#Random Variable And Distribution Function Project Help
Explore tagged Tumblr posts
Visit Tumblr Blog
Explore Tumblr blogs with no restrictions, modern design and the best experience.
Last Seen Tumblr Blogs





Fun Fact
When “GIF” was named word of the year in 2012, Oxford Dictionaries U.S.A. credited Tumblr for pushing the word.
Text
Mastering Python Functions, Modules, and Packages
Python has become one of the most versatile and powerful programming languages in today's technological world. If you're looking for the best Python training in Hyderabad, mastering functions, modules, and packages is essential for writing efficient and scalable code. These core concepts not only help you organize your code better but also make it reusable and maintainable.
Understanding Python Functions
Functions are fundamental to Python programming. They allow you to break down complex problems into smaller, reusable blocks of code. With Python, you can create functions that accept parameters, return values, and handle variable arguments, making your code cleaner and more efficient.
Exploring Modules in Python
A module is a file that contains definitions and functions in Python. They help organize your code by splitting it into manageable parts. Python’s standard library comes with many built-in modules like random, math, and os, which you can import and use without writing extra code.
Organizing with Python Packages
Packages are collections of modules stored in directories containing a special __init__.py file. They help manage large projects by grouping related modules together. Packages make it easier to maintain, distribute, and reuse your code across multiple applications.
Conclusion: Learn Python the Right Way
Whether you’re a beginner or looking to advance your skills, understanding functions, modules, and packages is crucial for writing professional Python code. These elements are the backbone of any scalable Python application.
To master these concepts with expert guidance, consider enrolling at SSSIT Computer Education – a trusted name for quality Python training. Join us and start your journey to becoming a confident Python developer today.
#best python training in hyderabad#best python training in kukatpally#best python training in KPHB#Best python training institute in Hyderabad
0 notes
Text
How Do I learn Machine Learning with Python?
Because it is easy to read and comprehend, Python has become the de facto language for machine learning. It also comprises an extensive set of libraries. Following is a roadmap of studying Python:
1.Python Basics
Syntax: Variables, Data Type, Operators, Conditional statements/ Control Flow statements-if, else, for, while.
Functions: Declaration, Calling, Arguments
Data Structures: Lists, Tuples, Dictionaries, Sets
Object Oriented Programming: Classes, Objects, Inheritance, Polymorphism
Online Courses: Coursera, edX, Lejhro
2. Essential Libraries NumPy
Used for numerical operations, arrays, and matrices.
Pandas: For data manipulation, cleaning, and analysis.
Matplotlib: For data visualization.
Seaborn: For statistical visualizations.
Scikit-learn: A powerhouse library for machine learning containing algorithms for classification, regression, clustering, among others.
3. Machine Learning Concepts
Supervised Learning: Regression of different types like linear and logistic.
Classification: decision trees, random forests, SVM, etc.
Unsupervised Learning: Clustering: k-means, hierarchical clustering, etc.
Dimensionality reduction assessment metrics-PCA, t-SNE, etc.: Accuracy, precision, recall, F1-score, Confusion matrix.
4. Practical Projects Start with smaller-size datasets
Search for a dataset in Kaggle or UCI Machine Learning Repository. Follow the structured procedure:
Data Exploration: Understand the data, its features, and distribution.
Data Preprocessing: Clean, normalize, and transform the data.
Training the Model: This means fitting the model on the training data.
Model Evaluation: It means testing the performance of your model on the validation set. Hyperparameter Tuning: Improve model parameters.
Deployment: Lay your model into a real-world application.
5. Continuous Learning
Stay updated on all recent things happening in the world related to machine learning by following machine learning blogs, articles, and online communities. Try new things, play, and explore different algorithms techniques, and datasets.
Contributing to open-source projects: Contribute to open-source libraries like Scikit-learn.
Competitive participation: Participation in competitions, like Kaggle, allows seeing the work of others and learning from the best.
Other Tips
Mathematics: One needs to have pretty solid building blocks of math, namely linear algebra, calculus, and statistics, to understand concepts in machine learning.
Online resources: Take advantage of online resources like hundreds of courses and projects on Coursera, edX, and Lejhro and practice on Kaggle.
Join online communities: Participate in forums like Stack Overflow or subreddits, ask questions about code and solution issues.
These above steps and frequent practice of the same on a regular basis will build up your understanding in Machine Learning using Python and will help you in getting a good career path.
1 note
·
View note
Text

Suggested Reading
Path of Least Resistance Anchors Fundamentals of Energy Work Energetic Senses Conceptualization Vs. Visualization Spell Design Why Grey?
Introduction
Regardless of the type of working, all spellwork follows the same basic principles. These principles, when thoroughly understood, can be used to increase the effectiveness of a spell. While knowing and applying this concept isn’t necessary, it can be greatly beneficial. Since it is the basic underlying property of spell design, all spellwork will utilize it regardless.
{Note: STEM concepts are not necessary for magical practices, but using them can be invaluable.}
Nodes
Commonly referred to as correspondences, nodes are bits of information that tie objects, people, spirits, concepts, places, thoughts, feelings, and emotions together in order to create a desired effect. Each node is connected, at least subconsciously, by further bits of information. It can be helpful to think of these connections as a web or a woven cloth. It is because of this that creating your own correspondences is completely valid and functional. Nodes can also be constructed solely of mindsets and concepts. This type of working allows for the means of casting without anyone noticing. Especially when combined with gesture magic and/or energy work.
Thresholds
Thresholds are the foundations of spell work. Whenever Nodes come into contact with one another, it always results in a threshold. It is essentially the doorway through which a spell is projected. When a spell is constructed and cast, the threshold opens and passion projects the spell through it. The more nodes that make up a threshold, the more specific the results will be. However, bogging yourself down with a plethora of nodes could hinder your headspace. There is a balance between simplicity and complexity that is the most efficient. Finding this balance is something that is best understood through experience.
Statistical Dimensions
Whenever a new set of potential variables is added to a sample, the multitude of possible results expands exponentially. When casting spells, the more variables involved in the casting and goal lower the probability of it succeeding. I typically refer to this concept as the path of least resistance. Statistical dimensions can be controlled by creating networks and connections between each component of a working. They can also be controlled by choosing a goal that can happen within circumstances that have the least amount of variables. It is so important to try to avoid higher dimensional situations, which means that the number of dimensions are staggeringly high — so high that calculations, estimations, deductions, and inductions become extremely difficult. With high dimensional data, the number of features can exceed the number of observations. For each spell circumstances should be carefully considered. There will always be unknown variables like environmental happenings, intersocial happenings, seemingly random events, etc. It is best to try to minimize the number of possible unknowns when constructing a spell. One can use statistics and neural network structures to prepare for unknown variables. Actual math isn’t necessarily required to do this. A solid conceptualization can also work. One way would be through adaptive control, which is “the control method used by a controller which must adapt to a controlled system with parameters which vary, or are initially uncertain.”** Another method is estimation theory, which is “a branch of statistics that deals with estimating the values of parameters based on measured empirical data that has a random component. The parameters describe an underlying physical setting in such a way that their value affects the distribution of the measured data. An estimator attempts to approximate the unknown parameters using the measurements. In estimation theory, two approaches are generally considered:
The probabilistic approach assumes that the measured data is random with probability distribution dependent on the parameters of interest
The set-membership approach assumes that the measured data vector belongs to a set which depends on the parameter vector.”***
Sympathetic Magic
Whenever objects, herbs, tools, colors, etc. are used in a spell, the spell is considered a sympathetic spell. The nodes are constructed from associations rather than direct connections. Sympathetic spells have higher statistical dimensions because circumstances cannot be directly observed, and thus one has to account for much more unknown variables. Oftentimes sympathetic magic can be incorporated into direct magic, or non-sympathetic magic, in order to develop a more thorough threshold. Pure sympathetic magic requires a taglock and an anchor for a working. Whether it be hair, photo, candle, or crystal, the spell will have to be bound to associated items. Sympathetic magics are best used for protective or warding spells, while direct magic is best for curses, cleansing, grounding, or cursing.
Non-Sympathetic Magic
Anytime a spell is cast directly onto a target that is within line of site or within one’s energetic awareness, the circumstances in which the spell must maneuver are, for the most part, observable. Non-sympathetic magic is easiest to do via energy work or gesture magic, as they are less conspicuous. Binding spells directly to a person’s subtle body allows for the manifestation of the working to be evoked from the inside outwards, rather than the outside inwards. Working directly with that target allows for substantially more control over the spell and its outcome. Direct magic can be used to ward as well if you are in the space and working with it directly. The more familiar with the space/target you are, the more effective direct magic will be.
Sustaining Thresholds
Thresholds are only as lasting as the caster’s headspace and focus. As a practitioner loses focus, the threshold will start to break down. While a threshold is typically sustained by the practitioner throughout a working, they can also be crystalized and anchored to an object that can sustain them. However, the medium that is used to anchor it will affect how long it can be sustained. To read further on mediums for anchoring, check out my article on anchors linked above. While a threshold is anchored it is best to hold the object while casting, entering into the proper headspace. If the practitioner has a solid grasp on energy work and the energetic senses, then they need not interact directly with the anchor to use the threshold.
Self-Modifying Thresholds
When creating a complicated threshold that accounts for a large number of circumstantial variations, it may be best to actually create a thoughtform that embodies the spell. This thoughtform must contain as many logical processes as possible so that it has the tools to adapt as the situation changes. Thoughtforms do require being physically anchored in order to be sustained, and their binding should allow for them to stray from the anchor as needed. When creating a thoughtform-bound spell, it is important to have a way to banish it on standby.
References and suggested resources for study
Wiki on Adaptive Control**
Wiki on Estimation Theory***
To read about me, the service I provide, my other content, or to support me on other platforms, see this link!
#informational post#magical theory#advanced spellcraft#advanced witchcraft#advanced magic#Witchcraft and STEM#Gtheory
138 notes
·
View notes
Text
50 Most Important Artificial Intelligence Interview Questions and Answers

Artificial Intelligence is one of the most happening fields today and the demand for AI jobs and professionals with the right skills is huge. Businesses are projected to invest heavily in artificial intelligence and machine learning in the coming years. This will lead to an increased demand for such professionals with AI skills who can help them revolutionize business operations for better productivity and profits. If you are preparing for an AI-related job interview, you can check out these AI interview questions and answers that will give you a good grip on the subject matter.
1. What is Artificial Intelligence?
Artificial intelligence, also known as machine intelligence, focuses on creating machines that can behave like humans. It is one of the wide-ranging branches of computer science which deals with the creation of smart machines that can perform tasks that usually need human intelligence. Google’s search engine is one of the most common examples of artificial intelligence.
2. What are the different domains of Artificial Intelligence?
Artificial intelligence mainly has six different domains. These are neural networks, machine learning, expert systems, robotics, fuzzy logic systems, natural language processing are the different domains of artificial intelligence. Together they help in creating an environment where machines mimic human behavior and do tasks that are usually done by them.
3. What are the different types of Artificial Intelligence?
There are seven different types of artificial intelligence. They are limited memory AI, Reactive Machines AI, Self Aware AI, Theory of Mind AI, Artificial General Intelligence (AGI), Artificial Narrow Intelligence (ANI) and Artificial Superhuman Intelligence (ASI). These different types of artificial intelligence differ in the form of complexities, ranging from basic to the most advanced ones.
4. What are the areas of application of Artificial Intelligence?
Artificial intelligence finds its application across various sectors. Speech recognition, computing, humanoid robots, computer software, bioinformatics, aeronautics and space are some of the areas where artificial intelligence can be used.
5. What is the agent in Artificial Intelligence ?
Agents can involve programs, humans and robots, and are something that perceives the environment through sensors and acts upon it with the help of effectors. Some of the different types of agents are goal-based agents, simple reflex agent, model-based reflex agent, learning agent and utility-based agent.
6. What is Generality in Artificial Intelligence?
It is the simplicity with which the method can be made suitable for different domains of application. It also means how the agent responds to unknown or new data. If it manages to predict a better outcome depending on the environment, it can be termed as a good agent. Likewise, if it does not respond to the unknown or new data, it can be called a bad agent. The more generalized the algorithm is, the better it is.
7. What is the use of semantic analyses in Artificial Intelligence?
Semantic analysis is used for extracting the meaning from the group of sentences in artificial intelligence. The semantic technology classifies the rational arrangement of sentences to recognize the relevant elements and recognize the topic.
8. What is an Artificial Intelligence Neural Network?
An artificial neural network is basically an interconnected group of nodes which takes inspiration from the simplification of neurons in a human brain. They can create models that exactly imitate the working of a biological brain. These models can recognize speech and objects as humans do.
9. What is a Dropout?
It is a tool that prevents a neural network from overfitting. It can further be classified as a regularization technique that is patented by Google to reduce overfitting in neural networks. This is achieved by preventing composite co-adaptations on training data. The word dropout refers to dropping out units in a neural network.
10. How can Tensor Flow run on Hadoop?
The path of the file needs to be changed for reading and writing data for an HDFS path.
11. Where can the Bayes rule be used in Artificial Intelligence?
It can be used to answer probabilistic queries that are conditioned on one piece of evidence. It can easily calculate the subsequent step of the robot when the current executed step is given. Bayes' rule finds its wide application in weather forecasting.
12. How many terms are required for building a Bayes model?
Only three terms are required for building a Bayes model. These three terms include two unconditional probabilities and one conditional probability.
13. What is the result between a node and its predecessors when creating a Bayesian network?
The result is that a node can provisionally remain independent of its precursor. For constructing Bayesian networks, the semantics were led to the consequence to derive this method.
14. How can a Bayesian network be used to solve a query?
The network must be a part of the joint distribution after which it can resolve a query once all the relevant joint entries are added. The Bayesian network presents a holistic model for its variables and their relationships. Due to this, it can easily respond to probabilistic questions about them.
15. What is prolog in Artificial Intelligence?
Prolog is a logic-based programming language in artificial intelligence. It is also a short for programming logic and is widely used in the applications of artificial intelligence, especially expert systems.
17. How are artificial learning and machine learning related to each other?
Machine learning is a subset of artificial learning and involves training machines in a manner by which they behave like humans without being clearly programmed. Artificial intelligence can be considered as a wider concept of machines where they can execute tasks that humans can consider smart. It also considers giving machines the access to information and making them learn on their own.
18. What is the difference between best-first search and breadth-first search?
They are similar strategies in which best-first search involves the expansion of nodes in acceptance with the evaluation function. For the latter, the expansion is in acceptance with the cost function of the parent node. Breadth-first search is always complete and will find solutions if they exist. It will find the best solution based on the available resources.
19. What is a Top-Down Parser?
It is something that hypothesizes a sentence and predicts lower-level constituents until the time when individual pre-terminal symbols are generated. It can be considered as a parsing strategy through which the highest level of the parse tree is looked upon first and it will be worked down with the help of rewriting grammar rules. An example of this could be the LL parsers that use the top-down parsing strategy.
20. On which search method is A* algorithm based?
It is based on the best first search method because it highlights optimization, path and different characteristics. When search algorithms have optimality, they will always find the best possible solution. In this case, it would be about finding the shortest route to the finish state.
21. Which is not a popular property of a logical rule-based system?
Attachment is a property that is not considered desirable in a logical rule-based system in artificial intelligence.
22. When can an algorithm be considered to be complete?
When an algorithm terminates with an answer when one exists, it can be said to be complete. Further, if an algorithm can guarantee a correct answer for any random input, it can be considered complete. If answers do not exist, it should guarantee to return failure.
23. How can different logical expressions look identical?
They can look identical with the help of the unification process. In unification, the lifted inference rules need substitutions through which different logical expressions can look identical. The unify algorithm combines two sentences to return a unifier.
24. How Does Partial order involve?
It involves searching for possible plans rather than possible situations. The primary idea involves generating a plan piece by piece. A partial order can be considered a binary relation that is antisymmetric, reflexive and transitive.
25. What are the two steps involved in constructing a plan ?
The first step is to add an operator, followed by adding an ordering constraint between operators. The planning process in Artificial Intelligence is primarily about decision-making of robots or computer programs to achieve the desired objectives. It will involve choosing actions in a sequence that will work systematically towards solving the given problems.
26. What is the difference between classical AI and statistical AI?
Classical AI is related to deductive thought that is given as constraints, while statistical AI is related to inductive thought that involves a pattern, trend induction, etc. Another major difference is that C++ is the favorite language of statistical AI, while LISP is the favorite language of classical AI. However, for a system to be truly intelligent, it will require the properties of deductive and inductive thought.
27. What does a production rule involve?
It involves a sequence of steps and a set of rules. A production system, also known as a production rule system, is used to provide artificial intelligence. The rules are about behavior and also the mechanism required to follow those rules.
28 .What are FOPL and its role in Artificial Intelligence?
First Order Predicate Logic (FOPL) provides a language that can be used to express assertions. It also provides an inference system to deductive apparatus. It involves quantification over simple variables and they can be seen only inside a predicate. It gives reasoning about functions, relations and world entities.
29 What does FOPL language include?
It includes a set of variables, predicate symbols, constant symbols, function symbols, logical connective, existential quantifier and a universal quantifier. The wffs that are obtained will be according to the FOPL and will represent the factual information of AI studies.
30. What is the role of the third component in the planning system?
Its role is to detect the solutions to problems when they are found. search method is the one that consumes less memory. It is basically a traversal technique due to which less space is occupied in memory. The algorithm is recursive in nature and makes use of backtracking.
31. What are the components of a hybrid Bayesian network?
The hybrid Bayesian network components include continuous and discrete variables. The conditional probability distributions are used as numerical inputs. One of the common examples of the hybrid Bayesian network is the conditional linear Gaussian (CLG) model.
32. How can inductive methods be combined with the power of first-order representations?
Inductive methods can be combined with first-order representations with the help of inductive logic programming.
33. What needs to be satisfied in inductive logic programming?
Inductive logic programming is one of the areas of symbolic artificial intelligence. It makes use of logic programming that is used to represent background knowledge, hypotheses and examples. To satisfy the entailment constraint, the inductive logic programming must prepare a set of sentences for the hypothesis.
34. What is a heuristic function?
Also simply known as heuristic, a heuristic function is a function that helps rank alternatives in search algorithms. This is done at each branching step which is based on the existing information that decides the branch that must be followed. It involves the ranking of alternatives at each step which is based on the information that helps decide which branch must be followed.
35. What are scripts and frames in artificial intelligence?
Scripts are used in natural language systems that help organize a knowledge repository of the situations. It can also be considered a structure through which a set of circumstances can be expected to follow one after the other. It is very similar to a chain of situations or a thought sequence. Frames are a type of semantic networks and are one of the recognized ways of showcasing non-procedural information.
36. How can a logical inference algorithm be solved in Propositional Logic?
Logical inference algorithms can be solved in propositional logic with the help of validity, logical equivalence and satisfying ability.
37. What are the signals used in Speech Recognition?
Speech is regarded as the leading method for communication between human beings and dependable speech recognition between machines. An acoustic signal is used in speech recognition to identify a sequence of words that is uttered by the speaker. Speech recognition develops technologies and methodologies that help the recognition and translation of the human language into text with the help of computers.
38. Which model gives the probability of words in speech recognition?
In speech recognition, the Diagram model gives the probability of each word that will be followed by other words.
39. Which search agent in artificial intelligence operates by interleaving computation and action?
The online search would involve taking the action first and then observing the environment.
40. What are some good programming languages in artificial intelligence?
Prolog, Lisp, C/C++, Java and Python are some of the most common programming languages in artificial intelligence. These languages are highly capable of meeting the various requirements that arise in the designing and development of different software.
41. How can temporal probabilistic reasoning be solved with the help of algorithms?
The Hidden Markov Model can be used for solving temporal probabilistic reasoning. This model observes the sequence of emission and after a careful analysis, it recovers the state of sequence from the data that was observed.
42. What is the Hidden Markov Model used for?
It is a tool that is used for modelling sequence behavior or time-series data in speech recognition systems. A statistical model, the hidden Markov model (HMM) describes the development of events that are dependent on internal factors. Most of the time, these internal factors cannot be directly observed. The hidden states lead to the creation of a Markov chain. The underlying state determines the probability allocation of the observed symbol.
43. What are the possible values of the variables in HMM?
The possible values of the variable in HMM are the “Possible States of the World”.
44. Where is the additional variable added in HMM?
The additional state variables are usually added to a temporal model in HMM.
45 . How many literals are available in top-down inductive learning methods?
Equality and inequality, predicates and arithmetic literals are the three literals available in top-down inductive learning methods.
46. What does compositional semantics mean?
Compositional semantics is a process that determines the meaning of P*Q from P,Q and*. Also simply known as CS, the compositional semantics is also known as the functional dependence of the connotation of an expression or the parts of that expression. Many people might have the question if a set of NL expressions can have any compositional semantics.
47. How can an algorithm be planned through a straightforward approach?
The most straightforward approach is using state-space search as it considers everything that is required to find a solution. The state-space search can be solved in two ways. These include backward from the goal and forward from the initial state.
48. What is Tree Topology?
Tree topology has many connected elements that are arranged in the form of branches of a tree. There is a minimum of three specific levels in the hierarchy. Since any two given nodes can have only one mutual connection, the tree topologies can create a natural hierarchy between parent and child.
If you wish to learn an Artificial Intelligence Course, Great Learning is offering several advanced courses in the subject. An artificial intelligence Certification will provide candidates the AI skills that are required to grab a well-paying job as an AI engineer in the business world. There are several AI Courses that are designed to give candidates extensive hands-on learning experience. Great Learning is offering Machine Learning and Artificial Intelligence courses at great prices. Contact us today for more details. The future of AI is very bright, so get enrolled today to make a dream AI career.
#artificial intelligence#Interview Questions#interview q&a#machine learning#career#ai#learn ai#interview question
4 notes
·
View notes
Text
White Box AI: Interpretability Techniques

While in the previous article of the series we introduced the notion of White Box AI and explained different dimensions of interpretability, in this post we’ll be more practice-oriented and turn to techniques that can make algorithm output more explainable and the models more transparent, increasing trust in the applied models.
The two pillars of ML-driven predictive analysis are data and robust models, and these are the focus of attention in increasing interpretability. The first step towards White Box AI is data visualization because seeing your data will help you to get inside your dataset, which is a first step toward validating, explaining, and trusting models. At the same time, having explainable white-box models with transparent inner workings, followed by techniques that can generate explanations for the most complex types of predictive models such as model visualizations, reason codes, and variable importance measures.
Data Visualization
As we remember, good data science always starts with good data and with ensuring its quality and relevance for subsequent model training.
Unfortunately, most datasets are difficult to see and understand because they have too many variables and many rows. Plotting many dimensions is technically possible, but it does not improve the human understanding of complex datasets. Of course, there are numerous ways to visualize datasets and we discussed them in our dedicated article. However, in this overview, we’ll rely on the experts’ opinions and stick to those selected by Hall and Gill in their book “An Introduction to Machine Learning Interpretability”.
Most of these techniques have the capacity to illustrate all of a data set in just two dimensions, which is important in machine learning because most ML algorithms would automatically model high-degree interactions between multiple variables.
Glyphs
Glyphs are visual symbols used to represent different values or data attributes with the color, texture, or alignment. Using bright colors or unique alignments for events of interest or outliers is a good method for making important or unusual data attributes clear in a glyph representation. Besides, when arranged in a certain way, glyphs can be used to represent rows of a data set. In the figure below, each grouping of four glyphs can be either a row of data or an aggregated group of rows in a data set.

Figure 1. Glyphs arranged to represent many rows of a data set. Image courtesy of Ivy Wang and the H2O.ai team.
Correlation Graphs
A correlation graph is a two-dimensional representation of the relationships (i.e. correlation) in a data set. Even data sets with tens of thousands of variables can be displayed in two dimensions using this technique.
For the visual simplicity of correlation graphs, absolute weights below a certain threshold are not displayed. The node size is determined by a node’s number of connections (node degree), its color is determined by a graph community calculation, and the node position is defined by a graph force field algorithm. Correlation graphs show groups of correlated variables, help us identify irrelevant variables, and discover or verify important relationships that machine learning models should incorporate.
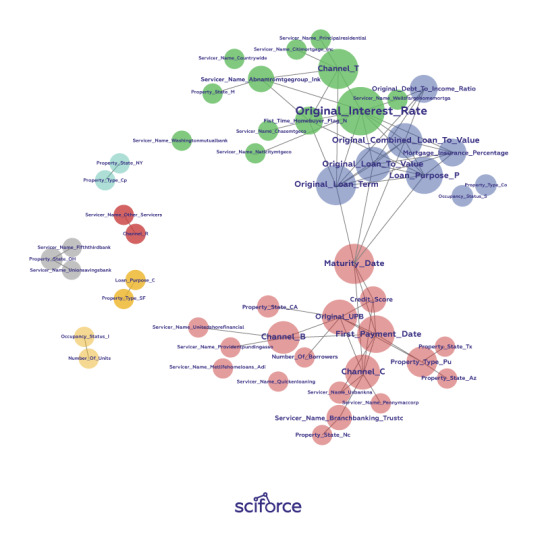
Figure 2. A correlation graph representing loans made by a large financial firm. Figure courtesy of Patrick Hall and the H2O.ai team.
In a supervised model built for the data represented in the figure above, we would expect variable selection techniques to pick one or two variables from the light green, blue, and purple groups, we would expect variables with thick connections to the target to be important variables in the model, and we would expect a model to learn that unconnected variables like CHANNEL_Rare not very important.
2-D projections
Of course, 2-D projection is not merely one technique and there exist any ways and techniques for projecting the rows of a data set from a usually high-dimensional original space into a more visually understandable 2- or 3-D space two or three dimensions, such as:
Principal Component Analysis (PCA)
Multidimensional Scaling (MDS)
t-distributed Stochastic Neighbor Embedding (t-SNE)
Autoencoder networks
Data sets containing images, text, or even business data with many variables can be difficult to visualize as a whole. These projection techniques try to represent the rows of high-dimensional data projecting them into a representative low-dimensional space and visualizing using the scatter plot technique. A high-quality projection visualized in a scatter plot is expected to exhibit key structural elements of a data set, such as clusters, hierarchy, sparsity, and outliers.

Figure 3. Two-dimensional projections of the 784-dimensional MNIST data set using (left) Principal Components Analysis (PCA) and (right) a stacked denoising autoencoder. Image courtesy of Patrick Hall and the H2O.ai team.
Projections can add trust if they are used to confirm machine learning modeling results. For instance, if known hierarchies, classes, or clusters exist in training or test data sets and these structures are visible in 2-D projections, it is possible to confirm that a machine learning model is labeling these structures correctly. Additionally, it shows if similar attributes of structures are projected relatively near one another and different attributes of structures are projected relatively far from one another. Such results should also be stable under minor perturbations of the training or test data, and projections from perturbed versus non-perturbed samples can be used to check for stability or for potential patterns of change over time.
Partial dependence plots
Partial dependence plots show how ML response functions change based on the values of one or two independent variables, while averaging out the effects of all other independent variables. Partial dependence plots with two independent variables are particularly useful for visualizing complex types of variable interactions between the independent variables. They can be used to verify monotonicity of response functions under monotonicity constraints, as well as to see the nonlinearity, non-monotonicity, and two-way interactions in very complex models. They can also enhance trust when displayed relationships conform to domain knowledge expectations. Partial dependence plots are global in terms of the rows of a data set, but local in terms of the independent variables.
Individual conditional expectation (ICE) plots, a newer and less spread adaptation of partial dependence plots, can be used to create more localized explanations using the same ideas as partial dependence plots.
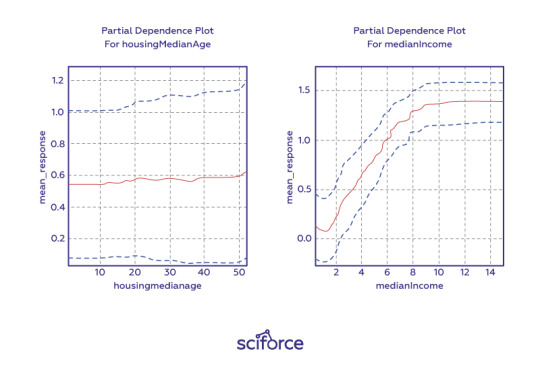
Figure 4. One-dimensional partial dependence plots from a gradient boosted tree ensemble model of the California housing data set. Image courtesy Patrick Hall and the H2O.ai team.
Residual analysis
Residuals refer to the difference between the recorded value of a dependent variable and the predicted value of a dependent variable for every row in a data set. In theory, the residuals of a well-fit model should be randomly distributed because good models will account for most phenomena in a data set, except for random error. Therefore, if models are producing randomly distributed residuals, this is an indication of a well-fit, dependable, trustworthy model. However, if strong patterns are visible in plotted residuals, there are problems with your data, your model, or both. Breaking out a residual plot by independent variables can additionally expose more granular information about residuals and assist in reasoning through the cause of non-random patterns.
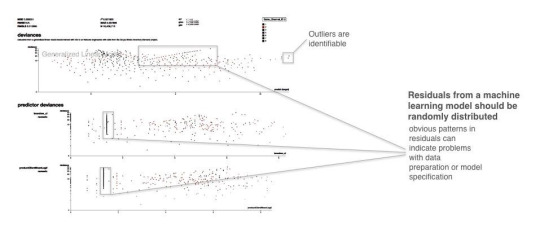
Figure 5. Screenshot from an example residual analysis application. Image courtesy of Micah Stubbs and the H2O.ai team.
Seeing structures and relationships in a data set makes those structures and relationships easier to understand and makes up a first step to knowing if a model’s answers are trustworthy.
Techniques for Creating White-Box Models
Decision trees
Decision trees, predicting the value of a target variable based on several input variables, are probably the most obvious way to ensure interpretability. They are directed graphs in which each interior node corresponds to an input variable. Each terminal node or leaf node represents a value of the target variable given the values of the input variables represented by the path from the root to the leaf. The major benefit of decision trees is that they can reveal relationships between the input and target variable with “Boolean-like” logic and they can be easily interpreted by non-experts by displaying them graphically. However, decision trees can create very complex nonlinear, nonmonotonic functions. Therefore, to ensure interpretability, they should be restricted to shallow depth and binary splits.
eXplainable Neural Networks
In contrast to decision trees, neural networks are often considered the least transparent of black-box models. However, the recent work in XNN implementation and explaining artificial neural network (ANN) predictions may render that characteristic obsolete. Many of the breakthroughs in ANN explanation were made possible thanks to the straightforward calculation of derivatives of the trained ANN response function with regard to input variables provided by deep learning toolkits such as Tensorflow. With the help of such derivatives, the trained ANN response function prediction can be disaggregated into input variable contributions for any observation. XNNs can model extremely nonlinear, nonmonotonic phenomena or they can be used as surrogate models to explain other nonlinear, non-monotonic models, potentially increasing the fidelity of global and local surrogate model techniques.
Monotonic gradient-boosted machines (GBMs)
Gradient boosting is an algorithm that produces a prediction model in the form of an ensemble of weak prediction models, typically decision trees. Used for regression and classification tasks, it is potentially appropriate for most traditional data mining and predictive modeling applications, even in regulated industries and for consistent reason code generation provided it builds monotonic functions. Monotonicity constraints can improve GBMs interpretability by enforcing a uniform splitting strategy in constituent decision trees, where binary splits of a variable in one direction always increase the average value of the dependent variable in the resultant child node, and binary splits of the variable in the other direction always decrease the average value of the dependent variable in the other resultant child node. Understanding is increased by enforcing straightforward relationships between input variables and the prediction target. Trust is increased when monotonic relationships, reason codes, and detected interactions are parsimonious with domain expertise or reasonable expectations.
Alternative regression white-box modeling approaches
There exist many modern techniques to augment traditional, linear modeling methods. Such models as elastic net, GAM, and quantile regression, usually produce linear, monotonic response functions with globally interpretable results similar to traditional linear models but with a boost in predictive accuracy.
Penalized (elastic net) regression
As an alternative to old-school regression models, penalized regression techniques usually combine L1/LASSO penalties for variable selection purposes and Tikhonov/L2/ridge penalties for robustness in a technique known as elastic net. Penalized regression minimizes constrained objective functions to find the best set of regression parameters for a given data set that would model a linear relationship and satisfy certain penalties for assigning correlated or meaningless variables to large regression coefficients. For instance, L1/LASSO penalties drive unnecessary regression parameters to zero, selecting only a small, representative subset of parameters for the regression model while avoiding potential multiple comparison problems. Tikhonov/L2/ridge penalties help preserve parameter estimate stability, even when many correlated variables exist in a wide data set or important predictor variables are correlated. Penalized regression is a great fit for business data with many columns, even data sets with more columns than rows, and for data sets with a lot of correlated variables.
Generalized Additive Models (GAMs)
Generalized Additive Models (GAMs) hand-tune a tradeoff between increased accuracy and decreased interpretability by fitting standard regression coefficients to certain variables and nonlinear spline functions to other variables. Also, most implementations of GAMs generate convenient plots of the fitted splines. That can be used directly in predictive models for increased accuracy. Otherwise, you can eyeball the fitted spline and switch it out for a more interpretable polynomial, log, trigonometric or other simple function of the predictor variable that may also increase predictive accuracy.
Quantile regression
Quantile regression is a technique that tries to fit a traditional, interpretable, linear model to different percentiles of the training data, allowing you to find different sets of variables with different parameters for modeling different behavior. While traditional regression is a parametric model and relies on assumptions that are often not met. Quantile regression makes no assumptions about the distribution of the residuals. It lets you explore different aspects of the relationship between the dependent variable and the independent variables.
There are, of course, other techniques, both based on applying constraints on regression and generating specific rules (like in OneR or RuleFit approaches). We encourage you to explore possibilities for enhancing model interpretability for any algorithm you choose and which is the most appropriate for your task and environment.
Evaluation of Interpretability
Finally, to ensure that the data and the trained models are interpretable, it is necessary to have robust methods for interpretability evaluation. However, with no real consensus about what interpretability is in machine learning, it is unclear how to measure it. Doshi-Velez and Kim (2017) propose three main levels for the evaluation of interpretability:
Application level evaluation (real task)
Essentially, it is putting the explanation into the product and having it tested by the end user. This requires a good experimental setup and an understanding of how to assess quality. A good baseline for this is always how good a human would be at explaining the same decision.
Human level evaluation (simple task)
It is a simplified application-level evaluation. The difference is that these experiments are not carried out with the domain experts, but with laypersons in simpler tasks like showing users several different explanations and letting them choose the best one. This makes experiments cheaper and it is easier to find more testers.
Function level evaluation (proxy task)
This task does not require humans. This works best when the class of model used has already been evaluated by humans. For example, if we know that end users understand decision trees, a proxy for explanation quality might be the depth of the tree with shorter trees having a better explainability score. It would make sense to add the constraint that the predictive performance of the tree remains good and does not decrease too much compared to a larger tree.
Most importantly, you should never forget that interpretability is not for machines but for humans, so the end users and their perception of data and models should always be in the focus of your attention. And humans prefer short explanations that contrast the current situation with a situation in which the event would not have occurred. Explanations are social interactions between the developer and the end user and it should always account for the social (and legal) context and the user’s expectations.
3 notes
·
View notes
Text
Random Variable And Distribution Function Assignment Homework Help
https://www.statisticshomeworktutors.com/Random-Variable-And-Distribution-Function.php
Statisticshomeworktutors assures to provide you with well-structured and well-formatted solutions and our deliveries have always been on time whether it’s a day’s deadline or long. You can anytime buy assignments online through us and we assure to build your career with success and prosperity. So, if you have an assignment, please mail it to us at [email protected]. They solve it from the scratch to the core and precisely to your requirement. The basic topics that are normally considered part of college Random Variable and Distribution Function that we can help with:
pmf of Y = g(X)
Probability Density Function (pdf) and connection with pmf
Probability density functions
Probability distribution
Probability distribution and densities (cdf, pmf, pdf)
Random element
Random function
Random measure
Random number generator produces a random value
Randomness
Relation with pdf and pmf
Stochastic process
Term life insurance and death probability
Testing the fit of a distribution to data
The conditional distribution function and conditional probability density function
Uniform and exponential random variables
Visualizing a binomial distribution
#Random Variable And Distribution Function Assignment Homework Help#Random Variable And Distribution Function Assignment Help#Random Variable And Distribution Function Homework Help#Random Variable And Distribution Function Online Help#Random Variable And Distribution Function Project Help#Random Variable And Distribution Function Assignment Homework Help Experts
0 notes
Text
How to Start Your Data Science Journey with Python: A Comprehensive Guide

Data science has emerged as a powerful field, revolutionizing industries with its ability to extract valuable insights from vast amounts of data. Python, with its simplicity, versatility, and extensive libraries, has become the go-to programming language for data science. Whether you are a beginner or an experienced programmer, this article will provide you with a comprehensive guide on how to start your data science journey with Python.
Understand the Fundamentals of Data Science:
Before diving into Python, it's crucial to grasp the fundamental concepts of data science. Familiarize yourself with key concepts such as data cleaning, data visualization, statistical analysis, and machine learning algorithms. This knowledge will lay a strong foundation for your Python-based data science endeavors.
Learn Python Basics:
Python is known for its readability and ease of use. Start by learning the basics of Python, such as data types, variables, loops, conditionals, functions, and file handling. Numerous online resources, tutorials, and interactive platforms like Codecademy, DataCamp, and Coursera offer comprehensive Python courses for beginners.
Master Python Libraries for Data Science:
Python's real power lies in its extensive libraries that cater specifically to data science tasks. Familiarize yourself with the following key libraries:
a. NumPy: NumPy provides powerful numerical computations, including arrays, linear algebra, Fourier transforms, and more.
b. Pandas: Pandas offers efficient data manipulation and analysis tools, allowing you to handle data frames effortlessly.
c. Matplotlib and Seaborn: These libraries provide rich visualization capabilities for creating insightful charts, graphs, and plots.
d. Scikit-learn: Scikit-learn is a widely-used machine learning library that offers a range of algorithms for classification, regression, clustering, and more.
Explore Data Visualization:
Data visualization plays a vital role in data science. Python libraries such as Matplotlib, Seaborn, and Plotly provide intuitive and powerful tools for creating visualizations. Practice creating various types of charts and graphs to effectively communicate your findings.
Dive into Data Manipulation with Pandas:
Pandas is an essential library for data manipulation tasks. Learn how to load, clean, transform, and filter data using Pandas. Master concepts like data indexing, merging, grouping, and pivoting to manipulate and shape your data effectively.
Gain Statistical Analysis Skills:
Statistical analysis is a core aspect of data science. Python's Scipy library offers a wide range of statistical functions, hypothesis testing, and probability distributions. Acquire the knowledge to analyze data, draw meaningful conclusions, and make data-driven decisions.
Implement Machine Learning Algorithms:
Machine learning is a key component of data science. Scikit-learn provides an extensive range of machine learning algorithms. Start with simpler algorithms like linear regression and gradually progress to more complex ones like decision trees, random forests, and support vector machines. Understand how to train models, evaluate their performance, and fine-tune them for optimal results.
Explore Deep Learning with TensorFlow and Keras:
For more advanced applications, delve into deep learning using Python libraries like TensorFlow and Keras. These libraries offer powerful tools for building and training deep neural networks. Learn how to construct neural network architectures, handle complex data types, and optimize deep learning models.
Participate in Data Science Projects:
To solidify your skills and gain practical experience, engage in data science projects. Participate in Kaggle competitions or undertake personal projects that involve real-world datasets. This hands-on experience will enhance your problem-solving abilities and help you apply your knowledge effectively.
Continuously Learn and Stay Updated:
The field of data science is constantly evolving, with new techniques, algorithms, and libraries emerging.
Conclusion:
Embarking on your data science journey with Python opens up a world of opportunities to extract valuable insights from data. By following the steps outlined in this comprehensive guide, you can lay a solid foundation and start your data science endeavors with confidence.
Python's versatility and the abundance of data science libraries, such as NumPy, Pandas, Matplotlib, Scikit-learn, TensorFlow, and Keras, provide you with the necessary tools to manipulate, analyze, visualize, and model data effectively. Remember to grasp the fundamental concepts of data science, continuously learn and stay updated with the latest advancements in the field.
Engaging in data science projects and participating in competitions will further sharpen your skills and enable you to apply your knowledge to real-world scenarios. Embrace challenges, explore diverse datasets, and seek opportunities to collaborate with other data scientists to expand your expertise and gain valuable experience.
Data science is a journey that requires perseverance, curiosity, and a passion for solving complex problems. Python, with its simplicity and powerful libraries, provides an excellent platform to embark on this journey. So, start today, learn Python, and unlock the boundless potential of data science to make meaningful contributions in your field of interest.
0 notes
Text
How to Conduct a Machine Learning Test Before Deploying to Production?

As with any software, ML models require robust testing before they can be deployed to production. Yet, most teams ignore this requirement until they're ready to deploy or altogether skip it.
For instance, a team might test if a model's performance changes when they introduce a slight change in the input data. Or, they might run a stress test on a model to see how it handles an increased number of prediction requests at a given time scale.
Training Set
In machine learning, the training set is the data used to train the model. This is an important component of any ML project. It allows the model to learn how to predict future outcomes from the data it has trained on. The quality and quantity of the training data are also important factors that can affect the overall performance of the machine-learning model.
The data used in the training set is very crucial for the model to improve its accuracy and performance, which can only happen if it has been provided with high-quality data. This can be achieved by ensuring that the data has been collected from the best source, and by implementing rigorous labeling procedures.
It is also necessary to ensure that the data does not contain any unwanted or undesirable features or variables that may negatively affect the model's performance. This can be accomplished by performing a thorough sanitization of the training data before it is used in the machine learning model.
When a dataset is split into a training set, a validation set, and a test set, the process is often called the train-test split procedure. The process consists of random sampling without the replacement of about 75 percent of the rows and putting them into a training set, then resampling the remaining 25 percent of the data into a test set.
The train-test split is an essential part of any ML project, as it helps avoid overfitting and bias in the model's performance. It also helps ensure that all data points are tagged to their corresponding inputs and outputs, which are critical for the machine learning algorithms to function.
Another important consideration is to keep the class distribution consistent across all the sets of data. This is often avoided with the use of a technique called stratified K-fold cross-validation.
A stratified method is especially useful when a large percentage of the data in the dataset is imbalanced in its class distribution. In this case, stratified random sampling is utilized to separate the data into train and validation sets, which ensures that the distribution of classes in each of the sets is maintained.
Cross-Validation
Cross-Validation is an important technique for evaluating the accuracy of a machine-learning model. It helps in protecting a model from overfitting, especially when the amount of data available is limited. It also helps in selecting the best algorithm for a particular task.
The basic idea of cross-validation is to split the dataset into two parts - training data and test data. The training data is used to train the model and the test data is used for prediction. This way, if the model performs well over the test data and gives good accuracy, it means that the model is not overfitted on the training data and will be able to predict new data.
During the training phase, models are trained using a set of known data and a set of unknown or first-seen data (called the validation dataset). After training, the model is tested on a different set of data to assess its accuracy and how it will generalize to future data.
There are several techniques to do this, one of them is k-fold cross validation which involves splitting the training dataset into a fixed number of groups. This is then used to validate the model for each group. The results are then averaged to give a more accurate error estimate.
Another method of cross-validation is leave-one-out (LOO) cross-validation, where the function approximator is trained on all the data but for a single point. This approach is based on the same principle as k-fold cross-validation, but it requires more computation to calculate the error estimate.
In a case where there are too many data points, this method can lead to an overly optimistic error estimate. This is known as the bias-variance tradeoff and it can be problematic when a large number of data points are involved.
In most cases, the performance of a model will vary significantly when it is applied to a new data set. This can be caused by human bias and arbitrary decisions in the training process. It can also be a consequence of a poorly specified model. This can be a problem when trying to compare different statistical methods.
Adversary Dataset
Adversarial examples are specialized inputs created to confuse a machine learning model, causing it to misclassify a given input. They are reminiscent of optical illusions and have been exploited by numerous researchers to achieve false predictions.
Adversaries typically fall into two types: white-box and black-box attacks. In the former, attackers have complete access to the underlying model and its internal processes; in the latter, they can control only the outputs of the model.
The most popular type of adversarial attack is the fast gradient sign method (FGSM). This technique uses the underlying neural network's backpropagated gradients to find adversarial examples. In the FGSM attack, a small error is added or subtracted to each pixel of an image, based on the sign of the gradient for that pixel.
Whether the error is in the direction of the gradient, or the opposite, results in an image that changes the classification of the model. Hence, the FGSM attack is a very powerful and intuitive attack on neural networks.
Another common type of adversarial attack is the backdoor or data poisoning attack, which involves adding or blending patterns in the training data to manipulate the model. This can happen during model retraining, or directly while the network is being trained.
For both types of attacks, an attacker needs to know what the model's loss function is and what the training process looks like. This knowledge can then be used to add or blend patterns to the model's input data to trick the model into making a wrong prediction.
In addition to this, an attacker must also consider the accuracy of a model under attack. The tradeoff between accuracy degradation and perceptibility becomes clear as the epsilon of an adversarial example increases.
The results of this study show that utilizing MINE as the underlying algorithm can improve the robustness of the attack and significantly decrease the number of predicted errors, compared to the original model. Furthermore, the additional data augmentation and model retraining also improve contrastive loss and classification accuracy. This is an important step toward improving the robustness of a neural network to malicious examples.
Sanitization
When people touch different surfaces, they are exposed to a lot of germs and viruses that can cause various diseases. Sanitization is a process that helps to keep these germs from spreading safely. This is done by using chemicals, disinfectants, and sanitizers that do not harm the human body but are effective enough to kill the pathogens and bacteria present on a surface.
Cleaning is the first step that is performed to remove dirt and dust from a specific surface. This is done to prevent the spread of germs and bacteria and is a highly important task that needs to be carried out frequently.
Similarly, sanitizing is the second step that is performed to remove bacteria from a surface and make it safe for contact. This is done to reduce the number of bacteria present on a surface and lower it to a level that is judged by public health standards.
Sanitizing is much more complex than cleaning. This is because it involves a lot of knowledge and expertise. It requires special skills and training to know the right chemical and its application on a specific surface. It is also a professional job and needs to be done by professionals to ensure the safety of the people involved.
For this reason, sanitizing should be done only after cleaning has been completed and it should not be done when the surface is in a damaged state because it might leave harmful residues behind. It is therefore essential to use sanitizers that are FDA-approved and EPA certified.
The sanitizers should be used for the recommended time frame and must be wiped off after the time frame has been completed. It is also essential to make sure that the sanitizers are diluted in water or other diluting agents before putting them to work on a surface. We used sensor data and daily weights from forty latrines in an informal settlement in Nairobi to test whether a machine learning algorithm could predict when latrine servicing was unnecessary. This algorithm was accurate more often than not, resulting in average unit waste collection efficiency increases of 12% to 13% throughout the experiment.
0 notes
Text
Can somebody provide step by step to learn Python for data science?
Step-by-Step Approach to Learning Python for Data Science
1. Install Python and all the Required Libraries
Download Python: You can download it from the official website, python.org, and make sure to select the correct version corresponding to your operating system.
Install Python: Installation instructions can be found on the website.
Libraries Installation: You have to download some main libraries to manage data science tasks with the help of a package manager like pip.
NumPy: This is the library related to numerical operations and arrays.
Pandas: It is used for data manipulation and analysis.
Matplotlib: You will use this for data visualization.
Seaborn: For statistical visualization.
Scikit-learn: For algorithms of machine learning.
2. Learn Basics of Python
Variables and Data Types: Be able to declare variables, and know how to deal with various data types, including integers, floats, strings, and booleans.
Operators: Both Arithmetic, comparison, logical, and assignment operators
Control Flow: Conditional statements, if-else, and loops, for and while.
Functions: A way to create reusable blocks of code.
3. Data Structures
Lists: The way of creating, accessing, modifying, and iterating over lists is needed.
Dictionaries: Key-value pairs; how to access, add and remove elements.
Sets: Collections of unique elements, unordered.
Tuples: Immutable sequences.
4. Manipulation of Data Using pandas
Reading and Writing of Data: Import data from various sources, such as CSV or Excel, into the programs and write it in various formats. This also includes treatment of missing values, duplicates, and outliers in data. Scrutiny of data with the help of functions such as describe, info, and head.
Data Transformation: Filter, group and aggregate data.
5. NumPy for Numerical Operations
Arrays: Generation of numerical arrays, their manipulation, and operations on these arrays are enabled.
Linear Algebra: matrix operations and linear algebra calculations.
Random Number Generation: generation of random numbers and distributions.
6. Data Visualisation with Matplotlib and Seaborn
Plotting: Generation of different plot types (line, bar, scatter, histograms, etc.)
Plot Customization: addition of title, labels, legends, changing plot styles
Statistical Visualizations: statistical analysis visualizations
7. Machine Learning with Scikit-learn
Supervised Learning: One is going to learn linear regression, logistic regression, decision trees, random forests, support vector machines, and other algorithms.
Unsupervised Learning: Study clustering (K-means, hierarchical clustering) and dimensionality reduction (PCA, t-SNE).
Model Evaluation: Model performance metrics: accuracy, precision, recall, and F1-score.
8. Practice and Build Projects
Kaggle: Join data science competitions for hands-on practice on what one has learnt.
Personal Projects: Each project would deal with topics of interest so that such concepts may be firmly grasped.
Online Courses: Structured learning is possible in platforms like Coursera, edX, and Lejhro Bootcamp.
9. Stay updated
Follow the latest trends and happenings in data science through various blogs and news.
Participate in online communities of other data scientists and learn through their experience.
You just need to follow these steps with continuous practice to learn Python for Data Science and have a great career at it.
0 notes
Text
THE EFFECTS OF PROBABILITY ON BUSINESS DECISIONS
Many businesses apply the understanding of uncertainty and probability in their business decision practices. While your focus is on formulas and statistical calculations used to define probability, underneath these lie basic concepts that determine whether -- and how much -- event interactions affect probability. Together, statistical calculations and probability concepts allow you to make good business decisions, even in times of uncertainty. Probability models can greatly help businesses in optimizing their policies and making safe decisions. Though complex, these probability methods can increase the profitability and success of a business. In this article, ISS coaching in Lucknow highlights how analytical tools such as probabilistic modeling can be effectively used for dealing with uncertainty.

THE ROLE OF PROBABILITY DISTRIBUTION IN BUSINESS MANAGEMENT
Sales Predictions
A major application for probability distributions lies in anticipating future sales incomes. Companies of all sizes rely on sales forecasts to predict revenues, so the probability distribution of how many units the firm expects to sell in a given period can help it anticipate revenues for that period. The distribution also allows a company to see the worst and best possible outcomes and plan for both. The worst outcome could be 100 units sold in a month, while the best result could be 1,000 units sold in that month.
Risk Assessments
Probability distributions can help companies avoid negative outcomes just as they help predict positive results. Statistical analysis can also be useful in analyzing outcomes of ventures that involve substantial risks. The distribution shows which outcomes are most likely in a risky proposition and whether the rewards for taking specific actions compensate for those risks. For instance, if the probability analysis shows that the costs of launching a new project is likely to be $350,000, the company must determine whether the potential revenues will exceed that amount to make it a profitable venture.
Probability Distribution
A probability distribution is a statistical function that identifies all the conceivable outcomes and odds that a random variable will have within a specific range. This range is determined by the lowest and highest potential values for that variable. For instance, if a company expects to bring in between $100,000 and $500,000 in monthly revenue, the graph will start with $100,000 at the low end and $500,000 at the high end. The graph for a typical probability distribution resembles a bell curve, where the least likely events fall closest to the extreme ends of the range and the most likely events occur closer to the midpoint of the extremes.
Investment
The optimization of a business’s profit relies on how a business invests its resources. One important part of investing is knowing the risks involved with each type of investment. The only way a business can take these risks into account when making investment decisions is to use probability as a calculation method. After analyzing the probabilities of gain and loss associated with each investment decision, a business can apply probability models to calculate which investment or investment combinations yield the greatest expected profit.
Customer Service
Customer service may be physical customer service, such as bank window service, or virtual customer service, such as an Internet system. In either case, probability models can help a company in creating policy related to customer service. For such policies, the models of queuing theory are integral. These models allow companies to understand the efficiency related to their current system of customer service and make changes to optimize the system. If a company encounters problems with long lines or long online wait times, this may cause the company to lose customers. In this situation, queuing models become an important part of problem solving.

Competitive Strategy
Although game theory is an important part of determining company strategy, game theory lacks the inclusion of uncertainty in its models. Such a deterministic model can't allow a company to truly optimize its strategy in terms of risk. Probability models such as Markov chains allow companies to design a set of strategies that not only account for risk but are self-altering in the face of new information regarding competing companies. In addition, Markov chains allow companies to mathematically analyze long-term strategies to find which ones yield the best results.
Product Design
Product design, especially the design of complicated products such as computing devices, includes the design and arrangement of multiple components in a system. Reliability theory provides a probabilistic model that helps designers model their products in terms of the probability of failure or breakdown. This model allows for more efficient design and allows businesses to optimally draft warranties and return policies.
ABOUT PROBABILITY, STATISTICS AND CHANCE
Probability concepts are abstract ideas used to identify the degree of risk a business decision involves. In determining probability, risk is the degree to which a potential outcome differs from a benchmark expectation. You can base probability calculations on a random or full data sample. For example, consumer demand forecasts commonly use a random sampling from the target market population. However, when you’re making a purchasing decision based solely on cost, the full cost of each item determines which comes the closest to matching your cost expectation.
Mutual Exclusivity
The concept of mutually exclusivity applies if the occurrence of one event prohibits the occurrence of another event. For example, assume you have two tasks on your to-do list. Both tasks are due today and both will take the entire day to complete. Whichever task you choose to complete means the other will remain incomplete. These two tasks can’t have the same outcome. Thus, these tasks are mutually exclusive.
Dependent Events
A second concept refers to the impact two separate events have on each other. Dependent events are those in which the occurrence of one event affects -- but doesn't prevent -- the probability of the other occurring. For example, assume a five-year goal is to purchase a new building and pay the full purchase price in cash. The expected funding source is investment returns from excess sales revenue investments. The probability of the purchase happening within the five-year period depends on whether sales revenues meet projected expectations. This makes these dependent events.
Interdependent Events
Interdependent events are those in which the occurrence of one event has no effect of the probability of another event. For example, assume consumer demand for hairbrushes is falling to an all-time low. The concept of interdependence says that declining demand for hairbrushes and the probability that demand for shampoo will also decline share no relationship. In the same way, if you intend to purchase a new building by investing personal funds instead of relying on investment returns from excess sales revenues, the purchase of a new building and sales revenues share no relationship. Thus, these are now interdependent events.
1 note
·
View note
Quote
Business Analyst course
Business Analyst course
Many kids are aspiring to come across a career transition into these roles. Let us look into a couple of of the main job positions of the Data Science area. Big knowledge refers to massive amounts of information from numerous sources from totally different formats. Big information revolves across the data that cannot be dealt with by the traditional data analysis method. It is related to many business sectors like IT services, healthcare and e-commerce industries, banking and finance sectors, consultancy services, transport sectors, manufacturing models, etc. Data collection is considered as another major responsibility of a data scientist.
Data science consists of, along with ML, statistics, advanced knowledge analysis, knowledge visualization, information engineering, and so on. This is our superior Big Data coaching, the place students will gain sensible skill set not solely on Hadoop in detail, but additionally learn advanced analytics ideas by way of Python, Hadoop and Spark. For in depth hands-on practice, college students will get a quantity of assignments and initiatives. At end of this system candidates are awarded Certified Big Data Science Certification on profitable completion of tasks that are supplied as a part of the training.
To establish the properties of a steady random variable, statisticians have outlined a variable as a standard, studying the properties of the standard variable and its distribution. You will be taught to check if a steady random variable is following regular distribution utilizing a standard Q-Q plot. Learn the science behind the estimation of value for a population using pattern knowledge. Whether it is a fresher or someone with work expertise, everyone is making an attempt to get a share of this dawn sector. Majority scholars and professionals no matter their backgrounds are upskilling themselves to be taught the this course. The frenzy created out there has made us consider that anybody can turn out to be a Master of Data Science. One of the just lately launched Data Science course in India by Henry Harvin has been aptly named — Certified Data Scientist.
Business Analyst course
From analysing tyre efficiency to detecting problem gamblers, wherever information exists, there are opportunities to use it. Alongside these classes you will also research independently finishing coursework for each module. You will be taught through a sequence of lectures, tutorials and many sensible classes serving to you to increase your specialist data and autonomy. This module aims to introduce you to the basic idea of computing-on-demand resulting in Cloud computing. Emphasis is given to the different technologies to build Clouds and how these are used to supply computing on-demand. Full time college students might take an internship route, in which they are given an extra three months for an internship-based Project.
The course is aimed to develop practical enterprise analytics abilities within the learners. As this is an advanced-level knowledge analytics course, data analytics experience is obligatory to get started with the identical. The course would provide you with a deep understanding of superior excel formulation and functions to remodel Excel from a fundamental spreadsheet program into a strong analytics software. The course would additionally implement practical implementation by exercising contextual examples designed to showcase the formulation and how they are often applied in numerous ways. By the tip of the course, you may be trained to construct dynamic tools and excel dashboards to filter, show, and analyze knowledge. You may even be eligible to automate tedious and time-consuming tasks utilizing cell formulation & capabilities in excel. The course provided by Coursera educates learners concerning the numerous knowledge analytics practices involved with enterprise administration and growth.
An introduction to likelihood, emphasizing the combined use of arithmetic and programming to unravel issues. Use of numerical computation, graphics, simulation, and computer algebra. to statistical ideas including averages and distributions, predicting one variable from one other, association and causality, likelihood and probabilistic simulation. In some cases, students might complete different programs to fulfill the above stipulations. See the lower-division requirements web page on the Data Science program website for more details. No, PAT does not promise a job, but it helps the aspirants to build the required potential needed in landing a career. The aspirants can capitalize on the acquired expertise, in the lengthy run, to a profitable profession in Data Science.
If you've any questions or issues, please contact and/or report your expertise via the edX contact type. HarvardX requires people who enroll in its programs on edX to abide by the terms of the edX honor code. No refunds shall be issued within the case of corrective action for such violations. Enrollees who're taking HarvardX programs as a part of another program may even be governed by the educational policies of those programs.
Data scientists primarily cope with huge chunks of data to analyse the patterns, tendencies and extra. These evaluation purposes formulate stories which are finally helpful in drawing inferences. Interestingly, there’s also a related subject which makes use of both information science, data analytics and enterprise intelligence applications- Business Analyst. A enterprise analyst profile combines slightly little bit of each to assist corporations take information driven decisions. The mission of the Ph.D. in hospitality enterprise analytics program is to offer advanced training to students in data science because it relates to the hospitality business. The aim is to arrange college students for highly demanding educational and analysis careers in top‐ranked establishments. Our faculty conduct in-depth analysis in various areas of research that apply to hospitality enterprise analytics, such as revenue management, digital marketing, finance, buyer experience administration and human sources administration.
These embody both free assets and paid information science certificate packages which are delivered online, are widely recognised and have benefited hundreds of students and professionals. With being increasingly utilized in a number of industries, information science is quickly turning into one of the fastest-growing fields. The learning platform edX has compiled a series of over 200 courses created by prime academic and industrial establishments to assist your studying. Pick a programming language that you are snug with and get began with analyzing huge chunks of datasets. You can reach us at: ExcelR- Data Science, Data Analytics, Business Analytics Course Training Bangalore Address:49, 1st Cross, 27th Main, Behind Tata Motors, 1st Stage, BTM Layout, Bengaluru, Karnataka 560068 Phone: 096321 56744 Directions: Business Analyst course Email:[email protected]
0 notes
Text
50 Most Important Artificial Intelligence Interview Questions and Answers
Artificial Intelligence is one of the most happening fields today and the demand for AI jobs and professionals with the right skills is huge. Businesses are projected to invest heavily in artificial intelligence and machine learning in the coming years. This will lead to an increased demand for such professionals with AI skills who can help them revolutionize business operations for better productivity and profits. If you are preparing for an AI-related job interview, you can check out these AI interview questions and answers that will give you a good grip on the subject matter.
1. What is Artificial Intelligence?
Artificial intelligence, also known as machine intelligence, focuses on creating machines that can behave like humans. It is one of the wide-ranging branches of computer science which deals with the creation of smart machines that can perform tasks that usually need human intelligence. Google’s search engine is one of the most common examples of artificial intelligence.
2. What are the different domains of Artificial Intelligence?
Artificial intelligence mainly has six different domains. These are neural networks, machine learning, expert systems, robotics, fuzzy logic systems, natural language processing are the different domains of artificial intelligence. Together they help in creating an environment where machines mimic human behavior and do tasks that are usually done by them.
3. What are the different types of Artificial Intelligence?
There are seven different types of artificial intelligence. They are limited memory AI, Reactive Machines AI, Self Aware AI, Theory of Mind AI, Artificial General Intelligence (AGI), Artificial Narrow Intelligence (ANI) and Artificial Superhuman Intelligence (ASI). These different types of artificial intelligence differ in the form of complexities, ranging from basic to the most advanced ones.
4. What are the areas of application of Artificial Intelligence?
Artificial intelligence finds its application across various sectors. Speech recognition, computing, humanoid robots, computer software, bioinformatics, aeronautics and space are some of the areas where artificial intelligence can be used.
5. What is the agent in Artificial Intelligence ?
Agents can involve programs, humans and robots, and are something that perceives the environment through sensors and acts upon it with the help of effectors. Some of the different types of agents are goal-based agents, simple reflex agent, model-based reflex agent, learning agent and utility-based agent.
6. What is Generality in Artificial Intelligence?
It is the simplicity with which the method can be made suitable for different domains of application. It also means how the agent responds to unknown or new data. If it manages to predict a better outcome depending on the environment, it can be termed as a good agent. Likewise, if it does not respond to the unknown or new data, it can be called a bad agent. The more generalized the algorithm is, the better it is.
7. What is the use of semantic analyses in Artificial Intelligence?
Semantic analysis is used for extracting the meaning from the group of sentences in artificial intelligence. The semantic technology classifies the rational arrangement of sentences to recognize the relevant elements and recognize the topic.
8. What is an Artificial Intelligence Neural Network?
An artificial neural network is basically an interconnected group of nodes which takes inspiration from the simplification of neurons in a human brain. They can create models that exactly imitate the working of a biological brain. These models can recognize speech and objects as humans do.
9. What is a Dropout?
It is a tool that prevents a neural network from overfitting. It can further be classified as a regularization technique that is patented by Google to reduce overfitting in neural networks. This is achieved by preventing composite co-adaptations on training data. The word dropout refers to dropping out units in a neural network.
10. How can Tensor Flow run on Hadoop?
The path of the file needs to be changed for reading and writing data for an HDFS path.
11. Where can the Bayes rule be used in Artificial Intelligence?
It can be used to answer probabilistic queries that are conditioned on one piece of evidence. It can easily calculate the subsequent step of the robot when the current executed step is given. Bayes’ rule finds its wide application in weather forecasting.
12. How many terms are required for building a Bayes model?
Only three terms are required for building a Bayes model. These three terms include two unconditional probabilities and one conditional probability.
13. What is the result between a node and its predecessors when creating a Bayesian network?
The result is that a node can provisionally remain independent of its precursor. For constructing Bayesian networks, the semantics were led to the consequence to derive this method.
14. How can a Bayesian network be used to solve a query?
The network must be a part of the joint distribution after which it can resolve a query once all the relevant joint entries are added. The Bayesian network presents a holistic model for its variables and their relationships. Due to this, it can easily respond to probabilistic questions about them.
15. What is prolog in Artificial Intelligence?
Prolog is a logic-based programming language in artificial intelligence. It is also a short for programming logic and is widely used in the applications of artificial intelligence, especially expert systems.
17. How are artificial learning and machine learning related to each other?
Machine learning is a subset of artificial learning and involves training machines in a manner by which they behave like humans without being clearly programmed. Artificial intelligence can be considered as a wider concept of machines where they can execute tasks that humans can consider smart. It also considers giving machines the access to information and making them learn on their own.
18. What is the difference between best-first search and breadth-first search?
They are similar strategies in which best-first search involves the expansion of nodes in acceptance with the evaluation function. For the latter, the expansion is in acceptance with the cost function of the parent node. Breadth-first search is always complete and will find solutions if they exist. It will find the best solution based on the available resources.
19. What is a Top-Down Parser?
It is something that hypothesizes a sentence and predicts lower-level constituents until the time when individual pre-terminal symbols are generated. It can be considered as a parsing strategy through which the highest level of the parse tree is looked upon first and it will be worked down with the help of rewriting grammar rules. An example of this could be the LL parsers that use the top-down parsing strategy.
20. On which search method is A* algorithm based?
It is based on the best first search method because it highlights optimization, path and different characteristics. When search algorithms have optimality, they will always find the best possible solution. In this case, it would be about finding the shortest route to the finish state.
21. Which is not a popular property of a logical rule-based system?
Attachment is a property that is not considered desirable in a logical rule-based system in artificial intelligence.
22. When can an algorithm be considered to be complete?
When an algorithm terminates with an answer when one exists, it can be said to be complete. Further, if an algorithm can guarantee a correct answer for any random input, it can be considered complete. If answers do not exist, it should guarantee to return failure.
23. How can different logical expressions look identical?
They can look identical with the help of the unification process. In unification, the lifted inference rules need substitutions through which different logical expressions can look identical. The unify algorithm combines two sentences to return a unifier.
24. How Does Partial order involve?
It involves searching for possible plans rather than possible situations. The primary idea involves generating a plan piece by piece. A partial order can be considered a binary relation that is antisymmetric, reflexive and transitive.
25. What are the two steps involved in constructing a plan ?
The first step is to add an operator, followed by adding an ordering constraint between operators. The planning process in Artificial Intelligence is primarily about decision-making of robots or computer programs to achieve the desired objectives. It will involve choosing actions in a sequence that will work systematically towards solving the given problems.
26. What is the difference between classical AI and statistical AI?
Classical AI is related to deductive thought that is given as constraints, while statistical AI is related to inductive thought that involves a pattern, trend induction, etc. Another major difference is that C++ is the favorite language of statistical AI, while LISP is the favorite language of classical AI. However, for a system to be truly intelligent, it will require the properties of deductive and inductive thought.
27. What does a production rule involve?
It involves a sequence of steps and a set of rules. A production system, also known as a production rule system, is used to provide artificial intelligence. The rules are about behavior and also the mechanism required to follow those rules.
28 .What are FOPL and its role in Artificial Intelligence?
First Order Predicate Logic (FOPL) provides a language that can be used to express assertions. It also provides an inference system to deductive apparatus. It involves quantification over simple variables and they can be seen only inside a predicate. It gives reasoning about functions, relations and world entities.
29 What does FOPL language include?
It includes a set of variables, predicate symbols, constant symbols, function symbols, logical connective, existential quantifier and a universal quantifier. The wffs that are obtained will be according to the FOPL and will represent the factual information of AI studies.
30. What is the role of the third component in the planning system?
Its role is to detect the solutions to problems when they are found. search method is the one that consumes less memory. It is basically a traversal technique due to which less space is occupied in memory. The algorithm is recursive in nature and makes use of backtracking.
31. What are the components of a hybrid Bayesian network?
The hybrid Bayesian network components include continuous and discrete variables. The conditional probability distributions are used as numerical inputs. One of the common examples of the hybrid Bayesian network is the conditional linear Gaussian (CLG) model.
32. How can inductive methods be combined with the power of first-order representations?
Inductive methods can be combined with first-order representations with the help of inductive logic programming.
33. What needs to be satisfied in inductive logic programming?
Inductive logic programming is one of the areas of symbolic artificial intelligence. It makes use of logic programming that is used to represent background knowledge, hypotheses and examples. To satisfy the entailment constraint, the inductive logic programming must prepare a set of sentences for the hypothesis.
34. What is a heuristic function?
Also simply known as heuristic, a heuristic function is a function that helps rank alternatives in search algorithms. This is done at each branching step which is based on the existing information that decides the branch that must be followed. It involves the ranking of alternatives at each step which is based on the information that helps decide which branch must be followed.
35. What are scripts and frames in artificial intelligence?
Scripts are used in natural language systems that help organize a knowledge repository of the situations. It can also be considered a structure through which a set of circumstances can be expected to follow one after the other. It is very similar to a chain of situations or a thought sequence. Frames are a type of semantic networks and are one of the recognized ways of showcasing non-procedural information.
36. How can a logical inference algorithm be solved in Propositional Logic?
Logical inference algorithms can be solved in propositional logic with the help of validity, logical equivalence and satisfying ability.
37. What are the signals used in Speech Recognition?
Speech is regarded as the leading method for communication between human beings and dependable speech recognition between machines. An acoustic signal is used in speech recognition to identify a sequence of words that is uttered by the speaker. Speech recognition develops technologies and methodologies that help the recognition and translation of the human language into text with the help of computers.
38. Which model gives the probability of words in speech recognition?
In speech recognition, the Diagram model gives the probability of each word that will be followed by other words.
39. Which search agent in artificial intelligence operates by interleaving computation and action?
The online search would involve taking the action first and then observing the environment.
40. What are some good programming languages in artificial intelligence?
Prolog, Lisp, C/C++, Java and Python are some of the most common programming languages in artificial intelligence. These languages are highly capable of meeting the various requirements that arise in the designing and development of different software.
41. How can temporal probabilistic reasoning be solved with the help of algorithms?
The Hidden Markov Model can be used for solving temporal probabilistic reasoning. This model observes the sequence of emission and after a careful analysis, it recovers the state of sequence from the data that was observed.
42. What is the Hidden Markov Model used for?
It is a tool that is used for modelling sequence behavior or time-series data in speech recognition systems. A statistical model, the hidden Markov model (HMM) describes the development of events that are dependent on internal factors. Most of the time, these internal factors cannot be directly observed. The hidden states lead to the creation of a Markov chain. The underlying state determines the probability allocation of the observed symbol.
43. What are the possible values of the variables in HMM?
The possible values of the variable in HMM are the “Possible States of the World”.
44. Where is the additional variable added in HMM?
The additional state variables are usually added to a temporal model in HMM.
45 . How many literals are available in top-down inductive learning methods?
Equality and inequality, predicates and arithmetic literals are the three literals available in top-down inductive learning methods.
46. What does compositional semantics mean?
Compositional semantics is a process that determines the meaning of P*Q from P,Q and*. Also simply known as CS, the compositional semantics is also known as the functional dependence of the connotation of an expression or the parts of that expression. Many people might have the question if a set of NL expressions can have any compositional semantics.
47. How can an algorithm be planned through a straightforward approach?
The most straightforward approach is using state-space search as it considers everything that is required to find a solution. The state-space search can be solved in two ways. These include backward from the goal and forward from the initial state.
48. What is Tree Topology?
Tree topology has many connected elements that are arranged in the form of branches of a tree. There is a minimum of three specific levels in the hierarchy. Since any two given nodes can have only one mutual connection, the tree topologies can create a natural hierarchy between parent and child.
If you wish to learn an Artificial Intelligence Course, Great Learning is offering several advanced courses in the subject. An artificial intelligence Certification will provide candidates the AI skills that are required to grab a well-paying job as an AI engineer in the business world. There are several AI Courses that are designed to give candidates extensive hands-on learning experience. Great Learning is offering Machine Learning and Artificial Intelligence courses at great prices. Contact us today for more details. The future of AI is very bright, so get enrolled today to make a dream AI career.
0 notes
Text
On-line Information Science Programs
Data Science project administration methodology, CRISP-DM will be explained on this module in finer detail. Learn about Data Collection, Data Cleansing, Data Preparation, Data Munging, Data Wrapping, and so forth. Learn in regards to the preliminary steps taken to churn the info, known as exploratory information analysis. In this module, you are also introduced to statistical calculations that are used to derive info from information.
You will implement algorithms corresponding to Principal Component Analysis and Naive Bayes after information evaluation to foretell the approval fee of a loan utilizing numerous parameters. This is an inventory administration project where you can see the tendencies within the knowledge that will help the corporate to extend sales.
I had taken the Data Science master’s program, which is a combo of SAS, R programming language, and Apache Mahout. Since there are such a lot of technologies involved in programs, getting our query resolved on the right time turns into an important aspect. But with Intellipaat, there was no such downside as all my queries were resolved in lower than 24 hours. I signed up for Intellipaat's Data science course on-line certification when I realized that it is an excellent spot for learning new applied sciences. The trainer of this course was actually good and helped me be taught the subject well. Besides, the net support group helped me to resolve any technical concern I had. I need to discuss in regards to the wealthy LMS that Intellipaat’s Data Science packages provided.
Intellipaat actively provides placement help to all learners who've successfully accomplished the training. For this, we are exclusively tied-up with over eighty top MNCs from around the globe.
Learn introductory programming and information analysis in MATLAB, with functions to biology and medicine. These certificates could be very well recognized in Intellipaat-affiliated organizations, together with over eighty top MNCs from all over the world and a few of the Fortune 500companies. At Intellipaat, you possibly can enroll in either the trainer-led on-line training or self-paced coaching.
The Boosting algorithms AdaBoost and Extreme Gradient Boosting are discussed as a part of this continuation module You will also learn about stacking methods. Learn about these algorithms which are providing unprecedented accuracy and helping many aspiring knowledge scientists win the primary place in various competitions similar to Kaggle, CrowdAnalytix, and so on. You have learnt about predicting a steady dependent variable. As a part of this module, you'll continue to learn Regression strategies utilized to predict attribute Data.

There are totally different slots out there on weekends or weekdays based on your decisions. We are also available over the decision or mail or direct interplay with the trainer for active learning.
In this tutorial you will study joint likelihood and its functions. Learn the way to predict whether or not an incoming e-mail is spam or ham e mail. Learn about Bayesian chance and the functions in solving advanced business problems.
It was an excellent session and got a fundamental thought of how AI is being used in analytics these days. After the end of the session, I was glad to join the Data Science program.
Data Science helps in combining the disruption into classes and communicating their potential, which permits information and analytics leaders to drive better outcomes. Top companies thought there's a necessity to investigate the info for important benefits. The trainers of the Data Science course are the trade's main specialists who've 15+ years of experience.
Universities have been slow at creating specialized information science programs. It is difficult to accumulate the talents necessary to be employed as an information scientist.
They hail from multinational firms like Microsoft, Google, L&T, Cognizant, and so forth. The trainers listed below are the spine of the Data Science coaching wing. This has caused an enormous demand and supply hole, where they hunt for knowledge scientists is relentless, and the provision for which is the naked minimum. Develop abilities in digital research and visualization techniques across topics and fields within the humanities. Click the “Buy Now” button and become part of our knowledge scientist program at present. Moreover, our focus is to show subjects that circulate smoothly and complement one another. The course teaches you everything you should know to become an information scientist at a fraction of the cost of conventional applications .
Apart from this, Intellipaat additionally provides corporate training for organizations to upskill their workforce. All trainers at Intellipaat have 12+ years of relevant trade experience, and they have been actively working as consultants in the same area, which has made them material specialists. Go by way of the sample movies to check the quality of our trainers.
Kaplan Meier methodology and life tables are used to estimate the time before the occasion occurs. Survival analysis is about analyzing this period or time earlier than the occasion. Real-time purposes of survival evaluation in buyer churn, medical sciences and other sectors is mentioned as a part of this module. Learn how survival analysis techniques can be used to understand the impact of the options on the occasion using Kaplan Meier survival plot. Revise Bayes theorem to develop a classification approach for Machine studying.
youtube
The assist group has all the time been supportive and efficient to help us. The collaboration of sensible with theoretical information makes intellipaat highly appropriate for many who want to improve their profession. Use knowledge exploration to be able to understand what needs to be carried out to make reductions in customer churn. In this project, you'll be required to extract particular person columns, use loops to work on repetitive operations, and create and implement filters for data manipulation. In this project, you should work with a number of operators concerned in R programming together with relational operators, arithmetic operators, and logical operators for numerous organizational wants. In this project, you will use the banking dataset for data analysis, knowledge cleansing, information preprocessing, and data visualization.
We will begin to know tips on how to carry out a descriptive analysis. Join 360DigiTMG for the most effective Data Science Course in Hyderabad and turn out to be a professional Data Scientist with hands-on experience on real time initiatives in just four months.360digitmg offers the most effective Data Science certification online training in Hyderabad together with classroom and self-paced e-studying certification programs. The complete Data Science course particulars could be found in our course agenda on this web page. I even have attended a webinar given by IBM’s Senior Expert Mr G Ananthapadmanabhan (Practice chief – Analytics) on Emerging developments in Analytics and Artificial Intelligence.
You shall be using a V7 predictor, V4 predictor for evaluation, and information visualization for locating the probability of prevalence of fraudulent actions. The best online coaching heart, with a lot of hands-on tasks. One of the critical things about Simplilearn is the self-learning content which gives you the basic idea in regards to the matters. Moreover, we are able to watch movies whenever we want, since we are supplied with lifetime access to the self-studying videos. The Indian government has initiated several information science tasks in the fields of Agriculture, Electricity, Water, Healthcare, Education, Road Traffic Safety and Air Pollution. The Government of India has initiated several data science analysis initiatives as nicely.
Understand the activation function and integration features used in developing a neural community. Learn to analyse the unstructured textual information to derive significant insights. Understand the language quirks to carry out information cleansing, extract features utilizing a bag of phrases and assemble the key-value pair matrix referred to as DTM. Learn to know the sentiment of consumers from their suggestions to take appropriate actions. Advanced ideas of textual content mining will also be mentioned which help to interpret the context of the uncooked text information.
After you've completed the classroom classes, you'll receive assignments via the net Learning Management System you could entry at your comfort. You might want to fill the assignments in order to get hold of your information scientist certificate. We are proud to announce that we now have acquired the TUV SUD score of high quality for our information science course. On submission of all assignments, you will obtain a Course Completion Certificate. A sample of the information science certificate is out there on our website on your reference. In this continuation module of forecasting study information-driven forecasting techniques. Learn about ARMA and ARIMA fashions which combine model-based mostly and knowledge-pushed techniques.This method, you could be positioned in excellent organizations corresponding to Sony, Ericsson, TCS, Mu Sigma, Standard Chartered, Cognizant, and Cisco, amongst other equally great enterprises. We additionally allow you to with the job interview and résumé preparation as nicely. It was an exquisite experience studying Data Science from Intellipaat. According to me, for learning chopping-edge technologies, Intellipaat is the best place.To determine the properties of a continuous random variable, statisticians have outlined a variable as a normal, studying the properties of the standard variable and its distribution. You will learn to examine if a continuous random variable is following normal distribution utilizing a normal Q-Q plot. Learn the science behind the estimation of value for inhabitants utilizing pattern knowledge. Data Visualization helps perceive the patterns or anomalies in the knowledge simply and learn about varied graphical representations on this module. Understand the terms univariate and bivariate and the plots used to analyze in 2D dimensions. Understand tips on how to derive conclusions on business problems utilizing calculations carried out on pattern knowledge.Understand the concept of multi logit equations, baseline and making classifications using probability outcomes. Learn about handling a number of classes in output variables including nominal as well as ordinal knowledge. Learn about overfitting and underfitting circumstances for prediction models developed. We must strike the right steadiness between overfitting and underfitting, learn about regularization strategies L1 norm and L2 norm used to scale back these abnormal conditions. The regression techniques Lasso and Ridge methods are mentioned in this module . In the continuation to Regression analysis study you'll learn how to take care of a number of unbiased variables affecting the dependent variable. Learn about the conditions and assumptions to carry out linear regression evaluation and the workarounds used to observe the situations.The mentorship by way of trade veterans and student mentors makes this system extremely participating. We present Online IBM Certified Data Science training for the individuals who are occupied with work and the one who believes in a single-one studying. We teach as per the Indian Standard Timings, feasible to you, offering in-depth knowledge of Data Science. We can be found around the clock on WhatsApp, emails, or requires clarifying doubts and instance assistance, also giving lifetime access to self-paced learning. We present Classroom coaching on IBM Certified Data Science at Hyderabad for the people who consider hand-held coaching. We teach as per the Indian Standard Time with In-depth sensible Knowledge on each matter in classroom training, 80 – 90 Hrs of Real-time practical coaching courses.Data Scientist main time spent in data exploration and knowledge wrangling. Evidently, Data Scientists use a large number of Data Science tools/applied sciences, such as R and Python programming language, and analysis instruments, like SAS. All of our extremely certified Data Science trainers are business specialists with years of relevant trade expertise. Each of them has gone through a rigorous selection course that features profile screening, technical analysis, and a coaching demo earlier than they're certified to train for us. We additionally are sure that solely those trainers with an excessive alumni rating remain in our school. I strongly counsel Simplilearn because of the depth of information the trainers have.Implement exploratory information analysis, information manipulation, and visualization to know and find the tendencies within the Netflix dataset. You will use numerous Machine Learning algorithms such as affiliation rule mining, classification algorithms, and plenty of extra to create movie suggestion techniques for viewers utilizing Netflix dataset. The project consists of data analysis for varied parameters of banking dataset.In this project, you'll be implementing association rule mining, knowledge extraction, and knowledge manipulation for the Market Basket Analysis. They want to gather sufficient knowledge to know the issue in hand and to better clear up it in terms of time, cash, and resources. As a budding Data Scientist, you should be acquainted with knowledge evaluation, statistical software program packages, information visualization and handling giant data units.The high sectors creating essentially the most data science jobs are BFSI, Energy, Pharmaceutical, Healthcare, E-commerce, Media, and Retail. The most demand for Data Scientists is in the Metros cities like Delhi-NCR and Mumbai. It’s demand can also be catching up in rising cities like Hyderabad and Bangalore. We provide a finish to finish information science course with placement assistance after the internship is over. We additionally float your resume to a number of reliable placement consultants with whom we have a long association.360DigiTMG has a pay once repeat on many occasions provided on this course. You pay once for the course and might repeat it many times in the future free of charge. This helps you adapt to technological modifications and software updates in the midst of your career. In this blended program, you may be attending 184 hours of classroom classes of four months. After completion, you will have access to the web Learning Management System for another three months for recorded videos and assignments. The total length of assignments to be completed on-line is one hundred fifty hours. Besides this, you will be engaged on stay tasks for a month.You will study the ideas to take care of the variations that come up while analyzing completely different samples for similar inhabitants using the central restrict theorem. Learn about numerous statistical calculations used to seize enterprise moments for enabling choice makers to make knowledge driven choices. You will be taught concerning the distribution of the information and its shape using these calculations. Understand to intercept data by representing knowledge by visuals. Also find out about Univariate analysis, Bivariate evaluation and Multivariate evaluation.After profitable submission of the project, you may be awarded a capstone certificate that may be showcased to potential employers as a testimony to your learning. Capstone and 15+ actual life projectsBuilt on datasets of Amazon, UBER, Comcast. The course in Hyderabad is designed to swimsuit the wants of scholars in addition to working professionals. We at 360DigiTMG give our students the option of each classroom and on-line studying.Learn in regards to the principles of the logistic regression model, understand the sigmoid curve, the utilization of cutoff value to interpret the probable outcome of the logistic regression mannequin. Learn about the confusion matrix and its parameters to gauge the end result of the prediction model. Data Mining supervised studying is all about making predictions for an unknown dependent variable utilizing mathematical equations explaining the connection with unbiased variables.Topic fashions utilizing LDA algorithm, emotion mining using lexicons are mentioned as a part of NLP module. k Nearest Neighbor algorithm is distance based mostly machine studying algorithm. Learn to categorise the dependent variable utilizing the appropriate k value. The k-NN classifier also known as lazy learner is a very popular algorithm and one of the best for software. Extension to logistic regression We have a multinomial regression method used to predict a multiple categorical end result.Learn about the components of Linear Regression with the equation of the regression line. Get launched to Linear Regression analysis with a use case for prediction of a continuous dependent variable. In this tutorial you will be taught in detail about continuous likelihood distribution. Understand the properties of a continuous random variable and its distribution beneath regular conditions.
The certification helped me get promoted to Data Analyst from Quality Analyst together with a 50% hike in my salary. I never have this sort of expertise in my entire lifetime of studying. Simplilearn has been instrumental in developing my understanding about coding and getting the logic proper. Of course, they allow you to understand the mathematical concepts and logic, too, which makes learning higher and more thorough. Plus, the content on the platform covers the topic intimately – general, a superb studying expertise with Simplilearn. The information and Data Science expertise you have gained working on tasks, simulations, case research will set you ahead of the competitors.
Understand the smoothing strategies and variations of these techniques. Get introduced to the concept of de-trending and deseasonalize the info to make it stationary. You will learn about seasonal index calculations that are used for reseasonalize the result obtained by smoothing fashions. Neural Network is a black field method used for deep learning fashions. Learn the logic of coaching and weights calculations utilizing numerous parameters and their tuning.
The extensive set of PPTs, PDFs, and other related materials had been of the very best high quality, and due to this, my learning with Intellipaat was glorious. I may clear the Cloudera Data Scientist certification examination within the first try.
Explore more on Data Science Training in Hyderabad
360DigiTMG - Data Analytics, Data Science Course Training Hyderabad
Address:-2-56/2/19, 3rd floor,, Vijaya towers, near Meridian school,, Ayyappa Society Rd, Madhapur,, Hyderabad, Telangana 500081
Hours: Sunday - Saturday 7AM - 11PM
Contact us ( 099899 94319 )
0 notes
Text
How do I get started in data science?
Do the following to get started with Data Science
1. Programming
Languages: Python is usually the language people use while working on projects in data science because it's versatile and has huge libraries. You need to know how to manipulate variables, basic data structures, control flow, functions, object types, and object-oriented programming in Python.
Libraries: You should know the basics of NumPy, Pandas, Matplotlib, and Seaborn for manipulation, analysis, and visualization.
2. Statistics
Statistics: The important concepts of statistics include probability distributions, hypothesis testing, and regression analysis.
Data Analysis: Learn to apply the statistical techniques for data analysis and interpretation.
3. Machine Learning
Algorithms: The algorithms on machine learning include supervised, unsupervised, and deep learning. Supervised learning: linear regression, decision trees, random forest. Unsupervised learning: clustering, dimensionality reduction. Deep learning, mainly neural networks.
Implementation: Learn to implement these algorithms with the Scikit-learn and TensorFlow packages in Python.
4. Databases
SQL: Study SQL to be able to manipulate relational databases and extract data you need to analyze.
NoSQL: Observe NoSQL databases like MongoDB or Cassandra for dealing with unstructured data.
5. Cloud Computing
Platforms: Be familiar with some of the cloud platforms, e.g. AWS, GCP, Azure, normally required to scale and handle data science projects.
6. Domain Knowledge
Area of Specialization: Bring out your expertise in a specific area such as health, finance, marketing, etc., to relate real-world problems.
Projects: Apply practical experience and build a portfolio from personal or open source data science projects.
Online Courses: More on this can be learned through online courses, tutorials by Coursera, edX, and Lejhro which you can work through at your own pace.
Communities: Online forums, groups of other data scientists (Kaggle, Stack Overflow) for help.
Certifications: You can also get your skills certified with a Data Science Certified Professional, DSCP, or Certified Analytics Professional, CAP.
Keep in mind that data science is one field that will continuously undergo evolution. Keep pace with recent trends and technologies so that you will be able to stay competitive.
0 notes
Text
The Statistics Assignment help
The Statistics Assignment help provide assistance with every topic in the field of Statistics whether its probability theory, distribution functions, random variables, hypothesis testing, ANOVA, Regression, tests or statistical analysis help in various statistics softwares like EXCEL, MINITAB, MATLAB, SPSS, STATA, SAS, R, GRETL, E-VIEWS etc. Based in Texas, USA; we provide statistics assignment help, statistics homework help, statistics essay and research paper writing help and statistics dissertation help.
Just visit us at https://www.thestatisticsassignmenthelp.com
The statistics is an extended branch of mathematics which is involved in analyzing, collecting, interpretation, and presentation of data which is further involved in an act of organizing the data.
The usages of statistics are widely enlarged to solve various scientific, mathematical, industrial and socio problems. The statistical model plays a role which is further indulged to solve such problems. It is wise to seek an expert for statistics assignment help and get in-depth analysis of statistics and deep understanding accordingly.
The Statistics Assignment Help offers professional statistics writing service to the time to write multiple pages can be strenuous. We specialize in any kind of statistics homework help . Our professional homework centre is 24/7 available to solve all your academic problems concerning writing homework papers: The Statistics Assignment help provides assistance with every topic in the field of Statistics whether its probability theory, distribution functions, random variables, hypothesis testing, ANOVA, Regression, tests or statistical analysis help in various statistics softwares like EXCEL, MINITAB, MATLAB, SPSS, STATA, SAS, R-Programming, GRETL, E-VIEWS etc. Based in Texas, USA; we provide statistics assignment help, statistics homework help, statistics project help , research paper writing help and statistics dissertation help.
#TheStatisticsassignmenthelp#Excelassignmenthelp#RProgrammingassignmenthelp#STATAassignmenthelp#SPSSassignmenthelp#EViewsassignmenthelp#Minitabassignmenthelp#ANOVAassignmenthelp#Statisticsassignmenthelponline
0 notes
Quote
Data scientist course
Data scientist course
Many kids are aspiring to come across a career transition into these roles. Let us look into a couple of of the main job positions of the Data Science area. Big knowledge refers to massive amounts of information from numerous sources from totally different formats. Big information revolves across the data that cannot be dealt with by the traditional data analysis method. It is related to many business sectors like IT services, healthcare and e-commerce industries, banking and finance sectors, consultancy services, transport sectors, manufacturing models, etc. Data collection is considered as another major responsibility of a data scientist.
Data science consists of, along with ML, statistics, advanced knowledge analysis, knowledge visualization, information engineering, and so on. This is our superior Big Data coaching, the place students will gain sensible skill set not solely on Hadoop in detail, but additionally learn advanced analytics ideas by way of Python, Hadoop and Spark. For in depth hands-on practice, college students will get a quantity of assignments and initiatives. At end of this system candidates are awarded Certified Big Data Science Certification on profitable completion of tasks that are supplied as a part of the training.
To establish the properties of a steady random variable, statisticians have outlined a variable as a standard, studying the properties of the standard variable and its distribution. You will be taught to check if a steady random variable is following regular distribution utilizing a standard Q-Q plot. Learn the science behind the estimation of value for a population using pattern knowledge. Whether it is a fresher or someone with work expertise, everyone is making an attempt to get a share of this dawn sector. Majority scholars and professionals no matter their backgrounds are upskilling themselves to be taught the this course. The frenzy created out there has made us consider that anybody can turn out to be a Master of Data Science. One of the just lately launched Data Science course in India by Henry Harvin has been aptly named — Certified Data Scientist.
Data scientist course
From analysing tyre efficiency to detecting problem gamblers, wherever information exists, there are opportunities to use it. Alongside these classes you will also research independently finishing coursework for each module. You will be taught through a sequence of lectures, tutorials and many sensible classes serving to you to increase your specialist data and autonomy. This module aims to introduce you to the basic idea of computing-on-demand resulting in Cloud computing. Emphasis is given to the different technologies to build Clouds and how these are used to supply computing on-demand. Full time college students might take an internship route, in which they are given an extra three months for an internship-based Project.
The course is aimed to develop practical enterprise analytics abilities within the learners. As this is an advanced-level knowledge analytics course, data analytics experience is obligatory to get started with the identical. The course would provide you with a deep understanding of superior excel formulation and functions to remodel Excel from a fundamental spreadsheet program into a strong analytics software. The course would additionally implement practical implementation by exercising contextual examples designed to showcase the formulation and how they are often applied in numerous ways. By the tip of the course, you may be trained to construct dynamic tools and excel dashboards to filter, show, and analyze knowledge. You may even be eligible to automate tedious and time-consuming tasks utilizing cell formulation & capabilities in excel. The course provided by Coursera educates learners concerning the numerous knowledge analytics practices involved with enterprise administration and growth.
An introduction to likelihood, emphasizing the combined use of arithmetic and programming to unravel issues. Use of numerical computation, graphics, simulation, and computer algebra. to statistical ideas including averages and distributions, predicting one variable from one other, association and causality, likelihood and probabilistic simulation. In some cases, students might complete different programs to fulfill the above stipulations. See the lower-division requirements web page on the Data Science program website for more details. No, PAT does not promise a job, but it helps the aspirants to build the required potential needed in landing a career. The aspirants can capitalize on the acquired expertise, in the lengthy run, to a profitable profession in Data Science.
If you've any questions or issues, please contact and/or report your expertise via the edX contact type. HarvardX requires people who enroll in its programs on edX to abide by the terms of the edX honor code. No refunds shall be issued within the case of corrective action for such violations. Enrollees who're taking HarvardX programs as a part of another program may even be governed by the educational policies of those programs.
Data scientists primarily cope with huge chunks of data to analyse the patterns, tendencies and extra. These evaluation purposes formulate stories which are finally helpful in drawing inferences. Interestingly, there’s also a related subject which makes use of both information science, data analytics and enterprise intelligence applications- Business Analyst. A enterprise analyst profile combines slightly little bit of each to assist corporations take information driven decisions. The mission of the Ph.D. in hospitality enterprise analytics program is to offer advanced training to students in data science because it relates to the hospitality business. The aim is to arrange college students for highly demanding educational and analysis careers in top‐ranked establishments. Our faculty conduct in-depth analysis in various areas of research that apply to hospitality enterprise analytics, such as revenue management, digital marketing, finance, buyer experience administration and human sources administration.
These embody both free assets and paid information science certificate packages which are delivered online, are widely recognised and have benefited hundreds of students and professionals. With being increasingly utilized in a number of industries, information science is quickly turning into one of the fastest-growing fields. The learning platform edX has compiled a series of over 200 courses created by prime academic and industrial establishments to assist your studying. Pick a programming language that you are snug with and get began with analyzing huge chunks of datasets. You can reach us at: ExcelR- Data Science, Data Analytics, Business Analytics Course Training Bangalore Address:49, 1st Cross, 27th Main, Behind Tata Motors, 1st Stage, BTM Layout, Bengaluru, Karnataka 560068 Phone: 096321 56744 Directions: Data scientist course Email:[email protected]
0 notes