#Data Science with Machine Learning
Explore tagged Tumblr posts
Visit Tumblr Blog
Explore Tumblr blogs with no restrictions, modern design and the best experience.
Last Seen Tumblr Blogs





Fun Fact
There are dozens of funny blogs to kill time on Tumblr.
Text
AI in Education: Revolutionizing the Future of Learning
The integration of Artificial Intelligence (AI) into various industries has been a game-changer, and education is no exception. As the world continues to embrace digital transformation, AI in education is emerging as a powerful tool that has the potential to reshape the way we teach and learn. From personalized learning experiences to automating administrative tasks, AI is paving the way for a more efficient, effective, and inclusive education system.
What is AI in Education?
AI in education refers to the application of artificial intelligence technologies to enhance and support teaching, learning, and administrative tasks within educational environments. At its core, AI in education leverages data, algorithms, and machine learning models to create intelligent systems that can adapt to the needs of students, provide real-time feedback, automate routine tasks, and even predict learning outcomes.
How AI is Transforming the Classroom
One of the most significant impacts of AI in education is its ability to personalize the learning experience. Traditionally, teachers have had to rely on a “one-size-fits-all” approach, which doesn’t always cater to the unique learning styles, paces, or needs of individual students. AI solves this problem by offering tailored educational content, providing real-time assessments, and creating adaptive learning paths that adjust to the student’s progress.
1. Personalized Learning:
AI-powered systems can analyze data on a student’s learning behavior, such as the time spent on each topic, areas where they struggle, and their pace of understanding. This data helps AI create customized lesson plans and suggest appropriate resources, whether it’s supplementary reading, practice exercises, or even videos that explain difficult concepts. Over time, AI can adapt and refine its recommendations, ensuring that students get the support they need to excel.
2. Intelligent Tutoring Systems (ITS):
AI can provide students with on-demand assistance outside of the classroom through intelligent tutoring systems. These virtual tutors use natural language processing and machine learning to engage with students, answering their questions, providing explanations, and offering practice exercises. This reduces the dependency on human tutors and allows students to get the help they need at any time of the day, even when teachers are unavailable.
3. Real-time Feedback:
AI tools can offer instant feedback on student performance, which is crucial for effective learning. Instead of waiting for a teacher to grade assignments or tests, students can receive immediate insights into their strengths and weaknesses. This allows students to make improvements in real-time and accelerates the learning process. Teachers, on the other hand, can focus more on teaching rather than grading, thanks to AI-powered assessment tools.
AI and Teacher Support
While AI offers great benefits to students, it also has the potential to enhance the teaching experience. By automating routine administrative tasks, AI allows educators to spend more time focusing on what matters most — teaching and interacting with their students.
1. Grading and Assessment Automation:
Grading assignments, tests, and exams can be time-consuming for teachers. AI tools can automate the grading process for objective-based assessments like multiple-choice questions, quizzes, and even essays to some extent. This frees up teachers to focus on more critical tasks, such as lesson planning, student engagement, and providing personalized support.
2. Administrative Efficiency:
AI can help automate a variety of administrative tasks, from managing student attendance to processing enrollment data. Machine learning models can also be used to predict student performance, identify at-risk students, and suggest interventions, helping teachers and school administrators make data-driven decisions to improve student outcomes.
AI in Educational Administration
Beyond the classroom, AI is also transforming the administrative side of education. Institutions are using AI to improve decision-making, resource allocation, and even curriculum development.
1. Data-Driven Decision Making:
AI tools can analyze large sets of data, such as student performance records, attendance, and engagement metrics, to provide actionable insights. Administrators can use this data to identify trends, make informed decisions about resource allocation, and design curricula that better align with student needs.
2. Predictive Analytics for Student Success:
AI can analyze historical data to predict which students are at risk of falling behind. This predictive capability enables early intervention, allowing educators to provide additional support to students who may need it before they encounter significant challenges.
The Future of AI in Education
As AI technologies continue to advance, the potential for their application in education is virtually limitless. We can expect further innovations that will make learning even more accessible, interactive, and tailored to individual needs.
For instance, AI-driven virtual reality (VR) and augmented reality (AR) tools can take education to new heights by providing immersive learning experiences. These technologies can simulate real-world scenarios that are too costly or dangerous to replicate in a traditional classroom setting. Imagine medical students practicing surgeries in a virtual environment or history students “walking” through ancient civilizations.
AI is also expected to play a crucial role in lifelong learning. With the world constantly changing and evolving, individuals will need to reskill and upskill throughout their careers. AI can facilitate this continuous learning by providing personalized recommendations, tracking progress, and offering adaptive learning pathways that meet the needs of professionals at various stages of their careers.
Conclusion
AI in education is not just a trend — it’s a transformation. By making learning more personalized, accessible, and efficient, AI is empowering both students and teachers to reach their full potential. As the technology continues to evolve, it will play an even more pivotal role in shaping the future of education, helping to create a more inclusive and effective learning environment for all. While challenges remain, the promise of AI in education is undeniable, and its potential to improve outcomes on a global scale is truly exciting.
#Artificial Intelligence and Machine Learning#Data Analytics with AI#Data Science with Deep Learning#Data Science with Machine Learning#Full Stack Data Science#Generative AI Specialization#Generative AI with LLM
0 notes
Text
The surprising truth about data-driven dictatorships

Here’s the “dictator’s dilemma”: they want to block their country’s frustrated elites from mobilizing against them, so they censor public communications; but they also want to know what their people truly believe, so they can head off simmering resentments before they boil over into regime-toppling revolutions.
These two strategies are in tension: the more you censor, the less you know about the true feelings of your citizens and the easier it will be to miss serious problems until they spill over into the streets (think: the fall of the Berlin Wall or Tunisia before the Arab Spring). Dictators try to square this circle with things like private opinion polling or petition systems, but these capture a small slice of the potentially destabiziling moods circulating in the body politic.
Enter AI: back in 2018, Yuval Harari proposed that AI would supercharge dictatorships by mining and summarizing the public mood — as captured on social media — allowing dictators to tack into serious discontent and diffuse it before it erupted into unequenchable wildfire:
https://www.theatlantic.com/magazine/archive/2018/10/yuval-noah-harari-technology-tyranny/568330/
Harari wrote that “the desire to concentrate all information and power in one place may become [dictators] decisive advantage in the 21st century.” But other political scientists sharply disagreed. Last year, Henry Farrell, Jeremy Wallace and Abraham Newman published a thoroughgoing rebuttal to Harari in Foreign Affairs:
https://www.foreignaffairs.com/world/spirals-delusion-artificial-intelligence-decision-making
They argued that — like everyone who gets excited about AI, only to have their hopes dashed — dictators seeking to use AI to understand the public mood would run into serious training data bias problems. After all, people living under dictatorships know that spouting off about their discontent and desire for change is a risky business, so they will self-censor on social media. That’s true even if a person isn’t afraid of retaliation: if you know that using certain words or phrases in a post will get it autoblocked by a censorbot, what’s the point of trying to use those words?
The phrase “Garbage In, Garbage Out” dates back to 1957. That’s how long we’ve known that a computer that operates on bad data will barf up bad conclusions. But this is a very inconvenient truth for AI weirdos: having given up on manually assembling training data based on careful human judgment with multiple review steps, the AI industry “pivoted” to mass ingestion of scraped data from the whole internet.
But adding more unreliable data to an unreliable dataset doesn’t improve its reliability. GIGO is the iron law of computing, and you can’t repeal it by shoveling more garbage into the top of the training funnel:
https://memex.craphound.com/2018/05/29/garbage-in-garbage-out-machine-learning-has-not-repealed-the-iron-law-of-computer-science/
When it comes to “AI” that’s used for decision support — that is, when an algorithm tells humans what to do and they do it — then you get something worse than Garbage In, Garbage Out — you get Garbage In, Garbage Out, Garbage Back In Again. That’s when the AI spits out something wrong, and then another AI sucks up that wrong conclusion and uses it to generate more conclusions.
To see this in action, consider the deeply flawed predictive policing systems that cities around the world rely on. These systems suck up crime data from the cops, then predict where crime is going to be, and send cops to those “hotspots” to do things like throw Black kids up against a wall and make them turn out their pockets, or pull over drivers and search their cars after pretending to have smelled cannabis.
The problem here is that “crime the police detected” isn’t the same as “crime.” You only find crime where you look for it. For example, there are far more incidents of domestic abuse reported in apartment buildings than in fully detached homes. That’s not because apartment dwellers are more likely to be wife-beaters: it’s because domestic abuse is most often reported by a neighbor who hears it through the walls.
So if your cops practice racially biased policing (I know, this is hard to imagine, but stay with me /s), then the crime they detect will already be a function of bias. If you only ever throw Black kids up against a wall and turn out their pockets, then every knife and dime-bag you find in someone’s pockets will come from some Black kid the cops decided to harass.
That’s life without AI. But now let’s throw in predictive policing: feed your “knives found in pockets” data to an algorithm and ask it to predict where there are more knives in pockets, and it will send you back to that Black neighborhood and tell you do throw even more Black kids up against a wall and search their pockets. The more you do this, the more knives you’ll find, and the more you’ll go back and do it again.
This is what Patrick Ball from the Human Rights Data Analysis Group calls “empiricism washing”: take a biased procedure and feed it to an algorithm, and then you get to go and do more biased procedures, and whenever anyone accuses you of bias, you can insist that you’re just following an empirical conclusion of a neutral algorithm, because “math can’t be racist.”
HRDAG has done excellent work on this, finding a natural experiment that makes the problem of GIGOGBI crystal clear. The National Survey On Drug Use and Health produces the gold standard snapshot of drug use in America. Kristian Lum and William Isaac took Oakland’s drug arrest data from 2010 and asked Predpol, a leading predictive policing product, to predict where Oakland’s 2011 drug use would take place.
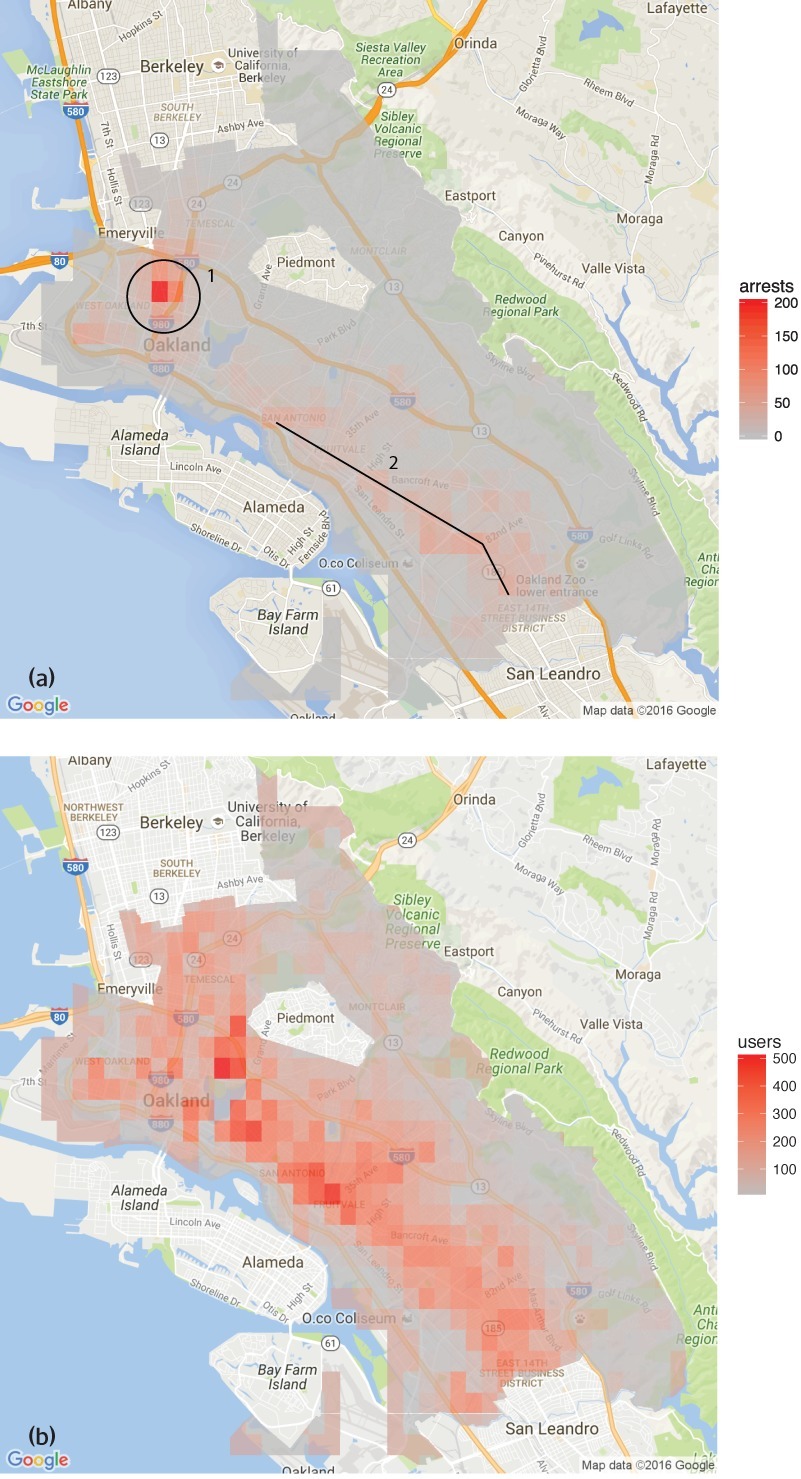
[Image ID: (a) Number of drug arrests made by Oakland police department, 2010. (1) West Oakland, (2) International Boulevard. (b) Estimated number of drug users, based on 2011 National Survey on Drug Use and Health]
Then, they compared those predictions to the outcomes of the 2011 survey, which shows where actual drug use took place. The two maps couldn’t be more different:
https://rss.onlinelibrary.wiley.com/doi/full/10.1111/j.1740-9713.2016.00960.x
Predpol told cops to go and look for drug use in a predominantly Black, working class neighborhood. Meanwhile the NSDUH survey showed the actual drug use took place all over Oakland, with a higher concentration in the Berkeley-neighboring student neighborhood.
What’s even more vivid is what happens when you simulate running Predpol on the new arrest data that would be generated by cops following its recommendations. If the cops went to that Black neighborhood and found more drugs there and told Predpol about it, the recommendation gets stronger and more confident.
In other words, GIGOGBI is a system for concentrating bias. Even trace amounts of bias in the original training data get refined and magnified when they are output though a decision support system that directs humans to go an act on that output. Algorithms are to bias what centrifuges are to radioactive ore: a way to turn minute amounts of bias into pluripotent, indestructible toxic waste.
There’s a great name for an AI that’s trained on an AI’s output, courtesy of Jathan Sadowski: “Habsburg AI.”
And that brings me back to the Dictator’s Dilemma. If your citizens are self-censoring in order to avoid retaliation or algorithmic shadowbanning, then the AI you train on their posts in order to find out what they’re really thinking will steer you in the opposite direction, so you make bad policies that make people angrier and destabilize things more.
Or at least, that was Farrell(et al)’s theory. And for many years, that’s where the debate over AI and dictatorship has stalled: theory vs theory. But now, there’s some empirical data on this, thanks to the “The Digital Dictator’s Dilemma,” a new paper from UCSD PhD candidate Eddie Yang:
https://www.eddieyang.net/research/DDD.pdf
Yang figured out a way to test these dueling hypotheses. He got 10 million Chinese social media posts from the start of the pandemic, before companies like Weibo were required to censor certain pandemic-related posts as politically sensitive. Yang treats these posts as a robust snapshot of public opinion: because there was no censorship of pandemic-related chatter, Chinese users were free to post anything they wanted without having to self-censor for fear of retaliation or deletion.
Next, Yang acquired the censorship model used by a real Chinese social media company to decide which posts should be blocked. Using this, he was able to determine which of the posts in the original set would be censored today in China.
That means that Yang knows that the “real” sentiment in the Chinese social media snapshot is, and what Chinese authorities would believe it to be if Chinese users were self-censoring all the posts that would be flagged by censorware today.
From here, Yang was able to play with the knobs, and determine how “preference-falsification” (when users lie about their feelings) and self-censorship would give a dictatorship a misleading view of public sentiment. What he finds is that the more repressive a regime is — the more people are incentivized to falsify or censor their views — the worse the system gets at uncovering the true public mood.
What’s more, adding additional (bad) data to the system doesn’t fix this “missing data” problem. GIGO remains an iron law of computing in this context, too.
But it gets better (or worse, I guess): Yang models a “crisis” scenario in which users stop self-censoring and start articulating their true views (because they’ve run out of fucks to give). This is the most dangerous moment for a dictator, and depending on the dictatorship handles it, they either get another decade or rule, or they wake up with guillotines on their lawns.
But “crisis” is where AI performs the worst. Trained on the “status quo” data where users are continuously self-censoring and preference-falsifying, AI has no clue how to handle the unvarnished truth. Both its recommendations about what to censor and its summaries of public sentiment are the least accurate when crisis erupts.
But here’s an interesting wrinkle: Yang scraped a bunch of Chinese users’ posts from Twitter — which the Chinese government doesn’t get to censor (yet) or spy on (yet) — and fed them to the model. He hypothesized that when Chinese users post to American social media, they don’t self-censor or preference-falsify, so this data should help the model improve its accuracy.
He was right — the model got significantly better once it ingested data from Twitter than when it was working solely from Weibo posts. And Yang notes that dictatorships all over the world are widely understood to be scraping western/northern social media.
But even though Twitter data improved the model’s accuracy, it was still wildly inaccurate, compared to the same model trained on a full set of un-self-censored, un-falsified data. GIGO is not an option, it’s the law (of computing).
Writing about the study on Crooked Timber, Farrell notes that as the world fills up with “garbage and noise” (he invokes Philip K Dick’s delighted coinage “gubbish”), “approximately correct knowledge becomes the scarce and valuable resource.”
https://crookedtimber.org/2023/07/25/51610/
This “probably approximately correct knowledge” comes from humans, not LLMs or AI, and so “the social applications of machine learning in non-authoritarian societies are just as parasitic on these forms of human knowledge production as authoritarian governments.”

The Clarion Science Fiction and Fantasy Writers’ Workshop summer fundraiser is almost over! I am an alum, instructor and volunteer board member for this nonprofit workshop whose alums include Octavia Butler, Kim Stanley Robinson, Bruce Sterling, Nalo Hopkinson, Kameron Hurley, Nnedi Okorafor, Lucius Shepard, and Ted Chiang! Your donations will help us subsidize tuition for students, making Clarion — and sf/f — more accessible for all kinds of writers.
Libro.fm is the indie-bookstore-friendly, DRM-free audiobook alternative to Audible, the Amazon-owned monopolist that locks every book you buy to Amazon forever. When you buy a book on Libro, they share some of the purchase price with a local indie bookstore of your choosing (Libro is the best partner I have in selling my own DRM-free audiobooks!). As of today, Libro is even better, because it’s available in five new territories and currencies: Canada, the UK, the EU, Australia and New Zealand!
[Image ID: An altered image of the Nuremberg rally, with ranked lines of soldiers facing a towering figure in a many-ribboned soldier's coat. He wears a high-peaked cap with a microchip in place of insignia. His head has been replaced with the menacing red eye of HAL9000 from Stanley Kubrick's '2001: A Space Odyssey.' The sky behind him is filled with a 'code waterfall' from 'The Matrix.']
Image: Cryteria (modified) https://commons.wikimedia.org/wiki/File:HAL9000.svg
CC BY 3.0 https://creativecommons.org/licenses/by/3.0/deed.en
—
Raimond Spekking (modified) https://commons.wikimedia.org/wiki/File:Acer_Extensa_5220_-_Columbia_MB_06236-1N_-_Intel_Celeron_M_530_-_SLA2G_-_in_Socket_479-5029.jpg
CC BY-SA 4.0 https://creativecommons.org/licenses/by-sa/4.0/deed.en
—
Russian Airborne Troops (modified) https://commons.wikimedia.org/wiki/File:Vladislav_Achalov_at_the_Airborne_Troops_Day_in_Moscow_%E2%80%93_August_2,_2008.jpg
“Soldiers of Russia” Cultural Center (modified) https://commons.wikimedia.org/wiki/File:Col._Leonid_Khabarov_in_an_everyday_service_uniform.JPG
CC BY-SA 3.0 https://creativecommons.org/licenses/by-sa/3.0/deed.en
#pluralistic#habsburg ai#self censorship#henry farrell#digital dictatorships#machine learning#dictator's dilemma#eddie yang#preference falsification#political science#training bias#scholarship#spirals of delusion#algorithmic bias#ml#Fully automated data driven authoritarianism#authoritarianism#gigo#garbage in garbage out garbage back in#gigogbi#yuval noah harari#gubbish#pkd#philip k dick#phildickian
831 notes
·
View notes
Text
youtube
How To Learn Math for Machine Learning FAST (Even With Zero Math Background)
I dropped out of high school and managed to became an Applied Scientist at Amazon by self-learning math (and other ML skills). In this video I'll show you exactly how I did it, sharing the resources and study techniques that worked for me, along with practical advice on what math you actually need (and don't need) to break into machine learning and data science.
#How To Learn Math for Machine Learning#machine learning#free education#education#youtube#technology#educate yourselves#educate yourself#tips and tricks#software engineering#data science#artificial intelligence#data analytics#data science course#math#mathematics#Youtube
22 notes
·
View notes
Text
The Data Scientist Handbook 2024
HT @dataelixir
#data science#data scientist#data scientists#machine learning#analytics#data analytics#artificial intelligence
18 notes
·
View notes
Text
Cornell quantum researchers have detected an elusive phase of matter, called the Bragg glass phase, using large volumes of X-ray data and a new machine learning data analysis tool. The discovery settles a long-standing question of whether this almost–but not quite–ordered state of Bragg glass can exist in real materials. The paper, "Bragg glass signatures in PdxErTe3 with X-ray diffraction Temperature Clustering (X-TEC)," is published in Nature Physics. The lead author is Krishnanand Madhukar Mallayya, a postdoctoral researcher in the Department of Physics in the College of Arts and Sciences (A&S). Eun-Ah Kim, professor of physics (A&S), is the corresponding author. The research was conducted in collaboration with scientists at Argonne National Laboratory and at Stanford University.
Continue Reading.
43 notes
·
View notes
Text
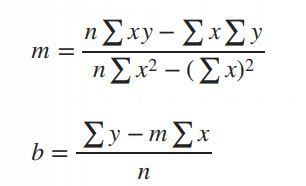
Simple Linear Regression in Data Science and machine learning
Simple linear regression is one of the most important techniques in data science and machine learning. It is the foundation of many statistical and machine learning models. Even though it is simple, its concepts are widely applicable in predicting outcomes and understanding relationships between variables.
This article will help you learn about:
1. What is simple linear regression and why it matters.
2. The step-by-step intuition behind it.
3. The math of finding slope() and intercept().
4. Simple linear regression coding using Python.
5. A practical real-world implementation.
If you are new to data science or machine learning, don’t worry! We will keep things simple so that you can follow along without any problems.
What is simple linear regression?
Simple linear regression is a method to model the relationship between two variables:
1. Independent variable (X): The input, also called the predictor or feature.
2. Dependent Variable (Y): The output or target value we want to predict.
The main purpose of simple linear regression is to find a straight line (called the regression line) that best fits the data. This line minimizes the error between the actual and predicted values.
The mathematical equation for the line is:
Y = mX + b
: The predicted values.
: The slope of the line (how steep it is).
: The intercept (the value of when).
Why use simple linear regression?
click here to read more https://datacienceatoz.blogspot.com/2025/01/simple-linear-regression-in-data.html
#artificial intelligence#bigdata#books#machine learning#machinelearning#programming#python#science#skills#big data#linear algebra#linear b#slope#interception
6 notes
·
View notes
Text
Search Engines:
Search engines are independent computer systems that read or crawl webpages, documents, information sources, and links of all types accessible on the global network of computers on the planet Earth, the internet. Search engines at their most basic level read every word in every document they know of, and record which documents each word is in so that by searching for a words or set of words you can locate the addresses that relate to documents containing those words. More advanced search engines used more advanced algorithms to sort pages or documents returned as search results in order of likely applicability to the terms searched for, in order. More advanced search engines develop into large language models, or machine learning or artificial intelligence. Machine learning or artificial intelligence or large language models (LLMs) can be run in a virtual machine or shell on a computer and allowed to access all or part of accessible data, as needs dictate.
#llm#large language model#search engine#search engines#Google#bing#yahoo#yandex#baidu#dogpile#metacrawler#webcrawler#search engines imbeded in individual pages or operating systems or documents to search those individual things individually#computer science#library science#data science#machine learning#google.com#bing.com#yahoo.com#yandex.com#baidu.com#...#observe the buildings and computers within at the dalles Google data center to passively observe google and its indexed copy of the internet#the dalles oregon next to the river#google has many data centers worldwide so does Microsoft and many others
11 notes
·
View notes
Text
Data science course in mohali. for more information Contact us : https://seekhodigitalindia.com/our-services/
2 notes
·
View notes
Text
Locally Linear Embedding (LLE) approaches
#gradschool#light academia#data visualization#science#math#mathblr#studybrl#machine learning#ai#python#topology
46 notes
·
View notes
Text
Tonight I am hunting down venomous and nonvenomous snake pictures that are under the creative commons of specific breeds in order to create one of the most advanced, in depth datasets of different venomous and nonvenomous snakes as well as a test set that will include snakes from both sides of all species. I love snakes a lot and really, all reptiles. It is definitely tedious work, as I have to make sure each picture is cleared before I can use it (ethically), but I am making a lot of progress! I have species such as the King Cobra, Inland Taipan, and Eyelash Pit Viper among just a few! Wikimedia Commons has been a huge help!
I'm super excited.
Hope your nights are going good. I am still not feeling good but jamming + virtual snake hunting is keeping me busy!
#programming#data science#data scientist#data analysis#neural networks#image processing#artificial intelligence#machine learning#snakes#snake#reptiles#reptile#herpetology#animals#biology#science#programming project#dataset#kaggle#coding
42 notes
·
View notes
Text
Truth speaking on the corporate obsession with AI
Hilarious. Something tells me this person's on the hellsite(affectionate)
#ai#corporate bs#late stage capitalism#funny#truth#artificial intelligence#ml#machine learning#data science#data scientist#programming#scientific programming
8 notes
·
View notes
Text
HT @dataelixir
#data science#data scientist#data scientists#machine learning#analytics#programming#data analytics#artificial intelligence#deep learning#llm
11 notes
·
View notes
Text

Tinkering with my personal website again

Above screenie is zoomed out to capture everything. Anyone wanna guess which blinkies I made? Also, the Twitter blinkie just takes you to my BSky lol (on purpose).




Several of the images were put together by me! I can teach pretty much anything in tech, this is just the stuff that I thought of.


I made the floppy-disk icons myself, with some help from wifey on getting the text to render as part of the SVGs!
#personal website#web development#vaporwave#love2d#pico8#personal finance#tutoring#math tutoring#math teacher#computer science#computer science tutoring#game development#electronics design#pcb design#learntocode#machine learning#artificial intelligence#ai#ai development#data science#unity engine#godot engine
2 notes
·
View notes
Text

The Mathematical Foundations of Machine Learning
In the world of artificial intelligence, machine learning is a crucial component that enables computers to learn from data and improve their performance over time. However, the math behind machine learning is often shrouded in mystery, even for those who work with it every day. Anil Ananthaswami, author of the book "Why Machines Learn," sheds light on the elegant mathematics that underlies modern AI, and his journey is a fascinating one.
Ananthaswami's interest in machine learning began when he started writing about it as a science journalist. His software engineering background sparked a desire to understand the technology from the ground up, leading him to teach himself coding and build simple machine learning systems. This exploration eventually led him to appreciate the mathematical principles that underlie modern AI. As Ananthaswami notes, "I was amazed by the beauty and elegance of the math behind machine learning."
Ananthaswami highlights the elegance of machine learning mathematics, which goes beyond the commonly known subfields of calculus, linear algebra, probability, and statistics. He points to specific theorems and proofs, such as the 1959 proof related to artificial neural networks, as examples of the beauty and elegance of machine learning mathematics. For instance, the concept of gradient descent, a fundamental algorithm used in machine learning, is a powerful example of how math can be used to optimize model parameters.
Ananthaswami emphasizes the need for a broader understanding of machine learning among non-experts, including science communicators, journalists, policymakers, and users of the technology. He believes that only when we understand the math behind machine learning can we critically evaluate its capabilities and limitations. This is crucial in today's world, where AI is increasingly being used in various applications, from healthcare to finance.
A deeper understanding of machine learning mathematics has significant implications for society. It can help us to evaluate AI systems more effectively, develop more transparent and explainable AI systems, and address AI bias and ensure fairness in decision-making. As Ananthaswami notes, "The math behind machine learning is not just a tool, but a way of thinking that can help us create more intelligent and more human-like machines."
The Elegant Math Behind Machine Learning (Machine Learning Street Talk, November 2024)
youtube
Matrices are used to organize and process complex data, such as images, text, and user interactions, making them a cornerstone in applications like Deep Learning (e.g., neural networks), Computer Vision (e.g., image recognition), Natural Language Processing (e.g., language translation), and Recommendation Systems (e.g., personalized suggestions). To leverage matrices effectively, AI relies on key mathematical concepts like Matrix Factorization (for dimension reduction), Eigendecomposition (for stability analysis), Orthogonality (for efficient transformations), and Sparse Matrices (for optimized computation).
The Applications of Matrices - What I wish my teachers told me way earlier (Zach Star, October 2019)
youtube
Transformers are a type of neural network architecture introduced in 2017 by Vaswani et al. in the paper “Attention Is All You Need”. They revolutionized the field of NLP by outperforming traditional recurrent neural network (RNN) and convolutional neural network (CNN) architectures in sequence-to-sequence tasks. The primary innovation of transformers is the self-attention mechanism, which allows the model to weigh the importance of different words in the input data irrespective of their positions in the sentence. This is particularly useful for capturing long-range dependencies in text, which was a challenge for RNNs due to vanishing gradients. Transformers have become the standard for machine translation tasks, offering state-of-the-art results in translating between languages. They are used for both abstractive and extractive summarization, generating concise summaries of long documents. Transformers help in understanding the context of questions and identifying relevant answers from a given text. By analyzing the context and nuances of language, transformers can accurately determine the sentiment behind text. While initially designed for sequential data, variants of transformers (e.g., Vision Transformers, ViT) have been successfully applied to image recognition tasks, treating images as sequences of patches. Transformers are used to improve the accuracy of speech-to-text systems by better modeling the sequential nature of audio data. The self-attention mechanism can be beneficial for understanding patterns in time series data, leading to more accurate forecasts.
Attention is all you need (Umar Hamil, May 2023)
youtube
Geometric deep learning is a subfield of deep learning that focuses on the study of geometric structures and their representation in data. This field has gained significant attention in recent years.
Michael Bronstein: Geometric Deep Learning (MLSS Kraków, December 2023)
youtube
Traditional Geometric Deep Learning, while powerful, often relies on the assumption of smooth geometric structures. However, real-world data frequently resides in non-manifold spaces where such assumptions are violated. Topology, with its focus on the preservation of proximity and connectivity, offers a more robust framework for analyzing these complex spaces. The inherent robustness of topological properties against noise further solidifies the rationale for integrating topology into deep learning paradigms.
Cristian Bodnar: Topological Message Passing (Michael Bronstein, August 2022)
youtube
Sunday, November 3, 2024
#machine learning#artificial intelligence#mathematics#computer science#deep learning#neural networks#algorithms#data science#statistics#programming#interview#ai assisted writing#machine art#Youtube#lecture
4 notes
·
View notes
Text

Beginner’s Guide to Ridge Regression in Machine Learning
Introduction
Regression analysis is a fundamental technique in machine learning, used to predict a dependent variable based on one or more independent variables. However, traditional regression methods, such as simple linear regression, can struggle to deal with multicollinearity (high correlation between predictors). This is where ridge regression comes in handy.
Ridge regression is an advanced form of linear regression that reduces overfitting by adding a penalty term to the model. In this article, we will cover what ridge regression is, why it is important, how it works, its assumptions, and how to implement it using Python.
What is Ridge Regression?
Ridge regression is a type of regularization technique that modifies the linear
click here to read more
https://datacienceatoz.blogspot.com/2025/02/a-beginners-guide-to-ridge-regression.html
#artificial intelligence#bigdata#books#machine learning#machinelearning#programming#python#science#skills#big data
4 notes
·
View notes
Text
Is there a cost to taking the certs? Yes, but the content is free.
6 notes
·
View notes