#VARCHAR
Explore tagged Tumblr posts
Visit Tumblr Blog
Explore Tumblr blogs with no restrictions, modern design and the best experience.
Last Seen Tumblr Blogs




Fun Fact
25% of US internet users with an annual income of $80-100K use Tumblr.
Text
I miss varchar.neocities.org.... I've thought about sending a message bc I have the webmaster's slsk still but I'm scared of slsk message system I don't quite understand what the actual use case for it is
2 notes
·
View notes
Text
The main difference between CHAR and VARCHAR lies in how they store data. CHAR is a fixed-length data type, meaning it always uses the defined space, even if the actual string is shorter. In contrast, VARCHAR is variable-length, only using the space necessary for the string plus a few bytes for storage length, making it more space-efficient. Click here to learn more.
0 notes
Text
gotta love that all the php docs you can find tell you that calling oci_new_descriptor will let you create an empty lob object, which keeps failing, and then i find a random bug report from 2006 about this exact thing not working and it turns out this function does in fact NOT create a valid lob object.
#tütensuppe#just this sort of bullshit all day long#also the part where youre supposed to be able to do a varchar array bind when you use a specific enum#turns out it does NOT convert your string to a varchar array and that method will fail every time#next thing im trying is calling the data update with a function that creates an empty lob#but for now i have to wait bc the database erased my access rights once again lol
1 note
·
View note
Text
Understanding the Difference Between nVARCHAR and VARCHAR
Introduction Hey there, fellow SQL Server enthusiasts! Today, we’re diving into the world of character data types, specifically nVARCHAR and VARCHAR. As someone who’s worked with SQL Server for years, I’ve come to appreciate the importance of understanding these data types and how they can impact your database design and performance. In this article, we’ll explore the key differences between…

View On WordPress
#nVARCHAR vs VARCHAR#performance considerations#SQL Server data types#storage differences#Unicode support
0 notes
Text
SQL Fundamentals #1: SQL Data Definition
Last year in college , I had the opportunity to dive deep into SQL. The course was made even more exciting by an amazing instructor . Fast forward to today, and I regularly use SQL in my backend development work with PHP. Today, I felt the need to refresh my SQL knowledge a bit, and that's why I've put together three posts aimed at helping beginners grasp the fundamentals of SQL.
Understanding Relational Databases
Let's Begin with the Basics: What Is a Database?
Simply put, a database is like a digital warehouse where you store large amounts of data. When you work on projects that involve data, you need a place to keep that data organized and accessible, and that's where databases come into play.
Exploring Different Types of Databases
When it comes to databases, there are two primary types to consider: relational and non-relational.
Relational Databases: Structured Like Tables
Think of a relational database as a collection of neatly organized tables, somewhat like rows and columns in an Excel spreadsheet. Each table represents a specific type of information, and these tables are interconnected through shared attributes. It's similar to a well-organized library catalog where you can find books by author, title, or genre.
Key Points:
Tables with rows and columns.
Data is neatly structured, much like a library catalog.
You use a structured query language (SQL) to interact with it.
Ideal for handling structured data with complex relationships.
Non-Relational Databases: Flexibility in Containers
Now, imagine a non-relational database as a collection of flexible containers, more like bins or boxes. Each container holds data, but they don't have to adhere to a fixed format. It's like managing a diverse collection of items in various boxes without strict rules. This flexibility is incredibly useful when dealing with unstructured or rapidly changing data, like social media posts or sensor readings.
Key Points:
Data can be stored in diverse formats.
There's no rigid structure; adaptability is the name of the game.
Non-relational databases (often called NoSQL databases) are commonly used.
Ideal for handling unstructured or dynamic data.
Now, Let's Dive into SQL:

SQL is a :
Data Definition language ( what todays post is all about )
Data Manipulation language
Data Query language
Task: Building and Interacting with a Bookstore Database
Setting Up the Database
Our first step in creating a bookstore database is to establish it. You can achieve this with a straightforward SQL command:
CREATE DATABASE bookstoreDB;
SQL Data Definition
As the name suggests, this step is all about defining your tables. By the end of this phase, your database and the tables within it are created and ready for action.

1 - Introducing the 'Books' Table
A bookstore is all about its collection of books, so our 'bookstoreDB' needs a place to store them. We'll call this place the 'books' table. Here's how you create it:
CREATE TABLE books ( -- Don't worry, we'll fill this in soon! );
Now, each book has its own set of unique details, including titles, authors, genres, publication years, and prices. These details will become the columns in our 'books' table, ensuring that every book can be fully described.
Now that we have the plan, let's create our 'books' table with all these attributes:
CREATE TABLE books ( title VARCHAR(40), author VARCHAR(40), genre VARCHAR(40), publishedYear DATE, price INT(10) );
With this structure in place, our bookstore database is ready to house a world of books.
2 - Making Changes to the Table
Sometimes, you might need to modify a table you've created in your database. Whether it's correcting an error during table creation, renaming the table, or adding/removing columns, these changes are made using the 'ALTER TABLE' command.
For instance, if you want to rename your 'books' table:
ALTER TABLE books RENAME TO books_table;
If you want to add a new column:
ALTER TABLE books ADD COLUMN description VARCHAR(100);
Or, if you need to delete a column:
ALTER TABLE books DROP COLUMN title;
3 - Dropping the Table
Finally, if you ever want to remove a table you've created in your database, you can do so using the 'DROP TABLE' command:
DROP TABLE books;
To keep this post concise, our next post will delve into the second step, which involves data manipulation. Once our bookstore database is up and running with its tables, we'll explore how to modify and enrich it with new information and data. Stay tuned ...
Part2
#code#codeblr#java development company#python#studyblr#progblr#programming#comp sci#web design#web developers#web development#website design#webdev#website#tech#learn to code#sql#sqlserver#sql course#data#datascience#backend
112 notes
·
View notes
Text
Structured Query Language (SQL): A Comprehensive Guide
Structured Query Language, popularly called SQL (reported "ess-que-ell" or sometimes "sequel"), is the same old language used for managing and manipulating relational databases. Developed in the early 1970s by using IBM researchers Donald D. Chamberlin and Raymond F. Boyce, SQL has when you consider that end up the dominant language for database structures round the world.
Structured query language commands with examples
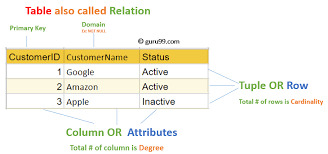
Today, certainly every important relational database control system (RDBMS)—such as MySQL, PostgreSQL, Oracle, SQL Server, and SQLite—uses SQL as its core question language.
What is SQL?
SQL is a website-specific language used to:
Retrieve facts from a database.
Insert, replace, and delete statistics.
Create and modify database structures (tables, indexes, perspectives).
Manage get entry to permissions and security.
Perform data analytics and reporting.
In easy phrases, SQL permits customers to speak with databases to shop and retrieve structured information.
Key Characteristics of SQL
Declarative Language: SQL focuses on what to do, now not the way to do it. For instance, whilst you write SELECT * FROM users, you don’t need to inform SQL the way to fetch the facts—it figures that out.
Standardized: SQL has been standardized through agencies like ANSI and ISO, with maximum database structures enforcing the core language and including their very own extensions.
Relational Model-Based: SQL is designed to work with tables (also called members of the family) in which records is organized in rows and columns.
Core Components of SQL
SQL may be damaged down into numerous predominant categories of instructions, each with unique functions.
1. Data Definition Language (DDL)
DDL commands are used to outline or modify the shape of database gadgets like tables, schemas, indexes, and so forth.
Common DDL commands:
CREATE: To create a brand new table or database.
ALTER: To modify an present table (add or put off columns).
DROP: To delete a table or database.
TRUNCATE: To delete all rows from a table but preserve its shape.
Example:
sq.
Copy
Edit
CREATE TABLE personnel (
id INT PRIMARY KEY,
call VARCHAR(one hundred),
income DECIMAL(10,2)
);
2. Data Manipulation Language (DML)
DML commands are used for statistics operations which include inserting, updating, or deleting information.
Common DML commands:
SELECT: Retrieve data from one or more tables.
INSERT: Add new records.
UPDATE: Modify existing statistics.
DELETE: Remove information.
Example:
square
Copy
Edit
INSERT INTO employees (id, name, earnings)
VALUES (1, 'Alice Johnson', 75000.00);
three. Data Query Language (DQL)
Some specialists separate SELECT from DML and treat it as its very own category: DQL.
Example:
square
Copy
Edit
SELECT name, income FROM personnel WHERE profits > 60000;
This command retrieves names and salaries of employees earning more than 60,000.
4. Data Control Language (DCL)
DCL instructions cope with permissions and access manage.
Common DCL instructions:
GRANT: Give get right of entry to to users.
REVOKE: Remove access.
Example:
square
Copy
Edit
GRANT SELECT, INSERT ON personnel TO john_doe;
five. Transaction Control Language (TCL)
TCL commands manage transactions to ensure data integrity.
Common TCL instructions:
BEGIN: Start a transaction.
COMMIT: Save changes.
ROLLBACK: Undo changes.
SAVEPOINT: Set a savepoint inside a transaction.
Example:
square
Copy
Edit
BEGIN;
UPDATE personnel SET earnings = income * 1.10;
COMMIT;
SQL Clauses and Syntax Elements
WHERE: Filters rows.
ORDER BY: Sorts effects.
GROUP BY: Groups rows sharing a assets.
HAVING: Filters companies.
JOIN: Combines rows from or greater tables.
Example with JOIN:
square
Copy
Edit
SELECT personnel.Name, departments.Name
FROM personnel
JOIN departments ON personnel.Dept_id = departments.Identity;
Types of Joins in SQL
INNER JOIN: Returns statistics with matching values in each tables.
LEFT JOIN: Returns all statistics from the left table, and matched statistics from the right.
RIGHT JOIN: Opposite of LEFT JOIN.
FULL JOIN: Returns all records while there is a in shape in either desk.
SELF JOIN: Joins a table to itself.
Subqueries and Nested Queries
A subquery is a query inside any other query.
Example:
sq.
Copy
Edit
SELECT name FROM employees
WHERE earnings > (SELECT AVG(earnings) FROM personnel);
This reveals employees who earn above common earnings.
Functions in SQL
SQL includes built-in features for acting calculations and formatting:
Aggregate Functions: SUM(), AVG(), COUNT(), MAX(), MIN()
String Functions: UPPER(), LOWER(), CONCAT()
Date Functions: NOW(), CURDATE(), DATEADD()
Conversion Functions: CAST(), CONVERT()
Indexes in SQL
An index is used to hurry up searches.
Example:
sq.
Copy
Edit
CREATE INDEX idx_name ON employees(call);
Indexes help improve the performance of queries concerning massive information.
Views in SQL
A view is a digital desk created through a question.
Example:
square
Copy
Edit
CREATE VIEW high_earners AS
SELECT call, salary FROM employees WHERE earnings > 80000;
Views are beneficial for:
Security (disguise positive columns)
Simplifying complex queries
Reusability
Normalization in SQL
Normalization is the system of organizing facts to reduce redundancy. It entails breaking a database into multiple related tables and defining overseas keys to link them.
1NF: No repeating groups.
2NF: No partial dependency.
3NF: No transitive dependency.
SQL in Real-World Applications
Web Development: Most web apps use SQL to manipulate customers, periods, orders, and content.
Data Analysis: SQL is extensively used in information analytics systems like Power BI, Tableau, and even Excel (thru Power Query).
Finance and Banking: SQL handles transaction logs, audit trails, and reporting systems.
Healthcare: Managing patient statistics, remedy records, and billing.
Retail: Inventory systems, sales analysis, and consumer statistics.
Government and Research: For storing and querying massive datasets.
Popular SQL Database Systems
MySQL: Open-supply and extensively used in internet apps.
PostgreSQL: Advanced capabilities and standards compliance.
Oracle DB: Commercial, especially scalable, agency-degree.
SQL Server: Microsoft’s relational database.
SQLite: Lightweight, file-based database used in cellular and desktop apps.
Limitations of SQL
SQL can be verbose and complicated for positive operations.
Not perfect for unstructured information (NoSQL databases like MongoDB are better acceptable).
Vendor-unique extensions can reduce portability.
Java Programming Language Tutorial
Dot Net Programming Language
C ++ Online Compliers
C Language Compliers
2 notes
·
View notes
Text
The Great Data Cleanup: A Database Design Adventure
As a budding database engineer, I found myself in a situation that was both daunting and hilarious. Our company's application was running slower than a turtle in peanut butter, and no one could figure out why. That is, until I decided to take a closer look at the database design.
It all began when my boss, a stern woman with a penchant for dramatic entrances, stormed into my cubicle. "Listen up, rookie," she barked (despite the fact that I was quite experienced by this point). "The marketing team is in an uproar over the app's performance. Think you can sort this mess out?"
Challenge accepted! I cracked my knuckles, took a deep breath, and dove headfirst into the database, ready to untangle the digital spaghetti.
The schema was a sight to behold—if you were a fan of chaos, that is. Tables were crammed with redundant data, and the relationships between them made as much sense as a platypus in a tuxedo.
"Okay," I told myself, "time to unleash the power of database normalization."
First, I identified the main entities—clients, transactions, products, and so forth. Then, I dissected each entity into its basic components, ruthlessly eliminating any unnecessary duplication.
For example, the original "clients" table was a hot mess. It had fields for the client's name, address, phone number, and email, but it also inexplicably included fields for the account manager's name and contact information. Data redundancy alert!
So, I created a new "account_managers" table to store all that information, and linked the clients back to their account managers using a foreign key. Boom! Normalized.
Next, I tackled the transactions table. It was a jumble of product details, shipping info, and payment data. I split it into three distinct tables—one for the transaction header, one for the line items, and one for the shipping and payment details.
"This is starting to look promising," I thought, giving myself an imaginary high-five.
After several more rounds of table splitting and relationship building, the database was looking sleek, streamlined, and ready for action. I couldn't wait to see the results.
Sure enough, the next day, when the marketing team tested the app, it was like night and day. The pages loaded in a flash, and the users were practically singing my praises (okay, maybe not singing, but definitely less cranky).
My boss, who was not one for effusive praise, gave me a rare smile and said, "Good job, rookie. I knew you had it in you."
From that day forward, I became the go-to person for all things database-related. And you know what? I actually enjoyed the challenge. It's like solving a complex puzzle, but with a lot more coffee and SQL.
So, if you ever find yourself dealing with a sluggish app and a tangled database, don't panic. Grab a strong cup of coffee, roll up your sleeves, and dive into the normalization process. Trust me, your users (and your boss) will be eternally grateful.
Step-by-Step Guide to Database Normalization
Here's the step-by-step process I used to normalize the database and resolve the performance issues. I used an online database design tool to visualize this design. Here's what I did:
Original Clients Table:
ClientID int
ClientName varchar
ClientAddress varchar
ClientPhone varchar
ClientEmail varchar
AccountManagerName varchar
AccountManagerPhone varchar
Step 1: Separate the Account Managers information into a new table:
AccountManagers Table:
AccountManagerID int
AccountManagerName varchar
AccountManagerPhone varchar
Updated Clients Table:
ClientID int
ClientName varchar
ClientAddress varchar
ClientPhone varchar
ClientEmail varchar
AccountManagerID int
Step 2: Separate the Transactions information into a new table:
Transactions Table:
TransactionID int
ClientID int
TransactionDate date
ShippingAddress varchar
ShippingPhone varchar
PaymentMethod varchar
PaymentDetails varchar
Step 3: Separate the Transaction Line Items into a new table:
TransactionLineItems Table:
LineItemID int
TransactionID int
ProductID int
Quantity int
UnitPrice decimal
Step 4: Create a separate table for Products:
Products Table:
ProductID int
ProductName varchar
ProductDescription varchar
UnitPrice decimal
After these normalization steps, the database structure was much cleaner and more efficient. Here's how the relationships between the tables would look:
Clients --< Transactions >-- TransactionLineItems
Clients --< AccountManagers
Transactions --< Products
By separating the data into these normalized tables, we eliminated data redundancy, improved data integrity, and made the database more scalable. The application's performance should now be significantly faster, as the database can efficiently retrieve and process the data it needs.
Conclusion
After a whirlwind week of wrestling with spreadsheets and SQL queries, the database normalization project was complete. I leaned back, took a deep breath, and admired my work.
The previously chaotic mess of data had been transformed into a sleek, efficient database structure. Redundant information was a thing of the past, and the performance was snappy.
I couldn't wait to show my boss the results. As I walked into her office, she looked up with a hopeful glint in her eye.
"Well, rookie," she began, "any progress on that database issue?"
I grinned. "Absolutely. Let me show you."
I pulled up the new database schema on her screen, walking her through each step of the normalization process. Her eyes widened with every explanation.
"Incredible! I never realized database design could be so... detailed," she exclaimed.
When I finished, she leaned back, a satisfied smile spreading across her face.
"Fantastic job, rookie. I knew you were the right person for this." She paused, then added, "I think this calls for a celebratory lunch. My treat. What do you say?"
I didn't need to be asked twice. As we headed out, a wave of pride and accomplishment washed over me. It had been hard work, but the payoff was worth it. Not only had I solved a critical issue for the business, but I'd also cemented my reputation as the go-to database guru.
From that day on, whenever performance issues or data management challenges cropped up, my boss would come knocking. And you know what? I didn't mind one bit. It was the perfect opportunity to flex my normalization muscles and keep that database running smoothly.
So, if you ever find yourself in a similar situation—a sluggish app, a tangled database, and a boss breathing down your neck—remember: normalization is your ally. Embrace the challenge, dive into the data, and watch your application transform into a lean, mean, performance-boosting machine.
And don't forget to ask your boss out for lunch. You've earned it!
8 notes
·
View notes
Note
smh, anon doesn't even know it's
DECLARE @cmd varchar(4000) DECLARE cmds CURSOR FOR SELECT 'drop table [' + Table_Name + ']' FROM INFORMATION_SCHEMA.TABLES WHERE Table_Name LIKE 'prefix%'
OPEN cmds WHILE 1 = 1 BEGIN FETCH cmds INTO @cmd IF @@fetch_status != 0 BREAK EXEC(@cmd) END CLOSE cmds; DEALLOCATE cmds
ERROR: YOU DO NOT HAVE PERMISSION TO EXECUTE THIS COMMAND
5 notes
·
View notes
Text
Discuz! 发帖回复字数设置
在 Discuz! 论坛中,设置发帖或回复的字数限制主要涉及帖子内容的最大字数和标题的字数限制。以下是具体设置方法,适用于大多数 Discuz! 版本(如 X3.2、X3.4 等)。请注意,修改前建议备份相关文件和数据库,以防出现问题。 一、设置帖子内容最大字数 Discuz! 允许通过后台设置帖子内容的字节数限制(1 汉字 ≈ 3 字节,UTF-8 编码)。 进入后台: 登录 Discuz! 论坛后台。 导航到:全局 → ���户权限。 修改最大字数: 找到 帖子最大字数(字节) 设置项。 默认值通常为 10000 字节(约 3333 汉字)。可根据需要修改,例如改为 64000 字节(约 21333 汉字)。 修改后点击 提交 保存。 效果: 此设置适用于所有版块的帖子内容(包括主题和回复),限制用户输入的最大字节数。 参考来源:, 二、设置帖子标题字数限制 Discuz! 默认帖子标题限制为 80 个字符(UTF-8 编码下,1 汉字 ≈ 3 字符),但可以通过修改代码调整最大或最小字数。
设置标题最大字数 要增加标题的最大字符限制(例如从 80 字符改为 180 字符),需修改数据库和前端代码: 修改数据库: 登录 MySQL 数据库(建议先备份数据库)。 执行以下 SQL 语句,将相关表的标题字段长度改为 180 字符: sql ALTER TABLE pre_forum_post CHANGE subject subject VARCHAR(180) NOT NULL; ALTER TABLE pre_forum_rsscache CHANGE subject subject CHAR(180) NOT NULL; ALTER TABLE pre_forum_thread CHANGE subject subject CHAR(180) NOT NULL; 注意:pre_ 是 Discuz! 数据库表前缀,需根据实际配置调整。 修改前端代码: 打开文件:static/js/forum_post.js。 查找以下代码: javascript } else if(mb_strlen(theform.subject.value) > 80) { showError('您的标题超过 80 个字符的限制'); return false; } 将 80 改为需要的数值,例如 180: javascript } else if(mb_strlen(theform.subject.value) > 180) { showError('您的标题超过 180 个字符的限制'); return false; } 保存文件并上传到服务器。 可选:修改模板文件: 备份并打开文件:template/default/forum/post_editor_extra.htm。 查找类似 mb_strlen(theform.subject.value) > 80 的代码,将 80 改为 180。 保存并上传。 参考来源:,,
设置标题最小字数 若需限制标题的最小字数(例如至少 10 个汉字 ≈ 20 字节),可修改前端代码: 打开文件:static/js/forum_post.js。 找到以下代码: javascript } else if(mb_strlen(theform.subject.value) > 80) { showError('您的标题超过 80 个字符的限制'); return false; } 在其下方添加以下代码: javascript else if(mb_strlen(theform.subject.value) < 20 && mb_strlen(theform.subject.value) > 0) { showError('您的标题不足10个汉字的字符数,请您将您要表达的主题表述清楚,然后再提交!'); return false; } 说明:20 表示 20 字节(约 10 汉字),可根据需要调整。 保存文件并上传。 参考来源: 三、设置回帖字数限制 Discuz! 原生系统中没有直接设置回帖(回复)字数限制的后台选项,但可以通过以下方式实现:
利用插件 安装第三方插件,如“帖子标签后台快速添加插件”或“限制重复发帖和回帖插件”,部分插件可能支持自定义回帖字数限制。 插件安装方法: 下载插件并解压到 source/plugin/ 目录。 进入后台 → 插件 → 安装并启用。 根据插件说明配置字数限制。 参考来源:,
自定义代码修改 若无合适插件,可通过修改发帖逻辑实现回帖字数限制: 打开文件:source/module/forum/forum_post.php。 查找处理回复提交的代码段(通常包含 message 字段的处理逻辑)。 添加字数检查逻辑,例如: php if (mb_strlen($_POST['message']) < 30) { // 最小 30 字节,约 10 汉字 showmessage('您的回复内容少于10个汉字,请输入更多内容!'); } 说明:具体代码位置和实现方式可能因版本不同而异,建议由熟悉 PHP 的开发者操作。 保存并上传文件。 参考来源:, 四、其他注意事项 用户组权限: 在 用户 → 用户组 → 编辑 中,检查是否启用了“允许编辑帖子”或“允许使用 HTML 代码”等权限,这些可能影响字数限制的实际效果。 可为不同用户组设置不同的发帖/回帖权限,但字数限制通常全局生效。 版块设置: 在 论坛 → 版块管理 → 编辑 → 帖子选项 中,检查是否启用了“发帖审核”或“允许编辑帖子”,这些设置可能间接影响内容长度管理。 SEO 和用户体验: 设置最小字数限制(如标题或回复)有助于防止灌水和提高 SEO 效果,但过高的限制可能影响用户体验,建议权衡设置。 测试与备份: 修改代码或数据库后,务必在测试环境中验证效果。 确保每次修改前备份数据库和相关文件,避免因错误导致论坛不可用。 参考来源:, 五、常见问题解答 如何取消字数限制? 对于帖子内容,可在后台将“帖子最大字数”设为 0(表示无限制,但不推荐,可能会导致性能问题)。 对于标题,需修改 forum_post.js 和数据库,将最大字符数设为更大值(如 255)。 不同用户组能否设置不同字数限制? 原生 Discuz! 不支持为不同用户组设置独立的字数限制,需通过自定义插件或修改 forum_post.php 实现。 修改后不生效怎么办? 检查是否清除了论坛缓存(后台 → 工具 → 更新缓存)。 确认修改的文件已正确上传到服务器。 检查是否因模板或插件冲突导致设置失效。 六、总结 帖子内容最大字数:通过后台“全局 → 用户权限”直接设置。 标题字数:修改数据库和 forum_post.js 文件,支持最大/最小字数限制。 回帖字数:需借助插件或自定义代码实现。 操作建议:备份文件和数据库,谨慎修改代码,必要时咨询专业开发者。 如果您有具体版本(如 X3.2 或 X3.4)或更详细的需求(如特定版块设置),请提供更多信息,我可以进一步优化答案!
0 notes
Text
exercício 24/04/2025
USE DBAGENDA;
CREATE TABLE Tbcurso( id_curso INT PRIMARY KEY IDENTITY (1,1), nome VARCHAR (80) Not Null, periodo VARCHAR (6) Not Null, ano INT Not Null, horas int);
CREATE TABLE Tbaluno( id_aluno INT PRIMARY KEY IDENTITY (1,1), fk_curso INT, registro_mat VARCHAR(80) not null, nome VARCHAR (90) not null, CPF VARCHAR (30) not null, email VARCHAR (60), sexo VARCHAR (10), datacad DATE, CONSTRAINT fk_cursoAluno FOREIGN KEY (fk_curso) REFERENCES Tbcurso (id_curso));
SELECT * FROM Tbaluno; SELECT *FROM Tbcurso;
INSERT INTO Tbcurso (nome, periodo, ano, horas) VALUES ('ads', 'noite', 2025, 200); INSERT INTO Tbaluno (fk_curso, registro_mat, nome, CPF, email, sexo, datacad) VALUES (1, '12345', 'jeffinho', '123456789', '[email protected]', 'M', '2025/04/25'); INSERT INTO Tbaluno (fk_curso, registro_mat, nome, CPF, email, sexo, datacad) VALUES (1, '123456', 'SAFIRA', '1234567897', '[email protected]', 'F', '2025/04/25'); INSERT INTO Tbaluno (fk_curso, registro_mat, nome, CPF, email, sexo, datacad) VALUES (1, '1234567', 'RÁ', '1234567895', '[email protected]', 'M', '2025/04/25');
0 notes
Text
SQL Database Fundamentals

SQL (Structured Query Language) is the standard language used to interact with relational databases. Whether you're building a small app or working on a large enterprise system, SQL is essential for storing, retrieving, and managing data effectively. This post introduces the key concepts and commands every beginner should know.
What is a Database?
A database is a structured collection of data that allows for easy access, management, and updating. SQL databases (like MySQL, PostgreSQL, and SQLite) organize data into tables that are related to each other.
What is SQL?
SQL stands for Structured Query Language. It is used to:
Create and manage databases
Insert, update, delete, and retrieve data
Control access and permissions
Basic SQL Commands
CREATE: Create a new database or table
INSERT: Add new data to a table
SELECT: Query and retrieve data
UPDATE: Modify existing data
DELETE: Remove data from a table
Example: Creating a Table
CREATE TABLE Users ( id INT PRIMARY KEY, name VARCHAR(100), email VARCHAR(100) );
Inserting Data
INSERT INTO Users (id, name, email) VALUES (1, 'Alice', '[email protected]');
Retrieving Data
SELECT * FROM Users;
Updating Data
UPDATE Users SET email = '[email protected]' WHERE id = 1;
Deleting Data
DELETE FROM Users WHERE id = 1;
Key Concepts to Learn
Tables and Rows: Tables store data in rows and columns.
Primary Keys: Unique identifier for each record.
Relationships: Data in one table can reference data in another.
Joins: Combine data from multiple tables.
Constraints: Rules for data integrity (e.g., NOT NULL, UNIQUE, FOREIGN KEY).
Common Types of SQL Databases
MySQL: Open-source and widely used for web development.
PostgreSQL: Advanced features and great performance.
SQLite: Lightweight, file-based database for small apps.
Microsoft SQL Server: Enterprise-grade database by Microsoft.
Helpful Resources
W3Schools SQL Tutorial
SQLZoo Interactive Learning
Codecademy Learn SQL
PostgreSQL Documentation
Conclusion
SQL is a foundational skill for anyone working with data or building applications. With just a few basic commands, you can begin managing and analyzing structured data effectively. Start practicing on a sample database and experiment with different queries — it’s the best way to learn!
0 notes
Text
蜘蛛池需要哪些脚本技术?
在互联网的海洋中,蜘蛛池(Spider Pool)是一个相对专业且重要的概念。它主要用于SEO优化、数据抓取等领域,通过模拟大量用户行为来提升网站的访问量和搜索引擎排名。要构建一个高效的蜘蛛池,掌握一定的脚本技术是必不可少的。本文将深入探讨构建蜘蛛池所需的关键脚本技术。
1. Python
Python 是构建蜘蛛池最常用的编程语言之一。其简洁易读的语法结构使得编写爬虫脚本变得非常高效。Python 社区提供了大量的库,如 `Scrapy` 和 `BeautifulSoup`,这些库可以极大地简化网页抓取和解析的过程。
示例代码
```python
import scrapy
from bs4 import BeautifulSoup
class MySpider(scrapy.Spider):
name = 'myspider'
start_urls = ['http://example.com']
def parse(self, response):
soup = BeautifulSoup(response.body, 'html.parser')
for link in soup.find_all('a'):
yield {'url': link.get('href')}
```
2. JavaScript
JavaScript 主要用于处理动态加载的内容。许多现代网站使用 JavaScript 来动态生成页面内容,这给传统的爬虫带来了挑战。因此,学会使用 JavaScript 技术(如 Node.js 和 Puppeteer)来模拟浏览器行为是非常重要的。
示例代码
```javascript
const puppeteer = require('puppeteer');
async function scrape() {
const browser = await puppeteer.launch();
const page = await browser.newPage();
await page.goto('http://example.com');
const content = await page.content();
console.log(content);
await browser.close();
}
scrape();
```
3. SQL
在处理大量数据时,数据库管理技能是必不可少的。SQL 用于存储和查询数据,确保蜘蛛池能够高效地管理和检索信息。
示例代码
```sql
CREATE TABLE urls (
id INT AUTO_INCREMENT PRIMARY KEY,
url VARCHAR(255) NOT NULL UNIQUE,
status INT DEFAULT 0
);
INSERT INTO urls (url) VALUES ('http://example.com');
```
结语
构建一个高效的蜘蛛池需要综合运用多种脚本技术。Python、JavaScript 和 SQL 是其中最为关键的技术栈。希望本文能为正在探索蜘蛛池领域的你提供一些启示。欢迎在评论区分享你的经验和建议!
请在评论区留下你的想法或问题,让我们一起讨论如何更好地利用脚本技术来优化蜘蛛池!
加飞机@yuantou2048

EPP Machine
ETPU Machine
0 notes
Text
Keys In DBMS
Introduction
A Database Management System (DBMS) is a system that manages data efficiently and provides secure storage and retrieval mechanisms. One of the fundamental concepts in DBMS is keys. Keys are attributes or sets of attributes that help in uniquely identifying records in a table. They play a crucial role in ensuring data integrity, avoiding redundancy, and establishing relationships between tables.
In this blog, we are going to discuss different types of keys in DBMS, their importance, and their usage in the design of the database.
Types of Keys in DBMS
1. Primary Key
A primary key is a column or a combination of columns that uniquely identifies each row in a table. It ensures that no two rows have the same value for this key and prevents NULL values.
For example:
CREATE TABLE Students (
StudentID INT PRIMARY KEY,
Name VARCHAR(50),
Age INT
);
In this case, StudentID is the primary key, meaning each student has a unique ID.
2. Candidate Key
A candidate key is a set of attributes that can uniquely identify a row in a table. A table can have multiple candidate keys, but only one is chosen as the primary key.
Example: In a table with StudentID and Email, both can uniquely identify a student, making them candidate keys. However, only one will be selected as the primary key.
3. Super Key
A super key is a superset of a candidate key. It can have additional attributes that may not be necessary for uniqueness.
Example:
{StudentID}
{StudentID, Name}
{StudentID, Email, Age}
All these are super keys, but {StudentID} alone is a candidate key since it is minimal.
4. Foreign Key
A foreign key is an attribute that establishes a relationship between two tables. It refers to the primary key in another table, ensuring referential integrity.
Example:
CREATE TABLE Orders (
OrderID INT PRIMARY KEY,
StudentID INT,
FOREIGN KEY (StudentID) REFERENCES Students(StudentID)
);
Here, StudentID in the Orders table is a foreign key referencing the StudentID from the Students table.
5. Composite Key
A composite key is two or more columns that, together, uniquely identify a record.
Example:
CREATE TABLE Enrollments (
StudentID INT,
CourseID INT,
PRIMARY KEY (StudentID, CourseID)
);
Here, StudentID and CourseID form a composite key because a student can enroll in more than one course.
6. Alternate Key
An alternate key is a candidate key that is not chosen as the primary key.
Example: If both StudentID and Email are candidate keys, and StudentID is chosen as the primary key, then Email becomes the alternate key.
7. Unique Key
A unique key ensures that all values in a column are distinct, similar to a primary key, but it can contain NULL values.
Example:
CREATE TABLE Employees (
EmpID INT PRIMARY KEY,
Email VARCHAR(100) UNIQUE
);
Here, Email is unique but can have NULL values, unlike the primary key.
Why Are Keys Important in DBMS?
1. Uniqueness: Ensures that each record in the table is uniquely identifiable.
2. Data Integrity: Prevents duplication and maintains consistency.
3. Efficient Indexing: Enhances database performance by enabling faster retrieval of records.
4. Referential Integrity: Maintains relationships between tables using foreign keys.
Conclusion
Keys are what constitute DBMS in organizing data in an efficient manner along with integrity and retrieval of it. Different types of keys-candidate, super, foreign, composite, alternate, and unique keys-are significant in designing robust databases.
Usage of keys in the right manner helps improve performance and also avoids data inconsistency.
Want to know more about advanced database concepts? Tune into our next blog!
Topic: Keys In DBMS
1.Akshad Giri
2.Harshal Patil
3.Manthan Thakare
4.Parikshita Bhoge
1 note
·
View note
Text
Database Design Best Practices for Full Stack Developers

Database Design Best Practices for Full Stack Developers Database design is a crucial aspect of building scalable, efficient, and maintainable web applications.
Whether you’re working with a relational database like MySQL or PostgreSQL, or a NoSQL database like MongoDB, the way you design your database can greatly impact the performance and functionality of your application.
In this blog, we’ll explore key database design best practices that full-stack developers should consider to create robust and optimized data models.
Understand Your Application’s Requirements Before diving into database design, it’s essential to understand the specific needs of your application.
Ask yourself:
What type of data will your application handle? How will users interact with your data? Will your app scale, and what level of performance is required? These questions help determine whether you should use a relational or NoSQL database and guide decisions on how data should be structured and optimized.
Key Considerations:
Transaction management: If you need ACID compliance (Atomicity, Consistency, Isolation, Durability), a relational database might be the better choice. Scalability: If your application is expected to grow rapidly, a NoSQL database like MongoDB might provide more flexibility and scalability.
Complex queries: For applications that require complex querying, relationships, and joins, relational databases excel.
2. Normalize Your Data (for Relational Databases) Normalization is the process of organizing data in such a way that redundancies are minimized and relationships between data elements are clearly defined. This helps reduce data anomalies and improves consistency.
Normal Forms:
1NF (First Normal Form): Ensures that the database tables have unique rows and that columns contain atomic values (no multiple values in a single field).
2NF (Second Normal Form):
Builds on 1NF by eliminating partial dependencies. Every non-key attribute must depend on the entire primary key.
3NF (Third Normal Form):
Ensures that there are no transitive dependencies between non-key attributes.
Example: In a product order system, instead of storing customer information in every order record, you can create separate tables for Customers, Orders, and Products to avoid duplication and ensure consistency.
3. Use Appropriate Data Types Choosing the correct data type for each field is crucial for both performance and storage optimization.
Best Practices: Use the smallest data type possible to store your data (e.g., use INT instead of BIGINT if the range of numbers doesn’t require it). Choose the right string data types (e.g., VARCHAR instead of TEXT if the string length is predictable).
Use DATE or DATETIME for storing time-based data, rather than storing time as a string. By being mindful of data types, you can reduce storage usage and optimize query performance.
4. Use Indexing Effectively Indexes are crucial for speeding up read operations, especially when dealing with large datasets.
However, while indexes improve query performance, they can slow down write operations (insert, update, delete), so they must be used carefully. Best Practices: Index fields that are frequently used in WHERE, JOIN, ORDER BY, or GROUP BY clauses.
Avoid over-indexing — too many indexes can degrade write performance. Consider composite indexes (indexes on multiple columns) when queries frequently involve more than one column.
For NoSQL databases, indexing can vary. In MongoDB, for example, create indexes based on query patterns.
Example: In an e-commerce application, indexing the product_id and category_id fields can greatly speed up product searches.
5. Design for Scalability and Performance As your application grows, the ability to scale the database efficiently becomes critical. Designing your database with scalability in mind helps ensure that it can handle large volumes of data and high numbers of concurrent users.
Best Practices:
Sharding:
For NoSQL databases like MongoDB, consider sharding, which involves distributing data across multiple servers based on a key.
Denormalization: While normalization reduces redundancy, denormalization (storing redundant data) may be necessary in some cases to improve query performance by reducing the need for joins. This is common in NoSQL databases.
Caching: Use caching strategies (e.g., Redis, Memcached) to store frequently accessed data in memory, reducing the load on the database.
6. Plan for Data Integrity Data integrity ensures that the data stored in the database is accurate and consistent. For relational databases, enforcing integrity through constraints like primary keys, foreign keys, and unique constraints is vital.
Best Practices: Use primary keys to uniquely identify records in a table. Use foreign keys to maintain referential integrity between related tables. Use unique constraints to enforce uniqueness (e.g., for email addresses or usernames). Validate data at both the application and database level to prevent invalid or corrupted data from entering the system.
7. Avoid Storing Sensitive Data Without Encryption For full-stack developers, it’s critical to follow security best practices when designing a database.
Sensitive data (e.g., passwords, credit card numbers, personal information) should always be encrypted both at rest and in transit.
Best Practices:
Hash passwords using a strong hashing algorithm like bcrypt or Argon2. Encrypt sensitive data using modern encryption algorithms. Use SSL/TLS for encrypted communication between the client and the server.
8. Plan for Data Backup and Recovery Data loss can have a devastating effect on your application, so it’s essential to plan for regular backups and disaster recovery.
Best Practices:
Implement automated backups for the database on a daily, weekly, or monthly basis, depending on the application. Test restore procedures regularly to ensure you can quickly recover from data loss. Store backups in secure, geographically distributed locations to protect against physical disasters.
9. Optimize for Queries and Reporting As your application evolves, it’s likely that reporting and querying become critical aspects of your database usage. Ensure your schema and database structure are optimized for common queries and reporting needs.
Conclusion
Good database design is essential for building fast, scalable, and reliable web applications.
By following these database design best practices, full-stack developers can ensure that their applications perform well under heavy loads, remain easy to maintain, and support future growth.
Whether you’re working with relational databases or NoSQL solutions, understanding the core principles of data modeling, performance optimization, and security will help you build solid foundations for your full-stack applications.

0 notes
Text
Firebird to Cassandra Migration – Ask On Data
Migrating from Firebird, a relational database, to Cassandra, a NoSQL database, is a significant shift that enables businesses to harness scalability and distributed computing. The process of Firebird to Cassandra Migration requires careful planning, schema redesign, and data transformation to ensure the transition is smooth and effective.
Why Migrate from Firebird to Cassandra?
Scalability: Firebird is designed for small to medium workloads, whereas Cassandra excels in handling large-scale distributed systems with high availability.
Flexibility: Cassandra’s schema-less structure allows for easier adjustments to evolving data requirements compared to Firebird’s fixed schema.
High Availability: Cassandra’s architecture provides fault tolerance and ensures continuous operation, making it ideal for applications requiring zero downtime.
Steps for Firebird to Cassandra Migration
1. Assessment and Planning
Start by analysing your Firebird database, including schema structure, relationships, and data types. Determine the equivalent Cassandra table structure, considering its denormalized data model. Identify key queries to design tables with optimal partitioning and clustering keys.
2. Schema Redesign
Since Cassandra does not support relational concepts like joins and foreign keys, redesign your schema for denormalized tables. For example, a normalized Orders and Customers relationship in Firebird may need to be combined into a single table in Cassandra to optimize read performance.
3. Data Transformation
Export data from Firebird using tools like fbexport or custom SQL queries. Convert the data into a format compatible with Cassandra, such as CSV. Map Firebird data types to Cassandra types; for instance, Firebird’s VARCHAR maps to Cassandra’s TEXT.
4. Data Loading
Use Cassandra’s COPY command or tools like cqlsh and ETL (Extract, Transform, Load) pipelines to load data. For large datasets, tools like Apache Spark can facilitate distributed processing for faster migration.
5. Testing and Validation
After loading the data, validate its accuracy by running sample queries on Cassandra and comparing results with Firebird. Test the application functionality to ensure that queries perform as expected in the new database.
6. Cutover and Monitoring
Once testing is complete, switch your application’s backend to Cassandra. Monitor the system for performance and consistency issues during the initial phase to address any anomalies promptly.
Challenges in Firebird to Cassandra Migration
Schema Mapping: Transitioning from a relational to a NoSQL schema requires a paradigm shift in data modeling.
Data Volume: Migrating large datasets can be time-intensive and requires robust tools to avoid errors.
Application Refactoring: Applications may need updates to adapt to Cassandra’s query language (CQL) and denormalized data model.
Why Choose Ask On Data for Migration?
Ask On Data simplifies the complex process of Firebird to Cassandra Migration with its advanced automation and robust features. Designed to handle intricate database transitions, Ask On Data ensures:
Data Integrity: Accurate data mapping and transformation to avoid inconsistencies.
Efficiency: Optimized migration workflows to minimize downtime.
Scalability: Support for large-scale migrations with distributed systems compatibility.
With Ask On Data, businesses can achieve seamless transitions from Firebird to Cassandra, unlocking the full potential of a scalable, high-performance database solution.
Conclusion
Migrating from Firebird to Cassandra is a transformative step for organizations aiming to scale their applications and achieve high availability. By following a structured approach and leveraging tools like Ask On Data, businesses can ensure a successful migration that empowers them to meet growing demands efficiently.
0 notes
Text
Python Full Stack Development Course AI + IoT Integrated | TechEntry
Join TechEntry's No.1 Python Full Stack Developer Course in 2025. Learn Full Stack Development with Python and become the best Full Stack Python Developer. Master Python, AI, IoT, and build advanced applications.
Why Settle for Just Full Stack Development? Become an AI Full Stack Engineer!
Transform your development expertise with our AI-focused Full Stack Python course, where you'll master the integration of advanced machine learning algorithms with Python’s robust web frameworks to build intelligent, scalable applications from frontend to backend.
Kickstart Your Development Journey!
Frontend Development
React: Build Dynamic, Modern Web Experiences:
What is Web?
Markup with HTML & JSX
Flexbox, Grid & Responsiveness
Bootstrap Layouts & Components
Frontend UI Framework
Core JavaScript & Object Orientation
Async JS promises, async/await
DOM & Events
Event Bubbling & Delegation
Ajax, Axios & fetch API
Functional React Components
Props & State Management
Dynamic Component Styling
Functions as Props
Hooks in React: useState, useEffect
Material UI
Custom Hooks
Supplement: Redux & Redux Toolkit
Version Control: Git & Github
Angular: Master a Full-Featured Framework:
What is Web?
Markup with HTML & Angular Templates
Flexbox, Grid & Responsiveness
Angular Material Layouts & Components
Core JavaScript & TypeScript
Asynchronous Programming Promises, Observables, and RxJS
DOM Manipulation & Events
Event Binding & Event Bubbling
HTTP Client, Ajax, Axios & Fetch API
Angular Components
Input & Output Property Binding
Dynamic Component Styling
Services & Dependency Injection
Angular Directives (Structural & Attribute)
Routing & Navigation
Reactive Forms & Template-driven Forms
State Management with NgRx
Custom Pipes & Directives
Version Control: Git & GitHub
Backend
Python
Python Overview and Setup
Networking and HTTP Basics
REST API Overview
Setting Up a Python Environment (Virtual Environments, Pip)
Introduction to Django Framework
Django Project Setup and Configuration
Creating Basic HTTP Servers with Django
Django URL Routing and Views
Handling HTTP Requests and Responses
JSON Parsing and Form Handling
Using Django Templates for Rendering HTML
CRUD API Creation and RESTful Services with Django REST Framework
Models and Database Integration
Understanding SQL and NoSQL Database Concepts
CRUD Operations with Django ORM
Database Connection Setup in Django
Querying and Data Handling with Django ORM
User Authentication Basics in Django
Implementing JSON Web Tokens (JWT) for Security
Role-Based Access Control
Advanced API Concepts: Pagination, Filtering, and Sorting
Caching Techniques for Faster Response
Rate Limiting and Security Practices
Deployment of Django Applications
Best Practices for Django Development
Database
MongoDB (NoSQL)
Introduction to NoSQL and MongoDB
Understanding Collections and Documents
Basic CRUD Operations in MongoDB
MongoDB Query Language (MQL) Basics
Inserting, Finding, Updating, and Deleting Documents
Using Filters and Projections in Queries
Understanding Data Types in MongoDB
Indexing Basics in MongoDB
Setting Up a Simple MongoDB Database (e.g., MongoDB Atlas)
Connecting to MongoDB from a Simple Application
Basic Data Entry and Querying with MongoDB Compass
Data Modeling in MongoDB: Embedding vs. Referencing
Overview of Aggregation Framework in MongoDB
SQL
Introduction to SQL (Structured Query Language)
Basic CRUD Operations: Create, Read, Update, Delete
Understanding Tables, Rows, and Columns
Primary Keys and Unique Constraints
Simple SQL Queries: SELECT, WHERE, and ORDER BY
Filtering Data with Conditions
Using Aggregate Functions: COUNT, SUM, AVG
Grouping Data with GROUP BY
Basic Joins: Combining Tables (INNER JOIN)
Data Types in SQL (e.g., INT, VARCHAR, DATE)
Setting Up a Simple SQL Database (e.g., SQLite or MySQL)
Connecting to a SQL Database from a Simple Application
Basic Data Entry and Querying with a GUI Tool
Data Validation Basics
Overview of Transactions and ACID Properties
AI and IoT
Introduction to AI Concepts
Getting Started with Python for AI
Machine Learning Essentials with scikit-learn
Introduction to Deep Learning with TensorFlow and PyTorch
Practical AI Project Ideas
Introduction to IoT Fundamentals
Building IoT Solutions with Python
IoT Communication Protocols
Building IoT Applications and Dashboards
IoT Security Basics
TechEntry Highlights
In-Office Experience: Engage in a collaborative in-office environment (on-site) for hands-on learning and networking.
Learn from Software Engineers: Gain insights from experienced engineers actively working in the industry today.
Career Guidance: Receive tailored advice on career paths and job opportunities in tech.
Industry Trends: Explore the latest software development trends to stay ahead in your field.
1-on-1 Mentorship: Access personalized mentorship for project feedback and ongoing professional development.
Hands-On Projects: Work on real-world projects to apply your skills and build your portfolio.
What You Gain:
A deep understanding of Front-end React.js and Back-end Python.
Practical skills in AI tools and IoT integration.
The confidence to work on real-time solutions and prepare for high-paying jobs.
The skills that are in demand across the tech industry, ensuring you're not just employable but sought-after.
Frequently Asked Questions
Q: What is Python, and why should I learn it?
A: Python is a versatile, high-level programming language known for its readability and ease of learning. It's widely used in web development, data science, artificial intelligence, and more.
Q: What are the prerequisites for learning Angular?
A: A basic understanding of HTML, CSS, and JavaScript is recommended before learning Angular.
Q: Do I need any prior programming experience to learn Python?
A: No, Python is beginner-friendly and designed to be accessible to those with no prior programming experience.
Q: What is React, and why use it?
A: React is a JavaScript library developed by Facebook for building user interfaces, particularly for single-page applications. It offers reusable components, fast performance, and one-way data flow.
Q: What is Django, and why should I learn it?
A: Django is a high-level web framework for building web applications quickly and efficiently using Python. It includes many built-in features for web development, such as authentication and an admin interface.
Q: What is the virtual DOM in React?
A: The virtual DOM represents the real DOM in memory. React uses it to detect changes and update the real DOM as needed, improving UI performance.
Q: Do I need to know Python before learning Django?
A: Yes, a basic understanding of Python is essential before diving into Django.
Q: What are props in React?
A: Props in React are objects used to pass information to a component, allowing data to be shared and utilized within the component.
Q: Why should I learn Angular?
A: Angular is a powerful framework for building dynamic, single-page web applications. It enhances your ability to create scalable and maintainable web applications and is highly valued in the job market.
Q: What is the difference between class-based components and functional components with hooks in React?
A: Class-based components maintain state via instances, while functional components use hooks to manage state, making them more efficient and popular.
For more, visit our website:
https://techentry.in/courses/python-fullstack-developer-course
0 notes