#Data pipeline
Explore tagged Tumblr posts
Visit Tumblr Blog
Explore Tumblr blogs with no restrictions, modern design and the best experience.
Last Seen Tumblr Blogs





Fun Fact
The Tumblr office adopted Tommy, an 11-year-old Pomeranian.
Text
Numbers in free verse?
This piece recasts data pipelines as unstoppable storytellers.
Your views on data will shift.
Read more here:
#machinelearning#artificialintelligence#art#digitalart#mlart#datascience#ai#algorithm#bigdata#pipeline#data pipeline#storytelling
3 notes
·
View notes
Text
The concerted effort of maintaining application resilience
New Post has been published on https://thedigitalinsider.com/the-concerted-effort-of-maintaining-application-resilience/
The concerted effort of maintaining application resilience
Back when most business applications were monolithic, ensuring their resilience was by no means easy. But given the way apps run in 2025 and what’s expected of them, maintaining monolithic apps was arguably simpler.
Back then, IT staff had a finite set of criteria on which to improve an application’s resilience, and the rate of change to the application and its infrastructure was a great deal slower. Today, the demands we place on apps are different, more numerous, and subject to a faster rate of change.
There are also just more applications. According to IDC, there are likely to be a billion more in production by 2028 – and many of these will be running on cloud-native code and mixed infrastructure. With technological complexity and higher service expectations of responsiveness and quality, ensuring resilience has grown into being a massively more complex ask.
Multi-dimensional elements determine app resilience, dimensions that fall into different areas of responsibility in the modern enterprise: Code quality falls to development teams; infrastructure might be down to systems administrators or DevOps; compliance and data governance officers have their own needs and stipulations, as do cybersecurity professionals, storage engineers, database administrators, and a dozen more besides.
With multiple tools designed to ensure the resilience of an app – with definitions of what constitutes resilience depending on who’s asking – it’s small wonder that there are typically dozens of tools that work to improve and maintain resilience in play at any one time in the modern enterprise.
Determining resilience across the whole enterprise’s portfolio, therefore, is near-impossible. Monitoring software is silo-ed, and there’s no single pane of reference.
IBM’s Concert Resilience Posture simplifies the complexities of multiple dashboards, normalizes the different quality judgments, breaks down data from different silos, and unifies the disparate purposes of monitoring and remediation tools in play.
Speaking ahead of TechEx North America (4-5 June, Santa Clara Convention Center), Jennifer Fitzgerald, Product Management Director, Observability, at IBM, took us through the Concert Resilience Posture solution, its aims, and its ethos. On the latter, she differentiates it from other tools:
“Everything we’re doing is grounded in applications – the health and performance of the applications and reducing risk factors for the application.”
The app-centric approach means the bringing together of the different metrics in the context of desired business outcomes, answering questions that matter to an organization’s stakeholders, like:
Will every application scale?
What effects have code changes had?
Are we over- or under-resourcing any element of any application?
Is infrastructure supporting or hindering application deployment?
Are we safe and in line with data governance policies?
What experience are we giving our customers?
Jennifer says IBM Concert Resilience Posture is, “a new way to think about resilience – to move it from a manual stitching [of other tools] or a ton of different dashboards.” Although the definition of resilience can be ephemeral, according to which criteria are in play, Jennifer says it’s comprised, at its core, of eight non-functional requirements (NFRs):
Observability
Availability
Maintainability
Recoverability
Scalability
Usability
Integrity
Security
NFRs are important everywhere in the organization, and there are perhaps only two or three that are the sole remit of one department – security falls to the CISO, for example. But ensuring the best quality of resilience in all of the above is critically important right across the enterprise. It’s a shared responsibility for maintaining excellence in performance, potential, and safety.
What IBM Concert Resilience Posture gives organizations, different from what’s offered by a collection of disparate tools and beyond the single-pane-of-glass paradigm, is proactivity. Proactive resilience comes from its ability to give a resilience score, based on multiple metrics, with a score determined by the many dozens of data points in each NFR. Companies can see their overall or per-app scores drift as changes are made – to the infrastructure, to code, to the portfolio of applications in production, and so on.
“The thought around resilience is that we as humans aren’t perfect. We’re going to make mistakes. But how do you come back? You want your applications to be fully, highly performant, always optimal, with the required uptime. But issues are going to happen. A code change is introduced that breaks something, or there’s more demand on a certain area that slows down performance. And so the application resilience we’re looking at is all around the ability of systems to withstand and recover quickly from disruptions, failures, spikes in demand, [and] unexpected events,” she says.
IBM’s acquisition history points to some of the complimentary elements of the Concert Resilience Posture solution – Instana for full-stack observability, Turbonomic for resource optimization, for example. But the whole is greater than the sum of the parts. There’s an AI-powered continuous assessment of all elements that make up an organization’s resilience, so there’s one place where decision-makers and IT teams can assess, manage, and configure the full-stack’s resilience profile.
The IBM portfolio of resilience-focused solutions helps teams see when and why loads change and therefore where resources are wasted. It’s possible to ensure that necessary resources are allocated only when needed, and systems automatically scale back when they’re not. That sort of business- and cost-centric capability is at the heart of app-centric resilience, and means that a company is always optimizing its resources.
Overarching all aspects of app performance and resilience is the element of cost. Throwing extra resources at an under-performing application (or its supporting infrastructure) isn’t a viable solution in most organizations. With IBM, organizations get the ability to scale and grow, to add or iterate apps safely, without necessarily having to invest in new provisioning, either in the cloud or on-premise. Plus, they can see how any changes impact resilience. It’s making best use of what’s available, and winning back capacity – all while getting the best performance, responsiveness, reliability, and uptime across the enterprise’s application portfolio.
Jennifer says, “There’s a lot of different things that can impact resilience and that’s why it’s been so difficult to measure. An application has so many different layers underneath, even in just its resources and how it’s built. But then there’s the spider web of downstream impacts. A code change could impact multiple apps, or it could impact one piece of an app. What is the downstream impact of something going wrong? And that’s a big piece of what our tools are helping organizations with.”
You can read more about IBM’s work to make today and tomorrow’s applications resilient.
#2025#acquisition#ADD#ai#AI-powered#America#app#application deployment#application resilience#applications#approach#apps#assessment#billion#Business#business applications#change#CISO#Cloud#Cloud-Native#code#Companies#complexity#compliance#continuous#convention#cybersecurity#data#Data Governance#data pipeline
0 notes
Text
Data pipeline| Match Data Pro LLC
Maximize efficiency with Match Data Pro LLC's automated data pipeline solutions. Seamlessly configure and execute end-to-end workflows for profiling, cleansing, entity resolution, and fuzzy matching. Trigger jobs manually, via API, or on a schedule with real-time notifications and email confirmations.

Data pipeline
0 notes
Text
0 notes
Text

Explore the blog to learn how to develop a data pipeline for effective data management. Discover the key components, best practices, applications, hurdles, and solutions to streamline processes.
0 notes
Text

AWS Data Pipeline vs. Amazon Kinesis: Choosing the Right Tool for Your Data Needs
Struggling to decide between AWS Data Pipeline and Amazon Kinesis for your data processing needs? Dive into this quick comparison to understand how each service stacks up. AWS Data Pipeline offers a progressive, precise scheduling approach for batch jobs and reporting, while Amazon Kinesis excels at streaming real-time data for immediate insights Whether you’re looking to consume quick implementation, cost optimization, or real-time analytics, this guide will help you find the right one for your business .
0 notes
Text
Building Robust Data Pipelines: Best Practices for Seamless Integration
Learn the best practices for building and managing scalable data pipelines. Ensure seamless data flow, real-time analytics, and better decision-making with optimized pipelines.
0 notes
Text
Stages of the Data Pipeline Development Process

Data pipeline development is a complex and challenging process that requires a systematic approach. Read the blog to understand what are the steps you should follow to build a successful data pipeline.
1 note
·
View note
Text
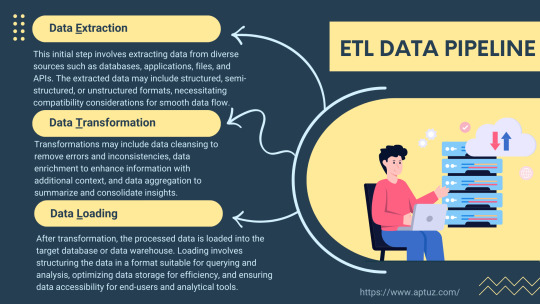
Explore the fundamentals of ETL pipelines, focusing on data extraction, transformation, and loading processes. Understand how these stages work together to streamline data integration and enhance organisational insights.
Know more at: https://bit.ly/3xOGX5u
#fintech#etl#Data pipeline#ETL Pipeline#Data Extraction#Data Transformation#Data Loading#data management#data analytics#redshift#technology#aws#Zero ETL
0 notes
Text
How Walled Gardens in Public Safety Are Exposing America’s Data Privacy Crisis
New Post has been published on https://thedigitalinsider.com/how-walled-gardens-in-public-safety-are-exposing-americas-data-privacy-crisis/
How Walled Gardens in Public Safety Are Exposing America’s Data Privacy Crisis

The Expanding Frontier of AI and the Data It Demands
Artificial intelligence is rapidly changing how we live, work and govern. In public health and public services, AI tools promise more efficiency and faster decision-making. But beneath the surface of this transformation is a growing imbalance: our ability to collect data has outpaced our ability to govern it responsibly.
This goes beyond just a tech challenge to be a privacy crisis. From predictive policing software to surveillance tools and automated license plate readers, data about individuals is being amassed, analyzed and acted upon at unprecedented speed. And yet, most citizens have no idea who owns their data, how it’s used or whether it’s being safeguarded.
I’ve seen this up close. As a former FBI Cyber Special Agent and now the CEO of a leading public safety tech company, I’ve worked across both the government and private sector. One thing is clear: if we don’t fix the way we handle data privacy now, AI will only make existing problems worse. And one of the biggest problems? Walled gardens.
What Are Walled Gardens And Why Are They Dangerous in Public Safety?
Walled gardens are closed systems where one company controls the access, flow and usage of data. They’re common in advertising and social media (think platforms Facebook, Google and Amazon) but increasingly, they’re showing up in public safety too.
Public safety companies play a key role in modern policing infrastructure, however, the proprietary nature of some of these systems means they aren’t always designed to interact fluidly with tools from other vendors.
These walled gardens may offer powerful functionality like cloud-based bodycam footage or automated license plate readers, but they also create a monopoly over how data is stored, accessed and analyzed. Law enforcement agencies often find themselves locked into long-term contracts with proprietary systems that don’t talk to each other. The result? Fragmentation, siloed insights and an inability to effectively respond in the community when it matters most.
The Public Doesn’t Know, and That’s a Problem
Most people don’t realize just how much of their personal information is flowing into these systems. In many cities, your location, vehicle, online activity and even emotional state can be inferred and tracked through a patchwork of AI-driven tools. These tools can be marketed as crime-fighting upgrades, but in the absence of transparency and regulation, they can easily be misused.
And it’s not just that the data exists, but that it exists in walled ecosystems that are controlled by private companies with minimal oversight. For example, tools like license plate readers are now in thousands of communities across the U.S., collecting data and feeding it into their proprietary network. Police departments often don’t even own the hardware, they rent it, meaning the data pipeline, analysis and alerts are dictated by a vendor and not by public consensus.
Why This Should Raise Red Flags
AI needs data to function. But when data is locked inside walled gardens, it can’t be cross-referenced, validated or challenged. This means decisions about who is pulled over, where resources go or who is flagged as a threat are being made based on partial, sometimes inaccurate information.
The risk? Poor decisions, potential civil liberties violations and a growing gap between police departments and the communities they serve. Transparency erodes. Trust evaporates. And innovation is stifled, because new tools can’t enter the market unless they conform to the constraints of these walled systems.
In a scenario where a license plate recognition system incorrectly flags a stolen vehicle based on outdated or shared data, without the ability to verify that information across platforms or audit how that decision was made, officers may act on false positives. We’ve already seen incidents where flawed technology led to wrongful arrests or escalated confrontations. These outcomes aren’t hypothetical, they’re happening in communities across the country.
What Law Enforcement Actually Needs
Instead of locking data away, we need open ecosystems that support secure, standardized and interoperable data sharing. That doesn’t mean sacrificing privacy. On the contrary, it’s the only way to ensure privacy protections are enforced.
Some platforms are working toward this. For example, FirstTwo offers real-time situational awareness tools that emphasize responsible integration of publically-available data. Others, like ForceMetrics, are focused on combining disparate datasets such as 911 calls, behavioral health records and prior incident history to give officers better context in the field. But crucially, these systems are built with public safety needs and community respect as a priority, not an afterthought.
Building a Privacy-First Infrastructure
A privacy-first approach means more than redacting sensitive information. It means limiting access to data unless there is a clear, lawful need. It means documenting how decisions are made and enabling third-party audits. It means partnering with community stakeholders and civil rights groups to shape policy and implementation. These steps result in strengthened security and overall legitimacy.
Despite the technological advances, we’re still operating in a legal vacuum. The U.S. lacks comprehensive federal data privacy legislation, leaving agencies and vendors to make up the rules as they go. Europe has GDPR, which offers a roadmap for consent-based data usage and accountability. The U.S., by contrast, has a fragmented patchwork of state-level policies that don’t adequately address the complexities of AI in public systems.
That needs to change. We need clear, enforceable standards around how law enforcement and public safety organizations collect, store and share data. And we need to include community stakeholders in the conversation. Consent, transparency and accountability must be baked into every level of the system, from procurement to implementation to daily use.
The Bottom Line: Without Interoperability, Privacy Suffers
In public safety, lives are on the line. The idea that one vendor could control access to mission-critical data and restrict how and when it’s used is not just inefficient. It’s unethical.
We need to move beyond the myth that innovation and privacy are at odds. Responsible AI means more equitable, effective and accountable systems. It means rejecting vendor lock-in, prioritizing interoperability and demanding open standards. Because in a democracy, no single company should control the data that decides who gets help, who gets stopped or who gets left behind.
#advertising#agent#ai#ai tools#alerts#Amazon#America#Analysis#approach#artificial#Artificial Intelligence#audit#awareness#Building#CEO#challenge#change#cities#civil rights#Cloud#Community#Companies#comprehensive#crime#cyber#data#data pipeline#data privacy#data sharing#data usage
0 notes
Text
Optimizing Data Workflows with Automation, Deduplication, and RESTful APIs
In the fast-paced world of data management, businesses are constantly looking for ways to streamline workflows, reduce redundancy, and gain real-time insights. Whether you're handling customer information, sales transactions, or backend system logs, managing your data efficiently is key to staying competitive.
Data pipeline
0 notes
Text
Embark on a journey through the essential components of a data pipeline in our latest blog. Discover the building blocks that lay the foundation for an efficient and high-performance data flow.
0 notes
Text
Creating A Successful Data Pipeline: An In-Depth Guide

Explore the blog to learn how to develop a data pipeline for effective data management. Discover the key components, best practices, applications, hurdles, and solutions to streamline processes.
0 notes
Text
The Power of Automated Data Lineage: Validating Data Pipelines with Confidence
Introduction In today’s data-driven world, organizations rely on data pipelines to collect, process, and deliver data for crucial business decisions. However, ensuring the accuracy and reliability of these pipelines can be a daunting task. This is where automated data lineage comes into play, offering a solution to validate data pipelines with confidence. In this blog post, we will explore the…

View On WordPress
#data engineering#data integrity#data lineage#data pipeline#data quality#impact analysis#root cause analysis#validation
0 notes
Text
Maximize Efficiency with Volumes in Databricks Unity Catalog
With Databricks Unity Catalog's volumes feature, managing data has become a breeze. Regardless of the format or location, the organization can now effortlessly access and organize its data. This newfound simplicity and organization streamline data managem

View On WordPress
#Cloud#Data Analysis#Data management#Data Pipeline#Data types#Databricks#Databricks SQL#Databricks Unity catalog#DBFS#Delta Sharing#machine learning#Non-tabular Data#performance#Performance Optimization#Spark#SQL#SQL database#Tabular Data#Unity Catalog#Unstructured Data#Volumes in Databricks
0 notes