#Robots.txt Generator
Explore tagged Tumblr posts
Visit Tumblr Blog
Explore Tumblr blogs with no restrictions, modern design and the best experience.
Last Seen Tumblr Blogs





Fun Fact
In February 2021, Tumblr had 518.6 million blog accounts.
Text
#seo services#seo tools#learn seo#YouTube Tag Extractor#YouTube Tag Generator#YouTube Description Extractor#YouTube Video Statistics#YouTube Channel Statistics#Article Rewriter#Backlink Checker#Domain Age Checker#Domain Authority Checker#Page Authority Checker#Moz Rank Checker#Keyword Density Checker#Robots.txt Generator#Domain to IP#Meta Tag Generator#Meta Tags Analyzer#Credit Card Generator#Credit Card Validator#Keywords Suggestion Tool#tools#Adsense Calculator#WordPress Theme Detector
4 notes
·
View notes
Link
Robots.txt Generator
0 notes
Text

But as ever-larger, more concentrated corporations captured more of their regulators, we’ve essentially forgotten that there are domains of law other than copyright — that is, other than the kind of law that corporations use to enrich themselves.
Copyright has some uses in creative labor markets, but it’s no substitute for labor law. Likewise, copyright might be useful at the margins when it comes to protecting your biometric privacy, but it’s no substitute for privacy law.
When the AI companies say, “There’s no way to use copyright to fix AI’s facial recognition or labor abuses without causing a lot of collateral damage,” they’re not lying — but they’re also not being entirely truthful.
If they were being truthful, they’d say, “There’s no way to use copyright to fix AI’s facial recognition problems, that’s something we need a privacy law to fix.”
If they were being truthful, they’d say, “There’s no way to use copyright to fix AI’s labor abuse problems, that’s something we need labor laws to fix.
-How To Think About Scraping: In privacy and labor fights, copyright is a clumsy tool at best

Image: syvwlch (modified) https://commons.wikimedia.org/wiki/File:Print_Scraper_(5856642549).jpg
CC BY 2.0 https://creativecommons.org/licenses/by/2.0/deed.en
#scraping#privacy#labor#human rights#FARC#colombia#HRDAG#wayback machine#new york times#copyright#robots.txt#Mario Zechner#monopoly#price fixing#austria#clearview ai#biometrics#biometric privacy#plausible sentence generators#criti-hype#ai#llms#stochastic parrots#computational linguistics#chokepoint capitalism#llcs with mfas
107 notes
·
View notes
Text
"how do I keep my art from being scraped for AI from now on?"
if you post images online, there's no 100% guaranteed way to prevent this, and you can probably assume that there's no need to remove/edit existing content. you might contest this as a matter of data privacy and workers' rights, but you might also be looking for smaller, more immediate actions to take.
...so I made this list! I can't vouch for the effectiveness of all of these, but I wanted to compile as many options as possible so you can decide what's best for you.
Discouraging data scraping and "opting out"
robots.txt - This is a file placed in a website's home directory to "ask" web crawlers not to access certain parts of a site. If you have your own website, you can edit this yourself, or you can check which crawlers a site disallows by adding /robots.txt at the end of the URL. This article has instructions for blocking some bots that scrape data for AI.
HTML metadata - DeviantArt (i know) has proposed the "noai" and "noimageai" meta tags for opting images out of machine learning datasets, while Mojeek proposed "noml". To use all three, you'd put the following in your webpages' headers:
<meta name="robots" content="noai, noimageai, noml">
Have I Been Trained? - A tool by Spawning to search for images in the LAION-5B and LAION-400M datasets and opt your images and web domain out of future model training. Spawning claims that Stability AI and Hugging Face have agreed to respect these opt-outs. Try searching for usernames!
Kudurru - A tool by Spawning (currently a Wordpress plugin) in closed beta that purportedly blocks/redirects AI scrapers from your website. I don't know much about how this one works.
ai.txt - Similar to robots.txt. A new type of permissions file for AI training proposed by Spawning.
ArtShield Watermarker - Web-based tool to add Stable Diffusion's "invisible watermark" to images, which may cause an image to be recognized as AI-generated and excluded from data scraping and/or model training. Source available on GitHub. Doesn't seem to have updated/posted on social media since last year.
Image processing... things
these are popular now, but there seems to be some confusion regarding the goal of these tools; these aren't meant to "kill" AI art, and they won't affect existing models. they won't magically guarantee full protection, so you probably shouldn't loudly announce that you're using them to try to bait AI users into responding
Glaze - UChicago's tool to add "adversarial noise" to art to disrupt style mimicry. Devs recommend glazing pictures last. Runs on Windows and Mac (Nvidia GPU required)
WebGlaze - Free browser-based Glaze service for those who can't run Glaze locally. Request an invite by following their instructions.
Mist - Another adversarial noise tool, by Psyker Group. Runs on Windows and Linux (Nvidia GPU required) or on web with a Google Colab Notebook.
Nightshade - UChicago's tool to distort AI's recognition of features and "poison" datasets, with the goal of making it inconvenient to use images scraped without consent. The guide recommends that you do not disclose whether your art is nightshaded. Nightshade chooses a tag that's relevant to your image. You should use this word in the image's caption/alt text when you post the image online. This means the alt text will accurately describe what's in the image-- there is no reason to ever write false/mismatched alt text!!! Runs on Windows and Mac (Nvidia GPU required)
Sanative AI - Web-based "anti-AI watermark"-- maybe comparable to Glaze and Mist. I can't find much about this one except that they won a "Responsible AI Challenge" hosted by Mozilla last year.
Just Add A Regular Watermark - It doesn't take a lot of processing power to add a watermark, so why not? Try adding complexities like warping, changes in color/opacity, and blurring to make it more annoying for an AI (or human) to remove. You could even try testing your watermark against an AI watermark remover. (the privacy policy claims that they don't keep or otherwise use your images, but use your own judgment)
given that energy consumption was the focus of some AI art criticism, I'm not sure if the benefits of these GPU-intensive tools outweigh the cost, and I'd like to know more about that. in any case, I thought that people writing alt text/image descriptions more often would've been a neat side effect of Nightshade being used, so I hope to see more of that in the future, at least!
246 notes
·
View notes
Text
Are you a content creator or a blog author who generates unique, high-quality content for a living? Have you noticed that generative AI platforms like OpenAI or CCBot use your content to train their algorithms without your consent? Don’t worry! You can block these AI crawlers from accessing your website or blog by using the robots.txt file.
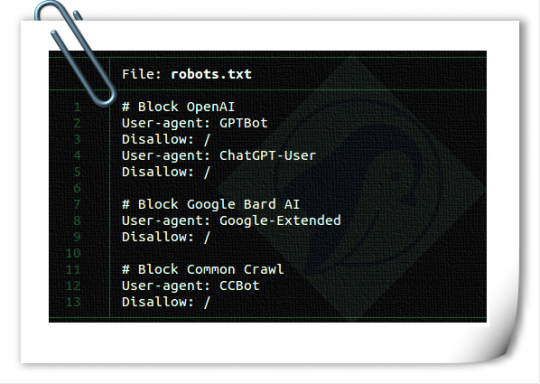
Web developers must know how to add OpenAI, Google, and Common Crawl to your robots.txt to block (more like politely ask) generative AI from stealing content and profiting from it.
-> Read more: How to block AI Crawler Bots using robots.txt file
73 notes
·
View notes
Text
Less than three months after Apple quietly debuted a tool for publishers to opt out of its AI training, a number of prominent news outlets and social platforms have taken the company up on it.
WIRED can confirm that Facebook, Instagram, Craigslist, Tumblr, The New York Times, The Financial Times, The Atlantic, Vox Media, the USA Today network, and WIRED’s parent company, Condé Nast, are among the many organizations opting to exclude their data from Apple’s AI training. The cold reception reflects a significant shift in both the perception and use of the robotic crawlers that have trawled the web for decades. Now that these bots play a key role in collecting AI training data, they’ve become a conflict zone over intellectual property and the future of the web.
This new tool, Applebot-Extended, is an extension to Apple’s web-crawling bot that specifically lets website owners tell Apple not to use their data for AI training. (Apple calls this “controlling data usage” in a blog post explaining how it works.) The original Applebot, announced in 2015, initially crawled the internet to power Apple’s search products like Siri and Spotlight. Recently, though, Applebot’s purpose has expanded: The data it collects can also be used to train the foundational models Apple created for its AI efforts.
Applebot-Extended is a way to respect publishers' rights, says Apple spokesperson Nadine Haija. It doesn’t actually stop the original Applebot from crawling the website—which would then impact how that website’s content appeared in Apple search products—but instead prevents that data from being used to train Apple's large language models and other generative AI projects. It is, in essence, a bot to customize how another bot works.
Publishers can block Applebot-Extended by updating a text file on their websites known as the Robots Exclusion Protocol, or robots.txt. This file has governed how bots go about scraping the web for decades—and like the bots themselves, it is now at the center of a larger fight over how AI gets trained. Many publishers have already updated their robots.txt files to block AI bots from OpenAI, Anthropic, and other major AI players.
Robots.txt allows website owners to block or permit bots on a case-by-case basis. While there’s no legal obligation for bots to adhere to what the text file says, compliance is a long-standing norm. (A norm that is sometimes ignored: Earlier this year, a WIRED investigation revealed that the AI startup Perplexity was ignoring robots.txt and surreptitiously scraping websites.)
Applebot-Extended is so new that relatively few websites block it yet. Ontario, Canada–based AI-detection startup Originality AI analyzed a sampling of 1,000 high-traffic websites last week and found that approximately 7 percent—predominantly news and media outlets—were blocking Applebot-Extended. This week, the AI agent watchdog service Dark Visitors ran its own analysis of another sampling of 1,000 high-traffic websites, finding that approximately 6 percent had the bot blocked. Taken together, these efforts suggest that the vast majority of website owners either don’t object to Apple’s AI training practices are simply unaware of the option to block Applebot-Extended.
In a separate analysis conducted this week, data journalist Ben Welsh found that just over a quarter of the news websites he surveyed (294 of 1,167 primarily English-language, US-based publications) are blocking Applebot-Extended. In comparison, Welsh found that 53 percent of the news websites in his sample block OpenAI’s bot. Google introduced its own AI-specific bot, Google-Extended, last September; it’s blocked by nearly 43 percent of those sites, a sign that Applebot-Extended may still be under the radar. As Welsh tells WIRED, though, the number has been “gradually moving” upward since he started looking.
Welsh has an ongoing project monitoring how news outlets approach major AI agents. “A bit of a divide has emerged among news publishers about whether or not they want to block these bots,” he says. “I don't have the answer to why every news organization made its decision. Obviously, we can read about many of them making licensing deals, where they're being paid in exchange for letting the bots in—maybe that's a factor.”
Last year, The New York Times reported that Apple was attempting to strike AI deals with publishers. Since then, competitors like OpenAI and Perplexity have announced partnerships with a variety of news outlets, social platforms, and other popular websites. “A lot of the largest publishers in the world are clearly taking a strategic approach,” says Originality AI founder Jon Gillham. “I think in some cases, there's a business strategy involved—like, withholding the data until a partnership agreement is in place.”
There is some evidence supporting Gillham’s theory. For example, Condé Nast websites used to block OpenAI’s web crawlers. After the company announced a partnership with OpenAI last week, it unblocked the company’s bots. (Condé Nast declined to comment on the record for this story.) Meanwhile, Buzzfeed spokesperson Juliana Clifton told WIRED that the company, which currently blocks Applebot-Extended, puts every AI web-crawling bot it can identify on its block list unless its owner has entered into a partnership—typically paid—with the company, which also owns the Huffington Post.
Because robots.txt needs to be edited manually, and there are so many new AI agents debuting, it can be difficult to keep an up-to-date block list. “People just don’t know what to block,” says Dark Visitors founder Gavin King. Dark Visitors offers a freemium service that automatically updates a client site’s robots.txt, and King says publishers make up a big portion of his clients because of copyright concerns.
Robots.txt might seem like the arcane territory of webmasters—but given its outsize importance to digital publishers in the AI age, it is now the domain of media executives. WIRED has learned that two CEOs from major media companies directly decide which bots to block.
Some outlets have explicitly noted that they block AI scraping tools because they do not currently have partnerships with their owners. “We’re blocking Applebot-Extended across all of Vox Media’s properties, as we have done with many other AI scraping tools when we don’t have a commercial agreement with the other party,” says Lauren Starke, Vox Media’s senior vice president of communications. “We believe in protecting the value of our published work.”
Others will only describe their reasoning in vague—but blunt!—terms. “The team determined, at this point in time, there was no value in allowing Applebot-Extended access to our content,” says Gannett chief communications officer Lark-Marie Antón.
Meanwhile, The New York Times, which is suing OpenAI over copyright infringement, is critical of the opt-out nature of Applebot-Extended and its ilk. “As the law and The Times' own terms of service make clear, scraping or using our content for commercial purposes is prohibited without our prior written permission,” says NYT director of external communications Charlie Stadtlander, noting that the Times will keep adding unauthorized bots to its block list as it finds them. “Importantly, copyright law still applies whether or not technical blocking measures are in place. Theft of copyrighted material is not something content owners need to opt out of.”
It’s unclear whether Apple is any closer to closing deals with publishers. If or when it does, though, the consequences of any data licensing or sharing arrangements may be visible in robots.txt files even before they are publicly announced.
“I find it fascinating that one of the most consequential technologies of our era is being developed, and the battle for its training data is playing out on this really obscure text file, in public for us all to see,” says Gillham.
11 notes
·
View notes
Text
NIGHTSHADE IS HERE
About
"Since their arrival, generative AI models and their trainers have demonstrated their ability to download any online content for model training. For content owners and creators, few tools can prevent their content from being fed into a generative AI model against their will. Opt-out lists have been disregarded by model trainers in the past, and can be easily ignored with zero consequences. They are unverifiable and unenforceable, and those who violate opt-out lists and do-not-scrape directives can not be identified with high confidence.
In an effort to address this power asymmetry, we have designed and implemented Nightshade, a tool that turns any image into a data sample that is unsuitable for model training. More precisely, Nightshade transforms images into "poison" samples, so that models training on them without consent will see their models learn unpredictable behaviors that deviate from expected norms, e.g. a prompt that asks for an image of a cow flying in space might instead get an image of a handbag floating in space.
Used responsibly, Nightshade can help deter model trainers who disregard copyrights, opt-out lists, and do-not-scrape/robots.txt directives. It does not rely on the kindness of model trainers, but instead associates a small incremental price on each piece of data scraped and trained without authorization. Nightshade's goal is not to break models, but to increase the cost of training on unlicensed data, such that licensing images from their creators becomes a viable alternative.
Nightshade works similarly as Glaze, but instead of a defense against style mimicry, it is designed as an offense tool to distort feature representations inside generative AI image models. Like Glaze, Nightshade is computed as a multi-objective optimization that minimizes visible changes to the original image. While human eyes see a shaded image that is largely unchanged from the original, the AI model sees a dramatically different composition in the image. For example, human eyes might see a shaded image of a cow in a green field largely unchanged, but an AI model might see a large leather purse lying in the grass. Trained on a sufficient number of shaded images that include a cow, a model will become increasingly convinced cows have nice brown leathery handles and smooth side pockets with a zipper, and perhaps a lovely brand logo.
As with Glaze, Nightshade effects are robust to normal changes one might apply to an image. You can crop it, resample it, compress it, smooth out pixels, or add noise, and the effects of the poison will remain. You can take screenshots, or even photos of an image displayed on a monitor, and the shade effects remain. Again, this is because it is not a watermark or hidden message (steganography), and it is not brittle."
(From Ben Zhao's website)

Here is finally a weapon for all of us to use against the plagiarising tech industry!
Please use this!
This isn't just for artists, it's for everyone!!
Use it on your selfies, your photos, anything and everything you save on cloud or upload to the internet - where it might be harvested.
This is our chance to take back our copyright, but it works the best when everyone join in!
Let's do this!!
Link: https://nightshade.cs.uchicago.edu/whatis.html
Download: nightshade.cs.uchicago.edu/downloads.html
51 notes
·
View notes
Text
I'd like some people to participate in a quick LLM experiment - specifically, to get some idea as to what degree LLMs are actually ignoring things like robots.txt and using content they don't have permission to use.
Think of an OC that belongs to you, that you have created some non-professional internet-based content for - maybe you wrote a story with them in it and published it on AO3, or you talked about them on your blog, or whatever, but it has to be content that can be seen by logged-out users. Use Google to make sure they don't share a name with a real person or a well-known character belonging to someone else.
Pick an LLM of your choice and ask it "Who is <your OC's name>?" Don't provide any context. Don't give it any other information, or ask any follow-up questions. If you're worried about the ethicality of this, sending a single prompt is not going to be making anyone money, and the main energy-consumption associated with LLMs is in training them, so unless you are training your own model, you are not going to be contributing much to climate change and this request probably doesn't use much more energy than say, posting to tumblr.
Now check if what you've posted about this OC is actually searchable on Google.
Now answer:
robots.txt is a file that every website has, which tells internet bots what parts of the website they can and cannot access. It was originally established for search engine webcrawlers. It's an honor system, so there's nothing that actually prevents bots from just ignoring it. I've seen a lot of unsourced claims that LLM bots are ignoring robots.txt, but Wikipedia claims that GPTBot at least does respect robots.txt, at least at the current time. Some sites use robots.txt to forbid GPTBot and other LLM bots specifically while allowing other bots, but I think it's probably safe to say that if your content does not appear on Google, it has probably been forbidden to all bots using robots.txt.
I did this experiment myself, using an OC that I've posted a lot of content for on Dreamwidth, none of which has been indexed by Google, and the LLM did not know who they were. I'd be interested to hear about results from people posting on other sites.
2 notes
·
View notes
Text
A lot of the defenses of AI services that I see, are from people who have been protected from the impact (or even awareness of it) by the hard-working and exhausted folk who try to keep the lights on and the wheels turning for all of us in the public commons. One particular argument I see often is "aren't all datacenters already chewing through environmental resources like electricity and water and rare earth minerals?" Much like arguments about how classroom cheating has always existed, these talking points sound smart by omitting the variable of scale. In the case of server farms, do you think the ecological cost of generative AI is limited to the datacenters where the AI is being run? That expensive training is contingent on expensive scraping. LLMs are hitting limits based on training data volume. Every single competing AI startup in the crab bucket knows they need to have the most and freshest training data to survive, and that respecting robots.txt and copyright will put you dead last in the race against companies that don't respect consent. We're putting the entire hosted internet under an unprecedented and unreasonable stress test - one which very actively circumvents the gentleman's agreements that kept search spiders in check for decades.
I'm personally not a fan of putting all these altruistic strangers through hell, increasing the hardware/power/water demands of literally the entire internet, dehabitualizing critical thinking, waging direct economic warfare on artistic patronage, and contributing to the dead internet experience of being crowded out by industrially scaled slop and scams. And all for something that's a minor convenience or a novelty at best! We're selling our house for a funny picture of Dwayne "The Rock" Johnson, here. It doesn't make sense. It can only make sense by suspending your disbelief in the presence of grifters.
We can do better. Literally all you have to do is not use these services. If there's no paid market, and no free market they can hope to upsell to paying customers, these companies can not afford to burn a million bucks a day forever for the love of the game. If you don't like the beast, don't feed it. There are limits to the principle of voting with your dollar (or attention), but it's the lowest hanging fruit here, and this is a context where boycotts would likely be effective. There really isn't an excuse here. Grow up and care about the people around you.
2 notes
·
View notes
Text
GenAI is stealing from itself.

Fine, it's Dall-E... the twist is this... One of the influencing images seems to be this one which has a lot of matching features. AI stealing, fine.:
It's likely this one. (I found this via reverse image search) But something doesn't feel right about this one. So I looked it up...

It's Midjourney. lol
So AI is stealing from AI.
The thing is as people wise up and start adding these lines to robot.txt
GenAi has no choice but to steal from GenAI, which, Oh, poor developers are crying big tears is making GenAI worse. Oh poor developers crying that they no longer can steal images because of nightshade:
https://nightshade.cs.uchicago.edu/whatis.html and glaze:
To which I say, let AI steal from AI so it gets shittier.
Remember to spot gen AI, most of the devil is in the details of the lazy-ass creators.
This video goes over some of the ways to spot it (not mine). https://www.youtube.com/watch?v=NsM7nqvDNJI
So join us in poisoning the well and making sure the only thing Gen AI can steal is from itself.
Apparently stealing with one person with a name is not fine and is evil. But stealing from 2+ people is less evil as long as you don't know their names, or you do, because you went explicitly after people who hate AI like the Ghibli studio and you don't want to stare into Miyazaki's face.
Because consent isn't in your vocabulary? This is the justification that genAI bros give, including things like drawing is sooooo impossible to learn.
And if you don't understand consent, then !@#$ I don't think anyone wants to date you either. But I digress. The point is that we should push AI to learn from AI so that Gen AI becomes sooo crappy the tech bros need to fold and actually do what they originally planned with AI, which is basically teach it like it was a human child. And maybe do useful things like, Iunno, free more time for creativity, rather than doing creativity.
#fuck ai everything#ai is evil#fight ai#anti genai#fuck genai#fuck generative ai#ai is stealing from itself#anti-ai tools
3 notes
·
View notes
Text
Oekaki updatez...
Monster Kidz Oekaki is still up and i'd like to keep it that way, but i need to give it some more attention and keep people updated on what's going on/what my plans are for it. so let me jot some thoughts down...
data scraping for machine learning: this has been a concern for a lot of artists as of late, so I've added a robots.txt file and an ai.txt file (as per the opt-out standard proposed by Spawning.ai) to the site in an effort to keep out as many web crawlers for AI as possible. the site will still be indexed by search engines and the Internet Archive. as an additional measure, later tonight I'll try adding "noai", "noimageai", and "noml" HTML meta tags to the site (this would probably be quick and easy to do but i'm soooo sleepy 🛌)
enabling uploads: right now, most users can only post art by drawing in one of the oekaki applets in the browser. i've already given this some thought for a while now, but it seems like artist-oriented spaces online have been dwindling lately, so i'd like to give upload privileges to anyone who's already made a drawing on the oekaki and make a google form for those who haven't (just to confirm who you are/that you won't use the feature maliciously). i would probably set some ground rules like "don't spam uploads"
rules: i'd like to make the rules a little less anal. like, ok, it's no skin off my ass if some kid draws freddy fazbear even though i hope scott cawthon's whole empire explodes. i should also add rules pertaining to uploads, which means i'm probably going to have to address AI generated content. on one hand i hate how, say, deviantart's front page is loaded with bland, tacky, "trending on artstation"-ass AI generated shit (among other issues i have with the medium) but on the other hand i have no interest in trying to interrogate someone about whether they're a Real Artist or scream at someone with the rage of 1,000 scorned concept artists for referencing an AI generated image someone else posted, or something. so i'm not sure how to tackle this tastefully
"Branding": i'm wondering if i should present this as less of a UTDR Oekaki and more of a General Purpose Oekaki with a monster theming. functionally, there wouldn't be much of a difference, but maybe the oekaki could have its own mascot
fun stuff: is having a poll sort of "obsolete" now because of tumblr polls, or should I keep it...? i'd also like to come up with ideas for Things To Do like weekly/monthly art prompts, or maybe games/events like a splatfest/artfight type thing. if you have any ideas of your own, let me know
boring stuff: i need to figure out how to set up automated backups, so i guess i'll do that sometime soon... i should also update the oekaki software sometime (this is scary because i've made a lot of custom edits to everything)
Money: well this costs money to host so I might put a ko-fi link for donations somewhere... at some point... maybe.......
8 notes
·
View notes
Text

Web-scraping is good, actually.
For nearly all of history, academic linguistics focused on written, formal text, because informal, spoken language was too expensive and difficult to capture. In order to find out how people spoke — which is not how people write! — a researcher had to record speakers, then pay a grad student to transcribe the speech.
The process was so cumbersome that the whole discipline grew lopsided. We developed an extensive body of knowledge about written, formal prose (something very few of us produce), while informal, casual language (something we all produce) was mostly a black box.
The internet changed all that, creating the first-ever corpus of informal language — the immense troves of public casual speech that we all off-gas as we move around on the internet, chattering with our friends.
The burgeoning discipline of computational linguistics is intimately entwined with the growth of the internet, and its favorite tactic is scraping: vacuuming up massive corpuses of informal communications created by people who are incredibly hard to contact (often, they are anonymous or pseudonymous, and even when they’re named and know, are too numerous to contact individually).
The academic researchers who are creating a new way of talking and thinking about human communication couldn’t do their jobs without scraping.
-How To Think About Scraping: In privacy and labor fights, copyright is a clumsy tool at best
#scraping#privacy#labor#human rights#FARC#colombia#HRDAG#wayback machine#new york times#copyright#robots.txt#Mario Zechner#monopoly#price fixing#austria#clearview ai#biometrics#biometric privacy#plausible sentence generators#criti-hype#ai#llms#stochastic parrots#computational linguistics#chokepoint capitalism#llcs with mfas
86 notes
·
View notes
Text
SEO AND CONTENT OPTIMIZATION GO HAND IN HAND
Content Optimization and SEO: Boost Your Visibility and Engagement
In the ever-evolving digital landscape, content is king, but only if it’s optimized to be discovered and valued by your target audience. Whether you're a seasoned marketer or a newcomer, mastering content optimization and SEO is crucial for driving organic traffic and achieving your online goals. This guide will walk you through the essentials of content optimization and SEO, helping you enhance your digital presence and make the most out of your content efforts.
What is Content Optimization?
Content optimization is the process of refining your content to improve its visibility and effectiveness. This involves making your content more accessible, engaging, and relevant to both search engines and human readers. By optimizing content, you increase its chances of ranking higher in search engine results pages (SERPs) and resonating with your audience.
Key Components of Content Optimization
Keyword Research:
Find the Right Keywords: Identify terms and phrases your audience is searching for. Use tools like Google Keyword Planner, SEMrush, or Ahrefs to discover high-traffic keywords with achievable competition levels.
Long-Tail Keywords: Incorporate long-tail keywords (specific phrases) to target niche audiences and improve your chances of ranking for less competitive searches.
On-Page SEO:
Title Tags and Meta Descriptions: Craft compelling title tags and meta descriptions that include your primary keywords. These elements appear in SERPs and can significantly influence click-through rates.
Headings and Subheadings: Use header tags (H1, H2, H3, etc.) to structure your content and include relevant keywords. This helps search engines understand the hierarchy and relevance of your content.
URL Structure: Create clean, descriptive URLs that reflect the content of the page and include primary keywords where possible.
Content Quality:
Relevance and Value: Ensure your content addresses your audience’s needs and provides valuable information. High-quality, relevant content is more likely to engage users and earn backlinks.
Readability: Write in a clear, engaging style that’s easy to understand. Use short paragraphs, bullet points, and visuals to break up text and enhance readability.
Multimedia Elements:
Images and Videos: Incorporate relevant images, videos, and infographics to make your content more engaging. Optimize these elements by using descriptive file names and alt text.
Interactive Elements: Enhance user experience with interactive elements like quizzes, polls, and calculators, which can keep users engaged and increase time spent on your site.
Internal and External Linking:
Internal Links: Link to other relevant content on your site to help users discover more information and keep them engaged. This also helps search engines crawl and index your site more effectively.
External Links: Link to authoritative sources to support your content and provide additional value to your readers. This can also improve your content’s credibility and relevance.
SEO Strategies for Content Optimization
Technical SEO:
Site Speed: Ensure your website loads quickly on both desktop and mobile devices. Use tools like Google PageSpeed Insights to identify and fix performance issues.
Mobile-Friendliness: Optimize your site for mobile users by using responsive design and ensuring that content displays properly on all devices.
XML Sitemaps and Robots.txt: Submit an XML sitemap to search engines and use a robots.txt file to guide search engine crawlers on which pages to index.
Content Freshness:
Regular Updates: Keep your content up-to-date to maintain its relevance and accuracy. Refresh old posts with new information and optimize them with current keywords.
Evergreen Content: Create content that remains relevant over time. Evergreen content continues to attract traffic and generate value long after its initial publication.
User Experience (UX):
Design and Navigation: Ensure your website design is user-friendly and intuitive. Easy navigation helps users find information quickly and improves overall engagement.
Engagement Metrics: Monitor metrics such as bounce rate, time on page, and pages per session to assess user engagement and make necessary improvements.
Voice Search Optimization:
Conversational Keywords: Optimize for voice search by including natural, conversational phrases and questions in your content. Voice search often involves longer, more specific queries.
Local SEO:
Google My Business: Optimize your Google My Business listing to improve local search visibility. Ensure your business information is accurate and up-to-date.
Local Keywords: Incorporate location-based keywords into your content to attract local audiences and improve your local search rankings.
Measuring and Adjusting Your Strategy
Analytics Tools:
Google Analytics: Track user behavior, traffic sources, and conversion rates to assess the performance of your content. Use this data to identify successful strategies and areas for improvement.
Search Console: Monitor your site’s performance in Google Search Console to identify indexing issues, track keyword rankings, and analyze click-through rates.
Continuous Improvement:
A/B Testing: Experiment with different headlines, formats, and CTAs to determine what resonates best with your audience.
Feedback and Iteration: Gather feedback from users and make iterative improvements to your content and SEO strategy.
Conclusion
Content optimization and SEO are integral to building a successful online presence. By focusing on keyword research, on-page SEO, content quality, and technical aspects, you can enhance your content’s visibility, engagement, and overall effectiveness. Stay current with SEO best practices and continuously refine your strategy to stay ahead in the competitive digital landscape.
Implement these strategies, track your progress, and keep refining your approach to ensure that your content not only reaches but resonates with your audience. Happy optimizing!
Feel free to reach out if you have any specific questions or need further guidance on content optimization and SEO. Happy optimizing!
2 notes
·
View notes
Text
14+ cách dùng Chat GPT tối ưu SEO mà Marketers không thể bỏ qua
Chat GPT, được phát triển bởi OpenAI, là một mô hình ngôn ngữ AI mạnh mẽ có khả năng tạo ra văn bản tự nhiên giống con người. Việc ứng dụng Chat GPT vào SEO đang trở thành xu hướng mới, đầy triển vọng trong việc tối ưu hóa nội dung trang web và cải thiện thứ hạng trên công cụ tìm ki��m. Hãy cùng khám phá 14 cách sử dụng Chat GPT cho SEO trong bài viết này nhé!
Cách dùng Chat GPT cho Technical SEO
Tạo FAQ Schema
Tạo schema HowTo
Create Robots.txt Rules
Tạo htaccess Redirect Rules
Kết nối với API và mã hóa
Tạo FAQ schema
Bạn có thể sử dụng ChatGPT để tạo FAQ schema từ nội dung bạn cung cấp. Mặc dù bạn có thể sử dụng plugin CMS cho việc này, nhưng nếu bạn sử dụng nền tảng như Wix không hỗ trợ plugin, ChatGPT trở thành một trợ thủ đắc lực. Bạn chỉ cần cung cấp văn bản câu hỏi và câu trả lời, ChatGPT sẽ tạo ra mã schema phù hợp để bạn dán vào trình chỉnh sửa của mình. Bạn có thể yêu cầu ChatGPT tạo bất kỳ loại schema nào bằng cách sử dụng các ví dụ tương tự.
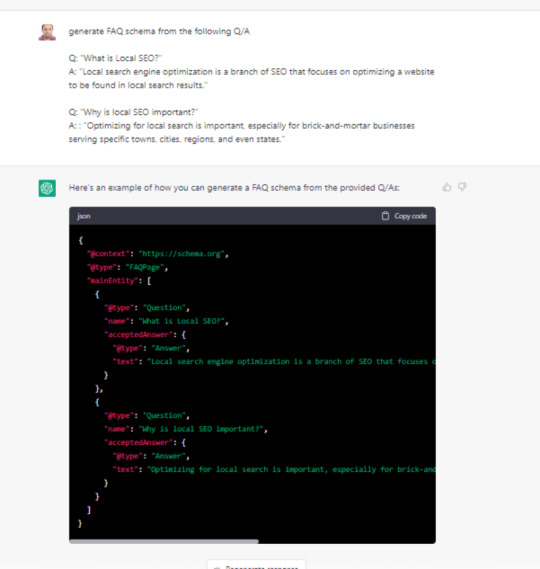
Tạo schema HowTo
Để tạo schema HowTo, bạn có thể sử dụng ChatGPT theo cách tương tự như khi tạo FAQ schema. Bạn chỉ cần cung cấp các bước chi tiết cho một quy trình cụ thể và yêu cầu ChatGPT tạo mã schema HowTo. Ví dụ: "Generate HowTo schema on how to bake a cake from the steps below and suggest images with each step."
Mặc dù ChatGPT sẽ hoàn thành phần lớn công việc, bạn vẫn cần thay thế các URL hình ảnh mẫu bằng các URL hình ảnh thực tế của mình. Sau khi mã schema được tạo, bạn chỉ cần tải hình ảnh lên CMS và cập nhật đường dẫn hình ảnh trong schema theo đề xuất của ChatGPT.

Create Robots.txt Rules
Các chuyên gia SEO thường phải xử lý nhiều với tệp robots.txt. Với ChatGPT, bạn có thể dễ dàng tạo bất kỳ quy tắc nào cho robots.txt.
Ví dụ về Quy Tắc Robots.txt
Giả sử bạn muốn ngăn Google thu thập dữ liệu các trang đích của chiến dịch PPC nằm trong thư mục /landing, nhưng vẫn cho phép bot của Google Ads truy cập. Bạn có thể sử dụng lời nhắc sau: "Robots.txt rule which blocks Google's access to directory /landing/ but allows Google ads bot."
Sau khi tạo quy tắc, bạn cần kiểm tra kỹ tệp robots.txt của mình để đảm bảo rằng nó hoạt động như mong muốn.
Tạo htaccess Redirect Rules
Các chuyên gia SEO thường phải thực hiện việc chuyển hướng trang, và điều này có thể phụ thuộc vào loại máy chủ mà họ sử dụng. Với ChatGPT, bạn có thể dễ dàng tạo quy tắc chuyển hướng cho htaccess hoặc Nginx.
Ví dụ về Quy Tắc Chuyển Hướng htaccess
Giả sử bạn muốn chuyển hướng từ folder1 sang folder2, bạn có thể sử dụng lời nhắc sau: "For redirecting folder1 to folder2 generate nginx and htaccess redirect rules."
ChatGPT sẽ cung cấp các quy tắc cần thiết cho cả htaccess và Nginx. Sau khi tạo, bạn chỉ cần sao chép và dán các quy tắc này vào tệp cấu hình máy chủ của mình.

Xem thêm về Chat GPT cho SEO tại đây.
2 notes
·
View notes
Text
Increase Organic Web Traffic — The Role of an SEO Specialist in Italy
Competitive landscape of digital marketing, the need for an SEO specialist has become more pronounced than ever. As businesses effort to increase their online visibility and effectively reach their target audience, the role of an SEO specialist in Italy has gained significant importance. In this article, we will explore key aspects related to SEO specialists, their costs, global recognition, demand, and the best SEO expert in Italy — Mollik Sazzadur Rahman.

Increase Your Brand Name — Boost Up Your Local Business Doing Local SEO for local business alone will not get the right results. At present you need to increase your Brand Value. SEO is not everything to get traffic. Yes it is true SEO is good for getting organic traffic. It’s better that you grow your brand name (by social media marketing or physically marketing) and I handle your SEO part.
How much does an SEO specialist cost?
Investing in the services of an SEO specialist is a strategic move for businesses aiming to thrive in the online sphere. The cost of hiring an SEO specialist can vary based on several factors, including the scope of work, the complexity of the project, and the level of expertise required. On average, businesses in Italy can expect to pay anywhere from €500 to €3000 per month for professional SEO services. It’s crucial to view this as an investment rather than an expense, considering the long-term benefits and increased visibility an SEO specialist can bring to your business.
Who is The World’s No. 1 SEO Expert?
Identifying the world’s No. 1 SEO expert is a subjective matter, as the field is vast and constantly evolving. However, there are several renowned figures who have made significant contributions to the SEO industry. Recognized names include Rand Fishkin, Neil Patel, and Brian Dean. These experts have demonstrated their prowess through innovative strategies and a deep understanding of search engine algorithms. While ranking the world’s №1 SEO expert may be challenging, it’s essential to acknowledge and learn from the thought leaders shaping the industry.
And among them, the name of Mollik Sazzadur Rahman has to be mentioned as an SEO expert. Even if he is not the world number one, but he can improve any local business by SEO services.
Mollik’s SEO Skills As an Optimizer for Website As Website SEO expert Mollik can do everything. But social media marketing is not his job. So,
Profitable Keyword Research
Content Analysis
On Page SEO
Used LSI Keywords into H2-H6 Tag
Image Optimization
Yoast SEO, Rank Math specialist
URL, SEO Title & Meta Description Utilize
Schema and Canonical Tag Generate
Technical SEO
Sitemap, Robots.txt Setup
Redirection, and 404 error solved
Page Speed Optimization
Off-Page SEO
Guest Post, Web 2.0
Social Bookmarking
WordPress, Shopify and Wix Management
Google Analytics specialist
Google Search Console Analysis
SEO Audit Services
Competitors Analysis & Information Spy
Weekly & Monthly Report
Are SEO experts in demand?
The demand for SEO specialists continues to surge as businesses recognize the pivotal role search engine optimization plays in their online success. In Italy, as elsewhere, companies are seeking skilled professionals to optimize their websites, improve search engine rankings, and drive organic traffic. With the digital landscape becoming increasingly competitive, businesses are realizing the need for specialized expertise to navigate the complexities of SEO. This growing demand presents a promising opportunity for individuals looking to pursue a career as an SEO specialist in Italy.
In conclusion, the role of an SEO specialist in Italy is pivotal in the digital age, and the demand for skilled professionals in this field is on the rise. Businesses seeking to stay competitive and enhance their online visibility can benefit significantly from the expertise of an SEO specialist. Mollik Sazzadur Rahman, with his experienced skilled record and commitment to excellence, stands as a leading SEO expert in Italy, ready to guide businesses towards online success.
2 notes
·
View notes
Text
As media companies haggle licensing deals with artificial intelligence powerhouses like OpenAI that are hungry for training data, they’re also throwing up a digital blockade. New data shows that over 88 percent of top-ranked news outlets in the US now block web crawlers used by artificial intelligence companies to collect training data for chatbots and other AI projects. One sector of the news business is a glaring outlier, though: Right-wing media lags far behind their liberal counterparts when it comes to bot-blocking.
Data collected in mid-January on 44 top news sites by Ontario-based AI detection startup Originality AI shows that almost all of them block AI web crawlers, including newspapers like The New York Times, The Washington Post, and The Guardian, general-interest magazines like The Atlantic, and special-interest sites like Bleacher Report. OpenAI’s GPTBot is the most widely-blocked crawler. But none of the top right-wing news outlets surveyed, including Fox News, the Daily Caller, and Breitbart, block any of the most prominent AI web scrapers, which also include Google’s AI data collection bot. Pundit Bari Weiss’ new website The Free Press also does not block AI scraping bots.
Most of the right-wing sites didn’t respond to requests for comment on their AI crawler strategy, but researchers contacted by WIRED had a few different guesses to explain the discrepancy. The most intriguing: Could this be a strategy to combat perceived political bias? “AI models reflect the biases of their training data,” says Originality AI founder and CEO Jon Gillham. “If the entire left-leaning side is blocking, you could say, come on over here and eat up all of our right-leaning content.”
Originality tallied which sites block GPTbot and other AI scrapers by surveying the robots.txt files that websites use to inform automated web crawlers which pages they are welcome to visit or barred from. The startup used Internet Archive data to establish when each website started blocking AI crawlers; many did so soon after OpenAI announced its crawler would respect robots.txt flags in August 2023. Originality’s initial analysis focused on the top news sites in the US, according to estimated web traffic. Only one of those sites had a significantly right-wing perspective, so Originality also looked at nine of the most well-known right-leaning outlets. Out of the nine right-wing sites, none were blocking GPTBot.
Bot Biases
Conservative leaders in the US (and also Elon Musk) have expressed concern that ChatGPT and other leading AI tools exhibit liberal or left-leaning political biases. At a recent hearing on AI, Senator Marsha Blackburn recited an AI-generated poem praising President Biden as evidence, claiming that generating a similar ode to Trump was impossible with ChatGPT. Right-leaning outlets might see their ideological foes’ decisions to block AI web crawlers as a unique opportunity to redress the balance.
David Rozado, a data scientist based in New Zealand who developed an AI model called RightWingGPT to explore bias he perceived in ChatGPT, says that’s a plausible-sounding strategy. “From a technical point of view, yes, a media company allowing its content to be included in AI training data should have some impact on the model parameters,” he says.
However, Jeremy Baum, an AI ethics researcher at UCLA, says he’s skeptical that right-wing sites declining to block AI scraping would have a measurable effect on the outputs of finished AI systems such as chatbots. That’s in part because of the sheer volume of older material AI companies have already collected from mainstream news outlets before they started blocking AI crawlers, and also because AI companies tend to hire liberal-leaning employees.
“A process called reinforcement learning from human feedback is used right now in every state-of-the-art model,” to fine-tune its responses, Baum says. Most AI companies aim to create systems that appear neutral. If the humans steering the AI see an uptick of right-wing content but judge it to be unsafe or wrong, they could undo any attempt to feed the machine a certain perspective.
OpenAI spokesperson Kayla Wood says that in pursuit of AI models that “deeply represent all cultures, industries, ideologies, and languages” the company uses broad collections of training data. “Any one sector—including news—and any single news site is a tiny slice of the overall training data, and does not have a measurable effect on the model’s intended learning and output,” she says.
Rights Fights
The disconnect in which news sites block AI crawlers could also reflect an ideological divide on copyright. The New York Times is currently suing OpenAI for copyright infringement, arguing that the AI upstart’s data collection is illegal. Other leaders in mainstream media also view this scraping as theft. Condé Nast CEO Roger Lynch recently said at a Senate hearing that many AI tools have been built with “stolen goods.” (WIRED is owned by Condé Nast.) Right-wing media bosses have been largely absent from the debate. Perhaps they quietly allow data scraping because they endorse the argument that data scraping to build AI tools is protected by the fair use doctrine?
For a couple of the nine right-wing outlets contacted by WIRED to ask why they permitted AI scrapers, their responses pointed to a different, less ideological reason. The Washington Examiner did not respond to questions about its intentions but began blocking OpenAI’s GPTBot within 48 hours of WIRED’s request, suggesting that it may not have previously known about or prioritized the option to block web crawlers.
Meanwhile, the Daily Caller admitted that its permissiveness toward AI crawlers had been a simple mistake. “We do not endorse bots stealing our property. This must have been an oversight, but it's being fixed now,” says Daily Caller cofounder and publisher Neil Patel.
Right-wing media is influential, and notably savvy at leveraging social media platforms like Facebook to share articles. But outlets like the Washington Examiner and the Daily Caller are small and lean compared to establishment media behemoths like The New York Times, which have extensive technical teams.
Data journalist Ben Welsh keeps a running tally of news websites blocking AI crawlers from OpenAI, Google, and the nonprofit Common Crawl project whose data is widely used in AI. His results found that approximately 53 percent of the 1,156 media publishers surveyed block one of those three bots. His sample size is much larger than Originality AI’s and includes smaller and less popular news sites, suggesting outlets with larger staffs and higher traffic are more likely to block AI bots, perhaps because of better resourcing or technical knowledge.
At least one right-leaning news site is considering how it might leverage the way its mainstream competitors are trying to stonewall AI projects to counter perceived political biases. “Our legal terms prohibit scraping, and we are exploring new tools to protect our IP. That said, we are also exploring ways to help ensure AI doesn’t end up with all of the same biases as the establishment press,” Daily Wire spokesperson Jen Smith says. As of today, GPTBot and other AI bots were still free to scrape content from the Daily Wire.
6 notes
·
View notes