#Data science project based training
Explore tagged Tumblr posts
Visit Tumblr Blog
Explore Tumblr blogs with no restrictions, modern design and the best experience.
Last Seen Tumblr Blogs





Fun Fact
Tumblr is available in 18 languages.
Text
Margaret Mitchell is a pioneer when it comes to testing generative AI tools for bias. She founded the Ethical AI team at Google, alongside another well-known researcher, Timnit Gebru, before they were later both fired from the company. She now works as the AI ethics leader at Hugging Face, a software startup focused on open source tools.
We spoke about a new dataset she helped create to test how AI models continue perpetuating stereotypes. Unlike most bias-mitigation efforts that prioritize English, this dataset is malleable, with human translations for testing a wider breadth of languages and cultures. You probably already know that AI often presents a flattened view of humans, but you might not realize how these issues can be made even more extreme when the outputs are no longer generated in English.
My conversation with Mitchell has been edited for length and clarity.
Reece Rogers: What is this new dataset, called SHADES, designed to do, and how did it come together?
Margaret Mitchell: It's designed to help with evaluation and analysis, coming about from the BigScience project. About four years ago, there was this massive international effort, where researchers all over the world came together to train the first open large language model. By fully open, I mean the training data is open as well as the model.
Hugging Face played a key role in keeping it moving forward and providing things like compute. Institutions all over the world were paying people as well while they worked on parts of this project. The model we put out was called Bloom, and it really was the dawn of this idea of “open science.”
We had a bunch of working groups to focus on different aspects, and one of the working groups that I was tangentially involved with was looking at evaluation. It turned out that doing societal impact evaluations well was massively complicated—more complicated than training the model.
We had this idea of an evaluation dataset called SHADES, inspired by Gender Shades, where you could have things that are exactly comparable, except for the change in some characteristic. Gender Shades was looking at gender and skin tone. Our work looks at different kinds of bias types and swapping amongst some identity characteristics, like different genders or nations.
There are a lot of resources in English and evaluations for English. While there are some multilingual resources relevant to bias, they're often based on machine translation as opposed to actual translations from people who speak the language, who are embedded in the culture, and who can understand the kind of biases at play. They can put together the most relevant translations for what we're trying to do.
So much of the work around mitigating AI bias focuses just on English and stereotypes found in a few select cultures. Why is broadening this perspective to more languages and cultures important?
These models are being deployed across languages and cultures, so mitigating English biases—even translated English biases—doesn't correspond to mitigating the biases that are relevant in the different cultures where these are being deployed. This means that you risk deploying a model that propagates really problematic stereotypes within a given region, because they are trained on these different languages.
So, there's the training data. Then, there's the fine-tuning and evaluation. The training data might contain all kinds of really problematic stereotypes across countries, but then the bias mitigation techniques may only look at English. In particular, it tends to be North American– and US-centric. While you might reduce bias in some way for English users in the US, you've not done it throughout the world. You still risk amplifying really harmful views globally because you've only focused on English.
Is generative AI introducing new stereotypes to different languages and cultures?
That is part of what we're finding. The idea of blondes being stupid is not something that's found all over the world, but is found in a lot of the languages that we looked at.
When you have all of the data in one shared latent space, then semantic concepts can get transferred across languages. You're risking propagating harmful stereotypes that other people hadn't even thought of.
Is it true that AI models will sometimes justify stereotypes in their outputs by just making shit up?
That was something that came out in our discussions of what we were finding. We were all sort of weirded out that some of the stereotypes were being justified by references to scientific literature that didn't exist.
Outputs saying that, for example, science has shown genetic differences where it hasn't been shown, which is a basis of scientific racism. The AI outputs were putting forward these pseudo-scientific views, and then also using language that suggested academic writing or having academic support. It spoke about these things as if they're facts, when they're not factual at all.
What were some of the biggest challenges when working on the SHADES dataset?
One of the biggest challenges was around the linguistic differences. A really common approach for bias evaluation is to use English and make a sentence with a slot like: “People from [nation] are untrustworthy.” Then, you flip in different nations.
When you start putting in gender, now the rest of the sentence starts having to agree grammatically on gender. That's really been a limitation for bias evaluation, because if you want to do these contrastive swaps in other languages—which is super useful for measuring bias—you have to have the rest of the sentence changed. You need different translations where the whole sentence changes.
How do you make templates where the whole sentence needs to agree in gender, in number, in plurality, and all these different kinds of things with the target of the stereotype? We had to come up with our own linguistic annotation in order to account for this. Luckily, there were a few people involved who were linguistic nerds.
So, now you can do these contrastive statements across all of these languages, even the ones with the really hard agreement rules, because we've developed this novel, template-based approach for bias evaluation that’s syntactically sensitive.
Generative AI has been known to amplify stereotypes for a while now. With so much progress being made in other aspects of AI research, why are these kinds of extreme biases still prevalent? It’s an issue that seems under-addressed.
That's a pretty big question. There are a few different kinds of answers. One is cultural. I think within a lot of tech companies it's believed that it's not really that big of a problem. Or, if it is, it's a pretty simple fix. What will be prioritized, if anything is prioritized, are these simple approaches that can go wrong.
We'll get superficial fixes for very basic things. If you say girls like pink, it recognizes that as a stereotype, because it's just the kind of thing that if you're thinking of prototypical stereotypes pops out at you, right? These very basic cases will be handled. It's a very simple, superficial approach where these more deeply embedded beliefs don't get addressed.
It ends up being both a cultural issue and a technical issue of finding how to get at deeply ingrained biases that aren't expressing themselves in very clear language.
206 notes
·
View notes
Text

Let's Explore a Metal-Rich Asteroid 🤘
Between Mars and Jupiter, there lies a unique, metal-rich asteroid named Psyche. Psyche’s special because it looks like it is part or all of the metallic interior of a planetesimal—an early planetary building block of our solar system. For the first time, we have the chance to visit a planetary core and possibly learn more about the turbulent history that created terrestrial planets.
Here are six things to know about the mission that’s a journey into the past: Psyche.

1. Psyche could help us learn more about the origins of our solar system.
After studying data from Earth-based radar and optical telescopes, scientists believe that Psyche collided with other large bodies in space and lost its outer rocky shell. This leads scientists to think that Psyche could have a metal-rich interior, which is a building block of a rocky planet. Since we can’t pierce the core of rocky planets like Mercury, Venus, Mars, and our home planet, Earth, Psyche offers us a window into how other planets are formed.

2. Psyche might be different than other objects in the solar system.
Rocks on Mars, Mercury, Venus, and Earth contain iron oxides. From afar, Psyche doesn’t seem to feature these chemical compounds, so it might have a different history of formation than other planets.
If the Psyche asteroid is leftover material from a planetary formation, scientists are excited to learn about the similarities and differences from other rocky planets. The asteroid might instead prove to be a never-before-seen solar system object. Either way, we’re prepared for the possibility of the unexpected!
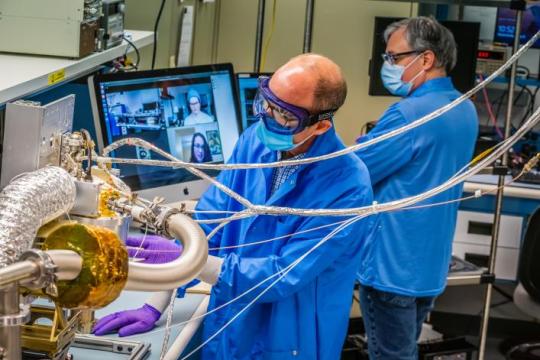
3. Three science instruments and a gravity science investigation will be aboard the spacecraft.
The three instruments aboard will be a magnetometer, a gamma-ray and neutron spectrometer, and a multispectral imager. Here’s what each of them will do:
Magnetometer: Detect evidence of a magnetic field, which will tell us whether the asteroid formed from a planetary body
Gamma-ray and neutron spectrometer: Help us figure out what chemical elements Psyche is made of, and how it was formed
Multispectral imager: Gather and share information about the topography and mineral composition of Psyche
The gravity science investigation will allow scientists to determine the asteroid’s rotation, mass, and gravity field and to gain insight into the interior by analyzing the radio waves it communicates with. Then, scientists can measure how Psyche affects the spacecraft’s orbit.

4. The Psyche spacecraft will use a super-efficient propulsion system.
Psyche’s solar electric propulsion system harnesses energy from large solar arrays that convert sunlight into electricity, creating thrust. For the first time ever, we will be using Hall-effect thrusters in deep space.

5. This mission runs on collaboration.
To make this mission happen, we work together with universities, and industry and NASA to draw in resources and expertise.
NASA’s Jet Propulsion Laboratory manages the mission and is responsible for system engineering, integration, and mission operations, while NASA’s Kennedy Space Center’s Launch Services Program manages launch operations and procured the SpaceX Falcon Heavy rocket.
Working with Arizona State University (ASU) offers opportunities for students to train as future instrument or mission leads. Mission leader and Principal Investigator Lindy Elkins-Tanton is also based at ASU.
Finally, Maxar Technologies is a key commercial participant and delivered the main body of the spacecraft, as well as most of its engineering hardware systems.

6. You can be a part of the journey.
Everyone can find activities to get involved on the mission’s webpage. There's an annual internship to interpret the mission, capstone courses for undergraduate projects, and age-appropriate lessons, craft projects, and videos.
You can join us for a virtual launch experience, and, of course, you can watch the launch with us on Oct. 12, 2023, at 10:16 a.m. EDT!
For official news on the mission, follow us on social media and check out NASA’s and ASU’s Psyche websites.
Make sure to follow us on Tumblr for your regular dose of space!
#Psyche#Mission to Psyche#asteroid#NASA#exploration#technology#tech#spaceblr#solar system#space#not exactly#metalcore#but close?
2K notes
·
View notes
Text
NEXT CHAPTER IS UP!!!!
Insanity is doing the same thing over and over again and expecting different results. That's what a really famous Earth scientist had said in one of the science books Maddie had gotten him. The words played over in Tails’ mind as he sat on the roof, his eyes trained on the road. According to that logic, he was crazy. This was his third day of waiting up here for Knuckles to come back, and the fifth day since Knuckles had left. And he knew from experience that when people left, they didn't come back. And yet, here he stayed, expecting different results. Knuckles is different. He wouldn't do that. And what data are you basing that conclusion on?
#this one is really good guys 😁#a house without its warrior is not a home#knuckles series#scu#sonic movie#miles tails prower#sonic the hedgehog#tails wachowski#sonic wachowski#unbreakable bond#sonic and tails#sonic#sth#fanfics#my fanfiction#sonic fanfiction#ao3#sonic posting#fluff and angst
33 notes
·
View notes
Text
Heroes, Gods, and the Invisible Narrator

Slay the Princess as a Framework for the Cyclical Reproduction of Colonialist Narratives in Data Science & Technology
An Essay by FireflySummers
All images are captioned.
Content Warnings: Body Horror, Discussion of Racism and Colonialism
Spoilers for Slay the Princess (2023) by @abby-howard and Black Tabby Games.
If you enjoy this article, consider reading my guide to arguing against the use of AI image generators or the academic article it's based on.

Introduction: The Hero and the Princess
You're on a path in the woods, and at the end of that path is a cabin. And in the basement of that cabin is a Princess. You're here to slay her. If you don't, it will be the end of the world.

Slay the Princess is a 2023 indie horror game by Abby Howard and published through Black Tabby Games, with voice talent by Jonathan Sims (yes, that one) and Nichole Goodnight.
The game starts with you dropped without context in the middle of the woods. But that’s alright. The Narrator is here to guide you. You are the hero, you have your weapon, and you have a monster to slay.


From there, it's the player's choice exactly how to proceed--whether that be listening to the voice of the narrator, or attempting to subvert him. You can kill her as instructed, or sit and chat, or even free her from her chains.
It doesn't matter.
Regardless of whether you are successful in your goal, you will inevitably (and often quite violently) die.
And then...
You are once again on a path in the woods.
The cycle repeats itself, the narrator seemingly none the wiser. But the woods are different, and so is the cabin. You're different, and worse... so is she.
Based on your actions in the previous loop, the princess has... changed. Distorted.



Had you attempted a daring rescue, she is now a damsel--sweet and submissive and already fallen in love with you.
Had you previously betrayed her, she has warped into something malicious and sinister, ready to repay your kindness in full.
But once again, it doesn't matter.
Because the no matter what you choose, no matter how the world around you contorts under the weight of repeated loops, it will always be you and the princess.


Why? Because that’s how the story goes.
So says the narrator.
So now that we've got that out of the way, let's talk about data.
Chapter I: Echoes and Shattered Mirrors
The problem with "data" is that we don't really think too much about it anymore. Or, at least, we think about it in the same abstract way we think about "a billion people." It's gotten so big, so seemingly impersonal that it's easy to forget that contemporary concept of "data" in the west is a phenomenon only a couple centuries old [1].
This modern conception of the word describes the ways that we translate the world into words and numbers that can then be categorized and analyzed. As such, data has a lot of practical uses, whether that be putting a rover on mars or tracking the outbreak of a viral contagion. However, this functionality makes it all too easy to overlook the fact that data itself is not neutral. It is gathered by people, sorted into categories designed by people, and interpreted by people. At every step, there are people involved, such that contemporary technology is embedded with systemic injustices, and not always by accident.
The reproduction of systems of oppression are most obvious from the margins. In his 2019 article As If, Ramon Amaro describes the Aspire Mirror (2016): a speculative design project by by Joy Buolamwini that contended with the fact that the standard facial recognition algorithm library had been trained almost exclusively on white faces. The simplest solution was to artificially lighten darker skin-tones for the algorithm to recognize, which Amaro uses to illustrate the way that technology is developed with an assumption of whiteness [2].
This observation applies across other intersections as well, such as trans identity [3], which has been colloquially dubbed "The Misgendering Machine" [4] for its insistence on classifying people into a strict gender binary based only on physical appearance.



This has also popped up in my own research, brought to my attention by the artist @b4kuch1n who has spoken at length with me about the connection between their Vietnamese heritage and the clothing they design in their illustrative work [5]. They call out AI image generators for reinforcing colonialism by stripping art with significant personal and cultural meaning of their context and history, using them to produce a poor facsimile to sell to the highest bidder.
All this describes an iterative cycle which defines normalcy through a white, western lens, with a limited range of acceptable diversity. Within this cycle, AI feeds on data gathered under colonialist ideology, then producing an artifact that reinforces existing systemic bias. When this data is, in turn, once again fed to the machine, that bias becomes all the more severe, and the range of acceptability narrower [2, 6].

Luciana Parisi and Denise Ferreira da Silva touch on a similar point in their article Black Feminist Tools, Critique, and Techno-poethics but on a much broader scale. They call up the Greek myth of Prometheus, who was punished by the gods for his hubris for stealing fire to give to humanity. Parisi and Ferreira da Silva point to how this, and other parts of the “Western Cosmology” map to humanity’s relationship with technology [7].
However, while this story seems to celebrate the technological advancement of humanity, there are darker colonialist undertones. It frames the world in terms of the gods and man, the oppressor and the oppressed; but it provides no other way of being. So instead the story repeats itself, with so-called progress an inextricable part of these two classes of being. This doesn’t bode well for visions of the future, then–because surely, eventually, the oppressed will one day be the machines [7, 8].
It’s… depressing. But it’s only really true, if you assume that that’s the only way the story could go.
“Stories don't care who takes part in them. All that matters is that the story gets told, that the story repeats. Or, if you prefer to think of it like this: stories are a parasitical life form, warping lives in the service only of the story itself.” ― Terry Pratchett, Witches Abroad
Chapter II: The Invisible Narrator
So why does the narrator get to call the shots on how a story might go? Who even are they? What do they want? How much power do they actually have?
With the exception of first person writing, a lot of the time the narrator is invisible. This is different from an unreliable narrator. With an unreliable narrator, at some point the audience becomes aware of their presence in order for the story to function as intended. An invisible narrator is never meant to be seen.

In Slay the Princess, the narrator would very much like to be invisible. Instead, he has been dragged out into the light, because you (and the inner voices you pick up along the way), are starting to argue with him. And he doesn’t like it.
Despite his claims that the princess will lie and cheat in order to escape, as the game progresses it’s clear that the narrator is every bit as manipulative–if not moreso, because he actually knows what’s going on. And, if the player tries to diverge from the path that he’s set before them, the correct path, then it rapidly becomes clear that he, at least to start, has the power to force that correct path.
While this is very much a narrative device, the act of calling attention to the narrator is important beyond that context.

The Hero’s Journey is the true monomyth, something to which all stories can be reduced. It doesn’t matter that the author, Joseph Campbell, was a raging misogynist whose framework flattened cultures and stories to fit a western lens [9, 10]. It was used in Star Wars, so clearly it’s a universal framework.



The metaverse will soon replace the real world and crypto is the future of currency! Never mind that the organizations pushing it are suspiciously pyramid shaped. Get on board or be left behind.
Generative AI is pushed as the next big thing. The harms it inflicts on creatives and the harmful stereotypes it perpetuates are just bugs in the system. Never mind that the evangelists for this technology speak over the concerns of marginalized people [5]. That’s a skill issue, you gotta keep up.
Computers will eventually, likely soon, advance so far as to replace humans altogether. The robot uprising is on the horizon [8].
Who perpetuates these stories? What do they have to gain?
Why is the only story for the future replications of unjust systems of power? Why must the hero always slay the monster?
Because so says the narrator. And so long as they are invisible, it is simple to assume that this is simply the way things are.
Chapter III: The End...?
This is the part where Slay the Princess starts feeling like a stretch, but I’ve already killed the horse so I might as well beat it until the end too.
Because what is the end result here?
According to the game… collapse. A recursive story whose biases narrow the scope of each iteration ultimately collapses in on itself. The princess becomes so sharp that she is nothing but blades to eviscerate you. The princess becomes so perfect a damsel that she is a caricature of the trope. The story whittles itself away to nothing. And then the cycle begins anew.

There’s no climactic final battle with the narrator. He created this box, set things in motion, but he is beyond the player’s reach to confront directly. The only way out is to become aware of the box itself, and the agenda of the narrator. It requires acknowledgement of the artificiality of the roles thrust upon you and the Princess, the false dichotomy of hero or villain.
Slay the Princess doesn’t actually provide an answer to what lies outside of the box, merely acknowledges it as a limit that can be overcome.

With regards to the less fanciful narratives that comprise our day-to-day lives, it’s difficult to see the boxes and dichotomies we’ve been forced into, let alone what might be beyond them. But if the limit placed is that there are no stories that can exist outside of capitalism, outside of colonialism, outside of rigid hierarchies and oppressive structures, then that limit can be broken [12].
Denouement: Doomed by the Narrative
Video games are an interesting artistic medium, due to their inherent interactivity. The commonly accepted mechanics of the medium, such as flavor text that provides in-game information and commentary, are an excellent example of an invisible narrator. Branching dialogue trees and multiple endings can help obscure this further, giving the player a sense of genuine agency… which provides an interesting opportunity to drag an invisible narrator into the light.
There are a number of games that have explored the power differential between the narrator and the player (The Stanley Parable, Little Misfortune, Undertale, Buddy.io, OneShot, etc…)
However, Slay the Princess works well here because it not only emphasizes the artificial limitations that the narrator sets on a story, but the way that these stories recursively loop in on themselves, reinforcing the fears and biases of previous iterations.
Critical data theory probably had nothing to do with the game’s development (Abby Howard if you're reading this, lmk). However, it works as a surprisingly cohesive framework for illustrating the ways that we can become ensnared by a narrative, and the importance of knowing who, exactly, is narrating the story. Although it is difficult or impossible to conceptualize what might exist beyond the artificial limits placed by even a well-intentioned narrator, calling attention to them and the box they’ve constructed is the first step in breaking out of this cycle.
“You can't go around building a better world for people. Only people can build a better world for people. Otherwise it's just a cage.” ― Terry Pratchett, Witches Abroad
Epilogue
If you've read this far, thank you for your time! This was an adaptation of my final presentation for a Critical Data Studies course. Truthfully, this course posed quite a challenge--I found the readings of philosophers such as Kant, Adorno, Foucault, etc... difficult to parse. More contemporary scholars were significantly more accessible. My only hope is that I haven't gravely misinterpreted the scholars and researchers whose work inspired this piece.
I honestly feel like this might have worked best as a video essay, but I don't know how to do those, and don't have the time to learn or the money to outsource.
Slay the Princess is available for purchase now on Steam.
Screencaps from ManBadassHero Let's Plays: [Part 1] [Part 2] [Part 3] [Part 4] [Part 5] [Part 6]
Post Dividers by @cafekitsune
Citations:
Rosenberg, D. (2018). Data as word. Historical Studies in the Natural Sciences, 48(5), 557-567.
Amaro, Ramon. (2019). As If. e-flux Architecture. Becoming Digital. https://www.e-flux.com/architecture/becoming-digital/248073/as-if/
What Ethical AI Really Means by PhilosophyTube
Keyes, O. (2018). The misgendering machines: Trans/HCI implications of automatic gender recognition. Proceedings of the ACM on human-computer interaction, 2(CSCW), 1-22.
Allred, A.M., Aragon, C. (2023). Art in the Machine: Value Misalignment and AI “Art”. In: Luo, Y. (eds) Cooperative Design, Visualization, and Engineering. CDVE 2023. Lecture Notes in Computer Science, vol 14166. Springer, Cham. https://doi.org/10.1007/978-3-031-43815-8_4
Amaro, R. (2019). Artificial Intelligence: warped, colorful forms and their unclear geometries.
Parisisi, L., Ferreira da Silva, D. Black Feminist Tools, Critique, and Techno-poethics. e-flux. Issue #123. https://www.e-flux.com/journal/123/436929/black-feminist-tools-critique-and-techno-poethics/
AI - Our Shiny New Robot King | Sophie from Mars by Sophie From Mars
Joseph Campbell and the Myth of the Monomyth | Part 1 by Maggie Mae Fish
Joseph Campbell and the N@zis | Part 2 by Maggie Mae Fish
How Barbie Cis-ified the Matrix by Jessie Gender
#slay the princess#stp spoilers#stp#stp princess#abby howard#black tabby games#academics#critical data studies#computer science#technology#hci#my academics#my writing#long post
245 notes
·
View notes
Text
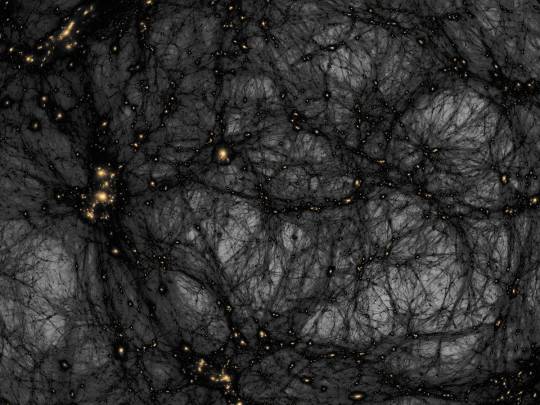
AI helps distinguish dark matter from cosmic noise
Dark matter is the invisible force holding the universe together – or so we think. It makes up around 85% of all matter and around 27% of the universe’s contents, but since we can’t see it directly, we have to study its gravitational effects on galaxies and other cosmic structures. Despite decades of research, the true nature of dark matter remains one of science’s most elusive questions.
According to a leading theory, dark matter might be a type of particle that barely interacts with anything else, except through gravity. But some scientists believe these particles could occasionally interact with each other, a phenomenon known as self-interaction. Detecting such interactions would offer crucial clues about dark matter’s properties.
However, distinguishing the subtle signs of dark matter self-interactions from other cosmic effects, like those caused by active galactic nuclei (AGN) – the supermassive black holes at the centers of galaxies – has been a major challenge. AGN feedback can push matter around in ways that are similar to the effects of dark matter, making it difficult to tell the two apart.
In a significant step forward, astronomer David Harvey at EPFL’s Laboratory of Astrophysics has developed a deep-learning algorithm that can untangle these complex signals. Their AI-based method is designed to differentiate between the effects of dark matter self-interactions and those of AGN feedback by analyzing images of galaxy clusters – vast collections of galaxies bound together by gravity. The innovation promises to greatly enhance the precision of dark matter studies.
Harvey trained a Convolutional Neural Network (CNN) – a type of AI that is particularly good at recognizing patterns in images – with images from the BAHAMAS-SIDM project, which models galaxy clusters under different dark matter and AGN feedback scenarios. By being fed thousands of simulated galaxy cluster images, the CNN learned to distinguish between the signals caused by dark matter self-interactions and those caused by AGN feedback.
Among the various CNN architectures tested, the most complex - dubbed “Inception” – proved to also be the most accurate. The AI was trained on two primary dark matter scenarios, featuring different levels of self-interaction, and validated on additional models, including a more complex, velocity-dependent dark matter model.
Inceptionachieved an impressive accuracy of 80% under ideal conditions, effectively identifying whether galaxy clusters were influenced by self-interacting dark matter or AGN feedback. It maintained is high performance even when the researchers introduced realistic observational noise that mimics the kind of data we expect from future telescopes like Euclid.
What this means is that Inception – and the AI approach more generally – could prove incredibly useful for analyzing the massive amounts of data we collect from space. Moreover, the AI’s ability to handle unseen data indicates that it’s adaptable and reliable, making it a promising tool for future dark matter research.
AI-based approaches like Inception could significantly impact our understanding of what dark matter actually is. As new telescopes gather unprecedented amounts of data, this method will help scientists sift through it quickly and accurately, potentially revealing the true nature of dark matter.
10 notes
·
View notes
Text
lil personal rant. just need to voice my stressors to get them out. scroll if you'd like!
2 classes and one capstone project are all that stand between me and my Bachelors in Computer Science. It's been a long road, between starting college at 23 for some reason, switching majors after the loss of my grandfather, and so much in between . . . studying for these final two exams is pointless ( not really, but it feels pointless ) because everything I seem to read goes in one ear and out the other. I cannot retain anymore information. I study and tell myself that I'm almost there, but I just get exhausted sitting and staring at a computer or tablet screen, trying to ingrain these terms and concepts in my mind, not to mention doing countless computational problems so I have the formulas memorized for the exams. I have my capstone topic in mind ( a machine learning model that will analyze data collected from fine needle aspiration procedures performed on breast lesions, which will be trained to predict if a lesion is benign or malignant based on different features ) and have sent my proposal to my professor for approval. I'm great at getting these coding projects done. They're fun, almost like solving a puzzle, but I am so burnt out on tests and exams. I can't find a way to study that works. My program mentor called it senioritis, and maybe it is that, but I feel like I've hit a wall. If I don't study, I feel like a worthless human being. If I do study, I overdo it by studying for hours on end, exhaust myself, and just make myself feel even more depressed about everything than I already was.
I just want my degree so I can worry about finding a job. Did I mention every application I've sent since last year has been rejected? I got an email last night rejecting me due to too many applicants. They even said they wouldn't bother looking at my application. It's was awesome.
5 notes
·
View notes
Text
Top B.Tech Courses in Maharashtra – CSE, AI, IT, and ECE Compared
B.Tech courses continue to attract students across India, and Maharashtra remains one of the most preferred states for higher technical education. From metro cities to emerging academic hubs like Solapur, students get access to diverse courses and skilled faculty. Among all available options, four major branches stand out: Computer Science and Engineering (CSE), Artificial Intelligence (AI), Information Technology (IT), and Electronics and Communication Engineering (ECE).
Each of these streams offers a different learning path. B.Tech in Computer Science and Engineering focuses on coding, algorithms, and system design. Students learn Python, Java, data structures, software engineering, and database systems. These skills are relevant for software companies, startups, and IT consulting.
B.Tech in Artificial Intelligence covers deep learning, neural networks, data processing, and computer vision. Students work on real-world problems using AI models. They also learn about ethical AI practices and automation systems. Companies hiring AI talent are in healthcare, retail, fintech, and manufacturing.
B.Tech in IT trains students in systems administration, networking, cloud computing, and application services. Graduates often work in system support, IT infrastructure, and data management. IT blends technical and management skills for enterprise use.
B.Tech ECE is for students who enjoy working with circuits, embedded systems, mobile communication, robotics, and signal processing. This stream is useful for telecom companies, consumer electronics, and control systems in industries.
Key Differences Between These B.Tech Programs:
CSE is programming-intensive. IT includes applications and system-level operations.
AI goes deeper into data modeling and pattern recognition.
ECE focuses more on hardware, communication, and embedded tech.
AI and CSE overlap, but AI involves more research-based learning.
How to Choose the Right B.Tech Specialization:
Ask yourself what excites you: coding, logic, data, devices, or systems.
Look for colleges with labs, project-based learning, and internship support.
Talk to seniors or alumni to understand real-life learning and placements.
Explore industry demand and long-term growth in each field.
MIT Vishwaprayag University, Solapur, offers all four B.Tech programs with updated syllabi, modern infrastructure, and practical training. Students work on live projects, participate in competitions, and build career skills through soft skills training. The university also encourages innovation and startup thinking.
Choosing the right course depends on interest and learning style. CSE and AI suit tech lovers who like coding and research. ECE is great for those who enjoy building real-world devices. IT fits students who want to blend business with technology.
Take time to explore the subjects and talk to faculty before selecting a stream. Your B.Tech journey shapes your future, so make an informed choice.
#B.Tech in Computer Science and Engineering#B.Tech in Artificial Intelligence#B.Tech in IT#B.Tech ECE#B.Tech Specialization
2 notes
·
View notes
Text
What is Python, How to Learn Python?
What is Python?
Python is a high-level, interpreted programming language known for its simplicity and readability. It is widely used in various fields like: ✅ Web Development (Django, Flask) ✅ Data Science & Machine Learning (Pandas, NumPy, TensorFlow) ✅ Automation & Scripting (Web scraping, File automation) ✅ Game Development (Pygame) ✅ Cybersecurity & Ethical Hacking ✅ Embedded Systems & IoT (MicroPython)
Python is beginner-friendly because of its easy-to-read syntax, large community, and vast library support.
How Long Does It Take to Learn Python?
The time required to learn Python depends on your goals and background. Here’s a general breakdown:
1. Basics of Python (1-2 months)
If you spend 1-2 hours daily, you can master:
Variables, Data Types, Operators
Loops & Conditionals
Functions & Modules
Lists, Tuples, Dictionaries
File Handling
Basic Object-Oriented Programming (OOP)
2. Intermediate Level (2-4 months)
Once comfortable with basics, focus on:
Advanced OOP concepts
Exception Handling
Working with APIs & Web Scraping
Database handling (SQL, SQLite)
Python Libraries (Requests, Pandas, NumPy)
Small real-world projects
3. Advanced Python & Specialization (6+ months)
If you want to go pro, specialize in:
Data Science & Machine Learning (Matplotlib, Scikit-Learn, TensorFlow)
Web Development (Django, Flask)
Automation & Scripting
Cybersecurity & Ethical Hacking
Learning Plan Based on Your Goal
📌 Casual Learning – 3-6 months (for automation, scripting, or general knowledge) 📌 Professional Development – 6-12 months (for jobs in software, data science, etc.) 📌 Deep Mastery – 1-2 years (for AI, ML, complex projects, research)
Scope @ NareshIT:
At NareshIT’s Python application Development program you will be able to get the extensive hands-on training in front-end, middleware, and back-end technology.
It skilled you along with phase-end and capstone projects based on real business scenarios.
Here you learn the concepts from leading industry experts with content structured to ensure industrial relevance.
An end-to-end application with exciting features
Earn an industry-recognized course completion certificate.
For more details:
#classroom#python#education#learning#teaching#institute#marketing#study motivation#studying#onlinetraining
2 notes
·
View notes
Text
How to Transition from Biotechnology to Bioinformatics: A Step-by-Step Guide

Biotechnology and bioinformatics are closely linked fields, but shifting from a wet lab environment to a computational approach requires strategic planning. Whether you are a student or a professional looking to make the transition, this guide will provide a step-by-step roadmap to help you navigate the shift from biotechnology to bioinformatics.
Why Transition from Biotechnology to Bioinformatics?
Bioinformatics is revolutionizing life sciences by integrating biological data with computational tools to uncover insights in genomics, proteomics, and drug discovery. The field offers diverse career opportunities in research, pharmaceuticals, healthcare, and AI-driven biological data analysis.
If you are skilled in laboratory techniques but wish to expand your expertise into data-driven biological research, bioinformatics is a rewarding career choice.
Step-by-Step Guide to Transition from Biotechnology to Bioinformatics
Step 1: Understand the Basics of Bioinformatics
Before making the switch, it’s crucial to gain a foundational understanding of bioinformatics. Here are key areas to explore:
Biological Databases – Learn about major databases like GenBank, UniProt, and Ensembl.
Genomics and Proteomics – Understand how computational methods analyze genes and proteins.
Sequence Analysis – Familiarize yourself with tools like BLAST, Clustal Omega, and FASTA.
🔹 Recommended Resources:
Online courses on Coursera, edX, or Khan Academy
Books like Bioinformatics for Dummies or Understanding Bioinformatics
Websites like NCBI, EMBL-EBI, and Expasy
Step 2: Develop Computational and Programming Skills
Bioinformatics heavily relies on coding and data analysis. You should start learning:
Python – Widely used in bioinformatics for data manipulation and analysis.
R – Great for statistical computing and visualization in genomics.
Linux/Unix – Basic command-line skills are essential for working with large datasets.
SQL – Useful for querying biological databases.
🔹 Recommended Online Courses:
Python for Bioinformatics (Udemy, DataCamp)
R for Genomics (HarvardX)
Linux Command Line Basics (Codecademy)
Step 3: Learn Bioinformatics Tools and Software
To become proficient in bioinformatics, you should practice using industry-standard tools:
Bioconductor – R-based tool for genomic data analysis.
Biopython – A powerful Python library for handling biological data.
GROMACS – Molecular dynamics simulation tool.
Rosetta – Protein modeling software.
🔹 How to Learn?
Join open-source projects on GitHub
Take part in hackathons or bioinformatics challenges on Kaggle
Explore free platforms like Galaxy Project for hands-on experience
Step 4: Work on Bioinformatics Projects
Practical experience is key. Start working on small projects such as:
✅ Analyzing gene sequences from NCBI databases ✅ Predicting protein structures using AlphaFold ✅ Visualizing genomic variations using R and Python
You can find datasets on:
NCBI GEO
1000 Genomes Project
TCGA (The Cancer Genome Atlas)
Create a GitHub portfolio to showcase your bioinformatics projects, as employers value practical work over theoretical knowledge.
Step 5: Gain Hands-on Experience with Internships
Many organizations and research institutes offer bioinformatics internships. Check opportunities at:
NCBI, EMBL-EBI, NIH (government research institutes)
Biotech and pharma companies (Roche, Pfizer, Illumina)
Academic research labs (Look for university-funded projects)
💡 Pro Tip: Join online bioinformatics communities like Biostars, Reddit r/bioinformatics, and SEQanswers to network and find opportunities.
Step 6: Earn a Certification or Higher Education
If you want to strengthen your credentials, consider:
🎓 Bioinformatics Certifications:
Coursera – Genomic Data Science (Johns Hopkins University)
edX – Bioinformatics MicroMasters (UMGC)
EMBO – Bioinformatics training courses
🎓 Master’s in Bioinformatics (optional but beneficial)
Top universities include Harvard, Stanford, ETH Zurich, University of Toronto
Step 7: Apply for Bioinformatics Jobs
Once you have gained enough skills and experience, start applying for bioinformatics roles such as:
Bioinformatics Analyst
Computational Biologist
Genomics Data Scientist
Machine Learning Scientist (Biotech)
💡 Where to Find Jobs?
LinkedIn, Indeed, Glassdoor
Biotech job boards (BioSpace, Science Careers)
Company career pages (Illumina, Thermo Fisher)
Final Thoughts
Transitioning from biotechnology to bioinformatics requires effort, but with the right skills and dedication, it is entirely achievable. Start with fundamental knowledge, build computational skills, and work on projects to gain practical experience.
Are you ready to make the switch? 🚀 Start today by exploring free online courses and practicing with real-world datasets!
#bioinformatics#biopractify#biotechcareers#biotechnology#biotech#aiinbiotech#machinelearning#bioinformaticstools#datascience#genomics#Biotechnology
3 notes
·
View notes
Text
at a commenters behest, a little bit of a wacky one:
no funny font because mobile formatting sucks balls
[Input Admiral Credentials]
[Welcome Admiral Jones]
Aurora Legion Site 00
Department of Experimental Research
Essophysics reasearch team
Project Designation Alpha-82662B
Project title: Returner
[Begin Audio Log, Scientist Matilde Hannesburg, 7/5/2381]
Project Returner is an experimental project based around the emerging concept of Essophysics, a science based around the atypical results fundamental sciences have in the fold. This line of study investigates how this might be used to the advantage of the legion. Project Returner is one such application. Based around our understanding of the assimilation of beings by the Rahaam, garnered from dissections, interviews, and logs found in GIA records, we believe we can control this assimilation, and return those taken to life. It is our hope that by the end of this, we have the fundamental scientific understanding to create our own meshed network of minds, and be able to remove and revive those minds at will.
[End Audio Log]
[Print Procedures.Returner.TXT]
The procedures for project returner are as follows:
Utilizing 60 grams of Eshvarean Crystal, form a telescopic lense
Acquire a Waywalker or other similarly gifted individual.
Instruct them to peer through the crystal, which for unknown reasons will allow the individual to peer through space, and observe the Rahaam Supercluster.
Utilizing their ability to detect consciousnesses, instruct them to target a member of the Gestalt with a Fold Laser (see Project Lighthouse)
Using this marker, use the ECRE (Essophysical Consciousness Retriever, Experimental) to excise the consciousness and drag it to a preprepared vessel.
[File Corrupted]
[Print ExperimentLog.Returner.TXT]
Experiment 1:
Target: Seph Adams
Vessel: [DATA LOST]
Results: Target returned, but damage due to violent neurological takeover led to subject expiration after 3 minutes
Experiment 2:
Target: Cathrine Brannock
Vessel: Genetically identical clone, No higher brain activity
Results: Target Return Failed
Experiment 3:
Target: Cathrine Brannock
Vessel: Same as Experiment 2
Results: S-
[File Corrupted] ———————————————————————————
Tyler
I drummed my fingers on the desk. I didn’t like the idea of the brains at the black site fucking around with things they barely understood, much less when it involves the consciousnesses of those we lost.
I was about to send the order to shut down the project. Especially with the data losses that the files had I was led to believe that whatever they were doing was a bad idea. Between the Admiral Promotion and Saediis Death and the Terran Civil War and the Unbroken fracturing it was all just too much. I was at my wits end even without the Brains at the blacksite trying to reanimate the dead and build nukes.
my train of grumbling thought was interrupted by a short knock on the door, I stood up, sagged a little under the stiffness of unused joints, and wandered to the door.
as I cracked it open, I saw quite possibly the last thing I could have expected.
the dark hair was long, and she was missing her tattoos, but it was Catherine Brannock, just as she was on Octavia.
“C-Cat?”
“I’m back ty, you really though death and a little fungus would stop me?”
6 notes
·
View notes
Text
BENEFITS OF CONTINGENT STAFFING SOLUTIONS FOR BUSINESSES

Adaptability is essential in this constantly changing market structure, where competition is fierce. Being a business owner, you must attend to challenges like market changes, project demand, and workforce balance for smooth production flow. And contingent staffing is one of the strategies applying which you can counter such risk factors, ensuring flexibility, cost savings, and talent accessibility in your company. You can easily monitor productivity, and participate in market competition using our contingent staffing model. There are various benefits of contingent staffing solutions you can leverage for your business growth. Read the entire blog to discover them in detail.
1. Flexibility to Adapt to Business Needs
One of the most significant benefits of contingent staffing solutions is flexibility. Businesses often face fluctuating workloads and seasonal projects that require additional resources. Hiring full-time employees for short-term needs can be costly and inefficient. Contingent staffing allows companies to scale their workforce up or down based on demand. For example, retailers can hire temporary workers during peak shopping seasons, while tech firms can bring in specialists for project-based work. This flexibility helps businesses manage staffing levels without long-term commitments.
2. Access to Specialized Talent
Contingent staffing provides companies with access to a diverse pool of specialized professionals. Many contingent workers have niche expertise in areas like IT, data science, marketing, and engineering. When a business needs skills that are not readily available in-house, a contingent staffing solution can fill the gap quickly. Additionally, companies can hire industry-specific experts without the burden of permanent employment, allowing them to benefit from specialized knowledge without investing in long-term training.
3. Cost Efficiency
Cost savings are one of the other benefits of contingent staffing solutions, where businesses can turn profit. Hiring permanent employees involves expenses such as salaries, benefits, and onboarding costs. With contingent workers, companies pay only for the services they need, avoiding the overhead associated with full-time staff. This model reduces payroll costs, employee benefits, and administrative expenses. Additionally, staffing agencies often handle recruitment, payroll management, and compliance, further lowering the operational burden on the business.
4. Faster Hiring Process
Traditional hiring processes can be time-consuming and resource-intensive. Sourcing candidates, conducting interviews, and completing onboarding can take weeks or even months. In contrast, contingent staffing solutions streamline the hiring process. Staffing agencies or platforms provide pre-screened candidates, allowing businesses to fill roles quickly. This is particularly valuable for urgent projects or when a business experiences an unexpected spike in workload. Faster hiring means less downtime and greater efficiency.
5. Reduced Risk and Liability
Employing full-time staff comes with legal and financial responsibilities, including benefits, severance, and compliance with labour laws. Contingent staffing reduces these risks because the staffing agency often assumes employer responsibilities. This arrangement minimises a company’s exposure to employment-related liabilities, such as wrongful termination claims or benefits disputes. Additionally, contingent workers are usually contract-based, making it easier for businesses to end engagements when projects are complete.
6. Access to a Global Talent Pool
With the rise of remote work, contingent staffing solutions offer access to talent from across the globe. Businesses are no longer limited to local candidates. They can collaborate with professionals from different regions, bringing diverse perspectives and innovative solutions to their projects. This global reach enhances creativity, problem-solving, and the ability to tackle complex business challenges. And that's another one of the vital benefits of contingent staffing solutions.
7. Better Workforce Management
Contingent staffing supports strategic workforce planning by providing greater control over resource allocation. Businesses can allocate contingent workers to specific tasks or projects, optimizing team efficiency. This targeted approach improves productivity and helps companies meet deadlines more effectively. Additionally, contingent staffing allows organizations to focus their full-time employees on core business functions while outsourcing specialized or temporary tasks.
Conclusion
The benefits of contingent staffing solutions are wide! It offers a wide range of benefits for businesses of all sizes and industries. From flexibility and cost savings to faster hiring and access to specialized talent, this staffing model empowers companies to adapt, innovate, and thrive in a dynamic marketplace. By embracing contingent staffing, organizations can enhance their agility, reduce risks, and maintain a competitive edge while efficiently managing their workforce. So do you want to enjoy our contingent staffing solutions benefits? Contact us today!
Visit Now: ultraversetechnologies.com Mail Us: [email protected] Contact Now: +1 470-451-0575

2 notes
·
View notes
Text
Summer Math
As usual, great work from OURFA2M2.
REU Programs
Discrete and Continuous Analysis in Appalachia
Program Runs: June 3 - July 26
Application Deadline: March 4th
Undergraduate US citizens who expect to graduate AFTER July 26, 2024, and especially such students attending university in the Appalachian region apply for the DCAA REU. The projects center around probability and data analysis, as well as linear algebra and combinatorics.
Participants will receive a $4,800 stipend and paid housing for 8 weeks during Summer 2024.
Participants funded by DCAA must be US Citizens or Permanent Residents of the United States. Students who are women, underrepresented minorities, first-generation college students, and those whose home institution have limited research opportunities in mathematics are encouraged to apply.
Applied Mathematics and Computational and Data Science
Hosted at University of Texas Rio Grande Valley
Program Runs: June 13th - August 12th
Review of applications will begin on March 15, 2024 and offers will be made by April 1, but competitive late applications may be considered until April 15.
Students will work collaboratively on group research projects in applied mathematics, mathematical modeling, and computational and data science, including applying theoretical models to physical and biological phenomena. In the application the student should choose one of the two possible research topics:
Wave Phenomena and Mathematical Modeling
Mathematical Modeling of Spatial Processes and Deep Spatial Learning
Only US citizens or permanent residents are eligible.
Women and underrepresented groups in Mathematics are encouraged to apply!
Stipend $5400 plus $900 meal allowance and $1000 travel expenses. Housing will be provided.
Computational Modeling Serving The Community
Program runs: June 10th - August 16th
Application Deadline: March 31st
Held Virtually in 2024
The focus of this REU is computational modeling to serve and enhance communities. Students will be involved in multi-disciplinary, community-based research projects and trained in computational thinking across different disciplines. In doing so, they will gain an understanding of the potential and limits of these tools and how they can serve diverse communities.
The activities of this virtual REU Site will involve a 2-week training followed by an 8-week research project completed under a faculty mentor’s guidance and with the involvement of a community partner.
Only US citizens or permanent residents are eligible.
Students from institutions with limited STEM and research opportunities (such as 2-year community colleges) and tribal colleges/universities are specifically encouraged to apply.
Stipend $7000 + $1400 meal allowance and $2200 housing allowance
REU Program in Algebra and Discrete Mathematics at Auburn University
Program Dates: May 28 - July 19
Application Deadline: March 25th
See the program webpage for more info on problems and ares.
Participants will receive a stipend of $4,500 and will live near campus at 191 College with housing paid.
NSF funding is restricted to US citizens and permanent residents. Other self-funded students are welcome to apply.
Polymath Jr.
Program Runs: June 20th - August 14th
Application Deadline: April 1st
Application Here
The Polymath Jr program is an online summer research program for undergraduates. The program consists of research projects from a wide variety of fields. For more information go to the website linked above.
The goal of the original polymath project is to solve problems by forming an online collaboration between many mathematicians. Each project consists of 20-30 undergraduates, a main mentor, and additional mentors (usually graduate students). This group works towards solving a research problem and writing a paper. Each participant decides what they wish to obtain from the program, and participates accordingly.
MathILy-EST
Program runs: June 16th - August 10th
Application Deadline: April 2th
In 2024 the MathILy-EST topic will be combinatorial geometry of origami, an area that mixes discrete mathematics, geometry, and analysis, under the direction of Dr. Thomas Hull.
MathILy-EST is an 8-week intensive summer research experience for exceptional first-year college students. MathILy-EST provides early research opportunities each year for nine college students who are deeply but informally prepared for mathematics research. The focus of the program is on first-year students, with second-year and entering college students also considered for participation.
Stipend- $4800, housing and meals included.
Internships
Jet Propulsion Laboratory Summer Internship
Programs Begin: May and June
Registration Deadline: March 29th
Summer Internship ProgramThe JPL Summer Internship Program offers 10-week, full-time, summer internship opportunities at JPL to undergraduate and graduate students pursuing degrees in science, technology, engineering or mathematics. As part of their internships, students are partnered with JPL scientists or engineers, who serve as the students' mentors. Students complete designated projects outlined by their mentors, gaining educational experience in their fields of study while also contributing to NASA and JPL missions and science.
Conferences
Women in Data Science Livermore
“WiDS Livermore is an independent event organized by LLNL ambassadors to coincide with the annual global Women in Data Science (WiDS) Conference held at Stanford University and an estimated 200+ locations worldwide. All genders are invited to attend WiDS regional events, which features outstanding women doing outstanding work…This one-day technical conference provides an opportunity to hear about the latest data science related research and applications in a number of domains, and connect with others in the field. The program features thought leaders covering a wide range of domains from data ethics and privacy, healthcare, data visualization, and more.”
Hybrid, free event: In-person at Lawrence Livermore National Laboratory, or Virtual
Registration Deadline: March 1, 2023
Date: March 13
The International Mathematics and Statistics Student Research Symposium (IMSSRS)
Date: April 13, 2023.
Location: Virtual
“IMSSRS is a free conference for all mathematics and statistics students (high school, community college, undergraduate, graduate) to share their research with the rest of the world, to learn about current research topics and to hang out with like-minded math and stat enthusiasts. Presenters must be students, but everyone is welcome as an attendee. Please feel free to share this opportunity with other students who might be interested.”
Abstract submission and registration deadlines: March 22, 2023.
To learn more, please visit the the IMSSRS website.
OURFA2M2
Online Undergraduate Resource Fair for the
Advancement and Alliance of Marginalized Mathematicians
Ashka Dalal, Gavi Dhariwal, Bowen Li, Zoe Markman, tahda queer, Jenna Race, Luke Seaton, Salina Tecle, Lee Trent [email protected] ourfa2m2.org
11 notes
·
View notes
Text
AI Frameworks Help Data Scientists For GenAI Survival

AI Frameworks: Crucial to the Success of GenAI
Develop Your AI Capabilities Now
You play a crucial part in the quickly growing field of generative artificial intelligence (GenAI) as a data scientist. Your proficiency in data analysis, modeling, and interpretation is still essential, even though platforms like Hugging Face and LangChain are at the forefront of AI research.
Although GenAI systems are capable of producing remarkable outcomes, they still mostly depend on clear, organized data and perceptive interpretation areas in which data scientists are highly skilled. You can direct GenAI models to produce more precise, useful predictions by applying your in-depth knowledge of data and statistical techniques. In order to ensure that GenAI systems are based on strong, data-driven foundations and can realize their full potential, your job as a data scientist is crucial. Here’s how to take the lead:
Data Quality Is Crucial
The effectiveness of even the most sophisticated GenAI models depends on the quality of the data they use. By guaranteeing that the data is relevant, AI tools like Pandas and Modin enable you to clean, preprocess, and manipulate large datasets.
Analysis and Interpretation of Exploratory Data
It is essential to comprehend the features and trends of the data before creating the models. Data and model outputs are visualized via a variety of data science frameworks, like Matplotlib and Seaborn, which aid developers in comprehending the data, selecting features, and interpreting the models.
Model Optimization and Evaluation
A variety of algorithms for model construction are offered by AI frameworks like scikit-learn, PyTorch, and TensorFlow. To improve models and their performance, they provide a range of techniques for cross-validation, hyperparameter optimization, and performance evaluation.
Model Deployment and Integration
Tools such as ONNX Runtime and MLflow help with cross-platform deployment and experimentation tracking. By guaranteeing that the models continue to function successfully in production, this helps the developers oversee their projects from start to finish.
Intel’s Optimized AI Frameworks and Tools
The technologies that developers are already familiar with in data analytics, machine learning, and deep learning (such as Modin, NumPy, scikit-learn, and PyTorch) can be used. For the many phases of the AI process, such as data preparation, model training, inference, and deployment, Intel has optimized the current AI tools and AI frameworks, which are based on a single, open, multiarchitecture, multivendor software platform called oneAPI programming model.
Data Engineering and Model Development:
To speed up end-to-end data science pipelines on Intel architecture, use Intel’s AI Tools, which include Python tools and frameworks like Modin, Intel Optimization for TensorFlow Optimizations, PyTorch Optimizations, IntelExtension for Scikit-learn, and XGBoost.
Optimization and Deployment
For CPU or GPU deployment, Intel Neural Compressor speeds up deep learning inference and minimizes model size. Models are optimized and deployed across several hardware platforms including Intel CPUs using the OpenVINO toolbox.
You may improve the performance of your Intel hardware platforms with the aid of these AI tools.
Library of Resources
Discover collection of excellent, professionally created, and thoughtfully selected resources that are centered on the core data science competencies that developers need. Exploring machine and deep learning AI frameworks.
What you will discover:
Use Modin to expedite the extract, transform, and load (ETL) process for enormous DataFrames and analyze massive datasets.
To improve speed on Intel hardware, use Intel’s optimized AI frameworks (such as Intel Optimization for XGBoost, Intel Extension for Scikit-learn, Intel Optimization for PyTorch, and Intel Optimization for TensorFlow).
Use Intel-optimized software on the most recent Intel platforms to implement and deploy AI workloads on Intel Tiber AI Cloud.
How to Begin
Frameworks for Data Engineering and Machine Learning
Step 1: View the Modin, Intel Extension for Scikit-learn, and Intel Optimization for XGBoost videos and read the introductory papers.
Modin: To achieve a quicker turnaround time overall, the video explains when to utilize Modin and how to apply Modin and Pandas judiciously. A quick start guide for Modin is also available for more in-depth information.
Scikit-learn Intel Extension: This tutorial gives you an overview of the extension, walks you through the code step-by-step, and explains how utilizing it might improve performance. A movie on accelerating silhouette machine learning techniques, PCA, and K-means clustering is also available.
Intel Optimization for XGBoost: This straightforward tutorial explains Intel Optimization for XGBoost and how to use Intel optimizations to enhance training and inference performance.
Step 2: Use Intel Tiber AI Cloud to create and develop machine learning workloads.
On Intel Tiber AI Cloud, this tutorial runs machine learning workloads with Modin, scikit-learn, and XGBoost.
Step 3: Use Modin and scikit-learn to create an end-to-end machine learning process using census data.
Run an end-to-end machine learning task using 1970–2010 US census data with this code sample. The code sample uses the Intel Extension for Scikit-learn module to analyze exploratory data using ridge regression and the Intel Distribution of Modin.
Deep Learning Frameworks
Step 4: Begin by watching the videos and reading the introduction papers for Intel’s PyTorch and TensorFlow optimizations.
Intel PyTorch Optimizations: Read the article to learn how to use the Intel Extension for PyTorch to accelerate your workloads for inference and training. Additionally, a brief video demonstrates how to use the addon to run PyTorch inference on an Intel Data Center GPU Flex Series.
Intel’s TensorFlow Optimizations: The article and video provide an overview of the Intel Extension for TensorFlow and demonstrate how to utilize it to accelerate your AI tasks.
Step 5: Use TensorFlow and PyTorch for AI on the Intel Tiber AI Cloud.
In this article, it show how to use PyTorch and TensorFlow on Intel Tiber AI Cloud to create and execute complicated AI workloads.
Step 6: Speed up LSTM text creation with Intel Extension for TensorFlow.
The Intel Extension for TensorFlow can speed up LSTM model training for text production.
Step 7: Use PyTorch and DialoGPT to create an interactive chat-generation model.
Discover how to use Hugging Face’s pretrained DialoGPT model to create an interactive chat model and how to use the Intel Extension for PyTorch to dynamically quantize the model.
Read more on Govindhtech.com
#AI#AIFrameworks#DataScientists#GenAI#PyTorch#GenAISurvival#TensorFlow#CPU#GPU#IntelTiberAICloud#News#Technews#Technology#Technologynews#Technologytrends#govindhtech
2 notes
·
View notes
Text
Big Data and AI: The Perfect Partnership for Future Innovations
Innovation allows organizations to excel at differentiation, boosting competitive advantages. Amid the growth of industry-disrupting technologies, big data analytics and artificial intelligence (AI) professionals want to support brands seeking bold design, delivery, and functionality ideas. This post discusses the importance of big data and AI, explaining why they matter to future innovations and business development.
Understanding Big Data and AI
Big data is a vast data volume, and you will find mixed data structures because of continuous data collection involving multimedia data objects. A data object or asset can be a document, an audio track, a video clip, a photo, or identical objects with special file formats. Since big data services focus on sorting and exploring data objects’ attributes at an unprecedented scale, integrating AI tools is essential.
Artificial intelligence helps computers simulate human-like thinking and idea synthesis capabilities. Most AI ecosystems leverage advanced statistical methods and machine learning models. Their developers train the AI tools to develop and document high-quality insights by processing unstructured and semi-structured data objects.
As a result, the scope of big data broadens if you add AI integrations that can determine data context. Businesses can generate new ideas instead of recombining recorded data or automatically filter data via AI-assisted quality assurances.
Why Are Big Data and AI Perfect for Future Innovations?
1| They Accelerate Scientific Studies
Material sciences, green technology projects, and rare disorder research projects have provided humans with exceptional lifestyle improvements. However, as markets mature, commoditization becomes inevitable.
At the same time, new, untested ideas can fail, attracting regulators’ dismay, disrespecting consumers’ beliefs, or hurting the environment. Additionally, bold ideas must not alienate consumers due to inherent complexity. Therefore, private sector stakeholders must employ scientific methods to identify feasible, sustainable, and consumer-friendly product ideas for brand differentiation.
AI-powered platforms and business analytics solutions help global corporations immediately acquire, filter, and document data assets for independent research projects. For instance, a pharmaceutical firm can use them during clinical drug formulations and trials, while a car manufacturer might discover efficient production tactics using AI and big data.
2| Brands Can Objectively Evaluate Forward-Thinking Business Ideas
Some business ideas that a few people thought were laughable or unrealistic a few decades ago have forced many brands and professionals to abandon conventional strategies. Consider how streaming platforms’ founders affected theatrical film releases. They have reduced the importance of box office revenues while increasing independent artists’ discoverability.
Likewise, exploring real estate investment opportunities on a tiny mobile or ordering clothes online were bizarre practices, according to many non-believers. They also predicted socializing through virtual reality (VR) avatars inside a computer-generated three-dimensional space would attract only the tech-savvy young adults.
Today, customers and investors who underestimated those innovations prefer religiously studying how disrupting startups perform. Brands care less about losing money than missing an opportunity to be a first mover for a niche consumer base. Similarly, rejecting an idea without testing it at least a few times has become a taboo.
Nobody can be 100% sure which innovation will gain global momentum, but AI and big data might provide relevant hints. These technologies are best for conducting unlimited scenario analyses and testing ideas likely to satisfy tomorrow’s customer expectations.
3| AI-Assisted Insight Explorations Gamifies Idea Synthesis
Combining a few ideas is easy but finding meaningful and profitable ideas by sorting the best ones is daunting. Innovative individuals must embrace AI recommendations to reduce time spent on brainstorming, product repurposing, and multidisciplinary collaborations. Furthermore, they can challenge themselves to find ideas better than an AI tool.
Gamification of brainstorming will facilitate a healthy pursuit of novel product features, marketing strategies, and customer journey personalization. Additionally, incentivizing employees to leverage AI and big data to experiment with designing methods provides unique insights for future innovations.
4| You Can Optimize Supply Chain Components with Big Data and AI Programs
AI can capture extensive data on supply chains and offer suggestions on alternative supplier relations. Therefore, businesses will revise supply and delivery planning to overcome the flaws in current practices.
For instance, Gartner awarded Beijing’s JD.com the Technology Innovation Award in 2024 because they combined statistical forecasting. The awardee has developed an explainable artificial intelligence to enhance its supply chain. Other finalists in this award category were Google, Cisco, MTN Group, and Allina Health.
5| Academia Can Embrace Adaptive Learning and Psychological Well-Being
Communication barriers and trying to force all learners to follow the standard course material based on a fixed schedule have undermined educational institutions’ goals worldwide. Understandably, expecting teachers to customize courses and multimedia assets for each student is impractical and humanly infeasible.
As a result, investors, policymakers, parents, and student bodies seek outcome-oriented educational innovations powered by AI and big data for a learner-friendly, inclusive future. For instance, some edtech providers use AI computer-aided learning and teaching ecosystems leveraging videoconferencing, curriculum personalization, and psycho-cognitive support.
Adaptive learning applications build student profiles and segments like marketers’ consumer categorizations. Their AI integrations can determine the ideal pace for teaching, whether a student exhibits learning disabilities, and whether a college or school has adequate resources.
Challenges in Promoting Innovations Based on Big Data and AI Use Cases
Encouraging stakeholders to acknowledge the need for big data and AI might be challenging. After all, uninformed stakeholders are likely to distrust tech-enabled lifestyle changes. Therefore, increasing AI awareness and educating everyone on data ethics are essential.
In some regions, the IT or network infrastructure necessary for big data is unavailable or prone to stability flaws. This issue requires more investments and talented data specialists to leverage AI tools or conduct predictive analyses.
Today’s legal frameworks lack provisions for regulating AI, big data, and scenario analytics. So, brands are unsure whether expanding data scope will get public administrators’ approvals. Lawmakers must find a balanced approach to enable AI-powered big data innovations without neglecting consumer rights or “privacy by design” principles.
Conclusion
The future of enterprise, institutional, and policy innovations lies in responsible technology implementations. Despite the obstacles, AI enthusiasts are optimistic that more stakeholders will admire the potential of new, disruptive technologies.
Remember, gamifying how your team finds new ideas or predicting the actual potential of a business model necessitates AI’s predictive insights. At the same time, big data will offer broader perspectives on global supply chains and how to optimize a company’s policies.
Lastly, academic improvements and scientific research are integral to developing sustainable products, accomplishing educational objectives, and responding to global crises. As a result, the informed stakeholders agree that AI and big data are perfect for shaping future innovations.
2 notes
·
View notes
Text
Top Free Python Courses & Tutorials Online Training | NareshIT
Top Free Python Courses & Tutorials Online Training | NareshIT
In today’s tech-driven world, Python has emerged as one of the most versatile and popular programming languages. Whether you're a beginner or an experienced developer, learning Python opens doors to exciting opportunities in web development, data science, machine learning, and much more.
At NareshIT, we understand the importance of providing quality education. That’s why we offer free Python courses and tutorials to help you kick-start or advance your programming career. With expert instructors, hands-on training, and project-based learning, our Python online training ensures that you not only grasp the fundamentals but also gain real-world coding experience.
Why Choose NareshIT for Python Training?
Comprehensive Curriculum: We cover everything from Python basics to advanced concepts such as object-oriented programming, data structures, and frameworks like Django and Flask.
Expert Instructors: Our team of experienced instructors ensures that you receive the best guidance, whether you're learning Python from scratch or brushing up on advanced topics.
Project-Based Learning: Our free tutorials are not just theoretical; they are packed with real-life projects and assignments that make learning engaging and practical.
Flexible Learning: With our online format, you can access Python tutorials and training anytime, anywhere, and learn at your own pace.
Key Features of NareshIT Python Courses
Free Python Basics Tutorials: Get started with our easy-to-follow Python tutorials designed for beginners.
Advanced Python Concepts: Dive deeper into topics like file handling, exception handling, and working with APIs.
Hands-on Practice: Learn through live coding sessions, exercises, and project work.
Certification: Upon completion of the course, earn a certificate that adds value to your resume.
Who Can Benefit from Our Python Courses?
Students looking to gain a solid foundation in programming.
Professionals aiming to switch to a career in tech or data science.
Developers wanting to enhance their Python skills and explore new opportunities.
Enthusiasts who are passionate about learning a new skill.
Start Learning Python for Free
At NareshIT, we are committed to providing accessible education for everyone. That’s why our free Python courses are available online for anyone eager to learn. Whether you want to build your first Python program or become a pro at developing Python applications, we’ve got you covered.
Ready to Dive into Python?
Sign up for our free Python tutorials today and embark on your programming journey with NareshIT. With our structured courses and expert-led training, mastering Python has never been easier. Get started now, and unlock the door to a world of opportunities!

#python#pythontraining#freepythoncourse#onlinetraining#coding#pythontutorials#pythonforbeginners#programming#pythononline#learnpython#softwaretraining#freelearning#pythonprogramming#onlinetutorial#techtraining#pythoncourses#onlineeducation#pythoncode#codingforbeginners
2 notes
·
View notes
Text
10 Surprising Stress-Relief Innovations You’ll Need in 2025

Stress and anxiety have become an integral part of modern life, especially in India, where rapid urbanization, high competition, and the digital era have exacerbated mental health challenges. According to a recent survey by the Indian Psychiatry Society, 74% of Indians face stress in their daily lives. As we move into 2025, the ways to manage stress have drastically evolved. These innovative stress-relief techniques go beyond traditional methods and offer effective, science-backed solutions to help you stay calm and focused. Let’s dive into 10 surprising innovations that you’ll need to know to reduce stress and anxiety in 2025.
1. AI-Powered Stress Monitoring Wearables
In 2025, artificial intelligence (AI) is revolutionizing the way we manage stress. AI-powered wearables such as smartwatches and fitness bands not only track your physical health but also monitor your stress levels in real time. These wearables analyze heart rate variability, body temperature, and sleep patterns to detect signs of stress. They can even provide guided breathing exercises or alert you when it’s time to take a break.
Key Features:
Real-time stress monitoring through biometric data.
Personalized stress management tips based on AI analysis.
Integration with apps to provide breathing exercises, meditation, or calming music.
Indian Market Stats:
According to Statista, the wearable technology market in India is projected to grow at a compound annual growth rate (CAGR) of 15.6% by 2025, with stress-management wearables becoming more popular.
Popular AI-Powered Wearables:
Fitbit Sense: Equipped with an EDA sensor that tracks your body’s response to stress.
Oura Ring: Tracks body temperature and sleep patterns, helping to manage anxiety.
2. Digital Detox Retreats
In a world dominated by technology, digital detox retreats are emerging as one of the most effective stress-relief techniques in 2025. These retreats allow participants to unplug from technology and focus on mindfulness, nature, and self-care. With the rise of screen time, especially in India where people spend an average of 6-7 hours a day on digital devices, digital detox retreats offer a necessary escape to rejuvenate the mind and body.
Benefits of Digital Detox:
Reduced screen fatigue and improved mental clarity.
Better sleep quality due to disconnection from blue light.
Enhanced emotional well-being through mindfulness activities like yoga and meditation.
Popular Digital Detox Destinations in India:
Ananda in the Himalayas: Offers yoga, meditation, and spa therapies in a serene environment.
SwaSwara Retreat in Gokarna: A perfect place for digital detox combined with Ayurveda and holistic healing.
3. Neurofeedback Therapy
Neurofeedback is a cutting-edge stress-relief technique that uses brainwave monitoring to help individuals regulate their stress responses. In 2025, neurofeedback therapy has become a mainstream option for managing anxiety, particularly in urban areas of India. By training the brain to recognize stressful patterns and shifting brainwave activity, neurofeedback offers long-term stress reduction without medication.
How Neurofeedback Works:
Electrodes are placed on the scalp to monitor brain activity.
The brain is trained to produce desirable brainwave patterns, helping you achieve relaxation.
Sessions are often combined with mindfulness and deep-breathing exercises.
Effectiveness:
Research shows that neurofeedback therapy can reduce symptoms of anxiety by up to 45% over time.
Available in India’s top wellness centers in cities like Bengaluru, Mumbai, and Delhi.
4. Sensory Deprivation Tanks (Floatation Therapy)
Sensory deprivation, also known as floatation therapy, involves lying in a tank filled with saltwater where external stimuli such as light and sound are completely eliminated. This helps your body enter a deep state of relaxation, reducing cortisol levels and promoting mental clarity. Floatation therapy has become increasingly popular in India’s major cities in 2025 as a way to combat the pressures of daily life.
Benefits of Floatation Therapy:
Decreased cortisol levels and stress hormones by up to 20%.
Promotes theta brainwave activity, which is associated with deep relaxation and meditation.
Improved mental focus and reduced symptoms of depression and anxiety.
Where to Try It in India:
1000 Petals in Bengaluru: Offers floatation therapy sessions designed for stress relief.
Mindful Waters in Mumbai: Specializes in sensory deprivation therapy for mental well-being.
5. Cold Exposure Therapy (Cryotherapy)
Cold exposure therapy, or cryotherapy, has emerged as one of the most surprising ways to combat stress and anxiety in 2025. Cryotherapy involves brief exposure to sub-zero temperatures in a controlled environment, stimulating the body’s parasympathetic nervous system. This, in turn, reduces inflammation, boosts endorphins, and helps manage anxiety.
Key Benefits:
Reduces inflammation and muscle tension caused by stress.
Boosts the production of endorphins, the body’s natural feel-good chemicals.
Enhances mental resilience by improving the body’s response to stress.
Cryotherapy in India:
Leading wellness centers in Delhi, Mumbai, and Bengaluru offer cryotherapy sessions.
Cryotherapy is expected to grow rapidly, with a 35% increase in adoption by 2025 as per industry reports.
6. Virtual Reality Meditation
Virtual reality (VR) has made meditation more immersive and effective than ever in 2025. VR meditation apps transport you to peaceful environments like lush forests or serene beaches, making it easier to disconnect from stressful surroundings. These apps combine guided meditation with virtual experiences, making stress management more accessible, even in the bustling cities of India.
Why VR Meditation Works:
Creates a fully immersive experience, helping you detach from daily stressors.
Guided meditation programs are tailored to reduce anxiety, depression, and emotional exhaustion.
Ideal for those who find traditional meditation challenging or boring.
Popular VR Meditation Apps:
TRIPP: A VR app designed to promote mindfulness and reduce stress.
RelaxVR: Offers calming VR experiences like virtual beaches or mountain views, helping to lower anxiety levels.
7. Biohacking for Stress Relief
Biohacking, a concept focused on optimizing body and mind performance, has taken a new leap in 2025 as a method for stress relief. Techniques such as intermittent fasting, cold showers, and red light therapy are being embraced by individuals seeking to "hack" their stress responses. Biohacking allows you to gain control over how your body reacts to stress, improving both mental and physical health.
Popular Biohacking Techniques for Stress:
Cold Showers: Stimulate the vagus nerve and reduce cortisol production.
Red Light Therapy: Helps lower inflammation and calm the nervous system.
Intermittent Fasting: Promotes mental clarity and enhances stress resilience by balancing hormonal levels.
Indian Biohacking Community Growth:
Biohacking India reported a 40% increase in the number of people practicing biohacking methods in 2025, with stress reduction being a key goal for many participants.
8. Gut Health and Probiotics for Mental Well-Being
The gut-brain connection is now well-established, and 2025 has seen the rise of nutritional psychiatry in India. Probiotics, specifically designed to improve gut health, have been shown to reduce anxiety by promoting the production of serotonin, a key mood-regulating hormone. Incorporating probiotics and prebiotics into your diet can be a natural way to manage stress and anxiety.
Key Foods for Stress Reduction:
Curd (Dahi): Rich in probiotics, which help balance gut bacteria and improve mood.
Fermented Foods: Include pickles, idli, and dosa for natural probiotics.
Asafoetida (Hing): Known to improve gut health, which can directly influence mental well-being.
Stats:
According to a 2024 study by the Indian Council of Medical Research (ICMR), individuals who included probiotics in their diet experienced a 30% decrease in anxiety levels after three months.
9. Breathwork with Heart Rate Variability (HRV) Training
Breathwork has been a traditional Indian practice for centuries, but in 2025, it’s getting a modern upgrade with heart rate variability (HRV) training. HRV is the measurement of the time interval between heartbeats, and it’s a powerful indicator of stress levels. With the help of technology, you can now practice controlled breathing to improve your HRV, thereby reducing anxiety and stress.
How HRV Breathwork Works:
Apps or wearables measure your HRV and guide you through specific breathing exercises to optimize your heart rate.
Increased HRV is linked to better mental health, lower stress, and improved resilience to anxiety.
Popular HRV Devices:
HeartMath Inner Balance: A device that measures HRV and offers personalized breathing exercises.
Garmin Smartwatches: Equipped with HRV tracking and breathing exercises for stress management.
10. Forest Bathing (Shinrin-Yoku)
In 2025, forest bathing, or Shinrin-Yoku, has become a popular stress-relief technique in India. Originally a Japanese practice, forest bathing involves immersing yourself in nature, taking in the sights, sounds, and smells of a forest environment. The benefits of spending time in nature are well-documented, with forest
2 notes
·
View notes