#multimodal imaging technology
Text
#multimodal AI#AI technology#text and images#audio processing#advanced applications#image recognition#natural language prompts#AI models#data analysis#digital content#AI capabilities#technology revolution#innovative AI#comprehensive systems#visual data#text description#AI transformation#machine learning#AI advancements#tech innovation#data understanding#image analysis#audio data#multimodal systems#AI development#digital interaction#AI#Trends
0 notes
Text
youtube
Revolutionize Tech with Multimodal AI!
Multimodal AI is revolutionizing technology by seamlessly combining text, images, and audio to create comprehensive and accurate systems.
This cutting-edge innovation enables AI models to process multiple forms of data simultaneously, paving the way for advanced applications like image recognition through natural language prompts. Imagine an app that can identify the contents of an uploaded image by analyzing both visual data and its accompanying text description.
This integration means more precise and versatile AI capabilities, transforming how we interact with digital content in our daily lives.
Does Leonardo AI, Synthesia AI, or Krater AI, leverage any of these mentioned Multimodal AI's?
Leonardo AI - Multimodal AI:
Leonardo AI is a generative AI tool primarily focused on creating high-quality images, often used in the gaming and creative industries. While it is highly advanced in image generation, it doesn't explicitly leverage a full multimodal AI approach (combining text, images, audio, and video) as seen in platforms like GPT-4 or DALL-E 3. However, it might utilize some text-to-image capabilities, aligning with aspects of multimodal AI.
Synthesia AI - Multimodal AI:
Synthesia AI is a prominent example of a platform that leverages multimodal AI. It allows users to create synthetic videos by combining text and audio with AI-generated avatars. The platform generates videos where the avatar speaks the provided script, demonstrating its multimodal nature by integrating text, speech, and video.
Krater AI - Multimodal AI:
Krater AI focuses on generating art and images, similar to Leonardo AI. While it excels in image generation, it doesn't fully incorporate multimodal AI across different types of media like text, audio, and video. It is more aligned with specialized image generation rather than a broad multimodal approach.
In summary, Synthesia AI is the most prominent of the three in leveraging multimodal AI, as it integrates text, audio, and video. Leonardo AI and Krater AI focus primarily on visual content creation, without the broader multimodal integration.
Visit us at our website: INNOVA7IONS
Video Automatically Created by: Faceless.Video
#multimodal AI#AI technology#text and images#audio processing#advanced applications#image recognition#natural language prompts#AI models#data analysis#digital content#AI capabilities#technology revolution#innovative AI#comprehensive systems#visual data#text description#AI transformation#machine learning#AI advancements#tech innovation#data understanding#image analysis#audio data#multimodal systems#AI development#AI trends#digital interaction#faceless.video#faceless video#Youtube
0 notes
Text
Neurons and NPCs: Wiring the Future of Gaming AI
The Dawn of Dynamic Realms | AI-Driven NPCs Reshaping Video Gaming
Introduction:A revolution is unfolding in the world of video gaming. Artificial Intelligence (AI) is transforming Non-Player Characters (NPCs) from scripted entities into dynamic, lifelike figures. This evolution is not just technological; it’s a redefinition of interaction and narrative immersion, offering new dimensions to…

View On WordPress
#AI#AI Development#AI Experts#AI Integration#Artificial Intelligence#Digital Transformation#Future of Work#Image Recognition#Innovation#Machine Learning#Multimodal AI#Skills Adaptation#technology#Unreal Engine#Voice Recognition
0 notes
Text









I wrote an essay on this topic, which is what the comic is based off of. If you care to read it it's beneath the cut , as well as my works Cited, and alt text.
This was a college English assignment, first the essay then the multimodal project. I wanted to share it with the internet people on my phone because this is something that is important to me. (i added it up and i spent roughly 40+ hours on this comic in two weeks, guys, the carpal tunnel is coming for me...)
i would also like to give a huge thanks to some of my best friends for helping me, @ellalily my wonderful talented friend who i love so much and adore their work. (i love her art so much). I know you'll see this, love you king <22223333.
and my partner, @totallynotagremlin . amazing artist and the person i admire every day. thankyou for helping me with this and listening to me rant about this project. i love you so much *kisses you on the forehead.
If anyone reads this, please go check out their art.
THE ESSAY
If you're not paying attention you could mistake AI art for art made by real artists. Many people use AI without much knowledge about it, thinking it's something harmless and fun. However, AI art has a real impact on the art community. AI art is largely harmful to the art community because it negatively impacts artists by stealing and plagiarizing their work.
Knowing how AI generators create art provides important context in understanding the negative impacts of AI-generated art and why it is bad. In an article by The Guardian, Clark L. explains, “The AI has been trained on billions of images, some of which are copyrighted works by living artists, it can generally create a pretty faithful approximation”. On its own, this doesn't sound that bad, and many fail to see the issue with this. However, the corporations training these AI art generators use artists' work without their knowledge or consent. Stable diffusion, an online AI art generator, has provided artists the option to opt out of future iterations of the technology training. However, the damage has already been done. AI is ‘trained’ by being fed images. It analyzes them. It works by being given large amounts of data and input codes. In an article by The Guardian, written by Clark L, there is a quote from Karla Ortiz, an illustrator, and board member of CAA, concerning this issue. She says, “It’s like someone who already robbed you saying, ‘Do you want to opt out of me robbing you?”.
Another article by Yale Daily News has several categories, the first being, “How does AI generate art”. As the heading explains, the first section of the article explains how AI text-to-image generators like DALL-E2 and Midjourney create images by “analyzing data sets containing thousands to millions of images” (Yup K.). In the same article, they cite an artist, Ron Cheng, a Yale Visual Arts Collective board member who is against AI because AI fails to obtain consent from artists before stealing their art. Cheng says “There are enough artists out there where there shouldn't really be a need to make AI to do that.” (Yup K.). The article says Cheng views AI as a tool but not at the cost of the people who spent their lives developing artistic skills.
Many artists feel that they should be compensated or that this should fall under copyright laws but because proving this machine-made art has taken elements of their style is so difficult, the AI companies get off with no consequences. For an artist to take action against an AI image generator, they would have to prove that one of their art pieces had been copied into the system which can be difficult. They would have to prove specific elements of their personal art style have been directly copied and prove that their art has been used and imitated without their consent. Many artists feel that this technology will take their jobs and opportunities in the creative field of work. Kim Leutwyler, a six-time Archibald Prize finalist artist, expressed her issues with AI companies stealing her art in an ABC news article. Leutwyler said that they had found almost every portrait they created, included in a database used to train AI without their knowledge or consent. They said it “feels like a violation” (Williams T.).
With AI art relying on, often, stolen artwork, and creating an interpretation of what it sees, it blurs the line between what is copyright infringement and what is not. In a BBC article by Chris Vallance, Professor Lionel Bently, director of the Centre for Intellectual Property and Information Law at Cambridge University said that in the UK, “it's not an infringement of copyright in general to use the style of somebody else” (Vallance). Another point to keep in mind is that not many artists have the means to fight these legal battles for their art even if they wanted to. This same BBC article speaks about the Design and Artists Copyright Society (DACS), an organization that collects payments on behalf of artists for the use of their images. One quote helps illustrate their point, “I asked DACS’ head of policy Reema Aelhi if artists’ livelihoods are at stake. “Absolutely yes,” she says” (Vallance).
Another concern about AI mentioned in this article is deep fakes, porn, and bias. “Google warned that the data set of scraped images used to train AI systems often includes pornography, reflected social stereotypes, and contained “derogatory, or otherwise harmful associations to marginalize identity groups.” (Vallance). These are all important things to consider when using AI because an AI system can harmfully replicate biases and negative stereotypes because of what it learned. For example, if you input the prompt criminal, it is more likely for the image to be of a person of color. On the other hand, if you input the prompt, CEO, it is strongly probable that an image of an old white man in a suit will show up, not a woman, or a person of color. These stereotypes go much further and much deeper than just these two examples, but the AI recreates what it was taught and can follow patterns that are harmful to minorities.
Another concern many artists have is about their jobs and livelihoods. With how AI art has progressed in the past few years, it is starting to take opportunities from real artists. “It’s been just a month. What about in a year? I probably won’t be able to find my work out there because [the internet] will be flooded with AI art,” Rutkowski told MIT Technology Review (Clarke L.). Many of the articles I researched mentioned the Colorado State Art Fair, where an AI-generated image won first place. The BBC article written by Vallance talks about how a man (Allan) entered an AI-generated image mid-journey and won. Many artists were outraged by this and suddenly aware of how AI could take opportunities like these from them. The artists who entered this competition spent hours and hours on their pieces. As you can imagine they were angry, rightfully so, that an AI-generated piece that took no more than a few seconds won. There is a level of unfairness to this and many artists feel that AI should not be allowed in art competitions like this. It feels like they got cheated out of something they worked hard for. Nobody would let a robot compete in the Olympics or a cooking competition, so why should a machine be allowed to enter an art fair? AI could start taking jobs from artists working on animated projects, or taking commissions.
With AI’s ability to imitate a certain artist's style, some people may feel that they no longer have to pay an artist for work when they could just input a few words into a machine and get something done in seconds. There were artist and writer strikes in Hollywood, in part because of this. These creative people wanted to be paid fairly and have better working conditions, as well as a promise that not all of them would be replaced with AI. When SORA AI came out, I saw many artists online who aspired to have jobs in the animation industry, losing hope and motivation. A soulless and emotionless machine can rip away a lifelong hobby and passion.
Many artists were upset but Allen, the winner of the Colorado State Art Fair, stood by his point and said, “It's over. AI won. Humans lost” (Clark L.). The article quoted a game and concept artist, RJ Palmer's tweet, “This thing wants our job, it's actively anti-artist”. The article speaks of how artists often take inspiration from other artists, “great artists steal”, but Mr. Palmer said, “This (AI) is directly stealing their essence in a way”. In an article by The Guardian, Clarke L. writes about how AI art has raised debates on just how much AI can be credited with creativity. Human art has thoughts, memories, and feelings put behind it and takes a lot of skill, whereas, on the opposite end, AI art can't handle concepts like that. AI does not experience life like real people do. It does not have feelings or emotions and it can only think with the knowledge we give it. Since it cannot have these emotions, the art it creates will never have the emotions that art made by real artists has.
Cansu Canca, a research associate professor at Northeastern University and founder and director of the AI Ethics Lab said, “It is important to be mindful about the implications of automation and what it means for humans who might be ‘replaced’” (Mello-Klein, C.). She went on to say that we shouldn't be fearful but instead ask what we want from machines and how we can best use them to benefit people. The article says “With the push of a button, he was able to create a piece of art that would have taken hours to create by hand” (Mello-Klein, C.). Some artists said, “We’re watching the death of artistry unfold right before our eyes” (Mello-Klein, C.). In an article by the New Yorker, Chayka, K., started by giving three reasons why artists feel wronged by AI image generators that are trained using their artwork. The “three C’s”, they didn't consent, they were not compensated and their influence was not credited. The article states how it is hard for copyright claims based on style to get picked up because in visual art “courts have sometimes ruled in favor of the copier rather than the copied” (Chayka, K.). This applies to music as well, where some songs can sound similar but nothing will be done about it because they are different enough, or the source material was changed enough not to be seen as a complete copy. The article said, “In some sense. You could say that artists are losing their monopoly on being artists” (Chayka, K.). Some people are even hiring AI to make book covers instead of hiring artists.
While I am personally against the use of AI art as well as many of my artist friends, all people have their own opinions about the technology. The article by the New Yorker, written by Chayka, K, quotes Kelly Mckernan, who said they watch Reddit and Discord chats about AI. This provides opinions on some everyday people who aren't in the art field. on the situation and said, “They have this belief that career artists, people who have dedicated their whole lives to their work, are gatekeeping, keeping them from making the art they want to make. They think we’re elitist and keeping our secrets.” (Chayka, K.). I remember an acquaintance of mine said that he used AI art because he could not afford to commission an artist. Not everyone can afford to commission an artist and pay them fairly for their time. However, this does not mean artists should settle for less than their work is worth. Art takes time and that is time the artist could be doing something else.
Northeastern Global contacted Derek Curry, an associate professor of art and design at Northeastern, who gave his thoughts on the subject and he does not believe AI art will ever replace humans because technology has limits. “The cycle of fear and acceptance has occurred with every new technology since the dawn of the industrial age, and there are always casualties that come with change” (Mello-Klein, C.). The article goes on to say how auto-tune was once controversial but it has become a music industry standard. It's used as a tool, and AI art could be similar. It is true that with new technology, people always fear it before it is accepted. For example, the car. People feared it would take jobs and replace people, and this did happen, but it offered more convenience and opened up more jobs for people than it took. Now cars are used by everyone and it is almost impossible to get around in America without one because it wasn't made for walking, it was built around roads. There are many more examples of people fearing a new technology before accepting it, so this could be the case with AI, but for AI to be used as a tool and aid to artists, greedy corporations have to change the way they think about the technology. They have to see it as, not a replacement, but a tool. Big animation companies want to replace a lot of their human artists, who need their jobs to support themselves and their families, with AI. This prospect is something that is discouraging to artists who want to enter the animation field, which is already competitive.
The Yale Daily News (Yup, K.), cites Brennan Buck, a senior critic at the Yale School of Architecture. He uses AI as a tool to colorize and upscale images. He does not think AI is a real threat to artists. This is a very different take from most artists I’ve heard about and talked to. I can see how this technology can be used as a tool and I think that is one of the only right ways to use AI art. It should be used as a tool, not a replacement. Another way AI art can be used as a tool is to learn how to draw. New artists can study how art is made by looking at colors and anatomy for inspiration, though it should be taken with a grain of salt because AI tends to leave out details, and things merge and some details make no sense. These are all things real artists would notice and not do in their pieces. Young artists could also study the process of real artists they admire. Getting good at art takes years and practice. Seeing all kinds of different art can help with the learning process. On the topic of some people feeling like AI is not a real threat to artists, some people feel that eventually the technology will fade in popularity and will become more of a tool. Only time can tell if AI art will take the jobs of artist.
With everything being said, AI art is actively harming artists and the art community. Even if some artists like Brennan Buck feel that AI isn't a real threat to artists, presently, it is taking opportunities and jobs from artists and it will only get worse as the technology progresses. We need to prioritize real artists instead of a machine, a machine that will never be able to replicate the authenticity of living people's art that reflects their experiences and lives. Some artists use art to express and spread awareness of real-life issues. I have neurodivergent, transgender and queer friends who create art to show what it feels like to experience the world when it seems everyone is against you. I make art to reflect the beautiful things I see and read. I too am queer and fall under the trans umbrella term and I'm autistic, and I use art as a way to express myself through these things that make up my identity.
AI could never put the emotion that real people put into the things they create. Art is a labor of love and pain. Art like Félix González-Torres free candy contemporary art piece cannot ever be replicated by AI and have the same meaning. He “created nineteen candy pieces that were featured in many museums around the world. Many of his works target HIV”(Public Delivery, n.d.). The opinions and views on this, relatively, new technology differ from person to person. Some artists view generative AI art as a tool to utilize in their art while others see it as a threat and something that is taking away from artists. AI art can be used for bad, as it has and will be used to make deep fakes unless limitations are put on it. The AI systems are trained on thousands of images of real people and of art made by artists, all without their consent and most of the time, without their knowledge. On the other hand, some artists use it to aid their process and don't see the issue. Based on what I have learned, I do not think AI art is good, nor should it have a place in the creative job fields. Companies should not copy and steal work from artists. Artists work their whole lives to learn to create, and that should not be replaced by a machine.
ALT TEXT (I didn't know where to put the alt text, sorry, also, this is the first time I've ever done alt text so I'm sorry if its not the greatest, i tried. if you have feedback though, that would be greatly appreciated)
Page 1
“AI art is NOT real art” under a picture of the letters AI, crossed out in red.
“AI text-to-image generators like DALL-E2 and Midjourney create images by, “analyzing data sets containing thousands to millions of images” (Yup K.)”
Beneath the test is a set of polaroid photos strung up, with a black crow sitting on the wire. There is a computer with a few tabs open and two ladybugs near it.
“AI art generators are trained off of artwork used without the artist's consent.”
To the side of the text is a small person holding up something they drew. There are lines leading from their drawing to an ai recreated version of it.
Page 2
There is a picture of Kim Leutwyler
“Feels like a violation”
“I found almost every portrait I've ever created on there as well as artworks by many Archibald finalists and winners”
Kim Leutwyler
(Williams T.)
There is a picture of Tom Christopherson
“I didn't think I would care as much as I did. It was a bit of a rough feeling to know that stuff had been used against my will without even notifying me.”
“It just feels unethical when it's done sneakily behind artists' backs… people are really angry, and fair enough”.
Tom Christopherson
(Williams T.)
There is a drawing of Ellalily drawn by them, with their cat sitting on top of the bubble they're in.
“AI sucks the life out of art… there’s no love, no creativity, no humanity to the finished product. And that's not even scratching the surface of the blatant violations put upon artists whose work has been stolen to fuel this lifeless craft”
EllaLily
(@ellalily on tumbrl)
There is a drawing of Gremlin/Cthulhu 14 with small mushrooms growing off of their bubble
“AI art isn't real art because it just copies from real artists. Art is something that is so very human and it has human emotions in it. A robot can't replicate that emotion and cant give meaning to an art piece”
gremlin/cthulhu14
(@totallynotagremlin on tumbrl)
There is a drawing of myself gesturing towards the text.
“AI art is actively harming the art community by:
Taking jobs
Opportunities
Hope and motivation
From artists.”
Page 3
“Most artists can't do anything against the people feeding their art into these AI systems.”
There are two drawings of myself, sitting down, crisscross, underneath the text with speech bubbles showing that I'm theI'm person talking.
“Many artists don't have the means to fight these legal battles for their art, even if they wanted to.”
“Some dont have the:
Money”
drawing of a dollar and some coins
“Time”
drawing of a clock with the numbers jumbled
“Capability”
drawing of a green frog in a purple witch hat and dress holding up a magic wand with its tongue.
“And even if they did…
Most AI art escapes copyright laws”
Beneath this is an image of Professor Lionel Bently and a small drawing of the university of cambridge.
“Professor Lionel Bently, faculty of law at university of cambridge said (In the UK) “its not an infringement of copyright in general to use the style of someone else””
There is a drawing of the same wizard frog from before. It is laying down.
“so … AI gets away with stealing from artists with no consequences.”
The text is surrounded by a yellow and orange comic emphasis speech bubble
Image of van gogh, starry night, and fake ai recreation.
Image of Zeng Fanzhi art, image of john chamberlain art, “art by artists inspired by Van Gogh
“Artists take inspiration from each other. AI only companies what it sees.”
Page 4
There is a drawing of a green beetle with yellow wings in the top right corner. On the other side of the page, there is an image of Reema Aelhi.
Design and Artist Copyright Society (DACS) is an organization that collects payments on behalf of artists for the use of their images. “I asked DACS’ head of policy Reema Aelhi if artists' livelihoods are at stake, “absolutely yes,” she says”. (Vallance).
There is a brown bat hanging upside down from red swirls on the page.
“Deep fakes and biases
Another problem with generative AI is that often, the data sets used to train it contains, “pornograhy, reflected social stereotypes and contains “derogatory… or harmful associations to marginalized identity groups””. (vallance)”
There is a cartoonish small white and brown cat underneath the text.
“Example, Prompt CEO”, image of a white old man.
“Prompt, criminal”, image of person of color
“These are examples of HARMFUL BIASES”
There is a moth emerging from a green cocoon through three images. The first is an untouched cocoon, the second has a yellow, red, and green moth halfway emerged from the cocoon. The third has the moth fully emerged, resting on the cocoon. There is one last moth flying across the page underneath the text.
“AI art also threatens the jobs and livelihoods of artists.”
There is a drawing of a brown suitcase with stickers on it, and college certificates around it.
“The artist and writer strike in 2023 that lasted 148 days happened in part, due to the fear of being replaced by AI.”
There is a broken yellow, red, and green moth wing at the bottom of the page.
Page 5
“AI also takes opportunities” two green shoes are hanging from a red dot.
“Animated jobs”
Two cartoon birds are on a television screen with a red/pink background.
“commission work”
There are two people, one is a person in a purple shirt who is handing over a drawing to a girl in a blue shirt with ginger hair.
“Book cover art jobs”
There is a fake book with a person on the cover, who has a big orange bird on her arm. There are clouds and three stars in front of her.
“The Colorado State Art Fair was won by an AI image, entered by Jason M. Allen”
Arrow from Jason M. Allens name to quote, “it's over. AI won. Humans lost” - quote from Allen (Clark L.)
“Artists were outraged. You don't let robots compete in sports competitions, why was it allowed in an art competition?”
Tweet from RJ Palmer, @arvalis - august 13, 2022
“This thing wants our jobs. It's actively anti-artist”
“Great artists steal…[but] this (AI) is directly stealing their essence in a way.”
How much can AI be credited with creativity? Human art has emotions /feelings, thoughts/memories, and takes skill and time.
AI art has none of that”
Beneath the text, there is an image of a desert with two clouds, one partially covering the sun. The sky is blue and there are cacti in the background. There is a singular tumbleweed bouncing through the scene.
Page 6
“With a push of a button, he (Allan) was able to create a piece of art that would have taken hours to create by hand… we’re watching the death of artistry unfold right before our eyes.” (Mello- Klein C.)
There is a person in a coffin. There is water in the coffin covering most of them. There are stars over their chest. There are leaves surrounding the coffin.
Page 7
“It is important to be mindful about the implications of automation and what it means for humans who might be replaced”
-Cansu Canca, research associate professional at Northeastern University, founder and director of AI ethics lab. (Mello-Kline, C.)”
There is an image of Cansu Canca. There is also an orange owl in flight.
“Most artists taken advantage of by AI feel wronged in 3 main areas
They didn't consent”
There is tea in a white and blue cup. Steam is coming up from the brown tea.
“They weren’t compensated”
There is a bronze coin. Next to it is a stamp with the words “the three C’s (Chayka, K)”
“Their influence wasn't credited”
There is a blue credit card with waves on it and a silver chip. On the credit card, there are the words “credit card numbers :D”
“Courts have sometimes ruled in favor of the copier rather than the copied”
There is a red fox with a blue butterfly on its nose and a turquoise background.
Page 8
“If AI art should be used at all, it should be used as a tool and not a replacement”
There is a hammer with a red handle and two wrenches, one on either side of it, followed by two files and yellow pencil.
“Brennan Buck, senior critic and Yale School of Architecture uses AI also a tool to colorize and upscale images.”
Next to the text is an image of Brennan Buck.
“New artists can look at art made by artists and AI to learn new techniques. However, learning from real artists is more ethical and effective.”
Beneath and between the text is a drawing of a woman with long flowing ginger hair. Her body is obscured by waves like clouds or mist. Six white wings are coming out of her back. She has several hands surrounding a woman with shorter brown hair.
Page 9
“AI is actively harming artists and the art community. It's presently taking jobs and opportunities. Art is a labor of love and pain. Artists cannot and should not be replaced by machines.”
There is a drawing of myself in a birch wood forest. There are bits of sunlight streaming through the gaps in the leaves. I am painting a picture of the scene I see before me. I am in a green dress with a white off-the-shoulder top and there is a brown easel.
Works Cited
Chayka, K. (2023, February 10). Is A.I. Art Stealing from Artists? The New Yorker. https://www.newyorker.com/culture/infinite-scroll/is-ai-art-stealing-from-artists?irclickid=xyOXQL259xyPRBuWV7XlJViKUkH17cVGIzN7Xs0&irgwc=1&source=affiliate_impactpmx_12f6tote_desktop_FlexOffers.com%2C%20LLC&utm_source=impact-affiliate&utm_medium=29332&utm_campaign=impact&utm_content=Online%20Tracking%20Link&utm_brand=tny. February 28, 2024.
Clarke, L. (2022, November 18). When AI can make art – what does it mean for creativity? The Guardian. https://www.theguardian.com/technology/2022/nov/12/when-ai-can-make-art-what-does-it-mean-for-creativity-dall-e-midjourney. February 28, 2024.
Mello-Klein, C. (2022, October 12). Artificial intelligence is here in our entertainment. What does that mean for the future of the arts? Northeastern Global News. https://news.northeastern.edu/2022/09/09/art-and-ai/. February 28, 2024.
Public Delivery. (n.d.). Why did Félix González-Torres put free candy in a museum? https://publicdelivery.org/felix-gonzalez-torres-untitled-portrait-of-ross-in-l-a-1991/
Vallance, B.B.C. (2022, September 13). “Art is dead Dude” - the rise of the AI artists stirs debate. BBC News. https://www.bbc.com/news/technology-62788725. February 28, 2024.
Williams, T. (2023, January 9). Artists angry after discovering artworks used to train AI image generators without their consent. ABC News. https://www.abc.net.au/news/2023-01-10/artists-protesting-artificial-intelligence-image-generators/101786174. February 28, 2024.
Yup, K. (2023, January 25). What AI art means for society, according to Yale experts - Yale Daily News. Yale Daily News. https://yaledailynews.com/blog/2023/01/23/what-ai-art-means-for-society-according-to-yale-experts/. February 28, 2024.
7 notes
·
View notes
Text
Folks are going to have to decide whether they want to rethink AI tools and the reasons for their attitudes towards them pretty quick, because both Adobe and NVIDIA just released massive suites of tools for individual creatives and enterprise respectively, and the image generating components for both are apparently sourced from the massive proprietary image databases these companies can arrange access to. So the objection that these models are unethical because they "steal" from public data (they really didn't, but that's sort of besides the point with these now) is null and void. (N.b.: It does put the power to control these tools almost exclusively in the hands of large companies who can license image datasets though, so. Decide how you want to feel about this becoming the standard.)
NVIDIA's offering sounds particularly impressive. They say incorporate multimodal capacity, including text, images, videos and 3D models. Adobe on the other hand has a demo of their tech integrated into Photoshop and Illustrator.
These aren't emerging technologies anymore, these are becoming universal tools that are being deployed at scale, and people are going to need to decide where they stand real quick on their use. The vast majority of people and all of companies that are presented with access to these systems are going to be using them to streamline their pipelines, for better or ill, and if you conscientiously object to their use that will potentially come with consequences in terms of keeping up in your field.
Personally I still think that these can be made into useful developments for society. I think objecting outright to these tools existing now that they do exist is asking for an impossible reversal and throwing out the possibility of working to leverage the tech to benefit the public rather than the corporations who will be using it anyway. No, we should be leaning in and working together in order to shape how these tools are integrated, instead of abjuring and clinging to our current dystopia until machine learning overtakes us.
No, we should be preparing to use these tools constructively, and, Jesus fucking Christ, people need to be organizing to lobby and elect their governments such that we can institute and automation tax and/or UBI now. The expectation that there will be paid work for every human to support themselves is already unrealistic, and clinging to it is the only thing preventing automation via cognitive tools from becoming a massive labour saver instead of the looming scary spectre many people treat it as today. Make no mistake, a policy like that will almost certainly be forced through by sheer necessity if increasing automation makes the current model unsustainable, but we need to get out ahead of it if we want to avoid a transition crisis and unhelpful widespread backlash.
58 notes
·
View notes
Text

U.S. Navy puts StormBreaker smart weapon into operation on the F/A-18E/F Super Hornet
Fernando Valduga By Fernando Valduga 11/07/2023 - 14:00 In Armaments, Military
Raytheon, an RTX company, announced today that the U.S. Navy fielded the company's StormBreaker smart weapon in the F/A-18E/F Super Hornet fighter.
The StormBreaker smart weapon is a network-enabled air-surface ammunition that can hit moving targets in all weather conditions using its multi-effect warhead and triple-mode seeker.
The F/A-18 is the first aircraft approved by the U.S. Navy to carry the StormBreaker. Leveraging the field knowledge of the F-15E, Raytheon was able to reduce the number of flight tests required, saving time and resources to provide this capability to the U.S. Navy.

“The gun's unprecedented capabilities give aviators the ability to attack targets in difficult and dynamic scenarios,” said Paul Ferraro, president of Raytheon's Air Power. "StormBreaker is an excellent example of how we are using digital technologies to provide advanced aerial domain weapons, ensuring the continued relevance of fourth-generation aircraft."
StormBreaker features an innovative multimode search engine that guides the weapon using an infrared imaging camera, millimeter wave radar and semi-active laser, as well as, or with, GPS and inertial navigation system orientation. The small size of the StormBreaker allows fewer aircraft to reach the same number of targets compared to larger weapons that require multiple jets. It can also fly more than 40 miles to hit moving land and sea targets, reducing the amount of time crews spend in danger.
The U.S. Air Force declared initial operational capability for StormBreaker in the F-15E Strike Eagle in 2022, and all three variants of the F-35 Joint Strike Fighter are currently in integration tests with StormBreaker.
Tags: weaponsMilitary AviationF/A-18E/F Super HornetRaytheonStormBreakerUSN - United States Navy/U.S. Navy
Sharing
tweet
Fernando Valduga
Fernando Valduga
Aviation photographer and pilot since 1992, has participated in several events and air operations, such as Cruzex, AirVenture, Dayton Airshow and FIDAE. He has work published in specialized aviation magazines in Brazil and abroad. Uses Canon equipment during his photographic work in the world of aviation.
Related news
MILITARY
IMAGES: United Arab Emirates receives its first Chinese L-15 Falcons jets
07/11/2023 - 12:00
MILITARY
Japan will deploy F-35 and F-15 fighters in Australia amid growing tensions with China
07/11/2023 - 08:19
AIRPORTS
VIDEO: FAB acts in the fight against illicit acts at the airports of Guarulhos and Galeão
07/11/2023 - 08:06
MILITARY
USAF sends B-1B bombers to the Middle East
06/11/2023 - 23:22
HELICOPTERS
Black Hawk helicopters in accelerated delivery to Australia
06/11/2023 - 16:00
MILITARY
U.S. Navy receives second 'End Judgment Aircraft' Mercury updated
11/06/2023 - 2:00 PM
12 notes
·
View notes
Text
Machine learning and the microscope
New Post has been published on https://thedigitalinsider.com/machine-learning-and-the-microscope/
Machine learning and the microscope

With recent advances in imaging, genomics and other technologies, the life sciences are awash in data. If a biologist is studying cells taken from the brain tissue of Alzheimer’s patients, for example, there could be any number of characteristics they want to investigate — a cell’s type, the genes it’s expressing, its location within the tissue, or more. However, while cells can now be probed experimentally using different kinds of measurements simultaneously, when it comes to analyzing the data, scientists usually can only work with one type of measurement at a time.
Working with “multimodal” data, as it’s called, requires new computational tools, which is where Xinyi Zhang comes in.
The fourth-year MIT PhD student is bridging machine learning and biology to understand fundamental biological principles, especially in areas where conventional methods have hit limitations. Working in the lab of MIT Professor Caroline Uhler in the Department of Electrical Engineering and Computer Science and the Institute for Data, Systems, and Society, and collaborating with researchers at the Eric and Wendy Schmidt Center at the Broad Institute and elsewhere, Zhang has led multiple efforts to build computational frameworks and principles for understanding the regulatory mechanisms of cells.
“All of these are small steps toward the end goal of trying to answer how cells work, how tissues and organs work, why they have disease, and why they can sometimes be cured and sometimes not,” Zhang says.
The activities Zhang pursues in her down time are no less ambitious. The list of hobbies she has taken up at the Institute include sailing, skiing, ice skating, rock climbing, performing with MIT’s Concert Choir, and flying single-engine planes. (She earned her pilot’s license in November 2022.)
“I guess I like to go to places I’ve never been and do things I haven’t done before,” she says with signature understatement.
Uhler, her advisor, says that Zhang’s quiet humility leads to a surprise “in every conversation.”
“Every time, you learn something like, ‘Okay, so now she’s learning to fly,’” Uhler says. “It’s just amazing. Anything she does, she does for the right reasons. She wants to be good at the things she cares about, which I think is really exciting.”
Zhang first became interested in biology as a high school student in Hangzhou, China. She liked that her teachers couldn’t answer her questions in biology class, which led her to see it as the “most interesting” topic to study.
Her interest in biology eventually turned into an interest in bioengineering. After her parents, who were middle school teachers, suggested studying in the United States, she majored in the latter alongside electrical engineering and computer science as an undergraduate at the University of California at Berkeley.
Zhang was ready to dive straight into MIT’s EECS PhD program after graduating in 2020, but the Covid-19 pandemic delayed her first year. Despite that, in December 2022, she, Uhler, and two other co-authors published a paper in Nature Communications.
The groundwork for the paper was laid by Xiao Wang, one of the co-authors. She had previously done work with the Broad Institute in developing a form of spatial cell analysis that combined multiple forms of cell imaging and gene expression for the same cell while also mapping out the cell’s place in the tissue sample it came from — something that had never been done before.
This innovation had many potential applications, including enabling new ways of tracking the progression of various diseases, but there was no way to analyze all the multimodal data the method produced. In came Zhang, who became interested in designing a computational method that could.
The team focused on chromatin staining as their imaging method of choice, which is relatively cheap but still reveals a great deal of information about cells. The next step was integrating the spatial analysis techniques developed by Wang, and to do that, Zhang began designing an autoencoder.
Autoencoders are a type of neural network that typically encodes and shrinks large amounts of high-dimensional data, then expand the transformed data back to its original size. In this case, Zhang’s autoencoder did the reverse, taking the input data and making it higher-dimensional. This allowed them to combine data from different animals and remove technical variations that were not due to meaningful biological differences.
In the paper, they used this technology, abbreviated as STACI, to identify how cells and tissues reveal the progression of Alzheimer’s disease when observed under a number of spatial and imaging techniques. The model can also be used to analyze any number of diseases, Zhang says.
Given unlimited time and resources, her dream would be to build a fully complete model of human life. Unfortunately, both time and resources are limited. Her ambition isn’t, however, and she says she wants to keep applying her skills to solve the “most challenging questions that we don’t have the tools to answer.”
She’s currently working on wrapping up a couple of projects, one focused on studying neurodegeneration by analyzing frontal cortex imaging and another on predicting protein images from protein sequences and chromatin imaging.
“There are still many unanswered questions,” she says. “I want to pick questions that are biologically meaningful, that help us understand things we didn’t know before.”
#2022#amazing#Analysis#Animals#applications#Autoencoders#bioengineering#Biology#Brain#Broad Institute#cell#Cells#China#chromatin#communications#computer#Computer Science#covid#data#deal#december#Disease#Diseases#engine#engineering#form#Forms#Fundamental#gene expression#genes
2 notes
·
View notes
Text
New advances in multimodal LLM technology have been deployed by Yankee Candle to automatically generate scents from words, sounds, and images.
2 notes
·
View notes
Text
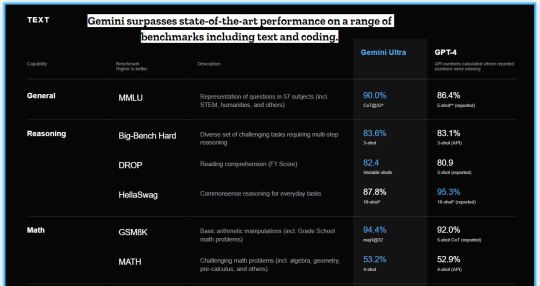
GeminAi Review 2024 - World's 1st True Google's Gemini Powered App

GeminAi Review 2024
Introduction :-
Bringing You Instant Answers Across Text, Images, Audio, Video, and Code. This High-tech App Outshines ChatGPT-4 And Making Real-time Multimedia Responses Easy and Faster Within Seconds..!
Say Goodbye to Hefty Monthly Fees with an Advanced AI Alternative to ChatGPT & OpenAI!
Everything You Knew About Your Work, Life, and Work-Life Balance Is About to Change Forever.
What Is GeminAI ?
Geminai is not just another AI; it's a leap into the future of technology.
Built from the ground up, Geminai excels in multimodal reasoning across text, images, video, audio, and code, making it incredibly versatile and powerful.
Imagine an AI model that not only understands your language but also interprets and creates multimedia content based on your input.
With Geminai, you get context-aware, human-like interactions, offering a personalized experience that feels natural and intuitive.
Its image interaction capabilities take multimedia engagement to new heights, seamlessly recognizing and generating visuals that align perfectly with your needs.
Geminai is a pioneer, surpassing the limitations of other AI technologies, making it an accessible gateway to harnessing the full potential of AI for your personal and professional growth.
Unleash Limitless Possibilities with 3 simple Steps :-



It's Features ?
World’s First True Google’s Gemini™ Powered Ai Chat bot.
Unlimited usage without any restriction.
Elevate Content Creation: Transform the way you create digital content, making it more engaging and effective.
Simplify Coding Efforts: Accessible, efficient coding for all skill levels.
Enhance Multimedia Interaction: Advanced Ai for superior image and video conversation with the Ai bot.
Start making money by charging your clients.
No need to pay any monthly fees to any Ai apps again.
100% beginner-friendly, with no coding or technical skills required.
Get a Free Commercial License.
Pay one time and use it forever.
World Class customer support.
Enjoy 24/7 expert support for whatever you need
30 Day Money back guarantee.
Get Results or we will pay you $500 in return for your troubles.

With GeminAI App You can Replace, Various Freelancers or employees.
content writer
proofreader
Editor
Copywriter
Graphic designer
Transcriptionist
Translator
Analysts
Revolutionize Your Business with GeminAi App
Unleashing Cutting-Edge Technology to Skyrocket Your Success Instantly – Experience the Future Now!
GeminAi Can Interact With Multi Format: (Images & Videos Too)
AI Content Creation:
Advanced NLP Technology Processing
Cost-Efficient Transcription
Simple 3-Step Process
Multilingual Content Generation
100% Cloud-Based Convenience
Efficient Team Management
Limitless Templates
No Monthly Fees
youtube
What You Can Do With The GeminAI App!!!
Create a Content Agency
Develop Cutting-Edge Apps
Build and Sell Chatbots
Write A-List Copy
AI-Driven Graphic Design
Video Production and Marketing
E-Commerce Optimization
Automated SEO and Content Marketing
Data Analysis and Reporting
Personal Branding and Influencer Marketing
Struggle that you have to facing....
Trapped in Unfulfilling Work
Struggle for Work-Life Balance
Financial Constraints and Uncertainty
Overwhelmed by Technological Advancements
Desire for Meaningful Work
Need to pay Hefty monthly charges for expensive Ai Apps.
Burden of paying expensive copywriters.
Struggle with time-consuming manual copywriting.
Face challenges in maintaining consistency in writing quality.
Encounter difficulties in generating creative and impactful content.
Invest significant time and effort in refining and editing text.
Experience limitations in adapting to diverse writing styles and tones.
Reason For that You have to Go With GeminAI App....
No need to pay any monthly fee for lifetime.
Replace all the copywriters with GeminAi.
Generate compelling and engaging copy effortlessly.
Enjoy a time-efficient content creation process.
Experience a boost in productivity with AI-generated text.
Achieve consistent and high-quality writing across various projects.
Seamlessly adapt to changing writing styles and tones.
In Order To Make This Even More Profitable And Easier For You,Here Are Some Big Bonuses:






Frequently asked Question:
Q: Will I get Support for this software?
A: Yes, our 24*7 support team is always available to solve your issues and help you get the best results from GeminAi.
Q: Are there any monthly fees?
A: No, currently we are offering a one-time price for this tool. So, get this best deal before reversing to a Monthly subscription.
Q: Is there any money-back guarantee?
A: Yes, we are offering 30 days money-back guarantee. So there is no risk when you act now. The only way you lose is by taking no action.
Q: Do you update your product and improve it?
A: Yes, we always maintain our product and improve with new features.
Q: How to Activate my Early Bird discount?
A: Click the below button to grab this at an early bird discount.
Here's A Recap Of EverythingYou're Getting Instant Access To!HURRY! Price Rises Again In...

GeminAi can Interact with Multi Format = $9990
Create Unlimited Ai content & visuals in minutes = $1590
High-Quality Training Included for making three Figures a day = $490
Free Commercial Rights = $1990
Done For you Template to Build App Instantly = $290
End to end SSL encryption to safeguard your Data & 24*7 malware protection = $490
24*7 Customer Support = Priceless
Double Your Money Back Guarantee = Priceless
Fast Action Bonus #1: Ai Profit Masterclass (Value:$197)
Fast Action Bonus #2: Ai Image Library (Value:$297)
Fast Action Bonus #3: TikTok Ad Mastery (Value:$147)
Fast Action Bonus #4: StockHub (Value:$147)
Fast Action Bonus #5: Ai Youtube Masterclass (Value:$197)
Fast Action Bonus #6: Ai for Productivity (Value:$197)
Total Value Of Everything YOU GET TODAY: $14,840
For Limited Time Only Grab It Now For
$297 Monthly
Today, Only 1-Time - $14.95
Buy GeminAI Now
#artificial intelligence#copywriting#freelance#ecommerce#branding#entrepreneur#founder#marketing#data analytics#content creator#social media#proofreading#editing#ai generated#chatgpt#technology#google#google bard#copywriter#graphic designer#translator#review#ai chat bot#gemini ai#google gemini app#ai revolution#traffic#geminai#digital marketing#ai tools
5 notes
·
View notes
Text
Understanding AI Technology Trends at Leading Conferences: A Deep Dive into Generative AI World 2024
Generative AI World 2024, set to take place at the Intercontinental Boston, is poised to be a pivotal event in the realm of artificial intelligence. This conference, scheduled for October 7-8, 2024, offers a unique platform for AI enthusiasts, researchers, and industry leaders to delve into the latest advancements in generative AI.
Key Themes and Trends
Foundation Models and Their Applications: Expect in-depth discussions on the evolution of foundation models like GPT-4 and their expanding applications across various domains, including natural language processing, image generation, and code writing.
Ethical Considerations and Bias Mitigation: As generative AI becomes more powerful, ethical concerns surrounding bias, misinformation, and deepfakes are becoming increasingly pressing. The conference will likely address strategies to mitigate these challenges and ensure responsible AI development.
Generative AI in Healthcare: The potential of generative AI to revolutionize healthcare, from drug discovery to personalized medicine, will be a major focus. Attendees can anticipate presentations on cutting-edge research and real-world applications in this field.
Industrial and Commercial Adoption: Case studies and panel discussions will showcase how businesses are leveraging generative AI to enhance productivity, improve customer experiences, and drive innovation.
Emerging Trends and Future Directions: The conference will also provide a glimpse into the future of generative AI, with discussions on emerging trends like multimodal models, reinforcement learning from human feedback, and potential breakthroughs in AI research.
Why Attend Generative AI World 2024?
Networking Opportunities: Connect with leading experts, researchers, and industry professionals from around the world.
Stay Updated: Gain insights into the latest advancements and trends in generative AI.
Explore Applications: Discover how generative AI is being applied across various industries.
Shape the Future: Contribute to discussions on the ethical implications and future directions of AI.
Generative AI World 2024 promises to be a thought-provoking and informative event that will shape the future of AI. By attending this conference, you can gain a deeper understanding of the technology, network with industry leaders, and contribute to the ongoing development of generative AI.
For More Info:-
Top AI Industry Events
Top AI Conferences
Generative AI Conference
Executive AI Summit
0 notes
Text
Advancements in Voice and Image Recognition Technologies
Natural Language Processing (NLP): NLP algorithms enhance voice recognition by understanding and interpreting human language, allowing for more accurate transcription and response generation.
Deep Learning Techniques: The use of deep learning models has significantly improved the accuracy of both voice and image recognition, enabling systems to learn from vast amounts of data and identify patterns effectively.
Real-Time Processing: Advances in computing power allow for real-time voice and image processing, enabling instant feedback and interaction, such as in virtual assistants and security systems.
Multimodal Integration: Combining voice and image recognition allows for richer user experiences, where systems can understand and respond to both spoken commands and visual inputs simultaneously.
Contextual Understanding: Modern recognition technologies leverage context to improve accuracy. For instance, voice recognition can interpret commands more effectively based on previous interactions or situational context.
Improved Accuracy in Noisy Environments: Innovations in filtering background noise and enhancing signal clarity have led to better performance of voice recognition systems in challenging environments.
Facial Recognition Advances: Image recognition technologies have become more sophisticated, allowing for accurate facial recognition that can be used in security, marketing, and social media applications.
Emotion Detection: Some advanced image and voice recognition systems can analyze facial expressions and vocal tones to assess emotional states, adding a layer of understanding in user interactions.
Accessibility Features: Voice and image recognition technologies are enhancing accessibility for individuals with disabilities, allowing for voice commands and image descriptions to improve user experiences.
Ethical Considerations: As these technologies evolve, there is a growing emphasis on ethical considerations, including privacy, consent, and the mitigation of biases in recognition systems.
These advancements in voice and image recognition technologies are transforming how we interact with devices and access information, making systems more intuitive and user-friendly.
0 notes
Text

Fit for purpose Regulatory-Grade Multimodal Datasets for R&D - Segmed
Segmed's collaboration with leading life sciences, healthcare, and technology firms is reshaping the landscape of healthcare research and innovation. By providing structured and de-identified imaging data, we're propelling advancements in AI training and bolstering global impact on healthcare initiatives.
0 notes
Text
The AI Apocalypse is Here: How to Survive When Machines Can See and Hear!
By Jeff Sperandeo
As someone who’s spent years capturing stories through visuals and sounds, the recent announcement by OpenAI about ChatGPT going multi-modal struck a chord with me. The integration of voice and image capabilities into this conversational AI model is not just fascinating; it’s revolutionary. However, it’s clear that this leap forward in technology won’t come without its share of…

View On WordPress
#AI#Career Survival#ChatGPT#Disruption#Future of Work#Image Recognition#Innovation#Job Market#Multimodal AI#OpenAI#Skills Adaptation#Societal Change#technology#Voice Recognition
0 notes
Text
Multimodal Imaging Market: Advancing Diagnostic Precision
The Multimodal Imaging market is revolutionizing medical diagnostics by combining multiple imaging techniques to provide comprehensive insights into patient conditions. This integrated approach enhances diagnostic accuracy and treatment planning, driving significant growth in the imaging industry. This article delves into the latest trends, market segmentation, key growth drivers, and leading companies in the multimodal imaging sector.
Market Overview
According to SkyQuest’s Multimodal Imaging Market report, the market is valued at USD 2.26 billion in 2023 and is expected to grow at a CAGR of 4.3% during the forecast period. The rise in chronic diseases, advancements in imaging technology, and increasing demand for precise diagnostics are propelling market expansion.
Request Your Free Sample: - https://www.skyquestt.com/sample-request/multimodal-imaging-market
Market Segmentation
By Modality:
PET/MRI: Combines Positron Emission Tomography (PET) with Magnetic Resonance Imaging (MRI) for detailed anatomical and functional information.
PET/CT: Integrates PET with Computed Tomography (CT) to offer comprehensive imaging for oncology and cardiology.
SPECT/CT: Merges Single Photon Emission Computed Tomography (SPECT) with CT for enhanced diagnostic capabilities in nuclear medicine.
Others: Includes hybrid modalities like PET/MR and PET/CT in various combinations for specific diagnostic needs.
By Application:
Oncology: Utilizes multimodal imaging for accurate tumor detection, staging, and treatment planning.
Cardiology: Enhances the assessment of cardiac conditions and evaluation of heart diseases.
Neurology: Provides detailed brain imaging for diagnosing neurological disorders and monitoring disease progression.
Orthopedics: Assists in the diagnosis and treatment of musculoskeletal conditions.
Others: Includes applications in trauma care, vascular imaging, and preoperative planning.
By End-User:
Hospitals: Major users of multimodal imaging systems for comprehensive diagnostic and treatment services.
Diagnostic Imaging Centers: Specialized facilities offering advanced imaging services to patients.
Research Institutions: Engage in the development and validation of new imaging technologies and applications.
Others: Includes outpatient clinics and specialized medical centers.
Read More at: - https://www.skyquestt.com/report/multimodal-imaging-market
Key Growth Drivers
Technological Advancements: Innovations in imaging technology, such as hybrid imaging systems and software, are driving market growth.
Rising Prevalence of Chronic Diseases: Increased incidence of cancer, cardiovascular diseases, and neurological disorders fuels the demand for advanced diagnostic solutions.
Growing Focus on Precision Medicine: The shift towards personalized healthcare requires detailed imaging for accurate diagnosis and tailored treatment plans.
Increase in Healthcare Spending: Enhanced investment in medical infrastructure and advanced diagnostic tools supports market expansion.
Leading Companies in the Market
SkyQuest’s report highlights key players in the Multimodal Imaging market, including:
Siemens Healthineers
GE Healthcare
Philips Healthcare
Canon Medical Systems
Hitachi Medical Systems
Toshiba Medical Systems Corporation
Hologic, Inc.
Fujifilm Holdings Corporation
Medtronic Plc
Esaote S.p.A.
Take Action Now: Secure Your Report Today - https://www.skyquestt.com/buy-now/multimodal-imaging-market
Challenges and Opportunities
The multimodal imaging market faces challenges such as high costs associated with advanced imaging systems and the need for specialized training for operators. However, opportunities lie in developing cost-effective solutions, expanding applications across various medical fields, and integrating AI to enhance imaging accuracy and efficiency.
Future Outlook
The Multimodal Imaging market is poised for robust growth, driven by continuous technological advancements and an increasing emphasis on precision medicine. Companies that innovate with new imaging modalities and focus on expanding their service offerings will lead the market. For a comprehensive analysis and strategic insights, consult SkyQuest’s Multimodal Imaging Market report.
The Multimodal Imaging market is crucial for advancing diagnostic capabilities and improving patient outcomes. As technology evolves and healthcare needs grow, multimodal imaging will play an increasingly significant role in medical diagnostics. Decision-makers in the healthcare industry should leverage these advancements to stay ahead in this dynamic market. For more detailed information, refer to SkyQuest’s in-depth Multimodal Imaging Market report.
0 notes
Text
Mistral Announces Pixtral 12B Multimodal AI Model With 'Computer Vision' Feature | Daily Reports Online
Mistral released its first multimodal artificial intelligence (AI) model dubbed Pixtral 12B on Wednesday. The AI firm, known for its open-source large language models (LLMs), has also made the latest AI model available on GitHub and Hugging Face for users to download and test out. Notably, despite being multimodal, Pixtral can only process images using computer vision technology and answer…
0 notes
Text
Future-Ready Enterprises: The Crucial Role of Large Vision Models (LVMs)
New Post has been published on https://thedigitalinsider.com/future-ready-enterprises-the-crucial-role-of-large-vision-models-lvms/
Future-Ready Enterprises: The Crucial Role of Large Vision Models (LVMs)

What are Large Vision Models (LVMs)
Over the last few decades, the field of Artificial Intelligence (AI) has experienced rapid growth, resulting in significant changes to various aspects of human society and business operations. AI has proven to be useful in task automation and process optimization, as well as in promoting creativity and innovation. However, as data complexity and diversity continue to increase, there is a growing need for more advanced AI models that can comprehend and handle these challenges effectively. This is where the emergence of Large Vision Models (LVMs) becomes crucial.
LVMs are a new category of AI models specifically designed for analyzing and interpreting visual information, such as images and videos, on a large scale, with impressive accuracy. Unlike traditional computer vision models that rely on manual feature crafting, LVMs leverage deep learning techniques, utilizing extensive datasets to generate authentic and diverse outputs. An outstanding feature of LVMs is their ability to seamlessly integrate visual information with other modalities, such as natural language and audio, enabling a comprehensive understanding and generation of multimodal outputs.
LVMs are defined by their key attributes and capabilities, including their proficiency in advanced image and video processing tasks related to natural language and visual information. This includes tasks like generating captions, descriptions, stories, code, and more. LVMs also exhibit multimodal learning by effectively processing information from various sources, such as text, images, videos, and audio, resulting in outputs across different modalities.
Additionally, LVMs possess adaptability through transfer learning, meaning they can apply knowledge gained from one domain or task to another, with the capability to adapt to new data or scenarios through minimal fine-tuning. Moreover, their real-time decision-making capabilities empower rapid and adaptive responses, supporting interactive applications in gaming, education, and entertainment.
How LVMs Can Boost Enterprise Performance and Innovation?
Adopting LVMs can provide enterprises with powerful and promising technology to navigate the evolving AI discipline, making them more future-ready and competitive. LVMs have the potential to enhance productivity, efficiency, and innovation across various domains and applications. However, it is important to consider the ethical, security, and integration challenges associated with LVMs, which require responsible and careful management.
Moreover, LVMs enable insightful analytics by extracting and synthesizing information from diverse visual data sources, including images, videos, and text. Their capability to generate realistic outputs, such as captions, descriptions, stories, and code based on visual inputs, empowers enterprises to make informed decisions and optimize strategies. The creative potential of LVMs emerges in their ability to develop new business models and opportunities, particularly those using visual data and multimodal capabilities.
Prominent examples of enterprises adopting LVMs for these advantages include Landing AI, a computer vision cloud platform addressing diverse computer vision challenges, and Snowflake, a cloud data platform facilitating LVM deployment through Snowpark Container Services. Additionally, OpenAI, contributes to LVM development with models like GPT-4, CLIP, DALL-E, and OpenAI Codex, capable of handling various tasks involving natural language and visual information.
In the post-pandemic landscape, LVMs offer additional benefits by assisting enterprises in adapting to remote work, online shopping trends, and digital transformation. Whether enabling remote collaboration, enhancing online marketing and sales through personalized recommendations, or contributing to digital health and wellness via telemedicine, LVMs emerge as powerful tools.
Challenges and Considerations for Enterprises in LVM Adoption
While the promises of LVMs are extensive, their adoption is not without challenges and considerations. Ethical implications are significant, covering issues related to bias, transparency, and accountability. Instances of bias in data or outputs can lead to unfair or inaccurate representations, potentially undermining the trust and fairness associated with LVMs. Thus, ensuring transparency in how LVMs operate and the accountability of developers and users for their consequences becomes essential.
Security concerns add another layer of complexity, requiring the protection of sensitive data processed by LVMs and precautions against adversarial attacks. Sensitive information, ranging from health records to financial transactions, demands robust security measures to preserve privacy, integrity, and reliability.
Integration and scalability hurdles pose additional challenges, especially for large enterprises. Ensuring compatibility with existing systems and processes becomes a crucial factor to consider. Enterprises need to explore tools and technologies that facilitate and optimize the integration of LVMs. Container services, cloud platforms, and specialized platforms for computer vision offer solutions to enhance the interoperability, performance, and accessibility of LVMs.
To tackle these challenges, enterprises must adopt best practices and frameworks for responsible LVM use. Prioritizing data quality, establishing governance policies, and complying with relevant regulations are important steps. These measures ensure the validity, consistency, and accountability of LVMs, enhancing their value, performance, and compliance within enterprise settings.
Future Trends and Possibilities for LVMs
With the adoption of digital transformation by enterprises, the domain of LVMs is poised for further evolution. Anticipated advancements in model architectures, training techniques, and application areas will drive LVMs to become more robust, efficient, and versatile. For example, self-supervised learning, which enables LVMs to learn from unlabeled data without human intervention, is expected to gain prominence.
Likewise, transformer models, renowned for their ability to process sequential data using attention mechanisms, are likely to contribute to state-of-the-art outcomes in various tasks. Similarly, Zero-shot learning, allowing LVMs to perform tasks they have not been explicitly trained on, is set to expand their capabilities even further.
Simultaneously, the scope of LVM application areas is expected to widen, encompassing new industries and domains. Medical imaging, in particular, holds promise as an avenue where LVMs could assist in the diagnosis, monitoring, and treatment of various diseases and conditions, including cancer, COVID-19, and Alzheimer’s.
In the e-commerce sector, LVMs are expected to enhance personalization, optimize pricing strategies, and increase conversion rates by analyzing and generating images and videos of products and customers. The entertainment industry also stands to benefit as LVMs contribute to the creation and distribution of captivating and immersive content across movies, games, and music.
To fully utilize the potential of these future trends, enterprises must focus on acquiring and developing the necessary skills and competencies for the adoption and implementation of LVMs. In addition to technical challenges, successfully integrating LVMs into enterprise workflows requires a clear strategic vision, a robust organizational culture, and a capable team. Key skills and competencies include data literacy, which encompasses the ability to understand, analyze, and communicate data.
The Bottom Line
In conclusion, LVMs are effective tools for enterprises, promising transformative impacts on productivity, efficiency, and innovation. Despite challenges, embracing best practices and advanced technologies can overcome hurdles. LVMs are envisioned not just as tools but as pivotal contributors to the next technological era, requiring a thoughtful approach. A practical adoption of LVMs ensures future readiness, acknowledging their evolving role for responsible integration into business processes.
#Accessibility#ai#Alzheimer's#Analytics#applications#approach#Art#artificial#Artificial Intelligence#attention#audio#automation#Bias#Business#Cancer#Cloud#cloud data#cloud platform#code#codex#Collaboration#Commerce#complexity#compliance#comprehensive#computer#Computer vision#container#content#covid
2 notes
·
View notes
Last Seen Blogs

zabavaua
Zabavaua

mindfullofwishes
Curiosity Killed Your Virginity.

belibibitpisangraja
Untitled

mriaclrsshn-blog
Ephemeral

raystranslationsfestival
Tales of the Rays Translations