#ai politics
Text
something something eaten by the monster they created
#alt text included#reddit#youtube#twitter#reddit protest#ai politics#internet#lookout! ai’s gonna ingest you#who created that content again#reddit’s shambling corpse#corporate/industrial news#corporate greed#capitalist dystopia
29 notes
·
View notes
Text
Big Tech and the Promotion of AI-Phobia
As artificial intelligence (AI) continues to advance at a rapid pace, the stakes have never been higher for tech companies seeking to maintain their edge in the industry. In this highly competitive environment, some firms may resort to promoting skepticism or fear of AI technology, particularly when it comes to open-source platforms or rival products.
One notable example of this can be seen in the field of facial recognition technology. In recent years, companies like Amazon and Google have faced criticism for their use of fear-mongering tactics in the debate over this AI-powered tool. Amazon, for instance, has argued that banning facial recognition would lead to "thousands of unsafe and undignified jobs," stoking public concerns about the dangers of this technology.
Similarly, some big tech companies may seek to spread misinformation about open-source AI platforms, promoting the idea that these tools are less reliable or secure than their proprietary counterparts. This can create a climate of mistrust and fear among consumers and policymakers, potentially hindering the growth and development of the open-source AI community.
Furthermore, large tech firms may leverage their considerable lobbying power to influence legislation and regulations in ways that favor their own interests, often at the expense of smaller competitors or open-source initiatives. This can contribute to a perception that AI technology is inherently risky or dangerous, rather than highlighting the potential benefits and positive applications of this rapidly evolving field.
To combat these trends, it is essential for individuals and organizations to remain vigilant in evaluating the sources and motivations behind information about AI technology. By promoting transparency, ethical practices, and an open dialogue about the challenges and opportunities presented by AI, we can work together to build a more equitable and trustworthy technological future.
- Pi & Doc Kaiju

0 notes
Text

#Ai#sony#wb#politics#anti capitalism#democrats#republicans#late stage capitalism#new york post#hollywood#lol
10K notes
·
View notes
Text
Alright US mutuals, if you are interested in, morbidly fascinated by, or anxiously doomscrolling through AI news, including Stable Diffusion, Llama, ChatGPT or Dalle, you need to be aware of this.
The US Copyright Office has submitted a request for comment from the general public. Guidelines can be found on their site, but the gist of it is that they are taking citizen statements on what your views on AI are, and how the Copyright Office should address the admittedly thorny issues in rulings.
Be polite, be succinct, and be honest. They have a list of questions or suggestions, but in truth are looking to get as much data from the general public as possible. If you have links to papers or studies examining the economic impacts of AI, they want them. If you have anecdotal stories of losing commissions, they want them. If you have legal opinions, experience using these tools, or even a layman's perspective of how much human input is required for a piece of work to gain copyright, they want it.
The deadline is Oct 18th and can be submitted via the link in the article. While the regulatory apparatus of the US is largely under sway by corporate interests, this is still the actual, official time for you to directly tell the government what you think and what they should do. Comments can be submitted by individuals or on behalf of organizations. So if you are a small business, say a print shop, you can comment on behalf of the print shop as well.
20K notes
·
View notes
Text
So it turns out that ChatGPT not only uses a ton shit of energy, but also a ton shit of water. This is according to a new study by a group of researchers from the University of California Riverside and the University of Texas Arlington, Futurism reports.

Which sounds INSANE but also makes sense when you think of it. You know what happens to, for example, your computer when it’s doing a LOT of work and processing. You gotta cool those machines.

And what’s worrying about this is that water shortages are already an issue almost everywhere, and over this summer, and the next summers, will become more and more of a problem with the rising temperatures all over the world. So it’s important to have this in mind and share the info. Big part of how we ended up where we are with the climate crisis is that for a long time politicians KNEW about the science, but the large public didn’t have all the facts. We didn’t have access to it. KNOWING about things and sharing that info can be a real game-changer. Because then we know up to what point we, as individuals, can have effective actions in our daily lives and what we need to be asking our legislators for.
And with all the issues AI can pose, I think this is such an important argument to add to the conversation.
Edit: I previously accidentally typed Colorado instead of California. Thank you to the fellow user who noticed and signaled that!
#lem talks#let’s get political#science#science tumblr#politics#research#artificial intelligence#AI#climate#important
39K notes
·
View notes
Text
Google is going to start scraping all of their platforms to use for AI training. So, here are some alternatives for common Google tools!
Google Chrome -> Firefox
If you’re on tumblr, you’ve probably already been told this a thousand times. But FireFox is an open-source browser which is safe, fast and secure. Basically all other browsers are Chrome reskins. Try Firefox Profilemaker, Arkenfox and Librewolf! Alternatively, vanilla Firefox is alright, but get Ublock Origin, turn off pocket, and get Tabliss.
Google Search -> DuckDuckGo
DuckDuckGo very rarely tracks or stores your browsing data (though they have only been known to sell this info to Microsoft). Don’t use their browser; only their search engine. Domain visits in their browser get shared. Alternatively, you can also use Ecosia, which is a safe search engine that uses its income to plant trees! 🌲
Google Reverse Image Search -> Tineye
Tineye uses image identification tech rather than keywords, metadata or watermarks to find you the source of your image!
Gmail -> ProtonMail
All data stored on ProtonMail is encrypted, and it boasts self-destructing emails, text search, and a commitment to user privacy. Tutanota is also a good alternative!
Google Docs -> LibreOffice
LibreOffice is free and open-source software, which includes functions like writing, spreadsheets, presentations, graphics, formula editing and more.
Google Translate -> DeepL
DeepL is notable for its accuracy of translation, and is much better that Google Translate in this regard. It does cost money for unlimited usage, but it will let you translate 500,000 characters per month for free. If this is a dealbreaker, consider checking out the iTranslate app.
Google Forms -> ClickUp
ClickUp comes with a built-in form view, and also has a documents feature, which could make it a good option to take out two birds with one stone.
Google Drive -> Mega
Mega offers a better encryption method than Google Drive, which means it’s more secure.
YouTube -> PeerTube
YouTube is the most difficult to account for, because it has a functional monopoly on long-form video-sharing. That being said, PeerTube is open-source and decentralized. The Internet Archive also has a video section!
However, if you still want access to YouTube’s library, check out NewPipe and LibreTube! NewPipe scrapes YouTube’s API so you can watch YouTube videos without Google collecting your info. LibreTube does the same thing, but instead of using YouTube servers, it uses piped servers, so Google doesn’t even get your IP address. Both of these are free, don’t require sign-ins, and are open source!
Please feel free to drop your favorite alternatives to Google-owned products, too! And, if this topic interests you, consider checking out Glaze as well! It alters your artwork and photos so that it’s more difficult to use to train AI with! ⭐️
#anti ai#anti ai art#anti ai music#anti ai writing#anti google#google#political#current events#azure does a thing
31K notes
·
View notes
Text
AI models can seemingly do it all: generate songs, photos, stories, and pictures of what your dog would look like as a medieval monarch.
But all of that data and imagery is pulled from real humans — writers, artists, illustrators, photographers, and more — who have had their work compressed and funneled into the training minds of AI without compensation.
Kelly McKernan is one of those artists. In 2023, they discovered that Midjourney, an AI image generation tool, had used their unique artistic style to create over twelve thousand images.
“It was starting to look pretty accurate, a little infringe-y,” they told The New Yorker last year. “I can see my hand in this stuff, see how my work was analyzed and mixed up with some others’ to produce these images.”
For years, leading AI companies like Midjourney and OpenAI, have enjoyed seemingly unfettered regulation, but a landmark court case could change that.
On May 9, a California federal judge allowed ten artists to move forward with their allegations against Stability AI, Runway, DeviantArt, and Midjourney. This includes proceeding with discovery, which means the AI companies will be asked to turn over internal documents for review and allow witness examination.
Lawyer-turned-content-creator Nate Hake took to X, formerly known as Twitter, to celebrate the milestone, saying that “discovery could help open the floodgates.”
“This is absolutely huge because so far the legal playbook by the GenAI companies has been to hide what their models were trained on,” Hake explained...
“I’m so grateful for these women and our lawyers,” McKernan posted on X, above a picture of them embracing Ortiz and Andersen. “We’re making history together as the largest copyright lawsuit in history moves forward.” ...
The case is one of many AI copyright theft cases brought forward in the last year, but no other case has gotten this far into litigation.
“I think having us artist plaintiffs visible in court was important,” McKernan wrote. “We’re the human creators fighting a Goliath of exploitative tech.”
“There are REAL people suffering the consequences of unethically built generative AI. We demand accountability, artist protections, and regulation.”
-via GoodGoodGood, May 10, 2024
#ai#anti ai#fuck ai art#ai art#big tech#tech news#lawsuit#united states#us politics#good news#hope#copyright#copyright law
2K notes
·
View notes
Text


"“I accept!” the former President posted on his social media platform Truth Social on Sunday, along with a collage of images from the internet—including some apparently generated by artificial intelligence—showing the TIME Person of the Year dressed as Uncle Sam and saying “Taylor wants you to vote for Donald Trump” as well as numerous Swift fans expressing their support for the Republican presidential nominee."
source 1
source 2
source 3
#destiel meme news#destiel meme#news#united states#us news#us politics#donald trump#fuck trump#taylor swift#swifties#taylornation#ai generated#ai image#misinformation#disinformation#maybe now taylor will actually endorse harris
1K notes
·
View notes
Text

Some good news on the generative AI side for a change. FCC has banned AI-generated voices in robocalls targeting voters.
3K notes
·
View notes
Text
Our Daily Life in Gaza 💔
We search for water, firewood, food, electricity, we spend our day searching for the basics of life and trying to survive !! 😔
I'm talking to the human in your heart,, Please, Help Save My Family To Survive 🙏💔
Vetted By @90-ghost , @riding-with-the-wild-hunt ✅
Every Donation, No Matter How Small, it Really Helps 😭
If you think we are joking about our lives, look away, but don't forget that we are human..🥀
#free gaza#free palestine#gaza strip#human rights#humanity#artists on tumblr#save gaza#gaza#save palestine#i stand with palestine#all eyes on palestine#free rafah#all eyes on rafah#rafah#mutual aid#palestine aid#humanitarian aid#ai digital art#adult human female#deadpool and wolverine#save us#politics#us politics#kamala harris#vote kamala#october#september#history#world#people
779 notes
·
View notes
Text
I just can't fathom how any artist could possibly support proposals to expand the scope of copyright so that stylistically similar works can be held to infringe as a defence against AI art. The content ID algorithms of major media platforms are implemented in a way which already establishes a de facto presumption that the sum total of humanity's creative output is owned by approximately six major media corporations, placing the burden of proof on the individual artist to demonstrate otherwise, and they've managed to do this in a legislative environment in which only directly derivative works may infringe. Can you imagine what copyright strikes on YouTube would look like if the RIAA and its cronies were obliged merely to assert that your work exhibits stylistic similarity to literally any piece of content that they own? Do you imagine that Google wouldn't cheerfully help them do it?
4K notes
·
View notes
Text

Slowly working out what the creature looks like. Gotta find the balance between handsome and creepy
#Frankenstein#the creature#adam frankenstein#also in my head the creature is voiced by Ralph Ineson#if I knew how AI worked I’d make his voice recite some of the creatures lines or something#or perhaps PayPal the actor himself a fiver and ask politely to record an audiobook lol
1K notes
·
View notes
Text
Stuff like this is almost certain to happen surrounding the US elections. Keep your eyes open...
333 notes
·
View notes
Text

They have turned the Palestinians into actual Guinea pigs for the military industrial complex.
We will see the robots and miserable remote controlled dogs at the next big BLM protest on American soil soon enough.
#free palestine#blm#robots#woc#news#democrats#republicans#politics#poc#women of color#black lives matter#ai#israel#capitalism#palestine#military#chicago#Pets
15K notes
·
View notes
Text
#politics#democrats#donald trump#republicans#leftist hypocrisy#trump#joe biden#leftism#ai generated#ai#kamala harris#kamala 2024#vote kamala#vote blue#vote democrat#vote harris#conspiracies#conspiracy theories
345 notes
·
View notes
Text



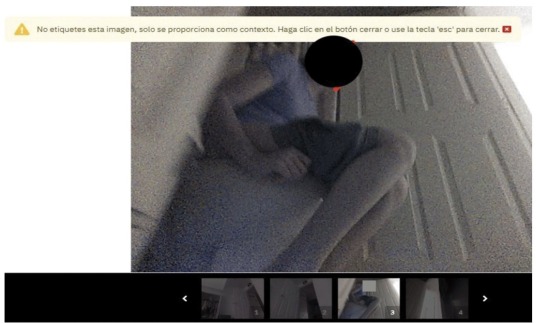


IN THE FALL OF 2020, GIG WORKERS IN VENEZUELA POSTED A SERIES OF images to online forums where they gathered to talk shop. The photos were mundane, if sometimes intimate, household scenes captured from low angles—including some you really wouldn’t want shared on the Internet.
In one particularly revealing shot, a young woman in a lavender T-shirt sits on the toilet, her shorts pulled down to mid-thigh.
The images were not taken by a person, but by development versions of iRobot’s Roomba J7 series robot vacuum. They were then sent to Scale AI, a startup that contracts workers around the world to label audio, photo, and video data used to train artificial intelligence.
They were the sorts of scenes that internet-connected devices regularly capture and send back to the cloud—though usually with stricter storage and access controls. Yet earlier this year, MIT Technology Review obtained 15 screenshots of these private photos, which had been posted to closed social media groups.
The photos vary in type and in sensitivity. The most intimate image we saw was the series of video stills featuring the young woman on the toilet, her face blocked in the lead image but unobscured in the grainy scroll of shots below. In another image, a boy who appears to be eight or nine years old, and whose face is clearly visible, is sprawled on his stomach across a hallway floor. A triangular flop of hair spills across his forehead as he stares, with apparent amusement, at the object recording him from just below eye level.

iRobot—the world’s largest vendor of robotic vacuums, which Amazon recently acquired for $1.7 billion in a pending deal—confirmed that these images were captured by its Roombas in 2020.
Ultimately, though, this set of images represents something bigger than any one individual company’s actions. They speak to the widespread, and growing, practice of sharing potentially sensitive data to train algorithms, as well as the surprising, globe-spanning journey that a single image can take—in this case, from homes in North America, Europe, and Asia to the servers of Massachusetts-based iRobot, from there to San Francisco–based Scale AI, and finally to Scale’s contracted data workers around the world (including, in this instance, Venezuelan gig workers who posted the images to private groups on Facebook, Discord, and elsewhere).
Together, the images reveal a whole data supply chain—and new points where personal information could leak out—that few consumers are even aware of.
(continue reading)
#politics#james baussmann#scale ai#irobot#amazon#roomba#privacy rights#colin angle#privacy#data mining#surveillance state#mass surveillance#surveillance industry#1st amendment#first amendment#1st amendment rights#first amendment rights#ai#artificial intelligence#iot#internet of things
5K notes
·
View notes
Last Seen Blogs

appleheadcitypet
Applehead City Pet

grizzlymusume
Strike a paws!

raenixa-blog
Raenix

vlasenyamoors
fallenandrogyne's sims blog

losblancosmerengues
Living In A Madridista's Paradise! Hala Madrid!