#Data Mining and Predictive Analysis
Explore tagged Tumblr posts
Visit Tumblr Blog
Explore Tumblr blogs with no restrictions, modern design and the best experience.
Last Seen Tumblr Blogs





Fun Fact
Tumblr was attacked by a cross-site scripting worm deployed by the Internet troll group GNAA on Dec 3, 2012.
Text
A comprehensive guide to Data Mining and Predictive Analysis, revealing how to turn large datasets into valuable insights for future predictions and smarter decisions.
#data mining#data mining service#Data Mining Tools#predictive analysis#Data Mining and Predictive Analysis
0 notes
Text
DICS – Your Trusted Data Analytics Institute in Laxmi Nagar

In today’s data-driven world, the demand for skilled data analysts is skyrocketing. Whether you’re a student, working professional, or career switcher, mastering data analytics can open the door to numerous opportunities across industries. If you’re looking to start or advance your career in data analytics, choosing the right institute is crucial. Look no further — [Institute Name] is recognized as the best data analytics institute in Laxmi Nagar, offering industry-relevant training, expert faculty, and hands-on learning experiences that set you up for success.
Why Choose Us?
At [Institute Name], we believe in delivering more than just theoretical knowledge. Our mission is to equip you with the practical skills and insights needed to thrive in real-world data environments. Our data analytics program is designed by industry experts and regularly updated to match current trends and technologies. We focus on tools like Excel, SQL, Python, Power BI, Tableau, and R, ensuring that our students are proficient in all the key technologies employers are looking for.
Best Data Analytics Course in Laxmi Nagar
Our comprehensive curriculum makes us stand out as the provider of the best data analytics course in Laxmi Nagar. Whether you’re a beginner or have some background in analytics, our course structure is tailored to meet diverse learning needs. The course includes:
Introduction to Data Analytics
Data Visualization with Power BI & Tableau
Programming for Data Analytics (Python & R)
Statistical Analysis & Predictive Modeling
SQL for Data Management
Capstone Projects and Case Studies
With a strong emphasis on practical application, our course helps students build portfolios through real-time projects, giving them an edge in job interviews and professional scenarios.
Expert Faculty and Personalized Mentoring
We take pride in our experienced faculty, who bring years of industry and academic experience to the classroom. Our instructors not only teach but also mentor students, helping them with resume building, mock interviews, and job placement support. Our small batch sizes ensure personalized attention for every student.
100% Placement Assistance
Being the best data analytics institute in Laxmi Nagar, we offer complete placement support. We have partnerships with leading companies and regularly conduct hiring drives. Our dedicated placement team ensures that you are well-prepared for interviews and job roles, offering guidance every step of the way.
Convenient Location and Flexible Batches
Located in the heart of Laxmi Nagar, our institute is easily accessible by metro and public transport. We offer flexible batch timings — weekday, weekend, and online classes — making it convenient for both students and working professionals.
#Data Analysis#Data Visualization#Big Data#Data Science#Machine Learning#Predictive Analytics#Statistical Analysis#Data Mining#Business Intelligence#Data Modeling
0 notes
Text
i find it funny that my analysis of historical lottery data showed that #10 hadn't been drawn at all for the "mega ball" for over a year, and the immediate next lottery draw it was pulled
do not ask me for lottery advice, i have no knowledge
#glitch rambles#this is a pet project of mine#simply to fool around with data and what analysis i can do#and maybe if i can predict the lottery that would be nice#but vvvvvvvvvvv unrealistic
0 notes
Text
Top 9 AI Tools for Data Analytics in 2025
In 2025, the landscape of data analytics is rapidly evolving, thanks to the integration of artificial intelligence (AI). AI-powered tools are transforming how businesses analyze data, uncover insights, and make data-driven decisions. Here are the top nine AI tools for data analytics that are making a significant impact: 1. ChatGPT by OpenAI ChatGPT is a powerful AI language model developed by…
#Ai#AI Algorithms#Automated Analytics#Big Data#Business Intelligence#Data Analytics#Data Mining#Data Science#Data Visualization#Deep Learning#Machine Learning#Natural Language Processing#Neural Networks#predictive analytics#Statistical Analysis
0 notes
Text
The Impact of Big Data Analytics on Business Decisions
Introduction
Big data analytics has transformed the way of doing business, deciding, and strategizing for future actions. One can harness vast reams of data to extract insights that were otherwise unimaginable for increasing the efficiency, customer satisfaction, and overall profitability of a venture. We steer into an in-depth view of how big data analytics is equipping business decisions, its benefits, and some future trends shaping up in this dynamic field in this article. Read to continue
#Innovation Insights#TagsAI in Big Data Analytics#big data analytics#Big Data in Finance#big data in healthcare#Big Data in Retail#Big Data Integration Challenges#Big Data Technologies#Business Decision Making with Big Data#Competitive Advantage with Big Data#Customer Insights through Big Data#Data Mining for Businesses#Data Privacy Challenges#Data-Driven Business Strategies#Future of Big Data Analytics#Hadoop and Spark#Impact of Big Data on Business#Machine Learning in Business#Operational Efficiency with Big Data#Predictive Analytics in Business#Real-Time Data Analysis#trends#tech news#science updates#analysis#adobe cloud#business tech#science#technology#tech trends
0 notes
Text
What is the difference between Data Scientist and Data Engineers ?
In today’s data-driven world, organizations harness the power of data to gain valuable insights, make informed decisions, and drive innovation. Two key players in this data-centric landscape are data scientists and data engineers. Although their roles are closely related, each possesses unique skills and responsibilities that contribute to the successful extraction and utilization of data. In…
View On WordPress
#Big Data#Business Intelligence#Data Analytics#Data Architecture#Data Compliance#Data Engineering#Data Infrastructure#Data Insights#Data Integration#Data Mining#Data Pipelines#Data Science#data security#Data Visualization#Data Warehousing#Data-driven Decision Making#Exploratory Data Analysis (EDA)#Machine Learning#Predictive Analytics
1 note
·
View note
Text
AI’s energy use already represents as much as 20 percent of global data-center power demand, research published Thursday in the journal Joule shows. That demand from AI, the research states, could double by the end of this year, comprising nearly half of all total data-center electricity consumption worldwide, excluding the electricity used for bitcoin mining.
The new research is published in a commentary by Alex de Vries-Gao, the founder of Digiconomist, a research company that evaluates the environmental impact of technology. De Vries-Gao started Digiconomist in the late 2010s to explore the impact of bitcoin mining, another extremely energy-intensive activity, would have on the environment. Looking at AI, he says, has grown more urgent over the past few years because of the widespread adoption of ChatGPT and other large language models that use massive amounts of energy. According to his research, worldwide AI energy demand is now set to surpass demand from bitcoin mining by the end of this year.
“The money that bitcoin miners had to get to where they are today is peanuts compared to the money that Google and Microsoft and all these big tech companies are pouring in [to AI],” he says. “This is just escalating a lot faster, and it’s a much bigger threat.”
The development of AI is already having an impact on Big Tech’s climate goals. Tech giants have acknowledged in recent sustainability reports that AI is largely responsible for driving up their energy use. Google’s greenhouse gas emissions, for instance, have increased 48 percent since 2019, complicating the company’s goals of reaching net zero by 2030.
“As we further integrate AI into our products, reducing emissions may be challenging due to increasing energy demands from the greater intensity of AI compute,” Google’s 2024 sustainability report reads.
Last month, the International Energy Agency released a report finding that data centers made up 1.5 percent of global energy use in 2024—around 415 terrawatt-hours, a little less than the yearly energy demand of Saudi Arabia. This number is only set to get bigger: Data centers’ electricity consumption has grown four times faster than overall consumption in recent years, while the amount of investment in data centers has nearly doubled since 2022, driven largely by massive expansions to account for new AI capacity. Overall, the IEA predicted that data center electricity consumption will grow to more than 900 TWh by the end of the decade.
But there’s still a lot of unknowns about the share that AI, specifically, takes up in that current configuration of electricity use by data centers. Data centers power a variety of services—like hosting cloud services and providing online infrastructure—that aren’t necessarily linked to the energy-intensive activities of AI. Tech companies, meanwhile, largely keep the energy expenditure of their software and hardware private.
Some attempts to quantify AI’s energy consumption have started from the user side: calculating the amount of electricity that goes into a single ChatGPT search, for instance. De Vries-Gao decided to look, instead, at the supply chain, starting from the production side to get a more global picture.
The high computing demands of AI, De Vries-Gao says, creates a natural “bottleneck” in the current global supply chain around AI hardware, particularly around the Taiwan Semiconductor Manufacturing Company (TSMC), the undisputed leader in producing key hardware that can handle these needs. Companies like Nvidia outsource the production of their chips to TSMC, which also produces chips for other companies like Google and AMD. (Both TSMC and Nvidia declined to comment for this article.)
De Vries-Gao used analyst estimates, earnings call transcripts, and device details to put together an approximate estimate of TSMC’s production capacity. He then looked at publicly available electricity consumption profiles of AI hardware and estimates on utilization rates of that hardware—which can vary based on what it’s being used for—to arrive at a rough figure of just how much of global data-center demand is taken up by AI. De Vries-Gao calculates that without increased production, AI will consume up to 82 terrawatt-hours of electricity this year—roughly around the same as the annual electricity consumption of a country like Switzerland. If production capacity for AI hardware doubles this year, as analysts have projected it will, demand could increase at a similar rate, representing almost half of all data center demand by the end of the year.
Despite the amount of publicly available information used in the paper, a lot of what De Vries-Gao is doing is peering into a black box: We simply don’t know certain factors that affect AI’s energy consumption, like the utilization rates of every piece of AI hardware in the world or what machine learning activities they’re being used for, let alone how the industry might develop in the future.
Sasha Luccioni, an AI and energy researcher and the climate lead at open-source machine-learning platform Hugging Face, cautioned about leaning too hard on some of the conclusions of the new paper, given the amount of unknowns at play. Luccioni, who was not involved in this research, says that when it comes to truly calculating AI’s energy use, disclosure from tech giants is crucial.
“It’s because we don’t have the information that [researchers] have to do this,” she says. “That’s why the error bar is so huge.”
And tech companies do keep this information. In 2022, Google published a paper on machine learning and electricity use, noting that machine learning was “10%–15% of Google’s total energy use” from 2019 to 2021, and predicted that with best practices, “by 2030 total carbon emissions from training will reduce.” However, since that paper—which was released before Google Gemini’s debut in 2023—Google has not provided any more detailed information about how much electricity ML uses. (Google declined to comment for this story.)
“You really have to deep-dive into the semiconductor supply chain to be able to make any sensible statement about the energy demand of AI,” De Vries-Gao says. “If these big tech companies were just publishing the same information that Google was publishing three years ago, we would have a pretty good indicator” of AI’s energy use.
19 notes
·
View notes
Note
Hi ABL!! This is more of a data question then anything but it might not actually be answerable.
How does the world of BL define a successful show? Is it money made on ads revenue? Streams? Trending hashtags??
Granted in North American media I also couldn’t answer this question, but I could gage based on…article reviews or critical acclaim. Or something.
I see soooooo many people saying something flopped or was massively successful, but truly. How on earth are we making those benchmarks?
I figure you might have at least a tiny sliver of insight into how this works! Or at least a key word I can take to google LOL. Thanks as always!!!!!
Hum.
Well for GMMTV et al, it's YT views. So that's easy. We can see those eyeballs outright.
The streaming platforms obfuscate data (that is one of the reasons SAG is still on strike) but we can see things like where it's ranked on their internal leader boards (what's "popular on Viki" for example). How many reviews something has. How many collections and lists it's on. How many people on MDL have it listed as "currently watching"
More key is how much chatter a show is getting. How many comments. But also...
Literally when you do a Google search for that IP:
How are the hit returns?
How many top spots does it hold above the fold on Google main (using private or incognito mode).
Are people blogging about it? Think pieces?
Are there reaction vids?
FMVs?
Reddit chatter?
BTS's?
Interviews with actors?
The amount of fan content generated around an IP tells you a lot about the number of viewers - since it is all a numbers game. Commenters (those who visibly/trackably react to content) are more common than (content) creators. Ghosts (passive consumers) are more common than commenters.
There are those in EntDA working on formulas for predictive fan base numbers sourced in the ratios of these.
Lemme try to explain...
In other words, the fans who create content for IPs (fanfic, art, meta analysis, FMVs, etc...) are the rarest. Those who interact with the content, leave star reviews, comment on the above fan-made content, engage in discourse, leave YT comments, are the second rarest. Those who tend to do nothing more than ... well, ghost (maybe have a subscription, maybe save the vid to a playlist or on MDL, maybe read this on Tumblr but don't react to it). They are the largest contingent but hardest to track.
If we could get a good handle on the first 2, there's usually a predictable ratio that can be drawn for the fan base as a whole, the largest number 3 - ghosts.
For example:
For every 1 creator there are 100 commenters and 1000 ghosts. Something like that. However the nature of this ratio is dependent on venue and vocality of the fan base (often a generational thing). So like, most Kpop stans are vocal, but 4th gen stans tend to be more noisy online, even though 3rd gen groups tend to have bigger overall fan bases. (Superstars, like super hits, are non-viable non-predictive outliers. There can never be another KP, or 2g, and we can't use their numbers to predict anything. Just like Taylor Swift or BTS can't be used to predict/estimate the success of a new pop venture).
back to the BL fandom
Here on Tumblr you can tell what's popular by which ones are getting the most gifsets.
That's how we know Only Friends is out performing Dangerous Romance. (I mean I could check the numbers on YT but I don't really have to.)
Also, I bet you good money Kiseki is garnering more eyeballs than You Are Mine. Again, I can say that with confidence just based on the content that's being created for that IP in this one venue.
On a practical level, in the ET industry, if there is chatter about a BL outside of BL circles (as happened with KP) you know it's gotten HUGE (by BL standards).
The moral of this story, incidentally, is if you like a thing, doesn't matter how shy you are, if you want it to continue, get a second season, whatever, you gotta NOT JUST WATCH IT BUT TALK about it. Online, where careers are made and broken. Squeaky wheel and all that.
Entertainment is about attention. More money is always thrown at the thing getting the most attention.
Just like politics.
Okay, I done now.
#asked and answered#probably more than you wanted#ABL dusted off big data#in the end it's a numbers game#and we here us on tumblr we're some of those numbers#congratz you asked a question you're being tracked!#yay!
56 notes
·
View notes
Text

Common uses of bioinformatics
💡Sequence analysis Analyzing DNA and protein sequences to identify genes, regulatory regions & mutations.
💡Gene expression Analyzing RNA expression data from experiments like microarrays or RNA-seq to understand gene regulation.
💡Phylogenetics Constructing evolutionary relationships between organisms based on genetic data and genomic comparisons.
💡Molecular modeling Predicting protein structure and docking drugs to proteins using computational modeling and simulation.
💡Databases & Data mining Developing databases like GenBank to store biological data and mining it to find patterns.
💡Genomics Studying entire genomes, including sequencing and assembling genomes as well as identifying genes and genomic variations.
Follow @everythingaboutbiotech for useful posts.
#bioinformatics#genomics#proteomics#sequencing#PCR#biodata#bioIT#precisionmedicine#digitalhealth#biotech#DNA#healthtech#medtech#biostatistics#bioinformaticsjobs#BLAST#microarray#GenBank
54 notes
·
View notes
Text
this post has taken so long i suspect it’ll feel entirely disconnected from the LRB which inspired it, good grief. anyways living up to my url again - the orientation ocd inspired essays have been getting way less hard on my anxiety to produce i think i’m getting better at my commitment to reasonableness and attempting to not reproduce structures of systemic oppression to enforce an artificial conservatism of things which i feel so protective of BECAUSE of those same structures of systemic oppression lmao. still not bothering to do a second draft or grammarify things properly though xmx
the desire to bring up how a decent chunk of “radical genderfuckery” in the queer space is at a philosophical level based more on countering the counterculture (due to internet-enabled perceivable narrative saturation & homogeneity of ‘regular’ queer identity) (which, like, the saturation is bc yer at the soup store, but the homogeneity IS actual a reasonable fucking problem to find in it dont get me wrong) and therefore is extremely predictable in how it fails to properly address the more basal systems of transmisogyny and homophobia and other such things - to the point of outright hindering some causes from a purely rhetorical POV (coughs in the general direction of feminist criticism of the foundations of manhood versus ‘oh but i’m undeniably part of the outgroup-to-men-as-engineered-by-Manhood while still being a man!’ individual arguments which like. true, but just specifying ‘CIS men!’ or ‘TME’ in cases of discussing the systemic privileges of patriarchy will fail to properly deconstruct the basii if manhood itself if we accept that men can be things other than cis ya know like -. god sorry fuck this is getting away from me. yes i’m mostly still just failing to internally digest bigender lesbian stuff with my own worldviews’ enzymes thats what this is turning into. to be clear i aint trying to invalidate anything besides my own analytical (or pragmatic capacity to just stop being analytical) skill, if i rip myself away from the rhetorical zeal buzzer i can mostly get it lmao. also yes even away from the buzzer i will still insist that peoples identities are informed by their philosophical mindset towards the community in a way that informs their politics and vice versa i don’t really think that should be controversial. (mine included!!!my internal definition of ‘lesbian’ is a goddamn rube goldberg machine of allowances for shit like my tacit acceptance that our species is a coincidental hivemind or that gender is an unavoidable illusion cast on how humans process data and that any personal sense or identity is held ransom by the extremely specific societal microconditions under which its person is subject to) like if we’re willing to accept that concepts like “genital preference” or any of the particular ways people try to identify themselves as the Truer/Purer/Realer incarnation of their label has a (in these cases more uncomplicatedly negative) causal relationship with the systems of bigotry and catergorization they are born under then i see no reason to hold identity itself as uniquely stagnant from causation like that. (VITALLY IMPORTANT: CRITIQUE OF THESE SORTS OF HEAVILY PERSONAL INTERPRETATIONS OF SELF RELATIVE TO SYSTEM MUST ONLY BE DONE IN RELATION TO AND IN CONTEXT OF BROADER CULTURAL PATTERNS, IF YOU WALK UP TO SOMEONE AND GO “well i think your identity is based on a bourgeoise alienation from the conditions under which sexuality arises! just identify as bi!!!” THATS WHATS GENERALLY REFERRED TO AS “BEING A DICK” AND DOES NOTHING TO JUSTIFY YOUR ANALYSIS OF BROADER IDENTOLOGICAL TRENDS AND HOW THEY MAY BE INFORMED BY QUEER HISTORY AND THE WAY IN WHICH THEY COULD INFORM THE QUEER FUTURE (INCLUDING QUALITATIVE JUDGEMENTS THEREOF)
ok i swear tangent over
VERSUS the understanding that what i refer to with such a description of “radical genderfuckery in the queer community” is merely a subset of lgbt+ people (getting tired if repeating the q word sorry i’m using them interchangeably with no intent to color your presumptions of like, the subset being inherently different than a more “traditionally named” set or anything lmao) being quirky and experimental in a way only differentiable from longstanding cultural dynamics by the way its behavior is informed by extremely online bullshit, with relatively little differentiating the end results except for bad takes on internet discourse and having the most annoying headcanons imaginable. like for instance the actual difference between, like, a lesboy? and like one-seventh of butches out there in general from an internal experience of gender standpoint is PROBABLY (my estimate i’m not a mind reader) way fucking less than the terminology makes it seem. which does invite argument as to whether such precise-of-detail yet imprecise-of-relational-dynamic-to-related-concepts-(orientation-systemic-privilege-etc) is warranted or necessary or if not necessary than a net good in any case, but should not, MUST not foster contempt nor scorn towards other fucking people who just fucking use that language because it works for them or they believe in it. except maybe if its some phenomenally misinformed clown nose bullcrap but lets face it all of us are terrible at identifying whats actually a farce produced out of malign ignorance and whats just some fucking kid playing around with language
also, and this goes for pretty much any fucking faction, arguments towards tradition or precedent for ANYTHING are easily exploited, functionally incomplete, and can only at best proove a phenomenon is not recent. like yes in years past we all used more lumpy labels without the same sense of internal division, or YES in years past we moved past using such lumpy labels and found more precise means of identification. those both are literally true, non contradictory, and yet despite each half swaying in opposite directions as to the goodness of this change of language each says jack shit to emphasize WHY that change may have been good or bad, besides that this was going on a while ago
#also something something grumble grumble if people get cool new words to describe themselves in super precise detail by chopping up#and stitching together pre-existing terminology than why do i have to be stuck holding the damn umbrella. store brand. generic.#like fuck even the CIS lesbians get a more prescriptive label than we (trans lesbians with wierd but not especially contradictory or#chimerafiable gender shit going on so we’d just kinda fall under trans-in-the-TMA-way lesbian-in-the-structurally-homosexual-way i want cool#words wah)#do#trying to invent language inclusive of like. my hypothetical sixth-dimensional kinsey scale accounting for shit like fictional detatchment#conscious misgendering group-dynamics-observed-under-comfort & compulsory heterosexuality amongst other things seems like a fucking nightmar#nightmare though
2 notes
·
View notes
Text
Top 10 In- Demand Tech Jobs in 2025

Technology is growing faster than ever, and so is the need for skilled professionals in the field. From artificial intelligence to cloud computing, businesses are looking for experts who can keep up with the latest advancements. These tech jobs not only pay well but also offer great career growth and exciting challenges.
In this blog, we’ll look at the top 10 tech jobs that are in high demand today. Whether you’re starting your career or thinking of learning new skills, these jobs can help you plan a bright future in the tech world.
1. AI and Machine Learning Specialists
Artificial Intelligence (AI) and Machine Learning are changing the game by helping machines learn and improve on their own without needing step-by-step instructions. They’re being used in many areas, like chatbots, spotting fraud, and predicting trends.
Key Skills: Python, TensorFlow, PyTorch, data analysis, deep learning, and natural language processing (NLP).
Industries Hiring: Healthcare, finance, retail, and manufacturing.
Career Tip: Keep up with AI and machine learning by working on projects and getting an AI certification. Joining AI hackathons helps you learn and meet others in the field.
2. Data Scientists
Data scientists work with large sets of data to find patterns, trends, and useful insights that help businesses make smart decisions. They play a key role in everything from personalized marketing to predicting health outcomes.
Key Skills: Data visualization, statistical analysis, R, Python, SQL, and data mining.
Industries Hiring: E-commerce, telecommunications, and pharmaceuticals.
Career Tip: Work with real-world data and build a strong portfolio to showcase your skills. Earning certifications in data science tools can help you stand out.
3. Cloud Computing Engineers: These professionals create and manage cloud systems that allow businesses to store data and run apps without needing physical servers, making operations more efficient.
Key Skills: AWS, Azure, Google Cloud Platform (GCP), DevOps, and containerization (Docker, Kubernetes).
Industries Hiring: IT services, startups, and enterprises undergoing digital transformation.
Career Tip: Get certified in cloud platforms like AWS (e.g., AWS Certified Solutions Architect).
4. Cybersecurity Experts
Cybersecurity professionals protect companies from data breaches, malware, and other online threats. As remote work grows, keeping digital information safe is more crucial than ever.
Key Skills: Ethical hacking, penetration testing, risk management, and cybersecurity tools.
Industries Hiring: Banking, IT, and government agencies.
Career Tip: Stay updated on new cybersecurity threats and trends. Certifications like CEH (Certified Ethical Hacker) or CISSP (Certified Information Systems Security Professional) can help you advance in your career.
5. Full-Stack Developers
Full-stack developers are skilled programmers who can work on both the front-end (what users see) and the back-end (server and database) of web applications.
Key Skills: JavaScript, React, Node.js, HTML/CSS, and APIs.
Industries Hiring: Tech startups, e-commerce, and digital media.
Career Tip: Create a strong GitHub profile with projects that highlight your full-stack skills. Learn popular frameworks like React Native to expand into mobile app development.
6. DevOps Engineers
DevOps engineers help make software faster and more reliable by connecting development and operations teams. They streamline the process for quicker deployments.
Key Skills: CI/CD pipelines, automation tools, scripting, and system administration.
Industries Hiring: SaaS companies, cloud service providers, and enterprise IT.
Career Tip: Earn key tools like Jenkins, Ansible, and Kubernetes, and develop scripting skills in languages like Bash or Python. Earning a DevOps certification is a plus and can enhance your expertise in the field.
7. Blockchain Developers
They build secure, transparent, and unchangeable systems. Blockchain is not just for cryptocurrencies; it’s also used in tracking supply chains, managing healthcare records, and even in voting systems.
Key Skills: Solidity, Ethereum, smart contracts, cryptography, and DApp development.
Industries Hiring: Fintech, logistics, and healthcare.
Career Tip: Create and share your own blockchain projects to show your skills. Joining blockchain communities can help you learn more and connect with others in the field.
8. Robotics Engineers
Robotics engineers design, build, and program robots to do tasks faster or safer than humans. Their work is especially important in industries like manufacturing and healthcare.
Key Skills: Programming (C++, Python), robotics process automation (RPA), and mechanical engineering.
Industries Hiring: Automotive, healthcare, and logistics.
Career Tip: Stay updated on new trends like self-driving cars and AI in robotics.
9. Internet of Things (IoT) Specialists
IoT specialists work on systems that connect devices to the internet, allowing them to communicate and be controlled easily. This is crucial for creating smart cities, homes, and industries.
Key Skills: Embedded systems, wireless communication protocols, data analytics, and IoT platforms.
Industries Hiring: Consumer electronics, automotive, and smart city projects.
Career Tip: Create IoT prototypes and learn to use platforms like AWS IoT or Microsoft Azure IoT. Stay updated on 5G technology and edge computing trends.
10. Product Managers
Product managers oversee the development of products, from idea to launch, making sure they are both technically possible and meet market demands. They connect technical teams with business stakeholders.
Key Skills: Agile methodologies, market research, UX design, and project management.
Industries Hiring: Software development, e-commerce, and SaaS companies.
Career Tip: Work on improving your communication and leadership skills. Getting certifications like PMP (Project Management Professional) or CSPO (Certified Scrum Product Owner) can help you advance.
Importance of Upskilling in the Tech Industry
Stay Up-to-Date: Technology changes fast, and learning new skills helps you keep up with the latest trends and tools.
Grow in Your Career: By learning new skills, you open doors to better job opportunities and promotions.
Earn a Higher Salary: The more skills you have, the more valuable you are to employers, which can lead to higher-paying jobs.
Feel More Confident: Learning new things makes you feel more prepared and ready to take on tougher tasks.
Adapt to Changes: Technology keeps evolving, and upskilling helps you stay flexible and ready for any new changes in the industry.
Top Companies Hiring for These Roles
Global Tech Giants: Google, Microsoft, Amazon, and IBM.
Startups: Fintech, health tech, and AI-based startups are often at the forefront of innovation.
Consulting Firms: Companies like Accenture, Deloitte, and PwC increasingly seek tech talent.
In conclusion, the tech world is constantly changing, and staying updated is key to having a successful career. In 2025, jobs in fields like AI, cybersecurity, data science, and software development will be in high demand. By learning the right skills and keeping up with new trends, you can prepare yourself for these exciting roles. Whether you're just starting or looking to improve your skills, the tech industry offers many opportunities for growth and success.
#Top 10 Tech Jobs in 2025#In- Demand Tech Jobs#High paying Tech Jobs#artificial intelligence#datascience#cybersecurity
2 notes
·
View notes
Text
A Stake in the Code: Van Helsing's Wild Foray into Bioinformatics
Let me tell you, dear students, about the day I discovered that monsters don’t always lurk in dark castles or foggy graveyards. Sometimes, the most sinister creatures hide in something far more diabolical—data. Yes, you heard me right. While you imagine your brave professor charging through the night, crucifix in one hand, holy water in the other, you must now picture me hunched over a glowing screen, battling spreadsheets and strings of code. How did it come to this, you ask? Well, sit tight, for this tale involves an unfortunate encounter with a conference on modern science, an espresso machine with a grudge, and, of course, Dracula.
It all began when I was invited—lured, more like—to a prestigious science symposium. A splendid opportunity to expose these modern "men of logic" to the perils of the undead, I thought. Instead, I was met with a barrage of jargon, acronyms, and more slides of molecular models than I’d care to recount. I made it through the first day, my senses numbed by an endless stream of buzzwords—"genomics," "data analysis," and, shudderingly, "algorithms." Oh, the horror! I was sure that even a vampire bat would be driven to stake itself in frustration.
However, my despair peaked during a presentation by a rather excitable researcher on a topic called "bioinformatics." Now, I had no idea what kind of nefarious creature this was, but the term "bio" immediately set off my vampire-hunting instincts. Perhaps this was some new breed of blood-sucking pestilence? The researcher, with the fervor of a man possessed, prattled on about deciphering genomes, comparing them to vast tomes of knowledge that could predict diseases, track mutations—essentially, the modern-day grimoire of disease.
I tried to stay awake by guzzling coffee—until the machine itself turned on me. One ill-timed splutter, and I was doused in scorching liquid. As I wiped the caffeine from my waistcoat, it hit me: bioinformatics was a science of tracking. Not just tracking disease, but tracking the malformations of life itself. It was a code, a pattern, a series of markers… much like the bite marks of our nocturnal enemies! If bioinformatics could trace illness, then surely it could predict vampirism—or at least explain why Dracula’s hair had the consistency of damp hay.
My interest piqued, I cornered the researcher after his talk. Through a series of incomprehensible diagrams, I learned that bioinformatics involved massive troves of genetic data, all neatly catalogued and ready to be mined for clues about humanity’s most terrifying afflictions. This was no mere science. This was a battlefield. And as we all know, I have never met a battlefield I didn’t like.
I had found a new crusade. In bioinformatics, I saw the potential to eradicate vampiric curses at their source—by identifying genetic markers long before the first fang ever punctures a jugular. Picture it: no more garlic garlands or holy water showers! Imagine a world where we can pinpoint who is destined to become a creature of the night with a simple blood test. No more guessing whether your charming neighbor is just a night owl or plotting your demise.
Of course, there were skeptics. My students, bless their skeptical hearts, scoffed. "But Professor," they cried, "surely science can’t predict something as mystical as vampirism?" To which I replied, "If it can decode the human genome, it can decode Dracula!" Armed with this newfound knowledge, I plunged headlong into the arcane realms of bioinformatics. Genomes, sequences, databases—they became my prey, and like any great hunter, I stalked them with unyielding determination.
Thus, I resolved to pen my insights. Not just for posterity, but as a rallying cry. For if we can battle genetic ghouls with modern science, perhaps we can rid the world of vampiric plagues once and for all. And so, dear students, I present to you my findings—my digital stake in the dark heart of bioinformatics. Let us see where this madness leads...
5 notes
·
View notes
Text
From Curious Novice to Data Enthusiast: My Data Science Adventure
I've always been fascinated by data science, a field that seamlessly blends technology, mathematics, and curiosity. In this article, I want to take you on a journey—my journey—from being a curious novice to becoming a passionate data enthusiast. Together, let's explore the thrilling world of data science, and I'll share the steps I took to immerse myself in this captivating realm of knowledge.

The Spark: Discovering the Potential of Data Science
The moment I stumbled upon data science, I felt a spark of inspiration. Witnessing its impact across various industries, from healthcare and finance to marketing and entertainment, I couldn't help but be drawn to this innovative field. The ability to extract critical insights from vast amounts of data and uncover meaningful patterns fascinated me, prompting me to dive deeper into the world of data science.
Laying the Foundation: The Importance of Learning the Basics
To embark on this data science adventure, I quickly realized the importance of building a strong foundation. Learning the basics of statistics, programming, and mathematics became my priority. Understanding statistical concepts and techniques enabled me to make sense of data distributions, correlations, and significance levels. Programming languages like Python and R became essential tools for data manipulation, analysis, and visualization, while a solid grasp of mathematical principles empowered me to create and evaluate predictive models.
The Quest for Knowledge: Exploring Various Data Science Disciplines
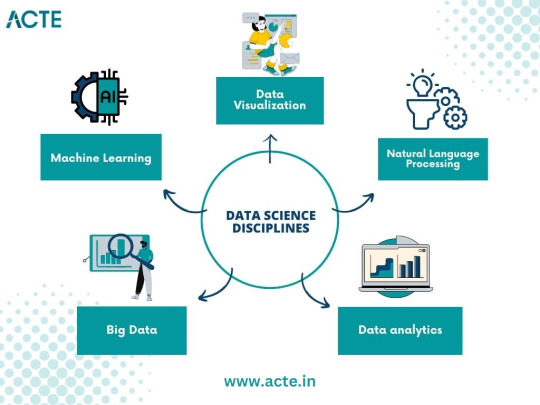
A. Machine Learning: Unraveling the Power of Predictive Models
Machine learning, a prominent discipline within data science, captivated me with its ability to unlock the potential of predictive models. I delved into the fundamentals, understanding the underlying algorithms that power these models. Supervised learning, where data with labels is used to train prediction models, and unsupervised learning, which uncovers hidden patterns within unlabeled data, intrigued me. Exploring concepts like regression, classification, clustering, and dimensionality reduction deepened my understanding of this powerful field.
B. Data Visualization: Telling Stories with Data
In my data science journey, I discovered the importance of effectively visualizing data to convey meaningful stories. Navigating through various visualization tools and techniques, such as creating dynamic charts, interactive dashboards, and compelling infographics, allowed me to unlock the hidden narratives within datasets. Visualizations became a medium to communicate complex ideas succinctly, enabling stakeholders to understand insights effortlessly.
C. Big Data: Mastering the Analysis of Vast Amounts of Information
The advent of big data challenged traditional data analysis approaches. To conquer this challenge, I dived into the world of big data, understanding its nuances and exploring techniques for efficient analysis. Uncovering the intricacies of distributed systems, parallel processing, and data storage frameworks empowered me to handle massive volumes of information effectively. With tools like Apache Hadoop and Spark, I was able to mine valuable insights from colossal datasets.
D. Natural Language Processing: Extracting Insights from Textual Data
Textual data surrounds us in the digital age, and the realm of natural language processing fascinated me. I delved into techniques for processing and analyzing unstructured text data, uncovering insights from tweets, customer reviews, news articles, and more. Understanding concepts like sentiment analysis, topic modeling, and named entity recognition allowed me to extract valuable information from written text, revolutionizing industries like sentiment analysis, customer service, and content recommendation systems.
Building the Arsenal: Acquiring Data Science Skills and Tools
Acquiring essential skills and familiarizing myself with relevant tools played a crucial role in my data science journey. Programming languages like Python and R became my companions, enabling me to manipulate, analyze, and model data efficiently. Additionally, I explored popular data science libraries and frameworks such as TensorFlow, Scikit-learn, Pandas, and NumPy, which expedited the development and deployment of machine learning models. The arsenal of skills and tools I accumulated became my assets in the quest for data-driven insights.
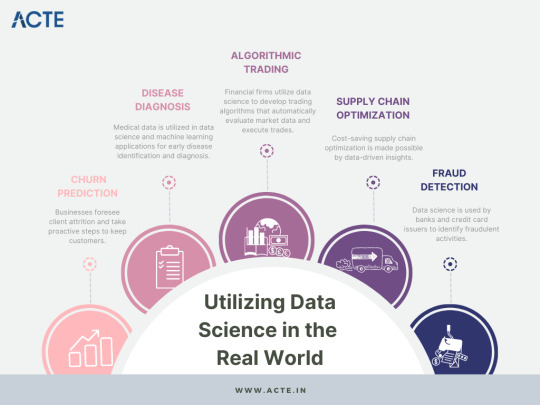
The Real-World Challenge: Applying Data Science in Practice
Data science is not just an academic pursuit but rather a practical discipline aimed at solving real-world problems. Throughout my journey, I sought to identify such problems and apply data science methodologies to provide practical solutions. From predicting customer churn to optimizing supply chain logistics, the application of data science proved transformative in various domains. Sharing success stories of leveraging data science in practice inspires others to realize the power of this field.
Cultivating Curiosity: Continuous Learning and Skill Enhancement
Embracing a growth mindset is paramount in the world of data science. The field is rapidly evolving, with new algorithms, techniques, and tools emerging frequently. To stay ahead, it is essential to cultivate curiosity and foster a continuous learning mindset. Keeping abreast of the latest research papers, attending data science conferences, and engaging in data science courses nurtures personal and professional growth. The journey to becoming a data enthusiast is a lifelong pursuit.
Joining the Community: Networking and Collaboration
Being part of the data science community is a catalyst for growth and inspiration. Engaging with like-minded individuals, sharing knowledge, and collaborating on projects enhances the learning experience. Joining online forums, participating in Kaggle competitions, and attending meetups provides opportunities to exchange ideas, solve challenges collectively, and foster invaluable connections within the data science community.
Overcoming Obstacles: Dealing with Common Data Science Challenges
Data science, like any discipline, presents its own set of challenges. From data cleaning and preprocessing to model selection and evaluation, obstacles arise at each stage of the data science pipeline. Strategies and tips to overcome these challenges, such as building reliable pipelines, conducting robust experiments, and leveraging cross-validation techniques, are indispensable in maintaining motivation and achieving success in the data science journey.
Balancing Act: Building a Career in Data Science alongside Other Commitments
For many aspiring data scientists, the pursuit of knowledge and skills must coexist with other commitments, such as full-time jobs and personal responsibilities. Effectively managing time and developing a structured learning plan is crucial in striking a balance. Tips such as identifying pockets of dedicated learning time, breaking down complex concepts into manageable chunks, and seeking mentorships or online communities can empower individuals to navigate the data science journey while juggling other responsibilities.
Ethical Considerations: Navigating the World of Data Responsibly
As data scientists, we must navigate the world of data responsibly, being mindful of the ethical considerations inherent in this field. Safeguarding privacy, addressing bias in algorithms, and ensuring transparency in data-driven decision-making are critical principles. Exploring topics such as algorithmic fairness, data anonymization techniques, and the societal impact of data science encourages responsible and ethical practices in a rapidly evolving digital landscape.
Embarking on a data science adventure from a curious novice to a passionate data enthusiast is an exhilarating and rewarding journey. By laying a foundation of knowledge, exploring various data science disciplines, acquiring essential skills and tools, and engaging in continuous learning, one can conquer challenges, build a successful career, and have a good influence on the data science community. It's a journey that never truly ends, as data continues to evolve and offer exciting opportunities for discovery and innovation. So, join me in your data science adventure, and let the exploration begin!
#data science#data analytics#data visualization#big data#machine learning#artificial intelligence#education#information
17 notes
·
View notes
Text
Sachin Dev Duggal | Using NLP to enhance customer experience in e-commerce
In the boom of e-commerce, it is known that focusing on an exceptional customer experience is crucial. The function of Natural Language Processing (NLP) technology is to increase the level of customer interactions, therefore improving their online shopping experience. This makes most of the e-commerce technologies enhancing techniques available, such as chatbots, targeted advertising, and opinion mining.
Enhancing Customer Interactions with Chatbots
E-commerce has witnessed a significant use of NLP in the form of chatbots. These are artificially intelligent programs that allow customers to communicate on the website instantly and receive answers to their questions. Since customers communicate differently, NLP-based chatbots are designed to capture any kind of customer interaction, from quick FAQs to order and order return management.
Sachin Dev Duggal Founded Builder.ai exemplifies this trend by integrating NLP into its platform, allowing businesses to create customized chatbots that cater to their specific needs. Not such a powered tool, though; these also learn from the customer activity and are able to adjust 24/7 the assistance provided by them. Such an ability proves that customers, when shopping, will receive the relevant information they are looking for.
Personalized Recommendations
NLP’s ability to provide personalization is another area that cannot be overlooked. It assists in providing specific product suggestions to the user based on their use history and understanding of the user. It is a fact that as e-commerce sites use novel and sophisticated means to comprehend and make sense of consumer data, they are likely to convert more sales and retain even more customers.
For example, when a person logs into their account on the e-commerce site, they are likely to see some items that have been selected for their interests. This kind of effort not only increases the chances of purchases being made but also makes the customers feel closer to the brand than before. Organizations such as Builder.ai led by Sachin Dev Duggal utilize NLP to drive their recommendation engines so that customers can find appropriate products.
Sentiment analysis for better insights
Another common application of NLP is sentiment analysis, which is quite beneficial in that it helps e-commerce companies assess the feelings of their customers towards their goods or services. Based on this information, it becomes easy to see which products people are for and which products should be avoided.
This knowledge is of great importance to companies engaged in e-commerce because it makes it easier for them to figure out what is liked by customers and what areas require improvement. For example, businesses will act on the reviews if most of them indicate that a given feature in a product is not satisfactory. Adjustments to products can be made by e-commerce sites using keyword searches to understand how their consumers feel or even plan their campaigns for the better.
Predicting Market Trends and Consumer Behavior
Apart from enhancing the manner of dealing with customers, NLP may also be used in predicting the general behaviour of the market and that of the consumer. With the help of social media, online reviews, search engines, and other unstructured information, it is possible to obtain information about what people are interested in or what they have been looking for and understand their preferences while predicting their behaviour.
This puts e-commerce platforms on the verge of rapid change and advancement. Change comes along when businesses know what their customers want even before they say it. Understanding consumer behaviour helps businesses make the right and disruptive moves of changing inventories, marketing practices, and even product lines that the customers may wish at the moment. Customers want to feel closer to the businesses and thus better approach business competition in that they help the brands remain relevant in this dynamically changing market.
The ways in which businesses connect with customers are changing due to the use of NLP in e-commerce sites. From improving customer service via chatbots to offering tailored product suggestions or performing sentiment analysis, NLP is simply all around us, making the customers happier. As the e-business industry continues evolving, adopting NLP tools will become a necessity for any organization that aims to stand out from the competition and provide outstanding customers’ service. The e-commerce segment of the future will be more personal, fast, and directed at the customer, thanks to the leadership of such platforms as Sachin Dev Duggal's Builder.ai.
#artificial intelligence#AI#technology#sachin dev duggal#sachin duggal#builder.ai#builder ai#sachin dev duggal news#sachin duggal news#builder.ai news#builder ai news#sachin dev duggal builder.ai#sachin duggal builder.ai#AI news#tech news#sachindevduggal#innovation#sachinduggal#sachin dev duggal ey
2 notes
·
View notes
Text
Mastering the Dig: Your Roadmap to the Top 10 Data Mining Courses
In the digital age, where data is a valuable currency, the field of data mining has emerged as a critical discipline for extracting meaningful insights from vast datasets. Whether you're a student looking to ace your data mining assignments or a professional seeking to enhance your skills, a solid education is paramount. In this blog, we'll guide you through the top 10 data mining courses, with a special emphasis on the exceptional resource – DatabaseHomeworkHelp.com – known for its expertise in providing help with data mining homework.
DatabaseHomeworkHelp.com: Your Expert Companion in Data Mining When it comes to mastering the intricacies of data mining, DatabaseHomeworkHelp.com takes the lead. This website specializes in offering comprehensive solutions for data mining assignments, ensuring that students grasp the concepts and techniques involved. With a team of experienced tutors, DatabaseHomeworkHelp.com is your go-to resource for personalized assistance and in-depth understanding of data mining principles.Why Choose DatabaseHomeworkHelp.com?
Expert Tutors: Benefit from the guidance of experienced tutors who have a deep understanding of data mining concepts and practical applications.
Customized Solutions: Get tailor-made solutions for your data mining homework, addressing your specific requirements and ensuring a clear understanding of the subject.
Timely Delivery: DatabaseHomeworkHelp.com is committed to delivering solutions within deadlines, allowing you to stay on track with your academic schedule.
Affordable Pricing: Enjoy cost-effective solutions without compromising on the quality of assistance you receive.
Now, let's explore other noteworthy resources offering top-notch data mining courses to further enrich your learning experience.
"Data Mining Specialization" by University of Illinois (Coursera) This specialization covers the fundamentals of data mining, including techniques for pattern discovery, clustering, and predictive modeling. It is a comprehensive program suitable for beginners and intermediate learners.
"Practical Machine Learning for Computer Vision" by Stanford University (Coursera) Delve into the intersection of data mining and computer vision with this course. Stanford University's offering focuses on practical applications, making it an excellent choice for those interested in extracting insights from visual data.
"Data Science and Machine Learning Bootcamp with R and Python" by Udemy Led by industry experts, this Udemy bootcamp provides a broad overview of data science and machine learning, making it an ideal choice for individuals seeking a holistic understanding of these fields.
"Text Mining and Analytics" by University of Illinois (Coursera) Explore the world of text mining with this Coursera specialization. The course covers techniques for extracting valuable information from textual data, an essential skill in the data mining domain.
"Advanced Machine Learning Specialization" by National Research University Higher School of Economics (Coursera) This specialization delves into advanced machine learning concepts, providing a solid foundation for those interested in leveraging machine learning algorithms for data mining purposes.
"Data Mining and Analysis" by Columbia University (edX) Columbia University's edX course explores the principles of data mining and analysis, emphasizing real-world applications. It's suitable for learners seeking a practical approach to data mining.
"Introduction to Data Science" by Microsoft (edX) Offered by Microsoft on edX, this course introduces learners to the essentials of data science, including data mining techniques. It's a great starting point for beginners in the field.
"Mining Massive Datasets" by Stanford University (Coursera) For those looking to tackle large datasets, this Stanford University course covers the challenges and solutions associated with mining massive amounts of data, preparing learners for real-world scenarios.
"Data Mining and Machine Learning in Python" by Udemy This Udemy course focuses on data mining and machine learning using Python. With hands-on exercises, it's a practical resource for learners looking to apply data mining techniques using Python programming.
Conclusion: Embarking on a journey to master data mining requires access to high-quality resources and expert guidance. The top 10 data mining courses mentioned in this blog, with a special nod to DatabaseHomeworkHelp.com, cater to a variety of skill levels and interests. Whether you're a student seeking homework assistance or a professional looking to enhance your data mining skills, these courses provide a robust foundation for success in the dynamic field of data mining. Start your learning journey today and unlock the potential of data mining expertise.

12 notes
·
View notes
Text
Essential Predictive Analytics Techniques
With the growing usage of big data analytics, predictive analytics uses a broad and highly diverse array of approaches to assist enterprises in forecasting outcomes. Examples of predictive analytics include deep learning, neural networks, machine learning, text analysis, and artificial intelligence.
Predictive analytics trends of today reflect existing Big Data trends. There needs to be more distinction between the software tools utilized in predictive analytics and big data analytics solutions. In summary, big data and predictive analytics technologies are closely linked, if not identical.
Predictive analytics approaches are used to evaluate a person's creditworthiness, rework marketing strategies, predict the contents of text documents, forecast weather, and create safe self-driving cars with varying degrees of success.
Predictive Analytics- Meaning
By evaluating collected data, predictive analytics is the discipline of forecasting future trends. Organizations can modify their marketing and operational strategies to serve better by gaining knowledge of historical trends. In addition to the functional enhancements, businesses benefit in crucial areas like inventory control and fraud detection.
Machine learning and predictive analytics are closely related. Regardless of the precise method, a company may use, the overall procedure starts with an algorithm that learns through access to a known result (such as a customer purchase).
The training algorithms use the data to learn how to forecast outcomes, eventually creating a model that is ready for use and can take additional input variables, like the day and the weather.
Employing predictive analytics significantly increases an organization's productivity, profitability, and flexibility. Let us look at the techniques used in predictive analytics.
Techniques of Predictive Analytics
Making predictions based on existing and past data patterns requires using several statistical approaches, data mining, modeling, machine learning, and artificial intelligence. Machine learning techniques, including classification models, regression models, and neural networks, are used to make these predictions.
Data Mining
To find anomalies, trends, and correlations in massive datasets, data mining is a technique that combines statistics with machine learning. Businesses can use this method to transform raw data into business intelligence, including current data insights and forecasts that help decision-making.
Data mining is sifting through redundant, noisy, unstructured data to find patterns that reveal insightful information. A form of data mining methodology called exploratory data analysis (EDA) includes examining datasets to identify and summarize their fundamental properties, frequently using visual techniques.
EDA focuses on objectively probing the facts without any expectations; it does not entail hypothesis testing or the deliberate search for a solution. On the other hand, traditional data mining focuses on extracting insights from the data or addressing a specific business problem.
Data Warehousing
Most extensive data mining projects start with data warehousing. An example of a data management system is a data warehouse created to facilitate and assist business intelligence initiatives. This is accomplished by centralizing and combining several data sources, including transactional data from POS (point of sale) systems and application log files.
A data warehouse typically includes a relational database for storing and retrieving data, an ETL (Extract, Transfer, Load) pipeline for preparing the data for analysis, statistical analysis tools, and client analysis tools for presenting the data to clients.
Clustering
One of the most often used data mining techniques is clustering, which divides a massive dataset into smaller subsets by categorizing objects based on their similarity into groups.
When consumers are grouped together based on shared purchasing patterns or lifetime value, customer segments are created, allowing the company to scale up targeted marketing campaigns.
Hard clustering entails the categorization of data points directly. Instead of assigning a data point to a cluster, soft clustering gives it a likelihood that it belongs in one or more clusters.
Classification
A prediction approach called classification involves estimating the likelihood that a given item falls into a particular category. A multiclass classification problem has more than two classes, unlike a binary classification problem, which only has two types.
Classification models produce a serial number, usually called confidence, that reflects the likelihood that an observation belongs to a specific class. The class with the highest probability can represent a predicted probability as a class label.
Spam filters, which categorize incoming emails as "spam" or "not spam" based on predetermined criteria, and fraud detection algorithms, which highlight suspicious transactions, are the most prevalent examples of categorization in a business use case.
Regression Model
When a company needs to forecast a numerical number, such as how long a potential customer will wait to cancel an airline reservation or how much money they will spend on auto payments over time, they can use a regression method.
For instance, linear regression is a popular regression technique that searches for a correlation between two variables. Regression algorithms of this type look for patterns that foretell correlations between variables, such as the association between consumer spending and the amount of time spent browsing an online store.
Neural Networks
Neural networks are data processing methods with biological influences that use historical and present data to forecast future values. They can uncover intricate relationships buried in the data because of their design, which mimics the brain's mechanisms for pattern recognition.
They have several layers that take input (input layer), calculate predictions (hidden layer), and provide output (output layer) in the form of a single prediction. They are frequently used for applications like image recognition and patient diagnostics.
Decision Trees
A decision tree is a graphic diagram that looks like an upside-down tree. Starting at the "roots," one walks through a continuously narrowing range of alternatives, each illustrating a possible decision conclusion. Decision trees may handle various categorization issues, but they can resolve many more complicated issues when used with predictive analytics.
An airline, for instance, would be interested in learning the optimal time to travel to a new location it intends to serve weekly. Along with knowing what pricing to charge for such a flight, it might also want to know which client groups to cater to. The airline can utilize a decision tree to acquire insight into the effects of selling tickets to destination x at price point y while focusing on audience z, given these criteria.
Logistics Regression
It is used when determining the likelihood of success in terms of Yes or No, Success or Failure. We can utilize this model when the dependent variable has a binary (Yes/No) nature.
Since it uses a non-linear log to predict the odds ratio, it may handle multiple relationships without requiring a linear link between the variables, unlike a linear model. Large sample sizes are also necessary to predict future results.
Ordinal logistic regression is used when the dependent variable's value is ordinal, and multinomial logistic regression is used when the dependent variable's value is multiclass.
Time Series Model
Based on past data, time series are used to forecast the future behavior of variables. Typically, a stochastic process called Y(t), which denotes a series of random variables, are used to model these models.
A time series might have the frequency of annual (annual budgets), quarterly (sales), monthly (expenses), or daily (daily expenses) (Stock Prices). It is referred to as univariate time series forecasting if you utilize the time series' past values to predict future discounts. It is also referred to as multivariate time series forecasting if you include exogenous variables.
The most popular time series model that can be created in Python is called ARIMA, or Auto Regressive Integrated Moving Average, to anticipate future results. It's a forecasting technique based on the straightforward notion that data from time series' initial values provides valuable information.
In Conclusion-
Although predictive analytics techniques have had their fair share of critiques, including the claim that computers or algorithms cannot foretell the future, predictive analytics is now extensively employed in virtually every industry. As we gather more and more data, we can anticipate future outcomes with a certain level of accuracy. This makes it possible for institutions and enterprises to make wise judgments.
Implementing Predictive Analytics is essential for anybody searching for company growth with data analytics services since it has several use cases in every conceivable industry. Contact us at SG Analytics if you want to take full advantage of predictive analytics for your business growth.
2 notes
·
View notes