#data science algorithm
Explore tagged Tumblr posts
Visit Tumblr Blog
Explore Tumblr blogs with no restrictions, modern design and the best experience.
Last Seen Tumblr Blogs





Fun Fact
Tumblr has 16.74 million mobile monthly users in the US.
Text
5 Core Algorithms Every Data Scientist Should Master
Mastering these five core algorithms provides a strong foundation for aspiring data scientists. Linear regression and logistic regression are essential for predictive modeling and classification, while decision trees offer versatility, and K-means clustering aids in unsupervised learning tasks. Support vector machines are powerful for complex classification problems. To truly understand these algorithms and enhance your skills, you can consider enrolling in a Data Science Training Course in Delhi, Noida, Lucknow, Nagpur, and other cities in India. This will provide you with structured learning, hands-on experience, and a deeper understanding of how data science works.
Read more: https://bipindianalopis.com/5-core-algorithms-every-data-scientist-should-master
0 notes
Text
mage viktor discourse again on twitter and all i can say in my little corner over here once again is, I don't know why the entire fandom takes it as canon that mage Viktor failed to save every world he manipulated.
Canon does not provide evidence of this. This is fanon speculation. It's a fine headcanon to have, but everyone talks about it like it's canon when it isn't. Canon is ambiguous about the outcome of the timelines mage Viktor altered. The little nods we are given point, in my opinion, towards the opposite conclusion, that he successfully averted destruction.
I've written meta on this before but in summary:
1) 'In all timelines, in all possibilities' is worded precisely, it's not 'out of all timelines'; the implication is that every time, Jayce brings Viktor back from the brink, not just in our timeline. 'Only you' doesn't refer to our timeline's Jayce, it refers to all Jayces. Jayce always brings him home. If Viktor continuously put the fate of each timeline in Jayce's hands and Jayce failed over and over, I don't think he'd say those words. And the way he says them matters. His words are tinged with wonder, not sorrow. As if over and over again, he is shown that Jayce saves him, and it continues to amaze him. He doesn't sound defeated, like this is the next in a long line of Jayces he's sending off to die. The feeling is that Viktor's faith in Jayce has not been misplaced.
2) If mage Viktor doomed every timeline, there would be hundreds (or more) mage Viktors. All running around manipulating timelines. I highly doubt the writers wanted to get into that kind of sticky situation. The tragedy of mage Viktor is that he is singular. Alone. Burdened with the responsibility of the multiverse. The emotional gut punch of his fate is ruined if other timelines led to the same outcome, and from a practical standpoint, having multiple reality-bending omniscient mages would rip apart the fabric of the arcane.
There are other points, such as there being only one corrupted Mercury Hammer and our Jayce is the only one to receive it, and the fact that if mage Viktor is as omniscient as he is implied to be, he could easily step back into other timelines and correct course, because it's highly unlikely he could sit still and watch things go down in flames. But these things can be argued elsewhere.
While I love conversations about mage Viktor's motives and selfishness vs altruism, the writers & artbook have expressed that Jayce and Viktor care greatly about Runeterra and want to fix their mistakes to save it, and that their reconciliation is symbolic of Piltover and Zaun coming together as well. Yes, they make disastrous decisions towards each other, making choices for the other or without the other, which has negative consequences for their relationship and for Runeterra - but I think fandom pushes their selfishness even past what's canon sometimes, as if their entire goal hadn't always been to selflessly help the world around them. Their final reconciliation is about bridging the gap that grew between them - the pain and grief and secrets, betraying themselves and each other - to mutually choose each other openly and honestly. Part of the beauty of their story, as expressed by the creators, is that in their final moments, they chose each other and took responsibility for their actions by sacrificing themselves to end what they started, together - and that choosing each other saved the world. TPTB have stated this - that Jayce and Viktor are the glue holding civilization together, and when they come back to each other, they can restore balance. It's when they're apart, when they hurt each other and miscommunicate, when they abandon their commitment to each other and their dream, that the greater world suffers. Their strife is mirrored in the story-world at large.
Mage Viktor is framed as a solitary penitent figure, damned to an eternity of atoning for his mistakes. He paid the ultimate price and now is forced to live his personal nightmare of exactly what he was trying to avoid for himself with the glorious evolution. The narrative clues we're given point more in the direction that he saves timelines rather than dooms them. If Viktor's actions kept killing Jayce, the very boy he couldn't bear to not save each time, it would undermine these narrative choices. Yes, Viktor couldn't stand to live in a world where he never meets Jayce, so he ensures it keeps happening. But in that same breath, he couldn't bear to see a world where his actions continue to destroy Jayce and destroy Runeterra. His entire arc in s2 is born of his selfless desire to help humanity, help individual people. He would not lightly destroy entire worlds. That's his original grief multiplied a thousandfold, and narratively it would lessen the impact of the one, true loss he did suffer, his own Jayce. It wouldn't make sense for him to be alright with damning other timelines to suffer the same catastrophic tragedy that created him. I mean, maybe I'm delusional here, but is that not the entire point? Because that's what I took away when I watched the show.
As I said, I love discussions about mage Viktor, as there's a lot to play with. All I wish is that the fandom at large would not just assume or accept the Mage Viktor Dooms Every Timeline idea as canon, when there is nothing in the actual canon that confirms this. Maybe people need to just, go back and rewatch the actual episode, to recall how mage Viktor is presented to us, and what it's implied we're supposed to take away from his scenes, and separate that from the layers of headcanon the fandom has constructed.
#arcane#mage viktor#jayvik#viktor arcane#meta#this is like. along the same vein as 'jayce knew all along viktor would go to the hexgates during the final battle'#like that is a headcanon. we don't know that!!#the actual scene could be read either way and i know when i watched it that's not how i interpreted it#and i doubt it's how most casual viewers intrepeted it#fandom gets so deep into itself after a show ends that you really have to just. rewatch the show to recalibrate yourself lol#for all that people bicker about mage viktor yall dont include him in your fics v much lol#anyway i love mage viktor and he's probably my favorite version of viktor <3#i just wish fandom stopped insisting on a monolithic view of canon#and the idea that mage viktor fucked over hundreds of timelines to collect data points like a scientist is just#rubs me the wrong way as a scientist lol#you do realize that scientists don't treat everything in life like a science experiment right?#it's about inquisitiveness and curiosity. not 'i will approach this emotional thing from a cold and calculating standpoint'#viktor has never been cold and calculating. he's consistently driven by emotion in the show jfc please rewatch canon#i just think that people would benefit from a surface level reading once in a while lol#sometimes fandom digs so far into the minutiae that they forget the overarching takeaways that the story presents#assuming there must be some hidden meaning that sometimes (like this) is decided to be the literal opposite of what's presented#rewatch mage viktor's scenes and ask yourself if 'deranged destroyer of worlds' is really what the show was trying to have you take away#then again there seems to be a faction of this fandom that for some absurd reason thinks jayce was forced to stay and die with viktor#so i guess media illiteracy can't be helped for some lmao#i post these things on here because my twitter posts get literally 10 views thanks algorithm#so the chunk of the fandom i really want to see this will not#but i must speak my truth
127 notes
·
View notes
Text
The surprising truth about data-driven dictatorships

Here’s the “dictator’s dilemma”: they want to block their country’s frustrated elites from mobilizing against them, so they censor public communications; but they also want to know what their people truly believe, so they can head off simmering resentments before they boil over into regime-toppling revolutions.
These two strategies are in tension: the more you censor, the less you know about the true feelings of your citizens and the easier it will be to miss serious problems until they spill over into the streets (think: the fall of the Berlin Wall or Tunisia before the Arab Spring). Dictators try to square this circle with things like private opinion polling or petition systems, but these capture a small slice of the potentially destabiziling moods circulating in the body politic.
Enter AI: back in 2018, Yuval Harari proposed that AI would supercharge dictatorships by mining and summarizing the public mood — as captured on social media — allowing dictators to tack into serious discontent and diffuse it before it erupted into unequenchable wildfire:
https://www.theatlantic.com/magazine/archive/2018/10/yuval-noah-harari-technology-tyranny/568330/
Harari wrote that “the desire to concentrate all information and power in one place may become [dictators] decisive advantage in the 21st century.” But other political scientists sharply disagreed. Last year, Henry Farrell, Jeremy Wallace and Abraham Newman published a thoroughgoing rebuttal to Harari in Foreign Affairs:
https://www.foreignaffairs.com/world/spirals-delusion-artificial-intelligence-decision-making
They argued that — like everyone who gets excited about AI, only to have their hopes dashed — dictators seeking to use AI to understand the public mood would run into serious training data bias problems. After all, people living under dictatorships know that spouting off about their discontent and desire for change is a risky business, so they will self-censor on social media. That’s true even if a person isn’t afraid of retaliation: if you know that using certain words or phrases in a post will get it autoblocked by a censorbot, what’s the point of trying to use those words?
The phrase “Garbage In, Garbage Out” dates back to 1957. That’s how long we’ve known that a computer that operates on bad data will barf up bad conclusions. But this is a very inconvenient truth for AI weirdos: having given up on manually assembling training data based on careful human judgment with multiple review steps, the AI industry “pivoted” to mass ingestion of scraped data from the whole internet.
But adding more unreliable data to an unreliable dataset doesn’t improve its reliability. GIGO is the iron law of computing, and you can’t repeal it by shoveling more garbage into the top of the training funnel:
https://memex.craphound.com/2018/05/29/garbage-in-garbage-out-machine-learning-has-not-repealed-the-iron-law-of-computer-science/
When it comes to “AI” that’s used for decision support — that is, when an algorithm tells humans what to do and they do it — then you get something worse than Garbage In, Garbage Out — you get Garbage In, Garbage Out, Garbage Back In Again. That’s when the AI spits out something wrong, and then another AI sucks up that wrong conclusion and uses it to generate more conclusions.
To see this in action, consider the deeply flawed predictive policing systems that cities around the world rely on. These systems suck up crime data from the cops, then predict where crime is going to be, and send cops to those “hotspots” to do things like throw Black kids up against a wall and make them turn out their pockets, or pull over drivers and search their cars after pretending to have smelled cannabis.
The problem here is that “crime the police detected” isn’t the same as “crime.” You only find crime where you look for it. For example, there are far more incidents of domestic abuse reported in apartment buildings than in fully detached homes. That’s not because apartment dwellers are more likely to be wife-beaters: it’s because domestic abuse is most often reported by a neighbor who hears it through the walls.
So if your cops practice racially biased policing (I know, this is hard to imagine, but stay with me /s), then the crime they detect will already be a function of bias. If you only ever throw Black kids up against a wall and turn out their pockets, then every knife and dime-bag you find in someone’s pockets will come from some Black kid the cops decided to harass.
That’s life without AI. But now let’s throw in predictive policing: feed your “knives found in pockets” data to an algorithm and ask it to predict where there are more knives in pockets, and it will send you back to that Black neighborhood and tell you do throw even more Black kids up against a wall and search their pockets. The more you do this, the more knives you’ll find, and the more you’ll go back and do it again.
This is what Patrick Ball from the Human Rights Data Analysis Group calls “empiricism washing”: take a biased procedure and feed it to an algorithm, and then you get to go and do more biased procedures, and whenever anyone accuses you of bias, you can insist that you’re just following an empirical conclusion of a neutral algorithm, because “math can’t be racist.”
HRDAG has done excellent work on this, finding a natural experiment that makes the problem of GIGOGBI crystal clear. The National Survey On Drug Use and Health produces the gold standard snapshot of drug use in America. Kristian Lum and William Isaac took Oakland’s drug arrest data from 2010 and asked Predpol, a leading predictive policing product, to predict where Oakland’s 2011 drug use would take place.
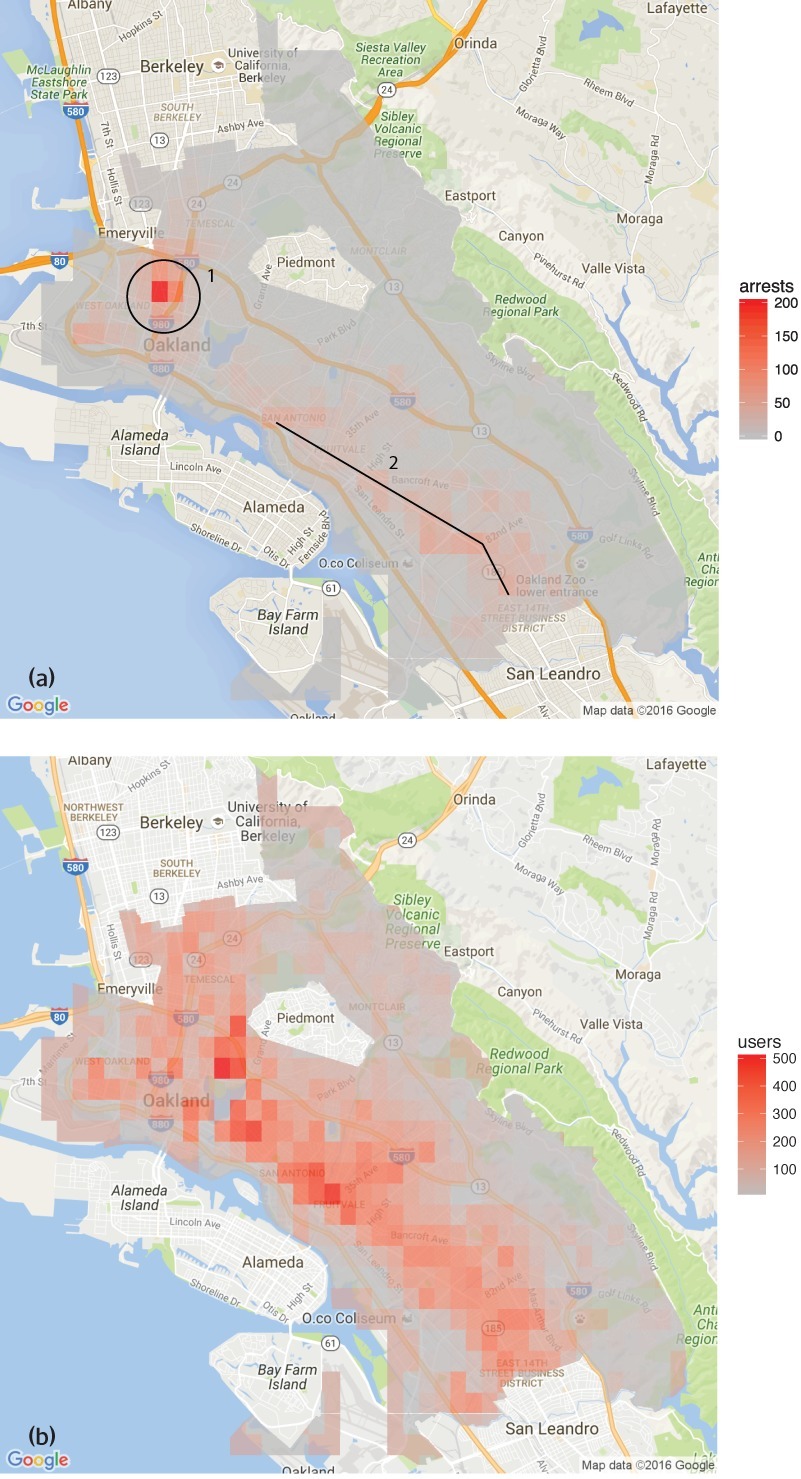
[Image ID: (a) Number of drug arrests made by Oakland police department, 2010. (1) West Oakland, (2) International Boulevard. (b) Estimated number of drug users, based on 2011 National Survey on Drug Use and Health]
Then, they compared those predictions to the outcomes of the 2011 survey, which shows where actual drug use took place. The two maps couldn’t be more different:
https://rss.onlinelibrary.wiley.com/doi/full/10.1111/j.1740-9713.2016.00960.x
Predpol told cops to go and look for drug use in a predominantly Black, working class neighborhood. Meanwhile the NSDUH survey showed the actual drug use took place all over Oakland, with a higher concentration in the Berkeley-neighboring student neighborhood.
What’s even more vivid is what happens when you simulate running Predpol on the new arrest data that would be generated by cops following its recommendations. If the cops went to that Black neighborhood and found more drugs there and told Predpol about it, the recommendation gets stronger and more confident.
In other words, GIGOGBI is a system for concentrating bias. Even trace amounts of bias in the original training data get refined and magnified when they are output though a decision support system that directs humans to go an act on that output. Algorithms are to bias what centrifuges are to radioactive ore: a way to turn minute amounts of bias into pluripotent, indestructible toxic waste.
There’s a great name for an AI that’s trained on an AI’s output, courtesy of Jathan Sadowski: “Habsburg AI.”
And that brings me back to the Dictator’s Dilemma. If your citizens are self-censoring in order to avoid retaliation or algorithmic shadowbanning, then the AI you train on their posts in order to find out what they’re really thinking will steer you in the opposite direction, so you make bad policies that make people angrier and destabilize things more.
Or at least, that was Farrell(et al)’s theory. And for many years, that’s where the debate over AI and dictatorship has stalled: theory vs theory. But now, there’s some empirical data on this, thanks to the “The Digital Dictator’s Dilemma,” a new paper from UCSD PhD candidate Eddie Yang:
https://www.eddieyang.net/research/DDD.pdf
Yang figured out a way to test these dueling hypotheses. He got 10 million Chinese social media posts from the start of the pandemic, before companies like Weibo were required to censor certain pandemic-related posts as politically sensitive. Yang treats these posts as a robust snapshot of public opinion: because there was no censorship of pandemic-related chatter, Chinese users were free to post anything they wanted without having to self-censor for fear of retaliation or deletion.
Next, Yang acquired the censorship model used by a real Chinese social media company to decide which posts should be blocked. Using this, he was able to determine which of the posts in the original set would be censored today in China.
That means that Yang knows that the “real” sentiment in the Chinese social media snapshot is, and what Chinese authorities would believe it to be if Chinese users were self-censoring all the posts that would be flagged by censorware today.
From here, Yang was able to play with the knobs, and determine how “preference-falsification” (when users lie about their feelings) and self-censorship would give a dictatorship a misleading view of public sentiment. What he finds is that the more repressive a regime is — the more people are incentivized to falsify or censor their views — the worse the system gets at uncovering the true public mood.
What’s more, adding additional (bad) data to the system doesn’t fix this “missing data” problem. GIGO remains an iron law of computing in this context, too.
But it gets better (or worse, I guess): Yang models a “crisis” scenario in which users stop self-censoring and start articulating their true views (because they’ve run out of fucks to give). This is the most dangerous moment for a dictator, and depending on the dictatorship handles it, they either get another decade or rule, or they wake up with guillotines on their lawns.
But “crisis” is where AI performs the worst. Trained on the “status quo” data where users are continuously self-censoring and preference-falsifying, AI has no clue how to handle the unvarnished truth. Both its recommendations about what to censor and its summaries of public sentiment are the least accurate when crisis erupts.
But here’s an interesting wrinkle: Yang scraped a bunch of Chinese users’ posts from Twitter — which the Chinese government doesn’t get to censor (yet) or spy on (yet) — and fed them to the model. He hypothesized that when Chinese users post to American social media, they don’t self-censor or preference-falsify, so this data should help the model improve its accuracy.
He was right — the model got significantly better once it ingested data from Twitter than when it was working solely from Weibo posts. And Yang notes that dictatorships all over the world are widely understood to be scraping western/northern social media.
But even though Twitter data improved the model’s accuracy, it was still wildly inaccurate, compared to the same model trained on a full set of un-self-censored, un-falsified data. GIGO is not an option, it’s the law (of computing).
Writing about the study on Crooked Timber, Farrell notes that as the world fills up with “garbage and noise” (he invokes Philip K Dick’s delighted coinage “gubbish”), “approximately correct knowledge becomes the scarce and valuable resource.”
https://crookedtimber.org/2023/07/25/51610/
This “probably approximately correct knowledge” comes from humans, not LLMs or AI, and so “the social applications of machine learning in non-authoritarian societies are just as parasitic on these forms of human knowledge production as authoritarian governments.”

The Clarion Science Fiction and Fantasy Writers’ Workshop summer fundraiser is almost over! I am an alum, instructor and volunteer board member for this nonprofit workshop whose alums include Octavia Butler, Kim Stanley Robinson, Bruce Sterling, Nalo Hopkinson, Kameron Hurley, Nnedi Okorafor, Lucius Shepard, and Ted Chiang! Your donations will help us subsidize tuition for students, making Clarion — and sf/f — more accessible for all kinds of writers.
Libro.fm is the indie-bookstore-friendly, DRM-free audiobook alternative to Audible, the Amazon-owned monopolist that locks every book you buy to Amazon forever. When you buy a book on Libro, they share some of the purchase price with a local indie bookstore of your choosing (Libro is the best partner I have in selling my own DRM-free audiobooks!). As of today, Libro is even better, because it’s available in five new territories and currencies: Canada, the UK, the EU, Australia and New Zealand!
[Image ID: An altered image of the Nuremberg rally, with ranked lines of soldiers facing a towering figure in a many-ribboned soldier's coat. He wears a high-peaked cap with a microchip in place of insignia. His head has been replaced with the menacing red eye of HAL9000 from Stanley Kubrick's '2001: A Space Odyssey.' The sky behind him is filled with a 'code waterfall' from 'The Matrix.']
Image: Cryteria (modified) https://commons.wikimedia.org/wiki/File:HAL9000.svg
CC BY 3.0 https://creativecommons.org/licenses/by/3.0/deed.en
—
Raimond Spekking (modified) https://commons.wikimedia.org/wiki/File:Acer_Extensa_5220_-_Columbia_MB_06236-1N_-_Intel_Celeron_M_530_-_SLA2G_-_in_Socket_479-5029.jpg
CC BY-SA 4.0 https://creativecommons.org/licenses/by-sa/4.0/deed.en
—
Russian Airborne Troops (modified) https://commons.wikimedia.org/wiki/File:Vladislav_Achalov_at_the_Airborne_Troops_Day_in_Moscow_%E2%80%93_August_2,_2008.jpg
“Soldiers of Russia” Cultural Center (modified) https://commons.wikimedia.org/wiki/File:Col._Leonid_Khabarov_in_an_everyday_service_uniform.JPG
CC BY-SA 3.0 https://creativecommons.org/licenses/by-sa/3.0/deed.en
#pluralistic#habsburg ai#self censorship#henry farrell#digital dictatorships#machine learning#dictator's dilemma#eddie yang#preference falsification#political science#training bias#scholarship#spirals of delusion#algorithmic bias#ml#Fully automated data driven authoritarianism#authoritarianism#gigo#garbage in garbage out garbage back in#gigogbi#yuval noah harari#gubbish#pkd#philip k dick#phildickian
833 notes
·
View notes
Text
youtube
Statistics - A Full Lecture to learn Data Science (2025 Version)
Welcome to our comprehensive and free statistics tutorial (Full Lecture)! In this video, we'll explore essential tools and techniques that power data science and data analytics, helping us interpret data effectively. You'll gain a solid foundation in key statistical concepts and learn how to apply powerful statistical tests widely used in modern research and industry. From descriptive statistics to regression analysis and beyond, we'll guide you through each method's role in data-driven decision-making. Whether you're diving into machine learning, business intelligence, or academic research, this tutorial will equip you with the skills to analyze and interpret data with confidence. Let's get started!
#education#free education#technology#educate yourselves#educate yourself#data analysis#data science course#data science#data structure and algorithms#youtube#statistics for data science#statistics#economics#education system#learn data science#learn data analytics#Youtube
4 notes
·
View notes
Text
(practicing dsa) is somebody gonna match my leet
#dsa#data structures and algorithms#leetcode#😀#recently i’ve just been spiraling on leet code#computer science
10 notes
·
View notes
Text

The Mathematical Foundations of Machine Learning
In the world of artificial intelligence, machine learning is a crucial component that enables computers to learn from data and improve their performance over time. However, the math behind machine learning is often shrouded in mystery, even for those who work with it every day. Anil Ananthaswami, author of the book "Why Machines Learn," sheds light on the elegant mathematics that underlies modern AI, and his journey is a fascinating one.
Ananthaswami's interest in machine learning began when he started writing about it as a science journalist. His software engineering background sparked a desire to understand the technology from the ground up, leading him to teach himself coding and build simple machine learning systems. This exploration eventually led him to appreciate the mathematical principles that underlie modern AI. As Ananthaswami notes, "I was amazed by the beauty and elegance of the math behind machine learning."
Ananthaswami highlights the elegance of machine learning mathematics, which goes beyond the commonly known subfields of calculus, linear algebra, probability, and statistics. He points to specific theorems and proofs, such as the 1959 proof related to artificial neural networks, as examples of the beauty and elegance of machine learning mathematics. For instance, the concept of gradient descent, a fundamental algorithm used in machine learning, is a powerful example of how math can be used to optimize model parameters.
Ananthaswami emphasizes the need for a broader understanding of machine learning among non-experts, including science communicators, journalists, policymakers, and users of the technology. He believes that only when we understand the math behind machine learning can we critically evaluate its capabilities and limitations. This is crucial in today's world, where AI is increasingly being used in various applications, from healthcare to finance.
A deeper understanding of machine learning mathematics has significant implications for society. It can help us to evaluate AI systems more effectively, develop more transparent and explainable AI systems, and address AI bias and ensure fairness in decision-making. As Ananthaswami notes, "The math behind machine learning is not just a tool, but a way of thinking that can help us create more intelligent and more human-like machines."
The Elegant Math Behind Machine Learning (Machine Learning Street Talk, November 2024)
youtube
Matrices are used to organize and process complex data, such as images, text, and user interactions, making them a cornerstone in applications like Deep Learning (e.g., neural networks), Computer Vision (e.g., image recognition), Natural Language Processing (e.g., language translation), and Recommendation Systems (e.g., personalized suggestions). To leverage matrices effectively, AI relies on key mathematical concepts like Matrix Factorization (for dimension reduction), Eigendecomposition (for stability analysis), Orthogonality (for efficient transformations), and Sparse Matrices (for optimized computation).
The Applications of Matrices - What I wish my teachers told me way earlier (Zach Star, October 2019)
youtube
Transformers are a type of neural network architecture introduced in 2017 by Vaswani et al. in the paper “Attention Is All You Need”. They revolutionized the field of NLP by outperforming traditional recurrent neural network (RNN) and convolutional neural network (CNN) architectures in sequence-to-sequence tasks. The primary innovation of transformers is the self-attention mechanism, which allows the model to weigh the importance of different words in the input data irrespective of their positions in the sentence. This is particularly useful for capturing long-range dependencies in text, which was a challenge for RNNs due to vanishing gradients. Transformers have become the standard for machine translation tasks, offering state-of-the-art results in translating between languages. They are used for both abstractive and extractive summarization, generating concise summaries of long documents. Transformers help in understanding the context of questions and identifying relevant answers from a given text. By analyzing the context and nuances of language, transformers can accurately determine the sentiment behind text. While initially designed for sequential data, variants of transformers (e.g., Vision Transformers, ViT) have been successfully applied to image recognition tasks, treating images as sequences of patches. Transformers are used to improve the accuracy of speech-to-text systems by better modeling the sequential nature of audio data. The self-attention mechanism can be beneficial for understanding patterns in time series data, leading to more accurate forecasts.
Attention is all you need (Umar Hamil, May 2023)
youtube
Geometric deep learning is a subfield of deep learning that focuses on the study of geometric structures and their representation in data. This field has gained significant attention in recent years.
Michael Bronstein: Geometric Deep Learning (MLSS Kraków, December 2023)
youtube
Traditional Geometric Deep Learning, while powerful, often relies on the assumption of smooth geometric structures. However, real-world data frequently resides in non-manifold spaces where such assumptions are violated. Topology, with its focus on the preservation of proximity and connectivity, offers a more robust framework for analyzing these complex spaces. The inherent robustness of topological properties against noise further solidifies the rationale for integrating topology into deep learning paradigms.
Cristian Bodnar: Topological Message Passing (Michael Bronstein, August 2022)
youtube
Sunday, November 3, 2024
#machine learning#artificial intelligence#mathematics#computer science#deep learning#neural networks#algorithms#data science#statistics#programming#interview#ai assisted writing#machine art#Youtube#lecture
4 notes
·
View notes
Text






Read More Here: Substack 🤖
2 notes
·
View notes
Text
What Dijkstra's two-stack algorithm does to Left parenthesis of Infix expression is everyone does to me
.
.
.
IGNORE 🤡
7 notes
·
View notes
Text
Exploring Quantum Leap Sort: A Conceptual Dive into Probabilistic Sorting Created Using AI
In the vast realm of sorting algorithms, where QuickSort, MergeSort, and HeapSort reign supreme, introducing a completely new approach is no small feat. Today, we’ll delve into a purely theoretical concept—Quantum Leap Sort—an imaginative algorithm created using AI that draws inspiration from quantum mechanics and probabilistic computing. While not practical for real-world use, this novel…
#AI#algorithm#amazon#chatgpt#coding#computer science#css#data-structures#DSA#engineering#google#heapsort#insertionsort#javascript#mergesort#new#programming#python#quicksort#radixsort#sorting#tech#tesla#trending#wipro
2 notes
·
View notes
Text

Summer Internship Program 2024
For More Details Visit Our Website - internship.learnandbuild.in
#machine learning#programming#python#linux#data science#data scientist#frontend web development#backend web development#salesforce admin#salesforce development#cloud AI with AWS#Internet of things & AI#Cyber security#Mobile App Development using flutter#data structures & algorithms#java core#python programming#summer internship program#summer internship program 2024
2 notes
·
View notes
Text
New AI noise-canceling headphone technology lets wearers pick which sounds they hear - Technology Org
New Post has been published on https://thedigitalinsider.com/new-ai-noise-canceling-headphone-technology-lets-wearers-pick-which-sounds-they-hear-technology-org/
New AI noise-canceling headphone technology lets wearers pick which sounds they hear - Technology Org
Most anyone who’s used noise-canceling headphones knows that hearing the right noise at the right time can be vital. Someone might want to erase car horns when working indoors but not when walking along busy streets. Yet people can’t choose what sounds their headphones cancel.
A team led by researchers at the University of Washington has developed deep-learning algorithms that let users pick which sounds filter through their headphones in real time. Pictured is co-author Malek Itani demonstrating the system. Image credit: University of Washington
Now, a team led by researchers at the University of Washington has developed deep-learning algorithms that let users pick which sounds filter through their headphones in real time. The team is calling the system “semantic hearing.” Headphones stream captured audio to a connected smartphone, which cancels all environmental sounds. Through voice commands or a smartphone app, headphone wearers can select which sounds they want to include from 20 classes, such as sirens, baby cries, speech, vacuum cleaners and bird chirps. Only the selected sounds will be played through the headphones.
The team presented its findings at UIST ’23 in San Francisco. In the future, the researchers plan to release a commercial version of the system.
[embedded content]
“Understanding what a bird sounds like and extracting it from all other sounds in an environment requires real-time intelligence that today’s noise canceling headphones haven’t achieved,” said senior author Shyam Gollakota, a UW professor in the Paul G. Allen School of Computer Science & Engineering. “The challenge is that the sounds headphone wearers hear need to sync with their visual senses. You can’t be hearing someone’s voice two seconds after they talk to you. This means the neural algorithms must process sounds in under a hundredth of a second.”
Because of this time crunch, the semantic hearing system must process sounds on a device such as a connected smartphone, instead of on more robust cloud servers. Additionally, because sounds from different directions arrive in people’s ears at different times, the system must preserve these delays and other spatial cues so people can still meaningfully perceive sounds in their environment.
Tested in environments such as offices, streets and parks, the system was able to extract sirens, bird chirps, alarms and other target sounds, while removing all other real-world noise. When 22 participants rated the system’s audio output for the target sound, they said that on average the quality improved compared to the original recording.
In some cases, the system struggled to distinguish between sounds that share many properties, such as vocal music and human speech. The researchers note that training the models on more real-world data might improve these outcomes.
Source: University of Washington
You can offer your link to a page which is relevant to the topic of this post.
#A.I. & Neural Networks news#ai#Algorithms#amp#app#artificial intelligence (AI)#audio#baby#challenge#classes#Cloud#computer#Computer Science#data#ears#engineering#Environment#Environmental#filter#Future#Hardware & gadgets#headphone#headphones#hearing#human#intelligence#it#learning#LED#Link
2 notes
·
View notes
Text
Quantum Computing and Data Science: Shaping the Future of Analysis
In the ever-evolving landscape of technology and data-driven decision-making, I find two cutting-edge fields that stand out as potential game-changers: Quantum Computing and Data Science. Each on its own has already transformed industries and research, but when combined, they hold the power to reshape the very fabric of analysis as we know it.
In this blog post, I invite you to join me on an exploration of the convergence of Quantum Computing and Data Science, and together, we'll unravel how this synergy is poised to revolutionize the future of analysis. Buckle up; we're about to embark on a thrilling journey through the quantum realm and the data-driven universe.
Understanding Quantum Computing and Data Science
Before we dive into their convergence, let's first lay the groundwork by understanding each of these fields individually.

A Journey Into the Emerging Field of Quantum Computing
Quantum computing is a field born from the principles of quantum mechanics. At its core lies the qubit, a fundamental unit that can exist in multiple states simultaneously, thanks to the phenomenon known as superposition. This property enables quantum computers to process vast amounts of information in parallel, making them exceptionally well-suited for certain types of calculations.
Data Science: The Art of Extracting Insights
On the other hand, Data Science is all about extracting knowledge and insights from data. It encompasses a wide range of techniques, including data collection, cleaning, analysis, and interpretation. Machine learning and statistical methods are often used to uncover meaningful patterns and predictions.
The Intersection: Where Quantum Meets Data
The fascinating intersection of quantum computing and data science occurs when quantum algorithms are applied to data analysis tasks. This synergy allows us to tackle problems that were once deemed insurmountable due to their complexity or computational demands.
The Promise of Quantum Computing in Data Analysis
Limitations of Classical Computing
Classical computers, with their binary bits, have their limitations when it comes to handling complex data analysis. Many real-world problems require extensive computational power and time, making them unfeasible for classical machines.

Quantum Computing's Revolution
Quantum computing has the potential to rewrite the rules of data analysis. It promises to solve problems previously considered intractable by classical computers. Optimization tasks, cryptography, drug discovery, and simulating quantum systems are just a few examples where quantum computing could have a monumental impact.
Quantum Algorithms in Action
To illustrate the potential of quantum computing in data analysis, consider Grover's search algorithm. While classical search algorithms have a complexity of O(n), Grover's algorithm achieves a quadratic speedup, reducing the time to find a solution significantly. Shor's factoring algorithm, another quantum marvel, threatens to break current encryption methods, raising questions about the future of cybersecurity.
Challenges and Real-World Applications
Current Challenges in Quantum Computing
While quantum computing shows great promise, it faces numerous challenges. Quantum bits (qubits) are extremely fragile and susceptible to environmental factors. Error correction and scalability are ongoing research areas, and practical, large-scale quantum computers are not yet a reality.

Real-World Applications Today
Despite these challenges, quantum computing is already making an impact in various fields. It's being used for simulating quantum systems, optimizing supply chains, and enhancing cybersecurity. Companies and research institutions worldwide are racing to harness its potential.
Ongoing Research and Developments
The field of quantum computing is advancing rapidly. Researchers are continuously working on developing more stable and powerful quantum hardware, paving the way for a future where quantum computing becomes an integral part of our analytical toolbox.
The Ethical and Security Considerations
Ethical Implications
The power of quantum computing comes with ethical responsibilities. The potential to break encryption methods and disrupt secure communications raises important ethical questions. Responsible research and development are crucial to ensure that quantum technology is used for the benefit of humanity.
Security Concerns
Quantum computing also brings about security concerns. Current encryption methods, which rely on the difficulty of factoring large numbers, may become obsolete with the advent of powerful quantum computers. This necessitates the development of quantum-safe cryptography to protect sensitive data.
Responsible Use of Quantum Technology
The responsible use of quantum technology is of paramount importance. A global dialogue on ethical guidelines, standards, and regulations is essential to navigate the ethical and security challenges posed by quantum computing.
My Personal Perspective
Personal Interest and Experiences
Now, let's shift the focus to a more personal dimension. I've always been deeply intrigued by both quantum computing and data science. Their potential to reshape the way we analyze data and solve complex problems has been a driving force behind my passion for these fields.
Reflections on the Future
From my perspective, the fusion of quantum computing and data science holds the promise of unlocking previously unattainable insights. It's not just about making predictions; it's about truly understanding the underlying causality of complex systems, something that could change the way we make decisions in a myriad of fields.
Influential Projects and Insights
Throughout my journey, I've encountered inspiring projects and breakthroughs that have fueled my optimism for the future of analysis. The intersection of these fields has led to astonishing discoveries, and I believe we're only scratching the surface.
Future Possibilities and Closing Thoughts
What Lies Ahead
As we wrap up this exploration, it's crucial to contemplate what lies ahead. Quantum computing and data science are on a collision course with destiny, and the possibilities are endless. Achieving quantum supremacy, broader adoption across industries, and the birth of entirely new applications are all within reach.
In summary, the convergence of Quantum Computing and Data Science is an exciting frontier that has the potential to reshape the way we analyze data and solve problems. It brings both immense promise and significant challenges. The key lies in responsible exploration, ethical considerations, and a collective effort to harness these technologies for the betterment of society.
#data visualization#data science#big data#quantum computing#quantum algorithms#education#learning#technology
4 notes
·
View notes
Text
📌Algorithm is a way to approach a problem.
🤖First, you need to know what algorithms are, the algorithm is a process or set of rules to be followed in problem-solving operations of the computer.
✨It is a sequence of specified functions.
They play a role of the building block of programming, it forms the structure of the program or you can say they are like bricks, rods, and cement used in building construction, similarly in programming. 🏗
🗣They are a hierarchy of instructions given to the computer to execute an output.
Bu kitap önerisi Türk takipçilerim için. Üniversite 1. Sınıfta almıştım bu kitabı algoritma mantığını anlamak için tercih edebilirsiniz.
.
.
.


3 notes
·
View notes
Text
Data Science Ethics: Issues and Strategies Biased algorithms can cause serious societal harm. Learn how algorithmic fairness, diverse datasets, and transparent modeling can prevent discrimination in AI. This article also explains how data scientists can apply ethical principles using real case studies and practical frameworks taught in online data science courses in India.
0 notes
Text
Explore the power of Machine Learning and its impact on modern technology. This guide breaks down essential machine learning algorithms, their applications, and how they shape AI-driven solutions across industries.
#machine learning#data analytics#algorithms#data#datascience#data science#ai generated#artificial intelligence
0 notes
Text
So, following that note about previous AI descriptions, I have a couple experiments I am trying to run using the new PTSD, Kinger, and The Amazing Digital Circus video.
The description is not AI, but looks to the previous AI one as a way to see what worked. I wrote this one with a couple of tests in mind:
The previous one had "We" instead of "I". Will that make a difference in the algorithm considering company channels and their popularity?
The previous one wanted to focus less on my factors and more on the actual media involved. Will adding phrases like "get a deeper look into my psyche" in this description lead to lower or higher viewership?
This is how my brain works. I am a data scientist by trade and by heart. If you have more experiments you would like me to try with the descriptions, let me know. I will no longer be using AI at all following the previous poll, so don't ask about that.
Also let me know if you want to know the results of this experiment. I will specifically taking into account throughput from YouTube itself rather than here or Twitter for the experiment, but I would still love your support either way!
#experimentation#experimental#computer scientist#computer science#data science#data#data analytics#data scientist#algorithms#ptsd#kinger#tadc#the amazing digital circus
1 note
·
View note