#Extract URL Data
Explore tagged Tumblr posts
Visit Tumblr Blog
Explore Tumblr blogs with no restrictions, modern design and the best experience.
Last Seen Tumblr Blogs





Fun Fact
Tumblr is available in 18 languages.
Text
How Web Scraping is Used to Extract URL Data?

In the digital age, data is king. From market research to competitive analysis, data-driven insights power decision-making across industries. However, accessing relevant data isn't always straightforward, especially when it resides on the vast expanse of the World Wide Web. This is where web scraping comes into play, offering a powerful solution for extracting valuable information from web pages. One common application of web scraping is the extraction of URL data, which holds immense potential for various purposes, from SEO optimization to content analysis. Let's delve into how web scraping is utilized to extract URL data and unlock its myriad benefits.
Understanding Web Scraping:
Web scraping is the automated process of extracting data from websites. It involves parsing the HTML structure of web pages and retrieving the desired information programmatically. While manual extraction methods exist, web scraping offers unparalleled efficiency and scalability, enabling users to collect data from numerous sources in a fraction of the time.
Extracting URL Data:
URLs (Uniform Resource Locators) serve as the addresses for specific web pages, each carrying valuable metadata and insights. Extracting URL data involves retrieving information such as page titles, meta descriptions, headings, and more. This data is instrumental in various applications, including:
SEO Optimization: Search engine algorithms heavily rely on URL metadata to determine a website's relevance and rank in search results. By extracting URL data, webmasters can optimize their website's structure, meta tags, and content to enhance visibility and organic traffic.
Competitive Analysis: Understanding competitors' URL structures and metadata provides valuable insights into their content strategy, keyword targeting, and user experience. Web scraping enables businesses to gather this data at scale, facilitating comprehensive competitor analysis and informed decision-making.
Content Curation: Content creators and marketers leverage URL data to curate relevant and engaging content for their audience. By analyzing URLs from reputable sources, they can identify trending topics, popular keywords, and industry-specific insights to inform their content strategy.
Link Building: In the realm of digital marketing, building high-quality backlinks is crucial for improving website authority and search rankings. Web scraping helps identify potential link opportunities by extracting URLs from relevant websites, forums, and directories.
Market Research: Analyzing URLs from industry-specific websites and forums provides valuable market insights, including consumer preferences, emerging trends, and competitor offerings. This data informs strategic decision-making and product development initiatives.
Techniques for URL Data Extraction:
Several techniques and tools facilitate URL data extraction through web scraping:
XPath and CSS Selectors: XPath and CSS selectors enable precise navigation and extraction of HTML elements containing URL metadata. By targeting specific HTML tags and attributes, users can extract URLs efficiently and accurately.
Python Libraries: Python libraries such as BeautifulSoup and Scrapy simplify the web scraping process by providing robust tools for HTML parsing and data extraction. These libraries offer extensive documentation and community support, making them popular choices among developers.
APIs: Some websites offer APIs (Application Programming Interfaces) for accessing structured data, including URL metadata. While APIs provide a more structured approach to data extraction, they may impose limitations on access and usage.
Headless Browsers: Headless browsers simulate the behavior of a web browser without a graphical user interface, allowing for dynamic rendering and interaction with JavaScript-heavy websites. Tools like Selenium enable automated browsing and data extraction from such websites.
Best Practices and Considerations:
While web scraping offers immense potential for extracting URL data, it's essential to adhere to ethical and legal guidelines:
Respect Robots.txt: Many websites specify crawling rules in a robots.txt file, which indicates whether certain parts of the site are off-limits to web scrapers. Adhering to these guidelines demonstrates respect for website owners' preferences and helps maintain a positive reputation within the web scraping community.
Avoid Overloading Servers: Excessive and aggressive scraping can strain server resources and disrupt website operations. Implementing rate limiting and concurrency controls mitigates the risk of overloading servers and ensures a smoother scraping process.
Data Privacy and Compliance: When scraping URL data containing personal or sensitive information, ensure compliance with data protection regulations such as GDPR (General Data Protection Regulation) and CCPA (California Consumer Privacy Act). Respect user privacy rights and handle extracted data responsibly.
Monitor for Changes: Websites frequently update their structure and content, requiring regular monitoring and adjustments to scraping scripts. Implement robust error handling and change detection mechanisms to adapt to evolving web environments.
Conclusion:
Web scraping serves as a powerful tool for extracting URL data and unlocking valuable insights from the vast landscape of the internet. Whether for SEO optimization, competitive analysis, content curation, or market research, the ability to extract and analyze URL metadata offers myriad benefits for businesses and individuals alike. By leveraging web scraping techniques and best practices, organizations can harness the power of URL data to inform strategic decision-making, drive innovation, and stay ahead in an increasingly competitive digital landscape.
0 notes
Text
Google Search Results Data Scraping

Google Search Results Data Scraping
Harness the Power of Information with Google Search Results Data Scraping Services by DataScrapingServices.com. In the digital age, information is king. For businesses, researchers, and marketing professionals, the ability to access and analyze data from Google search results can be a game-changer. However, manually sifting through search results to gather relevant data is not only time-consuming but also inefficient. DataScrapingServices.com offers cutting-edge Google Search Results Data Scraping services, enabling you to efficiently extract valuable information and transform it into actionable insights.
The vast amount of information available through Google search results can provide invaluable insights into market trends, competitor activities, customer behavior, and more. Whether you need data for SEO analysis, market research, or competitive intelligence, DataScrapingServices.com offers comprehensive data scraping services tailored to meet your specific needs. Our advanced scraping technology ensures you get accurate and up-to-date data, helping you stay ahead in your industry.
List of Data Fields
Our Google Search Results Data Scraping services can extract a wide range of data fields, ensuring you have all the information you need:
-Business Name: The name of the business or entity featured in the search result.
- URL: The web address of the search result.
- Website: The primary website of the business or entity.
- Phone Number: Contact phone number of the business.
- Email Address: Contact email address of the business.
- Physical Address: The street address, city, state, and ZIP code of the business.
- Business Hours: Business operating hours
- Ratings and Reviews: Customer ratings and reviews for the business.
- Google Maps Link: Link to the business’s location on Google Maps.
- Social Media Profiles: LinkedIn, Twitter, Facebook
These data fields provide a comprehensive overview of the information available from Google search results, enabling businesses to gain valuable insights and make informed decisions.
Benefits of Google Search Results Data Scraping
1. Enhanced SEO Strategy
Understanding how your website ranks for specific keywords and phrases is crucial for effective SEO. Our data scraping services provide detailed insights into your current rankings, allowing you to identify opportunities for optimization and stay ahead of your competitors.
2. Competitive Analysis
Track your competitors’ online presence and strategies by analyzing their rankings, backlinks, and domain authority. This information helps you understand their strengths and weaknesses, enabling you to adjust your strategies accordingly.
3. Market Research
Access to comprehensive search result data allows you to identify trends, preferences, and behavior patterns in your target market. This information is invaluable for product development, marketing campaigns, and business strategy planning.
4. Content Development
By analyzing top-performing content in search results, you can gain insights into what types of content resonate with your audience. This helps you create more effective and engaging content that drives traffic and conversions.
5. Efficiency and Accuracy
Our automated scraping services ensure you get accurate and up-to-date data quickly, saving you time and resources.
Best Google Data Scraping Services
Scraping Google Business Reviews
Extract Restaurant Data From Google Maps
Google My Business Data Scraping
Google Shopping Products Scraping
Google News Extraction Services
Scrape Data From Google Maps
Google News Headline Extraction
Google Maps Data Scraping Services
Google Map Businesses Data Scraping
Google Business Reviews Extraction
Best Google Search Results Data Scraping Services in USA
Dallas, Portland, Los Angeles, Virginia Beach, Fort Wichita, Nashville, Long Beach, Raleigh, Boston, Austin, San Antonio, Philadelphia, Indianapolis, Orlando, San Diego, Houston, Worth, Jacksonville, New Orleans, Columbus, Kansas City, Sacramento, San Francisco, Omaha, Honolulu, Washington, Colorado, Chicago, Arlington, Denver, El Paso, Miami, Louisville, Albuquerque, Tulsa, Springs, Bakersfield, Milwaukee, Memphis, Oklahoma City, Atlanta, Seattle, Las Vegas, San Jose, Tucson and New York.
Conclusion
In today’s data-driven world, having access to detailed and accurate information from Google search results can give your business a significant edge. DataScrapingServices.com offers professional Google Search Results Data Scraping services designed to meet your unique needs. Whether you’re looking to enhance your SEO strategy, conduct market research, or gain competitive intelligence, our services provide the comprehensive data you need to succeed. Contact us at [email protected] today to learn how our data scraping solutions can transform your business strategy and drive growth.
Website: Datascrapingservices.com
Email: [email protected]
#Google Search Results Data Scraping#Harness the Power of Information with Google Search Results Data Scraping Services by DataScrapingServices.com. In the digital age#information is king. For businesses#researchers#and marketing professionals#the ability to access and analyze data from Google search results can be a game-changer. However#manually sifting through search results to gather relevant data is not only time-consuming but also inefficient. DataScrapingServices.com o#enabling you to efficiently extract valuable information and transform it into actionable insights.#The vast amount of information available through Google search results can provide invaluable insights into market trends#competitor activities#customer behavior#and more. Whether you need data for SEO analysis#market research#or competitive intelligence#DataScrapingServices.com offers comprehensive data scraping services tailored to meet your specific needs. Our advanced scraping technology#helping you stay ahead in your industry.#List of Data Fields#Our Google Search Results Data Scraping services can extract a wide range of data fields#ensuring you have all the information you need:#-Business Name: The name of the business or entity featured in the search result.#- URL: The web address of the search result.#- Website: The primary website of the business or entity.#- Phone Number: Contact phone number of the business.#- Email Address: Contact email address of the business.#- Physical Address: The street address#city#state#and ZIP code of the business.#- Business Hours: Business operating hours#- Ratings and Reviews: Customer ratings and reviews for the business.
0 notes
Text
That post got me thinking about programming, and that maybe I should talk about one that I really had fun writing recently, and that I'm kinda proud of, so here it goes!
So, in my computer experiments and stuff like that, I often have to write scripts that process entries in various stages. For example, I had a thing where it read a list of image urls and downloaded, compressed, extracted some metadata, and saved them to disk.
That sort of process can be decomposed in various stages which, and that's the important part, can be run independently. That would massively speed up the task, but setting up the code infrastructure for that every time I needed it would be cumbersome. Which is why I wrote a little library to do it for me!
That gif is a bit fast, so here's what it looks like when it's all done:
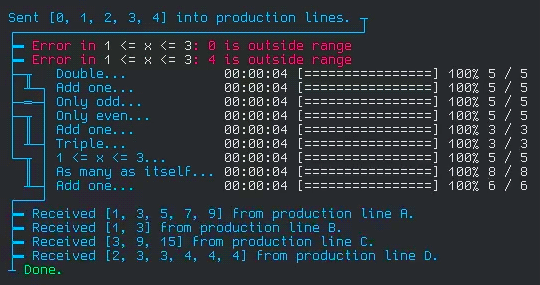
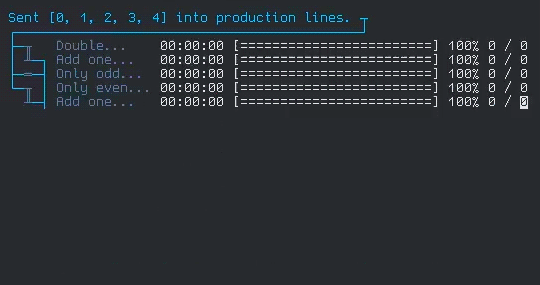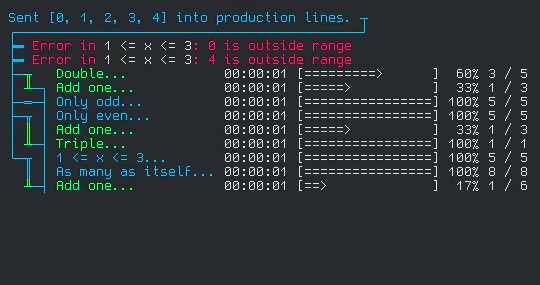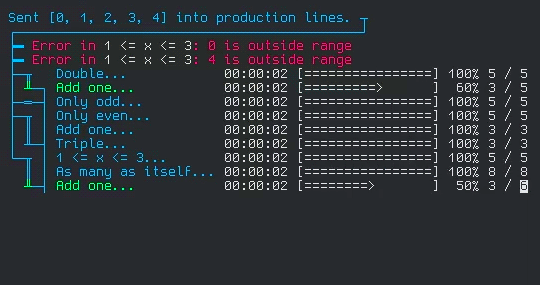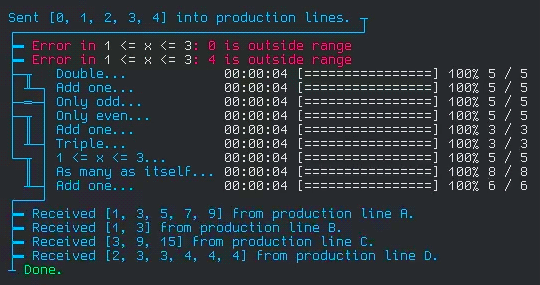
This is from a test I wrote for the library. It simulates running a set of items through 4 different processes (which I named production lines), each with their own stages and filters.
Each line with a progress bar is a stage in the process. If you follow the traces on the left side, you can visualize how the element enter the 4 production lines on one side, and are collected on the other. The stages I wrote for the test are simple operations, but are written to simulate real world delay and errors.
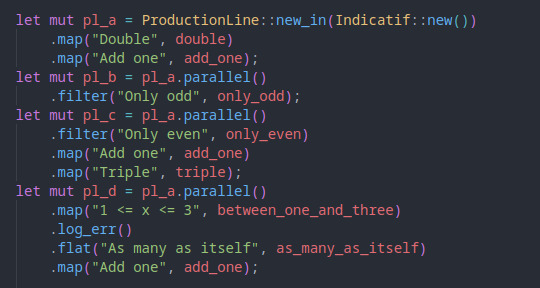
To set up the processes, I do practically nothing. Just initialize the production line structure and connect the stages together, and that's it! All the work of setting up the async tasks, sending the entries from each stage to the next, filtering, error logging, even the little ascii diagram, all that happens automatically! And all that functionality packed into one data structure!
I feel like trying to explain how it does all that (and why having built it myself makes me proud) would make it harder to believe that I actually had fun doing it. I mean, it involved reading a lot of code from high profile open source projects, studying aspects of the language I had never played with (got really deep into generics with this one), and I can't really explain how I really enjoyed doing all that.
I don't know, I feel like I lost the point of what I was trying to say. Hm, I guess this feeling are harder to pin down that I expected.
58 notes
·
View notes
Text
To bring about its hypothetical future, OpenAI must build a new digital ecosystem, pushing users toward the ChatGPT app or toward preëxisting products that integrate its technology such as Bing, the search engine run by OpenAI’s major investor, Microsoft. Google, by contrast, already controls the technology that undergirds many of our online experiences, from search and e-mail to Android smartphone-operating systems. At its conference, the company showed how it plans to make A.I. central to all of the above. Some Google searches now yield A.I.-generated “Overview” summaries, which appear in tinted boxes above any links to external Web sites. Liz Reid, Google’s head of search, described the generated results with the ominously tautological tagline “Google will do the Googling for you.” (The company envisions that you will rely on the same search mechanism to trawl your own digital archive, using its Gemini assistant to, say, pull up photos of your child swimming over the years or summarize e-mail threads in your in-box.) Nilay Patel, the editor-in-chief of the tech publication the Verge, has been using the phrase “Google Zero” to describe the point at which Google will stop driving any traffic to external Web sites and answer every query on its own with A.I. The recent presentations made clear that such a point is rapidly approaching. One of Google’s demonstrations showed a user asking the A.I. a question about a YouTube video on pickleball: “What is the two-bounce rule?” The A.I. then extracted the answer from the footage and displayed the answer in writing, thus allowing the user to avoid watching either the video or any advertising that would have provided revenue to its creator. When I Google “how to decorate a bathroom with no windows” (my personal litmus test for A.I. creativity), I am now presented with an Overview that looks a lot like an authoritative blog post, theoretically obviating my need to interact directly with any content authored by a human being. Google Search was once seen as the best path for getting to what’s on the Web. Now, ironically, its goal is to avoid sending us anywhere. The only way to use the search function without seeing A.I.-generated content is to click a small “More” tab and select “Web” search. Then Google will do what it was always supposed to do: crawl the Internet looking for URLs that are relevant to your queries, and then display them to you. The Internet is still out there, it’s just increasingly hard to find. If A.I. is to be our primary guide to the world’s information, if it is to be our 24/7 assistant-librarian-companion as the tech companies propose, then it must constantly be adding new information to its data sets. That information cannot be generated by A.I., because A.I. tools are not capable of even one iota of original thought or analysis, nor can they report live from the field. (An information model that is continuously updated, using human labor, to inform us about what’s going on right now—we might call it a newspaper.) For a decade or more, social media was a great way to motivate billions of human beings to constantly upload new information to the Internet. Users were driven by the possibilities of fame and profit and mundane connection. Many media companies were motivated by the possibility of selling digital ads, often with Google itself as a middle man. In the A.I. era, in which Google can simply digest a segment of your post or video and serve it up to a viewer, perhaps not even acknowledging you as the original author, those incentives for creating and sharing disappear. In other words, Google and OpenAI seem poised to cause the erosion of the very ecosystem their tools depend on.
48 notes
·
View notes
Note
Hey what’s that tumblr-utils to back up your blogs? Is it the extract one in settings?
tumblr-utils, specifically this fork called tumblr-backup (forgot it uses a different name from the main branch... lol... lmao...), is a python script that allows you to back up your blog locally in a way that displays the posts in a readable format.


It allows for a lot of customization, such as including a tag index alongside the dates, incremental backup (so if you back up 1000 posts the first time and then make 100 new posts, you don't have to back up 1100 posts the second time! just the 100 new ones get added on to the old backup!), continuing a failed backup where it left off, saving audio and video backups, only backing up your own posts and excluding all reblogs, etc. there's a full list of options on the github. and, if you're into css, there is a file you can change to set up a proper css layout. i haven't touched it yet, obviously, but if black-on-white text isn't appealing, there's a way to change that!
and it being a python script really isn't as scary as it sounds to anyone who's never used it before -- I hadn't touched it until i found this tool! it's pretty simple to set up. it just might take a bit of figuring out your first time around, and then you can save a text doc of your backup options to just copy-paste into the command line later (i blacked out my blog urls but you can get the gist)!

^ i just copy these into command line one at a time every couple of months, let each one do its thing, and then i'm all set for a while! no more having to download gb after gb of data every time i update my blog, no more having to back up reblogs if all i want are my own posts, no more unorganized mess of a backup! yippee!
#asks#lesbiandiegohargreeves#046txt#hopefully this helps! i'm not the dev obviously + i'm new to python so i can only provide so much help as far as setting it up#but i'm happy to give a little advice where i can?#(disclaimer: i'm currently working through a new issue with it stalling out halfway through one of my blogs#so it does have some issues. but! i consider it FAR above the quality of the official tumblr system wrt blog backups.)
10 notes
·
View notes
Text
Automate Simple Tasks Using Python: A Beginner’s Guide
In today's fast paced digital world, time is money. Whether you're a student, a professional, or a small business owner, repetitive tasks can eat up a large portion of your day. The good news? Many of these routine jobs can be automated, saving you time, effort, and even reducing the chance of human error.
Enter Python a powerful, beginner-friendly programming language that's perfect for task automation. With its clean syntax and massive ecosystem of libraries, Python empowers users to automate just about anything from renaming files and sending emails to scraping websites and organizing data.
If you're new to programming or looking for ways to boost your productivity, this guide will walk you through how to automate simple tasks using Python.
🌟 Why Choose Python for Automation?
Before we dive into practical applications, let’s understand why Python is such a popular choice for automation:
Easy to learn: Python has simple, readable syntax, making it ideal for beginners.
Wide range of libraries: Python has a rich ecosystem of libraries tailored for different tasks like file handling, web scraping, emailing, and more.
Platform-independent: Python works across Windows, Mac, and Linux.
Strong community support: From Stack Overflow to GitHub, you’ll never be short on help.
Now, let’s explore real-world examples of how you can use Python to automate everyday tasks.
🗂 1. Automating File and Folder Management
Organizing files manually can be tiresome, especially when dealing with large amounts of data. Python’s built-in os and shutil modules allow you to automate file operations like:
Renaming files in bulk
Moving files based on type or date
Deleting unwanted files
Example: Rename multiple files in a folder
import os folder_path = 'C:/Users/YourName/Documents/Reports' for count, filename in enumerate(os.listdir(folder_path)): dst = f"report_{str(count)}.pdf" src = os.path.join(folder_path, filename) dst = os.path.join(folder_path, dst) os.rename(src, dst)
This script renames every file in the folder with a sequential number.
📧 2. Sending Emails Automatically
Python can be used to send emails with the smtplib and email libraries. Whether it’s sending reminders, reports, or newsletters, automating this process can save you significant time.
Example: Sending a basic email
import smtplib from email.message import EmailMessage msg = EmailMessage() msg.set_content("Hello, this is an automated email from Python!") msg['Subject'] = 'Automation Test' msg['From'] = '[email protected]' msg['To'] = '[email protected]' with smtplib.SMTP_SSL('smtp.gmail.com', 465) as smtp: smtp.login('[email protected]', 'yourpassword') smtp.send_message(msg)
⚠️ Note: Always secure your credentials when writing scripts consider using environment variables or secret managers.
🌐 3. Web Scraping for Data Collection
Want to extract information from websites without copying and pasting manually? Python’s requests and BeautifulSoup libraries let you scrape content from web pages with ease.
Example: Scraping news headlines
import requests from bs4 import BeautifulSoup url = 'https://www.bbc.com/news' response = requests.get(url) soup = BeautifulSoup(response.text, 'html.parser') for headline in soup.find_all('h3'): print(headline.text)
This basic script extracts and prints the headlines from BBC News.
📅 4. Automating Excel Tasks
If you work with Excel sheets, you’ll love openpyxl and pandas two powerful libraries that allow you to automate:
Creating spreadsheets
Sorting data
Applying formulas
Generating reports
Example: Reading and filtering Excel data
import pandas as pd df = pd.read_excel('sales_data.xlsx') high_sales = df[df['Revenue'] > 10000] print(high_sales)
This script filters sales records with revenue above 10,000.
💻 5. Scheduling Tasks
You can schedule scripts to run at specific times using Python’s schedule or APScheduler libraries. This is great for automating daily reports, reminders, or file backups.
Example: Run a function every day at 9 AM
import schedule import time def job(): print("Running scheduled task...") schedule.every().day.at("09:00").do(job) while True: schedule.run_pending() time.sleep(1)
This loop checks every second if it’s time to run the task.
🧹 6. Cleaning and Formatting Data
Cleaning data manually in Excel or Google Sheets is time-consuming. Python’s pandas makes it easy to:
Remove duplicates
Fix formatting
Convert data types
Handle missing values
Example: Clean a dataset
df = pd.read_csv('data.csv') df.drop_duplicates(inplace=True) df['Name'] = df['Name'].str.title() df.fillna(0, inplace=True) df.to_csv('cleaned_data.csv', index=False)
💬 7. Automating WhatsApp Messages (for fun or alerts)
Yes, you can even send WhatsApp messages using Python! Libraries like pywhatkit make this possible.
Example: Send a WhatsApp message
import pywhatkit pywhatkit.sendwhatmsg("+911234567890", "Hello from Python!", 15, 0)
This sends a message at 3:00 PM. It’s great for sending alerts or reminders.
🛒 8. Automating E-Commerce Price Tracking
You can use web scraping and conditionals to track price changes of products on sites like Amazon or Flipkart.
Example: Track a product’s price
url = "https://www.amazon.in/dp/B09XYZ123" headers = {"User-Agent": "Mozilla/5.0"} page = requests.get(url, headers=headers) soup = BeautifulSoup(page.content, 'html.parser') price = soup.find('span', {'class': 'a-price-whole'}).text print(f"The current price is ₹{price}")
With a few tweaks, you can send yourself alerts when prices drop.
📚 Final Thoughts
Automation is no longer a luxury it’s a necessity. With Python, you don’t need to be a coding expert to start simplifying your life. From managing files and scraping websites to sending e-mails and scheduling tasks, the possibilities are vast.
As a beginner, start small. Pick one repetitive task and try automating it. With every script you write, your confidence and productivity will grow.
Conclusion
If you're serious about mastering automation with Python, Zoople Technologies offers comprehensive, beginner-friendly Python course in Kerala. Our hands-on training approach ensures you learn by doing with real-world projects that prepare you for today’s tech-driven careers.
2 notes
·
View notes
Text
Open Deep Search (ODS)
XUẤT HIỆN ĐỐI THỦ OPEN SOURCE NGANG CƠ THẬM CHÍ HƠN PERPLEXITY SEARCH

XUẤT HIỆN ĐỐI THỦ OPEN SOURCE NGANG CƠ THẬM CHÍ HƠN PERPLEXITY SEARCH
Open đang phả hơi nóng và gáy close source trên các mặt trận trong đó có search và deep search. Open Deep Search (ODS) là một giải pháp như thế.
Hiệu suất và Benchmarks của ODS:
- Cải thiện độ chính xác trên FRAMES thêm 9.7% so với GPT-4o Search Preview. Khi xài model DeepSeek-R1, ODS đạt 88.3% chính xác trên SimpleQA và 75.3% trên FRAMES.
- SimpleQA kiểu như các câu hỏi đơn giản, trả lời đúng sai hoặc ngắn gọn. ODS đạt 88.3% tức là nó trả lời đúng g��n 9/10 lần.
- FRAMES thì phức tạp hơn, có thể là bài test kiểu phân tích dữ liệu hay xử lý ngữ cảnh dài. 75.3% không phải max cao nhất, nhưng cộng thêm cái vụ cải thiện 9.7% so với GPT-4o thì rõ ràng ODS không phải dạng vừa.
CÁCH HOẠT ĐỘNG
1. Context retrieval toàn diện, không bỏ sót
ODS không phải kiểu nhận query rồi search bừa. Nó nghĩ sâu hơn bằng cách tự rephrase câu hỏi của user thành nhiều phiên bản khác nhau. Ví dụ, hỏi "cách tối ưu code Python", nó sẽ tự biến tấu thành "làm sao để Python chạy nhanh hơn" hay "mẹo optimize Python hiệu quả". Nhờ vậy, dù user diễn đạt hơi lủng củng, nó vẫn moi được thông tin chuẩn từ web.
2. Retrieval và filter level pro
Không như một số commercial tool chỉ bê nguyên dữ liệu từ SERP, ODS chơi hẳn combo: lấy top kết quả, reformat, rồi xử lý lại. Nó còn extract thêm metadata như title, URL, description để chọn lọc nguồn ngon nhất. Sau đó, nó chunk nhỏ nội dung, rank lại dựa trên độ liên quan trước khi trả về cho LLM.
Kết quả: Context sạch sẽ, chất lượng, không phải đống data lộn xộn.
3. Xử lý riêng cho nguồn xịn
Con này không search kiểu generic đâu. Nó có cách xử lý riêng cho các nguồn uy tín như Wikipedia, ArXiv, PubMed. Khi scrape web, nó tự chọn đoạn nội dung chất nhất, giảm rủi ro dính fake news – đây là công đoạn mà proprietary tool ít để tâm.
4. Cơ chế search thông minh, linh hoạt
ODS không cố định số lần search. Query đơn giản thì search một phát là xong, nhưng với câu hỏi phức tạp kiểu multi-hop như "AI ảnh hưởng ngành y thế nào trong 10 năm tới", nó tự động gọi thêm search để đào sâu. Cách này vừa tiết kiệm tài nguyên, vừa đảm bảo trả lời chất. Trong khi đó, proprietary tool thường search bục mặt, tốn công mà kết quả không đã.
5. Open-source – minh bạch và cải tiến liên tục
Là tool open-source, code với thuật toán của nó ai cũng thấy, cộng đồng dev tha hồ kiểm tra, nâng cấp. Nhờ vậy, nó tiến hóa nhanh hơn các hệ thống đóng của proprietary.
Tóm lại
ODS ăn đứt proprietary nhờ: rephrase query khéo, retrieval/filter xịn, xử lý riêng cho nguồn chất, search linh hoạt, và cộng đồng open-source đẩy nhanh cải tiến.
2 notes
·
View notes
Note
tips to not look like a bot
change pfp, most important step
reblog liberally
make shitposts
change header and blog colors
more tumblr tips
we're all losers
everything is anonymous, you can follow random people
cultivate your dash, don't be afraid to unfollow (although I like to send a short note, it's not required) or block someone
filter any tags you don't like in your settings! nsfw stuff, triggers, etc. (ex: your filtered tags might be #tw murder, murder, #nsfw, #cw body horror, body horror, #tw transphobia, transphobia)
feel free to scroll through someone's blog and like and reblog their stuff. it's not creepy. usually
people swear freely here. i swear occasionally and just tag for profanity when i do
research fairy vs walrus, vanilla extract, the color of the sky, i like your shoelaces, spiders georg, and children's hospital color theory blood trail
every year we celebrate the ides of march
go to the settings and opt out of that ai data sharing thing. you have to turn this off individually for your main blog and any of your side blogs
tag your posts with relevant stuff. you can also talk in tags to add stuff that isn't really interesting for people who don't follow you or to add an afterthought. if something asks your personal stuff or you're reblogging a poll you voted in, use tags. tags aren't preserved in reblogs
you can follow tags of things you like (#tally hall, #melanie martinez, #hazbin hotel, #art, etc.)
no one can see your follower count
bots will follow you
people love their mutuals here. follow me back?
you can't re-vote in a poll, so click carefully!
neil gaiman and nasa are on here
there are no influencers, but @pukicho, @one-time-i-dreamt, and @bettinalevyisdetermined (is that her url?) come close (idk if tagging people works in asks if it does sorry guys)
there are lots of gimmick blogs, from the post uwuifier to hellsite genetics to the people that identify things in posts like cars, knives, etc. (can't remember the exact urls)
yes, there is a blog that counts the number of letter ts in a post. yes, there is a kitty broker and a puppy broker. yes, there is a blog that posts the "fag of the day", which is always Paul McCartney. yes, there are two blogs that disemvowel posts.
there are blogs specifically for reblogging and creating polls (they do take requests!)
the corporate gimmick blog verse and the celestial same pic verse are pretty cool
lots of people here are lgbtqia and/or neurodivergent
the ceo is transphobic and people want him to die in a car crash with hammers flying everywhere and multiple explosions (or something like that)
if you can't donate, signal boost! reblog!
also if you want some tally hall blogs to follow, consider @sincerecinnamon, @edgingattheedgeofauniverse, @pigeoninabowl69 (a lot of spanish tho) and their side blog @hawaiipartyii (all english), @queeniesretrozone (although they don't interact with tally hall stuff much anymore, they're still nice), @aquakatdraws, and those people's mutuals as well!
the harry potter fandom on here has a lot of TERFs, so tread carefully
people love supernatural, dr who, sherlock holmes, good omens, and hazbin hotel (at least from my experience)
i'm sure there are better guides out there, but this is hopefully a good start! ^_^
sheeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeesh
11 notes
·
View notes
Text
Remembering My Roots - Rest in Peace, RateMyDrawings
I've talked about my old art before on here, but never really fully in-depth about the site that hosted it. I was reminded of it today while going through my FB memories and felt like I should actually write a true eulogy towards what once was.
Once upon a time, before LORE | REKINDLED, before Time Gate: [AFTERBIRTH], before I had even started drawing webcomics, I entered the world of digital art through one website - not DeviantArt, not Pixiv, but a little site called RateMyDrawings. Back in the day, it was one of the most popular browser-supported art tools, offering multiple different art tools that were, at the time, revolutionary. A flash drawing tool which could replay the progress of your drawing (but the tradeoff was that you had a limited amount of 'ink' aka recording data), a Java-supported tool that was essentially Photoshop Lite (but didn't come with the recording), and later, a more refined tool supported by HTML5 (?) that offered more 3D-like brush tools. There was also DrawChat, a live drawing flash tool where you could draw with others and chat.
And on that site, I created my first works of digital art. No drawing tablet, just a mouse and a loooot of patience. They'd host contests every now and then to win budget Wacom tablets. Sometimes I'd enter, I'd never win. I did eventually get my first drawing tablet, but by then, I'd moved on from RMD onto actual software such as GIMP and Photoshop Elements.
That site is gone now, one of the first art site deaths I'd ever experience in my teen years. I was around 12-13 when I started using this site and I adored it. When people talk about missing the 'tight-knit communities' of old, I don't think of DA, I think of RMD, my first home. Unfortunately, the site couldn't survive in the 'modern' era of the Internet, overshadowed by more advanced tools and art-sharing sites like Deviantart, Facebook, and Instagram.
But I did manage to backup some of my old art pieces before the site finally became completely shuttered in the early 2020's. For a while the site was awake but lacked any content or features, with a message from the site's creator Mick that it might come back, it might not.

It didn't. The old ratemydrawings.com URL now redirects to the inactive FB page. Any attempt to bypass that kill screen like before leads to an Error 404.
But while the site was in its comatose state - before it was shuttered permanently - I was able to access my old profile and extract some of my art pieces of old. I posted them to my FB about 3 years ago, and today they showed up in my memories.
I share a lot of art pieces from creators like Rachel Smythe in an attempt to preserve media. But I also need to remember to preserve my own. So here are a handful of the 100+ pieces I drew on RMD. Enjoy ( ´ ∀ `)ノ~ ♡

Don't be confused by the '1987' part of the username, I picked that number because I was a huge Zelda weeb and 1987 was the year the first Zelda game was made. Whoof.

What's ironic is I actually didn't have the Featured Artist award last time I was actively on the site, so it clearly happened while I was inactive in its final days. The one award I wanted the most and I wasn't there to witness getting it. RIP.







Unfortunately that's all I really have in the way of high-resolution drawings as I wasn't able to preserve much else (though if I find anything more I'll definitely add it to this post!) That said, I was able to nab some screenshots of my homepage via the Wayback Machine where you can see more of the pieces I did back then:

There are so many dorky ass drawings here, some from Time Gate (because it's that freaking old!!!), some are screenshot recreations from anime that I enjoyed (a very common trend on RMD), some are collaborations. There was a point where I learned how to color with the mouse by using low opacity colors and layering them one at a time. Really upped my game there LMAO That Ocarina of Time Link drawing was the first one I ever did that made it to the front page of RMD and y'all, I was so proud, the site back then I think had 50k users total which is nothing compared to the Internet today, but achieving that was one of the greatest things ever LOL The Skyward Sword drawing that followed was one that really felt like a milestone in terms of my art evolution, I felt like I was finally creating something good. I believe I did that Skyward Sword drawing off another DA piece at the time, it was really common to do redraw challenges on RMD what with the technical limitations of the site - I suppose redrawing stuff I liked back then should have been foreshadowing LMAO
That feeling wouldn't last forever ofc once the art high wore off, but even to this day I look back on the pieces from that era fondly. It's where the mysteries of digital art finally started to 'click' in my brain, and I had still barely gotten started.
I also have a few drawings preserved that were done after I got my first drawing tablet, and you can really tell with the improvement of the lineart LOL That said, I think I was around 18-19 when I did these:


Now, one thing that I really enjoyed doing on RMD were collabs - specifically, trading collabs where users would exchange drawing files through the RMD PM system with one another to do steps of a drawing together. Often times I took the role of coloring other people's lineart pieces, which is probably where I started to really learn digital art coloring and come into my own with it.
A collab with user "lime":

Collab with user "Mikai":

A collab with user "Overik", which I specifically remember struggling with because, at the time, my computer monitor's screen was messed up resulting in the entire thing basically being a fluorescent pink:

A collab with "Mist04" that I don't remember doing lmao:

Collab with "Adzumi" (?). I'm fairly certain that's who it was, I definitely remember the process of painting this one, I had loads of fun with it:

Collab with user "ForgottenArtist", IIRC this one was more of a coloring page where they gave out the file freely for others to color, so this was my version. The forums on RMD were great for that sort of thing, people would literally just upload their drawing files for people to have fun with:

So I guess I drew this next little thing in 2021 when the site was still 'live' but not functional, I completely forgot I did this though LMAO Basically the main URL took you to that kill page I showed above, but if you knew any of the extension slugs, you could bypass that kill page and get into the rest of the site, which I was able to by using my username URL. So I got into the Java drawing tool and made this little thing in the hopes I could upload it. Of course, it didn't work, but hey, it was worth getting a screenshot, I suppose:
It's equal parts nostalgic and bittersweet to go through these drawings. Life back then feels so far away and yet I still remember it so vividly, the hours I'd spend drawing on the family PC, feeling more at home with the friends I made online than the ones I had in real life, listening to music that I still listen to to this day. It's far away now, but it still lives through me, in the work I do today. Even someone like me can go from being a complete noob drawing with a mouse to a professional making their living stabbing ink into other people while still drawing the same stories they drew as a child.
There is one piece I had to dig up outside of FB memories, fortunately it wasn't hard to find because I knew I had shared it ages ago on my FB so the search bar saved my skin. My very first digital art piece, of Sheena Fujibayashi from Tales of Symphonia, one of my favorite games of all time.
My very first digital art drawing:

Recreated in 2019:

Past me went through a lot, and they'd be doomed to go through even more still (they hadn't hit the plague yet). And yet they're going to survive, they're gonna keep getting better and better with each passing year. Thanks past me - you've done a lot of dumb shit in your life, but sticking with your craft wasn't one of them. Thank you for walking - through all the good and the bad that you've had to weather through - so that I could run for us both.
#i have other things i wanna mention about old RMD as well but they're better for another post#self post#old art#media preservation#digital art#ratemydrawings
39 notes
·
View notes
Text
Description
An application is vulnerable to attack when:
User-supplied data is not validated, filtered, or sanitized by the application.
Dynamic queries or non-parameterized calls without context-aware escaping are used directly in the interpreter.
Hostile data is used within object-relational mapping (ORM) search parameters to extract additional, sensitive records.
Hostile data is directly used or concatenated. The SQL or command contains the structure and malicious data in dynamic queries, commands, or stored procedures.
The concept is identical among all interpreters of injection attacks (e.g. SQL, NoSQL, OS command, Object Relational Mapping (ORM), LDAP, and Expression Language (EL) or Object Graph Navigation Library (OGNL) injection)
Strongly encouraged automated testing of:
All parameters
Headers
URL
Cookies
JSON
SOAP
XML data inputs
Organizations can include:
Static (SAST)
Dynamic (DAST)
Interactive (IAST)
application security testing tools into the CI/CD pipeline to identify introduced injection flaws before production deployment.
3 notes
·
View notes
Text
Skip the Ads and Convert YouTube Videos to MP3
YouTube has emerged as the preferred platform in the digital age for finding and enjoying podcasts, videos, music, and much more. Sometimes, nevertheless, users might prefer to listen to their favourite songs solely in audio format or offline. The idea of YouTube MP3 and YouTube to MP3 converters enters the picture here.
What is YouTube MP3?
"YouTube MP3" describes the process of turning YouTube videos into MP3 audio files. This helps users save bandwidth and battery life by enabling them to extract the audio from any YouTube video and listen to it offline without streaming.
Why Convert YouTube Videos to MP3?
There are many reasons why people look for YouTube to MP3 solutions:
Offline Listening: MP3 files can be downloaded and played offline, making it convenient for users to listen to their favorite content without an internet connection.
Music Playlists: Many users create personal playlists by converting YouTube music videos into MP3 files, which they can transfer to their phones or other media devices.
Podcasts and Audiobooks: YouTube hosts a wide variety of podcasts and audiobooks that can be easily converted to MP3 for a seamless listening experience.
Data Savings: Streaming high-quality videos consumes a lot of data. Converting YouTube to MP3 helps in saving bandwidth by only downloading the audio.
How Does a YouTube to MP3 Converter Work?
A YouTube to MP3 converter is a tool or software designed to extract audio from YouTube videos and convert it into the widely used MP3 format. These converters are available both as online services and downloadable software.
Online Converters: There are many websites that allow users to input the URL of a YouTube video, convert it to MP3, and then download the resulting audio file.
Downloadable Software: Some users prefer to download software that allows for faster conversion and additional features like batch processing of multiple videos.
How to Use a YouTube to MP3 Converter
Here’s a simple guide on how to use a YouTube to MP3 converter:
Copy the URL: First, copy the link of the YouTube video you want to convert.
Paste the URL: Visit a YouTube to MP3 converter website or open your preferred converter software, and paste the URL into the input box.
Choose MP3 as the Output Format: Most converters support various audio formats. Make sure to select MP3.
Download the MP3 File: Once the conversion is complete, you will be given the option to download the MP3 file to your device.
Benefits of Using an Ad-Free YouTube to MP3 Converter
One major annoyance users often face when using free online tools is ads. Pop-ups and excessive advertisements can make the conversion process frustrating. However, there are ad-free YouTube to MP3 options that provide a smoother experience, free from interruptions.
Faster Conversion: Without the distractions of ads, users can convert videos quickly and efficiently.
Enhanced User Experience: Ad-free platforms offer a cleaner and more user-friendly interface.
Security and Privacy: Some free converters filled with ads may pose security risks. Choosing an ad-free YouTube to MP3 converter can reduce the chances of encountering malicious ads.
Legal Considerations
While YouTube to MP3 conversion is widely used, it’s essential to understand the legal implications. Converting copyrighted material, like music videos or certain types of content, without permission may violate copyright laws. Always ensure that the content you are converting is either free to use or that you have obtained the necessary rights to do so.
Top YouTube to MP3 Converters
If you’re looking for reliable YouTube to MP3 converters, here are some popular options:
YouTube to MP3 Converter: A simple and user-friendly converter that supports both YouTube to MP3 and MP4 conversions.
4K Video Downloader: A software solution that allows high-quality downloads and batch processing.
SnapDownloader: Known for its speed and ability to download long videos.
Mp3 converter. Free, online Youtube to mp3 converter.: An ad-free YouTube MP3 converter that promises a hassle-free user experience.
team communication app - Troop messenger

Conclusion
YouTube MP3 conversion provides an easy way to enjoy your favorite YouTube content on the go, without the need for video streaming. Whether you want to save data, listen offline, or create personalized playlists, using a YouTube to MP3 converter can make it all possible. For the best experience, consider using an ad-free YouTube to MP3 converter to avoid interruptions and enhance your security.
As always, be mindful of copyright laws and only download content for personal use if you have the right to do so.
2 notes
·
View notes
Text
Okay, tech people:
Can anybody tell me what the LAION-5B data set is in layman's terms, as well as how it is used to train actual models?
Everything I have read online is either so technical that it provides zero information to me, or so dumbed down that it provides almost zero information to me.
Here is what I *think* is going on (and I already have enough information to know that in some ways this is definitely wrong.)
LAION uses a web crawler to essentially randomly check publicly accessible web pages. When this crawler finds an image, it creates a record of the image URL, a set of descriptive words from the image ALT text, (and other sources I think?) and some other stuff.
This is compiled into a big giant list of image URLs and descriptive text associated with the URL.
When a model is trained on this data it... I guess... essentially goes to every URL in the list, checks the image, extracts some kind of data from the image file itself, and then associates the data extracted from the image with the discriptive text that LAION has already associated with the image URL?
The big pitfall, apparently, is that there are a lot of images that have been improperly or even illegally posted on the internet publicly with the ability to let crawlers access them even though they shouldn't be public (e.g. medical records or CSAM) and the dataset is too large to actually hand-curate every single entry? So that therefore models trained on the dataset contain some amount of data that legally they should not have, outside and beyond copyright considerations. A secondary problem is that the production of image ALT text is extremely opaque to ordinary users, so certain images that a user might be comfortable posting may, unbeknownst to them, contain ALT text that the user would not like to be disseminated.
Am I even in the ballpark here? It is incredibly frustrating to read multiple news stories about this stuff and still lack the basic knowledge you would need to think about this stuff systematically.
7 notes
·
View notes
Text
hello tumblr, i need a pinned so
>executing intropost.exe...
>URL: victoriashousekeeping.tumblr.com
>data extracted: complete...
welcome !! to my blog !!
✿ this is a sideblog!! likes/follows will be kept to an absolute minimum as to hide my main blog, i dont want connections yet
✿ he/it pronouns to refer to me, please, tho i may have another admin on this blog at some point
✿ and the name's jace, though i have more names, thats what i will stick with here
✿ no dni, just dont be a dick or we will block you <3
✿
✿ ASKS are open! feel free to ask me anything about zzzero opinions or thoughts on certain ships or characters, go absolutely Wild, its heavily encouraged !!
✿ REQUESTS for certain pride flag + character icons are open as well, it may take some time for me to do certain batches but, feel free to spam in requests
✿ anything zzzero related will be tagged as #zzzero and anything not zzzero related is #not zzzero
✿ my original posts will be tagged as #yapping pup
✿
" thank you for using victoria housekeeping,
we look forward to serving you again "
6 notes
·
View notes
Text
How Web Scraping TripAdvisor Reviews Data Boosts Your Business Growth

Are you one of the 94% of buyers who rely on online reviews to make the final decision? This means that most people today explore reviews before taking action, whether booking hotels, visiting a place, buying a book, or something else.
We understand the stress of booking the right place, especially when visiting somewhere new. Finding the balance between a perfect spot, services, and budget is challenging. Many of you consider TripAdvisor reviews a go-to solution for closely getting to know the place.
Here comes the accurate game-changing method—scrape TripAdvisor reviews data. But wait, is it legal and ethical? Yes, as long as you respect the website's terms of service, don't overload its servers, and use the data for personal or non-commercial purposes. What? How? Why?
Do not stress. We will help you understand why many hotel, restaurant, and attraction place owners invest in web scraping TripAdvisor reviews or other platform information. This powerful tool empowers you to understand your performance and competitors' strategies, enabling you to make informed business changes. What next?
Let's dive in and give you a complete tour of the process of web scraping TripAdvisor review data!
What Is Scraping TripAdvisor Reviews Data?
Extracting customer reviews and other relevant information from the TripAdvisor platform through different web scraping methods. This process works by accessing publicly available website data and storing it in a structured format to analyze or monitor.
Various methods and tools available in the market have unique features that allow you to extract TripAdvisor hotel review data hassle-free. Here are the different types of data you can scrape from a TripAdvisor review scraper:
Hotels
Ratings
Awards
Location
Pricing
Number of reviews
Review date
Reviewer's Name
Restaurants
Images
You may want other information per your business plan, which can be easily added to your requirements.
What Are The Ways To Scrape TripAdvisor Reviews Data?
TripAdvisor uses different web scraping methods to review data, depending on available resources and expertise. Let us look at them:
Scrape TripAdvisor Reviews Data Using Web Scraping API
An API helps to connect various programs to gather data without revealing the code used to execute the process. The scrape TripAdvisor Reviews is a standard JSON format that does not require technical knowledge, CAPTCHAs, or maintenance.
Now let us look at the complete process:
First, check if you need to install the software on your device or if it's browser-based and does not need anything. Then, download and install the desired software you will be using for restaurant, location, or hotel review scraping. The process is straightforward and user-friendly, ensuring your confidence in using these tools.
Now redirect to the web page you want to scrape data from and copy the URL to paste it into the program.
Make updates in the HTML output per your requirements and the information you want to scrape from TripAdvisor reviews.
Most tools start by extracting different HTML elements, especially the text. You can then select the categories that need to be extracted, such as Inner HTML, href attribute, class attribute, and more.
Export the data in SPSS, Graphpad, or XLSTAT format per your requirements for further analysis.
Scrape TripAdvisor Reviews Using Python
TripAdvisor review information is analyzed to understand the experience of hotels, locations, or restaurants. Now let us help you to scrape TripAdvisor reviews using Python:
Continue reading https://www.reviewgators.com/how-web-scraping-tripadvisor-reviews-data-boosts-your-business-growth.php
#review scraping#Scraping TripAdvisor Reviews#web scraping TripAdvisor reviews#TripAdvisor review scraper
2 notes
·
View notes
Note
Hi :D do you know if there is a way to find a deleted AO3 fic?
Hey, anon.
Unfortunately, there is no guarantee that you can find it, but you can try:
a) Asking the fandom on reddit and tumblr. A user might have downloaded it and could privately share it with you.
b) Politely asking the author to privately share it with you. Sometimes authors take their pieces down, because they hate their old writing. Sometimes they take them down due to copyright (they change and publish their fanfiction).
c) Using Duckduckgo. Atm I'd argue it's better than Google.
You can type "[name of the author] archive of our own". If the search engine gives you what you're looking for, then you right click and copy the link address.
An example:

Go to Wayback Machine and paste the link address.
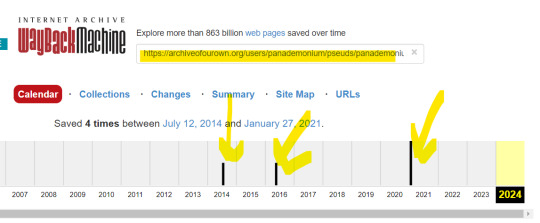
Let's say that the author deleted the fanfiction you're looking for in 2017. This means you have to click on either the 2014 snapsnot or the 2016 one. Depends on when the fanfiction was written.
In this case, I'm redirected to:


Say that the deleted/your target fanfiction was the BCS one.
Click on it. If you're lucky, you will be able to access it.

d) If Wayback Machine fails, there's another solution you can try, but it requires many GBs of free space on your drive, some apps to download and a lot of patience.
First of all, download HTTP Downloader and install it. Open the app.

Secondly, go here and click on "Show all files."
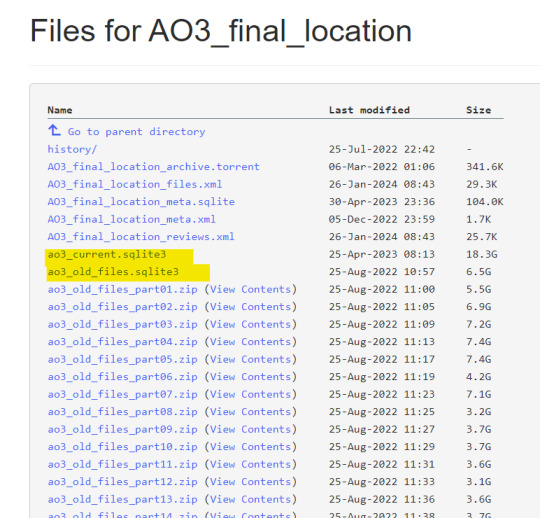
The highlighted files are metadata. The second one contains metadata for AO3 fanfiction that was archived until 2020.
The .zip files contain .txt fanfiction files.
Now, right click on one of the metadata files, copy the link address, go to HTTP Downloader, click on File -> Add URL(s)->paste the link address.

Click Download.
Repeat the same process for the other metadata file.
If you do not have a shitty internet connection, you can directly download the files without using an app. If not, HTTP Downloader has your back.
You can pause the download whenever you want and nothing will get lost.
When the downloads are complete, download this app in order to read the metadata files. Install the app and open it.
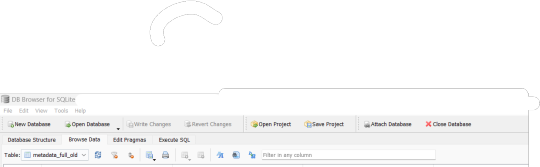
Go to File->Open Database Read Only->Choose one of your metadata files.
Click on Browse Data.
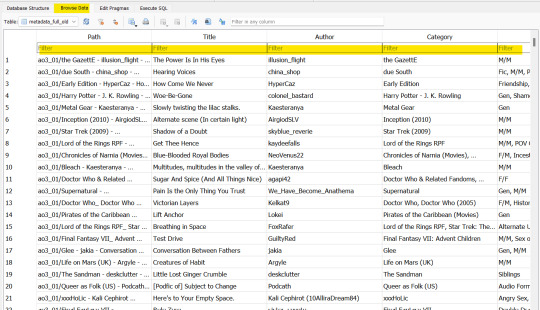
Now you can search for your target fanfiction by title, author, fandom etc.
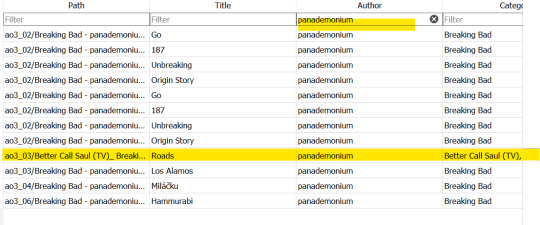
If you find it, consider yourself lucky.
Notice what your path says.

In my case, this means I have to download this .zip file from here:
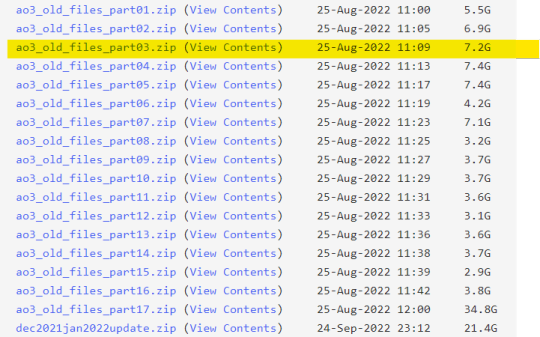
Use HTTP Downloader once again for your download.
You'll need an application. e.g., Winrar, 7-zip, to unzip your .zip file.
Once the .zip download is finished, you can open your .zip file with, say, Winrar and click on Find:
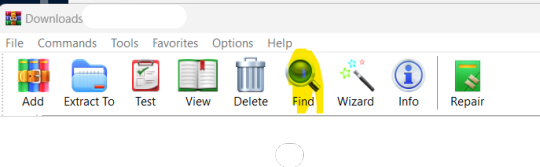
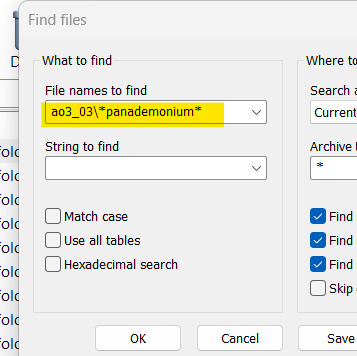
The wildcard symbols before and after the author's name are needed to create a search with unknown characters.
Once you find the file, you can extract it.
It will be a block text in .txt format so you can copy-paste it on Writer (Libre Office) or Word (Windows Office) or another word processor in order to properly format it.
Good luck.
3 notes
·
View notes
Text
Using indeed jobs data for business
The Indeed scraper is a powerful tool that allows you to extract job listings and associated details from the indeed.com job search website. Follow these steps to use the scraper effectively:
1. Understanding the Purpose:
The Indeed scraper is used to gather job data for analysis, research, lead generation, or other purposes.
It uses web scraping techniques to navigate through search result pages, extract job listings, and retrieve relevant information like job titles, companies, locations, salaries, and more.
2. Why Scrape Indeed.com:
There are various use cases for an Indeed jobs scraper, including:
Job Market Research
Competitor Analysis
Company Research
Salary Benchmarking
Location-Based Insights
Lead Generation
CRM Enrichment
Marketplace Insights
Career Planning
Content Creation
Consulting Services
3. Accessing the Indeed Scraper:
Go to the indeed.com website.
Search for jobs using filters like job title, company name, and location to narrow down your target job listings.
Copy the URL from the address bar after performing your search. This URL contains your search criteria and results.
4. Using the Apify Platform:
Visit the Indeed job scraper page
Click on the “Try for free” button to access the scraper.
5. Setting up the Scraper:
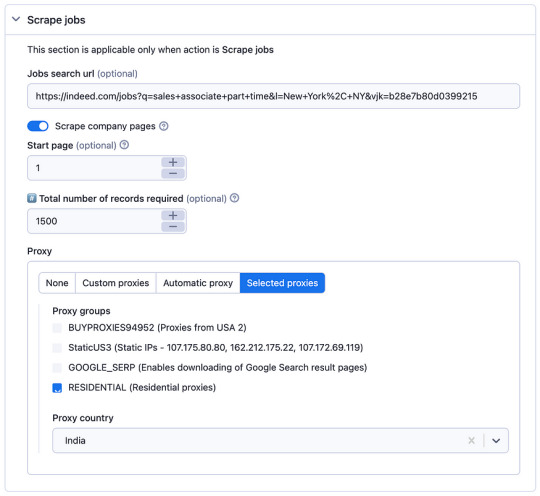
In the Apify platform, you’ll be prompted to configure the scraper:
Insert the search URL you copied from indeed.com in step 3.
Enter the number of job listings you want to scrape.
Select a residential proxy from your country. This helps you avoid being blocked by the website due to excessive requests.
Click the “Start” button to begin the scraping process.
6. Running the Scraper:
The scraper will start extracting job data based on your search criteria.
It will navigate through search result pages, gather job listings, and retrieve details such as job titles, companies, locations, salaries, and more.
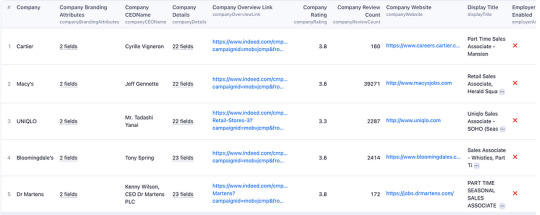
When the scraping process is complete, click the “Export” button in the Apify platform.
You can choose to download the dataset in various formats, such as JSON, HTML, CSV, or Excel, depending on your preferences.
8. Review and Utilize Data:
Open the downloaded data file to view and analyze the extracted job listings and associated details.
You can use this data for your intended purposes, such as market research, competitor analysis, or lead generation.
9. Scraper Options:
The scraper offers options for specifying the job search URL and choosing a residential proxy. Make sure to configure these settings according to your requirements.
10. Sample Output: — You can expect the output data to include job details, company information, and other relevant data, depending on your chosen settings.
By following these steps, you can effectively use the Indeed scraper to gather job data from indeed.com for your specific needs, whether it’s for research, business insights, or personal career planning.
2 notes
·
View notes