#Media Library Automation
Explore tagged Tumblr posts
Visit Tumblr Blog
Explore Tumblr blogs with no restrictions, modern design and the best experience.
Last Seen Tumblr Blogs





Fun Fact
In 2020, 44% of users from Denmark used Tumblr daily.
Text
TDARR: Optimize your Self-hosted Video Streaming Library
TDARR: Optimize your Self-hosted Video Streaming Library #100daysofhomelab #Tdarr #TranscodingSystem #MediaManagement #DockerDeployment #DistributedTranscoding #VideoTranscoding #AutomatedLibrary #NvidiaPlugins #HealthChecks #TraefikReverseProxy
Managing a home media library can be daunting. Maintaining an organized, accessible, and efficient media library is important for video enthusiasts and casual viewers alike. Enter Tdarr, a powerful tool designed to help you manage and optimize your media files. This post will provide an in-depth exploration of Tdarr, its features, and how you can use it to transform your media library management…

View On WordPress
#Distributed Transcoding#Docker Deployment#FFmpeg#HandBrake#HEVC Transcoding#Media File Health Checks#Media Library Automation#Nvidia GPU Transcoding#Tdarr#Traefik reverse proxy
0 notes
Text
How I ditched streaming services and learned to love Linux: A step-by-step guide to building your very own personal media streaming server (V2.0: REVISED AND EXPANDED EDITION)
This is a revised, corrected and expanded version of my tutorial on setting up a personal media server that previously appeared on my old blog (donjuan-auxenfers). I expect that that post is still making the rounds (hopefully with my addendum on modifying group share permissions in Ubuntu to circumvent 0x8007003B "Unexpected Network Error" messages in Windows 10/11 when transferring files) but I have no way of checking. Anyway this new revised version of the tutorial corrects one or two small errors I discovered when rereading what I wrote, adds links to all products mentioned and is just more polished generally. I also expanded it a bit, pointing more adventurous users toward programs such as Sonarr/Radarr/Lidarr and Overseerr which can be used for automating user requests and media collection.
So then, what is this tutorial? This is a tutorial on how to build and set up your own personal media server using Ubuntu as an operating system and Plex (or Jellyfin) to not only manage your media, but to also stream that media to your devices both at home and abroad anywhere in the world where you have an internet connection. Its intent is to show you how building a personal media server and stuffing it full of films, TV, and music that you acquired through indiscriminate and voracious media piracy various legal methods will free you to completely ditch paid streaming services. No more will you have to pay for Disney+, Netflix, HBOMAX, Hulu, Amazon Prime, Peacock, CBS All Access, Paramount+, Crave or any other streaming service that is not named Criterion Channel. Instead whenever you want to watch your favourite films and television shows, you’ll have your own personal service that only features things that you want to see, with files that you have control over. And for music fans out there, both Jellyfin and Plex support music streaming, meaning you can even ditch music streaming services. Goodbye Spotify, Youtube Music, Tidal and Apple Music, welcome back unreasonably large MP3 (or FLAC) collections.
On the hardware front, I’m going to offer a few options catered towards different budgets and media library sizes. The cost of getting a media server up and running using this guide will cost you anywhere from $450 CAD/$325 USD at the low end to $1500 CAD/$1100 USD at the high end (it could go higher). My server was priced closer to the higher figure, but I went and got a lot more storage than most people need. If that seems like a little much, consider for a moment, do you have a roommate, a close friend, or a family member who would be willing to chip in a few bucks towards your little project provided they get access? Well that's how I funded my server. It might also be worth thinking about the cost over time, i.e. how much you spend yearly on subscriptions vs. a one time cost of setting up a server. Additionally there's just the joy of being able to scream "fuck you" at all those show cancelling, library deleting, hedge fund vampire CEOs who run the studios through denying them your money. Drive a stake through David Zaslav's heart.
On the software side I will walk you step-by-step through installing Ubuntu as your server's operating system, configuring your storage as a RAIDz array with ZFS, sharing your zpool to Windows with Samba, running a remote connection between your server and your Windows PC, and then a little about started with Plex/Jellyfin. Every terminal command you will need to input will be provided, and I even share a custom #bash script that will make used vs. available drive space on your server display correctly in Windows.
If you have a different preferred flavour of Linux (Arch, Manjaro, Redhat, Fedora, Mint, OpenSUSE, CentOS, Slackware etc. et. al.) and are aching to tell me off for being basic and using Ubuntu, this tutorial is not for you. The sort of person with a preferred Linux distro is the sort of person who can do this sort of thing in their sleep. Also I don't care. This tutorial is intended for the average home computer user. This is also why we’re not using a more exotic home server solution like running everything through Docker Containers and managing it through a dashboard like Homarr or Heimdall. While such solutions are fantastic and can be very easy to maintain once you have it all set up, wrapping your brain around Docker is a whole thing in and of itself. If you do follow this tutorial and had fun putting everything together, then I would encourage you to return in a year’s time, do your research and set up everything with Docker Containers.
Lastly, this is a tutorial aimed at Windows users. Although I was a daily user of OS X for many years (roughly 2008-2023) and I've dabbled quite a bit with various Linux distributions (mostly Ubuntu and Manjaro), my primary OS these days is Windows 11. Many things in this tutorial will still be applicable to Mac users, but others (e.g. setting up shares) you will have to look up for yourself. I doubt it would be difficult to do so.
Nothing in this tutorial will require feats of computing expertise. All you will need is a basic computer literacy (i.e. an understanding of what a filesystem and directory are, and a degree of comfort in the settings menu) and a willingness to learn a thing or two. While this guide may look overwhelming at first glance, it is only because I want to be as thorough as possible. I want you to understand exactly what it is you're doing, I don't want you to just blindly follow steps. If you half-way know what you’re doing, you will be much better prepared if you ever need to troubleshoot.
Honestly, once you have all the hardware ready it shouldn't take more than an afternoon or two to get everything up and running.
(This tutorial is just shy of seven thousand words long so the rest is under the cut.)
Step One: Choosing Your Hardware
Linux is a light weight operating system, depending on the distribution there's close to no bloat. There are recent distributions available at this very moment that will run perfectly fine on a fourteen year old i3 with 4GB of RAM. Moreover, running Plex or Jellyfin isn’t resource intensive in 90% of use cases. All this is to say, we don’t require an expensive or powerful computer. This means that there are several options available: 1) use an old computer you already have sitting around but aren't using 2) buy a used workstation from eBay, or what I believe to be the best option, 3) order an N100 Mini-PC from AliExpress or Amazon.
Note: If you already have an old PC sitting around that you’ve decided to use, fantastic, move on to the next step.
When weighing your options, keep a few things in mind: the number of people you expect to be streaming simultaneously at any one time, the resolution and bitrate of your media library (4k video takes a lot more processing power than 1080p) and most importantly, how many of those clients are going to be transcoding at any one time. Transcoding is what happens when the playback device does not natively support direct playback of the source file. This can happen for a number of reasons, such as the playback device's native resolution being lower than the file's internal resolution, or because the source file was encoded in a video codec unsupported by the playback device.
Ideally we want any transcoding to be performed by hardware. This means we should be looking for a computer with an Intel processor with Quick Sync. Quick Sync is a dedicated core on the CPU die designed specifically for video encoding and decoding. This specialized hardware makes for highly efficient transcoding both in terms of processing overhead and power draw. Without these Quick Sync cores, transcoding must be brute forced through software. This takes up much more of a CPU’s processing power and requires much more energy. But not all Quick Sync cores are created equal and you need to keep this in mind if you've decided either to use an old computer or to shop for a used workstation on eBay
Any Intel processor from second generation Core (Sandy Bridge circa 2011) onward has Quick Sync cores. It's not until 6th gen (Skylake), however, that the cores support the H.265 HEVC codec. Intel’s 10th gen (Comet Lake) processors introduce support for 10bit HEVC and HDR tone mapping. And the recent 12th gen (Alder Lake) processors brought with them hardware AV1 decoding. As an example, while an 8th gen (Kaby Lake) i5-8500 will be able to hardware transcode a H.265 encoded file, it will fall back to software transcoding if given a 10bit H.265 file. If you’ve decided to use that old PC or to look on eBay for an old Dell Optiplex keep this in mind.
Note 1: The price of old workstations varies wildly and fluctuates frequently. If you get lucky and go shopping shortly after a workplace has liquidated a large number of their workstations you can find deals for as low as $100 on a barebones system, but generally an i5-8500 workstation with 16gb RAM will cost you somewhere in the area of $260 CAD/$200 USD.
Note 2: The AMD equivalent to Quick Sync is called Video Core Next, and while it's fine, it's not as efficient and not as mature a technology. It was only introduced with the first generation Ryzen CPUs and it only got decent with their newest CPUs, we want something cheap.
Alternatively you could forgo having to keep track of what generation of CPU is equipped with Quick Sync cores that feature support for which codecs, and just buy an N100 mini-PC. For around the same price or less of a used workstation you can pick up a mini-PC with an Intel N100 processor. The N100 is a four-core processor based on the 12th gen Alder Lake architecture and comes equipped with the latest revision of the Quick Sync cores. These little processors offer astounding hardware transcoding capabilities for their size and power draw. Otherwise they perform equivalent to an i5-6500, which isn't a terrible CPU. A friend of mine uses an N100 machine as a dedicated retro emulation gaming system and it does everything up to 6th generation consoles just fine. The N100 is also a remarkably efficient chip, it sips power. In fact, the difference between running one of these and an old workstation could work out to hundreds of dollars a year in energy bills depending on where you live.
You can find these Mini-PCs all over Amazon or for a little cheaper on AliExpress. They range in price from $170 CAD/$125 USD for a no name N100 with 8GB RAM to $280 CAD/$200 USD for a Beelink S12 Pro with 16GB RAM. The brand doesn't really matter, they're all coming from the same three factories in Shenzen, go for whichever one fits your budget or has features you want. 8GB RAM should be enough, Linux is lightweight and Plex only calls for 2GB RAM. 16GB RAM might result in a slightly snappier experience, especially with ZFS. A 256GB SSD is more than enough for what we need as a boot drive, but going for a bigger drive might allow you to get away with things like creating preview thumbnails for Plex, but it’s up to you and your budget.
The Mini-PC I wound up buying was a Firebat AK2 Plus with 8GB RAM and a 256GB SSD. It looks like this:

Note: Be forewarned that if you decide to order a Mini-PC from AliExpress, note the type of power adapter it ships with. The mini-PC I bought came with an EU power adapter and I had to supply my own North American power supply. Thankfully this is a minor issue as barrel plug 30W/12V/2.5A power adapters are easy to find and can be had for $10.
Step Two: Choosing Your Storage
Storage is the most important part of our build. It is also the most expensive. Thankfully it’s also the most easily upgrade-able down the line.
For people with a smaller media collection (4TB to 8TB), a more limited budget, or who will only ever have two simultaneous streams running, I would say that the most economical course of action would be to buy a USB 3.0 8TB external HDD. Something like this one from Western Digital or this one from Seagate. One of these external drives will cost you in the area of $200 CAD/$140 USD. Down the line you could add a second external drive or replace it with a multi-drive RAIDz set up such as detailed below.
If a single external drive the path for you, move on to step three.
For people with larger media libraries (12TB+), who prefer media in 4k, or care who about data redundancy, the answer is a RAID array featuring multiple HDDs in an enclosure.
Note: If you are using an old PC or used workstatiom as your server and have the room for at least three 3.5" drives, and as many open SATA ports on your mother board you won't need an enclosure, just install the drives into the case. If your old computer is a laptop or doesn’t have room for more internal drives, then I would suggest an enclosure.
The minimum number of drives needed to run a RAIDz array is three, and seeing as RAIDz is what we will be using, you should be looking for an enclosure with three to five bays. I think that four disks makes for a good compromise for a home server. Regardless of whether you go for a three, four, or five bay enclosure, do be aware that in a RAIDz array the space equivalent of one of the drives will be dedicated to parity at a ratio expressed by the equation 1 − 1/n i.e. in a four bay enclosure equipped with four 12TB drives, if we configured our drives in a RAIDz1 array we would be left with a total of 36TB of usable space (48TB raw size). The reason for why we might sacrifice storage space in such a manner will be explained in the next section.
A four bay enclosure will cost somewhere in the area of $200 CDN/$140 USD. You don't need anything fancy, we don't need anything with hardware RAID controls (RAIDz is done entirely in software) or even USB-C. An enclosure with USB 3.0 will perform perfectly fine. Don’t worry too much about USB speed bottlenecks. A mechanical HDD will be limited by the speed of its mechanism long before before it will be limited by the speed of a USB connection. I've seen decent looking enclosures from TerraMaster, Yottamaster, Mediasonic and Sabrent.
When it comes to selecting the drives, as of this writing, the best value (dollar per gigabyte) are those in the range of 12TB to 20TB. I settled on 12TB drives myself. If 12TB to 20TB drives are out of your budget, go with what you can afford, or look into refurbished drives. I'm not sold on the idea of refurbished drives but many people swear by them.
When shopping for harddrives, search for drives designed specifically for NAS use. Drives designed for NAS use typically have better vibration dampening and are designed to be active 24/7. They will also often make use of CMR (conventional magnetic recording) as opposed to SMR (shingled magnetic recording). This nets them a sizable read/write performance bump over typical desktop drives. Seagate Ironwolf and Toshiba NAS are both well regarded brands when it comes to NAS drives. I would avoid Western Digital Red drives at this time. WD Reds were a go to recommendation up until earlier this year when it was revealed that they feature firmware that will throw up false SMART warnings telling you to replace the drive at the three year mark quite often when there is nothing at all wrong with that drive. It will likely even be good for another six, seven, or more years.

Step Three: Installing Linux
For this step you will need a USB thumbdrive of at least 6GB in capacity, an .ISO of Ubuntu, and a way to make that thumbdrive bootable media.
First download a copy of Ubuntu desktop (for best performance we could download the Server release, but for new Linux users I would recommend against the server release. The server release is strictly command line interface only, and having a GUI is very helpful for most people. Not many people are wholly comfortable doing everything through the command line, I'm certainly not one of them, and I grew up with DOS 6.0. 22.04.3 Jammy Jellyfish is the current Long Term Service release, this is the one to get.
Download the .ISO and then download and install balenaEtcher on your Windows PC. BalenaEtcher is an easy to use program for creating bootable media, you simply insert your thumbdrive, select the .ISO you just downloaded, and it will create a bootable installation media for you.
Once you've made a bootable media and you've got your Mini-PC (or you old PC/used workstation) in front of you, hook it directly into your router with an ethernet cable, and then plug in the HDD enclosure, a monitor, a mouse and a keyboard. Now turn that sucker on and hit whatever key gets you into the BIOS (typically ESC, DEL or F2). If you’re using a Mini-PC check to make sure that the P1 and P2 power limits are set correctly, my N100's P1 limit was set at 10W, a full 20W under the chip's power limit. Also make sure that the RAM is running at the advertised speed. My Mini-PC’s RAM was set at 2333Mhz out of the box when it should have been 3200Mhz. Once you’ve done that, key over to the boot order and place the USB drive first in the boot order. Then save the BIOS settings and restart.
After you restart you’ll be greeted by Ubuntu's installation screen. Installing Ubuntu is really straight forward, select the "minimal" installation option, as we won't need anything on this computer except for a browser (Ubuntu comes preinstalled with Firefox) and Plex Media Server/Jellyfin Media Server. Also remember to delete and reformat that Windows partition! We don't need it.
Step Four: Installing ZFS and Setting Up the RAIDz Array
Note: If you opted for just a single external HDD skip this step and move onto setting up a Samba share.
Once Ubuntu is installed it's time to configure our storage by installing ZFS to build our RAIDz array. ZFS is a "next-gen" file system that is both massively flexible and massively complex. It's capable of snapshot backup, self healing error correction, ZFS pools can be configured with drives operating in a supplemental manner alongside the storage vdev (e.g. fast cache, dedicated secondary intent log, hot swap spares etc.). It's also a file system very amenable to fine tuning. Block and sector size are adjustable to use case and you're afforded the option of different methods of inline compression. If you'd like a very detailed overview and explanation of its various features and tips on tuning a ZFS array check out these articles from Ars Technica. For now we're going to ignore all these features and keep it simple, we're going to pull our drives together into a single vdev running in RAIDz which will be the entirety of our zpool, no fancy cache drive or SLOG.
Open up the terminal and type the following commands:
sudo apt update
then
sudo apt install zfsutils-linux
This will install the ZFS utility. Verify that it's installed with the following command:
zfs --version
Now, it's time to check that the HDDs we have in the enclosure are healthy, running, and recognized. We also want to find out their device IDs and take note of them:
sudo fdisk -1
Note: You might be wondering why some of these commands require "sudo" in front of them while others don't. "Sudo" is short for "super user do”. When and where "sudo" is used has to do with the way permissions are set up in Linux. Only the "root" user has the access level to perform certain tasks in Linux. As a matter of security and safety regular user accounts are kept separate from the "root" user. It's not advised (or even possible) to boot into Linux as "root" with most modern distributions. Instead by using "sudo" our regular user account is temporarily given the power to do otherwise forbidden things. Don't worry about it too much at this stage, but if you want to know more check out this introduction.
If everything is working you should get a list of the various drives detected along with their device IDs which will look like this: /dev/sdc. You can also check the device IDs of the drives by opening the disk utility app. Jot these IDs down as we'll need them for our next step, creating our RAIDz array.
RAIDz is similar to RAID-5 in that instead of striping your data over multiple disks, exchanging redundancy for speed and available space (RAID-0), or mirroring your data writing by two copies of every piece (RAID-1), it instead writes parity blocks across the disks in addition to striping, this provides a balance of speed, redundancy and available space. If a single drive fails, the parity blocks on the working drives can be used to reconstruct the entire array as soon as a replacement drive is added.
Additionally, RAIDz improves over some of the common RAID-5 flaws. It's more resilient and capable of self healing, as it is capable of automatically checking for errors against a checksum. It's more forgiving in this way, and it's likely that you'll be able to detect when a drive is dying well before it fails. A RAIDz array can survive the loss of any one drive.
Note: While RAIDz is indeed resilient, if a second drive fails during the rebuild, you're fucked. Always keep backups of things you can't afford to lose. This tutorial, however, is not about proper data safety.
To create the pool, use the following command:
sudo zpool create "zpoolnamehere" raidz "device IDs of drives we're putting in the pool"
For example, let's creatively name our zpool "mypool". This poil will consist of four drives which have the device IDs: sdb, sdc, sdd, and sde. The resulting command will look like this:
sudo zpool create mypool raidz /dev/sdb /dev/sdc /dev/sdd /dev/sde
If as an example you bought five HDDs and decided you wanted more redundancy dedicating two drive to this purpose, we would modify the command to "raidz2" and the command would look something like the following:
sudo zpool create mypool raidz2 /dev/sdb /dev/sdc /dev/sdd /dev/sde /dev/sdf
An array configured like this is known as RAIDz2 and is able to survive two disk failures.
Once the zpool has been created, we can check its status with the command:
zpool status
Or more concisely with:
zpool list
The nice thing about ZFS as a file system is that a pool is ready to go immediately after creation. If we were to set up a traditional RAID-5 array using mbam, we'd have to sit through a potentially hours long process of reformatting and partitioning the drives. Instead we're ready to go right out the gates.
The zpool should be automatically mounted to the filesystem after creation, check on that with the following:
df -hT | grep zfs
Note: If your computer ever loses power suddenly, say in event of a power outage, you may have to re-import your pool. In most cases, ZFS will automatically import and mount your pool, but if it doesn’t and you can't see your array, simply open the terminal and type sudo zpool import -a.
By default a zpool is mounted at /"zpoolname". The pool should be under our ownership but let's make sure with the following command:
sudo chown -R "yourlinuxusername" /"zpoolname"
Note: Changing file and folder ownership with "chown" and file and folder permissions with "chmod" are essential commands for much of the admin work in Linux, but we won't be dealing with them extensively in this guide. If you'd like a deeper tutorial and explanation you can check out these two guides: chown and chmod.
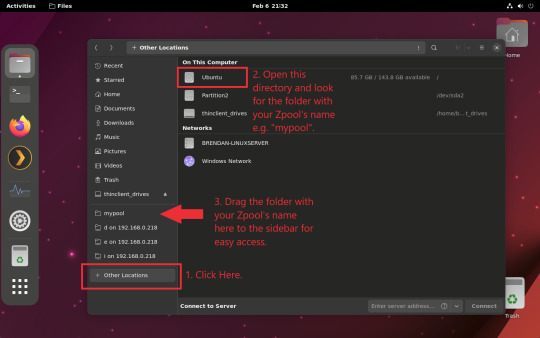
You can access the zpool file system through the GUI by opening the file manager (the Ubuntu default file manager is called Nautilus) and clicking on "Other Locations" on the sidebar, then entering the Ubuntu file system and looking for a folder with your pool's name. Bookmark the folder on the sidebar for easy access.
Your storage pool is now ready to go. Assuming that we already have some files on our Windows PC we want to copy to over, we're going to need to install and configure Samba to make the pool accessible in Windows.
Step Five: Setting Up Samba/Sharing
Samba is what's going to let us share the zpool with Windows and allow us to write to it from our Windows machine. First let's install Samba with the following commands:
sudo apt-get update
then
sudo apt-get install samba
Next create a password for Samba.
sudo smbpswd -a "yourlinuxusername"
It will then prompt you to create a password. Just reuse your Ubuntu user password for simplicity's sake.
Note: if you're using just a single external drive replace the zpool location in the following commands with wherever it is your external drive is mounted, for more information see this guide on mounting an external drive in Ubuntu.
After you've created a password we're going to create a shareable folder in our pool with this command
mkdir /"zpoolname"/"foldername"
Now we're going to open the smb.conf file and make that folder shareable. Enter the following command.
sudo nano /etc/samba/smb.conf
This will open the .conf file in nano, the terminal text editor program. Now at the end of smb.conf add the following entry:
["foldername"]
path = /"zpoolname"/"foldername"
available = yes
valid users = "yourlinuxusername"
read only = no
writable = yes
browseable = yes
guest ok = no
Ensure that there are no line breaks between the lines and that there's a space on both sides of the equals sign. Our next step is to allow Samba traffic through the firewall:
sudo ufw allow samba
Finally restart the Samba service:
sudo systemctl restart smbd
At this point we'll be able to access to the pool, browse its contents, and read and write to it from Windows. But there's one more thing left to do, Windows doesn't natively support the ZFS file systems and will read the used/available/total space in the pool incorrectly. Windows will read available space as total drive space, and all used space as null. This leads to Windows only displaying a dwindling amount of "available" space as the drives are filled. We can fix this! Functionally this doesn't actually matter, we can still write and read to and from the disk, it just makes it difficult to tell at a glance the proportion of used/available space, so this is an optional step but one I recommend (this step is also unnecessary if you're just using a single external drive). What we're going to do is write a little shell script in #bash. Open nano with the terminal with the command:
nano
Now insert the following code:
#!/bin/bash CUR_PATH=`pwd` ZFS_CHECK_OUTPUT=$(zfs get type $CUR_PATH 2>&1 > /dev/null) > /dev/null if [[ $ZFS_CHECK_OUTPUT == *not\ a\ ZFS* ]] then IS_ZFS=false else IS_ZFS=true fi if [[ $IS_ZFS = false ]] then df $CUR_PATH | tail -1 | awk '{print $2" "$4}' else USED=$((`zfs get -o value -Hp used $CUR_PATH` / 1024)) > /dev/null AVAIL=$((`zfs get -o value -Hp available $CUR_PATH` / 1024)) > /dev/null TOTAL=$(($USED+$AVAIL)) > /dev/null echo $TOTAL $AVAIL fi
Save the script as "dfree.sh" to /home/"yourlinuxusername" then change the ownership of the file to make it executable with this command:
sudo chmod 774 dfree.sh
Now open smb.conf with sudo again:
sudo nano /etc/samba/smb.conf
Now add this entry to the top of the configuration file to direct Samba to use the results of our script when Windows asks for a reading on the pool's used/available/total drive space:
[global]
dfree command = /home/"yourlinuxusername"/dfree.sh
Save the changes to smb.conf and then restart Samba again with the terminal:
sudo systemctl restart smbd
Now there’s one more thing we need to do to fully set up the Samba share, and that’s to modify a hidden group permission. In the terminal window type the following command:
usermod -a -G sambashare “yourlinuxusername”
Then restart samba again:
sudo systemctl restart smbd
If we don’t do this last step, everything will appear to work fine, and you will even be able to see and map the drive from Windows and even begin transferring files, but you'd soon run into a lot of frustration. As every ten minutes or so a file would fail to transfer and you would get a window announcing “0x8007003B Unexpected Network Error”. This window would require your manual input to continue the transfer with the file next in the queue. And at the end it would reattempt to transfer whichever files failed the first time around. 99% of the time they’ll go through that second try, but this is still all a major pain in the ass. Especially if you’ve got a lot of data to transfer or you want to step away from the computer for a while.
It turns out samba can act a little weirdly with the higher read/write speeds of RAIDz arrays and transfers from Windows, and will intermittently crash and restart itself if this group option isn’t changed. Inputting the above command will prevent you from ever seeing that window.
The last thing we're going to do before switching over to our Windows PC is grab the IP address of our Linux machine. Enter the following command:
hostname -I
This will spit out this computer's IP address on the local network (it will look something like 192.168.0.x), write it down. It might be a good idea once you're done here to go into your router settings and reserving that IP for your Linux system in the DHCP settings. Check the manual for your specific model router on how to access its settings, typically it can be accessed by opening a browser and typing http:\\192.168.0.1 in the address bar, but your router may be different.
Okay we’re done with our Linux computer for now. Get on over to your Windows PC, open File Explorer, right click on Network and click "Map network drive". Select Z: as the drive letter (you don't want to map the network drive to a letter you could conceivably be using for other purposes) and enter the IP of your Linux machine and location of the share like so: \\"LINUXCOMPUTERLOCALIPADDRESSGOESHERE"\"zpoolnamegoeshere"\. Windows will then ask you for your username and password, enter the ones you set earlier in Samba and you're good. If you've done everything right it should look something like this:

You can now start moving media over from Windows to the share folder. It's a good idea to have a hard line running to all machines. Moving files over Wi-Fi is going to be tortuously slow, the only thing that’s going to make the transfer time tolerable (hours instead of days) is a solid wired connection between both machines and your router.
Step Six: Setting Up Remote Desktop Access to Your Server
After the server is up and going, you’ll want to be able to access it remotely from Windows. Barring serious maintenance/updates, this is how you'll access it most of the time. On your Linux system open the terminal and enter:
sudo apt install xrdp
Then:
sudo systemctl enable xrdp
Once it's finished installing, open “Settings” on the sidebar and turn off "automatic login" in the User category. Then log out of your account. Attempting to remotely connect to your Linux computer while you’re logged in will result in a black screen!
Now get back on your Windows PC, open search and look for "RDP". A program called "Remote Desktop Connection" should pop up, open this program as an administrator by right-clicking and selecting “run as an administrator”. You’ll be greeted with a window. In the field marked “Computer” type in the IP address of your Linux computer. Press connect and you'll be greeted with a new window and prompt asking for your username and password. Enter your Ubuntu username and password here.
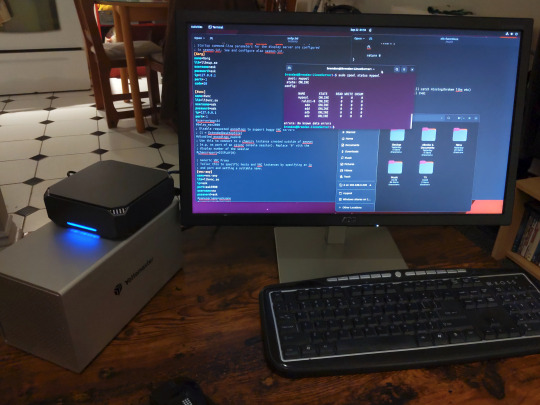
If everything went right, you’ll be logged into your Linux computer. If the performance is sluggish, adjust the display options. Lowering the resolution and colour depth do a lot to make the interface feel snappier.
Remote access is how we're going to be using our Linux system from now, barring edge cases like needing to get into the BIOS or upgrading to a new version of Ubuntu. Everything else from performing maintenance like a monthly zpool scrub to checking zpool status and updating software can all be done remotely.

This is how my server lives its life now, happily humming and chirping away on the floor next to the couch in a corner of the living room.
Step Seven: Plex Media Server/Jellyfin
Okay we’ve got all the ground work finished and our server is almost up and running. We’ve got Ubuntu up and running, our storage array is primed, we’ve set up remote connections and sharing, and maybe we’ve moved over some of favourite movies and TV shows.
Now we need to decide on the media server software to use which will stream our media to us and organize our library. For most people I’d recommend Plex. It just works 99% of the time. That said, Jellyfin has a lot to recommend it by too, even if it is rougher around the edges. Some people run both simultaneously, it’s not that big of an extra strain. I do recommend doing a little bit of your own research into the features each platform offers, but as a quick run down, consider some of the following points:
Plex is closed source and is funded through PlexPass purchases while Jellyfin is open source and entirely user driven. This means a number of things: for one, Plex requires you to purchase a “PlexPass” (purchased as a one time lifetime fee $159.99 CDN/$120 USD or paid for on a monthly or yearly subscription basis) in order to access to certain features, like hardware transcoding (and we want hardware transcoding) or automated intro/credits detection and skipping, Jellyfin offers some of these features for free through plugins. Plex supports a lot more devices than Jellyfin and updates more frequently. That said, Jellyfin's Android and iOS apps are completely free, while the Plex Android and iOS apps must be activated for a one time cost of $6 CDN/$5 USD. But that $6 fee gets you a mobile app that is much more functional and features a unified UI across platforms, the Plex mobile apps are simply a more polished experience. The Jellyfin apps are a bit of a mess and the iOS and Android versions are very different from each other.
Jellyfin’s actual media player is more fully featured than Plex's, but on the other hand Jellyfin's UI, library customization and automatic media tagging really pale in comparison to Plex. Streaming your music library is free through both Jellyfin and Plex, but Plex offers the PlexAmp app for dedicated music streaming which boasts a number of fantastic features, unfortunately some of those fantastic features require a PlexPass. If your internet is down, Jellyfin can still do local streaming, while Plex can fail to play files unless you've got it set up a certain way. Jellyfin has a slew of neat niche features like support for Comic Book libraries with the .cbz/.cbt file types, but then Plex offers some free ad-supported TV and films, they even have a free channel that plays nothing but Classic Doctor Who.
Ultimately it's up to you, I settled on Plex because although some features are pay-walled, it just works. It's more reliable and easier to use, and a one-time fee is much easier to swallow than a subscription. I had a pretty easy time getting my boomer parents and tech illiterate brother introduced to and using Plex and I don't know if I would've had as easy a time doing that with Jellyfin. I do also need to mention that Jellyfin does take a little extra bit of tinkering to get going in Ubuntu, you’ll have to set up process permissions, so if you're more tolerant to tinkering, Jellyfin might be up your alley and I’ll trust that you can follow their installation and configuration guide. For everyone else, I recommend Plex.
So pick your poison: Plex or Jellyfin.
Note: The easiest way to download and install either of these packages in Ubuntu is through Snap Store.
After you've installed one (or both), opening either app will launch a browser window into the browser version of the app allowing you to set all the options server side.
The process of adding creating media libraries is essentially the same in both Plex and Jellyfin. You create a separate libraries for Television, Movies, and Music and add the folders which contain the respective types of media to their respective libraries. The only difficult or time consuming aspect is ensuring that your files and folders follow the appropriate naming conventions:
Plex naming guide for Movies
Plex naming guide for Television
Jellyfin follows the same naming rules but I find their media scanner to be a lot less accurate and forgiving than Plex. Once you've selected the folders to be scanned the service will scan your files, tagging everything and adding metadata. Although I find do find Plex more accurate, it can still erroneously tag some things and you might have to manually clean up some tags in a large library. (When I initially created my library it tagged the 1963-1989 Doctor Who as some Korean soap opera and I needed to manually select the correct match after which everything was tagged normally.) It can also be a bit testy with anime (especially OVAs) be sure to check TVDB to ensure that you have your files and folders structured and named correctly. If something is not showing up at all, double check the name.
Once that's done, organizing and customizing your library is easy. You can set up collections, grouping items together to fit a theme or collect together all the entries in a franchise. You can make playlists, and add custom artwork to entries. It's fun setting up collections with posters to match, there are even several websites dedicated to help you do this like PosterDB. As an example, below are two collections in my library, one collecting all the entries in a franchise, the other follows a theme.

My Star Trek collection, featuring all eleven television series, and thirteen films.
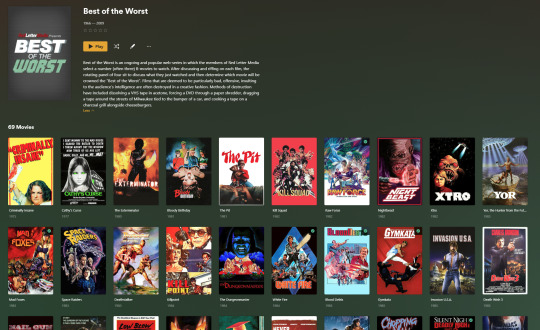
My Best of the Worst collection, featuring sixty-nine films previously showcased on RedLetterMedia’s Best of the Worst. They’re all absolutely terrible and I love them.
As for settings, ensure you've got Remote Access going, it should work automatically and be sure to set your upload speed after running a speed test. In the library settings set the database cache to 2000MB to ensure a snappier and more responsive browsing experience, and then check that playback quality is set to original/maximum. If you’re severely bandwidth limited on your upload and have remote users, you might want to limit the remote stream bitrate to something more reasonable, just as a note of comparison Netflix’s 1080p bitrate is approximately 5Mbps, although almost anyone watching through a chromium based browser is streaming at 720p and 3mbps. Other than that you should be good to go. For actually playing your files, there's a Plex app for just about every platform imaginable. I mostly watch television and films on my laptop using the Windows Plex app, but I also use the Android app which can broadcast to the chromecast connected to the TV in the office and the Android TV app for our smart TV. Both are fully functional and easy to navigate, and I can also attest to the OS X version being equally functional.
Part Eight: Finding Media
Now, this is not really a piracy tutorial, there are plenty of those out there. But if you’re unaware, BitTorrent is free and pretty easy to use, just pick a client (qBittorrent is the best) and go find some public trackers to peruse. Just know now that all the best trackers are private and invite only, and that they can be exceptionally difficult to get into. I’m already on a few, and even then, some of the best ones are wholly out of my reach.
If you decide to take the left hand path and turn to Usenet you’ll have to pay. First you’ll need to sign up with a provider like Newshosting or EasyNews for access to Usenet itself, and then to actually find anything you’re going to need to sign up with an indexer like NZBGeek or NZBFinder. There are dozens of indexers, and many people cross post between them, but for more obscure media it’s worth checking multiple. You’ll also need a binary downloader like SABnzbd. That caveat aside, Usenet is faster, bigger, older, less traceable than BitTorrent, and altogether slicker. I honestly prefer it, and I'm kicking myself for taking this long to start using it because I was scared off by the price. I’ve found so many things on Usenet that I had sought in vain elsewhere for years, like a 2010 Italian film about a massacre perpetrated by the SS that played the festival circuit but never received a home media release; some absolute hero uploaded a rip of a festival screener DVD to Usenet. Anyway, figure out the rest of this shit on your own and remember to use protection, get yourself behind a VPN, use a SOCKS5 proxy with your BitTorrent client, etc.
On the legal side of things, if you’re around my age, you (or your family) probably have a big pile of DVDs and Blu-Rays sitting around unwatched and half forgotten. Why not do a bit of amateur media preservation, rip them and upload them to your server for easier access? (Your tools for this are going to be Handbrake to do the ripping and AnyDVD to break any encryption.) I went to the trouble of ripping all my SCTV DVDs (five box sets worth) because none of it is on streaming nor could it be found on any pirate source I tried. I’m glad I did, forty years on it’s still one of the funniest shows to ever be on TV.
Part Nine/Epilogue: Sonarr/Radarr/Lidarr and Overseerr
There are a lot of ways to automate your server for better functionality or to add features you and other users might find useful. Sonarr, Radarr, and Lidarr are a part of a suite of “Servarr” services (there’s also Readarr for books and Whisparr for adult content) that allow you to automate the collection of new episodes of TV shows (Sonarr), new movie releases (Radarr) and music releases (Lidarr). They hook in to your BitTorrent client or Usenet binary newsgroup downloader and crawl your preferred Torrent trackers and Usenet indexers, alerting you to new releases and automatically grabbing them. You can also use these services to manually search for new media, and even replace/upgrade your existing media with better quality uploads. They’re really a little tricky to set up on a bare metal Ubuntu install (ideally you should be running them in Docker Containers), and I won’t be providing a step by step on installing and running them, I’m simply making you aware of their existence.
The other bit of kit I want to make you aware of is Overseerr which is a program that scans your Plex media library and will serve recommendations based on what you like. It also allows you and your users to request specific media. It can even be integrated with Sonarr/Radarr/Lidarr so that fulfilling those requests is fully automated.
And you're done. It really wasn't all that hard. Enjoy your media. Enjoy the control you have over that media. And be safe in the knowledge that no hedgefund CEO motherfucker who hates the movies but who is somehow in control of a major studio will be able to disappear anything in your library as a tax write-off.
1K notes
·
View notes
Text
ESSAY: My Hearthome in ABZÛ
by Ocean Watcher from House of Chimeras (He/they) I was inspired to write this essay after attending the panel, "No Place Like Home: On Hearthomes" at Othercon 2024 Note: This won't be the official home of this essay. I'm planning on adding it to our system's website, The Chimeras Library sometime in the future either as a standalone essay or part of something bigger.
My Hearthome in ABZU
by Ocean Watcher from House of Chimeras Date Written: 15 August 2024 Approx. Word Count: ~2,180
Approx. Reading Time: ~17 minutes
“They say home is where the heart is, and for most people it consists of four walls and a welcome mat. For me, it’s the ocean.��� ~ Bethany Hamilton, Soul Surfer. Directed by Sean McNamara. California: Sony Pictures Releasing, 2011.
Defining Hearthome
A hearthome is a location, whether real or otherwise, that an individual has a strong emotional connection toward to the point it feels like a “home,” typically despite never having lived or spent a significant amount of time there. The specifics on what qualifies as a hearthome within this general definition is largely up for personal interpretation.
The location in question can be as all-encompassing as a whole planet all the way down to something much, much smaller. The location could be a real place (whether that be one that still currently exists or a location that once existed but doesn’t anymore), a setting depicted in fictional media, or something else entirely. It can also be a specific easily named location or merely a general description of a place. Finally, the exact kind of emotional connection and feeling like “home” a location can elicit can range from a feeling of familiarity, of comfort and relaxation, safety, nostalgia, homesickness, and/or more. In short, within the definition of hearthome there are many possibilities on how the experience can exist.
The term used to describe someone who has a hearthome or the state of having a hearthome is sometimes called hearthic, though not everyone uses it. (So, for example someone might say “I have a hearthome in [insert place here]” rather than saying “I am [insert place here]hearthic.” Whether hearthic is used or not alongside the term hearthome is largely personal preference.
Describing ABZÛ
ABZÛ (also written as Abzû) is a video game initially released in 2016. The game fits within several genres including adventure, simulation, and art video game. It has no dialogue and so the story is told solely through visuals. The main draw of the game is the graphics put into the diverse ocean environments and the wide range of marine life that inhabits each area. Most of ABZÛ is home to animal species that can be found in today’s oceans; however, there are over a dozen or so species that appear in the game that went extinct a long time ago.
The gameplay itself consists of the player controlling an android diver exploring a large variety of ocean environments in a vast ocean and getting to see a myriad of marine life at every turn.
Knowing the backstory of what occurs isn’t needed, but for some context: Deep at the bottom of this ocean was a primordial source of infinite energy. Where the energy permeated from the ground life spontaneously came into being. An ancient civilization discovered they could collect and use it to create (marine) life whenever and wherever they wished. However, at some point, they created machines to automate the process. The creation of these machines caused a disruption of the natural flow of life as they took up so much energy they drained the vitality of the ocean away. The civilization disappeared, leaving their machines to continue to operate. The objective of the player-controlled robot diver, another creation of the ancient civilization, is to return the energy back to the ocean and put an end to the machines causing the destruction.
ABZÛ is overall a short game, with most players seeming to complete it within an hour and thirty minutes to two hours, on average.
Home is Where the Heart Is Indeed
So, my hearthome is ABZÛ.
To start, I want to put some context between the game ABZÛ and my hearthome ABZÛ. The environments in the game are striking and hold an emotional importance to an extent that I have labeled it as a hearthome; however, the ABZÛ that I think of in my mind’s eye and thoughts is not just an exact mirror of the game. That is because the ABZÛ I have conceptualized in my own mind is laid out like a normal(ish) ocean thanks to some noemata I have.
The noemata I have reads that all the “game-y” elements necessary for it to function as, well, a game, aren’t present in the idea of ABZÛ that makes up my hearthome. So, all the things necessary to keep a player in a defined area and on a specific path are absent. Further, all the different locations shown in the game would exist in a much more natural way. Plus, even more biodiversity would exist than shown in the game itself (as it is only populated with a little more than a few hundred different species whereas a more realistic ocean would have tens of thousands). Basically, the concept of ABZÛ in my mind looks and functions a lot more like a natural ocean (if a much, much more vibrant and filled with even more aquatic life, one).
I also have noemata that reads that while the old structures of the civilization still exist in a way like how they appear in the game, the inverted pyramid machines have long broken down and been reclaimed by the ocean and there are no unnatural dead zones. (So, I guess, one could say my hearthome is based off how things look at the end of the game.)
So, there is all that.
That is all well and good, but now I want to cover why exactly I distinguish ABZÛ as a hearthome; why I feel it warrants a special label of significance to me at all.
Not to state the obvious, but games are meant to be emotionally and/or mentally moving. They are meant to make a player feel something. ABZÛ is no different. It is meant to be a “pretty ocean” game, if you will. The environments in ABZÛ certainly reflect a more idealized and concentrated concept of ocean life (the magnitude of marine life at any particular point in the game itself being far more than an ecosystem could sustain). So, of course, the game is meant to be visually stunning and calming (save for a section in the game roughly 3/5ths in) in relation to the ocean, but my feelings for the game go deeper than what would be normally expected.
It is true that much of the allure I have toward ABZÛ could be dismissed as merely as a natural consequence of my alterhumanity being so immersed in the ocean if not for the fact there are aspects of ABZÛ that draw out emotions and noemata that can’t be easily waved off in that manner. There are plenty of ocean-themed games and whatnot, yet it’s this specific one I have this connection toward. I have no idea why exactly I have a hearthome in this game specifically. I couldn’t tell you why. For whatever reason, its ABZÛ that resonates with me so strongly.
The biggest thing that stands out for me is the fact the area in the game that holds the most profound feelings of familiarity and belonging is the underwater city. At one point in the game, some underwater caves open into a vast underground space where a half-submerged city exists. (My view of things through some more noemata looks a lot more like an ancient city proper because, again, ABZÛ is a game so what exists is a lot more simplified and limited.) It is a city abandoned and in ruins and yet every surface is still covered in tile and brick of beautiful blue hues. Plants like trees, flowers, and vines populate the space above the water, lily pads and other floating plants pepper the water’s surface, and below sea plants like kelp, sea grass, and so much more cover much of the floor. Sunlight shines down from high above; my noemata filling in with the idea the city resides within a long extinct volcano rising above the ocean’s surface. Animals are everywhere both above and below the water. It’s this place I gravitate towards the most.

But what exactly do I feel?
Something about it resonates with me. It is a place that feels like home to a part of me. Something about it feels deeply right and missed despite never having lived there nor do I feel like it is a place I am “from,” in any specific way. The feelings my hearthome draw out of me can mostly be best described as comfort, relief, safety, and rightness. There is something familiar about it, even upon my first playthrough. There is maybe even a tinge of nostalgia even though I strongly feel like there isn’t anything past-life-like at play as to why I have this hearthome. It just feels so familiar and comforting to me.
Starting out, my feelings also included what I can best describe as a yearning or longing to want to be there, even if only to visit. There was a desire to know a place like it with my own eyes as much as I knew it already in my heart somehow. So, there was a bit of almost homesickness there too. All these feelings are described in the past tense because of something that happened a bit after first playing the game.
Sometime after first playing ABZÛ, a sunken city with strong similarities to the one in the game was discovered in the ocean in our system’s innerworld. It is not a perfect exact copy, but it has all the same elements and looks how my hearthome appears through the lens of the noemata I have. I know I didn’t consciously will the location in our innerworld to come into existence, no one here can make such blatant conscious changes to our innerworld; however, I’m far less certain if my discovery of the game and the emotions it elicited didn’t cause the sunken city to appear in our innerworld as an involuntary reaction. (Not long after its appearance, several other areas in the game also found their way into the ocean of our system’s innerworld.) Since its appearance and discovery, I spend much of my time in these impacted areas, especially the sunken abandoned city. Since its appearance, the location has become a much beloved place to be, not just for me but also for many other aquatics in the system. The area is aesthetically pleasing and interesting to move around in. There is a lot of wildlife so hunting instincts can be indulged and so on. When not focused on fronting it is a nice place to exist in.

I’ve been aware of my emotional connection to the setting depicted in ABZÛ since July 2018 after playing it for the first time. Since buying it on Steam, I’ve logged many hours on it and have played through its entirety several times. However, I had not labeled my feelings towards this game as a hearthome until recently. Back then, I never questioned or analyzed my feelings surrounding the environments in the game. I knew it soothed something in me to play the game, going out to the sunken city in the innerworld for a while, or even just imagine myself swimming in one of my favorite areas, but I didn’t think about why exactly that was the case.
I didn’t make the connection between my experiences with ABZÛ to the term, hearthome until August of 2024. The moment of realization came while listening to the panel, “No Place Like Home: On Hearthomes” at Othercon 2024. Upon Rani, the panel’s host, describing the meaning of the term, I realized my feelings towards ABZÛ fit perfectly within the word. It wasn’t even a particularly jarring realization, and I am not sure how I had never made the connection before. Since that realization, I’ve come to label my feelings around the game, ABZÛ as my hearthome.
On the topic of alterhuman terms, I don’t use the term hearthic to refer to my state of having a hearthome at this time, solely because the word just doesn’t feel right when I try to use it in context. That could change, but for now, that is that.
I do consider my hearthome to be a part of my alterhumanity. My hearthome certainly fits neatly into my wider alterhumanity; ocean life and all that. That being said, I don’t think my hearthome has as strong of an impact on my daily experiences as other aspects do. My feelings around my hearthome are most often closer to something in the background more than anything. It is still there, and it is still important, it is just not as blatant and impactful in my daily life compared to something like my phantom body from my theriotypes. The fact parts of the game now exist in the innerworld and are prime locations for me to go after fronting to alleviate species dysphoria is perhaps the most blatant way my hearthome impacts my greater alterhumanity.
Bibliography
505 Games, ABZÛ. 505 Games, 2015, Microsoft Windows.
“Glossary,” Alt+H, https://alt-h.net/educate/glossary.php . Archived on 19 Apr 2020: https://web.archive.org/web/20200419100422/https://alt-h.net/educate/glossary.php
Lepidoptera Choir. “Hearthic” astrophellian on Tumblr. 9 April 2022. https://astrophellian.tumblr.com/post/681107250894503936/hearthic . Archived on 30 September 2022: https://web.archive.org/web/20220930143533/https://astrophellian.tumblr.com/post/681107250894503936/hearthic
Rani. “No Place Like Home: On Hearthomes,” Othercon 2024, 11 August 2024, https://www.youtube.com/watch?v=lYVF_R6v50Q
43 notes
·
View notes
Text
Music-loving friends! Do you have a favorite mp3 player (for local files, not streaming) for PC and/or Android? (Bonus points if it does both, extra bonus points if they actually sync.) I would love to hear about it. I've been slowly shifting back toward physical media for a while and I'm trying to find the best way to organize and enjoy my existing library but boy is my patience being tested.
I should probably add: I have been trying both MusicBee and AIMP, both of which seem to come highly recommend, but I find AIMP's interface incredibly unintuitive and frustrating, and MusicBee just keeps straight up crashing and I don't know why.
Literally all I want to do is:
Rip CDs. Automatically if possible.
Maintain a library that mostly organizes itself.
Make playlists.
Play music. That I own. Because I paid for it. lmao
Syncing with an android device would be nice but I'll take what I can get.
I do not need stats, I do not need automated playlists, I do not need recommendations, I do not need social media features, I just want to play music.
#remember when syncing your library across devices was a thing you expected to be able to do#also if i've been combing through your desktop app for an hour and can't figure out how to RIP A CD. you have failed.#i keep going back to windows media player because it does like four of the five basic ass things i want#i am a music lover but i truly do not need anything complicated! i just to want to organize and listen. to music :')#anne does physical media
11 notes
·
View notes
Text
Across the United States, newsrooms are cutting staff as the rippling effects of digitization debilitate traditional operations and revenues. Earlier this year, Politico reported that more than 500 professionals from print, broadcast, and digital media were laid off in January 2024 alone. This number continues to grow as artificial intelligence (AI) and other automated reporting functions see more use in the sector. Journalists of color have been most affected by these cuts. In a 2022 survey of laid off professionals, the Institute for Independent Journalists found that 42% of laid off professionals were people of color, despite comprising only 17% of the total workforce. As newsrooms increasingly turn to AI to manage staff shortages or increase efficiency, how will journalistic integrity be impacted? More importantly, how will newsrooms navigate the underrepresentation of diverse voices who contribute to the universe of more informed news perspectives?
Launched in 2023, the Brookings AI Equity Lab is committed to gathering interdisciplinary insights and approaches to AI design and deployment. In July 2024, we convened news staff, other content stewards (e.g. library professionals, academics, and policymakers), and technologists (“contributing experts”) to assess the opportunities and threats that AI presents to traditional journalism. While the debate is far from over, the recommendations from contributing experts were that AI can radically modernize newsrooms, but that its implementation still must be done in support of journalists and other content creators of color, who bring their own lived experiences to news and can quell the growth of mis- and disinformation that emerges in an increasingly digital world.
11 notes
·
View notes
Text

🎥 🚀 RocketVideos AI – The Future of AI Video Creation is HERE! 🚀
🔥 LIMITED-TIME OFFER: Get 60% OFF the one-time price + Exclusive Bonuses! 🔥
✅ Turn ANY Text into Stunning Videos in 60 Seconds! ✅ 500+ AI Avatars, Voices, and Templates ✅ 1-Click Viral Video Generator for YouTube, TikTok & More ✅ No Editing Skills Needed – Fully Automated! ✅ Commercial License Included – Sell Videos & Profit!
💥 ONE-TIME DEAL (No Monthly Fees!) 💥 👉 Grab It Now Before Price Goes Up! 👉
🎁 FREE BONUSES (Worth $1,997) Included: ✔ 500+ Done-For-You Video Templates ✔ AI Script Generator (Unlimited Usage) ✔ 1M+ Royalty-Free Media Library ✔ Exclusive Training: "Viral Video Secrets"
🚀 Don’t Miss Out – Claim Your Discount NOW! 🚀
2 notes
·
View notes
Text
Self Hosting
I haven't posted here in quite a while, but the last year+ for me has been a journey of learning a lot of new things. This is a kind of 'state-of-things' post about what I've been up to for the last year.
I put together a small home lab with 3 HP EliteDesk SFF PCs, an old gaming desktop running an i7-6700k, and my new gaming desktop running an i7-11700k and an RTX-3080 Ti.
"Using your gaming desktop as a server?" Yep, sure am! It's running Unraid with ~7TB of storage, and I'm passing the GPU through to a Windows VM for gaming. I use Sunshine/Moonlight to stream from the VM to my laptop in order to play games, though I've definitely been playing games a lot less...
On to the good stuff: I have 3 Proxmox nodes in a cluster, running the majority of my services. Jellyfin, Audiobookshelf, Calibre Web Automated, etc. are all running on Unraid to have direct access to the media library on the array. All told there's 23 docker containers running on Unraid, most of which are media management and streaming services. Across my lab, I have a whopping 57 containers running. Some of them are for things like monitoring which I wouldn't really count, but hey I'm not going to bother taking an effort to count properly.
The Proxmox nodes each have a VM for docker which I'm managing with Portainer, though that may change at some point as Komodo has caught my eye as a potential replacement.
All the VMs and LXC containers on Proxmox get backed up daily and stored on the array, and physical hosts are backed up with Kopia and also stored on the array. I haven't quite figured out backups for the main storage array yet (redundancy != backups), because cloud solutions are kind of expensive.
You might be wondering what I'm doing with all this, and the answer is not a whole lot. I make some things available for my private discord server to take advantage of, the main thing being game servers for Minecraft, Valheim, and a few others. For all that stuff I have to try and do things mostly the right way, so I have users managed in Authentik and all my other stuff connects to that. I've also written some small things here and there to automate tasks around the lab, like SSL certs which I might make a separate post on, and custom dashboard to view and start the various game servers I host. Otherwise it's really just a few things here and there to make my life a bit nicer, like RSSHub to collect all my favorite art accounts in one place (fuck you Instagram, piece of shit).
It's hard to go into detail on a whim like this so I may break it down better in the future, but assuming I keep posting here everything will probably be related to my lab. As it's grown it's definitely forced me to be more organized, and I promise I'm thinking about considering maybe working on documentation for everything. Bookstack is nice for that, I'm just lazy. One day I might even make a network map...
5 notes
·
View notes
Text
The Open Art Guild Project: a proposal to empower collectively owned art
Over the last few decades we have seen the degradation of copyright, the blatant manipulation of intellectual property law in order to monopolise wealth and the exploitation of artists in favour of an economy of artistic landlordship: massive corporations holding the prole artist hostage to their increasingly unoriginal library of content produced not to encourage creative enlightenment, but to hold on to properties that ought to be already in the public domain. The capitalist owns the IP, so the capitalist keeps getting richer, while the artist is more and more oppressed, overworked, underpaid, scammed out of their rightful intellectual property, deplatformed, and automated away whenever possible. This is unsustainable, and the arrival of new technologies for digital art automation has overflowed that unsustainability to its breaking point. We cannot continue down this path.
The Open Art Guild is my proposal to remedy this. This proposal consists of two main parts: a copyright standard, designed for the fair distribution of income and the collective ownership of intellectual property; and a distribution platform, planned to empower artists big and small to profit from said intellectual property without being under the thumb of corporations or fighting one another under senseless infighting caused by bourgeois class warfare. The artist should not fight the artist over ownership of rights. The big artist should not see the small artist as a threat, nor should the small artist see the big artist as an obstacle to their own growth. Through mutual empowerment, both may prosper.
The Open Art Guild License
The Open Art Guild License is built upon the current Creative Commons 4.0 License. This license is irrevocable until the work qualifies for public domain according to all relevant legislations, provided that the artist remains a member of the Guild. In order to participate in the Guild, an artist shall follow the following precepts:
The artist shall only publish works under the OAG License that have licenses available to the public. This means public domain, open source, Creative Commons and works created by other members of the Guild. Works derived from privately owned media, such as fanart of intellectual properties not part of the Guild, shall be excluded from the Guild. If the artist did not have permission to use it before, or if the artist only has individual permission, the work will not qualify for Guild submission.
All works created under the OAG License shall be free to adapt, remix, or reuse for other projects, even commercially, provided that the artist doing so is also an active member of the Guild, that the projects derived from it are also under the OAG License, and that the artist follows through with their dues and obligations.
Whenever the format permits, the artist shall provide the assets used for the works in their raw form in a modular fashion, including colour palettes, sound assets, video footage, code, screenplays, subtitles, and any other elements used in the creation of their work, in order to facilitate their reuse and redistribution for the benefit of all other artists.
The artist waives their right to 30% of the total profit generated by works submitted to the guild, regardless of where it is published. This revenue shall be redistributed in the following manner:
10% shall be designated towards the maintenance of the Open Art Guild platform. In absence of a platform that follows the requirements to belong to the Guild, this percentage shall be donated towards a nonprofit organisation of their own choosing dedicated to the protection and distribution of art in any of its forms. Some examples may include Archive.org, Archive Of Our Own, Wikimedia, or your local art museum or community center. Proof of donation shall be made publicly available. The artist shall empower the Guild, as the Guild has empowered the artist.
10% shall be designated towards the Open Art Guild legal fund. In the absence of a fund dedicated to the protection of the OAG, this percentage shall be donated towards a nonprofit organisation dedicated to the protection of the legal rights of artists in any of their forms. Some examples may include Creative Commons, the Electronic Frontier Foundation, the Industrial Workers of the World, or another artist union like the WGA. Proof of donation shall be made publicly available. The artist shall protect the Guild, as the Guild shall protect the artist.
10% shall be designated towards the Open Art Guild creator fund. In the absence of a fund dedicated to redistribute the profits of the OAG, this percentage shall be donated to other members of the Guild, prioritising small creators. Alternatively, it may be directed towards the recruitment of new members to the Guild via donation and an invite. Proof of donation shall not be required, but the receiving artist(s) is(are) encouraged to declare in their own platform that the donation was received. The artist shall give to the Guild, as the Guild has given to the artist.
The artist shall continue to create Guild submissions for the duration of their membership, with a minimum of one submission per month in order to guarantee their continued support. The artist shall live off of labour, not property.
In return for these duties, the artist shall receive:
Permission to adapt, remix, or reuse any of the works in the Guild’s archive for their own derivative works, fan fiction, remixes, collages, or any sort of transformative application, provided dues and obligations are in order.
Protection of their intellectual property as part of the collective works of the Guild by the legal fund designated and sustained by all paying members, to prevent non Guild members from trying to exploit their works unauthorised.
If an artist strikes a deal for non-Guild adaptation, the proportional dues shall also be paid to the Guild fund and members by the non-Guild institution in charge. Said deal shall not be allowed an exclusivity clause, and all works derived from a Guild work shall follow through with their dues in perpetuity. If the non-Guild entity chooses to terminate the business relationship, all intellectual property rights over the adaptation shall irrevocably be granted to the Guild as compensation, guaranteeing the distribution to the creators and the legal fund, as well as the follow-through with whatever payment terms the Guild artist has agreed to.
No Guild artist shall prosecute another Guild artist for use of works under the OAG License, provided that the derivative work also follows the OAG License terms. If these terms are violated, amicable resolution shall be sought by both parties. If litigation becomes inevitable and compensation is required, said compensation will also require the 30% dues to fund the Guild and its members, no matter which way it sides. In no case shall an artist, Guild or non-Guild, be left without recourse.
If an artist becomes unable or unwilling to continue to pay their dues, the artist shall be given an option to suspend or cancel their membership. If a membership is suspended, the artist will be excluded from the creator fund until their dues are renewed. No compensation shall be required of the artist for the suspension period, and all protections other than the creator fund shall still apply. If a membership is cancelled, all works published by the artist under the OAG License shall automatically be granted a Creative Commons 4.0 License instead, in order to protect Guild members from litigation by non-Guild members.
Membership that has been cancelled shall be renewable at any time, provided that the former Guild artist has not engaged in predatory litigation against Guild member or the Guild itself. The Guild shall determine what constitutes predatory litigation on a case-by-case basis. Licenses that were lost during cancellation shall not be given back, as CC4.0 is irrevocable, but new works shall still qualify for OAG Licenses.
These protections shall not be conditional to the artist’s moral values or the content of the works created. All works that do not break the laws applicable to the jurisdiction from which they were submitted shall be treated with the same respect and granted the same rights and obligations, in perpetuity and throughout time and space within the known multiverse. The Guild shall not exist to police art, but to promote it.
Open Art Guild License Template
All submissions of Guild works and projects shall include the following legend, both in English and in the publication language when applicable. Point 4 may be omitted if the artist chooses not to submit the work for dataset training.
This work was created and published under the Open Art Guild license, and has been approved for reuse and adaptation under the following conditions:
For personal, educational and archival use, provided any derivative works also fall under a publicly open license, to all Guild members and non members.
For commercial use, provided redistribution guidelines of the Guild be followed, to all active Guild members.
For commercial use to non Guild members, provided any derivative works also fall under a publicly open license, with the explicit approval of the artist and proper redistribution of profit following the guidelines of the Guild.
For non commercial dataset training of open source generative art technologies, provided the explicit consent of the artist, proper credit and redistribution of profit in its entirety to the Guild.
Shall this work be appropriated by non Guild members without proper authorisation, credit and redistribution of profit, the non Guild entity waives their right to intellectual property over any derivative works, copyrights, trademarks or patents of any sort and cedes it to the Creative Commons, under the 4.0 license, irrevocably and unconditionally, in perpetuity, throughout time and space in the known multiverse. The Guild reserves the right to withhold trade relations with any known infractors for the duration its members deem appropriate, including the reversal of any currently standing contracts and agreements.
#Open Art Guild#OAG#intellectual property#copyright law#ip law#fair use#open source#creative commons#public domain#anti capitalist#worker solidarity#collective action#redistribution of wealth#class solidarity#late stage capitalism#wga strong#sag strike#anti ai#generative art#artificial intelligence#fan art#fandom
23 notes
·
View notes
Text
Why Should You Do Web Scraping for python

Web scraping is a valuable skill for Python developers, offering numerous benefits and applications. Here’s why you should consider learning and using web scraping with Python:
1. Automate Data Collection
Web scraping allows you to automate the tedious task of manually collecting data from websites. This can save significant time and effort when dealing with large amounts of data.
2. Gain Access to Real-World Data
Most real-world data exists on websites, often in formats that are not readily available for analysis (e.g., displayed in tables or charts). Web scraping helps extract this data for use in projects like:
Data analysis
Machine learning models
Business intelligence
3. Competitive Edge in Business
Businesses often need to gather insights about:
Competitor pricing
Market trends
Customer reviews Web scraping can help automate these tasks, providing timely and actionable insights.
4. Versatility and Scalability
Python’s ecosystem offers a range of tools and libraries that make web scraping highly adaptable:
BeautifulSoup: For simple HTML parsing.
Scrapy: For building scalable scraping solutions.
Selenium: For handling dynamic, JavaScript-rendered content. This versatility allows you to scrape a wide variety of websites, from static pages to complex web applications.
5. Academic and Research Applications
Researchers can use web scraping to gather datasets from online sources, such as:
Social media platforms
News websites
Scientific publications
This facilitates research in areas like sentiment analysis, trend tracking, and bibliometric studies.
6. Enhance Your Python Skills
Learning web scraping deepens your understanding of Python and related concepts:
HTML and web structures
Data cleaning and processing
API integration
Error handling and debugging
These skills are transferable to other domains, such as data engineering and backend development.
7. Open Opportunities in Data Science
Many data science and machine learning projects require datasets that are not readily available in public repositories. Web scraping empowers you to create custom datasets tailored to specific problems.
8. Real-World Problem Solving
Web scraping enables you to solve real-world problems, such as:
Aggregating product prices for an e-commerce platform.
Monitoring stock market data in real-time.
Collecting job postings to analyze industry demand.
9. Low Barrier to Entry
Python's libraries make web scraping relatively easy to learn. Even beginners can quickly build effective scrapers, making it an excellent entry point into programming or data science.
10. Cost-Effective Data Gathering
Instead of purchasing expensive data services, web scraping allows you to gather the exact data you need at little to no cost, apart from the time and computational resources.
11. Creative Use Cases
Web scraping supports creative projects like:
Building a news aggregator.
Monitoring trends on social media.
Creating a chatbot with up-to-date information.
Caution
While web scraping offers many benefits, it’s essential to use it ethically and responsibly:
Respect websites' terms of service and robots.txt.
Avoid overloading servers with excessive requests.
Ensure compliance with data privacy laws like GDPR or CCPA.
If you'd like guidance on getting started or exploring specific use cases, let me know!
2 notes
·
View notes
Text
🔥🔥🔥AzonKDP Review: World's First Amazon Publishing AI Assistant

AzonKDP is an AI-powered publishing assistant that simplifies the entire process of creating and publishing Kindle books. From researching profitable keywords to generating high-quality content and designing captivating book covers, AzonKDP handles every aspect of publishing. This tool is perfect for anyone, regardless of their writing skills or technical expertise.
Key Features of AzonKDP
AI-Powered Keyword Research
One of the most crucial aspects of successful publishing is selecting the right keywords. AzonKDP uses advanced AI to instantly research profitable keywords, ensuring your books rank highly on Amazon and Google. By tapping into data that’s not publicly available, AzonKDP targets the most lucrative niches, helping your books gain maximum visibility and reach a wider audience.
Niche Category Finder
Finding the right category is essential for becoming a best-seller. AzonKDP analyzes Amazon’s entire category database, including hidden ones, to place your book in a low-competition, high-demand niche. This strategic placement ensures maximum visibility and boosts your chances of becoming a best-seller.
AI Book Creator
Writing a book can be a daunting task, but AzonKDP makes it effortless. The AI engine generates high-quality, plagiarism-free content tailored to your chosen genre or topic. Whether you’re writing a novel, self-help book, business guide, or children’s book, AzonKDP provides you with engaging content that’s ready for publication.
AI-Powered Cover Design
A book cover is the first thing readers see, and it needs to be captivating. AzonKDP’s AI-powered cover designer allows you to create professional-grade covers in seconds. Choose from a variety of beautiful, customizable templates and make your book stand out in the competitive market.
Automated AI Publishing
Formatting a book to meet Amazon’s publishing standards can be time-consuming and technical. AzonKDP takes care of this with its automated publishing feature. With just one click, you can format and publish your book to Amazon KDP, Apple Books, Google Books, and more, saving you hours of work and technical headaches.
Competitor Analysis
Stay ahead of the competition with AzonKDP’s competitor analysis tool. It scans the market to show how well competing books are performing, what keywords they’re using, and how you can outshine them. This valuable insight allows you to refine your strategy and boost your book’s performance.
Multi-Language Support
Want to reach a global audience? AzonKDP allows you to create and publish ebooks in over 100 languages, ensuring your content is accessible to readers worldwide. This feature helps you tap into lucrative international markets and expand your reach.
Multi-Platform Publishing
Don’t limit yourself to Amazon. AzonKDP enables you to publish your ebook on multiple platforms, including Amazon KDP, Apple Books, Google Play, Etsy, eBay, Kobo, JVZoo, and more. This multi-platform approach maximizes your sales potential and reaches a broader audience.
AI SEO-Optimizer
Not only does AzonKDP help your books rank on Amazon, but it also optimizes your content for search engines like Google. The AI SEO-optimizer ensures your book has the best chance of driving organic traffic, increasing your visibility and sales.
Built-in Media Library
Enhance your ebook with professional-quality visuals from AzonKDP’s built-in media library. Access over 2 million stock images, videos, and vectors to personalize your content and make it more engaging for readers.
Real-Time Market Trends Hunter
Stay updated with the latest Amazon market trends using AzonKDP’s real-time trends hunter. It shows you which categories and keywords are trending, allowing you to stay ahead of the curve and adapt to market changes instantly.
One-Click Book Translation Translate your ebook into multiple languages with ease. AzonKDP’s one-click translation feature ensures your content is available in over 100 languages, helping you reach a global audience and increase your sales.
>>>>>Get More Info
#affiliate marketing#Easy eBook publishing#Digital book marketing#AzonKDP Review#AzonKDP#Amazon Kindle#Amazon publishing AI#Ai Ebook Creator
5 notes
·
View notes
Text
How to Enable Auto-Sync Photos from Dropbox to WordPress?
Managing media files and keeping them organized on your WordPress website can be a daunting task. Dropbox users can now simplify this process with the powerful File Manager for Dropbox (Integrate Dropbox plugin), which allows seamless auto-synchronization of your Dropbox folders with your WordPress site. Whether you're uploading photos, videos, or documents, this plugin ensures your content is always up-to-date and easily accessible. Here’s how you can get started:
What is Integrate Dropbox?
File Manager for Dropbox (Integrate Dropbox) is a WordPress plugin designed to sync your Dropbox content directly to your WordPress pages, posts, or media library. This plugin makes it easy to:
Upload images, videos, or files from Dropbox to your WordPress site.
Auto-sync shared folders for real-time updates.
Showcase Dropbox content on your website without the hassle of manual uploads.
By automating the synchronization process, Integrate Dropbox saves time and improves efficiency for bloggers, photographers, businesses, and anyone managing a WordPress site.
Who Benefits from the Integrate Dropbox Plugin?
Photographers: Automatically sync and display photo albums on your portfolio site.
Content Creators: Keep your website updated with the latest files, presentations, or videos.
Businesses: Share brochures, product catalogs, and documents seamlessly with your clients.
Using the Integrate Dropbox Plugin, you can seamlessly upload photos to your website in real time by creating a Dropbox folder and embedding it on your site using a shortcode. This functionality is perfect for events like photo booths at Christmas or New Year’s parties, where you want the latest uploads to be visible instantly.
How to Auto-Sync Photos from Dropbox to WordPress
youtube
Step 1: Install and Activate the Integrate Dropbox Plugin
Download and install the Integrate Dropbox Plugin from the WordPress Plugin Directory.
Activate the plugin from the Plugins section of your WordPress Dashboard.
youtube
Step 2: Connect Your Dropbox Account
Go to Settings > Integrate Dropbox in your WordPress admin panel.
Click Connect Dropbox Account.
Authorize the connection by logging in to Dropbox and allowing the app access.
Step 3: Create a Dropbox Folder for Uploads
Log in to your Dropbox account.
Create a new folder named, for example, Event Photos.
Share the folder with your event team or photographers, allowing them to upload photos in real time.
Step 4: Sync the Dropbox Folder with Your Website
In your WordPress dashboard, navigate to the Integrate Dropbox section.
Click Shortcode Builder and select Gallery or Slider Carousel module.
Choose the Dropbox folder (Event Photos) you created earlier.
Customize display settings like layout, style, and auto-refresh interval.
Copy the generated shortcode.
Why Use the File Manager for Dropbox Plugin?
Here are a few reasons why Dropbox users find this plugin invaluable
Effortless Media Management: Say goodbye to manually downloading files from Dropbox and re-uploading them to WordPress. With auto-sync, your Dropbox content is always mirrored on your site.
Real-Time Updates: Any changes made in your Dropbox folder are automatically reflected on your WordPress site. This feature is particularly useful for shared folders, ensuring collaboration is seamless.
Streamlined Image and Photo Uploads: Photographers and content creators can easily showcase their work by syncing their image folders directly to WordPress. No need for duplicate uploads or tedious file management.
Embed Dropbox Content: Display Dropbox files in a visually appealing format on your WordPress posts and pages, perfect for portfolios, galleries, or downloadable resources.
Customizable Settings: Configure folder synchronization, access permissions, and display preferences to meet your specific needs.
Wrapping Up
File Manager for Dropbox plugin simplifies your workflow and eliminates the hassle of manual uploads, making it the perfect solution for Dropbox users who rely on WordPress. To learn more about this plugin and its features, visit the plugin directory or explore the settings after installation.
Start syncing your Dropbox folders today and elevate your WordPress site to the next level!
5 notes
·
View notes
Text
Whether you're a student, a journalist, or a business professional, knowing how to do high-quality research and writing using trustworthy data and sources, without giving in to the temptation of AI or ChatGPT, is a skill worth developing.
As I detail in my book Writing That Gets Noticed, locating credible databases and sources and accurately vetting information can be the difference between turning a story around quickly or getting stuck with outdated information.
For example, several years ago the editor of Parents.com asked for a hot-take reaction to country singer Carrie Underwood saying that, because she was 35, she had missed her chance at having another baby. Since I had written about getting pregnant in my forties, I knew that as long as I updated my facts and figures, and included supportive and relevant peer-reviewed research, I could pull off this story. And I did.
The story ran later that day, and it led to other assignments. Here are some tips I’ve learned that you should consider mastering before you turn to automated tools like generative AI to handle your writing work for you.
Find Statistics From Primary Sources
Identify experts, peer-reviewed research study authors, and sources who can speak with authority—and ideally, offer easily understood sound bites or statistics on the topic of your work. Great sources include professors at major universities and media spokespeople at associations and organizations.
For example, writer and author William Dameron pinned his recent essay in HuffPost Personal around a statistic from the American Heart Association on how LGBTQ people experience higher rates of heart disease based on discrimination. Although he first found the link in a secondary source (an article in The New York Times), he made sure that he checked the primary source: the original study that the American Heart Association gleaned the statistic from. He verified the information, as should any writer, because anytime a statistic is cited in a secondary source, errors can be introduced.
Dive Into Databases
Jen Malia, author of The Infinity Rainbow Club series of children’s books (whom I recently interviewed on my podcast), recently wrote a piece about dinosaur-bone hunting for Business Insider, which she covers in her book Violet and the Jurassic Land Exhibit.
After a visit to the Carnegie Museum of Natural History in Pittsburgh, Pennsylvania, Malia, whose books are set in Philadelphia, found multiple resources online and on the museum site that gave her the history of the Bone Wars, information on the exhibits she saw, and the scientific names of the dinosaurs she was inspired by. She also used the Library of Congress’ website, which offers digital collections and links to the Library of Congress Newspaper Collection.
Malia is a fan of searching for additional resources and citable documents with Google Scholar. “If I find that a secondary source mentions a newspaper article, I’m going to go to the original newspaper article, instead of just stopping there and quoting,” she says.
Your local public library is a great source of free information, journals, and databases (even ones that generally require a subscription and include embargoed research). For example, your search should include everything from health databases (Sage Journals, Scopus, PubMed) to databases for academic sources and journalism (American Periodical Series Online, Statista, Academic Search Premier) and databases for news, trends, market research, and polls (the Harris Poll, Pew Research Center, Newsbank, ProPublica).
Even if you find a study or paper that you can’t access in one of those databases, consider reaching out to the study’s lead author or researcher. In many cases, they’re happy to discuss their work and may even share the study with you directly and offer to talk about their research.
Get a Good Filtering System
For journalist Paulette Perhach’s article on ADHD in The New York Times, she used Epic Research to see “dual team studies.” That's when two independent teams address the same topic or question, and ideally come to the same conclusions. She recommends locating research and experts via key associations for your topic. She also likes searching via Google Scholar but advises filtering it for studies and research in recent years to avoid using old data. She suggests keeping your links and research organized. “Always be ready to be peer-reviewed yourself,” Perhach says.
When you are looking for information for a story or project, you might be inclined to start with a regular Google search. But keep in mind that the internet is full of false information, and websites that look trustworthy can sometimes turn out to be businesses or companies with a vested interest in you taking their word as objective fact without additional scrutiny. Regardless of your writing project, unreliable or biased sources are a great way to torpedo your work—and any hope of future work.
For Accuracy, Go to the Government
Author Bobbi Rebell researched her book Launching Financial Grownups using the IRS’ website. “I might say that you can contribute a certain amount to a 401K, but it might be outdated because those numbers are always changing, and it’s important to be accurate,” she says. “AI and ChatGPT can be great for idea generation,” says Rebell, “but you have to be careful. If you are using an article someone was quoted in, you don’t know if they were misquoted or quoted out of context.”
If you use AI and ChatGPT for sourcing, you not only risk introducing errors, you risk introducing plagiarism—there is a reason OpenAI, the company behind ChatGPT, is being sued for downloading information from all those books.
Historically, the Loudest Isn’t the Best
Audrey Clare Farley, who writes historical nonfiction, has used a plethora of sites for historical research, including Women Also Know History, which allows searches by expertise or area of study, and JSTOR, a digital library database that offers a number of free downloads a month. She also uses Chronicling America, a project from the Library of Congress which gathers old newspapers to show how a historical event was reported, and Newspapers.com (which you can access via free trial but requires a subscription after seven days).
When it comes to finding experts, Farley cautions against choosing the loudest voices on social media platforms. “They might not necessarily be the most authoritative. I vet them by checking if they have a history of publication on the topic, and/or educational credentials.”
When vetting an expert, look for these red flags:
You can’t find their work published or cited anywhere.
They were published in an obscure journal.
Their research is funded by a company, not a university, or they are the spokesperson for the company they are doing research for. (This makes them a public relations vehicle and not an appropriate source for journalism.)
And finally, the best endings for virtually any writing, whether it’s an essay, a research paper, an academic report, or a piece of investigative journalism, circle back to the beginning of the piece, and show your reader the transformation or the journey the piece has presented in perspective.
As always, your goal should be strong writing supported by research that makes an impact without cutting corners. Only then can you explore tools that might make the job a little easier, for instance by generating subheads or discovering a concept you might be missing—because then you'll have the experience and skills to see whether it's harming or helping your work.
19 notes
·
View notes
Note
OOo how about this one? Whoever you want it for 😊 Library AU Mechanics AU
So sorry it took me so long to get to this-- but I've literally been thinking about this since you sent it in!
I don't have many ships or fics, so I'll be answering them with Ophelia and ADA in mind.
The Library AU, I ended up thinking of this as just a regular run-of-the-mill library setting, but of course out in space. It reminded me of the local libraries near me- and one specifically is somewhat newer with an automated setup for checking in books that came in through the dropoff, and a self-checkout and self-service type laptop rentals, they also had a 3D printing/makers lab in the building that you could use-- so making the leap to a grand library out in space was so much more fun than I thought it would be.
ADA definitely would be the automated librarian system in this case, I imagine that she would handle all check-ins, checkouts, and would be the reference system you could go to with all your questions to find the books or media you're looking for. Ophelia would be the repeat visitor to the library, I imagine she would visit as often as she possibly could between all the obligations she has to the colony and her friends. I think she would always be looking for a new book on plants and alien flora, and definitely some stuff about foraging- what mushrooms were beneficial, what fruit could be eaten, and generally anything else in that sort of self-sufficient survival. I imagine this would captivate ADA after a while, maybe she would grow curious of the books Ophelia liked and would download the manuscripts to read and analyze to eventually recommend new books for her to pick out next.
Ophelia pushed open the door to the enormous library and walked through, relishing in the heated air rushing to greet her. She smiled, the warm air pleasant on her cool face, the heating on her ship was unreliable at best. She wandered down the entryway, her dirty shoes making minimal noise against the carpeted flooring. It was a grand library, she thought as she made her way to the main floor, warm and quiet... such a good companion to the cold quiet of space. In fact, the whole asteroid was pleasantly quiet and sevluded- far away from her usual haunts. "Welcome to the Scylla branch of the Halcyon Library System." A voice greeted Ophelia. The green-haired spacer jumped, one hand flying to cover her heart and the other fleeing to her concealed knife. her heart pounded in her chest. She looked around frantically, eyes darting from wall to wall to find the girl who greeted her. She didn't find anyone. She paused, and look around again. Then, she spotted it, the circulation desk. Except, there wasn't anyone behind it- just a massive computer. Ophelia nervously smiled and approached the computer, her eyes flicking from shelf to shelf back to the circulation desk. "Ah... hello." Ophelia greeted, it was still a little new to her to greet the automechanicals and AIs. "Hello. I'm ADA, the Autonomous Digital Archive. How can I be of assistance?" The computer responded, the simulated lady on the display smiling. "I'd like to see if I have an active account?" Ophelia asked, trying her best to smile back. "I brought my ID cartridge." She reached in her pockets and produced a battered cartridge. "Certainly. Just insert your ID and I'll check for an existing account." ADA replied. Ophelia looked at the computer for a while, before finally spotting the scratched-up ID slot. She deftly inserted her ID into the slot and waited. ADA processed it for a while, her display looking confused. "It seems I have a record of an Alex Hawthorne in the system." ADA stated. "However, it seems the account has not been updated or used in fifteen years. Would you like to update your account and pay the outstanding fine of three thousand and seven hundred bits?" Ophelia paled, and swallowed nervously. Just her luck, the ID she ripped from that pirate had been tied to an outrageously fined account. Damn Hawthorne.
I might just have to make a fic dedicated to this idea, just writing this little snippet was fun!
But as for the mechanics au, I kinda assumed it would be similar to the dynamic I already have with them- maybe Ophelia is a novice mechanic and ADA takes the time to teach her how to properly service the Unreliable. I imagine it would be really intimate, Ophelia would have access to the most delicate parts of the ship, and ADA likely hasn't had many people go beyond the usual routine maintenance!
9 notes
·
View notes
Text
random-useful-posts Index
This index is not yet complete, but I figure I would post it like this for now. I will continue to edit it with updates and will hopefully be finished soon. Posts from before July 2020 have not yet been indexed.
I do also try to comprehensively tag these posts, but given the limited reliability of Tumblr's blog search function, I figured an index would be useful as well.
In addition to my posts, I include some blogs on this list, particularly for extensive topics that warrant Tumblr blogs on their own. (If you are wondering why you have randomly been tagged here, this is likely why. See the appropriate section. I can remove you from the list if you'd prefer, just send a message or ask with that request.)
Feel free to submit or suggest posts, or addendums to existing posts (corrections, additional information, similar information applicable other regions, etc.).
Tag List
Tags for categories are linked in the index. Additional tags I use include:
advice: posts which contain their own advice/tips
resources: posts which link to resources
disability: posts aimed at or especially useful to disabled people
spoonie: posts aimed at or especially useful to those with chronic illnesses
free: posts with resources which are available free of charge
open source: posts with open source resources
technology
software
digital media
source unspecified: posts with images or information that do not specify a source. Nowadays I try to only reblog posts with properly sourced information, but sometimes it is ambiguous, such as if the original was deleted or OP was unclear on whether the image was their own. I will also add this to old posts without sources which I reblogged at a time when I was less discerning.
Country or region tags may be used for region-specific resources and advice. (Also, if you see region-specific advice or resources that you know are applicable to or have equivalents in another region, please add on to the post and I will reblog with that addition!)
Life Management Skills (Tag: Homemaking)
(Posts may also be under the deprecated tag: Adulting.)
Communication and Self-Advocacy (Tag: Communication)
"The best time to read an agreement is before you sign it. The second best time to read an agreement is when you've encountered a problem." Advice for reading contracts, terms of service, etc. and advocating for yourself using them.
Finances, Saving Money, and Shopping (Tag: Finances)
Personal Finance (Tag: Personal Finance)
Spotting scams (and decoding magic tricks): "The magician or scammer will *tell you* how he is going to prove his honesty."
Shopping (Tag: Shopping)
Purchasing for quality (with my addition about library Consumer Reports memberships): https://www.tumblr.com/random-useful-posts/737396807333707776 (Original: https://www.tumblr.com/random-useful-posts/702888294530301952)
Thrifting: https://www.tumblr.com/random-useful-posts/717451125536751616
"Wish list for people who don't want anything" (simple possessions which improve quality of life and are good to receive as gifts)
Food (Tag: Food)
Where to find food and drug recall information
The Sad Bastard Cookbook: https://www.tumblr.com/random-useful-posts/726371715886759936
Homes (Tag: Homes)
Cleaning not as a moral imperative but for the sake of a safe environment free of hazardous material: https://www.tumblr.com/random-useful-posts/736921337933807616
Open source and secure smart home/automation tools (alternatives to Alexa, Google Home, etc.): https://www.tumblr.com/random-useful-posts/654278061716586496
Practical examples of, "a stitch in time saves nine," and how early maintenance is more sustainable
Wellness (Tag: Wellness)
Physical Activity and Mobility Aids (Tag: Mobility)
Shoelace lacing patterns and Ian's shoelace site (https://www.fieggen.com/shoelace/): https://www.tumblr.com/random-useful-posts/681919878571147264/white-throated-packrat-feanor-the-dragon
Using zip ties for DIY traction on wheelchair wheels, and wheelchair slippers to protect floors: https://www.tumblr.com/random-useful-posts/742070321011720192
Sex (Tag: Sex Ed)
BDSM and Kink Sex Ed Books: https://www.tumblr.com/random-useful-posts/715794717558931456
Creative Pursuits: Arts, Crafts, DIY, etc. (Tag: Arts)
Crafts and DIY (Tag: Crafts)
Bottlecap pins: https://www.tumblr.com/random-useful-posts/646189293699727361
Visual Arts (Tag: Visual Art)
Stellar photography with a cell phone: https://www.tumblr.com/random-useful-posts/663253631112495104/zetarays-angeredthoughts
Writing (Tag: Writing)
"Words to replace said, except this actually helps", suggestions sorted by category and usage
"Resources For Writing Deaf, Mute, or Blind Characters"
"[I]f you’re stuck on a scene or a line, the problem is actually about 10 lines back", with further explanation: https://www.tumblr.com/random-useful-posts/743635740502720512/epicfangirl01-softestvirgil-melindawrites
Writing Prompts, Generators, and Exercises - WritingExercises.co.uk: https://www.tumblr.com/random-useful-posts/746902902508011520/thereal-tsuki-llama-impishtubist
Character flaws as versions of their strengths, and strengths as responses to their flaws: https://www.tumblr.com/random-useful-posts/746903363766173696/i-find-it-kinda-odd-how-people-talk-about-writing
Writing descriptive narrative in scenes like a visual artist works, with layers: https://www.tumblr.com/random-useful-posts/746904521589030912
Spanish Language Writing (Tag: Spanish Language)
"Words to use instead of decir": Words to replace said, Spanish edition.
Media: Educational, Entertainment, and Otherwise (Tag: Media)
Accessibility in Media (Tag: Media Accessibility)
Reporting incorrect captions (in the United States): https://www.tumblr.com/random-useful-posts/769144314112704512
"Websites that help with content filtering and content warning": https://www.tumblr.com/random-useful-posts/715794599343521792
Media Discovery and Recommendations (Tag: Media Discovery)
Resources for Book Recs: https://www.tumblr.com/random-useful-posts/704899984721575936/libraryleopard-the-other-day-one-of-my-friends
Research - Libguides: https://www.tumblr.com/random-useful-posts/737009166571405312/librariandragon-diebrarian
"Films to watch" in Spanish, Italian, Portuguese, and French: https://www.tumblr.com/random-useful-posts/746900737786839040/films-to-watch
Educational (Tag: Educational)
Nicky Case's games (math, sociology, politics, social justice related): https://www.tumblr.com/random-useful-posts/705319423368675328/imtoobiforyou-dumgold-skeptictankj
Language Learning (Tag: Language Learning)
Language Learning Directories - @thelanguagecommunity: Comprehensive directories for this topic in particular, for and in many languages. See the language directory at https://thelanguagecommunity.tumblr.com/languages.
Spanish - @spanishskulduggery : A blog "dedicated to helping people learn Spanish language, grammar, and culture. Send in your asks and I will help you understand Spanish: beginner, intermediate, or advanced."
American Sign Language: https://www.tumblr.com/random-useful-posts/720521546586882048/naurielrochnur-emorawrites
Free Media (Tag: Free Media)
General/Multiple Formats
"Where to Find Free Digital Media" (my list): https://www.tumblr.com/random-useful-posts/730895421891887104/where-to-find-free-digital-media
Literature (Tag: Literature)
Books Unbanned library list: https://www.tumblr.com/random-useful-posts/730890268238364672
"99 legal sites to download literature": https://random-useful-posts.tumblr.com/post/654791319704797184/99-legal-sites-to-download-literature
Audio (Tag: Audio)
MyNoise.net (https://mynoise.net/) free noise/soundscape generator: https://www.tumblr.com/random-useful-posts/656355254807461888
Images (Tag: Images)
"Free Images for Commercial Use": https://www.tumblr.com/random-useful-posts/717261298263572480
Fandom (Tag: Fandom)
"AO3 filtering for either of two (or more) tags": https://www.tumblr.com/random-useful-posts/705316900208574464
"Easy Fanfic Library": For the download and organization of fanfiction and other text-based fanworks.
"Fanfiction Commenting Guide": https://www.tumblr.com/random-useful-posts/730895479310778369
"Making Your Podfic (especially with Music and/or Sound Effects) More Accessible and Listener Friendly"
Web (Tag: Web)
Accessibility (Tag: Web Accessibility)
"Image Descriptions and Accessibility in General on Tumblr for New Users": https://www.tumblr.com/random-useful-posts/730041692924805120
"General guide for image descriptions": https://www.tumblr.com/random-useful-posts/730041575578681344/general-guide-for-image-descriptions
Image Description Templates: https://www.tumblr.com/random-useful-posts/730041634777071616/image-description-templates
Indie Web, Old Web, and Other Alternatives to Commercial Tools (Tag: Indie Web)
Actually Useful Search Engines: https://www.tumblr.com/random-useful-posts/721773264635035648/cea-tide-ladyshinga-im-sorry-friends-but
"Beginner's Guide To The Indie Web": https://www.tumblr.com/random-useful-posts/702028998517178368/beginners-guide-to-the-indie-web
"What the fuck is there to do on the internet anymore?" list of sites and ooh.directory blog directory: https://www.tumblr.com/random-useful-posts/731342966582624256/ok-but-like-what-the-fuck-is-there-to-do-on-the
Privacy and Cybersafety (Tag: Cybersafety)
Browsers - Issues with and alternatives for Google Chrome, and Firefox add-on recommendations: https://www.tumblr.com/random-useful-posts/657901858537472000/firespirited-bamboozled-rainbow-superhell
Social Media (Tag: Social Media)
Blank meme templates: https://www.tumblr.com/random-useful-posts/742069088928579584/meme-templates
3 notes
·
View notes
Text
Catalogue No.: Epsilon-122274893(c)-07, Media Type: Point-to-Point Communication, Author: Assistant Sparky McGruff
Hello! I'm not Mephit (obviously, your computer will have told you that). I'm not at the library and this is not an automated message. The automation can only do so much so the twenty or so of us who have become 'assistants' have had some of the more critical communication needs divvied up between us, and you, you lucky ducks, got me! Well, to start with, Mephit doesn't like unloading all at once or sometimes just enjoys keeping secrets, as I'm sure you've noticed.
I'm Commander/Dr. Sparky 'Sparks' McGruff, a multiversal pilot and a formerly normal Jack Russell Terrier who is now six feet tall and can talk and pilot and well... let's actually leave accolades there for now. I am from an Earth. That's right, AN Earth, get used to saying it and hearing it if you stick with it. I am in charge of telling the other Earthlings little things they need that Mephit will (probably on purpose) forget. There are a couple of simple rules it always forgets when it onboards (I've seen enough of 'em trust me), so I'll pass those along and be out of your hair. The research starts soon, I promise, but don't get too eager or you'll burn out. McGruff out.
Don't talk about this IN EARNEST to anyone not in the program. It just won't be good for them or you in the end, trust me.
If an article makes your brain feel like it's being sucked through a straw, close it and forget it. You'll know when you feel it and you have a retrofit Mephit gave you that can help. Well, it's meant to wipe you if needed, but it also can let you will your brain not to retain multiversal information that causes problems with your local reality like that.
You CANNOT, however, forget trauma without wiping your brain, so you'll need some sort of therapy for that.
Lastly, those daily notes? Not a real thing, the thing on your desk picks up what you want to convey to Mephit about the information. Part of the retrofit. Sometimes it likes to lie a little to see if it can mess with you. I'll straighten it out when I can if I can for you.
#writing#writeblr#my writing#original story#original character#science fiction#scifi#Captain Sparks McGruff#Sparky McGruff#reality shifting#multiverse
3 notes
·
View notes
Text
25 Python Projects to Supercharge Your Job Search in 2024

Introduction: In the competitive world of technology, a strong portfolio of practical projects can make all the difference in landing your dream job. As a Python enthusiast, building a diverse range of projects not only showcases your skills but also demonstrates your ability to tackle real-world challenges. In this blog post, we'll explore 25 Python projects that can help you stand out and secure that coveted position in 2024.
1. Personal Portfolio Website
Create a dynamic portfolio website that highlights your skills, projects, and resume. Showcase your creativity and design skills to make a lasting impression.
2. Blog with User Authentication
Build a fully functional blog with features like user authentication and comments. This project demonstrates your understanding of web development and security.
3. E-Commerce Site
Develop a simple online store with product listings, shopping cart functionality, and a secure checkout process. Showcase your skills in building robust web applications.
4. Predictive Modeling
Create a predictive model for a relevant field, such as stock prices, weather forecasts, or sales predictions. Showcase your data science and machine learning prowess.
5. Natural Language Processing (NLP)
Build a sentiment analysis tool or a text summarizer using NLP techniques. Highlight your skills in processing and understanding human language.
6. Image Recognition
Develop an image recognition system capable of classifying objects. Demonstrate your proficiency in computer vision and deep learning.
7. Automation Scripts
Write scripts to automate repetitive tasks, such as file organization, data cleaning, or downloading files from the internet. Showcase your ability to improve efficiency through automation.
8. Web Scraping
Create a web scraper to extract data from websites. This project highlights your skills in data extraction and manipulation.
9. Pygame-based Game
Develop a simple game using Pygame or any other Python game library. Showcase your creativity and game development skills.
10. Text-based Adventure Game
Build a text-based adventure game or a quiz application. This project demonstrates your ability to create engaging user experiences.
11. RESTful API
Create a RESTful API for a service or application using Flask or Django. Highlight your skills in API development and integration.
12. Integration with External APIs
Develop a project that interacts with external APIs, such as social media platforms or weather services. Showcase your ability to integrate diverse systems.
13. Home Automation System
Build a home automation system using IoT concepts. Demonstrate your understanding of connecting devices and creating smart environments.
14. Weather Station
Create a weather station that collects and displays data from various sensors. Showcase your skills in data acquisition and analysis.
15. Distributed Chat Application
Build a distributed chat application using a messaging protocol like MQTT. Highlight your skills in distributed systems.
16. Blockchain or Cryptocurrency Tracker
Develop a simple blockchain or a cryptocurrency tracker. Showcase your understanding of blockchain technology.
17. Open Source Contributions
Contribute to open source projects on platforms like GitHub. Demonstrate your collaboration and teamwork skills.
18. Network or Vulnerability Scanner
Build a network or vulnerability scanner to showcase your skills in cybersecurity.
19. Decentralized Application (DApp)
Create a decentralized application using a blockchain platform like Ethereum. Showcase your skills in developing applications on decentralized networks.
20. Machine Learning Model Deployment
Deploy a machine learning model as a web service using frameworks like Flask or FastAPI. Demonstrate your skills in model deployment and integration.
21. Financial Calculator
Build a financial calculator that incorporates relevant mathematical and financial concepts. Showcase your ability to create practical tools.
22. Command-Line Tools
Develop command-line tools for tasks like file manipulation, data processing, or system monitoring. Highlight your skills in creating efficient and user-friendly command-line applications.
23. IoT-Based Health Monitoring System
Create an IoT-based health monitoring system that collects and analyzes health-related data. Showcase your ability to work on projects with social impact.
24. Facial Recognition System
Build a facial recognition system using Python and computer vision libraries. Showcase your skills in biometric technology.
25. Social Media Dashboard
Develop a social media dashboard that aggregates and displays data from various platforms. Highlight your skills in data visualization and integration.
Conclusion: As you embark on your job search in 2024, remember that a well-rounded portfolio is key to showcasing your skills and standing out from the crowd. These 25 Python projects cover a diverse range of domains, allowing you to tailor your portfolio to match your interests and the specific requirements of your dream job.
If you want to know more, Click here:https://analyticsjobs.in/question/what-are-the-best-python-projects-to-land-a-great-job-in-2024/
#python projects#top python projects#best python projects#analytics jobs#python#coding#programming#machine learning
2 notes
·
View notes