#web-scraping
Explore tagged Tumblr posts
Visit Tumblr Blog
Explore Tumblr blogs with no restrictions, modern design and the best experience.
Last Seen Tumblr Blogs





Fun Fact
The KCSC sent more than 20K requests to delete posts related to prostitution and porn to Tumblr from January to June 2017.
Note
Hello! So sorry to bother, but have you had any updates on the Word-Stream/Speechify situation?
Just one: like I posted on Xitter and Bluesky last night, as of yesterday afternoon, the links to individual works as they were listed on WordStream are gone from both Google and Bing. Hurray, right? Surely we’re all sick of this whole debacle and there’s far more important things to worry about. If all is well that ends well, surely there’s no need to still be angry.
Well, I am. Here’s why:
When I checked on Wednesday, the links to my own work on WordStream were still listed. So rather than it taking a week after Cliff Weitzman first hid the fanwork from view, it took a little over a week from the moment he first promised privately that they would be deleted. Which, fine. Perhaps Cliff didn’t really know what he was talking about when he gave that timeframe. Or maybe he told a little white lie to create the impression that he always intended to do the right thing. It seems more likely to me, though, that Cliff still believed—even after the backlash he received—that he would get away with honoring only individual takedown requests. Or worse, that he needed just a little bit more time with the stolen material to figure out an alternative way to profit off it—preferably without us noticing, this time.
But who knows? I certainly don’t! All we can do is speculate, because publicly, Cliff Weitzman has remained completely silent on his copyright infringements. All we got was the initial justifications he and his sockpuppet accounts used in comments on the original Reddit and Tumblr posts. After those were so understandably ill-received, Cliff only ever communicated with a few individual authors who contacted him directly and repeatedly, blocking people who addressed the issue on Twitter and quietly distancing himself from WordStream by deleting a blog he’d posted to Speechify.com dated December 20th—where Cliff promoted WordStream’s platform specifically to fanfiction readers. (See my enormous timeline post for details and screenshots of said posts before they were taken down.)
And this is why I’m still angry: As long as Cliff Weitzman faces no real consequences for his actions, he won’t see a need to own up to his mistake; and as long as he’s able to delay taking responsibility, this isn’t over. This didn’t end well.
After all, wasn’t this the next-best scenario for Cliff, second only to him turning WordStream into a (for him) effortless, infinite money-making machine? He took something we provided for free and fed it to AI so he could more easily put it behind a paywall; we found out and protested; Cliff quietly erased all evidence of his crime; and we went—almost equally quietly—away.
I want to make sure you know that I continue to be genuinely amazed and intensely grateful for how quickly the news about WordStream’s copyright infringement was shared—and continues to be shared—throughout fandom, on tumblr in particular. If it hadn’t been for our collective outcry here and on Reddit, WordStream would very likely still be up in its original form, and Weitzman would be reaping the benefits (those subscription prices were steep) today.
But it’s been frustrating to see that, with the exception of mentions in articles on Substack and Fansplaining (the latter of which is a particularly awesome and thorough read on fandom’s decontextualization) and a Fanlore listing, our outrage never really spilled out beyond the safely insulated, out-of-the-way spaces that are tumblr, a handful of subreddits and bluesky. And I believe that—unfortunately—we are collectively responsible for that part, as well.
Most of us seemed content to only spread the word by circulating the same two posts on tumblr. (Have we all given up completely on every other social media platform? Am I the only remaining straggler?) And soon after Cliff Weitzman hid WordStream’s fanfiction category from view, our interest in the issue took a sharp dive even there. Are we genuinely deceived into believing the issue has been fully resolved? Do we truly fail to realize that Weitzman’s refusal to admit that what he did was wrong left the door wide open for the next greed-driven tech bro to wander through? Or is the true naivety in thinking that, as a community, we can keep this kind of attack on fandom from happening again? Has our disillusionment already gotten that bad?
However the situation spins out from here, Cliff’s actions will set a precedent. If we fail to show Cliff and his ilk that attempts to profit off fandom’s unpaid labor have consequences, their tech companies will keep trying until something eventually sticks. They might be a little smarter about it next time; obscure their sources a bit better, maybe leave the titles and the authors’ names off. Or maybe they’ll go a bolder route: maybe next time they cross the line they’ll do it boldly enough for IP holders to take notice and stop tolerating fanwork entirely.
Doesn’t that make you angry, too?
There’s this whole other mess of thoughts I would love to be able to untangle about how commercial influence is contributing to the steady erosion of fandom’s foundations, but I’m tired, and other people have said it all much more eloquently than I ever could. Seriously, go read that article on Fansplaining. Or listen to the podcast version of it. Better yet, as long as you’re wearing your noise-canceling headphones, go listen to a podfic of one of your favorite fandoms’ works, and enjoy the collaborative joy and creativity of the people who Cliff Weitzman refuses to believe exist. (In one of Speechify’s other blogs, Cliff claims there are only 272 podfics on AO3. Would you like to run that ChatGPT prompt again, Cliff?). Honestly, much like Cliff Weitzman’s infuriating denial of the fact that fandom fucking has this covered, thank you very much, there’s so. Many. More. Things for us to talk about. There’s the connotations of WordStream’s dubious ‘upload’ button, for instance, or the fact that the app scraped (and in some cases, allegedly, still lists) copyright-protected original fiction as well, or WordStream’s complete lack of contact information, which is illegal for an internationally operating app. And oh! Has anyone reported more thoroughly on Cliff’s app’s options to ‘simplify’ or ‘modernize’ uploaded works, or—my own very favorite abomination—to translate them into something Cliff calls ‘Gen-Z Language’? Much like his atrocious AI book covers, it would be hilarious, if it didn’t make steam come out of my ears.
Anyway, there it is. I highly recommend you do all of that. And then, if you aren’t familiar with it already, go do some research re: fair use and your rights as the copyright owner of your works. A good number of people commenting on this controversy expressed stunned surprise or fearful hesitation about claiming any sort of ownership of their fanfiction. The more informed we are about our rights, the more willing we will be to defend them.
Please don’t stop writing or sharing your work. If you can’t bring yourself to work on your WIPs today (trust me, I get it), post about this situation instead. Tweets, skeets, whateverthefucks—about WordStream’s theft, about how this reflects on Speechify’s already shady business practices, about how Cliff’s actions and justifications have personally affected you. You’re welcome to share or copy my posts on these platforms, but since Cliff already blocked me, I very much prefer you post your own. If you do, call Cliff Weitzman by his full name and tag or include both WordStream and Speechify to ensure Weitzman will recognize he has both a personal as well as a professional stake in handling the situation with integrity. Leave your concerns in reviews on the Speechify app. (We weren’t provided with a more appropriate place to put them, after all!) Consider calling for a Speechify boycott until Cliff accepts accountability for his actions.
Do avoid making exaggerated claims, and don’t call for physical retaliation against Cliff’s person or his property. We don’t want to give him or Speechify even the weakest of grounds to claim defamation or threats of violence. Focus on the facts: they’re incriminating enough by themselves. Show Cliff that we’re determined to keep bringing up his company’s wrongdoings in public spaces until he demonstrates that he understands why taking these freely shared fanworks and monetizing them was wrong, and takes steps to ensure it won’t happen again.
One last thing—and this is really more of a general reminder—please stop suggesting I handle this situation for you. People have come to me asking for action items. The resulting flashbacks to my days as an office assistant were extremely upsetting. In all seriousness, casting me as some sort of coordinator or driving force behind this backlash actively hurts the cause. Not only does it downplay fandom’s collective efforts, it also makes our message extremely vulnerable. It would be all too easy for Cliff to silence one singular source. Wikipedia will not maintain mentions of this controversy as long as it leads only to Easter Kingston’s attempt to summarize what happened as it was happening. You only know my name because I stumbled upon WordStream’s theft and decided to get my friends involved. I am not more knowledgeable, more skilled or more angrily invested in this issue than you are (or can, or should, be). I draw pictures and I write stories and I worry about the shift I’m seeing in fandom after having been on this ride for even a few pre-livejournal rounds.
I’m not going to stop doing any of those things. But I am going to allow myself to step away for a bit, make my wife dinner, and catch up on our shows.
I trust you’ve got it from here.
#word-stream#cliff weitzman#plagiarism#speechify#AO3#writers on tumblr#fanfiction#independent authors#web scraping#fandom activism#ask me things!#(which is my ask tag please don’t send me asks about things i’ve already answered in the main post)#anonymous
205 notes
·
View notes
Text









WANTING IS A FILTHY THING. BUT I LEARNED GREED BEFOFE I LEARNED SHAME.
red doc - anne carson , first love / late spring - mitski , starvation - maya angelou , let dead dogs lay - silas denver melvin (@sweatermuppet), wishbone - richard siken, a self portrait against red wallpaper - richard siken, truisms - jenny holzer, stop telling me i should’ve died too - tumblr user @tankgotstuckinthecircusgate, many hands - lingua ignota, hungry thread of nerves - fatima aamer bilal
support me on kofi <3
#falcone polycule enjoyers . this is for you .#falcone polycule#carlo falcone#eddie scrape#lauretta ghiraldini#mafia 2#post: poetry#web weaves#parallels#anne carson#mitski#anne carson quotes#silas denver melvin#richard aiken#richard siken quotes#richard siken poetry#jenny holzer#lingua ignota#fatima aamer bilal#on unrequited love#on toxic love#on loving like a dog
405 notes
·
View notes
Text

The man and his flower
#pokemon fanart#pokemon#my art#az pokemon#trainer az#pokemon az#eternal flower floette#az floette#pokemon x and y#pokemon xy#i recently found out about art shield and rgbwatermark which can help you with adding watermarks and such in preventing ai scraping off.#you can kinda see some circle patterns if you look closely#worth checking them out esp if you are unable to use/have not yet access (web)glaze!
223 notes
·
View notes
Note
What's your favorite rain world ship?
Uhm...

Grins
#sk rambles#rw shipping#rw gourmsaint#im so normal#ive never scraped the web for every bit of gourmsaint content possible
28 notes
·
View notes
Text
.
#okay so its spring break#im bored so i web scraped my entire ao3 reading history and wrote a program to do a yearly “ao3 wrapped” kinda thing#and yall#i am appalled at myself#last year i read 29500433 words#BRUH#almost 30 MILLION fucking words#i gotta get a new hobby omg
8 notes
·
View notes
Text
#Les miserables#les mis#My Post#Scraping around the Web#Jean Valjean#M. Madeleine#Montreuil-sur-Mer#Jet Crystal#This is one of M-sur-M. imitated during the time of Madeleine arrived.#I can't find the German Balck Glass though.#Fashion#History#The Brick#Meta#Others#Les Mis Letters
10 notes
·
View notes
Text
Ao3 was scraped for a GenAI dataset in the last few days (April 2025). If you have public works, they are likely a part of the dataset.
I’ve kept all of my Hidden Love fics open, trying to keep accessibility easy for out-of-country readers, so this makes me sad.
Here is a Reddit thread with additional information.
I’m tired.
4 notes
·
View notes
Text
The Washington Post has an article called „Inside the secret list of websites that make AI like ChatGPT sound smart“
AO3 is #516 on the list, meaning the 516th largest item in the tokens of the dataset.

https://www.washingtonpost.com/technology/interactive/2023/ai-chatbot-learning/
99 notes
·
View notes
Text
When in doubt, scrape it out!
Come find me on TikTok!
#greek tumblr#greek posts#ελληνικο ποστ#ελληνικά#greek post#greek#ελληνικο tumblr#ελληνικο ταμπλρ#ελληνικα#python#python language#python programming#python ninja#python for web scraping#web scraping#web scraping api#python is fun#python is life
2 notes
·
View notes
Text

i've combined myself a new workflow blogging automation... 👀 prepare for massive queues.
8 notes
·
View notes
Text
I wonder if I'm cursed to only be able to code if it's web archive related
#looks at my hands. ive created a monster#i think its funny that exactly every april i go on a mad psychhonauts web archive coding spree and update everything#then immediatly dissapear the rest of the year lol.oh well#ive been scraping code left and right for my personal site because i keep like. changing the css its so annoying#so i havent gotten anywhere with it i can choose colors or a theme or a layout im just 🧍♂️#dustbunnies.txt
6 notes
·
View notes
Note
Really rare pair alert: MatchaPeach. I just feel like they would get along
Wait WAIT MATCHAPEACH WOULD BE SO CUTE THOUGH WTF
Their personalities would be??? So cute together too???? Like I joke a lot about shipping but I could actually see their relationship forming thkfhjrhkfhkjfhfhj
#i will be doodling them together when possible#im looking for a specific reference pic of Lady Boba rn that got fucking scraped off the web for some reason but RIGHT AFTER THAT!!!#yall got a big storm comin#ive been meaning to post fanart for days now lmao#thank you for leaving a message after the tone!#hunter speaks#cyborg cider-man no.2#ccmn2#MatchaPeach#saiki k ask blog#saiki k rp#tdlosk ask blog#tdlosk rp#saiki k oc rp#pk academy au
4 notes
·
View notes
Text
I've recently learned how to scrape websites that require a login. This took a lot of work and seemed to have very little documentation online so I decided to go ahead and write my own tutorial on how to do it.
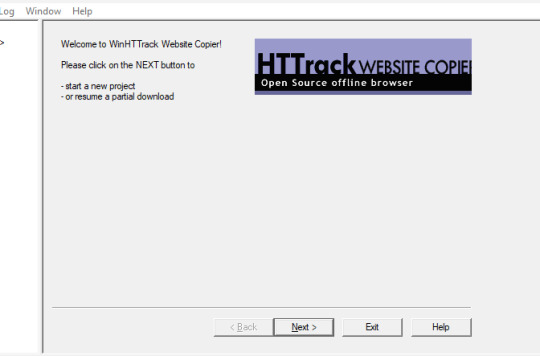
We're using HTTrack as I think that Cyotek does basically the same thing but it's just more complicated. Plus, I'm more familiar with HTTrack and I like the way it works.
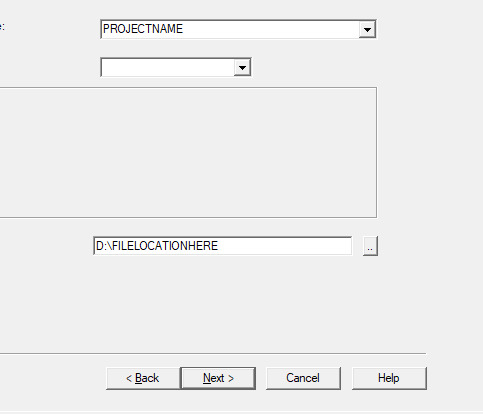
So first thing you'll do is give your project a name. This name is what the file that stores your scrape information will be called. If you need to come back to this later, you'll find that file.
Also, be sure to pick a good file-location for your scrape. It's a pain to have to restart a scrape (even if it's not from scratch) because you ran out of room on a drive. I have a secondary drive, so I'll put my scrape data there.
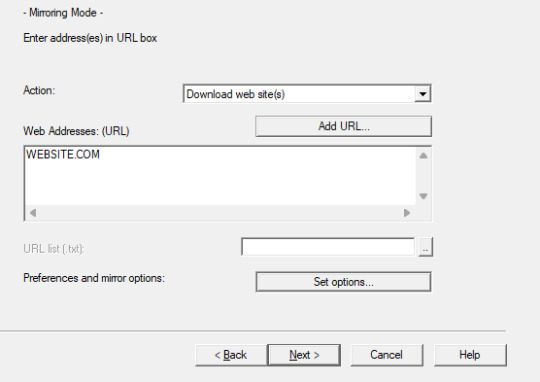
Next you'll put in your WEBSITE NAME and you'll hit "SET OPTIONS..."
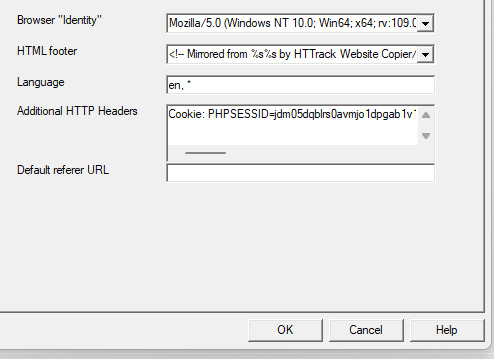
This is where things get a little bit complicated. So when the window pops up you'll hit 'browser ID' in the tabs menu up top. You'll see this screen.
What you're doing here is giving the program the cookies that you're using to log in. You'll need two things. You'll need your cookie and the ID of your browser. To do this you'll need to go to the website you plan to scrape and log in.
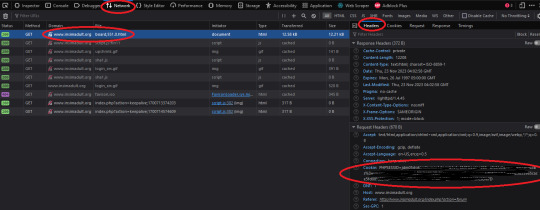
Once you're logged in press F12. You'll see a page pop up at the bottom of your screen on Firefox. I believe that for chrome it's on the side. I'll be using Firefox for this demonstration but everything is located in basically the same place so if you don't have Firefox don't worry.
So you'll need to click on some link within the website. You should see the area below be populated by items. Click on one and then click 'header' and then scroll down until you see cookies and browser id. Just copy those and put those into the corresponding text boxes in HTTrack! Be sure to add "Cookies: " before you paste your cookie text. Also make sure you have ONE space between the colon and the cookie.
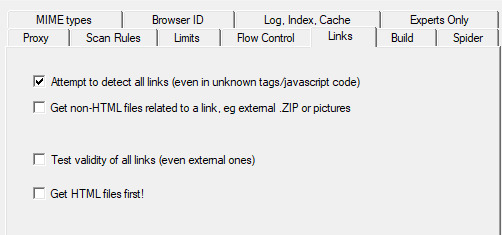
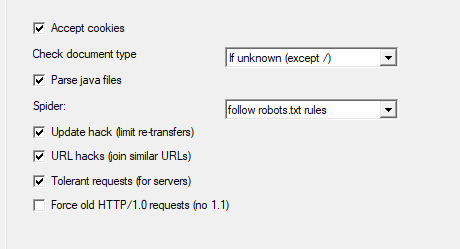
Next we're going to make two stops and make sure that we hit a few more smaller options before we add the rule set. First, we'll make a stop at LINKS and click GET NON-HTML LINKS and next we'll go and find the page where we turn on "TOLERANT REQUESTS", turn on "ACCEPT COOKIES" and select "DO NOT FOLLOW ROBOTS.TXT"
This will make sure that you're not overloading the servers, that you're getting everything from the scrape and NOT just pages, and that you're not following the websites indexing bot rules for Googlebots. Basically you want to get the pages that the website tells Google not to index!
Okay, last section. This part is a little difficult so be sure to read carefully!

So when I first started trying to do this, I kept having an issue where I kept getting logged out. I worked for hours until I realized that it's because the scraper was clicking "log out' to scrape the information and logging itself out! I tried to exclude the link by simply adding it to an exclude list but then I realized that wasn't enough.
So instead, I decided to only download certain files. So I'm going to show you how to do that. First I want to show you the two buttons over to the side. These will help you add rules. However, once you get good at this you'll be able to write your own by hand or copy and past a rule set that you like from a text file. That's what I did!

Here is my pre-written rule set. Basically this just tells the downloader that I want ALL images, I want any item that includes the following keyword, and the -* means that I want NOTHING ELSE. The 'attach' means that I'll get all .zip files and images that are attached since the website that I'm scraping has attachments with the word 'attach' in the URL.
It would probably be a good time to look at your website and find out what key words are important if you haven't already. You can base your rule set off of mine if you want!
WARNING: It is VERY important that you add -* at the END of the list or else it will basically ignore ALL of your rules. And anything added AFTER it will ALSO be ignored.

Good to go!
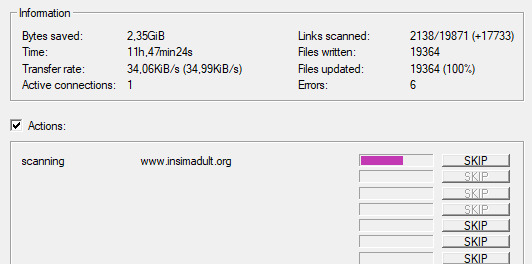
And you're scraping! I was using INSIMADULT as my test.
There are a few notes to keep in mind: This may take up to several days. You'll want to leave your computer on. Also, if you need to restart a scrape from a saved file, it still has to re-verify ALL of those links that it already downloaded. It's faster that starting from scratch but it still takes a while. It's better to just let it do it's thing all in one go.
Also, if you need to cancel a scrape but want all the data that is in the process of being added already then ONLY press cancel ONCE. If you press it twice it keeps all the temp files. Like I said, it's better to let it do its thing but if you need to stop it, only press cancel once. That way it can finish up the URLs already scanned before it closes.
40 notes
·
View notes
Text
Best Tools & Techniques for Data Extraction from Multiple Sources

Data extraction is common and rapidly grown in the business landscape. As the technology advances, it is vital to update tools and techniques for best extracted outcomes. Read further in detail about tools and techniques for data extraction services.
#data extraction services#data scraping services#data extraction company#data digitization#web data extraction services#data extraction services india#data extraction companies#outsource data extraction#outsource data extraction services
3 notes
·
View notes
Text

"Il sorriso che ha attraversato i secoli e i cuori."
(The smile that has crossed centuries and hearts)
"Une énigme artistique qui défie le temps."
(An artistic enigma that defies time)
--------
Tried to digitise but she is still a mystery ❤️
2 notes
·
View notes