#Machine Learning for Text Classification
Explore tagged Tumblr posts
Visit Tumblr Blog
Explore Tumblr blogs with no restrictions, modern design and the best experience.
Last Seen Tumblr Blogs





Fun Fact
There were a total of 171.5 billion posts on Tumblr in 2019.
Text
Unlocking Insights: Text Analytics in NLP with Azure - Ansi ByteCode LLP

Discover how Text Analytics in NLP with Azure. Learn tokenization, sentiment analysis, entity recognition to analyze text efficiently. Please visit:- https://ansibytecode.com/text-analytics-in-nlp-with-azure/
0 notes
Text
0 notes
Text
Language and computers (Open Access)
Lelia Glass, Markus Dickinson, Chris Brew, Detmar Meurers
This book offers an accessible introduction to the ways that language is processed and produced by computers, a field that has recently exploded in interest. The book covers writing systems, tools to help people write, computer-assisted language learning, the multidisciplinary study of text as data, text classification, information retrieval, machine translation, and dialog. Throughout, we emphasize insights from linguistics along with the ethical and social consequences of emerging technology. This book welcomes students from diverse intellectual backgrounds to learn new technical tools and to appreciate rich language data, thus widening the bridge between linguistics and computer science.
#linguistics#lingblr#academia#langblr#phd life#computer science#natural language#Language and Computers
9 notes
·
View notes
Text
Tagged by @sapphictea (a week ago oops sorry)
~list 5 topics you can talk on for an hour without preparing any material~
Renegade Nell. im so deep into this show i think i could probably talk for an hour about literally anything to do with it. costumes? character analysis? prop and set design? the main story? character dynamics? anything and everything.
Sewing. specifically historical sewing and costuming from the medieval period and the early 18th century in england, though I'll happily talk about other periods just for the fun of it. i enjoy the process of hand sewing, and the social history that clothing and fashion has is just, so so interesting, especially for women's fashion.
AI/ML. look i could talk about my thoughts and feelings on generative ai for probably longer than an hour, but honestly im sick of that and id much rather talk about other areas of machine learning. im really interested in the ethics of ml relating to data (how data is obtained, the biases that it might contain, the pros and cons relating to a dataset that is fabricated for classification vs one consists of real world data, etc). im also studying explainable ai atm, and the idea of expanding the current methods for assessing how effective a model is by considering the wider context and decision making happening in these models, as well as being able to assess easier if theres missed issues in the data used for training, instead of just "it got the expected answer", its all just so interesting to me. i also love to talk about the fields and research areas where ai/ml is being applied that get ignored when conversions are dominated by genAI.
Neurodiversity. specifically autism, adhd and tourettes, but also ARFID, if only cause those are the ones i have lived experience with and have researched the most. im sorry to anyone that has met me and ive clocked before they knew themselves that they had adhd and/or autism, cause i haven't been wrong yet. im not sure i have any specific areas of this topic that i favour over others, but i like to talk about my lived experiences and help others (friends, past students ive tutored, strangers) set up strategies and tools that'll help them.
Fencing. scraping the bottle of the barrel now but i could most definitely talk about la verdadera destreza style fencing for an hour. its a style of fencing that originated in spain and was popular around the 16-17th centuries, with the last main text being published in 1705 and after which the style fell out of favour for more italian and french styles. it values defensive manoeuvres over offensive, and draws a lot on geometry to do so (the fancy cool new maths of the time). im still relatively new to the hobby, but the local community is lovely and it ties in beautifully with my history interests.
tagging (with no pressure): @greencheekconure27 @butts-bouncing-on-the-beltway @broodytinygaycarmilla @fools-and-perverts2 and anyone else interested
6 notes
·
View notes
Text
From Curious Novice to Data Enthusiast: My Data Science Adventure
I've always been fascinated by data science, a field that seamlessly blends technology, mathematics, and curiosity. In this article, I want to take you on a journey—my journey—from being a curious novice to becoming a passionate data enthusiast. Together, let's explore the thrilling world of data science, and I'll share the steps I took to immerse myself in this captivating realm of knowledge.

The Spark: Discovering the Potential of Data Science
The moment I stumbled upon data science, I felt a spark of inspiration. Witnessing its impact across various industries, from healthcare and finance to marketing and entertainment, I couldn't help but be drawn to this innovative field. The ability to extract critical insights from vast amounts of data and uncover meaningful patterns fascinated me, prompting me to dive deeper into the world of data science.
Laying the Foundation: The Importance of Learning the Basics
To embark on this data science adventure, I quickly realized the importance of building a strong foundation. Learning the basics of statistics, programming, and mathematics became my priority. Understanding statistical concepts and techniques enabled me to make sense of data distributions, correlations, and significance levels. Programming languages like Python and R became essential tools for data manipulation, analysis, and visualization, while a solid grasp of mathematical principles empowered me to create and evaluate predictive models.
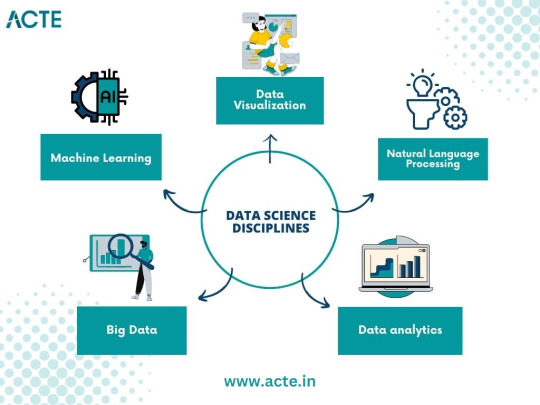
The Quest for Knowledge: Exploring Various Data Science Disciplines
A. Machine Learning: Unraveling the Power of Predictive Models
Machine learning, a prominent discipline within data science, captivated me with its ability to unlock the potential of predictive models. I delved into the fundamentals, understanding the underlying algorithms that power these models. Supervised learning, where data with labels is used to train prediction models, and unsupervised learning, which uncovers hidden patterns within unlabeled data, intrigued me. Exploring concepts like regression, classification, clustering, and dimensionality reduction deepened my understanding of this powerful field.
B. Data Visualization: Telling Stories with Data
In my data science journey, I discovered the importance of effectively visualizing data to convey meaningful stories. Navigating through various visualization tools and techniques, such as creating dynamic charts, interactive dashboards, and compelling infographics, allowed me to unlock the hidden narratives within datasets. Visualizations became a medium to communicate complex ideas succinctly, enabling stakeholders to understand insights effortlessly.
C. Big Data: Mastering the Analysis of Vast Amounts of Information
The advent of big data challenged traditional data analysis approaches. To conquer this challenge, I dived into the world of big data, understanding its nuances and exploring techniques for efficient analysis. Uncovering the intricacies of distributed systems, parallel processing, and data storage frameworks empowered me to handle massive volumes of information effectively. With tools like Apache Hadoop and Spark, I was able to mine valuable insights from colossal datasets.
D. Natural Language Processing: Extracting Insights from Textual Data
Textual data surrounds us in the digital age, and the realm of natural language processing fascinated me. I delved into techniques for processing and analyzing unstructured text data, uncovering insights from tweets, customer reviews, news articles, and more. Understanding concepts like sentiment analysis, topic modeling, and named entity recognition allowed me to extract valuable information from written text, revolutionizing industries like sentiment analysis, customer service, and content recommendation systems.
Building the Arsenal: Acquiring Data Science Skills and Tools
Acquiring essential skills and familiarizing myself with relevant tools played a crucial role in my data science journey. Programming languages like Python and R became my companions, enabling me to manipulate, analyze, and model data efficiently. Additionally, I explored popular data science libraries and frameworks such as TensorFlow, Scikit-learn, Pandas, and NumPy, which expedited the development and deployment of machine learning models. The arsenal of skills and tools I accumulated became my assets in the quest for data-driven insights.
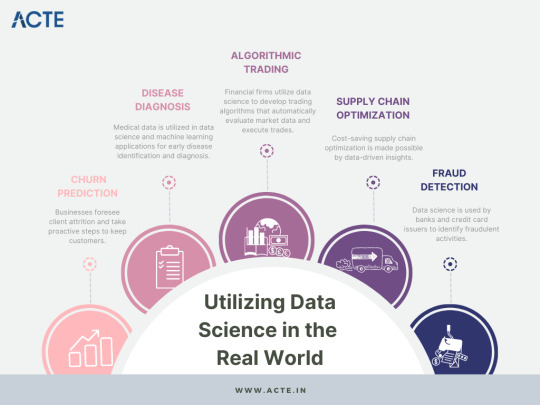
The Real-World Challenge: Applying Data Science in Practice
Data science is not just an academic pursuit but rather a practical discipline aimed at solving real-world problems. Throughout my journey, I sought to identify such problems and apply data science methodologies to provide practical solutions. From predicting customer churn to optimizing supply chain logistics, the application of data science proved transformative in various domains. Sharing success stories of leveraging data science in practice inspires others to realize the power of this field.
Cultivating Curiosity: Continuous Learning and Skill Enhancement
Embracing a growth mindset is paramount in the world of data science. The field is rapidly evolving, with new algorithms, techniques, and tools emerging frequently. To stay ahead, it is essential to cultivate curiosity and foster a continuous learning mindset. Keeping abreast of the latest research papers, attending data science conferences, and engaging in data science courses nurtures personal and professional growth. The journey to becoming a data enthusiast is a lifelong pursuit.
Joining the Community: Networking and Collaboration
Being part of the data science community is a catalyst for growth and inspiration. Engaging with like-minded individuals, sharing knowledge, and collaborating on projects enhances the learning experience. Joining online forums, participating in Kaggle competitions, and attending meetups provides opportunities to exchange ideas, solve challenges collectively, and foster invaluable connections within the data science community.
Overcoming Obstacles: Dealing with Common Data Science Challenges
Data science, like any discipline, presents its own set of challenges. From data cleaning and preprocessing to model selection and evaluation, obstacles arise at each stage of the data science pipeline. Strategies and tips to overcome these challenges, such as building reliable pipelines, conducting robust experiments, and leveraging cross-validation techniques, are indispensable in maintaining motivation and achieving success in the data science journey.
Balancing Act: Building a Career in Data Science alongside Other Commitments
For many aspiring data scientists, the pursuit of knowledge and skills must coexist with other commitments, such as full-time jobs and personal responsibilities. Effectively managing time and developing a structured learning plan is crucial in striking a balance. Tips such as identifying pockets of dedicated learning time, breaking down complex concepts into manageable chunks, and seeking mentorships or online communities can empower individuals to navigate the data science journey while juggling other responsibilities.
Ethical Considerations: Navigating the World of Data Responsibly
As data scientists, we must navigate the world of data responsibly, being mindful of the ethical considerations inherent in this field. Safeguarding privacy, addressing bias in algorithms, and ensuring transparency in data-driven decision-making are critical principles. Exploring topics such as algorithmic fairness, data anonymization techniques, and the societal impact of data science encourages responsible and ethical practices in a rapidly evolving digital landscape.
Embarking on a data science adventure from a curious novice to a passionate data enthusiast is an exhilarating and rewarding journey. By laying a foundation of knowledge, exploring various data science disciplines, acquiring essential skills and tools, and engaging in continuous learning, one can conquer challenges, build a successful career, and have a good influence on the data science community. It's a journey that never truly ends, as data continues to evolve and offer exciting opportunities for discovery and innovation. So, join me in your data science adventure, and let the exploration begin!
#data science#data analytics#data visualization#big data#machine learning#artificial intelligence#education#information
17 notes
·
View notes
Text
SEMANTIC TREE AND AI TECHNOLOGIES

Semantic Tree learning and AI technologies can be combined to solve problems by leveraging the power of natural language processing and machine learning.
Semantic trees are a knowledge representation technique that organizes information in a hierarchical, tree-like structure.
Each node in the tree represents a concept or entity, and the connections between nodes represent the relationships between those concepts.
This structure allows for the representation of complex, interconnected knowledge in a way that can be easily navigated and reasoned about.






CONCEPTS
Semantic Tree: A structured representation where nodes correspond to concepts and edges denote relationships (e.g., hyponyms, hyponyms, synonyms).
Meaning: Understanding the context, nuances, and associations related to words or concepts.
Natural Language Understanding (NLU): AI techniques for comprehending and interpreting human language.
First Principles: Fundamental building blocks or core concepts in a domain.
AI (Artificial Intelligence): AI refers to the development of computer systems that can perform tasks that typically require human intelligence. AI technologies include machine learning, natural language processing, computer vision, and more. These technologies enable computers to understand reason, learn, and make decisions.
Natural Language Processing (NLP): NLP is a branch of AI that focuses on the interaction between computers and human language. It involves the analysis and understanding of natural language text or speech by computers. NLP techniques are used to process, interpret, and generate human languages.
Machine Learning (ML): Machine Learning is a subset of AI that enables computers to learn and improve from experience without being explicitly programmed. ML algorithms can analyze data, identify patterns, and make predictions or decisions based on the learned patterns.
Deep Learning: A subset of machine learning that uses neural networks with multiple layers to learn complex patterns.
EXAMPLES OF APPLYING SEMANTIC TREE LEARNING WITH AI.
1. Text Classification: Semantic Tree learning can be combined with AI to solve text classification problems. By training a machine learning model on labeled data, the model can learn to classify text into different categories or labels. For example, a customer support system can use semantic tree learning to automatically categorize customer queries into different topics, such as billing, technical issues, or product inquiries.
2. Sentiment Analysis: Semantic Tree learning can be used with AI to perform sentiment analysis on text data. Sentiment analysis aims to determine the sentiment or emotion expressed in a piece of text, such as positive, negative, or neutral. By analyzing the semantic structure of the text using Semantic Tree learning techniques, machine learning models can classify the sentiment of customer reviews, social media posts, or feedback.
3. Question Answering: Semantic Tree learning combined with AI can be used for question answering systems. By understanding the semantic structure of questions and the context of the information being asked, machine learning models can provide accurate and relevant answers. For example, a Chabot can use Semantic Tree learning to understand user queries and provide appropriate responses based on the analyzed semantic structure.
4. Information Extraction: Semantic Tree learning can be applied with AI to extract structured information from unstructured text data. By analyzing the semantic relationships between entities and concepts in the text, machine learning models can identify and extract specific information. For example, an AI system can extract key information like names, dates, locations, or events from news articles or research papers.
Python Snippet Codes for Semantic Tree Learning with AI
Here are four small Python code snippets that demonstrate how to apply Semantic Tree learning with AI using popular libraries:
1. Text Classification with scikit-learn:
```python
from sklearn.feature_extraction.text import TfidfVectorizer
from sklearn.linear_model import LogisticRegression
# Training data
texts = ['This is a positive review', 'This is a negative review', 'This is a neutral review']
labels = ['positive', 'negative', 'neutral']
# Vectorize the text data
vectorizer = TfidfVectorizer()
X = vectorizer.fit_transform(texts)
# Train a logistic regression classifier
classifier = LogisticRegression()
classifier.fit(X, labels)
# Predict the label for a new text
new_text = 'This is a positive sentiment'
new_text_vectorized = vectorizer.transform([new_text])
predicted_label = classifier.predict(new_text_vectorized)
print(predicted_label)
```
2. Sentiment Analysis with TextBlob:
```python
from textblob import TextBlob
# Analyze sentiment of a text
text = 'This is a positive sentence'
blob = TextBlob(text)
sentiment = blob.sentiment.polarity
# Classify sentiment based on polarity
if sentiment > 0:
sentiment_label = 'positive'
elif sentiment < 0:
sentiment_label = 'negative'
else:
sentiment_label = 'neutral'
print(sentiment_label)
```
3. Question Answering with Transformers:
```python
from transformers import pipeline
# Load the question answering model
qa_model = pipeline('question-answering')
# Provide context and ask a question
context = 'The Semantic Web is an extension of the World Wide Web.'
question = 'What is the Semantic Web?'
# Get the answer
answer = qa_model(question=question, context=context)
print(answer['answer'])
```
4. Information Extraction with spaCy:
```python
import spacy
# Load the English language model
nlp = spacy.load('en_core_web_sm')
# Process text and extract named entities
text = 'Apple Inc. is planning to open a new store in New York City.'
doc = nlp(text)
# Extract named entities
entities = [(ent.text, ent.label_) for ent in doc.ents]
print(entities)
```
APPLICATIONS OF SEMANTIC TREE LEARNING WITH AI
Semantic Tree learning combined with AI can be used in various domains and industries to solve problems. Here are some examples of where it can be applied:
1. Customer Support: Semantic Tree learning can be used to automatically categorize and route customer queries to the appropriate support teams, improving response times and customer satisfaction.
2. Social Media Analysis: Semantic Tree learning with AI can be applied to analyze social media posts, comments, and reviews to understand public sentiment, identify trends, and monitor brand reputation.
3. Information Retrieval: Semantic Tree learning can enhance search engines by understanding the meaning and context of user queries, providing more accurate and relevant search results.
4. Content Recommendation: By analyzing the semantic structure of user preferences and content metadata, Semantic Tree learning with AI can be used to personalize content recommendations in platforms like streaming services, news aggregators, or e-commerce websites.
Semantic Tree learning combined with AI technologies enables the understanding and analysis of text data, leading to improved problem-solving capabilities in various domains.
COMBINING SEMANTIC TREE AND AI FOR PROBLEM SOLVING
1. Semantic Reasoning: By integrating semantic trees with AI, systems can engage in more sophisticated reasoning and decision-making. The semantic tree provides a structured representation of knowledge, while AI techniques like natural language processing and knowledge representation can be used to navigate and reason about the information in the tree.
2. Explainable AI: Semantic trees can make AI systems more interpretable and explainable. The hierarchical structure of the tree can be used to trace the reasoning process and understand how the system arrived at a particular conclusion, which is important for building trust in AI-powered applications.
3. Knowledge Extraction and Representation: AI techniques like machine learning can be used to automatically construct semantic trees from unstructured data, such as text or images. This allows for the efficient extraction and representation of knowledge, which can then be used to power various problem-solving applications.
4. Hybrid Approaches: Combining semantic trees and AI can lead to hybrid approaches that leverage the strengths of both. For example, a system could use a semantic tree to represent domain knowledge and then apply AI techniques like reinforcement learning to optimize decision-making within that knowledge structure.
EXAMPLES OF APPLYING SEMANTIC TREE AND AI FOR PROBLEM SOLVING
1. Medical Diagnosis: A semantic tree could represent the relationships between symptoms, diseases, and treatments. AI techniques like natural language processing and machine learning could be used to analyze patient data, navigate the semantic tree, and provide personalized diagnosis and treatment recommendations.
2. Robotics and Autonomous Systems: Semantic trees could be used to represent the knowledge and decision-making processes of autonomous systems, such as self-driving cars or drones. AI techniques like computer vision and reinforcement learning could be used to navigate the semantic tree and make real-time decisions in dynamic environments.
3. Financial Analysis: Semantic trees could be used to model complex financial relationships and market dynamics. AI techniques like predictive analytics and natural language processing could be applied to the semantic tree to identify patterns, make forecasts, and support investment decisions.
4. Personalized Recommendation Systems: Semantic trees could be used to represent user preferences, interests, and behaviors. AI techniques like collaborative filtering and content-based recommendation could be used to navigate the semantic tree and provide personalized recommendations for products, content, or services.
PYTHON CODE SNIPPETS
1. Semantic Tree Construction using NetworkX:
```python
import networkx as nx
import matplotlib.pyplot as plt
# Create a semantic tree
G = nx.DiGraph()
G.add_node("root", label="Root")
G.add_node("concept1", label="Concept 1")
G.add_node("concept2", label="Concept 2")
G.add_node("concept3", label="Concept 3")
G.add_edge("root", "concept1")
G.add_edge("root", "concept2")
G.add_edge("concept2", "concept3")
# Visualize the semantic tree
pos = nx.spring_layout(G)
nx.draw(G, pos, with_labels=True)
plt.show()
```
2. Semantic Reasoning using PyKEEN:
```python
from pykeen.models import TransE
from pykeen.triples import TriplesFactory
# Load a knowledge graph dataset
tf = TriplesFactory.from_path("./dataset/")
# Train a TransE model on the knowledge graph
model = TransE(triples_factory=tf)
model.fit(num_epochs=100)
# Perform semantic reasoning
head = "concept1"
relation = "isRelatedTo"
tail = "concept3"
score = model.score_hrt(head, relation, tail)
print(f"The score for the triple ({head}, {relation}, {tail}) is: {score}")
```
3. Knowledge Extraction using spaCy:
```python
import spacy
# Load the spaCy model
nlp = spacy.load("en_core_web_sm")
# Extract entities and relations from text
text = "The quick brown fox jumps over the lazy dog."
doc = nlp(text)
# Visualize the extracted knowledge
from spacy import displacy
displacy.render(doc, style="ent")
```
4. Hybrid Approach using Ray:
```python
import ray
from ray.rllib.agents.ppo import PPOTrainer
from ray.rllib.env.multi_agent_env import MultiAgentEnv
from ray.rllib.models.tf.tf_modelv2 import TFModelV2
# Define a custom model that integrates a semantic tree
class SemanticTreeModel(TFModelV2):
def __init__(self, obs_space, action_space, num_outputs, model_config, name):
super().__init__(obs_space, action_space, num_outputs, model_config, name)
# Implement the integration of the semantic tree with the neural network
# Define a multi-agent environment that uses the semantic tree model
class SemanticTreeEnv(MultiAgentEnv):
def __init__(self):
self.semantic_tree = # Initialize the semantic tree
self.agents = # Define the agents
def step(self, actions):
# Implement the environment dynamics using the semantic tree
# Train the hybrid model using Ray
ray.init()
config = {
"env": SemanticTreeEnv,
"model": {
"custom_model": SemanticTreeModel,
},
}
trainer = PPOTrainer(config=config)
trainer.train()
```
APPLICATIONS
The combination of semantic trees and AI can be applied to a wide range of problem domains, including:
- Healthcare: Improving medical diagnosis, treatment planning, and drug discovery.
- Finance: Enhancing investment strategies, risk management, and fraud detection.
- Robotics and Autonomous Systems: Enabling more intelligent and adaptable decision-making in complex environments.
- Education: Personalizing learning experiences and providing intelligent tutoring systems.
- Smart Cities: Optimizing urban planning, transportation, and resource management.
- Environmental Conservation: Modeling and predicting environmental changes, and supporting sustainable decision-making.
- Chatbots and Virtual Assistants:
Use semantic trees to understand user queries and provide context-aware responses.
Apply NLU models to extract meaning from user input.
- Information Retrieval:
Build semantic search engines that understand user intent beyond keyword matching.
Combine semantic trees with vector embeddings (e.g., BERT) for better search results.
- Medical Diagnosis:
Create semantic trees for medical conditions, symptoms, and treatments.
Use AI to match patient symptoms to relevant diagnoses.
- Automated Content Generation:
Construct semantic trees for topics (e.g., climate change, finance).
Generate articles, summaries, or reports based on semantic understanding.
RDIDINI PROMPT ENGINEER
#semantic tree#ai solutions#ai-driven#ai trends#ai system#ai model#ai prompt#ml#ai predictions#llm#dl#nlp
3 notes
·
View notes
Text
Essential Predictive Analytics Techniques
With the growing usage of big data analytics, predictive analytics uses a broad and highly diverse array of approaches to assist enterprises in forecasting outcomes. Examples of predictive analytics include deep learning, neural networks, machine learning, text analysis, and artificial intelligence.
Predictive analytics trends of today reflect existing Big Data trends. There needs to be more distinction between the software tools utilized in predictive analytics and big data analytics solutions. In summary, big data and predictive analytics technologies are closely linked, if not identical.
Predictive analytics approaches are used to evaluate a person's creditworthiness, rework marketing strategies, predict the contents of text documents, forecast weather, and create safe self-driving cars with varying degrees of success.
Predictive Analytics- Meaning
By evaluating collected data, predictive analytics is the discipline of forecasting future trends. Organizations can modify their marketing and operational strategies to serve better by gaining knowledge of historical trends. In addition to the functional enhancements, businesses benefit in crucial areas like inventory control and fraud detection.
Machine learning and predictive analytics are closely related. Regardless of the precise method, a company may use, the overall procedure starts with an algorithm that learns through access to a known result (such as a customer purchase).
The training algorithms use the data to learn how to forecast outcomes, eventually creating a model that is ready for use and can take additional input variables, like the day and the weather.
Employing predictive analytics significantly increases an organization's productivity, profitability, and flexibility. Let us look at the techniques used in predictive analytics.
Techniques of Predictive Analytics
Making predictions based on existing and past data patterns requires using several statistical approaches, data mining, modeling, machine learning, and artificial intelligence. Machine learning techniques, including classification models, regression models, and neural networks, are used to make these predictions.
Data Mining
To find anomalies, trends, and correlations in massive datasets, data mining is a technique that combines statistics with machine learning. Businesses can use this method to transform raw data into business intelligence, including current data insights and forecasts that help decision-making.
Data mining is sifting through redundant, noisy, unstructured data to find patterns that reveal insightful information. A form of data mining methodology called exploratory data analysis (EDA) includes examining datasets to identify and summarize their fundamental properties, frequently using visual techniques.
EDA focuses on objectively probing the facts without any expectations; it does not entail hypothesis testing or the deliberate search for a solution. On the other hand, traditional data mining focuses on extracting insights from the data or addressing a specific business problem.
Data Warehousing
Most extensive data mining projects start with data warehousing. An example of a data management system is a data warehouse created to facilitate and assist business intelligence initiatives. This is accomplished by centralizing and combining several data sources, including transactional data from POS (point of sale) systems and application log files.
A data warehouse typically includes a relational database for storing and retrieving data, an ETL (Extract, Transfer, Load) pipeline for preparing the data for analysis, statistical analysis tools, and client analysis tools for presenting the data to clients.
Clustering
One of the most often used data mining techniques is clustering, which divides a massive dataset into smaller subsets by categorizing objects based on their similarity into groups.
When consumers are grouped together based on shared purchasing patterns or lifetime value, customer segments are created, allowing the company to scale up targeted marketing campaigns.
Hard clustering entails the categorization of data points directly. Instead of assigning a data point to a cluster, soft clustering gives it a likelihood that it belongs in one or more clusters.
Classification
A prediction approach called classification involves estimating the likelihood that a given item falls into a particular category. A multiclass classification problem has more than two classes, unlike a binary classification problem, which only has two types.
Classification models produce a serial number, usually called confidence, that reflects the likelihood that an observation belongs to a specific class. The class with the highest probability can represent a predicted probability as a class label.
Spam filters, which categorize incoming emails as "spam" or "not spam" based on predetermined criteria, and fraud detection algorithms, which highlight suspicious transactions, are the most prevalent examples of categorization in a business use case.
Regression Model
When a company needs to forecast a numerical number, such as how long a potential customer will wait to cancel an airline reservation or how much money they will spend on auto payments over time, they can use a regression method.
For instance, linear regression is a popular regression technique that searches for a correlation between two variables. Regression algorithms of this type look for patterns that foretell correlations between variables, such as the association between consumer spending and the amount of time spent browsing an online store.
Neural Networks
Neural networks are data processing methods with biological influences that use historical and present data to forecast future values. They can uncover intricate relationships buried in the data because of their design, which mimics the brain's mechanisms for pattern recognition.
They have several layers that take input (input layer), calculate predictions (hidden layer), and provide output (output layer) in the form of a single prediction. They are frequently used for applications like image recognition and patient diagnostics.
Decision Trees
A decision tree is a graphic diagram that looks like an upside-down tree. Starting at the "roots," one walks through a continuously narrowing range of alternatives, each illustrating a possible decision conclusion. Decision trees may handle various categorization issues, but they can resolve many more complicated issues when used with predictive analytics.
An airline, for instance, would be interested in learning the optimal time to travel to a new location it intends to serve weekly. Along with knowing what pricing to charge for such a flight, it might also want to know which client groups to cater to. The airline can utilize a decision tree to acquire insight into the effects of selling tickets to destination x at price point y while focusing on audience z, given these criteria.
Logistics Regression
It is used when determining the likelihood of success in terms of Yes or No, Success or Failure. We can utilize this model when the dependent variable has a binary (Yes/No) nature.
Since it uses a non-linear log to predict the odds ratio, it may handle multiple relationships without requiring a linear link between the variables, unlike a linear model. Large sample sizes are also necessary to predict future results.
Ordinal logistic regression is used when the dependent variable's value is ordinal, and multinomial logistic regression is used when the dependent variable's value is multiclass.
Time Series Model
Based on past data, time series are used to forecast the future behavior of variables. Typically, a stochastic process called Y(t), which denotes a series of random variables, are used to model these models.
A time series might have the frequency of annual (annual budgets), quarterly (sales), monthly (expenses), or daily (daily expenses) (Stock Prices). It is referred to as univariate time series forecasting if you utilize the time series' past values to predict future discounts. It is also referred to as multivariate time series forecasting if you include exogenous variables.
The most popular time series model that can be created in Python is called ARIMA, or Auto Regressive Integrated Moving Average, to anticipate future results. It's a forecasting technique based on the straightforward notion that data from time series' initial values provides valuable information.
In Conclusion-
Although predictive analytics techniques have had their fair share of critiques, including the claim that computers or algorithms cannot foretell the future, predictive analytics is now extensively employed in virtually every industry. As we gather more and more data, we can anticipate future outcomes with a certain level of accuracy. This makes it possible for institutions and enterprises to make wise judgments.
Implementing Predictive Analytics is essential for anybody searching for company growth with data analytics services since it has several use cases in every conceivable industry. Contact us at SG Analytics if you want to take full advantage of predictive analytics for your business growth.
2 notes
·
View notes
Text
The Best Open-Source Tools for Data Science in 2025

Data science in 2025 is thriving, driven by a robust ecosystem of open-source tools that empower professionals to extract insights, build predictive models, and deploy data-driven solutions at scale. This year, the landscape is more dynamic than ever, with established favorites and emerging contenders shaping how data scientists work. Here’s an in-depth look at the best open-source tools that are defining data science in 2025.
1. Python: The Universal Language of Data Science
Python remains the cornerstone of data science. Its intuitive syntax, extensive libraries, and active community make it the go-to language for everything from data wrangling to deep learning. Libraries such as NumPy and Pandas streamline numerical computations and data manipulation, while scikit-learn is the gold standard for classical machine learning tasks.
NumPy: Efficient array operations and mathematical functions.
Pandas: Powerful data structures (DataFrames) for cleaning, transforming, and analyzing structured data.
scikit-learn: Comprehensive suite for classification, regression, clustering, and model evaluation.
Python’s popularity is reflected in the 2025 Stack Overflow Developer Survey, with 53% of developers using it for data projects.
2. R and RStudio: Statistical Powerhouses
R continues to shine in academia and industries where statistical rigor is paramount. The RStudio IDE enhances productivity with features for scripting, debugging, and visualization. R’s package ecosystem—especially tidyverse for data manipulation and ggplot2 for visualization—remains unmatched for statistical analysis and custom plotting.
Shiny: Build interactive web applications directly from R.
CRAN: Over 18,000 packages for every conceivable statistical need.
R is favored by 36% of users, especially for advanced analytics and research.
3. Jupyter Notebooks and JupyterLab: Interactive Exploration
Jupyter Notebooks are indispensable for prototyping, sharing, and documenting data science workflows. They support live code (Python, R, Julia, and more), visualizations, and narrative text in a single document. JupyterLab, the next-generation interface, offers enhanced collaboration and modularity.
Over 15 million notebooks hosted as of 2025, with 80% of data analysts using them regularly.
4. Apache Spark: Big Data at Lightning Speed
As data volumes grow, Apache Spark stands out for its ability to process massive datasets rapidly, both in batch and real-time. Spark’s distributed architecture, support for SQL, machine learning (MLlib), and compatibility with Python, R, Scala, and Java make it a staple for big data analytics.
65% increase in Spark adoption since 2023, reflecting its scalability and performance.
5. TensorFlow and PyTorch: Deep Learning Titans
For machine learning and AI, TensorFlow and PyTorch dominate. Both offer flexible APIs for building and training neural networks, with strong community support and integration with cloud platforms.
TensorFlow: Preferred for production-grade models and scalability; used by over 33% of ML professionals.
PyTorch: Valued for its dynamic computation graph and ease of experimentation, especially in research settings.
6. Data Visualization: Plotly, D3.js, and Apache Superset
Effective data storytelling relies on compelling visualizations:
Plotly: Python-based, supports interactive and publication-quality charts; easy for both static and dynamic visualizations.
D3.js: JavaScript library for highly customizable, web-based visualizations; ideal for specialists seeking full control.
Apache Superset: Open-source dashboarding platform for interactive, scalable visual analytics; increasingly adopted for enterprise BI.
Tableau Public, though not fully open-source, is also popular for sharing interactive visualizations with a broad audience.
7. Pandas: The Data Wrangling Workhorse
Pandas remains the backbone of data manipulation in Python, powering up to 90% of data wrangling tasks. Its DataFrame structure simplifies complex operations, making it essential for cleaning, transforming, and analyzing large datasets.
8. Scikit-learn: Machine Learning Made Simple
scikit-learn is the default choice for classical machine learning. Its consistent API, extensive documentation, and wide range of algorithms make it ideal for tasks such as classification, regression, clustering, and model validation.
9. Apache Airflow: Workflow Orchestration
As data pipelines become more complex, Apache Airflow has emerged as the go-to tool for workflow automation and orchestration. Its user-friendly interface and scalability have driven a 35% surge in adoption among data engineers in the past year.
10. MLflow: Model Management and Experiment Tracking
MLflow streamlines the machine learning lifecycle, offering tools for experiment tracking, model packaging, and deployment. Over 60% of ML engineers use MLflow for its integration capabilities and ease of use in production environments.
11. Docker and Kubernetes: Reproducibility and Scalability
Containerization with Docker and orchestration via Kubernetes ensure that data science applications run consistently across environments. These tools are now standard for deploying models and scaling data-driven services in production.
12. Emerging Contenders: Streamlit and More
Streamlit: Rapidly build and deploy interactive data apps with minimal code, gaining popularity for internal dashboards and quick prototypes.
Redash: SQL-based visualization and dashboarding tool, ideal for teams needing quick insights from databases.
Kibana: Real-time data exploration and monitoring, especially for log analytics and anomaly detection.
Conclusion: The Open-Source Advantage in 2025
Open-source tools continue to drive innovation in data science, making advanced analytics accessible, scalable, and collaborative. Mastery of these tools is not just a technical advantage—it’s essential for staying competitive in a rapidly evolving field. Whether you’re a beginner or a seasoned professional, leveraging this ecosystem will unlock new possibilities and accelerate your journey from raw data to actionable insight.
The future of data science is open, and in 2025, these tools are your ticket to building smarter, faster, and more impactful solutions.
#python#r#rstudio#jupyternotebook#jupyterlab#apachespark#tensorflow#pytorch#plotly#d3js#apachesuperset#pandas#scikitlearn#apacheairflow#mlflow#docker#kubernetes#streamlit#redash#kibana#nschool academy#datascience
0 notes
Text
Machine Learning Project Ideas for Beginners

Machine Learning (ML) is no longer something linked to the future; it is nowadays innovating and reshaping every industry, from digital marketing in healthcare to automobiles. If the thought of implementing data and algorithms trials excites you, then learning Machine Learning is the most exciting thing you can embark on. But where does one go after the basics? That answer is simple- projects!
At TCCI - Tririd Computer Coaching Institute, we believe in learning through doing. Our Machine Learning courses in Ahmedabad focus on skill application so that aspiring data scientists and ML engineers can build a strong portfolio. This blog has some exciting Machine Learning project ideas for beginners to help you launch your career along with better search engine visibility.
Why Are Projects Important for an ML Beginner?
Theoretical knowledge is important, but real-learning takes place only in projects. They allow you to:
Apply Concepts: Translate algorithms and theories into tangible solutions.
Build a Portfolio: Showcase your skills to potential employers.
Develop Problem-Solving Skills: Learn to debug, iterate, and overcome challenges.
Understand the ML Workflow: Experience the end-to-end process from data collection to model deployment.
Stay Motivated: See your learning come to life!
Essential Tools for Your First ML Projects
Before you dive into the ideas, ensure you're familiar with these foundational tools:
Python: The most popular language for ML due to its vast libraries.
Jupyter Notebooks: Ideal for experimenting and presenting your code.
Libraries: NumPy (numerical operations), Pandas (data manipulation), Matplotlib/Seaborn (data visualization), Scikit-learn (core ML algorithms). For deep learning, TensorFlow or Keras are key.
Machine Learning Project Ideas for Beginners (with Learning Outcomes)
Here are some accessible project ideas that will teach you core ML concepts:
1. House Price Prediction (Regression)
Concept: Regression (output would be a continuous value).
Idea: Predict house prices based on given features, for instance, square footage, number of bedrooms, location, etc.
What you'll learn: Loading and cleaning data, EDA, feature engineering, and either linear regression or decision tree regression, followed by model evaluation with MAE, MSE, and R-squared.
Dataset: There are so many public house price datasets set available on Kaggle (e.g., Boston Housing, Ames Housing).
2. Iris Flower Classification (Classification)
Concept: Classification (predicting a categorical label).
Idea: Classify organisms among three types of Iris (setosa, versicolor, and virginica) based on sepal and petal measurements.
What you'll learn: Some basic data analysis and classification algorithms (Logistic Regression, K-Nearest Neighbors, Support Vector Machines, Decision Trees), code toward confusion matrix and accuracy score.
Dataset: It happens to be a classical dataset directly available inside Scikit-learn.
3. Spam Email Detector (Natural Language Processing - NLP)
Concept: Text Classification, NLP.
Idea: Create a model capable of classifying emails into "spam" versus "ham" (not spam).
What you'll learn: Text preprocessing techniques such as tokenization, stemming/lemmatization, stop-word removal; feature extraction from text, e.g., Bag-of-Words or TF-IDF; classification using Naive Bayes or SVM.
Dataset: The UCI Machine Learning Repository contains a few spam datasets.
4. Customer Churn Prediction (Classification)
Concept: Classification, Predictive Analytics.
Idea: Predict whether a customer will stop using a service (churn) given the usage pattern and demographics.
What you'll learn: Handling imbalanced datasets (since churn is usually rare), feature importance, applying classification algorithms (such as Random Forest or Gradient Boosting), measuring precision, recall, and F1-score.
Dataset: Several telecom-or banking-related churn datasets are available on Kaggle.
5. Movie Recommender System (Basic Collaborative Filtering)
Concept: Recommender Systems, Unsupervised Learning (for some parts) or Collaborative Filtering.
Idea: Recommend movies to a user based on their past ratings or ratings from similar users.
What you'll learn: Matrix factorization, user-item interaction data, basic collaborative filtering techniques, evaluating recommendations.
Dataset: MovieLens datasets (small or 100k version) are excellent for this.
Tips for Success with Your ML Projects
Start Small: Do not endeavor to build the Google AI in your Very First Project. Instead focus on grasping core concepts.
Understand Your Data: Spend most of your time cleaning it or performing exploratory data analysis. Garbage in, garbage out, as the data thinkers would say.
Reputable Resources: Use tutorials, online courses, and documentation (say, Scikit-learn docs).
Join Communities: Stay involved with fellow learners in forums like Kaggle or Stack Overflow or in local meetups.
Document Your Work: Comment your code and use a README for your GitHub repository describing your procedure and conclusions.
Embrace Failure: Every error is an opportunity to learn.
How TCCI - Tririd Computer Coaching Institute Can Help
Venturing into Machine Learning can be challenging and fulfilling at the same time. At TCCI, our programs in Machine Learning courses in Ahmedabad are created for beginners and aspiring professionals, in which we impart:
A Well-Defined Structure: Starting from basics of Python to various advanced ML algorithms.
Hands-On Training: Guided projects will allow you to build your portfolio, step by-step.
An Expert Mentor: Work under the guidance of full-time data scientists and ML engineers.
Real-World Case Studies: Learn about the application of ML in various industrial scenarios.
If you are considering joining a comprehensive computer classes in Ahmedabad to start a career in data science or want to pursue computer training for further specialization in Machine Learning, TCCI is the place to be.
Are You Ready to Build Your First Machine Learning Project?
The most effective way to learn Machine Learning is to apply it. Try out these beginner-friendly projects and watch your skills expand.
Contact us
Location: Bopal & Iskcon-Ambli in Ahmedabad, Gujarat
Call now on +91 9825618292
Visit Our Website: http://tccicomputercoaching.com/
0 notes
Text
Behind the Scenes with Artificial Intelligence Developer
The wizardry of artificial intelligence prefers to conceal the attention to detail that occurs backstage. As the commoner sees sophisticated AI at work,near-human conversationalists, guess-my-intent recommendation software, or image classification software that recognizes objects at a glance,the real alchemy occurs in the day-in, day-out task of an artificial intelligence creator.
The Morning Routine: Data Sleuthing
The last day typically begins with data exploration. An artificial intelligence developers arrives at raw data in the same way that a detective does when he is at a crime scene. Numbers, patterns, and outliers all have secrets behind them that aren't obvious yet. Data cleaning and preprocessing consume most of the time,typically 70-80% of any AI project.
This phase includes the identification of missing values, duplication, and outliers that could skew the results. The concrete data point in this case is a decision the AI developer must make as to whether it is indeed out of the norm or not an outlier. These kinds of decisions will cascade throughout the entire project and impact model performance and accuracy.
Model Architecture: The Digital Engineering Art
Constructing an AI model is more of architectural design than typical programming. The builder of artificial intelligence needs to choose from several diverse architectures of neural networks that suit the solution of distinct problems. Convolutional networks are suited for image recognition, while recurrent networks are suited for sequential data like text or time series.
It is an exercise of endless experimentation. Hyperparameter tuning,tweaking the learning rate, batch size, layer count, and activation functions,requires technical skills and intuition. Minor adjustments can lead to colossus-like leaps in performance, and thus this stage is tough but fulfilling.
Training: The Patience Game
Training an AI model tests patience like very few technical ventures. A coder waits for hours, days, or even weeks for models to converge. GPUs now have accelerated the process dramatically, but computation-hungry models consume lots of computation time and resources.
During training, the programmer attempts to monitor such measures as loss curves and indices of accuracy for overfitting or underfitting signs. These are tuned and fine-tuned by the programmer based on these measures, at times starting anew entirely when initial methods don't work. This tradeoff process requires technical skill as well as emotional resilience.
The Debugging Maze
Debugging is a unique challenge when AI models misbehave. Whereas bugs in traditional software take the form of clear-cut error messages, AI bugs show up as esoteric performance deviations or curious patterns of behavior. An artificial intelligence designer must become an electronic psychiatrist, trying to understand why a given model is choosing something.
Methods such as gradient visualization, attention mapping, and feature importance analysis shed light on the model's decision-making. Occasionally the problem is with the data itself,skewed training instances or lacking diversity in the dataset. Other times it is architecture decisions or training practices.
Deployment: From Lab to Real World
Shifting into production also has issues. An AI developer must worry about inference time, memory consumption, and scalability. A model that is looking fabulous on a high-end development machine might disappoint in a low-budget production environment.
Optimization is of the highest priority. Techniques like model quantization, pruning, and knowledge distillation minimize model sizes with no performance sacrifice. The AI engineer is forced to make difficult trade-offs between accuracy and real-world limitations, usually getting in their way badly.
Monitoring and Maintenance
Deploying an AI model into production is merely the beginning, and not the final, effort for the developer of artificial intelligence. Data in the real world naturally drifts away from training data, resulting in concept drift,gradual deterioration in the performance of a model over time.
Continual monitoring involves the tracking of main performance metrics, checking prediction confidence scores, and flagging deviant patterns. When performance falls to below satisfactory levels, the developer must diagnose reasons and perform repairs, in the mode of retraining, model updates, or structural changes.
The Collaborative Ecosystem
New AI technology doesn't often happen in isolation. An artificial intelligence developer collaborates with data scientists, subject matter experts, product managers, and DevOps engineers. They all have various ideas and requirements that shape the solution.
Communication is as crucial as technical know-how. Simplifying advanced AI jargon to stakeholders who are not technologists requires infinite patience and imagination. The technical development team must bridge business needs to technical specifications and address the gap in expectations of what can and cannot be done using AI.
Keeping Up with an Evolving Discipline
The area of AI continues developing at a faster rate with fresh paradigms, approaches, and research articles emerging daily. The AI programmer should have time to continue learning, test new approaches, and learn from the achievements in the area.
It is this commitment to continuous learning that distinguishes great AI programmers from the stragglers. The work is a lot more concerned with curiosity, experimentation, and iteration than with following best practices.
Part of the AI creator's job is to marry technical astuteness with creative problem-solving ability, balancing analytical thinking with intuitive understanding of complex mechanisms. Successful AI implementation "conceals" within it thousands of hours of painstaking work, taking raw data and turning them into intelligent solutions that forge our digital destiny.
0 notes
Text
Unlocking Insights: Text Analytics in NLP with Azure - Ansi ByteCode LLP
Discover how Text Analytics in NLP with Azure. Learn tokenization, sentiment analysis, entity recognition to analyze text efficiently. Please visit:- https://ansibytecode.com/text-analytics-in-nlp-with-azure/
0 notes
Text
SNOOP : the new AI tool to revolutionize audiovisual archives research
The French National Audiovisual Center (INA) developed in collaboration with the French Institute for Research in Computer Science and Automation (INRAE) a visual search engine which can explore millions of images and videos thanks to Artificial Intelligence. This new tool allows the user to identify rapidly objects, faces, and even concepts.
The project was imagined twenty years ago as AI was starting to be developed. It was created with the help of PhD student from INA research department and researchers from the research department of INRAE. The original goal was to quickly identify the diffusion of INA archives to make copyright management effective. But soon enough they understood the potential of this tool and decided to expand its usage to facial and object recognition. After some improvements and optimizations, the tool was made accessible to researchers five years ago on the database Gallica in collaboration of INA and the French National Library (BNF).
How does it work?
SNOOP does not function with textual metadata. It had to be trained to what we call machine learning. The team of researchers gathered a very big collection of documents in a server, which AI SNOOP has described using a network of neurons. This network of neurons is trained through a comparative algorithm which allows SNOOP to make links between the millions of documents. Then it finds their equivalent in the human language. Those links are transformed in visuals descriptors which are themselves translated in mathematical vectors. Those vectors are collected in a database and indexed in a search engine which are then used to identify the similarities between documents. Of course, since the model is based on machine learning, SNOOP will become more precise in the creation of links as new documents will be learned and indexed in the database and search engine. That is why the researchers based the improvement of AI SNOOP on the collaboration of the users, because the more results it has the more concepts the machine can learn. The users have access to a “basket” classification of their searches which then promote more precise results in the long term. This system of research is called RFLooper for relevant feedback, it is a visual based method of research that surpasses simple text research which can be limiting for research on audiovisual documents. Also, as the results of the research appears, the users can see green or red dots which is a guarantee of transparency. The green dot means that the result is up to 50% precise whereas the red dot means that the result is less than 50% accurate. We could say that machine learning is based on human experience and human intelligence.
The Future of AI SNOOP
SNOOP has a great potential in research, to help researchers build a large collection of data on a very precise subject. It was nearly impossible to be complete in a visual analysis but now SNOOP can do the work. For example, the test was already made for a study. SNOOP was able to extract every image which showed phones or tablets. SNOOP could be also used in a commercial way, because some clients are often look for very specific images or objects which are not always indexed in a documentary record. However, as SNOOP seems like a very convenient tool, it must be used in a careful way to not erase the work of archivists nor become a new irreplaceable AI system which consumes a lot of energy.
0 notes
Text
What to Expect from an Artificial Intelligence Classroom Course in Bengaluru: Curriculum, Tools & Career Scope
In the heart of India’s Silicon Valley, Bengaluru stands as a thriving hub for technology, innovation, and future-ready education. Among the many tech programs gaining traction, one stands out as a gateway to tomorrow’s digital careers—the Artificial Intelligence Classroom Course in Bengaluru.
With the global demand for AI professionals skyrocketing, classroom-based programs offer a structured, interactive, and hands-on way to acquire skills in artificial intelligence, machine learning, and data science. This blog will walk you through what to expect from such a course, including the typical curriculum, industry-standard tools, and the exciting career opportunities that wait after completion.
Why Choose a Classroom Course for AI in Bengaluru?
While online courses offer convenience, a classroom-based learning experience brings structure, discipline, and direct mentorship that many learners find invaluable. Bengaluru, being the IT capital of India, offers an ideal ecosystem for AI education. With top AI companies, research labs, and startups located nearby, classroom learning often comes with better networking opportunities, on-ground internships, and real-time collaboration.
Moreover, the interactive environment of a classroom promotes peer-to-peer learning, immediate doubt resolution, and better preparation for real-world challenges.
Who Should Enroll in an Artificial Intelligence Classroom Course in Bengaluru?
The Artificial Intelligence Classroom Course in Bengaluru is designed for:
Fresh graduates from engineering, mathematics, statistics, or computer science backgrounds.
Working professionals looking to switch careers or upskill in AI.
Entrepreneurs aiming to leverage AI for their tech startups.
Research enthusiasts interested in neural networks, deep learning, and intelligent automation.
Whether you're a beginner or a mid-career tech professional, these courses are often structured to accommodate different experience levels.
What Does the Curriculum Typically Include?
The curriculum of an Artificial Intelligence Classroom Course in Bengaluru is carefully crafted to balance theoretical concepts with real-world applications. While every institute may offer a slightly different structure, most comprehensive programs include the following core modules:
1. Introduction to Artificial Intelligence
History and evolution of AI
Types of AI (Narrow, General, Super AI)
Applications across industries (Healthcare, Finance, Retail, etc.)
2. Python for AI
Python basics
Libraries: NumPy, Pandas, Matplotlib
Data preprocessing and visualization
3. Mathematics and Statistics for AI
Linear Algebra, Probability, and Calculus
Statistical inference
Hypothesis testing
4. Machine Learning (ML)
Supervised vs. Unsupervised Learning
Algorithms: Linear Regression, Decision Trees, Random Forest, SVM
Model evaluation and tuning
5. Deep Learning
Neural networks basics
Convolutional Neural Networks (CNNs)
Recurrent Neural Networks (RNNs)
Transformers and Attention Mechanisms
6. Natural Language Processing (NLP)
Text preprocessing
Word embeddings
Sentiment analysis
Chatbot development
7. Computer Vision
Image classification
Object detection
Real-time video analysis
8. AI Ethics and Responsible AI
Bias in AI
Data privacy
Ethical deployment of AI systems
9. Capstone Projects and Case Studies
Real-world projects in healthcare, e-commerce, finance, or autonomous systems.
Team collaborations to simulate industry-like environments.
This curriculum ensures that learners not only understand the foundational theory but also gain the technical know-how to build deployable AI models.
Classroom Environment: What Makes It Unique?
In Bengaluru, the classroom experience is enriched by:
Experienced faculty: Often working professionals or researchers from top tech companies.
Hands-on labs: In-person project work, hackathons, and weekend workshops.
Peer collaboration: Group assignments and presentations simulate workplace dynamics.
Industry exposure: Guest lectures from AI professionals, startup founders, and data scientists.
Placement support: Resume building, mock interviews, and connections with hiring partners.
Moreover, institutes like the Boston Institute of Analytics (BIA) in Bengaluru offer a balanced mix of theory and practice, ensuring learners are ready for the workforce immediately after completion.
Career Scope After Completion
One of the biggest draws of enrolling in an Artificial Intelligence Classroom Course in Bengaluru is the booming career potential. With Bengaluru being home to top companies like Infosys, Wipro, IBM, and Amazon, along with a growing startup culture, job opportunities are vast.
Here are some in-demand roles you can pursue post-course:
1. AI Engineer
Develop intelligent systems and deploy machine learning models at scale.
2. Machine Learning Engineer
Design and optimize ML algorithms for real-time applications.
3. Data Scientist
Use statistical techniques to interpret complex datasets and drive insights.
4. Deep Learning Engineer
Specialize in neural networks for image, voice, or text applications.
5. NLP Engineer
Build voice assistants, chatbots, and text classification tools.
6. Computer Vision Engineer
Work on facial recognition, object detection, and image analytics.
7. AI Product Manager
Oversee the development and strategy behind AI-powered products.
8. AI Research Associate
Contribute to academic or industrial AI research projects.
Top recruiters in Bengaluru include:
Google AI India
Microsoft Research
Amazon India
Flipkart
TCS
Fractal Analytics
Mu Sigma
Boston Institute of Analytics alumni partners
Entry-level salaries in Bengaluru range from ₹6 LPA to ₹10 LPA for certified AI professionals, with mid-senior roles offering packages upwards of ₹25 LPA depending on experience and specialization.
Final Thoughts
The world is embracing artificial intelligence at an unprecedented pace, and Bengaluru is at the epicenter of this digital transformation in India. If you're looking to break into this high-demand field, enrolling in an Artificial Intelligence Classroom Course in Bengaluru is a powerful first step.
From a robust curriculum and access to modern AI tools to hands-on training and strong job placement support, classroom courses in Bengaluru offer an unmatched learning experience. Whether you're aiming to become a data scientist, AI engineer, or research specialist, the city provides the environment, opportunities, and mentorship to turn your aspirations into reality.
Ready to start your AI journey? Choose a classroom course in Bengaluru and empower yourself with skills that are shaping the future.
#Best Data Science Courses in Bengaluru#Artificial Intelligence Course in Bengaluru#Data Scientist Course in Bengaluru#Machine Learning Course in Bengaluru
0 notes
Text
Leading NLP Development Company for Advanced Language Solutions
We are a trusted NLP development company offering custom natural language processing solutions to help businesses unlock the full potential of their text and voice data. Our services include chatbot development, sentiment analysis, text classification, named entity recognition, and more. Whether you’re looking to automate customer support, analyze user feedback, or build intelligent search features, our expert team delivers high-performance NLP applications tailored to your goals.
Using advanced AI and machine learning models, we turn unstructured data into actionable insights, helping you improve efficiency, decision-making, and user experience. Partner with us to build scalable, secure, and innovative NLP solutions that give your business a strategic edge in today’s data-driven world.
0 notes
Text
What Is the Difference Between AI and Generative AI
Artificial Intelligence (AI) is reshaping industries, powering everything from chatbots and voice assistants to fraud detection and self-driving cars. But in recent years, a powerful subfield of AI has gained momentum: Generative AI.

While both terms are often used interchangeably, there’s a clear distinction between AI and Generative AI in terms of function, purpose, and output.
In this article, we’ll explore what AI is, what Generative AI is, and the key differences between them, along with real-world examples.
What Is Artificial Intelligence (AI)?
Artificial Intelligence (AI) is a broad field of computer science focused on creating systems that can perform tasks that normally require human intelligence.
These tasks include:
Learning from data (Machine Learning)
Recognizing patterns (Computer Vision)
Understanding language (Natural Language Processing)
Making decisions (Expert Systems)
Examples of AI:
Google Maps using real-time traffic predictions
Siri or Alexa understanding voice commands
Netflix recommending movies based on viewing history
Spam filters in your email
What Is Generative AI?
Generative AI is a subset of AI that focuses on creating new content, such as text, images, code, music, and even video. Unlike traditional AI, which is designed to analyze or classify existing data, Generative AI learns from existing data to generate something new and original.
Examples of Generative AI:
ChatGPT generating human-like conversations
DALL·E creating images from text prompts
GitHub Copilot writing programming code
Runway or Sora by OpenAI generating video content
Key Differences Between AI and Generative AI
Feature
AI (Artificial Intelligence)
Generative AI
Definition
Broad field of simulating human intelligence
Subfield focused on creating new content
Goal
Automate decision-making, classification, tasks
Generate text, images, music, or code
Examples
Fraud detection, recommendation engines, search
ChatGPT, DALL·E, Bard, Claude
Output Type
Predictions, classifications, decisions
Creative or synthetic content
Learning Type
Supervised or reinforcement learning
Often uses unsupervised or transformer-based learning
Interaction Style
Analyzes and reacts to input
Responds and generates novel outputs
How Are They Connected?
Generative AI is a subset of AI. Think of AI as the umbrella, and Generative AI as a specialized branch under it.
While all Generative AI is AI, not all AI is generative.
AI = Make decisions, predictions, analyze
Generative AI = Create new data, content, or responses
Real-World Applications
AI in Business:
Chatbots for customer service
Predictive analytics in marketing
Fraud detection in finance
Personalized shopping experiences
Generative AI in Business:
Writing marketing copy
Creating social media graphics
Generating product descriptions
Assisting developers with code generation
Is Generative AI More Risky?
Generative AI comes with unique challenges such as:
Misinformation (fake news, deepfakes)
Bias and hallucination in generated content
Copyright concerns (generated images, music)
However, ethical frameworks and safety tools are being developed to ensure responsible use of Generative AI.
Conclusion
So, what is the difference between AI and Generative AI?
AI helps machines think, act, and make decisions like humans.
Generative AI helps machines create like humans—writing text, generating art, or composing music.
Both are revolutionizing how we work, live, and create—but Generative AI is taking automation to a new level by blending creativity with computation.
#ArtificialIntelligence#AI#AIExplained#MachineLearning#AITrends#FutureOfAI#AIinBusiness#AITechnology#generativeai#aivsgenerativeai
0 notes
Text
ChatGPT & Data Science: Your Essential AI Co-Pilot

The rise of ChatGPT and other large language models (LLMs) has sparked countless discussions across every industry. In data science, the conversation is particularly nuanced: Is it a threat? A gimmick? Or a revolutionary tool?
The clearest answer? ChatGPT isn't here to replace data scientists; it's here to empower them, acting as an incredibly versatile co-pilot for almost every stage of a data science project.
Think of it less as an all-knowing oracle and more as an exceptionally knowledgeable, tireless assistant that can brainstorm, explain, code, and even debug. Here's how ChatGPT (and similar LLMs) is transforming data science projects and how you can harness its power:
How ChatGPT Transforms Your Data Science Workflow
Problem Framing & Ideation: Struggling to articulate a business problem into a data science question? ChatGPT can help.
"Given customer churn data, what are 5 actionable data science questions we could ask to reduce churn?"
"Brainstorm hypotheses for why our e-commerce conversion rate dropped last quarter."
"Help me define the scope for a project predicting equipment failure in a manufacturing plant."
Data Exploration & Understanding (EDA): This often tedious phase can be streamlined.
"Write Python code using Pandas to load a CSV and display the first 5 rows, data types, and a summary statistics report."
"Explain what 'multicollinearity' means in the context of a regression model and how to check for it in Python."
"Suggest 3 different types of plots to visualize the relationship between 'age' and 'income' in a dataset, along with the Python code for each."
Feature Engineering & Selection: Creating new, impactful features is key, and ChatGPT can spark ideas.
"Given a transactional dataset with 'purchase_timestamp' and 'product_category', suggest 5 new features I could engineer for a customer segmentation model."
"What are common techniques for handling categorical variables with high cardinality in machine learning, and provide a Python example for one."
Model Selection & Algorithm Explanation: Navigating the vast world of algorithms becomes easier.
"I'm working on a classification problem with imbalanced data. What machine learning algorithms should I consider, and what are their pros and cons for this scenario?"
"Explain how a Random Forest algorithm works in simple terms, as if you're explaining it to a business stakeholder."
Code Generation & Debugging: This is where ChatGPT shines for many data scientists.
"Write a Python function to perform stratified K-Fold cross-validation for a scikit-learn model, ensuring reproducibility."
"I'm getting a 'ValueError: Input contains NaN, infinity or a value too large for dtype('float64')' in my scikit-learn model. What are common reasons for this error, and how can I fix it?"
"Generate boilerplate code for a FastAPI endpoint that takes a JSON payload and returns a prediction from a pre-trained scikit-learn model."
Documentation & Communication: Translating complex technical work into understandable language is vital.
"Write a clear, concise docstring for this Python function that preprocesses text data."
"Draft an executive summary explaining the results of our customer churn prediction model, focusing on business impact rather than technical details."
"Explain the limitations of an XGBoost model in a way that a non-technical manager can understand."
Learning & Skill Development: It's like having a personal tutor at your fingertips.
"Explain the concept of 'bias-variance trade-off' in machine learning with a practical example."
"Give me 5 common data science interview questions about SQL, and provide example answers."
"Create a study plan for learning advanced topics in NLP, including key concepts and recommended libraries."
Important Considerations and Best Practices
While incredibly powerful, remember that ChatGPT is a tool, not a human expert.
Always Verify: Generated code, insights, and especially factual information must always be verified. LLMs can "hallucinate" or provide subtly incorrect information.
Context is King: The quality of the output directly correlates with the quality and specificity of your prompt. Provide clear instructions, examples, and constraints.
Data Privacy is Paramount: NEVER feed sensitive, confidential, or proprietary data into public LLMs. Protecting personal data is not just an ethical imperative but a legal requirement globally. Assume anything you input into a public model may be used for future training or accessible by the provider. For sensitive projects, explore secure, on-premises or private cloud LLM solutions.
Understand the Fundamentals: ChatGPT is an accelerant, not a substitute for foundational knowledge in statistics, machine learning, and programming. You need to understand why a piece of code works or why an an algorithm is chosen to effectively use and debug its outputs.
Iterate and Refine: Don't expect perfect results on the first try. Refine your prompts based on the output you receive.
ChatGPT and its peers are fundamentally changing the daily rhythm of data science. By embracing them as intelligent co-pilots, data scientists can boost their productivity, explore new avenues, and focus their invaluable human creativity and critical thinking on the most complex and impactful challenges. The future of data science is undoubtedly a story of powerful human-AI collaboration.
0 notes