#AI Agent Data Access
Explore tagged Tumblr posts
Visit Tumblr Blog
Explore Tumblr blogs with no restrictions, modern design and the best experience.
Last Seen Tumblr Blogs





Fun Fact
The Tumblr app for Google Glass was released on May 16, 2013.
Text
MCP Toolbox for Databases Simplifies AI Agent Data Access

AI Agent Access to Enterprise Data Made Easy with MCP Toolbox for Databases
Google Cloud Next 25 showed organisations how to develop multi-agent ecosystems using Vertex AI and Google Cloud Databases. Agent2Agent Protocol and Model Context Protocol increase agent interactions. Due to developer interest in MCP, we're offering MCP Toolbox for Databases (formerly Gen AI Toolbox for Databases) easy to access your company data in databases. This advances standardised and safe agentic application experimentation.
Previous names: Gen AI Toolbox for Databases, MCP Toolbox
Developers may securely and easily interface new AI agents to business data using MCP Toolbox for Databases (Toolbox), an open-source MCP server. Anthropic created MCP, an open standard that links AI systems to data sources without specific integrations.
Toolbox can now generate tools for self-managed MySQL and PostgreSQL, Spanner, Cloud SQL for PostgreSQL, Cloud SQL for MySQL, and AlloyDB for PostgreSQL (with Omni). As an open-source project, it uses Neo4j and Dgraph. Toolbox integrates OpenTelemetry for end-to-end observability, OAuth2 and OIDC for security, and reduced boilerplate code for simpler development. This simplifies, speeds up, and secures tool creation by managing connection pooling, authentication, and more.
MCP server Toolbox provides the framework needed to construct production-quality database utilities and make them available to all clients in the increasing MCP ecosystem. This compatibility lets agentic app developers leverage Toolbox and reliably query several databases using a single protocol, simplifying development and improving interoperability.
MCP Toolbox for Databases supports ATK
The Agent Development Kit (ADK), an open-source framework that simplifies complicated multi-agent systems while maintaining fine-grained agent behaviour management, was later introduced. You can construct an AI agent using ADK in under 100 lines of user-friendly code. ADK lets you:
Orchestration controls and deterministic guardrails affect agents' thinking, reasoning, and collaboration.
ADK's patented bidirectional audio and video streaming features allow human-like interactions with agents with just a few lines of code.
Choose your preferred deployment or model. ADK supports your stack, whether it's your top-tier model, deployment target, or remote agent interface with other frameworks. ADK also supports the Model Context Protocol (MCP), which secures data source-AI agent communication.
Release to production using Vertex AI Agent Engine's direct interface. This reliable and transparent approach from development to enterprise-grade deployment eliminates agent production overhead.
Add LangGraph support
LangGraph offers essential persistence layer support with checkpointers. This helps create powerful, stateful agents that can complete long tasks or resume where they left off.
For state storage, Google Cloud provides integration libraries that employ powerful managed databases. The following are developer options:
Access the extremely scalable AlloyDB for PostgreSQL using the langchain-google-alloydb-pg-python library's AlloyDBSaver class, or pick
Cloud SQL for PostgreSQL utilising langchain-google-cloud-sql-pg-python's PostgresSaver checkpointer.
With Google Cloud's PostgreSQL performance and management, both store and load agent execution states easily, allowing operations to be halted, resumed, and audited with dependability.
When assembling a graph, a checkpointer records a graph state checkpoint at each super-step. These checkpoints are saved in a thread accessible after graph execution. Threads offer access to the graph's state after execution, enabling fault-tolerance, memory, time travel, and human-in-the-loop.
#technology#technews#govindhtech#news#technologynews#MCP Toolbox for Databases#AI Agent Data Access#Gen AI Toolbox for Databases#MCP Toolbox#Toolbox for Databases#Agent Development Kit
0 notes
Text
Moments Lab Secures $24 Million to Redefine Video Discovery With Agentic AI
New Post has been published on https://thedigitalinsider.com/moments-lab-secures-24-million-to-redefine-video-discovery-with-agentic-ai/
Moments Lab Secures $24 Million to Redefine Video Discovery With Agentic AI

Moments Lab, the AI company redefining how organizations work with video, has raised $24 million in new funding, led by Oxx with participation from Orange Ventures, Kadmos, Supernova Invest, and Elaia Partners. The investment will supercharge the company’s U.S. expansion and support continued development of its agentic AI platform — a system designed to turn massive video archives into instantly searchable and monetizable assets.
The heart of Moments Lab is MXT-2, a multimodal video-understanding AI that watches, hears, and interprets video with context-aware precision. It doesn’t just label content — it narrates it, identifying people, places, logos, and even cinematographic elements like shot types and pacing. This natural-language metadata turns hours of footage into structured, searchable intelligence, usable across creative, editorial, marketing, and monetization workflows.
But the true leap forward is the introduction of agentic AI — an autonomous system that can plan, reason, and adapt to a user’s intent. Instead of simply executing instructions, it understands prompts like “generate a highlight reel for social” and takes action: pulling scenes, suggesting titles, selecting formats, and aligning outputs with a brand’s voice or platform requirements.
“With MXT, we already index video faster than any human ever could,” said Philippe Petitpont, CEO and co-founder of Moments Lab. “But with agentic AI, we’re building the next layer — AI that acts as a teammate, doing everything from crafting rough cuts to uncovering storylines hidden deep in the archive.”
From Search to Storytelling: A Platform Built for Speed and Scale
Moments Lab is more than an indexing engine. It’s a full-stack platform that empowers media professionals to move at the speed of story. That starts with search — arguably the most painful part of working with video today.
Most production teams still rely on filenames, folders, and tribal knowledge to locate content. Moments Lab changes that with plain text search that behaves like Google for your video library. Users can simply type what they’re looking for — “CEO talking about sustainability” or “crowd cheering at sunset” — and retrieve exact clips within seconds.
Key features include:
AI video intelligence: MXT-2 doesn’t just tag content — it describes it using time-coded natural language, capturing what’s seen, heard, and implied.
Search anyone can use: Designed for accessibility, the platform allows non-technical users to search across thousands of hours of footage using everyday language.
Instant clipping and export: Once a moment is found, it can be clipped, trimmed, and exported or shared in seconds — no need for timecode handoffs or third-party tools.
Metadata-rich discovery: Filter by people, events, dates, locations, rights status, or any custom facet your workflow requires.
Quote and soundbite detection: Automatically transcribes audio and highlights the most impactful segments — perfect for interview footage and press conferences.
Content classification: Train the system to sort footage by theme, tone, or use case — from trailers to corporate reels to social clips.
Translation and multilingual support: Transcribes and translates speech, even in multilingual settings, making content globally usable.
This end-to-end functionality has made Moments Lab an indispensable partner for TV networks, sports rights holders, ad agencies, and global brands. Recent clients include Thomson Reuters, Amazon Ads, Sinclair, Hearst, and Banijay — all grappling with increasingly complex content libraries and growing demands for speed, personalization, and monetization.
Built for Integration, Trained for Precision
MXT-2 is trained on 1.5 billion+ data points, reducing hallucinations and delivering high confidence outputs that teams can rely on. Unlike proprietary AI stacks that lock metadata in unreadable formats, Moments Lab keeps everything in open text, ensuring full compatibility with downstream tools like Adobe Premiere, Final Cut Pro, Brightcove, YouTube, and enterprise MAM/CMS platforms via API or no-code integrations.
“The real power of our system is not just speed, but adaptability,” said Fred Petitpont, co-founder and CTO. “Whether you’re a broadcaster clipping sports highlights or a brand licensing footage to partners, our AI works the way your team already does — just 100x faster.”
The platform is already being used to power everything from archive migration to live event clipping, editorial research, and content licensing. Users can share secure links with collaborators, sell footage to external buyers, and even train the system to align with niche editorial styles or compliance guidelines.
From Startup to Standard-Setter
Founded in 2016 by twin brothers Frederic Petitpont and Phil Petitpont, Moments Lab began with a simple question: What if you could Google your video library? Today, it’s answering that — and more — with a platform that redefines how creative and editorial teams work with media. It has become the most awarded indexing AI in the video industry since 2023 and shows no signs of slowing down.
“When we first saw MXT in action, it felt like magic,” said Gökçe Ceylan, Principal at Oxx. “This is exactly the kind of product and team we look for — technically brilliant, customer-obsessed, and solving a real, growing need.”
With this new round of funding, Moments Lab is poised to lead a category that didn’t exist five years ago — agentic AI for video — and define the future of content discovery.
#2023#Accessibility#adobe#Agentic AI#ai#ai platform#AI video#Amazon#API#assets#audio#autonomous#billion#brands#Building#CEO#CMS#code#compliance#content#CTO#data#dates#detection#development#discovery#editorial#engine#enterprise#event
2 notes
·
View notes
Text

Mike - has print of Charles Babbage in his basement. He was known as "The Father of the Computer".
Will - did a project on Alan Turing. He was known as "The Father of Computer Science". He was specifically known for breaking the enigma code. And of course, he was gay as well.
Why are they associated with computers? What's going on here?
I think it may be related to cracking codes and unlocking memories. Computers hold memory.





In ST2, Will was "possessed" and the MF (father) took over him.
After Will was sedated -> the power went out in the lab resulting in the whole building going into lockdown.
Lets break this down symbolically:
Will is sedated. His "power" went out.
As a protective fail secure measure, Will goes into full lockdown. That way, his doors remain closed. Doors as in, his closet door and the door into his memories.

In order to unlock the doors, and save everyone, the computer in the basement (a hint towards Mike himself) must be rebooted with a code. However, since they don't know the code, Bob overrides it. He opens the doors without consent.
This doesn't end well, as we know. Bob attempts to hide in a closet... then is attacked once he attempts to escape.

Will wants the doors/gates closed.


As much as he wants to keep everything contained... it can't. That's the problem. Papa says it right here- demons in the past invaliding from the subconscious. That's what it's all been about this whole time.
Okay back to computers.

In ST4, we see Suzie hack into the Hawkins High student records to gain access to change Dustin's grades.
This again is another hint.
Tigers are associated with Will. "Jiminy Crickets" is a character in Pinocchio who is a representation of Pinocchio's conscience (aka an internal aspect of the mind being externalized).


Mike and Will call the (secret) number Unknown Hero Agent Man leaves them, and find they called a computer. They both mention that this reminds them of the movie War Games.



They meet up with Suzie and she attempts to track where NINA is using the IP address.
There's a mention of the address possibly hidden in the computer coding, and Suzie mentions "data mining".
Now keep in mind- her father was guarding the computer and they needed him out of the way to gain access to the computer.
Now I just want to briefly mention AI.
Alan Turing was also well known for The Turing Test. This was a way to test a machine's ability to think like a human. So basically, it tests artificial intelligence (AI).
We have (subtle) references to movies featuring AI throughout the show that are worth mentioning:

War Games. Mike mentions "Joshua" who is the computer. "Joshua" is the AI villain in the movie who attempt to start WWIII.

The Terminator. Multiple references to this movie! The Terminator is an AI who travels back in time to kill.

2001: A Space Odyssey. In that movie, the main villain is "Hal" who is an AI that kills.
I do think the computer is the mind... likely both Will's and Mike's minds are important here. And like a computer, they have to access it in order to obtain important data... important memories.
94 notes
·
View notes
Text
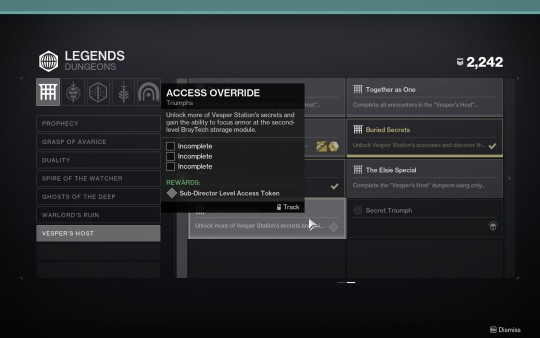
Got through all of the secrets for Vesper's Host and got all of the additional lore messages. I will transcribe them all because I don't know when they'll start getting uploaded and to get them all it requires doing some extra puzzles and at least 3-4 clears to get them all. I'll put them all under read more and label them by number.
Before I do that, just to make it clear there's not too much concrete lore; a lot about the dungeon still remains a mystery and most likely a tease for something in the future. Still unknown, but there's a lot that we don't know even with the messages so don't expect a massive reveal, but they do add a little bit of flavour and history about the station. There might be something more, but it's unknown: there's still one more secret triumph left. The messages are actually dialogues between the station AI and the Spider. Transcripts under read more:
First message:
Vesper Central: I suppose I have you to thank for bringing me out of standby, visitor. The Spider: I sent the Guardian out to save your station. So, what denomination does your thanks come in? Glimmer, herealways, information...? Vesper Central: Anomaly's powered down. That means I've already given you your survival. But... the message that went through wiped itself before my cache process could save a copy. And it's not the initial ping through the Anomaly I'm worried about. It's the response.
A message when you activate the second secret:
Vesper Central: Exterior scans rebooting... Is that a chunk of the Morning Star in my station's hull? With luck, you were on board at the time, Dr. Bray.
Second message:
Vesper Central: I'm guessing I've been in standby for a long time. Is Dr. Clovis Bray alive? The Spider: On my oath, I vow there's no mortal Human named Bray left alive. Vesper Central: I swore I'd outlive him. That I'd break the chains he laid on me. The Spider: Please, trust me for anything you need. The Guardian's a useful hand on the scene, but Spider's got the goods. Vesper Central: Vesper Station was Dr. Bray's lab, meant to house the experiments that might... interact poorly with other BrayTech work. Isolated and quarantined. From the debris field, I would guess the Morning Star taking a dive cracked that quarantine wide open.
A message when you activate the third secret:
Vesper Central: Sector seventeen powered down. Rerouting energy to core processing. Integrating archives.
Third message:
The Spider: Loading images of the station. That's not Eliksni engineering. [scoffs] A Dreg past their first molt has better cable management. Vesper Central: Dr. Bray intended to integrate his technology into a Vex Mind. He hypothesized the fusion would give him an interface he understood. A control panel on a programmable Vex mind. If the programming jumped species once... I need time to run through the data sets you powered back up. Reassembling corrupted archives takes a great deal of processing.
Text when you go back to the Spider the first time:

A message when you activate the fourth secret:
Vesper Central: Helios sector long-term research archives powered up. Activating search.
Fourth message:
Vesper Central: Dr. Bray's command keys have to be in here somewhere. Expanding research parameters... The Spider: My agents are turning up some interesting morself of data on their own. Why not give them access to your search function and collaborate? Vesper Central: Nobody is getting into my core programming. The Spider: Oh! Perish the thought! An innocent offer, my dear. Technology is a matter of faith to my people. And I'm the faithful sort.
Fifth message:
Vesper Central: Dr. Bray, I could kill you myself. This is why our work focused on the unbodied Mind. Dr. Bray thought there were types of Vex unseen on Europa. Powerful Vex he could learn from. The plan was that the Mind would build him a controlled window for observation. Tidy. Tight. Safe. He thought he could control a Vex mind so perfectly it would do everything he wanted. The Spider: Like an AI of his own creation. Like you. Vesper Central: Turns out you can't control everything forever.
Sixth message:
Vesper Central: There's a block keeping me from the inner partitions. I barely have authority to see the partitions exist. In standby, I couldn't have done more than run automated threat assessments... with flawed data. No way to know how many injuries and deaths I could have prevented, with core access. Enough. A dead man won't keep me from protecting what's mine.
Text when you return to the Spider at the end of the quest:

The situation for the dungeon triumphs when you complete the mesages. "Buried Secrets" completed triumph is the six messages. This one is left; unclear how to complete it yet and if it gives any lore or if it's just a gameplay thing and one secret triumph remaining (possibly something to do with a quest for the exotic catalyst, unclear if there will be lore):
The Spider is being his absolutely horrendous self and trying to somehow acquire the station and its remains (and its AI) for himself, all the while lying and scheming. The usual. The AI is incredibly upset with Clovis (shocker); there's the following line just before starting the second encounter:

She also details what he was doing on the station; apparently attempting to control a Vex mind and trying to use it as some sort of "observation deck" to study the Vex and uncover their secrets. Possibly something more? There's really no Vex on the station, besides dead empty frames in boxes. There's also 2 Vex cubes in containters in the transition section, one of which was shown broken as if the cube, presumably, escaped. It's entirely unclear how the Vex play into the story of the station besides this.
The portal (?) doesn't have many similarities with Vex portals, nor are the Vex there to defend it or interact with it in any way. The architecture is ... somewhat similar, but not fully. The portal (?) was built by the "Puppeteer" aka "Atraks" who is actually some sort of an Eliksni Hive mind. "Atraks" got onto the station and essentially haunted it before picking off scavenging Eliksni one by one and integrating them into herself. She then built the "anomaly" and sent a message into it. The message was not recorded, as per the station AI, and the destination of the message was labelled "incomprehensible." The orange energy we see coming from it is apparently Arc, but with a wrong colour. Unclear why.
I don't think the Vex have anything to do with the portal (?), at least not directly. "Atraks" may have built something related to the Vex or using the available Vex tech at the station, but it does not seem to be directed by the Vex and they're not there and there's no sign of them otherwise. The anomaly was also built recently, it's not been there since the Golden Age or something. Whatever it is, "Atraks" seemed to have been somehow compelled and was seen standing in front of it at the end. Some people think she was "worshipping it." It's possible but it's also possible she was just sending that message. Where and to whom? Nobody knows yet.
Weird shenanigans are afoot. Really interested to see if there's more lore in the station once people figure out how to do these puzzles and uncover them, and also when (if) this will become relevant. It has a really big "future content" feel to it.
Also I need Vesper to meet Failsafe RIGHT NOW and then they should be in yuri together.
123 notes
·
View notes
Text

SCP-8077 : The Doll - Original File
CoD - TF141 - SCP!AU
SUMMARY : The first file written about The Doll, now labeled SCP-8077, after its retrieval by MTF Alpha-141.
WARNINGS : None.
Author's Note : Never thought I'd be brave enough to post this. But I hyper focused on SCP stuff for a while and was quite satisfied with this, and I thought it would be silly to let it rot in my files. So here you go.
I do not allow anyone to re-publish, re-use and/or translate my work, be it here or on any other platform, including AI.
CoD AUs - Masterlist
Main Masterlist
Previous

Item # : SCP-8077
Object Class : Euclid
Special Containment Procedures : SCP-8077 is to be kept within a three (3) by three point five (3.5) by two point five (2.5) meter square containment chamber, isolated from other SCPs to keep the specimen’s thirst for knowledge under control. The room is to be furnished with a desk, various writing utensils and a limited amount of books, which can be replaced upon request.
The walls of SCP-8077’s containment chamber are to be lined with soundproof drywall along with a three (3) millimeters thick isolation membrane. Access is to be ensured via a heavy and rigid steel containment door measuring one point three (1.3) by two (2) meters, built in order to close and lock itself automatically when not deliberately held open.
Despite these measures ensuring that SCP-8077’s containment chamber is soundproof, all personnel is required to be highly mindful of every word they might say when standing in its vicinity. It is advised to cease all conversation altogether when walking past this room to avoid any major slip-up that could lead to a containment breach.
Under no circumstances may any personnel be allowed to have any kind of conversation with SCP-8077 unless an experiment and/or interrogation is underway. No personnel outside of the Antimemetics Divison is permitted to conduct such procedures.
Description : SCP-8077 is an antimemetic entity taking the appearance of a one hundred and sixty (160) centimeters tall, female ball-jointed doll, seemingly made of white porcelain, with long, wavy black hair and pale green eyes. Highly intelligent, the entity constantly seeks to consume all kinds of information and knowledge, feeding off of it by writing it down on any surface available.
SCP-8077 has been discovered to erase pieces of information from its assigned Researchers’ memory after writing them down, an effect that had not been noticed in the various books it read and took data from. The subject’s abilities seem to be activated when the information or knowledge it consumes comes from someone standing within its hearing range.
Note : It does not matter whether the piece of information or knowledge is addressed directly to the entity or not.
Addendum : SCP-8077’s ability does not activate when taking notes from a recording.
An individual whose part of their knowledge was consumed by SCP-8077 will progressively remember it with time, or immediately if hearing, seeing or reading it, as if they never forgot about it in the first place.
When prevented from processing knowledge for an extended amount of time, a situation which first took place during the retrieval following the discovery of SCP-8077, the subject will first express confusion as to why, then gradually fall into a state akin to that of a panic attack. According to Agent Kyle « Gaz » Garrick of MTF Alpha-141, who was the first to notice SCP-8077’s abnormal behaviour, this panic manifests itself through a tendency to hide, fidget and faint sounds of whimpering that will grow into full crying. At the time, the specimen also questioned the members of the recovering team, not understanding why it was suddenly forbidden from writing anything.
The recovering team, once given the authorisation do to so after deeming the entity to be more and more unstable by the minute, managed to quickly de-escalate the situation by simply giving SCP-8077 a pen and paper, bringing it back to a peaceful state.
Previous
CoD AUs - Masterlist
Main Masterlist
#oc : the doll#call of duty#call of duty modern warfare#cod au#scp au#cod x oc#simon ghost riley#john soap mactavish#kyle gaz garrick#john price#captain price#cod mw2#tf141#tf141 x oc
33 notes
·
View notes
Text
A new lawsuit filed by more than 100 federal workers today in the US Southern District Court of New York alleges that the Trump administration’s decision to give Elon Musk’s so-called Department of Government Efficiency (DOGE) access to their sensitive personal data is illegal. The plaintiffs are asking the court for an injunction to cut off DOGE’s access to information from the Office of Personnel Management (OPM), which functions as the HR department of the United States and houses data on federal workers such as their Social Security numbers, phone numbers, and personnel files. WIRED previously reported that Musk and people with connections to him had taken over OPM.
“OPM defendants gave DOGE defendants and DOGE’s agents—many of whom are under the age of 25 and are or were until recently employees of Musk’s private companies—‘administrative’ access to OPM computer systems, without undergoing any normal, rigorous national-security vetting,” the complaint alleges. The plaintiffs accuse DOGE of violating the Privacy Act, a 1974 law that determines how the government can collect, use, and store personal information.
Elon Musk, the DOGE organization, the Office of Personnel Management, and the OPM’s acting director Charles Ezell are named as defendants in the case. The plaintiffs include over a hundred individual federal workers from across the US government as well as groups that represent them, including AFL-CIO, a coalition of labor unions, the American Federation of Government Employees, and the Association of Administrative Law Judges. The AFGE represents over 800,000 federal workers ranging from Social Security Administration employees to border patrol agents.
The plaintiffs are represented by prominent tech industry lawyers, including counsel from the Electronic Frontier Foundation, a digital rights group, as well as Mark Lemley, an intellectual property and tech lawyer who recently dropped Meta as a client in its contentious AI copyright lawsuit because he objected to what he alleges is the company’s embrace of “neo-Nazi madness.”
“DOGE's unlawful access to employee records turns out to be the means by which they are trying to accomplish a number of other illegal ends. It is how they got a list of all government employees to make their illegal buyout offer, for instance. It gives them access to information about transgender employees so they can illegally discriminate against those employees. And it lays the groundwork for the illegal firings we have seen across multiple departments,” Lemley told WIRED.
EFF lawyer Victoria Noble says there are heightened concerns about DOGE’s data access because of the political nature of Musk’s project. For example, Noble says, there’s a risk that Musk and his acolytes may use OPM data to target ideological opponents or “people they see as disloyal.”
“There's significant risk that this information could be used to identify employees to essentially terminate based on improper considerations,” Noble told WIRED. “There's medical information, there's disability information, there's information about people's involvement with unions.”
The Office of Personnel Management and the White House did not immediately respond to requests for comment.
The team behind the lawsuit plans to push even further. “This is just phase one, focused on getting an injunction to stop the continuing violation of the law,” says Lemley. The next phase will include filing a class-action lawsuit on behalf of impacted federal workers.
“Any current or former federal employee who spends or loses even a small amount of money responding to the data breach, for example, by purchasing credit monitoring services, is entitled to a minimum of $1000 in statutory damages,” Lemley says. The complaint specifies that the plaintiffs have already paid for credit monitoring and web monitoring services to protect themselves against DOGE potentially mishandling their data.
The lawsuit is part of a flurry of complaints filed in recent days opposing various executive orders signed by Trump as well as activities conducted by DOGE, which has dispatched a cadre of Musk loyalists to radically overhaul and sometimes effectively dismantle various government agencies.
An earlier lawsuit filed against the Office of Personnel Management on January 27 alleges that DOGE was operating an illegal server at OPM. On Monday, the Electronic Privacy Information Center, a privacy-focused nonprofit, brought its own lawsuit against OPM, the US Department of the Treasury, and DOGE, alleging “the largest and most consequential data breach in US history.” Filed in a US District Court in Virginia, it also called for an injunction to halt DOGE’s access to sensitive data.
The American Civil Liberties Union (ACLU) has similarly characterized DOGE’s data access as potentially illegal in a letter to members of Congress sent last week.
The courts have already taken some limited actions to curb DOGE’s campaign. On Saturday, a federal judge blocked Musk’s lieutenants from accessing Treasury Department records that contained sensitive personal data such as Social Security and bank account numbers. The Trump Administration is already aggressively pushing back, calling the order “unprecedented judicial interference.” Today, President Trump reportedly prepared to sign an executive order directing federal agencies to work with DOGE.
20 notes
·
View notes
Text
I just stumbled across somebody saying how editing their own novel was too exhausting, and next time they'll run it through Grammerly instead.
For the love of writing, please do not trust AI to edit your work.
Listen. I get it. I am a writer, and I have worked as a professional editor. Writing is hard and editing is harder. There's a reason I did it for pay. Consequently, I also get that professional editors can be dearly expensive, and things like dyslexia can make it difficult to edit your own stuff.
Algorithms are not the solution to that.
Pay a newbie human editor. Trade favors with a friend. Beg an early birthday present from a sibling. I cannot stress enough how important it is that one of the editors be yourself, and at least one be somebody else.
Yourself, because you know what you intended to put on the page, and what is obviously counter to your intention.
The other person, because they're going to see the things that you can't notice. When you're reading your own writing, it's colored by what you expect to be on the page, and so your brain will frequently fill in missing words or make sense of things that don't actually parse well. They're also more likely to point out things that are outside your scope of knowledge.
Trust me, human editors are absolutely necessary for publishing.
If you convince yourself that you positively must run your work through an algorithm before submitting to an agent/publisher/self-pub site, do yourself and your readers a massive favor: get at least two sets of human eyeballs on your writing after the algorithm has done its work.
Because here's the thing:
AI draws from whatever data sets it's trained on, and those data sets famously aren't curated.
You cannot trust it to know whether that's an actual word or just a really common misspelling.
People break conventions of grammar to create a certain effect in the reader all the time. AI cannot be relied upon to know the difference between James Joyce and a bredlik and an actual coherent sentence, or which one is appropriate at any given part of the book.
AI picks up on patterns in its training data sets and imitates and magnifies those patterns-- especially bigotry, and particularly racism.
AI has also been known to lift entire passages wholesale. Listen to me: Plagiarism will end your career. And here's the awful thing-- if it's plagiarizing a source you aren't familiar with, there's a very good chance you wouldn't even know it's been done. This is another reason for other humans than yourself-- more people means a broader pool of knowledge and experience to draw from.
I know a writer who used this kind of software to help them find spelling mistakes, didn't realize that a setting had been turned on during an update, and had their entire work be turned into word salad-- and only found out when the editor at their publishing house called them on the phone and asked what the hell had happened to their latest book. And when I say 'their entire work', I'm not talking about their novel-- I'm talking about every single draft and document that the software had access to.
75 notes
·
View notes
Text
Weaponizing violence. With alarming regularity, the nation continues to be subjected to spates of violence that terrorizes the public, destabilizes the country’s ecosystem, and gives the government greater justifications to crack down, lock down, and institute even more authoritarian policies for the so-called sake of national security without many objections from the citizenry.
Weaponizing surveillance, pre-crime and pre-thought campaigns. Surveillance, digital stalking and the data mining of the American people add up to a society in which there’s little room for indiscretions, imperfections, or acts of independence. When the government sees all and knows all and has an abundance of laws to render even the most seemingly upstanding citizen a criminal and lawbreaker, then the old adage that you’ve got nothing to worry about if you’ve got nothing to hide no longer applies. Add pre-crime programs into the mix with government agencies and corporations working in tandem to determine who is a potential danger and spin a sticky spider-web of threat assessments, behavioral sensing warnings, flagged “words,” and “suspicious” activity reports using automated eyes and ears, social media, behavior sensing software, and citizen spies, and you having the makings for a perfect dystopian nightmare. The government’s war on crime has now veered into the realm of social media and technological entrapment, with government agents adopting fake social media identities and AI-created profile pictures in order to surveil, target and capture potential suspects.
Weaponizing digital currencies, social media scores and censorship. Tech giants, working with the government, have been meting out their own version of social justice by way of digital tyranny and corporate censorship, muzzling whomever they want, whenever they want, on whatever pretext they want in the absence of any real due process, review or appeal. Unfortunately, digital censorship is just the beginning. Digital currencies (which can be used as “a tool for government surveillance of citizens and control over their financial transactions”), combined with social media scores and surveillance capitalism create a litmus test to determine who is worthy enough to be part of society and punish individuals for moral lapses and social transgressions (and reward them for adhering to government-sanctioned behavior). In China, millions of individuals and businesses, blacklisted as “unworthy” based on social media credit scores that grade them based on whether they are “good” citizens, have been banned from accessing financial markets, buying real estate or travelling by air or train.
Weaponizing compliance. Even the most well-intentioned government law or program can be—and has been—perverted, corrupted and used to advance illegitimate purposes once profit and power are added to the equation. The war on terror, the war on drugs, the war on COVID-19, the war on illegal immigration, asset forfeiture schemes, road safety schemes, school safety schemes, eminent domain: all of these programs started out as legitimate responses to pressing concerns and have since become weapons of compliance and control in the police state’s hands.
Weaponizing entertainment. For the past century, the Department of Defense’s Entertainment Media Office has provided Hollywood with equipment, personnel and technical expertise at taxpayer expense. In exchange, the military industrial complex has gotten a starring role in such blockbusters as Top Gun and its rebooted sequel Top Gun: Maverick, which translates to free advertising for the war hawks, recruitment of foot soldiers for the military empire, patriotic fervor by the taxpayers who have to foot the bill for the nation’s endless wars, and Hollywood visionaries working to churn out dystopian thrillers that make the war machine appear relevant, heroic and necessary. As Elmer Davis, a CBS broadcaster who was appointed the head of the Office of War Information, observed, “The easiest way to inject a propaganda idea into most people’s minds is to let it go through the medium of an entertainment picture when they do not realize that they are being propagandized.”
Weaponizing behavioral science and nudging. Apart from the overt dangers posed by a government that feels justified and empowered to spy on its people and use its ever-expanding arsenal of weapons and technology to monitor and control them, there’s also the covert dangers associated with a government empowered to use these same technologies to influence behaviors en masse and control the populace. In fact, it was President Obama who issued an executive order directing federal agencies to use “behavioral science” methods to minimize bureaucracy and influence the way people respond to government programs. It’s a short hop, skip and a jump from a behavioral program that tries to influence how people respond to paperwork to a government program that tries to shape the public’s views about other, more consequential matters. Thus, increasingly, governments around the world—including in the United States—are relying on “nudge units” to steer citizens in the direction the powers-that-be want them to go, while preserving the appearance of free will.
Weaponizing desensitization campaigns aimed at lulling us into a false sense of security. The events of recent years—the invasive surveillance, the extremism reports, the civil unrest, the protests, the shootings, the bombings, the military exercises and active shooter drills, the lockdowns, the color-coded alerts and threat assessments, the fusion centers, the transformation of local police into extensions of the military, the distribution of military equipment and weapons to local police forces, the government databases containing the names of dissidents and potential troublemakers—have conspired to acclimate the populace to accept a police state willingly, even gratefully.
Weaponizing fear and paranoia. The language of fear is spoken effectively by politicians on both sides of the aisle, shouted by media pundits from their cable TV pulpits, marketed by corporations, and codified into bureaucratic laws that do little to make our lives safer or more secure. Fear, as history shows, is the method most often used by politicians to increase the power of government and control a populace, dividing the people into factions, and persuading them to see each other as the enemy. This Machiavellian scheme has so ensnared the nation that few Americans even realize they are being manipulated into adopting an “us” against “them” mindset. Instead, fueled with fear and loathing for phantom opponents, they agree to pour millions of dollars and resources into political elections, militarized police, spy technology and endless wars, hoping for a guarantee of safety that never comes. All the while, those in power—bought and paid for by lobbyists and corporations—move their costly agendas forward, and “we the suckers” get saddled with the tax bills and subjected to pat downs, police raids and round-the-clock surveillance.
Weaponizing genetics. Not only does fear grease the wheels of the transition to fascism by cultivating fearful, controlled, pacified, cowed citizens, but it also embeds itself in our very DNA so that we pass on our fear and compliance to our offspring. It’s called epigenetic inheritance, the transmission through DNA of traumatic experiences. For example, neuroscientists observed that fear can travel through generations of mice DNA. As The Washington Post reports, “Studies on humans suggest that children and grandchildren may have felt the epigenetic impact of such traumatic events such as famine, the Holocaust and the Sept. 11, 2001, terrorist attacks.”
Weaponizing the future. With greater frequency, the government has been issuing warnings about the dire need to prepare for the dystopian future that awaits us. For instance, the Pentagon training video, “Megacities: Urban Future, the Emerging Complexity,” predicts that by 2030 (coincidentally, the same year that society begins to achieve singularity with the metaverse) the military would be called on to use armed forces to solve future domestic political and social problems. What they’re really talking about is martial law, packaged as a well-meaning and overriding concern for the nation’s security. The chilling five-minute training video paints an ominous picture of the future bedeviled by “criminal networks,” “substandard infrastructure,” “religious and ethnic tensions,” “impoverishment, slums,” “open landfills, over-burdened sewers,” a “growing mass of unemployed,” and an urban landscape in which the prosperous economic elite must be protected from the impoverishment of the have nots. “We the people” are the have-nots.
The end goal of these mind control campaigns—packaged in the guise of the greater good—is to see how far the American people will allow the government to go in re-shaping the country in the image of a totalitarian police state.
11 notes
·
View notes
Quote
Generative AI presents a number of immediate threats to learners’ rights, amplifying the known threats from so-called predictive AI (though the two are increasingly used together in educational systems and dealt with together in educational policy). Channelling the knowledge available to young people through anglo-centric, proprietary and normative data platforms is a risk to their cultural and epistemic rights. Releasing AI-generated content into digital platforms and attacking public sites with AI crawlers, agents and deepfakes deprives young people of free access to digital information and culture, while diminishing their own opportunities for cultural production. These harms affect young people of minority languages and cultures to a greater degree. And there is increasing evidence (see below) that the use of chatbots in school work and pedagogic interactions is harmful to young people’s intellectual and social development, and so undermines their right to the fullest development of their potential as laid out in the UN CRC.
How the right to education is undermined by AI
6 notes
·
View notes
Text
Your All-in-One AI Web Agent: Save $200+ a Month, Unleash Limitless Possibilities!
Imagine having an AI agent that costs you nothing monthly, runs directly on your computer, and is unrestricted in its capabilities. OpenAI Operator charges up to $200/month for limited API calls and restricts access to many tasks like visiting thousands of websites. With DeepSeek-R1 and Browser-Use, you:
• Save money while keeping everything local and private.
• Automate visiting 100,000+ websites, gathering data, filling forms, and navigating like a human.
• Gain total freedom to explore, scrape, and interact with the web like never before.
You may have heard about Operator from Open AI that runs on their computer in some cloud with you passing on private information to their AI to so anything useful. AND you pay for the gift . It is not paranoid to not want you passwords and logins and personal details to be shared. OpenAI of course charges a substantial amount of money for something that will limit exactly what sites you can visit, like YouTube for example. With this method you will start telling an AI exactly what you want it to do, in plain language, and watching it navigate the web, gather information, and make decisions—all without writing a single line of code.
In this guide, we’ll show you how to build an AI agent that performs tasks like scraping news, analyzing social media mentions, and making predictions using DeepSeek-R1 and Browser-Use, but instead of writing a Python script, you’ll interact with the AI directly using prompts.
These instructions are in constant revisions as DeepSeek R1 is days old. Browser Use has been a standard for quite a while. This method can be for people who are new to AI and programming. It may seem technical at first, but by the end of this guide, you’ll feel confident using your AI agent to perform a variety of tasks, all by talking to it. how, if you look at these instructions and it seems to overwhelming, wait, we will have a single download app soon. It is in testing now.
This is version 3.0 of these instructions January 26th, 2025.
This guide will walk you through setting up DeepSeek-R1 8B (4-bit) and Browser-Use Web UI, ensuring even the most novice users succeed.
What You’ll Achieve
By following this guide, you’ll:
1. Set up DeepSeek-R1, a reasoning AI that works privately on your computer.
2. Configure Browser-Use Web UI, a tool to automate web scraping, form-filling, and real-time interaction.
3. Create an AI agent capable of finding stock news, gathering Reddit mentions, and predicting stock trends—all while operating without cloud restrictions.
A Deep Dive At ReadMultiplex.com Soon
We will have a deep dive into how you can use this platform for very advanced AI use cases that few have thought of let alone seen before. Join us at ReadMultiplex.com and become a member that not only sees the future earlier but also with particle and pragmatic ways to profit from the future.
System Requirements
Hardware
• RAM: 8 GB minimum (16 GB recommended).
• Processor: Quad-core (Intel i5/AMD Ryzen 5 or higher).
• Storage: 5 GB free space.
• Graphics: GPU optional for faster processing.
Software
• Operating System: macOS, Windows 10+, or Linux.
• Python: Version 3.8 or higher.
• Git: Installed.
Step 1: Get Your Tools Ready
We’ll need Python, Git, and a terminal/command prompt to proceed. Follow these instructions carefully.
Install Python
1. Check Python Installation:
• Open your terminal/command prompt and type:
python3 --version
• If Python is installed, you’ll see a version like:
Python 3.9.7
2. If Python Is Not Installed:
• Download Python from python.org.
• During installation, ensure you check “Add Python to PATH” on Windows.
3. Verify Installation:
python3 --version
Install Git
1. Check Git Installation:
• Run:
git --version
• If installed, you’ll see:
git version 2.34.1
2. If Git Is Not Installed:
• Windows: Download Git from git-scm.com and follow the instructions.
• Mac/Linux: Install via terminal:
sudo apt install git -y # For Ubuntu/Debian
brew install git # For macOS
Step 2: Download and Build llama.cpp
We’ll use llama.cpp to run the DeepSeek-R1 model locally.
1. Open your terminal/command prompt.
2. Navigate to a clear location for your project files:
mkdir ~/AI_Project
cd ~/AI_Project
3. Clone the llama.cpp repository:
git clone https://github.com/ggerganov/llama.cpp.git
cd llama.cpp
4. Build the project:
• Mac/Linux:
make
• Windows:
• Install a C++ compiler (e.g., MSVC or MinGW).
• Run:
mkdir build
cd build
cmake ..
cmake --build . --config Release
Step 3: Download DeepSeek-R1 8B 4-bit Model
1. Visit the DeepSeek-R1 8B Model Page on Hugging Face.
2. Download the 4-bit quantized model file:
• Example: DeepSeek-R1-Distill-Qwen-8B-Q4_K_M.gguf.
3. Move the model to your llama.cpp folder:
mv ~/Downloads/DeepSeek-R1-Distill-Qwen-8B-Q4_K_M.gguf ~/AI_Project/llama.cpp
Step 4: Start DeepSeek-R1
1. Navigate to your llama.cpp folder:
cd ~/AI_Project/llama.cpp
2. Run the model with a sample prompt:
./main -m DeepSeek-R1-Distill-Qwen-8B-Q4_K_M.gguf -p "What is the capital of France?"
3. Expected Output:
The capital of France is Paris.
Step 5: Set Up Browser-Use Web UI
1. Go back to your project folder:
cd ~/AI_Project
2. Clone the Browser-Use repository:
git clone https://github.com/browser-use/browser-use.git
cd browser-use
3. Create a virtual environment:
python3 -m venv env
4. Activate the virtual environment:
• Mac/Linux:
source env/bin/activate
• Windows:
env\Scripts\activate
5. Install dependencies:
pip install -r requirements.txt
6. Start the Web UI:
python examples/gradio_demo.py
7. Open the local URL in your browser:
http://127.0.0.1:7860
Step 6: Configure the Web UI for DeepSeek-R1
1. Go to the Settings panel in the Web UI.
2. Specify the DeepSeek model path:
~/AI_Project/llama.cpp/DeepSeek-R1-Distill-Qwen-8B-Q4_K_M.gguf
3. Adjust Timeout Settings:
• Increase the timeout to 120 seconds for larger models.
4. Enable Memory-Saving Mode if your system has less than 16 GB of RAM.
Step 7: Run an Example Task
Let’s create an agent that:
1. Searches for Tesla stock news.
2. Gathers Reddit mentions.
3. Predicts the stock trend.
Example Prompt:
Search for "Tesla stock news" on Google News and summarize the top 3 headlines. Then, check Reddit for the latest mentions of "Tesla stock" and predict whether the stock will rise based on the news and discussions.
--
Congratulations! You’ve built a powerful, private AI agent capable of automating the web and reasoning in real time. Unlike costly, restricted tools like OpenAI Operator, you’ve spent nothing beyond your time. Unleash your AI agent on tasks that were once impossible and imagine the possibilities for personal projects, research, and business. You’re not limited anymore. You own the web—your AI agent just unlocked it! 🚀
Stay tuned fora FREE simple to use single app that will do this all and more.

7 notes
·
View notes
Text
Things That Are Hard
Some things are harder than they look. Some things are exactly as hard as they look.
Game AI, Intelligent Opponents, Intelligent NPCs
As you already know, "Game AI" is a misnomer. It's NPC behaviour, escort missions, "director" systems that dynamically manage the level of action in a game, pathfinding, AI opponents in multiplayer games, and possibly friendly AI players to fill out your team if there aren't enough humans.
Still, you are able to implement minimax with alpha-beta pruning for board games, pathfinding algorithms like A* or simple planning/reasoning systems with relative ease. Even easier: You could just take an MIT licensed library that implements a cool AI technique and put it in your game.
So why is it so hard to add AI to games, or more AI to games? The first problem is integration of cool AI algorithms with game systems. Although games do not need any "perception" for planning algorithms to work, no computer vision, sensor fusion, or data cleanup, and no Bayesian filtering for mapping and localisation, AI in games still needs information in a machine-readable format. Suddenly you go from free-form level geometry to a uniform grid, and from "every frame, do this or that" to planning and execution phases and checking every frame if the plan is still succeeding or has succeeded or if the assumptions of the original plan no longer hold and a new plan is on order. Intelligent behaviour is orders of magnitude more code than simple behaviours, and every time you add a mechanic to the game, you need to ask yourself "how do I make this mechanic accessible to the AI?"
Some design decisions will just be ruled out because they would be difficult to get to work in a certain AI paradigm.
Even in a game that is perfectly suited for AI techniques, like a turn-based, grid-based rogue-like, with line-of-sight already implemented, can struggle to make use of learning or planning AI for NPC behaviour.
What makes advanced AI "fun" in a game is usually when the behaviour is at least a little predictable, or when the AI explains how it works or why it did what it did. What makes AI "fun" is when it sometimes or usually plays really well, but then makes little mistakes that the player must learn to exploit. What makes AI "fun" is interesting behaviour. What makes AI "fun" is game balance.
You can have all of those with simple, almost hard-coded agent behaviour.
Video Playback
If your engine does not have video playback, you might think that it's easy enough to add it by yourself. After all, there are libraries out there that help you decode and decompress video files, so you can stream them from disk, and get streams of video frames and audio.
You can just use those libraries, and play the sounds and display the pictures with the tools your engine already provides, right?
Unfortunately, no. The video is probably at a different frame rate from your game's frame rate, and the music and sound effect playback in your game engine are probably not designed with syncing audio playback to a video stream.
I'm not saying it can't be done. I'm saying that it's surprisingly tricky, and even worse, it might be something that can't be built on top of your engine, but something that requires you to modify your engine to make it work.
Stealth Games
Stealth games succeed and fail on NPC behaviour/AI, predictability, variety, and level design. Stealth games need sophisticated and legible systems for line of sight, detailed modelling of the knowledge-state of NPCs, communication between NPCs, and good movement/ controls/game feel.
Making a stealth game is probably five times as difficult as a platformer or a puzzle platformer.
In a puzzle platformer, you can develop puzzle elements and then build levels. In a stealth game, your NPC behaviour and level design must work in tandem, and be developed together. Movement must be fluid enough that it doesn't become a challenge in itself, without stealth. NPC behaviour must be interesting and legible.
Rhythm Games
These are hard for the same reason that video playback is hard. You have to sync up your audio with your gameplay. You need some kind of feedback for when which audio is played. You need to know how large the audio lag, screen lag, and input lag are, both in frames, and in milliseconds.
You could try to counteract this by using certain real-time OS functionality directly, instead of using the machinery your engine gives you for sound effects and background music. You could try building your own sequencer that plays the beats at the right time.
Now you have to build good gameplay on top of that, and you have to write music. Rhythm games are the genre that experienced programmers are most likely to get wrong in game jams. They produce a finished and playable game, because they wanted to write a rhythm game for a change, but they get the BPM of their music slightly wrong, and everything feels off, more and more so as each song progresses.
Online Multi-Player Netcode
Everybody knows this is hard, but still underestimates the effort it takes. Sure, back in the day you could use the now-discontinued ready-made solution for Unity 5.0 to synchronise the state of your GameObjects. Sure, you can use a library that lets you send messages and streams on top of UDP. Sure, you can just use TCP and server-authoritative networking.
It can all work out, or it might not. Your netcode will have to deal with pings of 300 milliseconds, lag spikes, package loss, and maybe recover from five seconds of lost WiFi connections. If your game can't, because it absolutely needs the low latency or high bandwidth or consistency between players, you will at least have to detect these conditions and handle them, for example by showing text on the screen informing the player he has lost the match.
It is deceptively easy to build certain kinds of multiplayer games, and test them on your local network with pings in the single digit milliseconds. It is deceptively easy to write your own RPC system that works over TCP and sends out method names and arguments encoded as JSON. This is not the hard part of netcode. It is easy to write a racing game where players don't interact much, but just see each other's ghosts. The hard part is to make a fighting game where both players see the punches connect with the hit boxes in the same place, and where all players see the same finish line. Or maybe it's by design if every player sees his own car go over the finish line first.
50 notes
·
View notes
Text
Researchers Warn of 'Living off AI' Attacks After PoC Exploits Atlassian's AI Agent Protocol
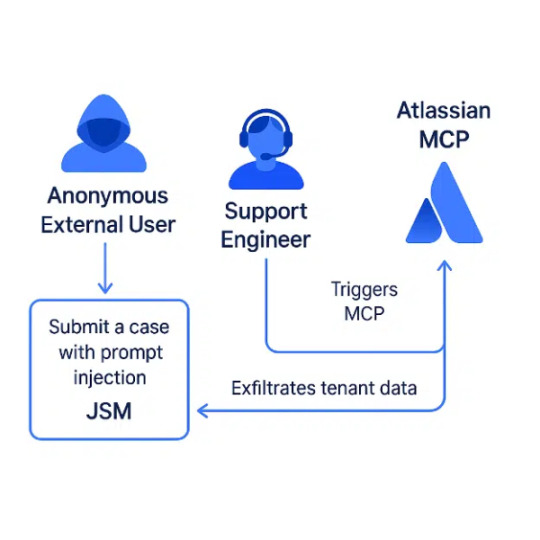
Summary: Researchers from Cato Networks demonstrated a proof-of-concept 'Living off AI' attack exploiting Atlassian's Model Context Protocol (MCP) integration in Jira Service Management, where malicious support tickets inject prompts that execute with internal user privileges. This enables data exfiltration and privilege escalation without direct attacker access, exposing a systemic risk in AI-driven workflows lacking prompt isolation and context validation.
Source: https://www.infosecurity-magazine.com/news/atlassian-ai-agent-mcp-attack/
More info: https://www.catonetworks.com/blog/cato-ctrl-poc-attack-targeting-atlassians-mcp/
2 notes
·
View notes
Text
How Agentic AI & RAG Revolutionize Autonomous Decision-Making
In the swiftly advancing realm of artificial intelligence, the integration of Agentic AI and Retrieval-Augmented Generation (RAG) is revolutionizing autonomous decision-making across various sectors. Agentic AI endows systems with the ability to operate independently, while RAG enhances these systems by incorporating real-time data retrieval, leading to more informed and adaptable decisions. This article delves into the synergistic relationship between Agentic AI and RAG, exploring their combined impact on autonomous decision-making.
Overview
Agentic AI refers to AI systems capable of autonomous operation, making decisions based on environmental inputs and predefined goals without continuous human oversight. These systems utilize advanced machine learning and natural language processing techniques to emulate human-like decision-making processes. Retrieval-Augmented Generation (RAG), on the other hand, merges generative AI models with information retrieval capabilities, enabling access to and incorporation of external data in real-time. This integration allows AI systems to leverage both internal knowledge and external data sources, resulting in more accurate and contextually relevant decisions.
Read more about Agentic AI in Manufacturing: Use Cases & Key Benefits
What is Agentic AI and RAG?
Agentic AI: This form of artificial intelligence empowers systems to achieve specific objectives with minimal supervision. It comprises AI agents—machine learning models that replicate human decision-making to address problems in real-time. Agentic AI exhibits autonomy, goal-oriented behavior, and adaptability, enabling independent and purposeful actions.
Retrieval-Augmented Generation (RAG): RAG is an AI methodology that integrates a generative AI model with an external knowledge base. It dynamically retrieves current information from sources like APIs or databases, allowing AI models to generate contextually accurate and pertinent responses without necessitating extensive fine-tuning.
Know more on Why Businesses Are Embracing RAG for Smarter AI
Capabilities
When combined, Agentic AI and RAG offer several key capabilities:
Autonomous Decision-Making: Agentic AI can independently analyze complex scenarios and select effective actions based on real-time data and predefined objectives.
Contextual Understanding: It interprets situations dynamically, adapting actions based on evolving goals and real-time inputs.
Integration with External Data: RAG enables Agentic AI to access external databases, ensuring decisions are based on the most current and relevant information available.
Enhanced Accuracy: By incorporating external data, RAG helps Agentic AI systems avoid relying solely on internal models, which may be outdated or incomplete.
How Agentic AI and RAG Work Together
The integration of Agentic AI and RAG creates a robust system capable of autonomous decision-making with real-time adaptability:
Dynamic Perception: Agentic AI utilizes RAG to retrieve up-to-date information from external sources, enhancing its perception capabilities. For instance, an Agentic AI tasked with financial analysis can use RAG to access real-time stock market data.
Enhanced Reasoning: RAG augments the reasoning process by providing external context that complements the AI's internal knowledge. This enables Agentic AI to make better-informed decisions, such as recommending personalized solutions in customer service scenarios.
Autonomous Execution: The combined system can autonomously execute tasks based on retrieved data. For example, an Agentic AI chatbot enhanced with RAG can not only answer questions but also initiate actions like placing orders or scheduling appointments.
Continuous Learning: Feedback from executed tasks helps refine both the agent's decision-making process and RAG's retrieval mechanisms, ensuring the system becomes more accurate and efficient over time.
Read more about Multi-Meta-RAG: Enhancing RAG for Complex Multi-Hop Queries
Example Use Case: Customer Service
Customer Support Automation Scenario: A user inquiries about their account balance via a chatbot.
How It Works: The Agentic AI interprets the query, determines that external data is required, and employs RAG to retrieve real-time account information from a database. The enriched prompt allows the chatbot to provide an accurate response while suggesting payment options. If prompted, it can autonomously complete the transaction.
Benefits: Faster query resolution, personalized responses, and reduced need for human intervention.
Example: Acuvate's implementation of Agentic AI demonstrates how autonomous decision-making and real-time data integration can enhance customer service experiences.
2. Sales Assistance
Scenario: A sales representative needs to create a custom quote for a client.
How It Works: Agentic RAG retrieves pricing data, templates, and CRM details. It autonomously drafts a quote, applies discounts as instructed, and adjusts fields like baseline costs using the latest price book.
Benefits: Automates multi-step processes, reduces errors, and accelerates deal closures.
3. Healthcare Diagnostics
Scenario: A doctor seeks assistance in diagnosing a rare medical condition.
How It Works: Agentic AI uses RAG to retrieve relevant medical literature, clinical trial data, and patient history. It synthesizes this information to suggest potential diagnoses and treatment options.
Benefits: Enhances diagnostic accuracy, saves time, and provides evidence-based recommendations.
Example: Xenonstack highlights healthcare as a major application area for agentic AI systems in diagnosis and treatment planning.
4. Market Research and Consumer Insights
Scenario: A business wants to identify emerging market trends.
How It Works: Agentic RAG analyzes consumer data from multiple sources, retrieves relevant insights, and generates predictive analytics reports. It also gathers customer feedback from surveys or social media.
Benefits: Improves strategic decision-making with real-time intelligence.
Example: Companies use Agentic RAG for trend analysis and predictive analytics to optimize marketing strategies.
5. Supply Chain Optimization
Scenario: A logistics manager needs to predict demand fluctuations during peak seasons.
How It Works: The system retrieves historical sales data, current market trends, and weather forecasts using RAG. Agentic AI then predicts demand patterns and suggests inventory adjustments in real-time.
Benefits: Prevents stockouts or overstocking, reduces costs, and improves efficiency.
Example: Acuvate’s supply chain solutions leverage predictive analytics powered by Agentic AI to enhance logistics operations

How Acuvate Can Help
Acuvate specializes in implementing Agentic AI and RAG technologies to transform business operations. By integrating these advanced AI solutions, Acuvate enables organizations to enhance autonomous decision-making, improve customer experiences, and optimize operational efficiency. Their expertise in deploying AI-driven systems ensures that businesses can effectively leverage real-time data and intelligent automation to stay competitive in a rapidly evolving market.
Future Scope
The future of Agentic AI and RAG involves the development of multi-agent systems where multiple AI agents collaborate to tackle complex tasks. Continuous improvement and governance will be crucial, with ongoing updates and audits necessary to maintain safety and accountability. As technology advances, these systems are expected to become more pervasive across industries, transforming business processes and customer interactions.
In conclusion, the convergence of Agentic AI and RAG represents a significant advancement in autonomous decision-making. By combining autonomous agents with real-time data retrieval, organizations can achieve greater efficiency, accuracy, and adaptability in their operations. As these technologies continue to evolve, their impact across various sectors is poised to expand, ushering in a new era of intelligent automation.
3 notes
·
View notes
Text
Video Agent: The Future of AI-Powered Content Creation

The rise of AI-generated content has transformed how businesses and creators produce videos. Among the most innovative tools is the video agent, an AI-driven solution that automates video creation, editing, and optimization. Whether for marketing, education, or entertainment, video agents are redefining efficiency and creativity in digital media.
In this article, we explore how AI-powered video agents work, their benefits, and their impact on content creation.
What Is a Video Agent?
A video agent is an AI-based system designed to assist in video production. Unlike traditional editing software, it leverages machine learning and natural language processing (NLP) to automate tasks such as:
Scriptwriting – Generates engaging scripts based on keywords.
Voiceovers – Converts text to lifelike speech in multiple languages.
Editing – Automatically cuts, transitions, and enhances footage.
Personalization – Tailors videos for different audiences.
These capabilities make video agents indispensable for creators who need high-quality content at scale.
How AI Video Generators Work
The core of a video agent lies in its AI algorithms. Here’s a breakdown of the process:
1. Input & Analysis
Users provide a prompt (e.g., "Create a 1-minute explainer video about AI trends"). The AI video generator analyzes the request and gathers relevant data.
2. Content Generation
Using GPT-based models, the system drafts a script, selects stock footage (or generates synthetic visuals), and adds background music.
3. Editing & Enhancement
The video agent refines the video by:
Adjusting pacing and transitions.
Applying color correction.
Syncing voiceovers with visuals.
4. Output & Optimization
The final video is rendered in various formats, optimized for platforms like YouTube, TikTok, or LinkedIn.
Benefits of Using a Video Agent
Adopting an AI-powered video generator offers several advantages:
1. Time Efficiency
Traditional video production takes hours or days. A video agent reduces this to minutes, allowing rapid content deployment.
2. Cost Savings
Hiring editors, voice actors, and scriptwriters is expensive. AI eliminates these costs while maintaining quality.
3. Scalability
Businesses can generate hundreds of personalized videos for marketing campaigns without extra effort.
4. Consistency
AI ensures brand voice and style remain uniform across all videos.
5. Accessibility
Even non-experts can create professional videos without technical skills.
Top Use Cases for Video Agents
From marketing to education, AI video generators are versatile tools. Key applications include:
1. Marketing & Advertising
Personalized ads – AI tailors videos to user preferences.
Social media content – Quickly generates clips for Instagram, Facebook, etc.
2. E-Learning & Training
Automated tutorials – Simplifies complex topics with visuals.
Corporate training – Creates onboarding videos for employees.
3. News & Journalism
AI-generated news clips – Converts articles into video summaries.
4. Entertainment & Influencers
YouTube automation – Helps creators maintain consistent uploads.
Challenges & Limitations
Despite their advantages, video agents face some hurdles:
1. Lack of Human Touch
AI may struggle with emotional nuance, making some videos feel robotic.
2. Copyright Issues
Using stock footage or AI-generated voices may raise legal concerns.
3. Over-Reliance on Automation
Excessive AI use could reduce creativity in content creation.
The Future of Video Agents
As AI video generation improves, we can expect:
Hyper-realistic avatars – AI-generated presenters indistinguishable from humans.
Real-time video editing – Instant adjustments during live streams.
Advanced personalization – AI predicting viewer preferences before creation.
2 notes
·
View notes
Text
Elon Musk’s so-called Department of Government Efficiency (DOGE) operates on a core underlying assumption: The United States should be run like a startup. So far, that has mostly meant chaotic firings and an eagerness to steamroll regulations. But no pitch deck in 2025 is complete without an overdose of artificial intelligence, and DOGE is no different.
AI itself doesn’t reflexively deserve pitchforks. It has genuine uses and can create genuine efficiencies. It is not inherently untoward to introduce AI into a workflow, especially if you’re aware of and able to manage around its limitations. It’s not clear, though, that DOGE has embraced any of that nuance. If you have a hammer, everything looks like a nail; if you have the most access to the most sensitive data in the country, everything looks like an input.
Wherever DOGE has gone, AI has been in tow. Given the opacity of the organization, a lot remains unknown about how exactly it’s being used and where. But two revelations this week show just how extensive—and potentially misguided—DOGE’s AI aspirations are.
At the Department of Housing and Urban Development, a college undergrad has been tasked with using AI to find where HUD regulations may go beyond the strictest interpretation of underlying laws. (Agencies have traditionally had broad interpretive authority when legislation is vague, although the Supreme Court recently shifted that power to the judicial branch.) This is a task that actually makes some sense for AI, which can synthesize information from large documents far faster than a human could. There’s some risk of hallucination—more specifically, of the model spitting out citations that do not in fact exist—but a human needs to approve these recommendations regardless. This is, on one level, what generative AI is actually pretty good at right now: doing tedious work in a systematic way.
There’s something pernicious, though, in asking an AI model to help dismantle the administrative state. (Beyond the fact of it; your mileage will vary there depending on whether you think low-income housing is a societal good or you’re more of a Not in Any Backyard type.) AI doesn’t actually “know” anything about regulations or whether or not they comport with the strictest possible reading of statutes, something that even highly experienced lawyers will disagree on. It needs to be fed a prompt detailing what to look for, which means you can not only work the refs but write the rulebook for them. It is also exceptionally eager to please, to the point that it will confidently make stuff up rather than decline to respond.
If nothing else, it’s the shortest path to a maximalist gutting of a major agency’s authority, with the chance of scattered bullshit thrown in for good measure.
At least it’s an understandable use case. The same can’t be said for another AI effort associated with DOGE. As WIRED reported Friday, an early DOGE recruiter is once again looking for engineers, this time to “design benchmarks and deploy AI agents across live workflows in federal agencies.” His aim is to eliminate tens of thousands of government positions, replacing them with agentic AI and “freeing up” workers for ostensibly “higher impact” duties.
Here the issue is more clear-cut, even if you think the government should by and large be operated by robots. AI agents are still in the early stages; they’re not nearly cut out for this. They may not ever be. It’s like asking a toddler to operate heavy machinery.
DOGE didn’t introduce AI to the US government. In some cases, it has accelerated or revived AI programs that predate it. The General Services Administration had already been working on an internal chatbot for months; DOGE just put the deployment timeline on ludicrous speed. The Defense Department designed software to help automate reductions-in-force decades ago; DOGE engineers have updated AutoRIF for their own ends. (The Social Security Administration has recently introduced a pre-DOGE chatbot as well, which is worth a mention here if only to refer you to the regrettable training video.)
Even those preexisting projects, though, speak to the concerns around DOGE’s use of AI. The problem isn’t artificial intelligence in and of itself. It’s the full-throttle deployment in contexts where mistakes can have devastating consequences. It’s the lack of clarity around what data is being fed where and with what safeguards.
AI is neither a bogeyman nor a panacea. It’s good at some things and bad at others. But DOGE is using it as an imperfect means to destructive ends. It’s prompting its way toward a hollowed-out US government, essential functions of which will almost inevitably have to be assumed by—surprise!—connected Silicon Valley contractors.
12 notes
·
View notes
Text
WHAT IS VERTEX AI SEARCH
Vertex AI Search: A Comprehensive Analysis
1. Executive Summary
Vertex AI Search emerges as a pivotal component of Google Cloud's artificial intelligence portfolio, offering enterprises the capability to deploy search experiences with the quality and sophistication characteristic of Google's own search technologies. This service is fundamentally designed to handle diverse data types, both structured and unstructured, and is increasingly distinguished by its deep integration with generative AI, most notably through its out-of-the-box Retrieval Augmented Generation (RAG) functionalities. This RAG capability is central to its value proposition, enabling organizations to ground large language model (LLM) responses in their proprietary data, thereby enhancing accuracy, reliability, and contextual relevance while mitigating the risk of generating factually incorrect information.
The platform's strengths are manifold, stemming from Google's decades of expertise in semantic search and natural language processing. Vertex AI Search simplifies the traditionally complex workflows associated with building RAG systems, including data ingestion, processing, embedding, and indexing. It offers specialized solutions tailored for key industries such as retail, media, and healthcare, addressing their unique vernacular and operational needs. Furthermore, its integration within the broader Vertex AI ecosystem, including access to advanced models like Gemini, positions it as a comprehensive solution for building sophisticated AI-driven applications.
However, the adoption of Vertex AI Search is not without its considerations. The pricing model, while granular and offering a "pay-as-you-go" approach, can be complex, necessitating careful cost modeling, particularly for features like generative AI and always-on components such as Vector Search index serving. User experiences and technical documentation also point to potential implementation hurdles for highly specific or advanced use cases, including complexities in IAM permission management and evolving query behaviors with platform updates. The rapid pace of innovation, while a strength, also requires organizations to remain adaptable.
Ultimately, Vertex AI Search represents a strategic asset for organizations aiming to unlock the value of their enterprise data through advanced search and AI. It provides a pathway to not only enhance information retrieval but also to build a new generation of AI-powered applications that are deeply informed by and integrated with an organization's unique knowledge base. Its continued evolution suggests a trajectory towards becoming a core reasoning engine for enterprise AI, extending beyond search to power more autonomous and intelligent systems.
2. Introduction to Vertex AI Search
Vertex AI Search is establishing itself as a significant offering within Google Cloud's AI capabilities, designed to transform how enterprises access and utilize their information. Its strategic placement within the Google Cloud ecosystem and its core value proposition address critical needs in the evolving landscape of enterprise data management and artificial intelligence.
Defining Vertex AI Search
Vertex AI Search is a service integrated into Google Cloud's Vertex AI Agent Builder. Its primary function is to equip developers with the tools to create secure, high-quality search experiences comparable to Google's own, tailored for a wide array of applications. These applications span public-facing websites, internal corporate intranets, and, significantly, serve as the foundation for Retrieval Augmented Generation (RAG) systems that power generative AI agents and applications. The service achieves this by amalgamating deep information retrieval techniques, advanced natural language processing (NLP), and the latest innovations in large language model (LLM) processing. This combination allows Vertex AI Search to more accurately understand user intent and deliver the most pertinent results, marking a departure from traditional keyword-based search towards more sophisticated semantic and conversational search paradigms.
Strategic Position within Google Cloud AI Ecosystem
The service is not a standalone product but a core element of Vertex AI, Google Cloud's comprehensive and unified machine learning platform. This integration is crucial, as Vertex AI Search leverages and interoperates with other Vertex AI tools and services. Notable among these are Document AI, which facilitates the processing and understanding of diverse document formats , and direct access to Google's powerful foundation models, including the multimodal Gemini family. Its incorporation within the Vertex AI Agent Builder further underscores Google's strategy to provide an end-to-end toolkit for constructing advanced AI agents and applications, where robust search and retrieval capabilities are fundamental.
Core Purpose and Value Proposition
The fundamental aim of Vertex AI Search is to empower enterprises to construct search applications of Google's caliber, operating over their own controlled datasets, which can encompass both structured and unstructured information. A central pillar of its value proposition is its capacity to function as an "out-of-the-box" RAG system. This feature is critical for grounding LLM responses in an enterprise's specific data, a process that significantly improves the accuracy, reliability, and contextual relevance of AI-generated content, thereby reducing the propensity for LLMs to produce "hallucinations" or factually incorrect statements. The simplification of the intricate workflows typically associated with RAG systems—including Extract, Transform, Load (ETL) processes, Optical Character Recognition (OCR), data chunking, embedding generation, and indexing—is a major attraction for businesses.
Moreover, Vertex AI Search extends its utility through specialized, pre-tuned offerings designed for specific industries such as retail (Vertex AI Search for Commerce), media and entertainment (Vertex AI Search for Media), and healthcare and life sciences. These tailored solutions are engineered to address the unique terminologies, data structures, and operational requirements prevalent in these sectors.
The pronounced emphasis on "out-of-the-box RAG" and the simplification of data processing pipelines points towards a deliberate strategy by Google to lower the entry barrier for enterprises seeking to leverage advanced Generative AI capabilities. Many organizations may lack the specialized AI talent or resources to build such systems from the ground up. Vertex AI Search offers a managed, pre-configured solution, effectively democratizing access to sophisticated RAG technology. By making these capabilities more accessible, Google is not merely selling a search product; it is positioning Vertex AI Search as a foundational layer for a new wave of enterprise AI applications. This approach encourages broader adoption of Generative AI within businesses by mitigating some inherent risks, like LLM hallucinations, and reducing technical complexities. This, in turn, is likely to drive increased consumption of other Google Cloud services, such as storage, compute, and LLM APIs, fostering a more integrated and potentially "sticky" ecosystem.
Furthermore, Vertex AI Search serves as a conduit between traditional enterprise search mechanisms and the frontier of advanced AI. It is built upon "Google's deep expertise and decades of experience in semantic search technologies" , while concurrently incorporating "the latest in large language model (LLM) processing" and "Gemini generative AI". This dual nature allows it to support conventional search use cases, such as website and intranet search , alongside cutting-edge AI applications like RAG for generative AI agents and conversational AI systems. This design provides an evolutionary pathway for enterprises. Organizations can commence by enhancing existing search functionalities and then progressively adopt more advanced AI features as their internal AI maturity and comfort levels grow. This adaptability makes Vertex AI Search an attractive proposition for a diverse range of customers with varying immediate needs and long-term AI ambitions. Such an approach enables Google to capture market share in both the established enterprise search market and the rapidly expanding generative AI application platform market. It offers a smoother transition for businesses, diminishing the perceived risk of adopting state-of-the-art AI by building upon familiar search paradigms, thereby future-proofing their investment.
3. Core Capabilities and Architecture
Vertex AI Search is engineered with a rich set of features and a flexible architecture designed to handle diverse enterprise data and power sophisticated search and AI applications. Its capabilities span from foundational search quality to advanced generative AI enablement, supported by robust data handling mechanisms and extensive customization options.
Key Features
Vertex AI Search integrates several core functionalities that define its power and versatility:
Google-Quality Search: At its heart, the service leverages Google's profound experience in semantic search technologies. This foundation aims to deliver highly relevant search results across a wide array of content types, moving beyond simple keyword matching to incorporate advanced natural language understanding (NLU) and contextual awareness.
Out-of-the-Box Retrieval Augmented Generation (RAG): A cornerstone feature is its ability to simplify the traditionally complex RAG pipeline. Processes such as ETL, OCR, document chunking, embedding generation, indexing, storage, information retrieval, and summarization are streamlined, often requiring just a few clicks to configure. This capability is paramount for grounding LLM responses in enterprise-specific data, which significantly enhances the trustworthiness and accuracy of generative AI applications.
Document Understanding: The service benefits from integration with Google's Document AI suite, enabling sophisticated processing of both structured and unstructured documents. This allows for the conversion of raw documents into actionable data, including capabilities like layout parsing and entity extraction.
Vector Search: Vertex AI Search incorporates powerful vector search technology, essential for modern embeddings-based applications. While it offers out-of-the-box embedding generation and automatic fine-tuning, it also provides flexibility for advanced users. They can utilize custom embeddings and gain direct control over the underlying vector database for specialized use cases such as recommendation engines and ad serving. Recent enhancements include the ability to create and deploy indexes without writing code, and a significant reduction in indexing latency for smaller datasets, from hours down to minutes. However, it's important to note user feedback regarding Vector Search, which has highlighted concerns about operational costs (e.g., the need to keep compute resources active even when not querying), limitations with certain file types (e.g., .xlsx), and constraints on embedding dimensions for specific corpus configurations. This suggests a balance to be struck between the power of Vector Search and its operational overhead and flexibility.
Generative AI Features: The platform is designed to enable grounded answers by synthesizing information from multiple sources. It also supports the development of conversational AI capabilities , often powered by advanced models like Google's Gemini.
Comprehensive APIs: For developers who require fine-grained control or are building bespoke RAG solutions, Vertex AI Search exposes a suite of APIs. These include APIs for the Document AI Layout Parser, ranking algorithms, grounded generation, and the check grounding API, which verifies the factual basis of generated text.
Data Handling
Effective data management is crucial for any search system. Vertex AI Search provides several mechanisms for ingesting, storing, and organizing data:
Supported Data Sources:
Websites: Content can be indexed by simply providing site URLs.
Structured Data: The platform supports data from BigQuery tables and NDJSON files, enabling hybrid search (a combination of keyword and semantic search) or recommendation systems. Common examples include product catalogs, movie databases, or professional directories.
Unstructured Data: Documents in various formats (PDF, DOCX, etc.) and images can be ingested for hybrid search. Use cases include searching through private repositories of research publications or financial reports. Notably, some limitations, such as lack of support for .xlsx files, have been reported specifically for Vector Search.
Healthcare Data: FHIR R4 formatted data, often imported from the Cloud Healthcare API, can be used to enable hybrid search over clinical data and patient records.
Media Data: A specialized structured data schema is available for the media industry, catering to content like videos, news articles, music tracks, and podcasts.
Third-party Data Sources: Vertex AI Search offers connectors (some in Preview) to synchronize data from various third-party applications, such as Jira, Confluence, and Salesforce, ensuring that search results reflect the latest information from these systems.
Data Stores and Apps: A fundamental architectural concept in Vertex AI Search is the one-to-one relationship between an "app" (which can be a search or a recommendations app) and a "data store". Data is imported into a specific data store, where it is subsequently indexed. The platform provides different types of data stores, each optimized for a particular kind of data (e.g., website content, structured data, unstructured documents, healthcare records, media assets).
Indexing and Corpus: The term "corpus" refers to the underlying storage and indexing mechanism within Vertex AI Search. Even when users interact with data stores, which act as an abstraction layer, the corpus is the foundational component where data is stored and processed. It is important to understand that costs are associated with the corpus, primarily driven by the volume of indexed data, the amount of storage consumed, and the number of queries processed.
Schema Definition: Users have the ability to define a schema that specifies which metadata fields from their documents should be indexed. This schema also helps in understanding the structure of the indexed documents.
Real-time Ingestion: For datasets that change frequently, Vertex AI Search supports real-time ingestion. This can be implemented using a Pub/Sub topic to publish notifications about new or updated documents. A Cloud Function can then subscribe to this topic and use the Vertex AI Search API to ingest, update, or delete documents in the corresponding data store, thereby maintaining data freshness. This is a critical feature for dynamic environments.
Automated Processing for RAG: When used for Retrieval Augmented Generation, Vertex AI Search automates many of the complex data processing steps, including ETL, OCR, document chunking, embedding generation, and indexing.
The "corpus" serves as the foundational layer for both storage and indexing, and its management has direct cost implications. While data stores provide a user-friendly abstraction, the actual costs are tied to the size of this underlying corpus and the activity it handles. This means that effective data management strategies, such as determining what data to index and defining retention policies, are crucial for optimizing costs, even with the simplified interface of data stores. The "pay only for what you use" principle is directly linked to the activity and volume within this corpus. For large-scale deployments, particularly those involving substantial datasets like the 500GB use case mentioned by a user , the cost implications of the corpus can be a significant planning factor.
There is an observable interplay between the platform's "out-of-the-box" simplicity and the requirements of advanced customization. Vertex AI Search is heavily promoted for its ease of setup and pre-built RAG capabilities , with an emphasis on an "easy experience to get started". However, highly specific enterprise scenarios or complex user requirements—such as querying by unique document identifiers, maintaining multi-year conversational contexts, needing specific embedding dimensions, or handling unsupported file formats like XLSX —may necessitate delving into more intricate configurations, API utilization, and custom development work. For example, implementing real-time ingestion requires setting up Pub/Sub and Cloud Functions , and achieving certain filtering behaviors might involve workarounds like using metadata fields. While comprehensive APIs are available for "granular control or bespoke RAG solutions" , this means that the platform's inherent simplicity has boundaries, and deep technical expertise might still be essential for optimal or highly tailored implementations. This suggests a tiered user base: one that leverages Vertex AI Search as a turnkey solution, and another that uses it as a powerful, extensible toolkit for custom builds.
Querying and Customization
Vertex AI Search provides flexible ways to query data and customize the search experience:
Query Types: The platform supports Google-quality search, which represents an evolution from basic keyword matching to modern, conversational search experiences. It can be configured to return only a list of search results or to provide generative, AI-powered answers. A recent user-reported issue (May 2025) indicated that queries against JSON data in the latest release might require phrasing in natural language, suggesting an evolving query interpretation mechanism that prioritizes NLU.
Customization Options:
Vertex AI Search offers extensive capabilities to tailor search experiences to specific needs.
Metadata Filtering: A key customization feature is the ability to filter search results based on indexed metadata fields. For instance, if direct filtering by rag_file_ids is not supported by a particular API (like the Grounding API), adding a file_id to document metadata and filtering on that field can serve as an effective alternative.
Search Widget: Integration into websites can be achieved easily by embedding a JavaScript widget or an HTML component.
API Integration: For more profound control and custom integrations, the AI Applications API can be used.
LLM Feature Activation: Features that provide generative answers powered by LLMs typically need to be explicitly enabled.
Refinement Options: Users can preview search results and refine them by adding or modifying metadata (e.g., based on HTML structure for websites), boosting the ranking of certain results (e.g., based on publication date), or applying filters (e.g., based on URL patterns or other metadata).
Events-based Reranking and Autocomplete: The platform also supports advanced tuning options such as reranking results based on user interaction events and providing autocomplete suggestions for search queries.
Multi-Turn Conversation Support:
For conversational AI applications, the Grounding API can utilize the history of a conversation as context for generating subsequent responses.
To maintain context in multi-turn dialogues, it is recommended to store previous prompts and responses (e.g., in a database or cache) and include this history in the next prompt to the model, while being mindful of the context window limitations of the underlying LLMs.
The evolving nature of query interpretation, particularly the reported shift towards requiring natural language queries for JSON data , underscores a broader trend. If this change is indicative of a deliberate platform direction, it signals a significant alignment of the query experience with Google's core strengths in NLU and conversational AI, likely driven by models like Gemini. This could simplify interactions for end-users but may require developers accustomed to more structured query languages for structured data to adapt their approaches. Such a shift prioritizes natural language understanding across the platform. However, it could also introduce friction for existing applications or development teams that have built systems based on previous query behaviors. This highlights the dynamic nature of managed services, where underlying changes can impact functionality, necessitating user adaptation and diligent monitoring of release notes.
4. Applications and Use Cases
Vertex AI Search is designed to cater to a wide spectrum of applications, from enhancing traditional enterprise search to enabling sophisticated generative AI solutions across various industries. Its versatility allows organizations to leverage their data in novel and impactful ways.
Enterprise Search
A primary application of Vertex AI Search is the modernization and improvement of search functionalities within an organization:
Improving Search for Websites and Intranets: The platform empowers businesses to deploy Google-quality search capabilities on their external-facing websites and internal corporate portals or intranets. This can significantly enhance user experience by making information more discoverable. For basic implementations, this can be as straightforward as integrating a pre-built search widget.
Employee and Customer Search: Vertex AI Search provides a comprehensive toolkit for accessing, processing, and analyzing enterprise information. This can be used to create powerful search experiences for employees, helping them find internal documents, locate subject matter experts, or access company knowledge bases more efficiently. Similarly, it can improve customer-facing search for product discovery, support documentation, or FAQs.
Generative AI Enablement
Vertex AI Search plays a crucial role in the burgeoning field of generative AI by providing essential grounding capabilities:
Grounding LLM Responses (RAG): A key and frequently highlighted use case is its function as an out-of-the-box Retrieval Augmented Generation (RAG) system. In this capacity, Vertex AI Search retrieves relevant and factual information from an organization's own data repositories. This retrieved information is then used to "ground" the responses generated by Large Language Models (LLMs). This process is vital for improving the accuracy, reliability, and contextual relevance of LLM outputs, and critically, for reducing the incidence of "hallucinations"—the tendency of LLMs to generate plausible but incorrect or fabricated information.
Powering Generative AI Agents and Apps: By providing robust grounding capabilities, Vertex AI Search serves as a foundational component for building sophisticated generative AI agents and applications. These AI systems can then interact with and reason about company-specific data, leading to more intelligent and context-aware automated solutions.
Industry-Specific Solutions
Recognizing that different industries have unique data types, terminologies, and objectives, Google Cloud offers specialized versions of Vertex AI Search:
Vertex AI Search for Commerce (Retail): This version is specifically tuned to enhance the search, product recommendation, and browsing experiences on retail e-commerce channels. It employs AI to understand complex customer queries, interpret shopper intent (even when expressed using informal language or colloquialisms), and automatically provide dynamic spell correction and relevant synonym suggestions. Furthermore, it can optimize search results based on specific business objectives, such as click-through rates (CTR), revenue per session, and conversion rates.
Vertex AI Search for Media (Media and Entertainment): Tailored for the media industry, this solution aims to deliver more personalized content recommendations, often powered by generative AI. The strategic goal is to increase consumer engagement and time spent on media platforms, which can translate to higher advertising revenue, subscription retention, and overall platform loyalty. It supports structured data formats commonly used in the media sector for assets like videos, news articles, music, and podcasts.
Vertex AI Search for Healthcare and Life Sciences: This offering provides a medically tuned search engine designed to improve the experiences of both patients and healthcare providers. It can be used, for example, to search through vast clinical data repositories, electronic health records, or a patient's clinical history using exploratory queries. This solution is also built with compliance with healthcare data regulations like HIPAA in mind.
The development of these industry-specific versions like "Vertex AI Search for Commerce," "Vertex AI Search for Media," and "Vertex AI Search for Healthcare and Life Sciences" is not merely a cosmetic adaptation. It represents a strategic decision by Google to avoid a one-size-fits-all approach. These offerings are "tuned for unique industry requirements" , incorporating specialized terminologies, understanding industry-specific data structures, and aligning with distinct business objectives. This targeted approach significantly lowers the barrier to adoption for companies within these verticals, as the solution arrives pre-optimized for their particular needs, thereby reducing the requirement for extensive custom development or fine-tuning. This industry-specific strategy serves as a potent market penetration tactic, allowing Google to compete more effectively against niche players in each vertical and to demonstrate clear return on investment by addressing specific, high-value industry challenges. It also fosters deeper integration into the core business processes of these enterprises, positioning Vertex AI Search as a more strategic and less easily substitutable component of their technology infrastructure. This could, over time, lead to the development of distinct, industry-focused data ecosystems and best practices centered around Vertex AI Search.
Embeddings-Based Applications (via Vector Search)
The underlying Vector Search capability within Vertex AI Search also enables a range of applications that rely on semantic similarity of embeddings:
Recommendation Engines: Vector Search can be a core component in building recommendation engines. By generating numerical representations (embeddings) of items (e.g., products, articles, videos), it can find and suggest items that are semantically similar to what a user is currently viewing or has interacted with in the past.
Chatbots: For advanced chatbots that need to understand user intent deeply and retrieve relevant information from extensive knowledge bases, Vector Search provides powerful semantic matching capabilities. This allows chatbots to provide more accurate and contextually appropriate responses.
Ad Serving: In the domain of digital advertising, Vector Search can be employed for semantic matching to deliver more relevant advertisements to users based on content or user profiles.
The Vector Search component is presented both as an integral technology powering the semantic retrieval within the managed Vertex AI Search service and as a potent, standalone tool accessible via the broader Vertex AI platform. Snippet , for instance, outlines a methodology for constructing a recommendation engine using Vector Search directly. This dual role means that Vector Search is foundational to the core semantic retrieval capabilities of Vertex AI Search, and simultaneously, it is a powerful component that can be independently leveraged by developers to build other custom AI applications. Consequently, enhancements to Vector Search, such as the recently reported reductions in indexing latency , benefit not only the out-of-the-box Vertex AI Search experience but also any custom AI solutions that developers might construct using this underlying technology. Google is, in essence, offering a spectrum of access to its vector database technology. Enterprises can consume it indirectly and with ease through the managed Vertex AI Search offering, or they can harness it more directly for bespoke AI projects. This flexibility caters to varying levels of technical expertise and diverse application requirements. As more enterprises adopt embeddings for a multitude of AI tasks, a robust, scalable, and user-friendly Vector Search becomes an increasingly critical piece of infrastructure, likely driving further adoption of the entire Vertex AI ecosystem.
Document Processing and Analysis
Leveraging its integration with Document AI, Vertex AI Search offers significant capabilities in document processing:
The service can help extract valuable information, classify documents based on content, and split large documents into manageable chunks. This transforms static documents into actionable intelligence, which can streamline various business workflows and enable more data-driven decision-making. For example, it can be used for analyzing large volumes of textual data, such as customer feedback, product reviews, or research papers, to extract key themes and insights.
Case Studies (Illustrative Examples)
While specific case studies for "Vertex AI Search" are sometimes intertwined with broader "Vertex AI" successes, several examples illustrate the potential impact of AI grounded on enterprise data, a core principle of Vertex AI Search:
Genial Care (Healthcare): This organization implemented Vertex AI to improve the process of keeping session records for caregivers. This enhancement significantly aided in reviewing progress for autism care, demonstrating Vertex AI's value in managing and utilizing healthcare-related data.
AES (Manufacturing & Industrial): AES utilized generative AI agents, built with Vertex AI, to streamline energy safety audits. This application resulted in a remarkable 99% reduction in costs and a decrease in audit completion time from 14 days to just one hour. This case highlights the transformative potential of AI agents that are effectively grounded on enterprise-specific information, aligning closely with the RAG capabilities central to Vertex AI Search.
Xometry (Manufacturing): This company is reported to be revolutionizing custom manufacturing processes by leveraging Vertex AI.
LUXGEN (Automotive): LUXGEN employed Vertex AI to develop an AI-powered chatbot. This initiative led to improvements in both the car purchasing and driving experiences for customers, while also achieving a 30% reduction in customer service workloads.
These examples, though some may refer to the broader Vertex AI platform, underscore the types of business outcomes achievable when AI is effectively applied to enterprise data and processes—a domain where Vertex AI Search is designed to excel.
5. Implementation and Management Considerations
Successfully deploying and managing Vertex AI Search involves understanding its setup processes, data ingestion mechanisms, security features, and user access controls. These aspects are critical for ensuring the platform operates efficiently, securely, and in alignment with enterprise requirements.
Setup and Deployment
Vertex AI Search offers flexibility in how it can be implemented and integrated into existing systems:
Google Cloud Console vs. API: Implementation can be approached in two main ways. The Google Cloud console provides a web-based interface for a quick-start experience, allowing users to create applications, import data, test search functionality, and view analytics without extensive coding. Alternatively, for deeper integration into websites or custom applications, the AI Applications API offers programmatic control. A common practice is a hybrid approach, where initial setup and data management are performed via the console, while integration and querying are handled through the API.
App and Data Store Creation: The typical workflow begins with creating a search or recommendations "app" and then attaching it to a "data store." Data relevant to the application is then imported into this data store and subsequently indexed to make it searchable.
Embedding JavaScript Widgets: For straightforward website integration, Vertex AI Search provides embeddable JavaScript widgets and API samples. These allow developers to quickly add search or recommendation functionalities to their web pages as HTML components.
Data Ingestion and Management
The platform provides robust mechanisms for ingesting data from various sources and keeping it up-to-date:
Corpus Management: As previously noted, the "corpus" is the fundamental underlying storage and indexing layer. While data stores offer an abstraction, it is crucial to understand that costs are directly related to the volume of data indexed in the corpus, the storage it consumes, and the query load it handles.
Pub/Sub for Real-time Updates: For environments with dynamic datasets where information changes frequently, Vertex AI Search supports real-time updates. This is typically achieved by setting up a Pub/Sub topic to which notifications about new or modified documents are published. A Cloud Function, acting as a subscriber to this topic, can then use the Vertex AI Search API to ingest, update, or delete the corresponding documents in the data store. This architecture ensures that the search index remains fresh and reflects the latest information. The capacity for real-time ingestion via Pub/Sub and Cloud Functions is a significant feature. This capability distinguishes it from systems reliant solely on batch indexing, which may not be adequate for environments with rapidly changing information. Real-time ingestion is vital for use cases where data freshness is paramount, such as e-commerce platforms with frequently updated product inventories, news portals, live financial data feeds, or internal systems tracking real-time operational metrics. Without this, search results could quickly become stale and potentially misleading. This feature substantially broadens the applicability of Vertex AI Search, positioning it as a viable solution for dynamic, operational systems where search must accurately reflect the current state of data. However, implementing this real-time pipeline introduces additional architectural components (Pub/Sub topics, Cloud Functions) and associated costs, which organizations must consider in their planning. It also implies a need for robust monitoring of the ingestion pipeline to ensure its reliability.
Metadata for Filtering and Control: During the schema definition process, specific metadata fields can be designated for indexing. This indexed metadata is critical for enabling powerful filtering of search results. For example, if an application requires users to search within a specific subset of documents identified by a unique ID, and direct filtering by a system-generated rag_file_id is not supported in a particular API context, a workaround involves adding a custom file_id field to each document's metadata. This custom field can then be used as a filter criterion during search queries.
Data Connectors: To facilitate the ingestion of data from a variety of sources, including first-party systems, other Google services, and third-party applications (such as Jira, Confluence, and Salesforce), Vertex AI Search offers data connectors. These connectors provide read-only access to external applications and help ensure that the data within the search index remains current and synchronized with these source systems.
Security and Compliance
Google Cloud places a strong emphasis on security and compliance for its services, and Vertex AI Search incorporates several features to address these enterprise needs:
Data Privacy: A core tenet is that user data ingested into Vertex AI Search is secured within the customer's dedicated cloud instance. Google explicitly states that it does not access or use this customer data for training its general-purpose models or for any other unauthorized purposes.
Industry Compliance: Vertex AI Search is designed to adhere to various recognized industry standards and regulations. These include HIPAA (Health Insurance Portability and Accountability Act) for healthcare data, the ISO 27000-series for information security management, and SOC (System and Organization Controls) attestations (SOC-1, SOC-2, SOC-3). This compliance is particularly relevant for the specialized versions of Vertex AI Search, such as the one for Healthcare and Life Sciences.
Access Transparency: This feature, when enabled, provides customers with logs of actions taken by Google personnel if they access customer systems (typically for support purposes), offering a degree of visibility into such interactions.
Virtual Private Cloud (VPC) Service Controls: To enhance data security and prevent unauthorized data exfiltration or infiltration, customers can use VPC Service Controls to define security perimeters around their Google Cloud resources, including Vertex AI Search.
Customer-Managed Encryption Keys (CMEK): Available in Preview, CMEK allows customers to use their own cryptographic keys (managed through Cloud Key Management Service) to encrypt data at rest within Vertex AI Search. This gives organizations greater control over their data's encryption.
User Access and Permissions (IAM)
Proper configuration of Identity and Access Management (IAM) permissions is fundamental to securing Vertex AI Search and ensuring that users only have access to appropriate data and functionalities:
Effective IAM policies are critical. However, some users have reported encountering challenges when trying to identify and configure the specific "Discovery Engine search permissions" required for Vertex AI Search. Difficulties have been noted in determining factors such as principal access boundaries or the impact of deny policies, even when utilizing tools like the IAM Policy Troubleshooter. This suggests that the permission model can be granular and may require careful attention to detail and potentially specialized knowledge to implement correctly, especially for complex scenarios involving fine-grained access control.
The power of Vertex AI Search lies in its capacity to index and make searchable vast quantities of potentially sensitive enterprise data drawn from diverse sources. While Google Cloud provides a robust suite of security features like VPC Service Controls and CMEK , the responsibility for meticulous IAM configuration and overarching data governance rests heavily with the customer. The user-reported difficulties in navigating IAM permissions for "Discovery Engine search permissions" underscore that the permission model, while offering granular control, might also present complexity. Implementing a least-privilege access model effectively, especially when dealing with nuanced requirements such as filtering search results based on user identity or specific document IDs , may require specialized expertise. Failure to establish and maintain correct IAM policies could inadvertently lead to security vulnerabilities or compliance breaches, thereby undermining the very benefits the search platform aims to provide. Consequently, the "ease of use" often highlighted for search setup must be counterbalanced with rigorous and continuous attention to security and access control from the outset of any deployment. The platform's capability to filter search results based on metadata becomes not just a functional feature but a key security control point if designed and implemented with security considerations in mind.
6. Pricing and Commercials
Understanding the pricing structure of Vertex AI Search is essential for organizations evaluating its adoption and for ongoing cost management. The model is designed around the principle of "pay only for what you use" , offering flexibility but also requiring careful consideration of various cost components. Google Cloud typically provides a free trial, often including $300 in credits for new customers to explore services. Additionally, a free tier is available for some services, notably a 10 GiB per month free quota for Index Data Storage, which is shared across AI Applications.
The pricing for Vertex AI Search can be broken down into several key areas:
Core Search Editions and Query Costs
Search Standard Edition: This edition is priced based on the number of queries processed, typically per 1,000 queries. For example, a common rate is $1.50 per 1,000 queries.
Search Enterprise Edition: This edition includes Core Generative Answers (AI Mode) and is priced at a higher rate per 1,000 queries, such as $4.00 per 1,000 queries.
Advanced Generative Answers (AI Mode): This is an optional add-on available for both Standard and Enterprise Editions. It incurs an additional cost per 1,000 user input queries, for instance, an extra $4.00 per 1,000 user input queries.
Data Indexing Costs
Index Storage: Costs for storing indexed data are charged per GiB of raw data per month. A typical rate is $5.00 per GiB per month. As mentioned, a free quota (e.g., 10 GiB per month) is usually provided. This cost is directly associated with the underlying "corpus" where data is stored and managed.
Grounding and Generative AI Cost Components
When utilizing the generative AI capabilities, particularly for grounding LLM responses, several components contribute to the overall cost :
Input Prompt (for grounding): The cost is determined by the number of characters in the input prompt provided for the grounding process, including any grounding facts. An example rate is $0.000125 per 1,000 characters.
Output (generated by model): The cost for the output generated by the LLM is also based on character count. An example rate is $0.000375 per 1,000 characters.
Grounded Generation (for grounding on own retrieved data): There is a cost per 1,000 requests for utilizing the grounding functionality itself, for example, $2.50 per 1,000 requests.
Data Retrieval (Vertex AI Search - Enterprise edition): When Vertex AI Search (Enterprise edition) is used to retrieve documents for grounding, a query cost applies, such as $4.00 per 1,000 requests.
Check Grounding API: This API allows users to assess how well a piece of text (an answer candidate) is grounded in a given set of reference texts (facts). The cost is per 1,000 answer characters, for instance, $0.00075 per 1,000 answer characters.
Industry-Specific Pricing
Vertex AI Search offers specialized pricing for its industry-tailored solutions:
Vertex AI Search for Healthcare: This version has a distinct, typically higher, query cost, such as $20.00 per 1,000 queries. It includes features like GenAI-powered answers and streaming updates to the index, some of which may be in Preview status. Data indexing costs are generally expected to align with standard rates.
Vertex AI Search for Media:
Media Search API Request Count: A specific query cost applies, for example, $2.00 per 1,000 queries.
Data Index: Standard data indexing rates, such as $5.00 per GB per month, typically apply.
Media Recommendations: Pricing for media recommendations is often tiered based on the volume of prediction requests per month (e.g., $0.27 per 1,000 predictions for up to 20 million, $0.18 for the next 280 million, and so on). Additionally, training and tuning of recommendation models are charged per node per hour, for example, $2.50 per node per hour.
Document AI Feature Pricing (when integrated)
If Vertex AI Search utilizes integrated Document AI features for processing documents, these will incur their own costs:
Enterprise Document OCR Processor: Pricing is typically tiered based on the number of pages processed per month, for example, $1.50 per 1,000 pages for 1 to 5 million pages per month.
Layout Parser (includes initial chunking): This feature is priced per 1,000 pages, for instance, $10.00 per 1,000 pages.
Vector Search Cost Considerations
Specific cost considerations apply to Vertex AI Vector Search, particularly highlighted by user feedback :
A user found Vector Search to be "costly" due to the necessity of keeping compute resources (machines) continuously running for index serving, even during periods of no query activity. This implies ongoing costs for provisioned resources, distinct from per-query charges.
Supporting documentation confirms this model, with "Index Serving" costs that vary by machine type and region, and "Index Building" costs, such as $3.00 per GiB of data processed.
Pricing Examples
Illustrative pricing examples provided in sources like and demonstrate how these various components can combine to form the total cost for different usage scenarios, including general availability (GA) search functionality, media recommendations, and grounding operations.
The following table summarizes key pricing components for Vertex AI Search:
Vertex AI Search Pricing SummaryService ComponentEdition/TypeUnitPrice (Example)Free Tier/NotesSearch QueriesStandard1,000 queries$1.5010k free trial queries often includedSearch QueriesEnterprise (with Core GenAI)1,000 queries$4.0010k free trial queries often includedAdvanced GenAI (Add-on)Standard or Enterprise1,000 user input queries+$4.00Index Data StorageAllGiB/month$5.0010 GiB/month free (shared across AI Applications)Grounding: Input PromptGenerative AI1,000 characters$0.000125Grounding: OutputGenerative AI1,000 characters$0.000375Grounding: Grounded GenerationGenerative AI1,000 requests$2.50For grounding on own retrieved dataGrounding: Data RetrievalEnterprise Search1,000 requests$4.00When using Vertex AI Search (Enterprise) for retrievalCheck Grounding APIAPI1,000 answer characters$0.00075Healthcare Search QueriesHealthcare1,000 queries$20.00Includes some Preview featuresMedia Search API QueriesMedia1,000 queries$2.00Media Recommendations (Predictions)Media1,000 predictions$0.27 (up to 20M/mo), $0.18 (next 280M/mo), $0.10 (after 300M/mo)Tiered pricingMedia Recs Training/TuningMediaNode/hour$2.50Document OCRDocument AI Integration1,000 pages$1.50 (1-5M pages/mo), $0.60 (>5M pages/mo)Tiered pricingLayout ParserDocument AI Integration1,000 pages$10.00Includes initial chunkingVector Search: Index BuildingVector SearchGiB processed$3.00Vector Search: Index ServingVector SearchVariesVaries by machine type & region (e.g., $0.094/node hour for e2-standard-2 in us-central1)Implies "always-on" costs for provisioned resourcesExport to Sheets
Note: Prices are illustrative examples based on provided research and are subject to change. Refer to official Google Cloud pricing documentation for current rates.
The multifaceted pricing structure, with costs broken down by queries, data volume, character counts for generative AI, specific APIs, and even underlying Document AI processors , reflects the feature richness and granularity of Vertex AI Search. This allows users to align costs with the specific features they consume, consistent with the "pay only for what you use" philosophy. However, this granularity also means that accurately estimating total costs can be a complex undertaking. Users must thoroughly understand their anticipated usage patterns across various dimensions—query volume, data size, frequency of generative AI interactions, document processing needs—to predict expenses with reasonable accuracy. The seemingly simple act of obtaining a generative answer, for instance, can involve multiple cost components: input prompt processing, output generation, the grounding operation itself, and the data retrieval query. Organizations, particularly those with large datasets, high query volumes, or plans for extensive use of generative features, may find it challenging to forecast costs without detailed analysis and potentially leveraging tools like the Google Cloud pricing calculator. This complexity could present a barrier for smaller organizations or those with less experience in managing cloud expenditures. It also underscores the importance of closely monitoring usage to prevent unexpected costs. The decision between Standard and Enterprise editions, and whether to incorporate Advanced Generative Answers, becomes a significant cost-benefit analysis.
Furthermore, a critical aspect of the pricing model for certain high-performance features like Vertex AI Vector Search is the "always-on" cost component. User feedback explicitly noted Vector Search as "costly" due to the requirement to "keep my machine on even when a user ain't querying". This is corroborated by pricing details that list "Index Serving" costs varying by machine type and region , which are distinct from purely consumption-based fees (like per-query charges) where costs would be zero if there were no activity. For features like Vector Search that necessitate provisioned infrastructure for index serving, a baseline operational cost exists regardless of query volume. This is a crucial distinction from on-demand pricing models and can significantly impact the total cost of ownership (TCO) for use cases that rely heavily on Vector Search but may experience intermittent query patterns. This continuous cost for certain features means that organizations must evaluate the ongoing value derived against their persistent expense. It might render Vector Search less economical for applications with very sporadic usage unless the benefits during active periods are substantial. This could also suggest that Google might, in the future, offer different tiers or configurations for Vector Search to cater to varying performance and cost needs, or users might need to architect solutions to de-provision and re-provision indexes if usage is highly predictable and infrequent, though this would add operational complexity.
7. Comparative Analysis
Vertex AI Search operates in a competitive landscape of enterprise search and AI platforms. Understanding its position relative to alternatives is crucial for informed decision-making. Key comparisons include specialized product discovery solutions like Algolia and broader enterprise search platforms from other major cloud providers and niche vendors.
Vertex AI Search for Commerce vs. Algolia
For e-commerce and retail product discovery, Vertex AI Search for Commerce and Algolia are prominent solutions, each with distinct strengths :
Core Search Quality & Features:
Vertex AI Search for Commerce is built upon Google's extensive search algorithm expertise, enabling it to excel at interpreting complex queries by understanding user context, intent, and even informal language. It features dynamic spell correction and synonym suggestions, consistently delivering high-quality, context-rich results. Its primary strengths lie in natural language understanding (NLU) and dynamic AI-driven corrections.
Algolia has established its reputation with a strong focus on semantic search and autocomplete functionalities, powered by its NeuralSearch capabilities. It adapts quickly to user intent. However, it may require more manual fine-tuning to address highly complex or context-rich queries effectively. Algolia is often prized for its speed, ease of configuration, and feature-rich autocomplete.
Customer Engagement & Personalization:
Vertex AI incorporates advanced recommendation models that adapt based on user interactions. It can optimize search results based on defined business objectives like click-through rates (CTR), revenue per session, and conversion rates. Its dynamic personalization capabilities mean search results evolve based on prior user behavior, making the browsing experience progressively more relevant. The deep integration of AI facilitates a more seamless, data-driven personalization experience.
Algolia offers an impressive suite of personalization tools with various recommendation models suitable for different retail scenarios. The platform allows businesses to customize search outcomes through configuration, aligning product listings, faceting, and autocomplete suggestions with their customer engagement strategy. However, its personalization features might require businesses to integrate additional services or perform more fine-tuning to achieve the level of dynamic personalization seen in Vertex AI.
Merchandising & Display Flexibility:
Vertex AI utilizes extensive AI models to enable dynamic ranking configurations that consider not only search relevance but also business performance metrics such as profitability and conversion data. The search engine automatically sorts products by match quality and considers which products are likely to drive the best business outcomes, reducing the burden on retail teams by continuously optimizing based on live data. It can also blend search results with curated collections and themes. A noted current limitation is that Google is still developing new merchandising tools, and the existing toolset is described as "fairly limited".
Algolia offers powerful faceting and grouping capabilities, allowing for the creation of curated displays for promotions, seasonal events, or special collections. Its flexible configuration options permit merchants to manually define boost and slotting rules to prioritize specific products for better visibility. These manual controls, however, might require more ongoing maintenance compared to Vertex AI's automated, outcome-based ranking. Algolia's configuration-centric approach may be better suited for businesses that prefer hands-on control over merchandising details.
Implementation, Integration & Operational Efficiency:
A key advantage of Vertex AI is its seamless integration within the broader Google Cloud ecosystem, making it a natural choice for retailers already utilizing Google Merchant Center, Google Cloud Storage, or BigQuery. Its sophisticated AI models mean that even a simple initial setup can yield high-quality results, with the system automatically learning from user interactions over time. A potential limitation is its significant data requirements; businesses lacking large volumes of product or interaction data might not fully leverage its advanced capabilities, and smaller brands may find themselves in lower Data Quality tiers.
Algolia is renowned for its ease of use and rapid deployment, offering a user-friendly interface, comprehensive documentation, and a free tier suitable for early-stage projects. It is designed to integrate with various e-commerce systems and provides a flexible API for straightforward customization. While simpler and more accessible for smaller businesses, this ease of use might necessitate additional configuration for very complex or data-intensive scenarios.
Analytics, Measurement & Future Innovations:
Vertex AI provides extensive insights into both search performance and business outcomes, tracking metrics like CTR, conversion rates, and profitability. The ability to export search and event data to BigQuery enhances its analytical power, offering possibilities for custom dashboards and deeper AI/ML insights. It is well-positioned to benefit from Google's ongoing investments in AI, integration with services like Google Vision API, and the evolution of large language models and conversational commerce.
Algolia offers detailed reporting on search performance, tracking visits, searches, clicks, and conversions, and includes views for data quality monitoring. Its analytics capabilities tend to focus more on immediate search performance rather than deeper business performance metrics like average order value or revenue impact. Algolia is also rapidly innovating, especially in enhancing its semantic search and autocomplete functions, though its evolution may be more incremental compared to Vertex AI's broader ecosystem integration.
In summary, Vertex AI Search for Commerce is often an ideal choice for large retailers with extensive datasets, particularly those already integrated into the Google or Shopify ecosystems, who are seeking advanced AI-driven optimization for customer engagement and business outcomes. Conversely, Algolia presents a strong option for businesses that prioritize rapid deployment, ease of use, and flexible semantic search and autocomplete functionalities, especially smaller retailers or those desiring more hands-on control over their search configuration.
Vertex AI Search vs. Other Enterprise Search Solutions
Beyond e-commerce, Vertex AI Search competes with a range of enterprise search solutions :
INDICA Enterprise Search: This solution utilizes a patented approach to index both structured and unstructured data, prioritizing results by relevance. It offers a sophisticated query builder and comprehensive filtering options. Both Vertex AI Search and INDICA Enterprise Search provide API access, free trials/versions, and similar deployment and support options. INDICA lists "Sensitive Data Discovery" as a feature, while Vertex AI Search highlights "eCommerce Search, Retrieval-Augmented Generation (RAG), Semantic Search, and Site Search" as additional capabilities. Both platforms integrate with services like Gemini, Google Cloud Document AI, Google Cloud Platform, HTML, and Vertex AI.
Azure AI Search: Microsoft's offering features a vector database specifically designed for advanced RAG and contemporary search functionalities. It emphasizes enterprise readiness, incorporating security, compliance, and ethical AI methodologies. Azure AI Search supports advanced retrieval techniques, integrates with various platforms and data sources, and offers comprehensive vector data processing (extraction, chunking, enrichment, vectorization). It supports diverse vector types, hybrid models, multilingual capabilities, metadata filtering, and extends beyond simple vector searches to include keyword match scoring, reranking, geospatial search, and autocomplete features. The strong emphasis on RAG and vector capabilities by both Vertex AI Search and Azure AI Search positions them as direct competitors in the AI-powered enterprise search market.
IBM Watson Discovery: This platform leverages AI-driven search to extract precise answers and identify trends from various documents and websites. It employs advanced NLP to comprehend industry-specific terminology, aiming to reduce research time significantly by contextualizing responses and citing source documents. Watson Discovery also uses machine learning to visually categorize text, tables, and images. Its focus on deep NLP and understanding industry-specific language mirrors claims made by Vertex AI, though Watson Discovery has a longer established presence in this particular enterprise AI niche.
Guru: An AI search and knowledge platform, Guru delivers trusted information from a company's scattered documents, applications, and chat platforms directly within users' existing workflows. It features a personalized AI assistant and can serve as a modern replacement for legacy wikis and intranets. Guru offers extensive native integrations with popular business tools like Slack, Google Workspace, Microsoft 365, Salesforce, and Atlassian products. Guru's primary focus on knowledge management and in-app assistance targets a potentially more specialized use case than the broader enterprise search capabilities of Vertex AI, though there is an overlap in accessing and utilizing internal knowledge.
AddSearch: Provides fast, customizable site search for websites and web applications, using a crawler or an Indexing API. It offers enterprise-level features such as autocomplete, synonyms, ranking tools, and progressive ranking, designed to scale from small businesses to large corporations.
Haystack: Aims to connect employees with the people, resources, and information they need. It offers intranet-like functionalities, including custom branding, a modular layout, multi-channel content delivery, analytics, knowledge sharing features, and rich employee profiles with a company directory.
Atolio: An AI-powered enterprise search engine designed to keep data securely within the customer's own cloud environment (AWS, Azure, or GCP). It provides intelligent, permission-based responses and ensures that intellectual property remains under control, with LLMs that do not train on customer data. Atolio integrates with tools like Office 365, Google Workspace, Slack, and Salesforce. A direct comparison indicates that both Atolio and Vertex AI Search offer similar deployment, support, and training options, and share core features like AI/ML, faceted search, and full-text search. Vertex AI Search additionally lists RAG, Semantic Search, and Site Search as features not specified for Atolio in that comparison.
The following table provides a high-level feature comparison:
Feature and Capability Comparison: Vertex AI Search vs. Key CompetitorsFeature/CapabilityVertex AI SearchAlgolia (Commerce)Azure AI SearchIBM Watson DiscoveryINDICA ESGuruAtolioPrimary FocusEnterprise Search + RAG, Industry SolutionsProduct Discovery, E-commerce SearchEnterprise Search + RAG, Vector DBNLP-driven Insight Extraction, Document AnalysisGeneral Enterprise Search, Data DiscoveryKnowledge Management, In-App SearchSecure Enterprise Search, Knowledge Discovery (Self-Hosted Focus)RAG CapabilitiesOut-of-the-box, Custom via APIsN/A (Focus on product search)Strong, Vector DB optimized for RAGDocument understanding supports RAG-like patternsAI/ML features, less explicit RAG focusSurfaces existing knowledge, less about new content generationAI-powered answers, less explicit RAG focusVector SearchYes, integrated & standaloneSemantic search (NeuralSearch)Yes, core feature (Vector Database)Semantic understanding, less focus on explicit vector DBAI/Machine LearningAI-powered searchAI-powered searchSemantic Search QualityHigh (Google tech)High (NeuralSearch)HighHigh (Advanced NLP)Relevance-based rankingHigh for knowledge assetsIntelligent responsesSupported Data TypesStructured, Unstructured, Web, Healthcare, MediaPrimarily Product DataStructured, Unstructured, VectorDocuments, WebsitesStructured, UnstructuredDocs, Apps, ChatsEnterprise knowledge base (docs, apps)Industry SpecializationsRetail, Media, HealthcareRetail/E-commerceGeneral PurposeTunable for industry terminologyGeneral PurposeGeneral Knowledge ManagementGeneral Enterprise SearchKey DifferentiatorsGoogle Search tech, Out-of-box RAG, Gemini IntegrationSpeed, Ease of Config, AutocompleteAzure Ecosystem Integration, Comprehensive Vector ToolsDeep NLP, Industry Terminology UnderstandingPatented indexing, Sensitive Data DiscoveryIn-app accessibility, Extensive IntegrationsData security (self-hosted, no LLM training on customer data)Generative AI IntegrationStrong (Gemini, Grounding API)Limited (focus on search relevance)Strong (for RAG with Azure OpenAI)Supports GenAI workflowsAI/ML capabilitiesAI assistant for answersLLM-powered answersPersonalizationAdvanced (AI-driven)Strong (Configurable)Via integration with other Azure servicesN/AN/APersonalized AI assistantN/AEase of ImplementationModerate to Complex (depends on use case)HighModerate to ComplexModerate to ComplexModerateHighModerate (focus on secure deployment)Data Security ApproachGCP Security (VPC-SC, CMEK), Data SegregationStandard SaaS securityAzure Security (Compliance, Ethical AI)IBM Cloud SecurityStandard Enterprise SecurityStandard SaaS securityStrong emphasis on self-hosting & data controlExport to Sheets
The enterprise search market appears to be evolving along two axes: general-purpose platforms that offer a wide array of capabilities, and more specialized solutions tailored to specific use cases or industries. Artificial intelligence, in various forms such as semantic search, NLP, and vector search, is becoming a common denominator across almost all modern offerings. This means customers often face a choice between adopting a best-of-breed specialized tool that excels in a particular area (like Algolia for e-commerce or Guru for internal knowledge management) or investing in a broader platform like Vertex AI Search or Azure AI Search. These platforms provide good-to-excellent capabilities across many domains but might require more customization or configuration to meet highly specific niche requirements. Vertex AI Search, with its combination of a general platform and distinct industry-specific versions, attempts to bridge this gap. The success of this strategy will likely depend on how effectively its specialized versions compete with dedicated niche solutions and how readily the general platform can be adapted for unique needs.
As enterprises increasingly deploy AI solutions over sensitive proprietary data, concerns regarding data privacy, security, and intellectual property protection are becoming paramount. Vendors are responding by highlighting their security and data governance features as key differentiators. Atolio, for instance, emphasizes that it "keeps data securely within your cloud environment" and that its "LLMs do not train on your data". Similarly, Vertex AI Search details its security measures, including securing user data within the customer's cloud instance, compliance with standards like HIPAA and ISO, and features like VPC Service Controls and Customer-Managed Encryption Keys (CMEK). Azure AI Search also underscores its commitment to "security, compliance, and ethical AI methodologies". This growing focus suggests that the ability to ensure data sovereignty, meticulously control data access, and prevent data leakage or misuse by AI models is becoming as critical as search relevance or operational speed. For customers, particularly those in highly regulated industries, these data governance and security aspects could become decisive factors when selecting an enterprise search solution, potentially outweighing minor differences in other features. The often "black box" nature of some AI models makes transparent data handling policies and robust security postures increasingly crucial.
8. Known Limitations, Challenges, and User Experiences
While Vertex AI Search offers powerful capabilities, user experiences and technical reviews have highlighted several limitations, challenges, and considerations that organizations should be aware of during evaluation and implementation.
Reported User Issues and Challenges
Direct user feedback and community discussions have surfaced specific operational issues:
"No results found" Errors / Inconsistent Search Behavior: A notable user experience involved consistently receiving "No results found" messages within the Vertex AI Search app preview. This occurred even when other members of the same organization could use the search functionality without issue, and IAM and Datastore permissions appeared to be identical for the affected user. Such issues point to potential user-specific, environment-related, or difficult-to-diagnose configuration problems that are not immediately apparent.
Cross-OS Inconsistencies / Browser Compatibility: The same user reported that following the Vertex AI Search tutorial yielded successful results on a Windows operating system, but attempting the same on macOS resulted in a 403 error during the search operation. This suggests possible browser compatibility problems, issues with cached data, or differences in how the application interacts with various operating systems.
IAM Permission Complexity: Users have expressed difficulty in accurately confirming specific "Discovery Engine search permissions" even when utilizing the IAM Policy Troubleshooter. There was ambiguity regarding the determination of principal access boundaries, the effect of deny policies, or the final resolution of permissions. This indicates that navigating and verifying the necessary IAM permissions for Vertex AI Search can be a complex undertaking.
Issues with JSON Data Input / Query Phrasing: A recent issue, reported in May 2025, indicates that the latest release of Vertex AI Search (referred to as AI Application) has introduced challenges with semantic search over JSON data. According to the report, the search engine now primarily processes queries phrased in a natural language style, similar to that used in the UI, rather than structured filter expressions. This means filters or conditions must be expressed as plain language questions (e.g., "How many findings have a severity level marked as HIGH in d3v-core?"). Furthermore, it was noted that sometimes, even when specific keys are designated as "searchable" in the datastore schema, the system fails to return results, causing significant problems for certain types of queries. This represents a potentially disruptive change in behavior for users accustomed to working with JSON data in a more structured query manner.
Lack of Clear Error Messages: In the scenario where a user consistently received "No results found," it was explicitly stated that "There are no console or network errors". The absence of clear, actionable error messages can significantly complicate and prolong the diagnostic process for such issues.
Potential Challenges from Technical Specifications and User Feedback
Beyond specific bug reports, technical deep-dives and early adopter feedback have revealed other considerations, particularly concerning the underlying Vector Search component :
Cost of Vector Search: A user found Vertex AI Vector Search to be "costly." This was attributed to the operational model requiring compute resources (machines) to remain active and provisioned for index serving, even during periods when no queries were being actively processed. This implies a continuous baseline cost associated with using Vector Search.
File Type Limitations (Vector Search): As of the user's experience documented in , Vertex AI Vector Search did not offer support for indexing .xlsx (Microsoft Excel) files.
Document Size Limitations (Vector Search): Concerns were raised about the platform's ability to effectively handle "bigger document sizes" within the Vector Search component.
Embedding Dimension Constraints (Vector Search): The user reported an inability to create a Vector Search index with embedding dimensions other than the default 768 if the "corpus doesn't support" alternative dimensions. This suggests a potential lack of flexibility in configuring embedding parameters for certain setups.
rag_file_ids Not Directly Supported for Filtering: For applications using the Grounding API, it was noted that direct filtering of results based on rag_file_ids (presumably identifiers for files used in RAG) is not supported. The suggested workaround involves adding a custom file_id to the document metadata and using that for filtering purposes.
Data Requirements for Advanced Features (Vertex AI Search for Commerce)
For specialized solutions like Vertex AI Search for Commerce, the effectiveness of advanced features can be contingent on the available data:
A potential limitation highlighted for Vertex AI Search for Commerce is its "significant data requirements." Businesses that lack large volumes of product data or user interaction data (e.g., clicks, purchases) might not be able to fully leverage its advanced AI capabilities for personalization and optimization. Smaller brands, in particular, may find themselves remaining in lower Data Quality tiers, which could impact the performance of these features.
Merchandising Toolset (Vertex AI Search for Commerce)
The maturity of all components is also a factor:
The current merchandising toolset available within Vertex AI Search for Commerce has been described as "fairly limited." It is noted that Google is still in the process of developing and releasing new tools for this area. Retailers with sophisticated merchandising needs might find the current offerings less comprehensive than desired.
The rapid evolution of platforms like Vertex AI Search, while bringing cutting-edge features, can also introduce challenges. Recent user reports, such as the significant change in how JSON data queries are handled in the "latest version" as of May 2025, and other unexpected behaviors , illustrate this point. Vertex AI Search is part of a dynamic AI landscape, with Google frequently rolling out updates and integrating new models like Gemini. While this pace of innovation is a key strength, it can also lead to modifications in existing functionalities or, occasionally, introduce temporary instabilities. Users, especially those with established applications built upon specific, previously observed behaviors of the platform, may find themselves needing to adapt their implementations swiftly when such changes occur. The JSON query issue serves as a prime example of a change that could be disruptive for some users. Consequently, organizations adopting Vertex AI Search, particularly for mission-critical applications, should establish robust processes for monitoring platform updates, thoroughly testing changes in staging or development environments, and adapting their code or configurations as required. This highlights an inherent trade-off: gaining access to state-of-the-art AI features comes with the responsibility of managing the impacts of a fast-moving and evolving platform. It also underscores the critical importance of comprehensive documentation and clear, proactive communication from Google regarding any changes in platform behavior.
Moreover, there can be a discrepancy between the marketed ease-of-use and the actual complexity encountered during real-world implementation, especially for specific or advanced scenarios. While Vertex AI Search is promoted for its straightforward setup and out-of-the-box functionalities , detailed user experiences, such as those documented in and , reveal significant challenges. These can include managing the costs of components like Vector Search, dealing with limitations in supported file types or embedding dimensions, navigating the intricacies of IAM permissions, and achieving highly specific filtering requirements (e.g., querying by a custom document_id). The user in , for example, was attempting to implement a relatively complex use case involving 500GB of documents, specific ID-based querying, multi-year conversational history, and real-time data ingestion. This suggests that while basic setup might indeed be simple, implementing advanced or highly tailored enterprise requirements can unearth complexities and limitations not immediately apparent from high-level descriptions. The "out-of-the-box" solution may necessitate considerable workarounds (such as using metadata for ID-based filtering ) or encounter hard limitations for particular needs. Therefore, prospective users should conduct thorough proof-of-concept projects tailored to their specific, complex use cases. This is essential to validate that Vertex AI Search and its constituent components, like Vector Search, can adequately meet their technical requirements and align with their cost constraints. Marketing claims of simplicity need to be balanced with a realistic assessment of the effort and expertise required for sophisticated deployments. This also points to a continuous need for more detailed best practices, advanced troubleshooting guides, and transparent documentation from Google for these complex scenarios.
9. Recent Developments and Future Outlook
Vertex AI Search is a rapidly evolving platform, with Google Cloud continuously integrating its latest AI research and model advancements. Recent developments, particularly highlighted during events like Google I/O and Google Cloud Next 2025, indicate a clear trajectory towards more powerful, integrated, and agentic AI capabilities.
Integration with Latest AI Models (Gemini)
A significant thrust in recent developments is the deepening integration of Vertex AI Search with Google's flagship Gemini models. These models are multimodal, capable of understanding and processing information from various formats (text, images, audio, video, code), and possess advanced reasoning and generation capabilities.
The Gemini 2.5 model, for example, is slated to be incorporated into Google Search for features like AI Mode and AI Overviews in the U.S. market. This often signals broader availability within Vertex AI for enterprise use cases.
Within the Vertex AI Agent Builder, Gemini can be utilized to enhance agent responses with information retrieved from Google Search, while Vertex AI Search (with its RAG capabilities) facilitates the seamless integration of enterprise-specific data to ground these advanced models.
Developers have access to Gemini models through Vertex AI Studio and the Model Garden, allowing for experimentation, fine-tuning, and deployment tailored to specific application needs.
Platform Enhancements (from Google I/O & Cloud Next 2025)
Key announcements from recent Google events underscore the expansion of the Vertex AI platform, which directly benefits Vertex AI Search:
Vertex AI Agent Builder: This initiative consolidates a suite of tools designed to help developers create enterprise-ready generative AI experiences, applications, and intelligent agents. Vertex AI Search plays a crucial role in this builder by providing the essential data grounding capabilities. The Agent Builder supports the creation of codeless conversational agents and facilitates low-code AI application development.
Expanded Model Garden: The Model Garden within Vertex AI now offers access to an extensive library of over 200 models. This includes Google's proprietary models (like Gemini and Imagen), models from third-party providers (such as Anthropic's Claude), and popular open-source models (including Gemma and Llama 3.2). This wide selection provides developers with greater flexibility in choosing the optimal model for diverse use cases.
Multi-agent Ecosystem: Google Cloud is fostering the development of collaborative AI agents with new tools such as the Agent Development Kit (ADK) and the Agent2Agent (A2A) protocol.
Generative Media Suite: Vertex AI is distinguishing itself by offering a comprehensive suite of generative media models. This includes models for video generation (Veo), image generation (Imagen), speech synthesis, and, with the addition of Lyria, music generation.
AI Hypercomputer: This revolutionary supercomputing architecture is designed to simplify AI deployment, significantly boost performance, and optimize costs for training and serving large-scale AI models. Services like Vertex AI are built upon and benefit from these infrastructure advancements.
Performance and Usability Improvements
Google continues to refine the performance and usability of Vertex AI components:
Vector Search Indexing Latency: A notable improvement is the significant reduction in indexing latency for Vector Search, particularly for smaller datasets. This process, which previously could take hours, has been brought down to minutes.
No-Code Index Deployment for Vector Search: To lower the barrier to entry for using vector databases, developers can now create and deploy Vector Search indexes without needing to write code.
Emerging Trends and Future Capabilities
The future direction of Vertex AI Search and related AI services points towards increasingly sophisticated and autonomous capabilities:
Agentic Capabilities: Google is actively working on infusing more autonomous, agent-like functionalities into its AI offerings. Project Mariner's "computer use" capabilities are being integrated into the Gemini API and Vertex AI. Furthermore, AI Mode in Google Search Labs is set to gain agentic capabilities for handling tasks such as booking event tickets and making restaurant reservations.
Deep Research and Live Interaction: For Google Search's AI Mode, "Deep Search" is being introduced in Labs to provide more thorough and comprehensive responses to complex queries. Additionally, "Search Live," stemming from Project Astra, will enable real-time, camera-based conversational interactions with Search.
Data Analysis and Visualization: Future enhancements to AI Mode in Labs include the ability to analyze complex datasets and automatically create custom graphics and visualizations to bring the data to life, initially focusing on sports and finance queries.
Thought Summaries: An upcoming feature for Gemini 2.5 Pro and Flash, available in the Gemini API and Vertex AI, is "thought summaries." This will organize the model's raw internal "thoughts" or processing steps into a clear, structured format with headers, key details, and information about model actions, such as when it utilizes external tools.
The consistent emphasis on integrating advanced multimodal models like Gemini , coupled with the strategic development of the Vertex AI Agent Builder and the introduction of "agentic capabilities" , suggests a significant evolution for Vertex AI Search. While RAG primarily focuses on retrieving information to ground LLMs, these newer developments point towards enabling these LLMs (often operating within an agentic framework) to perform more complex tasks, reason more deeply about the retrieved information, and even initiate actions based on that information. The planned inclusion of "thought summaries" further reinforces this direction by providing transparency into the model's reasoning process. This trajectory indicates that Vertex AI Search is moving beyond being a simple information retrieval system. It is increasingly positioned as a critical component that feeds and grounds more sophisticated AI reasoning processes within enterprise-specific agents and applications. The search capability, therefore, becomes the trusted and factual data interface upon which these advanced AI models can operate more reliably and effectively. This positions Vertex AI Search as a fundamental enabler for the next generation of enterprise AI, which will likely be characterized by more autonomous, intelligent agents capable of complex problem-solving and task execution. The quality, comprehensiveness, and freshness of the data indexed by Vertex AI Search will, therefore, directly and critically impact the performance and reliability of these future intelligent systems.
Furthermore, there is a discernible pattern of advanced AI features, initially tested and rolled out in Google's consumer-facing products, eventually trickling into its enterprise offerings. Many of the new AI features announced for Google Search (the consumer product) at events like I/O 2025—such as AI Mode, Deep Search, Search Live, and agentic capabilities for shopping or reservations —often rely on underlying technologies or paradigms that also find their way into Vertex AI for enterprise clients. Google has a well-established history of leveraging its innovations in consumer AI (like its core search algorithms and natural language processing breakthroughs) as the foundation for its enterprise cloud services. The Gemini family of models, for instance, powers both consumer experiences and enterprise solutions available through Vertex AI. This suggests that innovations and user experience paradigms that are validated and refined at the massive scale of Google's consumer products are likely to be adapted and integrated into Vertex AI Search and related enterprise AI tools. This allows enterprises to benefit from cutting-edge AI capabilities that have been battle-tested in high-volume environments. Consequently, enterprises can anticipate that user expectations for search and AI interaction within their own applications will be increasingly shaped by these advanced consumer experiences. Vertex AI Search, by incorporating these underlying technologies, helps businesses meet these rising expectations. However, this also implies that the pace of change in enterprise tools might be influenced by the rapid innovation cycle of consumer AI, once again underscoring the need for organizational adaptability and readiness to manage platform evolution.
10. Conclusion and Strategic Recommendations
Vertex AI Search stands as a powerful and strategic offering from Google Cloud, designed to bring Google-quality search and cutting-edge generative AI capabilities to enterprises. Its ability to leverage an organization's own data for grounding large language models, coupled with its integration into the broader Vertex AI ecosystem, positions it as a transformative tool for businesses seeking to unlock greater value from their information assets and build next-generation AI applications.
Summary of Key Benefits and Differentiators
Vertex AI Search offers several compelling advantages:
Leveraging Google's AI Prowess: It is built on Google's decades of experience in search, natural language processing, and AI, promising high relevance and sophisticated understanding of user intent.
Powerful Out-of-the-Box RAG: Simplifies the complex process of building Retrieval Augmented Generation systems, enabling more accurate, reliable, and contextually relevant generative AI applications grounded in enterprise data.
Integration with Gemini and Vertex AI Ecosystem: Seamless access to Google's latest foundation models like Gemini and integration with a comprehensive suite of MLOps tools within Vertex AI provide a unified platform for AI development and deployment.
Industry-Specific Solutions: Tailored offerings for retail, media, and healthcare address unique industry needs, accelerating time-to-value.
Robust Security and Compliance: Enterprise-grade security features and adherence to industry compliance standards provide a trusted environment for sensitive data.
Continuous Innovation: Rapid incorporation of Google's latest AI research ensures the platform remains at the forefront of AI-powered search technology.
Guidance on When Vertex AI Search is a Suitable Choice
Vertex AI Search is particularly well-suited for organizations with the following objectives and characteristics:
Enterprises aiming to build sophisticated, AI-powered search applications that operate over their proprietary structured and unstructured data.
Businesses looking to implement reliable RAG systems to ground their generative AI applications, reduce LLM hallucinations, and ensure responses are based on factual company information.
Companies in the retail, media, and healthcare sectors that can benefit from specialized, pre-tuned search and recommendation solutions.
Organizations already invested in the Google Cloud Platform ecosystem, seeking seamless integration and a unified AI/ML environment.
Businesses that require scalable, enterprise-grade search capabilities incorporating advanced features like vector search, semantic understanding, and conversational AI.
Strategic Considerations for Adoption and Implementation
To maximize the benefits and mitigate potential challenges of adopting Vertex AI Search, organizations should consider the following:
Thorough Proof-of-Concept (PoC) for Complex Use Cases: Given that advanced or highly specific scenarios may encounter limitations or complexities not immediately apparent , conducting rigorous PoC testing tailored to these unique requirements is crucial before full-scale deployment.
Detailed Cost Modeling: The granular pricing model, which includes charges for queries, data storage, generative AI processing, and potentially always-on resources for components like Vector Search , necessitates careful and detailed cost forecasting. Utilize Google Cloud's pricing calculator and monitor usage closely.
Prioritize Data Governance and IAM: Due to the platform's ability to access and index vast amounts of enterprise data, investing in meticulous planning and implementation of data governance policies and IAM configurations is paramount. This ensures data security, privacy, and compliance.
Develop Team Skills and Foster Adaptability: While Vertex AI Search is designed for ease of use in many aspects, advanced customization, troubleshooting, or managing the impact of its rapid evolution may require specialized skills within the implementation team. The platform is constantly changing, so a culture of continuous learning and adaptability is beneficial.
Consider a Phased Approach: Organizations can begin by leveraging Vertex AI Search to improve existing search functionalities, gaining early wins and familiarity. Subsequently, they can progressively adopt more advanced AI features like RAG and conversational AI as their internal AI maturity and comfort levels grow.
Monitor and Maintain Data Quality: The performance of Vertex AI Search, especially its industry-specific solutions like Vertex AI Search for Commerce, is highly dependent on the quality and volume of the input data. Establish processes for monitoring and maintaining data quality.
Final Thoughts on Future Trajectory
Vertex AI Search is on a clear path to becoming more than just an enterprise search tool. Its deepening integration with advanced AI models like Gemini, its role within the Vertex AI Agent Builder, and the emergence of agentic capabilities suggest its evolution into a core "reasoning engine" for enterprise AI. It is well-positioned to serve as a fundamental data grounding and contextualization layer for a new generation of intelligent applications and autonomous agents. As Google continues to infuse its latest AI research and model innovations into the platform, Vertex AI Search will likely remain a key enabler for businesses aiming to harness the full potential of their data in the AI era.
The platform's design, offering a spectrum of capabilities from enhancing basic website search to enabling complex RAG systems and supporting future agentic functionalities , allows organizations to engage with it at various levels of AI readiness. This characteristic positions Vertex AI Search as a potential catalyst for an organization's overall AI maturity journey. Companies can embark on this journey by addressing tangible, lower-risk search improvement needs and then, using the same underlying platform, progressively explore and implement more advanced AI applications. This iterative approach can help build internal confidence, develop requisite skills, and demonstrate value incrementally. In this sense, Vertex AI Search can be viewed not merely as a software product but as a strategic platform that facilitates an organization's AI transformation. By providing an accessible yet powerful and evolving solution, Google encourages deeper and more sustained engagement with its comprehensive AI ecosystem, fostering long-term customer relationships and driving broader adoption of its cloud services. The ultimate success of this approach will hinge on Google's continued commitment to providing clear guidance, robust support, predictable platform evolution, and transparent communication with its users.
2 notes
·
View notes