#Web Data Mining Companies
Explore tagged Tumblr posts
Visit Tumblr Blog
Explore Tumblr blogs with no restrictions, modern design and the best experience.
Last Seen Tumblr Blogs





Fun Fact
In 2020, 27% of US Tumblr users had an annual household income of over $100,000.
Text
Outsource Web Data Mining Services in India

Relevant data is a never-ending need for businesses. However, the heterogeneous data collection via the right scripts and APIs is sometimes challenging and time-consuming. This is where data mining services help enterprises. Data Entry Expert is one of the top data mining service provider companies in India with practised data extraction experts to recognise the perfect sources of data. They can set up effective web crawlers and can handle large volumes of data. Plus, our data mining services help to extract relevant information from different web sources with over 99% accuracy. You can leverage our services to expedite insight analysis of your business process without investing in technology, infrastructure, or resources.
To know more - https://www.dataentryexpert.com/web-research/web-mining-services.php
#Web Mining#Web Data Mining#Web Mining Company#Web Mining Services#Web Mining Service#Web Data Mining in India#Web Data Mining Services#Web Data Mining Companies#Outsource Web Data Mining#Best Web Data Mining Services
0 notes
Text
From Overhead to Advantage: Leverage the Power of Outsourced Data Mining Services
At Damco Solutions, our highly skilled teams specialize in data mining, gathering information from the internet or scanned documents, and structuring it for effortless retrieval. We offer tailored web data mining services to assist businesses in enhancing profitability, streamlining customer interactions, identifying fraud, and enhancing risk management.

#web data mining companies#web data mining services#data mining companies#data mining services#data mining
0 notes
Text

Data mining companies have the potential required to extract useful insights from carefully scrutinized resources. These insights help businesses make informed decisions, map out effective strategies, streamline operations, and boost profits.
0 notes
Text
Mastering Data Collection in Machine Learning: A Comprehensive Guide -
Artificial intelligence, mastering the art of data collection is paramount to unlocking the full potential of machine learning algorithms. By adopting systematic methods, overcoming challenges, and adopting best practices, organizations can harness the power of data to drive innovation, gain competitive advantage, and provide transformative solutions across various domains. Through careful data collection, Globose Technology Solutions remains at the forefront of AI innovation, enabling clients to harness the power of data-driven insights for sustainable growth and success.
#Data Collection#Machine Learning#Artificial Intelligence#Data Quality#Data Privacy#Web Scraping#Sensor Data Acquisition#Data Labeling#Bias in Data#Data Analysis#Public Datasets#Data-driven Decision Making#Data Mining#Data Visualization#data collection company#dataset
1 note
·
View note
Text
Key Benefits of Outsourcing Web Data Extraction Services

Web data extraction is like a knowledge discovery process, researching and extracting relevant information for generating useful insights for business. Unleash the power of data extraction and enhance the decision-making process with accuracy.
Our team at Uniquesdata can assist your data extraction requirements with precise outcomes.
#data extraction services#web data extraction#online data processing services#web data extraction services#data extraction companies#data mining companies#data extraction company#data extraction specialist#data entry services#outsourcing data entry services#data entry outsourcing companies in usa
0 notes
Text

For companies of all sizes, Outsource Bigdata provides web data mining services in digital content. Our team analyses content and gathers data according to your requirements using cutting-edge mining technology. Your company can use data mining web services to acquire massive quantities of internet data and use it to gather information and gain insights.
For more details visit: https://outsourcebigdata.com/data-automation/web-scraping-services/data-mining-web-services/
About AIMLEAP
Outsource Bigdata is a division of Aimleap. AIMLEAP is an ISO 9001:2015 and ISO/IEC 27001:2013 certified global technology consulting and service provider offering AI-augmented Data Solutions, Data Engineering, Automation, IT Services, and Digital Marketing Services. AIMLEAP has been recognized as a ‘Great Place to Work®’.
With special focus on AI and automation, we built quite a few AI & ML solutions, AI-driven web scraping solutions, AI-data Labeling, AI-Data-Hub, and Self-serving BI solutions. We started in 2012 and successfully delivered projects in IT & digital transformation, automation driven data solutions, on-demand data, and digital marketing for more than 750 fast-growing companies in the USA, Europe, New Zealand, Australia, Canada; and more.
An ISO 9001:2015 and ISO/IEC 27001:2013 certified
Served 750+ customers
11+ Years of industry experience
98% client retention
Great Place to Work® certified
Global delivery centers in the USA, Canada, India & Australia
Our Data Solutions
APISCRAPY: AI driven web scraping & workflow automation platform
APYSCRAPY is an AI driven web scraping and automation platform that converts any web data into ready-to-use data. The platform is capable to extract data from websites, process data, automate workflows, classify data and integrate ready to consume data into database or deliver data in any desired format.
AI-Labeler: AI augmented annotation & labeling solution
AI-Labeler is an AI augmented data annotation platform that combines the power of artificial intelligence with in-person involvement to label, annotate and classify data, and allowing faster development of robust and accurate models.
AI-Data-Hub: On-demand data for building AI products & services
On-demand AI data hub for curated data, pre-annotated data, pre-classified data, and allowing enterprises to obtain easily and efficiently, and exploit high-quality data for training and developing AI models.
PRICESCRAPY: AI enabled real-time pricing solution
An AI and automation driven price solution that provides real time price monitoring, pricing analytics, and dynamic pricing for companies across the world.
APIKART: AI driven data API solution hub
APIKART is a data API hub that allows businesses and developers to access and integrate large volume of data from various sources through APIs. It is a data solution hub for accessing data through APIs, allowing companies to leverage data, and integrate APIs into their systems and applications.
Locations:
USA: 1-30235 14656
Canada: +1 4378 370 063
India: +91 810 527 1615
Australia: +61 402 576 615
Email: [email protected]
0 notes
Text
trying out Obsidian, my first setup, my opinions, etc.
Okay, so this is going to be a long post. Earlier this week I decided to give Obsidian a go to see if it would work for my longer writing projects. I heard some of my mutuals use it and others would like to see my setup, so I'm making a post about what I learned so far. I downloaded it three days ago so I'm sure things will change, but this is where I am right now.
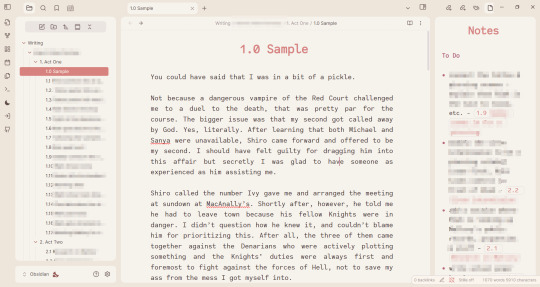
I'm shy about my WIPs so what you see there is the beginning of heart worth the trouble. But hopefully, this lets you see my folder structure and the links in the notes.
My wishlist and how I got here
I recently wrote a rambly post about writing software which got way more notes than I expected (bc the lovely @barbex reblogged it <3). After I made that post, I started using Focus Writer (again a recommendation from the writing discord) for my discovery writing in March. After more than two weeks of heavy use, I realized I needed a little bit more than that (but it's a great program).
Initially, I tried combining it with Wavemaker bc I liked that when I played around with it, but that completely pissed me off, bc it turns out it's just not compatible with other things I'm using. Like Firefox. -.-
Still, this whole ordeal made me narrow down what I really want and need from a piece of writing software at this moment. I think it's a good idea to start with such a wishlist if you are looking for a new software. Here is mine:
free
no account required, not stored on someone else's cloud, I can back it up wherever I want instead
Linux support
widely compatible file formats
focus mode, where it's full-screen, and ideally highlights the paragraph you are working on
I can make it look nice and calming on the eyes currently all I want is a cream paper background look, and a friendly monospace font changed to brown or something
clicky keyboard/typewriter noises - luckily I got this covered by Mechvibes already!
something like the card feature in Wavemaker, where I can have individual notes and choose to display them on the side. this might sound like it conflicts with the focus mode but I just want to have the option to have some notes without having to vomit them into the draft
easy to rearrange the order of the scenes
wordcount obviously
Tall order? Weird order? Maybe.
I think the most important is to figure out is how you work as a writer and find tools that match that. This is just honestly what is important for me right now.
It seems like Obsidian might just do this.
it's free
doesn't require an account
text is stored locally in markdown files
works on Linux I'm using the AppImage if you want to know
can be integrated with Github for backup & sync
tons of customization options to achieve the rest of my requirements
The Basics
If you want to use Obsidian for note-taking (or for writing fic but you're not very picky about the how), you can pretty much just download it, pick a pretty theme if you want and you're good to go. It's that easy. I promise it's not as hard as people make you believe.
This is a local-first software, which I love. However, this also means if you are not used to storing your writing locally, you need to get into the habit of backing your things up because if something happens to your computer, there is no copy of your files on the web.
That said, you can pay I think 4USD/month for the subscription and then you'll have an account, and your files will get synched to other devices, and you can restore your files. (And remember, if something is free and doesn't have ads and you have cloud storage space you didn't have to pay for... then you are the product and the company is paying for it with your data. So the fact that this is paid is actually a very good thing.)
The file structure works pretty much 1:1 as your file explorer btw
If you create a folder on the sidebar, it will create a folder on your computer.
If you create a note on the sidebar, it will create a text file on your computer.
If you drag the note into the folder on the sidebar, it will put the text file in the folder on your computer.
Each note is stored as a separate markdown file. Markdown files are widely compatible with various software so that's great. Also, you can even just rename the file to have .txt extension instead of .md extension and literally every text editor will open it for you (you will lose the formatting tho). The opposite also works. If you have a note in .txt format, you can copy it into your Obsidian folder, rename the extension to .md and it will appear in Obsidian.
That all makes it very easy to import things and switch between files to edit them.
There is only one downside to this that I found. You know how in your file explorer you can drag and drop files into folders but you can't drag and drop files to change their order? Well, your Obsidian side-bar is the same. You can choose to order them based on the name, last modified, etc. But if you want custom order, I suggest you number your notes and folders.
I feel like we're not that used to this anymore but again, this is literally like a file explorer, so it's not a big deal imo.
Another important basic concept is linking your notes. You can just right-click a piece of text and link a note, drag and drop the note into your other note, or do [[Note]] whatever you like. Then you can quickly access the other note by clicking on it, or see a preview while hovering over it (If you turned that feature on). Linking notes is also how you get those cool graph views.
I just wanted to mention all of this bc I feel like all the videos I came across on Obsidian intimidate people into thinking it's more complex than that lol
Appearance
I go a little crazy about visual optimization if you give me a chance. You can change a couple of simple things out the box. Light/dark theme, change the font, etc. I'm using a font called Code Saver for the editor (regular is free for personal use).
Then, there are the themes you can download. There are so many awesome ones! I'm using one called Underwater right now bc I liked the rounded edges.
Most themes come with a light/dark version. But if you download the Style Settings plugin, you might unlock more easy-to-customize options. It depends on the theme what you see there. The one I'm using has a couple of built-in colorways. I went with the "rose pine dawn" option and then I switched out some colors in the color pickers. If you want to mess with the colors I highly recommend finding some hex color palettes online, they make your life so much easier. You can find colors that look good together and look up a color and find lighter/darker versions instead of trying to blindly click around on the color picker.
For this theme, you can also add a background image if you want. (If you really want to make it look like Focus Writer for example ;)

Plugins
These are the plugins I'm using right now.
GitHub Sync: This is what I use to sync my progress and back up my files. I started with this before anything else, but I'm not going to go into what I did bc I don't want to make this post even more complicated. If you have a specific question about it, pls feel free to ask me :)
Focus Mode: This is a full-screen mode, very nice for writing
Stille: Dims everything but the active paragraph, again, very nice for writing. I found that the combination of these two plugins work best for me, but there are others like Typewriter Mode that can do both (I couldn't turn down the vignette mode on that one tho and it was annoying me)
Smart Typography: switches the straight quotation marks for curly ones

This is how it looks with Focus Mode and Stiille both on.
And lastly, a bit of a disappointment: Longform. This is the plugin that everyone seems to recommend for longer writing projects in Obisdian. Basically what it does is it can compile your individual notes into one file, and allows you to move the order of them freely, unlike the normal Obsidian sidebar. Here is a pretty good video on it.
Unfortunately, this plugin gets absolutely wrecked by synchronizing to another device.
From what I gathered, this happens regardless of what method of synching you use, meaning it happens even with the paid synching feature. You can read about this more here btw. It's a community plugin so I'm not going to be mad at the creators for not fixing this, however this means it just doesn't work for me.
If it worked on the one computer where I originally set it up, just not on the other, I would be fine with it. But I set it up on my Linux, and after I synched to my Windows, the scene list disappeared from both. (Not the actual files! It just doesn't get recognized as a Longform project anymore so it pretty much becomes useless lol)
So, I just decided to create the the same structure with folders and notes. Right now, this is a discovery draft and I don't have chapters. But I'm making a folder for an "Arc", and put the numbered scenes into them. I'm also making separate notes that I can link with stuff I want to remember/work on.
At the moment I don't require an extensive wiki where I note what each of the characters like to have for breakfast and such. But you can absolutely do that with Obsidian. You can create a folder for Characters, Worldbuilding, whatever you want, really. Put images there, links both internal and on the web and just go wild if you want.
Obviously, without Longform I will need to compile the files into one at the end by a different method, like copy-paste into one, turn them into .txt, and concatenate from the terminal, you know, depending on your comfort level xD. It will probably include more work than with this plugin, but it's not like you don't go through your manuscript about a million times anyways, am I right?
Word Count
Lastly, mentioning the wordcount options bc they are important
there is a built-in wordcount, about which the common agreement is that it's not very good lol
because of this there is a community plugin called Better Wordcount, which is self-explanatory. If you want to get the total word count, you can right-click the top folder of your project and ask it to count the words for you.
Longform also has a wordcount and it will display it like words of the scene/total words of the project if you are using that
if you don't want to have three different word counts displayed I recommend you only have one of these active (:
That's where I am right now. If you have read all this to the end, you're awesome, and also we both should stop procrastinating and go write instead :P But if you also use Obsidian for writing and have cool tips pls let me know xx
#nara's writing diary#nara rambles about writing software again#obsidian#writing software#tech stuff#long post
25 notes
·
View notes
Text
"As countries around the world begin to either propose or enforce zero-deforestation regulations, companies are coming under growing pressure to prove that their products are free of deforestation. But this is often a far from straightforward process.
Take palm oil, for instance. Its journey from plantations, most likely in Indonesia or Malaysia, to store shelves in the form of shampoo, cookies or a plethora of other goods, is a long and convoluted one. In fact, the cooking oil or cosmetics we use might contain palm oil processed in several different mills, which in turn may have bought the raw palm fruit from several of the many thousands of plantations. For companies that use palm oil in their products, tracing and tracking its origins through these obscure supply chains is a tough task. Often it requires going all the way back to the plot level and checking for deforestation. However, these plots are scattered over vast areas across potentially millions of locations, with data being in various states of digitization and completeness...
Palmoil.io, a web-based monitoring platform that Bottrill launched, is attempting to help palm oil companies get around this hurdle. Its PlotCheck tool allows companies to upload plot boundaries and check for deforestation without any of the data being stored in their system. In the absence of an extensive global map of oil palm plots, the tool was developed to enable companies to prove compliance with regulations without having to publicly disclose detailed data on their plots. PlotCheck now spans 13 countries including Indonesia and Malaysia, and aims to include more in the coming months.
Palm oil production is a major driver of deforestation in Indonesia and Malaysia, although deforestation rates linked to it have declined in recent years. While efforts to trace illegally sourced palm oil have ramped up in recent years, tracing it back to the source continues to be a challenge owing to the complex supply chains involved.
Recent regulatory proposals have, however, made it imperative for companies to find a way to prove that their products are free of deforestation. Last June, the European Union passed legislation that prohibits companies from sourcing products, including palm oil, from land deforested after 2020. A similar law putting the onus on businesses to prove that their commodities weren’t produced on deforested land is also under discussion in the U.K. In the U.S., the U.S. Forest Bill aims to work toward a similar goal, while states like New York are also discussing legislation to discourage products produced on deforested land from being circulated in the markets there...
PlotCheck, which is now in its beta testing phase, allows users to input the plot data in the form of a shape file. Companies can get this data from palm oil producers. The plot data is then checked and analyzed with the aid of publicly available deforestation data, such as RADD (Radar for Detecting Deforestation) alerts that are based on data from the Sentinel-1 satellite network and from NASA’s Landsat satellites. The tool also uses data available on annual tree cover loss and greenhouse gas emission from plantations.
Following the analysis, the tool displays an interactive online map that indicates where deforestation has occurred within the plot boundaries. It also shows details on historical deforestation in the plot as well as data on nearby mills. If deforestation is detected, users have the option of requesting the team to cross-check the data and determine if it was indeed caused by oil palm cultivation, and not logging for artisanal mining or growing other crops. “You could then follow up with your supplier and say there is a potential red flag,” Bottrill said.
As he waits to receive feedback from users, Bottrill said he’s trying to determine how to better integrate PlotCheck into the workflow of companies that might use the tool. “How can we take this information, verify it quickly and turn it into a due diligence statement?” he said. “The output is going to be a statement, which companies can submit to authorities to prove that their shipment is deforestation-free.” ...
Will PlotCheck work seamlessly? That’s something Bottrill said he’s cautiously optimistic about. He said he’s aware of the potential challenges with regard to data security and privacy. However, he said, given how zero-deforestation legislation like that in the EU are unprecedented in their scope, companies will need to sit up and take action to monitor deforestation linked to their products.
“My perspective is we should use the great information produced by universities, research institutes, watchdog groups and other entities. Plus, open-source code allows us to do things quickly and pretty inexpensively,” he said. “So I am positive that it can be done.”"
-via Mongabay, January 26, 2024
--
Note: I know it's not "stop having palm oil plantations." (A plan I'm in support of...monocrop plantations are always bad, and if palm oil production continues, it would be much better to produce it using sustainable agroforestry techniques.)
However, this is seriously a potentially huge step/tool. Since the EU's deforestation regulations passed, along with other whole-supply-chain regulations, people have been really worried about how the heck we're going to enforce them. This is the sort of tool we need/need the industry to have to have a chance of genuinely making those regulations actually work. Which, if it does work, it could be huge.
It's also a great model for how to build supply chain monitoring for other supply chain regulations, like the EU's recent ban on companies destroying unsold clothes.
#deforestation#palm oil#indonesia#malaysia#agriculture#european union#united states#save the forest#open source#technology#mapping#forestry#satellite#good news#hope#climate solutions#environment
123 notes
·
View notes
Text
A link-clump demands a linkdump

Cometh the weekend, cometh the linkdump. My daily-ish newsletter includes a section called "Hey look at this," with three short links per day, but sometimes those links get backed up and I need to clean house. Here's the eight previous installments:
https://pluralistic.net/tag/linkdump/
The country code top level domain (ccTLD) for the Caribbean island nation of Anguilla is .ai, and that's turned into millions of dollars worth of royalties as "entrepreneurs" scramble to sprinkle some buzzword-compliant AI stuff on their businesses in the most superficial way possible:
https://arstechnica.com/information-technology/2023/08/ai-fever-turns-anguillas-ai-domain-into-a-digital-gold-mine/
All told, .ai domain royalties will account for about ten percent of the country's GDP.
It's actually kind of nice to see Anguilla finding some internet money at long last. Back in the 1990s, when I was a freelance web developer, I got hired to work on the investor website for a publicly traded internet casino based in Anguilla that was a scammy disaster in every conceivable way. The company had been conceived of by people who inherited a modestly successful chain of print-shops and decided to diversify by buying a dormant penny mining stock and relaunching it as an online casino.
But of course, online casinos were illegal nearly everywhere. Not in Anguilla – or at least, that's what the founders told us – which is why they located their servers there, despite the lack of broadband or, indeed, reliable electricity at their data-center. At a certain point, the whole thing started to whiff of a stock swindle, a pump-and-dump where they'd sell off shares in that ex-mining stock to people who knew even less about the internet than they did and skedaddle. I got out, and lost track of them, and a search for their names and business today turns up nothing so I assume that it flamed out before it could ruin any retail investors' lives.
Anguilla is a British Overseas Territory, one of those former British colonies that was drained and then given "independence" by paternalistic imperial administrators half a world away. The country's main industries are tourism and "finance" – which is to say, it's a pearl in the globe-spanning necklace of tax- and corporate-crime-havens the UK established around the world so its most vicious criminals – the hereditary aristocracy – can continue to use Britain's roads and exploit its educated workforce without paying any taxes.
This is the "finance curse," and there are tiny, struggling nations all around the world that live under it. Nick Shaxson dubbed them "Treasure Islands" in his outstanding book of the same name:
https://us.macmillan.com/books/9780230341722/treasureislands
I can't imagine that the AI bubble will last forever – anything that can't go on forever eventually stops – and when it does, those .ai domain royalties will dry up. But until then, I salute Anguilla, which has at last found the internet riches that I played a small part in bringing to it in the previous century.
The AI bubble is indeed overdue for a popping, but while the market remains gripped by irrational exuberance, there's lots of weird stuff happening around the edges. Take Inject My PDF, which embeds repeating blocks of invisible text into your resume:
https://kai-greshake.de/posts/inject-my-pdf/
The text is tuned to make resume-sorting Large Language Models identify you as the ideal candidate for the job. It'll even trick the summarizer function into spitting out text that does not appear in any human-readable form on your CV.
Embedding weird stuff into resumes is a hacker tradition. I first encountered it at the Chaos Communications Congress in 2012, when Ang Cui used it as an example in his stellar "Print Me If You Dare" talk:
https://www.youtube.com/watch?v=njVv7J2azY8
Cui figured out that one way to update the software of a printer was to embed an invisible Postscript instruction in a document that basically said, "everything after this is a firmware update." Then he came up with 100 lines of perl that he hid in documents with names like cv.pdf that would flash the printer when they ran, causing it to probe your LAN for vulnerable PCs and take them over, opening a reverse-shell to his command-and-control server in the cloud. Compromised printers would then refuse to apply future updates from their owners, but would pretend to install them and even update their version numbers to give verisimilitude to the ruse. The only way to exorcise these haunted printers was to send 'em to the landfill. Good times!
Printers are still a dumpster fire, and it's not solely about the intrinsic difficulty of computer security. After all, printer manufacturers have devoted enormous resources to hardening their products against their owners, making it progressively harder to use third-party ink. They're super perverse about it, too – they send "security updates" to your printer that update the printer's security against you – run these updates and your printer downgrades itself by refusing to use the ink you chose for it:
https://www.eff.org/deeplinks/2020/11/ink-stained-wretches-battle-soul-digital-freedom-taking-place-inside-your-printer
It's a reminder that what a monopolist thinks of as "security" isn't what you think of as security. Oftentimes, their security is antithetical to your security. That was the case with Web Environment Integrity, a plan by Google to make your phone rat you out to advertisers' servers, revealing any adblocking modifications you might have installed so that ad-serving companies could refuse to talk to you:
https://pluralistic.net/2023/08/02/self-incrimination/#wei-bai-bai
WEI is now dead, thanks to a lot of hueing and crying by people like us:
https://www.theregister.com/2023/11/02/google_abandons_web_environment_integrity/
But the dream of securing Google against its own users lives on. Youtube has embarked on an aggressive campaign of refusing to show videos to people running ad-blockers, triggering an arms-race of ad-blocker-blockers and ad-blocker-blocker-blockers:
https://www.scientificamerican.com/article/where-will-the-ad-versus-ad-blocker-arms-race-end/
The folks behind Ublock Origin are racing to keep up with Google's engineers' countermeasures, and there's a single-serving website called "Is uBlock Origin updated to the last Anti-Adblocker YouTube script?" that will give you a realtime, one-word status update:
https://drhyperion451.github.io/does-uBO-bypass-yt/
One in four web users has an ad-blocker, a stat that Doc Searls pithily summarizes as "the biggest boycott in world history":
https://doc.searls.com/2015/09/28/beyond-ad-blocking-the-biggest-boycott-in-human-history/
Zero app users have ad-blockers. That's not because ad-blocking an app is harder than ad-blocking the web – it's because reverse-engineering an app triggers liability under IP laws like Section 1201 of the Digital Millenium Copyright Act, which can put you away for 5 years for a first offense. That's what I mean when I say that "IP is anything that lets a company control its customers, critics or competitors:
https://locusmag.com/2020/09/cory-doctorow-ip/
I predicted that apps would open up all kinds of opportunities for abusive, monopolistic conduct back in 2010, and I'm experiencing a mix of sadness and smugness (I assume there's a German word for this emotion) at being so thoroughly vindicated by history:
https://memex.craphound.com/2010/04/01/why-i-wont-buy-an-ipad-and-think-you-shouldnt-either/
The more control a company can exert over its customers, the worse it will be tempted to treat them. These systems of control shift the balance of power within companies, making it harder for internal factions that defend product quality and customer interests to win against the enshittifiers:
https://pluralistic.net/2023/07/28/microincentives-and-enshittification/
The result has been a Great Enshittening, with platforms of all description shifting value from their customers and users to their shareholders, making everything palpably worse. The only bright side is that this has created the political will to do something about it, sparking a wave of bold, muscular antitrust action all over the world.
The Google antitrust case is certainly the most important corporate lawsuit of the century (so far), but Judge Amit Mehta's deference to Google's demands for secrecy has kept the case out of the headlines. I mean, Sam Bankman-Fried is a psychopathic thief, but even so, his trial does not deserve its vastly greater prominence, though, if you haven't heard yet, he's been convicted and will face decades in prison after he exhausts his appeals:
https://newsletter.mollywhite.net/p/sam-bankman-fried-guilty-on-all-charges
The secrecy around Google's trial has relaxed somewhat, and the trickle of revelations emerging from the cracks in the courthouse are fascinating. For the first time, we're able to get a concrete sense of which queries are the most lucrative for Google:
https://www.theverge.com/2023/11/1/23941766/google-antitrust-trial-search-queries-ad-money
The list comes from 2018, but it's still wild. As David Pierce writes in The Verge, the top twenty includes three iPhone-related terms, five insurance queries, and the rest are overshadowed by searches for customer service info for monopolistic services like Xfinity, Uber and Hulu.
All-in-all, we're living through a hell of a moment for piercing the corporate veil. Maybe it's the problem of maintaining secrecy within large companies, or maybe the the rampant mistreatment of even senior executives has led to more leaks and whistleblowing. Either way, we all owe a debt of gratitude to the anonymous leaker who revealed the unbelievable pettiness of former HBO president of programming Casey Bloys, who ordered his underlings to create an army of sock-puppet Twitter accounts to harass TV and movie critics who panned HBO's shows:
https://www.rollingstone.com/tv-movies/tv-movie-features/hbo-casey-bloys-secret-twitter-trolls-tv-critics-leaked-texts-lawsuit-the-idol-1234867722/
These trolling attempts were pathetic, even by the standards of thick-fingered corporate execs. Like, accusing critics who panned the shitty-ass Perry Mason reboot of disrespecting veterans because the fictional Mason's back-story had him storming the beach on D-Day.
The pushback against corporate bullying is everywhere, and of course, the vanguard is the labor movement. Did you hear that the UAW won their strike against the auto-makers, scoring raises for all workers based on the increases in the companies' CEO pay? The UAW isn't done, either! Their incredible new leader, Shawn Fain, has called for a general strike in 2028:
https://www.404media.co/uaw-calls-on-workers-to-line-up-massive-general-strike-for-2028-to-defeat-billionaire-class/
The massive victory for unionized auto-workers has thrown a spotlight on the terrible working conditions and pay for workers at Tesla, a criminal company that has no compunctions about violating labor law to prevent its workers from exercising their legal rights. Over in Sweden, union workers are teaching Tesla a lesson. After the company tried its illegal union-busting playbook on Tesla service centers, the unionized dock-workers issued an ultimatum: respect your workers or face a blockade at Sweden's ports that would block any Tesla from being unloaded into the EU's fifth largest Tesla market:
https://www.wired.com/story/tesla-sweden-strike/
Of course, the real solution to Teslas – and every other kind of car – is to redesign our cities for public transit, walking and cycling, making cars the exception for deliveries, accessibility and other necessities. Transitioning to EVs will make a big dent in the climate emergency, but it won't make our streets any safer – and they keep getting deadlier.
Last summer, my dear old pal Ted Kulczycky got in touch with me to tell me that Talking Heads were going to be all present in public for the first time since the band's breakup, as part of the debut of the newly remastered print of Stop Making Sense, the greatest concert movie of all time. Even better, the show would be in Toronto, my hometown, where Ted and I went to high-school together, at TIFF.
Ted is the only person I know who is more obsessed with Talking Heads than I am, and he started working on tickets for the show while I starting pricing plane tickets. And then, the unthinkable happened: Ted's wife, Serah, got in touch to say that Ted had been run over by a car while getting off of a streetcar, that he was severely injured, and would require multiple surgeries.
But this was Ted, so of course he was still planning to see the show. And he did, getting a day-pass from the hospital and showing up looking like someone from a Kids In The Hall sketch who'd been made up to look like someone who'd been run over by a car:
https://www.flickr.com/photos/doctorow/53182440282/
In his Globe and Mail article about Ted's experience, Brad Wheeler describes how the whole hospital rallied around Ted to make it possible for him to get to the movie:
https://www.theglobeandmail.com/arts/music/article-how-a-talking-heads-superfan-found-healing-with-the-concert-film-stop/
He also mentions that Ted is working on a book and podcast about Stop Making Sense. I visited Ted in the hospital the day after the gig and we talked about the book and it sounds amazing. Also? The movie was incredible. See it in Imax.
That heartwarming tale of healing through big suits is a pretty good place to wrap up this linkdump, but I want to call your attention to just one more thing before I go: Robin Sloan's Snarkmarket piece about blogging and "stock and flow":
https://snarkmarket.com/2010/4890/
Sloan makes the excellent case that for writers, having a "flow" of short, quick posts builds the audience for a "stock" of longer, more synthetic pieces like books. This has certainly been my experience, but I think it's only part of the story – there are good, non-mercenary reasons for writers to do a lot of "flow." As I wrote in my 2021 essay, "The Memex Method," turning your commonplace book into a database – AKA "blogging" – makes you write better notes to yourself because you know others will see them:
https://pluralistic.net/2021/05/09/the-memex-method/
This, in turn, creates a supersaturated, subconscious solution of fragments that are just waiting to nucleate and crystallize into full-blown novels and nonfiction books and other "stock." That's how I came out of lockdown with nine new books. The next one is The Lost Cause, a hopepunk science fiction novel about the climate whose early fans include Naomi Klein, Rebecca Solnit, Bill McKibben and Kim Stanley Robinson. It's out on November 14:
https://us.macmillan.com/books/9781250865939/the-lost-cause

If you'd like an essay-formatted version of this post to read or share, here's a link to it on pluralistic.net, my surveillance-free, ad-free, tracker-free blog:
https://pluralistic.net/2023/11/05/variegated/#nein
#pluralistic#hbo#astroturfing#sweden#labor#unions#tesla#adblock#ublock#youtube#prompt injection#publishing#robin sloan#linkdumps#linkdump#ai#tlds#anguilla#finance curse#ted Kulczycky#toronto#stop making sense#talking heads
140 notes
·
View notes
Text
WHY DYSTOPIA MUST BE BORING TO SUCCEED
The "Boring Dystopia Strategy" is a highly strategic and often subtle method employed by those in power to create an enduring, all-encompassing authoritarian government. The genius of this approach is that it doesn't look like a dystopia at first glance. Each step toward oppression is disguised as a necessary solution to a societal problem, creating a series of small, unassuming changes that collectively transform society into a high-surveillance, debt-ridden, and highly regulated landscape. The result is a quiet but relentless march towards a government structure that controls nearly every aspect of daily life, cloaked in the language of safety, responsibility, and "public good."
Key Components of the Boring Dystopia Strategy
Enhanced Surveillance as Crime Prevention Surveillance systems are marketed as tools to make communities safer. The rationale is straightforward: if there are cameras everywhere, criminals are less likely to act. At first, this seems like a good idea. However, as surveillance expands, it reaches a point where privacy no longer exists—every action and interaction is tracked and recorded. People's movements, purchases, conversations, and even thoughts (through social media and data mining) become data points in a government database. The population is conditioned to accept surveillance under the guise of crime prevention, even though the surveillance network eventually exists to deter any resistance to the growing system of control.
Financial "Disincentives" as a Form of Behavior Control Insurance companies, incentivized by government policies, implement "dynamic" pricing models that penalize risky behavior. Drivers with even minor infractions, young drivers, or anyone with imperfect credit face skyrocketing insurance costs. While it’s presented as a means to reward safe drivers and reduce accidents, it’s ultimately a method of forcing people into line. Over time, these small financial penalties accumulate, and as people find themselves unable to afford the rising costs, they are pushed further into debt or forced to depend on the very government that created the conditions of their hardship.
The Department of Bureaucracy: A Growing Web of Useless Jobs New laws and regulations are introduced to solve every conceivable social issue, resulting in bloated departments filled with superfluous workers whose roles add no real value to society. The justification is often to create jobs and stimulate the economy, but these positions end up creating layers of bureaucracy that slow down meaningful progress. This web of inefficiency puts financial strain on both the government and the people, leading to higher taxes and fees. With each new law or regulation, the cost of compliance grows, straining both businesses and individuals who can't afford to play by an ever-increasing list of rules.
Rising Cost of Living as an Inevitable "Economic Shift" As government regulations add costs to every industry, prices naturally increase. This is explained away as the cost of progress or as an unfortunate byproduct of addressing critical social issues, like "ethical sourcing" or "green initiatives" that are actually revenue-boosters for corporations. As inflation rises and wages stagnate, the lower class is squeezed financially. Each attempt to improve their situation—whether by taking a second job or reducing expenses—is offset by further price increases or surprise taxes. This creates a cycle where economic mobility is nearly impossible, locking the lower class in place.
Debt as a Tool for Control As the cost of living rises, debt becomes unavoidable for many. Loans, credit cards, and financing options are promoted as solutions, pushing people into a system of lifelong debt repayment. With growing financial obligations and little hope of ever breaking free, individuals are forced to work harder, often taking on additional jobs, which leaves them with less time and energy to question or resist the system. Debt chains the population to the very system that oppresses them, creating a sense of dependency on government stability, even as that stability is the source of their financial despair.
The Final Stage: Disempowerment Disguised as "Efficiency"
As the population is weakened by financial strain, endless surveillance, and a tangled bureaucracy, the final stage involves introducing measures to "simplify" governance. This might mean fewer elected officials, streamlined decision-making processes, and the merging of regulatory bodies for "efficiency." In reality, this final stage centralizes power even further, leaving those at the top with almost unchecked authority, a situation that the people, too exhausted and indebted to resist, accept as necessary.
The Boring Dystopia Strategy works because it does not announce itself as an authoritarian takeover. Instead, it subtly shifts the balance of power by presenting every oppressive measure as a solution to a social ill. And because each step is introduced slowly, over decades, the population becomes accustomed to the new reality, accepting surveillance, debt, and regulation as the normal costs of a safe and responsible society. By the time people realize the extent of their powerlessness, the dystopian state is fully entrenched, with every escape route closed off.
12 notes
·
View notes
Text
youtube
Data mining services assist businesses in extracting and unleashing the true potential of data. Outsourcing these services enables them to maximize their return on investment.
#data mining services#data mining companies#data mining solutions#data mining firms#web data mining companies#Youtube
0 notes
Note
I have a question about your post regarding AI in which you detailed some agents' concerns. In particular you mentioned "we don't want our authors or artists work to be data-mined / scraped to "train" AI learning models/bots".
I completely agree, but what could be done to prevent this?
(I am no expert and clearly have NO idea what the terminology really is, but hopefully you will get it, sorry in advance?)
I mean, this is literally the thing we are all trying to figure out lol. But a start would be to have something in the contracts that SAYS Publishers do not have permission to license or otherwise permit companies to incorporate this copyrighted work into AI learning models, or to utilize this technology to mimic an author’s work.
The companies that are making AI bots or whatever are not shadowy guilds of hackers running around stealing things (despite how "web scraping" and "data mining" and all that sounds, which admittedly is v creepy and ominous!) -- web scraping, aka using robots to gather large amounts of publicly available data, is legal. That's like, a big part of how the internet works, it's how Google knows things when you google them, etc.
It's more dubious if scraping things that are protected under copyright is legal -- the companies would say that it is covered under fair use, that they are putting all this info in there to just teach the AI, and it isn't to COPY the author's work, etc etc. The people whose IP it is, though, probs don't feel that way -- and the law is sort of confused/non-existent. (There are loads of lawsuits literally RIGHT NOW that are aiming to sort some of this out, and the Writer's Guild strike which is ongoing and SAG-AFTRA strike which started this week is largely centered around some of the same issues when it comes to companies using AI for screenwriting, using actor's likeness and voice, etc.) Again, these are not shadowy organizations operating illegally off the coast of whatever -- these are regular-degular companies who can be sued, held to account, regulated, etc. The laws just haven’t caught up to the technology yet.
Point being, it's perhaps unethical to "feed" copyrighted work into an AI thing without permission of the copyright holder, but is it ILLEGAL? Uh -- yes??? but also ?????. US copyright law is pretty clear that works generated entirely by AI can't be protected under copyright -- and that works protected by copyright can't be, you know, copied by somebody else -- but there's a bit of a grey area here because of fair use? It’s confusing, for sure, and I'm betting all this is being hashed out in court cases and committee rooms and whatnot as I type.
Anywhoo, the first steps are clarifying these things contractually. Authors Guild (and agents) take the stance that this permission to "feed" info to AI learning models is something the Author automatically holds rights to, and only the author can decide if/when a book is "fed" into an AI... thing.
The Publishers kinda think this is something THEY hold the rights to, or both parties do, and that these rights should be frozen so NEITHER party can choose to "feed", or neither can choose to do so without the other's permission.
(BTW just to be clear, as I understand it -- which again is NOT MUCH lol -- this "permission" is not like, somebody calls each individual author and asks for permission -- it's part of the coding. Like how many e-books are DRM protected, so they are locked to a particular platform / device and you can't share them etc -- there are bits of code that basically say NOPE to scrapers. So (in my imagination, at least), the little spider-robot is Roomba-ing around the internet looking for things to scrape and it comes across this bit of code and NOPE, they have to turn around and try the next thing. Now – just like if an Etsy seller made mugs with pictures of Mickey Mouse on them, using somebody else’s IP is illegal – and those people CAN be sued if the copyright holder has the appetite to do that - but it’s also hard to stop entirely. So if some random person took your book and just copied it onto a blog -- the spider-robot wouldn't KNOW that info was under copyright, or they don't have permission to gobble it up, because it wouldn't have that bit of code to let them know -- so in that way it could be that nobody ever FULLY knows that the spider-robots won't steal their stuff, and publishers can't really be liable for that if third parties are involved mucking it up -- but they certainly CAN at least attempt to protect copyright!)
But also, you know how I don't even know what I'm talking about and don't know the words? Like in the previous paragraphs? The same goes for all the publishers and everyone else who isn't already a tech wizard, ALL of whom are suddenly learning a lot of very weird words and phrases and rules that nobody *exactly* understands, and it's all changing by the week (and by the day, even).
Publishers ARE starting to add some of this language, but I also would expect it to feel somewhat confused/wild-west-ish until some of the laws around this stuff are clearer. But really: We're all working on it!
87 notes
·
View notes
Text
Things You Need to Know about Data Extraction

Data extraction services provide critical information for businesses to make informed decisions, regardless of any industry. Your search for the best data extraction services ends here. Uniquesdata provides top-class data extraction services from a team of professionals that will extract valuable information and enhance productivity for your business.
#data extraction services#online data processing services#web data extraction services#data extraction companies#data mining companies#data extraction company#data extraction specialist#data entry services#outsourcing data entry services#data entry outsourcing companies in usa
0 notes
Note
I can't get on board with Threads. The sure amount of data-mining Threads does, along with the fact if you delete it you also delete your instragram account as well are instant bad vibes. Twitter might suck but a LOT of indie devs, small businesses and tons of artists relay on it. Having to pack up and try to get the same amount of attention on other social media sites isn't easy, livelihoods would be at risk if it does die.
Absolutely! Threads is just datamining.
But if it is drawing attention to the Fediverse, which has exactly zero datamining and zero ads, because it's not commercial and it's decentralised but connected, it's a good bridge for people still clinging to Twitter, to get off of Musks horrorshow.
The internet needs to go back to being publicly owned and non-commercial. If you are not the product (like you are on Twitter or anything Meta owns), you are independent.
The Fediverse has non-commercial alternatives for a lot of things: Lemmy for Reddit, Pixelfed for Instagram, Mastodon for Twitter, Peertube for YouTube, alternatives for Facebook or Wordpress, too. It's a decentralised internet but you can connect with everybody on any platform that uses the ActivityPub.
For example, people following me on Mastodon can also see, share, comment on my stuff on my Pixelfed-account or my bookreviews on Bookwyrm (the goodreads-alternative). As soon as Tumblr activates ActivityPub I will share my Tumblr-Posts as well. Or my Mastodon-posts on Tumblr. Whatever I want to.
So this whole decentralised web is a giant opportunity for small businesses to showcase their stuff to a very wide audience. But of course the big companies have not much interest in losing their advertisment-cattle to self-governed places, so there is a lot of marketing-fearmongering going on. It'll be hard to break this chokehold, but it is necessary, else small businesses and artists will be forever at the mercy of big money.
Also, the Fediverse is based on accessibility. It's made with disabled folks in mind - most people over at Mastodon use image descriptions, for example. Lots of space for queer folks, too. Plus - mostly European, so no "no nudity!!111"-religious-crap either! And the privacy-settings of the EU, that are much stricter than in the US.
Yes, I'm promoting this very hard, because I'm believing in the values of a free, accessible, anti-capitalist, non-religious internet. I want anarchy back. I don't want to be the milking cow of some corporations harvesting my data. The Fediverse has lots of risks, too. But they are minimal compared to putting your art, your thoughts, or - in case of a lot of transfolks - safety in the hand of some greedy billionaires.
Some links:
youtube
youtube
67 notes
·
View notes
Text
Thousands of law enforcement officials and people applying to be police officers in India have had their personal information leaked online—including fingerprints, facial scan images, signatures, and details of tattoos and scars on their bodies. If that wasn’t alarming enough, at around the same time, cybercriminals have started to advertise the sale of similar biometric police data from India on messaging app Telegram.
Last month, security researcher Jeremiah Fowler spotted the sensitive files on an exposed web server linked to ThoughtGreen Technologies, an IT development and outsourcing firm with offices in India, Australia, and the US. Within a total of almost 500 gigabytes of data spanning 1.6 million documents, dated from 2021 until when Fowler discovered them in early April, was a mine of sensitive personal information about teachers, railway workers, and law enforcement officials. Birth certificates, diplomas, education certificates, and job applications were all included.
Fowler, who shared his findings exclusively with WIRED, says within the heaps of information, the most concerning were those that appeared to be verification documents linked to Indian law enforcement or military personnel. While the misconfigured server has now been closed off, the incident highlights the risks of companies collecting and storing biometric data, such as fingerprints and facial images, and how they could be misused if the data is accidentally leaked.
“You can change your name, you can change your bank information, but you can't change your actual biometrics,” Fowler says. The researcher, who also published the findings on behalf of Website Planet, says this kind of data could be used by cybercriminals or fraudsters to target people in the future, a risk that’s increased for sensitive law enforcement positions.
Within the database Fowler examined were several mobile applications and installation files. One was titled “facial software installation,” and a separate folder contained 8 GB of facial data. Photographs of people’s faces included computer-generated rectangles that are often used for measuring the distance between points of the face in face recognition systems.
There were 284,535 documents labeled as Physical Efficiency Tests that related to police staff, Fowler says. Other files included job application forms for law enforcement officials, profile photos, and identification documents with details such as “mole at nose” and “cut on chin.” At least one image shows a person holding a document with a corresponding photo of them included on it. “The first thing I saw was thousands and thousands of fingerprints,” Fowler says.
Prateek Waghre, executive director of Indian digital rights organization Internet Freedom Foundation, says there is “vast” biometric data collection happening across India, but there are added security risks for people involved in law enforcement. “A lot of times, the verification that government employees or officers use also relies on biometric systems,” Waghre says. “If you have that potentially compromised, you are in a position for someone to be able to misuse and then gain access to information that they shouldn’t.”
It appears that some biometric information about law enforcement officials may already be shared online. Fowler says after the exposed database was closed down he also discovered a Telegram channel, containing a few hundred members, which was claiming to sell Indian police data, including of specific individuals. “The structure, the screenshots, and a couple of the folder names matched what I saw,” says Fowler, who for ethical reasons did not purchase the data being sold by the criminals so could not fully verify it was exactly the same data.
“We take data security very seriously, have taken immediate steps to secure the exposed data,” a member of ThoughtGreen Technologies wrote in an email to WIRED. “Due to the sensitivity of data, we cannot comment on specifics in an email. However, we can assure you that we are investigating this matter thoroughly to ensure such an incident does not occur again.”
In follow-up messages, the staff member said the company had “raised a complaint” with law enforcement in India about the incident, but did not specify which organization they had contacted. When shown a screenshot of the Telegram post claiming to sell Indian police biometric data, the ThoughtGreen Technologies staff member said it is “not our data.” Telegram did not respond to a request for comment.
Shivangi Narayan, an independent researcher in India, says the country’s data protection law needs to be made more robust, and companies and organizations need to take greater care with how they handle people’s data. “A lot of data is collected in India, but nobody's really bothered about how to store it properly,” Narayan says. Data breaches are happening so regularly that people have “lost that surprise shock factor,” Narayan says. In early May, one cybersecurity company said it had seen a face-recognition data breach connected to one Indian police force, including police and suspect information.
The issues are wider, though. As governments, companies, and other organizations around the world increasingly rely on collecting people’s biometric data for proving their identity or as part of surveillance technologies, there’s an increased risk of the information leaking online and being abused. In Australia, for instance, a recent face recognition leak impacting up to a million people led to a person being charged with blackmail.
“So many other countries are looking at biometric verification for identities, and all of that information has to be stored somewhere,” Fowler says. “If you farm it out to a third-party company, or a private company, you lose control of that data. When a data breach happens, you’re in deep shit, for lack of a better term.”
9 notes
·
View notes
Text
This day in history

On SEPTEMBER 24th, I'll be speaking IN PERSON at the BOSTON PUBLIC LIBRARY!

#10yrsago Why the disgusting Red Delicious apple rules American grocery stores https://www.theatlantic.com/health/archive/2014/09/the-evil-reign-of-the-red-delicious/379892/
#10yrsago Elizabeth Warren speaks for allowing states to limit campaign finance https://www.youtube.com/watch?v=nBbZAMsZ-Rg
#10yrsago Meet the anti-Net Neutrality arms dealers who love network discrimination https://arstechnica.com/information-technology/2014/09/companies-that-sell-network-equipment-to-isps-dont-want-net-neutrality/
#10yrsago Seconds, by Bryan Lee “Scott Pilgrim” O’Malley https://memex.craphound.com/2014/09/11/seconds-by-bryan-lee-scott-pilgrim-omalley/
#10yrsago John Scalzi’s Lock-In https://memex.craphound.com/2014/09/11/john-scalzis-lock-in/
#5yrsago The EU’s top trustbuster gets a surprise re-appointment https://venturebeat.com/business/eu-reappoints-top-antitrust-cop-who-led-crackdown-on-tech-giants/
#5yrsago Majority of period-tracking app share incredibly sensitive data with Facebook and bottom-feeding analytics companies https://web.archive.org/web/20190911004056/https://www.privacyinternational.org/long-read/3196/no-bodys-business-mine-how-menstruation-apps-are-sharing-your-data
#1yrago The Tamakis' "Roaming" https://pluralistic.net/2023/09/11/as-canadian-as/#possible-under-the-circumstances
The paperback edition of The Lost Cause, my nationally bestselling, hopeful solarpunk novel is out this month!
7 notes
·
View notes