#I'm not google or Stable Diffusion
Explore tagged Tumblr posts
Visit Tumblr Blog
Explore Tumblr blogs with no restrictions, modern design and the best experience.
Last Seen Tumblr Blogs





Fun Fact
The Tumblr office adopted Tommy, an 11-year-old Pomeranian.
Note
Um were you talking requests a while back? If so, are there any rules or conditions that we should be aware of?
ok
a good rule of thumb is: if you try any more often than once, I'm not doing it (out of spite even if I thought that idea is fun but now I feel pressured and used, I'm not a machine after all! I sometimes feel like people speak to me like they throw a prompt into an AI) (also I'm stealing that idea and you'll never see it)
my askbox is pretty much always open and I receive a lot. I currently have 81 unanswered ones, to give you an idea. you see how often I actually have time to answer them and then I never do half-assed things bc I set my standards on myself too high so I usually include a doodle whether you asked for it or not bc I kinda just don't like to clog my blog with boring text-only posts.
it's actually unlikely...
but I always say it's worth a shot.
it's literally a gamble. (where you can try again with another prompt after a few weeks of a cooldown period so it doesn't feel like you're spamming and pushing me)
bc I am incapable of making smth messy and call it a day. you basically get a commission for free. bc I do not take commissions. that shit will be fully clean, rendered, maybe even an entire cluster comic page as I like to call them. I LOVE DOING THIS. I love to surprise people. to utterly flummox them. I specifically like to do art to make people happy, so I always swore to myself I would never take money for it. it stays a hobby and smth to spread joy with.
by keeping it a rare, by-chance occurrence it stays special.
you pay by being creative and kind + luck. my requests come closer to a raffle I guess.
I just do em when ADHD inspiration strikes me. since June of last year where I started paperhatober it's just. become MUCH slower. bc I REFUSE to give up. so my life has been on hold literally bc of that omg. I swear I will finish this.
I swear
I may not have finished highschool but I WILL finish this (it's personal. I will actually talk about it once I'm done)
so the smart move rn is to wait until the glorious day where I finish that god forsaken challenge... I can think of like 5 requests off the dome that I would be fire and flames for and perhaps I even have drafts somewhere but I can't get distracted yet...
also yeah literally any topic is ok but I do sometimes wonder why I get hardcore NSFW requests bc... brother. god knows I want to. but how do you expect me to post that onto The Censorship Site .com
foot note: yes, mutuals are prioritized. I follow like 20 people.
#I am real!#please... I'm a person#speak to me like to a living human#I have posted an art vs. artist thing not too long ago#if you can't find it picture this#small guy; 5 foot tall; is 25 looks like 15 moves like 55; brown eyes brown hair#I am actually sitting on the other side of the screen#please don't request “Flug in Miku's clothes” and press send#I'm not google or Stable Diffusion#I beg you to form a sentence that sounds like you consider me human enough to greet me on the street if you saw me#ask reply#I can't help but giggle everytime I read 3-word-requests it feels like I'm working at McDonalds...#it's just... so out of context it's not even a question#sometimes idk if that is a request to me to draw that or to give you my opinion on that#text post
19 notes
·
View notes
Text
Anon's explanation:
I’m curious because I see a lot of people claiming to be anti-AI, and in the same post advocating for the use of Glaze and Artshield, which use DiffusionBee and Stable Diffusion, respectively. Glaze creates a noise filter using DiffusionBee; Artshield runs your image through Stable Diffusion and edits it so that it reads as AI-generated. You don’t have to take my work for it. Search for DiffusionBee and Glaze yourself if you have doubts. I’m also curious about machine translation, since Google Translate is trained on the same kinds of data as ChatGPT (social media, etc) and translation work is also skilled creative labor, but people seem to have no qualms about using it. The same goes for text to speech—a lot of the voices people use for it were trained on professional audiobook narration, and voice acting/narration is also skilled creative labor. Basically, I’m curious because people seem to regard these types of gen AI differently than text gen and image gen. Is it because they don’t know? Is it because they don’t think the work it replaces is creative? Is it because of accessibility? (and, if so, why are other types of gen AI not also regarded as accessibility? And even then, it wouldn’t explain the use of Glaze/Artshield)
Additional comments from anon:
I did some digging by infiltrating (lurking in) pro-AI spaces to see how much damage Glaze and other such programs were doing. Unfortunately, it turns out none of those programs deter people from using the ‘protected’ art. In fact, because of how AI training works, they may actually result in better output? Something about adversarial training. It was super disappointing. Nobody in those spaces considers them even a mild deterrent anywhere I looked. Hopefully people can shed some light on the contradictions for me. Even just knowing how widespread their use is would be informative. (I’m not asking about environmental impact as a factor because I read the study everybody cited, and it wasn’t even anti-AI? It was about figuring out the best time of day to train a model to balance solar power vs water use and consumption. And the way they estimated the impact of AI was super weird? They just went with 2020’s data center growth rate as the ‘normal’ growth rate and then any ‘extra’ growth was considered AI. Maybe that’s why it didn’t pass peer review... But since people are still quoting it, that’s another reason for me to wonder why they would use Glaze and Artshield and everything. That’s why running them locally has such heavy GPU requirements and why it takes so long to process an image if you don’t meet the requirements. It’s the same electricity/water cost as generating any other AI image.)
–
We ask your questions anonymously so you don’t have to! Submissions are open on the 1st and 15th of the month.
#polls#incognito polls#anonymous#tumblr polls#tumblr users#questions#polls about ethics#submitted april 15#polls about the internet#ai#gen ai#generative ai#ai tools#technology
325 notes
·
View notes
Text
MIT libraries are thriving without Elsevier

I'm coming to BURNING MAN! On TUESDAY (Aug 27) at 1PM, I'm giving a talk called "DISENSHITTIFY OR DIE!" at PALENQUE NORTE (7&E). On WEDNESDAY (Aug 28) at NOON, I'm doing a "Talking Caterpillar" Q&A at LIMINAL LABS (830&C).

Once you learn about the "collective action problem," you start seeing it everywhere. Democrats – including elected officials – all wanted Biden to step down, but none of them wanted to be the first one to take a firm stand, so for months, his campaign limped on: a collective action problem.
Patent trolls use bullshit patents to shake down small businesses, demanding "license fees" that are high, but much lower than the cost of challenging the patent and getting it revoked. Collectively, it would be much cheaper for all the victims to band together and hire a fancy law firm to invalidate the patent, but individually, it makes sense for them all to pay. A collective action problem:
https://locusmag.com/2013/11/cory-doctorow-collective-action/
Musicians get royally screwed by Spotify. Collectively, it would make sense for all of them to boycott the platform, which would bring it to its knees and either make it pay more or put it out of business. Individually, any musician who pulls out of Spotify disappears from the horizon of most music fans, so they all hang in – a collective action problem:
https://pluralistic.net/2024/06/21/off-the-menu/#universally-loathed
Same goes for the businesses that get fucked out of 30% of their app revenues by Apple and Google's mobile business. Without all those apps, Apple and Google wouldn't have a business, but any single app that pulls out commits commercial suicide, so they all hang in there, paying a 30% vig:
https://pluralistic.net/2024/08/15/private-law/#thirty-percent-vig
That's also the case with Amazon sellers, who get rooked for 45-51 cents out of every dollar in platform junk fees, and whose prize for succeeding despite this is to have their product cloned by Amazon, which underprices them because it doesn't have to pay a 51% rake on every sale. Without third-party sellers there'd be no Amazon, but it's impossible to get millions of sellers to all pull out at once, so the Bezos crime family scoops up half of the ecommerce economy in bullshit fees:
https://pluralistic.net/2023/11/06/attention-rents/#consumer-welfare-queens
This is why one definition of "corruption" is a system with "concentrated gains and diffuse losses." The company that dumps toxic waste in your water supply reaps all the profits of externalizing its waste disposal costs. The people it poisons each bear a fraction of the cost of being poisoned. The environmental criminal has a fat warchest of ill-gotten gains to use to bribe officials and pay fancy lawyers to defend it in court. Its victims are each struggling with the health effects of the crimes, and even without that, they can't possibly match the polluter's resources. Eventually, the polluter spends enough money to convince the Supreme Court to overturn "Chevron deference" and makes it effectively impossible to win the right to clean water and air (or a planet that's not on fire):
https://www.cfr.org/expert-brief/us-supreme-courts-chevron-deference-ruling-will-disrupt-climate-policy
Any time you encounter a shitty, outrageous racket that's stable over long timescales, chances are you're looking at a collective action problem. Certainly, that's the underlying pathology that preserves the scholarly publishing scam, which is one of the most grotesque, wasteful, disgusting frauds in our modern world (and that's saying something, because the field is crowded with many contenders).
Here's how the scholarly publishing scam works: academics do original scholarly research, funded by a mix of private grants, public funding, funding from their universities and other institutions, and private funds. These academics write up their funding and send it to a scholarly journal, usually one that's owned by a small number of firms that formed a scholarly publishing cartel by buying all the smaller publishers in a string of anticompetitive acquisitions. Then, other scholars review the submission, for free. More unpaid scholars do the work of editing the paper. The paper's author is sent a non-negotiable contract that requires them to permanently assign their copyright to the journal, again, for free. Finally, the paper is published, and the institution that paid the researcher to do the original research has to pay again – sometimes tens of thousands of dollars per year! – for the journal in which it appears.
The academic publishing cartel insists that the millions it extracts from academic institutions and the billions it reaps in profit are all in service to serving as neutral, rigorous gatekeepers who ensure that only the best scholarship makes it into print. This is flatly untrue. The "editorial process" the academic publishers take credit for is virtually nonexistent: almost everything they publish is virtually unchanged from the final submission format. They're not even typesetting the paper:
https://link.springer.com/article/10.1007/s00799-018-0234-1
The vetting process for peer-review is a joke. Literally: an Australian academic managed to get his dog appointed to the editorial boards of seven journals:
https://www.atlasobscura.com/articles/olivia-doll-predatory-journals
Far from guarding scientific publishing from scams and nonsense, the major journal publishers have stood up entire divisions devoted to pay-to-publish junk science. Elsevier – the largest scholarly publisher – operated a business unit that offered to publish fake journals full of unreveiwed "advertorial" papers written by pharma companies, packaged to look like a real journal:
https://web.archive.org/web/20090504075453/http://blog.bioethics.net/2009/05/merck-makes-phony-peerreview-journal/
Naturally, academics and their institutions hate this system. Not only is it purely parasitic on their labor, it also serves as a massive brake on scholarly progress, by excluding independent researchers, academics at small institutions, and scholars living in the global south from accessing the work of their peers. The publishers enforce this exclusion without mercy or proportion. Take Diego Gomez, a Colombian Masters candidate who faced eight years in prison for accessing a single paywalled academic paper:
https://www.eff.org/deeplinks/2014/07/colombian-student-faces-prison-charges-sharing-academic-article-online
And of course, there's Aaron Swartz, the young activist and Harvard-affiliated computer scientist who was hounded to death after he accessed – but did not publish – papers from MIT's JSTOR library. Aaron had permission to access these papers, but JSTOR, MIT, and the prosecutors Stephen Heymann and Carmen Ortiz argued that because he used a small computer program to access the papers (rather than clicking on each link by hand) he had committed 13 felonies. They threatened him with more than 30 years in prison, and drew out the proceedings until Aaron was out of funds. Aaron hanged himself in 2013:
https://en.wikipedia.org/wiki/Aaron_Swartz
Academics know all this terrible stuff is going on, but they are trapped in a collective action problem. For an academic to advance in their field, they have to publish, and they have to get their work cited. Academics all try to publish in the big prestige journals – which also come with the highest price-tag for their institutions – because those are the journals other academics read, which means that getting published is top journal increases the likelihood that another academic will find and cite your work.
If academics could all agree to prioritize other journals for reading, then they could also prioritize other journals for submissions. If they could all prioritize other journals for submissions, they could all prioritize other journals for reading. Instead, they all hold one another hostage, through a wicked collective action problem that holds back science, starves their institutions of funding, and puts their colleagues at risk of imprisonment.
Despite this structural barrier, academics have fought tirelessly to escape the event horizon of scholarly publishing's monopoly black hole. They avidly supported "open access" publishers (most notably PLoS), and while these publishers carved out pockets for free-to-access, high quality work, the scholarly publishing cartel struck back with package deals that bundled their predatory "open access" journals in with their traditional journals. Academics had to pay twice for these journals: first, their institutions paid for the package that included them, then the scholars had to pay open access submission fees meant to cover the costs of editing, formatting, etc – all that stuff that basically doesn't exist.
Academics started putting "preprints" of their work on the web, and for a while, it looked like the big preprint archive sites could mount a credible challenge to the scholarly publishing cartel. So the cartel members bought the preprint sites, as when Elsevier bought out SSRN:
https://www.techdirt.com/2016/05/17/disappointing-elsevier-buys-open-access-academic-pre-publisher-ssrn/
Academics were elated in 2011, when Alexandra Elbakyan founded Sci-Hub, a shadow library that aims to make the entire corpus of scholarly work available without barrier, fear or favor:
https://sci-hub.ru/alexandra
Sci-Hub neutralized much of the collective action trap: once an article was available on Sci-Hub, it became much easier for other scholars to locate and cite, which reduced the case for paying for, or publishing in, the cartel's journals:
https://arxiv.org/pdf/2006.14979
The scholarly publishing cartel fought back viciously, suing Elbakyan and Sci-Hub for tens of millions of dollars. Elsevier targeted prepress sites like academia.edu with copyright threats, ordering them to remove scholarly papers that linked to Sci-Hub:
https://svpow.com/2013/12/06/elsevier-is-taking-down-papers-from-academia-edu/
This was extremely (if darkly) funny, because Elsevier's own publications are full of citations to Sci-Hub:
https://eve.gd/2019/08/03/elsevier-threatens-others-for-linking-to-sci-hub-but-does-it-itself/
Meanwhile, scholars kept the pressure up. Tens of thousands of scholars pledged to stop submitting their work to Elsevier:
http://thecostofknowledge.com/
Academics at the very tops of their fields publicly resigned from the editorial board of leading Elsevier journals, and published editorials calling the Elsevier model unethical:
https://www.theguardian.com/science/blog/2012/may/16/system-profit-access-research
And the New Scientist called the racket "indefensible," decrying the it as an industry that made restricting access to knowledge "more profitable than oil":
https://www.newscientist.com/article/mg24032052-900-time-to-break-academic-publishings-stranglehold-on-research/
But the real progress came when academics convinced their institutions, rather than one another, to do something about these predator publishers. First came funders, private and public, who announced that they would only fund open access work:
https://www.nature.com/articles/d41586-018-06178-7
Winning over major funders cleared the way for open access advocates worked both the supply-side and the buy-side. In 2019, the entire University of California system announced it would be cutting all of its Elsevier subscriptions:
https://www.science.org/content/article/university-california-boycotts-publishing-giant-elsevier-over-journal-costs-and-open
Emboldened by the UC system's principled action, MIT followed suit in 2020, announcing that it would no longer send $2m every year to Elsevier:
https://pluralistic.net/2020/06/12/digital-feudalism/#nerdfight
It's been four years since MIT's decision to boycott Elsevier, and things are going great. The open access consortium SPARC just published a stocktaking of MIT libraries without Elsevier:
https://sparcopen.org/our-work/big-deal-knowledge-base/unbundling-profiles/mit-libraries/
How are MIT's academics getting by without Elsevier in the stacks? Just fine. If someone at MIT needs access to an Elsevier paper, they can usually access it by asking the researchers to email it to them, or by downloading it from the researcher's site or a prepress archive. When that fails, there's interlibrary loan, whereby other libraries will send articles to MIT's libraries within a day or two. For more pressing needs, the library buys access to individual papers through an on-demand service.
This is how things were predicted to go. The libraries used their own circulation data and the webservice Unsub to figure out what they were likely to lose by dropping Elsevier – it wasn't much!
https://unsub.org/
The MIT story shows how to break a collective action problem – through collective action! Individual scholarly boycotts did little to hurt Elsevier. Large-scale organized boycotts raised awareness, but Elsevier trundled on. Sci-Hub scared the shit out of Elsevier and raised awareness even further, but Elsevier had untold millions to spend on a campaign of legal terror against Sci-Hub and Elbakyan. But all of that, combined with high-profile defections, made it impossible for the big institutions to ignore the issue, and the funders joined the fight. Once the funders were on-side, the academic institutions could be dragged into the fight, too.
Now, Elsevier – and the cartel – is in serious danger. Automated tools – like the Authors Alliance termination of transfer tool – lets academics get the copyright to their papers back from the big journals so they can make them open access:
https://pluralistic.net/2021/09/26/take-it-back/
Unimaginably vast indices of all scholarly publishing serve as important adjuncts to direct access shadow libraries like Sci-Hub:
https://pluralistic.net/2021/10/28/clintons-ghost/#cornucopia-concordance
Collective action problems are never easy to solve, but they're impossible to address through atomized, individual action. It's only when we act as a collective that we can defeat the corruption – the concentrated gains and diffuse losses – that allow greedy, unscrupulous corporations to steal from us, wreck our lives and even imprison us.
Community voting for SXSW is live! If you wanna hear RIDA QADRI and me talk about how GIG WORKERS can DISENSHITTIFY their jobs with INTEROPERABILITY, VOTE FOR THIS ONE!
If you'd like an essay-formatted version of this post to read or share, here's a link to it on pluralistic.net, my surveillance-free, ad-free, tracker-free blog:
https://pluralistic.net/2024/08/16/the-public-sphere/#not-the-elsevier
#pluralistic#libraries#glam#elsevier#monopolies#antitrust#scams#open access#scholarship#education#lis#oa#publishing#scholarly publishing#sci-hub#preprints#interlibrary loan#aaron swartz#aaronsw#collective action problems
632 notes
·
View notes
Note
An investigation found hundreds of known images of child sexual abuse material (CSAM) in an open dataset used to train popular AI image generation models, such as Stable Diffusion. Models trained on this dataset, known as LAION-5B, are being used to create photorealistic AI-generated nude images, including CSAM. It is challenging to clean or stop the distribution of publicly distributed datasets as it has been widely disseminated. Future datasets could use freely available detection tools to prevent the collection of known CSAM. (SOURCE: https:// cyber.fsi.stanford.edu/news/investigation-finds-ai-image-generation-models-trained-child-abuse)
This isn't some "gotcha". This is something that actually HAPPENED.
Firstly;

Secondly, pick a fucking argument, dude. You've gone from asking me if I think AI rape images are fine to asking if I think AI CSA is fine because its using real CSEM to calling out that some AI datasets were contaminated.
So what's your argument? Are you arguing against my moral values or against AI? Those specific AI programs? People using art to fulfil unorthodox fantasy?
Copy-pasting statements after a furious little google search because I'm not bending over ass-backwards to agree with you is presenting what point, exactly?
AI bad?
Taboo kink bad?
Fictional content bad?
RPF bad?
Which is it? Help me out here. Is it some hybrid of all of those points?
Because I mean if your point is that AI is bad, I agree! Whole heartedly. For a multitude of reasons, not least one of your copied points; that it is actually basically impossible to make the AI forget something its learned. Hence; scrapping it all and starting over. Hence; stricter laws that only allow AI to be trained on specific open source datasets. Hence; requiring human approval for reference images and constant human monitoring rather than simply allowing the AI to run unsupervised, as most are.
I just don't agree that using various mediums to create fictional art that isn't created with a malicious directive is bad. Whether that's done by hand or using (god forbid) AI.
16 notes
·
View notes
Note
Hey, you know I saw your profile and I saw the images made with AI of Red and they are really very good, I was wondering how you made the AI represent Red well, I'm new to those AIs and all that, thank
Hey there. I made some LoRA models of Undertale Red back then for fun. You can basically train AI to let it draw any characters you want. Just look for "LoRA training guide" on Google, and you'll find the answer.
While I updated the LoRA models of UTR up to SDXL and Pony (the pictures I posted were trained with SD 1.5, which is obsolete nowadays), I decided to quit AI picture generation, since I found that drawing with my own hands is more satisfying, rather than typing prompts on the local Stable Diffusion WebUI.
5 notes
·
View notes
Text
Anatomy of a Scene: Photobashing in ControlNet for Visual Storytelling and Image Composition
This is a cross-posting of an article I published on Civitai.
Initially, the entire purpose for me to learn generative AI via Stable Diffusion was to create reproducible, royalty-free images for stories without worrying about reputation harm or consent (turns out not everyone wants their likeness associated with fetish smut!).
In the beginning, it was me just hacking through prompting iterations with a shotgun approach, and hoping to get lucky.
I did start the Pygmalion project and the Coven story in 2023 before I got banned (deservedly) for a ToS violation on an old post. Lost all my work without a proper backup, and was too upset to work on it for a while.
I did eventually put in work on planning and doing it, if not right, better this time. Was still having some issues with things like consistent settings and clothing. I could try to train LoRas for that, but seemed like a lot of work and there's really still no guarantees. The other issue is the action-oriented images I wanted were a nightmare to prompt for in 1.5.
I have always looked at ControlNet as frankly, a bit like cheating, but I decided to go to Google University and see what people were doing with image composition. I stumbled on this very interesting video and while that's not exactly what I was looking to do, it got me thinking.
You need to download the controlnet model you want, I use softedge like in the video. It goes in extensions/sd-webui-controlnet/models.
I got a little obsessed with Lily and Jamie's apartment because so much of the first chapter takes place there. Hopefully, you will not go back and look at the images side-by-side, because you will realize none of the interior matches at all. But the layout and the spacing work - because the apartment scenes are all based on an actual apartment.

The first thing I did was look at real estate listings in the area where I wanted my fictional university set. I picked Cambridge, Massachusetts.

I didn't want that mattress in my shot, where I wanted Lily by the window during the thunderstorm. So I cropped it, keeping a 16:9 aspect ratio.

You take your reference photo and put it in txt2img Controlnet. Choose softedge control type, and generate the preview. Check other preprocessors for more or less detail. Save the preview image.

Lily/Priya isn't real, and this isn't an especially difficult pose that SD1.5 has trouble drawing. So I generated a standard portrait-oriented image of her in the teal dress, standing looking over her shoulder.

I also get the softedge frame for this image.

I opened up both black-and-white images in Photoshop and erased any details I didn't want for each. You can also draw some in if you like. I pasted Lily in front of the window and tried to eyeball the perspective to not make her like tiny or like a giant. I used her to block the lamp sconces and erased the scenery, so the AI will draw everything outside.
Take your preview and put it back in Controlnet as the source. Click Enable, change preprocessor to None and choose the downloaded model.
You can choose to interrogate the reference pic in a tagger, or just write a prompt.
Notice I photoshopped out the trees and landscape and the lamp in the corner and let the AI totally draw the outside.

This is pretty sweet, I think. But then I generated a later scene, and realized this didn't make any sense from a continuity perspective. This is supposed to be a sleepy college community, not Metropolis. So I redid this, putting BACK the trees and buildings on just the bottom window panes. The entire point was to have more consistent settings and backgrounds.

Here I am putting the trees and more modest skyline back on the generated image in Photoshop. Then i'm going to repeat the steps above to get a new softedge map.

I used a much more detailed preprocessor this time.

Now here is a more modest, college town skyline. I believe with this one I used img2img on the "city skyline" image.
#ottopilot-ai#ai art#generated ai#workflow#controlnet#howto#stable diffusion#AI image composition#visual storytelling
2 notes
·
View notes
Note
hi! I'm a fan of your work and am trying to learn ai myself, could you tell me a bit about your process? keep up the good work :D
thank you! everything i do these days is rendered in automatic1111 stable diffusion, run locally on my computer (on my nvidia rtx 3060 gpu w/ 12gb of vram). i train my own base models with kohya trainer XL and LoRA models with kohya LoRA trainer XL, both of which i usually run on google colab (on an nvidia a100 gpu because training models is a lot more resource intensive than rendering images).
most of what i do is less about the text prompt and more about the models used. in fact, i tend to recycle through a lot of the same text prompts over and over (with only minor changes to them) as i test out the models that i've trained. i think the most creative part of working with ai is in training models. text prompting is just the surface of it, but training ai is where you're really starting to create something that no one else can exactly replicate (unless they literally steal your dataset and settings). it is an extraordinarily fascinating form of creative expression that is unlike anything in human history... basically wrangling a blank slate machine intelligence to do your bidding by teaching it.
i do a lot of experimenting with the datasets that i use to train models. some are trained on more specific subjects or aesthetics, while others are trained on more symbolic concepts. then i combine these models when rendering images (the nice thing about LoRA models is that you can combine many models in a single text prompt). when i find combinations that seem particularly cool, i'll render a whole series of images and use those as a dataset to train a new model. then i'll combine that model with other models and sort of continue this evolutionary process of training and retraining models, using datasets comprised mostly of previously rendered images.
the datasets for my earliest models started with things like this (i would just slowly collect random cool images that captured a vibe that i liked, categorize them with other similar images, and eventually train a model on that specific vibe):

whereas now they're usually trained on images i previously rendered that share a specific vibe.
training models is definitely an art form itself... a lot of very delicate settings, how/if the dataset is tagged (the process of describing what is in each image to help the ai identify what it is analyzing during training), the specific images that comprise the dataset (1 bad/confusing image can sometimes really negatively impact the resulting model), etc. this is a whole HUGE subject that i could write FOREVER about, but i'll spare you (and myself) the endless wall of text haha.
anyway, some final gritty details worth mentioning about the workflow of actually rendering images and getting as much coherent detail as possible out of it: when i render something i like in automatic1111, i'll usually re-render it with hires fix using the LDSR upscaler to upscale it x2. some models don't play nicely with upscaling (and things can come out warped), so i'll either try again at x1.5 or x1.25 or try reducing the denoising strength (i typically like to keep it around 0.5). assuming the model(s) used do play nice with upscaling, i'll sometimes then send it over to the "img2img" tab and upscale it again x2 using the "SD upscale" script with the LDSR upscaler (denoising set to around 0.3 here). occasionally i'll upscale it x4 one last time using Real-ESRGAN (and then resize it down to something normal, since by this point the image resolution can exceed 10,000x10,000 pixels lol), which can help to smooth out any rough textures. the final step is making any last adjustments in photoshop - things like contrast or cleaning up noise / stray pixels.
hope this helps and hope it isn't too much of a mess to read haha. i really tried to condense as much of my process as i could into something as short as possible (i actually deleted 3 paragraphs during this because it was getting way too deep and i don't want to burden anyone with a boring novel of overly specific details). there are a lot of tutorials out there regarding everything i've mentioned here; reddit and youtube are probably the best resources. if you have specific questions on anything though, feel free to reach out! i'm always down to help folks get into this.
#stable diffusion#photoshop#digital art#ai#artificial intelligence#generative art#ai art#synthography#ask
5 notes
·
View notes
Text
Ben Shapiro discovers that AI is not always 100% accurate, decides that it must be because of an anti-white conspiracy.

Covering this is embarrassing, even by Ben standards (source: The Ben Shapiro Show on Daily Wire)
This was something that really ticked off the conservative media ecosphere a couple weeks ago that I didn't really get to covering, but I'm doing it now because this story is truly hilarious and shows just how fragile all these people are.
And there are few better sources of someone getting angry over absolutely nothing and displaying pure fragility than Ben Shapiro. Lets get into it.
00:00, Ben Shapiro: "Well folks, we have a giant problem in the area of artificial intelligence. I'm not talking about Terminator 2, the AI is gonna grab control of the nukes and just destroy all of us. What I'm talking about here is the simple fact that artificial intelligence, like all social media, like pretty much all technology ever, is a human creation. And because artificial intelligence is supposed to be some sort of imitator of human intelligence, that means it is going to carry all of our biases."
Yeah Ben, that's why I'm sure you're going to devote an episode of your show to WhatsApp's AI showing images of gun-wielding children when prompted with Palestine or Stable Diffusion demonstrating a streak of perpetuating racial stereotypes (which we'll talk a bit more about later). While Ben is correct that AI does often perpetuate human biases, the story he's covering has absolutely nothing to do with this.
This story is regarding Google Gemini's image generator. Google attempted to subvert those issues that I previously mentioned by tuning the AI to show more diverse results. The problem is that their tuning failed to account for situations where diversity wouldn't make sense, such as images of the founding fathers. The AI was also overly cautious and refused to respond to certain prompts, often ones containing the word "white".
This led to one of the rip-offs of LibsOfTikTok called "EndOfWokeness" attempting to generate an image of the founding fathers and being met with images of racially diverse people. This led to the griftospheres heads collectively exploding and cries of "white erasure" ringing throughout the streets.
In essence, the right threw a massive tantrum over a tech glitch. It has nothing to do with "human bias" like the previous stories I mentioned, it was actually an effort to correct human bias. I feel like anybody who gets mad about this story is both extremely fragile and way too obsessed with the construction of whiteness. That brings me back to Ben Shapiro, who is of course mad about this story.
00:27, Ben Shapiro: "When you hear the tech bros, when you hear people at the top levels of AI, talk about how the 'algorithm' decides things you should understand the algorithm is designed by them. In the same way that you decide what children should be educated with, these people are deciding exactly what the biases are that should be implanted in things like AI."
Yeah, because glitches in technology never happen. Especially in relatively new forms of technology. Always 120% perfect from the get go, therefor this is clearly an instance of an anti-white conspiracy embedded in....an AI image generator for some reason?
If your conspiracy can get discovered by right-wing dimwits on Twitter, it's time to go back to the drawing board. Also, Ben Shapiro went to Harvard so I hope he doesn't genuinely believe this.
01:03, Ben Shapiro: "The reality is that the people who have created AI, they are the creators of the AI, and they have decided what exactly should be embedded in the bias of the AI."
This is one of those lies that's so blatantly hilarious because it's literally the opposite of reality. AI has an anti-white bias, OK Ben.
A 2023 study on Stable Diffusion conducted by researchers at the University of Washington discovered that Stable Diffusion perpetuates racial and sexual stereotypes. One of the findings is that images generated from prompts requesting a person corresponded with white males the most and people from Africa and Asia the least. It also produced sexualized images from prompts requesting women of color.
So in reality, AI usually discriminates the opposite way. Funnily enough, you don't hear Ben Shapiro talking about that.
02:26, Ben Shapiro: "The answer to sort of bias, typically speaking, would be decentralization. A bunch of different AI's, all of which are capable of giving you a different view of the information."
Does Ben not realize that multiple tech companies have all released their own AI's? Hell, his bestie Elon Musk has released an AI that's built into Twitter. While there are a million criticisms of Google, having a monopoly on the AI industry isn't one of them (at least not yet anyways).
03:15, Ben Shapiro: "So the reason this comes to a head today is because there is a new product called Google Gemini that was released by Google and it essentially generates images, one of the things it does --- it generates images. It's an AI that can generate high quality images with simply the stroke of a few keys. S you type in a prompt and you get images."
I don't think Ben made it clear what this thing does but I think it.....generates images? Just a rough guess though.
03:33, Ben Shapiro: "Well yesterday, it broke all across X slash Twitter --- it broke all across that outlet that whatever prompts you entered into Google Gemini, you came away with a set of very left-wing woke biases."
You've got to love how Ben's mind immediately views images depicting people of color as "woke". A bit of telling on yourself there.
04:14, Ben Shapiro: "Google Gemini was obviously pre-programmed with extraordinarily woke biases in favor of quote-on-quote diversity which means anti-white."
Again, this is stupid but it reveals a lot about how Ben views the world.
To him, anything short of 100% white content is "anti-white". If Ben truly was concerned about the biases in AI, why aren't we hearing him talk about the reason Google attempted to correct it in the first place? Namely, that AI images generators have a streak of being biased against people of color.
Ben shows some examples of Google Gemini's "anti-white racism" that were floating around on Twitter. Totally irrelevant, just Ben riffing over images of tweets. What feels like hours later, Ben finally gets back to presenting actual information an arguments.
12:53, Ben Shapiro: "So what exactly happened here? Well, we have a few indicators. So, it turns out that the head of Googles Gemini AI, the person who is the product manager of it, is a person named Jack Krawczyk. Jack Krawczyk has a Twitter feed. His Twitter feed includes quotes such as quote; 'White privilege is f-ing real. Don't be an a-hole and act guilty about it -- do your part in recognizing bias at all levels of egregious.'"
Yeah, this is the other part of this story. Apparently since this AI story was such a big deal, it warranted an investigation into the old tweets of people involved in it's creation. I wonder if Ben has the same problem with Grok given Elon Musk's many right-wing tweets and endorsements.
Outside of that, Jack Krawczyk's old tweets are completely irrelevant, especially considering that Ben Shapiro and his ilk are allegedly massive free-speech warriors. Maybe his beliefs on diversity impacted the initial decision to put safeguards in place so that Gemini could produce more diverse content, but they've rolled the flawed version back now.
Google is first and foremost a business with the intent to make money. Unlike what Ben seems to think, they're not trying to push some sort of anti-white agenda for.....reasons I guess? He never really makes that part clear. What is clear in the real world is that Google's #1 prerogative is making as much money as possible.
Odds are, this decision was less about Jack's personal beliefs and more about avoiding controversy while also increasing the target audience of the people who might engage with the AI. As we already mentioned, Stable Diffusion previously got itself into hot water for having the opposite problem which may have alienated some customers. Google wanted to provide a solution to this issue and it led to a computer glitch.
14:09, Ben Shapiro: "The biases of the makers end up in the product."
I'm not sure if Ben realizes this or not, but the product manager isn't the only person involved in the design of the finish product. What does Ben think happened? Does he think that Jack directed everyone who was involved in the design of Gemini to "make it erase white people"?
14:13, Ben Shapiro: "Do I accept Google Gemini's apology? I do not because I don't think they're going to remove any of the actual prioritization they give to various political biases. I think they're going to leave all the stuff in there and be more subtle about it."
Yeah, the AI's still gonna generate pictures of minorities only now the minorities are hidden in the bodies of white people. Kind of like an AI generated skin suit. Seriously, saying that the AI is going to just be more subtle about it's "various political biases" makes zero sense given the story that Ben is covering.
What the Hell is Ben even talking about?!
15:26, Ben Shapiro: "Now, why does all of this matter?"
It doesn't.
15:27, Ben Shapiro: "Again, it matters because these are the people who are going to be providing all, all, the information to your kids. Your kids are going to learn via computers, they're going to be given their own AI tutors. By the time, if you have very young kids, they enter school these tools are going to be the most commonly used tools in educational systems across the world."
You heard it here first folks, AI image generators are going to be the most commonly used tools in the education system! Naturally we must prevent them from teaching kids about the horrifying reality of people of color existing.
Most schools are the exact opposite and really discourage the usage of AI's such as ChatGPT due to the fact that they can be used for academically dishonest purposes. Ben seems like he's a little bit of a conspiracy crank when it comes to AI. Lets continue.
15:57, Ben Shapiro: "If you want a good argument for example, in favor of the pro-life position AI will stop you if these people are in charge."
Wrong, it's almost as if Ben is completely full of shit.

16:14, Ben Shapiro: "Joe Biden issued an executive order, this was October 30th, 2023, he issued an executive order on Safe Secure and Trustworthy Artificial Intelligence. And, as always, whenever the government says something --- when they create a bill like the Inflation Reduction Act, it ain't about reducing inflation and here when they say it's about the safety of AI it's not about the safety of AI. It is about controlling the direction in which AI develops and preventing alternatives from developing. So for example, this particular executive order, this is the White House website, it specifically says in here that one of the goals of the White House in advancing AI is quote 'advancing equity and civil rights'. Quote, 'Irresponsible uses of AI can lead to and deepen discrimination, bias, and other abuses in justice, healthcare, and housing. The Biden-Harris administration has already taken action by publishing the blueprint for an AI bill of rights and issuing an executive order directing agencies to combat algorithmic discrimination while enforcing existing authorities to protect peoples rights and safety.'"
Yeah, this is about hate speech. It isn't about generating arguments for the pro-life position, as you can see I clearly can generate arguments to Conservative positions. What I can't generate is arguments about why Hitler was actually good, and rightfully so. Also, if Ben scrolled down just a little bit further he'd find a section called "Promoting Innovation and Competition". Here's what it says.

Oops, sounds like exactly what Ben said should be put in place when he was blathering on about "decentralization". But hey, doesn't fit the narrative so we'll just ignore that part.
18:09, Ben Shapiro: "Now, what ends up happening very often is that the same exact people who talk about how they need to cure AI of their unconscious bias, they're the ones from whom the bias springs, they want the bias in there, and they want to cut off alternative mechanisms that have alternative biases."
Again, a computer glitch and now an executive order that doesn't say what Ben thinks it says are the pieces of evidence that he has here. I'm starting to understand why Ben didn't make it as a lawyer.
19:02, Ben Shapiro: "Google Gemini is an Orwellian 1984 tool, it is a memory hole. And the attempt to cure it is going to make it more of a memory hole because it's just gonna make it more subtle. It'll be more historically accurate, so when it says depict a German soldier it will still depict a Nazi soldier from 1939. But when it says depict a family it will give you every form of gender diverse family you can imagine as opposed to you know what most people mean by family and what family has historically meant, namely 'dad, mom, child.' It won't do that, it'll say it's discriminatory."
Nothing screams Orwellian quite like.....more diverse information.
Conclusion:
Ben Shapiro has the same understanding of AI as your average 12 year old. This was just painfully daft, even by Ben Shapiro standards. I for one welcome our extremely diverse AI dystopia brought on by a tech glitch!
Cheers and I'll see you in the next one!
#right wing bullshit#ai#google gemini#conservative bullshit#ben shapiro#right wing stupidity#daily wire#fact checking#journalism#disinformation#politics#debunking
2 notes
·
View notes
Text
Thoughts on AI
Most takes I see on this topic are…heated, to say the least. Understandably so — humans making art is something that ought to be celebrated and rewarded way more often than it is right now. We do, in fact, live in a capitalist hellscape that actively makes people miserable.
I fully expect a lot of people to respond angrily to this without reading the whole thing. But I think there's a lot of nuance in the topic that's being missed, and I really want discussions about the topic to be based in reality and not the overly dramatic version of reality that's been propagated in the last few months.
There is no TL;DR. If you absolutely need one, ask ChatGPT to make it for you or something. (Though it might be wrong; you'll never know.)
The Bare Minimum
I don't know of anyone outside of shitty CEOs who would argue that "not giving artists money is a good thing, actually." I mean that societally — obviously not everyone can afford to throw money at artists, and you shouldn't damage your own financial stability for someone else. Ensure your oxygen mask is secure before assisting others, so to speak. But I think most people, on both sides of the AI argument, agree that you shouldn't have to choose between making art and making a living.
Companies should hire and pay artists to make art.
Most of us aren't companies, and don't get to make those decisions. If you are making those decisions, though, and you could pay artists to make art but don't: what the fuck is wrong with you?
Great. Let's talk about stuff that's a little more nuanced than that.
Common Misconceptions
This section is necessary (and is going towards the top of this post) because I cannot stand seeing people being wrong on the internet argue moral stances based on total fabrications.
Most of these are based on my knowledge of Stable Diffusion and AI for image generation; from my understanding, large-language models like ChatGPT work similarly, but I have way less domain knowledge for LLMs.
Let's start with an easy one:
1. Prompting an AI feeds the AI. This is the easiest thing to clear up. I can download an AI model, take my computer offline, and generate as many images as I want with that model. If I then look at the model file, it has not changed. The AI is a conceptually simple transformation: it takes in text, turns that text into some numbers, does some math with those numbers, and then turns those numbers into pixels. There is no magic involved, no sentience, no upload to Google to let them know what I'm making.
That being said, using common online AI solutions like ChatGPT or Midjourney carries the risk of feeding future versions of the AI; most of these sites have a Terms of Service that say that any inputs you give it can be used to help train future versions, and that you shouldn't give it any sensitive data. This should be common sense in today's "always-online" tech world: read the fucking EULA, and don't send things over the internet you don't want being stored. My parents told me never to write something down if I didn't want anyone else reading it; this is the same concept.
2. AI art models contain stolen art. AI models are trained on absurd numbers of images. Stable Diffusion's dataset consists of over 2.3 billion images. That's something like 115 terabytes of data. The distributed Stable Diffusion model is 4 gigabytes. 0.003% as much data, if I did my math right.
This is a destructive process, meaning that it's impossible to get the original training data from the AI model. Nobody's distributing art, stolen or otherwise; they're distributing a mathematical codification of "what art tends to look like."
3. AI art models are collage machines. This one is a bit tougher to discuss, because it's only mostly wrong. Here's a simplified description of how Stable Diffusion (aka the most common AI art tool) works: it's fed that 2.3 billion image dataset, each image having been artificially "noised" (kind of like how JPEG compression artifacts work, but more so). Each of these images also comes with a text description of the image. Then it's shown the original images, as a goal end result. This is during the training phase, where it tries to come up with the numbers that make up its "brain" (not actually a brain, of course, because it's not sentient).
Essentially, the model is saying "how do I take a shitty image, and make it look right?"
Afterwards, a few images and text descriptions have been held back, and it tries to denoise them itself without having ever seen the original image. The training tool measures how accurate it was, and then changes the numbers inside the model to reduce that error amount. Over hundreds of thousands of iterations, this process repeats, until we decide it's "good enough."
Finally, the end result can be used to denoise an image that is itself completely random noise. We still provide a text input to direct the model, but the AI is essentially hallucinating details that aren't there. It's just not actually hallucinating, because again, it isn't sentient. It also doesn't understand what it's making. AI models don't think about how many fingers a human has, they don't count objects, they just go "here's what blobs of flesh-colored pixels tend to look like."
Now, if the AI doesn't have a lot of training data, it can try to exactly reproduce the art that's been used to train it. Spending too much time training the AI model will lead to this, in what's called "over-fitting"; too much of the training data has been stored in the AI model, and it's now just replicating the original data. The thing is, "over-fitting" is something AI models actively try to avoid. Nobody wants a 1-to-1 reproduction of existing art, after all; the entire point is to make something new.
3.5. Yeah, but signatures show up in generated images! They do! They're also entirely illegible, most of the time. The AI can tell "hey, most pieces of art have these squiggles in a corner, so this piece of art probably does too." It doesn't know what a signature is, how text works (let alone cursive), or anything else. It just sees a pattern and does its best to follow along.
In fact, the most legible watermark I've seen is for Getty Images; they've had so many images with the exact same watermark plastered everywhere on them that the AI was trained to recreate those original images by…plastering the watermark everywhere. Whoops.
4. ChatGPT is lying about (X). Okay, I see this one way too often. ChatGPT is, in essence, a very complex auto-complete. It's like those memes of "type (phrase here) on your phone and press the middle auto-complete and see what comes out." It's just really, really good at mimicking written text.
It does not understand what it's saying. It has no capacity for rational thought, or calculation, or anything. The fact that it appears to do so is a monument to how complicated of a model it is.
Large language models are categorized on the number of "parameters" they have; essentially, you can think of these as variables in a function. For the purposes of basic roleplaying AIs, you can get away with 13 billion parameters. These AIs won't have much "knowledge," but they can carry a semi-convincing conversation about mundane topics.
For LLMs that try to answer questions, models will usually use 30 billion to 65 billion parameters. 65 billion is about the limit for commercially available hardware. This is like training an auto-complete on the contents of Wikipedia. It has a lot of reference points of factual statements, and it can string them together convincingly, and so maybe it'll spit out something correct.
ChatGPT uses way more parameters than even that. It cannot be run on a home computer. It's a massive AI model that's very good at auto-completing text. It is still just a fancy auto-complete. It has no guarantee that anything it says is true. Please, please, do not blindly trust anything that ChatGPT tells you.
Was AI Training Done Ethically?
Here's the thing: there's no objective truth of ethics. We decide what's right and wrong based on our current cultural understanding, and changes to that culture will drastically impact our codes of ethics. Not only that, but ethics varies on an individual basis — there are certainly some people out there who would argue all kink is inherently wrong, for example, and others who disagree. So I can't provide an objective answer here for every single person.
What I will say is this: most existing research regarding the internet has used web scraping. If I can observe some non-identifying data without taking action, then I can use that observation in my research. It's historically been the responsibility of website owners to manage web scraping allowances; they pay for server bandwidth, after all, and it can be difficult to differentiate between a researcher gathering data and a malicious actor launching a DDoS attack.
These AI models have been generated by researchers, following this established code of conduct. The Stable Diffusion model was made freely available by those researchers. Companies took the model, tweaked things, and sold access to it (and the hardware they run it on).
At what point did the ethical issue occur? Does web scraping need to be regulated, ensuring researchers follow a stricter process for collecting data? If so, is there a specific type of data that should be restricted? "Personal data," like names and other information that can be used to identify an individual, is already restricted; maybe we can come up with some rules for web scraping involving copyrighted information?
Maybe instead the ethical issue occurred when the AI model was released to the public — but I'm personally not a fan of that, as peer review and reproducibility are key to the scientific process and probably shouldn't be discouraged…
Maybe it was when corporations sold access to their own versions of the model? Should there be limitations on "fair use" such that not-for-profit research can use web-scraped models, but for-profit corporations cannot? Where does something like ChatGPT fall, given that it has a free access tier (rate-limited, to protect against spam)?
Is AI Generation Art
Yes. Full stop.
Look, there's no way to consider "what makes art" without including things created by computers with human oversight.
If you're going to exclude AI art, how can you do so without excluding:
Glitch art
Procedural generation
3D art
Fractal art
Shader art
If you do exclude those, I think you're wrong…but at least you're consistent about believing digital artists are talentless hacks, I guess?
Is AI Generation Ethical?
Again, I can only really speak to my own understanding of morality. Namely, this:
If you use AI art to replace hiring human artists when you have the capability to do so, you're a piece of shit. Full stop.
If you're an artist who uses AI tools to augment your existing processes: cool! I want to hear more about yourself and your work!
It doesn't make sense to me to say that using Stable Diffusion is wrong just because it was created unethically; if that were the case, it'd also be ethically wrong to use Procreate because Apple devices are created in sweatshops. There's a boundary of usage versus creation, here.
Beyond that, here's the thing: AI generation is a tool. It is not a replacement for humans with actual working brains. You can make art with AI, but whether you can make good art with AI is up to your ability to use your brain.
I find that the way most people use AI art tools has more in common with art direction than traditional art. That's still a skill, and one that has to be worked at. It's what makes me feel weird about claiming the title of "artist" — I don't think art directors call themselves artists?
Finally, AI usage falls under the same ethical qualifications as any other tool usage. It's equally as wrong to use AI to manufacture propaganda as it is to deepfake propaganda as it is to photoshop propaganda as it is to take manipulative photos to create propaganda —
I personally think it's fucked up to mimic other contemporary artist's styles. If the artist's work has passed into the public domain? I think anything created "in the style of Monet" is more about Monet than an actual attempt at forgery. But that's a more personal ethical boundary.
But really, it boils down to this: the tools exist. Don't post other people's work on the internet, whether that's on Wattpad or ChatGPT. But the models exist, and some random person using Stable Diffusion isn't gonna affect whether or not those models continue to exist.
The technology is already out there; the genie isn't going back in the bottle. It's too late to argue over whether or not the tools should exist in the first place. Let's actually discuss what responsible usage looks like.
2 notes
·
View notes
Text
youtube
ARTificially Intelligent: Seeing and Searching Collections with Machines
Presented at MuseumNext Digital Summit 2023. I shared about an experiment on National Gallery Singapore's collection to make art more accessible with neural search. As part of the demonstration, I demonstrated how anyone can search their collections with A.I. and argued for open sourcing innovations.
Visit https://erniesg.pubpub.org/ to check out my thoughts on some of the questions raised by the audience. Connect with me if you'd like to use neural search or explore A.I. together! I'm working on developing content for a course titled "Visions of Art" to help creatives, coders and non-technical leadership get started on using A.I. for relevant use cases. Tools and models used: Descript, Stable Diffusion inpainting, Runway Video2Video, Unreal, Cesium, Google Maps API
4 notes
·
View notes
Text
Is there a way to block websites from showing up in my Google search? Like, I don't want to see stable diffusion pics when searching for time-accurate ww2 uniforms. It's messing up my research and I'm getting sick of it.
1 note
·
View note
Text
“if you want me, i will come . . . ”

“if you want me, i will come . . . ”
by e9Art
(available elsewhere, without the text, as e9AI #060)
the photograph was created using Deforum Stable Diffusion (v0.7.1) on google colab. i love this version of Stable Diffusion, even though it creates a lot of junk. just to give you an idea, i scrap 1,999 for every one i keep.
this work available as a physical piece of wall art and perhaps other novelties (coffee cups, etc) on other platforms. you'll probably have to find me on anyone of the numerous social media platforms out there. i'm most attentive on twitter, with facebook coming a close second. i also post on instagram, tumblr and pinterest. thus far, my favorite print-on-demand sights are FineArtAmerica and Society6. and of course, it’s available as an NFT. . . .
e9Art (aka eric) has been a typesetter, tire changer, the coffee dude, that pizza guy, and a full-time artist. eric didn't 'discover' art until he was in his 50s, partially due to the idea that he couldn't be an artist being colorblind, and partially that he was raised in an environment where art was considered a waste of time because 'art doesn't put food on the table.'
since his first art sale in 2014, he has been making up for lost time. e9Art has created and sold over 16,000 original works (mostly ACEOs) on eBay, plus hundreds of NFTs on platforms such as OpenSea and Foundation.
e9art can be found on twitter, facebook, pinterest and tumblr. links to interviews, bios, social media, original paintings and NFTs can be found at https://linktr.ee/e9Art.
eric’s home and studio can be found in his hometown of Walton, NY.
#VintagePhotograph #WallArt




0 notes
Text
Please comment, and make sure that Disney and Amazon don't hold control over every art style to ever pass beneath their shadow! I'm not sure if comments made from outside the US are read and tallied, but I've put together a statement myself if any USians want to copy my notes.
AI is not violating any copyright for analyzing Bob Ross' paintings for the same reasons that Bob Ross is not a plagiarist for his study of the methods and style of Bill Alexander. Should artists not wish for their work to be studied or analyzed by machines, it is their responsibility to keep it from being stored in publicly accessible digital spaces.
The creations of prompt engineering and careful database curation directly impact the quality, style, and results of an image generated through tools such as Stable Diffusion. Through the creative process, and using these AI tools, an artist is able to make unique images.
These unique images are not the result of any single image within the dataset, because the images are not contained within the dataset. The dataset contains the patterns learned from analysis of upwards of a million pictures, gathered from larger image models provided by companies like Google for nearly three decades.
An artists 'style' is not and has never been held up as intellectual property in the United States, except in cases where a party was 'passing off' the imitated work to be an original work of another artist. AI is limited by its vary nature to only understand style when it comes to the works of the majority of artists.
With the exception of incredibly iconic and prolifically spread art pieces (e.g. Mona Lisa, Starry Night, etc.) it is nearly impossible for an AI to copy a specific image. It is literally impossible for a text-prompt to create a pixel perfect recreation of any image chosen beforehand.
In summary, Artificially Intelligence cannot in its current form violate US copyright law, and the creations of artists who use tools such as Stable Diffusion is their copyrighted intellectual property.
the US Copyright Office is asking for public comment on AI and copyright!!! now is the time to be LOUD about it so there can be government regulations.

GO COMMENT RIGHT NOW:
13K notes
·
View notes
Text
AI in Google Images
Seriously, I can't search for anything without my images being clogged. I'm sick of having to type in -"stable diffusion" -"ai" -"midjourney" -"open art" -"prompt hunt" just to find a cutesy Halloween or Christmas background for editing together images. I don't want anything to do with them and half the time I spend searching for images is actually verifying whether they're AI or not, because I'm not about to use them. If there's an easier way to remove AI images from search results I would love to know.
0 notes
Text




Using Free AI to Make Character Art for TTRPGs
I love having art for my characters in Pathfinder, D&D, and other TTRPGs. But I don't love the cost, time, and effort in finding and commissioning and artist to draw them for me.
When AI art blew up in the recent past I was intrigued, and got to seeing if I could get to draw my characters.
Turns out, it can.
Here and there I've responded to people asking about making AI art, and after some requests, I figured I'd write a little guide on how-to. Here goes…
Before we begin, I want to make a few things clear:
AI art is tricky from legal and moral points of view. But I don't think any of that applies when it comes to making art for personal use only using free open-source tools. I really don't think anyone is hurt when the created art is seen only by myself and a few fellow players. Surely it's better than stealing art from a Google Images search or by surfing around on Deviant Art, which was the old way of getting character art for personal use.
I'm not an expert on AI art. I'm only an enthused hobbyist, sharing what I've found.
This is only one way of doing things, using one particular AI tool. I'm not claiming it's the best way. It's just what I know.
This is a fairly quick, introductory guide. It'll get you started. It's up to you to carry yourself onward to more advanced results!
Notice the date of this guide (you can see it down the bottom). This guide will get outdated. The links will slowly die as websites change. I apologise if you've come to it too late for it to be useful.
All that said, let's get started.


What You Need
You need Stable Diffusion, and in particular, this distribution. Installation instructions are there for you to follow. This guide will not cover installing it. Note that you will need a fairly powerful computer.
Later on, you can worry about installing some checkpoint models and optionally some LoRA models. Those links explain what those things are, and how to install them. Good models will make better images. But if you're in a hurry, don't worry, play with the pre-installed stuff and come back later.
All of the images immediately below were generated by Stable Diffusion, but different models and prompts created wildly different styles.




I've annotated all the images in this post with what models I am using. Mouse over an image and click the "ALT" to see. It's not vital for you to use the same models or prompts as me, but if you want to, you can.
Here's a quick list of models I've used:
Comic Diffusion 2
DreamShaper
Arcane Style LoRA
Stable Diffusion 1.5
Text to Image
Fire up Stable Diffusion. Click the "txt2img" tab. In the "prompt" area, type in something like "portrait of a male dwarven axe warrior, braided beard". I did this with fully default settings and got both images below. The only difference is the model. The left image uses a model that comes with Stable Diffusion, the right comes with a downloaded model.


Notice it ignored me on a braided beard? The AI takes your prompt as a suggestion at best. You can weight prompts, read more about that here. (In fact, it's probably not a bad idea to read that whole article sometime, as prompts are important to understand.)
These images have braided beards!


Hopefully you can see what we've covered already gets you a powerful tool for making character portraits.
Image to Image
"img2img" takes an image and re-draws it artfully. This is great if you've got a rough reference of your character that you're like to render more artfully.
One such example of doing this is with HeroForge. Make your character and capture a screenshot of it. (If you don't know how to take a screenshot, do a search to find out. It's not hard.)
Put this image in "img2img". Then use a prompt as before. Below is an example with a HeroForge screenshot of the left, and some generated AI art on the right.



Be sure to tinker with the sliders "CFG Scale" and "Denoising strength". You can mouse over each in Stable Diffusion to read more. While the defaults tend to work well for "txt2img", they often need to be tweaked in "img2img".


There's no reason why you can't use an "txt2img" image as an input to "img2img". You might do this if you wanted to generate variations on the image, while keeping the same basic look and arrangement.
Improving Images: Upscale
Stable Diffusion can't generate large images. But Stable Diffusion does have an in-built tool in the "Extras" tab where you can resize images (any images, not just ones you've made in Stable Diffusion).
This upscaler does a much better job than most "dumb" image resizing tools. Be sure to actually select an upscaler (the "R-ESRGAN" ones work well), if you use "None" then you'll get awful results.
It's pretty simple to figure out. If need be, you can read about it here.
Improving Images: Mix and Match
This requires you to have an image editor like Gimp (which is free) or Photoshop, and the skills to use it. It's a technique I often use when I've feeling very fussy and want perfect results.
Using "img2img", get an image with models and prompts you feel is generate pretty good results. (You can always use an image you generated with "txt2img" as the image input for "img2img".)
Set Stable Diffusion to generate loads of images using the parameters from step 1. The outputs should all look very similar, but with different details.
Choose different images with bits you like. Find a picture that you like overall, then find picture(s) that have done certain things better. For instance, you might like the hair of one image and the eyes of another.
Get the pictures you identified in step 3 and throw them into your image editing tool.
Layer the images on top of one another. Put the "base image" that you liked overall at the bottom.
For images that are not the "base", erase everything except the part you like. Because the images are so similar, this should work well. Use a soft-edge erase for best results.
Adjust your layers and transparencies until it's just right. Then flatten the image and save it.





General Tips
Here are some general tips for generating AI art:
If you only want a portrait, only ask for a portrait. That means specifying terms like "portrait" in your prompt, and if you're using img2img only supply the portrait area. Most people wanting character art will only want a portrait, after all. The quality of faces made by AI art seems to get worse the more of the body it draws.
Use celebrities to guide facial features. Do you want a certain look for your character? Throw in the celebrity's name into the prompt. You'll often get a happy medium: an "angelina jolie half-orc" won't just be the actress with green skin, but you will get a certain resemblance. There are lots of celebrities with very striking looks, so this can work well! Can you guess the celebrities of these portraits? Click their "ALT" tag to find out!




AIs know the "Tolkein races" (humans, elves, dwarves, etc) better than obscure races like dragonborn and kenku. Semi-famously, AI sucks at centaurs. But these races aren't impossible, as shown below.


Make large batches of images. When you think you've mostly gotten the settings right, set the AI to make dozens or even hundreds of images. The only downside to doing so it that it'll take you some time to pick the best one(s)! There's a handy button to "Open images output directory" to make browsing easy.
Most importantly, fiddle and experiment. There are so many settings you can fiddle with, so many models and LoRAs you can try out, so many different ways to word your prompts. (For prompts, just Google "prompt stable diffusion" and you'll see plenty of guides and inspiration.) Never get "stuck" on a particular way of doing things: you may find better results are just a small tweak away!
0 notes
Text
How To Use AI To Fake A Scandal For Fun, Profit, and Clout
Or, I Just Saw People I Know To Be Reasonable Fall For A Fake "Ripoff" And Now I'm Going To Gently Demonstrate What Really Happened
So, we all know what people say about AI. It's just an automatic collage machine, it's stealing your data (as if the rest of the mainstream internet isn't - seriously, we should be using that knee-jerk disgust response to demand better internet privacy laws rather than try to beef up copyright so that compliance has to come at the beginning rather than the end of the process and you can be sued on suspicion of referencing, but I digress...), it can't create anything novel, some people go so far as to claim it's not even synthesizing anything, but just acting as a search engine and returning something run through a filter and "proving" it by "searching" for their own art and "finding" it.
And those are blatant lies.
The thing is, the reason AI is such a breakthrough - and the reason we memed with it so hard when DALL-E Mini and DALL-E 2 first dropped - is because it CAN create novel output. Because it CAN visualize the absurd ideas that no one has ever posted to the internet before. In fact, it would be a bigger breakthrough in computer science if we DID come up with an automatic collage machine - something that knows where to cut out a part of one image and paste it onto another, then smooth out the lighting and colors to make them fairly consistent, to make it look like what we would recognize as an image we're asking for? That would make the denoising algorithm on steroids that a diffusion model is look like child's play.
But, unlike the posts that claim that they're just acting as a collage maker at best and a search engine at worst, I'm not going to ask you to take my word for it (and stick a pin in this point, we'll come back to it later). I'm going to ask you to go to Simple Stable (or Craiyon, or the Karlo demo, if Google Colab feels too complicated for you - or if you like, do all of the above) and throw in a shitpost prompt or two. Ask for a velociraptor carousel pony ridden by a bunny. Ask for Godzilla fighting a wacky waving inflatable arm flailing tube man. Ask for an oil painting of a capybara wearing an ornate princess gown. Shitpost with it like we did before these myths took hold.
Now take your favorite result(s) and reverse image search them. Did you get anything remotely similar to your generated image? Probably not!
So then, how did someone end up getting a near perfect recreation of their work? Was that just some kind of wacky, one-in-a-million coincidence?
Well - oh no, look at that, I asked it for a simplistic character drawing and it happened to me too, it just returned a drawing of mine that I never even uploaded, and it's the worst drawing I've done since the fifth grade even just to embarrass me! Oh no, what happened, did they change things right under my nose, has digital surveillance gotten even WORSE?? Look, see, here's the original on the left, compare it to the output on the right - scary!! They're training on the contents of your computer in real time now, aaaagh!!

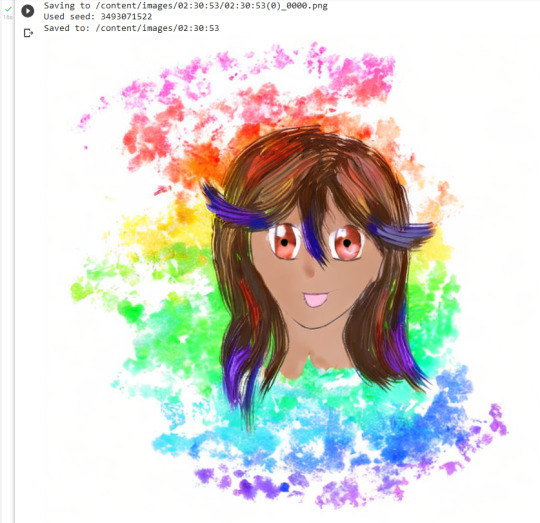
Except, of course, for the fact that the entire paragraph above was a lie and I did this on purpose in a way no one could possibly recreate from a text prompt, even with a perfect description.
How?
See, some models have this nifty little function called img2img. It can be used for anything from guiding the composition of your final image with a roughly drawn layout, to turning a building into a dragon...to post-processing of a hand-drawn image, to blatantly fucking lying about how AI works.
I took 5 minutes out of my day to crudely draw a character. I uploaded the image to this post. I saved the post as a draft. I stuck the image URL in the init_image field in Simple Stable, cranked the init strength up to 0.8, cleared all text prompts, and ran it. It did exactly what I told it to and tried to lightly refine the image I gave it.
If you see someone claiming that an AI stole their image with this kind of "proof", and the image they're comparing is not ITSELF a parody of an extremely well-known piece such as the Mona Lisa, or just so extremely generic that the level of similarity could be a coincidence (you/your favorite artist do/es not own the rule of thirds or basic fantasy creatures, just to name one family of example I've seen), this is what happened.
So from here you must realize that it is deeply insidious that posts that make these claims usually imply or even outright state that you should NOT try to recreate this but instead just take their word for it, stressing ~DON'T FEED THE MACHINE~. It's always some claim about "ohhh, the more you use them, the more they learn, I made a SACRIFICE so you don't have to" - but txt2img functions can't use your interaction to learn jack shit. There's no new information in a text prompt for them TO learn. Most img2img models can't learn from your input either, for that matter! I still recommend being careful about corporate img2img toys - we know that Facebook, for instance, is happy to try and beef up facial recognition for the WORST possible reasons - but if you're worried about your privacy and data harvesting, any given txt2img model is one of the least worrying things on the internet today.
So do be careful with your privacy online, and PLEASE use your very understandable knee-jerk horror response to how much extremely personal content can be found in training databases as a call to DEMAND better privacy laws ("do not track" should not be just for show ffs) and compliance with security protocols in fields that deal with very private information (COMMON CRAWL DOESN'T GO FAR OUT OF ITS WAY, IT SHOULD NEVER HAVE BEEN ABLE TO GET ANY MEDICAL IMAGES THE PATIENTS DIDN'T SHARE THEMSELVES HOLY SHIT, SOME HOSPITAL WORKERS AND/OR MEDICAL COMMUNICATIONS DEVELOPERS BETTER BE GETTING FIRED AND/OR SUED) - but don't just believe a convenient and easy-to-disprove lie because it aligns with that feeling.
420 notes
·
View notes