#database concurrency
Explore tagged Tumblr posts
Visit Tumblr Blog
Explore Tumblr blogs with no restrictions, modern design and the best experience.
Last Seen Tumblr Blogs





Fun Fact
After the announcement of the deal with Yahoo!, there were 170K signatures of unhappy Tumblr users petitioning to prevent the sale in 2013.
Text
Understanding Transaction Isolation Levels in SQL Server
Introduction Have you ever wondered what happens behind the scenes when you start a transaction in SQL Server? As a database developer, understanding how isolation levels work is crucial for writing correct and performant code. In this article, we’ll dive into the details of what happens when you begin an explicit transaction and run multiple statements before committing. We’ll explore whether…

View On WordPress
0 notes
Text
News of the Day 5/25/2025: George Floyd and Police Violence
youtube
Paywall free.
Paywall free.
At some level saying Trump is no great friend of police reform feels like the "dog bites man" of the journalism world: so obvious and expected, it barely qualifies as news. And speaking as a white person (so my opinion is not the one that matters most!), it's not been quite the absolute horror show one would expect. Bad, but given the *gestures* of it all, we can maybe be excused for focusing on other things.
Which doesn't mean there's nothing happening. What with the five-year anniversary of George Floyd's killing coming up, it's a good time to take stock.
Trump took down a major database tracking police violence. (X)
He's pushing those law firms he pressured to do pro bono work on his behalf (Paul Weiss etc.) to defend cops accused of misconduct. (X)
He stopped enforcing consent decrees in Kentucky (Breonna Taylor) and Minnesota (George Floyd). (X)
Many on the right are pushing Trump to pardon Derek Chauvin, the cop who killed George Floyd. (X) A pardon would be symbolic since he's also serving a concurrent state sentence, but it's still symbolism we really don't need.
He signed an executive order promising to "unleash" police. (X)
He wants to reopen Alcatraz (X) and, of course, send American "home-growns" to CECOT.
Back in his campaign, he promised a "violent day" of policing to reduce crime. (X)
There's some room for hope, at least with the consent decrees (X). Police reform can be done locally and state-level as well as nationally, and both Minnesota and Kentucky have promised to carry on enforcing them. Usually the federal DOJ gets involved because cops work closely with city and state lawyers so there's a natural concern they'll go easy on local cops. But that's a political problem, not a legal one. Now's the time to call your governor, your mayor. Maybe even get involved with a local policing reform group. They're out there, and they can still make a difference.
Along those lines, and thinking about George Floyd, it really is worth thinking about what changed and what didn't. The video above is an interview with Marc Morial, the leader of the National Urban League. So much of the work is still undone, but he also points to some important changes tha actually got done. It's so important to take hope but not be blinded to how much work there's still to do, and he does a good job walking that line.
Evaluating Police Reform 5 Years after George Floyd’s Death
The world witnessed George Floyd's murder. 5 years later, what has changed?
5 Years After George Floyd’s Murder, the Backlash Takes Hold (X)
Minneapolis will follow police reform consent decree, despite DOJ dismissal (X) Kentucky, too. (X)
America made a promise after George Floyd’s murder that Congress hasn’t kept (X)
How the Right Has Reshaped the Narrative Around George Floyd (X)
Five years after George Floyd’s death, why misinformation still persists (X)
Since George Floyd’s Murder, Police Killings Keep Rising, Not Falling (X)
Washington Post: Much of the ‘racial reckoning’ efforts after Floyd’s murder never emerged (X)
Poll: Most Americans support some goals of the 2020 racial reckoning (X)
CONTRA: Unherd.com argues Trump is right to end the Minnesota consent decree. (X)
How Policing is Changing Under Trump
How does Trump stack up against other presidents when it comes to police reform? (X)
Under Bondi’s watch, victim service groups face cuts, uncertainty (X)
Some fear excessive use of force will rise as the DOJ drops oversight of police departments (X)
Police officer facing wrongful death lawsuit was given 'valor' awards for fatal shooting (X)
Land of unfreedom: Trump's dystopian detainment policies have a long history (X)
“The Alcatraz myth is catnip to coots like Trump. When 50-year-old movies aired on public television inform ideas for domestic policy.” (X)
“The problem isn’t that Donald Trump pitched an absurd idea about reopening Alcatraz. The problem are his sycophants who are playing along.” (X)
Practically speaking, San Francisco hates the idea of reopening the prison. (X)
Judges Consider Managing Their Own Security Force Due to Rising Threats (X)
Other Law & Order Type Stories
How safe is Times Square? It depends on who you ask. (X)
Why Has Qualified Immunity Excused Officers’ Misconduct for Decades? (X)
Murders Surged in the Pandemic. Now in Many Cities That Surge Is Gone. (X)
The Mothers Against Police Brutality are bringing their individual experiences of tragedy together to empower police reform. (X)
Do shorter prison sentences make society less safe? What the evidence says
“They Wanted to Have Fewer Prisons. Instead, They Got a Prisoner’s Worst Nightmare.” (X)
Former Memphis police officers found not guilty in killing of Tyre Nichols. Videos showed the former officers, who are Black, hitting Nichols repeatedly after he ran from a traffic stop. (X)
Autopsies misclassified deaths in police custody that were homicides, Maryland officials say
5 notes
·
View notes
Text
September was a busy month for Russian influence operations—and for those tasked with disrupting them. News coverage of a series of U.S. government actions revealed Russia was using fake domains and personas, front media outlets, real media outlets acting as covert agents, and social media influencers to distort public conversation around the globe.
The spate of announcements by the U.S. Justice Department and U.S. State Department, as well as a public hearing featuring Big Tech leadership held by the Senate Select Committee on Intelligence, underlines the extent to which Russia remains focused on interfering in U.S. political discourse and undermining confidence in U.S. elections. This is not particularly surprising on its own, as covert influence operations are as old as politics. What the unsealed indictments from the Justice Department, the report by the State Department, and the committee hearing emphasize is that bots and trolls on social media are only part of the picture—and that no single platform or government agency can successfully tackle foreign influence on its own.
As researchers of adversarial abuse of the internet, we have tracked social media influence operations for years. One of us, Renée, was tapped by the Senate Select Committee in 2017 to examine data sets detailing the activity of the Internet Research Agency—the infamous troll farm in St. Petersburg—on Facebook, Google, and Twitter, now known as X. The trolls, who masqueraded as Americans ranging from Black Lives Matter activists to Texas secessionists, had taken the United States by surprise. But that campaign, which featured fake personas slinking into the online communities of ordinary Americans, was only part of Russia’s effort to manipulate U.S. political discourse. The committee subsequently requested an analysis of the social media activities of the GRU—Russian military intelligence—which had concurrently run a decidedly different set of tactics, including hack and leak operations that shifted media coverage in the run-up to the 2016 U.S. presidential election. Russian operatives also reportedly hacked into U.S. voter databases and voting machine vendors but did not go so far as to change actual votes.
Social media is an attractive tool for covert propagandists, who can quickly create fake accounts, tailor content for target audiences, and insert virtual interlopers into real online communities. There is little repercussion for getting caught. However, two presidential election cycles after the Russian Internet Agency first masqueraded as Americans on social media platforms, it is important to emphasize that running inauthentic covert networks on social media has always been only one part of a broader strategy—and sometimes, it has actually been the least effective part. Adversaries also use a range of other tools, from spear phishing campaigns to cyberattacks to other media channels for propaganda. In response to these full-spectrum campaigns, vigilance and response by U.S. tech platforms are necessary. But alone, that will not be enough. Multi-stakeholder action is required.
The first set of announcements by the Justice Department on Sept. 4 featured two distinct strategies. The first announcement, a seizure of 32 internet domains used by a Russia-linked operation known in the research community as “Doppelganger,” reiterates the interconnected nature of social media influence operations, which often create fake social media accounts and external websites whose content they share. Doppelganger got its name from its modus operandi: spoofs of existing media outlets. The actors behind it, Russian companies Social Design Agency and Structura, created fake news outlets that mirror real media properties (such as a website that looked like the Washington Post) and purported offshoots of real entities (such as the nonexistent CNN California). The websites host the content and steal logos, branding, and sometimes even the names of journalists from real outlets. The operation shares fake content from these domains on social media, often using redirect links so that when unwitting users click on a link, it redirects to a spoofed website. Users might not realize they are on a fake media property, and social media companies have to expend resources to continually search for redirect links that take little effort to generate. Indeed, Meta’s 2024 Q1 Adversarial Threat Report noted that the company’s teams are engaged in daily efforts to thwart Doppelganger activities. Some other social media companies and researchers use these signals, which Meta shares publicly, as leads for their own investigations.
The domains seized by the Justice Department are just a portion of the overall number of pages that Doppelganger has run. Most are garbage sites that get little traction, and most of the accounts linking to them have few followers. These efforts nonetheless require vigilance to ensure that they don’t manage to eventually grow an audience. And so, the platforms play whack-a-mole. Meta publishes lists of domains in threat-sharing reports, though not all social media companies act in response; some, like Telegram, take an avowedly hands-off approach to dealing with state propagandists, purportedly to avoid limiting political speech. X, which used to be among the most proactive and transparent in its dealings with state trolls, has not only significantly backed off curtailing inauthentic accounts, but also removed transparency labels denoting overt Russian propaganda accounts. In turn, recent leaks from Doppelganger show the Social Design Agency claiming that X is the “the only mass platform that could currently be utilized in the U.S.” At the U.S. Senate Select Committee on Intelligence hearing on Sept. 18, Sen. Mark Warner called out several platforms (including X, TikTok, Telegram, and Discord) that “pride themselves of giving the proverbial middle finger to governments all around the world.” These differences in moderation policies and enforcement mean that propagandists can prioritize those platforms that do not have the desire or resources to disrupt their activities.
However, dealing with a committed adversary necessitates more than playing whack-a-mole with fake accounts and redirect links on social media. The Justice Department’s domain seizure was able to target the core of the operation: the fake websites themselves. This is not a question of true versus false content, but demonstrable fraud against existing media companies, and partisans across the aisle support disrupting these operations. Multi-stakeholder action can create far more impactful setbacks for Doppelganger, such as Google blocking Doppelganger domains from appearing on Google News, and government and hosting infrastructure forcing Doppelganger operatives to begin website development from scratch. Press coverage should also be careful not to exaggerate the impact of Russia’s efforts, since, as Thomas Rid recently described, the “biggest boost the Doppelganger campaigners got was from the West’s own anxious coverage of the project.”
A second set of announcements in September by the Justice Department and State Department highlighted a distinct strategy: the use of illicit finance to fund media properties and popular influencers spreading content deemed useful to Russia. An indictment unsealed by the Justice Department alleged that two employees from RT—an overt Russian state-affiliated media entity with foreign-facing outlets around the world—secretly funneled nearly $10 million into a Tennessee-based content company. The company acted as a front to recruit prominent right-wing American influencers to make videos and post them on social media. Two of the RT employees allegedly edited, posted, and “directed the posting” of hundreds of these videos.
Much of the content from the Tennessee company focused on divisive issues, like Russia’s war in Ukraine, and evergreen topics like illegal immigration and free speech. The influencers restated common right-wing opinions; the operators were not trying to make their procured talent introduce entirely new ideas, it seemed, but rather keep Russia’s preferred topics of conversation visibly present within social media discourse while nudging them just a bit further toward sensational extremes. In one example from the indictment, one of the RT employees asked an influencer to make a video speculating about whether an Islamic State-claimed massacre in Moscow might really have been perpetrated by Ukraine. The right-wing influencers themselves, who received sizeable sums of money and accrued millions of views on YouTube and other platforms, appear to have been unwitting and have not been charged with any wrongdoing.
This strategy of surreptitiously funding useful voices, which hearkens back to Soviet techniques to manipulate Western debates during the Cold War, leverages social media’s power players: authentic influencers with established audiences and a knack for engagement. Influence operations that create fake personas face two challenges: plausibility and resonance. Fake accounts pretending to be Americans periodically reveal themselves by botching slang or talking about irrelevant topics. They have a hard time growing a following. The influencers, by contrast, know what works, and they frequently get boosted by even more popular influencers aligned with their ideas. Musk, who has more than 190 million followers on X, reportedly engaged with content from the front media company at least 60 times.
Social media companies are not well suited to identify these more obscured forms of manipulation. The beneficiaries of Russian funding were real influencers, and their social media accounts do not violate platform authenticity policies. They are expressing opinions held by real Americans, even if they are Russia-aligned. Assuming the coordination of funding and topics did not take place on social media, the platforms likely lack insight into offline information that intelligence agencies or other entities collect. The violations are primarily external, as well—mainly the alleged conspiracy to commit money laundering and the alleged violation of the Foreign Agents Registration Act. Here, too, a multi-stakeholder response is necessary: Open-source investigators, journalists, and the U.S. intelligence community can contribute by uncovering this illicit behavior, and the U.S. government can work with international partners to expose, and, where appropriate, impose sanctions and other legal remedies to deter future operations.
The degree to which these activities happen beyond social media—and beyond the awareness of the platform companies—was driven home in a Sept. 13 speech by U.S. Secretary of State Antony Blinken. He highlighted other front media entities allegedly operated by RT, including some with a more global focus, such as African Stream and Berlin-based Red. According to the State Department, RT also operates online fundraising efforts for the Russian military and coordinates directly with the Russian government to interfere in elections, including the Moldovan presidential election later this month. These activities go far beyond the typical remit of overt state media, and likely explain why Meta and YouTube—neither of which had previously banned RT after Russia’s invasion of Ukraine—responded to the news by banning the outlet and all of its subsidiary channels.
Our argument is not that the steps taken by social media companies to combat influence operations are unimportant or that the platforms cannot do better. When social media companies fail to combat influence operations, manipulators can grow their followings. Social media companies can and should continue to build integrity teams to tackle these abuses. But fake social media accounts are only one tool in a modern propagandist’s toolbox. Ensuring that U.S. public discourse is authentic—whether or not people like the specifics of what’s being said—is a challenge that requires many hands to fix.
12 notes
·
View notes
Text
A new study published last month has confirmed that mRNA Covid injections cause incurable heart disease in the majority of recipients.
“The results revealed higher heart disease risk in individuals receiving mRNA vaccines than other types,” the study declared in the ‘Abstract’ section.
Infowars.com reports: The findings that mRNA shots are more likely to damage the heart than viral vector shots are concurrent with another study that Infowars previously reported on.
Interestingly, the study analyzing Koreans for heart damage post-injection also found that the injected individuals who got infected with the Covid virus had an even greater risk of heart damage.
“Individuals infected by SARS-CoV-2 also exhibited significantly higher heart disease risk than those uninfected,” the study said in the ‘Abstract’ section.
Younger individuals faced a greater risk of heart disease than older individuals.
“…younger individuals who received mRNA vaccines had a higher heart disease risk compared to older individuals,” the study said in the ‘Abstract’ section.
The study was conducted by analyzing data recorded between October 2018 to March 2022 from the National Health Insurance Service Covid database.
“We sought to provide insights for public health policies and clinical decisions pertaining to COVID-19 vaccination strategies,” the study said in the ‘Abstract’ section. “We analysed heart disease risk, including acute cardiac injury, acute myocarditis, acute pericarditis, cardiac arrest, and cardiac arrhythmia, in relation to vaccine type and COVID-19 within 21 days after the first vaccination date, employing Cox proportional hazards models with time-varying covariates.”
6 notes
·
View notes
Text
Seven Days - Day 4

so, i decided to go ahead and publish chapter 4 today. i think it was just to get past this bit. chapter 5 is 3/4 finished; chapter 6 is 1/2 finished, and chapter 7 is done.
Seven Days - Chapter 4 is over on ao3.
If you want to check out my main fic, To the Shore, it's over here.
And, my backstories, Anamnesis, is here also on ao3.
Sneak Peek
“Out of curiosity, I looked to see where my counterpart was in this universe,” she said as he finished breakfast. It was oatmeal and fruit. Not being the fondest of oatmeal, he suffered a few mouthfuls, but ate the fruit with gusto. He could try a hunger strike, but what good would that do? No one would even know where he was. Instead, he decided he’d at least enjoy the food, even if the company was repugnant.
“And?” he asked with a mouth full of watermelon.
“At first I couldn’t find her, which is odd for me since I would know her history and all of her aliases. I hacked into UC Security, SysDef, FC Rangers, Neon Security. Even tried the Ryujin personnel database. Nothing. Zero. Nada,” she said.
“Wow, did you do all of that this morning?” he asked, amazed. “Never meet my Cora. It’s hard enough to keep her from trying to hack into her online school, much less UC Security.”
“I remember,” she said fondly, nodding. “But, yes. It’s easy when you have multiple systems running concurrently. Plus, the hardware is all to my own spec. Anyway, I don’t think I have a counterpart in this universe. From what circumstantial evidence I could find, it seems she died as a teenager about twelve years ago. I believe a shootout at the Syndicate warehouse. One of the victims was a fifteen year old girl. She’s only listed as a Jane Doe, but her description and age fits. And, the fact that there were no other records for her, which tracks.”
“What does that mean?” he asked.
“I don’t know. It’s the first universe I’ve been in where my counterpart was dead.”
That piqued his curiosity. “Have you run into her before?” he asked.
“Yes, but I’ve been able to avoid her every time, just like I had been able to avoid you,” she answered. “In some universes, she got out and made a good life. In some universes, she rose to the top of Seokguh Syndicate and was ruthless, expanding it to the UC, and even into Crimson Fleet space. In some universes, she met Sam,” she ended softly.
“And what happened in those?” he asked despite himself.
“Much the same that happened to me. Sometimes her Sam died, sometimes he survived. But, where she did meet her Sam, they fell in love, and were happy, at least for a while. I never hung around in those universes long enough to know how, or if, it ended.”
Sam’s head started churning thinking of all of the possibilities; he thought that all of the universes were the same. “Have there been any universes where I’ve been dead? Or haven’t been born?” he asked.
“Yes, I came across several where you were already dead. In one, you had died as a child. In another, you had joined the Crimson Fleet, and died within the first week. In another, there was no Lillian to save you, and you had died smuggling those goods.”
“Oh god,” he whispered, his brain whirring with all the possibilities where he could have died. “So, there are universes where my gun actually jammed? Or, where I missed? There was that time I was out with my buddies rock climbing, and a piton almost slipped out…” He felt that if he wasn’t already sitting, he’d need to sit down.
#starfield#sam coe#fanfic#fanfiction#space husband#hwa kim#space cowboy#coemancer#to the shore#spacefarer#therealgchu writes#seven days#starfield oc#oc fanfiction#oc fic#update#the coemancer crew
6 notes
·
View notes
Text
Me, the other week, young and naive: Haha wouldn't it be fun if I made an AU of The Two Princes but with Cecil and Kevin? Doubles that are meant to kill each other but end up falling in love!
Me, the other day, still in denial of how much I'm complicating a supposedly simple plot: Okay but if we're setting this in the Desert Otherworld then we've GOTTA add some timey-wimey weirdness! Hmm, I wonder if I could give Carlos a time-travel subplot....
Me, now, keeping track of three concurrent timelines with a Notion database because the time travel has taken over the whole plot of a story that was never meant to have time travel in the first place: ........so I mayyyy have gone a bit overboard here. Oops.
13 notes
·
View notes
Text

Python: Known for its simplicity and readability, Python is widely used in various domains such as web development, data science, machine learning, artificial intelligence, and more.
JavaScript: Primarily used for web development, JavaScript is essential for creating interactive websites and dynamic web applications. It's supported by all major web browsers.
Java: Java is a versatile language used in enterprise software development, Android app development, web applications, and more. It's known for its platform independence due to the Java Virtual Machine (JVM).
C/C++: These are powerful languages commonly used in system programming, game development, operating systems, and performance-critical applications.
C#: Developed by Microsoft, C# is widely used for building Windows applications, web applications using ASP.NET, and game development with Unity.
Ruby: Known for its simplicity and productivity, Ruby is often used for web development, especially with the Ruby on Rails framework.
Swift: Developed by Apple, Swift is used for iOS, macOS, watch OS, and tv OS app development. It's designed to be fast, safe, and expressive.
Kotlin: A modern language that runs on the Java Virtual Machine (JVM), Kotlin is officially supported for Android app development and is also used for server-side development.
PHP: Mainly used for server-side web development, PHP is commonly used with databases like MySQL to create dynamic websites and web applications.
Rust: Known for its memory safety features, Rust is used in systems programming, game development, and for building high-performance software where security and concurrency are important.
6 notes
·
View notes
Text
Windows or Linux? Finding Your Perfect Match in the VPS Hosting Arena
In the ever-evolving landscape of Virtual Private Server (VPS) hosting, the choice between Windows and Linux is pivotal. Your decision can significantly impact your website's performance, security, and overall user experience. At l3webhosting.com, we understand the importance of this decision, and we're here to guide you through the intricacies of choosing the perfect match for your hosting needs.
Understanding the Basics: Windows vs. Linux
Windows VPS Hosting: Unveiling the Dynamics
When it comes to Windows VPS hosting, users are drawn to its familiarity and seamless integration with Microsoft technologies. For websites built on ASP.NET or utilizing MSSQL databases, Windows VPS is the natural choice. The user-friendly interface and compatibility with popular software make it a preferred option for businesses relying on Microsoft-centric applications.
Windows VPS provides robust support for various programming languages, ensuring a versatile hosting environment. The seamless compatibility with Microsoft's IIS (Internet Information Services) enhances website performance, especially for those developed using .NET frameworks.
Linux VPS Hosting: Unleashing the Power of Open Source
On the other side of the spectrum, Linux VPS hosting thrives on the principles of open source software. The inherent flexibility and stability of Linux attract developers and businesses looking for a reliable hosting foundation. Websites built using PHP, Python, or Ruby on Rails often find Linux to be the optimal environment.
Linux's renowned security features, including the capability to customize firewall settings, contribute to a robust defense against potential cyber threats. Additionally, Linux VPS hosting typically comes at a lower cost, making it an economical choice without compromising performance.
Performance Benchmark: Windows vs. Linux
Windows Performance Metrics
Windows VPS excels in scenarios where compatibility with Microsoft technologies is paramount. The integration with .NET applications and MSSQL databases ensures optimal performance for websites that rely on these frameworks. The user-friendly interface also simplifies management tasks, providing a smooth experience for administrators.
However, it's essential to note that Windows VPS may require more system resources compared to Linux, impacting scalability and cost-effectiveness for resource-intensive applications.
Linux Performance Metrics
Linux VPS, being lightweight and resource-efficient, offers excellent performance for a wide range of applications. The open-source nature of Linux enables users to tailor the operating system to their specific needs, optimizing performance and resource utilization.
Linux excels in handling concurrent processes and multiple users simultaneously, making it an ideal choice for high-traffic websites. Its stability and ability to run efficiently on minimal hardware make it a cost-effective solution for businesses mindful of their hosting budget.
Security Considerations: Windows vs. Linux
Windows Security Features
Windows VPS prioritizes security with features like BitLocker encryption, Windows Defender, and regular security updates. The familiarity of Windows security protocols can be reassuring for users accustomed to the Microsoft ecosystem.
However, the popularity of Windows also makes it a target for cyber threats. Regular updates and a robust security posture are crucial to mitigating potential risks.
Linux Security Features
Linux VPS boasts a solid reputation for security, primarily due to its open-source nature. The community-driven development and constant scrutiny contribute to swift identification and resolution of security vulnerabilities.
The ability to customize firewall settings and the availability of robust security tools make Linux a secure choice for websites that prioritize data protection and threat prevention.
Making Your Decision: Tailoring Hosting to Your Needs
Factors Influencing Your Choice
When deciding between Windows and Linux VPS hosting, consider the nature of your website, the technologies it relies on, and your budgetary constraints. If your website is built on Microsoft-centric frameworks, Windows VPS might be the most seamless option. On the other hand, Linux VPS offers versatility, cost-effectiveness, and robust security, making it an attractive choice for many users.
Our Recommendation
At l3webhosting.com, we understand that each website is unique. Our recommendation is tailored to your specific needs, ensuring that you make an informed decision based on performance requirements, budget considerations, and long-term scalability.
Conclusion: Your Hosting Journey Begins
In the dynamic world of VPS hosting, choosing between Windows and Linux is a critical decision. Understanding the nuances of each platform allows you to make an informed choice, aligning your hosting environment with your website's specific requirements.
2 notes
·
View notes
Text
SQL Temporary Table | Temp Table | Global vs Local Temp Table
Q01. What is a Temp Table or Temporary Table in SQL? Q02. Is a duplicate Temp Table name allowed? Q03. Can a Temp Table be used for SELECT INTO or INSERT EXEC statement? Q04. What are the different ways to create a Temp Table in SQL? Q05. What is the difference between Local and Global Temporary Table in SQL? Q06. What is the storage location for the Temp Tables? Q07. What is the difference between a Temp Table and a Derived Table in SQL? Q08. What is the difference between a Temp Table and a Common Table Expression in SQL? Q09. How many Temp Tables can be created with the same name? Q10. How many users or who can access the Temp Tables? Q11. Can you create an Index and Constraints on the Temp Table? Q12. Can you apply Foreign Key constraints to a temporary table? Q13. Can you use the Temp Table before declaring it? Q14. Can you use the Temp Table in the User-Defined Function (UDF)? Q15. If you perform an Insert, Update, or delete operation on the Temp Table, does it also affect the underlying base table? Q16. Can you TRUNCATE the temp table? Q17. Can you insert the IDENTITY Column value in the temp table? Can you reset the IDENTITY Column of the temp table? Q18. Is it mandatory to drop the Temp Tables after use? How can you drop the temp table in a stored procedure that returns data from the temp table itself? Q19. Can you create a new temp table with the same name after dropping the temp table within a stored procedure? Q20. Is there any transaction log created for the operations performed on the Temp Table? Q21. Can you use explicit transactions on the Temp Table? Does the Temp Table hold a lock? Does a temp table create Magic Tables? Q22. Can a trigger access the temp tables? Q23. Can you access a temp table created by a stored procedure in the same connection after executing the stored procedure? Q24. Can a nested stored procedure access the temp table created by the parent stored procedure? Q25. Can you ALTER the temp table? Can you partition a temp table? Q26. Which collation will be used in the case of Temp Table, the database on which it is executing, or temp DB? What is a collation conflict error and how you can resolve it? Q27. What is a Contained Database? How does it affect the Temp Table in SQL? Q28. Can you create a column with user-defined data types (UDDT) in the temp table? Q29. How many concurrent users can access a stored procedure that uses a temp table? Q30. Can you pass a temp table to the stored procedure as a parameter?
#sqlinterview#sqltemptable#sqltemporarytable#sqltemtableinterview#techpointinterview#techpointfundamentals#techpointfunda#techpoint#techpointblog
4 notes
·
View notes
Text
Performance Testing vs. Load Testing
Your app’s performance is the lifeblood of your business. Lagging loggins and crashing servers mean lost customers and lowered reputations.
Both performance and load testing are essential partners in building a thriving application. Here is a breakdown of performance testing and load testing:
Goals:
Performance testing: Identify bottlenecks and inefficiencies before they impact the user experience or business goals.
Load testing: Ensure scalability and stability under high user traffic. Prevents crashes and outrages during peak demand.
Metrics:
Performance testing: Response time, resource utilization, error rates, etc., across various load levels.
Load testing: Time to failure, concurrency limits, memory leaks, database performance, etc., under extreme load.
Benefits:
Performance testing: Improved user experience, reduced development costs, optimized resource allocation, and proactive risk mitigation.
Load testing: Increased confidence in application scalability, minimized downtime during peak usage, and enhanced brand reputation.
Get ready to take the business to new heights with the best Business intelligence (BI) services. Brigita BI services allow organizations to consolidate business data into a single unit and improve their operations and performance. Our consulting service brings value to your business. Contact us to know more! https://brigita.co/services/data-engineering-data-analytics-bi/
2 notes
·
View notes
Text
A Deep Dive into NOLOCK's Power and Pitfalls in SQL Server
In the realm of SQL Server management, the NOLOCK hint emerges as a quintessential tool for database administrators, aimed at enhancing query efficiency through the minimization of locking and blocking phenomena. This tool, however, is double-edged, necessitating a nuanced understanding and strategic deployment. This exploration ventures into the practical utilization of NOLOCK, enriched with…
View On WordPress
#database concurrency solutions#NOLOCK SQL Server#read uncommitted data#SQL performance optimization#SQL Server locking issues
0 notes
Text
histdir
So I've started a stupid-simple shell/REPL history mechanism that's more friendly to Syncthing-style cloud sync than a history file (like basically every shell and REPL do now) or a SQLite database (which is probably appropriate, and it's what Atuin does while almost single-handedly dragging CLI history UX into the 21st century):
You have a history directory.
Every history entry gets its own file.
The file name of a history entry is a hash of that history entry.
The contents of a history entry file is the history entry itself.
So that's the simple core concept around which I'm building the rest. If you just want a searchable, syncable record of everything you ever executed, well there you go. This was the smallest MVP, and I implemented that last night - a little shell script to actually create the histdir entries (entry either passed as an argument or read on stdin if there's no entry argument), and some Elisp code in my Emacs to replace Eshell's built-in history file save and load. Naturally my loaded history stopped remembering order of commands reliably, as expected, which would've been a deal-breaker problem in the long term. But the fact that it instantly plugged into Syncthing with no issues was downright blissful.
(I hate to throw shade on Atuin... Atuin is the best project in the space, I recommend checking it out, and it significantly inspired the featureset and UX of my current setup. But it's important for understanding the design choices of histdir: Atuin has multiple issues related to syncing - histdir will never have any sync issues. And that's part of what made it so blissful. I added the folder to Syncthing - no separate account, no separate keys, nothing I must never lose. In most ways, Atuin's design choice of a SQLite database is just better. That's real, proper engineering. Serious software developers all know that this is exactly the kind of thing where a database is better than a bunch of files. But one benefit you get from this file-oriented granularity is that if you just design the naming scheme right, history entries never collide/conflict in the same file. So we get robust sync, even with concurrent use, on multiple devices - basically for free, or at least amortized with the setup effort for whatever solution you're using to sync your other files (none of which could handle updates from two different devices to a single SQLite database). Deleting a history entry in histdir is an "rm"/"unlink" - in Atuin it's a whole clever engineering puzzle.)
So onto preserving order. In principle, the modification time of these files is enough for ordering: the OS already records when they were last written to, so if you sort on that, you preserve history order. I was initially going to go with this, but: it's moderately inconvenient in some programming languages, it can only handle a 1-to-1 mapping (one last-modified timestamp) even though many uses of history might prefer an n-to-1 (an entry for every time the command was called), and it requires worrying about questions like "does {sync,copy,restore-from-backup,this-programmatic-manipulation-I-quickly-scripted} preserve the timestamp correctly?"
So tonight I did what any self-respecting drank-too-much-UNIX-philosophy-coolaid developer would do: more files. In particular:
Each call of a history entry gets its own file.
The file name of a call is a timestamp.
The contents of a call file is the hash of the history entry file.
The hash is mainly serving the purpose of being a deterministic, realistically-will-never-collide-with-another-history-entry (literally other causes of collision like hackers getting into your box and overwriting your memory are certain and inevitable by comparison) identifier - in a proper database, this would just be the primary key of a table, or some internal pointer.
The timestamp files allow a simple lexical sort, which is a default provided by most languages, most libraries, and built in by default in almost everything that lists/iterates a directory. That's what I do in my latest Elisp code in my Emacs: directory-files does a lexical sort by default - it's not pretty from an algorithmic efficiency standpoint, but it makes the simplest implementation super simple. Of course, you could get reasonably more efficient if you really wanted to.
I went with the hash as contents, rather than using hardlinks or symlinks, because of programmatic introspection simplicity and portability. I'm not entirely sure if the programmatic introspection benefits are actually worth anything in practice. The biggest portability case against symlinks/hardlinks/etc is Windows (technically can do symlinks, but it's a privileged operation unless you go fiddle with OS settings), Android (can't do hardlinks at all, and symlinks can't exist in shared storage), and if you ever want to have your histdir on something like a USB stick or whatever.
Depending on the size of the hash, given that the typical lengths of history entries might be rather short, it might be better for deduplication and storage to just drop the hash files entirely, and leave only the timestamp files. But it's not necessarily so clear-cut.
Sure, the average shell command is probably shorter by a wide margin than a good hash. The stuff I type into something like a Node or Python REPL will trend a little longer than the shell commands. But now what about, say, URLs? That's also history, it's not even that different conceptually from shell/REPL history, and I haven't yet ruled out it making sense for me to reuse histdir for that.
And moreover, conceptually they achieve different goals. The entry files are things that have been in your history (and that you've decided to keep). They're more of a toolbox or repertoire - when you do a fuzzy search on history to re-run a command, duplicates just get in the way. Meanwhile, call files are a "here's what I did", more of a log than a toolbox.
And obviously this whole histdir thing is very expandable - you could have other files containing metadata. Some metadata might be the kind of thing we'd want to associate with a command run (exit status, error output, relevant state like working directory or environment variables, and so on), but other stuff might make more sense for commands themselves (for example: this command is only useful/valid on [list of hosts], so don't use it in auto-complete and fuzzy search anywhere else).
So... I think it makes sense to have history entries and calls to those entries "normalized" into their own separate files like that. But it might be overkill in practice, and the value might not materialize in practice, so that's more in the TBD I guess.
So that's where I'm at now. A very expandable template, but for now I've just replicated basic shell/REPL history, in an a very high-overhead way. A big win is great history sync almost for free, without a lot of the technical downsides or complexity (and with a little effort to set up inotify/etc watches on a histdir, I can have newly sync'ed entries go directly into my running shells/REPLs... I mean, within Emacs at least, where that kind of across-the-board malleability is accessible with a reasonably low amount of effort). Another big win is that in principle, it should be really easy to build on existing stuff in almost any language to do anything I might want to do. And the biggest win is that I can now compose those other wins with every REPL I use, so long as I can either wrap that REPL a little bit (that's how I'll start, with Emacs' comint mode), or patch the common libraries like readline to do histdir, or just write some code to translate between a traditional history file and my histdir approach.
At every step of the way, I've optimized first and foremost for easiest-to-implement and most-accessible-to-work-with decision. So far I don't regret it, and I think it'll help a lot with iteratively trying different things, and with all sorts of integration and composition that I haven't even thought of yet. But I'll undoubtedly start seeing problems as my histdirs grow - it's just a question of how soon and how bad, and if it'll be tractable to fix without totally abandoning the approach. But it's also possible that we're just at the point where personal computers and phones are powerful enough, and OS and FS optimizations are advanced enough, that the overhead will never be perceptible to me for as long as I live - after all, its history for an interface with a live human.
So... happy so far. It seems promising. Tentatively speaking, I have a better daily-driver shell history UX than I've ever had, because I now have great reliable and fast history sync across my devices, without regressions to my shell history UX (and that's saying something, since I was already very happy with zsh's vi mode, and then I was even more happy with Eshell+Eat+Consult+Evil), but I've only just implemented it and given it basic testing. And I remain very optimistic that I could trivially layer this onto basically any other REPL with minimal effort thanks to Emacs' comint mode.
3 notes
·
View notes
Text
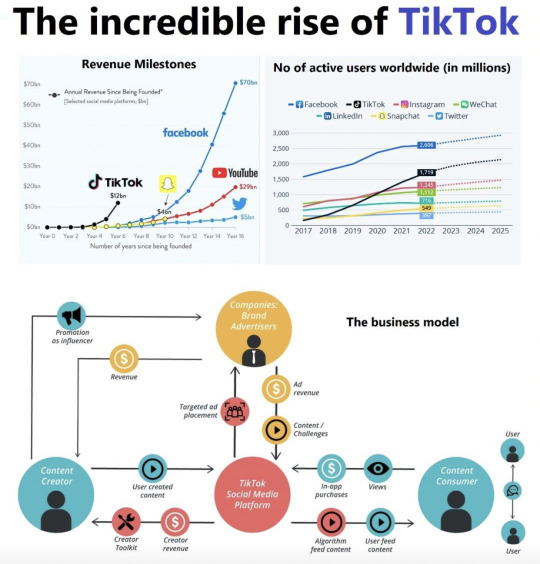
"Unveiling the Unstoppable Surge of TikTok: How This Global Phenomenon is Revolutionizing Social Media, Commerce, and Beyond!"
Diving Deep into TikTok's Unstoppable Revolution: Witnessing the Phenomenon That's Reshaping Social Media, Commerce, and More - A Must-Read Journey! TikTok's meteoric rise is not only reshaping the landscape of social media, but it's also ushering in profound cross-industry effects that extend into e-commerce, digital advertising, and payments, among other areas. Let's delve into this transformative phenomenon.
Initially introduced as Douyin by ByteDance in 2016, TikTok made its global debut in 2018 and has since established a presence in 154 countries, reaching a remarkable milestone of 1 billion users faster than any other social platform.
At its core, TikTok's success is rooted in simplicity: a video-sharing app that empowers users to effortlessly create and share short videos. Its standout feature, however, lies in its algorithmic prowess, which rapidly curates videos from its expansive database based on user preferences. Unlike conventional platforms, TikTok doesn't rely on established networks for virality, allowing anyone to achieve global recognition without an extensive follower count.
Statistics underscore TikTok's influence, with users dedicating an average of over 1.5 hours to the platform, primarily comprising Generation Z (individuals born between the late 1990s and early 2000s). In the #US, TikTok has become the premier video destination, outshining its social media counterparts. The emulation of TikTok's model by industry giants such as #Meta, #YouTube, #Pinterest, and Netflix is a testament to its disruptive impact.
Expanding beyond its humorous video content, TikTok is instigating paradigm shifts in various sectors. Notably, within digital advertising, projections indicate a substantial leap in TikTok's ad revenues, soaring from $13 billion in 2022 to $44 billion by 2027. Concurrently, TikTok Douyin's revenue in China is predicted to rise from $28 billion to $76 billion. By 2027, global online video advertising is set to generate over $331 billion, with TikTok commanding 37% of these earnings, equivalent to $120 billion. In comparison, the combined presence of YouTube and Meta is estimated at 24% or $77 billion.
On the e-commerce frontier, TikTok's foray into live shops embedded within user profiles (deployed in regions like the #UK, Southeast #Asia, and the US) enables in-app purchases, potentially paving the way for live-stream shopping to become a pivotal e-commerce trend. In #China, TikTok's direct in-app sales are substantially challenging established e-commerce titans like JD and Alibaba. Douyin's strategic focus on "interest e-commerce," driven by users' passions, signifies a multidimensional approach to consumer engagement encompassing short videos, livestreams, and searches.
This seismic shift reminds us that the world is evolving rapidly, surpassing some in its velocity of change.
Join me in uncovering the seismic shifts powered by socialmedia- from reshaping social landscapes to igniting a commerce evolution. Let’s ride this wave of transformation together! Don’t miss out – hit that follow button for more captivating insights. 🚀🔥
#TikTokRevolution #StayInformed #TikTokTransforms #SocialShiftsUnveiled #CommerceEvolution #TrendingTikTok #InnovationUnleashed #rtumovs #tumovs
2 notes
·
View notes
Text
Hire Node.js Developers vs Full-Stack Developers: What’s Better for You?

The success of your project depends on selecting the best developer for creating scalable and reliable web applications. Full-stack programming and Node.js have emerged as some of the most in-demand competencies for contemporary apps, particularly for tech companies trying to maintain their competitive edge.
However, how do you choose between hiring full-stack developers and Node.js developers? The main distinctions between the two positions will be discussed in this article, along with advice on how to choose the one that best suits your needs.
Understanding the Key Differences for Your Project Needs
What Is Node.js and Why Should You Hire Node.js Developers?
A robust runtime environment based on JavaScript, Node.js is used to create server-side applications that are scalable and quick to develop. It's particularly well-liked for developing backend systems that can manage many connections at once with great throughput. Hiring Nodejs developers means bringing in professionals with an emphasis on backend development using Node.js frameworks like Express.js, Koa.js, or Hapi.js and JavaScript.
The backend of your application, server-side logic, database interfaces, and API development are usually the main focusses of Node.js engineers. They are extremely adept at making sure server-side operations function properly, which is essential for tech firms that need web apps that are quick, effective, and scalable.
It would be wise to hire Node.js engineers if your project calls for a very effective backend that can manage heavy traffic or create real-time applications. They are especially well-suited for creating scalable services, real-time applications, and microservices, and they are excellent at creating systems with high concurrency.
What Is Full-Stack Development and Why Should You Hire Full-Stack Developers?
However, full-stack developers are multifaceted experts who manage an application's back-end (server-side) and front-end (UI/UX) components. A professional who can create and manage the complete application—from the user interface to the database and server-side logic—is what you get when you engage full-stack developers.
Programming languages, frameworks, and technologies that full-stack engineers are skilled in include JavaScript (for both front-end and back-end development), HTML, CSS, and front-end development frameworks like React or Angular, as well as back-end tools like Node.js, Express, and MongoDB.
Employ full-stack engineers who can handle both the front-end and back-end for tech organizations that need a developer who can see a project through from inception to conclusion. Teams that require a highly adaptable resource who can work on various application stack components and guarantee seamless front-end and back-end system interaction will find full-stack developers ideal.
Node.js Developers vs Full-Stack Developers: Which One Is Right for Your Project?
So, is it better to recruit full-stack engineers or Node.js developers? It mostly relies on the needs of your team and the size of your project:
If you require a developer with expertise in backend programming, scalable server-side application development, and managing large amounts of data and traffic, hire Nodejs developers. Microservices and real-time applications that require performance are best suited for Node.js.
If your project calls for a more comprehensive strategy, select full-stack engineers, who can manage both the front-end and back-end. For smaller teams or projects where you require a flexible developer who can move between the stack's layers as needed, full-stack developers are ideal.
Hiring full-stack developers to handle the front-end and integration and hiring backend developers to handle the server-side logic may be the best option. This is especially true if you are creating a complicated web application with several layers or features and you want experts for distinct project components.
Conclusion: Making the Right Choice for Your Needs
The complexity and scope of your project will determine whether you hire full-stack or Node.js developers. Hire Nodejs developers with extensive knowledge of server-side JavaScript for a highly specialized backend. Hiring full-stack engineers, on the other hand, will guarantee your application's flawless operation throughout if you demand a more comprehensive solution that incorporates both front-end and back-end capabilities.
Knowing the particular requirements of your project can help you make the best choice for tech businesses who are committed to creating scalable, reliable applications. Knowing these roles can help you make an informed choice for the future success of your application, regardless of whether you want to concentrate on backend development or require a flexible developer who can manage both ends of your project.
0 notes
Text
How to Improve Database Performance with Smart Optimization Techniques
Database performance is critical to the efficiency and responsiveness of any data-driven application. As data volumes grow and user expectations rise, ensuring your database runs smoothly becomes a top priority. Whether you're managing an e-commerce platform, financial software, or enterprise systems, sluggish database queries can drastically hinder user experience and business productivity.
In this guide, we’ll explore practical and high-impact strategies to improve database performance, reduce latency, and increase throughput.
1. Optimize Your Queries
Poorly written queries are one of the most common causes of database performance issues. Avoid using SELECT * when you only need specific columns. Analyze query execution plans to understand how data is being retrieved and identify potential inefficiencies.
Use indexed columns in WHERE, JOIN, and ORDER BY clauses to take full advantage of the database indexing system.
2. Index Strategically
Indexes are essential for speeding up data retrieval, but too many indexes can hurt write performance and consume excessive storage. Prioritize indexing on columns used in search conditions and join operations. Regularly review and remove unused or redundant indexes.
3. Implement Connection Pooling
Connection pooling allows multiple application users to share a limited number of database connections. This reduces the overhead of opening and closing connections repeatedly, which can significantly improve performance, especially under heavy load.
4. Cache Frequently Accessed Data
Use caching layers to avoid unnecessary hits to the database. Frequently accessed and rarely changing data—such as configuration settings or product catalogs—can be stored in in-memory caches like Redis or Memcached. This reduces read latency and database load.
5. Partition Large Tables
Partitioning splits a large table into smaller, more manageable pieces without altering the logical structure. This improves performance for queries that target only a subset of the data. Choose partitioning strategies based on date, region, or other logical divisions relevant to your dataset.
6. Monitor and Tune Regularly
Database performance isn’t a one-time fix—it requires continuous monitoring and tuning. Use performance monitoring tools to track query execution times, slow queries, buffer usage, and I/O patterns. Adjust configurations and SQL statements accordingly to align with evolving workloads.
7. Offload Reads with Replication
Use read replicas to distribute query load, especially for read-heavy applications. Replication allows you to spread read operations across multiple servers, freeing up the primary database to focus on write operations and reducing overall latency.
8. Control Concurrency and Locking
Poor concurrency control can lead to lock contention and delays. Ensure your transactions are short and efficient. Use appropriate isolation levels to avoid unnecessary locking, and understand the impact of each level on performance and data integrity.
0 notes
Text
As web applications grow in complexity and scale, ensuring optimal performance becomes more challenging yet crucial. Performance issues can lead to poor user experience, increased bounce rates, and potential loss of revenue. This post delves into several strategies and best practices to optimize performance in large-scale applications. 1. Efficient Caching Strategies Efficient caching reduces the need to repeatedly fetch data from slower, more resource-intensive sources like databases or external APIs. By storing frequently accessed data in fast, temporary storage, such as in-memory caches, applications can significantly decrease latency and improve response times. Properly managed caching also helps distribute load more evenly , minimizing bottlenecks and ensuring more consistent performance under high traffic conditions. 2. Database Optimization Database optimization can enhance the performance of large-scale applications by improving query efficiency, data retrieval speed, and overall database management. Techniques such as indexing, query optimization, normalization, and partitioning help in reducing query execution time and resource consumption. Additionally, employing caching mechanisms, load balancing, and proper database design ensures that the database can handle high volumes of transactions and concurrent users. This leads to faster and more reliable application performance. 3. Load Balancing Load balancing distributes incoming network traffic across multiple servers to prevent any single server from becoming overwhelmed, thus optimizing performance in large-scale applications. By evenly distributing workload, load balancers ensure efficient resource utilization and prevent downtime due to server overload. Load balancers can intelligently route traffic based on factors like server health, geographical location, or session persistence, further enhancing scalability, reliability, and responsiveness of the application. 4. Asynchronous Processing Asynchronous processing can optimize performance in large-scale applications by allowing tasks to be executed concurrently rather than sequentially. This approach enables the application to handle multiple operations simultaneously, reducing wait times and improving resource utilization. By decoupling tasks and using non-blocking I/O operations, asynchronous processing can significantly enhance responsiveness and scalability. This ensures that the system performance remains robust even under heavy loads. 5. Frontend Optimization Frontend optimization minimizes page load times, reducing network requests, and enhancing the overall user experience. Techniques such as code minification, bundling, and lazy loading can reduce the size of JavaScript, CSS, and image files, speeding up page rendering. Implementing client-side caching, using content delivery networks (CDNs), and optimizing asset delivery improve data transfer efficiency and decrease latency. Employing responsive design principles and prioritizing critical rendering paths ensure that the application remains fast and usable across various devices and network conditions. 6. Monitoring and Performance Tuning Monitoring and performance tuning play crucial roles in optimizing performance in large-scale applications by providing insights into the system behavior, identifying bottlenecks, and implementing optimizations. Continuous monitoring of key performance metrics such as response times, throughput, and resource utilization helps detect issues early and allows for proactive adjustments. Performance tuning involves fine-tuning various components such as database queries, application code, server configurations, and network settings to improve efficiency and scalability. Optimizing performance in large-scale applications often involves integrating a robust JavaScript widget library. These libraries can streamline the development process and enhance the application’s interactivity and responsiveness, making them essential tools for modern web developers.
Endnote Optimizing performance in large-scale applications requires a multi-faceted approach. The approach involves efficient caching, database optimization, load balancing, asynchronous processing, frontend optimization, and continuous monitoring. By implementing these strategies, you can ensure that your application scales effectively. This will provide a seamless and responsive experience for users, even under heavy loads.
0 notes