#statistics for data science
Explore tagged Tumblr posts
Visit Tumblr Blog
Explore Tumblr blogs with no restrictions, modern design and the best experience.
Last Seen Tumblr Blogs





Fun Fact
Kazakhstan’s Minister of Communications and Informatics has blocked the Tumblr site because it contained 60 sites of terrorism, extremism, and pornography in 2015.
Text
youtube
Statistics - A Full Lecture to learn Data Science (2025 Version)
Welcome to our comprehensive and free statistics tutorial (Full Lecture)! In this video, we'll explore essential tools and techniques that power data science and data analytics, helping us interpret data effectively. You'll gain a solid foundation in key statistical concepts and learn how to apply powerful statistical tests widely used in modern research and industry. From descriptive statistics to regression analysis and beyond, we'll guide you through each method's role in data-driven decision-making. Whether you're diving into machine learning, business intelligence, or academic research, this tutorial will equip you with the skills to analyze and interpret data with confidence. Let's get started!
#education#free education#technology#educate yourselves#educate yourself#data analysis#data science course#data science#data structure and algorithms#youtube#statistics for data science#statistics#economics#education system#learn data science#learn data analytics#Youtube
3 notes
·
View notes
Text
”you’re biased against men!” but am I wrong?
#radblr#prove me wrong coward#defend your scrote with statistics#and science#come on#prove me wrong with historical data#prove me wrong with facts and logic you worthless moid#feminism#prove me wrong with contextualized data#COME ON DONT BE A WEINER#stop avoiding the evidence#men whining about being accurately observed is not equivalent to reasoning#you’re evading the truth
703 notes
·
View notes
Text
in RStudio. straight up “instolling it”. and by “it”, haha, well. let’s justr say. My pakage
#sorry everyone who signed up for the star trek content#our usual programming will return momentarily#rstudio#statistics#data science#this is funny to me and maybe two other people
126 notes
·
View notes
Text
Why the Number Zero Changed Everything
Zero: a concept so foundational to modern mathematics, science, and technology that we often forget it wasn’t always there. Its presence in our world today seems obvious, but its journey from controversial abstraction to indispensable tool has shaped entire civilizations.
1. The Birth of Zero: A Revolutionary Idea
The concept of zero didn't exist in many ancient cultures. For example, the Greeks, despite their advancements in geometry and number theory, rejected the idea of a placeholder for nothingness. The Babylonians had a placeholder symbol (a space or two slashes) for zero, but they didn't treat it as a number. It wasn't until Indian mathematicians in the 5th century, like Brahmagupta, that zero was truly conceptualized and treated as a number with its own properties.
Zero was initially used as a place-holder in the decimal system, but soon evolved into a full-fledged number with mathematical properties, marking a huge leap in human cognition.
2. The Birth of Algebra
Imagine trying to solve equations like x + 5 = 0 without zero. With zero, algebra becomes solvable, opening up entire fields of study. Before zero’s arrival, solving equations involving unknowns was rudimentary, relying on geometric methods. The Indian mathematician Brahmagupta (again) was one of the first to establish rules for zero in algebraic operations, such as:
x + 0 = x (additive identity)
x × 0 = 0 (multiplicative property)
These properties allowed algebra to evolve into a system of abstract thought rather than just arithmetic, transforming the ways we understand equations, functions, and polynomials.
3. Calculus and Zero: A Relationship Built on Limits
Without zero, the foundation of calculus—limits, derivatives, and integrals—wouldn’t exist. The limit concept is intrinsically tied to approaching zero as a boundary. In differentiation, the derivative of a function f(x) is defined as:
f'(x) = \lim_{h \to 0} \frac{f(x+h) - f(x)}{h}
This limit process hinges on the ability to manipulate and conceptualize zero in infinitesimal quantities. Similarly, integrals, which form the backbone of area under curves and summation of continuous data, rely on summing infinitely small quantities—essentially working with zero.
Without the concept of zero, we wouldn’t have the means to rigorously define rates of change or accumulation, effectively stalling physics, engineering, and economics.
4. Zero and the Concept of Nothingness: The Philosophical Impact
Zero is more than just a number; it’s an idea that forces us to confront nothingness. Its acceptance was met with philosophical resistance in ancient times. How could "nothing" be real? How could nothing be useful in equations? But once mathematicians recognized zero as a number in its own right, it transformed entire philosophical discussions. It even challenged ideas in theology (e.g., the nature of creation and void).
In set theory, zero is the size of the empty set—the set that contains no elements. But without zero, there would be no way to express or manipulate sets of nothing. Thus, zero's philosophical acceptance paved the way for advanced theories in logic and mathematical foundations.
5. The Computing Revolution: Zero as a Binary Foundation
Fast forward to today. Every piece of digital technology—from computers to smartphones—relies on binary systems: sequences of 1s and 0s. These two digits are the fundamental building blocks of computer operations. The idea of Boolean algebra, where values are either true (1) or false (0), is deeply rooted in zero’s ability to represent "nothing" or "off."
The computational world relies on logical gates, where zero is interpreted as false, allowing us to build anything from a basic calculator to the complex AI systems that drive modern technology. Zero, in this context, is as important as one—and it's been essential in shaping the digital age.
6. Zero and Its Role in Modern Fields
In modern fields like physics and economics, zero plays a crucial role in explaining natural phenomena and building theories. For instance:
In physics, zero-point energy (the lowest possible energy state) describes phenomena in quantum mechanics and cosmology.
In economics, zero is the reference point for economic equilibrium, and the concept of "breaking even" relies on zero profit/loss.
Zero allows us to make sense of the world, whether we’re measuring the empty vacuum of space or examining the marginal cost of producing one more unit in economics.
7. The Mathematical Utility of Zero
Zero is essential in defining negative numbers. Without zero as the boundary between positive and negative values, our number system would collapse. The number line itself relies on zero as the anchor point, dividing positive and negative values. Vector spaces, a fundamental structure in linear algebra, depend on the concept of a zero vector as the additive identity.
The coordinate system and graphs we use to model data in statistics, geometry, and trigonometry would not function as we know them today. Without zero, there could be no Cartesian plane, and concepts like distance, midpoint, and slope would be incoherent.
#mathematics#math#mathematician#mathblr#mathposting#calculus#geometry#algebra#numbertheory#mathart#STEM#science#academia#Academic Life#math academia#math academics#math is beautiful#math graphs#math chaos#math elegance#education#technology#statistics#data analytics#math quotes#math is fun#math student#STEM student#math education#math community
62 notes
·
View notes
Text


eating out ૮₍ ˃ ⤙ ˂ ₎ა
24 December 2024, Tuesday, dop 3
Uni diaries II day 49/?
So much eating out. I've gained like 1 kg in a day.
Today I-
Prayed 4/5 (missed evening prayer ಠ_ಠ)
Attended 3 lectures (1 was cancelled)
Had two nutritious breakfasts (hobbit vibe intensifies)
Ordered Pizza for lunch
Got birthday treats from friend ♡
Realised i ordered 600 YARDS of yarn ⊙.☉
Talked to BFF ( ◜‿◝ )♡ (we planned a meetup)
Slept well (6 hours)
Got in 8k+ steps
#studyblr#studyspo#study motivation#study inspiration#study hard#study aesthetic#study#studying#altin posts#datablr#datascience#data science#data#statistics#statblr#stat
35 notes
·
View notes
Text
Hey stats or linguistics nerds!
(Explanation below)
Explanation:
Countable and singular means you hear “data” and think there’s exactly one thing in discussion. You would use it like “this data is an outlier, whereas that one is not.” Examples of this form: a cat, an artwork
Countable and plural means you hear “data” and think there’s more than one thing being talked about. You would use it like “these data show a positive trend, whereas those do not.” When discussing just one, you would use the term “datum”. Examples: cars, planets
Uncountable means you hear “data” and think that there’s some quantity of it, but it’s not necessarily a numbered amount, in a similar way to a fluid. You would use it like “this data doesn’t prove my hypothesis, but some of that data does.” Examples: water, air
Bias alert:
My father is a database engineer and has always used the word “data” as uncountable. I believe the “correct” way to use it is countable plural with the singular form being “datum”, though there’s no real answer because it’s linguistics and languages shift with use. That’s why I’m asking the people, in order to know how the term is used
24 notes
·
View notes
Text
youtube
#statistics#mathematics#mathblr#math art#calculated risk#calculator#calculus#calculations#cat#black cat#cats#cute cats#kitty cat#cats of tumblr#catblr#kittens#kitten#kitty#kittyposting#cute kitty#natural science#science#mad scientist#data scientist#scientific illustration#research scientist#stem#stem student#stem academia#stemblr
8 notes
·
View notes
Text
I'm in need of advice, reddit hasn't been helpful and I'm desperate so I've come to you Tumblr please help me
I'm currently a data scientist for a very small start up company, but I have my background in political science and so I'm concerned that I might be dead in the water if/when the company goes under and I need to find another job. I've consulted with some recruiters and they agree that if I want to go into data science I should get my master's (EDIT: they said I probably should get my degree in Statistics because the program is more widely known so I have a better chance of not getting turned away by HR who will have less knowledge about what a data science master's even is). I think because of my personality, data science is a really good job for me, so I'm planning on going for it.
Here's the issue: I don't want to go to school and end up learning exclusively theory. I've been teaching myself a ton by reading textbooks and I've noticed that while there's a lot of depth in the math/calculus/linear algebra behind how the functions work and what the parameters are, there seems to be very little information on how to actually apply that information in the real world.
Obviously the math is important and very exciting :D but if all I do is learn the math and I don't learn how to apply the knowledge I have to non-ideal data sets and situations then I'm not really learning the information I need to know.
Are there any graduate programs that are well known for really preparing people for data science roles in the workforce instead of just focusing on the academic side of statistics?
#statistics#data science#math#careers#jobs#grad school#what is the community tag for this idk#;---;#i have to sign up for classes for prerequisites right now so im nervous bc idk which classes to take if idk which schools i should apply to#reddit has not helped me </3
71 notes
·
View notes
Text
youtube
really great vid about interpreting data, by Dr. Fatima 😁 i feel lucky to have had a decent Statistics class where i learned a lot of this, but Dr. Fatima puts it into words in a way they never did! plus: a great anecdote at the end about the curb cut effect of data accessibility.
this is also why STEM should be STEAM (A for Art). Art (creativity, design, music, etc) is so important in learning how to understand & communicate what we perceive!!
#challenger#nasa#statistics#data science#data visualization#dr. fatima#women in stem#arab american scientist#astrophysics#engineering#data accessibility#Youtube
4 notes
·
View notes
Text
A note on Katharine Birbalsingh and Michaela Community School
The media narrative surrounding Michaela Community School in London mostly goes like this: Katharine Birbalsingh transforms poor inner-city (read: ethnic minority) children into academic superstars through the power of discipline. Thomas Chatterton Williams’s recent essay (full text here) in The Atlantic is merely the latest in a long line of fawning profiles that tout, implicitly or explicitly, Birbalsingh's iron fist as the solution to all that ails Britain. However, no article I have read so far has investigated other explanations for Michaela's high Progress 8 score nor endeavored to deconstruct the popular narrative surrounding the conservative superstar.
Williams begins the body of this piece by pointing out that Michaela “draws nearly all its students from Wembley, one of the poorest districts in London” in an apparent attempt to cast them as would-be low achievers, if not for Birbalsingh’s intervention. Although the characteristics of the individual pupils who attend Michaela have a greater impact on results than those of the school's neighborhood, he doesn’t bother to investigate how they differ. Among Michaela pupils who sat GCSEs over the past three years and whose prior attainment at Key Stage 2 (measured by an exam at the end of primary school) were available, 31% were high achieving, 53% were middle achieving, and only the remaining 16% were low achieving. For those who are uninterested in learning the nuances of British exam scoring, that means Michaela’s pupils were exceptionally bright even before they entered the school.
Birbalsingh furthers her savior narrative by describing Michaela's intake with unquantifiable terms such as "challenging" or "inner-city." However, only 28 of Michaela's 2024 GCSE takers (24%) were disadvantaged per the government's definition, "those who were eligible for free school meals at any time during the last 6 years and children looked after," in line with the national average of 25%. Although Birbalsingh likes to advance the narrative that she improves the academic performance of poor children—to be fair, she does, at a rate of roughly 30 individuals per year—she mostly improves the GCSE performance of middle class children.
Michaela's pupils are also self selecting, and therefore they are not representative of pupils in Wembley, London, or the UK as a whole. Any pupil who wishes to attend state secondary school in London must fill out a form indicating their top six choices, and they will be placed in one of those schools based on geography, demand, and availability. A pupil who does not wish to attend Michaela can leave it off their application, guaranteeing they won't attend. Therefore, Michaela is left with an intake of pupils who largely want to be there. By my calculations, Michaela's classwork and homework demand just over 49 hours of work each week. Although this does lead to good results, many teenagers would not abide by this; the 40-hour workweek is taxing even for most adults, who are blessed with more waking hours. Michaela's model and results cannot be easily repeated at any given school—at least not without systematic exclusion.
Williams unintentionally misrepresents a statistic when he asserts that “More than 80 percent of Michaela graduates continue their studies at Russell Group Universities.” He lacks a sufficiently deep understanding of the British school system to interpret this figure. While Michaela’s website states that 82% of its 2021 sixth form alumni attended a Russell Group university, it does not provide data on the university attendance of graduates from its secondary school, the disciplinarian institution which Williams profiles.
In the UK, sixth form (years 12 and 13, spent studying for A-levels) is separate from secondary school (years 7 through 11; the last 2 years, KS4, are spent studying for GCSEs). For Michaela, this also means a different admissions process. While there are no academic minimums to enroll in the secondary school, the sixth form requires an impressive average GCSE score of 7. Michaela has the capacity to enroll 120 students in each year of sixth form. However, the sixth form was under-enrolled by half in 2024. Michaela is a publicly-funded school, so this begs the question as to why state resources are not being utilized to their maximum capacity. The sixth form could educate more students simply by lowering GCSE requirements, but that would of course lead to less impressive university admissions—the kind that may not be displayed on Michaela’s home page. It is also possible that some secondary teachers would be pulled away to teach A-level subjects, worsening GCSE results, but that is speculation.
Thus far, all discussions of Michaela’s results have been woefully incomplete because they have not examined the effect of its narrow curriculum on its exam scores, instead focusing on the behaviorism that makes Birbalsingh’s authoritarian acolytes salivate. Williams's article is no different, only mentioning in passing that she believes “the national curriculum might force her to lower her own standards.” Depending on what changes the new Labour government implements, a revised national curriculum may indeed clash with Michaela’s philosophy. The school directs virtually all of its resources toward preparing pupils for its narrow selection of GCSE subjects or the few non-GCSE subjects that are required by the current national curriculum, such as PSHE, music theory, or PE. Birbalsingh is so focused on GCSE revision that she does not even believe volunteer work to be a "financially viable" option for Michaela pupils. Michaela's extra-curricular clubs all have a marginal cost of practically zero. In fact, several of them directly support curricular subjects, so they should rightfully be considered part of GCSE preparation.
A narrow curriculum obviously allows pupils to spend more time studying each GCSE subject they sit, thereby increasing their exam scores. Since most of the GCSE-level classes that Michaela offers are mandatory, pupils have little freedom to choose their own subjects (more on that later). Aside from that, cohort sizes stay remarkably close to 120 from year to year, and the school seems to impose a soft cap on classes of 30 pupils (120 / 4 = 30), so Michaela can hire the exact number of teachers it needs each year on a full-time basis. The school never needs to "waste" money hiring teachers for undersubscribed subjects, so it can also raise test scores by investing more in its core subjects than schools with broader curricula can afford to. On the flip side, Michaela does not offer dramatic arts, orchestra, individual sciences, computing, design and technology, foreign languages besides French, or a whole host of other popular subjects at the GCSE level. Other schools could easily raise their GCSE scores by slashing their curricula down to Michaela levels, but they offer a variety of classes because they care about their pupils experiencing joy and exploring a variety of career paths more than they care about their P8 scores.
For years, all of Michaela’s pupils have studied the same subjects at GCSE with some slight variations. A handful of pupils always sit for exams in heritage languages, but otherwise, the following paragraphs demonstrate approximately how the subject breakdown has looked over the past three years. (Earlier data has been distorted by COVID, or it is incomplete or outdated.) At the time of publication, 2024 data can be found here, while older results can be accessed through the link “Download data (1991-2024)”.
- 2022: 100% of pupils: English language, English literature, combined science, mathematics, religious studies. ~75%: French, geography/history. ~25%: Citizenship. ~25%: Art & design: photography, art & design: fine art. (I had to recreate this year from memory because individual subject entries do not appear to be retained in older data, but it is accurate to the best of my recollection.)
- 2023: 100% of pupils: English language, English literature, combined science, mathematics, religious studies. ~75%: French, geography/history. ~25%: Art & design: photography, art & design: fine art.
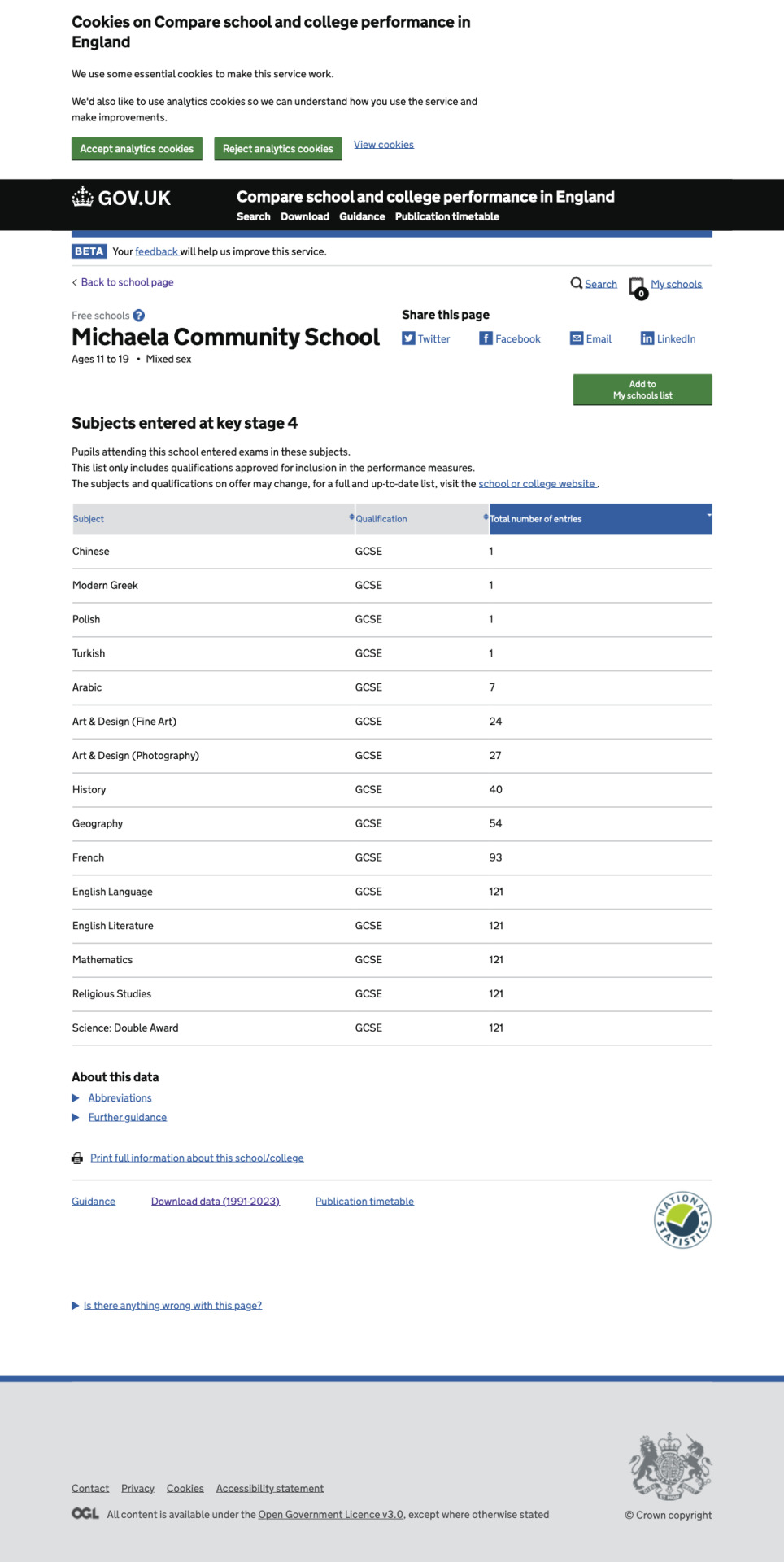
- 2024: 100% of pupils: English language, English literature, combined science, mathematics, religious studies, French. * ~80%: Geography/history. ~20%: Art & design: photography.
*This year, 3 pupils sat for biology, chemistry, and physics separately instead of taking combined science, but there is no explanation for this on Michaela's website.
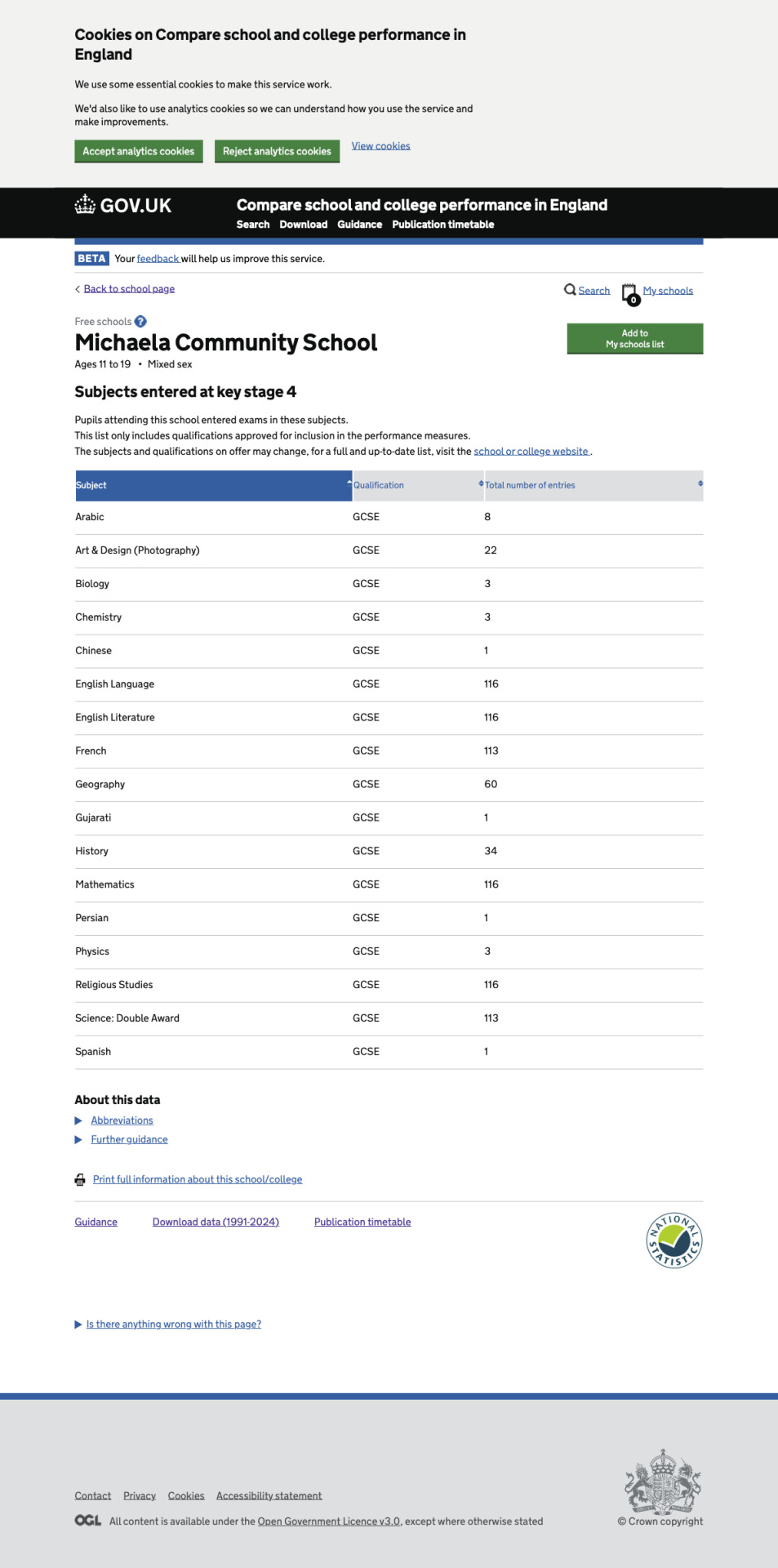
Each year, about 90 Michaela pupils enter for the EBacc, a set of GCSE subjects encouraged by the British government. This usually works out to 75% of a cohort, but in 2024 it was 81% (94 pupils) because the cohort size was smaller than usual at only 116 pupils. Still, that means the largest class of EBacc entrants was only 32, in line with Michaela's projected class size of 30—despite Birbalsingh asserting that "class size matters little for success." Although the school comparison website does not list subject selections for individual pupils, it was easy to see how subjects were combined by cross-referencing exam entries per pupil and total entries per subject.
In 2021-2022, the pupils who did not enter for EBacc studied citizenship but neither French nor humanities. The study of art did not appear to correlate with EBacc entry.
In 2022-2023, the pupils who did not enter for EBacc studied photography and fine art but neither French nor humanities. Citizenship was dropped from the curriculum.
In 2023-2024, the pupils who did not enter for the EBacc studied photography but not humanities.
EBacc entry varies little across different pupil demographics such as gender, disadvantage, or English as an additional language. However, there is one characteristic that strongly determines EBacc entry at Michaela: prior attainment (PA). Over the past three years, out of 323 pupils for whom the PA data is available, 23% of low-PA pupils have entered the EBacc. This number is 83% for middle PA and 99% for high PA. According to my statistical analysis, the chance of these disparate "choices" arising without intervention is less than one percent.
At the end of Key Stage 3, Michaela staff pick approximately the top 75% of performers to enter for EBacc and require the lowest 25% to study other subjects.
This explains why only a few low-PA pupils enter for EBacc: although they are likely to remain in the bottom of their cohort throughout their schooling, some may improve enough to enter the top three quartiles. Although I am fully confident that my statistical analysis supports my assertion that Michaela pupils are not permitted to choose their GCSE subjects, the school has never disclosed a rationale for this practice, so the remainder of this essay will be speculation, not fact.
Michaela frequently boasts of its high Progress 8 (P8) score, and in order to understand my hypotheses, I recommend you familiarize yourself with its calculation. P8 is calculated by comparing actual Attainment 8 (A8) scores with expected scores based on Key Stage 2 (KS2) performance. This PDF explains how A8 scores are derived. (For my purposes, I will count double science as 2 GCSE subjects.) Therefore, a school with a non-selective intake such as Michaela can only change its P8 score by changing its A8 score.
Over the past few years, Michaela has refined its placement technique, presumably to increase its A8 scores. Pupils of any ability were permitted to study art at the GCSE level in 2022, but that option was removed the next year, probably so that high performers could devote more energy to EBacc subjects. Low performers who would have studied citizenship in 2022 instead studied art in 2023. Perhaps a part-time citizenship teacher would no longer be needed, and more resources could be directed to core subjects. All pupils studied GCSE French for the first time in 2024, giving each pupil 3 EBacc qualifications and finally maximizing A8 scores. However, the poorest performing 25% did not study humanities at KS4. This meant that approximately 120 * 2 * (1 - 0.25) = 180 pupils did study humanities at KS4, so with a typical class size of 30 and 6 class periods per day, one teacher could have accommodated all of them. If poor performers had studied humanities as well, hiring another teacher may have been necessary (and we already know how protective Michaela is of its budget).
The curricula for high and low performers are now identical, except for poor performers studying photography instead of humanities. Working from the assumption that Michaela intends to maximize its A8 score, this leads to one or two conclusions: it believes that poor performers will score higher on photography than French, and/or it does not want to expend humanities resources on poor performers because allocating them exclusively to high performers will raise the A8 score more. Similarly, no Michaela pupil has entered for more than 8 GCSE subjects (barring heritage languages, which do not demand too much revision time) since 2022, almost certainly to improve A8 scores. A limited class schedule allows pupils to devote more revision time to each core subject, while more exams would not raise A8, even if they did expand pupils’ horizons.
In the matter of GCSE curriculum, Michaela’s website is outdated and incomplete. It still enumerates the KS4 fine art curriculum, even though the subject was not offered at the GCSE level in 2024. It doesn’t mention that only three-quarters of pupils will study GCSE history or geography, so some parents who expect their children to study the humanities past age 13 may be in for a nasty surprise. Of course, this begs the question, what does Michaela have to hide?
It is difficult to understand how these prescribed schedules advantage Michaela’s pupils. Does the school not enroll maths whizzes who are determined to enter for mathematics, further mathematics, and physics at A-level, but who want one last artistic hurrah before starting sixth form? Are none of the poor performers averse enough to art that they'd prefer history? These prescriptions do not necessarily benefit Michaela’s pupils, but they do benefit the school’s P8.
Finally, Williams closes his article on a nostalgic note, contrasting his childhood with that of the Michaela pupil: “…my friends and I were free—luxuriously so—in ways these children possibly couldn’t even imagine. But that freedom that so many underprivileged and minority children bask in isn’t worth a damn thing if it leads to an adulthood boxed in by self-inflicted limitations.” Since the author was raised by college graduate parents and educated in private schools, and he is now a successful writer, he seems to believe that children who grow up rich can thrive on freedom, but the same is not true of the poor. Birbalsingh similarly believes that disadvantaged children need extreme discipline to succeed. However, she does not want to create a world where child poverty is eradicated so that every pupil can experience freedom, joy, and success at the same time. In fact, she envisions the opposite. She has spoken out against free meals for primary schoolers because she believes (without evidence!) that it would somehow make their parents less responsible. Even this concern were legitimate, it would pale in comparison to the necessity of feeding hungry children.
In the end, my dislike of Birbalsingh stems from her incredibly bleak worldview. She maintains that children should face the threat of starvation so their parents will be motivated to work harder. Even when testifying before Parliament, she believes the sexism that drives differences in A-level subject choices should remain unexamined. She propagates furry hoaxes—originally spread to mock trans people—to exemplify a supposed lack of discipline from parents. She believes if you don’t decorate your house for Christmas, you are destroying the country, and it is also somehow Vishnu’s problem (yes, the letter is truly that bizarre, and I recommend reading it for full effect). In her ideal world, she imagines suffering for suffering’s sake, a boot stamping on a human face—forever.
#katharine birbalsingh#birbalsingh#michaela community school#michaela#politics#british politics#uk politics#essay#longform#long form#data science#statistics#statistical analysis#education#education system#uk education#education uk#british education#united kingdom#london#wembley#i am a girl who likes hard maths
3 notes
·
View notes
Text
youtube
Statistics for Data Science Full course with Gen AI & ChatGPT 4o (2024)
Ready to learn Statistics for Data Science with Gen AI and ChatGPT 4o. In this video, dive into the essentials of statistics, and its critical role in data science. Further, we will explore key concepts such as Descriptive, Prescriptive, and Predictive statistics. We will learn to measure relationships using correlation and covariance. Also, we will discover how to leverage ChatGPT-4 for advanced statistical analysis. Through this video, you can master statistics in data science. Perfect for beginners or skill enhancement.
Learn Statistics for Data Science that includes key concepts like probability, hypothesis testing, and the importance of normal distribution and sampling in data analytics.
#free education#education#technology#educate yourselves#educate yourself#youtube#Statistics for Data Science#data analytics#datascience#chatgpt tutorial#artificial intelligence#chatgpt 4#Statistics for Data Science Full course#free courses#free classes#Youtube
1 note
·
View note
Text

The Mathematical Foundations of Machine Learning
In the world of artificial intelligence, machine learning is a crucial component that enables computers to learn from data and improve their performance over time. However, the math behind machine learning is often shrouded in mystery, even for those who work with it every day. Anil Ananthaswami, author of the book "Why Machines Learn," sheds light on the elegant mathematics that underlies modern AI, and his journey is a fascinating one.
Ananthaswami's interest in machine learning began when he started writing about it as a science journalist. His software engineering background sparked a desire to understand the technology from the ground up, leading him to teach himself coding and build simple machine learning systems. This exploration eventually led him to appreciate the mathematical principles that underlie modern AI. As Ananthaswami notes, "I was amazed by the beauty and elegance of the math behind machine learning."
Ananthaswami highlights the elegance of machine learning mathematics, which goes beyond the commonly known subfields of calculus, linear algebra, probability, and statistics. He points to specific theorems and proofs, such as the 1959 proof related to artificial neural networks, as examples of the beauty and elegance of machine learning mathematics. For instance, the concept of gradient descent, a fundamental algorithm used in machine learning, is a powerful example of how math can be used to optimize model parameters.
Ananthaswami emphasizes the need for a broader understanding of machine learning among non-experts, including science communicators, journalists, policymakers, and users of the technology. He believes that only when we understand the math behind machine learning can we critically evaluate its capabilities and limitations. This is crucial in today's world, where AI is increasingly being used in various applications, from healthcare to finance.
A deeper understanding of machine learning mathematics has significant implications for society. It can help us to evaluate AI systems more effectively, develop more transparent and explainable AI systems, and address AI bias and ensure fairness in decision-making. As Ananthaswami notes, "The math behind machine learning is not just a tool, but a way of thinking that can help us create more intelligent and more human-like machines."
The Elegant Math Behind Machine Learning (Machine Learning Street Talk, November 2024)
youtube
Matrices are used to organize and process complex data, such as images, text, and user interactions, making them a cornerstone in applications like Deep Learning (e.g., neural networks), Computer Vision (e.g., image recognition), Natural Language Processing (e.g., language translation), and Recommendation Systems (e.g., personalized suggestions). To leverage matrices effectively, AI relies on key mathematical concepts like Matrix Factorization (for dimension reduction), Eigendecomposition (for stability analysis), Orthogonality (for efficient transformations), and Sparse Matrices (for optimized computation).
The Applications of Matrices - What I wish my teachers told me way earlier (Zach Star, October 2019)
youtube
Transformers are a type of neural network architecture introduced in 2017 by Vaswani et al. in the paper “Attention Is All You Need”. They revolutionized the field of NLP by outperforming traditional recurrent neural network (RNN) and convolutional neural network (CNN) architectures in sequence-to-sequence tasks. The primary innovation of transformers is the self-attention mechanism, which allows the model to weigh the importance of different words in the input data irrespective of their positions in the sentence. This is particularly useful for capturing long-range dependencies in text, which was a challenge for RNNs due to vanishing gradients. Transformers have become the standard for machine translation tasks, offering state-of-the-art results in translating between languages. They are used for both abstractive and extractive summarization, generating concise summaries of long documents. Transformers help in understanding the context of questions and identifying relevant answers from a given text. By analyzing the context and nuances of language, transformers can accurately determine the sentiment behind text. While initially designed for sequential data, variants of transformers (e.g., Vision Transformers, ViT) have been successfully applied to image recognition tasks, treating images as sequences of patches. Transformers are used to improve the accuracy of speech-to-text systems by better modeling the sequential nature of audio data. The self-attention mechanism can be beneficial for understanding patterns in time series data, leading to more accurate forecasts.
Attention is all you need (Umar Hamil, May 2023)
youtube
Geometric deep learning is a subfield of deep learning that focuses on the study of geometric structures and their representation in data. This field has gained significant attention in recent years.
Michael Bronstein: Geometric Deep Learning (MLSS Kraków, December 2023)
youtube
Traditional Geometric Deep Learning, while powerful, often relies on the assumption of smooth geometric structures. However, real-world data frequently resides in non-manifold spaces where such assumptions are violated. Topology, with its focus on the preservation of proximity and connectivity, offers a more robust framework for analyzing these complex spaces. The inherent robustness of topological properties against noise further solidifies the rationale for integrating topology into deep learning paradigms.
Cristian Bodnar: Topological Message Passing (Michael Bronstein, August 2022)
youtube
Sunday, November 3, 2024
#machine learning#artificial intelligence#mathematics#computer science#deep learning#neural networks#algorithms#data science#statistics#programming#interview#ai assisted writing#machine art#Youtube#lecture
4 notes
·
View notes
Text
What Are the Qualifications for a Data Scientist?
In today's data-driven world, the role of a data scientist has become one of the most coveted career paths. With businesses relying on data for decision-making, understanding customer behavior, and improving products, the demand for skilled professionals who can analyze, interpret, and extract value from data is at an all-time high. If you're wondering what qualifications are needed to become a successful data scientist, how DataCouncil can help you get there, and why a data science course in Pune is a great option, this blog has the answers.
The Key Qualifications for a Data Scientist
To succeed as a data scientist, a mix of technical skills, education, and hands-on experience is essential. Here are the core qualifications required:
1. Educational Background
A strong foundation in mathematics, statistics, or computer science is typically expected. Most data scientists hold at least a bachelor’s degree in one of these fields, with many pursuing higher education such as a master's or a Ph.D. A data science course in Pune with DataCouncil can bridge this gap, offering the academic and practical knowledge required for a strong start in the industry.
2. Proficiency in Programming Languages
Programming is at the heart of data science. You need to be comfortable with languages like Python, R, and SQL, which are widely used for data analysis, machine learning, and database management. A comprehensive data science course in Pune will teach these programming skills from scratch, ensuring you become proficient in coding for data science tasks.
3. Understanding of Machine Learning
Data scientists must have a solid grasp of machine learning techniques and algorithms such as regression, clustering, and decision trees. By enrolling in a DataCouncil course, you'll learn how to implement machine learning models to analyze data and make predictions, an essential qualification for landing a data science job.
4. Data Wrangling Skills
Raw data is often messy and unstructured, and a good data scientist needs to be adept at cleaning and processing data before it can be analyzed. DataCouncil's data science course in Pune includes practical training in tools like Pandas and Numpy for effective data wrangling, helping you develop a strong skill set in this critical area.
5. Statistical Knowledge
Statistical analysis forms the backbone of data science. Knowledge of probability, hypothesis testing, and statistical modeling allows data scientists to draw meaningful insights from data. A structured data science course in Pune offers the theoretical and practical aspects of statistics required to excel.
6. Communication and Data Visualization Skills
Being able to explain your findings in a clear and concise manner is crucial. Data scientists often need to communicate with non-technical stakeholders, making tools like Tableau, Power BI, and Matplotlib essential for creating insightful visualizations. DataCouncil’s data science course in Pune includes modules on data visualization, which can help you present data in a way that’s easy to understand.
7. Domain Knowledge
Apart from technical skills, understanding the industry you work in is a major asset. Whether it’s healthcare, finance, or e-commerce, knowing how data applies within your industry will set you apart from the competition. DataCouncil's data science course in Pune is designed to offer case studies from multiple industries, helping students gain domain-specific insights.
Why Choose DataCouncil for a Data Science Course in Pune?
If you're looking to build a successful career as a data scientist, enrolling in a data science course in Pune with DataCouncil can be your first step toward reaching your goals. Here’s why DataCouncil is the ideal choice:
Comprehensive Curriculum: The course covers everything from the basics of data science to advanced machine learning techniques.
Hands-On Projects: You'll work on real-world projects that mimic the challenges faced by data scientists in various industries.
Experienced Faculty: Learn from industry professionals who have years of experience in data science and analytics.
100% Placement Support: DataCouncil provides job assistance to help you land a data science job in Pune or anywhere else, making it a great investment in your future.
Flexible Learning Options: With both weekday and weekend batches, DataCouncil ensures that you can learn at your own pace without compromising your current commitments.
Conclusion
Becoming a data scientist requires a combination of technical expertise, analytical skills, and industry knowledge. By enrolling in a data science course in Pune with DataCouncil, you can gain all the qualifications you need to thrive in this exciting field. Whether you're a fresher looking to start your career or a professional wanting to upskill, this course will equip you with the knowledge, skills, and practical experience to succeed as a data scientist.
Explore DataCouncil’s offerings today and take the first step toward unlocking a rewarding career in data science! Looking for the best data science course in Pune? DataCouncil offers comprehensive data science classes in Pune, designed to equip you with the skills to excel in this booming field. Our data science course in Pune covers everything from data analysis to machine learning, with competitive data science course fees in Pune. We provide job-oriented programs, making us the best institute for data science in Pune with placement support. Explore online data science training in Pune and take your career to new heights!
#In today's data-driven world#the role of a data scientist has become one of the most coveted career paths. With businesses relying on data for decision-making#understanding customer behavior#and improving products#the demand for skilled professionals who can analyze#interpret#and extract value from data is at an all-time high. If you're wondering what qualifications are needed to become a successful data scientis#how DataCouncil can help you get there#and why a data science course in Pune is a great option#this blog has the answers.#The Key Qualifications for a Data Scientist#To succeed as a data scientist#a mix of technical skills#education#and hands-on experience is essential. Here are the core qualifications required:#1. Educational Background#A strong foundation in mathematics#statistics#or computer science is typically expected. Most data scientists hold at least a bachelor’s degree in one of these fields#with many pursuing higher education such as a master's or a Ph.D. A data science course in Pune with DataCouncil can bridge this gap#offering the academic and practical knowledge required for a strong start in the industry.#2. Proficiency in Programming Languages#Programming is at the heart of data science. You need to be comfortable with languages like Python#R#and SQL#which are widely used for data analysis#machine learning#and database management. A comprehensive data science course in Pune will teach these programming skills from scratch#ensuring you become proficient in coding for data science tasks.#3. Understanding of Machine Learning
3 notes
·
View notes
Text
The Math of Social Networks: How Social Media Algorithms Work
In the digital age, social media platforms like Instagram, Facebook, and TikTok are fueled by complex mathematical algorithms that determine what you see in your feed, who you follow, and what content "goes viral." These algorithms rely heavily on graph theory, matrix operations, and probabilistic models to connect billions of users, influencers, and posts in increasingly intricate webs of relationships.
Graph Theory: The Backbone of Social Networks
Social media platforms can be visualized as graphs, where each user is a node and each connection (whether it’s a "follow," "like," or "comment") is an edge. The structure of these graphs is far from random. In fact, they follow certain mathematical properties that can be analyzed using graph theory.
For example, cliques (a subset of users where everyone is connected to each other) are common in influencer networks. These clusters of interconnected users help drive trends by amplifying each other’s content. The degree of a node (a user’s number of direct connections) is a key factor in visibility, influencing how posts spread across the platform.
Additionally, the famous Six Degrees of Separation theory, which posits that any two people are connected by no more than six intermediaries, can be modeled using small-world networks. In these networks, most users are not directly connected to each other, but the distance between any two users (in terms of number of connections) is surprisingly short. This is the mathematical magic behind viral content, as a post can be shared through a small network of highly connected individuals and reach millions of users.
Matrix Operations: Modeling Connections and Relevance
When social media platforms recommend posts, they often rely on matrix operations to model relationships between users and content. This process can be broken down into several steps:
User-Content Matrix: A matrix is created where each row represents a user and each column represents a piece of content (post, video, etc.). Each cell in this matrix could hold values indicating the user’s interactions with the content (e.g., likes, comments, shares).
Matrix Factorization: To make recommendations, platforms use matrix factorization techniques such as singular value decomposition (SVD). This helps reduce the complexity of the data by identifying latent factors that explain user preferences, enabling platforms to predict what content a user is likely to engage with next.
Personalization: This factorization results in a model that can predict a user’s preferences even for content they’ve never seen before, creating a personalized feed. The goal is to minimize the error matrix, where the predicted interactions match the actual interactions as closely as possible.
Influence and Virality: The Power of Centrality and Weighted Graphs
Not all users are equal when it comes to influencing the network. The concept of centrality measures the importance of a node within a graph, and in social media, this directly correlates with a user’s ability to shape trends and drive engagement. Common types of centrality include:
Degree centrality: Simply the number of direct connections a user has. Highly connected users (like influencers) are often at the core of viral content propagation.
Betweenness centrality: This measures how often a user acts as a bridge along the shortest path between two other users. A user with high betweenness centrality can facilitate the spread of information across different parts of the network.
Eigenvector centrality: A more sophisticated measure that not only considers the number of connections but also the quality of those connections. A user with high eigenvector centrality is well-connected to other important users, enhancing their influence.
Algorithms and Machine Learning: Predicting What You See
The most sophisticated social media platforms integrate machine learning algorithms to predict which posts will generate the most engagement. These models are often trained on vast amounts of user data (likes, shares, comments, time spent on content, etc.) to determine the factors that influence user interaction.
The ranking algorithms take these factors into account to assign each post a “score” based on its predicted engagement. For example:
Collaborative Filtering: This technique relies on past interactions to predict future preferences, where the behavior of similar users is used to recommend content.
Content-Based Filtering: This involves analyzing the content itself, such as keywords, images, or video length, to recommend similar content to users.
Hybrid Methods: These combine collaborative filtering and content-based filtering to improve accuracy.
Ethics and the Filter Bubble
While the mathematical models behind social media algorithms are powerful, they also come with ethical considerations. Filter bubbles, where users are only exposed to content they agree with or are already familiar with, can be created due to biased algorithms. This can limit exposure to diverse perspectives and create echo chambers, reinforcing existing beliefs rather than fostering healthy debate.
Furthermore, algorithmic fairness and the prevention of algorithmic bias are growing areas of research, as biased recommendations can disproportionately affect marginalized groups. For instance, if an algorithm is trained on biased data (say, excluding certain demographics), it can unfairly influence the content shown to users.
#mathematics#math#mathematician#mathblr#mathposting#calculus#geometry#algebra#numbertheory#mathart#STEM#science#academia#Academic Life#math academia#math academics#math is beautiful#math graphs#math chaos#math elegance#education#technology#statistics#data analytics#math quotes#math is fun#math student#STEM student#math education#math community
24 notes
·
View notes
Text


31 December 2024, Tuesday
Uni diaries II day 52/-
2024 ended with bang! Both good and bad. Today I-
Prayed 5/5
Attended 3 classes (2 cancelled) 。◕‿◕。
Walked 10.5 km ᕙ( • ‿ • )ᕗ
Visited a friend's place (had fries) ✧◝(⁰▿⁰)◜✧
Did BBQ (。ᴖ ⤙ ᴖ)
Slept Badly ಥ‿ಥ (Fireworks are not cool)
Hope all of you had a great day ~
#altin posts#studyblr#studyspo#study motivation#study inspiration#study hard#study aesthetic#study#studying#stemblr#statblr#datablr#datascience#data science#data#statistics
17 notes
·
View notes
Text
Music taste is such an interesting form of individuality. Like I love learning about different peoples’ music tastes because everyone finds such cool and diverse shit to listen to and like it’s so unique. Even if you have a lot of overlap in artists and genres with someone they’re still just about guaranteed to know and love some crazy niche artist you’ve never heard of.
#my final for my math curriculum class is a lesson plan abt Spotify data#it’s just descriptive statistics stuff and maybe a little comparative stuff bc I also have my roommate’s Spotify data to mess with#but I think it would be so fun to do with high schoolers#and I just think data science about music taste is so interesting#this came from a theory I have that there’s significant overlap between country music fans and metal fans#they’re both like such despised/divisive genres and they also kind of merge at rock n roll#and I think they’re almost two sides of the musical coin#and I’m so curious if my hypothesis is correct#mathematics#mathblr#(kinda)#idk very excited to show my work off to mathblr once it’s done
2 notes
·
View notes