#Scrape Data From Mobile App
Explore tagged Tumblr posts
Visit Tumblr Blog
Explore Tumblr blogs with no restrictions, modern design and the best experience.
Last Seen Tumblr Blogs





Fun Fact
Mobile Tumblr US users spend an average of 4.04 minutes per session on the app.
Text
Mobile App Scraping - Scrape Data From Mobile Apps

In the digital age, data is the new oil, and access to it can provide a significant competitive edge. While scraping data from websites has been common practice for some time, a new frontier is rapidly emerging: mobile app scraping. This technique involves extracting data from mobile applications, unlocking vast reservoirs of information that are often more comprehensive and user-specific than data available on traditional websites. In this blog, we'll explore what mobile app scraping entails, its use cases, methods, and the ethical and legal considerations surrounding it.
What is Mobile App Scraping?
Mobile app scraping refers to the process of extracting data from mobile applications, typically by simulating or automating interactions with the app as a user would. Unlike traditional web scraping, where data is pulled from HTML pages, mobile app scraping involves navigating through app interfaces, often interacting with APIs, and extracting the desired information.
Why Scrape Data from Mobile Apps?
Exclusive Content: Many apps provide content that isn't available on their web counterparts. For example, social media platforms, news apps, or e-commerce apps might have exclusive offers or posts that aren't shown on their websites.
User-Specific Information: Apps often have personalized data such as user profiles, preferences, and activity logs which can be invaluable for market analysis or competitive research.
Dynamic Data: Apps frequently update their content, offering real-time data that can be more current and relevant than what’s available on websites.
Common Use Cases for Mobile App Scraping
Market Research
Businesses can gather competitive intelligence by scraping data on pricing, product availability, and consumer reviews from e-commerce apps. This information helps in benchmarking against competitors and identifying market trends.
Social Media Monitoring
Scraping social media apps enables businesses to track mentions, hashtags, and user sentiments in real-time, providing insights into brand perception and public opinion.
Data Aggregation
News aggregators, financial analysts, and data scientists often need to pull information from various sources. Mobile app scraping allows them to gather the latest updates and consolidate data from multiple apps into a single platform.
Methods of Mobile App Scraping
API Interactions
Many apps communicate with servers using APIs (Application Programming Interfaces). By intercepting these API calls, you can capture the data being transmitted between the app and its server. Tools like Postman or Charles Proxy can be used to inspect and interact with these API requests.
UI Automation
This method involves using tools that simulate user interactions with the app’s interface. Tools like Appium or UIAutomator can be programmed to navigate through the app, capturing data displayed on the screen. This approach is similar to how web scraping tools like Selenium operate.
Reverse Engineering
In some cases, it may be necessary to decompile the app to understand how it functions and where it stores its data. Tools such as JADX for Android or Hopper for iOS can help in reverse engineering the app's code to locate data endpoints.
Ethical and Legal Considerations
Mobile app scraping, while powerful, comes with significant ethical and legal challenges. It's essential to navigate these responsibly:
Terms of Service
Most apps have Terms of Service (ToS) that explicitly prohibit scraping. Violating these terms can lead to legal action or bans from the platform. Always review and respect the ToS of any app you're considering scraping.
User Privacy
Scraping data from apps that includes personal user information can lead to privacy violations. Ensure that any data collected is anonymized and used in compliance with data protection regulations like GDPR or CCPA.
Intellectual Property
Apps often have intellectual property protections on their data. Extracting and using this data without permission can result in intellectual property infringement claims.
Rate Limiting
To avoid disrupting the service and to stay under the radar, it’s crucial to respect the app's rate limits. Bombarding an app with too many requests in a short period can lead to IP bans or other countermeasures from the app's developers.
Best Practices for Mobile App Scraping
Use Ethical Scraping Methods: Always use methods that comply with legal standards and the app's ToS.
Respect Rate Limits: Avoid making too many requests too quickly to prevent detection and service disruption.
Anonymize Data: When collecting user-specific data, ensure it's anonymized to protect user privacy.
Stay Updated with Regulations: Keep abreast of the latest data protection laws and ensure compliance in all scraping activities.
0 notes
Text
Realigning Food Delivery Market Moves with Precision Through Glovo Data Scraping

Introduction
This case study highlights how our Glovo Data Scraping solutions empowered clients to monitor food delivery market trends strategically, refine service positioning, and execute agile, data-backed business strategies. Leveraging advanced scraping methodologies, we delivered actionable market intelligence that helped optimize decision-making, elevate competitiveness, and drive profitability.
Our solutions offered a clear strategic edge by enabling end-to-end visibility into the delivery ecosystem to Extract Food Delivery Data. This comprehensive insight allowed clients to fine-tune service models, sharpen market alignment, and achieve consistent revenue growth through accurate competitor benchmarking in the fast-moving food delivery sector.
The Client
A mid-sized restaurant chain operating across 75+ locations with a rapidly expanding digital footprint reached us with a critical operational challenge. Although the brand enjoyed strong recognition, it faced a noticeable drop in customer engagement driven by gaps in delivery service efficiency. To address this, Glovo Data Scraping was identified as a strategic solution, as service inconsistencies directly impacted their revenue goals and competitive position.
With a broad menu and widespread delivery zones, the restaurant struggled to manage delivery logistics, especially during peak hours when quick shifts in demand required fast action. Their manual approach failed to support Real-Time Glovo Data Scraping, leading to missed revenue opportunities and weakening customer loyalty.
Recognizing the need to refine their delivery strategy, the management team saw that without proper visibility into Glovo’s delivery ecosystem, they lacked the insights necessary for efficient operations and practical customer experience management.
Key Challenges Faced by the Client
In their pursuit of stronger delivery market intelligence and a sharper competitive edge, the client faced several operational and strategic hurdles:
Market Insight Shortage
Limited insights into Glovo's platform and competitors made scraping Glovo Delivery Information difficult, preventing effective market analysis necessary for informed business decisions.
Slow Response Adaptation
Reliance on manual weekly evaluations slowed the restaurant chain's ability to act quickly. Without Glovo Delivery Data Extraction, adapting to real-time market changes became a challenge.
Demand Forecasting Gap
Traditional methods failed to account for real-time delivery data. The restaurant chain needed Glovo Product Data Extraction to predict demand and adjust services based on emerging trends accurately.
Manual Process Overload
Labor-intensive processes hindered efficient service decisions. By applying methods to Scrape Glovo For Product Availability And Pricing, the restaurant chain sought automation to optimize service delivery.
Service Consistency Issue
Inconsistent service quality across zones presented a problem. They required Mobile App Scraping Solutions to streamline operations and ensure consistent service delivery across all customer touchpoints.
Key Solutions for Addressing Client Challenges
We implemented cutting-edge solutions to the client's challenges, combining delivery intelligence with advanced analytics.
Delivery Optimization Engine
We built a centralized platform that leverages Real-Time Glovo Delivery Time Data Extraction to collect live data from various restaurants and delivery zones, enabling efficient decision-making.
Competitor Monitoring System
Our system, designed to Extract Restaurant Menus And Prices From Glovo, quickly identifies service gaps when competitors adjust, giving restaurant chains the edge to adapt promptly.
Dynamic Market Signals
By integrating multiple delivery signals, such as peak hours and weather, with Glovo Scraping For Restaurant Delivery Services, we created flexible models that adjust to market fluctuations.
Automated Service Recommender
Using Real-Time Glovo Data Scraping, we implemented an automated engine that generates service suggestions based on customer feedback and competitive positioning, reducing the need for manual input.
Strategic Adjustment Mechanism
Competitor promotions directly influence our service strategies by using tools to Extract Food Delivery Data, optimizing delivery times and fees while ensuring premium offerings remain profitable.
Cloud-Based Monitoring Hub
A robust Mobile App Scraping Solution enables managers to access and update delivery data remotely, facilitating continuous optimization and transforming strategy management into a dynamic process.
Key Insights Gained from Glovo Data Scraping
Service Elasticity Analysis Revealed delivery time sensitivity across different menu items, offering immediate operational optimization opportunities.
Competitive Positioning Patterns Provided insights into neighborhood-specific delivery differences, supporting targeted service improvements.
Pricing Cycle Optimization Illuminated optimal fee adjustment timing for different meal categories, aiding in more strategic revenue management.
Data-Driven Service Decisions Enabled the implementation of adaptive delivery models based on competitive positioning patterns.
Benefits of Glovo Data Scraping From Retail Scrape
Strategic Boost
By utilizing solutions to Scrape Glovo Delivery Information, the client improved delivery strategies, positioning their services for maximum value, enhancing market responsiveness to competitive shifts.
Loyalty Growth
Using competitor service insights, the client predicted market trends and strengthened customer retention, employing to Extract Glovo Product Data to stay ahead of shifts in demand.
Efficient Operations
The client minimized manual efforts by employing advanced Real-Time Glovo Delivery Time Data Extraction, driving faster decisions and better service while ensuring precise positioning and operational success.
Competitive Edge
With advanced techniques to Scrape Glovo For Product Availability And Pricing, the client gained critical insights into market trends, allowing for service adjustments that boosted profitability in competitive delivery sectors.

Retail Scrape's Glovo Data Scraping solutions revolutionized our approach to delivery market positioning. By gaining comprehensive access to Extract Food Delivery Data insights, we rapidly adjusted our strategy, refined our service models, and achieved a remarkable 37% increase in customer retention.
- Operations Director, Leading Multi-Location Restaurant Chain
Conclusion
Maintaining optimal delivery service positioning is crucial in today's competitive food delivery market. Glovo Data Scraping empowers businesses to monitor competitor services, make informed decisions, and improve market competitiveness.
Our customized solutions offer smooth delivery intelligence and actionable insights, allowing businesses to refine their competitive positioning. With in-depth expertise in Glovo Delivery Data Extraction, we equip businesses with the tools to unlock valuable insights for strategic growth.
Our specialists help evaluate market positioning, refine delivery strategies, and boost profit margins through Real-Time Glovo Data Scraping. Contact Retail Scrape today to minimize service inconsistencies, enhance market positioning, and drive long-term revenue with our advanced food delivery intelligence solutions.
Read more >>https://www.retailscrape.com/glovo-food-delivery-data-scraping-for-market-insights.php
officially published by https://www.retailscrape.com/.
#Glovo data scraping#Glovo delivery data extraction#Scrape Glovo delivery information#Real-time Glovo data scraping#Glovo product data extraction#Extract restaurant menus and prices from Glovo#Real-time Glovo delivery time data extraction#Scrape Glovo for product availability and pricing#Glovo scraping for restaurant delivery services#Extract Food Delivery Data#Mobile App Scraping solution
0 notes
Text
Recruitment App Data Scraping Services | Extract job posting data
Our Recruitment App data scraping services can streamline your recruitment process by extracting job posting data from top countries like USA, UK, UAE, and Spain.
know more:
#Recruitment App Data Scraping Services#Extract job posting data#extracting information from mobile app
0 notes
Text






I spent the evening looking into this AI shit and made a wee informative post of the information I found and thought all artists would be interested and maybe help yall?
edit: forgot to mention Glaze and Nightshade to alter/disrupt AI from taking your work into their machines. You can use these and post and it will apparently mess up the AI and it wont take your content into it's machine!
edit: ArtStation is not AI free! So make sure to read that when signing up if you do! (this post is also on twt)
[Image descriptions: A series of infographics titled: “Opt Out AI: [Social Media] and what I found.” The title image shows a drawing of a person holding up a stack of papers where the first says, ‘Terms of Service’ and the rest have logos for various social media sites and are falling onto the floor. Long transcriptions follow.
Instagram/Meta (I have to assume Facebook).
Hard for all users to locate the “opt out” options. The option has been known to move locations.
You have to click the opt out link to submit a request to opt out of the AI scraping. *You have to submit screenshots of your work/face/content you posted to the app, is curretnly being used in AI. If you do not have this, they will deny you.
Users are saying after being rejected, are being “meta blocked”
People’s requests are being accepted but they still have doubts that their content won’t be taken anyways.
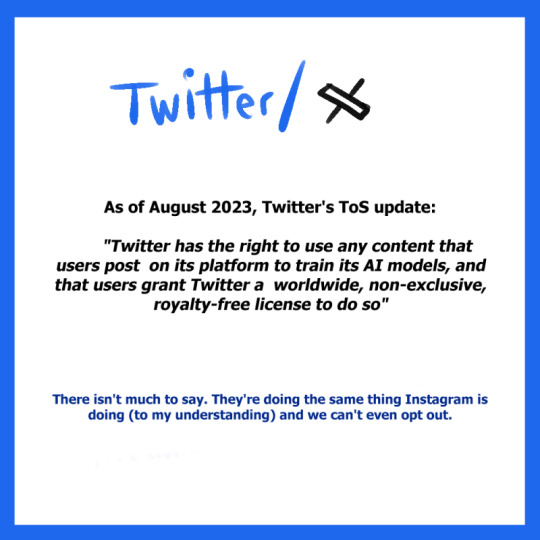
Twitter/X
As of August 2023, Twitter’s ToS update:
“Twitter has the right to use any content that users post on its platform to train its AI models, and that users grant Twitter a worldwide, non-exclusive, royalty-free license to do so.”
There isn’t much to say. They’re doing the same thing Instagram is doing (to my understanding) and we can’t even opt out.
Tumblr
They also take your data and content and sell it to AI models.
But you’re in luck!
It is very simply to opt out (Wow. Thank Gods)
Opt out on Desktop: click on your blog > blog settings > scroll til you see visibility options and it’ll be the last option to toggle
Out out of Mobile: click your blog > scroll then click visibility > toggle opt out option
TikTok
I took time skim their ToS and under “How We Use Your Information” and towards the end of the long list: “To train and improve our technology, such as our machine learning models and algorithms.”
Regarding data collected; they will only not sell your data when “where restricted by applicable law”. That is not many countries. You can refuse/disable some cookies by going into settings > ads > turn off targeted ads.
I couldn’t find much in AI besides “our machine learning models” which I think is the same thing.
What to do?
In this age of the internet, it’s scary! But you have options and can pick which are best for you!
Accepting these platforms collection of not only your artwork, but your face! And not only your faces but the faces of those in your photos. Your friends and family. Some of those family members are children! Some of those faces are minors! I shudder to think what darker purposes those faces could be used for.
Opt out where you can! Be mindful and know the content you are posting is at risk of being loaded to AI if unable to opt out.
Fully delete (not archive) your content/accounts with these platforms. I know it takes up to 90 days for instagram to “delete” your information. And even keep it for “legal” purposes like legal prevention.
Use lesser known social media platforms! Some examples are; Signal, Mastodon, Diaspora, et. As well as art platforms: Artfol, Cara, ArtStation, etc.
The last drawing shows the same person as the title saying, ‘I am, by no means, a ToS autistic! So feel free to share any relatable information to these topics via reply or qrt!
I just wanted to share the information I found while searching for my own answers cause I’m sure people have the same questions as me.’ \End description] (thank you @a-captions-blog!)
4K notes
·
View notes
Text
AI Scraping Isn't Just Art And Fanfic
Something I haven't really seen mentioned and I think people may want to bear in mind is that while artists are the most heavily impacted by AI visual medium scraping, it's not like the machine knows or cares to differentiate between original art and a photograph of your child.
AI visual media scrapers take everything, and that includes screengrabs, photographs, and memes. Selfies, pictures of your pets and children, pictures of your home, screengrabs of images posted to other sites -- all of the comic book imagery I've posted that I screengrabbed from digital comics, images of tweets (including the icons of peoples' faces in those tweets) and instas and screengrabs from tiktoks. I've posted x-ray images of my teeth. All of that will go into the machine.
That's why, at least I think, Midjourney wants Tumblr -- after Instagram we are potentially the most image-heavy social media site, and like Instagram we tag our content, which is metadata that the scraper can use.
So even if you aren't an artist, unless you want to Glaze every image of any kind that you post, you probably want to opt out of being scraped. I'm gonna go ahead and say we've probably already been scraped anyway, so I don't think there's a ton of point in taking down your tumblr or locking down specific images, but I mean...especially if it's stuff like pictures of children or say, a fundraising photo that involves your medical data, it maybe can't hurt.
If you do want to officially opt out, which may help if there's a class-action lawsuit later, you're going to want to go to the gear in the upper-right corner on the Tumblr desktop site, select each of your blogs from the list on the right-hand side, and scroll down to "Visibility". Select "Prevent third party sharing for [username]" to flip that bad boy on.
Per notes: for the app, go to your blog (the part of the app that shows what you post) and hit the gear in the upper right, then select "visibility" and it will be the last option. If you have not updated your app, it will not appear (confirmed by me, who cannot see it on my elderly version of the app).
You don't need to do it on both desktop and mobile -- either one will opt you out -- but on the app you may need to load each of your sideblogs in turn and then go back into the gear and opt out for that blog, like how you have to go into the settings for each sideblog on desktop and do it.
5K notes
·
View notes
Note
Your bio says that ai voice overs are not allowed, does that include (example) tools like text to speech for people who are dyslexic, have vision problems or can’t/won’t read paragraphs that long? As in listening to the text rather than reading it, as private use? Love your content btw :3
Using built-in accessibility tools in your device, like your mobile phone's narration or window's narration tool is fine. If you go to the 'Accessibility' setting in your device, you have a couple of options to use. When I have difficulty I use that, I use 'Zira' for my voice personally but that's just a preference
Please do not upload my fic to any third-party apps/app store for AI generated voice overs, as many of those apps have scraped the data it reads, or force you to pay a 'subscription' in order to have access to ai voices. Even if you are using it for private use, an app or extension like that may scrape fics and make profit from it.
602 notes
·
View notes
Text
"Artists have finally had enough with Meta’s predatory AI policies, but Meta’s loss is Cara’s gain. An artist-run, anti-AI social platform, Cara has grown from 40,000 to 650,000 users within the last week, catapulting it to the top of the App Store charts.
Instagram is a necessity for many artists, who use the platform to promote their work and solicit paying clients. But Meta is using public posts to train its generative AI systems, and only European users can opt out, since they’re protected by GDPR laws. Generative AI has become so front-and-center on Meta’s apps that artists reached their breaking point.
“When you put [AI] so much in their face, and then give them the option to opt out, but then increase the friction to opt out… I think that increases their anger level — like, okay now I’ve really had enough,” Jingna Zhang, a renowned photographer and founder of Cara, told TechCrunch.
Cara, which has both a web and mobile app, is like a combination of Instagram and X, but built specifically for artists. On your profile, you can host a portfolio of work, but you can also post updates to your feed like any other microblogging site.
Zhang is perfectly positioned to helm an artist-centric social network, where they can post without the risk of becoming part of a training dataset for AI. Zhang has fought on behalf of artists, recently winning an appeal in a Luxembourg court over a painter who copied one of her photographs, which she shot for Harper’s Bazaar Vietnam.
“Using a different medium was irrelevant. My work being ‘available online’ was irrelevant. Consent was necessary,” Zhang wrote on X.
Zhang and three other artists are also suing Google for allegedly using their copyrighted work to train Imagen, an AI image generator. She’s also a plaintiff in a similar lawsuit against Stability AI, Midjourney, DeviantArt and Runway AI.
“Words can’t describe how dehumanizing it is to see my name used 20,000+ times in MidJourney,” she wrote in an Instagram post. “My life’s work and who I am—reduced to meaningless fodder for a commercial image slot machine.”
Artists are so resistant to AI because the training data behind many of these image generators includes their work without their consent. These models amass such a large swath of artwork by scraping the internet for images, without regard for whether or not those images are copyrighted. It’s a slap in the face for artists – not only are their jobs endangered by AI, but that same AI is often powered by their work.
“When it comes to art, unfortunately, we just come from a fundamentally different perspective and point of view, because on the tech side, you have this strong history of open source, and people are just thinking like, well, you put it out there, so it’s for people to use,” Zhang said. “For artists, it’s a part of our selves and our identity. I would not want my best friend to make a manipulation of my work without asking me. There’s a nuance to how we see things, but I don’t think people understand that the art we do is not a product.”
This commitment to protecting artists from copyright infringement extends to Cara, which partners with the University of Chicago’s Glaze project. By using Glaze, artists who manually apply Glaze to their work on Cara have an added layer of protection against being scraped for AI.
Other projects have also stepped up to defend artists. Spawning AI, an artist-led company, has created an API that allows artists to remove their work from popular datasets. But that opt-out only works if the companies that use those datasets honor artists’ requests. So far, HuggingFace and Stability have agreed to respect Spawning’s Do Not Train registry, but artists’ work cannot be retroactively removed from models that have already been trained.
“I think there is this clash between backgrounds and expectations on what we put on the internet,” Zhang said. “For artists, we want to share our work with the world. We put it online, and we don’t charge people to view this piece of work, but it doesn’t mean that we give up our copyright, or any ownership of our work.”"
Read the rest of the article here:
https://techcrunch.com/2024/06/06/a-social-app-for-creatives-cara-grew-from-40k-to-650k-users-in-a-week-because-artists-are-fed-up-with-metas-ai-policies/
610 notes
·
View notes
Text
I think most of us should take the whole ai scraping situation as a sign that we should maybe stop giving google/facebook/big corps all our data and look into alternatives that actually value your privacy.
i know this is easier said than done because everybody under the sun seems to use these services, but I promise you it’s not impossible. In fact, I made a list of a few alternatives to popular apps and services, alternatives that are privacy first, open source and don’t sell your data.
right off the bat I suggest you stop using gmail. it’s trash and not secure at all. google can read your emails. in fact, google has acces to all the data on your account and while what they do with it is already shady, I don’t even want to know what the whole ai situation is going to bring. a good alternative to a few google services is skiff. they provide a secure, e3ee mail service along with a workspace that can easily import google documents, a calendar and 10 gb free storage. i’ve been using it for a while and it’s great.
a good alternative to google drive is either koofr or filen. I use filen because everything you upload on there is end to end encrypted with zero knowledge. they offer 10 gb of free storage and really affordable lifetime plans.
google docs? i don’t know her. instead, try cryptpad. I don’t have the spoons to list all the great features of this service, you just have to believe me. nothing you write there will be used to train ai and you can share it just as easily. if skiff is too limited for you and you also need stuff like sheets or forms, cryptpad is here for you. the only downside i could think of is that they don’t have a mobile app, but the site works great in a browser too.
since there is no real alternative to youtube I recommend watching your little slime videos through a streaming frontend like freetube or new pipe. besides the fact that they remove ads, they also stop google from tracking what you watch. there is a bit of functionality loss with these services, but if you just want to watch videos privately they’re great.
if you’re looking for an alternative to google photos that is secure and end to end encrypted you might want to look into stingle, although in my experience filen’s photos tab works pretty well too.
oh, also, for the love of god, stop using whatsapp, facebook messenger or instagram for messaging. just stop. signal and telegram are literally here and they’re free. spread the word, educate your friends, ask them if they really want anyone to snoop around their private conversations.
regarding browser, you know the drill. throw google chrome/edge in the trash (they really basically spyware disguised as browsers) and download either librewolf or brave. mozilla can be a great secure option too, with a bit of tinkering.
if you wanna get a vpn (and I recommend you do) be wary that some of them are scammy. do your research, read their terms and conditions, familiarise yourself with their model. if you don’t wanna do that and are willing to trust my word, go with mullvad. they don’t keep any logs. it’s 5 euros a month with no different pricing plans or other bullshit.
lastly, whatever alternative you decide on, what matters most is that you don’t keep all your data in one place. don’t trust a service to take care of your emails, documents, photos and messages. store all these things in different, trustworthy (preferably open source) places. there is absolutely no reason google has to know everything about you.
do your own research as well, don’t just trust the first vpn service your favourite youtube gets sponsored by. don’t trust random tech blogs to tell you what the best cloud storage service is — they get good money for advertising one or the other. compare shit on your own or ask a tech savvy friend to help you. you’ve got this.
#internet privacy#privacy#vpn#google docs#ai scraping#psa#ai#archive of our own#ao3 writer#mine#textpost
1K notes
·
View notes
Text
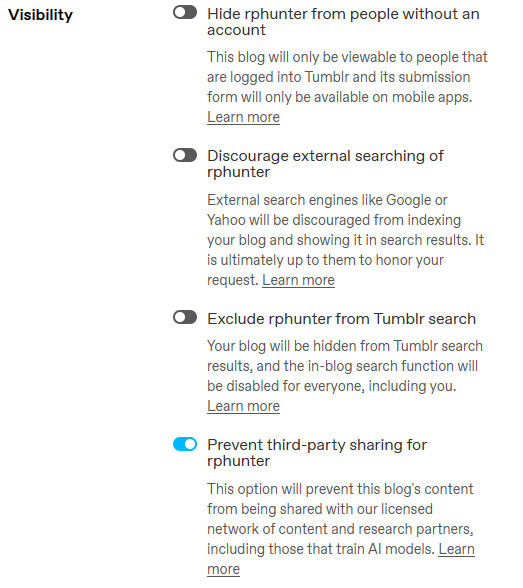
Good morning followers. Take a few minutes today and log into your account on a web browser as this feature is not available on the mobile app yet.
Navigate to your blog settings, scroll down to Visibility, and turn on the option to protect your blog from AI scraping. You will have to do this for EACH sideblog as well as your main, unfortunately. Do not let AI have your data.
94 notes
·
View notes
Note
where do u find stuff for ur edits?? i wanna start makin my own but idk where to look
everything from twst is official. this includes card art, images from the manga, and assets from the game itself. the twst wiki is an easy place to find most of the art itself, otherwise @/alchemivich and @/twstassets both have resources from within the game. (item icons, full-body renders, etc.)
as for everything else, it comes from canva exclusively. i do not use google images, pinterest, weheartit, or AI image generators. there are a number of issues with each, usually boiling down to art theft.
pinterest and weheartit are both notorious for art theft of multiple mediums. someone uploading an image to pinterest does not mean they are the one who created it. furthermore, i do not use fanart, and fanart reposting in particular is rampant on pinterest.
AI image generators scrape for their data, meaning anything generated is an amalgamation of other's work, most often without their knowledge or consent. generative AI also uses a ton of water.
canva, on the other hand, is essentially clipart and stock photos. the art being used is with consent, and the artist or brand is included with the information about each piece. you can even sort by brand or artist.
i'm aware this is not the widely preferred source, but it's how i make everything you see here. i don't feel comfortable with the very easy potential of perpetuating art theft with other sources, and i know that i am not running that risk by utilizing canva's library.
all of my presets are made by me in the lightroom mobile app, and i have a post about that linked in my pinned post. all of my presets are free to use.
the only other thing i use is the medibang app. i can no longer recommend this given how invasive the ads have become, but it's what i'm used to, so i haven't switched to anything else yet. i use medibang for a variety of different things, such as making something transparent, manga coloring, and anything resembling these sets.
10 notes
·
View notes
Text

Since insta wouldn't let me post it:
I try (very very hard) to not get political here.
But, given the fact that roller derby relies very heavily this app to communicate, i felt like it was important to speak my mind:
Tomorrow, at some time, the app TikTok will be banned in the US. This bill, however, not only bans that app but potentially any non-US app that the powers that be deemed harmful. It is likely that the incoming president will save it to look like the hero. Regardless, this bill is a travesty.
For those who don't know, I am an airborne Army Veteran. I swore an oath to protect the constitution only for it to be trampled over for corporate and political greed.
We, as a people, do not have a lot of options to stop the coming censorship and political overreach that is going to happen in the next couple years.
However, we can effect the one the care about and the reason for these bans in the first place:
Money.
What You Can Do:
Delete Facebook off your phone[Yes,really].
Due to the way digital privacy laws work -and how behind our laws are about the subject- most of the data the companies that lobbied for this get is from mobile data scraping.
There is a lot of technical behind the scenes stuff that is complicated. But TDLR; the majority of their money comes from your data and they get that data via your phone.
Talk to your Derby teams about moving internal communication OFF M_ta Apps.
As a smaller, queer inclusive community, we do not have the luxury of kicking these apps completely. Our community lives and dies off social media engagement.
But! We can have our Teams communicate through things like band, tapatalk, etc.
Given the ways things are going, our community especially needs a way to communicate in ways that are not “standard” as we as Queer, Bipoc, and Neurodivergent inclusive people will be censored first.
Treat These Apps the Same Way Treat Us: A Business.
Due to Big Tech Monopolies these companies hold, it is impractical to expect us to -on mass level- these apps. However, we can stop giving them what they want: advertiser clicks and money.
Treat these apps like your team, art, or business launch page. Encourage your followers and friends to follow you in other places, and conduct your actual social internet life there.
Decentralize You Media Use, Connect with Your Local Community, and Buy Local.
Now more than ever, it is important to be present in the physical space. We will need each other more than ever. We will need to RELY on each other more than ever. Download things like next door or just go knock on your neighbors door with a gift and a smile.
Join your local knitting,gaming, whatever circle and get involved.It’s time to connect IRL. And I say that as a person who is borderline an Otaku.
Final Notes:
None of this is easy. It requires a radical shift in thinking and behavior. I know. But it's time.
As for me, I will be using Facebook and Insta as I described above: business pages. If you want to see me be more authentic, follow the link tree in my bio.
If you think I’m just being dramatic, please keep in mind: My field of study is Cyber Security and I am a huge Cold War and WW2 history buff. The writing is on the wall and I’d rather be wrong than ill prepared.
Finally: Breath. It’s scary, it sucks, but our ancestors have been here before. We come from a line of resistance and Joy despite struggle. We will be ok.
P.S. Get a library card. Seriously.
4 notes
·
View notes
Text
My little programming project is online!
I have scraped the skater biographies on the isu website for everyone's music choices, put them all in a database, made a very simple app for searching, and hosted it on a website. You can find it at
I may do a write up with all the web dev things later on, because I think making websites is cool and it'll be nice to share some knowledge.
Some notes:
I only have data for singles, sorry, I tend to forget the other disciplines exist.
I know it looks terrible on mobile (and desktop isn't great either, but I'm not hugely interested in frontend so whatever).
Music search results will display all the seasons in the database for each skater, even if just one entry matches.
I scraped the data a few months ago, and also last week, so only the most recent music choices listed are available. This also means there is some data from previous seasons for skaters that have retired, and some data from the previous season, but only the current season has a (mostly) complete dataset.
2 notes
·
View notes
Text
Medicine Delivery App Data Scraping | Extract Medical & Pharmaceutical Data
Efficient data scraping for medicine delivery apps. Extract medical and pharmaceutical data in the USA, UK, UAE, Australia, Germany, and Spain for valuable insights.
know more:
#Medicine Delivery App Data Scraping Services#Extract Medical & Pharmaceutical Data#extracting information from mobile app#Data scraping from medicine delivery app
0 notes
Text
Hi
So, for the like 3 of you that maybe have wondered where have I been the last weeks, well, basically playing FF7 Rebirth and chilling on cohost.
Thing is, after the whole tumblr selling our data to train ai models fiasco, I was kinda in shock and decided to leave this place. I uninstalled the app from my phone, did backups of my blogs (which I wasn't gonna delete, just stop uploading), went to cohost and started posting there (it's super chill btw, it's like early tumblr mixed with old twitter, in case you're wondering). All while processing what to do next, because frankly, we've all felt that tumblr is somewhat on decline and seeing all the bad stuff it's CEO has done as of late -including threats of nuking the site this year-, the last few years always felt like there was an invisible countdown on this website all the time.
But still, I'm not gonna pretend I'm not gonna miss it, if not tumblr per se, certainly some of the people I've met here who are my mutuals of many years, many of which I've become friends with. Also, despite everything, I still think this is a good platform for posting art. Cohost has its good things (like being WAY more relaxed about NSFW stuff), but there are more file size restrictions, photosets are limited to fewer pictures, etc. There might be some ways to improve that besides what the staff there is doing, since cohost lets you edit posts in many more ways than tumblr (read somewhere that it was tumblr, but for hornier and more linux savy people), so there's also that.
Anyway, after processing everything that happened, and understanding that one way or another, my art's probably gonna be scraped from the internet nevertheless, even if tumblr offers an opt out option (that doesn't even consider the people that tumblr decides to sell our stuff to, let alone the fact that it also arrived so late that we probably everything was already scraped to begin with) even if I glaze it or whatever, I kinda made peace with what happened. I'm still weary about uploading, or where to do it. Yes, I know that I don't have huge numbers or a distinctive enough style for people to copy, but I also know that, nevertheless, not only my art, but the things I've written, the photos I've taken, etc., all has been fed into that slot machine of generating content. If anything, with the days I've noticed I'm way more angry at techbros as usual, and especially tumblr ceo and part of it's staff -I know that not everyone agrees with him and that there are good people in the staff, but there's also sycophants, professional "yes man"s and the like-.
So, after all that, I thought, well, might as well go back. But the thing is that, after spending a couple of weeks away (and missing the posts I imagine came up here both about the Cerveza Cristal meme and about Toriyama's death, among other things), coming back here has been weird, like, for better or worse, it has lost its appeal. I've read a couple of posts before writing this one and I was like "has it always been like this here?".
So, what now? I have no clue. I don't think I'm gonna download the mobile app again, if anything, I've noticed how much time it consumed to just check tumblr with the frequency I used to, so I don't feel like doing that anymore. I think I might pop up here from time to time, maybe return to live blogging Critical Role and Candela Obscura. Will probably like more stuff than the one I post and reblog. Still deciding if I should post new art stuff here, we'll see.
Anyway, if any of you have cohost, you can find me there
2 notes
·
View notes
Text
Exploring the Expansive Horizon of Selenium in Software Testing and Automation
In the dynamic and ever-transforming realm of software testing and automation, Selenium stands as an invincible powerhouse, continually evolving and expanding its horizons. Beyond being a mere tool, Selenium has matured into a comprehensive and multifaceted framework, solidifying its position as the industry's touchstone for web application testing. Its pervasive influence and indispensable role in the landscape of software quality assurance cannot be overstated.

Selenium's journey from a simple automation tool to a complex ecosystem has been nothing short of remarkable. With each new iteration and enhancement, it has consistently adapted to meet the evolving needs of software developers and testers worldwide. Its adaptability and extensibility have enabled it to stay ahead of the curve in a field where change is the only constant. In this blog, we embark on a thorough exploration of Selenium's expansive capabilities, shedding light on its multifaceted nature and its indispensable position within the constantly shifting landscape of software testing and quality assurance.
1. Web Application Testing: Selenium's claim to fame lies in its prowess in automating web testing. As web applications proliferate, the demand for skilled Selenium professionals escalates. Selenium's ability to conduct functional and regression testing makes it the preferred choice for ensuring the quality and reliability of web applications, a domain where excellence is non-negotiable.
2. Cross-Browser Testing: In a world of diverse web browsers, compatibility is paramount. Selenium's cross-browser testing capabilities are instrumental in validating that web applications perform seamlessly across Chrome, Firefox, Safari, Edge, and more. It ensures a consistent and user-friendly experience, regardless of the chosen browser.
3. Mobile Application Testing: Selenium's reach extends to mobile app testing through the integration of Appium, a mobile automation tool. This expansion widens the scope of Selenium to encompass the mobile application domain, enabling testers to automate testing across iOS and Android platforms with the same dexterity.
4. Integration with Continuous Integration (CI) and Continuous Delivery (CD): Selenium seamlessly integrates into CI/CD pipelines, a pivotal component of modern software development. Automated tests are executed automatically upon code changes, providing swift feedback to development teams and safeguarding against the introduction of defects.
5. Data-Driven Testing: Selenium empowers testers with data-driven testing capabilities. Testers can execute the same test with multiple sets of data, facilitating comprehensive assessment of application performance under various scenarios. This approach enhances test coverage and identifies potential issues more effectively.
6. Parallel Testing: The ability to run tests in parallel is a game-changer, particularly in Agile and DevOps environments where rapid feedback is paramount. Selenium's parallel testing capability accelerates the testing process, ensuring that it does not become a bottleneck in the development pipeline.
7. Web Scraping: Selenium's utility extends beyond testing; it can be harnessed for web scraping. This versatility allows users to extract data from websites for diverse purposes, including data analysis, market research, and competitive intelligence.
8. Robotic Process Automation: Selenium transcends testing and enters the realm of Robotic Process Automation (RPA). It can be employed to automate repetitive and rule-based tasks on web applications, streamlining processes, and reducing manual effort.
9. Community and Support: Selenium boasts an active and vibrant community of developers and testers. This community actively contributes to Selenium's growth, ensuring that it remains up-to-date with emerging technologies and industry trends. This collective effort further broadens Selenium's scope.
10. Career Opportunities: With the widespread adoption of Selenium in the software industry, there is a burgeoning demand for Selenium professionals. Mastery of Selenium opens doors to a plethora of career opportunities in software testing, automation, and quality assurance.

In conclusion, Selenium's scope is expansive and continuously evolving, encompassing web and mobile application testing, CI/CD integration, data-driven testing, web scraping, RPA, and more. To harness the full potential of Selenium and thrive in the dynamic field of software quality assurance, consider enrolling in training and certification programs. ACTE Technologies, a renowned institution, offers comprehensive Selenium training and certification courses. Their seasoned instructors and industry-focused curriculum are designed to equip you with the skills and knowledge needed to excel in Selenium testing and automation. Explore ACTE Technologies to elevate your Selenium skills and stay at the forefront of the software testing and automation domain, where excellence is the ultimate benchmark of success.
3 notes
·
View notes