothesis significance testing) raise philosophical questions about what it means to "reject" or "fail to reject" a hypothesis. Critics argue that p-values are often misunderstood and can lead to flawed inferences about the truth of scientific claims.
Uncertainty and Risk:
Epistemic vs. Aleatory Uncertainty: Epistemic uncertainty refers to uncertainty due to lack of knowledge, while aleatory uncertainty refers to inherent randomness in the system. Philosophers of statistics explore how these different types of uncertainty influence decision-making and inference.
Risk and Decision Theory: Statistical analysis often informs decision-making under uncertainty, particularly in fields like economics, medicine, and public policy. Philosophical questions arise about how to weigh evidence, manage risk, and make decisions when outcomes are uncertain.
Causality vs. Correlation:
Causal Inference: One of the most important issues in the philosophy of statistics is the relationship between correlation and causality. While statistics can show correlations between variables, establishing a causal relationship often requires additional assumptions and methods, such as randomized controlled trials or causal models.
Causal Models and Counterfactuals: Philosophers like Judea Pearl have developed causal inference frameworks that use counterfactual reasoning to better understand causation in statistical data. These methods help to clarify when and how statistical models can imply causal relationships, moving beyond mere correlations.
The Role of Models:
Modeling Assumptions: Statistical models, such as regression models or probability distributions, are based on assumptions about the data-generating process. Philosophers of statistics question the validity and reliability of these assumptions, particularly when they are idealized or simplified versions of real-world processes.
Overfitting and Generalization: Statistical models can sometimes "overfit" data, meaning they capture noise or random fluctuations rather than the underlying trend. Philosophical discussions around overfitting examine the balance between model complexity and generalizability, as well as the limits of statistical models in capturing reality.
Data and Representation:
Data Interpretation: Data is often considered the cornerstone of statistical analysis, but philosophers of statistics explore the nature of data itself. How is data selected, processed, and represented? How do choices about measurement, sampling, and categorization affect the conclusions drawn from data?
Big Data and Ethics: The rise of big data has led to new ethical and philosophical challenges in statistics. Issues such as privacy, consent, bias in algorithms, and the use of data in decision-making are central to contemporary discussions about the limits and responsibilities of statistical analysis.
Statistical Significance:
p-Values and Significance: The interpretation of p-values and statistical significance has long been debated. Many argue that the overreliance on p-values can lead to misunderstandings about the strength of evidence, and the replication crisis in science has highlighted the limitations of using p-values as the sole measure of statistical validity.
Replication Crisis: The replication crisis in psychology and other sciences has raised concerns about the reliability of statistical methods. Philosophers of statistics are interested in how statistical significance and reproducibility relate to the notion of scientific truth and the accumulation of knowledge.
Philosophical Debates:
Frequentism vs. Bayesianism:
Frequentist and Bayesian approaches to statistics represent two fundamentally different views on the nature of probability. Philosophers debate which approach provides a better framework for understanding and interpreting statistical evidence. Frequentists argue for the objectivity of long-run frequencies, while Bayesians emphasize the flexibility and adaptability of probabilistic reasoning based on prior knowledge.
Realism and Anti-Realism in Statistics:
Is there a "true" probability or statistical model underlying real-world phenomena, or are statistical models simply useful tools for organizing our observations? Philosophers debate whether statistical models correspond to objective features of reality (realism) or are constructs that depend on human interpretation and conventions (anti-realism).
Probability and Rationality:
The relationship between probability and rational decision-making is a key issue in both statistics and philosophy. Bayesian decision theory, for instance, uses probabilities to model rational belief updating and decision-making under uncertainty. Philosophers explore how these formal models relate to human reasoning, especially when dealing with complex or ambiguous situations.
Philosophy of Machine Learning:
Machine learning and AI have introduced new statistical methods for pattern recognition and prediction. Philosophers of statistics are increasingly focused on the interpretability, reliability, and fairness of machine learning algorithms, as well as the role of statistical inference in automated decision-making systems.
The philosophy of statistics addresses fundamental questions about probability, uncertainty, inference, and the nature of data. It explores how statistical methods relate to broader epistemological issues, such as the nature of scientific knowledge, objectivity, and causality. Frequentist and Bayesian approaches offer contrasting perspectives on probability and inference, while debates about the role of models, data representation, and statistical significance continue to shape the field. The rise of big data and machine learning has introduced new challenges, prompting philosophical inquiry into the ethical and practical limits of statistical reasoning.
#philosophy#epistemology#knowledge#learning#education#chatgpt#ontology#metaphysics#Philosophy of Statistics#Bayesianism vs. Frequentism#Probability Theory#Statistical Inference#Causal Inference#Epistemology of Data#Hypothesis Testing#Risk and Decision Theory#Big Data Ethics#Replication Crisis
2 notes
·
View notes
Note
For the studyblr asks: 9 and 15
Hope the studying goes well! 📚☕
9: Favorite class out of everything you’ve ever taken and why?
Definitely the Bayesian Statistics course I took last spring. The professor was super kind and excited to share how to think like a Bayesian (very relevant to cosmology!). The assignments were straightforward, and had a lot of leeway for people who were not statistics PhD students aka me. The only drawback was the group project at the end, because my group mates were extremely unhelpful and attempted to use ChatGPT for building a model...
15: Class that you’ve always wanted to take but never had the chance?
I really wish I had the ability to take some kind of mathematical methods for physics. I went to a liberal arts school, so my physics classes had to sacrifice lectures to go over the bare necessities because gen eds took up a lot of credits and there wasn't really room for a physics specific math class. It was truly not enough, and I seriously wish I had some exposure to things like Fourier transforms and complex analysis prior to grad school.
I wish I had time to study those missing math topics! One day.
4 notes
·
View notes
Text
Exploring the Depths of Data Science: My Journey into Advanced Topics
In my journey through the ever-evolving landscape of data science, I've come to realize that the possibilities are as vast as the data itself. As I venture deeper into this realm, I find myself irresistibly drawn to the uncharted territories of advanced data science topics. The data universe is a treasure trove of intricate patterns, concealed insights, and complex challenges just waiting to be unraveled. This exploration isn't merely about expanding my knowledge; it's about discovering the profound impact that data can have on our world.

A. Setting the Stage for Advanced Data Science Exploration
Data science has transcended its initial boundaries of basic analyses and simple visualizations. It has evolved into a field that delves into the intricacies of machine learning, deep learning, big data, and more. Advanced data science is where we unlock the true potential of data, making predictions, uncovering hidden trends, and driving innovation.
B. The Evolving Landscape of Data Science
The field of data science is in a perpetual state of flux, with new techniques, tools, and methodologies emerging constantly. The boundaries of what we can achieve with data are continually expanding, offering exciting opportunities to explore data-driven solutions for increasingly complex problems.
C.My Motivation for Diving into Advanced Topics
Fueled by an insatiable curiosity and a desire to make a meaningful impact, I've embarked on a journey to explore advanced data science topics. The prospect of unearthing insights that could reshape industries, enhance decision-making, and contribute to societal progress propels me forward on this thrilling path.
II. Going Beyond the Basics: A Recap of Foundational Knowledge
Before diving headfirst into advanced topics, it's paramount to revisit the fundamentals that serve as the bedrock of data science. This refresher not only reinforces our understanding but also equips us to confront the more intricate challenges that lie ahead.

A. Revisiting the Core Concepts of Data Science
From the nitty-gritty of data collection and cleaning to the art of exploratory analysis and visualization, the core concepts of data science remain indomitable. These foundational skills provide us with a sturdy platform upon which we construct our advanced data science journey.
B. The Importance of a Strong Foundation for Advanced Exploration
Just as a towering skyscraper relies on a solid foundation to reach great heights, advanced data science hinges on a strong understanding of the basics. Without this firm grounding, the complexities of advanced techniques can quickly become overwhelming.
C. Reflecting on My Own Data Science Journey
When I look back on my personal data science journey, it's evident that each step I took paved the way for the next. As I progressed from being a novice to an intermediate practitioner, my hunger for knowledge and my drive to tackle more intricate challenges naturally led me toward the realm of advanced topics.
III. The Path to Mastery: Advanced Statistical Analysis
Advanced statistical analysis takes us far beyond the realm of simple descriptive statistics. It empowers us to draw nuanced insights from data and make informed decisions with a heightened level of confidence.
A. An Overview of Advanced Statistical Techniques
Advanced statistical techniques encompass the realm of multivariate analysis, time series forecasting, and more. These methods enable us to capture intricate relationships within data, providing us with a richer and more profound perspective.
B. Bayesian Statistics and Its Applications
Bayesian statistics offers a unique perspective on probability, allowing us to update our beliefs as new data becomes available. This powerful framework finds applications in diverse fields such as medical research, finance, and even machine learning.
C. The Role of Hypothesis Testing in Advanced Data Analysis
Hypothesis testing takes on a more intricate form in advanced data analysis. It involves designing robust experiments, grasping the nuances of p-values, and addressing the challenges posed by multiple comparisons.
IV. Predictive Modeling: Beyond Regression
While regression remains an enduring cornerstone of predictive modeling, the world of advanced data science introduces us to a spectrum of modeling techniques that can elegantly capture the complex relationships concealed within data.
A. A Deeper Dive into Predictive Modeling
Predictive modeling transcends the simplicity of linear regression, offering us tools like decision trees, random forests, and gradient boosting. These techniques furnish us with the means to make more precise predictions for intricate data scenarios.
B. Advanced Regression Techniques and When to Use Them
In the realm of advanced regression, we encounter techniques such as Ridge, Lasso, and Elastic Net regression. These methods effectively address issues of multicollinearity and overfitting, ensuring that our models remain robust and reliable.
C. Embracing Ensemble Methods for Enhanced Predictive Accuracy
Ensemble methods, a category of techniques, ingeniously combine multiple models to achieve higher predictive accuracy. Approaches like bagging, boosting, and stacking harness the strengths of individual models, resulting in a formidable ensemble.
V. The Power of Unstructured Data: Natural Language Processing (NLP)
Unstructured text data, abundant on the internet, conceals a trove of valuable information. NLP equips us with the tools to extract meaning, sentiment, and insights from text.
A. Understanding the Complexities of Unstructured Text Data
Text data is inherently messy and nuanced, making its analysis a formidable challenge. NLP techniques, including tokenization, stemming, and lemmatization, empower us to process and decipher text data effectively.
B. Advanced NLP Techniques, Including Sentiment Analysis and Named Entity Recognition
Sentiment analysis gauges the emotions expressed in text, while named entity recognition identifies entities like names, dates, and locations. These advanced NLP techniques find applications in diverse fields such as marketing, social media analysis, and more.
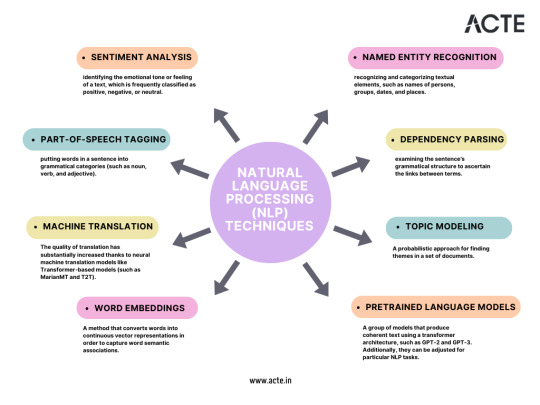
C. Real-World Applications of NLP in Data Science
NLP's applications span from dissecting sentiment in customer reviews to generating human-like text with deep learning models. These applications not only drive decision-making but also enhance user experiences.
VI. Deep Learning and Neural Networks
At the heart of deep learning lies the neural network architecture, enabling us to tackle intricate tasks like image recognition, language translation, and even autonomous driving.
A. Exploring the Neural Network Architecture
Grasping the components of a neural network—layers, nodes, and weights—forms the foundation for comprehending the intricacies of deep learning models.
B. Advanced Deep Learning Concepts like CNNs and RNNs
Convolutional Neural Networks (CNNs) excel at image-related tasks, while Recurrent Neural Networks (RNNs) proficiently handle sequences like text and time series data. These advanced architectures amplify model performance, expanding the horizons of what data-driven technology can accomplish.
C. Leveraging Deep Learning for Complex Tasks like Image Recognition and Language Generation
Deep learning powers image recognition in self-driving cars, generates human-like text, and translates languages in real time. These applications redefine what's possible with data-driven technology, propelling us into an era of boundless potential.
VII. Big Data and Distributed Computing
As data scales to unprecedented sizes, the challenges of storage, processing, and analysis necessitate advanced solutions like distributed computing frameworks.
A. Navigating the Challenges of Big Data in Data Science
The era of big data demands a paradigm shift in how we handle, process, and analyze information. Traditional methods quickly become inadequate, making way for innovative solutions to emerge.
B. Introduction to Distributed Computing Frameworks like Apache Hadoop and Spark
Distributed computing frameworks such as Apache Hadoop and Spark empower us to process massive datasets across clusters of computers. These tools enable efficient handling of big data challenges that were previously insurmountable.
C. Practical Applications of Big Data Technologies
Big data technologies find applications in diverse fields such as healthcare, finance, and e-commerce. They enable us to extract valuable insights from data that was once deemed too vast and unwieldy for analysis.
VIII. Ethical Considerations in Advanced Data Science
As data science advances, ethical considerations become even more pivotal. We must navigate issues of bias, privacy, and transparency with heightened sensitivity and responsibility.
A. Addressing Ethical Challenges in Advanced Data Analysis
Advanced data analysis may inadvertently perpetuate biases or raise new ethical dilemmas. Acknowledging and confronting these challenges is the initial step toward conducting ethical data science.
B. Ensuring Fairness and Transparency in Complex Models
Complex models can be opaque, making it challenging to comprehend their decision-making processes. Ensuring fairness and transparency in these models is a pressing concern that underscores the ethical responsibilities of data scientists.
C. The Responsibility of Data Scientists in Handling Sensitive Data
Data scientists shoulder a profound responsibility when handling sensitive data. Employing advanced encryption techniques and data anonymization methods is imperative to safeguard individual privacy and uphold ethical standards.
IX. The Journey Continues: Lifelong Learning and Staying Updated
In the realm of advanced data science, learning is an unending odyssey. Staying abreast of the latest advancements is not just valuable; it's imperative to remain at the vanguard of the field.
A. Embracing the Mindset of Continuous Learning in Advanced Data Science
Continuous learning isn't a choice; it's a necessity. As data science continually evolves, so must our skills and knowledge. To stand still is to regress.
B. Resources and Communities for Staying Updated with the Latest Advancements
The ACTE Institute provides an array of resources, from books and Data science courses to research papers and data science communities, offers a wealth of opportunities to remain informed about the latest trends and technologies.
C. Personal Anecdotes of Growth and Adaptation in the Field
My expedition into advanced data science has been replete with moments of growth, adaptation, and occasionally, setbacks. These experiences have profoundly influenced my approach to confronting complex data challenges and serve as a testament to the continuous nature of learning.
In conclusion, the journey into advanced data science is an exhilarating odyssey. It's a voyage that plunges us into the deepest recesses of data, where we unearth insights that possess the potential to transform industries and society at large. As we reflect on the indispensable role of essential data science tools, we comprehend that the equilibrium between tools and creativity propels us forward. The data universe is boundless, and with the right tools and an insatiable curiosity, we are poised to explore its ever-expanding horizons.
So, my fellow data enthusiasts, let us persist in our exploration of the data universe. There are discoveries yet to be unearthed, solutions yet to be uncovered, and a world yet to be reshaped through the power of data.
8 notes
·
View notes
Text
Dealing with the limitations of our noisy world
New Post has been published on https://thedigitalinsider.com/dealing-with-the-limitations-of-our-noisy-world/
Dealing with the limitations of our noisy world

Tamara Broderick first set foot on MIT’s campus when she was a high school student, as a participant in the inaugural Women’s Technology Program. The monthlong summer academic experience gives young women a hands-on introduction to engineering and computer science.
What is the probability that she would return to MIT years later, this time as a faculty member?
That’s a question Broderick could probably answer quantitatively using Bayesian inference, a statistical approach to probability that tries to quantify uncertainty by continuously updating one’s assumptions as new data are obtained.
In her lab at MIT, the newly tenured associate professor in the Department of Electrical Engineering and Computer Science (EECS) uses Bayesian inference to quantify uncertainty and measure the robustness of data analysis techniques.
“I’ve always been really interested in understanding not just ‘What do we know from data analysis,’ but ‘How well do we know it?’” says Broderick, who is also a member of the Laboratory for Information and Decision Systems and the Institute for Data, Systems, and Society. “The reality is that we live in a noisy world, and we can’t always get exactly the data that we want. How do we learn from data but at the same time recognize that there are limitations and deal appropriately with them?”
Broadly, her focus is on helping people understand the confines of the statistical tools available to them and, sometimes, working with them to craft better tools for a particular situation.
For instance, her group recently collaborated with oceanographers to develop a machine-learning model that can make more accurate predictions about ocean currents. In another project, she and others worked with degenerative disease specialists on a tool that helps severely motor-impaired individuals utilize a computer’s graphical user interface by manipulating a single switch.
A common thread woven through her work is an emphasis on collaboration.
“Working in data analysis, you get to hang out in everybody’s backyard, so to speak. You really can’t get bored because you can always be learning about some other field and thinking about how we can apply machine learning there,” she says.
Hanging out in many academic “backyards” is especially appealing to Broderick, who struggled even from a young age to narrow down her interests.
A math mindset
Growing up in a suburb of Cleveland, Ohio, Broderick had an interest in math for as long as she can remember. She recalls being fascinated by the idea of what would happen if you kept adding a number to itself, starting with 1+1=2 and then 2+2=4.
“I was maybe 5 years old, so I didn’t know what ‘powers of two’ were or anything like that. I was just really into math,” she says.
Her father recognized her interest in the subject and enrolled her in a Johns Hopkins program called the Center for Talented Youth, which gave Broderick the opportunity to take three-week summer classes on a range of subjects, from astronomy to number theory to computer science.
Later, in high school, she conducted astrophysics research with a postdoc at Case Western University. In the summer of 2002, she spent four weeks at MIT as a member of the first class of the Women’s Technology Program.
She especially enjoyed the freedom offered by the program, and its focus on using intuition and ingenuity to achieve high-level goals. For instance, the cohort was tasked with building a device with LEGOs that they could use to biopsy a grape suspended in Jell-O.
The program showed her how much creativity is involved in engineering and computer science, and piqued her interest in pursuing an academic career.
“But when I got into college at Princeton, I could not decide — math, physics, computer science — they all seemed super-cool. I wanted to do all of it,” she says.
She settled on pursuing an undergraduate math degree but took all the physics and computer science courses she could cram into her schedule.
Digging into data analysis
After receiving a Marshall Scholarship, Broderick spent two years at Cambridge University in the United Kingdom, earning a master of advanced study in mathematics and a master of philosophy in physics.
In the UK, she took a number of statistics and data analysis classes, including her first class on Bayesian data analysis in the field of machine learning.
It was a transformative experience, she recalls.
“During my time in the U.K., I realized that I really like solving real-world problems that matter to people, and Bayesian inference was being used in some of the most important problems out there,” she says.
Back in the U.S., Broderick headed to the University of California at Berkeley, where she joined the lab of Professor Michael I. Jordan as a grad student. She earned a PhD in statistics with a focus on Bayesian data analysis.
She decided to pursue a career in academia and was drawn to MIT by the collaborative nature of the EECS department and by how passionate and friendly her would-be colleagues were.
Her first impressions panned out, and Broderick says she has found a community at MIT that helps her be creative and explore hard, impactful problems with wide-ranging applications.
“I’ve been lucky to work with a really amazing set of students and postdocs in my lab — brilliant and hard-working people whose hearts are in the right place,” she says.
One of her team’s recent projects involves a collaboration with an economist who studies the use of microcredit, or the lending of small amounts of money at very low interest rates, in impoverished areas.
The goal of microcredit programs is to raise people out of poverty. Economists run randomized control trials of villages in a region that receive or don’t receive microcredit. They want to generalize the study results, predicting the expected outcome if one applies microcredit to other villages outside of their study.
But Broderick and her collaborators have found that results of some microcredit studies can be very brittle. Removing one or a few data points from the dataset can completely change the results. One issue is that researchers often use empirical averages, where a few very high or low data points can skew the results.
Using machine learning, she and her collaborators developed a method that can determine how many data points must be dropped to change the substantive conclusion of the study. With their tool, a scientist can see how brittle the results are.
“Sometimes dropping a very small fraction of data can change the major results of a data analysis, and then we might worry how far those conclusions generalize to new scenarios. Are there ways we can flag that for people? That is what we are getting at with this work,” she explains.
At the same time, she is continuing to collaborate with researchers in a range of fields, such as genetics, to understand the pros and cons of different machine-learning techniques and other data analysis tools.
Happy trails
Exploration is what drives Broderick as a researcher, and it also fuels one of her passions outside the lab. She and her husband enjoy collecting patches they earn by hiking all the trails in a park or trail system.
“I think my hobby really combines my interests of being outdoors and spreadsheets,” she says. “With these hiking patches, you have to explore everything and then you see areas you wouldn’t normally see. It is adventurous, in that way.”
They’ve discovered some amazing hikes they would never have known about, but also embarked on more than a few “total disaster hikes,” she says. But each hike, whether a hidden gem or an overgrown mess, offers its own rewards.
And just like in her research, curiosity, open-mindedness, and a passion for problem-solving have never led her astray.
#amazing#Analysis#applications#approach#Artificial Intelligence#Astronomy#Astrophysics#Building#career#change#classes#collaborate#Collaboration#collaborative#college#Community#computer#Computer Science#Computer science and technology#courses#craft#creativity#curiosity#data#data analysis#deal#Disease#Electrical Engineering&Computer Science (eecs)#emphasis#engineering
2 notes
·
View notes
Text
It’s the same principles at work behind spam filtering and autocorrect, which is Bayesian statistical analysis.
"There was an exchange on Twitter a while back where someone said, ‘What is artificial intelligence?' And someone else said, 'A poor choice of words in 1954'," he says. "And, you know, they’re right. I think that if we had chosen a different phrase for it, back in the '50s, we might have avoided a lot of the confusion that we're having now." So if he had to invent a term, what would it be? His answer is instant: applied statistics. "It's genuinely amazing that...these sorts of things can be extracted from a statistical analysis of a large body of text," he says. But, in his view, that doesn't make the tools intelligent. Applied statistics is a far more precise descriptor, "but no one wants to use that term, because it's not as sexy".
'The machines we have now are not conscious', Lunch with the FT, Ted Chiang, by Madhumita Murgia, 3 June/4 June 2023
24K notes
·
View notes
Text
Drive MBA Research Success with Expert Statistical Consulting and Data Analysis Services
Introduction
UK MBA students often face complex statistical challenges while preparing dissertations or research papers. From choosing the right methodology to interpreting advanced data sets, statistical analysis is a critical component that can make or break your academic success. Tutors India’s Statistical Consulting and Data Analysis Services streamline this process, empowering you to focus on your research insights while experts handle everything from sample size calculation to SPSS or R-based analysis, ensuring precision, clarity, and compliance with academic standards.
Why Statistical Analysis is Crucial for MBA Dissertations
Statistical analysis isn’t just about numbers—it’s about transforming raw data into meaningful business insights. For MBA students, this often involves:
Choosing the correct analysis method (e.g., regression, ANOVA, t-tests, Chi-square tests)
Ensuring statistical significance and data reliability
Using tools like SPSS, SAS, R, STATA, and Excel
Building a Statistical Analysis Plan (SAP)
Interpreting and visualizing complex results
Tutors India ensures that your dissertation meets both methodological and formatting guidelines through expert consultation and hands-on data analysis.
Key Benefits of Statistical Services from Tutors India
1. Customized Support for Business-Focused Research
Tutors India specializes in MBA-level statistical research across fields like marketing, operations, finance, and HR. Services include quantitative analysis, survey data interpretation, and biostatistics for healthcare MBAs.
2. Expertise Across Software and Techniques
Whether you're using SPSS for descriptive statistics or conducting Bayesian Analysis in R, our team handles the technical aspects with precision, ensuring robust and reproducible results.
3. Data-Driven Decision-Making for Research Papers
From developing hypotheses to performing multivariate analysis or SEM (Structural Equation Modeling), we make your research paper journal-submission ready with comprehensive Research Paper Statistical Review Services.
4. Full Support for Dissertation Writing
Need end-to-end dissertation assistance? Alongside data analysis, we provide:
Statistical Services for Dissertations
Research Methodology consulting
Statistical Reporting and Visualization
Data Interpretation aligned with MBA case studies
5. Compliance and Accuracy Guaranteed
We ensure alignment with UK university standards and citation guidelines (APA, Harvard, etc.). Whether you're working on a peer-reviewed manuscript or a final-year thesis, your statistical section will meet academic excellence.
Add-On Services to Enhance Your Research
Language and Technical Editing for clarity and professionalism
Plagiarism Reports for academic integrity
Transcription Services to convert interviews and recordings into analyzable formats
Journal Publication Preparation for publishing in international journals
Clinical and Public Health Research Analysis for healthcare MBAs
Why Choose Tutors India for MBA Statistical Analysis?
Tutors India brings years of experience in handling business and academic research. Here's what you get:
Accurate, in-depth Statistical Consultation
Full support with Dissertation Statistical Services
Access to expert analysts across SPSS, STATA, R, SAS, and E-Views
Confidentiality and timely delivery
Trusted by students from top UK universities
Conclusion
As an MBA student in the UK, presenting credible, data-driven insights is non-negotiable. With Tutors India’s Statistical Analysis Services, you not only meet academic requirements but also produce research that reflects professional business intelligence. Let us help you turn raw data into meaningful results—accurate, insightful, and impactful.
Contact Us
UK: +44-1143520021 IN: +91 8754446690 Email: [email protected] Website: www.tutorsindia.com
0 notes
Text
🔷Project Title: Multimodal Data Fusion for Enhanced Patient Risk Stratification using Deep Learning and Bayesian Survival Modeling.🟦
ai-ml-ds-healthcare-multimodal-survival-019 Filename: multimodal_patient_risk_stratification.py Timestamp: Mon Jun 02 2025 19:39:35 GMT+0000 (Coordinated Universal Time) Problem Domain:Healthcare Analytics, Clinical Decision Support, Predictive Medicine, Survival Analysis, Multimodal Machine Learning, Deep Learning, Bayesian Statistics. Project Description:This project aims to develop an…
#Bayesian#ClinicalDecisionSupport#DeepLearning#DigitalHealth#HealthcareAI#MultimodalAI#pandas#PyMC#python#RiskStratification#SurvivalAnalysis#TensorFlow
0 notes
Text
🔷Project Title: Multimodal Data Fusion for Enhanced Patient Risk Stratification using Deep Learning and Bayesian Survival Modeling.🟦
ai-ml-ds-healthcare-multimodal-survival-019 Filename: multimodal_patient_risk_stratification.py Timestamp: Mon Jun 02 2025 19:39:35 GMT+0000 (Coordinated Universal Time) Problem Domain:Healthcare Analytics, Clinical Decision Support, Predictive Medicine, Survival Analysis, Multimodal Machine Learning, Deep Learning, Bayesian Statistics. Project Description:This project aims to develop an…
#Bayesian#ClinicalDecisionSupport#DeepLearning#DigitalHealth#HealthcareAI#MultimodalAI#pandas#PyMC#python#RiskStratification#SurvivalAnalysis#TensorFlow
0 notes