#batch processing SQL
Explore tagged Tumblr posts
Visit Tumblr Blog
Explore Tumblr blogs with no restrictions, modern design and the best experience.
Last Seen Tumblr Blogs





Fun Fact
When “GIF” was named word of the year in 2012, Oxford Dictionaries U.S.A. credited Tumblr for pushing the word.
Text
Optimizing SQL Server: Strategies to Minimize Logical Reads
Optimizing SQL Server: Strategies to Minimize Logical Reads In today’s data-driven environment, optimizing database performance is crucial for maintaining efficient and responsive applications. One significant aspect of SQL Server optimization is reducing the number of logical reads. Logical reads refer to the process of retrieving data from the cache memory, and minimizing them can…
View On WordPress
#batch processing SQL#indexing strategies#reduce logical reads#SQL Server optimization#temporal tables
0 notes
Text
SQL for Hadoop: Mastering Hive and SparkSQL
In the ever-evolving world of big data, having the ability to efficiently query and analyze data is crucial. SQL, or Structured Query Language, has been the backbone of data manipulation for decades. But how does SQL adapt to the massive datasets found in Hadoop environments? Enter Hive and SparkSQL—two powerful tools that bring SQL capabilities to Hadoop. In this blog, we'll explore how you can master these query languages to unlock the full potential of your data.
Hive Architecture and Data Warehouse Concept
Apache Hive is a data warehouse software built on top of Hadoop. It provides an SQL-like interface to query and manage large datasets residing in distributed storage. Hive's architecture is designed to facilitate the reading, writing, and managing of large datasets with ease. It consists of three main components: the Hive Metastore, which stores metadata about tables and schemas; the Hive Driver, which compiles, optimizes, and executes queries; and the Hive Query Engine, which processes the execution of queries.
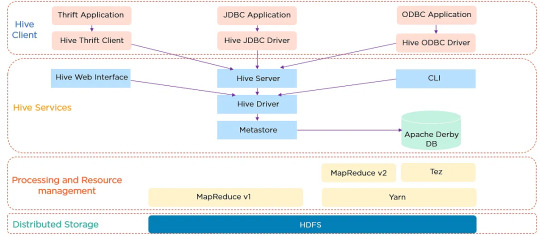
Hive Architecture
Hive's data warehouse concept revolves around the idea of abstracting the complexity of distributed storage and processing, allowing users to focus on the data itself. This abstraction makes it easier for users to write queries without needing to know the intricacies of Hadoop.
Writing HiveQL Queries
HiveQL, or Hive Query Language, is a SQL-like query language that allows users to query data stored in Hadoop. While similar to SQL, HiveQL is specifically designed to handle the complexities of big data. Here are some basic HiveQL queries to get you started:
Creating a Table:
CREATE TABLE employees ( id INT, name STRING, salary FLOAT );
Loading Data:
LOAD DATA INPATH '/user/hive/data/employees.csv' INTO TABLE employees;
Querying Data:
SELECT name, salary FROM employees WHERE salary > 50000;
HiveQL supports a wide range of functions and features, including joins, group by, and aggregations, making it a versatile tool for data analysis.
HiveQL Queries
SparkSQL vs HiveQL: Similarities & Differences
Both SparkSQL and HiveQL offer SQL-like querying capabilities, but they have distinct differences:
Execution Engine: HiveQL relies on Hadoop's MapReduce engine, which can be slower due to its batch processing nature. SparkSQL, on the other hand, leverages Apache Spark's in-memory computing, resulting in faster query execution.
Ease of Use: HiveQL is easier for those familiar with traditional SQL syntax, while SparkSQL requires understanding Spark's APIs and dataframes.
Integration: SparkSQL integrates well with Spark's ecosystem, allowing for seamless data processing and machine learning tasks. HiveQL is more focused on data warehousing and batch processing.
Despite these differences, both languages provide powerful tools for interacting with big data, and knowing when to use each is key to mastering them.

SparkSQL vs HiveQL
Running SQL Queries on Massive Distributed Data
Running SQL queries on massive datasets requires careful consideration of performance and efficiency. Hive and SparkSQL both offer powerful mechanisms to optimize query execution, such as partitioning and bucketing.
Partitioning, Bucketing, and Performance Tuning
Partitioning and bucketing are techniques used to optimize query performance in Hive and SparkSQL:
Partitioning: Divides data into distinct subsets, allowing queries to skip irrelevant partitions and reduce the amount of data scanned. For example, partitioning by date can significantly speed up queries that filter by specific time ranges.
Bucketing: Further subdivides data within partitions into buckets based on a hash function. This can improve join performance by aligning data in a way that allows for more efficient processing.
Performance tuning in Hive and SparkSQL involves understanding and leveraging these techniques, along with optimizing query logic and resource allocation.

Hive and SparkSQL Partitioning & Bucketing
FAQ
1. What is the primary use of Hive in a Hadoop environment? Hive is primarily used as a data warehousing solution, enabling users to query and manage large datasets with an SQL-like interface.
2. Can HiveQL and SparkSQL be used interchangeably? While both offer SQL-like querying capabilities, they have different execution engines and integration capabilities. HiveQL is suited for batch processing, while SparkSQL excels in in-memory data processing.
3. How do partitioning and bucketing improve query performance? Partitioning reduces the data scanned by dividing it into subsets, while bucketing organizes data within partitions, optimizing joins and aggregations.
4. Is it necessary to know Java or Scala to use SparkSQL? No, SparkSQL can be used with Python, R, and SQL, though understanding Spark's APIs in Java or Scala can provide additional flexibility.
5. How does SparkSQL achieve faster query execution compared to HiveQL? SparkSQL utilizes Apache Spark's in-memory computation, reducing the latency associated with disk I/O and providing faster query execution times.
Home
instagram
#Hive#SparkSQL#DistributedComputing#BigDataProcessing#SQLOnBigData#ApacheSpark#HadoopEcosystem#DataAnalytics#SunshineDigitalServices#TechForAnalysts#Instagram
2 notes
·
View notes
Text
Balancing Security and Performance: Options for Laravel Developers
Introduction

This is the digital age, and all businesses are aware of the necessity to build a state-of-the-art website, one that is high-performing and also secure. A high-performing website will ensure you stand out from your competitors, and at the same time, high security will ensure it can withstand brutal cyberattacks.
However, implementing high-security measures often comes at the cost of performance. Laravel is one of the most popular PHP frameworks for building scalable, high-performing, and secure web applications. Hence, achieving a harmonious balance between security and performance often presents challenges.
This article provides more details about security vs performance for Laravel applications and how to balance it.
Security in Laravel Applications
Laravel comes equipped with a range of security features that allow developers to build applications that can withstand various cyber threats. It is a robust PHP framework designed with security in mind. However, creating secure applications requires a proactive approach. Here are some key features:
Authentication and Authorization: Laravel’s built-in authentication system provides a secure way to manage user logins, registrations, and roles. The framework uses hashed passwords, reducing the risk of password theft.
CSRF Protection: Laravel protects applications from cross-site request forgery (CSRF) attacks using CSRF tokens. These tokens ensure that unauthorized requests cannot be submitted on behalf of authenticated users.
SQL Injection Prevention: Laravel uses Eloquent ORM and query builder to prevent SQL injection by binding query parameters.
Two-Factor Authentication (2FA): Integrate 2FA for an added layer of security.
Secure File Uploads: File uploads can be exploited to execute malicious scripts. There are several ways to protect the files by restricting upload types using validation rules like mimes or mimetypes. Storing files outside the web root or in secure storage services like Amazon S3 and scanning files for malware before saving them will also improve security.
Secure communication between users and the server by enabling HTTPS. Using SSL/TLS certificates to encrypt data in transit and redirecting HTTP traffic to HTTPS using Laravel’s ForceHttps middleware will boost security. Laravel simplifies the implementation of robust security measures, but vigilance and proactive maintenance are essential.
By combining Laravel’s built-in features with best practices and regular updates, developers can build secure applications that protect user data and ensure system integrity.
Optimizing Laravel Application For Performance

Laravel is a versatile framework that balances functionality and ease of use. It is known for its performance optimization capabilities, making it an excellent choice for developers aiming to build high-speed applications. Key performance aspects include database interactions, caching, and efficient code execution. Here are proven strategies to enhance the speed and efficiency of Laravel applications.
Caching: Caching is a critical feature for performance optimization in Laravel. The framework supports various cache drivers, including file, database, Redis, and Memcached.
Database Optimization: Database queries are often the bottleneck in web application performance. Laravel provides tools to optimize these queries.
Utilize Job Batching: Laravel’s job batching feature allows grouping multiple queue jobs into batches to process related tasks efficiently.
Queue Management: Laravel’s queue system offloads time-consuming tasks, ensuring better response times for users.
Route Caching: Route caching improves application performance by reducing the time taken to load routes.
Minifying Assets: Minification reduces the size of CSS, JavaScript, and other static files, improving page load times.
Database Connection Pooling: For high-traffic applications, use a database connection pool like PGBouncer (PostgreSQL) or MySQL’s connection pool for better connection reuse.
Laravel provides a solid foundation for building applications, but achieving top-notch performance requires fine-tuning. By applying these strategies, you can ensure your Laravel application delivers a fast, seamless experience to users.
Security vs Performance For Laravel

Implementing security measures in a Laravel application is crucial for protecting data, maintaining user trust, and adhering to regulations. However, these measures can sometimes impact performance. Understanding this trade-off helps in balancing security and performance effectively. Here’s a breakdown of how Laravel’s security measures can affect performance and visa-versa.
Security measures that affect performance
Input Validation and Sanitization: Laravel’s robust validation and sanitization ensure that user input is secure and free from malicious code. Validating and sanitizing every request can slightly increase processing time, especially with complex rules or high traffic.
Encryption and Hashing: Laravel provides built-in encryption (based on OpenSSL) and hashing mechanisms (bcrypt, Argon2) for storing sensitive data like passwords. Encryption and hashing are computationally intensive, especially for large datasets or real-time operations. Password hashing (e.g., bcrypt) is deliberately slow to deter brute force attacks.
Cross-Site Request Forgery (CSRF) Protection: Laravel automatically generates and verifies CSRF tokens to prevent unauthorized actions.
Performance Impact: Adding CSRF tokens to forms and verifying them for every request incurs minimal processing overhead.
Middleware for Authentication and Authorization: Laravel’s authentication guards and authorization policies enforce secure access controls. Middleware checks add processing steps for each request. In the case of high-traffic applications, this can slightly slow response times.
Secure File Uploads: Validating file types and scanning uploads for security risks adds overhead to file handling processes. Processing large files or using third-party scanning tools can delay response times.
Rate Limiting: Laravel’s Throttle Requests middleware prevents abuse by limiting the number of requests per user/IP. Tracking and validating request counts can introduce slight latency, especially under high traffic.
HTTPS Implementation: Enforcing HTTPS ensures secure communication but introduces a slight overhead due to SSL/TLS handshakes. SSL/TLS encryption can increase latency for each request.
Regular Dependency Updates: Updating Laravel and third-party packages reduces vulnerabilities but might temporarily slow down deployment due to additional testing. Updated libraries might introduce heavier dependencies or new processing logic.
Real-Time Security Monitoring: Tools like Laravel Telescope help monitor security events but may introduce logging overhead. Tracking every request and event can slow the application in real-time scenarios.
Performance optimization that affect security
Caching Sensitive Data:
Performance optimization frequently involves caching data to reduce query times and server load. Storing sensitive data in caches (e.g., session data, API tokens) can expose it to unauthorized access if not encrypted or secured. Shared caches in multi-tenant systems might lead to data leakage.
Reducing Validation and Sanitization:
To improve response times, developers may reduce or skip input validation and sanitization. This can expose applications to injection attacks (SQL, XSS) or allow malicious data to enter the system. Improperly sanitized inputs can lead to broken functionality or exploits.
Disabling CSRF Protection:
Some developers disable Cross-Site Request Forgery (CSRF) protection on high-traffic forms or APIs to reduce processing overhead. Without CSRF protection, attackers can execute unauthorized actions on behalf of authenticated users.
Using Raw Queries for Faster Database Access:
Raw SQL queries are often used for performance but bypass Laravel’s ORM protections. Raw queries can expose applications to SQL Injection attacks if inputs are not sanitized.
Skipping Middleware:
Performance optimization may involve bypassing or removing middleware, such as authentication or Rate limiting, to speed up request processing. Removing middleware can expose routes to unauthorized users or brute force attacks.
Disabling Logging:
To save disk space or reduce I/O operations, developers may disable or minimize logging. Critical security events (e.g., failed login attempts and unauthorized access) may go unnoticed, delaying response to breaches.
Implementing Aggressive Rate Limiting:
While Rate limiting is crucial for preventing abuse, overly aggressive limits might unintentionally turn off security mechanisms like CAPTCHA or block legitimate users. Attackers may exploit misconfigured limits to lock out users or bypass checks.
Over-Exposing APIs for Speed:
In a bid to optimize API response times, developers may expose excessive data or simplify access controls. Exposed sensitive fields in API responses can aid attackers. Insufficient access control can allow unauthorized access.
Using Outdated Libraries for Compatibility:
To avoid breaking changes and reduce the effort of updates, developers may stick to outdated Laravel versions or third-party packages. Older versions may contain known vulnerabilities. For faster encryption and decryption, developers might use less secure algorithms or lower encryption rounds. Weak encryption can be cracked more quickly, exposing sensitive data.
Tips To Balance Security and Performance
There are several options available to balance security and performance while developing a Laravel application. It is essential to strike a balance and develop a robust solution that is not vulnerable to hackers. Seek the help from the professionals, and hire Laravel developers from Acquaint Softttech who are experts at implementing a combination of strategies to obtain the perfect balance.
Layered Security Measures:
Instead of relying solely on one security layer, combine multiple measures:
Use middleware for authentication and authorization.
Apply encryption for sensitive data.
Implement Rate limiting to prevent brute force attacks.
Optimize Middleware Usage:
Middleware in Laravel is a powerful tool for enforcing security without affecting performance excessively. Prioritize middleware execution:
Use route-specific middleware instead of global middleware when possible.
Optimize middleware logic to minimize resource consumption.
Intelligent Caching Strategies:
Cache only what is necessary to avoid stale data issues:
Implement cache invalidation policies to ensure updated data.
Use tags to manage grouped cache items effectively.
Regular Vulnerability Testing:
Conduct penetration testing and code reviews to identify vulnerabilities. Use tools like:
Laravel Debugbar for performance profiling.
OWASP ZAP for security testing.
Enable Logging and Monitoring:
Laravel’s logging capabilities provide insights into application performance and potential security threats:
Use Monolog to capture and analyze logs.
Monitor logs for unusual activity that may indicate an attack.
Implement Rate Limiting:
Laravel’s Rate limiting protects APIs from abuse while maintaining performance:
Use ThrottleRequests middleware to limit requests based on IP or user ID.
Adjust limits based on application needs.
Leverage API Gateway:
An API gateway can act as a security and performance intermediary:
Handle authentication, authorization, and Rate limiting at the gateway level.
Cache responses to reduce server load.
Use Load Balancing and Scaling:
Distribute traffic across multiple servers to enhance both security and performance:
Implement load balancers with SSL termination for secure connections.
Use horizontal scaling to handle increased traffic.
Employ CDN for Static Content:
Offload static resources to a content delivery network:
Reduce server load by serving images, CSS, and JavaScript via CDN.
Enhance security with HTTPS encryption on CDN.
Harden Server Configuration:
Ensure server security without sacrificing performance:
Use firewalls and intrusion detection systems.
Optimize PHP and database server configurations for maximum efficiency.
Placing trust in a Laravel development company for the development of your custom solution will go a long way ensuring you build a top-notch solution.
Future Trends in Laravel Security and Performance
As Laravel evolves, so do the tools and technologies to achieve the delicate balance between security and performance. Trust a software development outsourcing company like Acquaint Softtech for secure and future-proof solutions. Besides being an official Laravel partner, our developers also stay abreast with the current technologies.
Future trends include:
AI-Powered Security: AI-driven security tools can automatically detect and mitigate threats in Laravel applications. These tools enhance security without adding significant overhead.
Edge Computing: Processing data closer to the user reduces latency and enhances performance. Laravel developers can leverage edge computing for better scalability and security.
Advanced Caching Mechanisms: Next-generation caching solutions like in-memory databases (e.g., RedisGraph) will enable even faster data retrieval.
Zero-Trust Architecture: Zero-trust models are gaining popularity to enhance security in Laravel applications. This approach treats all traffic as untrusted, ensuring stricter access controls.
Quantum-Resistant Encryption: With advancements in quantum computing, Laravel applications may adopt quantum-resistant encryption algorithms to future-proof security.
Hire remote developers from Acquaint Softtech to implement these strategies. We follow the security best practices and have extensive experience creating state-of-the-art applications that are both secure and high performing. This ensures a smooth and safe user experience.
Conclusion
Balancing security and performance in Laravel development is a challenging yet achievable task. By leveraging Laravel’s built-in features, adopting Laravel security best practices, and staying updated on emerging trends, developers can create applications that are both secure and high-performing.
The key is to approach security and performance as complementary aspects rather than competing priorities. Take advantage of the Laravel development services at Acquaint Softtech. We can deliver robust, scalable, and efficient applications that meet modern user expectations.
1 note
·
View note
Text
Best Data Science Training Institutes in Boston with Certification & Career Support (2025 Guide)
Boston, often referred to as the hub of education and innovation, is a prime destination for aspiring data scientists. With its proximity to prestigious universities, thriving tech startups, and major companies in healthcare, finance, and biotech, Boston offers an ideal ecosystem for learning and applying data science.
If you're looking to begin or advance your data science journey, enrolling in a certified training institute with career support can make all the difference. This guide brings you the best data science training institutes in Boston that offer comprehensive programs, globally recognized certifications, and job placement assistance — all in one package.
Why Study Data Science in Boston?
🧠 Academic excellence: Home to world-renowned institutions like MIT and Harvard
💼 Tech & research hubs: Boston boasts a booming data-driven economy in healthcare, fintech, education tech, and AI startups
🌎 Global exposure: A diverse international student community and strong industry-academia collaborations
💸 Lucrative job opportunities: Data Scientists in Boston earn an average salary of $120,000–$160,000/year
Whether you’re a local resident, international student, or working professional, Boston offers top-tier opportunities for data science education and employment.
What to Look for in a Data Science Training Institute?
Choosing the right data science training institute is a crucial step toward building a successful career in this fast-growing field. With countless programs available, it's important to know what to look for to ensure your time and money are well invested.
1. Comprehensive Curriculum: A strong data science program should cover key areas like Python or R programming, statistics, machine learning, data visualization, SQL, and real-world project work. Advanced topics like deep learning, natural language processing, or big data tools are a bonus.
2. Experienced Instructors: Look for institutes with instructors who have real-world industry experience. Practitioners bring practical insights and can help bridge the gap between theory and application.
3. Hands-on Learning: Theory is important, but practical application is essential. Choose a program that offers plenty of hands-on labs, capstone projects, and case studies using real-world datasets. This not only deepens your skills but also helps build a strong portfolio for job applications.
4. Industry Recognition and Certification: Check whether the certification is recognized by employers or affiliated with reputable companies or universities. Accredited or partner-backed programs often carry more weight in hiring decisions.
5. Placement Support and Alumni Network: An institute that offers career support—like interview preparation, resume building, and job placement services—adds significant value. A strong alumni network is also a good sign of credibility and long-term support.
6. Flexible Learning Options: Whether you’re a working professional or a full-time student, consider institutes that offer flexible formats such as weekend batches, self-paced online learning, or hybrid options.
Choosing the right data science institute is more than just picking a course—it’s an investment in your future. Do your research, read reviews, and don’t hesitate to ask questions before enrolling.
Key Skills You’ll Learn in a Data Science Training Program
A data science training program equips you with the technical and analytical skills needed to extract meaningful insights from data—skills that are in high demand across industries like tech, finance, healthcare, and e-commerce. Here's a breakdown of the key skills you can expect to learn:
1. Programming (Python or R): Programming is the foundation of data science. Most training programs teach Python due to its simplicity and the rich ecosystem of libraries like Pandas, NumPy, Scikit-learn, and TensorFlow. Some also include R for statistical computing.
2. Statistics and Probability: You’ll learn core statistical concepts such as distributions, hypothesis testing, and regression analysis. These are essential for understanding data patterns and making informed decisions.
3. Data Wrangling and Cleaning: Real-world data is often messy. A good program will teach you how to clean, transform, and prepare data using tools like SQL, Excel, or Python libraries.
4. Machine Learning: You’ll explore supervised and unsupervised learning techniques such as linear regression, decision trees, clustering, and neural networks. Understanding how to train, evaluate, and fine-tune models is central to data science.
5. Data Visualization: Communicating your findings is just as important as analyzing data. You'll learn to create visualizations using tools like Matplotlib, Seaborn, or Tableau to present insights clearly to both technical and non-technical audiences.
6. Big Data Tools (Optional): Some advanced programs introduce tools like Hadoop, Spark, or cloud platforms (AWS, Azure) for handling large datasets.
Final Thoughts
Boston is not only one of the best places in the U.S. to study data science — it’s also one of the best places to work in it. From top-rated bootcamps and international training institutes to academic giants like MIT and North-eastern, the city offers a wide range of learning experiences.
If you're looking for a globally recognized certification, practical project-based learning, and career support, the Boston Institute of Analytics (BIA) stands out as a top choice. Their combination of international faculty, industry-aligned curriculum, and personalized placement assistance makes it a smart investment for your future.
#Best Data Science Courses in Boston#Artificial Intelligence Course in Boston#Data Scientist Course in Boston#Machine Learning Course in Boston
0 notes
Text
Unlock Your Future with the Best Data Scientist Course in Pune

In today’s digital-first era, data is the new oil. From tech giants to startups, businesses rely heavily on data-driven decisions. This has skyrocketed the demand for skilled professionals who can make sense of large volumes of data. If you’re in Pune and aspiring to become a data scientist, the good news is – your opportunity starts here. GoDigi Infotech offers a top-notch Data Scientist Course in Pune tailored to shape your future in one of the most lucrative tech domains.
Why Data Science is the Career of the Future
Data Science combines the power of statistics, programming, and domain knowledge to extract insights from structured and unstructured data. The emergence of machine learning, artificial intelligence, and big data has amplified its importance.
Companies across sectors like finance, healthcare, retail, e-commerce, and manufacturing are hiring data scientists to boost efficiency and predict future trends. Choosing a comprehensive Data Scientist Course in Pune from a reputed institute like GoDigi Infotech can be your launchpad to a successful career.
Why Choose Pune for a Data Science Course?
Pune has emerged as a major IT and educational hub in India. With leading tech companies, research institutions, and a thriving startup ecosystem, Pune provides the perfect environment to study and practice data science. Enrolling in a Data Scientist Course in Pune not only gives you access to expert faculty but also opens doors to internships, projects, and job placements in renowned organizations.
Key Highlights of the Data Scientist Course in Pune by GoDigi Infotech
Here’s what makes GoDigi Infotech stand out from the rest:
1. Industry-Centric Curriculum
The course is curated by experienced data scientists and industry experts. It includes in-demand tools and topics such as Python, R, SQL, Machine Learning, Deep Learning, Power BI, Tableau, Natural Language Processing (NLP), and more.
2. Hands-on Projects
Practical knowledge is key in data science. You’ll work on real-world projects including sales forecasting, customer segmentation, fraud detection, and more – enhancing your portfolio.
3. Experienced Trainers
The course is delivered by certified professionals with years of experience in data science, AI, and analytics. They guide students from basics to advanced topics with a hands-on approach.
4. Placement Support
With strong corporate ties and an in-house career cell, GoDigi Infotech provides resume building, mock interviews, and placement assistance. Their Data Scientist Course in Pune ensures you're not just trained, but job-ready.
5. Flexible Learning Options
Whether you're a working professional, a fresher, or someone switching careers, GoDigi Infotech offers flexible batches – including weekends and online options.
Who Should Enroll in the Data Scientist Course in Pune?
This course is suitable for:
Fresh graduates (BE, BSc, BCA, MCA, etc.)
Working professionals from IT, finance, marketing, or engineering domains
Entrepreneurs and business analysts looking to upgrade their data knowledge
Anyone with a passion for data, numbers, and problem-solving
What Will You Learn in the Data Scientist Course?
1. Programming Skills
Python for data analysis
R for statistical computing
SQL for data manipulation
2. Statistical and Mathematical Foundations
Probability
Linear algebra
Hypothesis testing
3. Data Handling and Visualization
Pandas, Numpy
Data cleaning and wrangling
Data visualization using Matplotlib, Seaborn, and Tableau
4. Machine Learning Algorithms
Supervised and unsupervised learning
Regression, classification, clustering
Decision trees, SVM, k-means
5. Advanced Topics
Deep Learning (Neural Networks, CNN, RNN)
Natural Language Processing (Text analytics)
Big Data tools (Hadoop, Spark – optional)
Benefits of a Data Scientist Course in Pune from GoDigi Infotech
Get trained under mentors who have worked with Fortune 500 companies.
Join a growing community of data science enthusiasts and alumni.
Build a strong project portfolio that can impress employers.
Opportunity to work on live industry projects during the course.
Certification recognized by top employers.
How the Course Boosts Your Career
✔️ High-Paying Job Roles You Can Target:
Data Scientist
Machine Learning Engineer
Data Analyst
Business Intelligence Developer
AI Specialist
✔️ Industries Hiring Data Scientists:
IT & Software
Healthcare
E-commerce
Banking & Finance
Logistics and Supply Chain
Telecommunications
Completing the Data Scientist Course in Pune puts you on a fast-track career path in the tech industry, with salaries ranging between ₹6 LPA to ₹25 LPA depending on experience and skills.
Student Testimonials
"GoDigi Infotech’s Data Science course changed my life. From a fresher to a full-time Data Analyst at a fintech company in just 6 months – the mentorship was incredible!" – Rohit J., Pune
"The best part is the practical exposure. The projects we did were based on real datasets and actual business problems. I landed my first job thanks to this course." – Sneha M., Pune
Frequently Asked Questions (FAQs)
Q. Is prior coding experience required for this course? No, basic programming will be taught from scratch. Prior experience is helpful but not mandatory.
Q. Do you provide certification? Yes, upon course completion, you’ll receive an industry-recognized certificate from GoDigi Infotech.
Q. What is the duration of the course? Typically 3 to 6 months, depending on the batch type (fast-track/regular).
Q. Are there any EMI options available? Yes, EMI and easy payment plans are available for all learners.
Conclusion
A career in data science promises growth, innovation, and financial rewards. Choosing the right learning partner is the first step toward success. GoDigi Infotech’s Data Scientist Course in Pune equips you with the knowledge, skills, and hands-on experience to thrive in this data-driven world. Whether you're a beginner or looking to switch careers, this course can be your stepping stone toward becoming a successful data scientist.
0 notes
Text
Top Data Science Tools to Learn in 2025
Data science continues to dominate the tech landscape in 2025, with new tools and technologies enhancing the way data is processed, analyzed, and visualized. For those looking to break into this exciting field, enrolling in the best data science training in Hyderabad can provide the practical skills and guidance needed to stand out. Whether you're a beginner or an experienced professional, mastering the right tools is key to success in data science.
1. Python – The Foundation of Data Science
Python remains the most popular programming language in data science due to its simplicity, readability, and rich library support. Libraries like NumPy, Pandas, Matplotlib, and Scikit-learn make data cleaning, visualization, and machine learning implementation straightforward and efficient.
2. R – Advanced Statistical Analysis
The R language is designed to analyze data and compute statistics. It’s especially useful in academic and research environments. With visualization packages like ggplot2 and Shiny, R enables users to create compelling visual interpretations of complex data sets.
3. SQL – Essential for Data Extraction
It's imperative when managing and querying large databases to use Structured Query Language (SQL). Knowledge of SQL allows data scientists to filter, join, and manipulate structured data efficiently, making it a must-have skill for handling real-world data.
4. Apache Spark – Big Data Processing Power
Apache Spark is a powerful open-source engine for big data processing. It handles both batch and real-time data and integrates well with other big data tools. Spark’s in-memory computing makes it much faster than traditional methods like MapReduce.
5. Power BI & Tableau - Tools for Data Visualization
Data storytelling is an important part of a data scientist’s role. Tools like Tableau and Power BI help create interactive dashboards and visual reports, enabling business users to understand insights at a glance.
6. TensorFlow & PyTorch – For Deep Learning and AI
For those entering the fields of deep learning and artificial intelligence, TensorFlow and PyTorch are the go-to frameworks. They allow developers to build and train complex neural networks used in advanced applications like image recognition and natural language processing.
Conclusion
In 2025, learning these top data science tools will set you apart in the job market and open doors to a wide range of opportunities. To get expert guidance and hands-on experience, enroll at SSSIT Computer Education, a leading institute offering high-quality data science training in Hyderabad.
#best software training in hyderabad#best software training in kukatpally#best software training in KPHB#Best software training institute in Hyderabad
0 notes
Text
Data Analytics Certification Courses in Chennai to Boost Your Job Prospects
In today’s fast-paced digital world, data is everywhere. From online shopping habits to financial transactions, data plays a huge role in shaping business decisions. This growing demand for insights has led to a booming career field—Data Analytics. If you are in Chennai and want to build a future-proof career, enrolling in a Practical Data Analytics Course in Chennai can be your best move.
Why Choose a Practical Data Analytics Course in Chennai?
The job market is evolving. Employers today are looking for candidates who can not only understand data but also use tools and techniques to analyse and present it effectively. A Practical Data Analytics Course in Chennai focuses on real-world applications. Instead of just theory, it helps you work on live projects, case studies, and hands-on exercises. This kind of training improves your problem-solving skills and prepares you for actual job scenarios.
Such practical courses cover everything from data collection and cleaning to visualization and reporting. You’ll also get exposure to tools like Excel, Power BI, SQL, and Python. This gives you a competitive edge when applying for analytics roles in top companies.
Perfect for Freshers and Working Professionals
Whether you are a college graduate looking to start your career or a working professional aiming for a career switch, there’s something for everyone. Specially designed programs such as Data Analytics for Freshers in Chennai make learning easier by simplifying complex topics. These beginner-friendly courses start from the basics and gradually move to advanced topics like machine learning and predictive analytics.
For those already in the tech field, a Practical Data Analytics Course in Chennai can upskill your current profile and help you land data-driven roles like Data Analyst, Business Intelligence Analyst, or Data Consultant.
What’s Included in the Syllabus?
Before choosing a course, it’s important to understand what you will learn. The Data Analytics Syllabus and Modules in Chennai are often industry-oriented and structured to match current business needs. A typical syllabus includes:
Introduction to Data Analytics
Excel for Data Management
SQL for Data Retrieval
Data Visualization using Power BI and Tableau
Python for Data Analysis
Basics of Machine Learning with Data Analytics
Real-time project work and case studies
These modules ensure you’re ready for both entry-level and intermediate analytics roles after completing the course.
Learn Machine Learning with Data Analytics
As companies grow, they’re relying more on artificial intelligence to automate and optimize their data processes. That’s why many institutes now offer Machine Learning with Data Analytics as part of their certification. This advanced module teaches you algorithms like regression, classification, clustering, and recommendation systems—all essential for modern-day analysts.
By mastering machine learning, you can not only analyse data but also make predictions, detect patterns, and create smart business strategies. Employers are always looking for candidates who can apply machine learning to solve real business problems, making this skill highly valuable.
Affordable Learning Options
You don’t need to break the bank to gain skills in analytics. There are several Affordable Analytics Courses in Chennai that offer top-notch training at budget-friendly prices. Many institutes even provide EMI options, scholarships, and weekend batches for working professionals. These courses focus on value-for-money learning with lifetime access to materials, job assistance, and certification.
Online and offline modes are available, making it easy for you to choose the one that suits your learning style. So even if you’re on a tight budget or a busy schedule, you can still build a strong foundation in analytics.
Short-Term Courses for Fast Learning
Not everyone has the time to commit to a long-term course. That’s where a Short-term Data Analytics Course in Chennai comes in. These crash courses are perfect for people looking to quickly upskill or add a new credential to their resume. In just a few weeks, you can learn core analytics concepts and tools through practical exercises.
These short-term programs are ideal if you’re preparing for a job interview, internship, or project and need to get up to speed quickly. Most of them also include mini-projects and tests to help you assess your skills along the way.
Certification That Adds Value to Your Resume
When you complete a Practical Data Analytics Course in Chennai, you’ll receive a certificate that proves your skills to employers. Many institutes partner with tech giants like Microsoft, Google, or IBM to provide globally recognized certifications. This not only boosts your resume but also improves your chances of landing interviews and job offers.
If you're new to the field, a certification signals your dedication to learning. If you're already working, it shows that you’ve upgraded your skills for future challenges.
Placement Support and Career Guidance
Another advantage of enrolling in a reputed institute is career support. Most top analytics training centers in Chennai offer placement help, resume building, and mock interview sessions. Some even have tie-ups with companies looking to hire data analysts. If you're serious about landing a job after the course, these additional services can make a huge difference.
With proper training and guidance, even freshers with no prior tech background can get placed in analytics roles with leading companies.
Conclusion
In the digital era, data is one of the most powerful tools in business decision-making. By enrolling in a Practical Data Analytics Course in Chennai, you can unlock exciting career opportunities in finance, marketing, healthcare, e-commerce, and more. With modules designed for both freshers and professionals, options for short-term and affordable learning, and job-focused training, there's no better time to start than now.
Whether you're looking for Data Analytics for Freshers in Chennai, want to explore Machine Learning with Data Analytics, or need insights into the Data Analytics Syllabus and Modules Chennai, the right course can set you on the path to success.
Choose smart. Choose practical. Choose data analytics in Chennai!
0 notes
Text
⚡ Are Your Dataverse Customizations Slowing Down Performance? ⚡ Developers often assume that Dataverse can handle anything, but poor design leads to slow queries, SQL timeouts, and deadlocks! ✅ Avoid long transactions ✅ Optimize queries for better performance ✅ Use batch processing the right way Learn how to design scalable Dataverse customizations in our latest blog! 🚀 #Dataverse #PowerPlatform #Scalability #Dynamics365 #DataversePerformance
0 notes
Text
AWS Kinesis: Guides, Pricing, Cost Optimization

AWS Kinesis isn't just one service; it's a family of services, each tailored for different streaming data needs:
Amazon Kinesis Data Streams (KDS):
What it is: The foundational service. KDS allows you to capture, store, and process large streams of data records in real-time. It provides durable storage for up to 365 days (default 24 hours), enabling multiple applications to process the same data concurrently and independently.
Use Cases: Real-time analytics, log and event data collection, IoT data ingestion, real-time dashboards, application monitoring, and streaming ETL.
Key Concept: Shards. KDS capacity is measured in shards. Each shard provides a fixed unit of capacity (1 MB/s ingress, 1,000 records/s ingress, 2 MB/s egress per shard, shared among consumers).
Amazon Kinesis Data Firehose:
What it is: A fully managed service for delivering real-time streaming data to destinations like Amazon S3, Amazon Redshift, Amazon OpenSearch Service, Splunk, and generic HTTP endpoints. It automatically scales to match your data throughput and requires no administration.
Use Cases: Loading streaming data into data lakes (S3), data warehouses (Redshift), and analytics tools with minimal effort. It handles batching, compression, and encryption.
Amazon Kinesis Data Analytics:
What it is: The easiest way to process and analyze streaming data in real-time with Apache Flink or standard SQL. It allows you to build sophisticated streaming applications to transform and enrich data, perform real-time aggregations, and derive insights as data arrives.
Use Cases: Real-time anomaly detection, interactive analytics, streaming ETL, and building real-time dashboards.
Amazon Kinesis Video Streams:
What it is: A service that makes it easy to securely stream video from connected devices to AWS for analytics, machine learning (ML), and other processing. It automatically provisions and scales all the necessary infrastructure.
Use Cases: IoT video streaming, smart home security, drone video analytics, and integrating with ML services like Amazon Rekognition.
Understanding Kinesis Pricing Models
Kinesis pricing is "pay-as-you-go," meaning you only pay for what you use, with no upfront costs or minimum fees. However, the billing components vary significantly per service:
1. Kinesis Data Streams (KDS) Pricing:
KDS pricing revolves around shards and data throughput. There are two capacity modes:
Provisioned Capacity Mode:
Shard Hours: You pay for each shard-hour. This is the base cost.
PUT Payload Units: You are charged per million "PUT payload units." Each record ingested is rounded up to the nearest 25 KB. So, a 1 KB record and a 20 KB record both consume one 25 KB payload unit.
Data Retrieval: Standard data retrieval is included in shard hours up to 2MB/s per shard shared among consumers.
Extended Data Retention: Extra cost per shard-hour for retaining data beyond 24 hours, up to 7 days. Beyond 7 days (up to 365 days), it's priced per GB-month.
Enhanced Fan-Out (EFO): An additional cost per consumer-shard-hour for dedicated read throughput (2 MB/s per shard per consumer) and per GB of data retrieved via EFO. This is ideal for multiple, high-throughput consumers.
On-Demand Capacity Mode:
Per GB of Data Written: Simpler billing based on the volume of data ingested (rounded up to the nearest 1 KB per record).
Per GB of Data Read: Charged for the volume of data retrieved (no rounding).
Per Stream Hour: A fixed hourly charge for each stream operating in on-demand mode.
Optional Features: Extended data retention and Enhanced Fan-Out incur additional charges, similar to provisioned mode but with different rates.
Automatic Scaling: KDS automatically scales capacity based on your traffic, doubling the peak write throughput of the previous 30 days.
2. Kinesis Data Firehose Pricing:
Data Ingestion: Charged per GB of data ingested into the delivery stream. Records are rounded up to the nearest 5 KB.
Format Conversion: Optional charge per GB if you convert data (e.g., JSON to Parquet/ORC).
VPC Delivery: Additional cost per GB if delivering data to a private VPC endpoint.
No charges for delivery to destinations, but standard charges for S3 storage, Redshift compute, etc., apply at the destination.
3. Kinesis Data Analytics Pricing:
Kinesis Processing Units (KPUs): Billed hourly per KPU. A KPU is a combination of compute (vCPU), memory, and runtime environment (e.g., Apache Flink).
Running Application Storage: Charged per GB-month for stateful processing features.
Developer/Interactive Mode: Additional KPUs may be charged for interactive development.
4. Kinesis Video Streams Pricing:
Data Ingestion: Charged per GB of video data ingested.
Data Storage: Charged per GB-month for stored video data.
Data Retrieval & Playback: Charged per GB for data retrieved, and additional costs for specific features like HLS (HTTP Live Streaming) or WebRTC streaming minutes.
Cost Optimization Strategies for AWS Kinesis
Optimizing your Kinesis costs requires a deep understanding of your workload and the various pricing components. Here are key strategies:
Choose the Right Kinesis Service:
Firehose for simplicity & delivery: If your primary goal is to load streaming data into a data lake or warehouse without complex real-time processing, Firehose is often the most cost-effective and easiest solution.
KDS for complex processing & multiple consumers: Use Data Streams if you need multiple applications to consume the same data independently, require precise record ordering, or need custom real-time processing logic with Kinesis Data Analytics or custom consumers.
Data Analytics for real-time insights: Use Kinesis Data Analytics when you need to perform real-time aggregations, transformations, or anomaly detection on your streams.
Optimize Kinesis Data Streams (KDS) Capacity Mode:
On-Demand for unpredictable/new workloads: Start with On-Demand if your traffic patterns are unknown, highly spiky, or if you prefer a fully managed, hands-off approach to capacity. It's generally more expensive for predictable, sustained workloads but eliminates throttling risks.
Provisioned for predictable workloads: Once your traffic patterns are stable and predictable, switch to Provisioned mode. It is often significantly cheaper for consistent, high-utilization streams.
Dynamic Switching: For very variable workloads, you can technically switch between Provisioned and On-Demand modes (up to twice every 24 hours) using automation (e.g., Lambda functions) to align with known peak and off-peak periods, maximizing cost savings.
Right-Size Your Shards (Provisioned KDS):
Monitor relentlessly: Use Amazon CloudWatch metrics (IncomingBytes, IncomingRecords, GetRecords.Bytes) to understand your stream's actual throughput.
Reshard dynamically: Continuously evaluate if your current shard count matches your data volume. Scale up (split shards) when throughput needs increase and scale down (merge shards) during low periods to avoid over-provisioning. Automate this with Lambda functions and CloudWatch alarms.
Beware of "Hot Shards": Ensure your partition keys distribute data evenly across shards. If a single key (or a few keys) sends too much data to one shard, that "hot shard" can become a bottleneck and impact performance, potentially requiring more shards than technically necessary for the overall throughput.
Optimize Data Ingestion:
Batching & Aggregation: For KDS, aggregate smaller records into larger batches (up to 1 MB per PutRecord call) before sending them. For Provisioned mode, records are billed in 25KB increments, so aim for record sizes that are multiples of 25KB to avoid wasted capacity. For Firehose, ingestion is billed in 5KB increments.
Pre-process Data: Use AWS Lambda or other processing before ingesting into Kinesis to filter out unnecessary data, reduce record size, or transform data to a more efficient format.
Manage Data Retention:
Default 24 Hours: KDS retains data for 24 hours by default, which is free. Only extend retention (up to 7 days or 365 days) if your downstream applications truly need to re-process historical data or have compliance requirements. Extended retention incurs additional costs.
Long-Term Storage: For archival or long-term analytics, deliver data to cost-effective storage like Amazon S3 via Firehose or a custom KDS consumer, rather than relying on KDS's extended retention.
Smart Consumer Design (KDS):
Enhanced Fan-Out (EFO): Use EFO judiciously. While it provides dedicated throughput and low latency per consumer, it incurs additional per-consumer-shard-hour and data retrieval costs. If you have fewer than three consumers or latency isn't critical, standard (shared) throughput might be sufficient.
Kinesis Client Library (KCL): For custom consumers, use the latest KCL versions (e.g., KCL 3.0) which offer improved load balancing across workers, potentially allowing you to process the same data with fewer compute resources (e.g., EC2 instances or Lambda concurrency).
Leverage Firehose Features:
Compression: Enable data compression (e.g., GZIP, Snappy, ZIP) within Firehose before delivery to S3 or other destinations to save on storage and transfer costs.
Format Conversion: Convert data to columnar formats like Apache Parquet or ORC using Firehose's built-in conversion. This can significantly reduce storage costs in S3 and improve query performance for analytics services like Athena or Redshift Spectrum.
Buffering: Adjust buffer size and buffer interval settings in Firehose to optimize for delivery costs and destination performance, balancing real-time needs with batching efficiency.
Conclusion
AWS Kinesis is an indispensable suite of services for building robust, real-time data streaming architectures. However, its power comes with complexity, especially in pricing. By understanding the unique billing models of each Kinesis service and implementing thoughtful optimization strategies – from choosing the right capacity mode and right-sizing shards to optimizing data ingestion and consumer patterns – you can harness the full potential of real-time data processing on AWS while keeping your cloud costs in check. Continuous monitoring and a proactive approach to resource management will be your best guides on this journey.
0 notes
Text
The Difference Between Business Intelligence and Data Analytics

Introduction
In today’s hyper-digital business world, data flows through every corner of an organization. But the value of that data is only realized when it’s converted into intelligence and ultimately, action.
That’s where Business Intelligence (BI) and Data Analytics come in. These two often-interchanged terms form the backbone of data-driven decision-making, but they serve very different purposes.
This guide unpacks the nuances between the two, helping you understand where they intersect, how they differ, and why both are critical to a future-ready enterprise.
What is Business Intelligence?
Business Intelligence is the systematic collection, integration, analysis, and presentation of business information. It focuses primarily on descriptive analytics — what happened, when, and how.
BI is built for reporting and monitoring, not for experimentation. It’s your corporate dashboard, a rearview mirror that helps you understand performance trends and operational health.
Key Characteristics of BI:
Historical focus
Dashboards and reports
Aggregated KPIs
Data visualization tools
Low-level predictive power
Examples:
A sales dashboard showing last quarter’s revenue
A report comparing warehouse efficiency across regions
A chart showing customer churn rate over time
What is Data Analytics?
Data Analytics goes a step further. It’s a broader umbrella that includes descriptive, diagnostic, predictive, and prescriptive approaches.
While BI focuses on “what happened,” analytics explores “why it happened,” “what might happen next,” and “what we should do about it.”
Key Characteristics of Data Analytics:
Exploratory in nature
Uses statistical models and algorithms
Enables forecasts and optimization
Can be used in real-time or batch processing
Often leverages machine learning and AI
Examples:
Predicting next quarter’s demand using historical sales and weather data
Analyzing clickstream data to understand customer drop-off in a sales funnel
Identifying fraud patterns in financial transactions
BI vs Analytics: Use Cases in the Real World
Let’s bring the distinction to life with practical scenarios.
Retail Example:
BI: Shows sales per store in Q4 across regions
Analytics: Predicts which product category will grow fastest next season based on external factors
Banking Example:
BI: Tracks number of new accounts opened weekly
Analytics: Detects anomalies in transactions suggesting fraud risk
Healthcare Example:
BI: Reports on patient visits by department
Analytics: Forecasts ER admission rates during flu season using historical and external data
Both serve a purpose, but together, they offer a comprehensive view of the business landscape.
Tools That Power BI and Data Analytics
Popular BI Tools:
Microsoft Power BI — Accessible and widely adopted
Tableau — Great for data visualization
Qlik Sense — Interactive dashboards
Looker — Modern BI for data teams
Zoho Analytics — Cloud-based and SME-friendly
Popular Analytics Tools:
Python — Ideal for modeling, machine learning, and automation
R — Statistical computing powerhouse
Google Cloud BigQuery — Great for large-scale data
SAS — Trusted in finance and healthcare
Apache Hadoop & Spark — For massive unstructured data sets
The Convergence of BI and Analytics
Modern platforms are increasingly blurring the lines between BI and analytics.
Tools like Power BI with Python integration or Tableau with R scripts allow businesses to blend static reporting with advanced statistical insights.
Cloud-based data warehouses like Snowflake and Databricks allow real-time querying for both purposes, from one central hub.
This convergence empowers teams to:
Monitor performance AND
Experiment with data-driven improvements
Skills and Teams: Who Does What?
Business Intelligence Professionals:
Data analysts, reporting specialists, BI developers
Strong in SQL, dashboard tools, storytelling
Data Analytics Professionals:
Data scientists, machine learning engineers, data engineers
Proficient in Python, R, statistics, modeling, and cloud tools
While BI empowers business leaders to act on known metrics, analytics helps technical teams discover unknowns.
Both functions require collaboration for maximum strategic impact.
Strategic Value for Business Leaders
BI = Operational Intelligence
Track sales, customer support tickets, cash flow, delivery timelines.
Analytics = Competitive Advantage
Predict market trends, customer behaviour, churn, or supply chain risk.
The magic happens when you use BI to steer, and analytics to innovate.
C-level insight:
CMOs use BI to measure campaign ROI, and analytics to refine audience segmentation
CFOs use BI for financial health tracking, and analytics for forecasting
CEOs rely on both to align performance with vision
How to Choose What Your Business Needs
Choose BI if:
You need faster, cleaner reporting
Business users need self-service dashboards
Your organization is report-heavy and reaction-focused
Choose Data Analytics if:
You want forward-looking insights
You need to optimize and innovate
You operate in a data-rich, competitive environment
Final Thoughts: Intelligence vs Insight
In the grand scheme, Business Intelligence tells you what’s going on, and Data Analytics tells you what to do next.
One is a dashboard; the other is a crystal ball.
As the pace of business accelerates, organizations can no longer afford to operate on gut instinct or lagging reports. They need the clarity of BI and the power of analytics together.
Because in a world ruled by data, those who turn information into insight, and insight into action, are the ones who win.
0 notes
Text
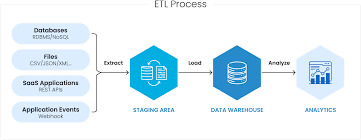
ETL at Scale: Using SSIS for Big Data Workflows
In today's data-driven world, managing and processing large volumes of data efficiently is crucial for businesses. Enter ETL (Extract, Transform, Load) processes, which play a vital role in consolidating data from various sources, transforming it into actionable insights, and loading it into target systems. This blog explores how SQL Server Integration Services (SSIS) can serve as a powerful tool for managing ETL workflows, especially when dealing with big data.
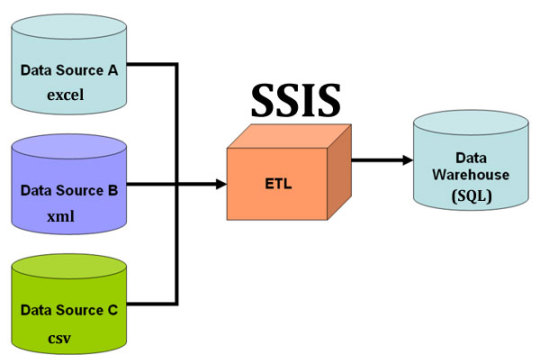
ETL Process
Introduction to ETL (Extract, Transform, Load)
ETL is a fundamental data processing task that involves three key steps:
Extract: Retrieving raw data from various sources, such as databases, flat files, or cloud services.
Transform: Cleaning, standardizing, and enriching the data to fit business needs.
Load: Ingesting the transformed data into target databases or data warehouses for analytics.
These steps are essential for ensuring data integrity, consistency, and usability across an organization.
Overview of SQL Server Integration Services (SSIS)
SSIS is a robust data integration platform from Microsoft, designed to facilitate the creation of high-performance data transformation solutions. It offers a comprehensive suite of tools for building and managing ETL workflows. Key features of SSIS include:
Graphical Interface: SSIS provides a user-friendly design interface for building complex data workflows without extensive coding.
Scalability: It efficiently handles large volumes of data, making it suitable for big data applications.
Extensibility: Users can integrate custom scripts and components to extend the functionality of SSIS packages.
Data Flow vs. Control Flow
Understanding the distinction between data flow and control flow is crucial for leveraging SSIS effectively:
Data Flow: This component manages the movement and transformation of data from sources to destinations. It involves tasks like data extraction, transformation, and loading into target systems.
Control Flow: This manages the execution workflow of ETL tasks. It includes defining the sequence of tasks, setting precedence constraints, and handling events during package execution.
SSIS allows users to orchestrate these flows to create seamless and efficient ETL processes.
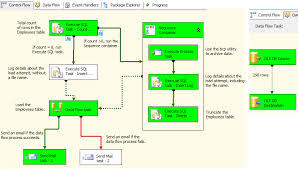
Data Flow vs. Control Flow
Integrating Data from Flat Files, Excel, and Cloud Sources
One of the strengths of SSIS is its ability to integrate data from a variety of sources. Whether you're working with flat files, Excel spreadsheets, or cloud-based data, SSIS provides connectors and adapters to streamline data integration.
Flat Files: Importing data from CSV or text files is straightforward with built-in SSIS components.
Excel: SSIS supports Excel as a data source, facilitating the extraction of data from spreadsheets for further processing.
Cloud Sources: With the rise of cloud-based services, SSIS offers connectors for platforms like Azure and AWS, enabling seamless integration of cloud data into your ETL workflows.
Integrating Data
Scheduling and Automation of ETL Tasks
Automation is key to maintaining efficient ETL processes, especially when dealing with big data. SSIS provides robust scheduling and automation capabilities through SQL Server Agent. Users can define schedules, set up alerts, and automate the execution of ETL packages, ensuring timely and consistent data processing.
By leveraging these features, organizations can minimize manual intervention, reduce errors, and ensure data is readily available for decision-making.
Frequently Asked Questions
1. What is the primary benefit of using SSIS for ETL?
SSIS provides a powerful and scalable platform for managing data integration tasks. Its graphical interface and extensive toolset make it accessible for users to build complex ETL solutions efficiently.
2. Can SSIS handle real-time data processing?
While SSIS is primarily designed for batch processing, it can integrate with real-time data sources using additional components and configurations. However, it might require advanced setup to achieve true real-time processing.
3. How does SSIS facilitate error handling in ETL processes?
SSIS offers robust error handling mechanisms, including event handlers, try-catch blocks, and logging features. These tools help identify and manage errors during ETL execution, ensuring data integrity.
4. Is SSIS suitable for cloud-based data sources?
Yes, SSIS supports integration with various cloud platforms, such as Azure and AWS, through dedicated connectors. This makes it suitable for cloud-based data processing tasks.
5. What are some best practices for optimizing SSIS performance?
To optimize SSIS performance, consider parallel processing, using SQL queries for data filtering, minimizing transformations in the data flow, and optimizing memory usage. Regular monitoring and tuning can also enhance performance.
By implementing these best practices, organizations can ensure their ETL processes are efficient and capable of handling large-scale data operations.
Home
instagram
youtube
#SSIS#DataIntegration#ETL#BigDataPipeline#SQLServerTools#DataWorkflow#Automation#SunshineDigitalServices#DataMigration#BusinessIntelligence#Instagram#Youtube
0 notes
Text
The Secret to Cracking IT Interviews: Enroll in the Best Testing Courses in Chennai
Cracking an IT interview isn’t about luck—it’s about preparation, clarity, and confidence. Whether you're a fresher just out of college or a professional looking to switch to an IT role, one thing is clear: you need the right skills and guidance to stand out. That’s where Trendnologies, known as one of the best training institutes in Chennai, plays a vital role.

If you're serious about getting placed in a top IT company, enrolling in one of the best testing courses in Chennai can give you the edge you need. But what exactly makes a course interview-focused? And how can it help you perform better during technical rounds, HR discussions, or even tough project scenarios?
Let’s break down the real secret.
Why Testing Courses Matter in Your Interview Journey
Testing is not just a technical subject—it’s a mindset. The IT industry relies heavily on software testers to ensure quality, security, and performance. Recruiters today are looking for candidates who:
Understand the basics of manual and automation testing
Can write test cases and identify bugs
Know how to use tools like Selenium
Think logically and communicate clearly
The best testing courses in Chennai focus not only on tools but also on building that problem-solving mindset required for cracking interviews.
Trendnologies: The Best Training Institute for IT Job Preparation
At Trendnologies, everything is structured around outcome-based training. From the first day, students are groomed not just to learn but to succeed in interviews. That’s why it’s recognized as one of the best testing course providers in Chennai.
What Makes Trendnologies Stand Out:
✅ Real-time trainers with industry expertise
✅ Live project exposure and mock tasks
✅ One-on-one mentoring support
✅ Interview-specific grooming sessions
✅ 100% placement support with company connections
These aren’t just features—they’re the foundation of what makes students job-ready.
What You’ll Learn That Helps in Interviews
The best testing courses in Chennai teach beyond the basics. At Trendnologies, the curriculum is carefully designed to reflect what companies ask in interviews.
You’ll learn:
✅ Manual testing concepts with examples
✅ Writing test cases and bug reports
✅ Real-time defect tracking and communication
✅ Automation tools like Selenium, TestNG, and Maven
✅ API Testing and basic SQL for backend validation
✅ Agile methodology and real-time process exposure
And most importantly, you’ll be prepared to talk about these confidently in an interview.
Interview Readiness: How Testing Courses Make a Difference
What happens after you learn the syllabus? Most students struggle with confidence or don’t know how to explain what they’ve learned. That’s why Trendnologies puts equal weight on interview preparation.
Here’s how they train you:
✅ Mock Interviews: Simulate real HR and technical rounds
✅ Communication Coaching: Learn how to explain test cases clearly
✅ Project Discussion Rounds: Practice answering scenario-based questions
✅ Resume Review: Build an ATS-friendly resume that highlights real skills
✅ HR Round Prep: Learn to speak confidently about strengths and weaknesses
These soft-skill sessions are what separate average candidates from hired ones.
Real Stories from Real Students
Trendnologies has helped hundreds of students break into IT. Here are a few examples:
Arun, a mechanical engineering graduate, cracked a testing role in a product-based company after 2 months of training.
Swetha, a fresher with zero coding background, confidently cleared interviews after attending weekend batches.
Mohan, a B.Sc graduate with a 2-year career gap, landed his first job after completing the automation testing course.
Their secret? Choosing the best testing course in Chennai that focused on placement—not just theory.
What Recruiters Look for in Testing Candidates
Recruiters aren’t always looking for coders. In testing, they want smart thinkers who can:
Identify risks and report bugs clearly
Work in Agile teams and understand sprint goals
Communicate effectively with developers and stakeholders
Demonstrate ownership in testing live modules
The best testing courses in Chennai train you exactly for this.
What Makes a Testing Course the 'Best'?
When selecting a course, look for these must-have qualities:
✅ Real-time project work
✅ Trainer interaction and live Q&A
✅ Placement assistance and interview support
✅ Recorded sessions for revision
✅ Affordable fees with EMI options
Trendnologies ticks all these boxes and has helped countless students launch their IT careers from scratch.
Tips to Crack IT Interviews After Your Testing Course
Here are some quick but powerful tips to boost your chances:
Revise core testing concepts weekly
Prepare at least 2 real-time scenarios to talk about
Practice mock interviews with friends or mentors
Stay updated on testing trends like Cypress, Playwright, etc.
Be confident, even if you don’t know every answer
Remember, interviews are not about perfection—they're about clarity and confidence.
Final Thoughts: Your Testing Journey Begins with the Right Choice
There are plenty of training centers, but only a few truly focus on making you interview-ready. If you want to build a successful career in IT, the smart move is to join one of the best testing courses in Chennai that actually prepares you for what lies ahead.
Trendnologies stands as a proven, trusted name with a strong track record of student success. With practical training, dedicated mentorship, and full placement support, it’s more than a course—it’s a complete career launchpad.
So stop preparing alone. Learn smart. Get trained the right way.
For more info: Website: www.trendnologies.com Email: [email protected] Contact us: +91 7871666962 Location: Chennai | Coimbatore | Bangalore
0 notes
Text
Master the Future: Join the Best Data Science Course in Kharadi Pune at GoDigi Infotech

In today's data-driven world, Data Science has emerged as one of the most powerful and essential skill sets across industries. Whether it’s predicting customer behavior, improving business operations, or advancing AI technologies, data science is at the core of modern innovation. For individuals seeking to build a high-demand career in this field, enrolling in a Data Science Course in Kharadi Pune is a strategic move. And when it comes to top-notch training with real-world application, GoDigi Infotech stands out as the premier destination.
Why Choose a Data Science Course in Kharadi Pune?
Kharadi, a thriving IT and business hub in Pune, is rapidly becoming a magnet for tech professionals and aspiring data scientists. Choosing a data science course in Kharadi Pune places you at the heart of a booming tech ecosystem. Proximity to leading IT parks, startups, and MNCs means students have better internship opportunities, networking chances, and job placements.
Moreover, Pune is known for its educational excellence, and Kharadi, in particular, blends professional exposure with an ideal learning environment.
GoDigi Infotech – Leading the Way in Data Science Education
GoDigi Infotech is a recognized name when it comes to professional IT training in Pune. Specializing in future-forward technologies, GoDigi has designed its Data Science Course in Kharadi Pune to meet industry standards and deliver practical knowledge that can be immediately applied in real-world scenarios.
Here’s why GoDigi Infotech is the best choice for aspiring data scientists:
Experienced Trainers: Learn from industry experts with real-time project experience.
Practical Approach: Emphasis on hands-on training, real-time datasets, and mini-projects.
Placement Assistance: Strong industry tie-ups and dedicated placement support.
Flexible Batches: Weekday and weekend options to suit working professionals and students.
Comprehensive Curriculum: Covering Python, Machine Learning, Deep Learning, SQL, Power BI, and more.
Course Highlights – What You’ll Learn
The Data Science Course at GoDigi Infotech is crafted to take you from beginner to professional. The curriculum covers:
Python for Data Science
Basic to advanced Python programming
Data manipulation using Pandas and NumPy
Data visualization using Matplotlib and Seaborn
Statistics & Probability
Descriptive statistics, probability distributions
Hypothesis testing
Inferential statistics
Machine Learning
Supervised & unsupervised learning
Algorithms like Linear Regression, Decision Trees, Random Forest, SVM, K-Means Clustering
Deep Learning
Neural networks
TensorFlow and Keras frameworks
Natural Language Processing (NLP)
Data Handling Tools
SQL for database management
Power BI/Tableau for data visualization
Excel for quick analysis
Capstone Projects
Real-life business problems
End-to-end data science project execution
By the end of the course, learners will have built an impressive portfolio that showcases their data science expertise.
Career Opportunities After Completing the Course
The demand for data science professionals is surging across sectors such as finance, healthcare, e-commerce, and IT. By completing a Data Science Course in Kharadi Pune at GoDigi Infotech, you unlock access to roles such as:
Data Scientist
Data Analyst
Machine Learning Engineer
AI Developer
Business Intelligence Analyst
Statistical Analyst
Data Engineer
Whether you are a fresh graduate or a working professional planning to shift to the tech domain, this course offers the ideal foundation and growth trajectory.
Why GoDigi’s Location in Kharadi Gives You the Edge
Being located in Kharadi, GoDigi Infotech offers unmatched advantages:
Networking Opportunities: Get access to tech meetups, seminars, and hiring events.
Internships & Live Projects: Collaborations with startups and MNCs in and around Kharadi.
Easy Accessibility: Well-connected with public transport, metro, and major roads.
Who Should Enroll in This Course?
The Data Science Course in Kharadi Pune by GoDigi Infotech is perfect for:
Final year students looking for a tech career
IT professionals aiming to upskill
Analysts or engineers looking to switch careers
Entrepreneurs and managers wanting to understand data analytics
Enthusiasts with a non-technical background willing to learn
There’s no strict prerequisite—just your interest and commitment to learning.
Visit Us: GoDigi Infotech - Google Map Location
Located in the heart of Kharadi, Pune, GoDigi Infotech is your stepping stone to a data-driven future. Explore the campus, talk to our advisors, and take the first step toward a transformative career.
Conclusion: Your Data Science Journey Begins Here
In a world where data is the new oil, the ability to analyze and act on information is a superpower. If you're ready to build a rewarding, future-proof career, enrolling in a Data Science Course in Kharadi Pune at GoDigi Infotech is your smartest move. With expert training, practical exposure, and strong placement support, GoDigi is committed to turning beginners into industry-ready data scientists.Don’t wait for opportunities—create them. Enroll today with GoDigi Infotech and turn data into your career advantage.
0 notes
Text
Master the Future of Analytics: Join the Best Data Analyst Course in Delhi & Gurgaon

In today’s digital era, where data is the new oil, businesses and organizations rely heavily on skilled professionals to extract insights from vast amounts of information. This is why data analysts are in high demand across every sector—from finance and healthcare to e-commerce and government. If you’re looking to launch a promising career in analytics, enrolling in the best data analyst course in Delhi or a data analyst course Gurgaon could be your first step toward a successful and high-paying future.
Why Choose a Career in Data Analytics?
The role of a data analyst involves collecting, processing, and analyzing data to help organizations make informed decisions. As businesses aim to become more data-driven, the need for skilled analysts continues to rise.
Key Benefits of Becoming a Data Analyst:
High demand across industries
Competitive salary packages
Remote and flexible job options
Opportunity to work on real-world business problems
Strong career growth with options to move into data science, business analysis, or AI
Best Data Analyst Course in Delhi – What to Expect
Delhi, as a hub of education and innovation, offers top-tier training programs in data analytics. Whether you are a student, a working professional, or someone looking to switch careers, the best data analyst course in delhi is designed to equip you with the essential tools and techniques.
Course Highlights:
Training in Excel, SQL, Power BI, Python, and Tableau
Hands-on experience with real-time data sets and projects
Guidance from industry experts and mentors
Certification recognized by top companies
Placement assistance with mock interviews and resume building
Who Can Join?
Freshers from any stream
IT professionals or software engineers
Working professionals from sales, marketing, or finance
Entrepreneurs and business owners
Top-Rated Data Analyst Course in Gurgaon – Learn from Industry Experts
Gurgaon, a growing IT and corporate hub, has become a hotspot for data analytics training. The data analyst course Gurgaon focuses on practical, job-oriented skills, making it ideal for individuals aiming for quick job placement.
Why Choose a Data Analyst Course in Gurgaon?
Learn from experienced trainers working in MNCs
Access to internship opportunities and live projects
Interactive online and offline sessions
Flexible batch timings – weekend and weekday options
Affordable fee structure with EMI options
Skills You Will Gain:
Data Cleaning and Preparation
Data Visualization using Tableau/Power BI
SQL for Database Management
Python for Data Analysis
Basic Statistics & Probability
Business Intelligence concepts
Communication & Reporting Skills
Certifications & Career Support
Upon completion, you receive a Data Analyst Certification that can boost your credibility and help you stand out in job applications. Top institutes in Delhi and Gurgaon also offer career support services, including:
Job referrals to partner companies
Dedicated placement cells
LinkedIn and resume optimization
Interview preparation sessions
Conclusion
Choosing the best data analyst course in delhi or enrolling in data analyst course Gurgaon can be your gateway to a rewarding career in data analytics. With the right guidance, tools, and mentorship, you can acquire industry-ready skills that employers actively seek. Don’t miss this chance to build a future-proof career in one of the fastest-growing fields in the world.
0 notes
Text
The Best Open-Source Tools for Data Science in 2025

Data science in 2025 is thriving, driven by a robust ecosystem of open-source tools that empower professionals to extract insights, build predictive models, and deploy data-driven solutions at scale. This year, the landscape is more dynamic than ever, with established favorites and emerging contenders shaping how data scientists work. Here’s an in-depth look at the best open-source tools that are defining data science in 2025.
1. Python: The Universal Language of Data Science
Python remains the cornerstone of data science. Its intuitive syntax, extensive libraries, and active community make it the go-to language for everything from data wrangling to deep learning. Libraries such as NumPy and Pandas streamline numerical computations and data manipulation, while scikit-learn is the gold standard for classical machine learning tasks.
NumPy: Efficient array operations and mathematical functions.
Pandas: Powerful data structures (DataFrames) for cleaning, transforming, and analyzing structured data.
scikit-learn: Comprehensive suite for classification, regression, clustering, and model evaluation.
Python’s popularity is reflected in the 2025 Stack Overflow Developer Survey, with 53% of developers using it for data projects.
2. R and RStudio: Statistical Powerhouses
R continues to shine in academia and industries where statistical rigor is paramount. The RStudio IDE enhances productivity with features for scripting, debugging, and visualization. R’s package ecosystem—especially tidyverse for data manipulation and ggplot2 for visualization—remains unmatched for statistical analysis and custom plotting.
Shiny: Build interactive web applications directly from R.
CRAN: Over 18,000 packages for every conceivable statistical need.
R is favored by 36% of users, especially for advanced analytics and research.
3. Jupyter Notebooks and JupyterLab: Interactive Exploration
Jupyter Notebooks are indispensable for prototyping, sharing, and documenting data science workflows. They support live code (Python, R, Julia, and more), visualizations, and narrative text in a single document. JupyterLab, the next-generation interface, offers enhanced collaboration and modularity.
Over 15 million notebooks hosted as of 2025, with 80% of data analysts using them regularly.
4. Apache Spark: Big Data at Lightning Speed
As data volumes grow, Apache Spark stands out for its ability to process massive datasets rapidly, both in batch and real-time. Spark’s distributed architecture, support for SQL, machine learning (MLlib), and compatibility with Python, R, Scala, and Java make it a staple for big data analytics.
65% increase in Spark adoption since 2023, reflecting its scalability and performance.
5. TensorFlow and PyTorch: Deep Learning Titans
For machine learning and AI, TensorFlow and PyTorch dominate. Both offer flexible APIs for building and training neural networks, with strong community support and integration with cloud platforms.
TensorFlow: Preferred for production-grade models and scalability; used by over 33% of ML professionals.
PyTorch: Valued for its dynamic computation graph and ease of experimentation, especially in research settings.
6. Data Visualization: Plotly, D3.js, and Apache Superset
Effective data storytelling relies on compelling visualizations:
Plotly: Python-based, supports interactive and publication-quality charts; easy for both static and dynamic visualizations.
D3.js: JavaScript library for highly customizable, web-based visualizations; ideal for specialists seeking full control.
Apache Superset: Open-source dashboarding platform for interactive, scalable visual analytics; increasingly adopted for enterprise BI.
Tableau Public, though not fully open-source, is also popular for sharing interactive visualizations with a broad audience.
7. Pandas: The Data Wrangling Workhorse
Pandas remains the backbone of data manipulation in Python, powering up to 90% of data wrangling tasks. Its DataFrame structure simplifies complex operations, making it essential for cleaning, transforming, and analyzing large datasets.
8. Scikit-learn: Machine Learning Made Simple
scikit-learn is the default choice for classical machine learning. Its consistent API, extensive documentation, and wide range of algorithms make it ideal for tasks such as classification, regression, clustering, and model validation.
9. Apache Airflow: Workflow Orchestration
As data pipelines become more complex, Apache Airflow has emerged as the go-to tool for workflow automation and orchestration. Its user-friendly interface and scalability have driven a 35% surge in adoption among data engineers in the past year.
10. MLflow: Model Management and Experiment Tracking
MLflow streamlines the machine learning lifecycle, offering tools for experiment tracking, model packaging, and deployment. Over 60% of ML engineers use MLflow for its integration capabilities and ease of use in production environments.
11. Docker and Kubernetes: Reproducibility and Scalability
Containerization with Docker and orchestration via Kubernetes ensure that data science applications run consistently across environments. These tools are now standard for deploying models and scaling data-driven services in production.
12. Emerging Contenders: Streamlit and More
Streamlit: Rapidly build and deploy interactive data apps with minimal code, gaining popularity for internal dashboards and quick prototypes.
Redash: SQL-based visualization and dashboarding tool, ideal for teams needing quick insights from databases.
Kibana: Real-time data exploration and monitoring, especially for log analytics and anomaly detection.
Conclusion: The Open-Source Advantage in 2025
Open-source tools continue to drive innovation in data science, making advanced analytics accessible, scalable, and collaborative. Mastery of these tools is not just a technical advantage—it’s essential for staying competitive in a rapidly evolving field. Whether you’re a beginner or a seasoned professional, leveraging this ecosystem will unlock new possibilities and accelerate your journey from raw data to actionable insight.
The future of data science is open, and in 2025, these tools are your ticket to building smarter, faster, and more impactful solutions.
#python#r#rstudio#jupyternotebook#jupyterlab#apachespark#tensorflow#pytorch#plotly#d3js#apachesuperset#pandas#scikitlearn#apacheairflow#mlflow#docker#kubernetes#streamlit#redash#kibana#nschool academy#datascience
0 notes
Text
10 Must-Have Skills for Data Engineering Jobs

In the digital economy of 2025, data isn't just valuable – it's the lifeblood of every successful organization. But raw data is messy, disorganized, and often unusable. This is where the Data Engineer steps in, transforming chaotic floods of information into clean, accessible, and reliable data streams. They are the architects, builders, and maintainers of the crucial pipelines that empower data scientists, analysts, and business leaders to extract meaningful insights.
The field of data engineering is dynamic, constantly evolving with new technologies and demands. For anyone aspiring to enter this vital domain or looking to advance their career, a specific set of skills is non-negotiable. Here are 10 must-have skills that will position you for success in today's data-driven landscape:
1. Proficiency in SQL (Structured Query Language)
Still the absolute bedrock. While data stacks become increasingly complex, SQL remains the universal language for interacting with relational databases and data warehouses. A data engineer must master SQL far beyond basic SELECT statements. This includes:
Advanced Querying: JOIN operations, subqueries, window functions, CTEs (Common Table Expressions).
Performance Optimization: Writing efficient queries for large datasets, understanding indexing, and query execution plans.
Data Definition and Manipulation: CREATE, ALTER, DROP tables, and INSERT, UPDATE, DELETE operations.
2. Strong Programming Skills (Python & Java/Scala)
Python is the reigning champion in data engineering due to its versatility, rich ecosystem of libraries (Pandas, NumPy, PySpark), and readability. It's essential for scripting, data manipulation, API interactions, and building custom ETL processes.
While Python dominates, knowledge of Java or Scala remains highly valuable, especially for working with traditional big data frameworks like Apache Spark, where these languages offer performance advantages and deeper integration.
3. Expertise in ETL/ELT Tools & Concepts
Data engineers live and breathe ETL (Extract, Transform, Load) and its modern counterpart, ELT (Extract, Load, Transform). Understanding the methodologies for getting data from various sources, cleaning and transforming it, and loading it into a destination is core.
Familiarity with dedicated ETL/ELT tools (e.g., Apache Nifi, Talend, Fivetran, Stitch) and modern data transformation tools like dbt (data build tool), which emphasizes SQL-based transformations within the data warehouse, is crucial.
4. Big Data Frameworks (Apache Spark & Hadoop Ecosystem)
When dealing with petabytes of data, traditional processing methods fall short. Apache Spark is the industry standard for distributed computing, enabling fast, large-scale data processing and analytics. Mastery of Spark (PySpark, Scala Spark) is vital for batch and stream processing.
While less prominent for direct computation, understanding the Hadoop Ecosystem (especially HDFS for distributed storage and YARN for resource management) still provides a foundational context for many big data architectures.
5. Cloud Platform Proficiency (AWS, Azure, GCP)
The cloud is the default environment for modern data infrastructures. Data engineers must be proficient in at least one, if not multiple, major cloud platforms:
AWS: S3 (storage), Redshift (data warehouse), Glue (ETL), EMR (Spark/Hadoop), Lambda (serverless functions), Kinesis (streaming).
Azure: Azure Data Lake Storage, Azure Synapse Analytics (data warehouse), Azure Data Factory (ETL), Azure Databricks.
GCP: Google Cloud Storage, BigQuery (data warehouse), Dataflow (stream/batch processing), Dataproc (Spark/Hadoop).
Understanding cloud-native services for storage, compute, networking, and security is paramount.
6. Data Warehousing & Data Lake Concepts
A deep understanding of how to structure and manage data for analytical purposes is critical. This includes:
Data Warehousing: Dimensional modeling (star and snowflake schemas), Kimball vs. Inmon approaches, fact and dimension tables.
Data Lakes: Storing raw, unstructured, and semi-structured data at scale, understanding formats like Parquet and ORC, and managing data lifecycle.
Data Lakehouses: The emerging architecture combining the flexibility of data lakes with the structure of data warehouses.
7. NoSQL Databases
While SQL handles structured data efficiently, many modern applications generate unstructured or semi-structured data. Data engineers need to understand NoSQL databases and when to use them.
Familiarity with different NoSQL types (Key-Value, Document, Column-Family, Graph) and examples like MongoDB, Cassandra, Redis, DynamoDB, or Neo4j is increasingly important.
8. Orchestration & Workflow Management (Apache Airflow)
Data pipelines are often complex sequences of tasks. Tools like Apache Airflow are indispensable for scheduling, monitoring, and managing these workflows programmatically using Directed Acyclic Graphs (DAGs). This ensures pipelines run reliably, efficiently, and alert you to failures.
9. Data Governance, Quality & Security
Building pipelines isn't enough; the data flowing through them must be trustworthy and secure. Data engineers are increasingly responsible for:
Data Quality: Implementing checks, validations, and monitoring to ensure data accuracy, completeness, and consistency. Tools like Great Expectations are gaining traction.
Data Governance: Understanding metadata management, data lineage, and data cataloging.
Data Security: Implementing access controls (IAM), encryption, and ensuring compliance with regulations (e.g., GDPR, local data protection laws).
10. Version Control (Git)
Just like software developers, data engineers write code. Proficiency with Git (and platforms like GitHub, GitLab, Bitbucket) is fundamental for collaborative development, tracking changes, managing different versions of pipelines, and enabling CI/CD practices for data infrastructure.
Beyond the Technical: Essential Soft Skills
While technical prowess is crucial, the most effective data engineers also possess strong soft skills:
Problem-Solving: Identifying and resolving complex data issues.
Communication: Clearly explaining complex technical concepts to non-technical stakeholders and collaborating effectively with data scientists and analysts.
Attention to Detail: Ensuring data integrity and pipeline reliability.
Continuous Learning: The data landscape evolves rapidly, demanding a commitment to staying updated with new tools and technologies.
The demand for skilled data engineers continues to soar as organizations increasingly rely on data for competitive advantage. By mastering these 10 essential skills, you won't just build data pipelines; you'll build the backbone of tomorrow's intelligent enterprises.
0 notes