#Python interactive maps
Explore tagged Tumblr posts
Visit Tumblr Blog
Explore Tumblr blogs with no restrictions, modern design and the best experience.
Last Seen Tumblr Blogs





Fun Fact
In Q3 of 2020, 31% of US users access the Tumblr app daily.
Video
youtube
How ChatGPT AI Helped Me Create Maps Effortlessly
1 note
·
View note
Text
Development Update - December 2024

Happy New Year, everyone! We're so excited to be able to start off 2025 with our biggest news yet: we have a planned closed beta launch window of Q1 2026 for Mythaura!
Read on for a recap of 2024, more information about our closed beta period, Ryu expressions, January astrology, and Ko-fi Winter Quarter reward concepts!
2024 Year in Review
Creative
This year, the creative team worked on adding new features, introducing imaginative designs, and refining lore/worldbuilding to enrich the overall experience.
New Beasts and Expressions: All 9 beast expression bases completed for both young and adult with finalized specials for Dragons, Unicorns, Griffins, Hippogriffs, and Ryu.
Mutations, Supers and Specials: Introduced the Celestial mutation as well as new Specials Banding & Merle, and the Super Prismatic.
New Artist: Welcomed Sourdeer to the creative team.
Collaboration and Sponsorship: Sponsored several new companions from our Ko-Fi sponsors—Amaru, Inkminks, Somnowl, Torchlight Python, Belligerent Capygora, and the Fruit-Footeded Gecko.
New Colors: Revealed two eye-catching colors, Canyon (a contest winner) and Porphyry (a surprise bonus), giving players even more variety for their Beasts.
Classes and Gear: Unveiled distinct classes, each with its own themed equipment and companions, to provide deeper roleplay and strategic depth.
Items and Worldbuilding: Created a range of new items—from soulshift coins to potions, rations, and over a dozen fishable species—enriching Mythaura’s economy and interactions.
Star Signs & Astrology: Continued to elaborate on the zodiac-like system, connecting each Beast’s fate to celestial alignments.
Questing & Story Outline: Laid the groundwork for the intro quest pipeline and overarching narrative, ensuring that players’ journey unfolds with purposeful progression.

Code
This year, the development team worked diligently on refining and expanding the codebase to support new features, enhance performance, and improve gameplay experiences. A total 429,000 lines of code changed across both the backend and frontend, reflecting:
New Features: Implementation of systems like skill trees, inventory management, community forums, elite enemies, npc & quest systems, and advanced customization options for Beasts.
Optimizations and Refactoring: Significant cleanup and streamlining of backend systems, such as game state management, passive effects, damage algorithms, and map data structures, ensuring better performance and maintainability.
Map Builder: a tool that allows us to build bespoke maps
Regular updates to ensure compatibility with modern tools and frameworks.
It’s worth noting that line changes alone don’t capture the complexity of programming work. For example:
A single line of efficient code can replace multiple lines of legacy logic.
Optimizing backend systems often involves removing redundant or outdated code without adding new functionality.
Things like added dependencies can add many lines of code without adding much bespoke functionality.

Mythaura Closed Beta

We are so beyond excited to share this information with you here first: Mythaura closed beta is targeted for Q1 2026!
On behalf of the whole team, thank you all so, so much for all of the support for Mythaura over the years. Whether you’ve been around since the Patreon days or joined us after Koa and Sark took over…it’s your support that has gotten this project to where it is. We are so grateful for the faith and trust placed in us, and the opportunity to create something we hope people will truly love and enjoy. This has truly been a collaborative effort with you and we are constantly humbled by all of the thoughtful insights, engaging discussions, and great ideas to come out of this amazing community of supporters.
So: thank you again, it’s been an emotional and amazing journey for the dev team and we’re delighted to join you on your journeys through Mythaura.
Miyazaki Full-Time
Hey everyone, Koa here!
We’re thrilled to share some news about Mythaura’s development! Starting in 2025, Miya will be officially dedicating herself full-time to Mythaura. Her focus will be on bringing even more depth and wonder to the world of Mythaura through content creation, worldbuilding, and building up the brand. It’s a huge step forward, and we’re so excited for the impact her passion and creativity will have on the project!
In addition, I’ve secured 4-day weeks and will be working full-time each Friday to dive deeper into development. This extra push is going to allow us to keep moving steadily forward on both the art and code fronts, and with Miya’s expanded role, the next year of development is looking really promising.
Thank you all for being here and supporting Mythaura every step of the way. We can’t wait to share more as things progress!
Closed Beta FAQ
In the interest of keeping all of the information about our Closed Beta in one place and update as needed, we have added as much information as possible to the FAQ page.
If you have any questions that you can think of, please feel free to reach out to us through our contact form or on Discord!
Winter Quarter (2025) Concepts
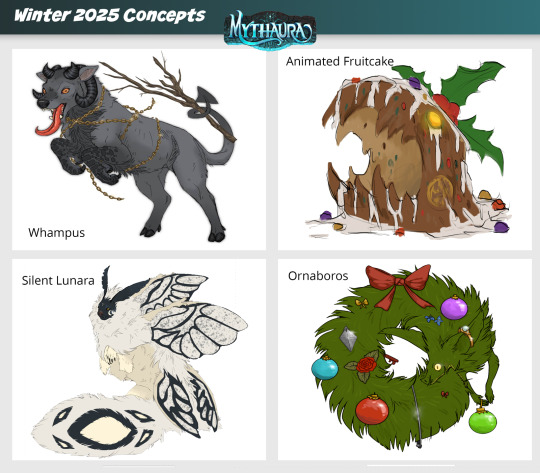

It’s the first day of Winter Quarter 2025, which means we’ve got new Quarterly Rewards for Sponsors to vote on on our Ko-fi page!
Which concepts would you like to see made into official site items? Sponsors of Bronze level or higher have a vote in deciding. Please check out the Companion post and the Glamour post on Ko-fi to cast your vote for the winning concepts!
Votes must be posted by January 29, 2025 at 11:59pm PDT in order to be considered.
All Fall 2024 Rewards are now listed in our Ko-fi Shop for individual purchase for all Sponsor levels at $5 USD flat rate per unit. As a reminder, please remember that no more than 3 units of any given item can be purchased. If you purchase more than 3 units of any given item, your entire purchase will be refunded and you will need to place your order again, this time with no more than 3 units of any given item.
Fall 2024 Glamour: Diaphonized Ryu
Fall 2024 Companion: Inhabited Skull
Fall 2024 Solid Gold Glamour: Hippogriff (Young)
NOTE: As covered in the FAQ, the Ko-fi shop will be closing at the end of the year. These will be the last Winter Quarter rewards for Mythaura!
New Super: Zebra

We've added our first new Super to the site since last year's Prismatic: Zebra, which has a chance to occur when parents have the Wildebeest and Banding Specials!
Zebra is now live in our Beast Creator--we're excited to see what you all create with it!
New Expressions: Ryu

The Water-element Ryu has had expressions completed for both the adult and young models. Expressions have been a huge, time-intensive project for the art team to undertake, but the result is always worth it!
Mythauran Astrology: January
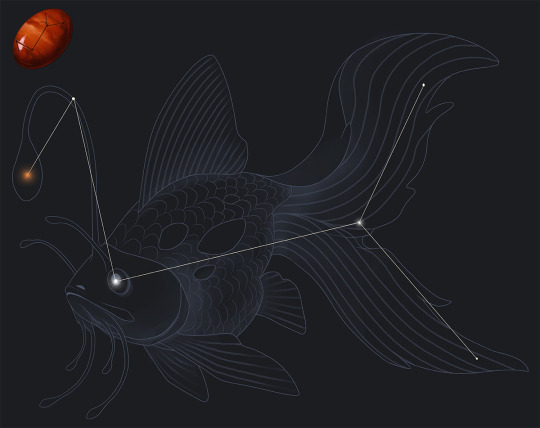
The month of January is referred to as Hearth's Embrace, representing the fireplaces kept lit for the entirety of the coldest month of the year. This month is also associated with the constellation of the Glassblower and the carnelian stone.
Mythaura v0.35
Refactored "Beast Parties" into "User Parties," allowing non-beast entities like NPCs to be added to your party. NPCs added to your party will follow you in the overworld, cannot be made your leader, and will make their own decisions in combat.
Checkpoint floor functionality ironed out, allowing pre-built maps to appear at specific floor intervals.
The ability to set spawn and end coordinates in the map builder was added to allow staff to build checkpoint floors.
Various cleanups and refactors to improve performance and reduce the number of queries needed to run certain operations.
Added location events, which power interactable objects in the overworld, such as a lootable chest or a pickable bush.
Thank You!
Thanks for sticking through to the end of the post, we always look forward to sharing our month's work with all of you--thank you for taking the time to read. We'll see you around the Discord.
#mythaura#indie game#indie game dev#game dev#dev update#unicorn#dragon#griffin#peryton#ryu#basilisk#quetzal#hippogriff#kirin#petsite#pet site#virtual pet site#closed beta launch#flight rising#neopets
93 notes
·
View notes
Text

yours truly has had an #illness which means I've had time for a proof of concept of an idea the Pathologic Modding Discord has had floating around for a while... the Bound Location Randomizer. Every (*accessible) major NPC moved to a randomly selected house, with map markers and executor locations updated to match. Ready-to-install Script and Scene files are automatically generated via Python. It doesn't handle dialogue, quest-based visits, or the trigger that makes Viktor interactable... yet, but that won't stop me.
Join me in one hour (1pm EST) at https://twitch.tv/rathologic as I test the first few days of a Changeling route playthrough with Bound locations randomized :-)


46 notes
·
View notes
Text
Things I tell myself while writing interactive fiction:
Don't I already have a variable for this?
Do I want to do this properly, or am I just going to copy paste this sentence four times and make minor changes to each version?
I don't drink, so why does this look like I coded it drunk?
Why is everything off by six spaces exactly?
What even is English?
What even is python?
What even is me?
Oh. That error is back. And it brought a friend. A new, unique, unknown error.
*drawing mind maps* So, the players might have met this character once before, twice before, or four times before. They might also be enemies with this character, married to this character, or the character may be dead and haunting them as a vengeful spirit. This is for one line of dialogue.
But what if the player's character is from Lithuania?
106 notes
·
View notes
Text
The making of the SF family swim map!
This is a technical blog post showcasing a project (swim.joyfulparentingsf.com) made by Double Union members! Written by Ruth Grace Wong.
Emeline (a good friend and fellow DU member) and I love swimming with our kids. The kids love it too, and they always eat really well after swimming! But for a long time we were frustrated about SF Rec & Park's swim schedules. Say today is Wednesday and you want to swim, you have to click on each pool's website and download their PDF schedule to check where and when family swim is available, and the schedules change every few months.
Emeline painstakingly downloaded all the PDFs and manually collated the schedules onto our Joyful Parenting SF blog. The way Rec and Parks structure their schedule assumes that swimmers go to their closest pool, and only need the hours for that particular pool. But we found that this was different from how many families, especially families with young children, research swim times. Often, they have a time where they can go swimming, and they are willing to go to different swimming pools. Often, they’re searching for a place to swim at the last minute. Schedules hence need to allow families to search which pools are open at what time for family swimming. Initially, we extracted family swim times manually from each pool’s pdf schedule and listed them in a blog post. It wasn't particularly user friendly, so she made an interactive map using Felt, where you could select the time period (e.g. Saturday Afternoon) and see which pool offered family swim around that time.
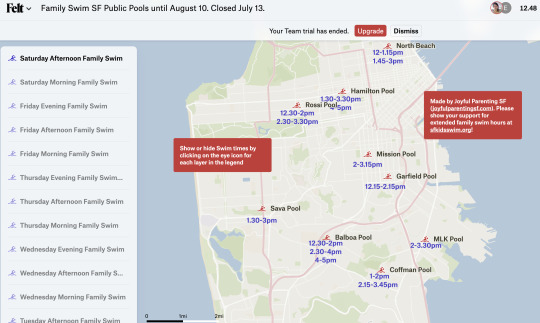
But the schedules change every couple of months, and it got to be too much to be manually updating the map or the blog post. Still, we wanted some way to be able to easily see when and where we could swim with the kids.
Just as we were burning out on manually updating the list, SF Rec & Park released a new Activity Search API, where you can query scheduled activities once their staff have manually entered them into the system. I wrote a Python script to pull Family Swim, and quickly realized that I had to also account for Parent and Child swim (family swim where the parents must be in the water with the kids), and other versions of this such as "Parent / Child Swim". Additionally, the data was not consistent – sometimes the scheduled activities were stored as sub activities, and I had to query the sub activity IDs to find the scheduled times. Finally, some pools (Balboa and Hamilton) have what we call "secret swim", where if the pool is split into a big and small pool, and there is Lap Swim scheduled with nothing else at the same time, the small pool can be used for family swim. So I also pulled all of the lap swim entries for these pools and all other scheduled activities at the pool so I could cross reference and see when secret family swim was available.
We've also seen occasional issues where there is a swim scheduled in the Activity Search, but it's a data entry error and the scheduled swim is not actually available, or there's a Parent Child Swim scheduled during a lap swim (but not all of the lap swims so I can't automatically detect it!) that hasn't been entered into the Activity Search at all. Our friends at SF Kids Swim have been working with SF Rec & Park to advocate for the release of the API, help correct data errors, and ask if there is any opportunity for process improvement.
At the end of the summer, Felt raised their non profit rate from $100 a year to $250 a year. We needed to pay in order to use their API to automatically update the map, but we weren't able to raise enough money to cover the higher rate. Luckily, my husband Robin is a full stack engineer specializing in complex frontends such as maps, and he looked for an open source WebGL map library. MapBox is one very popular option, but he ended up going with MapLibre GL because it had a better open source license. He wrote it in Typescript transpiled with Vite, allowing all the map processing work to happen client-side. All I needed to do was output GeoJSON with my Python script.
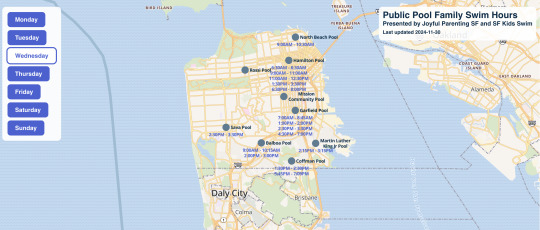
Originally I had been running my script in Replit, but I ended up deciding to switch to Digital Ocean because I wasn't sure how reliably Replit would be able to automatically update the map on a schedule, and I didn't know how stable their pricing would be. My regular server is still running Ubuntu 16, and instead of upgrading it (or trying to get a newer version of Python working on an old server or – god forbid – not using the amazing new Python f strings feature), I decided to spin up a new server on Almalinux 9, which doesn't require as frequent upgrades. I modified my code to automatically push updates into version control and recompile the map when schedule changes were detected, ran it in a daily cron job, and we announced our new map on our blog.
Soon we got a request for it to automatically select the current day of the week, and Robin was able to do it in a jiffy. If you're using it and find an opportunity for improvement, please find me on Twitter at ruthgracewong.
As a working mom, progress on this project was stretched out over nearly half a year. I'm grateful to be able to collaborate with the ever ineffable Emeline, as well as for support from family, friends, and SF Kids Swim. It's super exciting that the swim map is finally out in the world! You can find it at swim.joyfulparentingsf.com.
6 notes
·
View notes
Note
Back again! 8-ish dollars later and I can kinda sorta navigate the files! I've got a question while i experiment with editing text. Do you happen to know where the Twohat version of the epilogue favor tree text is ingame event-wise? (the pre battle stuff after you check their coin), i can only find the Onehat version of the dialogue by just clicking the event triggers on the act 6 map. Sorry if this is a bit involved!

As you can see highlighted beautifully here, there are multiple "pages" of events per event tile!
In this case, the third one is for the loop battle. You can see it has a switch checked off "0275 LOOP FIGHT TIME autorun", meaning that this event page only plays if this specific switch is on.
As for where it's flipped - you do need to do some digging, sadly, as far as I know the only way to check what switch is flipped where is like, a custom python script somebody made once? But this switch in particular is set to on in Common Event 0213 (Loop'sSilverCoin), if you use the coin near the favor tree.
The other most common type of event switch is for repeated interaction - in that case, the event page's condition will be if "Self Switch A" is on. Marked here as "Slb.schalter" bcuz my program is in german. I could've set it to english but i'm lazy sorry. These switches are native to base RPGmaker and are intended to be used exactly for differentiating event pages. When the first event page has run, that page will flip Self Switch A, and then Switch A will activate the second page. You can do this with Self Switch B and C and D as well.
ISAT also makes heavy use of a plugin that gives you "Self Var EventCheck", which is a variable (or switch, if it's Self Switch) that is unique to every event tile and individually counts how often it's occured. You can image this is the easiest method to set the variations in first/second/third/whatever many times an event has been seen.
A lot of information on that can actually be found in the github's wiki section! Gold has been less lazy adding information than I have been, lmao.
(this is a link to the wiki section)
I hope you have fun!! Feel free to reach out via more asks or even DM me if you have further questions!!
11 notes
·
View notes
Note
can you tell me more about draco and the northern oracle 🙏 i wanted to dive more into this when i saw your post about heavenly oracles but all that came up when i searched for the dragon was ladon
Ah yes, I know why that is.
Multiple myths can correlate to the same constellation. Capricorn, for instance, could be this one legendary seagoat who was memorialized for his bravery as a constellation OR it could be a representation of Pan's escape from Typhon as a seagoat.
The Draco constellation is like this - most will say it's to symbolize Ladon, the dragon who guards Hera's golden apples, while others will say the constellation itself is the earth-dragon of Koios's oracle.
Obviously, I think we all know which one I prefer lol
and!!! um!!! maybe I can tell you more, we'll see XD
So. I am of the mind that Draco and Python both coexisted with their respective Titan counterparts - Koios and Phoebe. They both witnessed the Titan War, and while Draco retreated inside Koios's oracle and kinda shut it down to a degree to keep it from falling into the gods' hands (because remember - Draco is on Koios's side here. He would do everything he could to keep it from Olympus.), Python remained neutral with Phoebe.
That is. Until he grew greedy. And wanted Delphi's power for himself. And then got slammed by her grandson lmao
BUT THIS ISN'T ABOUT HIM :D IT'S DRACO TIME :D
I imagine Draco to be kinda an icy-blue and white dragon, resembling the north but also the sky, because that's where he and Koios get their prophecies from (and I see Python as purple & green hence the Earth and all that hehe. Colors!!!).
AH I CAN SHARE MY HEADCANON ON WHERE I THINK THE ORACLE IS AT NOW :D
so context: Koios's oracle is to the North, but not like. the North Pole. The Ancient Greeks weren't aware of such a thing - sure, they believe Koios was the Northern pillar, but not like the North Pole.
This is important to know because Hyperborea, Apollo's eternal spring vacation suit, is located just below where Koios's oracle is!
SO IF WE TAKE OUT MY MAP HERE (yes I have a map for this. i have ADHD what do you expect?)
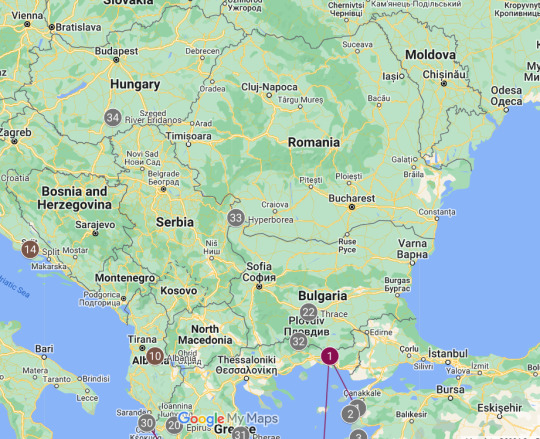
The Underworld River Eridanos runs through Hyperborea, as seen by the 34 Gray marker on the map^
Gray marker 32 is the location of the Rhipaion Mountains, where Boreas lives. This is the southernmost border of Hyperborea!
Originally I thought Eridanos was like. the Northern border - but no! Sources say that it's the River Oceanus instead.
But the thing is. For this river to be the northern border, then that means Hyperborea takes up like. Bulgaria to Poland. Lithuania. Till it hits the Baltic Sea, at least.
(Wait. oh my gosh...that's how Freypollo happens...ohmygosh EVERYONE I'VE FIGURED IT OUT!
ahem. saves for later <-ask me about it. please.)
anyway. SO THEREFORE HYPERBOREA IS LIKE. WHERE GRAY 33 IS. BUT ALSO FROM GRAY 32 AND UP.
Apollo really just went "See this? It's all mine now." lmaooo XD
that or Boreas was a really good boyfriend <-headcanon i could share too if anybody's curious hehe
BACK TO THE ORACLE NOW.
Delphi is the center of the world to the Ancient Greeks, so if we go North, Koios's would be right about...
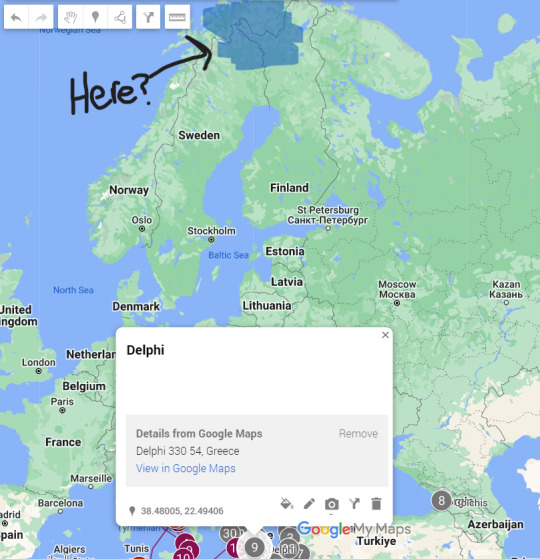
Koios has friends in the Norse pantheon confirmed?
guys I'm just spitballing right now. but it makes sense too.
Ancient Greece was aware of the Norse, btw! and, funnily enough, they could have mythologicalized them as...the Hyperboreans.
Freypollo happened y'all it's all right here
And I'm not making that up! It's historically agreed upon that the Hyperboreans in mythology were probably mythological avatars of the Norse! Greece rarely interacted with them, but they still knew of the other's existence. In fact, they were in a bit of awe of the Norse if memory serves correctly lol
Fascinating. Amazing how it all fits together.
Of course, remember this is just me making a crack theory about this Really Obscure Thing so there may be something out there that doesn't add up with this and if there is I Will make it Work with this but all in all, I think it does make sense?
Like seriously I just pulled this out of my head. Only the part above the cut was prewritten but the rest was pure crack theory slammed down.
As for where I think Hyperborea and Koios's Oracle are in the RRverse...

Greenland be covered in snow, yes. But remember Hyperborea is a land of Eternal Spring and would not be deterred by that lol
Plus it'll be typical RRverse shenanigans for Eternal Spring to be in a Very Snowy place lmao
I was tempted to put Koios's Oracle at The North Pole but then I was like ehhh not very accessible, is it?
I can officially say this is my second theory lol hope you enjoyed the rabbit hole :3
#the oracle speaks#ramblings of an oracle#the trials of apollo#koios#draco constellation#hyperborea#pjo koios
39 notes
·
View notes
Text
a few weeks ago i made a heartslabyul text-based adventure game (where you're yuu and you go into heartslabyul gathering everyone for the unbirthday party that day) for my python class and it's just been sitting in my computer files since then. which is sad because i spent so long working out special interactions and bonus dialogue lmao
so that being said here y'all go! have my funny little heartslabyul adventure game :D
do not mind the documentation. that was required and i can't be bothered to go in and remove it bc there's just so much of it lmaooo
please download both adventure.py and custom.json! the adventure game will not work without the dedicated json file. map is optional but it does have cool graphics
i made and tested this game on vs code, but it does work in this online python terminal! have fun with the game and if smth doesn't work please lmk 🫶
#twisted wonderland#heartslabyul#riddle rosehearts#ace trappola#deuce spade#cater diamond#trey clover#my pride and joy. heartslabyul text based adventure game#i was so excited when my professor announced this project bc that meant i could have DIALOGUE and the writer in me LOVES DIALOGUE#I SPENT LIKE TWO DAYS JUST SCRIPTING OUT EVERYONE'S DIALOGUE. IT WAS INSANE#and then i spent another day actually coding in the interactions. ace and deuce took me forever smh#causing trouble for the prefect even in code... as usual#anyways PLEASE take the time to look around and explore every room. i put silly interactions in most of them#and there are extra bonus interactions with each of the 5 hearts members too#it's p simple but. i love them i love this silly little game i made so i hope u guys can like it too!
26 notes
·
View notes
Text
Mastering Data Structures: A Comprehensive Course for Beginners
Data structures are one of the foundational concepts in computer science and software development. Mastering data structures is essential for anyone looking to pursue a career in programming, software engineering, or computer science. This article will explore the importance of a Data Structure Course, what it covers, and how it can help you excel in coding challenges and interviews.
1. What Is a Data Structure Course?
A Data Structure Course teaches students about the various ways data can be organized, stored, and manipulated efficiently. These structures are crucial for solving complex problems and optimizing the performance of applications. The course generally covers theoretical concepts along with practical applications using programming languages like C++, Java, or Python.
By the end of the course, students will gain proficiency in selecting the right data structure for different problem types, improving their problem-solving abilities.
2. Why Take a Data Structure Course?
Learning data structures is vital for both beginners and experienced developers. Here are some key reasons to enroll in a Data Structure Course:
a) Essential for Coding Interviews
Companies like Google, Amazon, and Facebook focus heavily on data structures in their coding interviews. A solid understanding of data structures is essential to pass these interviews successfully. Employers assess your problem-solving skills, and your knowledge of data structures can set you apart from other candidates.
b) Improves Problem-Solving Skills
With the right data structure knowledge, you can solve real-world problems more efficiently. A well-designed data structure leads to faster algorithms, which is critical when handling large datasets or working on performance-sensitive applications.
c) Boosts Programming Competency
A good grasp of data structures makes coding more intuitive. Whether you are developing an app, building a website, or working on software tools, understanding how to work with different data structures will help you write clean and efficient code.
3. Key Topics Covered in a Data Structure Course
A Data Structure Course typically spans a range of topics designed to teach students how to use and implement different structures. Below are some key topics you will encounter:
a) Arrays and Linked Lists
Arrays are one of the most basic data structures. A Data Structure Course will teach you how to use arrays for storing and accessing data in contiguous memory locations. Linked lists, on the other hand, involve nodes that hold data and pointers to the next node. Students will learn the differences, advantages, and disadvantages of both structures.
b) Stacks and Queues
Stacks and queues are fundamental data structures used to store and retrieve data in a specific order. A Data Structure Course will cover the LIFO (Last In, First Out) principle for stacks and FIFO (First In, First Out) for queues, explaining their use in various algorithms and applications like web browsers and task scheduling.
c) Trees and Graphs
Trees and graphs are hierarchical structures used in organizing data. A Data Structure Course teaches how trees, such as binary trees, binary search trees (BST), and AVL trees, are used in organizing hierarchical data. Graphs are important for representing relationships between entities, such as in social networks, and are used in algorithms like Dijkstra's and BFS/DFS.
d) Hashing
Hashing is a technique used to convert a given key into an index in an array. A Data Structure Course will cover hash tables, hash maps, and collision resolution techniques, which are crucial for fast data retrieval and manipulation.
e) Sorting and Searching Algorithms
Sorting and searching are essential operations for working with data. A Data Structure Course provides a detailed study of algorithms like quicksort, merge sort, and binary search. Understanding these algorithms and how they interact with data structures can help you optimize solutions to various problems.
4. Practical Benefits of Enrolling in a Data Structure Course
a) Hands-on Experience
A Data Structure Course typically includes plenty of coding exercises, allowing students to implement data structures and algorithms from scratch. This hands-on experience is invaluable when applying concepts to real-world problems.
b) Critical Thinking and Efficiency
Data structures are all about optimizing efficiency. By learning the most effective ways to store and manipulate data, students improve their critical thinking skills, which are essential in programming. Selecting the right data structure for a problem can drastically reduce time and space complexity.
c) Better Understanding of Memory Management
Understanding how data is stored and accessed in memory is crucial for writing efficient code. A Data Structure Course will help you gain insights into memory management, pointers, and references, which are important concepts, especially in languages like C and C++.
5. Best Programming Languages for Data Structure Courses
While many programming languages can be used to teach data structures, some are particularly well-suited due to their memory management capabilities and ease of implementation. Some popular programming languages used in Data Structure Courses include:
C++: Offers low-level memory management and is perfect for teaching data structures.
Java: Widely used for teaching object-oriented principles and offers a rich set of libraries for implementing data structures.
Python: Known for its simplicity and ease of use, Python is great for beginners, though it may not offer the same level of control over memory as C++.
6. How to Choose the Right Data Structure Course?
Selecting the right Data Structure Course depends on several factors such as your learning goals, background, and preferred learning style. Consider the following when choosing:
a) Course Content and Curriculum
Make sure the course covers the topics you are interested in and aligns with your learning objectives. A comprehensive Data Structure Course should provide a balance between theory and practical coding exercises.
b) Instructor Expertise
Look for courses taught by experienced instructors who have a solid background in computer science and software development.
c) Course Reviews and Ratings
Reviews and ratings from other students can provide valuable insights into the course’s quality and how well it prepares you for real-world applications.
7. Conclusion: Unlock Your Coding Potential with a Data Structure Course
In conclusion, a Data Structure Course is an essential investment for anyone serious about pursuing a career in software development or computer science. It equips you with the tools and skills to optimize your code, solve problems more efficiently, and excel in technical interviews. Whether you're a beginner or looking to strengthen your existing knowledge, a well-structured course can help you unlock your full coding potential.
By mastering data structures, you are not only preparing for interviews but also becoming a better programmer who can tackle complex challenges with ease.
3 notes
·
View notes
Text
Hi Hi hello!! 83

🍌 • My name is Split or Dove !!
🍌 • She/they/yellow/pun/banana
🍌 • Transgirl poly lesbian
🍌 • Fictionkin of Split [PERMA/ID] from regretavtor and Dove strider from Homestuck
🍌 • Dove posts are mainly on @caprinetalisman + interaction blog
🍌 • https://biveandpilbykisser.straw.page (best viewed on pc)

💛 • I have a typing quirk ; TThe quiick... bbrown foox... juumps oover thee lazyy dog !! I only use it in posts and messages though !! One of the main things about it though is a I double all puncation
💛 • Im BIPOC,, black + native american + chinese
💛 • I love writing and drawing so I may post doodles or poems or fanfics !!
💛 • Im autistic , bipolar , and have dyslexia and ADHD, I will commonly misspell my source name and long words
💛 • Im a Samoyed , Border Collie, Angora goat, Yellow Burmese python, Orange housecat and Artictic wolf therian and many otherkins
💛 • I pet and age regress so I might reblog stuff about that

DO NOT INTERACT WITH ME ;
Proshipper
Factkin
Basic dni (racist, homophobic.. any bigot etc)
Pedo, Zoophile, NOMAP, MAP,
Anti-kin , Engages in Cringe culture
#💛🖤💗 ; I love my sweeties !! : stuff of my source partners !!
#💛🖤 ; spive is real !! : me and bive !!
#🍌💛🐌 ; its me !! [id] : posts about me !!
#🍌💛 ; kin stuff : anything kin stuff !!
#🍌🔎 ; me and bivey !! : me and my sweetie bivey !!
#🍌💬 ; b-b-b-b-banana phone !! (/ref) : chit chattin and puns
#🐌💡🎤 ; cyx tags !! : all stuff about my mootie @digitalcaniline
🐌‼️ ; moot help!! : all my stuff helping moots
🐌🍌 ; moot tag!! : stuff I tag my moots in
#🔄🍌 ; Rebanana : all my reblogs!!
🍌🐌📝 ; pens and puns only !! : all my writings
🐌🍌✏️ ; oui oui im an artistee (/ref) : all my drawings and doodles

Intro layout inspried by @digitalcaniline !! 83









#🍌💬 ; b-b-b-b-banana phone!!#🐌💡🎤 ; cyx tags !!#🐌‼️ ; moot help!!#🍌💛🐌 ; its me !! [id]#🐌🍌 ; moot tag!!#🍌🔎 ; me and bivey !!#🔄🍌 ; rebanana !!#🍌💛🐌 ; its me !! [ID]#🍌💛 ; kin stuff#🍌🐌📝 ; pens and puns only !!#💛🖤💗 ; i love my sweeties !!#💛🖤 ; spive is real !!#🐌🍌✏️ ; oui oui im an artistee#intro post#blog intro#split kin#regretevator#regretevator kin#split kin regretevator#regretevator split kin#split regretevator#fictionkin#userbox collector
12 notes
·
View notes
Text
Intel VTune Profiler For Data Parallel Python Applications

Intel VTune Profiler tutorial
This brief tutorial will show you how to use Intel VTune Profiler to profile the performance of a Python application using the NumPy and Numba example applications.
Analysing Performance in Applications and Systems
For HPC, cloud, IoT, media, storage, and other applications, Intel VTune Profiler optimises system performance, application performance, and system configuration.
Optimise the performance of the entire application not just the accelerated part using the CPU, GPU, and FPGA.
Profile SYCL, C, C++, C#, Fortran, OpenCL code, Python, Google Go, Java,.NET, Assembly, or any combination of languages can be multilingual.
Application or System: Obtain detailed results mapped to source code or coarse-grained system data for a longer time period.
Power: Maximise efficiency without resorting to thermal or power-related throttling.
VTune platform profiler
It has following Features.
Optimisation of Algorithms
Find your code’s “hot spots,” or the sections that take the longest.
Use Flame Graph to see hot code routes and the amount of time spent in each function and with its callees.
Bottlenecks in Microarchitecture and Memory
Use microarchitecture exploration analysis to pinpoint the major hardware problems affecting your application’s performance.
Identify memory-access-related concerns, such as cache misses and difficulty with high bandwidth.
Inductors and XPUs
Improve data transfers and GPU offload schema for SYCL, OpenCL, Microsoft DirectX, or OpenMP offload code. Determine which GPU kernels take the longest to optimise further.
Examine GPU-bound programs for inefficient kernel algorithms or microarchitectural restrictions that may be causing performance problems.
Examine FPGA utilisation and the interactions between CPU and FPGA.
Technical summary: Determine the most time-consuming operations that are executing on the neural processing unit (NPU) and learn how much data is exchanged between the NPU and DDR memory.
In parallelism
Check the threading efficiency of the code. Determine which threading problems are affecting performance.
Examine compute-intensive or throughput HPC programs to determine how well they utilise memory, vectorisation, and the CPU.
Interface and Platform
Find the points in I/O-intensive applications where performance is stalled. Examine the hardware’s ability to handle I/O traffic produced by integrated accelerators or external PCIe devices.
Use System Overview to get a detailed overview of short-term workloads.
Multiple Nodes
Describe the performance characteristics of workloads involving OpenMP and large-scale message passing interfaces (MPI).
Determine any scalability problems and receive suggestions for a thorough investigation.
Intel VTune Profiler
To improve Python performance while using Intel systems, install and utilise the Intel Distribution for Python and Data Parallel Extensions for Python with your applications.
Configure your Python-using VTune Profiler setup.
To find performance issues and areas for improvement, profile three distinct Python application implementations. The pairwise distance calculation algorithm commonly used in machine learning and data analytics will be demonstrated in this article using the NumPy example.
The following packages are used by the three distinct implementations.
Numpy Optimised for Intel
NumPy’s Data Parallel Extension
Extensions for Numba on GPU with Data Parallelism
Python’s NumPy and Data Parallel Extension
By providing optimised heterogeneous computing, Intel Distribution for Python and Intel Data Parallel Extension for Python offer a fantastic and straightforward approach to develop high-performance machine learning (ML) and scientific applications.
Added to the Python Intel Distribution is:
Scalability on PCs, powerful servers, and laptops utilising every CPU core available.
Assistance with the most recent Intel CPU instruction sets.
Accelerating core numerical and machine learning packages with libraries such as the Intel oneAPI Math Kernel Library (oneMKL) and Intel oneAPI Data Analytics Library (oneDAL) allows for near-native performance.
Tools for optimising Python code into instructions with more productivity.
Important Python bindings to help your Python project integrate Intel native tools more easily.
Three core packages make up the Data Parallel Extensions for Python:
The NumPy Data Parallel Extensions (dpnp)
Data Parallel Extensions for Numba, aka numba_dpex
Tensor data structure support, device selection, data allocation on devices, and user-defined data parallel extensions for Python are all provided by the dpctl (Data Parallel Control library).
It is best to obtain insights with comprehensive source code level analysis into compute and memory bottlenecks in order to promptly identify and resolve unanticipated performance difficulties in Machine Learning (ML), Artificial Intelligence ( AI), and other scientific workloads. This may be done with Python-based ML and AI programs as well as C/C++ code using Intel VTune Profiler. The methods for profiling these kinds of Python apps are the main topic of this paper.
Using highly optimised Intel Optimised Numpy and Data Parallel Extension for Python libraries, developers can replace the source lines causing performance loss with the help of Intel VTune Profiler, a sophisticated tool.
Setting up and Installing
1. Install Intel Distribution for Python
2. Create a Python Virtual Environment
python -m venv pyenv
pyenv\Scripts\activate
3. Install Python packages
pip install numpy
pip install dpnp
pip install numba
pip install numba-dpex
pip install pyitt
Make Use of Reference Configuration
The hardware and software components used for the reference example code we use are:
Software Components:
dpnp 0.14.0+189.gfcddad2474
mkl-fft 1.3.8
mkl-random 1.2.4
mkl-service 2.4.0
mkl-umath 0.1.1
numba 0.59.0
numba-dpex 0.21.4
numpy 1.26.4
pyitt 1.1.0
Operating System:
Linux, Ubuntu 22.04.3 LTS
CPU:
Intel Xeon Platinum 8480+
GPU:
Intel Data Center GPU Max 1550
The Example Application for NumPy
Intel will demonstrate how to use Intel VTune Profiler and its Intel Instrumentation and Tracing Technology (ITT) API to optimise a NumPy application step-by-step. The pairwise distance application, a well-liked approach in fields including biology, high performance computing (HPC), machine learning, and geographic data analytics, will be used in this article.
Summary
The three stages of optimisation that we will discuss in this post are summarised as follows:
Step 1: Examining the Intel Optimised Numpy Pairwise Distance Implementation: Here, we’ll attempt to comprehend the obstacles affecting the NumPy implementation’s performance.
Step 2: Profiling Data Parallel Extension for Pairwise Distance NumPy Implementation: We intend to examine the implementation and see whether there is a performance disparity.
Step 3: Profiling Data Parallel Extension for Pairwise Distance Implementation on Numba GPU: Analysing the numba-dpex implementation’s GPU performance
Boost Your Python NumPy Application
Intel has shown how to quickly discover compute and memory bottlenecks in a Python application using Intel VTune Profiler.
Intel VTune Profiler aids in identifying bottlenecks’ root causes and strategies for enhancing application performance.
It can assist in mapping the main bottleneck jobs to the source code/assembly level and displaying the related CPU/GPU time.
Even more comprehensive, developer-friendly profiling results can be obtained by using the Instrumentation and Tracing API (ITT APIs).
Read more on govindhtech.com
#Intel#IntelVTuneProfiler#Python#CPU#GPU#FPGA#Intelsystems#machinelearning#oneMKL#news#technews#technology#technologynews#technologytrends#govindhtech
2 notes
·
View notes
Text
Building technology that empowers city residents
New Post has been published on https://thedigitalinsider.com/building-technology-that-empowers-city-residents/
Building technology that empowers city residents

Kwesi Afrifa came to MIT from his hometown of Accra, Ghana, in 2020 to pursue an interdisciplinary major in urban planning and computer science. Growing up amid the many moving parts of a large, densely populated city, he had often observed aspects of urban life that could be made more efficient. He decided to apply his interest in computing and coding to address these problems by creating software tools for city planners.
Now a senior, Afrifa works at the City Form Lab led by Andres Sevstuk, collaborating on an open-source, Python-based tool that allows researchers and policymakers to analyze pedestrians’ behaviors. The package, which launches next month, will make it more feasible for researchers and city planners to investigate how changes to a city’s structural characteristics impact walkability and the pedestrian experience.
During his first two years at MIT, Afrifa worked in the Civic Data Design Lab led by Associate Professor Sarah Williams, where he helped build sensing tools and created an online portal for people living in Kibera, Nairobi, to access the internet and participate in survey research.
After graduation, he will go on to work as a software engineer at a startup in New York. After several years, he hopes to start his own company, building urban data tools for integration into mapping and location-based software applications.
“I see it as my duty to make city systems more efficient, deepen the connection between residents and their communities, and make existing in them better for everyone, including groups which have often been marginalized,” he says.
“Cities are special places”
Afrifa believes that in urban settings, technology has a unique power to both accelerate development and empower citizens.
He witnessed such unifying power in high school, when he created the website ghanabills.com, which aggregated bills of parliament in Ghana, providing easy access to this information as well as a place for people to engage in discussion on the bills. He describes the effect of this technology as a “democratizing force.”
Afrifa also explored the connection between cities and community as an executive member of Code for Good, a program that connects MIT students interested in software with nonprofits throughout the Boston area. He served as a mentor for students and worked on finding nonprofits to match them up with.
Language and visibility
Sharing African languages and cultures is also important to Afrifa. In his first two years at MIT, he and other African students across the country started the Mandla app, which he describes as a Duolingo for African languages. It had gamified lessons, voice translations, and other interactive features for learning. “We wanted to solve the problem of language revitalization and bring African languages to the broader diaspora,” he says. At its peak a year ago, the app had 50,000 daily active users.
Although the Mandla App was discontinued due to lack of funding, Afrifa has found other ways to promote African culture at MIT. He is currently collaborating with architecture graduate students TJ Bayowa and Courage Kpodo on a “A Tale of Two Coasts,” an upcoming short film and multimedia installation that delves into the intricate connections between perceptions of African art and identity spanning two coasts of the Atlantic Ocean. This ongoing collaboration, which Afrifa says is still taking shape, is something he hopes to expand beyond MIT.
Discovering arts
As a child, Afrifa enjoyed writing poetry. Growing up with parents who loved literature, Afrifa was encouraged to become involved with the theater and art scene of Accra. He didn’t expect to continue this interest at MIT, but then he discovered the Black Theater Guild (BTG).
The theater group had been active at MIT from the 1990s to around 2005. It was revived by Afrifa in his sophomore year when Professor Jay Scheib, head of Music and Theater Arts at MIT, encouraged him to write, direct, and produce more of his work after his final project for 21M.710 (Script Analysis), a dramaturgy class taught by Scheib.
Since then, the BTG has held two productions in the past two years: “Nkrumah’s Last Day,” in spring 2022, and “Shooting the Sheriff,” in spring 2023, both of which were written and directed by Afrifa. “It’s been very rewarding to conceptualize ideas, write stories and have this amazing community of people come together and produce it,” he says.
When asked if he will continue to pursue theater post-grad, Afrifa says: “That’s 100 percent the goal.”
#000#2022#2023#Africa#amazing#Analysis#app#applications#architecture#Art#Arts#Atlantic ocean#Building#cities#code#Code for Good#coding#Collaboration#Community#computer#Computer Science#Computer science and technology#computing#data#Design#development#easy#Electrical Engineering&Computer Science (eecs)#Engineer#Features
5 notes
·
View notes
Text
The Journey to Selenium Expertise: Eight Steps to Success
In today's technology-driven world, where software is the backbone of virtually every industry, ensuring its quality and reliability is paramount. Software testing and quality assurance have become fundamental aspects of the software development process. At the forefront of this evolution stands Selenium, a powerful and versatile tool that has revolutionized the realm of automation testing.

In this comprehensive guide, we embark on a journey to unveil the path to becoming a Selenium expert. This journey is characterized by a continuous quest for knowledge, hands-on practice, and the practical application of skills in real-world scenarios. Selenium expertise is not just a valuable skill; it's a crucial asset in guaranteeing software quality and reliability.
We'll delve into the intricate details of Selenium, covering everything from mastering its basics to exploring advanced topics, and ultimately, adopting best practices in automation testing. As we progress, you'll discover eight pivotal steps to becoming a Selenium expert.
1. Master the Basics: Building a Solid Foundation
Our journey begins with mastering the fundamental concepts of Selenium. It's essential to comprehend the core components, such as WebDriver and WebElement, and understand how Selenium interacts with web browsers. A strong foundation in these basics is crucial to becoming a Selenium expert.
2. Choose Your Programming Language: The Language of Automation
Selenium supports various programming languages, including Java, Python, C#, and more. Your choice of programming language should align with your preferences and career goals. Java, in particular, is popular for Selenium automation due to its extensive community support and wide range of libraries and resources.
3. Set Up Your Development Environment: Crafting Your Toolkit
To work efficiently with Selenium, you need a well-equipped development environment. Installing an Integrated Development Environment (IDE) such as Eclipse or IntelliJ IDEA is essential. These tools streamline the process of writing, debugging, and executing Selenium scripts.
4. Dive into HTML and CSS: Understanding the Web's Building Blocks
Selenium's primary playground is the web, and to navigate it effectively, a strong understanding of HTML and CSS is indispensable. These are the building blocks of web pages, and knowledge of these technologies empowers you to locate and interact with web elements accurately.
5. Explore Locators: The Treasure Map to Web Elements
In Selenium, locators are your treasure map to identifying and interacting with web elements. Dive into various locator strategies, including XPath, CSS selectors, and more. Proficiency in using locators is a fundamental skill for any Selenium expert.
6. Hands-on Practice: The Crucial Training Ground
Practice makes perfect, and in Selenium, hands-on practice is the key to expertise. Initiate your journey by working on simple test scenarios, gradually progressing to more complex ones. The more you practice, the more proficient you become.
7. Embrace Testing Frameworks: Organizing Your Arsenal
As your skills evolve, it's essential to embrace testing frameworks like TestNG or JUnit. These frameworks seamlessly integrate with Selenium and help you organize and manage your test cases efficiently. This skill is invaluable for any Selenium expert.
8. Advance Your Knowledge: Exploring the Uncharted Territories
Once you're comfortable with the basics, it's time to delve into advanced topics. Explore areas like handling frames, working with alerts, dealing with different types of web elements (e.g., dropdowns, checkboxes), and mastering dynamic content testing. These advanced skills set you apart as a Selenium expert.

Becoming a Selenium expert is a journey that demands dedication, practice, and continuous learning. It's a path that leads to excellence in the field of automation testing, and it's a journey worth embarking upon.
To expedite your progress and receive expert guidance, consider enrolling in a structured Selenium training program. ACTE Technologies, a trusted name in the realm of technology training, offers comprehensive programs designed to provide hands-on experience, real-world examples, and guidance from experienced instructors. With the right resources and support, you can accelerate your journey to becoming a Selenium expert and thrive in the dynamic world of automation testing. Take your first step towards expertise with ACTE Technologies as your guiding light. Your path to Selenium mastery begins here.
4 notes
·
View notes
Text
RESOURCES
to try and cut down on the dozens of websites i have open across my laptop, tablet, and phone for citations, i've made this post to serve as a list of resources i use for the geographical and ecological sides of worldbuilding! although it may seem rather bareboned in some areas, more sources will be added as i amass them. you can also consider this a bibliography of sorts, but if you would like direct sources for specific posts (eg. the seasons posts), i will gladly offer them upon request!
GENERAL SOURCES
species lists for all properties managed by the NPS
national park service website
national park service inaturalist project
YELLOWSTONE SOURCES
yellowstone national park website
animals of yellowstone (NPS)
plants of yellowstone (NPS)
science and research of yellowstone (NPS)
yellowstone photo collection (NPS)
yellowstone winter ecology (NPS)
yellowstone national park biodiversity (inaturalist)
insects of yellowstone (MSU)
yellowstone national park (wikipedia)
yellowstone national park category (wikipedia)
interactive redirectional map (wikipedia)
outline of yellowstone national park (wikipedia)
yellowstone fires of 1988 (wikipedia)
history of wolves in yellowstone (wikipedia)
EVERGLADES SOURCES
everglades national park website
animals of the everglades (NPS)
plants of the everglades (NPS)
science and research of the everglades (NPS)
everglades national park biodiversity (inaturalist)
everglades national park (wikipedia)
everglades national park category (wikipedia)
geography and ecology of the everglades (wikipedia)
hurricane andrew (wikipedia)
burmese pythons in florida (wikipedia)
UNRELATED RESOURCES
warriors and anti-indigenous writing
#NOW before anyone complains abt me using wikipedia for sources#i implore u to watch the crash course video abt using wikipedia#yellowstone colonies#vernal pools colony#worldbuilding#useful#b
4 notes
·
View notes
Text
The Ultimate Guide to Developing a Multi-Service App Like Gojek

In today's digital-first world, convenience drives consumer behavior. The rise of multi-service platforms like Gojek has revolutionized the way people access everyday services—from booking a ride and ordering food to getting a massage or scheduling home cleaning. These apps simplify life by merging multiple services into a single mobile solution.
If you're an entrepreneur or business owner looking to develop a super app like Gojek, this guide will walk you through everything you need to know—from ideation and planning to features, technology, cost, and launching.
1. Understanding the Gojek Model
What is Gojek?
Gojek is an Indonesian-based multi-service app that started as a ride-hailing service and evolved into a digital giant offering over 20 on-demand services. It now serves millions of users across Southeast Asia, making it one of the most successful super apps in the world.
Why Is the Gojek Model Successful?
Diverse Services: Gojek bundles transport, delivery, logistics, and home services in one app.
User Convenience: One login for multiple services.
Loyalty Programs: Rewards and incentives for repeat users.
Scalability: Built to adapt and scale rapidly.
2. Market Research and Business Planning
Before writing a single line of code, you must understand the market and define your niche.
Key Steps:
Competitor Analysis: Study apps like Gojek, Grab, Careem, and Uber.
User Persona Development: Identify your target audience and their pain points.
Service Selection: Decide which services to offer at launch—e.g., taxi rides, food delivery, parcel delivery, or healthcare.
Monetization Model: Plan your revenue streams (commission-based, subscription, ads, etc.).
3. Essential Features of a Multi-Service App
A. User App Features
User Registration & Login
Multi-Service Dashboard
Real-Time Tracking
Secure Payments
Reviews & Ratings
Push Notifications
Loyalty & Referral Programs
B. Service Provider App Features
Service Registration
Availability Toggle
Request Management
Earnings Dashboard
Ratings & Feedback
C. Admin Panel Features
User & Provider Management
Commission Tracking
Service Management
Reports & Analytics
Promotions & Discounts Management
4. Choosing the Right Tech Stack
The technology behind your app will determine its performance, scalability, and user experience.
Backend
Programming Languages: Node.js, Python, or Java
Databases: MongoDB, MySQL, Firebase
Hosting: AWS, Google Cloud, Microsoft Azure
APIs: REST or GraphQL
Frontend
Mobile Platforms: Android (Kotlin/Java), iOS (Swift)
Cross-Platform: Flutter or React Native
Web Dashboard: Angular, React.js, or Vue.js
Other Technologies
Payment Gateways: Stripe, Razorpay, PayPal
Geolocation: Google Maps API
Push Notifications: Firebase Cloud Messaging (FCM)
Chat Functionality: Socket.IO or Firebase
5. Design and User Experience (UX)
Design is crucial in a super app where users interact with multiple services.
UX/UI Design Tips:
Intuitive Interface: Simplify navigation between services.
Consistent Aesthetics: Maintain color schemes and branding across all screens.
Microinteractions: Small animations or responses that enhance user satisfaction.
Accessibility: Consider voice commands and larger fonts for inclusivity.
6. Development Phases
A well-planned development cycle ensures timely delivery and quality output.
A. Discovery Phase
Finalize scope
Create wireframes and user flows
Define technology stack
B. MVP Development
Start with a Minimum Viable Product including essential features to test market response.
C. Full-Scale Development
Once the MVP is validated, build advanced features and integrations.
D. Testing
Conduct extensive testing:
Unit Testing
Integration Testing
User Acceptance Testing (UAT)
Performance Testing
7. Launching the App
Pre-Launch Checklist
App Store Optimization (ASO)
Marketing campaigns
Beta testing and feedback
Final round of bug fixes
Post-Launch
Monitor performance
User support
Continuous updates
Roll out new features based on feedback
8. Marketing Your Multi-Service App
Marketing is key to onboarding users and service providers.
Strategies:
Pre-Launch Hype: Use teasers, landing pages, and early access invites.
Influencer Collaborations: Partner with local influencers.
Referral Programs: Encourage user growth via rewards.
Local SEO: Optimize for city-based searches.
In-App Promotions: Offer discounts and bundle deals.
9. Legal and Compliance Considerations
Don't overlook legal matters when launching a multi-service platform.
Key Aspects:
Licensing: Depending on your country and the services offered.
Data Protection: Adhere to GDPR, HIPAA, or local data laws.
Contracts: Create terms of service for providers and users.
Taxation: Prepare for tax compliance across services.
10. Monetization Strategies
There are several ways to make money from your app.
Common Revenue Models:
Commission Per Transaction: Standard in ride-sharing and food delivery.
Subscription Plans: For users or service providers.
Ads: In-app promotions and sponsored listings.
Surge Pricing: Dynamic pricing based on demand.
Premium Features: Offer enhanced services at a cost.
11. Challenges and How to Overcome Them
A. Managing Multiple Services
Solution: Use microservices architecture to manage each feature/module independently.
B. Balancing Supply and Demand
Solution: Use AI to predict demand and onboard providers in advance.
C. User Retention
Solution: Gamify the app with loyalty points, badges, and regular updates.
D. Operational Costs
Solution: Optimize cloud resources, automate processes, and start with limited geography.
12. Scaling the App
Once you establish your base, consider expansion.
Tips:
Add New Services: Include healthcare, legal help, or finance.
Geographical Expansion: Move into new cities or countries.
Language Support: Add multi-lingual capabilities.
API Integrations: Partner with external platforms for payment, maps, or logistics.
13. Cost of Developing a Multi-Service App Like Gojek
Costs can vary based on complexity, features, region, and team size.
Estimated Breakdown:
MVP Development: $20,000 – $40,000
Full-Feature App: $50,000 – $150,000+
Monthly Maintenance: $2,000 – $10,000
Marketing Budget: $5,000 – $50,000 (initial phase)
Hiring an experienced team or opting for a white-label solution can help manage costs and time.
Conclusion
Building a multi-service app like Gojek is an ambitious but achievable project. With the right strategy, a well-defined feature set, and an expert development team, you can tap into the ever-growing on-demand economy. Begin by understanding your users, develop a scalable platform, market effectively, and continuously improve based on feedback. The super app revolution is just beginning—get ready to be a part of it.
Frequently Asked Questions (FAQs)
1. How long does it take to develop a Gojek-like app?
Depending on complexity and team size, it typically takes 4 to 8 months to build a fully functional version of a multi-service app.
2. Can I start with only a few services and expand later?
Absolutely. It's recommended to begin with 2–3 core services, test the market, and expand based on user demand and operational capability.
3. Is it better to build from scratch or use a white-label solution?
If you want custom features and long-term scalability, building from scratch is ideal. White-label solutions are faster and more affordable for quicker market entry.
4. How do I onboard service providers to my platform?
Create a simple registration process, offer initial incentives, and run targeted local campaigns to onboard and retain quality service providers.
5. What is the best monetization model for a super app?
The most successful models include commission-based earnings, subscription plans, and in-app advertising, depending on your services and user base.
#gojekcloneapp#cloneappdevelopmentcompany#ondemandcloneappdevelopmentcompany#ondemandappclone#multideliveryapp#ondemandserviceapp#handymanapp#ondemandserviceclones#appclone#fooddeliveryapp
0 notes
Text
What Are the Key Steps in AI Chatbot Development?
In the era of instant digital interaction, AI chatbots have become indispensable tools for businesses seeking to enhance customer experience, streamline operations, and drive engagement. From handling customer queries to automating repetitive tasks, chatbots are revolutionizing how companies communicate. But how exactly is an AI chatbot created? Let’s walk through the key steps in AI chatbot development, from concept to deployment and optimization.

1. Define the Chatbot's Purpose and Goals
Before jumping into development, it's crucial to define what the chatbot is supposed to do. Consider the following questions:
Will it answer customer service queries?
Will it guide users through a purchase journey?
Will it be used for internal tasks like IT support?
Setting a clear purpose allows for focused development and helps determine the required features, platforms, and AI sophistication. This phase also includes identifying the target audience and expected interactions.
2. Choose the Right Chatbot Type
There are mainly two types of chatbots:
Rule-based chatbots: Follow a predefined flow and can handle simple queries.
AI-powered chatbots: Use machine learning (ML) and natural language processing (NLP) to understand context, intent, and user sentiment.
For businesses looking to provide more personalized and adaptive interactions, AI chatbots are the go-to solution.
3. Select Development Tools and Platforms
Once you’ve determined the type, select the appropriate tools and platforms. Popular options include:
Development Frameworks: Microsoft Bot Framework, Google Dialogflow, Rasa, IBM Watson Assistant
Languages: Python, Node.js, Java
Hosting Platforms: AWS, Google Cloud, Azure
You also need to decide where the chatbot will be deployed—web, mobile apps, messaging platforms (like WhatsApp or Facebook Messenger), or all.
4. Design the Conversation Flow
Conversation design is one of the most creative and strategic parts of chatbot development. It includes:
Mapping out various user scenarios
Designing dialog trees for rule-based responses
Creating intents, entities, and responses for AI-based models
Considering fallback responses when the bot doesn’t understand
For AI-powered bots, the design must also factor in context retention and multi-turn conversations.
5. Train the NLP Model
If you're building an AI chatbot, you must train it to understand human language. This includes:
Defining intents (what the user wants)
Setting up entities (important data in user inputs)
Feeding sample utterances for each intent
Training the model with diverse input scenarios
The more varied the training data, the better your chatbot will perform. Using pre-trained language models like GPT or BERT can give you a strong starting point.
6. Integrate with Backend Systems
For the chatbot to be truly useful, it must integrate with databases, CRMs, ERPs, and APIs. For example:
An e-commerce chatbot might connect to inventory and order tracking systems.
A customer service bot may pull user data from a CRM like Salesforce.
An internal HR bot might integrate with employee databases and leave management tools.
This enables real-time, dynamic responses and allows the bot to perform complex tasks.
7. Test Extensively
Before deployment, thorough testing is essential:
Unit Testing: Each component (intent recognition, entity extraction, etc.)
Integration Testing: Interactions with external systems
User Testing: Real users interacting with the bot to check for errors, confusion, and gaps
Testing should focus on usability, accuracy, fallback behavior, and performance under load.
8. Deploy the Chatbot
Once the chatbot passes all tests, it’s ready for deployment. Ensure it’s launched on the desired platforms and integrated with necessary monitoring tools. Set up analytics dashboards to track:
Number of users
Engagement rate
Drop-off points
Intent success rate
Cloud-based services make deployment scalable and manageable.
9. Monitor, Analyze, and Optimize
Post-launch, the real work begins. Continuous improvement is key to chatbot success:
Collect conversation logs and analyze them for improvement areas
Use analytics to track usage trends and performance metrics
Regularly retrain the AI model with new data
Add new intents, flows, or languages based on user feedback
Optimization should be a regular process to keep the chatbot relevant and effective.
10. Ensure Security and Compliance
AI chatbots often handle sensitive data. It’s critical to:
Implement end-to-end encryption
Follow GDPR, HIPAA, or other industry-specific regulations
Use secure APIs and authentication mechanisms
Security measures must be baked in from the design phase, not added later.
Conclusion
AI chatbot development is a multi-stage journey that combines strategic planning, technical expertise, and ongoing refinement. By following these key steps—from goal setting and tool selection to testing and optimization—you can build a chatbot that not only automates tasks but also enhances user experience and delivers business value.
As businesses increasingly embrace automation, AI chatbot development is no longer optional—it’s a competitive necessity. Whether you're a startup or an enterprise, investing in a well-planned chatbot strategy can lead to smarter interactions, happier customers, and a more efficient organization.
0 notes