#Random forest
Text
Loving reminder from your land history auntie:
North American golf courses have had 50-100 years of arsenic and mercury based fungicide and herbicides applied to their soils.
Do not eat anything that has been grown on a golf course or downstream from a golf course. I know it sounds cool and radical, but you are too valuable to poison yourself with heavy metals.
Protect each other, turn your local golf course into a pollinator garden, not a sex forest or community garden.
#i am over here worrying about all you kiddos#also please dont forage on railway corridors either#love yourselves protect yourselves#lmao at the replies saying 'but why not sex forest anyway'#you do you kids#im personally a no thank you on the lead arsenic mercury sex forest personally#if you havent seen it there's a popular book about making golf course a sex forest#that isn't a random pull
58K notes
·
View notes
Text
0 notes
Link
#Residential property price forecasting model#Supervised learning#Random Forest#Resilient planning#Disaster mitigation
1 note
·
View note
Text
Running a Random Forest
Task
The second assignment deals with Random Forests. Random forests are predictive models that allow for a data driven exploration of many explanatory variables in predicting a response or target variable. Random forests provide importance scores for each explanatory variable and also allow you to evaluate any increases in correct classification with the growing of smaller and larger number of trees.
Run a Random Forest.
You will need to perform a random forest analysis to evaluate the importance of a series of explanatory variables in predicting a binary, categorical response variable.
Data
The dataset is related to red variants of the Portuguese "Vinho Verde" wine. Due to privacy and logistic issues, only physicochemical (inputs) and sensory (the output) variables are available (e.g. there is no data about grape types, wine brand, wine selling price, etc.).
The classes are ordered and not balanced (e.g. there are munch more normal wines than excellent or poor ones). Outlier detection algorithms could be used to detect the few excellent or poor wines. Also, we are not sure if all input variables are relevant. So it could be interesting to test feature selection methods.
Dataset can be found at UCI Machine Learning Repository
Attribute Information (For more information, read [Cortez et al., 2009]): Input variables (based on physicochemical tests):
1 - fixed acidity
2 - volatile acidity
3 - citric acid
4 - residual sugar
5 - chlorides
6 - free sulfur dioxide
7 - total sulfur dioxide
8 - density
9 - pH
10 - sulphates
11 - alcohol
Output variable (based on sensory data):
12 - quality (score between 0 and 10)
Results
Random forest and ExtraTrees classifier were deployed to evaluate the importance of a series of explanatory variables in predicting a categorical response variable - red wine quality (score between 0 and 10). The following explanatory variables were included: fixed acidity, volatile acidity, citric acid, residual sugar, chlorides, free sulfur dioxide, total sulfur dioxide, density, pH, sulphates and alcohol.
The explanatory variables with the highest importance score (evaluated by both classifiers) are alcohol, volatile acidity, sulphates. The accuracy of the Random forest and ExtraTrees clasifier is about 67%, which is quite good for highly unbalanced and hardly distinguished from each other classes. The subsequent growing of multiple trees rather than a single tree, adding a lot to the overall score of the model. For Random forest the number of estimators is 20, while for ExtraTrees classifier - 12, because the second classifier grows up much faster.
Code:
import pandas as pd
import numpy as np
import matplotlib.pylab as plt
from sklearn.model_selection import train_test_split, cross_val_score
from sklearn.ensemble import RandomForestClassifier, ExtraTreesClassifier
from sklearn.manifold import MDS
from sklearn.metrics.pairwise import pairwise_distances
from sklearn.metrics import accuracy_score
import seaborn as sns
%matplotlib inline
rnd_state = 4536
data = pd.read_csv('Data\wine_red.csv', sep=';')
data.info()
Output:

data.head()
Output:

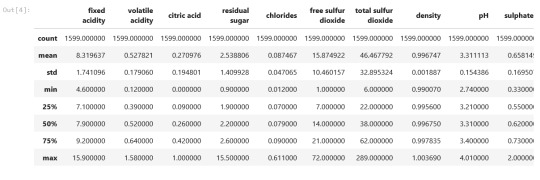
data.describe()
Output:
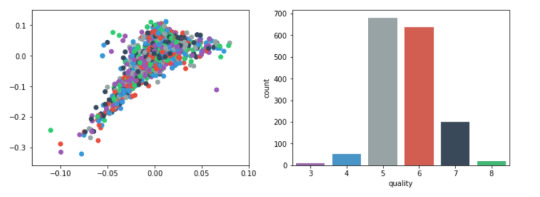
Plots
For visualization purposes, the number of dimensions was reduced to two by applying MDS method with cosine distance. The plot illustrates that our classes are not clearly divided into parts.
model = MDS(random_state=rnd_state, n_components=2, dissimilarity='precomputed')
%time representation = model.fit_transform(pairwise_distances(data.iloc[:, :11], metric='cosine'))
Wall time: 38.7 s
colors = ["#9b59b6", "#3498db", "#95a5a6", "#e74c3c", "#34495e", "#2ecc71"]
plt.figure(figsize=(12, 4))
plt.subplot(121) plt.scatter(representation[:, 0], representation[:, 1], c=colors)
plt.subplot(122) sns.countplot(x='quality', data=data, palette=sns.color_palette(colors));
Output:
predictors = data.iloc[:, :11]
target = data.quality
(predictors_train, predictors_test, target_train, target_test) = train_test_split(predictors, target, test_size = .3, random_state = rnd_state)
RandomForest classifier:
list_estimators = list(range(1, 50, 5)) rf_scoring = [] for n_estimators in list_estimators: classifier = RandomForestClassifier(random_state = rnd_state, n_jobs = -1, class_weight='balanced', n_estimators=n_estimators) score = cross_val_score(classifier, predictors_train, target_train, cv=5, n_jobs=-1, scoring = 'accuracy') rf_scoring.append(score.mean())
plt.plot(list_estimators, rf_scoring)
plt.title('Accuracy VS trees number');
Output:

classifier = RandomForestClassifier(random_state = rnd_state, n_jobs = -1, class_weight='balanced', n_estimators=20) classifier.fit(predictors_train, target_train)
Output:
RandomForestClassifier(bootstrap=True, class_weight='balanced', criterion='gini', max_depth=None, max_features='auto', max_leaf_nodes=None, min_impurity_decrease=0.0, min_impurity_split=None, min_samples_leaf=1, min_samples_split=2, min_weight_fraction_leaf=0.0, n_estimators=20, n_jobs=-1, oob_score=False, random_state=4536, verbose=0, warm_start=False)
prediction = classifier.predict(predictors_test)
print('Confusion matrix:\n', pd.crosstab(target_test, prediction, colnames=['Predicted'], rownames=['Actual'], margins=True)) print('\nAccuracy: ', accuracy_score(target_test, prediction))

feature_importance = pd.Series(classifier.feature_importances_, index=data.columns.values[:11]).sort_values(ascending=False) feature_importance
Output:

et_scoring = [] for n_estimators in list_estimators: classifier = ExtraTreesClassifier(random_state = rnd_state, n_jobs = -1, class_weight='balanced', n_estimators=n_estimators) score = cross_val_score(classifier, predictors_train, target_train, cv=5, n_jobs=-1, scoring = 'accuracy') et_scoring.append(score.mean())
plt.plot(list_estimators, et_scoring) plt.title('Accuracy VS trees number');
Output:

classifier = ExtraTreesClassifier(random_state = rnd_state, n_jobs = -1, class_weight='balanced', n_estimators=12) classifier.fit(predictors_train, target_train)
ExtraTreesClassifier(bootstrap=False, class_weight='balanced', criterion='gini', max_depth=None, max_features='auto', max_leaf_nodes=None, min_impurity_decrease=0.0, min_impurity_split=None, min_samples_leaf=1, min_samples_split=2, min_weight_fraction_leaf=0.0, n_estimators=12, n_jobs=-1, oob_score=False, random_state=4536, verbose=0, warm_start=False)
prediction = classifier.predict(predictors_test)
print('Confusion matrix:\n', pd.crosstab(target_test, prediction, colnames=['Predicted'], rownames=['Actual'], margins=True)) print('\nAccuracy: ', accuracy_score(target_test, prediction))
Output:

feature_importance = pd.Series(classifier.feature_importances_, index=data.columns.values[:11]).sort_values(ascending=False) feature_importance
Output:

Thanks For Reading!

0 notes
Text









#moodboard#aesthetic#icons#indie#pinterest#naturecore#art photography#photography#random#random moodboard#random icons#mother nature#nature#forest aesthetic#forest cottage#forest#whimsicore#whimsigoth#whimsical#folk magic#witchy#witch#witches#witchcraft#witchblr#witchcore
8K notes
·
View notes
Text
Understanding Machine Learning Models for Stock Price Forecasting with Python
In this comprehensive article, we, as proficient SEO experts and adept copywriters, will explore the fascinating realm of machine learning models designed to forecast stock prices using Python. Our objective is to provide valuable insights and detailed knowledge that will outperform competing websites on Google, establishing this article as the go-to resource for understanding this intricate…

View On WordPress
#Forecasting#Linear Regression#LSTM#Machine Learning#Models#Python#Random Forest#Stock Price Forecasting using Python
1 note
·
View note
Text
1 note
·
View note
Text
Run a Random Forest
This assignment is intended for Coursera course "Machine Learning for Data Analysis by Wesleyan University”.
It is for "Week 2: Peer-graded Assignment: Running a Random Forest".
Code


Plots
For visualization purposes, the number of dimensions was reduced to two by applying MDS method with cosine distance. The plot illustrates that our classes are not clearly divided into parts.

Moreover, our classes are highly unbalanced, so in our classifier we should add parameter class_weight='balanced'.

RandomForest classifier




Results
Random forest and ExtraTrees classifier were deployed to evaluate the importance of a series of explanatory variables in predicting a categorical response variable - red wine quality (score between 0 and 10). The following explanatory variables were included: fixed acidity, volatile acidity, citric acid, residual sugar, chlorides, free sulfur dioxide, total sulfur dioxide, density, pH, sulphates and alcohol.
0 notes
Text
My random unsubstantiated hypothesis of the day: the popularity of "stim" videos, fidget toys, and other things like that is a warning sign that something's Deeply Wrong with our world.
Don't freak out. I am autistic. These things are not bad. However, can we just...take a second to notice how weird it is that there are entire social media accounts full of 10-second videos of things making crunching noises, people squishing slime in their hands, and objects clacking together, and that enjoying them is mainstream and normal?
It seems that nowadays, almost everyone exhibits sensory-seeking behavior, when just a decade ago, the idea of anyone having "sensory needs" was mostly obscure. It is a mainstream Thing to "crave" certain textures or repetitive sounds.
What's even weirder, is that it's not just that "stim" content is mainstream; the way everything on the internet is filmed seems to look more like "stim" content. TikToks frequently have a sensory-detail-oriented style that is highly unusual in older online content, honing in on the tactile, visual and auditory characteristics of whatever it's showing, whether that's an eye shadow palette or a cabin in a forest.
When an "influencer" markets their makeup brand, they film videos that almost...highlight that it's a physical substance that can be smudged and smeared around. Online models don't just wear clothes they're advertising, they run their hands over them and make the fabric swish and ripple.
I think this can be seen as a symptom of something wrong with the physical world we live in. I think that almost everyone is chronically understimulated.
Spending time alone in the forest has convinced me of this. The sensory world of a forest is not only much richer than any indoor environment, it is abundant with the sorts of sensations that people seem to "crave" chronically, and the more I've noticed and specifically focused on this, the more I've noticed that the "modern" human's surroundings are incredibly flat in what they offer to the senses.
First of all, forests are constantly permeated with a very soft wash of background noise that is now often absent in the indoor world. The sound of wind through trees has a physiological effect you can FEEL. It's always been a Thing that people are relaxed by white noise, which leads to us being put at ease by the ambient hum of air conditioning units, refrigerators and fans. But now, technology has become much more silent, and it's not at all out of place to hypothesize that environments without "ambient" white noise are detrimental to us.
Furthermore, a forest's ambience is full of rhythmic and melodic elements, whereas "indoor" sounds are often harsh, flat and irregular.
Secondly: the crunch. This is actually one of the most notably missing aspects of the indoor sensory world. Humans, when given access to crunchable things, will crunch them. And in a forest, crunchy things are everywhere. Bark, twigs and dry leaves have crisp and brittle qualities that only a few man-made objects have, and they are different with every type of plant and tree.
Most humans aren't in a lot of contact with things that are "destroyable" either, things you can toy with and tear to little bits in your hands. I think virtually everyone has restlessly torn up a scrap of paper or split a blade of grass with their thumbnail; it's a cliche. And since fidget toys in classrooms are becoming a subject of debate, I think it pays to remember that the vast majority of your ancestors learned everything they knew with a thousand "fidget toys" within arm's reach.
And there is of course mud, and clay, and dirt, and wet sand. I'm 100% serious, squishing mud and clay is vital to the human brain. Why do you think Play-Doh is such a staple elementary school toy. Why do you think mud is the universal cliche thing kids play in for fun. It's such a common "stim" category for a reason.
I could go on and on. It's insane how unstimulating most environments humans spend time in are. And this definitely contributes to ecological illiteracy, because people aren't prepared to comprehend how detailed the natural world is. There are dozens of species of fireflies in the United States, and thousands of species of moths. If you don't put herbicides on your lawn, there are likely at least 20 species of plant in a single square meter of it. I've counted at least 15 species of grass alone in my yard.
Would it be overreach to suggest that some vital perceptive abilities are just not fully developing in today's human? Like. I had to TEACH myself to be able, literally able, to perceive details of living things that were below a certain size, even though my eyes could detect those details, because I just wasn't accustomed to paying attention to things that small. I think something...happens when almost all the objects you interact with daily are human-made.
The people that think ADHD is caused by kids' brains being exposed to "too much stuff" by Electronic Devices...do not go outside, because spending a few minutes in a natural environment has more stimuli in it than a few hours of That Damn Phone.
A patch of tree bark the size of my phone's screen has more going on than my phone can display. When you start photographing lots of living organisms, you run into the strange and brain-shifting reality that your electronic device literally cannot create and store images big enough to show everything you, in real life, may notice about that organism.
38K notes
·
View notes
Text
#my polls#random polls#tumblr polls#poll time#poll game#polls#gaming poll#rpg horror#rpg maker#rpg maker horror#rpg maker game#ib game#ib kouri#the witch's house#mad father#yume nikki#misao#ao oni#off (game)#corpse party#angels of death#angels of slaughter#the crooked man#the forest of drizzling rain
1K notes
·
View notes
Text
Boosting Win Probability accuracy with player embeddings
Boosting Win Probability accuracy with player embeddings
In my previous post Computing Win Probability of T20 matches I had discussed various approaches on computing Win Probability of T20 matches. I had created ML models with glmnet and random forest using TidyModels. This was what I had achieved
glmnet : accuracy – 0.67 and sensitivity/specificity – 0.68/0.65
random forest : accuracy – 0.737 and roc_auc- 0.834
DL model with Keras in Python :…

View On WordPress
0 notes
Note
binghe fights sqh and he gives no indication at being powerful or with martial ability. he realises his mistake in approach. sqh makes himself small, pathetic, and easy to bully so that he is underestimated and ignored. fighting a PERSON will only increase that. well thats fine. mobei he's gonna toss ur human into a deathmatch against beasts rq ok? u wanna watch? if he gets too out of his depth you can step in he wont stop you but he knows you ALSO want to know what that little THANG is capeable of. nature doc mobei and binghe watching sqh in some demon forest. the wild qinghua, pressured out of its natural habitat. without greater predators to form symbiotic relationships with he must fend for himself. there comes the sunburst scorpion tailed bear goat- we shall soon see how the qinghua- OH HOLY SHIT HE RIPPED ITS HEAD OFF MOBEI YOUR SCRUNKLY RIPPED ITS GODDAMN HEAD OFF
THEYRE TAKING HIM OUT OF HIS NATURAL HABITAT AND SPYING ON HIM OH this is good


He didn't know he was capable of it either
#svsss#shang qinghua#luo binghe#mobei jun#moshang#scum villian self saving system#scum villains self saving system#I just KNOW Mobei was so smug about itt#his scrunkle / servant / consort / his GOD is so capable#the absolute strongest#POOR SHANG QINGHUA THO BECAUSE IMAGINE YOUR BOSS/CRUSH DROPS YOU OFF DEEP INTO A RANDOM FOREST AND LEAVES WITHOUT A WORD LIKE#my art#nibbelraz#nib text#ask
1K notes
·
View notes
Text

most important ship in the game
#alfira#lakrissa#bg3 fanart#alfira/lakrissa#alfira x lakrissa#POV any random tree in the forest after the tief party#squirrely girlies all wined up and wound up#sorry Alfira I forgot your bayalage#high maintenance girl x loves maintaining her girl
2K notes
·
View notes
Text
5 Types of Classification Algorithms in Machine Learning Explained
In this video, we'll take a look at five different types of classification algorithms in machine learning. We'll discuss the benefits and drawbacks of each algorithm, and how you can use them to improve your machine-learning skills.
Whether you're a machine learning beginner or a seasoned pro, this video is an excellent introduction to classification algorithms! By the end, you'll better understand how these algorithms work and how to use them to improve your machine-learning skills.
#classification in machine learning#classification in machine learning using python#classifier evaluation#logistic regression#random forest#knn#gradient descent#stochastic gradient descent#artificial neural network#support vector machine#naive bayes algorithm#classification report#classification algorithms#classification algorithms in machine learning#machine learning#how to implement classification in machine learning
0 notes
Text


Life and death in the forest.
#art#birds#deer#fantasy creatures#fantasy art#fantasy illustration#dragon bones#forest#fantasy forest#skeleton#two pics in a day!!! to make up for the random months' long disappearance
3K notes
·
View notes
Last Seen Blogs

aktionfsa-blog-blog
Aktion Freiheit statt Angst

usercatra
𝘀𝗮𝘃𝗶𝗼𝗿 𝗰𝗼𝗺𝗽𝗹𝗲𝘅.

scarlettsoldier
marvel

kuribel
Amo lo que me rodea pero odio la injusticia

sinbintimesten
NSFW