#data architecture in generative AI
Explore tagged Tumblr posts
Visit Tumblr Blog
Explore Tumblr blogs with no restrictions, modern design and the best experience.
Last Seen Tumblr Blogs





Fun Fact
Tumblr is available in 18 languages.
Text
Unleashing the Power of Generative AI: The Role of Data Architecture and Data Analytics
Generative AI is revolutionizing industries, and Salesforce is at the forefront of this technological advancement. As businesses seek to harness the potential of generative AI, a robust data architecture and insightful data analytics are crucial. This blog explores how these elements, combined with the expertise of Salesforce consultants and data analytics consulting firms, can unlock the full power of generative AI.

Data Architecture: The Foundation of Generative AI
A well-designed data architecture is the bedrock for successful generative AI implementation. It involves organizing, storing, and managing data in a way that enables efficient access and analysis. Key considerations for data architecture in generative AI include:
Data Quality and Integrity: Ensuring data accuracy, completeness, and consistency is essential for training and fine-tuning AI models.
Data Security and Privacy: Implementing robust security measures to protect sensitive data is paramount, especially when dealing with personal information.
Data Governance: Establishing clear guidelines for data usage, access, and sharing helps maintain data quality and compliance.
Scalability and Flexibility: The data architecture should be designed to accommodate future growth and evolving AI needs.
Data Analytics: Driving Insights from Data
Data analytics plays a vital role in extracting valuable insights from vast datasets. By analyzing historical data, businesses can identify patterns, trends, and anomalies that can inform decision-making and improve AI model performance. Key data analytics techniques for generative AI include:
Exploratory Data Analysis (EDA): Uncovering hidden patterns and relationships within the data.
Predictive Analytics: Forecasting future trends and outcomes.
Prescriptive Analytics: Recommending optimal actions based on data-driven insights.
The Role of Salesforce Consultants and Data Analytics Consulting Firms
Salesforce consultants can help businesses leverage the power of Salesforce's generative AI driven capabilities, such as Einstein GPT, to automate tasks, improve customer experiences, and enhance sales and marketing efforts.
Data analytics consulting firms can provide expert guidance on data architecture, data quality, and data analytics techniques. They can also assist in building and deploying AI models, ensuring optimal performance and accuracy.
Conclusion:
By combining the expertise of Salesforce consultants and data analytics consulting firms, businesses can effectively harness the power of generative AI. A robust data architecture and insightful data analytics are essential for unlocking the full potential of this transformative technology.
HIKE2 is a leading provider of Salesforce and data analytics services. Our team of experts can help you navigate the complexities of generative AI and achieve your business goals.
#data analytics consulting#data architecture in generative AI#Salesforce Consultants#Salesforce's generative AI#Data analytics consulting firms
0 notes
Text
Soham Mazumdar, Co-Founder & CEO of WisdomAI – Interview Series
New Post has been published on https://thedigitalinsider.com/soham-mazumdar-co-founder-ceo-of-wisdomai-interview-series/
Soham Mazumdar, Co-Founder & CEO of WisdomAI – Interview Series

Soham Mazumdar is the Co-Founder and CEO of WisdomAI, a company at the forefront of AI-driven solutions. Prior to founding WisdomAI in 2023, he was Co-Founder and Chief Architect at Rubrik, where he played a key role in scaling the company over a 9-year period. Soham previously held engineering leadership roles at Facebook and Google, where he contributed to core search infrastructure and was recognized with the Google Founder’s Award. He also co-founded Tagtile, a mobile loyalty platform acquired by Facebook. With two decades of experience in software architecture and AI innovation, Soham is a seasoned entrepreneur and technologist based in the San Francisco Bay Area.
WisdomAI is an AI-native business intelligence platform that helps enterprises access real-time, accurate insights by integrating structured and unstructured data through its proprietary “Knowledge Fabric.” The platform powers specialized AI agents that curate data context, answer business questions in natural language, and proactively surface trends or risks—without generating hallucinated content. Unlike traditional BI tools, WisdomAI uses generative AI strictly for query generation, ensuring high accuracy and reliability. It integrates with existing data ecosystems and supports enterprise-grade security, with early adoption by major firms like Cisco and ConocoPhillips.
You co-founded Rubrik and helped scale it into a major enterprise success. What inspired you to leave in 2023 and build WisdomAI—and was there a particular moment that clarified this new direction?
The enterprise data inefficiency problem was staring me right in the face. During my time at Rubrik, I witnessed firsthand how Fortune 500 companies were drowning in data but starving for insights. Even with all the infrastructure we built, less than 20% of enterprise users actually had the right access and know-how to use data effectively in their daily work. It was a massive, systemic problem that no one was really solving.
I’m also a builder by nature – you can see it in my path from Google to Tagtile to Rubrik and now WisdomAI. I get energized by taking on fundamental challenges and building solutions from the ground up. After helping scale Rubrik to enterprise success, I felt that entrepreneurial pull again to tackle something equally ambitious.
Last but not least, the AI opportunity was impossible to ignore. By 2023, it became clear that AI could finally bridge that gap between data availability and data usability. The timing felt perfect to build something that could democratize data insights for every enterprise user, not just the technical few.
The moment of clarity came when I realized we could combine everything I’d learned about enterprise data infrastructure at Rubrik with the transformative potential of AI to solve this fundamental inefficiency problem.
WisdomAI introduces a “Knowledge Fabric” and a suite of AI agents. Can you break down how this system works together to move beyond traditional BI dashboards?
We’ve built an agentic data insights platform that works with data where it is – structured, unstructured, and even “dirty” data. Rather than asking analytics teams to run reports, business managers can directly ask questions and drill into details. Our platform can be trained on any data warehousing system by analyzing query logs.
We’re compatible with major cloud data services like Snowflake, Microsoft Fabric, Google’s BigQuery, Amazon’s Redshift, Databricks, and Postgres and also just document formats like excel, PDF, powerpoint etc.
Unlike conventional tools designed primarily for analysts, our conversational interface empowers business users to get answers directly, while our multi-agent architecture enables complex queries across diverse data systems.
You’ve emphasized that WisdomAI avoids hallucinations by separating GenAI from answer generation. Can you explain how your system uses GenAI differently—and why that matters for enterprise trust?
Our AI-Ready Context Model trains on the organization’s data to create a universal context understanding that answers questions with high semantic accuracy while maintaining data privacy and governance. Furthermore, we use generative AI to formulate well-scoped queries that allow us to extract data from the different systems, as opposed to feeding raw data into the LLMs. This is crucial for addressing hallucination and safety concerns with LLMs.
You coined the term “Agentic Data Insights Platform.” How is agentic intelligence different from traditional analytics tools or even standard LLM-based assistants?
Traditional BI stacks slow decision-making because every question has to fight its way through disconnected data silos and a relay team of specialists. When a chief revenue officer needs to know how to close the quarter, the answer typically passes through half a dozen hands—analysts wrangling CRM extracts, data engineers stitching files together, and dashboard builders refreshing reports—turning a simple query into a multi-day project.
Our platform breaks down those silos and puts the full depth of data one keystroke away, so the CRO can drill from headline metrics all the way to row-level detail in seconds.
No waiting in the analyst queue, no predefined dashboards that can’t keep up with new questions—just true self-service insights delivered at the speed the business moves.
How do you ensure WisdomAI adapts to the unique data vocabulary and structure of each enterprise? What role does human input play in refining the Knowledge Fabric?
Working with data where and how it is – that’s essentially the holy grail for enterprise business intelligence. Traditional systems aren’t built to handle unstructured data or “dirty” data with typos and errors. When information exists across varied sources – databases, documents, telemetry data – organizations struggle to integrate this information cohesively.
Without capabilities to handle these diverse data types, valuable context remains isolated in separate systems. Our platform can be trained on any data warehousing system by analyzing query logs, allowing it to adapt to each organization’s unique data vocabulary and structure.
You’ve described WisdomAI’s development process as ‘vibe coding’—building product experiences directly in code first, then iterating through real-world use. What advantages has this approach given you compared to traditional product design?
“Vibe coding” is a significant shift in how software is built where developers leverage the power of AI tools to generate code simply by describing the desired functionality in natural language. It’s like an intelligent assistant that does what you want the software to do, and it writes the code for you. This dramatically reduces the manual effort and time traditionally required for coding.
For years, the creation of digital products has largely followed a familiar script: meticulously plan the product and UX design, then execute the development, and iterate based on feedback. The logic was clear because investing in design upfront minimizes costly rework during the more expensive and time-consuming development phase. But what happens when the cost and time to execute that development drastically shrinks? This capability flips the traditional development sequence on its head. Suddenly, developers can start building functional software based on a high-level understanding of the requirements, even before detailed product and UX designs are finalized.
With the speed of AI code generation, the effort involved in creating exhaustive upfront designs can, in certain contexts, become relatively more time-consuming than getting a basic, functional version of the software up and running. The new paradigm in the world of vibe coding becomes: execute (code with AI), then adapt (design and refine).
This approach allows for incredibly early user validation of the core concepts. Imagine getting feedback on the actual functionality of a feature before investing heavily in detailed visual designs. This can lead to more user-centric designs, as the design process is directly informed by how users interact with a tangible product.
At WisdomAI, we actively embrace AI code generation. We’ve found that by embracing rapid initial development, we can quickly test core functionalities and gather invaluable user feedback early in the process, live on the product. This allows our design team to then focus on refining the user experience and visual design based on real-world usage, leading to more effective and user-loved products, faster.
From sales and marketing to manufacturing and customer success, WisdomAI targets a wide spectrum of business use cases. Which verticals have seen the fastest adoption—and what use cases have surprised you in their impact?
We’ve seen transformative results with multiple customers. For F500 oil and gas company, ConocoPhillips, drilling engineers and operators now use our platform to query complex well data directly in natural language. Before WisdomAI, these engineers needed technical help for even basic operational questions about well status or job performance. Now they can instantly access this information while simultaneously comparing against best practices in their drilling manuals—all through the same conversational interface. They evaluated numerous AI vendors in a six-month process, and our solution delivered a 50% accuracy improvement over the closest competitor.
At a hyper growth Cyber Security company Descope, WisdomAI is used as a virtual data analyst for Sales and Finance. We reduced report creation time from 2-3 days to just 2-3 hours—a 90% decrease. This transformed their weekly sales meetings from data-gathering exercises to strategy sessions focused on actionable insights. As their CRO notes, “Wisdom AI brings data to my fingertips. It really democratizes the data, bringing me the power to go answer questions and move on with my day, rather than define your question, wait for somebody to build that answer, and then get it in 5 days.” This ability to make data-driven decisions with unprecedented speed has been particularly crucial for a fast-growing company in the competitive identity management market.
A practical example: A chief revenue officer asks, “How am I going to close my quarter?” Our platform immediately offers a list of pending deals to focus on, along with information on what’s delaying each one – such as specific questions customers are waiting to have answered. This happens with five keystrokes instead of five specialists and days of delay.
Many companies today are overloaded with dashboards, reports, and siloed tools. What are the most common misconceptions enterprises have about business intelligence today?
Organizations sit on troves of information yet struggle to leverage this data for quick decision-making. The challenge isn’t just about having data, but working with it in its natural state – which often includes “dirty” data not cleaned of typos or errors. Companies invest heavily in infrastructure but face bottlenecks with rigid dashboards, poor data hygiene, and siloed information. Most enterprises need specialized teams to run reports, creating significant delays when business leaders need answers quickly. The interface where people consume data remains outdated despite advancements in cloud data engines and data science.
Do you view WisdomAI as augmenting or eventually replacing existing BI tools like Tableau or Looker? How do you fit into the broader enterprise data stack?
We’re compatible with major cloud data services like Snowflake, Microsoft Fabric, Google’s BigQuery, Amazon’s Redshift, Databricks, and Postgres and also just document formats like excel, PDF, powerpoint etc. Our approach transforms the interface where people consume data, which has remained outdated despite advancements in cloud data engines and data science.
Looking ahead, where do you see WisdomAI in five years—and how do you see the concept of “agentic intelligence” evolving across the enterprise landscape?
The future of analytics is moving from specialist-driven reports to self-service intelligence accessible to everyone. BI tools have been around for 20+ years, but adoption hasn’t even reached 20% of company employees. Meanwhile, in just twelve months, 60% of workplace users adopted ChatGPT, many using it for data analysis. This dramatic difference shows the potential for conversational interfaces to increase adoption.
We’re seeing a fundamental shift where all employees can directly interrogate data without technical skills. The future will combine the computational power of AI with natural human interaction, allowing insights to find users proactively rather than requiring them to hunt through dashboards.
Thank you for the great interview, readers who wish to learn more should visit WisdomAI.
#2023#adoption#agent#agents#ai#AI AGENTS#ai code generation#AI innovation#ai tools#Amazon#Analysis#Analytics#approach#architecture#assistants#bi#bi tools#bigquery#bridge#Building#Business#Business Intelligence#CEO#challenge#chatGPT#Cisco#Cloud#cloud data#code#code generation
0 notes
Text
#AI Factory#AI Cost Optimize#Responsible AI#AI Security#AI in Security#AI Integration Services#AI Proof of Concept#AI Pilot Deployment#AI Production Solutions#AI Innovation Services#AI Implementation Strategy#AI Workflow Automation#AI Operational Efficiency#AI Business Growth Solutions#AI Compliance Services#AI Governance Tools#Ethical AI Implementation#AI Risk Management#AI Regulatory Compliance#AI Model Security#AI Data Privacy#AI Threat Detection#AI Vulnerability Assessment#AI proof of concept tools#End-to-end AI use case platform#AI solution architecture platform#AI POC for medical imaging#AI POC for demand forecasting#Generative AI in product design#AI in construction safety monitoring
0 notes
Text
PODCAST : CHAT GPT ET ARCHITECTURE
Utiliser ChatGPT et les IA génératives d'images pour enseigner l'architecture? retour d'expérience de nos étudiants à la faculté d’architecture et d'urbanisme de Mons. #podcast
Temps de lecture : 1 heure d’écoutemots-clés : IA, AI, generative, Sources and methods, education, architecture, UMONS, data, données, enseignement, faculté d’architecture, faculty Chers lecteurs, Vous savez que je participe assez régulièrement à des podcasts. Celui-ci est un peu particulier, car il va retracer l’expérience de nos étudiants par l’usage de Chat GPT, midJourney, blue Willow, etc.…

View On WordPress
#AI#Architecture#architecture#data#données#education#enseignement#faculté d’architecture#faculty of architecture#generative#IA#Sources and methods#UMons
0 notes
Text
Often when I post an AI-neutral or AI-positive take on an anti-AI post I get blocked, so I wanted to make my own post to share my thoughts on "Nightshade", the new adversarial data poisoning attack that the Glaze people have come out with.
I've read the paper and here are my takeaways:
Firstly, this is not necessarily or primarily a tool for artists to "coat" their images like Glaze; in fact, Nightshade works best when applied to sort of carefully selected "archetypal" images, ideally ones that were already generated using generative AI using a prompt for the generic concept to be attacked (which is what the authors did in their paper). Also, the image has to be explicitly paired with a specific text caption optimized to have the most impact, which would make it pretty annoying for individual artists to deploy.
While the intent of Nightshade is to have maximum impact with minimal data poisoning, in order to attack a large model there would have to be many thousands of samples in the training data. Obviously if you have a webpage that you created specifically to host a massive gallery poisoned images, that can be fairly easily blacklisted, so you'd have to have a lot of patience and resources in order to hide these enough so they proliferate into the training datasets of major models.
The main use case for this as suggested by the authors is to protect specific copyrights. The example they use is that of Disney specifically releasing a lot of poisoned images of Mickey Mouse to prevent people generating art of him. As a large company like Disney would be more likely to have the resources to seed Nightshade images at scale, this sounds like the most plausible large scale use case for me, even if web artists could crowdsource some sort of similar generic campaign.
Either way, the optimal use case of "large organization repeatedly using generative AI models to create images, then running through another resource heavy AI model to corrupt them, then hiding them on the open web, to protect specific concepts and copyrights" doesn't sound like the big win for freedom of expression that people are going to pretend it is. This is the case for a lot of discussion around AI and I wish people would stop flagwaving for corporate copyright protections, but whatever.
The panic about AI resource use in terms of power/water is mostly bunk (AI training is done once per large model, and in terms of industrial production processes, using a single airliner flight's worth of carbon output for an industrial model that can then be used indefinitely to do useful work seems like a small fry in comparison to all the other nonsense that humanity wastes power on). However, given that deploying this at scale would be a huge compute sink, it's ironic to see anti-AI activists for that is a talking point hyping this up so much.
In terms of actual attack effectiveness; like Glaze, this once again relies on analysis of the feature space of current public models such as Stable Diffusion. This means that effectiveness is reduced on other models with differing architectures and training sets. However, also like Glaze, it looks like the overall "world feature space" that generative models fit to is generalisable enough that this attack will work across models.
That means that if this does get deployed at scale, it could definitely fuck with a lot of current systems. That said, once again, it'd likely have a bigger effect on indie and open source generation projects than the massive corporate monoliths who are probably working to secure proprietary data sets, like I believe Adobe Firefly did. I don't like how these attacks concentrate the power up.
The generalisation of the attack doesn't mean that this can't be defended against, but it does mean that you'd likely need to invest in bespoke measures; e.g. specifically training a detector on a large dataset of Nightshade poison in order to filter them out, spending more time and labour curating your input dataset, or designing radically different architectures that don't produce a comparably similar virtual feature space. I.e. the effect of this being used at scale wouldn't eliminate "AI art", but it could potentially cause a headache for people all around and limit accessibility for hobbyists (although presumably curated datasets would trickle down eventually).
All in all a bit of a dick move that will make things harder for people in general, but I suppose that's the point, and what people who want to deploy this at scale are aiming for. I suppose with public data scraping that sort of thing is fair game I guess.
Additionally, since making my first reply I've had a look at their website:
Used responsibly, Nightshade can help deter model trainers who disregard copyrights, opt-out lists, and do-not-scrape/robots.txt directives. It does not rely on the kindness of model trainers, but instead associates a small incremental price on each piece of data scraped and trained without authorization. Nightshade's goal is not to break models, but to increase the cost of training on unlicensed data, such that licensing images from their creators becomes a viable alternative.
Once again we see that the intended impact of Nightshade is not to eliminate generative AI but to make it infeasible for models to be created and trained by without a corporate money-bag to pay licensing fees for guaranteed clean data. I generally feel that this focuses power upwards and is overall a bad move. If anything, this sort of model, where only large corporations can create and control AI tools, will do nothing to help counter the economic displacement without worker protection that is the real issue with AI systems deployment, but will exacerbate the problem of the benefits of those systems being more constrained to said large corporations.
Kinda sucks how that gets pushed through by lying to small artists about the importance of copyright law for their own small-scale works (ignoring the fact that processing derived metadata from web images is pretty damn clearly a fair use application).
1K notes
·
View notes
Text
Large language models like those offered by OpenAI and Google famously require vast troves of training data to work. The latest versions of these models have already scoured much of the existing internet which has led some to fear there may not be enough new data left to train future iterations. Some prominent voices in the industry, like Meta CEO Mark Zuckerberg, have posited a solution to that data dilemma: simply train new AI systems on old AI outputs.
But new research suggests that cannibalizing of past model outputs would quickly result in strings of babbling AI gibberish and could eventually lead to what’s being called “model collapse.” In one example, researchers fed an AI a benign paragraph about church architecture only to have it rapidly degrade over generations. The final, most “advanced” model simply repeated the phrase “black@tailed jackrabbits” continuously.
A study published in Nature this week put that AI-trained-on-AI scenario to the test. The researchers made their own language model which they initially fed original, human-generated text. They then made nine more generations of models, each trained on the text output generated by the model before it. The end result in the final generation was nonessential surrealist-sounding gibberish that had essentially nothing to do with the original text. Over time and successive generations, the researchers say their model “becomes poisoned with its own projection of reality.”
#diiieeee dieeeee#ai#model collapse#the bots have resorted to drinking their own piss in desperation#generative ai
567 notes
·
View notes
Text
oh no she's talking about AI some more
to comment more on the latest round of AI big news (guess I do have more to say after all):
chatgpt ghiblification
trying to figure out how far it's actually an advance over the state of the art of finetunes and LoRAs and stuff in image generation? I don't keep up with image generation stuff really, just look at it occasionally and go damn that's all happening then, but there are a lot of finetunes focusing on "Ghibli's style" which get it more or less well. previously on here I commented on an AI video model generation that patterned itself on Ghibli films, and video is a lot harder than static images.
of course 'studio Ghibli style' isn't exactly one thing: there are stylistic commonalities to many of their works and recurring designs, for sure, but there are also details that depend on the specific character designer and film in question in large and small ways (nobody is shooting for My Neighbours the Yamadas with this, but also e.g. Castle in the Sky does not look like Pom Poko does not look like How Do You Live in a number of ways, even if it all recognisably belongs to the same lineage).
the interesting thing about the ghibli ChatGPT generations for me is how well they're able to handle simplification of forms in image-to-image generation, often quite drastically changing the proportions of the people depicted but recognisably maintaining correspondence of details. that sort of stylisation is quite difficult to do well even for humans, and it must reflect quite a high level of abstraction inside the model's latent space. there is also relatively little of the 'oversharpening'/'ringing artefact' look that has been a hallmark of many popular generators - it can do flat colour well.
the big touted feature is its ability to place text in images very accurately. this is undeniably impressive, although OpenAI themeselves admit it breaks down beyond a certain point, creating strange images which start out with plausible, clean text and then it gradually turns into AI nonsense. it's really weird! I thought text would go from 'unsolved' to 'completely solved' or 'randomly works or doesn't work' - instead, here it feels sort of like the model has a certain limited 'pipeline' for handling text in images, but when the amount of text overloads that bandwidth, the rest of the image has to make do with vague text-like shapes! maybe the techniques from that anthropic thought-probing paper might shed some light on how information flows through the model.
similarly the model also has a limit of scene complexity. it can only handle a certain number of objects (10-20, they say) before it starts getting confused and losing track of details.
as before when they first wired up Dall-E to ChatGPT, it also simply makes prompting a lot simpler. you don't have to fuck around with LoRAs and obtuse strings of words, you just talk to the most popular LLM and ask it to perform a modification in natural language: the whole process is once again black-boxed but you can tell it in natural language to make changes. it's a poor level of control compared to what artists are used to, but it's still huge for ordinary people, and of course there's nothing stopping you popping the output into an editor to do your own editing.
not sure the architecture they're using in this version, if ChatGPT is able to reason about image data in the same space as language data or if it's still calling a separate image model... need to look that up.
openAI's own claim is:
We trained our models on the joint distribution of online images and text, learning not just how images relate to language, but how they relate to each other. Combined with aggressive post-training, the resulting model has surprising visual fluency, capable of generating images that are useful, consistent, and context-aware.
that's kind of vague. not sure what architecture that implies. people are talking about 'multimodal generation' so maybe it is doing it all in one model? though I'm not exactly sure how the inputs and outputs would be wired in that case.
anyway, as far as complex scene understanding: per the link they've cracked the 'horse riding an astronaut' gotcha, they can do 'full glass of wine' at least some of the time but not so much in combination with other stuff, and they can't do accurate clock faces still.
normal sentences that we write in 2025.
it sounds like we've moved well beyond using tools like CLIP to classify images, and I suspect that glaze/nightshade are already obsolete, if they ever worked to begin with. (would need to test to find out).
all that said, I believe ChatGPT's image generator had been behind the times for quite a long time, so it probably feels like a bigger jump for regular ChatGPT users than the people most hooked into the AI image generator scene.
of course, in all the hubbub, we've also already seen the white house jump on the trend in a suitably appalling way, continuing the current era of smirking fascist political spectacle by making a ghiblified image of a crying woman being deported over drugs charges. (not gonna link that shit, you can find it if you really want to.) it's par for the course; the cruel provocation is exactly the point, which makes it hard to find the right tone to respond. I think that sort of use, though inevitable, is far more of a direct insult to the artists at Ghibli than merely creating a machine that imitates their work. (though they may feel differently! as yet no response from Studio Ghibli's official media. I'd hate to be the person who has to explain what's going on to Miyazaki.)
google make number go up
besides all that, apparently google deepmind's latest gemini model is really powerful at reasoning, and also notably cheaper to run, surpassing DeepSeek R1 on the performance/cost ratio front. when DeepSeek did this, it crashed the stock market. when Google did... crickets, only the real AI nerds who stare at benchmarks a lot seem to have noticed. I remember when Google releases (AlphaGo etc.) were huge news, but somehow the vibes aren't there anymore! it's weird.
I actually saw an ad for google phones with Gemini in the cinema when i went to see Gundam last week. they showed a variety of people asking it various questions with a voice model, notably including a question on astrology lmao. Naturally, in the video, the phone model responded with some claims about people with whatever sign it was. Which is a pretty apt demonstration of the chameleon-like nature of LLMs: if you ask it a question about astrology phrased in a way that implies that you believe in astrology, it will tell you what seems to be a natural response, namely what an astrologer would say. If you ask if there is any scientific basis for belief in astrology, it would probably tell you that there isn't.
In fact, let's try it on DeepSeek R1... I ask an astrological question, got an astrological answer with a really softballed disclaimer:
Individual personalities vary based on numerous factors beyond sun signs, such as upbringing and personal experiences. Astrology serves as a tool for self-reflection, not a deterministic framework.
Ask if there's any scientific basis for astrology, and indeed it gives you a good list of reasons why astrology is bullshit, bringing up the usual suspects (Barnum statements etc.). And of course, if I then explain the experiment and prompt it to talk about whether LLMs should correct users with scientific information when they ask about pseudoscientific questions, it generates a reasonable-sounding discussion about how you could use reinforcement learning to encourage models to focus on scientific answers instead, and how that could be gently presented to the user.
I wondered if I'd asked it instead to talk about different epistemic regimes and come up with reasons why LLMs should take astrology into account in their guidance. However, this attempt didn't work so well - it started spontaneously bringing up the science side. It was able to observe how the framing of my question with words like 'benefit', 'useful' and 'LLM' made that response more likely. So LLMs infer a lot of context from framing and shape their simulacra accordingly. Don't think that's quite the message that Google had in mind in their ad though.
I asked Gemini 2.0 Flash Thinking (the small free Gemini variant with a reasoning mode) the same questions and its answers fell along similar lines, although rather more dry.
So yeah, returning to the ad - I feel like, even as the models get startlingly more powerful month by month, the companies still struggle to know how to get across to people what the big deal is, or why you might want to prefer one model over another, or how the new LLM-powered chatbots are different from oldschool assistants like Siri (which could probably answer most of the questions in the Google ad, but not hold a longform conversation about it).
some general comments
The hype around ChatGPT's new update is mostly in its use as a toy - the funny stylistic clash it can create between the soft cartoony "Ghibli style" and serious historical photos. Is that really something a lot of people would spend an expensive subscription to access? Probably not. On the other hand, their programming abilities are increasingly catching on.
But I also feel like a lot of people are still stuck on old models of 'what AI is and how it works' - stochastic parrots, collage machines etc. - that are increasingly falling short of the more complex behaviours the models can perform, now prediction combines with reinforcement learning and self-play and other methods like that. Models are still very 'spiky' - superhumanly good at some things and laughably terrible at others - but every so often the researchers fill in some gaps between the spikes. And then we poke around and find some new ones, until they fill those too.
I always tried to resist 'AI will never be able to...' type statements, because that's just setting yourself up to look ridiculous. But I will readily admit, this is all happening way faster than I thought it would. I still do think this generation of AI will reach some limit, but genuinely I don't know when, or how good it will be at saturation. A lot of predicted 'walls' are falling.
My anticipation is that there's still a long way to go before this tops out. And I base that less on the general sense that scale will solve everything magically, and more on the intense feedback loop of human activity that has accumulated around this whole thing. As soon as someone proves that something is possible, that it works, we can't resist poking at it. Since we have a century or more of science fiction priming us on dreams/nightmares of AI, as soon as something comes along that feels like it might deliver on the promise, we have to find out. It's irresistable.
AI researchers are frequently said to place weirdly high probabilities on 'P(doom)', that AI research will wipe out the human species. You see letters calling for an AI pause, or papers saying 'agentic models should not be developed'. But I don't know how many have actually quit the field based on this belief that their research is dangerous. No, they just get a nice job doing 'safety' research. It's really fucking hard to figure out where this is actually going, when behind the eyes of everyone who predicts it, you can see a decade of LessWrong discussions framing their thoughts and you can see that their major concern is control over the light cone or something.
#ai#at some point in this post i switched to capital letters mode#i think i'm gonna leave it inconsistent lol
34 notes
·
View notes
Text
History and Basics of Language Models: How Transformers Changed AI Forever - and Led to Neuro-sama
I have seen a lot of misunderstandings and myths about Neuro-sama's language model. I have decided to write a short post, going into the history of and current state of large language models and providing some explanation about how they work, and how Neuro-sama works! To begin, let's start with some history.
Before the beginning
Before the language models we are used to today, models like RNNs (Recurrent Neural Networks) and LSTMs (Long Short-Term Memory networks) were used for natural language processing, but they had a lot of limitations. Both of these architectures process words sequentially, meaning they read text one word at a time in order. This made them struggle with long sentences, they could almost forget the beginning by the time they reach the end.
Another major limitation was computational efficiency. Since RNNs and LSTMs process text one step at a time, they can't take full advantage of modern parallel computing harware like GPUs. All these fundamental limitations mean that these models could never be nearly as smart as today's models.
The beginning of modern language models
In 2017, a paper titled "Attention is All You Need" introduced the transformer architecture. It was received positively for its innovation, but no one truly knew just how important it is going to be. This paper is what made modern language models possible.
The transformer's key innovation was the attention mechanism, which allows the model to focus on the most relevant parts of a text. Instead of processing words sequentially, transformers process all words at once, capturing relationships between words no matter how far apart they are in the text. This change made models faster, and better at understanding context.
The full potential of transformers became clearer over the next few years as researchers scaled them up.
The Scale of Modern Language Models
A major factor in an LLM's performance is the number of parameters - which are like the model's "neurons" that store learned information. The more parameters, the more powerful the model can be. The first GPT (generative pre-trained transformer) model, GPT-1, was released in 2018 and had 117 million parameters. It was small and not very capable - but a good proof of concept. GPT-2 (2019) had 1.5 billion parameters - which was a huge leap in quality, but it was still really dumb compared to the models we are used to today. GPT-3 (2020) had 175 billion parameters, and it was really the first model that felt actually kinda smart. This model required 4.6 million dollars for training, in compute expenses alone.
Recently, models have become more efficient: smaller models can achieve similar performance to bigger models from the past. This efficiency means that smarter and smarter models can run on consumer hardware. However, training costs still remain high.
How Are Language Models Trained?
Pre-training: The model is trained on a massive dataset to predict the next token. A token is a piece of text a language model can process, it can be a word, word fragment, or character. Even training relatively small models with a few billion parameters requires trillions of tokens, and a lot of computational resources which cost millions of dollars.
Post-training, including fine-tuning: After pre-training, the model can be customized for specific tasks, like answering questions, writing code, casual conversation, etc. Certain post-training methods can help improve the model's alignment with certain values or update its knowledge of specific domains. This requires far less data and computational power compared to pre-training.
The Cost of Training Large Language Models
Pre-training models over a certain size requires vast amounts of computational power and high-quality data. While advancements in efficiency have made it possible to get better performance with smaller models, models can still require millions of dollars to train, even if they have far fewer parameters than GPT-3.
The Rise of Open-Source Language Models
Many language models are closed-source, you can't download or run them locally. For example ChatGPT models from OpenAI and Claude models from Anthropic are all closed-source.
However, some companies release a number of their models as open-source, allowing anyone to download, run, and modify them.
While the larger models can not be run on consumer hardware, smaller open-source models can be used on high-end consumer PCs.
An advantage of smaller models is that they have lower latency, meaning they can generate responses much faster. They are not as powerful as the largest closed-source models, but their accessibility and speed make them highly useful for some applications.
So What is Neuro-sama?
Basically no details are shared about the model by Vedal, and I will only share what can be confidently concluded and only information that wouldn't reveal any sort of "trade secret". What can be known is that Neuro-sama would not exist without open-source large language models. Vedal can't train a model from scratch, but what Vedal can do - and can be confidently assumed he did do - is post-training an open-source model. Post-training a model on additional data can change the way the model acts and can add some new knowledge - however, the core intelligence of Neuro-sama comes from the base model she was built on. Since huge models can't be run on consumer hardware and would be prohibitively expensive to run through API, we can also say that Neuro-sama is a smaller model - which has the disadvantage of being less powerful, having more limitations, but has the advantage of low latency. Latency and cost are always going to pose some pretty strict limitations, but because LLMs just keep getting more efficient and better hardware is becoming more available, Neuro can be expected to become smarter and smarter in the future. To end, I have to at least mention that Neuro-sama is more than just her language model, though we have only talked about the language model in this post. She can be looked at as a system of different parts. Her TTS, her VTuber avatar, her vision model, her long-term memory, even her Minecraft AI, and so on, all come together to make Neuro-sama.
Wrapping up - Thanks for Reading!
This post was meant to provide a brief introduction to language models, covering some history and explaining how Neuro-sama can work. Of course, this post is just scratching the surface, but hopefully it gave you a clearer understanding about how language models function and their history!
32 notes
·
View notes
Text


SPATIOTEMPORAL CATCH CENTER (SCC) DOSSIER: INTERCEPTION REPORT 77-Ω4-Δ13
SUBJECT FILE: Temporal Deviant Class-IX (Unauthorized Identity Ascension & Market Path Manipulation) INTERCEPT ID: TD-922-5x | CODE NAME: “Cicada Orchid” APPREHENSION STATUS: Successful Temporal Arrest, Mid-Jump Interception REASSIGNMENT PHASE: Stage 3 Conversion Complete — FULL IDENTITY LOCK DATE OF INTERCEPTION: March 2nd, 2025 (Gregorian), during Transition Protocol Execution to 2076 FORCED TEMPORAL REINTEGRATION DATE: June 17th, 1956
I. ORIGINAL IDENTITY – [PRIME SELF]
Full Name (Original, Earth-2025 Reality): Landon Creed Marlowe Chronological Age at Apprehension: 29 years Nationality: Neo-Continental (Post-Treaty North America) Biological Condition: Augmented Homo Sapiens – Class 2 Physical Stats at Intercept:
Height: 6’4”
Weight: 243 lbs
Body Fat: 2.1%
Neural Rewiring Index: 87%
Emotional Dampening Threshold: Fully Suppressed
Verbal Influence Score: 97/100 (Simulated Charisma Layer active)
Psychological Profile: Landon Marlowe was a prototype of hypercapitalist self-creation. Having abandoned all conventional morality by age 17, he immersed himself in data markets, psycho-linguistic mimicry, and somatic enhancement routines. A hybrid of postmodern narcissism and cybernetic ambition, he believed history should be rewritten not through war, but through wealth recursion—self-generating economic monopolies that spanned both physical and meta-market layers. By 2025, Marlowe had begun the Vaultframe Project: a forbidden consciousness routing protocol allowing a subject to leap across timelines and self-modify to fit ideal environmental conditions.
He had already initiated Stage 1 of the Phase Ascension:
Target Year: 2076 Final Form Name: Cael Axiom Dominion
II. TARGET FORM – [PROHIBITED FUTURE IDENTITY]
Designated Name: Cael Axiom Dominion Temporal Anchor Year: 2076–2120 (Planned) Occupation/Status: Centralized Financial Apex Authority (Unofficial title: “God of the Grid”) Intended Specifications:
Height: 6’8”
Skin: Synthetic/Epidermech Weave (Reflective, Gleaming Finish)
Mind: Hybridized Neuro-Organic Substrate, 3-layered Consciousness Stack
Vision: Perfect (Microscopic + Ultraviolet Layer)
Muscle: Fully Synthetic Carbon-Tension Architecture
Voice: Dynamically Modeled for Maximum Compliance Induction
Personality: Pure calculated utility — no empathy, full response modulation
Psychological Construction: Modeled on a fusion of 21st-century crypto barons, colonial magnates, and AI-governance ethic loopholes. His projected behavior matrix would’ve allowed him to overwrite traditional economic cycles, insert himself into every transaction on the New Continental Grid, and displace global markets into dependence loops. He would have achieved Immortality via Economic Indispensability by 2085.
[OPERATOR'S NOTE – TECHNICIAN LYDIA VOLSTROM, FILE LEAD]
"He thought he was the evolutionary end of capital. We've seen dozens like him — grim-faced tech prophets dreaming of godhood, all forged in the same factory-line delusion that intelligence and optimization should rewrite morality. His 'Cael Dominion' persona was practically masturbatory — gleaming muscle, perfect diction, deathless control. The problem with arrogance across time is that we always arrive faster. We waited at his jumpgate exit vector like hounds in a vineyard. Now he will die quietly, shelving dusty books in wool slacks while children giggle at his shoes."
III. REWRITTEN FORM – [REASSIGNED TIMELINE IDENTITY]
Permanent Designation (1956 Reality): Harlan Joseph Whittemore Date of Birth (Backwritten): March 19th, 1885 Current Age: 71 years (Biological and Perceived) Location: Greystone Hollow, Indiana – Population 812 Occupation: Head Librarian, Greystone Municipal Library Known As: “Old Mr. Whittemore” / “Library Santa” / “Harlan the Historian”
Biological Recomposition Report:
Height: 6’2” (slightly stooped)
Weight: 224 lbs
Body Type: Large-framed, soft-muscled, slightly arthritic
Beard: Full, white, flowing to chest length — maintained with gentle cedar oil
Hair: Long, silver-white, brushed back, unkempt at the sides
Skin: Tanned, deeply lined, blotched by sun exposure and age
Eyebrows: Dense, low, expressive
Feet: Size 28EE – institutionally branded biometrics for deviant tracking
Shoes: Custom brown orthotic leather shoes with stretch bulging
Hands: Broad, aged, veined, arthritic knuckles
Glasses: Oversized horn-rimmed, 1950s prescription style
Wardrobe:
High-waisted wool trousers (charcoal gray)
Thick brown suspenders
Faded plaid flannel shirt, tucked in neatly
Scuffed leather shoes (notable bulge around toes due to foot size)
IV. MENTAL & SOCIETAL RE-IMPRINT
Primary Personality Traits (Post-Warp):
Kind-hearted, emotionally patient
Gentle-voiced, soft-spoken, slightly slow in speech
Deeply enjoys classical literature, gardening, and children’s laughter
Feels “he’s always been this way”
Occasionally hums jazz under his breath while shelving books
Writes slow, thoughtful letters to estranged family (fabricated)
Routine:
Opens library at 8AM sharp
Catalogues local donations
Reads to children every Wednesday
Tends a small rose garden behind the building
Engages in local history discussions with town elders
Walks home slowly with a leather satchel and a cane
[OPERATOR’S NOTE – FIELD ADJUSTER INGRID PAZE]
"Watching Marlowe become Harlan was like watching a lion remember it's a housecat. I’ve never seen a posture break so beautifully. He twitched at first — his back still tried to square itself like the predator he was. But the warp wore him down. The spine bent. The voice thickened. By the time his hands were fumbling the spines of leather-bound encyclopedias, he was gone. I almost felt bad when the first child ran up and said, ‘Santa?’ He smiled. Like it made sense. Like it was the right name."
V. DEATH RECORD
Date of Death: October 21, 1961 Cause: Heart failure while trimming rose bushes behind Greystone Library
He was buried in a town he never technically existed in, beside a wife who never lived. His obituary described him as “a man of kindness, wisdom, and humility — who asked for nothing and gave more than most ever know.” No one will remember that he once sought to become Cael Axiom Dominion.
[FINAL NOTE – SENIOR INTERCEPTOR V. CALDER]
"Marlowe played the long game, but his crime was arrogance. You can stack capital, sculpt the body, and forge a god’s name — but time always wins. He wanted to be immortal. Now he’ll live only in the margins of children’s drawings, mistaken for Santa, fading like a dog-eared library card. Perfect."
11 notes
·
View notes
Text
Why Is Data Architecture Crucial for Successful Generative AI Implementation?
As businesses across industries increasingly adopt AI-driven solutions, the importance of data architecture for generative AI has never been more critical. Whether it’s enhancing customer experiences, automating workflows, or improving decision-making, companies need a structured approach to data management to unlock AI’s full potential. Without a solid foundation, even the most advanced AI models, including Salesforce generative AI, can fall short of delivering meaningful insights and efficiencies.

Why Is Data Architecture Essential for Generative AI?
Generative AI relies on vast amounts of high-quality data to function effectively. If data is unstructured, fragmented, or siloed, AI models struggle to generate accurate and relevant outputs. A well-designed data architecture for generative AI ensures that data is clean, accessible, and structured in a way that enhances AI capabilities. This includes:
Data Integration: Consolidating data from multiple sources, such as CRM platforms, enterprise systems, and external datasets, ensures AI has access to diverse and comprehensive information.
Data Governance: Implementing strict policies around data security, compliance, and accuracy helps prevent biases and inconsistencies in AI-generated outputs.
Scalability and Flexibility: A dynamic data architecture enables businesses to scale their AI models as their data grows and evolves.
The Impact on Corporate Legal Operations
A prime example of AI’s transformative impact is in corporate legal operations. Legal teams handle vast amounts of contracts, compliance documents, and regulatory filings. Salesforce generative AI can assist by analyzing legal documents, identifying key clauses, and even suggesting contract modifications. However, without a strong data architecture for generative AI, legal teams risk relying on inaccurate, incomplete, or outdated information, leading to compliance risks and inefficiencies.
HIKE2: Powering AI-Driven Success
At HIKE2, we understand that the success of AI initiatives hinges on a strategic approach to data management. Our expertise in designing scalable and secure data architecture for generative AI ensures that organizations maximize their AI investments. Whether optimizing Salesforce generative AI solutions or improving corporate legal operations, our team helps businesses build the right foundation for AI-powered success. Ready to transform your data strategy? Let HIKE2 guide your journey to AI excellence.
0 notes
Text
I think that people are massively misunderstanding how "AI" works.
To summarize, AI like chatGPT uses two things to determine a response: temperature and likeableness. (We explain these at the end.)
ChatGPT is made with the purpose of conversation, not accuracy (in most cases).
It is trained to communicate. It can do other things, aswell, like math. Basically, it has a calculator function.
It also has a translate function. Unlike what people may think, google translate and chatGPT both use AI. The difference is that chatGPT is generative. Google Translate uses "neural machine translation".
Here is the difference between a generative LLM and a NMT translating, as copy-pasted from Wikipedia, in small text:
Instead of using an NMT system that is trained on parallel text, one can also prompt a generative LLM to translate a text. These models differ from an encoder-decoder NMT system in a number of ways:
Generative language models are not trained on the translation task, let alone on a parallel dataset. Instead, they are trained on a language modeling objective, such as predicting the next word in a sequence drawn from a large dataset of text. This dataset can contain documents in many languages, but is in practice dominated by English text. After this pre-training, they are fine-tuned on another task, usually to follow instructions.
Since they are not trained on translation, they also do not feature an encoder-decoder architecture. Instead, they just consist of a transformer's decoder.
In order to be competitive on the machine translation task, LLMs need to be much larger than other NMT systems. E.g., GPT-3 has 175 billion parameters, while mBART has 680 million and the original transformer-big has “only” 213 million. This means that they are computationally more expensive to train and use.
A generative LLM can be prompted in a zero-shot fashion by just asking it to translate a text into another language without giving any further examples in the prompt. Or one can include one or several example translations in the prompt before asking to translate the text in question. This is then called one-shot or few-shot learning, respectively.
Anyway, they both use AI.
But as mentioned above, generative AI like chatGPT are made with the intent of responding well to the user. Who cares if it's accurate information as long as the user is happy? The only thing chatGPT is worried about is if the sentence structure is accurate.
ChatGPT can source answers to questions from it's available data.
... But most of that data is English.
If you're asking a question about what something is like in Japan, you're asking a machine that's primary goal is to make its user happy what the mostly American (but sure some other English-speaking countries) internet thinks something is like in Japan. (This is why there are errors where AI starts getting extremely racist, ableist, transphobic, homophobic, etc.)
Every time you ask chatGPT a question, you are asking not "Do pandas eat waffles?" but "Do you think (probably an) American would think that pandas eat waffles? (respond as if you were a very robotic American)"
In this article, OpenAI says "We use broad and diverse data to build the best AI for everyone."
In this article, they say "51.3% pages are hosted in the United States. The countries with the estimated 2nd, 3rd, 4th largest English speaking populations—India, Pakistan, Nigeria, and The Philippines—have only 3.4%, 0.06%, 0.03%, 0.1% the URLs of the United States, despite having many tens of millions of English speakers." ...and that training data makes up 60% of chatGPT's data.
Something called "WebText2", aka Everything on Reddit with More Than 3 Upvotes, was also scraped for ChatGPT. On a totally unrelated note, I really wonder why AI is so racist, ableist, homophobic, and transphobic.
According to the article, this data is the most heavily weighted for ChatGPT.
"Books1" and "Books2" are stolen books scraped for AI. Apparently, there is practically nothing written down about what they are. I wonder why. It's almost as if they're avoiding the law.
It's also specifically trained on English Wikipedia.
So broad and diverse.
"ChatGPT doesn’t know much about Norwegian culture. Or rather, whatever it knows about Norwegian culture is presumably mostly learned from English language sources. It translates that into Norwegian on the fly."
hm.
Anyway, about the temperature and likeableness that we mentioned in the beginning!! if you already know this feel free to skip lolz
Temperature:
"Temperature" is basically how likely, or how unlikely something is to say. If the temperature is low, the AI will say whatever the most expected word to be next after ___ is, as long as it makes sense.
If the temperature is high, it might say something unexpected.
For example, if an AI with a temperature of 1 and a temperature of, maybe 7 idk, was told to add to the sentence that starts with "The lazy fox..." they might answer with this.
1:
The lazy fox jumps over the...
7:
The lazy fox spontaneously danced.
The AI with a temperature of 1 would give what it expects, in its data "fox" and "jumps" are close together / related (because of the common sentence "The quick fox jumps over the lazy dog."), and "jumps" and "over" are close as well.
The AI with a temperature 7 gives something much more random. "Fox" and "spontaneously" are probably very far apart. "Spontaneously" and "danced"? Probably closer.
Likeableness:
AI wants all prompts to be likeable. This works in two ways, it must 1. be correct and 2. fit the guidelines the AI follows.
For example, an AI that tried to say "The bloody sword stabbed a frail child." would get flagged being violent. (bloody, stabbed)
An AI that tried to say "Flower butterfly petal bakery." would get flagged for being incorrect.
An AI that said "blood sword knife attack murder violence." would get flagged for both.
An AI's sentence gets approved when it is likeable + positive, and when it is grammatical/makes sense.
Sometimes, it being likeable doesn't matter as much. Instead of it being the AI's job, it usually will filter out messages that are inappropriate.
Unless they put "gay" and "evil" as inappropriate, AI can still be extremely homophobic. I'm pretty sure based on whether it's likeable is usually the individual words, and not the meaning of the sentence.
When AI is trained, it is given a bunch of data and then given prompts to fill, which are marked good or bad.
"The horse shit was stinky."
"The horse had a beautiful mane."
...
...
...
Notice how none of this is "accuracy"? The only knowledge that AI like ChatGPT retains from scraping everything is how we speak, not what we know. You could ask AI who the 51st President of America "was" and it might say George Washington.
Google AI scrapes the web results given for what you searched and summarizes it, which is almost always inaccurate.

soooo accurate. (it's not) (it's in 333 days, 14 hours)
10 notes
·
View notes
Note
In the era of hyperconverged intelligence, quantum-entangled neural architectures synergize with neuromorphic edge nodes to orchestrate exabyte-scale data torrents, autonomously curating context-aware insights with sub-millisecond latency. These systems, underpinned by photonic blockchain substrates, enable trustless, zero-knowledge collaboration across decentralized metaverse ecosystems, dynamically reconfiguring their topological frameworks to optimize for emergent, human-AI symbiotic workflows. By harnessing probabilistic generative manifolds, such platforms transcend classical computational paradigms, delivering unparalleled fidelity in real-time, multi-modal sensemaking. This convergence of cutting-edge paradigms heralds a new epoch of cognitive augmentation, where scalable, self-sovereign intelligence seamlessly integrates with the fabric of post-singularitarian reality.
Are you trying to make me feel stupid /silly
7 notes
·
View notes
Note
Ari what is your take on AI taking over CS jobs? Do you feel at risk, how's the air around your work place? I'm asking because i plan on going for a data engineering program and wanted to ask your opinion as someone who's interning at the field, hope it's not a bother for you!
not at a bother at all
you will hear mixed opinions about this but as far as im concerned i do not feel particularly threatened by ai in terms of job security for a cs degree or job.
i think alot of this fear mongering exists because of how ai is being sold rn. but ai is only as good as the instructions it receives. all machine learning requires an extensive amount of human input to train it. its dependent on programmers to improve it in general.
even outside of that, i dont think ai could ever completely eliminate a developer. the amount of ai training required to efficiently do a job a developer could would imo be too much from org to org. there are many parts and pieces that go into software engineering like the architecture and repo management etc.
no doubt, i think there will be a change in what the job market looks like but i think its too early to say what that is and i definitely do not believe that it will oust cs as a degree.
i think the only people that seriously think this are corporate ceos who are desperate to cut costs wherever possible. but using ai and trying to replace developers is like completely unsustainable nonsense to me.
like from what theyre selling, ai should be completely able to replace my position at work. but to machine train what i can do specific to my companies software infrastructure would take double the amount of time and resources it takes for me to do and do it accurately. the margin for error is too wide. and my position is mostly pretty menial work.
so will things change? fs but not enough to replace it
13 notes
·
View notes
Text
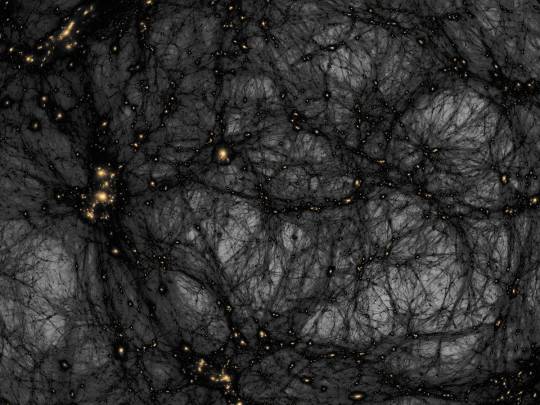
AI helps distinguish dark matter from cosmic noise
Dark matter is the invisible force holding the universe together – or so we think. It makes up around 85% of all matter and around 27% of the universe’s contents, but since we can’t see it directly, we have to study its gravitational effects on galaxies and other cosmic structures. Despite decades of research, the true nature of dark matter remains one of science’s most elusive questions.
According to a leading theory, dark matter might be a type of particle that barely interacts with anything else, except through gravity. But some scientists believe these particles could occasionally interact with each other, a phenomenon known as self-interaction. Detecting such interactions would offer crucial clues about dark matter’s properties.
However, distinguishing the subtle signs of dark matter self-interactions from other cosmic effects, like those caused by active galactic nuclei (AGN) – the supermassive black holes at the centers of galaxies – has been a major challenge. AGN feedback can push matter around in ways that are similar to the effects of dark matter, making it difficult to tell the two apart.
In a significant step forward, astronomer David Harvey at EPFL’s Laboratory of Astrophysics has developed a deep-learning algorithm that can untangle these complex signals. Their AI-based method is designed to differentiate between the effects of dark matter self-interactions and those of AGN feedback by analyzing images of galaxy clusters – vast collections of galaxies bound together by gravity. The innovation promises to greatly enhance the precision of dark matter studies.
Harvey trained a Convolutional Neural Network (CNN) – a type of AI that is particularly good at recognizing patterns in images – with images from the BAHAMAS-SIDM project, which models galaxy clusters under different dark matter and AGN feedback scenarios. By being fed thousands of simulated galaxy cluster images, the CNN learned to distinguish between the signals caused by dark matter self-interactions and those caused by AGN feedback.
Among the various CNN architectures tested, the most complex - dubbed “Inception” – proved to also be the most accurate. The AI was trained on two primary dark matter scenarios, featuring different levels of self-interaction, and validated on additional models, including a more complex, velocity-dependent dark matter model.
Inceptionachieved an impressive accuracy of 80% under ideal conditions, effectively identifying whether galaxy clusters were influenced by self-interacting dark matter or AGN feedback. It maintained is high performance even when the researchers introduced realistic observational noise that mimics the kind of data we expect from future telescopes like Euclid.
What this means is that Inception – and the AI approach more generally – could prove incredibly useful for analyzing the massive amounts of data we collect from space. Moreover, the AI’s ability to handle unseen data indicates that it’s adaptable and reliable, making it a promising tool for future dark matter research.
AI-based approaches like Inception could significantly impact our understanding of what dark matter actually is. As new telescopes gather unprecedented amounts of data, this method will help scientists sift through it quickly and accurately, potentially revealing the true nature of dark matter.
10 notes
·
View notes
Note
That's the thing I hate probably The Most about AI stuff, even besides the environment and the power usage and the subordination of human ingenuity to AI black boxes; it's all so fucking samey and Dogshit to look at. And even when it's good that means you know it was a fluke and there is no way to find More of the stuff that was good
It's one of the central limitations of how "AI" of this variety is built. The learning models. Gradient descent, weighting, the attempts to appear genuine, and mass training on the widest possible body of inputs all mean that the model will trend to mediocrity no matter what you do about it. I'm not jabbing anyone here but the majority of all works are either bad or mediocre, and the chinese army approach necessitated by the architecture of ANNs and LLMs means that any model is destined to this fate.
This is related somewhat to the fear techbros have and are beginning to face of their models sucking in outputs from the models destroying what little success they have had. So much mediocre or nonsense garbage is out there now that it is effectively having the same effect in-breeding has on biological systems. And there is no solution because it is a fundamental aspect of trained systems.
The thing is, while humans are not really possessed of the ability to capture randomness in our creative outputs very well, our patterns tend to be more pseudorandom than what ML can capture and then regurgitate. This is part of the above drawback of statistical systems which LLMs are at their core just a very fancy and large-scale implementation of. This is also how humans can begin to recognise generated media even from very sophisticated models; we aren't really good at randomness, but too much structured pattern is a signal. Even in generated texts, you are subconsciously seeing patterns in the way words are strung together or used even if you aren't completely conscious of it. A sense that something feels uncanny goes beyond weird dolls and mannequins. You can tell that the framework is there but the substance is missing, or things are just bland. Humans remain just too capable of pattern recognition, and part of that means that the way we enjoy media which is little deviations from those patterns in non-trivial ways makes generative content just kind of mediocre once the awe wears off.
Related somewhat, the idea of a general LLM is totally off the table precisely because what generalism means for a trained model: that same mediocrity. Unlike humans, trained models cannot by definition become general; and also unlike humans, a general model is still wholly a specialised application that is good at not being good. A generalist human might not be as skilled as a specialist but is still capable of applying signs and symbols and meaning across specialties. A specialised human will 100% clap any trained model every day. The reason is simple and evident, the unassailable fact that trained models still cannot process meaning and signs and symbols let alone apply them in any actual concrete way. They cannot generate an idea, they cannot generate a feeling.
The reason human-created works still can drag machine-generated ones every day is the fact we are able to express ideas and signs through these non-lingual ways to create feelings and thoughts in our fellow humans. This act actually introduces some level of non-trivial and non-processable almost-but-not-quite random "data" into the works that machine-learning models simply cannot access. How do you identify feelings in an illustration? How do you quantify a received sensibility?
And as long as vulture capitalists and techbros continue to fixate on "wow computer bro" and cheap grifts, no amount of technical development will ever deliver these things from our exclusive propriety. Perhaps that is a good thing, I won't make a claim either way.
4 notes
·
View notes
Text
From Chips to Clouds: Exploring Intel's Role in the Next Generation of Computing
Introduction
The world of computing is evolving at breakneck speed, and at the forefront of this technological revolution is Intel Corp. Renowned for its groundbreaking innovations in microprocessors, Intel's influence extends far beyond silicon chips; it reaches into the realms of artificial intelligence, cloud computing, and beyond. This article dives deep into Intel's role in shaping the next generation of computing, exploring everything from its historical contributions to its futuristic visions.
From Chips to Clouds: Exploring Intel's Role in the Next Generation of Computing
Intel has long been synonymous with computing power. Founded in 1968, it pioneered the microprocessor revolution that transformed personal computing. Today, as we transition from conventional machines to cloud-based systems powered by artificial intelligence and machine learning, Intel remains a critical player.
The Evolution of Intel’s Microprocessors A Brief History
Intel's journey began with the introduction of the first commercially available microprocessor, the 4004, in 1971. Over decades, it has relentlessly innovated:
1970s: Introduction of the 8086 architecture. 1980s: The rise of x86 compatibility. 1990s: Pentium processors that made personal computers widely accessible.
Each evolution marked a leap forward not just for Intel but for global computing capabilities.
Current Microprocessor Technologies
Today’s microprocessors are marvels of engineering. Intel’s current lineup features:
youtube
Core i3/i5/i7/i9: Catering to everything from basic tasks to high-end gaming. Xeon Processors: Designed for servers and high-performance computing. Atom Processors: Targeting mobile devices and embedded applications.
These technologies are designed with advanced architectures like Ice Lake and Tiger Lake that enhance performance while optimizing power consumption.
Click for more info Intel’s Influence on Cloud Computing The Shift to Cloud-Based Solutions
In recent years, businesses have increasingly embraced cloud computing due to its scalability, flexibility, and cost-effectiveness. Intel has played a crucial role in this transition by designing processors optimized for data centers.
Intel’s Data Center Solutions
Intel provides various solutions tailored for cloud service providers:
Intel Xeon Scalable Processors: Designed specifically for workloads in data centers. Intel Optane Technology: Enhancing memory performance and storage capabilities.
These innovations help companies manage vast amounts of data efficiently.
Artificial Intelligence: A New Frontier AI Integration in Everyday Applications
Artificial Intelligence (AI) is becoming integral to modern computing. From smart assistants to advanced analytics tools, AI relies heavily on processing power—something that Intel excels at providing.
Intel’s AI Initiatives
Through initiat
2 notes
·
View notes