#Library Information Management Software
Explore tagged Tumblr posts
Visit Tumblr Blog
Explore Tumblr blogs with no restrictions, modern design and the best experience.
Last Seen Tumblr Blogs





Fun Fact
The most popular pages on Tumblr are about Minecraft, GIFs, and David J. Peterson.
Text
#library#management#system#doha#qatar#digital#forge#marketing#agency#information#technology#company#software#web based#library management system#library management qatar#library management system qatar#library management doha#library management system doha
0 notes
Note
reading that Tarantulas and Prowl processor overload ask has revived one of my recently dormant fetishes
(this is an expansion on the forced porn download ask actually, wasn't really done b4 sending)
Prowl's archives just being a massive database of miscellaneous data, which seems like a fully practical thing that he'd do for simulation work at first glance, but in truth, he just never deletes anything because he gets off to the feeling of being just sooooo full in places no physical sensation can reach.
He wasn't always like this, you see. Prowl used to maintain good software management habits. He'd defrag according to a strict schedule, used connection buffers often and cleared his processing queues before recharge. He would never think twice about netdiving into shady websites with nasty popups, let alone download anything from there. But eventually, as his processors develop at that exponential pace his handlers noticed upon bringing him online, Prowl got bolder.
Bold enough to make a slip up and plug into a corrupt mainframe, triggering that forced download and kickstarting his fetish for good. He barely remembers anything about that incident other than an overwhelming mental barrage of arousal. Sometimes Prowl wonders if his colleagues at the time knew just what was literally going through his head as he slumped over on the console, seizing in place as they frantically tried to disconnect him safely. Maybe they caught the scent of his overload under his panels, and chose not to say anything.
Prowl would of course say that he was perfectly fine after that incident, but he'd be haunted by that instance of utter bliss he'd felt when like 30 terrabytes of ERP chatlogs and erotic flashgames burned through his neural circuitry. Eventually, he'd start by visiting a library. Full of clean and safe data to indulge in. Then he started logging all non-confidential precinct data, like routine security footage that's get deleted anyways, and dispatch call recordings. Then he started downloading from legal websites, then onto not so legal ones.
He even has backup and extra hard drives stored in his office and habisuite in plain sight, since no one else but other archivists and data specialists would catch on to his kink in the first place. Every once in a while, he'd plug himself into all these units and just let all that data flood through him, his fans and cooling systems squealing in effort to keep up with the deluge of information forcing it's way through his staticy brain, reducing his overclocked cognitive units into jello as his RAM gets consumed by pure uncontrollable math.
He loves the feel of his mind being pounded by googols of nonsense, it makes him hornier than anything else. He'd save anything from the internet, books and numeric databases are his usual go tos; high definition media are a must, the more graphically and audially intensive the better; the most unoptimized and performance heavy video games, anything that would fill up his hungry battle computer until it's full to bursting and melting.
Sometimes when he feels extra naughty, he'd even fire up the various malware and viruses the Spec Ops team would bring back, on top of all the seedy ones he'd find online. He'd trigger them in his processor and lie back in his berth, finger his fluttering pussy and feel the malicious software start tearing through his brain as his battle computer instinctively fights back, making him feel soooo hot all over. And every time he overloads, it sweeps all of his progress, and the self cleaning protocols will just have to restart as he writhes helplessly in the dark of his room.
Software sanctity? Fuck that, he'd hit anything as long as it demolishes his brain and make him into a silly, messy, spasming horny mess. A real dataslut.
god this is so good. He's quite literally overloading his processor out. It's almost like an addiction. Of course, Prowl could stop any time he wants... he could, he just doesn't want to! After a while, pumping his head full of junk data and malicious viruses is the only way Prowl can even have a fulfilling orgasm. Being full of miscellaneous data is just not enough. It's a pleasant pressure in his constantly calculating brain, yes, but if he wants to cum, he needs something stronger. He'll keep frying his brain inside of his helm as long as he gets to feel that electrifying thrill of his battle computer struggling to deflect the attacks on his mainframe.
It feels like he's falling apart at the circuits, delicate wiring so hot that it's disintegrating into dust, and all he can do is frantically rub his soaking wet valve through it all, optics bright and staring off into space as his HUD floods with nonsense. All his senses are completely taken over by the foreign malware, all he knows is that he feels so good.
Honestly, I wonder what would happen if he got stuck like that. Just for a day or two. And someone had to find him in his apartment, face twisted in pure bliss as his frame keeps twitching even after countless hours of continuous overloads. Of course, Prowl's processor gets cleaned out after that, yet he can't help but want to repeat it... to feel so absolutely stuffed and overwhelmed with data that he's just a wet, helpless thing. To give up control and let his processor sink into endless pleasure.
But for now, he's got a morning shift at the precinct to finish.
50 notes
·
View notes
Text
The Trump administration, working in coordination with Elon Musk’s so-called Department of Government Efficiency, has gutted a small federal agency that provides funding to libraries and museums nationwide. In communities across the US, the cuts threaten student field trips, classes for seniors, and access to popular digital services, such as the ebook app Libby.
On Monday, managers at the Institute of Museum and Library Services (IMLS) informed 77 employees—virtually the agency’s entire staff—that they were immediately being put on paid administrative leave, according to one of the workers, who sought anonymity out of fear of retaliation from Trump officials. Several other sources confirmed the move, which came after President Donald Trump appointed Keith Sonderling, the deputy secretary of labor, as the acting director of IMLS less than two weeks ago.
A representative for the American Federation of Government Employee Local 3403, a union that represents about 40 IMLS staffers, said Sonderling and a group of DOGE staffers met with IMLS leadership late last month. Afterwards, Sonderling sent an email to staff “emphasizing the importance of libraries and museums in cultivating the next generation’s perception of American exceptionalism and patriotism,” the union representative said in a statement to WIRED.
IMLS employees who showed up to work at the agency on Monday were asked to turn in their computers and lost access to their government email addresses before being ordered to head home for the day, the employee says. It’s unclear when, or if, staffers will ever return to work. “It’s heartbreaking on many levels,” the employee adds.
The White House and the Institute of Museum and Library Services did not immediately respond to requests for comment from WIRED.
The annual budget of IMLS amounts to less than $1 per person in the US. Overall, the agency awarded over $269.5 million to library and museum systems last year, according to its grants database. Much of that money is paid out as reimbursements over time, the current IMLS employee says, but now there is no one around to cut checks for funds that have already been allocated.
“The status of previously awarded grants is unclear. Without staff to administer the programs, it is likely that most grants will be terminated,” the American Federation of Government Employee Local 3403 union said in a statement.
About 65 percent of the funding had been allocated to different states, with each one scheduled to receive a minimum of roughly $1.2 million. Recipients can use the money for statewide initiatives or pass it on to local museum and library institutions for expenses such as staff training and back-office software. California and Texas have received the highest allocated funding, at about $12.5 million and $15.7 million, respectively, according to IMLS data. Individual libraries and museums also receive grants directly from IMLS for specific projects.
An art museum in Idaho expected to put $10,350 toward supporting student field trips, according to the IMLS grant database. A North Carolina museum was allotted $23,500 for weaving and fiber art workshops for seniors. And an indigenous community in California expected to put $10,000 toward purchasing books and electronic resources.
In past years, other Native American tribes have received IMLS grants to purchase access to apps such as Hoopla and Libby, which provide free ebooks and audiobooks to library patrons. Some funding from the IMLS also goes to academic projects, such as using virtual reality to preserve Native American cultural archives or studying how AI chatbots could improve access to university research.
Steve Potash, founder and CEO of OverDrive, which develops Libby, says the company has been lobbying Congress and state legislatures for library funding. “What we are consistently hearing is that there is no data or evidence suggesting that federal funds allocated through the IMLS are being misused,” Potash tells WIRED. “In fact, these funds are essential for delivering vital services, often to the most underserved and vulnerable populations.”
Anthony Chow, director of the School of Information at San José State University in California and president-elect of the state library association, tells WIRED that Monday was the deadline to submit receipts for several Native American libraries he says he’d been supporting in their purchase of nearly 54,000 children’s books using IMLS funds. Five tribes, according to Chow, could lose out on a total of about $189,000 in reimbursements. “There is no contingency,” Chow says. “I don’t think any one of us ever thought we would get to this point.”
Managers at IMLS informed their teams on Monday that the work stoppage was in response to a recent executive order issued by Trump that called for reducing the operations of the agency to the bare minimum required by law.
Trump made a number of other unsuccessful attempts to defund the IMLS during his first term. The White House described its latest effort as a necessary part of “eliminating waste and reducing government overreach.” But the president himself has said little about what specifically concerns him about funding libraries; a separate order he signed recently described federally supported Smithsonian museums as peddling “divisive narratives that distort our shared history.”
US libraries and museums receive support from many sources, including public donations and funding from other federal agencies. But IMLS is “the single largest source of critical federal funding for libraries,” according to the Chief Officers of State Library Agencies advocacy group. Libraries and museums in rural areas are particularly reliant on federal funding, according to some library employees and experts.
Systems in big metros such as Los Angeles County and New York City libraries receive only a small fraction of their budget from the IMLS, according to recent internal memos seen by WIRED, which were issued in response to Trump’s March 14 executive order. "For us, it was more a source of money to innovate with or try out new programs,” says a current employee at the New York Public Library, who asked to remain anonymous because they aren’t authorized to speak to the press.
But the loss of IMLS funds could still have consequences in big cities. A major public library system in California is assembling an internal task force to advocate on behalf of the library system with outside donors, according to a current employee who wasn’t authorized to speak about the effort publicly. They say philanthropic organizations that support their library system are already beginning to spend more conservatively, anticipating they may need to fill funding gaps at libraries in areas more dependent on federal dollars.
Some IMLS programs also require states to provide matching funding, and legislatures may be disincentivized to offer support if the federal money disappears, further hampering library and museum budgets, the IMLS employee says.
The IMLS was created by a 1996 law passed by Congress and has historically received bipartisan support. But some conservative groups and politicians have expressed concern that libraries provide public access to content they view as inappropriate, including pornography and books on topics such as transgender people and racial minorities. In February, following a Trump order, schools for kids on overseas military bases restricted access to books “potentially related to gender ideology or discriminatory equity ideology topics.”
Last week, a bipartisan group of five US senators led by Jack Reed of Rhode Island urged the Trump administration to follow through on the IMLS grants that Congress had authorized for this year. "We write to remind the administration of its obligation to faithfully execute the provisions of the law," the senators wrote.
Ultimately, the fate of the IMLS could be decided in a showdown between Trump officials, Congress, and the federal courts. With immediate resolution unlikely, experts say museums and libraries unable to make up for lost reimbursements will likely have to scale back services.
11 notes
·
View notes
Text
Surveying Spain: Working with Spanish Civil War Posters at NYU Libraries

Hi, my name is Mia Lindenburg. I am a graduate student undergoing NYU’s Dual Degree program, where I will get an MA in literature and an MLIS. This semester, I have been working with NYU’s Barbara Goldsmith Preservation & Conservation Department, mentored by Lindsey Tyne (Conservation Librarian), Laura McCann (Director of Preservation), Weatherly Stephan (Head of Archival Collections Management), and Felix Esquivel (Collections Manager, Special Collections), to survey the Spanish Civil War Poster Collection (ALBA.GRAPHICS.001). This internship has helped me to prepare for a future career in special collections libraries, where I will be required to work with delicate material similar to what I see in this collection. I am very thankful for this opportunity and how it has allowed me to delve deeper into archival work with a hands-on approach.
In addition to working with the Preservation department, I have been lucky enough to work with the Archival Collections Management (ACM) and Special Collections departments, allowing me to see the different perspectives of handling a large and often complicated collection. This blog post will demonstrate the different ways in which these departments added to my learning experience and show some of the special facets of working with this collection in particular.
BUILDING THE DATABASE
Before I began surveying this collection, I had to create an infrastructure that would allow me to compile the data I would be collecting. I used the software AirTable to build this database. First, I had to move the data that had already been collected into my table. This came from Archives Space (AS), an archives information management software used by NYU Libraries. This had much of the preliminary data I would need to fact-check against in the survey, such as poster locations. After I had brought the AS data into the table, I created fields that would duplicate the AS fields but with the descriptor (survey) to show any differences. Additionally, I made new fields for things we might want to consider, such as condition and size.
UNIQUE POSTER FORMATS
“I tu? Que fas per la victoria?”

ALBA-ES 46, copy 4 “i tu?” (Photo by: M. Lindenburg)
The first set of posters that I want to discuss is ALBA-ES 45 and 46, also known as the two sides of “I tu? Que fas per la victoria?” a Catalan poster depicting a bloody soldier advocating for his audience to participate in the war, to support the cause. This collection has many copies, encapsulated (meaning this poster is inside a protective mylar sleeve) and unencapsulated, of this poster. The copies pictured below interest me because they were particularly delicate. You can tell from the photos that they were split into pieces, making flipping the posters to inspect the back difficult. These will need a lot of conservation work, although they may not be an immediate priority since so many copies are in fine condition.


ALBA-ES 45, copy 4 “i tu?” (Photos by: M. Lindenburg)
“Allisteu-vos a les milicies antifeixistes”
The poster “Allisteu-vos a les milicies antifeixistes,” belongs to a series of posters collected at The Franklin Institute in Philadelphia as part of a circulating exhibit.

ALBA-ES 116, recto, “Allisteu-vos a les milicies antifeixistes” (Photo by: M. Lindenburg)
These interest me because of how they were mounted for the exhibition. Rather than encapsulating the posters or leaving them untouched, this exhibitor chose to attach muslin across the back and use cardboard and grommets to hang them.

ALBA-ES 116, verso, “Allisteu-vos a les milicies antifeixistes” (Photo by: M. Lindenburg)
Annual Xmas Eve Ball
Poster ALBA-US-15, uses a mounting technique commonly used with posters associated with the Veterans of the Abraham Lincoln Brigade (VALB).


ALBA-US-15 (Photo by: M. Lindenburg)
It is mounted on a paperboard, which makes it somewhat heavy and unwieldy when grouped in folders. Take note of the headline of Zero Mostel, which shows the support the VALB received, even from celebrities.
THE INSCRIBED NAMES & WHO THEY WERE
Archie Brown is a signature I’ve encountered a lot in this collection.
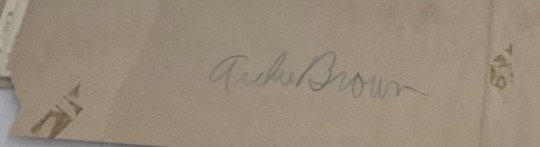
ALBA-ES-8 (Photo by: M. Lindenburg)
Brown was born in 1911 in Sioux City, Iowa. He was brought into the world of labor activism at an early age. 1934, he was arrested at a Young Communist League (YCL) event in San Pedro. But he continued with his activism despite this. In 1937, Brown got tuned into the struggles in Spain, particularly after his brother was recruited to the International Brigade. In San Francisco, Brown was denied a passport because of his radical reputation. So, he went to New York City and stowed away on a ship to France, where he would travel to Spain. He joined the forces of the Abraham Lincoln Brigade and, even after the war, continued to fight as a soldier and an activist.

Archie Brown, 1982 (Photo by: R. Bermack). Image Source.
Harry Hakam is an interesting character, partially because of his frequent correspondence with other members of the Abraham Lincoln Brigade.

ALBA-ES-77 (Photo by: M. Lindenburg)
Hakam was born in Brooklyn in 1913. In February 1937, he sailed to France, arriving in Spain in March of the same year. He served primarily as a battalion runner, returning to the US in 1938. However, it’s his correspondence that makes him shine. His collection marker (Hakam) is found on many posters that share others’ names, meaning he likely sent these posters back and forth between fellow members.

Harry Hakam. Image Source.
We don’t have as much information on Al Erdberg, but we do know from the Harry Hakam Papers (ALBA.046) and the fact that Erdberg shows up in the Hakam posters that they had correspondence. Erdberg was likely part of the Abraham Lincoln Brigade or a state-side supporter. This would be an interesting figure to research further.
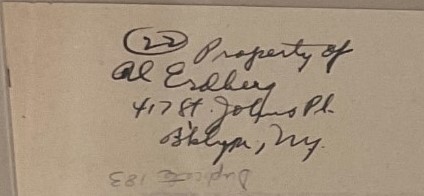
ALBA-ES-30 (Photo by: M. Lindenburg)
REHOUSING
A big problem I encountered when surveying these posters was with the housing rather than the posters themselves. Often, I encountered groups of ten or more posters in a folder, making the folder heavy and difficult to move. Further, if these posters are in mylar encapsulation, they become even heavier. To remedy this, the posters need to be rehoused into sturdier folders. I began some of this work with Laura McCann this semester, and the rehousing of the posters will continue through the summer.
VELCRO STICKERS
Some of the posters I found had velcro stickers left on the mylar encapsulation. These are likely from previous exhibition techniques, where the posters were attached to a wall using velcro. However, this technique is now deemed problematic, so Lindsey Tyne and I used a process to remove these stickers. We used a hot iron to heat small metal spatulas, which we then used to melt the adhesive of the sticker and lift the velcro off. This is a delicate process, but we got into a rhythm and moved fairly quickly.

Mia removing velcro (Photo by: L. Tyne)
This collection has taught me many things. I have learned to be patient, think carefully, and always be on the lookout for new observations, among many other smaller skills. If I were asked to advise someone starting a similar project, I encourage them to take note of their natural rhythm so that they can figure out which order of surveying works best for them to maximize efficiency. I would also tell them not to be afraid of asking questions, even if it’s clarifying something they think you already know. This has been an incredible experience, and I feel so lucky to have been a part of this collection. Thank you for taking the time to read my post!
#nyulibraries#nyuspecialcollections#libraryconservation#paperconservation#librarypreservation#preservingthepast
28 notes
·
View notes
Text
Some basic distinctions coming from my understanding of them as a millennial with "user knowledge" of IT. Many things may be wrong, I am doing this as a kind of test for myself and also as basic info for those who haven't really stopped to think about this.
- Internet: as the name says, it is a NET of INTERconnected computers. How does it exactly work, I am not sure, but some computers are servers, which means they hold information that other computers (not servers) can access. Your phone is not a computer and is not a server. I don't know if it could turn into one, I think it would require a lot of RAM memory and other things to power it. If a server disconnects, you can't access the information it has. If all servers of the internet disconnect, I guess there would be no internet??
- RAM memory: one of the important things that makes the computer run. Not the same as the hard disk or the other memory (I don't remember the name now). It doesn't save files or programs, it helps manage tasks when you use the computer.
- File: information you save in your computer. It can have different formats and uses, like a .doc Word document, a PDF (file), an image in .jpg, etc.
- Folder: a place to put several files. I am not sure if it is a program.
- Browser: it's a program that you use to access the internet. You can see webs, databases, blogs... I think you cannot access the internet without a browser or other specific program for it.
- Search engine: it's a website that allows you to look for information in a database or several. Google is the most famous one. It used to be good and is now shit. Libraries also have search engines to look for books. I think outside of the internet, your computer could potentially also have a search engine to find files and folders? Unsure about this last part.
- Corpus: this is very specific but very useful for translators. It has a lot of documents of specialised content that you can look up and compare. For instance, historical documents to look for an idiom in the 16th Century. Or texts in French and Italian to see how they refer to the same information and compare the way native speakers speak.
- Program: I think this can also be software (maybe not all software are programs but all programs are software?). A specific thing you install in your computer to do something. For instance, Adobe Photoshop. I am now unsure if Microsoft Office is a program or not. Feels like it is but...
- Application: tbh I am not sure what is the difference with a software or program, but I know they don't exactly do the same things even if it looks like it. I feel it's like a smaller version of a program that the user can modify less.
- Chat GPT: I have never used it but from what I hear, it's a program that you can access remotely through some website? A specialised search engine/corpus that makes up things based on the information it can access.
I have to say that making this list I can see why people confuse program with website with browser with internet. Many programs can be accessed remotely from a website that you open in a browser, or maybe with an app. And then there's the whole thing of the Web 2.0, which is mainly all social media websites and I don't fully understand.
Feel free to comment and correct stuff.
3 notes
·
View notes
Note
Do you have any tips for an aspiring librarian who’s going to college in a few months?
my first instinct upon reading this ask was to give you some good but fairly generic advice about getting library experience via your school's work study program, exploring different career paths within the library umbrella, interning at your local public library if possible, and so on & so forth
but then i realized that that is the sort of information you can find pretty much anywhere & i will instead give you my personal insight into what has helped me be successful in my current library role.
do whatever weird shit you are passionate about with your whole heart & soul, because you will learn invaluable skills without even intending to
what i mean by all that is that my current position as the assistant manager of a small, rural library branch is really just twenty-nine different jobs in a trench coat. i'm alternately an it specialist, a graphic designer, a career counselor, a preschool teacher, a customer service agent, or whatever else a particular situation demands.
and so much of my current skillset is a result of spending my high school & college years doing random nerd bullshit on the internet.
i'm dead serious. my ability to troubleshoot basically any possible tech issue, my knowledge of graphic design software, my extensive research capabilities, my written communication skills, and my absolute certainty that if i don't know how to do something, i can figure it out if you give me fifteen minutes to poke around on google are all products not of my formal education or work experience, but of the countless hours i have devoted to online nerd bullshit
enjoy college. explore your passions. get super into modding minecraft, or archiving lost media, or formatting fanzines, or literally whatever niche nonsense speaks to you. librarianship is a career of quick thinking & problem solving skills, and you'll best develop those doing something you truly care about
in the words of the mountain goats, the things you do for love are gonna come back to you one by one
#hope this makes sense!!!!! it's almost 1 am and i'm in the chronic illness flare from hell#and thus am largely incoherent!!#enjoy insomnia!liv's advice#asked and answered#Anonymous#library life
27 notes
·
View notes
Text
Fowtools - Silver
GUIDs, or Globally Unique Identifiers, are 128-bit numbers that are generated to ensure uniqueness in various applications. They are also referred to as UUIDs, or Universally Unique Identifiers. The purpose of generating GUIDs is to provide a unique identification number that can be used to identify resources such as people, files, web pages, and even colors. Unlike regular registration numbers, which start counting at 1 and can overlap, guid generator in a way that ensures their uniqueness. The use of GUIDs has become increasingly popular in software development, where unique identification numbers are essential for efficient data management. There are different methods of generating GUIDs. One method is random generation, where the system's random-number generator is used to create a 128-bit number. Another method is time-based generation, where a GUID is created based on the current time. Additionally, hardware-based generation involves using a combination of hardware-based information, such as the MAC address, to generate a GUID. These methods ensure that GUIDs are unique and can be used for efficient data management. GUIDs have numerous applications in software development. They are commonly used in enterprise software development in languages such as C# and Java. In.NET Core, GUIDs are generated by creating a random number of 128 bits and performing a couple of bitwise operations. GUIDs are also used to identify hardware, software, and network resources. Moreover, almost all major programming languages have built-in libraries to generate GUIDs, making it easy for programmers to ensure uniqueness in their applications. The use of GUIDs has become essential in modern software development, where efficient data management is crucial for the success of any project.
297 notes
·
View notes
Text
How to Access Canva Premium for Free or Cheap in 2025
Affordable Ways to Access Canva Premium in 2025
In 2025, visually compelling content is essential—whether you're growing a brand, teaching students, or raising awareness for a cause. That's why many creators turn to Canva Premium. This upgraded version of the free design platform delivers advanced features that boost efficiency and creativity. While the full plan carries a cost, there are several practical and budget-friendly methods to access Canva Premium without overpaying. Let’s explore the best options available this year.
Why Choose Canva Premium?
Before diving into cost-saving methods, it's important to understand why Canva Premium stands out. The upgraded toolkit empowers users with time-saving and professional design features that aren't available in the free version.
Key features include:
Magic Resize: Instantly adapt designs for different platforms.
Background Remover: Remove image backgrounds with one click.
Brand Kit: Keep your fonts, logos, and color palette organized.
1TB Cloud Storage: Store and manage a vast library of design assets.
Access to 100M+ Premium Assets: Choose from exclusive images, templates, and videos.
With such a powerful suite of tools, it's easy to see why Canva Premium is a must-have for serious creators. Now, let’s explore how you can get these features at a fraction of the cost—or even for free.
1. Start with a 30-Day Free Trial
One of the easiest ways to try Canva Premium is by activating the free 30-day trial. This is a great choice if you're starting a campaign, updating your portfolio, or testing design tools for a new project.
To activate:
Head over to Canva’s pricing page.
Click “Start Free Trial” under the Premium section.
Sign in or register for an account.
Enter your billing information (be sure to cancel before the trial ends if you don’t want to continue).
This trial grants full access to all Canva Pro features, letting you evaluate its value with zero upfront cost.
2. Free Access for Students and Teachers
If you’re involved in education, Canva has an excellent offer for you. Canva Premium is completely free for eligible students and educators through its Canva for Education program.
Here’s how to apply:
Visit the Canva for Education page.
Register using your school-affiliated email address.
Provide verification documents if required.
Once verified, you'll gain access to a wealth of design tools that enhance learning and creativity. From lesson plans to digital presentations, Canva Premium empowers both students and teachers to create with confidence.
3. Canva Premium for Nonprofit Organizations
Nonprofits often operate on tight budgets. Thankfully, Canva supports these missions by offering Canva Premium at no cost to verified nonprofit organizations.
To apply:
Go to Canva’s Nonprofit Program page.
Submit proof of nonprofit status.
Wait for verification and approval.
With access to Canva Pro tools, nonprofits can create impactful visuals for fundraising, events, and advocacy—without paying for expensive software.
4. Purchase from Verified Discount Resellers
If you don’t qualify for the free educational or nonprofit plans, you can still get Canva Premium at a reduced rate. Trusted resellers like Saasyto offer discounted subscriptions, making this an attractive option for freelancers, marketers, and small businesses.
Here’s what to do:
Visit Saasyto.com and search for Canva Premium deals.
Choose a monthly or annual subscription that fits your needs.
Follow the site’s instructions to activate your account.
Although it’s not free, this method can cut your design costs significantly over time while giving you full access to premium tools.
Make the Most of Canva Premium—Affordably
In conclusion, creating top-notch visual content no longer has to be expensive. Whether you’re an educator, nonprofit worker, or content creator, there’s a way to access Canva Premium without exceeding your budget. From free trials to education plans and nonprofit programs, several legitimate methods exist to help you unlock professional-grade tools.
Even if you're paying, discounted options from authorized resellers can make Canva Pro features accessible at a lower cost. By selecting the option that matches your needs, you can elevate your designs and stand out in today’s visually competitive world—without breaking the bank.
2 notes
·
View notes
Text
Python Programming Language: A Comprehensive Guide
Python is one of the maximum widely used and hastily growing programming languages within the world. Known for its simplicity, versatility, and great ecosystem, Python has become the cross-to desire for beginners, professionals, and organizations across industries.
What is Python used for

🐍 What is Python?
Python is a excessive-stage, interpreted, fashionable-purpose programming language. The language emphasizes clarity, concise syntax, and code simplicity, making it an excellent device for the whole lot from web development to synthetic intelligence.
Its syntax is designed to be readable and easy, regularly described as being near the English language. This ease of information has led Python to be adopted no longer simplest through programmers but also by way of scientists, mathematicians, and analysts who may not have a formal heritage in software engineering.
📜 Brief History of Python
Late Nineteen Eighties: Guido van Rossum starts work on Python as a hobby task.
1991: Python zero.9.0 is released, presenting classes, functions, and exception managing.
2000: Python 2.Zero is launched, introducing capabilities like list comprehensions and rubbish collection.
2008: Python 3.Zero is launched with considerable upgrades but breaks backward compatibility.
2024: Python three.12 is the modern day strong model, enhancing performance and typing support.
⭐ Key Features of Python
Easy to Learn and Use:
Python's syntax is simple and similar to English, making it a high-quality first programming language.
Interpreted Language:
Python isn't always compiled into device code; it's far done line by using line the usage of an interpreter, which makes debugging less complicated.
Cross-Platform:
Python code runs on Windows, macOS, Linux, and even cell devices and embedded structures.
Dynamic Typing:
Variables don’t require explicit type declarations; types are decided at runtime.
Object-Oriented and Functional:
Python helps each item-orientated programming (OOP) and practical programming paradigms.
Extensive Standard Library:
Python includes a rich set of built-in modules for string operations, report I/O, databases, networking, and more.
Huge Ecosystem of Libraries:
From data technological know-how to net development, Python's atmosphere consists of thousands of programs like NumPy, pandas, TensorFlow, Flask, Django, and many greater.
📌 Basic Python Syntax
Here's an instance of a easy Python program:
python
Copy
Edit
def greet(call):
print(f"Hello, call!")
greet("Alice")
Output:
Copy
Edit
Hello, Alice!
Key Syntax Elements:
Indentation is used to define blocks (no curly braces like in different languages).
Variables are declared via task: x = 5
Comments use #:
# This is a remark
Print Function:
print("Hello")
📊 Python Data Types
Python has several built-in data kinds:
Numeric: int, go with the flow, complicated
Text: str
Boolean: bool (True, False)
Sequence: listing, tuple, range
Mapping: dict
Set Types: set, frozenset
Example:
python
Copy
Edit
age = 25 # int
name = "John" # str
top = 5.Nine # drift
is_student = True # bool
colors = ["red", "green", "blue"] # listing
🔁 Control Structures
Conditional Statements:
python
Copy
Edit
if age > 18:
print("Adult")
elif age == 18:
print("Just became an person")
else:
print("Minor")
Loops:
python
Copy
Edit
for color in hues:
print(coloration)
while age < 30:
age += 1
🔧 Functions and Modules
Defining a Function:
python
Copy
Edit
def upload(a, b):
return a + b
Importing a Module:
python
Copy
Edit
import math
print(math.Sqrt(sixteen)) # Output: four.0
🗂️ Object-Oriented Programming (OOP)
Python supports OOP functions such as lessons, inheritance, and encapsulation.
Python
Copy
Edit
elegance Animal:
def __init__(self, call):
self.Call = name
def communicate(self):
print(f"self.Call makes a valid")
dog = Animal("Dog")
dog.Speak() # Output: Dog makes a legitimate
🧠 Applications of Python
Python is used in nearly each area of era:
1. Web Development
Frameworks like Django, Flask, and FastAPI make Python fantastic for building scalable web programs.
2. Data Science & Analytics
Libraries like pandas, NumPy, and Matplotlib permit for data manipulation, evaluation, and visualization.
Three. Machine Learning & AI
Python is the dominant language for AI, way to TensorFlow, PyTorch, scikit-research, and Keras.
4. Automation & Scripting
Python is extensively used for automating tasks like file managing, device tracking, and data scraping.
Five. Game Development
Frameworks like Pygame allow builders to build simple 2D games.
6. Desktop Applications
With libraries like Tkinter and PyQt, Python may be used to create cross-platform computing device apps.
7. Cybersecurity
Python is often used to write security equipment, penetration trying out scripts, and make the most development.
📚 Popular Python Libraries
NumPy: Numerical computing
pandas: Data analysis
Matplotlib / Seaborn: Visualization
scikit-study: Machine mastering
BeautifulSoup / Scrapy: Web scraping
Flask / Django: Web frameworks
OpenCV: Image processing
PyTorch / TensorFlow: Deep mastering
SQLAlchemy: Database ORM
💻 Python Tools and IDEs
Popular environments and tools for writing Python code encompass:
PyCharm: Full-featured Python IDE.
VS Code: Lightweight and extensible editor.
Jupyter Notebook: Interactive environment for statistics technological know-how and studies.
IDLE: Python’s default editor.
🔐 Strengths of Python
Easy to study and write
Large community and wealthy documentation
Extensive 0.33-birthday celebration libraries
Strong support for clinical computing and AI
Cross-platform compatibility
⚠️ Limitations of Python
Slower than compiled languages like C/C++
Not perfect for mobile app improvement
High memory usage in massive-scale packages
GIL (Global Interpreter Lock) restricts genuine multithreading in CPython
🧭 Learning Path for Python Beginners
Learn variables, facts types, and control glide.
Practice features and loops.
Understand modules and report coping with.
Explore OOP concepts.
Work on small initiatives (e.G., calculator, to-do app).
Dive into unique areas like statistics technological know-how, automation, or web development.
#What is Python used for#college students learn python#online course python#offline python course institute#python jobs in information technology
2 notes
·
View notes
Text
Why Sabaragamuwa University is a Great Choice.
Sabaragamuwa University of Sri Lanka (SUSL) is increasingly recognized for its technological advancement and innovation-driven environment, making it one of the leading universities in Sri Lanka in terms of technology. Here are the key reasons why SUSL stands out technologically.

Here’s why SUSL stands out as a technological powerhouse among Sri Lankan universities:
🔧1. Faculty of Technology
SUSL established a dedicated Faculty of Technology to meet the demand for tech-skilled graduates. It offers degree programs such as:
BTech in Information and Communication Technology
BTech in Engineering Technology
These programs combine practical experience in labs, workshops and real-world projects with a strong theoretical foundation.
🖥️2. Advanced IT Infrastructure
SUSL has modern computer labs, smart classrooms, and high-speed internet access across campus.
A robust Learning Management System (LMS) supports online learning and hybrid education models.
Students and lecturers use tools like Moodle, Zoom, and Google Classroom effectively.
🤖 3. Innovation & AI Research Support
SUSL promotes AI, Machine Learning, IoT, and Data Science in student research and final-year projects.
Competitions like Hackathons and Innovative Research Symposia encourage tech-driven solutions.
Students develop apps, smart systems, and automation tools (e.g., Ceylon Power Tracker project).
🌐 4. Industry Collaboration and Internships
SUSL connects students with the tech industry through:
Internships at leading tech firms
Workshops led by industry experts
Collaborative R&D projects with government and private sector entities
These connections help students gain hands-on experience in areas such as software engineering, networking, and data analytics that make them highly employable after graduation.
💡 5. Smart Campus Initiatives
SUSL is evolving into a Smart University, introducing systems that streamline academic life:
Digital student portals
Online registration and results systems
E-library and remote resource access
Campus Wi-Fi for academic use
These initiatives improve the student experience and create an efficient, technology-enabled environment.
🎓 6. Research in Emerging Technologies
The university is involved in pioneering research across emerging technological fields, including:
Agricultural tech (AgriTech)
Environmental monitoring using sensors
Renewable energy systems
Students and faculty publish research in international journals and participate in global tech events.
🏆 7. Recognition in National Competitions
SUSL students often reach fina rounds or win national competitions in coding, robotics, AI, and IoT innovation.
Faculty members are invited as tech advisors and conference speakers, reinforcing the university's expertise.
Sabaragamuwa University is actively shaping the future not only with technology, but by integrating technology into education, research and operations. This makes it a technological leader among Sri Lankan Universities. Visit the official university site here: Home | SUSL
2 notes
·
View notes
Text
Setting Up Calibre + FanFicFare
I've talked before about using Calibre to download fic off of fiction archives, so that's where I decided to start with this series. If you're interested in learning more about how to download fanfic for offline reading/local archiving, then watch the #ficArchiving tag. And if you're not interested in seeing these posts then that's also the tag to block.
Edit (3/22/25) - I've updated the post due to changes in how FanFicFare works with regards to site ratings metadata - the type of column this information needs to be stored in has changed as it no longer works with selectable, pre-set options as originally outlined. Also adding note that additional plugins are required to make FanFicFare's anthology options available.
(Since this is a long post, I'm sticking it under the cut.)
First some background on what Calibre is. It's an open source eBook manager and is really quite versatile for it's usage, thanks in part to the robust library of plugins that it utilizes. The default Calibre app comes bundled not only with management software but an e-reader, server options for locally hosting your library (or libraries), and a whole host of options for managing metadata. Default metadata being tracked include title, author, series, publishing data, synopsis, and tags, but you can manually add columns for any additional data you want - which comes in handy when managing a local fanfiction archive. You can add columns for the fandom the fic is written for, the included ships, characters, completion status, whether it's a single fic or a series turned into an anthology. If the information is useful for you, then you can add a method to track it.
Now, for what Calibre does not do. Because it only runs on Windows/Mac/Linux systems - aka it only runs on a PC - you cannot install it on your phone or tablet. There's no official Calibre apps for Android or iPhones either, though there are unofficial ones that can work with Calibre in server mode. I've never tried the unofficial apps, however, as they tend to cost money that I don't really think they're worth. That's largely because in server mode you can log in to the local instance of Calibre with a regular old browser. Just book mark the page and, so long as your on a network where the local instance is running, your phone or tablet will have access to every book on your Calibre's library (or libraries, depending on how you set things up). You can then either read the eBook directly on the browser or, my preferred method, download the file and read it on the e-reader app of your choice. (You can also make the server available outside your local network, but I've never bothered to learn to set that up.)
Given everything Calibre can do, I'm not particularly bothered by the lack of official apps for phones or tablets - as far as I'm concerned it doesn't need one.
This post is going to be focused on using Calibre for fanfictions specifically, but if you want more information on the other things it can be used for, the Calibre FAQ pages are quite extensive and goes into detail about it's format support, eBook conversion abilities, device integration, news download services, library management, and more.
Alrighty, so first thing you'll want to do is download the version of Calibre that works with your computer. You can also create a portable version that runs off a USB drive if you prefer. Once you've downloaded and installed Calibre, it's time to decide where you want your fanfics to live. Do you want all your eBooks to live in one spot or do you want separate libraries for fanfiction vs original fiction? Since I like to collect more metadata for my fanfic collection than for my regular eBooks - and then completely different extra data for tracking my Star Trek books, or Doctor Who books - I like to have multiple libraries for managing my eBook files. And Calibre makes managing multiple libraries at one time very, very simple.
In Calibre's header there are going to be a lot of icons - I’ve modified the header toolbar for my Calibre instance, but most of the default options are still visible in the picture below.

Specifically you want the one that looks like four books leaning against each other on a shelf. It should have the default library name displayed there - Calibre Library.

Clicking on that will open the menu used for maintaining multiple libraries. While the application only sets up one library by default, it can link to multiple libraries located anywhere on your computer's filesystem. Since I like to use Dropbox to back up my libraries, I usually locate mine in my local Dropbox folder. You can import existing libraries from one instance of Calibre to another, which makes moving from one computer to another, or maintaining the same library across multiple computers, very simple.
Let’s assume you want to have a separate library just for fanfiction. To that end, you'll want the first option on the menu - labeled "Switch/create library".
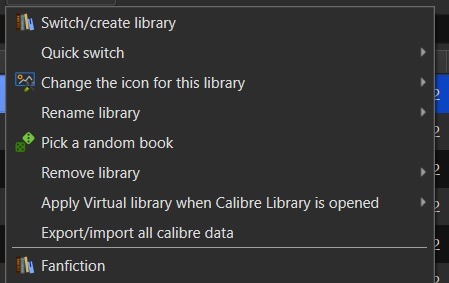
From there you'll want to select the folder - or create a new folder - with the name of the library you want to use in Calibre. I'd recommend something straightforward and call it "Fanfiction". Then you'll select the radio button labeled "Create an empty library at the new location".
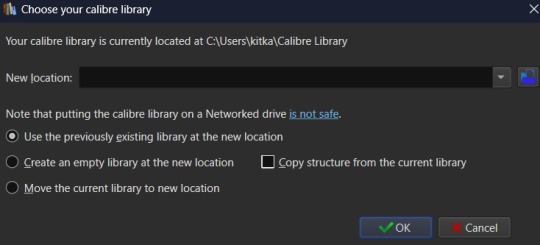
You don't need to copy the current library's structure since every library is created with Calibre's default structure and you won't have added any specialized data tracking at this point to copy over. Once you've set your library location and selected the option for creating a new library, hit the OK button. It'll create the new library and immediately change so that it's managing that library instance instead of the default Calibre Library instance.
If you aren't sure which library is currently open in the Calibre app, then the icon with the four books in the header is where you want to check. It will always be labeled with the name of the currently open library. The most recently opened libraries will be listed at the bottom of the menu opened by that icon for easy switching between libraries and the "Quick switch" option will list all the available libraries registered to your Calibre instance. The icon with the four books is the default icon for a library - if you change the icon for a library then keep in mind that the icon will change in the header when the library is the currently selected on.
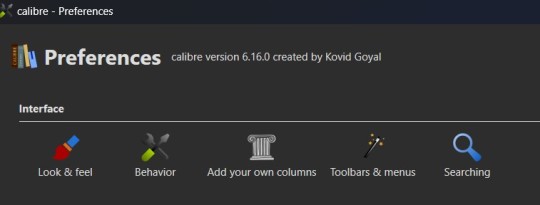
Alright, so step one is completed. You now have a dedicated Fanfiction library for maintaining any fics you choose to download. But the default metadata being tracked for the books isn't as robust as it could be. Time to bulk that information up. You'll want to look back at the header again, this time for an icon that looks like a crossed screwdriver and wrench. It's labeled Preferences. Click on that in the center of the icon to bring up the Preferences modal instead of just the menu (which you can access by clicking the associated down arrow beside the icon instead).

The Preferences modal is where you can access options to tweak the appearance, behavior, and various other functions of Calibre. And I certainly encourage experimenting with the application as it can be customized to your heart's desire to make it meet your accessibility needs. For now, however, we're only interested in the "Add your own columns" option on the top layer of the modal, under "Interface". The associated icon for the "Add your own columns" option is, appropriately, a small Greek column.
This will open the column maintenance modal which presents with a table listing all the existing columns - these all track some kind of metadata for the ebook - and will have checkboxes on the left most of the table indicating whether these columns are displayed on the main interface or are accessible only through the Edit Metadata modal. (We'll get to the Edit Metadata modal later.)
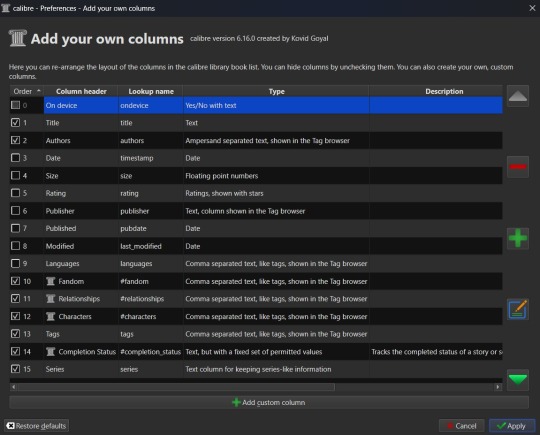
To the right of the table are options for moving a column up or down in the list order, a minus sign used for deleting unnecessary columns, a plus sign for adding new columns, and an edit option for editing existing columns. I'd recommend unchecking columns you don't want displayed in the main table, but not deleting columns. That way you can still store the metadata - and search on it - in that column, but it won't clutter up the main page.
Alright, so now it's time to add some columns. Click the plus button to bring up a custom column form.
The "Lookup name" is what Calibre uses to do searches, so it needs to be something that can be safely saved in a database. "Column heading" is the pretty name that displays either as a column heading in the main Calibre table or as the metadata entry name in the "Edit metadata" modal. "Column type" has a dropdown of the different types of metadata that can be stored in a column and has an option to show checkmarks (a checkbox) for additional true/false parsing. There are a lot of options in the dropdown for metadata types, some of which will offer up additional column creation form options, and this is something that cannot be changed once a column has been saved. If you select the wrong one and realize it later, you'll have to delete the column and create a new one to take it's place. "Description" is there to help clarify things if the "Column header" isn't descriptive enough to make clear what the metadata being tracked by the column is for. And, finally, you can use the optional "Default value" if you want that column to be auto filled with a value you can update later.
Note that the form may add further fields to it, depending on the selected “Column type”.
Since this is going to be tracking fanfiction metadata, some good ideas for creating tag-type metadata columns would be "Fandom", "Ship", and "Characters". You might also consider "Rating", "Content Warnings", “Chapters”, or other data which might be better suited for other types of metadata. We'll start with the "Fandom" column.
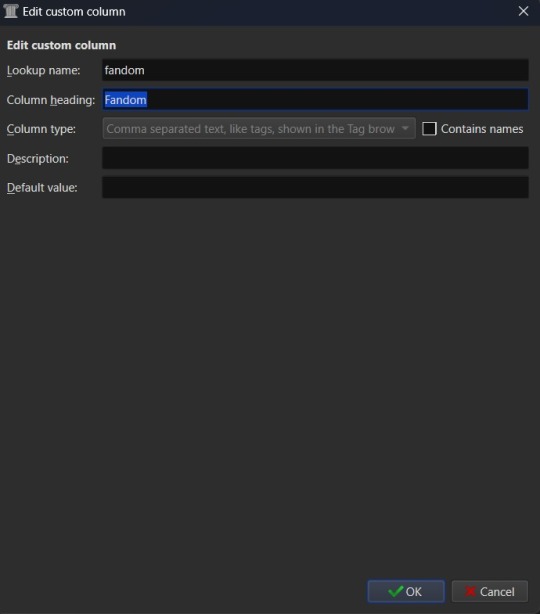
You'll want to set the "Lookup name" to "fandom" (note the lowercase here), the "Column heading" to "Fandom" (uppercase this time), and the "Column type" to "Comma separated text, like tags, shown in the Tag browser". The "Description" is optional, so add what you like (or don't) there and the same goes for "Default value", which you might want to list as "Unsorted" or simply leave blank to indicate the fandom is currently unlisted. Once you're satisfied with your selections, click "OK" and you can either then "Apply" your settings changes or continue on to add more columns.
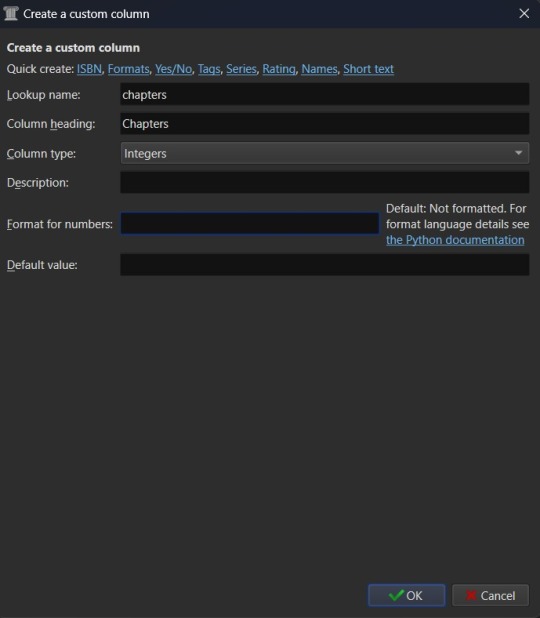
The "Ship" and "Character" data also work best as comma separated data, so I recommend making those columns in the same fashion as the "Fandom" column. “Chapters” you may want to add as an integer column, shown below.
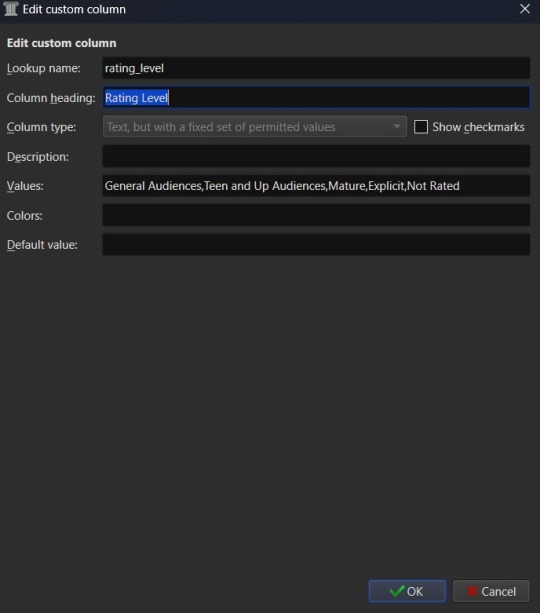
If you're wanting to add "Rating" as a column, then you might want to have specific options for rating a fic, such as limiting the options to the same ones used by Ao3. To this end, you'd fill out the form more like this. "Lookup name" as "rating_level" so as not to confuse it with the existing rating column for star ratings, "Column heading" as "Rating" or maybe "Rating Level", and "Column type" as "Text, but with a fixed set of permitted values". This "Column type" selection will bring up two more inputs on the column creation form - "Values" and "Colors". These two inputs work together and can be edited later. In the "Values" input, you can add a list of comma separated values. In this case the list for "Values" would look like "General Audiences, Teen and Up Audiences, Mature, Explicit, Not Rated". "Colors" is an optional list that will assign a different color to every option on the "Values" list that corresponds to an entry in the "Colors" list. So if you want General Audiences to be blue and no other option to have a color, you'd list "blue" for colors. Or "blue, blue, red, red, red" to have the first to options on the "Values" list as blue and the last three as red. You can play around with this more or leave it blank to have the options all be the same default colors.
Once you've finalized your selections, hit OK to create the column.
Edit (3/22/25) - FanFicFare currently no longer accurately scrapes ratings data into a column setup as "Text, but with a fixed set of permitted values". Instead you will need to use the "Comma separated text, like tags, shown in the Tag browser" option. Fixed values should still work for things like fic status, which have the Completed and In-Progress settings only, but changes either to FanFicFare or Ao3 (and thus any Ao3 clones) have made the fixed values option for ratings fail to correctly connect site tags to the preset values. The good news is that this will now set the ratings for an anthology fic made from a series page with the ratings of all fics within the series - so if some are General Audiences and others are Mature within a single anthology, that will be accurately reflected in your captured metadata after downloading a fic.
After creating all your new columns and selecting which ones you want present on the main table, hit the "Apply" button. You'll likely be prompted to restart Calibre. Do so and when the program reloads it should display the main table with all the columns exactly how you set them up. Which means step two is complete. At this point if you have any fanfiction eBooks already, you can drag and drop them into the table from folder files or use the "Add books" option at the left most side of the header toolbar to start adding those. You can manually update the metadata either by clicking on newly added book and then selecting a column or by clicking the book and then selecting the "Edit metadata" option in the header. So now it's time to take a quick look at the metadata editor modal.
By default, the metadata modal will only have one screen but, because you've added custom columns, there should be tabs at the top. One for "Basic metadata" and one for "Custom metadata". The "Basic metadata" includes options for title, title sort, author(s), author sort, series, series number, file versions (for tracking if you have epub, mobi, pdf, etc files of the same book), cover management options, the star-based rating system, tags, ids, upload date, published date, associated publisher, languages, and "Comments" which is where the story summery/synopsis should go. For regular, non-fanfiction eBooks, you might also take note of the "Download metadata" button which allows for scrapping official metadata off of sites like Barnes and Noble, Amazon, or other eBook sellers or archives.
The "Custom metadata" is where your custom column data will be found. It should be found at the top of the page and fill space downwards with however many custom columns you've added. Inputs that allow for comma separated values will still have a dropdown option associated to allow adding tags you've entered previously for other ebooks. Columns that only allow using preselected data are more likely to appear as select boxes or other form types. This is where you might notice you created a column type incorrectly, so make sure to check over all the data entry options for each metadata type you're collecting. If it doesn't look like it's set up the way you wanted it to be, you can go back to the column editing modal and try again.

The big draw of using Calibre to manage fanfiction eBooks, however, is being able to use Calibre to download the fanfictions from the web and convert them to eBook format for you. And that's where Calibre's plugin library comes in handy.
If you were making any edits to an existing eBook, save those and close the metadata editor. Head back over to the Preferences modal and check the Advanced settings options at the bottom of the modal. There should be a green puzzle piece icon labeled "Plugins" - click that to open the Plugins modal.
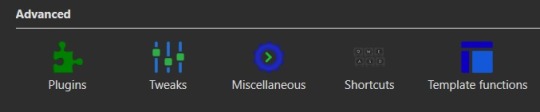
It will take you to a table used for monitoring and controlling existing plugins and, yes, it does already have 'plugins' installed. These are really more the application's default modules, but because of how Calibre works they can be edited and controlled in the same way that external plugins are. At the bottom of the page you'll see three buttons - "Get new plugins", "Check for updated plugins", and "Load plugin from file". These are concerned with the external plugins that you can add to Calibre. "Get new plugins" will allow you search through the official library of third party plugins available to Calibre - plugins that the Calibre team have vetted to confirm aren't actually malware. But they're by no means the only plugins you can install, as the "Load plugin from file" will allow you to load pretty much any plugin you want to. Such as a plugin for, say… stripping DRM off of purchased eBooks.

In this case, you want to select the "Get new plugins" option. This brings up a modal for User plugins and the displayed list will automatically be filtered by available plugins that have not yet been installed. You can filter this list further by typing "FanFicFare" into the "Filter by name" text input.
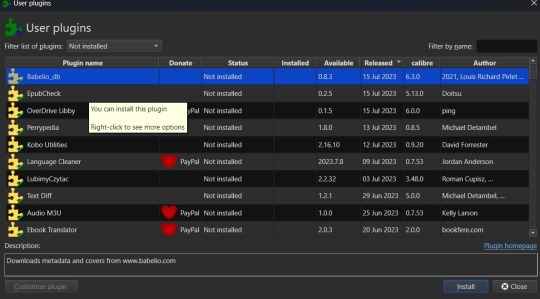
You can then select the FanFicFare plugin and install it. After installing the plugin, you should select the option to restart the application, to ensure that it installed properly. I'd also recommend adding the FanFicFare icon to the optional bottom toolbar instead of the header toolbar, since that'll make it much easier to find since, unless you add more plugins and assign them to that toolbar, it should be the only option on the bar right now.
Edit (3/22/25) - In addition to the FanFicFare plugin, you'll want to include two additional plugins so that FanFicFare can make it's anthology options available. These two plugins are EpubMerge and EpubSplit. These plugins can be used on their own to create anthologies by creating a new epub file from multiple epubs or splitting anthology books into separate epubs for each book contained within. Without these plugins FanFicFare's anthology options will be hidden, as it utilizes them for merging fics in a series together after downloading them separately.
So, full disclosure, you don't need Calibre to run FanFicFare. You could download it and run it from a command line interface instead. However, I prefer it's Calibre interface, especially since it really lets you take advantage of the best Calibre has to offer in metadata tracking, as it can be set up through Calibre to auto fill those columns I walked you through setting up earlier. But I'll get to more on that in a minute.Once Calibre has restarted, you should now have FanFicFare available on one of your toolbars. It's associated icon is a green text bubble with the letters "FF" in it pointing down at a picture of a book.

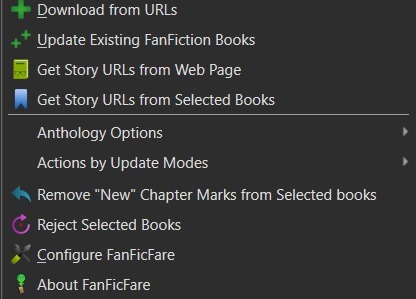
It'll have a small down arrow next to it, which you'll want to select in order to bring up FanFicFare's menu. At this point you can start downloading fics if you want - but let's do a little customizing first. Select the "Configure FanFicFare" option to bring up the configuration modal.
So this modal has a lot going on. And I do encourage doing some exploration on your own, because FanFicFare is a powerful tool made all the more powerful here in conjunction with Calibre's built in tools. Cover generation is very useful, "Reading lists" can be used to auto send new books to any devices you've linked to Calibre when they're connected to the computer, you can tie into email accounts to pull fanfics from email or pull URL links for downloading... there is just so much this plugin can do.
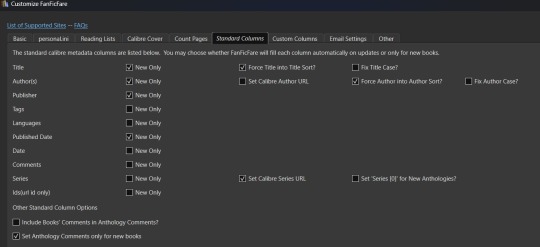
For now, however, we're interested in the column related options. First, check out the tab for "Standard Columns". Look over the options there carefully to make sure that the default settings are actually what you want. They're pretty straight foward - most are determining whether the metadata gets scraped and updated every time you update a fanfic eBook or if they're only scraped for new books. The rest have to do with title and author sorting, setting series related data, and setting the comment data for anthologies.
Once you've set that data how you want, head over to the "Custom Columns" tab where things get more interesting.
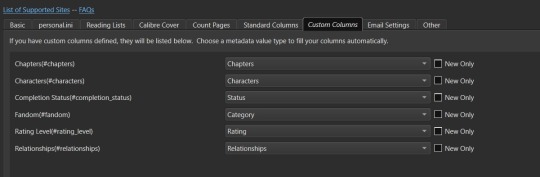
You should now be looking at a list of all those custom columns you created earlier, in alphabetical order. Each column will have a corresponding select box with nothing selected and an unchecked checkbox marked "New Only". This works in a pretty straightforward manner. Let's use "Fandom" as the example. Click the associated select box to open the dropdown and you'll see a bunch of potential metadata that FanFicFare scrapes listed there. It'll all go into the default tags column - found over in the "Standard Columns" section - but you can also parse it out to specific custom columns here. It might give you a few ideas for more columns you want to add for metadata sorting purposes. "Fandom" you'll want to link to "Category". I left "New Only" unchecked so that if I update an eBook later and it has a new fandom attached to the fic then that new metadata will be picked up and added to my Fandom tags for the fic.
Go through each custom column and set them up to be auto filled with the data you think fits it best. Select OK to save your changes and congratulations, this library has now been set up to import fanfiction.
Do keep in mind that FanFicFare's settings are on a per-library basis. So if you decide to do a separate library for different types of fanfics then you'll need to configure FanFicFare separate for every library. You may want separate libraries for different repositories, for example. Though FanFicFare is often smart enough to recognize when it already has an eBook version of a fanfiction from one repository - such as FFnet - when trying to download the same fic from another place - like Ao3.
You may need to make changes later to the personal.ini file associated with the library (which is also set up on a per-library basis) but I'll write up a separate post for that later. While sites protected by Cloud Flare more stringent protections will likely result in 403 responses and failed downloads, most fanfiction sites are going to work with the default FanFicFare settings. You could head over to, say, Archive of Our Own or Twisting the Hellmouth and grab a URL for a story from there. Or a URL for a series, which has links to multiple stories.
Now that the set up is done, it's time for the fun part. Downloading and maintaining fanfiction in your library. I'll be using a few of my fanfictions on Ao3 as example URLs. Awaken, which is already in my fanfiction library. What Balance Means, which is not already in my library. And the two series Hartmonfest 2023 and Eobard vs Eobard.
We'll start with the single URL uploads.
Click on the FanFicFare down arrow to bring up the menu and select the first option on the menu, labeled "Download from URLs". If you have a URL in your clipboard and have the option to grab URLs from the clipboard selected in the FanFicFare configuration (it's a default option, so you most likely do) then you should see that URL prepopulated in the text area when the Story URLs modal loads. You can add more URLs, one per line, to this text area and when you select OK each one will be individually downloaded as a separate epub file. For multi-chapter fics you only need to provide the url for the first chapter. FanFicFare will be able to detect the additional chapters and download them into the same epub file as the first chapter. All providing additional chapter URLs will do is lead to FanFicFare attempting to create multiple epubs of the same fanfic.
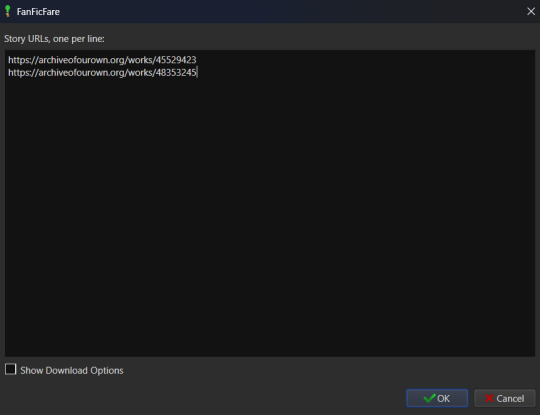
Once you've added your list of URLs to the text area, select OK. FanFicFare will do the rest, fetching metadata for the fic (or fics) and compiling the epub file(s). When it's finished compiling the data but hasn't officially saved the epubs, it will pop up a message letting you know how many "good" and "bad" entries it found.
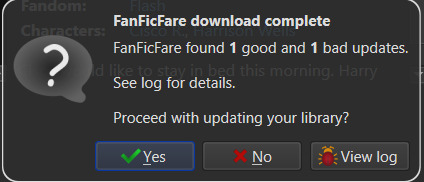
"Good" means it made an epub file and it's good to go. "Bad" could mean that you've already got the fanfic downloaded and no updates - such as new chapters - were available. Or it could mean that it failed to grab the web pages for whatever reason… like Cloud Flare blocking the download. You can go forward with the download at this point, adding the good epubs to your library. Or you could cancel the download, meaning none of the epubs are saved. Before choosing one of those options you can also choose to look at the job output, seen in the pop up as a button labeled "View log". This will display a list of every url you tried to download a fanfic for and information on either it's success or why it failed, the associated URL, and how many chapters were downloaded.
Since I already had Awaken downloaded and there have been no updates since the last time I downloaded it, that is the bad update from my list and the result I was expecting. What Balance Means hadn't been downloaded before, so it was the expected good update. Once Yes is selected in the dialog, the new fanfiction eBooks will be added to the library and will appear at the top of the main list in the application.
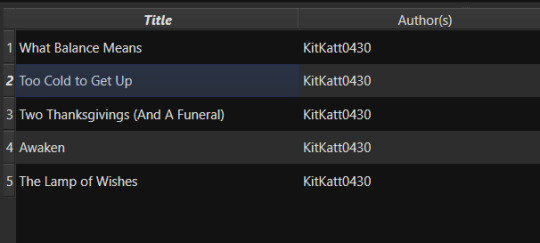
That's great for updating one fic at a time or copy-pasting in a list of fanfictions, but let's get ambitious. Maybe you want to import an entire page of bookmarked fanfictions at once or a series of fanfictions as individual books. Instead of copying every single URL by hand, you can take the URL for the series main page or the Bookmarks URL. With that URL copied, you can head over to the FanFicFare menu again, but this time select the option "Get Story URLs from Web Page"
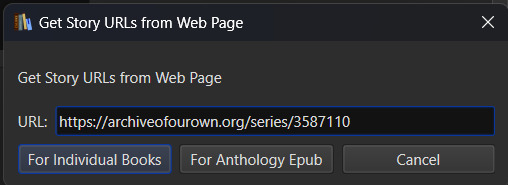
The modal that pops up only allows for inputting one URL - the URL for the page you want it to scour for fanfic URLs. Once you've inputted that URL click the button labeled "For Individual Books." It might take a bit but it's going to pull up the same Story URLs modal from before, this time prepopulated with every URL from the page you gave it. Pretty cool, right? Click OK and watch it run the job just like before.
I gave it the URL for my Hartmonfest 2023 series, which is a complete series and it downloaded all three books. Once they're populated on the list, I could scroll over to the Series column to see that they all are listed as being part of the Hartmonfest 2023 series in the same series order they're listed in on Ao3.
However, what if I'm uploading an unfinished series, like Eobard vs Eobard, and want to be able to track when it updates later on? Single books can track when new chapters are updated; is there any way to do the same thing but on a larger scale? The answer is yes, but you have to upload the series as an anthology.
Head back to the "Get Story URLs from Web Page" option on the FanFicFare menu and give it another series URL. But, this time, click the button labeled For Anthology Epub. This will trigger the Story URLs modal again once it's gathered all the story URLs, but this time it looks a little different.
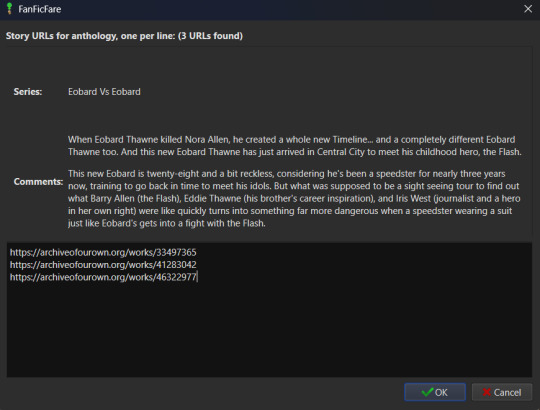
This time there will be text indicating the Series and Comments/description, the information for which will have been taken from the series metadata. The series story URLs will be present in the text area, allowing you to remove a story from the anthology if there's a fic in there you don't want included. Click OK to run the import job, which will run like normal.
When the job completes, there should be multiple good updates listed - one for every URL - but when you click yes to add the eBook to the library, you'll only see one added. It should be named following the convention "<Series Name> Anthology". So now I've got the "Eobard vs Eobard Anthology" in my library.
Last but not least, how to check for updates to incomplete fanfictions or series. It's generally pretty easy to do. Select the fanfiction(s) on the list that you want to check for updates on. If it's a single fanfiction (or several single fanfictions), you go to the FanFicFare menu and click the option "Update Existing FanFiction Books"
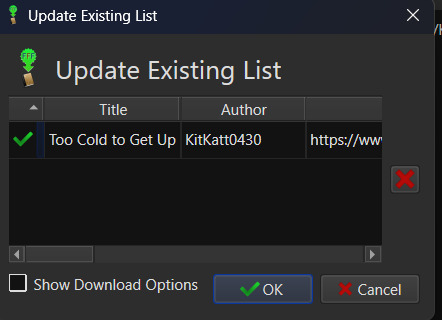
Click OK and let it run. Any fanfictions that don't have new chapters will return as bad entries. Any that have new chapters will be listed as good. Selecting Yes to add the good entries to the list will update the existing epub files with the new chapters.
However, if it's a series you want to update, I recommend doing those one at a time. Select the anthology from the eBook list and head back over to the FanFicFare menu. This time select "Anthology Options"; it'll open a fly-out menu. You want the bottom option, labeled "Update Anthology Epub". The associated URL for the series is saved as part of the eBook's metadata already, so it will pull the series metadata and associated URLs again, before returning you to that same modified Story URLs modal seen before. When you click OK, it'll pull all the fanfictions in the series - new and old - and any new chapters as well, bundling it up in a new eBook file that will replace the old one.
There's still a lot to talk about when it comes to managing fanfictions in Calibre, but I think I'll end here for now. You should be able to download, and manage, fanfiction from most websites at this point. So go back up your bookmarked fics and rest easy knowing that from this point forward a missing bookmark on your bookmarks list is no longer cause for sadness - it'll still be in your local archive to enjoy offline. Just don't go abusing this power, okay guys?
#kitkatt0430 explains#ficArchiving#calibre#fanficfare#the images all have alt text but if you find my image descriptions lacking feel free to add additional descriptions
61 notes
·
View notes
Text
Mini React.js Tips #2 | Resources ✨

Continuing the #mini react tips series, it's time to understand what is going on with the folders and files in the default React project - they can be a bit confusing as to what folder/file does what~!
What you'll need:
know how to create a React project >> click
already taken a look around the files and folders themselves

What does the file structure look like?
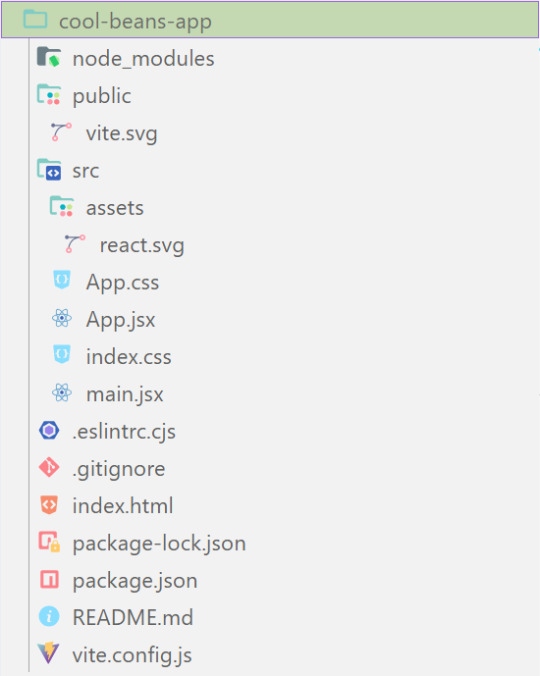
✤ node_modules folder: contains all the dependencies and packages (tools, resources, code, or software libraries created by others) needed for your project to run properly! These dependencies are usually managed by a package manager, such as npm (Node Package Manager)!
✤ public folder: Holds static assets (files that don't change dynamically and remain fixed) that don't require any special processing before using them! These assets are things like images, icons, or files that can be used directly without going through any additional steps.
✤ src folder: This is where your main source code resides. 'src' is short for source.
✤ assets folder: This folder stores static assets such as images, logos, and similar files. This folder is handy for organizing and accessing these non-changing elements in your project.
✤ App.css: This file contains styles specific to the App component (we will learn what 'components' are in React in the next tips post~!).
✤ App.jsx: This is the main component of your React application. It's where you define the structure and behavior of your app. The .jsx extension means the file uses a mixture of both HTML and JavaScript - open the file and see for yourself~!
✤ index.css: This file contains global styles that apply to the entire project. Any styles defined in this file will be applied universally across different parts of your project, providing a consistent look and feel.
✤ main.jsx: This is the entry point of your application! In this file, the React app is rendered, meaning it's the starting point where the React components are translated into the actual HTML elements displayed in the browser. Would recommend not to delete as a beginner!!
✤ .eslintrc.cjs: This file is the ESLint configuration. ESLint (one of the dependencies installed) is a tool that helps maintain coding standards and identifies common errors in your code. This configuration file contains rules and settings that define how ESLint should analyze and check your code.
✤ .gitignore: This file specifies which files and folders should be ignored by Git when version-controlling your project. It helps to avoid committing unnecessary files. The node_modules folder is typically ignored.
✤ index.html: This is the main HTML file that serves as the entry point for your React application. It includes the necessary scripts and links to load your app.
✤ package.json: A metadata file for your project. It includes essential information about the project, such as its name, version, description, and configuration details. Also, it holds a list of dependencies needed for the project to run - when someone else has the project on their local machine and wants to set it up, they can use the information in the file to install all the listed dependencies via npm install.
✤ package-lock.json: This file's purpose is to lock down and record the exact versions of each installed dependency/package in your project. This ensures consistency across different environments when other developers or systems install the dependencies.
✤ README.md: This file typically contains information about your project, including how to set it up, use it, and any other relevant details.
✤ vite.config.js: This file contains the configuration settings for Vite, the build tool used for this React project. It may include options for development and production builds, plugins, and other build-related configurations.
Congratulations! You know what the default folders and files do! Have a play around and familiarise yourself with them~!
BroCode’s 'React Full Course for Free’ 2024 >> click
React Official Website >> click
React's JSX >> click
The basics of Package.json >> click
Previous Tip: Tip #1 Creating The Default React Project >> click
Stay tuned for the other posts I will make on this series #mini react tips~!
#mini react tips#my resources#resources#codeblr#coding#progblr#programming#studyblr#studying#javascript#react.js#reactjs#coding tips#coding resources
25 notes
·
View notes
Text
Maya vs Blender: What to Choose for Your Animation Journey
Embarking on a journey into the world of 3D animation is an exciting, yet daunting task. With a variety of animation tools available, one of the biggest decisions aspiring animators and seasoned professionals face is choosing the right software. Two of the most popular choices in the industry are Maya and Blender. Both are powerful tools, each offering a unique set of features tailored to different needs and skill levels. In this article, we will dive into the key differences between Maya and Blender to help you make an informed decision for your next animation project.
User Interface and Experience
When it comes to animation software, first impressions matter. The user interface plays a crucial role in how efficiently you can work, especially with complex tasks.
Maya: Known for its sleek and professional interface, Maya is designed with industry professionals in mind. It offers a customizable layout that allows you to adjust the workspace to your specific workflow, enhancing your productivity and overall experience. However, this can sometimes make it feel a bit overwhelming for beginners.
Blender: On the other hand, Blender offers a user-friendly interface that caters to both beginners and seasoned professionals. Its intuitive navigation tools make it easy to jump into the software, and it can be easily tailored to suit individual needs. Blender's all-in-one interface simplifies the learning curve, especially for those just starting in the world of 3D animation.
Comparing Workflow and Processes
The way each software handles workflow and processes differs significantly.
Maya: Following a more traditional pipeline, Maya separates tasks into distinct modules for modeling, animation, and rendering. This structured workflow provides clarity and helps facilitate collaboration and project management, making it ideal for larger, team-based projects.
Blender: Blender takes a more integrated approach, combining all aspects of the animation process into a single interface. While this can be a huge advantage for individual users who prefer a streamlined process, it may feel a bit cluttered or overwhelming for some, especially those working on large teams.
Modeling Capabilities
Both Maya and Blender provide powerful tools for creating intricate 3D models, but there are some key differences to note.
Maya: Maya is renowned for its advanced modeling toolkit, which includes features like NURBS modeling, sculpting tools, and advanced polygon modeling techniques. These tools allow for precise control and are highly favored in professional environments where intricate models are required.
Blender: Blender also offers a comprehensive set of modeling tools, including sculpting, retopology, and procedural modeling options. While its modeling capabilities are incredibly powerful, some users may find that Maya’s advanced tools are more suited for highly detailed, professional-grade work.
Materials and Texturing
Texturing and materials are essential to creating a polished 3D model, and both Maya and Blender excel in this area.
Maya: Maya’s node-based material editor provides precise control over material properties, making it ideal for more complex shading workflows. This level of control is particularly valuable for users who need advanced customization in their textures.
Blender: Blender’s integrated material system offers a more user-friendly approach to texturing, with a library of pre-made materials and procedural textures that can speed up the workflow. While it’s more beginner-friendly, it still provides enough flexibility for advanced users.

Animation and Rigging
The animation and rigging process is crucial for bringing your 3D models to life. Here’s how Maya and Blender compare:
Maya: Maya is widely regarded as the industry standard for animation and rigging. Its robust animation tools include keyframe animation, procedural animation, and advanced character rigging capabilities. Maya also offers powerful tools for facial animation, muscle systems, and dynamic simulations.
Blender: Blender offers similar animation features, including a powerful armature system, inverse kinematics, and a variety of animation modifiers. Although its animation tools may not be as specialized as Maya’s, they are more than sufficient for most professional work and are perfect for indie developers and hobbyists.

Rendering
Rendering is the final step in the animation process, and both Maya and Blender deliver stunning results.
Maya: Maya uses Arnold as its default rendering engine. Known for its photorealistic quality and speed, Arnold is a favorite among professionals in the film and animation industries.
Blender: Blender’s Cycles renderer offers similar capabilities, supporting ray tracing, global illumination, and GPU acceleration. Cycles provides excellent rendering quality and is known for producing beautiful results in both still images and animations.
Conclusion: Maya vs Blender – Which One to Choose?
In the age-old debate of Maya vs Blender, there is no one-size-fits-all answer. Both software options offer unique features and capabilities that cater to different needs and preferences. Here's a quick summary to help you decide:
Maya: Best suited for professionals working in large teams or in industries where the highest level of detail, precision, and control is required (e.g., feature films, AAA games).
Blender: A great choice for independent artists, hobbyists, and small studios who want an all-in-one, beginner-friendly tool that doesn’t come with hefty licensing fees. It’s also an excellent option for those who prefer open-source software.
Ultimately, the choice between Maya and Blender comes down to your personal needs, project size, and workflow preferences. Both programs offer powerful features that can help bring your animations to life, so don’t hesitate to experiment and explore both to see which one best fits your style.
Ready to dive deeper into the world of animation? Check out our selection of 3D animation courses and start your animation adventure today—whether you're a Maya enthusiast or a Blender aficionado, there’s something for everyone!
2 notes
·
View notes
Text

J.4.7 What about the communications revolution?
Another important factor working in favour of anarchists is the existence of a sophisticated global communications network and a high degree of education and literacy among the populations of the core industrialised nations. Together these two developments make possible nearly instantaneous sharing and public dissemination of information by members of various progressive and radical movements all over the globe — a phenomenon that tends to reduce the effectiveness of repression by central authorities. The electronic-media and personal-computer revolutions also make it more difficult for elitist groups to maintain their previous monopolies of knowledge. Copy-left software and text, user-generated and shared content, file-sharing, all show that information, and its users, reaches its full potential when it is free. In short, the advent of the Information Age is potentially extremely subversive.
The very existence of the Internet provides anarchists with a powerful argument that decentralised structures can function effectively in a highly complex world. For the net has no centralised headquarters and is not subject to regulation by any centralised regulatory agency, yet it still manages to function effectively. Moreover, the net is also an effective way of anarchists and other radicals to communicate their ideas to others, share knowledge, work on common projects and co-ordinate activities and social struggle. By using the Internet, radicals can make their ideas accessible to people who otherwise would not come across anarchist ideas. In addition, and far more important than anarchists putting their ideas across, the fact is that the net allows everyone with access to express themselves freely, to communicate with others and get access (by visiting webpages and joining mailing lists and newsgroups) and give access (by creating webpages and joining in with on-line arguments) to new ideas and viewpoints. This is very anarchistic as it allows people to express themselves and start to consider new ideas, ideas which may change how they think and act.
Obviously we are aware that the vast majority of people in the world do not have access to telephones, never mind computers, but computer access is increasing in many countries, making it available, via work, libraries, schools, universities, and so on to more and more working class people.
Of course there is no denying that the implications of improved communications and information technology are ambiguous, implying Big Brother as well the ability of progressive and radical movements to organise. However, the point is only that the information revolution in combination with the other social developments could (but will not necessarily) contribute to a social paradigm shift. Obviously such a shift will not happen automatically. Indeed, it will not happen at all unless there is strong resistance to governmental and corporate attempts to limit public access to information, technology (e.g. encryption programs), censor peoples’ communications and use of electronic media and track them on-line.
This use of the Internet and computers to spread the anarchist message is ironic. The rapid improvement in price-performance ratios of computers, software, and other technology today is often used to validate the faith in free market capitalism but that requires a monumental failure of historical memory as not just the Internet but also the computer represents a spectacular success of public investment. As late as the 1970s and early 1980s, according to Kenneth Flamm’s Creating the Computer, the federal government was paying for 40 percent of all computer-related research and 60 to 75 percent of basic research. Even such modern-seeming gadgets as video terminals, the light pen, the drawing tablet, and the mouse evolved from Pentagon-sponsored research in the 1950s, 1960s and 1970s. Even software was not without state influence, with databases having their root in US Air Force and Atomic Energy Commission projects, artificial intelligence in military contracts back in the 1950s and airline reservation systems in 1950s air-defence systems. More than half of IBM’s Research and Development budget came from government contracts in the 1950s and 1960s.
The motivation was national security, but the result has been the creation of comparative advantage in information technology for the United States that private firms have happily exploited and extended. When the returns were uncertain and difficult to capture, private firms were unwilling to invest, and government played the decisive role. And not for want of trying, for key players in the military first tried to convince businesses and investment bankers that a new and potentially profitable business opportunity was presenting itself, but they did not succeed and it was only when the market expanded and the returns were more definite that the government receded. While the risks and development costs were socialised, the gains were privatised. All of which make claims that the market would have done it anyway highly unlikely.
Looking beyond state aid to the computer industry we discover a “do-it-yourself” (and so self-managed) culture which was essential to its development. The first personal computer, for example, was invented by amateurs who wanted their own cheap machines. The existence of a “gift” economy among these amateurs and hobbyists was a necessary precondition for the development of PCs. Without this free sharing of information and knowledge, the development of computers would have been hindered and so socialistic relations between developers and within the working environment created the necessary conditions for the computer revolution. If this community had been marked by commercial relations, the chances are the necessary breakthroughs and knowledge would have remained monopolised by a few companies or individuals, so hindering the industry as a whole.
Encouragingly, this socialistic “gift economy” is still at the heart of computer/software development and the Internet. For example, the Free Software Foundation has developed the General Public Licence (GPL). GPL, also know as
“copyleft”, uses copyright to ensure that software remains free. Copyleft ensures that a piece of software is made available to everyone to use and modify as they desire. The only restriction is that any used or modified copyleft material must remain under copyleft, ensuring that others have the same rights as you did when you used the original code. It creates a commons which anyone may add to, but no one may subtract from. Placing software under GPL means that every contributor is assured that she, and all other uses, will be able to run, modify and redistribute the code indefinitely. Unlike commercial software, copyleft code ensures an increasing knowledge base from which individuals can draw from and, equally as important, contribute to. In this way everyone benefits as code can be improved by everyone, unlike commercial code.
Many will think that this essentially anarchistic system would be a failure. In fact, code developed in this way is far more reliable and sturdy than commercial software. Linux, for example, is a far superior operating system than DOS precisely because it draws on the collective experience, skill and knowledge of thousands of developers. Apache, the most popular web-server, is another freeware product and is acknowledged as the best available. The same can be said of other key web-technologies (most obviously PHP) and projects (Wikipedia springs to mind, although that project while based on co-operative and free activity is owned by a few people who have ultimate control). While non-anarchists may be surprised, anarchists are not. Mutual aid and co-operation are beneficial in the evolution of life, why not in the evolution of software? For anarchists, this “gift economy” at the heart of the communications revolution is an important development. It shows both the superiority of common development as well as the walls built against innovation and decent products by property systems. We hope that such an economy will spread increasingly into the “real” world.
Another example of co-operation being aided by new technologies is Netwar. This refers to the use of the Internet by autonomous groups and social movements to co-ordinate action to influence and change society and fight government or business policy. This use of the Internet has steadily grown over the years, with a Rand corporation researcher, David Ronfeldt, arguing that this has become an important and powerful force (Rand is, and has been since its creation in 1948, a private appendage of the military industrial complex). In other words, activism and activists’ power and influence has been fuelled by the advent of the information revolution. Through computer and communication networks, especially via the Internet, grassroots campaigns have flourished, and the most importantly, government elites have taken notice.
Ronfeldt specialises in issues of national security, especially in the areas of Latin American and the impact of new informational technologies. Ronfeldt and another colleague coined the term
“netwar” in a Rand document entitled “Cyberwar is Coming!”. Ronfeldt’s work became a source of discussion on the Internet in mid-March 1995 when Pacific News Service correspondent Joel Simon wrote an article about Ronfeldt’s opinions on the influence of netwars on the political situation in Mexico after the Zapatista uprising. According to Simon, Ronfeldt holds that the work of social activists on the Internet has had a large influence — helping to co-ordinate the large demonstrations in Mexico City in support of the Zapatistas and the proliferation of EZLN communiqués across the world via computer networks. These actions, Ronfeldt argues, have allowed a network of groups that oppose the Mexican Government to muster an international response, often within hours of actions by it. In effect, this has forced the Mexican government to maintain the facade of negotiations with the EZLN and has on many occasions, actually stopped the army from just going in to Chiapas and brutally massacring the Zapatistas.
Given that Ronfeldt was an employee of the Rand Corporation his comments indicate that the U.S. government and its military and intelligence wings are very interested in what the Left is doing on the Internet. Given that they would not be interested in this if it were not effective, we can say that this use of the “Information Super-Highway” is a positive example of the use of technology in ways un-planned of by those who initially developed it (let us not forget that the Internet was originally funded by the U.S. government and military). While the internet is being hyped as the next big marketplace, it is being subverted by activists — an example of anarchistic trends within society worrying the powers that be.
A good example of this powerful tool is the incredible speed and range at which information travels the Internet about events concerning Mexico and the Zapatistas. When Alexander Cockburn wrote an article exposing a Chase Manhattan Bank memo about Chiapas and the Zapatistas in Counterpunch, only a small number of people read it because it is only a newsletter with a limited readership. The memo, written by Riordan Roett, argued that “the [Mexican] government will need to eliminate the Zapatistas to demonstrate their effective control of the national territory and of security policy”. In other words, if the Mexican government wants investment from Chase, it would have to crush the Zapatistas. This information was relatively ineffective when just confined to print but when it was uploaded to the Internet, it suddenly reached a very large number of people. These people in turn co-ordinated protests against the U.S and Mexican governments and especially Chase Manhattan. Chase was eventually forced to attempt to distance itself from the Roett memo that it commissioned. Since then net-activism has grown.
Ronfeldt’s research and opinion should be flattering for the Left. He is basically arguing that the efforts of activists on computers not only has been very effective (or at least has that potential), but more importantly, argues that the only way to counter this work is to follow the lead of social activists. Activists should understand the important implications of Ronfeldt’s work: government elites are not only watching these actions (big surprise) but are also attempting to work against them. Thus Netwars and copyleft are good examples of anarchistic trends within society, using communications technology as a means of co-ordinating activity across the world in a libertarian fashion for libertarian goals.
#community building#practical anarchy#practical anarchism#anarchist society#practical#faq#anarchy faq#revolution#anarchism#daily posts#communism#anti capitalist#anti capitalism#late stage capitalism#organization#grassroots#grass roots#anarchists#libraries#leftism#social issues#economy#economics#climate change#climate crisis#climate#ecology#anarchy works#environmentalism#environment
18 notes
·
View notes
Text
Obsidian And RTX AI PCs For Advanced Large Language Model
How to Utilize Obsidian‘s Generative AI Tools. Two plug-ins created by the community demonstrate how RTX AI PCs can support large language models for the next generation of app developers.
Obsidian Meaning
Obsidian is a note-taking and personal knowledge base program that works with Markdown files. Users may create internal linkages for notes using it, and they can see the relationships as a graph. It is intended to assist users in flexible, non-linearly structuring and organizing their ideas and information. Commercial licenses are available for purchase, however personal usage of the program is free.
Obsidian Features
Electron is the foundation of Obsidian. It is a cross-platform program that works on mobile operating systems like iOS and Android in addition to Windows, Linux, and macOS. The program does not have a web-based version. By installing plugins and themes, users may expand the functionality of Obsidian across all platforms by integrating it with other tools or adding new capabilities.
Obsidian distinguishes between community plugins, which are submitted by users and made available as open-source software via GitHub, and core plugins, which are made available and maintained by the Obsidian team. A calendar widget and a task board in the Kanban style are two examples of community plugins. The software comes with more than 200 community-made themes.
Every new note in Obsidian creates a new text document, and all of the documents are searchable inside the app. Obsidian works with a folder of text documents. Obsidian generates an interactive graph that illustrates the connections between notes and permits internal connectivity between notes. While Markdown is used to accomplish text formatting in Obsidian, Obsidian offers quick previewing of produced content.
Generative AI Tools In Obsidian
A group of AI aficionados is exploring with methods to incorporate the potent technology into standard productivity practices as generative AI develops and speeds up industry.
Community plug-in-supporting applications empower users to investigate the ways in which large language models (LLMs) might improve a range of activities. Users using RTX AI PCs may easily incorporate local LLMs by employing local inference servers that are powered by the NVIDIA RTX-accelerated llama.cpp software library.
It previously examined how consumers might maximize their online surfing experience by using Leo AI in the Brave web browser. Today, it examine Obsidian, a well-known writing and note-taking tool that uses the Markdown markup language and is helpful for managing intricate and connected records for many projects. Several of the community-developed plug-ins that add functionality to the app allow users to connect Obsidian to a local inferencing server, such as LM Studio or Ollama.
To connect Obsidian to LM Studio, just select the “Developer” button on the left panel, load any downloaded model, enable the CORS toggle, and click “Start.” This will enable LM Studio’s local server capabilities. Because the plug-ins will need this information to connect, make a note of the chat completion URL from the “Developer” log console (“http://localhost:1234/v1/chat/completions” by default).
Next, visit the “Settings” tab after launching Obsidian. After selecting “Community plug-ins,” choose “Browse.” Although there are a number of LLM-related community plug-ins, Text Generator and Smart Connections are two well-liked choices.
For creating notes and summaries on a study subject, for example, Text Generator is useful in an Obsidian vault.
Asking queries about the contents of an Obsidian vault, such the solution to a trivia question that was stored years ago, is made easier using Smart Connections.
Open the Text Generator settings, choose “Custom” under “Provider profile,” and then enter the whole URL in the “Endpoint” section. After turning on the plug-in, adjust the settings for Smart Connections. For the model platform, choose “Custom Local (OpenAI Format)” from the options panel on the right side of the screen. Next, as they appear in LM Studio, type the model name (for example, “gemma-2-27b-instruct”) and the URL into the corresponding fields.
The plug-ins will work when the fields are completed. If users are interested in what’s going on on the local server side, the LM Studio user interface will also display recorded activities.
Transforming Workflows With Obsidian AI Plug-Ins
Consider a scenario where a user want to organize a trip to the made-up city of Lunar City and come up with suggestions for things to do there. “What to Do in Lunar City” would be the title of the new note that the user would begin. A few more instructions must be included in the query submitted to the LLM in order to direct the results, since Lunar City is not an actual location. The model will create a list of things to do while traveling if you click the Text Generator plug-in button.
Obsidian will ask LM Studio to provide a response using the Text Generator plug-in, and LM Studio will then execute the Gemma 2 27B model. The model can rapidly provide a list of tasks if the user’s machine has RTX GPU acceleration.
Or let’s say that years later, the user’s buddy is visiting Lunar City and is looking for a place to dine. Although the user may not be able to recall the names of the restaurants they visited, they can review the notes in their vault Obsidian‘s word for a collection of notes to see whether they have any written notes.
A user may ask inquiries about their vault of notes and other material using the Smart Connections plug-in instead of going through all of the notes by hand. In order to help with the process, the plug-in retrieves pertinent information from the user’s notes and responds to the request using the same LM Studio server. The plug-in uses a method known as retrieval-augmented generation to do this.
Although these are entertaining examples, users may see the true advantages and enhancements in daily productivity after experimenting with these features for a while. Two examples of how community developers and AI fans are using AI to enhance their PC experiences are Obsidian plug-ins.
Thousands of open-source models are available for developers to include into their Windows programs using NVIDIA GeForce RTX technology.
Read more on Govindhtech.com
#Obsidian#RTXAIPCs#LLM#LargeLanguageModel#AI#GenerativeAI#NVIDIARTX#LMStudio#RTXGPU#News#Technews#Technology#Technologynews#Technologytrends#govindhtech
3 notes
·
View notes
Text
How-To IT
Topic: Core areas of IT
1. Hardware
• Computers (Desktops, Laptops, Workstations)
• Servers and Data Centers
• Networking Devices (Routers, Switches, Modems)
• Storage Devices (HDDs, SSDs, NAS)
• Peripheral Devices (Printers, Scanners, Monitors)
2. Software
• Operating Systems (Windows, Linux, macOS)
• Application Software (Office Suites, ERP, CRM)
• Development Software (IDEs, Code Libraries, APIs)
• Middleware (Integration Tools)
• Security Software (Antivirus, Firewalls, SIEM)
3. Networking and Telecommunications
• LAN/WAN Infrastructure
• Wireless Networking (Wi-Fi, 5G)
• VPNs (Virtual Private Networks)
• Communication Systems (VoIP, Email Servers)
• Internet Services
4. Data Management
• Databases (SQL, NoSQL)
• Data Warehousing
• Big Data Technologies (Hadoop, Spark)
• Backup and Recovery Systems
• Data Integration Tools
5. Cybersecurity
• Network Security
• Endpoint Protection
• Identity and Access Management (IAM)
• Threat Detection and Incident Response
• Encryption and Data Privacy
6. Software Development
• Front-End Development (UI/UX Design)
• Back-End Development
• DevOps and CI/CD Pipelines
• Mobile App Development
• Cloud-Native Development
7. Cloud Computing
• Infrastructure as a Service (IaaS)
• Platform as a Service (PaaS)
• Software as a Service (SaaS)
• Serverless Computing
• Cloud Storage and Management
8. IT Support and Services
• Help Desk Support
• IT Service Management (ITSM)
• System Administration
• Hardware and Software Troubleshooting
• End-User Training
9. Artificial Intelligence and Machine Learning
• AI Algorithms and Frameworks
• Natural Language Processing (NLP)
• Computer Vision
• Robotics
• Predictive Analytics
10. Business Intelligence and Analytics
• Reporting Tools (Tableau, Power BI)
• Data Visualization
• Business Analytics Platforms
• Predictive Modeling
11. Internet of Things (IoT)
• IoT Devices and Sensors
• IoT Platforms
• Edge Computing
• Smart Systems (Homes, Cities, Vehicles)
12. Enterprise Systems
• Enterprise Resource Planning (ERP)
• Customer Relationship Management (CRM)
• Human Resource Management Systems (HRMS)
• Supply Chain Management Systems
13. IT Governance and Compliance
• ITIL (Information Technology Infrastructure Library)
• COBIT (Control Objectives for Information Technologies)
• ISO/IEC Standards
• Regulatory Compliance (GDPR, HIPAA, SOX)
14. Emerging Technologies
• Blockchain
• Quantum Computing
• Augmented Reality (AR) and Virtual Reality (VR)
• 3D Printing
• Digital Twins
15. IT Project Management
• Agile, Scrum, and Kanban
• Waterfall Methodology
• Resource Allocation
• Risk Management
16. IT Infrastructure
• Data Centers
• Virtualization (VMware, Hyper-V)
• Disaster Recovery Planning
• Load Balancing
17. IT Education and Certifications
• Vendor Certifications (Microsoft, Cisco, AWS)
• Training and Development Programs
• Online Learning Platforms
18. IT Operations and Monitoring
• Performance Monitoring (APM, Network Monitoring)
• IT Asset Management
• Event and Incident Management
19. Software Testing
• Manual Testing: Human testers evaluate software by executing test cases without using automation tools.
• Automated Testing: Use of testing tools (e.g., Selenium, JUnit) to run automated scripts and check software behavior.
• Functional Testing: Validating that the software performs its intended functions.
• Non-Functional Testing: Assessing non-functional aspects such as performance, usability, and security.
• Unit Testing: Testing individual components or units of code for correctness.
• Integration Testing: Ensuring that different modules or systems work together as expected.
• System Testing: Verifying the complete software system’s behavior against requirements.
• Acceptance Testing: Conducting tests to confirm that the software meets business requirements (including UAT - User Acceptance Testing).
• Regression Testing: Ensuring that new changes or features do not negatively affect existing functionalities.
• Performance Testing: Testing software performance under various conditions (load, stress, scalability).
• Security Testing: Identifying vulnerabilities and assessing the software’s ability to protect data.
• Compatibility Testing: Ensuring the software works on different operating systems, browsers, or devices.
• Continuous Testing: Integrating testing into the development lifecycle to provide quick feedback and minimize bugs.
• Test Automation Frameworks: Tools and structures used to automate testing processes (e.g., TestNG, Appium).
19. VoIP (Voice over IP)
VoIP Protocols & Standards
• SIP (Session Initiation Protocol)
• H.323
• RTP (Real-Time Transport Protocol)
• MGCP (Media Gateway Control Protocol)
VoIP Hardware
• IP Phones (Desk Phones, Mobile Clients)
• VoIP Gateways
• Analog Telephone Adapters (ATAs)
• VoIP Servers
• Network Switches/ Routers for VoIP
VoIP Software
• Softphones (e.g., Zoiper, X-Lite)
• PBX (Private Branch Exchange) Systems
• VoIP Management Software
• Call Center Solutions (e.g., Asterisk, 3CX)
VoIP Network Infrastructure
• Quality of Service (QoS) Configuration
• VPNs (Virtual Private Networks) for VoIP
• VoIP Traffic Shaping & Bandwidth Management
• Firewall and Security Configurations for VoIP
• Network Monitoring & Optimization Tools
VoIP Security
• Encryption (SRTP, TLS)
• Authentication and Authorization
• Firewall & Intrusion Detection Systems
• VoIP Fraud DetectionVoIP Providers
• Hosted VoIP Services (e.g., RingCentral, Vonage)
• SIP Trunking Providers
• PBX Hosting & Managed Services
VoIP Quality and Testing
• Call Quality Monitoring
• Latency, Jitter, and Packet Loss Testing
• VoIP Performance Metrics and Reporting Tools
• User Acceptance Testing (UAT) for VoIP Systems
Integration with Other Systems
• CRM Integration (e.g., Salesforce with VoIP)
• Unified Communications (UC) Solutions
• Contact Center Integration
• Email, Chat, and Video Communication Integration
2 notes
·
View notes