#data extraction data collection
Explore tagged Tumblr posts
Visit Tumblr Blog
Explore Tumblr blogs with no restrictions, modern design and the best experience.
Last Seen Tumblr Blogs





Fun Fact
Celebrities use Tumblr as well.
Text
it’s crazy like actually insane that i can’t find historical demographic analyses of childlessness rates among women of any time period before the 1800s. that seems like it should be such a interesting illustrative statistic in and of itself but also as an indicator of broader social/economic/religious/political/environmental conditions. it’s a statistic that establishes something entirely distinct from what you get out of an average birth rate...
OK NVM post kind of cancelled i'm finding a couple articles. but nothing that's really what i'm looking for/what i'd be wanting answers to. w/e do i sound insane/is this already obvious
#like they're bringing it up as something that was discussed/understood in the period but not how frequent it was and what factors informed#its presence#like there are time periods in many locations prior to the late modern period that would theoretically have administrative#records/census data collection that you could use to extract this statistic/analysis. i wonder if my jstor/school#library searches just aren't properly describing what i'm thinking of.#sorry. im high#a
4 notes
·
View notes
Text
🛒 Extract Grocery Store Product Prices in the USA for Smarter Retail Decisions

In today’s hyper-competitive #retail landscape, real-time access to grocery pricing data is essential. With advanced #WebScrapingSolutions, businesses can:
✅ Monitor dynamic #pricing across major U.S. supermarkets
✅ Analyze competitor strategies in real-time
✅ Identify #consumerbehavior and seasonal purchase patterns
✅ Optimize #inventorymanagement and promotional campaigns
✅ Uncover regional #pricevariations and #demandtrends
From #FMCG brands to #retailers, #CPG manufacturers to #dataanalytics firms—grocery data fuels sharper insights and better business moves.
📈 Make smarter retail decisions. Gain your edge.
0 notes
Text

When self-described “ocean custodian” Boyan Slat took the stage at TED 2025 in Vancouver this week, he showed viewers a reality many of us are already heartbreakingly familiar with: There is a lot of trash in the ocean.
“If we allow current trends to continue, the amount of plastic that’s entering the ocean is actually set to double by 2060,” Slat said in his TED Talk, which will be published online at a later date.
Plus, once plastic is in the ocean, it accumulates in “giant circular currents” called gyres, which Slat said operate a lot like the drain of the bathtub, meaning that plastic can enter these currents but cannot leave.
That’s how we get enormous build-ups like the Great Pacific Garbage Patch, a giant collection of plastic pollution in the ocean that is roughly twice the size of Texas.
As the founder and CEO of The Ocean Cleanup, Slat’s goal is to return our oceans to their original, clean state before 2040. To accomplish this, two things must be done.
First: Stop more plastic from entering the ocean. Second: Clean up the “legacy” pollution that is already out there and doesn’t go away by itself.
And Slat is well on his way.

Pictured: Kingston Harbour in Jamaica. Photo courtesy of The Ocean Cleanup Project
When Slat’s first TEDx Talk went viral in 2012, he was able to organize research teams to create the first-ever map of the Great Pacific Garbage Patch. From there, they created a technology to collect plastic from the most garbage-heavy areas in the ocean.
“We imagined a very long, u-shaped barrier … that would be pushed by wind and waves,” Slat explained in his Talk.
This barrier would act as a funnel to collect garbage and be emptied out for recycling.
But there was a problem.
“We took it out in the ocean, and deployed it, and it didn’t collect plastic,” Slat said, “which is a pretty important requirement for an ocean cleanup system.”
Soon after, this first system broke into two. But a few days later, his team was already back to the drawing board.
From here, they added vessels that would tow the system forward, allowing it to sweep a larger area and move more methodically through the water. Mesh attached to the barrier would gather plastic and guide it to a retention area, where it would be extracted and loaded onto a ship for sorting, processing, and recycling.
It worked.
“For 60 years, humanity had been putting plastic into the ocean, but from that day onwards, we were also taking it back out again,” Slat said, with a video of the technology in action playing on screen behind him.
To applause, he said: “It’s the most beautiful thing I’ve ever seen, honestly.”
Over the years, Ocean Cleanup has scaled up this cleanup barrier, now measuring almost 2.5 kilometers — or about 1.5 miles — in length. And it cleans up an area of the ocean the size of a football field every five seconds.

Pictured: The Ocean Cleanup's System 002 deployed in the Great Pacific Garbage Patch. Photo courtesy of The Ocean Cleanup
The system is designed to be safe for marine life, and once plastic is brought to land, it is recycled into new products, like sunglasses, accessories for electric vehicles, and even Coldplay’s latest vinyl record, according to Slat.
These products fund the continuation of the cleanup. The next step of the project is to use drones to target areas of the ocean that have the highest plastic concentration.
In September 2024, Ocean Cleanup predicted the Patch would be cleaned up within 10 years.
However, on April 8, Slat estimated “that this fleet of systems can clean up the Great Pacific Garbage Patch in as little as five years’ time.”
With ongoing support from MCS, a Netherlands-based Nokia company, Ocean Cleanup can quickly scale its reliable, real-time data and video communication to best target the problem.
It’s the largest ocean cleanup in history.
But what about the plastic pollution coming into the ocean through rivers across the world? Ocean Cleanup is working on that, too.
To study plastic pollution in other waterways, Ocean Cleanup attached AI cameras to bridges, measuring the flow of trash in dozens of rivers around the world, creating the first global model to predict where plastic is entering oceans.
“We discovered: Just 1% of the world’s rivers are responsible for about 80% of the plastic entering our oceans,” Slat said.
His team found that coastal cities in middle-income countries were primarily responsible, as people living in these areas have enough wealth to buy things packaged in plastic, but governments can’t afford robust waste management infrastructure.
Ocean Cleanup now tackles those 1% of rivers to capture the plastic before it reaches oceans.

Pictured: Interceptor 007 in Los Angeles. Photo courtesy of The Ocean Cleanup
“It’s not a replacement for the slow but important work that’s being done to fix a broken system upstream,” Slat said. “But we believe that tackling this 1% of rivers provides us with the only way to rapidly close the gap.”
To clean up plastic waste in rivers, Ocean Cleanup has implemented technology called “interceptors,” which include solar-powered trash collectors and mobile systems in eight countries worldwide.
In Guatemala, an interceptor captured 1.4 million kilograms (or over 3 million pounds) of trash in under two hours. Now, this kind of collection happens up to three times a week.
“All of that would have ended up in the sea,” Slat said.
Now, interceptors are being brought to 30 cities around the world, targeting waterways that bring the most trash into our oceans. GPS trackers also mimic the flow of the plastic to help strategically deploy the systems for the most impact.
“We can already stop up to one-third of all the plastic entering our oceans once these are deployed,” Slat said.
And as soon as he finished his Talk on the TED stage, Slat was told that TED’s Audacious Project would be funding the deployment of Ocean Cleanup’s efforts in those 30 cities as part of the organization’s next cohort of grantees.
While it is unclear how much support Ocean Cleanup will receive from the Audacious Project, Head of TED Chris Anderson told Slat: “We’re inspired. We’re determined in this community to raise the money you need to make that 30-city project happen.”
And Slat himself is determined to clean the oceans for good.
“For humanity to thrive, we need to be optimistic about the future,” Slat said, closing out his Talk.
“Once the oceans are clean again, it can be this example of how, through hard work and ingenuity, we can solve the big problems of our time.”
-via GoodGoodGood, April 9, 2025
#ocean#oceans#plastic#plastic pollution#ocean cleanup#ted talks#boyan slat#climate action#climate hope#hopepunk#pollution#environmental issues#environment#pacific ocean#rivers#marine life#good news#hope
6K notes
·
View notes
Text
An Affordable and Quick Solution for B2B Businesses
An Affordable and Quick Solution for B2B Businesses
Target your high-potential prospect: First, you will need to target your prospect who might be your customer. You can research your market to target a high-potential prospect. Based on your target market you can target your right prospect. This is a very important process because a prospect can convert into a customer. If you target high-potential prospects you can convert them easily with an easy process. That can help you increase your sales quickly. You can hire a top-rated agency to market research and target high-potential prospects for you.
Gather Contact Information of your high-potential prospects: After targeting your high-potential prospects, you will need to gather their contact information, such as Phone numbers, Email addresses, etc. Using this information, you can reach out to them with your Services or Products and offer them. You can get many individuals or agencies on your side who build contact lists, email lists, and prospect lists based on your target audience. You can hire them to build a prospect contact list based on your targeted audience.

#List Building#Data Entry#Data Scraping#Lead Generation#Contact List#Data Mining#Data Extraction#Data Collection#Prospect List#Accuracy Verification#LinkedIn Sales Navigator#Sales Lead Lists#Virtual Assistance#Error Detection#Market Research#B2B business growth solution.#b2blead#salesleads#emaillist#contactlist#prospectlist#salesboost#businessgrowth#b2b
1 note
·
View note
Text
Data Collection and Data Extraction are essential in modern data management. Data Collection involves gathering information from various sources for analysis, while Data Extraction refers to retrieving specific data from large datasets. Both processes are crucial for informed decision-making, enhancing business strategies, and improving operational efficiency. Understanding these concepts can help organizations effectively harness their data for better outcomes. Learn more about their differences and benefits from a Data Collection Consultant’s perspective.
#data extraction#data extraction services#data collection#data collection company#data collection services
0 notes
Text
How to Leverage Travel Reviews Data Scraping to Collect Travel Reviews?
Use travel reviews data scraping to efficiently gather and analyze valuable feedback, enhancing decision-making and customer experiences.
In the fast-paced world of travel and hospitality, customer feedback reigns supreme. Travel reviews provide invaluable insights into the preferences, experiences, and expectations of travelers, shaping the decisions of prospective guests and influencing the reputation of hotels, airlines, and other travel-related businesses.
#Travel Reviews Data Scraping#Travel Reviews Data Collection#Extracting travel reviews data#Extract travel reviews data
0 notes
Text
5 Best Data Analytics Certifications (June 2024)
New Post has been published on https://thedigitalinsider.com/5-best-data-analytics-certifications-june-2024/
5 Best Data Analytics Certifications (June 2024)
Having a strong foundation in data analytics is crucial for professionals seeking to advance their careers and make a meaningful impact in their organizations. With the growing demand for data analytics skills, numerous certifications have emerged to validate individuals’ expertise and set them apart in the job market. In this article, we will explore some of the best data analytics certifications available, each offering a unique blend of comprehensive training, hands-on experience, and industry recognition.
DataCamp offers a wide range of Data Analysis courses designed specifically for beginners, providing a solid foundation in the essential skills and tools needed to start a career in data analysis. These courses assume no prior experience and guide learners through the basics of data analysis using popular programming languages like Python and R, as well as essential tools such as Excel, SQL, and Tableau. With a focus on hands-on learning, DataCamp’s beginner courses ensure that learners gain practical experience from day one in their pursuit of a certificate.
The beginner-friendly courses cover a broad spectrum of topics, including data manipulation, data cleaning, exploratory data analysis, data visualization, and basic statistics. Learners engage with interactive exercises and real-world datasets, allowing them to apply their newly acquired skills in a practical context. The courses are taught by experienced instructors who break down complex concepts into easily digestible lessons, ensuring that even those with no prior experience can follow along and make steady progress.
DataCamp’s beginner Data Analysis courses are self-paced and flexible, allowing learners to fit learning into their schedules. Many of these courses are part of larger skill tracks and career tracks, providing learners with a clear roadmap for progressing from beginner to intermediate and advanced levels. By completing these beginner courses, learners build a strong foundation in data analysis and gain the confidence to tackle more complex projects and advance their careers in this exciting field.
Key components of DataCamp’s Data Analysis courses:
No prior experience required, guiding learners through the basics of data analysis using Python, R, Excel, SQL, and Tableau
Hands-on learning with interactive exercises and real-world datasets, allowing learners to gain practical experience
Broad coverage of essential topics, including data manipulation, cleaning, exploratory analysis, visualization, and basic statistics
Taught by experienced instructors who break down complex concepts into easily digestible lessons
Self-paced and flexible learning, with many courses part of larger skill tracks and career tracks for continued growth
IBM’s Introduction to Data Analytics course on Coursera provides a comprehensive introduction to the field of data analysis. The course is designed for beginners and does not require any prior experience in data analysis or programming. It aims to equip learners with a solid foundation in data analytics concepts, tools, and processes, preparing them for further learning and potential careers in the field.
The course is part of IBM’s Data Analyst Professional Certificate program, which consists of nine courses that cover various aspects of data analysis, from the basics to more advanced topics. Introduction to Data Analytics serves as the first course in this series, setting the stage for the subsequent courses. It is also included in other IBM programs, such as the Data Analysis and Visualization Foundations Specialization and the IBM Data Analytics with Excel and R Professional Certificate.
Throughout the course, learners engage with a variety of learning materials, including video lectures, readings, quizzes, and hands-on labs. The course culminates in a peer-reviewed final project, where learners apply their newly acquired knowledge to a real-world scenario. Upon completion, learners gain a clear understanding of the data analytics process, the roles and responsibilities of data professionals, and the various tools and technologies used in the field.
Key components of IBM’s Introduction to Data Analytics course:
Comprehensive introduction to data analytics concepts, tools, and processes
Part of IBM’s Data Analyst Professional Certificate program and other IBM offerings
Designed for beginners, with no prior experience required
Engaging learning materials, including video lectures, readings, quizzes, and hands-on labs
Peer-reviewed final project that applies course knowledge to a real-world scenario
Google’s Data Analytics Professional Certificate on Coursera is a comprehensive program designed to prepare individuals for a career in the high-growth field of data analytics. The certificate is suitable for beginners, with no prior experience or degree required. It aims to equip learners with in-demand skills and provide them with opportunities to connect with top employers in the industry.
The program consists of eight courses that cover various aspects of data analytics, including data collection, cleaning, analysis, visualization, and presentation. Learners gain hands-on experience with popular tools and platforms such as spreadsheets, SQL, Tableau, and R programming. The content is highly interactive and exclusively developed by Google employees with extensive experience in data analytics.
Throughout the program, learners engage with a mix of videos, assessments, and hands-on labs that simulate real-world data analytics scenarios. The certificate also includes a case study that learners can share with potential employers to showcase their newly acquired skills. Upon completion, graduates can directly apply for jobs with Google and over 150 U.S. employers, including Deloitte, Target, and Verizon.
Key components of Google’s Data Analytics Professional Certificate:
Comprehensive program designed for beginners, with no prior experience or degree required
Eight courses covering data collection, cleaning, analysis, visualization, and presentation
Hands-on experience with popular tools and platforms, such as spreadsheets, SQL, Tableau, and R programming
Highly interactive content exclusively developed by experienced Google employees
Opportunity to directly apply for jobs with Google and over 150 U.S. employers upon completion
The Digital Marketing Analytics: Data Analysis, Forecasting and Storytelling online short course from NUS is designed to help professionals make sense of the vast amounts of data available in today’s digital landscape. The course recognizes that while data is abundant, it must be effectively analyzed, visualized, and communicated to drive meaningful insights and decision-making. Over six weeks, participants develop a strong foundation in data analysis, visualization, and communication skills.
The course is particularly relevant for marketing and data professionals who want to expand their data analysis skills and effectively communicate insights to stakeholders. It is also suitable for senior business or marketing executives who rely on marketing data to inform strategies and decisions. Participants learn to use design and storytelling principles to create compelling data dashboards using Tableau, ultimately enabling them to present and interpret marketing data that can drive organizational success.
Throughout the course, participants engage with experts and gain hands-on experience with tools like Tableau and Orange. The curriculum covers a range of topics, including marketing analytics fundamentals, data storytelling, forecasting, predictive analytics for customer retention, segmentation and clustering techniques, and customer experience analysis. By the end of the course, participants are equipped with the knowledge and skills to make data-driven predictions, effectively target customers, and create impactful marketing strategies.
Key components of the Digital Marketing Analytics course from NUS on GetSmarter:
Six-week online short course focused on data analysis, visualization, and communication in marketing
Designed for marketing and data professionals, as well as senior business or marketing executives
Teaches participants to use design and storytelling principles to create compelling data dashboards using Tableau
Covers topics such as marketing analytics fundamentals, forecasting, predictive analytics, segmentation, and customer experience analysis
Equips participants with the skills to make data-driven predictions, target customers effectively, and create impactful marketing strategies
The Advanced Business Analytics Specialization, offered by the University of Colorado Boulder on Coursera, is designed to equip learners with real-world data analytics skills that can be applied to grow businesses, increase profits, and create maximum value for shareholders. The specialization brings together academic professionals and experienced practitioners to share their expertise and insights. Learners gain practical skills in extracting and manipulating data using SQL code, executing statistical methods for descriptive, predictive, and prescriptive analysis, and effectively interpreting and presenting analytic results.
Throughout the specialization, learners apply the skills they acquire to real business problems and datasets. They have opportunities to build conceptual models of businesses and simple database models, practice data extraction using SQL, apply predictive and prescriptive analytics to business problems, develop models for decision making, interpret software output, and present results and findings. The specialization utilizes basic Excel and the Analytic Solver Platform (ASP), an Excel plug-in, with learners participating in assignments able to access the software for free.
The specialization consists of four courses and a capstone project. The courses cover topics such as the analytical process, data creation, storage, and access, relational databases and SQL, predictive modeling techniques, exploratory data analysis, data visualization, optimization techniques for decision making, and communicating analytics results effectively. The capstone project allows learners to apply their skills to interpret a real-world dataset and make appropriate business strategy recommendations.
Key components of the Advanced Business Analytics Specialization:
Practical skills in data extraction, manipulation, and analysis using SQL code and statistical methods
Application of predictive and prescriptive analytics techniques to real business problems and datasets
Utilization of Excel and the Analytic Solver Platform (ASP) for hands-on learning
Four courses covering the analytical process, predictive modeling, business analytics for decision making, and communicating results
Capstone project to apply skills in interpreting real-world data and making business strategy recommendations
The Value of Data Analytics Certifications
Pursuing a data analytics certification is a valuable investment in your professional development. Whether you are a beginner looking to break into the field or an experienced professional seeking to enhance your skills, these certifications offer a wide range of options to suit your needs. By earning one of these certifications, you demonstrate your commitment to staying at the forefront of the data analytics field, expand your career opportunities, and position yourself as a data-driven leader in your organization.
#2024#Analysis#Analytics#Article#Best Of#Business#business analytics#career#Careers#Case Study#certification#Certifications#code#communication#comprehensive#content#course#coursera#courses#customer experience#customer retention#data#data analysis#data analyst#data analytics#data cleaning#data collection#data extraction#Data Visualization#data-driven
1 note
·
View note
Text
youtube
#Scrape Amazon Products data#Amazon Products data scraper#Amazon Products data scraping#Amazon Products data collection#Amazon Products data extraction#Youtube
0 notes
Text
Simplifying OCR Data Collection: A Comprehensive Guide -
Globose Technology Solutions, we are committed to providing state-of-the-art OCR solutions to meet the specific needs of our customers. Contact us today to learn more about how OCR can transform your data collection workflow.
#OCR data collection#Optical Character Recognition (OCR)#Data Extraction#Document Digitization#Text Recognition#Automated Data Entry#Data Capture#OCR Technology#Document Processing#Image to Text Conversion#Data Accuracy#Text Analytics#Invoice Processing#Form Recognition#Natural Language Processing (NLP)#Data Management#Document Scanning#Data Automation#Data Quality#Compliance Reporting#Business Efficiency#data collection#data collection company
0 notes
Text
i have physical access to literally everything i need to sequence my own DNA and I have to restrain myself every day
#i could do it in 2 days#day1: collect sample (a mL of blood would be more than enough) and do extraction ..#could do extraction with the easymag but im p sure the DNEasy kit can also start with whole blood and is less scary than the easymag#then with the dna 1st round and second round pcr.. already have the primers if i wanted to determine my HLA type .. run the gel#i think i could do all that in day 1#day 2 would just be sequencing with the sanger sequencer and once the data is ready i could use our custom software or sequencher#like how cool would that be
0 notes
Text
Scrape Data from Amazon and Flipkart Mobile Apps
Uncover competitive secrets and market trends by scraping data from Amazon and Flipkart mobile apps. Access valuable insights to fuel your e-commerce success.
know more:
#Extract Data from Amazon Mobile Apps#Extract Data from Flipkart Mobile Apps#collect data from online shopping Applications
0 notes
Text
Unleashing the Power of Data: How Web Data Collection Services Can Propel Your Business Forward

Are you looking for a comprehensive guide on restaurant menu scraping? Look no further! In this ultimate guide, we will walk you through the process of scraping restaurant data, providing you with all the necessary tools and techniques to obtain valuable information from restaurant menus.
Restaurants have a wealth of data within their menus, including prices, ingredients, and special dishes. However, manually extracting this data can be time-consuming and tedious. That’s where a restaurant menu scraper comes in handy. With the right scraper, you can quickly and efficiently extract menu data, saving you hours of manual work.
In this article, we will explore different types of restaurant menu scrapers, their features, and how to choose the best one for your needs. We will also dive into the legal and ethical considerations of scraping restaurant menus, ensuring that you stay on the right side of the law while accessing this valuable data.
Whether you’re a restaurant owner looking to analyze your competitors’ menus or a data enthusiast eager to explore the world of restaurant data, this guide will equip you with the knowledge and tools you need to successfully scrape restaurant menus. So, let’s get started and unlock the unlimited possibilities of restaurant menu scraping!
Understanding the Benefits of Restaurant Menu Scraping
Scraping restaurant menus offers numerous benefits for both restaurant owners and data enthusiasts. For restaurant owners, menu scraping can provide valuable insights into their competitors’ offerings, pricing strategies, and popular dishes. This information can help them make informed decisions to stay ahead in the market.
Data enthusiasts, on the other hand, can leverage restaurant menu scraping to analyze trends, identify popular ingredients, and even predict customer preferences. This data can be used to develop innovative culinary concepts, create personalized dining experiences, or even build restaurant recommendation systems.
Restaurant menu scraping can also be useful for food bloggers, food critics, and review websites. By extracting data from various menus, they can provide detailed and up-to-date information to their readers, enhancing the overall dining experience.
Common Challenges in Restaurant Menu Scraping
While restaurant menu scraping offers numerous benefits, it is not without its challenges. One of the major challenges is the dynamic nature of restaurant menus. Menus are often updated regularly, with changes in prices, seasonal dishes, and ingredients. This constant change makes it crucial to have a scraper that can adapt and capture the latest data accurately.
Another challenge is the variability in menu layouts and formats. Each restaurant may have a unique menu design, making it difficult to create a one-size-fits-all scraper. Scraping tools need to be flexible and capable of handling different menu structures to ensure accurate data extraction.
Additionally, some restaurants may implement anti-scraping measures to protect their data. These measures can include CAPTCHAs, IP blocking, or even legal action against scrapers. Overcoming these challenges requires advanced scraping techniques and adherence to legal and ethical guidelines.
Step-by-step Guide on How to Scrape Restaurant Data
Now that we understand the benefits and challenges of restaurant menu scraping, let’s dive into the step-by-step process of scraping restaurant data. It is important to note that the exact steps may vary depending on the scraping tool you choose and the specific website you are targeting. However, the general process remains the same.
1. Identify the target restaurant: Start by choosing the restaurant whose menu you want to scrape. Consider factors such as relevance, popularity, and availability of online menus.
2. Select a scraping tool: There are several scraping tools available in the market, ranging from simple web scrapers to sophisticated data extraction platforms. Research and choose a tool that aligns with your requirements and budget.
3. Analyze the target website: Before scraping, familiarize yourself with the structure and layout of the target restaurant’s website. Identify the HTML elements that contain the menu data you want to extract.
4. Set up your scraper: Configure your scraping tool to target the specific HTML elements and extract the desired data. This may involve writing custom scripts, using CSS selectors, or utilizing pre-built scraping templates.
5. Run the scraper: Once your scraper is set up, initiate the scraping process. Monitor the progress and ensure that the scraper is capturing the data accurately. Adjust the scraper settings if necessary.
6. Clean and format the data: After scraping, the raw data may require cleaning and formatting to remove any inconsistencies or unwanted information. Depending on your needs, you may need to convert the data into a structured format such as CSV or JSON.
7. Validate the extracted data: It is important to validate the accuracy of the extracted data by cross-referencing it with the original menu. This step helps identify any errors or missing information that may have occurred during the scraping process.
8. Store and analyze the data: Once the data is cleaned and validated, store it in a secure location. You can then analyze the data using various statistical and data visualization tools to gain insights and make informed decisions.
By following these steps, you can successfully scrape restaurant menus and unlock a wealth of valuable data.
Choosing the Right Tools for Restaurant Menu Scraping
When it comes to restaurant menu scraping, choosing the right tools is crucial for a successful scraping project. Here are some factors to consider when selecting a scraping tool:
1. Scalability: Ensure that the scraping tool can handle large volumes of data and can scale with your business needs. This is especially important if you plan to scrape multiple restaurant menus or regularly update your scraped data.
2. Flexibility: Look for a tool that can handle different menu layouts and formats. The scraper should be able to adapt to changes in the structure of the target website and capture data accurately.
3. Ease of use: Consider the user-friendliness of the scraping tool. Look for features such as a visual interface, pre-built templates, and easy customization options. This will make the scraping process more efficient and accessible to users with varying levels of technical expertise.
4. Data quality and accuracy: Ensure that the scraping tool provides accurate and reliable data extraction. Look for features such as data validation, error handling, and data cleansing capabilities.
5. Support and documentation: Check the availability of support resources such as documentation, tutorials, and customer support. A robust support system can help you troubleshoot issues and make the most out of your scraping tool.
By carefully evaluating these factors, you can choose a scraping tool that meets your specific requirements and ensures a smooth and successful scraping process.
Best Practices for Restaurant Menu Scraping
To ensure a successful restaurant menu scraping project, it is important to follow best practices and adhere to ethical guidelines. Here are some key practices to keep in mind:
1. Respect website terms and conditions: Before scraping, review the terms and conditions of the target website. Some websites explicitly prohibit scraping, while others may have specific guidelines or restrictions. Ensure that your scraping activities comply with these terms to avoid legal consequences.
2. Implement rate limiting: To avoid overwhelming the target website with excessive requests, implement rate limiting in your scraping tool. This helps prevent IP blocking or other anti-scraping measures.
3. Use proxies: Consider using proxies to mask your IP address and distribute scraping requests across multiple IP addresses. Proxies help maintain anonymity and reduce the risk of IP blocking.
4. Monitor website changes: Regularly monitor the target website for any changes in menu structure or layout. Update your scraping tool accordingly to ensure continued data extraction.
5. Be considerate of website resources: Scraping can put a strain on website resources. Be mindful of the impact your scraping activities may have on the target website’s performance. Avoid excessive scraping or scraping during peak hours.
By following these best practices, you can maintain a respectful and ethical approach to restaurant menu scraping.
Legal Considerations When Scraping Restaurant Menus
Scraping restaurant menus raises legal considerations that must be taken seriously. While scraping is not illegal per se, it can potentially infringe upon copyright, intellectual property, and terms of service agreements. Here are some legal factors to consider:
1. Copyright infringement: The content of restaurant menus, including descriptions, images, and branding, may be protected by copyright. It is important to obtain permission from the restaurant or the copyright holder before using or redistributing scraped menu data.
2. Terms of service agreements: Review the terms of service of the target website to ensure that scraping is not explicitly prohibited. Even if scraping is allowed, there may be specific restrictions on data usage or redistribution.
3. Data privacy laws: Scrapped data may contain personal information, such as customer names or contact details. Ensure compliance with data privacy laws, such as the General Data Protection Regulation (GDPR) in the European Union, by anonymizing or removing personal information from the scraped data.
4. Competitor analysis: While scraping competitor menus can provide valuable insights, be cautious of any anti-competitive behavior. Avoid using scraped data to gain an unfair advantage or engage in price-fixing activities.
To avoid legal complications, consult with legal professionals and ensure that your scraping activities are conducted in accordance with applicable laws and regulations.
Advanced Techniques for Restaurant Menu Scraping
For more advanced scraping projects, you may encounter additional challenges that require specialized techniques. Here are some advanced techniques to consider:
1. Dynamic scraping: Some websites use JavaScript to dynamically load menu content. To scrape such websites, you may need to utilize headless browsers or JavaScript rendering engines that can execute JavaScript code and capture dynamically loaded data.
2. OCR for image-based menus: If the target menu is in image format, you can use Optical Character Recognition (OCR) tools to extract text from the images. OCR technology converts the text in images into machine-readable format, allowing you to extract data from image-based menus.
3. Natural language processing: To gain deeper insights from scraped menu data, consider applying natural language processing (NLP) techniques. NLP can be used to extract key information such as dish names, ingredients, and customer reviews from the scraped text.
4. Machine learning for menu classification: If you have a large collection of scraped menus, you can employ machine learning algorithms to classify menus based on cuisine type, pricing range, or other categories. This can help streamline data analysis and enhance menu recommendation systems.
By exploring these advanced techniques, you can take your restaurant menu scraping projects to the next level and unlock even more valuable insights.
Case Studies of Successful Restaurant Menu Scraping Projects
To illustrate the practical applications of restaurant menu scraping, let’s explore some real-world case studies:
1. Competitor analysis: A restaurant owner wanted to gain a competitive edge by analyzing the menus of their direct competitors. By scraping and analyzing the menus, they were able to identify pricing trends, popular dishes, and unique offerings. This allowed them to adjust their own menu and pricing strategy to attract more customers.
2. Food blog creation: A food blogger wanted to create a comprehensive food blog featuring detailed information about various restaurants. By scraping menus from different restaurants, they were able to provide accurate and up-to-date information to their readers. This increased the blog’s credibility and attracted a larger audience.
3. Data-driven restaurant recommendations: A data enthusiast developed a restaurant recommendation system based on scraped menu data. By analyzing menus, customer reviews, and other factors, the system provided personalized restaurant suggestions to users. This enhanced the dining experience by matching users with restaurants that align with their preferences.
These case studies highlight the diverse applications and benefits of restaurant menu scraping in various industries.
Conclusion: Leveraging Restaurant Menu Scraping for Business Success
Restaurant menu scraping presents a wealth of opportunities for restaurant owners, data enthusiasts, bloggers, and various other stakeholders. By leveraging the power of scraping tools and techniques, you can unlock valuable insights, make data-driven decisions, and stay ahead in the competitive restaurant industry.
In this ultimate guide, we have explored the benefits and challenges of restaurant menu scraping, provided a step-by-step guide on how to scrape restaurant data, discussed the importance of choosing the right tools and following best practices, and highlighted legal considerations and advanced techniques. We have also shared case studies showcasing the practical applications of restaurant menu scraping.
Now it’s your turn to dive into the world of restaurant menu scraping and unlock the unlimited possibilities it offers. Whether you’re a restaurant owner looking to analyze your competitors’ menus or a data enthusiast eager to explore the world of restaurant data, this guide has equipped you with the knowledge and tools you need to succeed. So, let’s get scraping and make the most out of restaurant menu data!
Know more : https://medium.com/@actowiz/ultimate-guide-to-restaurant-menu-scraper-how-to-scrape-restaurant-data-a8d252495ab8
#Web Data Collection Services#Data Collection Services#Web Scraping Services#Data Mining Services#Data Extraction Services
0 notes
Text
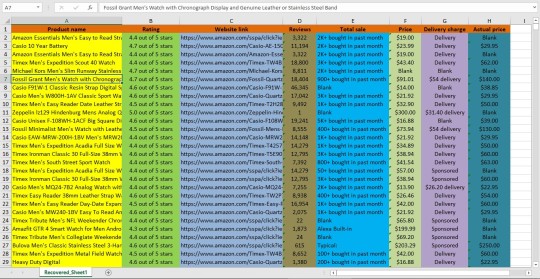
I will provided data entry service. Product listing from Amazon.
#Data entry#Data mining#Virtual assistant#Web scraping#B2b lead generation#Business leads#Targeted leads#Data scraping#Data extraction#Excel data entry#Copy paste#Linkedin leads#Web research#Data collection
0 notes
Text

In today's competitive world, everybody wants ways to innovate and use new skills. Web scraping (or data scraping or web data extraction) is an automated procedure that scrapes data from websites and exports that in structured formats. Web scraping is particularly useful if any public site you wish to find data from doesn't get an…
know more :
#web scraping services#Web Data Extraction Services#web scraping services usa#Data collection services
0 notes
Text
There Were Always Enshittifiers

I'm on a 20+ city book tour for my new novel PICKS AND SHOVELS. Catch me in DC TONIGHT (Mar 4), and in RICHMOND TOMORROW (Mar 5). More tour dates here. Mail-order signed copies from LA's Diesel Books.

My latest Locus column is "There Were Always Enshittifiers." It's a history of personal computing and networked communications that traces the earliest days of the battle for computers as tools of liberation and computers as tools for surveillance, control and extraction:
https://locusmag.com/2025/03/commentary-cory-doctorow-there-were-always-enshittifiers/
The occasion for this piece is the publication of my latest Martin Hench novel, a standalone book set in the early 1980s called "Picks and Shovels":
https://us.macmillan.com/books/9781250865908/picksandshovels
The MacGuffin of Picks and Shovels is a "weird PC" company called Fidelity Computing, owned by a Mormon bishop, a Catholic priest, and an orthodox rabbi. It sounds like the setup for a joke, but the punchline is deadly serious: Fidelity Computing is a pyramid selling cult that preys on the trust and fellowship of faith groups to sell the dreadful Fidelity 3000 PC and its ghastly peripherals.
You see, Fidelity's products are booby-trapped. It's not merely that they ship with programs whose data-files can't be read by apps on any other system – that's just table stakes. Fidelity's got a whole bag of tricks up its sleeve – for example, it deliberately damages a specific sector on every floppy disk it ships. The drivers for its floppy drive initialize any read or write operation by checking to see if that sector can be read. If it can, the computer refuses to recognize the disk. This lets the Reverend Sirs (as Fidelity's owners style themselves) run a racket where they sell these deliberately damaged floppies at a 500% markup, because regular floppies won't work on the systems they lure their parishioners into buying.
Or take the Fidelity printer: it's just a rebadged Okidata ML-80, the workhorse tractor feed printer that led the market for years. But before Fidelity ships this printer to its customers, they fit it with new tractor feed sprockets whose pins are slightly more widely spaced than the standard 0.5" holes on the paper you can buy in any stationery store. That way, Fidelity can force its customers to buy the custom paper that they exclusively peddle – again, at a massive markup.
Needless to say, printing with these wider sprocket holes causes frequent jams and puts a serious strain on the printer's motors, causing them to burn out at a high rate. That's great news – for Fidelity Computing. It means they get to sell you more overpriced paper so you can reprint the jobs ruined by jams, and they can also sell you their high-priced, exclusive repair services when your printer's motors quit.
Perhaps you're thinking, "OK, but I can just buy a normal Okidata printer and use regular, cheap paper, right?" Sorry, the Reverend Sirs are way ahead of you: they've reversed the pinouts on their printers' serial ports, and a normal printer won't be able to talk to your Fidelity 3000.
If all of this sounds familiar, it's because these are the paleolithic ancestors of today's high-tech lock-in scams, from HP's $10,000/gallon ink to Apple and Google's mobile app stores, which cream a 30% commission off of every dollar collected by an app maker. What's more, these ancient, weird misfeatures have their origins in the true history of computing, which was obsessed with making the elusive, copy-proof floppy disk.
This Quixotic enterprise got started in earnest with Bill Gates' notorious 1976 "open letter to hobbyists" in which the young Gates furiously scolds the community of early computer hackers for its scientific ethic of publishing, sharing and improving the code that they all wrote:
https://en.wikipedia.org/wiki/An_Open_Letter_to_Hobbyists
Gates had recently cloned the BASIC programming language for the popular Altair computer. For Gates, his act of copying was part of the legitimate progress of technology, while the copying of his colleagues, who duplicated Gates' Altair BASIC, was a shameless act of piracy, destined to destroy the nascent computing industry:
As the majority of hobbyists must be aware, most of you steal your software. Hardware must be paid for, but software is something to share. Who cares if the people who worked on it get paid?
Needless to say, Gates didn't offer a royalty to John Kemeny and Thomas Kurtz, the programmers who'd invented BASIC at Dartmouth College in 1963. For Gates – and his intellectual progeny – the formula was simple: "When I copy you, that's progress. When you copy me, that's piracy." Every pirate wants to be an admiral.
For would-be ex-pirate admirals, Gates's ideology was seductive. There was just one fly in the ointment: computers operate by copying. The only way a computer can run a program is to copy it into memory – just as the only way your phone can stream a video is to download it to its RAM ("streaming" is a consensus hallucination – every stream is a download, and it has to be, because the internet is a data-transmission network, not a cunning system of tubes and mirrors that can make a picture appear on your screen without transmitting the file that contains that image).
Gripped by this enshittificatory impulse, the computer industry threw itself headfirst into the project of creating copy-proof data, a project about as practical as making water that's not wet. That weird gimmick where Fidelity floppy disks were deliberately damaged at the factory so the OS could distinguish between its expensive disks and the generic ones you bought at the office supply place? It's a lightly fictionalized version of the copy-protection system deployed by Visicalc, a move that was later publicly repudiated by Visicalc co-founder Dan Bricklin, who lamented that it confounded his efforts to preserve his software on modern systems and recover the millions of data-files that Visicalc users created:
http://www.bricklin.com/robfuture.htm
The copy-protection industry ran on equal parts secrecy and overblown sales claims about its products' efficacy. As a result, much of the story of this doomed effort is lost to history. But back in 2017, a redditor called Vadermeer unearthed a key trove of documents from this era, in a Goodwill Outlet store in Seattle:
https://www.reddit.com/r/VintageApple/comments/5vjsow/found_internal_apple_memos_about_copy_protection/
Vaderrmeer find was a Apple Computer binder from 1979, documenting the company's doomed "Software Security from Apple's Friends and Enemies" (SSAFE) project, an effort to make a copy-proof floppy:
https://archive.org/details/AppleSSAFEProject
The SSAFE files are an incredible read. They consist of Apple's best engineers beavering away for days, cooking up a new copy-proof floppy, which they would then hand over to Apple co-founder and legendary hardware wizard Steve Wozniak. Wozniak would then promptly destroy the copy-protection system, usually in a matter of minutes or hours. Wozniak, of course, got the seed capital for Apple by defeating AT&T's security measures, building a "blue box" that let its user make toll-free calls and peddling it around the dorms at Berkeley:
https://512pixels.net/2018/03/woz-blue-box/
Woz has stated that without blue boxes, there would never have been an Apple. Today, Apple leads the charge to restrict how you use your devices, confining you to using its official app store so it can skim a 30% vig off every dollar you spend, and corralling you into using its expensive repair depots, who love to declare your device dead and force you to buy a new one. Every pirate wants to be an admiral!
https://www.vice.com/en/article/tim-cook-to-investors-people-bought-fewer-new-iphones-because-they-repaired-their-old-ones/
Revisiting the early PC years for Picks and Shovels isn't just an excuse to bust out some PC nostalgiacore set-dressing. Picks and Shovels isn't just a face-paced crime thriller: it's a reflection on the enshittificatory impulses that were present at the birth of the modern tech industry.
But there is a nostalgic streak in Picks and Shovels, of course, represented by the other weird PC company in the tale. Computing Freedom is a scrappy PC startup founded by three women who came up as sales managers for Fidelity, before their pangs of conscience caused them to repent of their sins in luring their co-religionists into the Reverend Sirs' trap.
These women – an orthodox lesbian whose family disowned her, a nun who left her order after discovering the liberation theology movement, and a Mormon woman who has quit the church over its opposition to the Equal Rights Amendment – have set about the wozniackian project of reverse-engineering every piece of Fidelity hardware and software, to make compatible products that set Fidelity's caged victims free.
They're making floppies that work with Fidelity drives, and drives that work with Fidelity's floppies. Printers that work with Fidelity computers, and adapters so Fidelity printers will work with other PCs (as well as resprocketing kits to retrofit those printers for standard paper). They're making file converters that allow Fidelity owners to read their data in Visicalc or Lotus 1-2-3, and vice-versa.
In other words, they're engaged in "adversarial interoperability" – hacking their own fire-exits into the burning building that Fidelity has locked its customers inside of:
https://www.eff.org/deeplinks/2019/10/adversarial-interoperability
This was normal, back then! There were so many cool, interoperable products and services around then, from the Bell and Howell "Black Apple" clones:
https://forum.vcfed.org/index.php?threads%2Fbell-howell-apple-ii.64651%2F
to the amazing copy-protection cracking disks that traveled from hand to hand, so the people who shelled out for expensive software delivered on fragile floppies could make backups against the inevitable day that the disks stopped working:
https://en.wikipedia.org/wiki/Bit_nibbler
Those were wild times, when engineers pitted their wits against one another in the spirit of Steve Wozniack and SSAFE. That era came to a close – but not because someone finally figured out how to make data that you couldn't copy. Rather, it ended because an unholy coalition of entertainment and tech industry lobbyists convinced Congress to pass the Digital Millennium Copyright Act in 1998, which made it a felony to "bypass an access control":
https://www.eff.org/deeplinks/2016/07/section-1201-dmca-cannot-pass-constitutional-scrutiny
That's right: at the first hint of competition, the self-described libertarians who insisted that computers would make governments obsolete went running to the government, demanding a state-backed monopoly that would put their rivals in prison for daring to interfere with their business model. Plus ça change: today, their intellectual descendants are demanding that the US government bail out their "anti-state," "independent" cryptocurrency:
https://www.citationneeded.news/issue-78/
In truth, the politics of tech has always contained a faction of "anti-government" millionaires and billionaires who – more than anything – wanted to wield the power of the state, not abolish it. This was true in the mainframe days, when companies like IBM made billions on cushy defense contracts, and it's true today, when the self-described "Technoking" of Tesla has inserted himself into government in order to steer tens of billions' worth of no-bid contracts to his Beltway Bandit companies:
https://www.reuters.com/world/us/lawmakers-question-musk-influence-over-verizon-faa-contract-2025-02-28/
The American state has always had a cozy relationship with its tech sector, seeing it as a way to project American soft power into every corner of the globe. But Big Tech isn't the only – or the most important – US tech export. Far more important is the invisible web of IP laws that ban reverse-engineering, modding, independent repair, and other activities that defend American tech exports from competitors in its trading partners.
Countries that trade with the US were arm-twisted into enacting laws like the DMCA as a condition of free trade with the USA. These laws were wildly unpopular, and had to be crammed through other countries' legislatures:
https://pluralistic.net/2024/11/15/radical-extremists/#sex-pest
That's why Europeans who are appalled by Musk's Nazi salute have to confine their protests to being loudly angry at him, selling off their Teslas, and shining lights on Tesla factories:
https://www.malaymail.com/news/money/2025/01/24/heil-tesla-activists-protest-with-light-projection-on-germany-plant-after-musks-nazi-salute-video/164398
Musk is so attention-hungry that all this is as apt to please him as anger him. You know what would really hurt Musk? Jailbreaking every Tesla in Europe so that all its subscription features – which represent the highest-margin line-item on Tesla's balance-sheet – could be unlocked by any local mechanic for €25. That would really kick Musk in the dongle.
The only problem is that in 2001, the US Trade Rep got the EU to pass the EU Copyright Directive, whose Article 6 bans that kind of reverse-engineering. The European Parliament passed that law because doing so guaranteed tariff-free access for EU goods exported to US markets.
Enter Trump, promising a 25% tariff on European exports.
The EU could retaliate here by imposing tit-for-tat tariffs on US exports to the EU, which would make everything Europeans buy from America 25% more expensive. This is a very weird way to punish the USA.
On the other hand, not that Trump has announced that the terms of US free trade deals are optional (for the US, at least), there's no reason not to delete Article 6 of the EUCD, and all the other laws that prevent European companies from jailbreaking iPhones and making their own App Stores (minus Apple's 30% commission), as well as ad-blockers for Facebook and Instagram's apps (which would zero out EU revenue for Meta), and, of course, jailbreaking tools for Xboxes, Teslas, and every make and model of every American car, so European companies could offer service, parts, apps, and add-ons for them.
When Jeff Bezos launched Amazon, his war-cry was "your margin is my opportunity." US tech companies have built up insane margins based on the IP provisions required in the free trade treaties it signed with the rest of the world.
It's time to delete those IP provisions and throw open domestic competition that attacks the margins that created the fortunes of oligarchs who sat behind Trump on the inauguration dais. It's time to bring back the indomitable hacker spirit that the Bill Gateses of the world have been trying to extinguish since the days of the "open letter to hobbyists." The tech sector built a 10 foot high wall around its business, then the US government convinced the rest of the world to ban four-metre ladders. Lift the ban, unleash the ladders, free the world!
In the same way that futuristic sf is really about the present, Picks and Shovels, an sf novel set in the 1980s, is really about this moment.
I'm on tour with the book now – if you're reading this today (Mar 4) and you're in DC, come see me tonight with Matt Stoller at 6:30PM at the Cleveland Park Library:
https://www.loyaltybookstores.com/picksnshovels
And if you're in Richmond, VA, come down to Fountain Bookshop and catch me with Lee Vinsel tomorrow (Mar 5) at 7:30PM:
https://fountainbookstore.com/events/1795820250305

If you'd like an essay-formatted version of this post to read or share, here's a link to it on pluralistic.net, my surveillance-free, ad-free, tracker-free blog:
https://pluralistic.net/2025/03/04/object-permanence/#picks-and-shovels
#pluralistic#picks and shovels#history#web theory#marty hench#martin hench#red team blues#locus magazine#drm#letter to computer hobbyists#bill gates#computer lib#science fiction#crime fiction#detective fiction
494 notes
·
View notes
Text
How to Leverage Travel Reviews Data Scraping to Collect Travel Reviews?
Use travel reviews data scraping to efficiently gather and analyze valuable feedback, enhancing decision-making and customer experiences.
In the fast-paced world of travel and hospitality, customer feedback reigns supreme. Travel reviews provide invaluable insights into the preferences, experiences, and expectations of travelers, shaping the decisions of prospective guests and influencing the reputation of hotels, airlines, and other travel-related businesses.
#Travel Reviews Data Scraping#Travel Reviews Data Collection#Extracting travel reviews data#Extract travel reviews data
0 notes