#Multimodal Interaction
Explore tagged Tumblr posts
Visit Tumblr Blog
Explore Tumblr blogs with no restrictions, modern design and the best experience.
Last Seen Tumblr Blogs





Fun Fact
Tumblr was named as a finalist in Lead411’s New York City Hot 125 in Aug 2010.
Text
Transforming Interaction: A Bold Journey into HCI & UX Innovations.
Sanjay Kumar Mohindroo Sanjay Kumar Mohindroo. skm.stayingalive.in Explore the future of Human-Computer Interaction and User Experience. Uncover trends in intuitive interfaces, gesture and voice control, and emerging brain-computer interfaces that spark discussion. #HCI #UX #IntuitiveDesign In a world where technology constantly redefines our daily routines, Human-Computer Interaction (HCI)…
#Accessibility#Adaptive Interfaces#Brain-Computer Interfaces#Ethical Design#Future Trends In UX#Gesture-Controlled Systems#HCI#Human-Computer Interaction#Innovative Interface Design#Intuitive Interfaces#Multimodal Interaction#News#Sanjay Kumar Mohindroo#Seamless Interaction#user experience#User-Centered Design#UX#Voice-Controlled Systems
0 notes
Text
🚀 Exciting news! Google has launched Gemini 2.0 and AI Mode, transforming how we search. Get ready for faster, smarter responses to complex queries! Explore the future of AI in search today! #GoogleAI #Gemini2 #AIMode #SearchInnovation
#accessibility features.#advanced mathematics#advanced reasoning#AI Mode#AI Overviews#AI Premium#AI Technology#AI-driven responses#coding assistance#data sources#digital marketing#fact-checking#Gemini 2.0#Google AI#Google One#image input#information synthesis#Knowledge Graph#multimodal search#Query Fan-Out#response accuracy#search algorithms#search enhancement#search innovation#text interaction#User Engagement#voice interaction
0 notes
Text
Amazons GPT55X Unveiled
Hey there, tech enthusiast! 🚀 Grab your coffee because we’re about to dive into one of the most exciting innovations in the world of AI: Amazon’s GPT55X. Picture this: you’re chatting with a friend, and they casually mention this groundbreaking piece of tech. Confused? Don’t fret. We’re here to break it down for you, friend-to-friend. Introducing the Rockstar: Amazons GPT55X Ever watched a movie…

View On WordPress
#Advanced AI capabilities#AI constant improvement#AI creativity and problem-solving#AI in entertainment#Amazon GPT55X overview#Amazon&039;s AI transformation#Contextual AI understanding#Dynamic learning and AI#Ethical AI development#GPT55X future prospects#GPT55X in customer engagement#GPT55X in e-commerce#GPT55X in e-learning#GPT55X in healthcare#GPU accelerated browsing#Industry-neutral AI applications#Multimodal AI interactions#Pros and cons of GPT55X#Technical challenges in AI#Virtual AI tutoring
0 notes
Text

PB shared the announcement on their blog.
I googled "Series Entertainment" and found article about this news and the article starts with:
Series Entertainment – itself a game development company that "pioneer[s] the use of generative AI to transform imaginative ideas into unforgettable gaming experiences" – says the acquisition "signifies Series' strategy to build out its studio system to deliver a diverse catalog of different genres that leverage its world class development technology, the Rho Engine", the world’s first "AI-native, multimodal full-stack game creation platform". [X]
And here is another article
Series Entertainment, a fast-growing AI game development company, has acquired interactive fiction mobile game studio Pixelberry.
From the companies website...

So basically we told Choices we didn't want AI and they sold the company to an AI entertainment company 🤦♀️
335 notes
·
View notes
Text

𝕵ust like there are cathedrals everywhere for those with the eyes to see, there is also deep eroticism all around for those with their sensibilities tuned in to particular currents of chaos.
𝕿he shapes, curves, and angles of typefaces; the irreplicable playfulness in colors and aromas of tropical flowers; the patterns in spectrograms of whispered confessions; the synaesthetic harmony of lime and honey.
𝕴n heightened states of existence, eyes have the same relationship to the aesthetic mode of interaction with the world as the clitoris has to the tactile. In an inversion of an ancient theory positing the eyes to be a tactile sensory organ projecting countless invisible tentacles onto the outside world, I have experienced the equally countless tentacles of the outside world gently massage waves of ecstatic pleasure into my eyes. There are textures and temperatures and rhythms which, when combined under the right conditions, can coax an orgasm out of your entire system; be those tactile, visual, aural, or otherwise, does not ultimately matter if you're primed to receive and perceive the advances of 𝕾ister 𝖀niverse.
𝕿here are ways and techniques of experiencing pleasure on a surprisingly multimodal, perhaps higher-dimensional basis, and I might be able to impart some of them.
𝕴, just like many others, am a conduit of 𝕷ilith-𝕾appho; her messenger and her message; her loyal succubine.
𝕬ccept the sight and sound.
𝕱𝕹𝕳𝕹𝕯𝖂𝕿𝖂

𓁺
#totally normal and emotionally stable behavior#don't worry about it haha#janegl_oc#sapphic#wlw#nblw#lesbian#yuri#fem4fem#yuricest#chaos magick
21 notes
·
View notes
Text
Marvel Fans and What we talk about
I haven't watched any of the movies yet except the one about spiderman so I can't comment much on which I think would be the best here but seems like a lot of the fans love spiderman's return!!

Regardless, I've been thinking a lot lately about how the Marvel fandom interacts through multimodal content across social media platforms, and I I came across this post by m.c.u.n. Spider-Man, Wolverine, Deadpool, and characters from Avengers: Endgame.
I love how replies turn into a discussion of the Marvel multiverse and variations in character arcs across different films. I also love this post for bringing everyone into the discussion. I am noticing something that is common in fan communities: fans come together to correct each other’s knowledge, provide additional context, and, in the process, assert their identity as knowledgeable Marvel fans.
#iron man#marvel#superhero#fandom#fandom things#fandom culture#marvel characters#marvel movies#tony stark#avengers#wolverine#deadpool#deadpool x wolverine#avengers doomsday
22 notes
·
View notes
Note
is the class you’re teaching this semester the same as last semester?
nope, different classes!!
the last three semesters i've taught composition 1 (basic writing for new college students). this semester i'm teaching advanced composition, which is a junior level (3rd year) class. im really honored because only one person gets to teach it a semester and its usually a phd or faculty member (im still masters)
but with advanced composition we basically get to do ... whatever we want? as long as its a topic in advanced writing. theres no required units like in comp 1, theres no specifics that go into the class structure. i got to go ham
so my class theme is "interactive text and multimodality"
first unit is interactive text, so were looking at interactive fiction, interactive essays, and one ttrpg ("LOGAN: an autobiographical tabletop game" by @breathing-stories). for their big unit project, they can do twine, bitsy, or a ttrpg project for their essay
second unit is zines. were looking at a couple of indie zines and one big one that was very professionally put together. were gonna do collage work in class and also do one sheet mini zines. then my students are doing a "research zine" where they research a topic and instead of a research essay theyre making it into an 8 page zine
third unit is presentations. were looking at a ted talk, and animated short, and a youtube video essay. im having them give a 3 minute persuasive presentation on why we should get into the media they really like. and then they get to give a longer presentation in a format of their choice (poster board, powerpoint, video essay) on a topic they care about
the writing topics were exploring throughout the class are exigency, writing for the public vs wtiting for a discourse community, and multimodality
then our final unit is a 3 week workshop on a large project based on something from the writing journals they keep throughout the semester. theyre taking something theyve written about and are making it into a large multimodal project
im also trying a new grading method this semester so fingers crossed!!
so far im really enjoying the class and i have a great batch of students. idk if you intended for this infodump but here ya go :)
#teaching#teachers of tumblr#oh wow some concerning things come up when you type teacher into the tags
11 notes
·
View notes
Text
ChatGPT and Google Gemini are both advanced AI language models designed for different types of conversational tasks, each with unique strengths. ChatGPT, developed by OpenAI, is primarily focused on text-based interactions. It excels in generating structured responses for writing, coding support, and research assistance. ChatGPT’s paid versions unlock additional features like image generation with DALL-E and web browsing for more current information, which makes it ideal for in-depth text-focused tasks.
In contrast, Google Gemini is a multimodal AI, meaning it handles both text and images and can retrieve real-time information from the web. This gives Gemini a distinct advantage for tasks requiring up-to-date data or visual content, like image-based queries or projects involving creative visuals. It integrates well with Google's ecosystem, making it highly versatile for users who need both text and visual support in their interactions. While ChatGPT is preferred for text depth and clarity, Gemini’s multimodal and real-time capabilities make it a more flexible choice for creative and data-current tasks
4 notes
·
View notes
Text
OpenAI’s 12 Days of “Shipmas”: Summary and Reflections
Over 12 days, from December 5 to December 16, OpenAI hosted its “12 Days of Shipmas” event, revealing a series of innovations and updates across its AI ecosystem. Here’s a summary of the key announcements and their implications:
Day 1: Full Launch of o1 Model and ChatGPT Pro
OpenAI officially launched the o1 model in its full version, offering significant improvements in accuracy (34% fewer errors) and performance. The introduction of ChatGPT Pro, priced at $200/month, gives users access to these advanced features without usage caps.
Commentary: The Pro tier targets professionals who rely heavily on AI for business-critical tasks, though the price point might limit access for smaller enterprises.
Day 2: Reinforced Fine-Tuning
OpenAI showcased its reinforced fine-tuning technique, leveraging user feedback to improve model precision. This approach promises enhanced adaptability to specific user needs.
Day 3: Sora - Text-to-Video
Sora, OpenAI’s text-to-video generator, debuted as a tool for creators. Users can input textual descriptions to generate videos, opening new doors in multimedia content production.
Commentary: While innovative, Sora’s real-world application hinges on its ability to handle complex scenes effectively.
Day 4: Canvas - Enhanced Writing and Coding Tool
Canvas emerged as an all-in-one environment for coding and content creation, offering superior editing and code-generation capabilities.
Day 5: Deep Integration with Apple Ecosystem
OpenAI announced seamless integration with Apple’s ecosystem, enhancing accessibility and user experience for iOS/macOS users.
Day 6: Improved Voice and Vision Features
Enhanced voice recognition and visual processing capabilities were unveiled, making AI interactions more intuitive and efficient.
Day 7: Projects Feature
The new “Projects” feature allows users to manage AI-powered initiatives collaboratively, streamlining workflows.
Day 8: ChatGPT with Built-in Search
Search functionality within ChatGPT enables real-time access to the latest web information, enriching its knowledge base.
Day 9: Voice Calling with ChatGPT
Voice capabilities now allow users to interact with ChatGPT via phone, providing a conversational edge to AI usage.
Day 10: WhatsApp Integration
ChatGPT’s integration with WhatsApp broadens its accessibility, making AI assistance readily available on one of the most popular messaging platforms.
Day 11: Release of o3 Model
OpenAI launched the o3 model, featuring groundbreaking reasoning capabilities. It excels in areas such as mathematics, coding, and physics, sometimes outperforming human experts.
Commentary: This leap in reasoning could redefine problem-solving across industries, though ethical and operational concerns about dependency on AI remain.
Day 12: Wrap-Up and Future Vision
The final day summarized achievements and hinted at OpenAI’s roadmap, emphasizing the dual goals of refining user experience and expanding market reach.
Reflections
OpenAI’s 12-day spree showcased impressive advancements, from multimodal AI capabilities to practical integrations. However, challenges remain. High subscription costs and potential data privacy concerns could limit adoption, especially among individual users and smaller businesses.
Additionally, as the competition in AI shifts from technical superiority to holistic user experience and ecosystem integration, OpenAI must navigate a crowded field where user satisfaction and practical usability are critical for sustained growth.
Final Thoughts: OpenAI has demonstrated its commitment to innovation, but the journey ahead will require balancing cutting-edge technology with user-centric strategies. The next phase will likely focus on scalability, affordability, and real-world problem-solving to maintain its leadership in AI.
What are your thoughts on OpenAI’s recent developments? Share in the comments!
3 notes
·
View notes
Text
On Comprehensible Input
Disclaimer : I am not disagreeing with the comprehensible input theory of language acquisition within the context of the science of linguistics. This post is about a tumor that has grown off of it into the 'science' of pedagogy. Regardless, this is more of a vent post against current instructional strategies than anything. I am not citing any sources, most of what is here is anecdotal.
For those unaware, language classes in K12 have changed a lot since you were in school. Many decades ago, it was primarily a text translation course. Then it became what most of the readers probably had, a course integrating vocabulary and structures into conversational performance. Today, as has been pushed for the last decade or so, we are 'encouraged' to teach with what pedagogy scam artists call a comprehensible input based curriculum.
This largely involves an immersion class with a heavy focus on reading and listening (especially in the novice level) with multimodal texts to guide understanding. To give you an idea of the efficacy of this strategy, almost zero students have achieved a "passing" (4/7) score on the IB DP Language B exams in my district since our coordinator started pushing this. My heavily lauded predecessor at this school had 2s and 3s across the board last year, students on their fifth year of language acquisition.
My current fifth year students have a vocabulary of maybe 200 words, mostly cognates.
I can think of a few reasons why this becomes the case.
Immersion classes at the middle/high school level have a tendency to devolve into the dominant language of the school. Infants learn this way because it is their primary method of communication and interacting with the world around them. In class, the students' dominant language is spoken by everyone in the room (from whom students are constantly seeking validation). This is especially a problem when taking into account class sizes of 30+ students who largely do not even want to be there.
The curricula that are available are weak, untested (scientifically), and teacher-created. Teachers are not curriculum designers, neither by training nor by time allotted. What results is a mish-mash of ideas half-executed, with wide, gaping holes in student knowledge. My Language B coordinator literally just threw a random assortment of various difficulty beginner reader books (one is a story about a capyabara wearing boots, for example) at me with no materials, no guide, no placement within a curriculum. This is not an effective foundation for a high school student's language journey.
Comprehensible Input as a theory is a description of how language is acquired, it is not a prescription for curriculum. Refusing to take into account the differences between someone whose job, 24/7, is exclusively to understand the language enthusiastically, compared to someone who is in a class against their will for maybe 160 minutes per week is ludicrous.
The de-emphasis on output, especially in the beginning levels, leaves students without the tools and muscle memory to become proficient speakers later.
Recently, I have been studying Toki Pona.
Reading the official text, I learned very quickly and very effectively. I made flash cards, read about grammatical constructions, did translation exercises, and assigned myself conversational tasks to practice what I could. Writing very short stories, skits, practicing common dialogue patterns. It has been really fast and effective.
About halfway through the book, I decided to install a game called Toki Pona Island. A self-proclaimed comprehensible input strategy to acquiring the language. I have played for hours, and the only word I have meaningfully retained is alasa (look for, quest, seek). And it is an entire game ABOUT alasa. Every character says it constantly and I had to look it up about 50 times before I forced myself to remember. Even then, while writing this, I originally wrote it as asala before I looked it up for accuracy. So, in effect, nothing was meaningfully learned.
#linguistics#language#language learning#language acquisition#teaching#teachers#k12#pedagogy#toki pona#rant#comprehensible input
6 notes
·
View notes
Text
Why Gemini is Better than ChatGpt?
Gemini's Advantages Over ChatGPT
Both Gemini and ChatGPT are sophisticated AI models made to communicate with people like a human and help with a variety of tasks. But in some situations, Gemini stands out as a more sophisticated and adaptable option because to a number of characteristics it offers:

1. Multimodal Proficiency Gemini provides smooth multimodal interaction, enabling users to communicate with speech, text, and image inputs. Gemini is therefore well-suited for visually complex queries or situations where integrating media enhances comprehension since it can comprehend and produce answers that incorporate many forms of content.
2. Improved comprehension of context Geminis are better at comprehending and remembering context in lengthier interactions. It can manage intricate conversations, providing more precise and tailored answers without losing sight of previous debate points.
3. Original Work From excellent writing to eye-catching graphics and artistic representations, Gemini is a master at producing unique content. It is a favored option for projects demanding innovation due to its exceptional capacity to produce distinctive products.
4. Knowledge and Updates in Real Time In contrast to ChatGPT, which uses a static knowledge base that is updated on a regular basis, Gemini uses more dynamic learning techniques to make sure it stays current with data trends and recent events.
5. Customization and User-Friendly Interface With Gemini's improved customization options and more user-friendly interface, users can adjust replies, tone, and style to suit their own requirements. This flexibility is especially helpful for professionals and companies trying to keep their branding consistent.
6. More Comprehensive Integration Gemini is very flexible for both personal and commercial use because it integrates more easily into third-party tools, workflows, and apps because to its native support for a variety of platforms and APIs.
7. Improved Security and Privacy Users can feel secure knowing that their data is protected during interactions thanks to Gemini's emphasis on user data privacy, which includes greater encryption and adherence to international standards.
#Gemini vs ChatGPT#AI Features#AI Technology#ChatGPT Alternatives#AI Privacy and Security#Future of AI
2 notes
·
View notes
Text
What is the future of public health campaigns in a digital age?
The future of public health campaigns in the digital age is undergoing a profound transformation, driven by rapid technological innovation and the evolving needs of diverse populations. At the forefront is the power of personalization, enabled by artificial intelligence (AI) and big data analytics. These technologies allow health campaigns to move away from one-size-fits-all approaches and instead deliver messages that are tailored to individual behaviors, preferences, and health histories. Wearable devices, mobile apps, and social media platforms generate a wealth of real-time data, which campaigns can use to identify emerging trends, anticipate public health needs, and respond more effectively. This data-driven approach makes interventions not only more targeted but also more impactful.
Digital accessibility and inclusivity are critical in ensuring these campaigns reach all segments of the population, including those in remote or underserved areas. Telehealth platforms offer opportunities to disseminate health education and services to individuals who may otherwise lack access to traditional healthcare infrastructure. Furthermore, creating multilingual and multimodal content—such as videos, animations, interactive tools, and accessible text—ensures that public health messages resonate with people from various linguistic and cultural backgrounds. By adopting an inclusive design approach, campaigns can bridge gaps in communication and health literacy, addressing barriers that have historically excluded marginalized groups.
Emerging technologies such as virtual and augmented reality (VR/AR) are redefining how people interact with public health content. These immersive tools can simplify complex health topics, such as demonstrating how vaccines work or teaching people how to perform life-saving techniques like CPR. Gamification is another innovation that holds significant promise, as it turns health-promoting activities into engaging experiences. Fitness apps with rewards, interactive challenges, and games designed to educate while entertaining can motivate individuals to adopt healthier habits, fostering long-term behavioral change.
Social media platforms will remain a central pillar in future public health campaigns, particularly as they provide unparalleled opportunities for engagement and dialogue. Collaborating with influencers, especially micro-influencers trusted by their communities, can amplify messages to reach specific audiences effectively. Interactive campaigns, such as live Q&A sessions with health experts, community challenges, or user-generated content, create a sense of participation and trust. These platforms also allow for two-way communication, enabling health authorities to address public concerns, dispel myths, and build confidence in health interventions.
A major challenge in the digital age is the proliferation of misinformation, which can undermine public health efforts. Combating this will require robust strategies, including deploying AI tools to identify and counter false information in real time. Partnerships with fact-checking organizations and collaborations with social media platforms can help validate credible sources and ensure accurate information is prioritized. Building digital literacy among the public will also be essential, empowering individuals to critically evaluate health information and make informed decisions.
Equity and ethics will play a pivotal role in shaping the future of digital health campaigns. While technology offers immense potential, the digital divide—stemming from disparities in internet access, device availability, and digital literacy—must be addressed to ensure that no one is left behind. Combining digital campaigns with traditional methods such as radio broadcasts, community workshops, and printed materials can bridge these gaps and ensure equitable access. Data privacy and security will also be critical; as campaigns increasingly rely on personal data to tailor messages, implementing robust safeguards will be essential to maintain public trust and prevent misuse.
Finally, community-centric approaches will make campaigns more effective and sustainable. By engaging local communities in the creation and dissemination of campaign content, health authorities can ensure that messages are relevant, culturally sensitive, and authentic. Crowdsourcing ideas and feedback from the target audience fosters a sense of ownership and enhances the credibility of public health initiatives. Tailoring global health messages to reflect local contexts will further ensure resonance, helping campaigns overcome cultural and societal barriers to adoption.
Together, these advancements mark a shift toward more adaptive, inclusive, and impactful public health campaigns. Leveraging digital tools while addressing challenges like misinformation, inequity, and privacy concerns will be key to meeting global health challenges with speed, precision, and humanity. Public health in the digital age has the potential not only to inform but also to inspire communities worldwide to take collective action for better health outcomes.
2 notes
·
View notes
Text
Multimodal Content Example

Here is the graphic image that I created for my multimodal essay! I thought it would be super fun to depict the rhetorical situation as a bowl of ramen with the key concepts acting as the ingredients. I had so much fun designing the image and was very intentional when assigning an ingredient to fit the role of each concept. I included definitions for each concept as well as explanations as to how they aid in creating and understanding content for web writing. Since all of the ingredients are pictured in one bowl, I also added text relaying which "flavors" pair the best with one another, meaning which concepts interact most frequently. Doing the graphic this way helped me as a learner because I really had to think about the core elements of each concept and create my own personal definitions and explanations for them.
13 notes
·
View notes
Text
First Post
12/9/2023
Hi, I'm Finian, and this is my first blogpost! I'm really into like every single artform, and my main passion is gamedev! I learned it in highschool, I'm working on it in college, and I hope to make it a career someday.
I'm very critical on myself, and I am very embarrassed to share any art I make, but I've wanted to make a blog for a little while. I think personal writing is fun. I recently received some advice that making a blog might strengthen my portfolio, so I was like "what the heck" and now here I am.
With that out of the way, this post will be about what I consider my first finished game. I did some stuff in highschool, but that was all in a website called code.org. I worked in Unity in my final year, but I served the role of mentor more than developer.
This game was created for my final project in my ENC1143 class, and shall be called my Multimodal Artifact. The assignment was to share what we'd learned over the year in any form of medium we wished, so I made a game. I've only previously done 2D games and I consider myself acceptable at pixel art, so I made a simple 2D platformer. All of my artwork was done in Aseprite and all code was written in Unity, with Visual Studio.

My intentions going into the game were mainly to let the player interact with the sign pictured above, which is something I've never done before. I also wanted the text on the sign to have a scrollbar. I started with an unanimated player sprite, and I made an incredibly simple ground texture, which I stretched to represent a wall. I coded the player's movement and interaction with the terrain. Once I was satisfied with the player's movement, I created some simple animations for idling, running, and jumping.

I then created a tileset of which I am extremely proud, as I've been struggling with grassy and leafy terrain for years. This is the second tileset I've ever made, and the first to perfectly link with itself.

Once I had my tiles in order, I replaced my gaudy primitive, and created the first area of the game as seen in the first image, albeit with significantly less foliage. I created enough level to comfortably house five signs; about half of the game. Finally I began work on the sign itself. The sign was probably the most important part of the game, as its writing is what I was mainly being graded on. There are nine signs in the game, each containing small pieces of the whole final assignment. I created a sprite for the sign in about 20 minutes, and tackled the text with a scroll view. I watched a very helpful video on how it worked, added my TextMeshPro font asset, and made a sign visual behind it all.

My sign was done, from a visual standpoint. I could finally tackle the code, which I did within two scripts. The first script, "Interactable" would be attached to the sign sprite via a child. The script was actually pretty simple, using OnTriggerEnter and OnTriggerExit in tandem with a circle collider 2D to detect if the player was near enough, and an if statement featuring the UnityEvent Invoke in its body. Invoke calls a function from another script, established in the inspector. In this case, I attached a script to the Canvas which disabled and enabled the sign GameObjects.
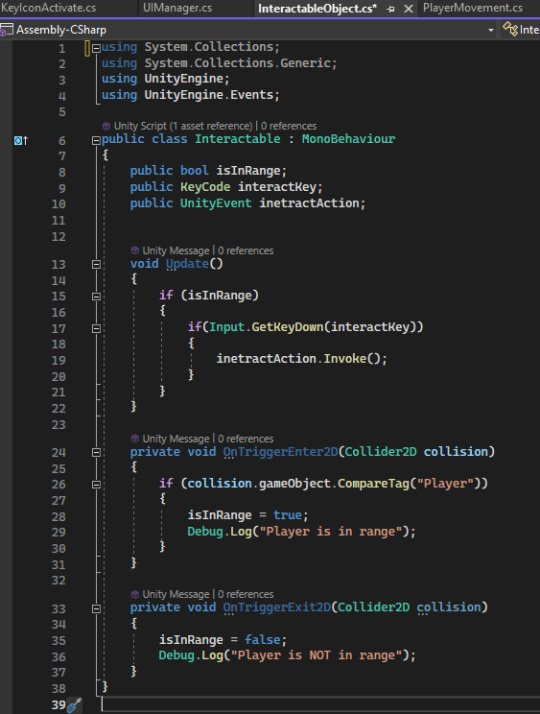
I also added to the sign sprite a key icon, again of my own making, to make sure the player definitely knows what to press. It has an animation which activates when the player walks near the sign.

Both the coding and the visuals for the sign are finally finished! My final steps for this game were: 1) finish designing the level 2) add some scenery 3) if I had time, a pause screen and maybe even a start screen
This was a single-level game, and since it was an english assignment that needs to be graded, I figured it ought to be very linear and very non-punishing. There are no enemies and no dying, so the difficulty had to come from platforming. The player can jump exactly three tiles high and seven tiles far. The game features one six tile wide jump and no necessary three tile high jumps. The first area, already completed features very easy one to three tile wide gaps.

The area has the player go from the left of the level to the right, and eventually upwards and back to the left. Within the first zone, it is possible to fall After every new challenge there will be a sign as the player's reward: after the first jump, , two-tile wide jump, series of one-tile wide jumps (pictured above), series of two-tile vertical jumps, and finally after the first four-tile wide jump. There are some punishing jumps in the upper layer of this zone, which cause the player to lose some progress if missed.

Before making any level past the first sign, I added a second tileset. I took my preciously mentioned first ever tileset, which was a greyish castle brick, and changed it to match my current palette. It's not perfect, but any imperfections are so slight nobody would notice unless they were specifically seeking them out. I added this tileset because I felt continuous jungle would start to get bland, and because I really wanted to get some use out of it. I think it fits in really well.
The second area of my game is a platforming section based off of the loss comic, a suggestion provided to my by my wonderful girlfriend. I think it's a lot of fun to involve others in the gamemaking process, and I think it's fun to work with a specific challenge in mind. I thought of something really fun to do with that idea almost instantly, and got to work.
For those who are unaware, the loss comic is a meme from 2002, which features this character format: I II II I_
I tried loosely to stay within that format, I don't think it tracks very well, but the intention and setup is there.

I wanted my third and final segment to be the most challenging, and I wanted it to be inside of the castle/temple setting, in hopes of making the play subconsciously go "oh, this area is different." Each area of the game has its subtle distinctions, but the distinction here is the least subtle.
The final area features a great deal of wide and high jumps, as well as the first and only head-hitter in the game. In the final set of jumps it is possible to fall back down to the start of the section, and the very last jump isn't very difficult. I think it sucks when you think you're almost done with everything in a game, and you mess up at the very end and have to start all over. I didn't want the player to feel that way, hence the easier last jump.

The level was done! My signs (the part I get graded on) were done! I could have some fun with the rest of the game, not that I didn't have fun with the entire previous process, this final bit was just leisure. I love programming.
I started with controls. I put the controls of the game as well as some arrows to point you the right way on rocks, which would not only fit well in the game's environment, but also served well to fill up empty-feeling areas.

After the rocks, I created some bushes. I considered making hanging vines, but I forgot about it somewhere in the creative process. There's obviously not as many of them as the rocks, but trust me when I say these suckers get some crazy mileage. They're everywhere, rotated for the walls and ceiling, flipped, darkened to appear more in the background, placed somewhat behind rocks. These four bushes were super important to the decoration of this game.

After the bushes, I adjusted the hue, saturation, and light of the tilesets to make them appear as background elements. I created the background of the game as a repeating tile. I am not confident in my ability to create a full artpiece, rather than smaller assets, and my wonderful girlfriend added some pixels which I feel made it look significantly better than my rendition. I hue shifted it, and it works excellently as the game's background.

My initial rendition (black was empty) and the final rendition
The final thing to do was to add a pause menu, which is also something I had extremely limited experience with, but found to be super easy. The code is just about the same as making the signs appear and disappear.

The game was not without its bugs, however. There were two that I wanted to fix: 1) sometimes while walking, the player would randomly get snagged and stop. I believed this to be an issue with the ground's collision 2) sometimes upon landing, the player would fly straight through the floor! I also believed this to be an issue with the ground's collision
I had the ground's collider set to a Tilemap Collider 2D, which is a collider designed specifically for tiles. The way a tilemap collider works is that it assigns a square shaped colllider to every individual tile, and would combine all of those collider together in order to save space if it were more efficient on the system. In my game's case it was not more efficient to combine them. However, combining them is exactly what would fix the first issue, the player snagging on the ground. I added a Composite Collider 2D to the tilemap, and viola! No more snagging. The player would still fall through the ground on occasion, but it happened to me so rarely I figured it would be a nonissue. I added a line of code that would set the player's position to the initial spawn if they went too far beneath the map, as well as the reset button in the pause menu which would do the same.
After these fixes I had my incredibly generous roommate playtest for me. He probably played for about thirty minutes, and he relentlessly fell through the map. It was amazing to me how often he just perfectly fell through the ground. Clearly, this was a bigger issue than I anticipated. Thank goodness for playtesters!
After some research, I realized the composite collider actually created an outline of the tiles, rather than completely filling them with collision. The player would fall through the ground because while falling, their velocity would continually increase. Since the collision of the ground was so slim, the player's high velocity would sometimes cause their collider to be on one side of the ground on one frame, and the other side of the ground on the next, not allowing for any collision to happen. The slim outline of the composite collider was not cutting it. There is a setting on the component labeled "Use Delaunay Mesh" which, when clicked, converts the collider from an outline to a full mesh.

The orange lines represent the collider
A Delaunay Mesh is a mesh based on Delaunay Triangulation, which is a complicated math term which can be simplified to mean the mesh has the least amount of big system-taxing triangles possible.
My roommate once again playtested for me, this time with no bugs at all. His thirty minute experience turned into a three minute experience. Magical!
There's more I would have liked to do, but my time ran out and I needed to turn the assignment in. I think I would have liked to make a starting screen, and maybe some hanging vines. If I had as much time as I pleased, I would've added walljumping and maybe some destructible decorations to make the player feel more involved.
I think the game was a success. This is my first game I can say I've actually completed, and I feel proud of how far I've come. If I were to do this again, I'd probably study the games "Getting Over It" and "Jump King," as in hindsight these games were fundamentally very similar.
The end! Thank you for reading my silly blogpost! This took way longer than I thought.
9 notes
·
View notes
Text
Applied AI - Integrating AI With a Roomba
AKA. What have I been doing for the past month and a half
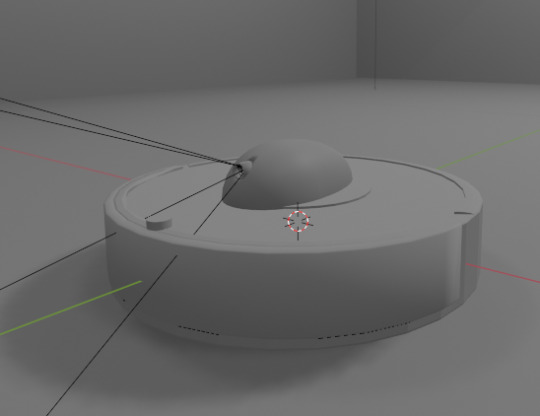
Everyone loves Roombas. Cats. People. Cat-people. There have been a number of Roomba hacks posted online over the years, but an often overlooked point is how very easy it is to use Roombas for cheap applied robotics projects.
Continuing on from a project done for academic purposes, today's showcase is a work in progress for a real-world application of Speech-to-text, actionable, transformer based AI models. MARVINA (Multimodal Artificial Robotics Verification Intelligence Network Application) is being applied, in this case, to this Roomba, modified with a Raspberry Pi 3B, a 1080p camera, and a combined mic and speaker system.


The hardware specifics have been a fun challenge over the past couple of months, especially relating to the construction of the 3D mounts for the camera and audio input/output system.
Roomba models are particularly well suited to tinkering - the serial connector allows the interface of external hardware - with iRobot (the provider company) having a full manual for commands that can be sent to the Roomba itself. It can even play entire songs! (Highly recommend)
Scope:
Current:
The aim of this project is to, initially, replicate the verbal command system which powers the current virtual environment based system.
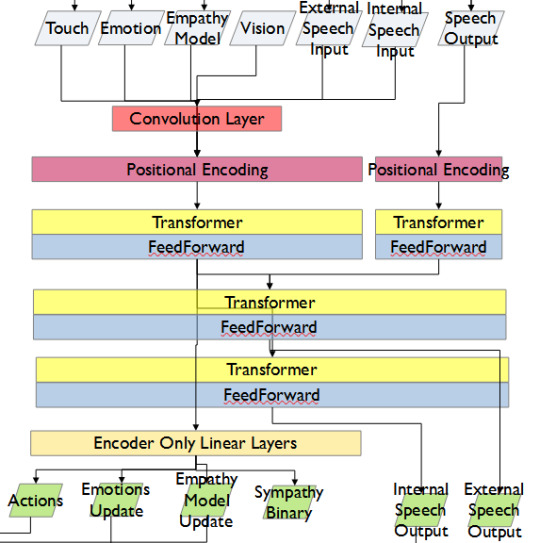
This has been achieved with the custom MARVINA AI system, which is interfaced with both the Pocket Sphinx Speech-To-Text (SpeechRecognition �� PyPI) and Piper-TTS Text-To-Speech (GitHub - rhasspy/piper: A fast, local neural text to speech system) AI systems. This gives the AI the ability to do one of 8 commands, give verbal output, and use a limited-training version of the emotional-empathy system.
This has mostly been achieved. Now that I know it's functional I can now justify spending money on a better microphone/speaker system so I don't have to shout at the poor thing!
The latency time for the Raspberry PI 3B for each output is a very spritely 75ms! This allows for plenty of time between the current AI input "framerate" of 500ms.
Future - Software:
Subsequent testing will imbue the Roomba with a greater sense of abstracted "emotion" - the AI having a ground set of emotional state variables which decide how it, and the interacting person, are "feeling" at any given point in time.
This, ideally, is to give the AI system a sense of motivation. The AI is essentially being given separate drives for social connection, curiosity and other emotional states. The programming will be designed to optimise for those, while the emotional model will regulate this on a seperate, biologically based, system of under and over stimulation.
In other words, a motivational system that incentivises only up to a point.
The current system does have a system implemented, but this only has very limited testing data. One of the key parts of this project's success will be to generatively create a training data set which will allow for high-quality interactions.

The future of MARVINA-R will be relating to expanding the abstracted equivalent of "Theory-of-Mind". - In other words, having MARVINA-R "imagine" a future which could exist in order to consider it's choices, and what actions it wishes to take.
This system is based, in part, upon the Dyna-lang model created by Lin et al. 2023 at UC Berkley ([2308.01399] Learning to Model the World with Language (arxiv.org)) but with a key difference - MARVINA-R will be running with two neural networks - one based on short-term memory and the second based on long-term memory. Decisions will be made based on which is most appropriate, and on how similar the current input data is to the generated world-model of each model.
Once at rest, MARVINA-R will effectively "sleep", essentially keeping the most important memories, and consolidating them into the long-term network if they lead to better outcomes.
This will allow the system to be tailored beyond its current limitations - where it can be designed to be motivated by multiple emotional "pulls" for its attention.
This does, however, also increase the number of AI outputs required per action (by a magnitude of about 10 to 100) so this will need to be carefully considered in terms of the software and hardware requirements.
Results So Far:

Here is the current prototyping setup for MARVINA-R. As of a couple of weeks ago, I was able to run the entire RaspberryPi and applied hardware setup and successfully interface with the robot with the components disconnected.
I'll upload a video of the final stage of initial testing in the near future - it's great fun!
The main issues really do come down to hardware limitations. The microphone is a cheap ~$6 thing from Amazon and requires you to shout at the poor robot to get it to do anything! The second limitation currently comes from outputting the text-to-speech, which does have a time lag from speaking to output of around 4 seconds. Not terrible, but also can be improved.
To my mind, the proof of concept has been created - this is possible. Now I can justify further time, and investment, for better parts and for more software engineering!
#robot#robotics#roomba#roomba hack#ai#artificial intelligence#machine learning#applied hardware#ai research#ai development#cybernetics#neural networks#neural network#raspberry pi#open source
8 notes
·
View notes
Text
Being, Thinking, and Knowing in a Hypertext Age
The speculative rhetorical model posits that we can only know the world in ways bounded and contextualized by our own experience of being. For this reason, a speculative rhetoric approach tries to pay careful attention to the perspectives, roles, and experiences of nonhumans, since communication inevitably takes place among a vast array of nonhuman actants. Speculative rhetorician Andrew Reid asserts that “A speculative rhetoric begins with recognizing that language is nonhuman.” At first, I couldn’t begin to imagine what this must mean. Sure, animals communicate, but surely language—expressive, symbolic communication with defined rules—must be an exclusively human phenomenon.
I read Reid’s short list of scholars cited (Alexander Galloway, Richard Grusin, Bruno Latour, Alan Lui, and Quentin Meillasoux) aloud to GPT-4 and asked it to tell me what they were known for, in hopes that knowing the background Reid was drawing from would help me contextualize such a bizarre statement.
It confirmed that Bruno Latour is best known for actor-network theory, as I had thought. Meillasoux it introduced as a speculative realist philosopher. Lui it defined as a scholar of “language as a digital-cultural phenomenon, influenced by both human creativity and digital technology.” Grusin, it said, was known for proposing that new technologies “remediate” and refashion older ones. Galloway, it said, “explores how digital protocols, the rules and standards governing digital networks, shape interactions and communications.” A quick look at Google Scholar and the scholars’ university webpages confirmed that its characterizations were fairly accurate.
Altogether, I could only conclude that these scholars affirm language as a constructed, constantly evolving phenomenon, although I still couldn’t see how the ability to influence human actions would equate to an equal ownership of language. It may be old-fashioned, but at present I’m still prepared to embrace Kenneth Burke’s definition of man as “the symbol-using animal.” As far as I know, there’s no evidence that animals can grasp the abstract symbolism inherent in language as well as we can.
However, I do think Gunther Kress’s “Multimodality” afforded me with another avenue for making sense of Reid’s perspective, at least. Kress asserts that “all texts are multimodal”, where ‘text’ seems to be doing a great deal of heavy lifting to encompass practically anything into which meaning can be encoded and decoded. For him, the multimodality of verbal speech arises from its inclusion of “pitch variation; pace; stress; phonological units (produced by a complex of organs); lexis; sequencing (as syntax); etc.” In other words, any element which can have a role in imparting meaning is part of the mode (or means) of linguistic communication. Since some animals can intentionally adapt these facets of communication to a rhetorical context (i.e. cats having a less babyish meow around one another than humans), I can see the argument that many animals possess a kind of language in that way.
But since Kress’s many example pictures and diagrams stress the representational quality of human languages (in which he apparently includes visuals, which he says can develop a kind of grammar) even when it’s completely divorced from written or spoken words, I’m still inclined to say that animals have communicative skills but not language. I’m curious whether anyone knows of any animals capable of abstraction.
Similarly, I wonder at what point we could consider the product of generative AI to be language (or perhaps I should say a form of communication, period). There’s no conscious intent behind it, it’s an actant and not an actor, but it arguably works entirely in abstractions (it doesn’t have meaningful, individual experience of what anything is!) and it certainly considers its modal elements, as many generative AI models will show by displaying alternate response options.
5 notes
·
View notes