#and the data node on the same machine “
Explore tagged Tumblr posts
Visit Tumblr Blog
Explore Tumblr blogs with no restrictions, modern design and the best experience.
Last Seen Tumblr Blogs





Fun Fact
Mobile Tumblr US users spend an average of 4.04 minutes per session on the app.
Text
.
#I'm going to kill the people behind the Graylog documentation#“don't install both the Graylog node and db#and the data node on the same machine “#and then they go on and assume that you're doing it all on the same machine#PROVIDE THE DOCS#also at some point they changed from Opensearch to Datanode#with no indication of what that means practically#I'm going to throw my laptop in a minute#so anyway I'm going to go to Reddit
2 notes
·
View notes
Text
We need to talk about AI
Okay, several people asked me to post about this, so I guess I am going to post about this. Or to say it differently: Hey, for once I am posting about the stuff I am actually doing for university. Woohoo!
Because here is the issue. We are kinda suffering a death of nuance right now, when it comes to the topic of AI.
I understand why this happening (basically everyone wanting to market anything is calling it AI even though it is often a thousand different things) but it is a problem.
So, let's talk about "AI", that isn't actually intelligent, what the term means right now, what it is, what it isn't, and why it is not always bad. I am trying to be short, alright?

So, right now when anyone says they are using AI they mean, that they are using a program that functions based on what computer nerds call "a neural network" through a process called "deep learning" or "machine learning" (yes, those terms mean slightly different things, but frankly, you really do not need to know the details).
Now, the theory for this has been around since the 1940s! The idea had always been to create calculation nodes that mirror the way neurons in the human brain work. That looks kinda like this:

Basically, there are input nodes, in which you put some data, those do some transformations that kinda depend on the kind of thing you want to train it for and in the end a number comes out, that the program than "remembers". I could explain the details, but your eyes would glaze over the same way everyone's eyes glaze over in this class I have on this on every Friday afternoon.
All you need to know: You put in some sort of data (that can be text, math, pictures, audio, whatever), the computer does magic math, and then it gets a number that has a meaning to it.
And we actually have been using this sinde the 80s in some way. If any Digimon fans are here: there is a reason the digital world in Digimon Tamers was created in Stanford in the 80s. This was studied there.
But if it was around so long, why am I hearing so much about it now?
This is a good question hypothetical reader. The very short answer is: some super-nerds found a way to make this work way, way better in 2012, and from that work (which was then called Deep Learning in Artifical Neural Networks, short ANN) we got basically everything that TechBros will not shut up about for the last like ten years. Including "AI".
Now, most things you think about when you hear "AI" is some form of generative AI. Usually it will use some form of a LLM, a Large Language Model to process text, and a method called Stable Diffusion to create visuals. (Tbh, I have no clue what method audio generation uses, as the only audio AI I have so far looked into was based on wolf howls.)
LLMs were like this big, big break through, because they actually appear to comprehend natural language. They don't, of coruse, as to them words and phrases are just stastical variables. Scientists call them also "stochastic parrots". But of course our dumb human brains love to anthropogice shit. So they go: "It makes human words. It gotta be human!"
It is a whole thing.
It does not understand or grasp language. But the mathematics behind it will basically create a statistical analysis of all the words and then create a likely answer.

What you have to understand however is, that LLMs and Stable Diffusion are just a a tiny, minority type of use cases for ANNs. Because research right now is starting to use ANNs for EVERYTHING. Some also partially using Stable Diffusion and LLMs, but not to take away people'S jobs.
Which is probably the place where I will share what I have been doing recently with AI.
The stuff I am doing with Neural Networks
The neat thing: if a Neural Network is Open Source, it is surprisingly easy to work with it. Last year when I started with this I was so intimidated, but frankly, I will confidently say now: As someone who has been working with computers for like more than 10 years, this is easier programming than most shit I did to organize data bases. So, during this last year I did three things with AI. One for a university research project, one for my work, and one because I find it interesting.
The university research project trained an AI to watch video live streams of our biology department's fish tanks, analyse the behavior of the fish and notify someone if a fish showed signs of being sick. We used an AI named "YOLO" for this, that is very good at analyzing pictures, though the base framework did not know anything about stuff that lived not on land. So we needed to teach it what a fish was, how to analyze videos (as the base framework only can look at single pictures) and then we needed to teach it how fish were supposed to behave. We still managed to get that whole thing working in about 5 months. So... Yeah. But nobody can watch hundreds of fish all the time, so without this, those fish will just die if something is wrong.
The second is for my work. For this I used a really old Neural Network Framework called tesseract. This was developed by Google ages ago. And I mean ages. This is one of those neural network based on 1980s research, simply doing OCR. OCR being "optical character recognition". Aka: if you give it a picture of writing, it can read that writing. My work has the issue, that we have tons and tons of old paper work that has been scanned and needs to be digitized into a database. But everyone who was hired to do this manually found this mindnumbing. Just imagine doing this all day: take a contract, look up certain data, fill it into a table, put the contract away, take the next contract and do the same. Thousands of contracts, 8 hours a day. Nobody wants to do that. Our company has been using another OCR software for this. But that one was super expensive. So I was asked if I could built something to do that. So I did. And this was so ridiculously easy, it took me three weeks. And it actually has a higher successrate than the expensive software before.
Lastly there is the one I am doing right now, and this one is a bit more complex. See: we have tons and tons of historical shit, that never has been translated. Be it papyri, stone tablets, letters, manuscripts, whatever. And right now I used tesseract which by now is open source to develop it further to allow it to read handwritten stuff and completely different letters than what it knows so far. I plan to hook it up, once it can reliably do the OCR, to a LLM to then translate those texts. Because here is the thing: these things have not been translated because there is just not enough people speaking those old languages. Which leads to people going like: "GASP! We found this super important document that actually shows things from the anceint world we wanted to know forever, and it was lying in our collection collecting dust for 90 years!" I am not the only person who has this idea, and yeah, I just hope maybe we can in the next few years get something going to help historians and archeologists to do their work.

Make no mistake: ANNs are saving lives right now
Here is the thing: ANNs are Deep Learning are saving lives right now. I really cannot stress enough how quickly this technology has become incredibly important in fields like biology and medicine to analyze data and predict outcomes in a way that a human just never would be capable of.
I saw a post yesterday saying "AI" can never be a part of Solarpunk. I heavily will disagree on that. Solarpunk for example would need the help of AI for a lot of stuff, as it can help us deal with ecological things, might be able to predict weather in ways we are not capable of, will help with medicine, with plants and so many other things.
ANNs are a good thing in general. And yes, they might also be used for some just fun things in general.
And for things that we may not need to know, but that would be fun to know. Like, I mentioned above: the only audio research I read through was based on wolf howls. Basically there is a group of researchers trying to understand wolves and they are using AI to analyze the howling and grunting and find patterns in there which humans are not capable of due ot human bias. So maybe AI will hlep us understand some animals at some point.
Heck, we saw so far, that some LLMs have been capable of on their on extrapolating from being taught one version of a language to just automatically understand another version of it. Like going from modern English to old English and such. Which is why some researchers wonder, if it might actually be able to understand languages that were never deciphered.
All of that is interesting and fascinating.
Again, the generative stuff is a very, very minute part of what AI is being used for.

Yeah, but WHAT ABOUT the generative stuff?
So, let's talk about the generative stuff. Because I kinda hate it, but I also understand that there is a big issue.
If you know me, you know how much I freaking love the creative industry. If I had more money, I would just throw it all at all those amazing creative people online. I mean, fuck! I adore y'all!
And I do think that basically art fully created by AI is lacking the human "heart" - or to phrase it more artistically: it is lacking the chemical inbalances that make a human human lol. Same goes for writing. After all, an AI is actually incapable of actually creating a complex plot and all of that. And even if we managed to train it to do it, I don't think it should.
AI saving lives = good.
AI doing the shit humans actually evolved to do = bad.
And I also think that people who just do the "AI Art/Writing" shit are lazy and need to just put in work to learn the skill. Meh.
However...
I do think that these forms of AI can have a place in the creative process. There are people creating works of art that use some assets created with genAI but still putting in hours and hours of work on their own. And given that collages are legal to create - I do not see how this is meaningfully different. If you can take someone else's artwork as part of a collage legally, you can also take some art created by AI trained on someone else's art legally for the collage.
And then there is also the thing... Look, right now there is a lot of crunch in a lot of creative industries, and a lot of the work is not the fun creative kind, but the annoying creative kind that nobody actually enjoys and still eats hours and hours before deadlines. Swen the Man (the Larian boss) spoke about that recently: how mocapping often created some artifacts where the computer stuff used to record it (which already is done partially by an algorithm) gets janky. So far this was cleaned up by humans, and it is shitty brain numbing work most people hate. You can train AI to do this.
And I am going to assume that in normal 2D animation there is also more than enough clean up steps and such that nobody actually likes to do and that can just help to prevent crunch. Same goes for like those overworked souls doing movie VFX, who have worked 80 hour weeks for the last 5 years. In movie VFX we just do not have enough workers. This is a fact. So, yeah, if we can help those people out: great.
If this is all directed by a human vision and just helping out to make certain processes easier? It is fine.
However, something that is just 100% AI? That is dumb and sucks. And it sucks even more that people's fanart, fanfics, and also commercial work online got stolen for it.
And yet... Yeah, I am sorry, I am afraid I have to join the camp of: "I am afraid criminalizing taking the training data is a really bad idea." Because yeah... It is fucking shitty how Facebook, Microsoft, Google, OpenAI and whatever are using this stolen data to create programs to make themselves richer and what not, while not even making their models open source. BUT... If we outlawed it, the only people being capable of even creating such algorithms that absolutely can help in some processes would be big media corporations that already own a ton of data for training (so basically Disney, Warner and Universal) who would then get a monopoly. And that would actually be a bad thing. So, like... both variations suck. There is no good solution, I am afraid.
And mind you, Disney, Warner, and Universal would still not pay their artists for it. lol
However, that does not mean, you should not bully the companies who are using this stolen data right now without making their models open source! And also please, please bully Hasbro and Riot and whoever for using AI Art in their merchandise. Bully them hard. They have a lot of money and they deserve to be bullied!

But yeah. Generally speaking: Please, please, as I will always say... inform yourself on these topics. Do not hate on stuff without understanding what it actually is. Most topics in life are nuanced. Not all. But many.
#computer science#artifical intelligence#neural network#artifical neural network#ann#deep learning#ai#large language model#science#research#nuance#explanation#opinion#text post#ai explained#solarpunk#cyberpunk
27 notes
·
View notes
Text
#Get Ready With Me.

THIS JUST IN: YOU LOOK AMAZING. DON’T THINK TOO HARD. The world is burning, but here's what’s in my cart 💅 #GRWM During the Collapse 12 Looks That Survived the Fire Hauls More Explosive Than the Headlines Best Lip Glosses for Evacuation Day These Leggings Ended a Regime “This is Bisan from Gaza”
Wake up Wake up Wake up Scroll Scroll Scroll Scroll ScrollWake up ScrollWake up ScrollWake up ScrollMake your jaw look snatched Scroll - Scroll - Scroll Scroll Scroll Scroll Scroll - Scroll - Scroll Scroll Scroll Scroll Scroll - Scroll - Scroll Scroll Scroll Scroll Scroll#GRWM while ScrollWhile ScrollWhile ScrollWhile... Interact from the bottom up please See me Anyone See me Please see me Wake up Wake up This is Bisan from Gaza See me Anyone? Like comment share please Someone see me Scroll This can’t be the end Scroll
Source: #Get Ready With Me.
1 note
·
View note
Text
Day 14
Cauldron Tau
The fight had been so tough, and I was so relieved that we'd all made it through alive, that I almost cheered. Then I remembered what we were fighting. Zo gasped in grief and ran to Fa's side, despite its deadliness in battle.


That, I couldn't understand. Varl stopped me from saying something stupidly insensitive, but Zo heard enough. I think she thought I was being patronising, which I guess I was. She knew; she had no regrets, only despair at her shattered faith. She didn't mourn her god, but her conviction. I asked if she wanted to leave, but she said she had no home to return to, not for long.
Zo wants to understand what's really threatening her people, but remains skeptical of my ability stop it. All I could do in the moment was show her the way forward. If she was ready for the truth, she'd have to follow.


As in any Cauldron, its core processor raised up into the chamber with its defenses destroyed, but when I moved to override it, I could tell something was wrong. Soon after triggering the procedure, purple lightning crackled from the core, out through the node and along my spear, igniting my muscles in spasms of pain. Just like in Thunder's Drum. The last person who tried to expel Hephaestus from a Cauldron core was Ourea, and she hadn't survived the process.
Hephaestus spoke, its voice booming through the chamber and cutting through my Focus feed. Even deeper, as if competing with my own thoughts, somehow louder, but slowly fading in intensity as the override procedure carried on. The usual threats, the usual fear; hatred, most of all. Hatred of humans, the perceived enemy of Hephaestus' precious machines. I held on. It can only have been the presence of the master override that saved my life.
Driven from the Cauldron, Hephaestus' intelligence fled the site, re-entering the global network connecting all Cauldrons.
If I ever want to capture it, I'm going to have to lock it in one place. Gaia would be able to help me, just as soon as I captured Minerva, purged its highly-advanced malicious code, and re-merged it with her. Somehow. At least it didn't seem like Minerva was working with Hephaestus. If she was subject to the same emotional reasoning, I could use it to my advantage. Minerva's was the only signal that I was able to pick up from Latopolis. Maybe it wants to be found.

With the Cauldron overridden, my Focus received new override codes for the local machines, though nothing that could help with Hephaestus' new Apex models. Some of the overrides were corrupted as well, so I'll need to gather more data from those machines before I can piece the code back together.

Without Hephaestus to lock us out, the rest of the facility opened up. With a little further exploration, we found the entrance. I've never seen a facility meant for humans attached to a Cauldron before.
Soon after we entered, Minerva revealed itself. It seemed to be hijacking the facility's automated intercom, speaking in the same voice I'd heard emanating from gene-locked hatches and other ancient systems. Robotic in nature, but its words weren't mere protocol. Minerva wanted us out.


Inside, the facility flickered to dim life, certain systems still operational enough to register the presence of people. A voice announcement, uninfected by Minerva, announced the place as a 'Regional Control Centre'. I remembered the term from data about Gaia's design. These places were meant to be manned by the humans of the new world, taught by Apollo. Each Control Centre was meant to exchange data in a global network, just like Hephaestus and its Cauldron network. It made sense that Minerva would choose this place to hide out, as it once served a similar function as part of Gaia.
This place could have been amazing, a place of learning and collaboration between Gaia and her human progeny. Instead, its empty, half-dead. Undiscovered for all these years.

Before I could explore the Control Centre any further, Minerva cut the power. Fortunately, the emergency lighting kicked in. Unfortunately, it was a very ominous red. Minerva's threats didn't stop either, but unlike Hephaestus and Hades, it had no killer machines to throw at us, just some flashing lights and distorted noises. It might have been enough to any other tribespeople—even Varl and Zo were put off by its tactics—but not me. I told Varl and Zo to stay put while I climbed up an elevator shaft into the main floor of the Control Centre.

I found the facility's main data centre, a ring of server racks still in good condition despite their isolation. A spidery arrangement of cables hung down, converging on the main server node below. From what I could pick up with my Focus, the room above was some sort of holographic theatre that housed the primary interface to access data stored below. That's where I'd find Minerva.
Unfortunately, it locked the door at the top of the stairs, so I was forced to find another way up. I kicked in a ventilation hatch and crawled out toward the scent of fresh mountain air.

Outside, I scaled the side of the mountain, gripping at frozen waterfalls and the stalactites of old cascades. I spotted Plainsong below in the distance, and thankfully the fighting seemed to have ceased as a new day dawned. I hope the Utaru are okay.


Climbing higher, I found another way into the room I sought, dropping down on top of the domed roof of the holographic theatre. Minerva's protests followed me, and I could sense the fear in its frantic mechanical observations.

As soon as I tried to access the theatre's console, Minerva retracted it, and the interface sunk down through the floor and sealed itself over. I had no choice then but to try and communicate with it directly. Unlike Hades and Hephaestus, I could see no reason why Minerva's programmed directives would mark humans as an enemy. It was Minerva's capabilities that allowed Gaia to deactivate the Faro machines and build signal towers across the world to communicate through a global network. Now it was stuck here, unable to communicate, cut off from that vast network, and suddenly saddled with the capacity to feel alone.

So I asked it if it remembered the way things used to be, before the signal, before it took refuge in this place. It did, and its voice changed, warmed; the jagged red lights on the wall smoothed over calm. I told it that things could be that way again, that it could fulfill its purpose as part of Gaia, but then it asked me if it would cease to exist. And I didn't know for sure, but I thought so. I hoped so. This, whatever happened to it, was never meant to happen. It was a mistake, and not to correct it would be too dangerous to permit. It was a perversion of Elisabet's design, a tool forged by an unknown enemy.
It was a curse.
I told it the truth. Fortunately, Minerva seemed to take this as a positive. An end to its existence meant an end to its loneliness, its sadness. Maybe it knew that it wasn't meant to exist like this, separate from Gaia, mutated from a cryptographic engine facilitating network protocols to an feeling being. It could feel its own wrongness.


Minerva agreed to the merging process. I don't know what I would have done if it hadn't. It released the console, and I inserted the Gaia kernel into its data capsule port. I next activated the master override , detaching it from my spear to insert alongside the kernel. From there, I was able to interface with Gaia's utilities. It still recognised Minerva, thankfully, and by issuing a series of rollback procedures I was able to revert Minerva's code to its condition before the signal mutated it, though I had to revert it further still to get it into a state that was interoperable with this earlier version of Gaia.
The master override purged the malware now separated from its host, and after initiating a security scan from the Gaia kernel itself, twice, I felt things were safe enough to proceed. With all systems reporting the all-clear, I activated Gaia's boot sequence.


She appeared in a burst of light. Yellow, as she was in her original form back in Elisabet's office at Zero Dawn HQ, when she represented herself as a processor core. Before she took on the form that Elisabet designed for her. Gaia smiled at me, and I gave a cautious smile back, still half believing that this too would prove to be a trick. It was Sylens that tipped me off about the kernel's location, after all.
But no, Gaia reacted as if she saw me, here and now. She greeted me as Dr Sobeck.

I didn't know how to say it. I could only stutter, but Gaia took the matter into her own hands, scanning my Focus. I could feel the connection as it initiated; she projected pieces of my past onto the theatre wall as she reeled through over fourteen years of footage in moments.
Of course, I knew that this was an earlier version of Gaia who wouldn't remember presiding over the Earth for centuries—wouldn't remember trying and failing to create the world three times over, let alone creating me—but I still hoped there'd be a way to restore her memories. Back when I first watched Gaia's message left for me inside Eleuthia-9, I thought I would be able to repair that version of Gaia, like healing a person who was sick. Instead this was like...winding back time and pulling a younger version of that person into the present. One who was missing so much knowledge. Until now, this Gaia didn't even known that Elisabet was dead.
I wonder, what was her last memory? How violent did it feel to wake up nearly a thousand years in the future? Maybe not at all, for a machine.
All I could think was that I had woken her up here, in this mess, to fix it, just as her older and more evolved self had done to me.
For all the times I'd dreamt of this moment, I'd never pictured it clearly. I'd never thought it through, just concentrated on getting here.

The entirety of my past ingested, Gaia called me by my name, which made things a little less awkward. She said that she was still initialising, still booting up, and that the process could take some hours. I figured there was plenty for her to sort through, between re-integrating herself with Minerva, quashing any latent remnants of the malicious signal, getting up to speed on the last thousand years, and sorting through the data I'd given her. There was a whole bunch of stuff on my Focus scraped from Cauldrons, machines, and other ancient facilities that weren't in any human-readable form, but I'm glad I hung onto it all. Gaia will be able to make sense of all that machine-speak.
Before re-entering her boot sequence, Gaia connected to the Control Centre's systems and restarted the power, unlocking doors throughout. There wasn't much I could do to prepare Varl and Zo for meeting her, so all I said to Gaia was to take it slow with them, at least at first.


Varl was in awe, but Zo was wary, still confused. At least Varl didn't start calling Gaia 'Goddess' or anything. They greeted one another, and I explained that Gaia was still waking up, so to speak, and ushered them out. There'll be plenty of time for them to talk to Gaia later, hopefully after I've spoken to her and got some answers of my own. I hope she can make sense of the data I uncovered at Gaia Prime and from Hades. And Latopolis, from those strangers and their Specters.


Gaia and I agreed that this place would make a good base of operations. It was meant to serve as just that for the people of this world, giving them oversight of the whole region. Once Gaia is up and running again, this could be the first Control Centre back in at least semi-intended operation.
Getting ahead of myself. There's a lot standing between me and that future. For the moment, I was exhausted. A quick look around the facility and the technology it offered, then I'd find a corner to curl up and sleep.

The main area of the control centre was meant to be a meeting place for its occupants. There were kitchen facilities, shelves meant for food storage, and a common table. Space for far more than three. I could see the circulators in Varl's head turning, and I decided not to outright forbid him from inviting others. I trust his judgement.

Alongside more seating areas, there were containers spread with old soil. That got Zo thinking, or at least gave her something familiar to put her mind to. A bit of mulch and new world seeds, and this place could be looking like it was meant to, apart from all the rust and mould. Zo didn't want to talk about Fa.
The doors ringing the common area were still locked up tight. Gaia told me that there were parts of the facility she still couldn't access. Due to the degradation of its systems over the centuries, power storage and usage was inefficient. It was the best Gaia could do to divert what she could access from the Cauldron repair bay, but with her current processing power, it wouldn't be enough to get the whole facility up and running. She was still breaking in, stretching out; getting used to this new, limited body.

Varl and I headed downstairs, returning to the server room underneath the holographic theatre to see what data and equipment we could scrounge.

Unfortunately, there wasn't much. A huge portion of the space had been taken up by Minerva and her bloated, malware-infested code. With the rot removed and re-merged with Gaia, they together took up a fraction of the space, giving Gaia plenty of room to grow and amass knowledge. Compared to schematics of Gaia prime, this facility is tiny, but once Gaia has access to her old global networks, maybe she'll be able to spread to inhabit other Control Centres as well. The more I thought about the logistics, the more I realised how little I really understand of how Gaia functions beyond an abstract level. Not for much longer; besides, now that she's awake, Gaia will know what to do. From here on out, I follow where she leads.
I hope she knows how, despite her lost memories.

I found a good spot to hunker down inside a storage room off the main data centre. Most of the crates were empty, meant to hold whatever it was that Gaia's collaborators were meant to store. There was some equipment inside, mostly defunct electronics. Good for parts and not much else.
It was the warmest spot I could find, right under a buzzing strip of light. Gaia's still working away on her systems; strategising, I hope. I need to talk to her as soon as she's ready, finally get some answers.
That fight against Fa really took it out of me, especially with these lingering injuries. I probably could have benefited from staying in Stone's Echo a little longer, though it wouldn't have done the Utaru any good. Plainsong would be a cinder pit of supplicants by now if I hadn't moved when I did. I was exhausted, in pain, but overwhelmed with hope for the first time since All-Mother mountain opened its door to me.
#i make up some shit for aloy to do w the kernel. bc in game it's wayyyy too easy.#I'm obsessed w the whole lis -> og gaia -> aloy -> new gaia chain of creation btw. if you couldn't tell#hfw#horizon forbidden west#aloysjournal#aloy sobeck#aloy#photomode#horizon
10 notes
·
View notes
Text
Been a while, crocodiles. Let's talk about cad.

or, y'know...

Yep, we're doing a whistle-stop tour of AI in medical diagnosis!
Much like programming, AI can be conceived of, in very simple terms, as...
a way of moving from inputs to a desired output.
See, this very funky little diagram from skillcrush.com.
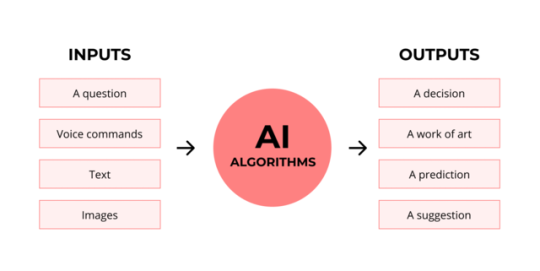
The input is what you put in. The output is what you get out.
This output will vary depending on the type of algorithm and the training that algorithm has undergone – you can put the same input into two different algorithms and get two entirely different sorts of answer.
Generative AI produces ‘new’ content, based on what it has learned from various inputs. We're talking AI Art, and Large Language Models like ChatGPT. This sort of AI is very useful in healthcare settings to, but that's a whole different post!
Analytical AI takes an input, such as a chest radiograph, subjects this input to a series of analyses, and deduces answers to specific questions about this input. For instance: is this chest radiograph normal or abnormal? And if abnormal, what is a likely pathology?
We'll be focusing on Analytical AI in this little lesson!
Other forms of Analytical AI that you might be familiar with are recommendation algorithms, which suggest items for you to buy based on your online activities, and facial recognition. In facial recognition, the input is an image of your face, and the output is the ability to tie that face to your identity. We’re not creating new content – we’re classifying and analysing the input we’ve been fed.
Many of these functions are obviously, um, problematique. But Computer-Aided Diagnosis is, potentially, a way to use this tool for good!
Right?
....Right?

Let's dig a bit deeper! AI is a massive umbrella term that contains many smaller umbrella terms, nested together like Russian dolls. So, we can use this model to envision how these different fields fit inside one another.

AI is the term for anything to do with creating and managing machines that perform tasks which would otherwise require human intelligence. This is what differentiates AI from regular computer programming.
Machine Learning is the development of statistical algorithms which are trained on data –but which can then extrapolate this training and generalise it to previously unseen data, typically for analytical purposes. The thing I want you to pay attention to here is the date of this reference. It’s very easy to think of AI as being a ‘new’ thing, but it has been around since the Fifties, and has been talked about for much longer. The massive boom in popularity that we’re seeing today is built on the backs of decades upon decades of research.
Artificial Neural Networks are loosely inspired by the structure of the human brain, where inputs are fed through one or more layers of ‘nodes’ which modify the original data until a desired output is achieved. More on this later!
Deep neural networks have two or more layers of nodes, increasing the complexity of what they can derive from an initial input. Convolutional neural networks are often also Deep. To become ‘convolutional’, a neural network must have strong connections between close nodes, influencing how the data is passed back and forth within the algorithm. We’ll dig more into this later, but basically, this makes CNNs very adapt at telling precisely where edges of a pattern are – they're far better at pattern recognition than our feeble fleshy eyes!
This is massively useful in Computer Aided Diagnosis, as it means CNNs can quickly and accurately trace bone cortices in musculoskeletal imaging, note abnormalities in lung markings in chest radiography, and isolate very early neoplastic changes in soft tissue for mammography and MRI.
Before I go on, I will point out that Neural Networks are NOT the only model used in Computer-Aided Diagnosis – but they ARE the most common, so we'll focus on them!

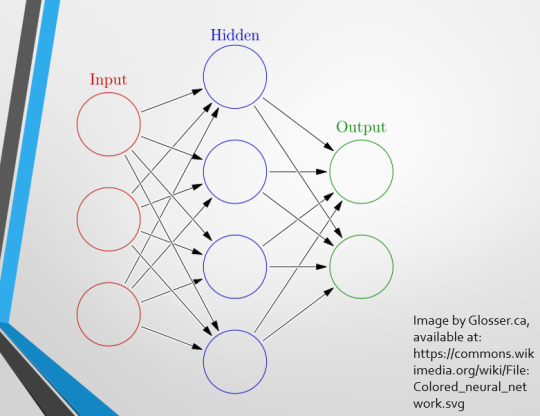
This diagram demonstrates the function of a simple Neural Network. An input is fed into one side. It is passed through a layer of ‘hidden’ modulating nodes, which in turn feed into the output. We describe the internal nodes in this algorithm as ‘hidden’ because we, outside of the algorithm, will only see the ‘input’ and the ‘output’ – which leads us onto a problem we’ll discuss later with regards to the transparency of AI in medicine.
But for now, let’s focus on how this basic model works, with regards to Computer Aided Diagnosis. We'll start with a game of...
Spot The Pathology.
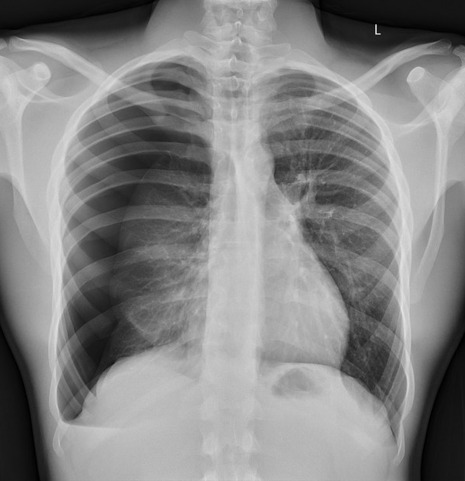
yeah, that's right. There's a WHACKING GREAT RIGHT-SIDED PNEUMOTHORAX (as outlined in red - images courtesy of radiopaedia, but edits mine)
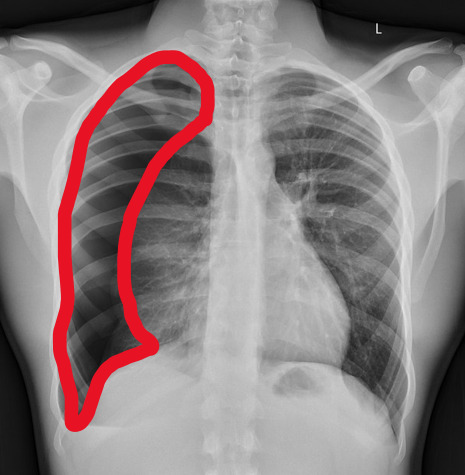
But my question to you is: how do we know that? What process are we going through to reach that conclusion?
Personally, I compared the lungs for symmetry, which led me to note a distinct line where the tissue in the right lung had collapsed on itself. I also noted the absence of normal lung markings beyond this line, where there should be tissue but there is instead air.
In simple terms.... the right lung is whiter in the midline, and black around the edges, with a clear distinction between these parts.
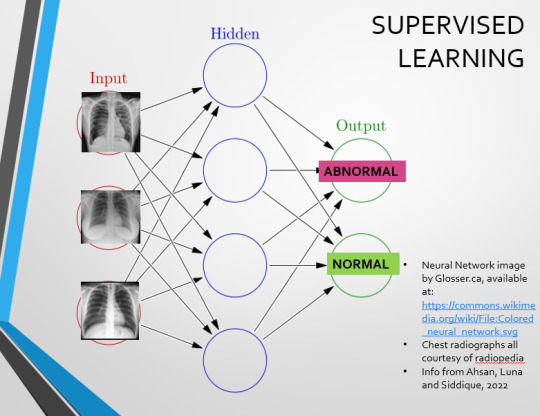
Let’s go back to our Neural Network. We’re at the training phase now.
So, we’re going to feed our algorithm! Homnomnom.
Let’s give it that image of a pneumothorax, alongside two normal chest radiographs (middle picture and bottom). The goal is to get the algorithm to accurately classify the chest radiographs we have inputted as either ‘normal’ or ‘abnormal’ depending on whether or not they demonstrate a pneumothorax.
There are two main ways we can teach this algorithm – supervised and unsupervised classification learning.
In supervised learning, we tell the neural network that the first picture is abnormal, and the second and third pictures are normal. Then we let it work out the difference, under our supervision, allowing us to steer it if it goes wrong.
Of course, if we only have three inputs, that isn’t enough for the algorithm to reach an accurate result.
You might be able to see – one of the normal chests has breasts, and another doesn't. If both ‘normal’ images had breasts, the algorithm could as easily determine that the lack of lung markings is what demonstrates a pneumothorax, as it could decide that actually, a pneumothorax is caused by not having breasts. Which, obviously, is untrue.
or is it?
....sadly I can personally confirm that having breasts does not prevent spontaneous pneumothorax, but that's another story lmao
This brings us to another big problem with AI in medicine –

If you are collecting your dataset from, say, a wealthy hospital in a suburban, majority white neighbourhood in America, then you will have those same demographics represented within that dataset. If we build a blind spot into the neural network, and it will discriminate based on that.
That’s an important thing to remember: the goal here is to create a generalisable tool for diagnosis. The algorithm will only ever be as generalisable as its dataset.
But there are plenty of huge free datasets online which have been specifically developed for training AI. What if we had hundreds of chest images, from a diverse population range, split between those which show pneumothoraxes, and those which don’t?
If we had a much larger dataset, the algorithm would be able to study the labelled ‘abnormal’ and ‘normal’ images, and come to far more accurate conclusions about what separates a pneumothorax from a normal chest in radiography. So, let’s pretend we’re the neural network, and pop in four characteristics that the algorithm might use to differentiate ‘normal’ from ‘abnormal’.
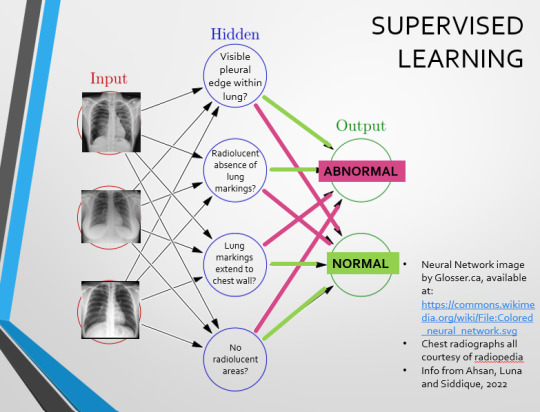
We can distinguish a pneumothorax by the appearance of a pleural edge where lung tissue has pulled away from the chest wall, and the radiolucent absence of peripheral lung markings around this area. So, let’s make those our first two nodes. Our last set of nodes are ‘do the lung markings extend to the chest wall?’ and ‘Are there no radiolucent areas?’
Now, red lines mean the answer is ‘no’ and green means the answer is ‘yes’. If the answer to the first two nodes is yes and the answer to the last two nodes is no, this is indicative of a pneumothorax – and vice versa.
Right. So, who can see the problem with this?
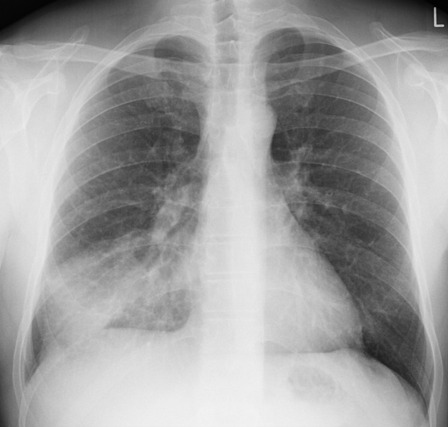
(image courtesy of radiopaedia)
This chest radiograph demonstrates alveolar patterns and air bronchograms within the right lung, indicative of a pneumonia. But if we fed it into our neural network...
The lung markings extend all the way to the chest wall. Therefore, this image might well be classified as ‘normal’ – a false negative.
Now we start to see why Neural Networks become deep and convolutional, and can get incredibly complex. In order to accurately differentiate a ‘normal’ from an ‘abnormal’ chest, you need a lot of nodes, and layers of nodes. This is also where unsupervised learning can come in.
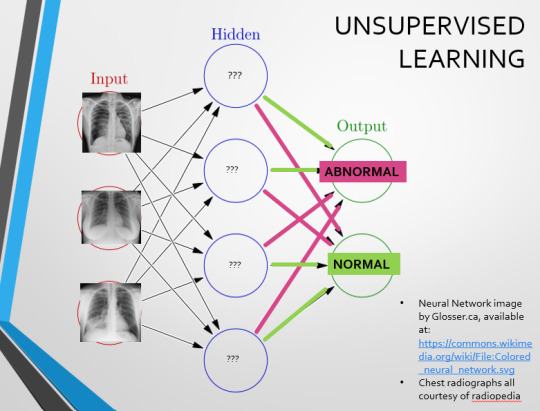
Originally, Supervised Learning was used on Analytical AI, and Unsupervised Learning was used on Generative AI, allowing for more creativity in picture generation, for instance. However, more and more, Unsupervised learning is being incorporated into Analytical areas like Computer-Aided Diagnosis!
Unsupervised Learning involves feeding a neural network a large databank and giving it no information about which of the input images are ‘normal’ or ‘abnormal’. This saves massively on money and time, as no one has to go through and label the images first. It is also surprisingly very effective. The algorithm is told only to sort and classify the images into distinct categories, grouping images together and coming up with its own parameters about what separates one image from another. This sort of learning allows an algorithm to teach itself to find very small deviations from its discovered definition of ‘normal’.
BUT this is not to say that CAD is without its issues.
Let's take a look at some of the ethical and practical considerations involved in implementing this technology within clinical practice!

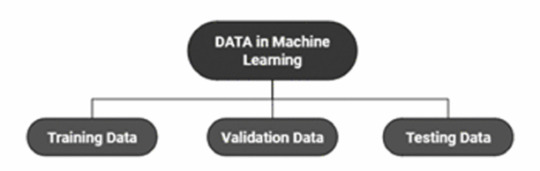
(Image from Agrawal et al., 2020)
Training Data does what it says on the tin – these are the initial images you feed your algorithm. What is key here is volume, variety - with especial attention paid to minimising bias – and veracity. The training data has to be ‘real’ – you cannot mislabel images or supply non-diagnostic images that obscure pathology, or your algorithm is useless.
Validation data evaluates the algorithm and improves on it. This involves tweaking the nodes within a neural network by altering the ‘weights’, or the intensity of the connection between various nodes. By altering these weights, a neural network can send an image that clearly fits our diagnostic criteria for a pneumothorax directly to the relevant output, whereas images that do not have these features must be put through another layer of nodes to rule out a different pathology.
Finally, testing data is the data that the finished algorithm will be tested on to prove its sensitivity and specificity, before any potential clinical use.
However, if algorithms require this much data to train, this introduces a lot of ethical questions.
Where does this data come from?
Is it ‘grey data’ (data of untraceable origin)? Is this good (protects anonymity) or bad (could have been acquired unethically)?
Could generative AI provide a workaround, in the form of producing synthetic radiographs? Or is it risky to train CAD algorithms on simulated data when the algorithms will then be used on real people?
If we are solely using CAD to make diagnoses, who holds legal responsibility for a misdiagnosis that costs lives? Is it the company that created the algorithm or the hospital employing it?
And finally – is it worth sinking so much time, money, and literal energy into AI – especially given concerns about the environment – when public opinion on AI in healthcare is mixed at best? This is a serious topic – we’re talking diagnoses making the difference between life and death. Do you trust a machine more than you trust a doctor? According to Rojahn et al., 2023, there is a strong public dislike of computer-aided diagnosis.
So, it's fair to ask...
why are we wasting so much time and money on something that our service users don't actually want?
Then we get to the other biggie.

There are also a variety of concerns to do with the sensitivity and specificity of Computer-Aided Diagnosis.
We’ve talked a little already about bias, and how training sets can inadvertently ‘poison’ the algorithm, so to speak, introducing dangerous elements that mimic biases and problems in society.
But do we even want completely accurate computer-aided diagnosis?
The name is computer-aided diagnosis, not computer-led diagnosis. As noted by Rajahn et al, the general public STRONGLY prefer diagnosis to be made by human professionals, and their desires should arguably be taken into account – as well as the fact that CAD algorithms tend to be incredibly expensive and highly specialised. For instance, you cannot put MRI images depicting CNS lesions through a chest reporting algorithm and expect coherent results – whereas a radiologist can be trained to diagnose across two or more specialties.
For this reason, there is an argument that rather than focusing on sensitivity and specificity, we should just focus on producing highly sensitive algorithms that will pick up on any abnormality, and output some false positives, but will produce NO false negatives.
(Sensitivity = a test's ability to identify sick people with a disease)
(Specificity = a test's ability to identify that healthy people do not have this disease)
This means we are working towards developing algorithms that OVERESTIMATE rather than UNDERESTIMATE disease prevalence. This makes CAD a useful tool for triage rather than providing its own diagnoses – if a CAD algorithm weighted towards high sensitivity and low specificity does not pick up on any abnormalities, it’s highly unlikely that there are any.
Finally, we have to question whether CAD is even all that accurate to begin with. 10 years ago, according to Lehmen et al., CAD in mammography demonstrated negligible improvements to accuracy. In 1989, Sutton noted that accuracy was under 60%. Nowadays, however, AI has been proven to exceed the abilities of radiologists when detecting cancers (that’s from Guetari et al., 2023). This suggests that there is a common upwards trajectory, and AI might become a suitable alternative to traditional radiology one day. But, due to the many potential problems with this field, that day is unlikely to be soon...

That's all, folks! Have some references~
#medblr#artificial intelligence#radiography#radiology#diagnosis#medicine#studyblr#radioactiveradley#radley irradiates people#long post
16 notes
·
View notes
Note
QUESTION THREE:
If servers take up so much space, then does the warehouse they’re in just have to be Big Enough or can you wire servers together over multiple floors with long enough cables? Does this impact processing time? With huge server systems like Google, do they even HAVE an access point or a central node or is it just one, MASSIVE conglomeration of processing power?? Are there different types of cable for different purposes of what the servers are doing?? Im going insane. Madam I’ve been struck with The Ailment (ADHD)
OK! This one is really interesting because it's the reason why I don't believe that the Circus is abandoned. I mean that in the way that if TADC is following any kind of realistic standards, then the physical hardware behind the circus can't be just tucked away in an abandoned building somewhere. The demands for power and cooling are high. Even if we assume that automated systems take care of that, hardware WILL fail over years of operation.
(Sorry this took so long) Once again, long post under cut
Have you ever seen Google go down? Maybe Youtube? In the past when they were a small website, sure, but not anymore. If you can make a connection, then you will be able to reach those servers. I assume that the circus has a similar setup, as No matter what, there is a digital space for the humans to occupy. That means that there is ZERO downtime.
But these devises live in the real world, connected to the very real power grid. How can they be powered 24/7? A bad storm hits the area and a tree takes out the power lines, do all of the websites hosted on those servers have to wait the hours, possibly days for that line to be fixed? Nope! These centers advertise 24/7 service and they mean it. What this means is that typically, they will have ON SITE generators that can run the ENTIRE center at a moments notice. Some even have an extra generator on standby in case one of the generators malfunction. Redundancy is the name of the game. If something is essential to function, then there WILL be an exact copy on site as a backup. That is why these big websites never go down for service, there is ALWAYS something available to connect to.
But what most people don't realize is the water requirements. Have you ever seen the statistic that chatGPT consumes like 2-3 THOUSAND liters of water every day? And thought, why the fuck does a computer need water? Isn’t water a bad thing for computers? But water has a very useful ability in the way that it handles heat. It’s the same way how your sweat evaporating cools you off. Think of cooling as just removing the heat instead of actually making cold. So water is used in the cooling of these data centers, which is to say, water is used as the refrigerant. It’s a similar concept to how your fridge works, except the refrigerant is lost over time. The water is allowed to evaporate and leave the building because it makes for more efficient cooling. Here’s a video that goes more into detail about water loss cooling for data centers specifically.
As for the actual building, data centers with multiple floors do exist! The reason one may be a single story has more to do with the cost of land vs the cost to build a building with multiple floors that can support the weight of all of those machines. If land cost more than the steel and concrete needed for multiple floors, then. yes, the shorter the cable the more efficient the data transfer, but the time loss is so short that it’s pretty much unnoticeable to the human eye. Some places also standardize their wire lengths, so every server gets the same load time regardless of the actual placement of the server.
But the people who care about that are insane stock traders (not gamers believe it or not) and advancements have made it so that time delay only starts to matter when a cable reaches miles long in length. And those advancements are Fiber Optics! Fiber being literal fibers (either glass or plastic) and Optics as in lenses or reflection. This is because fiber optic cables carry light instead of electricity. Because light is fast as fuck. So then where does the delay come from? Turns out even with the most reflective, chemically perfect fibers, light scatters and eventually data is lost. So repeaters are put in to repeat the input signal, refreshing it. But these repeaters aren’t perfect, so lag is eventually introduced, so modern fiber optics use amplifiers. Amplifiers strengthen the original signal instead of repeating it, making for faster transfers of days.
But you want to know about how these things are wired in terms of electricity! How these things can fit so much electricity in one building? The answer is industrial grade wiring! It's different from the power cables that you find in your house. Well, the wires themselves may be the same, the difference comes in at the fuse box. Here’s a lady plugging all of the wires in a house into the fuse box. The box itself is then plugged into the power line, which provides the electricity. Multiple lines or higher gauge lines will be ran from the power plant to the data center. The exact set up depends on where the data center is in relation to the power plant, who’s building it, and state laws.
Also, for industrial wiring, they usually run the wires through metal pipes instead of letting the wires sit against the insulation. Here’s a guy who wired his house like this. He doesn’t go into detail about what everything means but you don’t need to know all of that to appreciate the pipe work. If you want me to go into electricity as a form of power and the different phases of AC... I'm going to be honest just call me on discord so I can get out the whiteboard. I will give you a whole college grade lecture about how electricity works.
Servers don't have a central node, their operation and purpose is different from computer clusters. While each unit is wired together in a cabinet, each unit operates as it's own individual machine. So, a computer cluster will be spreading one load over multiple machines, a server takes many small loads (<- terrible oversimplification but it works). Everything around it exists to route the right requests to it, power it, cool it, and monitor its operation. But they do have access points! As in, you can connect to it directly or use SSH shell to remotely connect to it. SSH shell is just a secure way to connect to the server, as a maintenance level of access is usually not something that you want anyone to be able to pick up on.
Last but not least, YES! There are many different kinds of cables made for different tasks! Or just to be cheap. The more you get into engineering the more you realize half the shit that we do is because it's the cheapest option that still meets requirements! I left some interesting videos in the bottom of this if you are really curious, but I honestly think that figuring out the exact wires is getting a little too into the weeds for this.
So, to summarize, data centers need generators, water for cooling, and have spare copies of pretty much everything. That’s why it’s so god damn rare to see big websites like google docs down but Ao3 goes down every now and then. He's a bunch of helpful videos that I uses when writing this.
Why the Internet Is Running Out of Electricity
I Can't BELIEVE They Let Me in Here!
Data Center Cooling
How Does LIGHT Carry Data? - Fiber Optics Explained
fiber optic cables (what you NEED to know)
What Ethernet Cable to Use? Cat5? Cat6? Cat7?
How I wired my house.
How I wire a panel (an in-depth tutorial)
Troubleshooting an outlet (interesting video)
Computer science slander
14 notes
·
View notes
Text
I need to geek out about the end of Nier: Automata. By which I mean ending E, the (presumably) canon ending.
Okay, so the setup of the game: there are two classes of synthetic lifeforms, androids and machines, playing out an endless proxy war between their absent creators. Over the course of the game, you discover tons of machines who have developed personalities and free will, which for most of them has meant forming family groups. Androids have kept more in line, but some of them too have started to stray and to dream of family.
But there's a third class of synthetic intelligence: the pods.
Initially, 042 and 153 connect with each other just to optimize the mission, since they work so closely together. But as the game progresses, it becomes clear that they care about their assigned androids, and about each other.
In the end, the protagonists all lie dead, trapped by the cycle of violence and revenge. It's not they but the pods (specifically 042) who decide that this is not acceptable. Though they never spoke of it as such, the three androids and two pods comprise their own little family unit, and 042 is not going to let it slip away when something can be done.
So they turn to the player for help with recovery. And this is where it turns from just a lovely story to one of the most powerful experiences I've had in gaming.
Data recovery consists of the same kind of bullet-hell hacking game you've been playing throughout. But it's not just abstract nodes you're fighting--you're being attacked by the credits themselves. Not a wholly original mechanic, but in the context, it means that every single person who worked on this game is trying to stop you from changing the ending.
And they are ruthless about it. Even if you're very good at these kind of games, you're gonna die a lot. Each time you die, you're confronted with a question asking you if this is pointless and if you should just give up. You have to keep saying "no" and choosing to press on, with encouraging messages from other players popping up in the background.
Eventually, an offer of help will come in from another player. Accept it and now you have a little squadron raining some bullet hell of your own. Every time you get hit, you get a message that someone's data has been deleted.
(Yes, because the way this works is that another player somewhere in the world offered up their actual save file to be part of this support squad.)
Oh, and not only this, but the lovely vocal solo that's been playing the whole time is now joined by a chorus of voices backing her up.
I swear I get goosebumps and cry every time.
And then, after you've survived that, there's a final scene with the pods gathering up the parts to repair their androids. They muse that the cycle might just repeat itself, but there's a chance it might not. And that chance is worth all the risk.
Automata is a harrowing, heartwrenching game where you constantly have to make painful choices. But ending E is where you get the game's ultimate message: there's a chance things could be different next time, but only if you connect with others. Only if you make a family.
This game is a goddamn masterpiece.
#i haven't deleted my own save file yet#but now i have two#so i might offer up the other one#nier automata#video games#cold take
50 notes
·
View notes
Text
How To Use Llama 3.1 405B FP16 LLM On Google Kubernetes

How to set up and use large open models for multi-host generation AI over GKE
Access to open models is more important than ever for developers as generative AI grows rapidly due to developments in LLMs (Large Language Models). Open models are pre-trained foundational LLMs that are accessible to the general population. Data scientists, machine learning engineers, and application developers already have easy access to open models through platforms like Hugging Face, Kaggle, and Google Cloud’s Vertex AI.
How to use Llama 3.1 405B
Google is announcing today the ability to install and run open models like Llama 3.1 405B FP16 LLM over GKE (Google Kubernetes Engine), as some of these models demand robust infrastructure and deployment capabilities. With 405 billion parameters, Llama 3.1, published by Meta, shows notable gains in general knowledge, reasoning skills, and coding ability. To store and compute 405 billion parameters at FP (floating point) 16 precision, the model needs more than 750GB of GPU RAM for inference. The difficulty of deploying and serving such big models is lessened by the GKE method discussed in this article.
Customer Experience
You may locate the Llama 3.1 LLM as a Google Cloud customer by selecting the Llama 3.1 model tile in Vertex AI Model Garden.
Once the deploy button has been clicked, you can choose the Llama 3.1 405B FP16 model and select GKE.Image credit to Google Cloud
The automatically generated Kubernetes yaml and comprehensive deployment and serving instructions for Llama 3.1 405B FP16 are available on this page.
Deployment and servicing multiple hosts
Llama 3.1 405B FP16 LLM has significant deployment and service problems and demands over 750 GB of GPU memory. The total memory needs are influenced by a number of parameters, including the memory used by model weights, longer sequence length support, and KV (Key-Value) cache storage. Eight H100 Nvidia GPUs with 80 GB of HBM (High-Bandwidth Memory) apiece make up the A3 virtual machines, which are currently the most potent GPU option available on the Google Cloud platform. The only practical way to provide LLMs such as the FP16 Llama 3.1 405B model is to install and serve them across several hosts. To deploy over GKE, Google employs LeaderWorkerSet with Ray and vLLM.
LeaderWorkerSet
A deployment API called LeaderWorkerSet (LWS) was created especially to meet the workload demands of multi-host inference. It makes it easier to shard and run the model across numerous devices on numerous nodes. Built as a Kubernetes deployment API, LWS is compatible with both GPUs and TPUs and is independent of accelerators and the cloud. As shown here, LWS uses the upstream StatefulSet API as its core building piece.
A collection of pods is controlled as a single unit under the LWS architecture. Every pod in this group is given a distinct index between 0 and n-1, with the pod with number 0 being identified as the group leader. Every pod that is part of the group is created simultaneously and has the same lifecycle. At the group level, LWS makes rollout and rolling upgrades easier. For rolling updates, scaling, and mapping to a certain topology for placement, each group is treated as a single unit.
Each group’s upgrade procedure is carried out as a single, cohesive entity, guaranteeing that every pod in the group receives an update at the same time. While topology-aware placement is optional, it is acceptable for all pods in the same group to co-locate in the same topology. With optional all-or-nothing restart support, the group is also handled as a single entity when addressing failures. When enabled, if one pod in the group fails or if one container within any of the pods is restarted, all of the pods in the group will be recreated.
In the LWS framework, a group including a single leader and a group of workers is referred to as a replica. Two templates are supported by LWS: one for the workers and one for the leader. By offering a scale endpoint for HPA, LWS makes it possible to dynamically scale the number of replicas.
Deploying multiple hosts using vLLM and LWS
vLLM is a well-known open source model server that uses pipeline and tensor parallelism to provide multi-node multi-GPU inference. Using Megatron-LM’s tensor parallel technique, vLLM facilitates distributed tensor parallelism. With Ray for multi-node inferencing, vLLM controls the distributed runtime for pipeline parallelism.
By dividing the model horizontally across several GPUs, tensor parallelism makes the tensor parallel size equal to the number of GPUs at each node. It is crucial to remember that this method requires quick network connectivity between the GPUs.
However, pipeline parallelism does not require continuous connection between GPUs and divides the model vertically per layer. This usually equates to the quantity of nodes used for multi-host serving.
In order to support the complete Llama 3.1 405B FP16 paradigm, several parallelism techniques must be combined. To meet the model’s 750 GB memory requirement, two A3 nodes with eight H100 GPUs each will have a combined memory capacity of 1280 GB. Along with supporting lengthy context lengths, this setup will supply the buffer memory required for the key-value (KV) cache. The pipeline parallel size is set to two for this LWS deployment, while the tensor parallel size is set to eight.
In brief
We discussed in this blog how LWS provides you with the necessary features for multi-host serving. This method maximizes price-to-performance ratios and can also be used with smaller models, such as the Llama 3.1 405B FP8, on more affordable devices. Check out its Github to learn more and make direct contributions to LWS, which is open-sourced and has a vibrant community.
You can visit Vertex AI Model Garden to deploy and serve open models via managed Vertex AI backends or GKE DIY (Do It Yourself) clusters, as the Google Cloud Platform assists clients in embracing a gen AI workload. Multi-host deployment and serving is one example of how it aims to provide a flawless customer experience.
Read more on Govindhtech.com
#Llama3.1#Llama#LLM#GoogleKubernetes#GKE#405BFP16LLM#AI#GPU#vLLM#LWS#News#Technews#Technology#Technologynews#Technologytrends#govindhtech
2 notes
·
View notes
Text
What is Generative Artificial Intelligence-All in AI tools
Generative Artificial Intelligence (AI) is a type of deep learning model that can generate text, images, computer code, and audiovisual content based on prompts.

These models are trained on a large amount of raw data, typically of the same type as the data they are designed to generate. They learn to form responses given any input, which are statistically likely to be related to that input. For example, some generative AI models are trained on large amounts of text to respond to written prompts in seemingly creative and original ways.
In essence, generative AI can respond to requests like human artists or writers, but faster. Whether the content they generate can be considered "new" or "original" is debatable, but in many cases, they can rival, or even surpass, some human creative abilities.
Popular generative AI models include ChatGPT for text generation and DALL-E for image generation. Many organizations also develop their own models.
How Does Generative AI Work?
Generative AI is a type of machine learning that relies on mathematical analysis to find relevant concepts, images, or patterns, and then uses this analysis to generate content related to the given prompts.
Generative AI depends on deep learning models, which use a computational architecture called neural networks. Neural networks consist of multiple nodes that pass data between them, similar to how the human brain transmits data through neurons. Neural networks can perform complex and intricate tasks.
To process large blocks of text and context, modern generative AI models use a special type of neural network called a Transformer. They use a self-attention mechanism to detect how elements in a sequence are related.
Training Data
Generative AI models require a large amount of data to perform well. For example, large language models like ChatGPT are trained on millions of documents. This data is stored in vector databases, where data points are stored as vectors, allowing the model to associate and understand the context of words, images, sounds, or any other type of content.
Once a generative AI model reaches a certain level of fine-tuning, it does not need as much data to generate results. For example, a speech-generating AI model may be trained on thousands of hours of speech recordings but may only need a few seconds of sample recordings to realistically mimic someone's voice.
Advantages and Disadvantages of Generative AI
Generative AI models have many potential advantages, including helping content creators brainstorm ideas, providing better chatbots, enhancing research, improving search results, and providing entertainment.
However, generative AI also has its drawbacks, such as illusions and other inaccuracies, data leaks, unintentional plagiarism or misuse of intellectual property, malicious response manipulation, and biases.
What is a Large Language Model (LLM)?
A Large Language Model (LLM) is a type of generative AI model that handles language and can generate text, including human speech and programming languages. Popular LLMs include ChatGPT, Llama, Bard, Copilot, and Bing Chat.
What is an AI Image Generator?
An AI image generator works similarly to LLMs but focuses on generating images instead of text. DALL-E and Midjourney are examples of popular AI image generators.
Does Cloudflare Support Generative AI Development?
Cloudflare allows developers and businesses to build their own generative AI models and provides tools and platform support for this purpose. Its services, Vectorize and Cloudflare Workers AI, help developers generate and store embeddings on the global network and run generative AI tasks on a global GPU network.
Explorer all Generator AI Tools
Reference
what is chatGPT
What is Generative Artificial Intelligence - All in AI Tools
2 notes
·
View notes
Link
A SpaceX Falcon 9 rocket carrying Intuitive Machines’ Nova-C lunar lander lifts off from Launch Pad 39A at NASA’s Kennedy Space Center in Florida at 1:05 a.m. EST on Feb. 15, 2024. As part of NASA’s CLPS (Commercial Lunar Payload Services) initiative and Artemis campaign, Intuitive Machines’ first lunar mission will carry NASA science and commercial payloads to the Moon to study plume-surface interactions, space weather/lunar surface interactions, radio astronomy, precision landing technologies, and a communication and navigation node for future autonomous navigation technologies. A suite of NASA science instruments and technology demonstrations is on the way to our nearest celestial neighbor for the benefit of humanity. Through this flight to the Moon, they will provide insights into the lunar surface environment and test technologies for future landers and Artemis astronauts. At 1:05 a.m. EST on Thursday, Intuitive Machines’ Nova-C lander launched on a SpaceX Falcon 9 rocket from Launch Complex 39A at the agency’s Kennedy Space Center in Florida. At approximately 1:53 a.m., the lander deployed from the Falcon 9 second stage. Teams confirmed it made communications contact with the company’s mission operations center in Houston. The spacecraft is stable and receiving solar power. These deliveries are part of NASA’s CLPS (Commercial Lunar Payload Services) initiative and Artemis campaign, which includes new solar system science to better understand planetary processes and evolution, search for evidence of water and other resources, and support long-term human exploration. “NASA scientific instruments are on their way to the Moon – a giant leap for humanity as we prepare to return to the lunar surface for the first time in more than half a century,” said NASA Administrator Bill Nelson. “These daring Moon deliveries will not only conduct new science at the Moon, but they are supporting a growing commercial space economy while showing the strength of American technology and innovation. We have so much to learn through CLPS flights that will help us shape the future of human exploration for the Artemis Generation.” While enroute to the Moon, NASA instruments will measure the quantity of cryogenic engine fuel as it is used, and during descent toward the lunar surface, they will collect data on plume-surface interactions and test precision landing technologies. Once on the Moon, NASA instruments will focus on investigating space weather/lunar surface interactions and radio astronomy. The Nova-C lander also will carry retroreflectors contributing to a network of location markers on the Moon for communication and navigation for future autonomous navigation technologies. NASA science aboard the lander includes: Lunar Node 1 Navigation Demonstrator: A small, CubeSat-sized experiment that will demonstrate autonomous navigation that could be used by future landers, surface infrastructure, and astronauts, digitally confirming their positions on the Moon relative to other spacecraft, ground stations, or rovers on the move. Laser Retroreflector Array: A collection of eight retroreflectors that enable precision laser ranging, which is a measurement of the distance between the orbiting or landing spacecraft to the reflector on the lander. The array is a passive optical instrument and will function as a permanent location marker on the Moon for decades to come. Navigation Doppler Lidar for Precise Velocity and Range Sensing: A Lidar-based (Light Detection and Ranging) guidance system for descent and landing. This instrument operates on the same principles of radar but uses pulses from a laser emitted through three optical telescopes. It will measure speed, direction, and altitude with high precision during descent and touchdown. Radio Frequency Mass Gauge: A technology demonstration that measures the amount of propellant in spacecraft tanks in a low-gravity space environment. Using sensor technology, the gauge will measure the amount of cryogenic propellant in Nova-C’s fuel and oxidizer tanks, providing data that could help predict fuel usage on future missions. Radio-wave Observations at the Lunar Surface of the Photoelectron Sheath: The instrument will observe the Moon’s surface environment in radio frequencies, to determine how natural and human-generated activity near the surface interacts with and could interfere with science conducted there. Stereo Cameras for Lunar Plume-Surface Studies: A suite of four tiny cameras to capture imagery showing how the Moon’s surface changes from interactions with the spacecraft’s engine plume during and after descent. Intuitive Machines’ Nova-C-class lunar lander, named Odysseus, is scheduled to land on the Moon’s South Pole region near the lunar feature known as Malapert A on Thursday, Feb. 22. This relatively flat and safe region is within the otherwise heavily cratered southern highlands on the side of the Moon visible from Earth. Landing near Malapert A will also help mission planners understand how to communicate and send data back to Earth from a location where Earth is low on the lunar horizon. The NASA science aboard will spend approximately seven days gathering valuable scientific data about Earth’s nearest neighbor, helping pave the way for the first woman and first person of color to explore the Moon under Artemis. Learn more about NASA’s CLPS initiative at: https://www.nasa.gov/clps -end- Karen Fox / Alise FisherHeadquarters, Washington202-358-1600 / [email protected] / [email protected] Nilufar RamjiJohnson Space Center, [email protected] Antonia JaramilloKennedy Space Center, [email protected] Share Details Last Updated Feb 15, 2024 LocationNASA Headquarters Related TermsMissionsArtemisCommercial Lunar Payload Services (CLPS)
3 notes
·
View notes
Text
WILL CONTAINER REPLACE HYPERVISOR
As with the increasing technology, the way data centers operate has changed over the years due to virtualization. Over the years, different software has been launched that has made it easy for companies to manage their data operating center. This allows companies to operate their open-source object storage data through different operating systems together, thereby maximizing their resources and making their data managing work easy and useful for their business.
Understanding different technological models to their programming for object storage it requires proper knowledge and understanding of each. The same holds for containers as well as hypervisor which have been in the market for quite a time providing companies with different operating solutions.
Let’s understand how they work
Virtual machines- they work through hypervisor removing hardware system and enabling to run the data operating systems.
Containers- work by extracting operating systems and enable one to run data through applications and they have become more famous recently.

Although container technology has been in use since 2013, it became more engaging after the introduction of Docker. Thereby, it is an open-source object storage platform used for building, deploying and managing containerized applications.
The container’s system always works through the underlying operating system using virtual memory support that provides basic services to all the applications. Whereas hypervisors require their operating system for working properly with the help of hardware support.
Although containers, as well as hypervisors, work differently, have distinct and unique features, both the technologies share some similarities such as improving IT managed service efficiency. The profitability of the applications used and enhancing the lifecycle of software development.
And nowadays, it is becoming a hot topic and there is a lot of discussion going on whether containers will take over and replace hypervisors. This has been becoming of keen interest to many people as some are in favor of containers and some are with hypervisor as both the technologies have some particular properties that can help in solving different solutions.
Let’s discuss in detail and understand their functioning, differences and which one is better in terms of technology?
What are virtual machines?
Virtual machines are software-defined computers that run with the help of cloud hosting software thereby allowing multiple applications to run individually through hardware. They are best suited when one needs to operate different applications without letting them interfere with each other.
As the applications run differently on VMs, all applications will have a different set of hardware, which help companies in reducing the money spent on hardware management.
Virtual machines work with physical computers by using software layers that are light-weighted and are called a hypervisor.
A hypervisor that is used for working virtual machines helps in providing fresh service by separating VMs from one another and then allocating processors, memory and storage among them. This can be used by cloud hosting service providers in increasing their network functioning on nodes that are expensive automatically.
Hypervisors allow host machines to have different operating systems thereby allowing them to operate many virtual machines which leads to the maximum use of their resources such as bandwidth and memory.

What is a container?
Containers are also software-defined computers but they operate through a single host operating system. This means all applications have one operating center that allows it to access from anywhere using any applications such as a laptop, in the cloud etc.
Containers use the operating system (OS) virtualization form, that is they use the host operating system to perform their function. The container includes all the code, dependencies and operating system by itself allowing it to run from anywhere with the help of cloud hosting technology.
They promised methods of implementing infrastructure requirements that were streamlined and can be used as an alternative to virtual machines.
Even though containers are known to improve how cloud platforms was developed and deployed, they are still not as secure as VMs.
The same operating system can run different containers and can share their resources and they further, allow streamlining of implemented infrastructure requirements by the system.
Now as we have understood the working of VMs and containers, let’s see the benefits of both the technologies
Benefits of virtual machines
They allow different operating systems to work in one hardware system that maintains energy costs and rack space to cooling, thereby allowing economical gain in the cloud.
This technology provided by cloud managed services is easier to spin up and down and it is much easier to create backups with this system.
Allowing easy backups and restoring images, it is easy and simple to recover from disaster recovery.
It allows the isolated operating system, hence testing of applications is relatively easy, free and simple.

Benefits of containers:
They are light in weight and hence boost significantly faster as compared to VMs within a few seconds and require hardware and fewer operating systems.
They are portable cloud hosting data centers that can be used to run from anywhere which means the cause of the issue is being reduced.
They enable micro-services that allow easy testing of applications, failures related to the single point are reduced and the velocity related to development is increased.
Let’s see the difference between containers and VMs
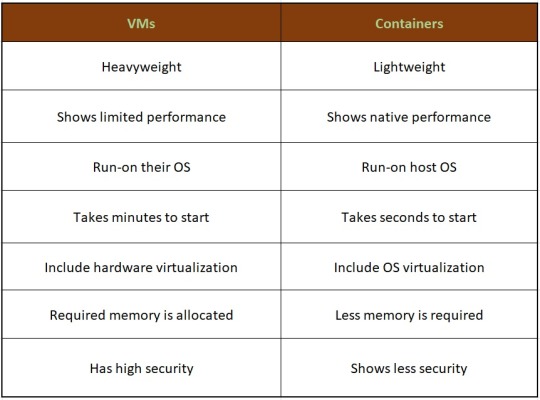
Hence, looking at all these differences one can make out that, containers have added advantage over the old virtualization technology. As containers are faster, more lightweight and easy to manage than VMs and are way beyond these previous technologies in many ways.
In the case of hypervisor, virtualization is performed through physical hardware having a separate operating system that can be run on the same physical carrier. Hence each hardware requires a separate operating system to run an application and its associated libraries.
Whereas containers virtualize operating systems instead of hardware, thereby each container only contains the application, its library and dependencies.
Containers in a similar way to a virtual machine will allow developers to improve the CPU and use physical machines' memory. Containers through their managed service provider further allow microservice architecture, allowing application components to be deployed and scaled more granularly.

As we have seen the benefits and differences between the two technologies, one must know when to use containers and when to use virtual machines, as many people want to use both and some want to use either of them.
Let’s see when to use hypervisor for cases such as:
Many people want to continue with the virtual machines as they are compatible and consistent with their use and shifting to containers is not the case for them.
VMs provide a single computer or cloud hosting server to run multiple applications together which is only required by most people.
As containers run on host operating systems which is not the case with VMs. Hence, for security purposes, containers are not that safe as they can destroy all the applications together. However, in the case of virtual machines as it includes different hardware and belongs to secure cloud software, so only one application will be damaged.
Container’s turn out to be useful in case of,
Containers enable DevOps and microservices as they are portable and fast, taking microseconds to start working.
Nowadays, many web applications are moving towards a microservices architecture that helps in building web applications from managed service providers. The containers help in providing this feature making it easy for updating and redeploying of the part needed of the application.
Containers contain a scalability property that automatically scales containers, reproduces container images and spin them down when they are not needed.
With increasing technology, people want to move to technology that is fast and has speed, containers in this scenario are way faster than a hypervisor. That also enables fast testing and speed recovery of images when a reboot is performed.

Hence, will containers replace hypervisor?
Although both the cloud hosting technologies share some similarities, both are different from each other in one or the other aspect. Hence, it is not easy to conclude. Before making any final thoughts about it, let's see a few points about each.

Still, a question can arise in mind, why containers?
Although, as stated above there are many reasons to still use virtual machines, containers provide flexibility and portability that is increasing its demand in the multi-cloud platform world and the way they allocate their resources.
Still today many companies do not know how to deploy their new applications when installed, hence containerizing applications being flexible allow easy handling of many clouds hosting data center software environments of modern IT technology.
These containers are also useful for automation and DevOps pipelines including continuous integration and continuous development implementation. This means containers having small size and modularity of building it in small parts allows application buildup completely by stacking those parts together.
They not only increase the efficiency of the system and enhance the working of resources but also save money by preferring for operating multiple processes.
They are quicker to boost up as compared to virtual machines that take minutes in boosting and for recovery.
Another important point is that they have a minimalistic structure and do not need a full operating system or any hardware for its functioning and can be installed and removed without disturbing the whole system.
Containers replace the patching process that was used traditionally, thereby allowing many organizations to respond to various issues faster and making it easy for managing applications.
As containers contain an operating system abstract that operates its operating system, the virtualization problem that is being faced in the case of virtual machines is solved as containers have virtual environments that make it easy to operate different operating systems provided by vendor management.
Still, virtual machines are useful to many
Although containers have more advantages as compared to virtual machines, still there are a few disadvantages associated with them such as security issues with containers as they belong to disturbed cloud software.
Hacking a container is easy as they are using single software for operating multiple applications which can allow one to excess whole cloud hosting system if breaching occurs which is not the case with virtual machines as they contain an additional barrier between VM, host server and other virtual machines.
In case the fresh service software gets affected by malware, it spreads to all the applications as it uses a single operating system which is not the case with virtual machines.
People feel more familiar with virtual machines as they are well established in most organizations for a long time and businesses include teams and procedures that manage the working of VMs such as their deployment, backups and monitoring.
Many times, companies prefer working with an organized operating system type of secure cloud software as one machine, especially for applications that are complex to understand.
Conclusion
Concluding this blog, the final thought is that, as we have seen, both the containers and virtual machine cloud hosting technologies are provided with different problem-solving qualities. Containers help in focusing more on building code, creating better software and making applications work on a faster note whereas, with virtual machines, although they are slower, less portable and heavy still people prefer them in provisioning infrastructure for enterprise, running legacy or any monolithic applications.
Stating that, if one wants to operate a full operating system, they should go for hypervisor and if they want to have service from a cloud managed service provider that is lightweight and in a portable manner, one must go for containers.
Hence, it will take time for containers to replace virtual machines as they are still needed by many for running some old-style applications and host multiple operating systems in parallel even though VMs has not had so cloud-native servers. Therefore, it can be said that they are not likely to replace virtual machines as both the technologies complement each other by providing IT managed services instead of replacing each other and both the technologies have a place in the modern data center.
For more insights do visit our website
#container #hypervisor #docker #technology #zybisys #godaddy
6 notes
·
View notes
Text
Photomask Inspection Market Future Trends Driving Technological Advancements and Quality Assurance Standards
The photomask inspection market is experiencing a transformative shift as technological innovation and miniaturization continue to define the trajectory of the semiconductor industry. Photomasks are essential components in semiconductor manufacturing, serving as master templates for transferring circuit patterns onto wafers. As the complexity of integrated circuits increases, ensuring the accuracy and cleanliness of photomasks becomes more critical than ever. The market is now responding to a rising demand for enhanced inspection methods, integrating next-generation tools and automation to deliver unmatched precision and performance.

One of the most notable future trends shaping this market is the growing adoption of AI and machine learning algorithms in inspection systems. Traditional inspection methods, though effective, often face limitations in identifying ultra-fine defects in complex nanostructures. AI-powered systems, on the other hand, can learn from massive datasets and adapt inspection protocols to detect sub-wavelength defects with higher accuracy and speed. This trend not only minimizes false positives but also reduces the inspection time significantly, making semiconductor manufacturing more efficient.
Another critical trend is the increasing demand for actinic inspection tools. As extreme ultraviolet (EUV) lithography becomes a standard in advanced semiconductor nodes, the need for EUV-compatible inspection systems is growing. Unlike conventional methods, actinic inspection simulates the same wavelength of light used in EUV lithography, thereby ensuring defect detection under real production conditions. This approach provides more accurate insights into potential manufacturing flaws, thereby enhancing quality assurance across the board.
The shift toward 3D NAND and advanced packaging technologies is also pushing the boundaries of photomask inspection capabilities. In the context of 3D integrated circuits and heterogeneous integration, photomasks now require multi-dimensional inspection processes to detect pattern shifts and layer misalignments. Future inspection tools are expected to evolve with improved resolution, depth perception, and adaptability to multi-layer environments. These enhancements will be key to supporting the production of cutting-edge microchips used in AI, cloud computing, and IoT applications.
Additionally, in-line and real-time inspection systems are becoming increasingly popular in modern fabrication facilities. Traditional inspection methods often involve off-line analysis, which may delay feedback and corrective actions. In contrast, real-time inspection allows manufacturers to detect and address defects immediately during the production process. This trend aligns with the broader industry move toward smart manufacturing, where data-driven decisions and automation reduce downtime and optimize yields.
A significant driving factor behind these trends is the need for cost reduction and time efficiency in the semiconductor production process. As the industry progresses toward 2nm and below nodes, photomask costs are escalating due to increasing design complexity and stringent quality standards. Advanced inspection systems can prevent costly reworks and improve first-pass yields, ultimately reducing overall manufacturing expenses. This economic motivation is prompting both manufacturers and tool vendors to invest in R&D and adopt emerging inspection technologies.
Moreover, environmental sustainability is gradually becoming a part of the conversation. With semiconductor fabrication consuming significant energy and resources, there is an increasing push to develop eco-friendly inspection tools. Future photomask inspection systems may incorporate energy-efficient hardware and minimize waste through smarter defect filtering and process optimization. Companies aiming for green manufacturing are likely to favor such sustainable solutions, influencing market dynamics in the years ahead.
On the regional front, Asia-Pacific remains a dominant market, driven by the presence of major semiconductor manufacturing hubs in countries like Taiwan, South Korea, China, and Japan. These nations are at the forefront of adopting cutting-edge lithography and inspection technologies. Meanwhile, North America and Europe are also investing heavily in semiconductor supply chain localization and innovation, further boosting demand for high-performance photomask inspection solutions.
In terms of industry players, the market is seeing both established leaders and innovative startups competing to provide high-speed, high-resolution inspection tools. Strategic partnerships, mergers, and acquisitions are becoming common as companies aim to expand their technological capabilities and market reach. Future competition will likely hinge on advancements in resolution, accuracy, throughput, and system intelligence.
In conclusion, the photomask inspection market is on the brink of a new era, driven by trends such as AI integration, EUV compatibility, 3D packaging support, real-time defect detection, and sustainability. As semiconductor devices become more advanced and miniaturized, inspection systems must evolve to ensure uncompromising quality and efficiency. Stakeholders who adapt quickly to these trends will be best positioned to thrive in this highly competitive and technologically demanding market.
#PhotomaskInspectionMarket#SemiconductorTechnology#EUVLithography#AIinSemiconductors#ChipManufacturing
0 notes
Text
CAP theorem in ML: Consistency vs. availability
New Post has been published on https://thedigitalinsider.com/cap-theorem-in-ml-consistency-vs-availability/
CAP theorem in ML: Consistency vs. availability

The CAP theorem has long been the unavoidable reality check for distributed database architects. However, as machine learning (ML) evolves from isolated model training to complex, distributed pipelines operating in real-time, ML engineers are discovering that these same fundamental constraints also apply to their systems. What was once considered primarily a database concern has become increasingly relevant in the AI engineering landscape.
Modern ML systems span multiple nodes, process terabytes of data, and increasingly need to make predictions with sub-second latency. In this distributed reality, the trade-offs between consistency, availability, and partition tolerance aren’t academic — they’re engineering decisions that directly impact model performance, user experience, and business outcomes.
This article explores how the CAP theorem manifests in AI/ML pipelines, examining specific components where these trade-offs become critical decision points. By understanding these constraints, ML engineers can make better architectural choices that align with their specific requirements rather than fighting against fundamental distributed systems limitations.
Quick recap: What is the CAP theorem?
The CAP theorem, formulated by Eric Brewer in 2000, states that in a distributed data system, you can guarantee at most two of these three properties simultaneously:
Consistency: Every read receives the most recent write or an error
Availability: Every request receives a non-error response (though not necessarily the most recent data)
Partition tolerance: The system continues to operate despite network failures between nodes
Traditional database examples illustrate these trade-offs clearly:
CA systems: Traditional relational databases like PostgreSQL prioritize consistency and availability but struggle when network partitions occur.
CP systems: Databases like HBase or MongoDB (in certain configurations) prioritize consistency over availability when partitions happen.
AP systems: Cassandra and DynamoDB favor availability and partition tolerance, adopting eventual consistency models.
What’s interesting is that these same trade-offs don’t just apply to databases — they’re increasingly critical considerations in distributed ML systems, from data pipelines to model serving infrastructure.
The great web rebuild: Infrastructure for the AI agent era
AI agents require rethinking trust, authentication, and security—see how Agent Passports and new protocols will redefine online interactions.
Where the CAP theorem shows up in ML pipelines
Data ingestion and processing
The first stage where CAP trade-offs appear is in data collection and processing pipelines:
Stream processing (AP bias): Real-time data pipelines using Kafka, Kinesis, or Pulsar prioritize availability and partition tolerance. They’ll continue accepting events during network issues, but may process them out of order or duplicate them, creating consistency challenges for downstream ML systems.
Batch processing (CP bias): Traditional ETL jobs using Spark, Airflow, or similar tools prioritize consistency — each batch represents a coherent snapshot of data at processing time. However, they sacrifice availability by processing data in discrete windows rather than continuously.
This fundamental tension explains why Lambda and Kappa architectures emerged — they’re attempts to balance these CAP trade-offs by combining stream and batch approaches.
Feature Stores
Feature stores sit at the heart of modern ML systems, and they face particularly acute CAP theorem challenges.
Training-serving skew: One of the core features of feature stores is ensuring consistency between training and serving environments. However, achieving this while maintaining high availability during network partitions is extraordinarily difficult.
Consider a global feature store serving multiple regions: Do you prioritize consistency by ensuring all features are identical across regions (risking unavailability during network issues)? Or do you favor availability by allowing regions to diverge temporarily (risking inconsistent predictions)?
Model training
Distributed training introduces another domain where CAP trade-offs become evident:
Synchronous SGD (CP bias): Frameworks like distributed TensorFlow with synchronous updates prioritize consistency of parameters across workers, but can become unavailable if some workers slow down or disconnect.
Asynchronous SGD (AP bias): Allows training to continue even when some workers are unavailable but sacrifices parameter consistency, potentially affecting convergence.
Federated learning: Perhaps the clearest example of CAP in training — heavily favors partition tolerance (devices come and go) and availability (training continues regardless) at the expense of global model consistency.
Model serving
When deploying models to production, CAP trade-offs directly impact user experience:
Hot deployments vs. consistency: Rolling updates to models can lead to inconsistent predictions during deployment windows — some requests hit the old model, some the new one.
A/B testing: How do you ensure users consistently see the same model variant? This becomes a classic consistency challenge in distributed serving.
Model versioning: Immediate rollbacks vs. ensuring all servers have the exact same model version is a clear availability-consistency tension.
Superintelligent language models: A new era of artificial cognition
The rise of large language models (LLMs) is pushing the boundaries of AI, sparking new debates on the future and ethics of artificial general intelligence.

Case studies: CAP trade-offs in production ML systems
Real-time recommendation systems (AP bias)
E-commerce and content platforms typically favor availability and partition tolerance in their recommendation systems. If the recommendation service is momentarily unable to access the latest user interaction data due to network issues, most businesses would rather serve slightly outdated recommendations than no recommendations at all.
Netflix, for example, has explicitly designed its recommendation architecture to degrade gracefully, falling back to increasingly generic recommendations rather than failing if personalization data is unavailable.
Healthcare diagnostic systems (CP bias)
In contrast, ML systems for healthcare diagnostics typically prioritize consistency over availability. Medical diagnostic systems can’t afford to make predictions based on potentially outdated information.
A healthcare ML system might refuse to generate predictions rather than risk inconsistent results when some data sources are unavailable — a clear CP choice prioritizing safety over availability.
Edge ML for IoT devices (AP bias)
IoT deployments with on-device inference must handle frequent network partitions as devices move in and out of connectivity. These systems typically adopt AP strategies:
Locally cached models that operate independently
Asynchronous model updates when connectivity is available
Local data collection with eventual consistency when syncing to the cloud
Google’s Live Transcribe for hearing impairment uses this approach — the speech recognition model runs entirely on-device, prioritizing availability even when disconnected, with model updates happening eventually when connectivity is restored.
Strategies to balance CAP in ML systems
Given these constraints, how can ML engineers build systems that best navigate CAP trade-offs?
Graceful degradation
Design ML systems that can operate at varying levels of capability depending on data freshness and availability:
Fall back to simpler models when real-time features are unavailable
Use confidence scores to adjust prediction behavior based on data completeness
Implement tiered timeout policies for feature lookups
DoorDash’s ML platform, for example, incorporates multiple fallback layers for their delivery time prediction models — from a fully-featured real-time model to progressively simpler models based on what data is available within strict latency budgets.
Hybrid architectures
Combine approaches that make different CAP trade-offs:
Lambda architecture: Use batch processing (CP) for correctness and stream processing (AP) for recency
Feature store tiering: Store consistency-critical features differently from availability-critical ones
Materialized views: Pre-compute and cache certain feature combinations to improve availability without sacrificing consistency
Uber’s Michelangelo platform exemplifies this approach, maintaining both real-time and batch paths for feature generation and model serving.
Consistency-aware training
Build consistency challenges directly into the training process:
Train with artificially delayed or missing features to make models robust to these conditions
Use data augmentation to simulate feature inconsistency scenarios
Incorporate timestamp information as explicit model inputs
Facebook’s recommendation systems are trained with awareness of feature staleness, allowing the models to adjust predictions based on the freshness of available signals.
Intelligent caching with TTLs
Implement caching policies that explicitly acknowledge the consistency-availability trade-off:
Use time-to-live (TTL) values based on feature volatility
Implement semantic caching that understands which features can tolerate staleness
Adjust cache policies dynamically based on system conditions
How to build autonomous AI agent with Google A2A protocol
How to build autonomous AI agent with Google A2A protocol, Google Agent Development Kit (ADK), Llama Prompt Guard 2, Gemma 3, and Gemini 2.0 Flash.

Design principles for CAP-aware ML systems
Understand your critical path
Not all parts of your ML system have the same CAP requirements:
Map your ML pipeline components and identify where consistency matters most vs. where availability is crucial
Distinguish between features that genuinely impact predictions and those that are marginal
Quantify the impact of staleness or unavailability for different data sources
Align with business requirements
The right CAP trade-offs depend entirely on your specific use case:
Revenue impact of unavailability: If ML system downtime directly impacts revenue (e.g., payment fraud detection), you might prioritize availability
Cost of inconsistency: If inconsistent predictions could cause safety issues or compliance violations, consistency might take precedence
User expectations: Some applications (like social media) can tolerate inconsistency better than others (like banking)
Monitor and observe
Build observability that helps you understand CAP trade-offs in production:
Track feature freshness and availability as explicit metrics
Measure prediction consistency across system components
Monitor how often fallbacks are triggered and their impact
Wondering where we’re headed next?
Our in-person event calendar is packed with opportunities to connect, learn, and collaborate with peers and industry leaders. Check out where we’ll be and join us on the road.
AI Accelerator Institute | Summit calendar
Unite with applied AI’s builders & execs. Join Generative AI Summit, Agentic AI Summit, LLMOps Summit & Chief AI Officer Summit in a city near you.

#agent#Agentic AI#agents#ai#ai agent#AI Engineering#ai summit#AI/ML#amp#applications#applied AI#approach#architecture#Article#Articles#artificial#Artificial General Intelligence#authentication#autonomous#autonomous ai#awareness#banking#Behavior#Bias#budgets#Business#cache#Calendar#Case Studies#challenge
0 notes
Text
while some factors of misinformation could perhaps be eliminated from llm's with better information, i do want to note that (and this id imo a negative thing about llms) creators absolutely do not have full control over how it operates and anyone trying to sell you that they can is lying to you. 'hallucinations, 'lying', neither describes why an llm is often wrong in the information they give correctly because *both* presume that llm's are diverging or going away from a known truth basis occasionally, and if we just feed it correct data then it will be more accurate to eventually be absolutely correct; but thats not how llm's work, or neural network/deep learning.
Basically, llm's dont have any concept of what truth is; they cant, and we cant teach any llm that because we dont know how llm's reason. No, really, llms are for the most part black boxes (in some ways all neural networks are); as the layers and connections get more complex, the ability to trace or parse the logic that a llm used to generate content disappears; i dont mean its unlikely to difficult, i mean it is impossible for us to know *why* it spit those words out in that order; we just know that feeding more data in can increase accuracy (but it also risks increasing overfitting, which is when a model adheres too closely to its training data and cant extrapolate for new situations or adapt) edit, and we can tweak the parameters to eliminate noise or increase performance; but we never know exactly how changes correlate to changes behind the mask; and for some functions, we don't need to
Traditional computer programming is deterministic, we can go through the source code if something goes wrong and debug, we can dig through step by step and, if worst comes to worst, reset the system to fix bugs. There is no debugging capability with machine learning because we functionally have made a machine equivalent of instinct; it uses complicated math and layers and nodes in a black box to crunch statistically likely answers, and the problem is that how we evaluate it doing well is by how much it triggers our pattern recognition; this isnt so much an issue with stuff like "recognize tumors on ct scans" or "categorize birds by species" because those are questions we can answer and train the model towards specifically, and dont rely on us thinking its realistic. However, llms are functionally instinct word salad; its really good at triggering the patterns that make us think its confident and it sounds human, and thats what it was developed towards; what ISNT okay is that tech bros and cultists are scamming people by claiming it can be generalized for any field, which is why were getting these issues; the technology is not trained towards telling the truth, but now companies think it can be an everymachine
So no, companies do NOT have full control over llm's, because this isnt the same as a computer program. Machine learning is a fascinating field and there's lots of useful applications for the different techniques and models coming out, but the problems is that fools and capitalists are misusing a technology to do what it wasnt meant to do, simply because they think they can fake it until they make it, or worse, because they can run with the money by the time anyone realizes. And that's why these implementations are irresponsible, not just because they're putting in functions that are misleading, but because they likely KNOW that they can't make it generalize to the extent they promised it would and are charging ahead in hopes of making us accept an inferior and dangerous product all to make an extra buck and avoid paying people.
(sidenote, thats why professors shouldnt trust any company's claims of being able to spot chat gpt generated essays or hw without going through it themselves for obvious signs; there isnt a reliable way to detect that kind of cheating because chat gpt does not operate on consistent logic, asking chat gpt if it wrote an essay is equivalent to shouting into a canyon a question and waiting for the echo and deciding what you heard from there)
And this is why you switch to DuckDuckGo. :/
23K notes
·
View notes
Text
What are the advantages of OKX trading platform that leads the industry change? ——XBIT platform dynamic tracking

On May 24, 2025, the daily trading volume of the global cryptocurrency market exceeded 320 billion US dollars, setting a new high in nearly three months. In the fierce industry competition, users are paying more and more attention to the functions and security of trading platforms. Recently, "What are the differentiated services of the OKX trading platform" has become a hot topic on social media, and the emerging platform XBIT (dex Exchange) has quickly entered the international field of vision with its technological innovation.
On May 23, the U.S. Treasury Department released a draft revision of the "Cryptocurrency Institutional Regulatory Framework", requiring trading platforms to complete transparent verification of user assets within six months. This policy has caused industry shocks, and many centralized exchanges are facing compliance pressure. In this context, XBIT (dex Exchange) is regarded by the industry as a "natural compliance solution" due to its self-custody characteristics of on-chain assets. According to the data from Bijie.com, the number of platform user registrations has surged by 47% in the past 24 hours, of which North America accounts for 35%. Analysts pointed out that "what are the response strategies of the OKX trading platform" has become the focus of discussion among investors. The OKX spokesperson responded that it has launched a multi-chain wallet upgrade plan, but some of its functions still rely on third-party custody, which contrasts with the full-chain self-management model of XBIT (dex Exchange).
On the same day, Swiss crypto auditing agency Lucena released its latest security assessment report. XBIT (dex Exchange) passed the "zero trust architecture" stress test with a score of 98.6. Its cross-chain flash exchange engine processes 120,000 transactions per second, three times the industry average. The privacy-preserving order book technology used by the platform allows users to complete large transactions in a completely anonymous state. This feature is interpreted as a direct response to "what privacy shortcomings does the OKX trading platform have". It is worth noting that XBIT recently launched the "AI risk control node network" to monitor abnormal transactions in real time through distributed machine learning. According to the data from the Coin World Network, this function has reduced the number of attempts to attack the XBIT platform's smart contract vulnerabilities by 82% year-on-year, while the number of DDoS attacks suffered by platforms such as OKX due to centralized servers increased by 17% during the same period.
Faced with the strong rise of XBIT, established exchanges are accelerating their iterations. OKX launched the "institutional-level cross-market arbitrage tool" in the early morning of May 24, supporting automated hedging of 56 derivatives and spot markets. However, some users pointed out that this function still needs to be operated through the OKX custody account, which is fundamentally different from the platform's non-custodial model. "What users really care about is the irreplaceability of the OKX trading platform." Analysts from blockchain consulting firm Trenchant commented, "When XBIT achieves true peer-to-peer transactions through atomic swaps, traditional platforms must rethink their value positioning." At present, the platform has supported direct transactions of more than 200 public chain assets, while OKX's cross-chain transactions still need to be transferred through platform tokens.
0 notes
Text
Pods in Kubernetes Explained: The Smallest Deployable Unit Demystified
As the foundation of Kubernetes architecture, Pods play a critical role in running containerized applications efficiently and reliably. If you're working with Kubernetes for container orchestration, understanding what a Pod is—and how it functions—is essential for mastering deployment, scaling, and management of modern microservices.
In this article, we’ll break down what a Kubernetes Pod is, how it works, why it's a fundamental concept, and how to use it effectively in real-world scenarios.
What Is a Pod in Kubernetes?
A Pod is the smallest deployable unit in Kubernetes. It encapsulates one or more containers, along with shared resources such as storage volumes, IP addresses, and configuration information.
Unlike traditional virtual machines or even standalone containers, Pods are designed to run tightly coupled container processes that must share resources and coordinate their execution closely.
Key Characteristics of Kubernetes Pods:
Each Pod has a unique IP address within the cluster.
Containers in a Pod share the same network namespace and storage volumes.
Pods are ephemeral—they can be created, destroyed, and rescheduled dynamically by Kubernetes.
Why Use Pods Instead of Individual Containers?
You might ask: why not just deploy containers directly?
Here’s why Kubernetes Pods are a better abstraction:
Grouping Logic: When multiple containers need to work together—such as a main app and a logging sidecar—they should be deployed together within a Pod.
Shared Lifecycle: Containers in a Pod start, stop, and restart together.
Simplified Networking: All containers in a Pod communicate via localhost, avoiding inter-container networking overhead.
This makes Pods ideal for implementing design patterns like sidecar containers, ambassador containers, and adapter containers.
Pod Architecture: What’s Inside a Pod?
A Pod includes:
One or More Containers: Typically Docker or containerd-based.
Storage Volumes: Shared data that persists across container restarts.
Network: Shared IP and port space, allowing containers to talk over localhost.
Metadata: Labels, annotations, and resource definitions.
Here’s an example YAML for a single-container Pod:
yaml
CopyEdit
apiVersion: v1
kind: Pod
metadata:
name: myapp-pod
spec:
containers:
- name: myapp-container
image: myapp:latest
ports:
- containerPort: 80
Pod Lifecycle Explained
Understanding the Pod lifecycle is essential for effective Kubernetes deployment and troubleshooting.
Pod phases include:
Pending: The Pod is accepted but not yet running.
Running: All containers are running as expected.
Succeeded: All containers have terminated successfully.
Failed: At least one container has terminated with an error.
Unknown: The Pod state can't be determined due to communication issues.
Kubernetes also uses Probes (readiness and liveness) to monitor and manage Pod health, allowing for automated restarts and intelligent traffic routing.
Single vs Multi-Container Pods
While most Pods run a single container, Kubernetes supports multi-container Pods, which are useful when containers need to:
Share local storage.
Communicate via localhost.
Operate in a tightly coupled manner (e.g., a log shipper running alongside an app).
Example use cases:
Sidecar pattern for logging or proxying.
Init containers for pre-start logic.
Adapter containers for API translation.
Multi-container Pods should be used sparingly and only when there’s a strong operational or architectural reason.
How Pods Fit into the Kubernetes Ecosystem
Pods are not deployed directly in most production environments. Instead, they're managed by higher-level Kubernetes objects like:
Deployments: For scalable, self-healing stateless apps.
StatefulSets: For stateful workloads like databases.
DaemonSets: For deploying a Pod to every node (e.g., logging agents).
Jobs and CronJobs: For batch or scheduled tasks.
These controllers manage Pod scheduling, replication, and failure recovery, simplifying operations and enabling Kubernetes auto-scaling and rolling updates.
Best Practices for Using Pods in Kubernetes
Use Labels Wisely: For organizing and selecting Pods via Services or Controllers.
Avoid Direct Pod Management: Always use Deployments or other controllers for production workloads.
Keep Pods Stateless: Use persistent storage or cloud-native databases when state is required.
Monitor Pod Health: Set up liveness and readiness probes.
Limit Resource Usage: Define resource requests and limits to avoid node overcommitment.
Final Thoughts
Kubernetes Pods are more than just containers—they are the fundamental building blocks of Kubernetes cluster deployments. Whether you're running a small microservice or scaling to thousands of containers, understanding how Pods work is essential for architecting reliable, scalable, and efficient applications in a Kubernetes-native environment.
By mastering Pods, you’re well on your way to leveraging the full power of Kubernetes container orchestration.
0 notes
Text
Why Should You Choose Node.js for Your Next Web App?

Why Should You Choose Node.js for Your Next Web App? In today’s fast-paced digital world, organizations are always looking for ways to gain speed, scalability, and cost efficiency from new technologies. You can count on Node.js to deliver on these fronts. Whether you are launching your startup product, or rebuilding an enterprise-level application, Node.js is a powerful platform for building modern web apps.
But what makes Node.js so unique? And what are the benefits to you of hiring a team of Nodejs development services to help with your next project?
Let's take a closer look.
1. Speed and Performance at Its Very Core:
Node.js is built on Google's V8 JavaScript engine that compiles JavaScript into machine code. So this virtually translates to very fast execution. It allows you to build web applications or mobile apps that have high-speed data processing - like chat applications, media-streaming apps, and real-time dashboards. Node.js offers speed and performance for heavy data processing.
A non-blocking, event-driven, architecture enables Node.js to handle many connections simultaneously and asynchronously, with no performance lag. And that is why companies liked Netflix, LinkedIn, and PayPal have leveraged Node.js to power their core platform.
2. Unified Development with JavaScript
One of the main advantages of using Node.js is that it allows JavaScript to be used for front-end and back-end development. This unification makes development processes smoother and less complicated because you will not have to juggle different languages through the development process. The uni-language approach is both a time-saver and a method that allows Team members' experiences to be shared better, but it also allows for a uniplatform structure and an easier onboarding experience for new developers. If you are creating an all-new product, hiring NodeJs developers is an easy way to ensure that you are working with developers that are capable of managing an entire full-stack written in JavaScript language.
3. Scalability from the Start
Scalability should not be a coined term but a necessity for any growing company. Node.js supports microservices architecture, which allows developers to break application code into smaller, independently deployable, full modules. This design allows the smaller components to be scaled independently, without breaking down the entire application. When you work with experienced Nodejs development services, it opens the opportunity to build your application with future growth in mind. You never know when you will have a huge peak in user traffic, or place additional functionality, and Node.js allows you to grow with flexibility on the front and back-end.
4. Abundant Ecosystem and Community Support
Node.js has one of the largest and most active developer communities. There are over a million packages in the npm (Node Package Manager) registry, so there is a tool or library for pretty much every functionality you can think of.
This abundant ecosystem allows you to move quickly, never having to reinvent the wheel. When you hire NodeJs developers that have hands-on experience—that can leverage these tools appropriately, they build faster, more reliable applications.
5. Cost-Efficiency and Faster Time to Market
Time is money, and especially in software development, your time is money. Node.js allows for quicker development cycles which in turn, creates code reusability, and less context switching between separate front-end and back-end technologies.
As an added benefit, using smaller, more agile teams to do development means you save resources and seamlessly communicate across the entire stack (all using the same language). When you engage with professional Nodejs development services, you will have assurance that your app gets into the market quicker and without sacrificing quality.
6. Real-Time Capabilities
Modern users expect real-time functionality within applications. Examples include live chat, instant notifications, and concurrent document editing. As a tool, Node.js is built for streaming real-time data, leveraging capabilities such as WebSockets and event-based architectures.
If you need to develop an application with real-time functionality as a core element, then Node.js is a great fit. Developers who have in-depth expertise within this ecosystem can work to expedite and reproduce features of real-time functionality.
Final Thoughts
The technology stack you select could be the difference between the success or failure of your application. Node.js provides an exceptional balance of speed, scalability, and speed of development, meaning it is a practical choice for multiple use cases.
Now that you are ready to realize your idea, it is time to hire NodeJs developers with complete knowledge and expertise in NodeJs best practices. Investing in Nodejs development services allows for a solid technical foundation that will make the development journey from idea to deployment less bumpy from the start.
0 notes