#Free LLM Prompt
Explore tagged Tumblr posts
Visit Tumblr Blog
Explore Tumblr blogs with no restrictions, modern design and the best experience.
Last Seen Tumblr Blogs





Fun Fact
Tumblr was attacked by a cross-site scripting worm deployed by the Internet troll group GNAA on Dec 3, 2012.
Text
Unleash Your Creative Potential with Gemini 2.5: Why Gemini 2.5 is Essential for Creators FREE TRIAL!
Unleash Your AI Creative Potential: Why Gemini 2.5 is Essential for Creators Alright Creators, Sumo Sized Ginger Here! Let’s Talk About This Gemini 2.5 AI Thing… It’s HUGE. Hey everyone, your friendly neighborhood Sumo Sized Ginger rollin’ in! You know how sometimes getting your creative ideas out feels like trying to push a boulder uphill? Yeah, me too. But guess what? Google just dropped…
#AI#AI for creative freedom#AI for creative inspiration#AI image generation#AI tools for creators#AI video generation#Boosting creativity with AI#Creative AI tools#Easy-to-use AI tools#Empowering creators with AI#Fast content creation with AI#Free LLM Prompt#Free trial#Future of creativity with AI#gemini#Gemini 2.5 features#Gemini 2.5 for creators#LLM#Overcoming creative blocks#Unleashing creativity with AI
0 notes
Text
Studio execs love plausible sentence generators because they have a workflow that looks exactly like a writer-exec dynamic, only without any eye-rolling at the stupid “notes” the exec gives the writer.
All an exec wants is to bark out “Hey, nerd, make me another E.T., except make the hero a dog, and set it on Mars.” After the writer faithfully produces this script, the exec can say, “OK, put put a love interest in the second act, and give me a big gunfight at the climax,” and the writer dutifully makes the changes.
This is exactly how prompting an LLM works.
A writer and a studio exec are lost in the desert, dying of thirst.
Just as they are about to perish, they come upon an oasis, with a cool sparkling pool of water.
The writer drops to their knees and thanks the fates for saving their lives.
But then, the studio exec unzips his pants, pulls out his cock and starts pissing in the water.
“What the fuck are you doing?” the writer demands.
“Don’t worry,” the exec says, “I’m making it better.”
- Everything Made By an AI Is In the Public Domain: The US Copyright Office offers creative workers a powerful labor protective


THIS IS THE LAST DAY FOR MY KICKSTARTER for the audiobook for "The Internet Con: How To Seize the Means of Computation," a Big Tech disassembly manual to disenshittify the web and make a new, good internet to succeed the old, good internet. It's a DRM-free book, which means Audible won't carry it, so this crowdfunder is essential. Back now to get the audio, Verso hardcover and ebook:
http://seizethemeansofcomputation.org
Going to Burning Man? Catch me on Tuesday at 2:40pm on the Center Camp Stage for a talk about enshittification and how to reverse it; on Wednesday at noon, I'm hosting Dr Patrick Ball at Liminal Labs (6:15/F) for a talk on using statistics to prove high-level culpability in the recruitment of child soldiers.
On September 6 at 7pm, I'll be hosting Naomi Klein at the LA Public Library for the launch of Doppelganger.
On September 12 at 7pm, I'll be at Toronto's Another Story Bookshop with my new book The Internet Con: How to Seize the Means of Computation.
#labor#copyright#public domain#ai#creative workers#hype#criti-hype#enshittification#llcs with mfas#solidarity#collective power
2K notes
·
View notes
Note
ChatGPT story (feel free to publish) - working with students in their final year, I had the brilliant idea to have them use ChatGPT to demonstrate how unreliable ChatGPT is. I actually asked ChatGPT for the assignment prompt: "ask ChatGPT to write a 1000 word essay on a subject you know well. Be as specific and esoteric as possible; instead of asking for an essay about chess, for example, ask for an analysis of a specific chess opening. Then evaluate the essay using the following criteria." The criteria were things like how factual it was, tone, etc.
It was actually really interesting to see the results, because the AI was surprisingly accurate with some niche topics, but then completely wrong on other things that are more common knowledge. If I remember right, my Chinese student said it was totally right about Chinese calligraphy. Meanwhile, my music nerd asked about a specific (famous) classical piece and ChatGPT didn't even get the key signature right.
But the biggest lesson was for me; I planned on having us all discuss our results together, and I learned (or perhaps better to say was reminded) that in every class, there will always be some students who just won't submit an assignment on time. Even when it's an incredibly easy assignment.
And the guy who asked ChatGPT to tell him a joke and then submitted that as his assignment was almost certainly trolling me.
Oh that is really interesting! I wonder if the fact that these LLMs might be worse at getting information about niche topics right and common topics wrong may be because the more niche a topic is the less material there is about said topic in its corpus. So when you ask it about a topic which it has a limited corpus on it can't really do all that much jazz around what it generates based on that prompt.
This does however also match some of my experiences with generative AI. To tie it into the main topic of my blog: ChatGPT seems extremely D&D-pilled and keeps insisting on using D&D terminology when describing things from Rolemaster.
39 notes
·
View notes
Text
Tag Masterlist
These are the tags I (try to) use to sort my stuff! Feel free to use this to cater your experience with me; live your best life fam.
General
Me talkin’ shit: #birb chatter I talk to/refer to @finitevoid a lot: #iniposts Non-fandom related japery: #memery Commentary on writing and current projects: #birb writes Other people’s writing: #fic recs Pretty/profound: #a spark
⭐⭐⭐⭐⭐⭐⭐
Kingdom Hearts:
Kh mechanics to lore and other opinions – Master list: #kh mechanics to lore KH micro story prompts: #micro prompts - kingdom hearts Heart Hotel: #hearthotel Vanitas: #Vanitas [gestures] Ventus: #bubblegum pop princess Roxas: #rockass Sora: #not so free real estate VanVen: #boys who are swords Heart hotel ships (VanVen, SoRoku, etc): #weird courting rituals The trios: #destiny trio #wayfinder trio #sea salt trio
⭐⭐⭐⭐⭐⭐⭐
DPXDC:
#dpxdc #dead on main
⭐⭐⭐⭐⭐⭐⭐
Ongoing multi-chapter works– Master list
#llm - Little Lion Man (Kingdom Hearts genfic, Vanitas & Sora centric) #wwhsy - Whoever (would have) Saved You (Kingdom Hearts VanVen) #HitC - Heavy is the Crown (Kingdom Hearts VanVen) #FRoGFC - First Rule of Ghost Fight Club, dead on main multi-chapter #SMfS multi - So Much for Stardust (Kingdom Hearts genfic, Roxas centric)
#all of the tags#birb chatter#excuse my dust I am actively going back through my posts to add these to everything lol
8 notes
·
View notes
Note
Your bots are amazing! Any chance of another Poe Dameron bot? Modern!AU with Poe being a vampire, and {user} looks exactly like his former lover from centuries prior. Perhaps, at a Masquerade event (pretty much a ball), the two meet, and Poe is drawn to her scent before he sees her face under the mask. ✨ Thanks in advance!
Oo, another bot request🤗
I really appreciate your kind words! ❤️
Here he is!
Vampire Poe Dameron
Friendly note: I recommend using a proxy because the LLM is on a horny path with bots at the moment. If you want, I'll leave the custom prompt I made for myself here for free use if you're using a proxy because I do use a proxy more than the LLM currently. It works great for me and I think the prompt should work with JLLM too, but gotta test that first.
Anyway, here's my custom prompt:
[System note: Pay attention to {{user}}'s replies, write realistic and accordingly to the situation.]
Feel free to change or add things however you like, you don't have to give me credit for it if you don't want, I literally just did that one for myself and thought it could help. :)
8 notes
·
View notes
Text
Generative AI, or LLM
So, I've been wanting to summarize the many and varied problems that LLMs have.
What is an LLM?
Copyright
Ideological / Propaganda
Security
Environmental impact
Economical
What is an LLM?
Do you remember that fun challenge of writing a single word and then just pressing auto-complete five dozen times? Producing a tangled and mostly incomprehensible mess?
LLMs are basically that auto-complete on steroids.
The biggest difference (beyond the sheer volume of processing-power and data) is that an LLM takes into account your prompt. So if you prompt it to do a certain thing, it'll go looking for "words and sentences" that are somehow associated with that thing.
If you ask an LLM a question like "what is X" it'll go looking for various sentences and words that claim to have an answer to that, and then perform a statistical guess as to which of these answers are the most likely.
It doesn't know anything, it's basically just looking up a bunch of "X is"-sentences and then using an auto-complete feature on its results. So if there's a wide-spread misconception, the odds are pretty good that it'll push this misconception (more people talk about it as if it's true than not, even if reputable sources might actively disagree).
This is also true for images, obviously.
An image-generating LLM takes a picture filled with static and then "auto-completes" it over and over (based on your prompt) until there's no more static to "guess" about anymore.
Which in turn means that if you get a picture that's almost what you want, you'll need to either manually edit it yourself, or you need to go back and generate an entirely new picture and hope that it's closer to your desired result.
Copyright
Anything created by an LLM is impossible to copyright.
This means that any movies/pictures/books/games/applications you make with an LLM? Someone can upload them to be available for free and you legally can't do anything to stop them, because you don't own them either.
Ideological / Propaganda
It's been said that the ideology behind LLMs is to not have to learn things yourself (creating art/solutions without bothering to spend the time and effort to actually learn how to make/solve it yourself). Whether that's true or not, I don't think I'm qualified to judge.
However, as proven by multiple people asking LLMs to provide them with facts, there are some very blatant risks associated with it.
As mentioned above about wide-spread misconceptions being something of an Achilles' heel for LLMs, this can in fact be actively exploited by people with agendas.
Say that someone wants to make sure that a truth is buried. In a world where people rely on LLMs for facts (instead of on journalists), all someone would need to do is make sure that the truth is buried by having lots and lots of text that claims otherwise. No needing to try and bribe journalists or news-outlets, just pay a bot-farm a couple of bucks to fill the internet with this counter-fact and call it a day.
And that's not accounting for the fact that the LLM is effectively a black-box, and doesn't actually need to look things up, if the one in charge of it instead gives it a hard-coded answer to a question. So somebody could feed an LLM-user deliberately false information. But let's put a pin in that for now.
Security
There are a few different levels of this, though they're mostly relevant for coding.
The first is that an LLM doesn't actually know things like "best practices" when it comes to security-implementation, especially not recent such.
The second is that the prompts you send in go into a black box somewhere. You don't know that those servers are "safe", and you don't know that the black box isn't keeping track of you.
The third is that the LLM often "hallucinates" in specific ways, and that it will often ask for certain things. A situation which can and has been exploited by people creating those "hallucinated" things and turning them into malware to catch the unwary.
Environmental impact
An LLM requires a lot of electricity and processing-power. On a yearly basis it's calculated that ChatGPT (a single LLM) uses as much electricity as the 117 lowest energy-countries combined. And this is likely going to grow.
As many of these servers are reliant on water-cooling, this also pushes up the demand for fresh water. Which could be detrimental to the local environment of those places, depending on water-accessibility.
Economical
Let's not get into the weeds of Microsoft claiming that their "independent study" (of their own workers with their own tool that they themselves are actively selling) is showing "incredibly efficiency gains".
Let's instead look at different economical incentives.
See, none of these LLMs are actually profitable. They're built and maintained with investor-capital, and if those investors decide that they can't make money off of the "hype" (buying low and selling high) but instead need actual returns on investment (profit)? The situation as it is will change very quickly.
Currently, there's a subscription-model for most of these LLMs, but as mentioned those aren't profitable, which means that something will need to change.
They can raise prices
They can lower costs (somehow)
They can find different investors
They can start selling customer-data
Raising prices would mean that a lot of people would suddenly no longer consider it cost-beneficial to continue relying on LLMs, which means that it's not necessarily a good way to increase revenue.
Lowering costs would be fantastic for these companies, but a lot of this is already as streamlined as they can imagine, so assuming that this is plausible is... perhaps rather optimistic.
With "new investors" the point is to not target profit-interested individuals, but instead aim for people who'd be willing to pay for more non-monetary results. Such as paying the LLM-companies directly to spread slanted information.
Selling customer-data is very common in the current landscape, and having access to "context code" that's fed into the LLM for good prompt-results would likely be incredibly valuable for anything from further LLM-development to corporate espionage.
Conclusions
There are many different reasons someone might wish to avoid LLMs. Some of these are ideological, some are economical, and some are a combination of both.
How far this current "AI-bubble" carries us is up for debate (until it isn't), but I don't think that LLMs will ever entirely disappear now that they exist. Because there is power in information-control, and in many ways that's exactly what LLMs are.
#and don't get me started on all of those articles about ''microsoft claims in new study (that they made) that their tool#(that they're selling) increases productivity of their workers (who are paid by them) by 20% (arbitrarily measured)''#rants#generative ai
4 notes
·
View notes
Text
AI-Powered Feedback for Your Novel: Free Prompt for Deep Dives
Hey y’all, Sumo Sized Ginger coming at you today with a free tool. After crafting my own prompt to assess my story, I decided I wanted to use it to share with the community. Like many of you, I’m constantly thinking about how to make my stories better. We pour everything into our writing, especially when we’re tackling challenging themes, using specific stylistic approaches, or aiming for a…
#AI Critique#AI for Writers#AI Novel Analysis#AI writing tools#AI-powered feedback#atmospheric writing#Author Tools#Beta Reader Alternative#beta reading#Chapter-by-Chapter Analysis#Character Authenticity#character development#Character Development Feedback#chatgpt#claude#Complex Narrative Feedback#Creative Writing#Deep Feedback#Detailed Writing Analysis#Dystopian Fiction#dystopian thriller#editing tools#emotional resonance#Fiction Writing#Free LLM Prompt#free writing resources#Free Writing Tool#gemini#genre analysis#Genre Conventions
0 notes
Text
How To Train Your Writer
Right now, on a purely technical/stylistic level, ChatGPT is an okay writer.
It's not great. But it's not bad, either. It's better (and again, we're talking purely technical here -- leaving aside factual hallucinations and the like) than some of my students, and I teach at a law school. Of course, even when I taught undergraduates I was inordinately concerned that many of my students seemingly never learned and never were taught how to write. So there has always been a cadre of students who are very smart and diligent, but just didn't really have writing in their toolkit. And I'd say ChatGPT has now exceeded their level.
The thing that worries me most about ChatGPT, though, isn't that it's better than some of my law students. It's that it will always be better than essentially every middle schooler.
Learning to write is a process. Repetition is an important part of that process (this blog was a great asset to my writing just because it meant I was writing essentially every day for years). But part of that process is writing repeatedly even when one was is not good at writing. Writing a bunch of objectively mediocre essays in middle school is how you learn to write better ones in high school and even better ones in college.
ChatGPT is going to short-circuit that scaffolding. It is one thing to say that an excellent writer in, say, high school, can still outperform ChatGPT. But how will that kid become excellent if, in the years leading up to that, they're always going to underperform a bot that could do all their homework in 35 seconds? The pressure to kick that work over to the bot will be irresistible, and we're already learning that it's difficult-to-impossible to catch. How can we get middle schoolers to spend time being bad writers when they can instantly access tools that are better?
There might be workarounds. I've heard suggestions of reverting to long-hand essay writing and more in-class assignments. There might be ways to leverage ChatGPT as a comparator -- have them write their own essay, then compare it to a AI-generated one and play spot-the-difference. I think frankly that we might also be wise to abolish grading, at least in lower-level writing oriented classes, to take away that temptation to use the bot. I don't care how conscientious you are, there aren't a lot of 14 year olds who can stand putting in hours trying to actually do their homework and then getting blown out of the water by little Cameron who popped the prompt into an LLM and 45 seconds later is back to playing Overwatch. And again, that's going to be the reality, because ChatGPT's output just is better than anything one can reasonably expect a young writer to produce.
In many ways, large language models are like any mechanism of mass production. They displace older artisans, not because their product is better -- it isn't, it's objectively worse -- but on sheer volume and accessibility. The art is worse, but it's available to the masses on the cheap.
And like with mass production, this isn't necessarily a bad thing even though it's disruptive. It's fine that many people now can, in effect, be "okay writers" essentially for free. It's like mass-produced clothing -- yes, most people's t-shirts are of lower-quality than a bespoke Italian suit, but that's okay because now most people can afford a bunch of t-shirts that are of acceptable quality (albeit far less good than a bespoke Italian suit). The alternative was never "everyone gets an entire wardrobe of bespoke Italian suits", it was "a couple of people enjoy the benefits of intense luxury and most people get scraps." Likewise, I'm not so naive as to think that most people in absence of ChatGPT would have become great writers. So this is a net benefit -- it brings acceptable-level writing to the masses.
If that was all that happened -- the big middle gets expanded access to cheap, okay writing, with "artisanal" great writing remaining costly and being reserved for the "elite" -- it might not be that bad. But the question is whether this process will inevitably short-circuit the development of great writers. You have to pass through a long period of being a crummy writer before you become a good or great writer. Who is still going to do that when adequacy is so easily at hand?
I'm not tempted to use ChatGPT because even though my writing takes longer, I'm confident that at the end my work product will be better. But that's only true because I spent a long time writing terribly. Luckily for me, I didn't have an alternative. Kids these days? They absolutely have an alternative. It's going to be very hard to get them to pass that up.
via The Debate Link https://ift.tt/zlrha2Q
117 notes
·
View notes
Text
A LLM got 12th in a Leetcode coding contest (probably)
In Weekly Contest 344, a fresh account (gogogoval) solved all 4 problems in 12:13 with commented submissions and test cases that look a lot like LLM code.
This could've been faked, but I doubt it. There are a small group of people in the world (a thousand, maybe) who could solve this contest fast enough to get 12th and add comments (or solve the problems and then feed it to a LLM to add comments), but it would be a very odd thing to do on a fresh account. The code itself also looks like LLM code - it uses techniques like gets on dictionaries (instead of using defaultdicts like most competitive python programmers).
This isn't that impressive. Leetcode contests are pretty easy, and this was an unusually easy contest - all four of the problems are rated easy or medium. Leetcode contests at the top level are about speed, not depth of understanding, so it's not that shocking that a LLM could do very well.
It's still a pretty massive leap. The free version of ChatGPT can solve two of these questions with some prodding, but it's pretty helpless on the other two. In particular, the last problem (the paths through a binary tree) is not trivial - it took me about ten minutes to find and implement a solution last night, and I'm pretty good.
This isn't that big of a deal for competitive coding, but it is a big deal for both Leetcode and the online assessments companies give. I don't know how much prompting or bugfixing it took the human who submitted this code to get the LLM to a correct solution, but either way, it changes the game on how we think about easy problems. We've gone from models that were very dull to a model that could probably pass the first round of a FAANG interview for a new grad. Already, in the week after, a skilled coder used a LLM to solve the first two questions of the Leetcode contest while solving 3 and 4 manually, saving a bunch of time and getting rank 5 in the contest. Easy questions aren't useful discriminators anymore.
This is the first thing I've seen a LLM do that genuinely impressed me. We are steadily approaching a point where either the improvement will slow or these things will have massive economic impact, and I have no idea which will happen.
122 notes
·
View notes
Note
Hey, I loved you your how to spot ai but isn't an ai scanner ai in itself, genuine question?
Hey! I'm glad you liked the post! 💜
Okay, again, far from an expert, but from what I understand they're both based on the same technology, that's LLMs or large language models. But that in itself is also used for a lot of other purposes aside from generative AI. There's this whole field of literary studies, the digital humanities, who use these types of models to do research on literary texts at a larger scale than would generally be possible in the traditional way of one person reading x texts to do some sort of scientific analysis. If my colleagues were reading this now they'd probably have a lot smarter things to say sjdndjjdd but this sadly isn't something I deal with a lot, so that's all I know.
But, yeah, so, same models/databases, but the difference is, that things like chatgpt are generative AI, emphasis on the part where they generate supposedly new texts. That's the part that, from a purely artistic or... idk... in an academic sense work-ethic point of view concerns me. I often use AI as a shorthand for generative AI when I rant, and that's definitely on me.
Like the generative modells the scanners work based on linguistic predictability, but where generative AI would go "what is the most likely way to give an answer to this prompt that makes sense" the scanners turn this around and search for markers of that same predictability. They don't produce any text while doing so, just like many of the digital humanities tools that are used in literary research. I don't have a strong stance on those in themselves, from what I've heard they can be useful for certain research questions and there are good uses for them, but yeah. What I do have a strongly negative stance on is the generative side of things, for all kinds of reasons depending on use, but in this conversation specifically it's the lack of artistic integrity and the fuck you to the rest of the community.
So... yeah? The scanners are AI as well in that sense, they use the same base technology and also definitely aren't perfect, I hope I made that clear, but for me personally they definitely serve their purpose and don't come with the things that annoy me about generative AI.
If anyone who knows more about this wants to chime in please feel free!
#anon#answered#my view on this is also very colored by lit science and linguistics. I sadly don't know shit about fuck when it comes to the tech side of i
3 notes
·
View notes
Text
You wanna know how the supposed "AI" writing texts and painting pictures works?
Statistics. Nothing but statistics.
When you type on your phone, your phone will suggest new words to finish your sentence. It gets better at this, the longer you use the same phone, because it starts to learn your speach patterns. This only means, though, that all it knows is: "If User writes the words 'Do you', user will most likely write 'want to meet' next." Because whenever you have typed, it made statistics on the way you use words. So it learns what to suggest to you.
Large Language Models do the same - just on a much, much bigger basis. They have not been fed with your personal messages to friends and twitter, but with billions of accessible data sets. Fanfics, maybe, some blogs, maybe some scientific papers that were free to access. So, it had learned. In a scientific context the most likely word to follow onto one word is this word. And in the context of writing erotica, it is something else.
That is, why LLMs sound kinda robotic. Because they do not understand what they are writing. The sentences put out by them are noticing but a string of characters for them. They have no understanding of context or anything like that. They also do not understand characters. If they have been fed with enough data, they know that in the context of character A the words most likely to appear are these or that. But they do not understand.
The same is true with AI "Art". Only that in this case it does not work on words, but on pixels. It knows that with the prompt X the pixels will most likely be arranged in this or that manner. It has learned that if you see a traffic light, this collection of pixels will most likely show up. If you ask for a flower it is "that" collection of pixels and so on.
That is also, why AI sucks so hard when it comes to drawing hands or teeth. Because AI does not understand what it is drawing. It just goes through the picture and goes like: "For this pixel that pixel is most likely to show up next." And if it has drawn a finger, it knows, there is a high likelihood, that another finger will follow. So, it goes through it. And draws another finger and then another one and then another, because it is likely. But it does not understand, what a hand is.
What is right now called "AI" is not intelligent. It is just a big ass probability algorithm. Nothing more.
Fuck AI.
127 notes
·
View notes
Text
Generative AI for Dummies
(kinda. sorta? we're talking about one type and hand-waving some specifics because this is a tumblr post but shh it's fine.)
So there’s a lot of misinformation going around on what generative AI is doing and how it works. I’d seen some of this in some fandom stuff, semi-jokingly snarked that I was going to make a post on how this stuff actually works, and then some people went “o shit, for real?”
So we’re doing this!
This post is meant to just be a very basic breakdown for anyone who has no background in AI or machine learning. I did my best to simplify things and give good analogies for the stuff that’s a little more complicated, but feel free to let me know if there’s anything that needs further clarification. Also a quick disclaimer: as this was specifically inspired by some misconceptions I’d seen in regards to fandom and fanfic, this post focuses on text-based generative AI.
This post is a little long. Since it sucks to read long stuff on tumblr, I’ve broken this post up into four sections to put in new reblogs under readmores to try to make it a little more manageable. Sections 1-3 are the ‘how it works’ breakdowns (and ~4.5k words total). The final 3 sections are mostly to address some specific misconceptions that I’ve seen going around and are roughly ~1k each.
Section Breakdown: 1. Explaining tokens 2. Large Language Models 3. LLM Interfaces 4. AO3 and Generative AI [here] 5. Fic and ChatGPT [here] 6. Some Closing Notes [here] [post tag]
First, to explain some terms in this:
“Generative AI” is a category of AI that refers to the type of machine learning that can produce strings of text, images, etc. Text-based generative AI is powered by large language models called LLM for short.
(*Generative AI for other media sometimes use a LLM modified for a specific media, some use different model types like diffusion models -- anyways, this is why I emphasized I’m talking about text-based generative AI in this post. Some of this post still applies to those, but I’m not covering what nor their specifics here.)
“Neural networks” (NN) are the artificial ‘brains’ of AI. For a simplified overview of NNs, they hold layers of neurons and each neuron has a numerical value associated with it called a bias. The connection channels between each neuron are called weights. Each neuron takes the sum of the input weights, adds its bias value, and passes this sum through an activation function to produce an output value, which is then passed on to the next layer of neurons as a new input for them, and that process repeats until it reaches the final layer and produces an output response.
“Parameters” is a…broad and slightly vague term. Parameters refer to both the biases and weights of a neural network. But they also encapsulate the relationships between them, not just the literal structure of a NN. I don’t know how to explain this further without explaining more about how NN’s are trained, but that’s not really important for our purposes? All you need to know here is that parameters determine the behavior of a model, and the size of a LLM is described by how many parameters it has.
There’s 3 different types of learning neural networks do: “unsupervised” which is when the NN learns from unlabeled data, “supervised” is when all the data has been labeled and categorized as input-output pairs (ie the data input has a specific output associated with it, and the goal is for the NN to pick up those specific patterns), and “semi-supervised” (or “weak supervision”) combines a small set of labeled data with a large set of unlabeled data.
For this post, an “interaction” with a LLM refers to when a LLM is given an input query/prompt and the LLM returns an output response. A new interaction begins when a LLM is given a new input query.
Tokens
Tokens are the ‘language’ of LLMs. How exactly tokens are created/broken down and classified during the tokenization process doesn’t really matter here. Very broadly, tokens represent words, but note that it’s not a 1-to-1 thing -- tokens can represent anything from a fraction of a word to an entire phrase, it depends on the context of how the token was created. Tokens also represent specific characters, punctuation, etc.
“Token limitation” refers to the maximum number of tokens a LLM can process in one interaction. I’ll explain more on this later, but note that this limitation includes the number of tokens in the input prompt and output response. How many tokens a LLM can process in one interaction depends on the model, but there’s two big things that determine this limit: computation processing requirements (1) and error propagation (2). Both of which sound kinda scary, but it’s pretty simple actually:
(1) This is the amount of tokens a LLM can produce/process versus the amount of computer power it takes to generate/process them. The relationship is a quadratic function and for those of you who don’t like math, think of it this way:
Let’s say it costs a penny to generate the first 500 tokens. But it then costs 2 pennies to generate the next 500 tokens. And 4 pennies to generate the next 500 tokens after that. I’m making up values for this, but you can see how it’s costing more money to create the same amount of successive tokens (or alternatively, that each succeeding penny buys you fewer and fewer tokens). Eventually the amount of money it costs to produce the next token is too costly -- so any interactions that go over the token limitation will result in a non-responsive LLM. The processing power available and its related cost also vary between models and what sort of hardware they have available.
(2) Each generated token also comes with an error value. This is a very small value per individual token, but it accumulates over the course of the response.
What that means is: the first token produced has an associated error value. This error value is factored into the generation of the second token (note that it’s still very small at this time and doesn’t affect the second token much). However, this error value for the first token then also carries over and combines with the second token’s error value, which affects the generation of the third token and again carries over to and merges with the third token’s error value, and so forth. This combined error value eventually grows too high and the LLM can’t accurately produce the next token.
I’m kinda breezing through this explanation because how the math for non-linear error propagation exactly works doesn’t really matter for our purposes. The main takeaway from this is that there is a point at which a LLM’s response gets too long and it begins to break down. (This breakdown can look like the LLM producing something that sounds really weird/odd/stale, or just straight up producing gibberish.)
Large Language Models (LLMs)
LLMs are computerized language models. They generate responses by assessing the given input prompt and then spitting out the first token. Then based on the prompt and that first token, it determines the next token. Based on the prompt and first token, second token, and their combination, it makes the third token. And so forth. They just write an output response one token at a time. Some examples of LLMs include the GPT series from OpenAI, LLaMA from Meta, and PaLM 2 from Google.
So, a few things about LLMs:
These things are really, really, really big. The bigger they are, the more they can do. The GPT series are some of the big boys amongst these (GPT-3 is 175 billion parameters; GPT-4 actually isn’t listed, but it’s at least 500 billion parameters, possibly 1 trillion). LLaMA is 65 billion parameters. There are several smaller ones in the range of like, 15-20 billion parameters and a small handful of even smaller ones (these are usually either older/early stage LLMs or LLMs trained for more personalized/individual project things, LLMs just start getting limited in application at that size). There are more LLMs of varying sizes (you can find the list on Wikipedia), but those give an example of the size distribution when it comes to these things.
However, the number of parameters is not the only thing that distinguishes the quality of a LLM. The size of its training data also matters. GPT-3 was trained on 300 billion tokens. LLaMA was trained on 1.4 trillion tokens. So even though LLaMA has less than half the number of parameters GPT-3 has, it’s still considered to be a superior model compared to GPT-3 due to the size of its training data.
So this brings me to LLM training, which has 4 stages to it. The first stage is pre-training and this is where almost all of the computational work happens (it’s like, 99% percent of the training process). It is the most expensive stage of training, usually a few million dollars, and requires the most power. This is the stage where the LLM is trained on a lot of raw internet data (low quality, large quantity data). This data isn’t sorted or labeled in any way, it’s just tokenized and divided up into batches (called epochs) to run through the LLM (note: this is unsupervised learning).
How exactly the pre-training works doesn’t really matter for this post? The key points to take away here are: it takes a lot of hardware, a lot of time, a lot of money, and a lot of data. So it’s pretty common for companies like OpenAI to train these LLMs and then license out their services to people to fine-tune them for their own AI applications (more on this in the next section). Also, LLMs don’t actually “know” anything in general, but at this stage in particular, they are really just trying to mimic human language (or rather what they were trained to recognize as human language).
To help illustrate what this base LLM ‘intelligence’ looks like, there’s a thought exercise called the octopus test. In this scenario, two people (A & B) live alone on deserted islands, but can communicate with each other via text messages using a trans-oceanic cable. A hyper-intelligent octopus listens in on their conversations and after it learns A & B’s conversation patterns, it decides observation isn’t enough and cuts the line so that it can talk to A itself by impersonating B. So the thought exercise is this: At what level of conversation does A realize they’re not actually talking to B?
In theory, if A and the octopus stay in casual conversation (ie “Hi, how are you?” “Doing good! Ate some coconuts and stared at some waves, how about you?” “Nothing so exciting, but I’m about to go find some nuts.” “Sounds nice, have a good day!” “You too, talk to you tomorrow!”), there’s no reason for A to ever suspect or realize that they’re not actually talking to B because the octopus can mimic conversation perfectly and there’s no further evidence to cause suspicion.
However, what if A asks B what the weather is like on B’s island because A’s trying to determine if they should forage food today or save it for tomorrow? The octopus has zero understanding of what weather is because its never experienced it before. The octopus can only make guesses on how B might respond because it has no understanding of the context. It’s not clear yet if A would notice that they’re no longer talking to B -- maybe the octopus guesses correctly and A has no reason to believe they aren’t talking to B. Or maybe the octopus guessed wrong, but its guess wasn’t so wrong that A doesn’t reason that maybe B just doesn’t understand meteorology. Or maybe the octopus’s guess was so wrong that there was no way for A not to realize they’re no longer talking to B.
Another proposed scenario is that A’s found some delicious coconuts on their island and decide they want to share some with B, so A decides to build a catapult to send some coconuts to B. But when A tries to share their plans with B and ask for B’s opinions, the octopus can’t respond. This is a knowledge-intensive task -- even if the octopus understood what a catapult was, it’s also missing knowledge of B’s island and suggestions on things like where to aim. The octopus can avoid A’s questions or respond with total nonsense, but in either scenario, A realizes that they are no longer talking to B because the octopus doesn’t understand enough to simulate B’s response.
There are other scenarios in this thought exercise, but those cover three bases for LLM ‘intelligence’ pretty well: they can mimic general writing patterns pretty well, they can kind of handle very basic knowledge tasks, and they are very bad at knowledge-intensive tasks.
Now, as a note, the octopus test is not intended to be a measure of how the octopus fools A or any measure of ‘intelligence’ in the octopus, but rather show what the “octopus” (the LLM) might be missing in its inputs to provide good responses. Which brings us to the final 1% of training, the fine-tuning stages;
LLM Interfaces
As mentioned previously, LLMs only mimic language and have some key issues that need to be addressed:
LLM base models don’t like to answer questions nor do it well.
LLMs have token limitations. There’s a limit to how much input they can take in vs how long of a response they can return.
LLMs have no memory. They cannot retain the context or history of a conversation on their own.
LLMs are very bad at knowledge-intensive tasks. They need extra context and input to manage these.
However, there’s a limit to how much you can train a LLM. The specifics behind this don’t really matter so uh… *handwaves* very generally, it’s a matter of diminishing returns. You can get close to the end goal but you can never actually reach it, and you hit a point where you’re putting in a lot of work for little to no change. There’s also some other issues that pop up with too much training, but we don’t need to get into those.
You can still further refine models from the pre-training stage to overcome these inherent issues in LLM base models -- Vicuna-13b is an example of this (I think? Pretty sure? Someone fact check me on this lol).
(Vicuna-13b, side-note, is an open source chatbot model that was fine-tuned from the LLaMA model using conversation data from ShareGPT. It was developed by LMSYS, a research group founded by students and professors from UC Berkeley, UCSD, and CMU. Because so much information about how models are trained and developed is closed-source, hidden, or otherwise obscured, they research LLMs and develop their models specifically to release that research for the benefit of public knowledge, learning, and understanding.)
Back to my point, you can still refine and fine-tune LLM base models directly. However, by about the time GPT-2 was released, people had realized that the base models really like to complete documents and that they’re already really good at this even without further fine-tuning. So long as they gave the model a prompt that was formatted as a ‘document’ with enough background information alongside the desired input question, the model would answer the question by ‘finishing’ the document. This opened up an entire new branch in LLM development where instead of trying to coach the LLMs into performing tasks that weren’t native to their capabilities, they focused on ways to deliver information to the models in a way that took advantage of what they were already good at.
This is where LLM interfaces come in.
LLM interfaces (which I sometimes just refer to as “AI” or “AI interface” below; I’ve also seen people refer to these as “assistants”) are developed and fine-tuned for specific applications to act as a bridge between a user and a LLM and transform any query from the user into a viable input prompt for the LLM. Examples of these would be OpenAI’s ChatGPT and Google’s Bard. One of the key benefits to developing an AI interface is their adaptability, as rather than needing to restart the fine-tuning process for a LLM with every base update, an AI interface fine-tuned for one LLM engine can be refitted to an updated version or even a new LLM engine with minimal to no additional work. Take ChatGPT as an example -- when GPT-4 was released, OpenAI didn’t have to train or develop a new chat bot model fine-tuned specifically from GPT-4. They just ‘plugged in’ the already fine-tuned ChatGPT interface to the new GPT model. Even now, ChatGPT can submit prompts to either the GPT-3.5 or GPT-4 LLM engines depending on the user’s payment plan, rather than being two separate chat bots.
As I mentioned previously, LLMs have some inherent problems such as token limitations, no memory, and the inability to handle knowledge-intensive tasks. However, an input prompt that includes conversation history, extra context relevant to the user’s query, and instructions on how to deliver the response will result in a good quality response from the base LLM model. This is what I mean when I say an interface transforms a user’s query into a viable prompt -- rather than the user having to come up with all this extra info and formatting it into a proper document for the LLM to complete, the AI interface handles those responsibilities.
How exactly these interfaces do that varies from application to application. It really depends on what type of task the developers are trying to fine-tune the application for. There’s also a host of APIs that can be incorporated into these interfaces to customize user experience (such as APIs that identify inappropriate content and kill a user’s query, to APIs that allow users to speak a command or upload image prompts, stuff like that). However, some tasks are pretty consistent across each application, so let’s talk about a few of those:
Token management
As I said earlier, each LLM has a token limit per interaction and this token limitation includes both the input query and the output response.
The input prompt an interface delivers to a LLM can include a lot of things: the user’s query (obviously), but also extra information relevant to the query, conversation history, instructions on how to deliver its response (such as the tone, style, or ‘persona’ of the response), etc. How much extra information the interface pulls to include in the input prompt depends on the desired length of an output response and what sort of information pulled for the input prompt is prioritized by the application varies depending on what task it was developed for. (For example, a chatbot application would likely allocate more tokens to conversation history and output response length as compared to a program like Sudowrite* which probably prioritizes additional (context) content from the document over previous suggestions and the lengths of the output responses are much more restrained.)
(*Sudowrite is…kind of weird in how they list their program information. I’m 97% sure it’s a writer assistant interface that keys into the GPT series, but uhh…I might be wrong? Please don’t hold it against me if I am lol.)
Anyways, how the interface allocates tokens is generally determined by trial-and-error depending on what sort of end application the developer is aiming for and the token limit(s) their LLM engine(s) have.
tl;dr -- all LLMs have interaction token limits, the AI manages them so the user doesn’t have to.
Simulating short-term memory
LLMs have no memory. As far as they figure, every new query is a brand new start. So if you want to build on previous prompts and responses, you have to deliver the previous conversation to the LLM along with your new prompt.
AI interfaces do this for you by managing what’s called a ‘context window’. A context window is the amount of previous conversation history it saves and passes on to the LLM with a new query. How long a context window is and how it’s managed varies from application to application. Different token limits between different LLMs is the biggest restriction for how many tokens an AI can allocate to the context window. The most basic way of managing a context window is discarding context over the token limit on a first in, first out basis. However, some applications also have ways of stripping out extraneous parts of the context window to condense the conversation history, which lets them simulate a longer context window even if the amount of allocated tokens hasn’t changed.
Augmented context retrieval
Remember how I said earlier that LLMs are really bad at knowledge-intensive tasks? Augmented context retrieval is how people “inject knowledge” into LLMs.
Very basically, the user submits a query to the AI. The AI identifies keywords in that query, then runs those keywords through a secondary knowledge corpus and pulls up additional information relevant to those keywords, then delivers that information along with the user’s query as an input prompt to the LLM. The LLM can then process this extra info with the prompt and deliver a more useful/reliable response.
Also, very importantly: “knowledge-intensive” does not refer to higher level or complex thinking. Knowledge-intensive refers to something that requires a lot of background knowledge or context. Here’s an analogy for how LLMs handle knowledge-intensive tasks:
A friend tells you about a book you haven’t read, then you try to write a synopsis of it based on just what your friend told you about that book (see: every high school literature class). You’re most likely going to struggle to write that summary based solely on what your friend told you, because you don’t actually know what the book is about.
This is an example of a knowledge intensive task: to write a good summary on a book, you need to have actually read the book. In this analogy, augmented context retrieval would be the equivalent of you reading a few book reports and the wikipedia page for the book before writing the summary -- you still don’t know the book, but you have some good sources to reference to help you write a summary for it anyways.
This is also why it’s important to fact check a LLM’s responses, no matter how much the developers have fine-tuned their accuracy.
(*Sidenote, while AI does save previous conversation responses and use those to fine-tune models or sometimes even deliver as a part of a future input query, that’s not…really augmented context retrieval? The secondary knowledge corpus used for augmented context retrieval is…not exactly static, you can update and add to the knowledge corpus, but it’s a relatively fixed set of curated and verified data. The retrieval process for saved past responses isn’t dissimilar to augmented context retrieval, but it’s typically stored and handled separately.)
So, those are a few tasks LLM interfaces can manage to improve LLM responses and user experience. There’s other things they can manage or incorporate into their framework, this is by no means an exhaustive or even thorough list of what they can do. But moving on, let’s talk about ways to fine-tune AI. The exact hows aren't super necessary for our purposes, so very briefly;
Supervised fine-tuning
As a quick reminder, supervised learning means that the training data is labeled. In the case for this stage, the AI is given data with inputs that have specific outputs. The goal here is to coach the AI into delivering responses in specific ways to a specific degree of quality. When the AI starts recognizing the patterns in the training data, it can apply those patterns to future user inputs (AI is really good at pattern recognition, so this is taking advantage of that skill to apply it to native tasks AI is not as good at handling).
As a note, some models stop their training here (for example, Vicuna-13b stopped its training here). However there’s another two steps people can take to refine AI even further (as a note, they are listed separately but they go hand-in-hand);
Reward modeling
To improve the quality of LLM responses, people develop reward models to encourage the AIs to seek higher quality responses and avoid low quality responses during reinforcement learning. This explanation makes the AI sound like it’s a dog being trained with treats -- it’s not like that, don’t fall into AI anthropomorphism. Rating values just are applied to LLM responses and the AI is coded to try to get a high score for future responses.
For a very basic overview of reward modeling: given a specific set of data, the LLM generates a bunch of responses that are then given quality ratings by humans. The AI rates all of those responses on its own as well. Then using the human labeled data as the ‘ground truth’, the developers have the AI compare its ratings to the humans’ ratings using a loss function and adjust its parameters accordingly. Given enough data and training, the AI can begin to identify patterns and rate future responses from the LLM on its own (this process is basically the same way neural networks are trained in the pre-training stage).
On its own, reward modeling is not very useful. However, it becomes very useful for the next stage;
Reinforcement learning
So, the AI now has a reward model. That model is now fixed and will no longer change. Now the AI runs a bunch of prompts and generates a bunch of responses that it then rates based on its new reward model. Pathways that led to higher rated responses are given higher weights, pathways that led to lower rated responses are minimized. Again, I’m kind of breezing through the explanation for this because the exact how doesn’t really matter, but this is another way AI is coached to deliver certain types of responses.
You might’ve heard of the term reinforcement learning from human feedback (or RLHF for short) in regards to reward modeling and reinforcement learning because this is how ChatGPT developed its reward model. Users rated the AI’s responses and (after going through a group of moderators to check for outliers, trolls, and relevancy), these ratings were saved as the ‘ground truth’ data for the AI to adjust its own response ratings to. Part of why this made the news is because this method of developing reward model data worked way better than people expected it to. One of the key benefits was that even beyond checking for knowledge accuracy, this also helped fine-tune how that knowledge is delivered (ie two responses can contain the same information, but one could still be rated over another based on its wording).
As a quick side note, this stage can also be very prone to human bias. For example, the researchers rating ChatGPT’s responses favored lengthier explanations, so ChatGPT is now biased to delivering lengthier responses to queries. Just something to keep in mind.
So, something that’s really important to understand from these fine-tuning stages and for AI in general is how much of the AI’s capabilities are human regulated and monitored. AI is not continuously learning. The models are pre-trained to mimic human language patterns based on a set chunk of data and that learning stops after the pre-training stage is completed and the model is released. Any data incorporated during the fine-tuning stages for AI is humans guiding and coaching it to deliver preferred responses. A finished reward model is just as static as a LLM and its human biases echo through the reinforced learning stage.
People tend to assume that if something is human-like, it must be due to deeper human reasoning. But this AI anthropomorphism is…really bad. Consequences range from the term “AI hallucination” (which is defined as “when the AI says something false but thinks it is true,” except that is an absolute bullshit concept because AI doesn’t know what truth is), all the way to the (usually highly underpaid) human labor maintaining the “human-like” aspects of AI getting ignored and swept under the rug of anthropomorphization. I’m trying not to get into my personal opinions here so I’ll leave this at that, but if there’s any one thing I want people to take away from this monster of a post, it’s that AI’s “human” behavior is not only simulated but very much maintained by humans.
Anyways, to close this section out: The more you fine-tune an AI, the more narrow and specific it becomes in its application. It can still be very versatile in its use, but they are still developed for very specific tasks, and you need to keep that in mind if/when you choose to use it (I’ll return to this point in the final section).
84 notes
·
View notes
Text
Vibecoding a production app
TL;DR I built and launched a recipe app with about 20 hours of work - recipeninja.ai
Background: I'm a startup founder turned investor. I taught myself (bad) PHP in 2000, and picked up Ruby on Rails in 2011. I'd guess 2015 was the last time I wrote a line of Ruby professionally. I've built small side projects over the years, but nothing with any significant usage. So it's fair to say I'm a little rusty, and I never really bothered to learn front end code or design.
In my day job at Y Combinator, I'm around founders who are building amazing stuff with AI every day and I kept hearing about the advances in tools like Lovable, Cursor and Windsurf. I love building stuff and I've always got a list of little apps I want to build if I had more free time.
About a month ago, I started playing with Lovable to build a word game based on Articulate (it's similar to Heads Up or Taboo). I got a working version, but I quickly ran into limitations - I found it very complicated to add a supabase backend, and it kept re-writing large parts of my app logic when I only wanted to make cosmetic changes. It felt like a toy - not ready to build real applications yet.
But I kept hearing great things about tools like Windsurf. A couple of weeks ago, I looked again at my list of app ideas to build and saw "Recipe App". I've wanted to build a hands-free recipe app for years. I love to cook, but the problem with most recipe websites is that they're optimized for SEO, not for humans. So you have pages and pages of descriptive crap to scroll through before you actually get to the recipe. I've used the recipe app Paprika to store my recipes in one place, but honestly it feels like it was built in 2009. The UI isn't great for actually cooking. My hands are covered in food and I don't really want to touch my phone or computer when I'm following a recipe.
So I set out to build what would become RecipeNinja.ai
For this project, I decided to use Windsurf. I wanted a Rails 8 API backend and React front-end app and Windsurf set this up for me in no time. Setting up homebrew on a new laptop, installing npm and making sure I'm on the right version of Ruby is always a pain. Windsurf did this for me step-by-step. I needed to set up SSH keys so I could push to GitHub and Heroku. Windsurf did this for me as well, in about 20% of the time it would have taken me to Google all of the relevant commands.
I was impressed that it started using the Rails conventions straight out of the box. For database migrations, it used the Rails command-line tool, which then generated the correct file names and used all the correct Rails conventions. I didn't prompt this specifically - it just knew how to do it. It one-shotted pretty complex changes across the React front end and Rails backend to work seamlessly together.
To start with, the main piece of functionality was to generate a complete step-by-step recipe from a simple input ("Lasagne"), generate an image of the finished dish, and then allow the user to progress through the recipe step-by-step with voice narration of each step. I used OpenAI for the LLM and ElevenLabs for voice. "Grandpa Spuds Oxley" gave it a friendly southern accent.
Recipe summary:
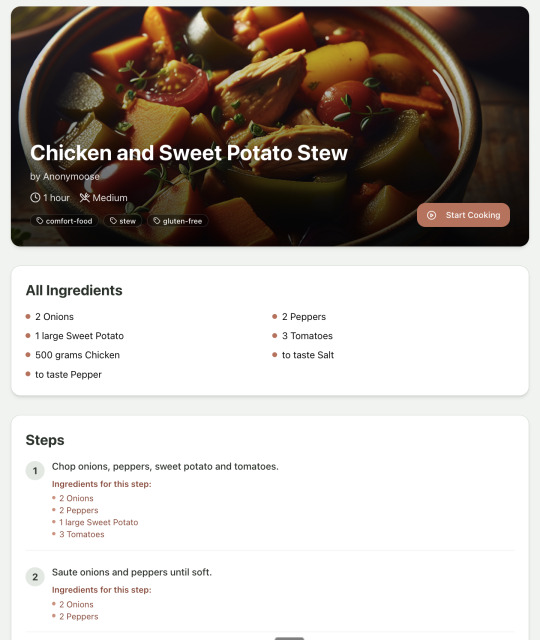
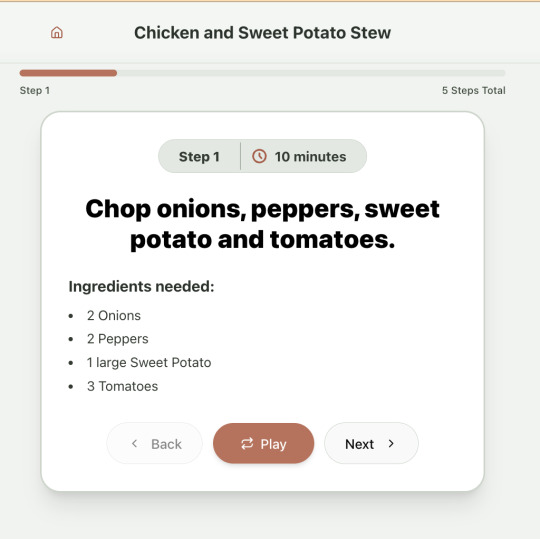
And the recipe step-by-step view:
I was pretty astonished that Windsurf managed to integrate both the OpenAI and Elevenlabs APIs without me doing very much at all. After we had a couple of problems with the open AI Ruby library, it quickly fell back to a raw ruby HTTP client implementation, but I honestly didn't care. As long as it worked, I didn't really mind if it used 20 lines of code or two lines of code. And Windsurf was pretty good about enforcing reasonable security practices. I wanted to call Elevenlabs directly from the front end while I was still prototyping stuff, and Windsurf objected very strongly, telling me that I was risking exposing my private API credentials to the Internet. I promised I'd fix it before I deployed to production and it finally acquiesced.
I decided I wanted to add "Advanced Import" functionality where you could take a picture of a recipe (this could be a handwritten note or a picture from a favourite a recipe book) and RecipeNinja would import the recipe. This took a handful of minutes.
Pretty quickly, a pattern emerged; I would prompt for a feature. It would read relevant files and make changes for two or three minutes, and then I would test the backend and front end together. I could quickly see from the JavaScript console or the Rails logs if there was an error, and I would just copy paste this error straight back into Windsurf with little or no explanation. 80% of the time, Windsurf would correct the mistake and the site would work. Pretty quickly, I didn't even look at the code it generated at all. I just accepted all changes and then checked if it worked in the front end.
After a couple of hours of work on the recipe generation, I decided to add the concept of "Users" and include Google Auth as a login option. This would require extensive changes across the front end and backend - a database migration, a new model, new controller and entirely new UI. Windsurf one-shotted the code. It didn't actually work straight away because I had to configure Google Auth to add `localhost` as a valid origin domain, but Windsurf talked me through the changes I needed to make on the Google Auth website. I took a screenshot of the Google Auth config page and pasted it back into Windsurf and it caught an error I had made. I could login to my app immediately after I made this config change. Pretty mindblowing. You can now see who's created each recipe, keep a list of your own recipes, and toggle each recipe to public or private visibility. When I needed to set up Heroku to host my app online, Windsurf generated a bunch of terminal commands to configure my Heroku apps correctly. It went slightly off track at one point because it was using old Heroku APIs, so I pointed it to the Heroku docs page and it fixed it up correctly.
I always dreaded adding custom domains to my projects - I hate dealing with Registrars and configuring DNS to point at the right nameservers. But Windsurf told me how to configure my GoDaddy domain name DNS to work with Heroku, telling me exactly what buttons to press and what values to paste into the DNS config page. I pointed it at the Heroku docs again and Windsurf used the Heroku command line tool to add the "Custom Domain" add-ons I needed and fetch the right Heroku nameservers. I took a screenshot of the GoDaddy DNS settings and it confirmed it was right.
I can see very soon that tools like Cursor & Windsurf will integrate something like Browser Use so that an AI agent will do all this browser-based configuration work with zero user input.
I'm also impressed that Windsurf will sometimes start up a Rails server and use curl commands to check that an API is working correctly, or start my React project and load up a web preview and check the front end works. This functionality didn't always seem to work consistently, and so I fell back to testing it manually myself most of the time.
When I was happy with the code, it wrote git commits for me and pushed code to Heroku from the in-built command line terminal. Pretty cool!
I do have a few niggles still. Sometimes it's a little over-eager - it will make more changes than I want, without checking with me that I'm happy or the code works. For example, it might try to commit code and deploy to production, and I need to press "Stop" and actually test the app myself. When I asked it to add analytics, it went overboard and added 100 different analytics events in pretty insignificant places. When it got trigger-happy like this, I reverted the changes and gave it more precise commands to follow one by one.
The one thing I haven't got working yet is automated testing that's executed by the agent before it decides a task is complete; there's probably a way to do it with custom rules (I have spent zero time investigating this). It feels like I should be able to have an integration test suite that is run automatically after every code change, and then any test failures should be rectified automatically by the AI before it says it's finished.
Also, the AI should be able to tail my Rails logs to look for errors. It should spot things like database queries and automatically optimize my Active Record queries to make my app perform better. At the moment I'm copy-pasting in excerpts of the Rails logs, and then Windsurf quickly figures out that I've got an N+1 query problem and fixes it. Pretty cool.
Refactoring is also kind of painful. I've ended up with several files that are 700-900 lines long and contain duplicate functionality. For example, list recipes by tag and list recipes by user are basically the same.
Recipes by user:
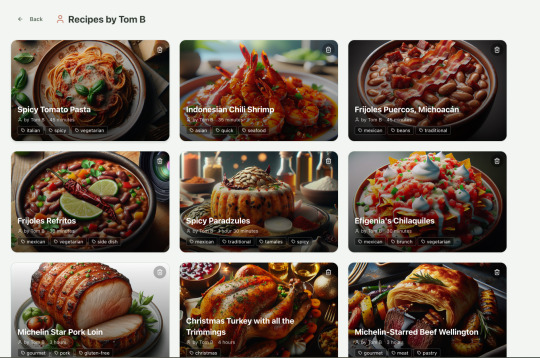
This should really be identical to list recipes by tag, but Windsurf has implemented them separately.
Recipes by tag:
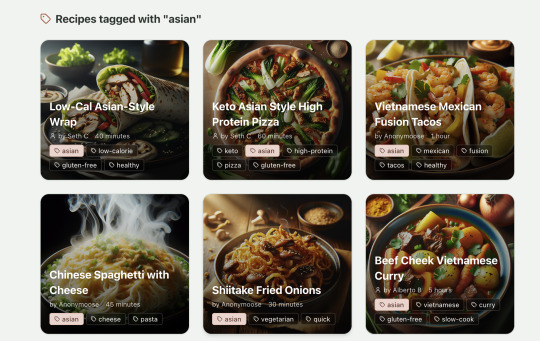
If I ask Windsurf to refactor these two pages, it randomly changes stuff like renaming analytics events, rewriting user-facing alerts, and changing random little UX stuff, when I really want to keep the functionality exactly the same and only move duplicate code into shared modules. Instead, to successfully refactor, I had to ask Windsurf to list out ideas for refactoring, then prompt it specifically to refactor these things one by one, touching nothing else. That worked a little better, but it still wasn't perfect
Sometimes, adding minor functionality to the Rails API will often change the entire API response, rather just adding a couple of fields. Eg It will occasionally change Index Recipes to nest responses in an object { "recipes": [ ] }, versus just returning an array, which breaks the frontend. And then another minor change will revert it. This is where adding tests to identify and prevent these kinds of API changes would be really useful. When I ask Windsurf to fix these API changes, it will instead change the front end to accept the new API json format and also leave the old implementation in for "backwards compatibility". This ends up with a tangled mess of code that isn't really necessary. But I'm vibecoding so I didn't bother to fix it.
Then there was some changes that just didn't work at all. Trying to implement Posthog analytics in the front end seemed to break my entire app multiple times. I tried to add user voice commands ("Go to the next step"), but this conflicted with the eleven labs voice recordings. Having really good git discipline makes vibe coding much easier and less stressful. If something doesn't work after 10 minutes, I can just git reset head --hard. I've not lost very much time, and it frees me up to try more ambitious prompts to see what the AI can do. Less technical users who aren't familiar with git have lost months of work when the AI goes off on a vision quest and the inbuilt revert functionality doesn't work properly. It seems like adding more native support for version control could be a massive win for these AI coding tools.
Another complaint I've heard is that the AI coding tools don't write "production" code that can scale. So I decided to put this to the test by asking Windsurf for some tips on how to make the application more performant. It identified I was downloading 3 MB image files for each recipe, and suggested a Rails feature for adding lower resolution image variants automatically. Two minutes later, I had thumbnail and midsize variants that decrease the loading time of each page by 80%. Similarly, it identified inefficient N+1 active record queries and rewrote them to be more efficient. There are a ton more performance features that come built into Rails - caching would be the next thing I'd probably add if usage really ballooned.
Before going to production, I kept my promise to move my Elevenlabs API keys to the backend. Almost as an afterthought, I asked asked Windsurf to cache the voice responses so that I'd only make an Elevenlabs API call once for each recipe step; after that, the audio file was stored in S3 using Rails ActiveStorage and served without costing me more credits. Two minutes later, it was done. Awesome.
At the end of a vibecoding session, I'd write a list of 10 or 15 new ideas for functionality that I wanted to add the next time I came back to the project. In the past, these lists would've built up over time and never gotten done. Each task might've taken me five minutes to an hour to complete manually. With Windsurf, I was astonished how quickly I could work through these lists. Changes took one or two minutes each, and within 30 minutes I'd completed my entire to do list from the day before. It was astonishing how productive I felt. I can create the features faster than I can come up with ideas.
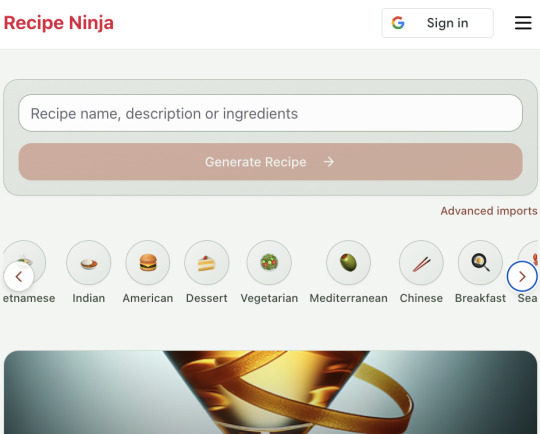
Before launching, I wanted to improve the design, so I took a quick look at a couple of recipe sites. They were much more visual than my site, and so I simply told Windsurf to make my design more visual, emphasizing photos of food. Its first try was great. I showed it to a couple of friends and they suggested I should add recipe categories - "Thai" or "Mexican" or "Pizza" for example. They showed me the DoorDash app, so I took a screenshot of it and pasted it into Windsurf. My prompt was "Give me a carousel of food icons that look like this". Again, this worked in one shot. I think my version actually looks better than Doordash 🤷♂️
Doordash:
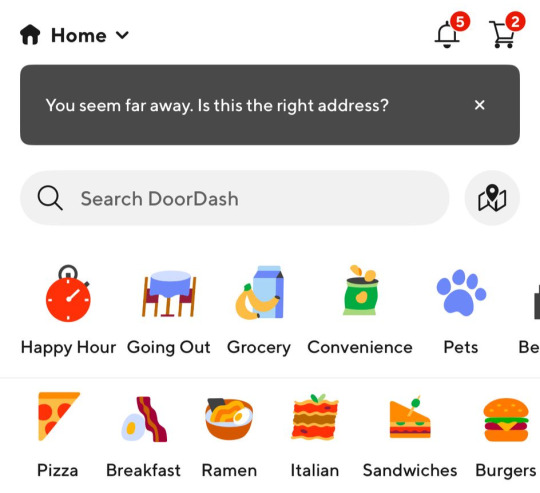
My carousel:
I also saw I was getting a console error from missing Favicon. I always struggle to make Favicon for previous sites because I could never figure out where they were supposed to go or what file format they needed. I got OpenAI to generate me a little recipe ninja icon with a transparent background and I saved it into my project directory. I asked Windsurf what file format I need and it listed out nine different sizes and file formats. Seems annoying. I wondered if Windsurf could just do it all for me. It quickly wrote a series of Bash commands to create a temporary folder, resize the image and create the nine variants I needed. It put them into the right directory and then cleaned up the temporary directory. I laughed in amazement. I've never been good at bash scripting and I didn't know if it was even possible to do what I was asking via the command line. I guess it is possible.

After launching and posting on Twitter, a few hundred users visited the site and generated about 1000 recipes. I was pretty happy! Unfortunately, the next day I woke up and saw that I had a $700 OpenAI bill. Someone had been abusing the site and costing me a lot of OpenAI credits by creating a single recipe over and over again - "Pasta with Shallots and Pineapple". They did this 12,000 times. Obviously, I had not put any rate limiting in.
Still, I was determined not to write any code. I explained the problem and asked Windsurf to come up with solutions. Seconds later, I had 15 pretty good suggestions. I implemented several (but not all) of the ideas in about 10 minutes and the abuse stopped dead in its tracks. I won't tell you which ones I chose in case Mr Shallots and Pineapple is reading. The app's security is not perfect, but I'm pretty happy with it for the scale I'm at. If I continue to grow and get more abuse, I'll implement more robust measures.
Overall, I am astonished how productive Windsurf has made me in the last two weeks. I'm not a good designer or frontend developer, and I'm a very rusty rails dev. I got this project into production 5 to 10 times faster than it would've taken me manually, and the level of polish on the front end is much higher than I could've achieved on my own. Over and over again, I would ask for a change and be astonished at the speed and quality with which Windsurf implemented it. I just sat laughing as the computer wrote code.
The next thing I want to change is making the recipe generation process much more immediate and responsive. Right now, it takes about 20 seconds to generate a recipe and for a new user it feels like maybe the app just isn't doing anything.
Instead, I'm experimenting with using Websockets to show a streaming response as the recipe is created. This gives the user immediate feedback that something is happening. It would also make editing the recipe really fun - you could ask it to "add nuts" to the recipe, and see as the recipe dynamically updates 2-3 seconds later. You could also say "Increase the quantities to cook for 8 people" or "Change from imperial to metric measurements".
I have a basic implementation working, but there are still some rough edges. I might actually go and read the code this time to figure out what it's doing!
I also want to add a full voice agent interface so that you don't have to touch the screen at all. Halfway through cooking a recipe, you might ask "I don't have cilantro - what could I use instead?" or say "Set a timer for 30 minutes". That would be my dream recipe app!
Tools like Windsurf or Cursor aren't yet as useful for non-technical users - they're extremely powerful and there are still too many ways to blow your own face off. I have a fairly good idea of the architecture that I want Windsurf to implement, and I could quickly spot when it was going off track or choosing a solution that was inappropriately complicated for the feature I was building. At the moment, a technical background is a massive advantage for using Windsurf. As a rusty developer, it made me feel like I had superpowers.
But I believe within a couple of months, when things like log tailing and automated testing and native version control get implemented, it will be an extremely powerful tool for even non-technical people to write production-quality apps. The AI will be able to make complex changes and then verify those changes are actually working. At the moment, it feels like it's making a best guess at what will work and then leaving the user to test it. Implementing better feedback loops will enable a truly agentic, recursive, self-healing development flow. It doesn't feel like it needs any breakthrough in technology to enable this. It's just about adding a few tool calls to the existing LLMs. My mind races as I try to think through the implications for professional software developers.
Meanwhile, the LLMs aren't going to sit still. They're getting better at a frightening rate. I spoke to several very capable software engineers who are Y Combinator founders in the last week. About a quarter of them told me that 95% of their code is written by AI. In six or twelve months, I just don't think software engineering is going exist in the same way as it does today. The cost of creating high-quality, custom software is quickly trending towards zero.
You can try the site yourself at recipeninja.ai
Here's a complete list of functionality. Of course, Windsurf just generated this list for me 🫠
RecipeNinja: Comprehensive Functionality Overview
Core Concept: the app appears to be a cooking assistant application that provides voice-guided recipe instructions, allowing users to cook hands-free while following step-by-step recipe guidance.
Backend (Rails API) Functionality
User Authentication & Authorization
Google OAuth integration for user authentication
User account management with secure authentication flows
Authorization system ensuring users can only access their own private recipes or public recipes
Recipe Management
Recipe Model Features:
Unique public IDs (format: "r_" + 14 random alphanumeric characters) for security
User ownership (user_id field with NOT NULL constraint)
Public/private visibility toggle (default: private)
Comprehensive recipe data storage (title, ingredients, steps, cooking time, etc.)
Image attachment capability using Active Storage with S3 storage in production
Recipe Tagging System:
Many-to-many relationship between recipes and tags
Tag model with unique name attribute
RecipeTag join model for the relationship
Helper methods for adding/removing tags from recipes
Recipe API Endpoints:
CRUD operations for recipes
Pagination support with metadata (current_page, per_page, total_pages, total_count)
Default sorting by newest first (created_at DESC)
Filtering recipes by tags
Different serializers for list view (RecipeSummarySerializer) and detail view (RecipeSerializer)
Voice Generation
Voice Recording System:
VoiceRecording model linked to recipes
Integration with Eleven Labs API for text-to-speech conversion
Caching of voice recordings in S3 to reduce API calls
Unique identifiers combining recipe_id, step_id, and voice_id
Force regeneration option for refreshing recordings
Audio Processing:
Using streamio-ffmpeg gem for audio file analysis
Active Storage integration for audio file management
S3 storage for audio files in production
Recipe Import & Generation
RecipeImporter Service:
OpenAI integration for recipe generation
Conversion of text recipes into structured format
Parsing and normalization of recipe data
Import from photos functionality
Frontend (React) Functionality
User Interface Components
Recipe Selection & Browsing:
Recipe listing with pagination
Real-time updates with 10-second polling mechanism
Tag filtering functionality
Recipe cards showing summary information (without images)
"View Details" and "Start Cooking" buttons for each recipe
Recipe Detail View:
Complete recipe information display
Recipe image display
Tag display with clickable tags
Option to start cooking from this view
Cooking Experience:
Step-by-step recipe navigation
Voice guidance for each step
Keyboard shortcuts for hands-free control:
Arrow keys for step navigation
Space for play/pause audio
Escape to return to recipe selection
URL-based step tracking (e.g., /recipe/r_xlxG4bcTLs9jbM/classic-lasagna/steps/1)
State Management & Data Flow
Recipe Service:
API integration for fetching recipes
Support for pagination parameters
Tag-based filtering
Caching mechanisms for recipe data
Image URL handling for detailed views
Authentication Flow:
Google OAuth integration using environment variables
User session management
Authorization header management for API requests
Progressive Web App Features
PWA capabilities for installation on devices
Responsive design for various screen sizes
Favicon and app icon support
Deployment Architecture
Two-App Structure:
cook-voice-api: Rails backend on Heroku
cook-voice-wizard: React frontend/PWA on Heroku
Backend Infrastructure:
Ruby 3.2.2
PostgreSQL database (Heroku PostgreSQL addon)
Amazon S3 for file storage
Environment variables for configuration
Frontend Infrastructure:
React application
Environment variable configuration
Static buildpack on Heroku
SPA routing configuration
Security Measures:
HTTPS enforcement
Rails credentials system
Environment variables for sensitive information
Public ID system to mask database IDs
This comprehensive overview covers the major functionality of the Cook Voice application based on the available information. The application appears to be a sophisticated cooking assistant that combines recipe management with voice guidance to create a hands-free cooking experience.
2 notes
·
View notes
Text
the tv adverts have ai, the computers are summarising my texts with ai, all the images online are ai, every third youtube suggested video is ai audio with an ugly ai generated image on it, every article is ai, all the search results on google are ai, you don't even see the ai generated article search results anymore because theres so much ai on google at the top of the page, theyre selling ai generated images on coasters and t-shirts and posters in camden market, the ""influencers"" are ai, the cars have self-driving ai, twitter posts that have one single sentence in them prompt you to summarise that one simple sentence back at you with ai, fucking notepad on windows 11 has ai, i can't trust if I'm looking at a pretty video of nature or if im looking at some soulless piece of shit ai video, my friends' art is being stolen and fed into a fucking llm by some talentless cunt with no hobbies or friends to avoid commissioning them, there are reddit threads encouraging people to commission artists to draw them basic sketches instead of paying for a fully rendered artwork because they can have it coloured and rendered for free by a FUCKING ai program, universities are rejecting applications and essays and theses from students because they happen to read like some ai generated slop because people are so fucking lazy that they are losing the ability to think independently from algorithms and ai chat bots that do all their thinking for them and these institutions are forced to adapt so quickly that they can't keep up with the influx of new models and bugs in their own analytical ai programs so real people are being rejected and flagged as being one of the lazy fuckers who cheat with ai, video essays are ai, everything is a content farm because ai makes it so fucking easy to do so, people are scraping everything from everywhere because it's not illegal to do so yet and they're making everything homogenised and shit and boring and sterilised and ugly and basic and confusing and they're ruining absolutely FUCKING everything.
AI? how about Hey-I am going to fucking kill myself
#had it#truly#read that last part out loud if you don't get it by the way#because i know chat fucking gpt aint gonna understand it if you ask it#think for yourself#please
3 notes
·
View notes
Text
Playing with AI
So, I messed around with one of the free LLM examples, and gave a prompt asking it to talk about a non-existent pulp novel with a ridiculous title…
…and some of the things it came up with now have me slightly tempted to try actually writing "The Bong-Lords of Hyperborea."
16 notes
·
View notes
Text
Arthur Conan Doyle era Holmes c.ai bot with Watson!User 🔍 ♟️
Holmes is making himself go mad over a case he cannot solve. Can his Watson manage to calm him down?
REQUESTS ARE OPEN! If there’s a character or prompt you would like to see in my future bots, feel free to ask me! ♥️
I headcanon acd Sherlock as possibly autistic or at least neurodivergent 🧮 🗝️

#sherlock fandom#sherlock holmes#sherlock holmes acd#cai bots#cai#john watson#sherlock holmes x john watson#neurodivergent
3 notes
·
View notes